1. Introduction
Beer is the most consumed alcoholic beverage worldwide and is produced by the fermentation of sugars in the wort by yeasts [
1]. The production of beer in 2019 was 1912 million hectoliters (hl), while in 2020, the production reduced to 1820 million hl due to the COVID-19 pandemic [
2]. Beer production is a complex biochemical process in which the main ingredients are water, malt (sugar source), yeast, and hops [
3]; however, other products can be added, such as fruits, chocolate, and coffee grains, among others.
The fermentation stage is crucial to guarantee good quality beer since it is when all the nutrients, flavor, and odor components are produced, in addition to ethanol. At this stage, yeast is introduced in the wort (broth that is rich in sugars) from the boiling stage at the desired temperature. The main chemical reaction is the conversion of these sugars into ethanol and carbon dioxide, along with biomass growth and heat generation. At the same time, several secondary reactions occur, generating several components at lower concentrations that contribute to the flavor and aroma characteristics.
To enhance the fermentation, several factors, such as yeast pitching rate, dissolved oxygen, batch pressure, and temperature, must be taken care of by the brewers [
4]. Among these factors, temperature is important as it helps accelerate the fermentation but needs to remain within controlled bonds to avoid yeast death (above 30 °C), the production of undesirable byproducts, and the growth of bacteria, damaging the final product. Therefore, rigorous control of the temperature inside the fermenter must be exercised to ensure product quality and alleviate variations between batches.
In the brewing industry, time-varying temperature profiles are established along the fermentation process in order to alleviate the above-mentioned potential issues [
5]. Looking for the appropriate temperature profile is, however, not an easy task, and experimental determination can be time-consuming. Model-based optimization is, therefore, an appealing alternative. Dynamic models can be useful not only to optimize the operating conditions, but also to design state estimators reconstructing online non-measured variables or designing controllers to ensure close setpoint tracking [
6].
To this end, Gee and Ramirez [
7] proposed a detailed model of beer fermentation describing biomass growth and the production of flavor compounds through macroscopic reactions inferred from biological pathways. This model segregates the sugars into glucose, maltose, and maltotriose. The derivation of the corresponding sugar uptake kinetics is, therefore, the center of interest, and the related parameters are assumed to be temperature-dependent. However, this model is unlikely to be applicable for control purposes since it involves variables that require specific monitoring equipment beyond the standards of most fermenters. Andrés-Toro et al. [
8], conversely, proposed to segregate the yeast (biomass) into three types: lag, active, and death, while the sugars are considered as a whole. Sugar monitoring, therefore, appears simpler, and the model also takes account of industrial operational characteristics as well as the undesired beer flavor caused by ethanol and byproduct (diacetyl and ethyl acetate) formation. The main drawback of this model is the difficulty in obtaining accurate biomass data. Trelea et al. [
9] developed what can be considered as, so far, the most practical model, where only three states are considered: the dissolved carbon dioxide concentration used as an image of the growing biomass, the ethanol concentration, and the sugar concentration. The main advantage of this latter model lies in its practical control-oriented description of the fermentation process, considering variables that can be easily measured and tracked.
The objective of this work is to revisit these classical models, propose a few adaptations, and develop a thorough study of the parameter estimation problem based on a popular fermentation device, e.g., a 30-L stainless-steel Grainfather® fermenter. Two alternative mathematical models are considered, one based on yeast (biomass) and the other on carbon dioxide. The difference between these models is discussed in terms of biological interpretation, bioreactor instrumentation, and data collection (i.e., parameter estimation, model validation, and process control perspectives). As a result, models with good predictive capability are proposed together with their experimental validation.
This paper is organized as follows. The next section describes the experimental setup, while
Section 3 presents a review of dynamic models of beer fermentation, together with possible model adaptations required to represent the considered case study.
Section 4 develops a structural identifiability analysis based on the software tool Strike Goldd [
10].
Section 5 introduces a parameter identification procedure, including parametric sensitivity analysis and model validation. The last section draws the main conclusions of this work and discusses the monitoring and control perspectives.
