Discrimination of the Red Jujube Varieties Using a Portable NIR Spectrometer and Fuzzy Improved Linear Discriminant Analysis



Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Spectra Collection
2.3. NIR Spectra Preprocessing
2.4. Data Analysis Methods
2.4.1. Principal Component Analysis
2.4.2. Linear Discriminant Analysis
2.4.3. Improved Linear Discriminant Analysis
2.4.4. Fuzzy Improved Linear Discriminant Analysis
- Define the matrices , and ;
- B←;
- Eigen decomposition of B as ;
- ,;
2.4.5. K Nearest Neighbor
2.5. Software
3. Results and Discussion
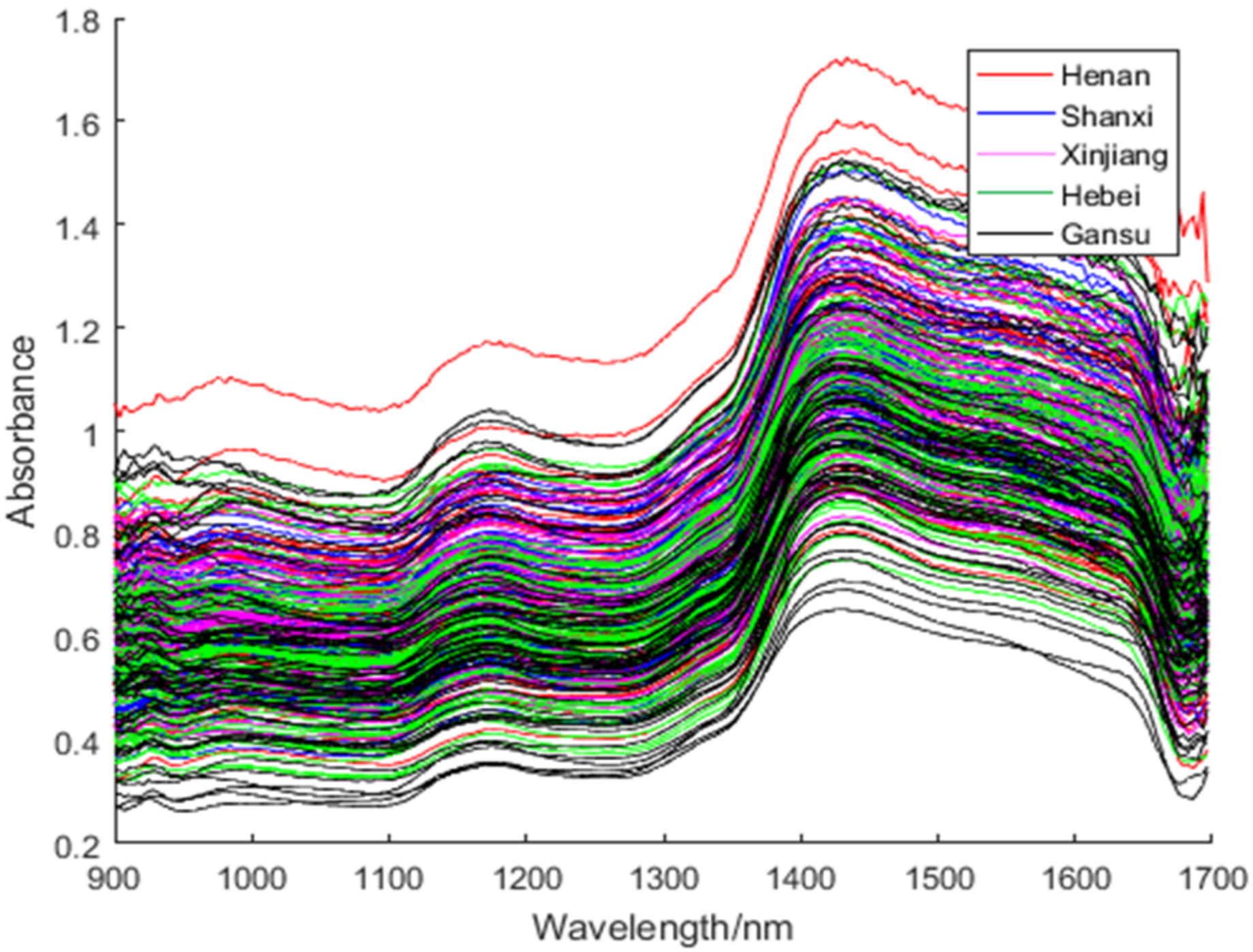
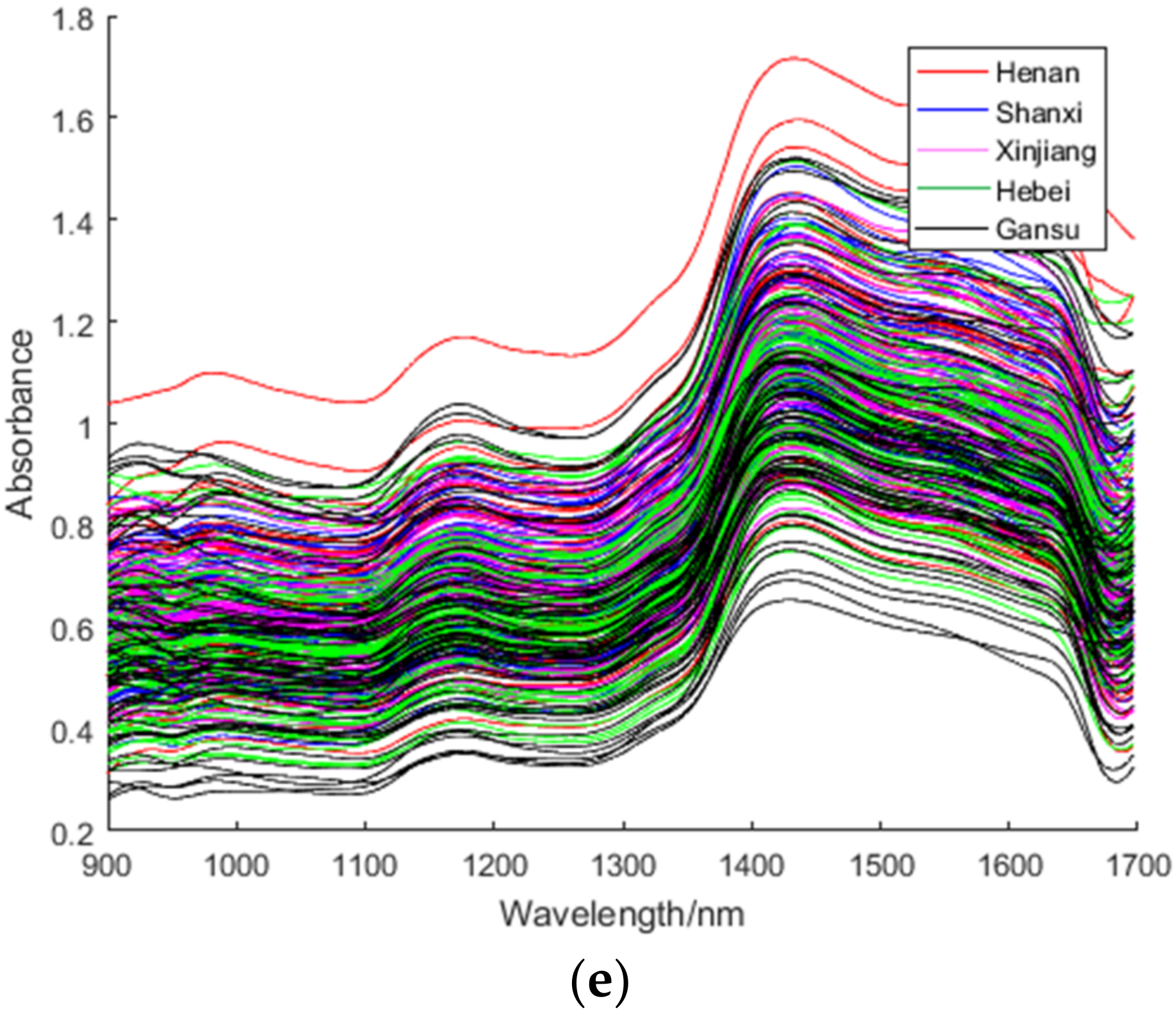
3.1. Spectral Analysis