2. Beer Fermentation Experimental Set-Up
The pilot plant consists of a stainless-steel conical fermenter (30 L, Grainfather®), which has a built-in sensor to measure the temperature of the liquid content. This sensor is paired to a control system connected to a glycol chiller (Grainfather®) to keep the temperature regulated. Ethanol and carbon dioxide concentrations are measured online, respectively, with a tilt® hydrometer and a Plaato® airlock.
The hydrometer is introduced in the wort and keeps floating in a tilted position, measuring the specific gravity which also allows, based on some predetermined correlations, for assessing the percentage of alcohol. The sensor also has an integrated temperature sensor. The airlock consists of four components: a lid, a bubbler, a Tritan, and a smart part (containing the temperature and infrared sensors). This device measures the evenly-sized bubbles of carbon dioxide released by the wort and converts them into liters of . The data are stored and displayed in the Brewblox® interface.
Besides the two online probes, a CDR BeerLab
® analyzer is used to obtain offline measurements of sugar, ethanol, and vicinal diketone (VDK) concentrations. The scheme of the full experimental setup is displayed in
Figure 1.
In this study, ale beer fermentation was considered and carried out at a temperature ranging from 17 to 26 °C. To obtain the wort, the malt is crushed using a mill. Indeed, the grain must only be broken, but not grounded. The next step is mashing, where sugars are obtained from starch. The crushed grain is added to a boiler tank (35 L, Grainfather
®) containing 19 L of water at 48 °C. The mashing step consists of four stages at different temperatures and times described in
Table 1. Once mashing is finished, the grain is rinsed with water at 75 °C until 24 L of wort is obtained. Usually, the quantity of added water is 8 L. Then, the wort is boiled to sterilize the liquid. The latter step is carried out for 80 min at 100 °C. Hop is added at 40 min and 65 min. Eventually, the wort is cooled down as fast as possible to the desired fermentation temperature with the help of a counter-flow wort cooler. The cold wort is transferred in the fermentation tank, filled up to 17 L.
A set of four isothermal batch fermentations without agitation are carried out using different operating conditions described in
Table 2. Each experiment is carried out once, but two replicates are taken and analyzed for each sample. The total sampling volume represents less than 10% of the initial wort volume (17 L), a condition to neglect the volume changes. Samples are taken every 2 to 3 h during the first 36 h. After this period, the process enters a stationary phase and the sampling time is therefore adapted at irregular, longer, time intervals. To analyze the samples with the CDR BeerLab
®, it is necessary to achieve preprocessing, including degasification and centrifugation to eliminate everything that could interfere during the measurement.
4. Structural Identifiability and Observability of the Models
Identifiability globally refers to the possibility of identifying the model parameters from the available data. A model is structurally identifiable if all the parameters can be uniquely determined from ideal measurements of its outputs, i.e., collected in continuous time without errors or noise, and the knowledge of the dynamic equations [
17]. If this property is not met, any further effort to estimate the non-identifiable parameters will be vain. However, the identifiability analysis is often omitted due to the assumed complexity of the mathematical developments required to achieve the analysis. Recently, several methodologies and toolboxes have been developed to significantly ease the task, as reviewed in [
18]. Some of these software tools are DAISY [
19], GENSSI [
20], STRIKE-GOLDD [
10], and SIAN [
21].
On the other hand, practical identifiability deals with the possibility of assessing all or some of the model parameters under realistic conditions, e.g., sampled data and measurement noise. The Fisher Information Matrix (FIM) is useful to assess practical identifiability through a rank test condition. An ill-conditioned FIM can indicate poor practical parameter identifiability even if structural identifiability is met.
In this work, STRIKE-GOLDD (STRuctural Identifiability taken as Extended-Generalized Observability with Lie Derivatives and Decomposition) was used to investigate the structural identifiability of the proposed beer fermentation models. This software tool has been developed in MATLAB® and addresses identifiability based on the concept of observability. To this end, the model is extended by considering its model parameters as state variables with zero dynamics. The results obtained for both models indicate that structural identifiability is ensured only when all the state variables are measured.
Another property of interest is observability, which is a prerequisite to the design of a state observer to reconstruct nonmeasured state variables. The results of the analysis are provided in
Table 3 and
Table 4 for the two dynamic models. For the model based on biomass, the analysis reveals that the set of three measurements
is necessary to guarantee observability. The set
shows partial observability as
cannot be reconstructed but biomass
X could. The carbon dioxide model requires the measurement of
together with another variable (
or
E or
S) to fulfill the observability condition. An observer could, therefore, be designed to estimate the sugar concentration online, which is the most expensive measurement using an online or at-line hardware probe.
5. Parameter Identification Problem
Parameter identification is achieved using classical nonlinear parameter estimation techniques [
22]. The procedure considers a Weighted Least-Square (WLS) criterion, i.e., a weighted sum of squared differences between model predictions and experimental measurements:
where J is the value of the cost function,
is the vector of
N measured variables at the measurement instant
(
),
is the model prediction that depends on the set of
P parameters
to be identified, and W is a normalization matrix where the diagonal elements are chosen as the squares of the maximum measurements values of each component concentration. This choice allows normalization of the prediction errors, and is particularly well-suited to a relative error model where it is assumed that the error is proportional to the maximum values of the observed variables:
The estimated parameter set is obtained by minimizing a cost function
as follows:
To achieve the minimization of (
32), a two-step procedure is implemented: (a) a multi-start strategy defines random sets of initial parameter values to cover as much as possible of the search field. The minimization of (
32) is first performed using the Matlab
® optimizer fminsearch (Nelder-Mead algorithm); (b) the Matlab lsqnonlin optimizer is subsequently used from the identified global minimum (i.e., the smallest local minimum identified in the search space by fminsearch) to refine the minimization and compute the Jacobian matrix containing the model parameter sensitivities, denoted
. These sensitivities can be exploited to compute the Fisher Information Matrix (FIM) defined as:
where
is the a posteriori covariance matrix of the measurement errors, which can be evaluated using the weighting matrix W (Equation (
31)) and an a posteriori estimator of the relative measurement error:
where
is the value of the cost function at the optimum,
represents the total number of data, and
P is the number of estimated parameters
. An estimate of the parameter estimation error covariance matrix can then be inferred from the Cramer–Rao bound as follows:
From the diagonal of the covariance matrix
, the standard deviations for each parameter can be extracted and the corresponding coefficients of variations can be calculated as:
To achieve the estimation of the parameters of the beer fermentation models, a total of 4 batch experiments are considered as shown in
Table 2. Out of these 4 experiments, 3 are used for parameter estimation and model direct validation (experiments 2 to 4), while experiment 1 is used for cross-validation. An important point of the current work is the use of all the samples of experiments 2, 3, 4 to achieve the identification, including two temperature-varying parameters, i.e., the specific growth rate
and the
reduction rate
. Previous studies have indeed demonstrated that the other parameters do not change significantly with temperature. In addition to the stoichiometric and kinetic parameters, the initial conditions are also considered unknown (and are therefore estimated) since possibly corrupted by measurement noise.
5.1. Biomass Model
This model counts 8 parameters (
,
,
,
,
,
,
,
) to be estimated. The dependence on temperature of the parameters
and
, is formulated as follows:
introducing the additional parameters
a,
b,
c,
d. Several nonlinear model structures have been considered to correlate the parameters with the temperature. It turned out that the selected logarithmic structure provides the best results.
In practice, the identification proceeds in three steps: (a) a first parameter estimation without explicit temperature dependence (i.e., and are considered constant), (b) an estimation of the four parameters linked to the temperature dependence (the others being fixed at their previously estimated values), and (c) a global identification of all the parameters starting from the previous estimates.
Good practice recommends partitioning the data using a ratio of approximately 75/25 for parameter estimation (and subsequent direct validation), and cross-validation, respectively. Accordingly, three experimental data sets are used in direct validation and the remaining one in cross-validation. Since the parameter estimation procedure aims at capturing information on the process in a wide range of operations, it is legitimate to include experiments with different initial sugar and biomass concentrations and temperature levels. Particularly, it is important to collect informative data regarding the evolution of
and
with respect to temperature in (
37). Among the several possible data partitions, one possible combination appears to be: experiments 2, 3, 4 for parameter estimation (and direct validation) and experiment 1 for cross-validation. Indeed, experiments 1 and 2 are carried out at the same temperature, but experiment 2 also includes different sugar and biomass initial conditions.
Table 5 reports the values of the estimated parameters and their coefficients of variations.
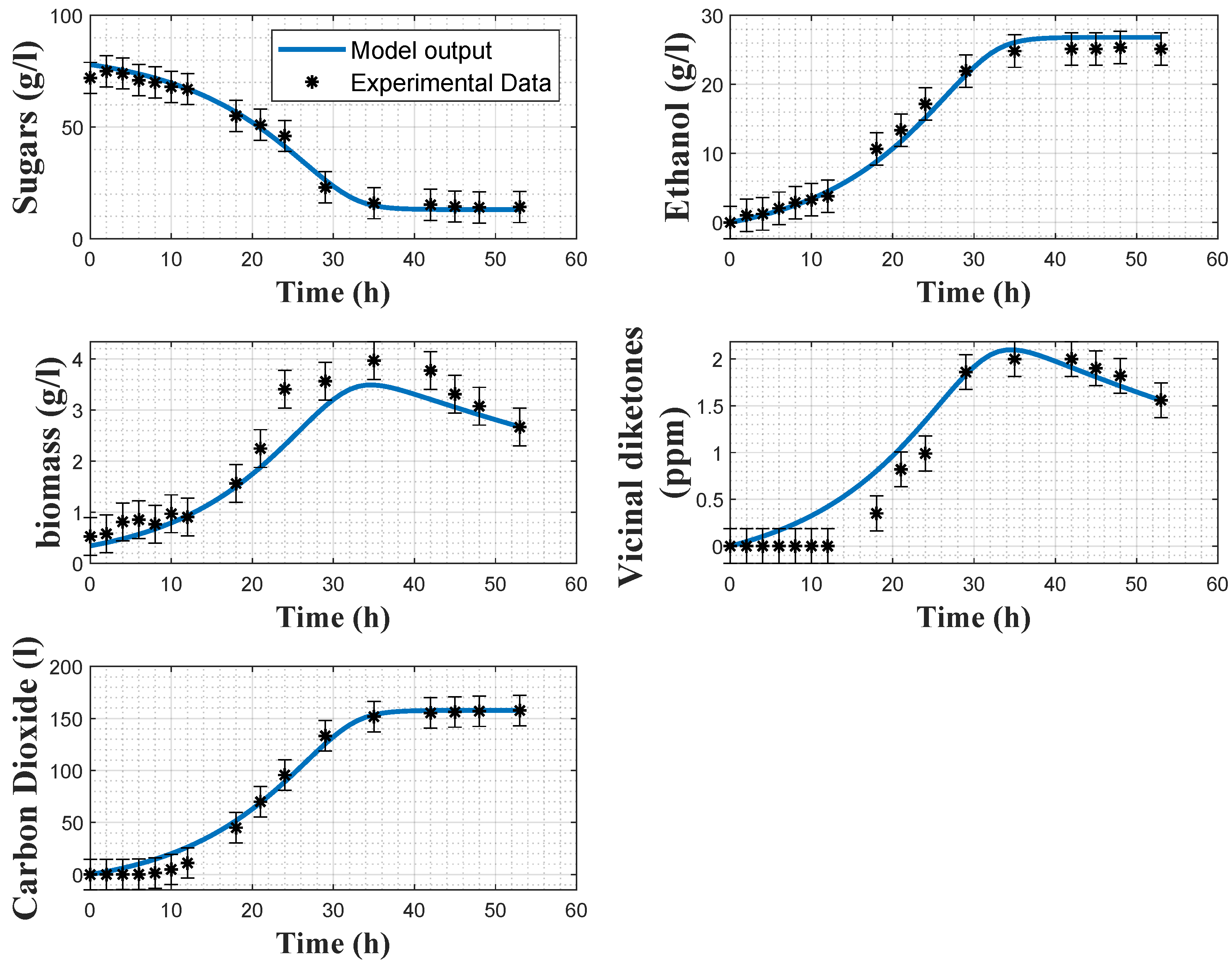
Figure 2 and
Figure 3 show some direct validation results, i.e., the fitting of the model to the experimental data collected in experiments 2 and 4 together with the a posteriori error bars on the experimental data. The model reproduces quite well the dynamics of the several variables, even if the biomass predictions sometimes deviate from the confidence intervals of the data, and some deviations in the VDK production are also observed in the early hours. The coefficients of variations confirm the good estimation results, as the maximum relative CV is
for the minimum substrate quota
.
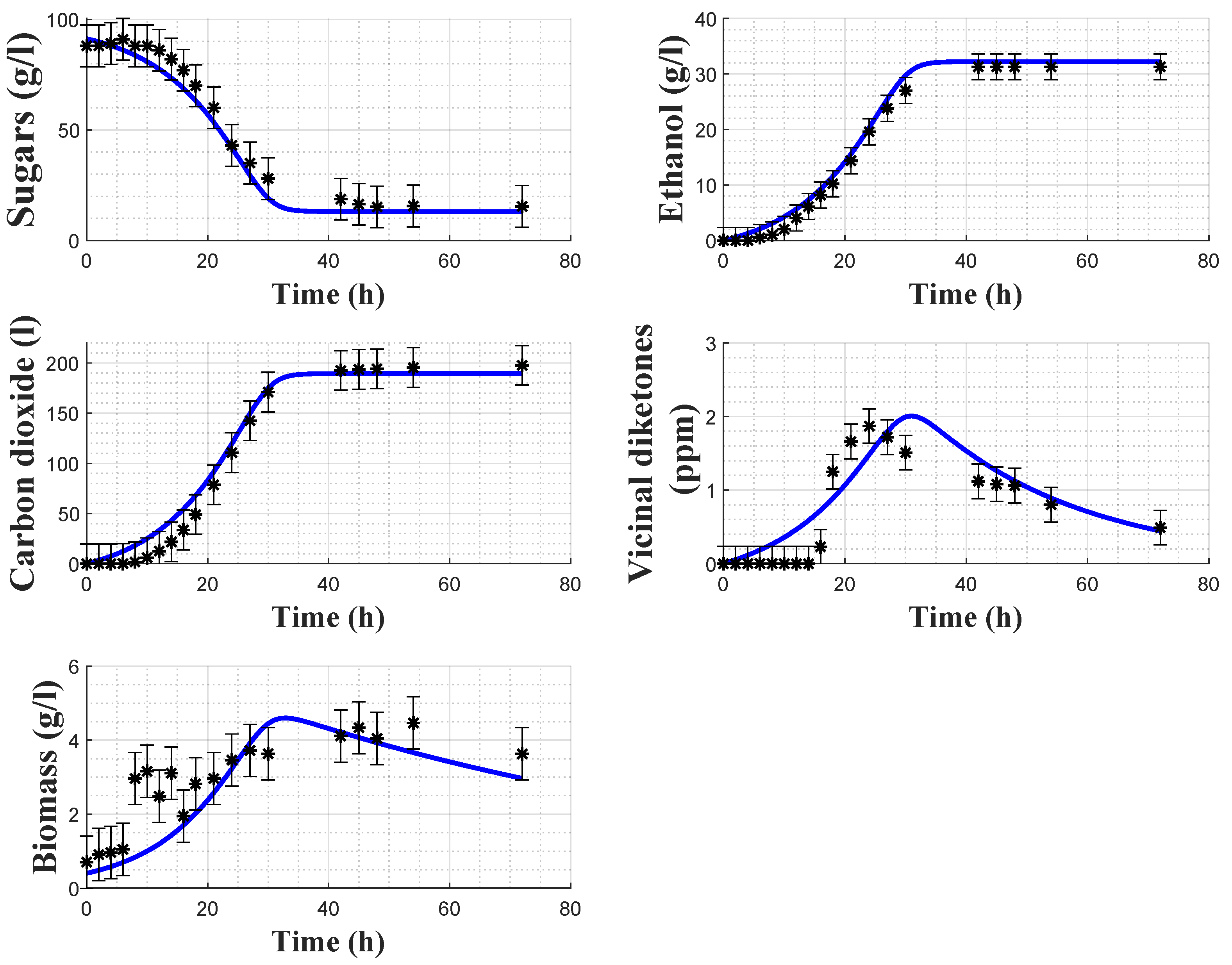
In order to assess the model predictive capacity, cross-validation is achieved using the dataset from experiment 1. In this case, only the initial conditions are estimated while the parameters are kept fixed. As shown in
Figure 4, the model predicts satisfactorily the experimental data. The biomass data again has some uncertainty, which can probably be linked to several factors such as cell counting errors, biomass mixing (to counteract biomass settling and collect representative samples) and nitrogen limitation [
23].
Vicinal diketone dynamics present a varying latency phase followed by production/consumption, both driven by biomass dynamics. The uncertainty on the latency period compromises the resulting fitting since biomass does not exhibit the same behavior in the early phase of fermentation.
5.2. Carbon Dioxide Model
A similar procedure was applied to estimate the values of the carbon dioxide model parameters. In this case, the dependence on temperature of
and
is best represented by:
Hence, the resulting model counts 10 parameters (
,
,
,
,
,
a,
b,
c,
d,
e), and
Table 6 reports the estimated values with their respective coefficients of variations. As can be noticed, the latter are smaller than the ones of the previous model, mainly due to the absence of biomass measurement and the associated uncertainty.
The identification is again decomposed into distinctive steps: (a) estimation of the parameters without temperature dependence and with an arbitrary value for whose practical identifiability is poor, (b) estimation of with all the other parameters fixed at their previously estimated values, (c) estimation of the parameter linked to the temperature dependence (a to e) with all the others fixed to their previous values, and (d) final re-estimation of all the parameters.
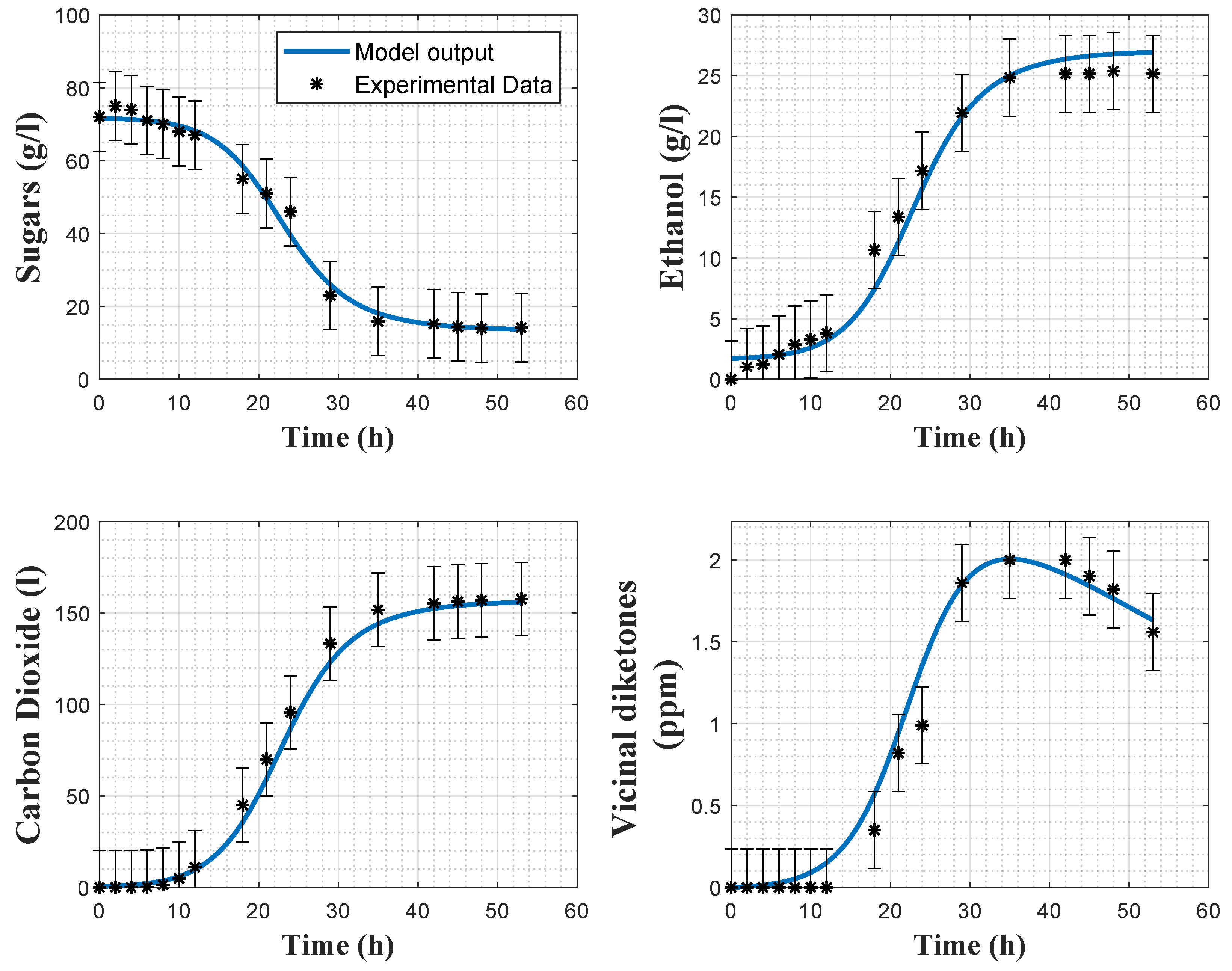
Figure 5 and
Figure 6 show the direct validation with experiments 2 and 4, as well as the a posteriori error bars on the experimental data.
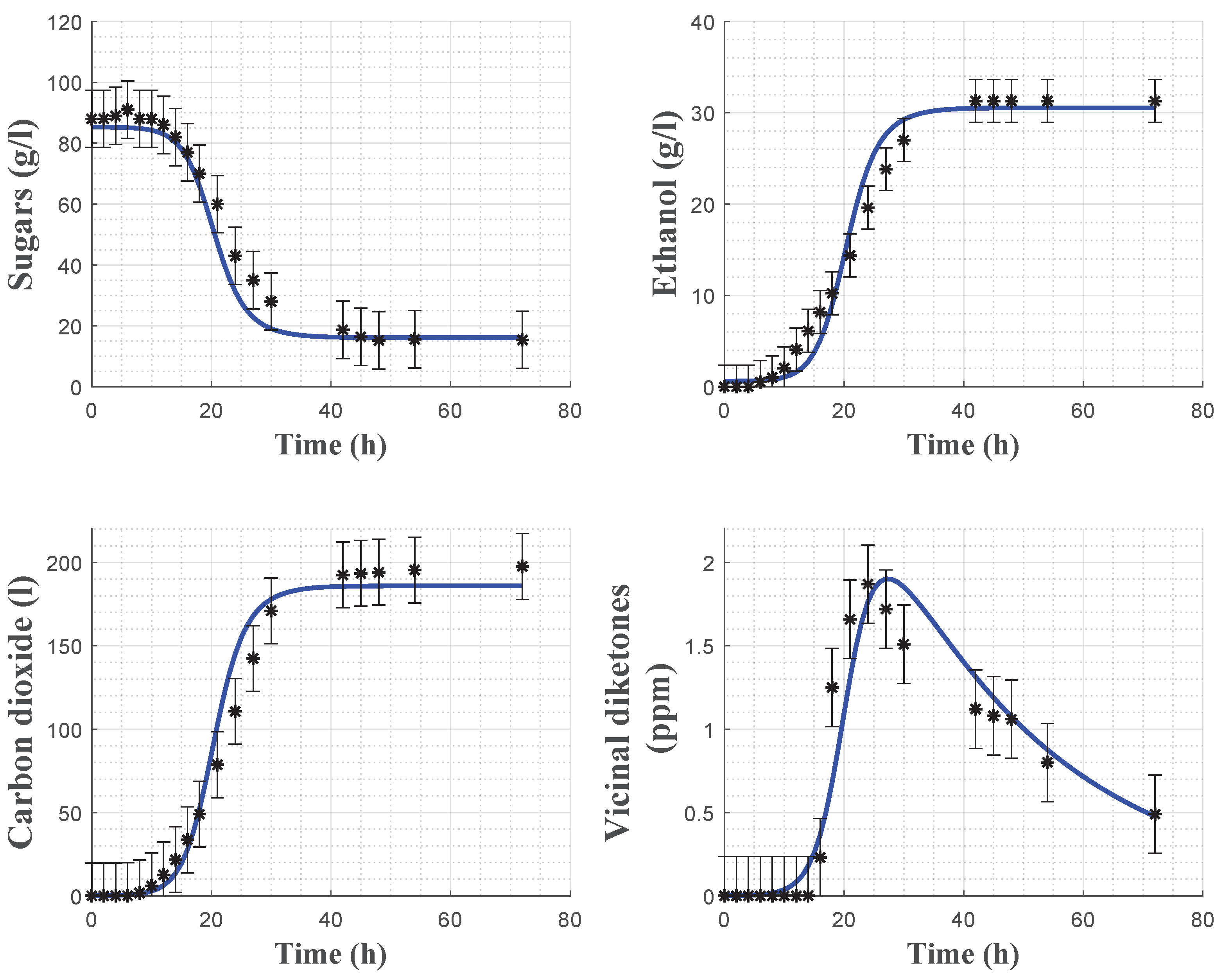
Model cross-validation using experiment 1 is shown in
Figure 7 and confirms the satisfactory predictive capacity of the model, except for some minor deviations in the evolution of the VDKs due to the presence of a time-varying latency phase.
In
Table 7, the root means square errors (RMSEs) are provided for each experiment and each variable separately. The cost function residuals of the direct validations are also provided. It can be observed that, overall, the RMSE values are small for both models. Regarding the biomass model,
X and
present larger RMSEs than the other variables, due to the observed deviations between the model prediction and the experimental data in
Figure 2 and
Figure 3. Regarding the carbon dioxide model, RMSEs indicate a better fit with the experimental data. This statement is confirmed by
Figure 5 and
Figure 6. Cross-validation results also support this analysis since the RMSEs of the biomass and carbon dioxide models are, respectively, 1.997 and 0.846.
Discriminating among the proposed models is difficult since they target different variables. However, taking into account the cost function residuals, the carbon dioxide model fit better to the current operating conditions and monitoring set-up (J = 0.72) than the biomass model (J = 1.76). Furthermore, from a practical point of view, the identification of the dioxide carbon model requires a sensor configuration that is easier to set up, limiting offline analytical analysis. Conversely, the identification of the biomass model requires offline cell counting to measure yeast concentration. Moreover, considering process control, carbon dioxide online sensors are affordable, whereas biomass sensors are expensive (alternatively a biomass software sensor could be developed based on the measurements of , E, VDK). The main advantage of the biomass model lies in the provided information about the biomass metabolic state during the fermentation process, allowing a more straightforward detection of possible contamination.
6. Conclusions
The demand for processes with more rigorous quality standards, as is the case in the pharmaceutical industry, has led to the development of approaches such as process analytical technologies (PAT), now being extended to the agro-food sector and, more specifically, to the brewing industry. This work is motivated by the growing importance of mathematical modeling, in the context of PAT, to design process digital twins that can support lab-scale operations. Model-based advanced monitoring and control techniques can indeed be developed in view of optimizing and improving the process. In this study, two alternative models, initially proposed in seminal works, are adapted and identified under realistic experimental conditions. One of the models is based on the description of the biomass evolution, while the other, more pragmatic, considers carbon dioxide, a more accessible variable that can be measured with cheap sensors. These models take account of the temperature influence in a simple way. A systematic identification procedure is described. Cross-validation highlights the good predictive capability of both models, which are good candidates for model-based control.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}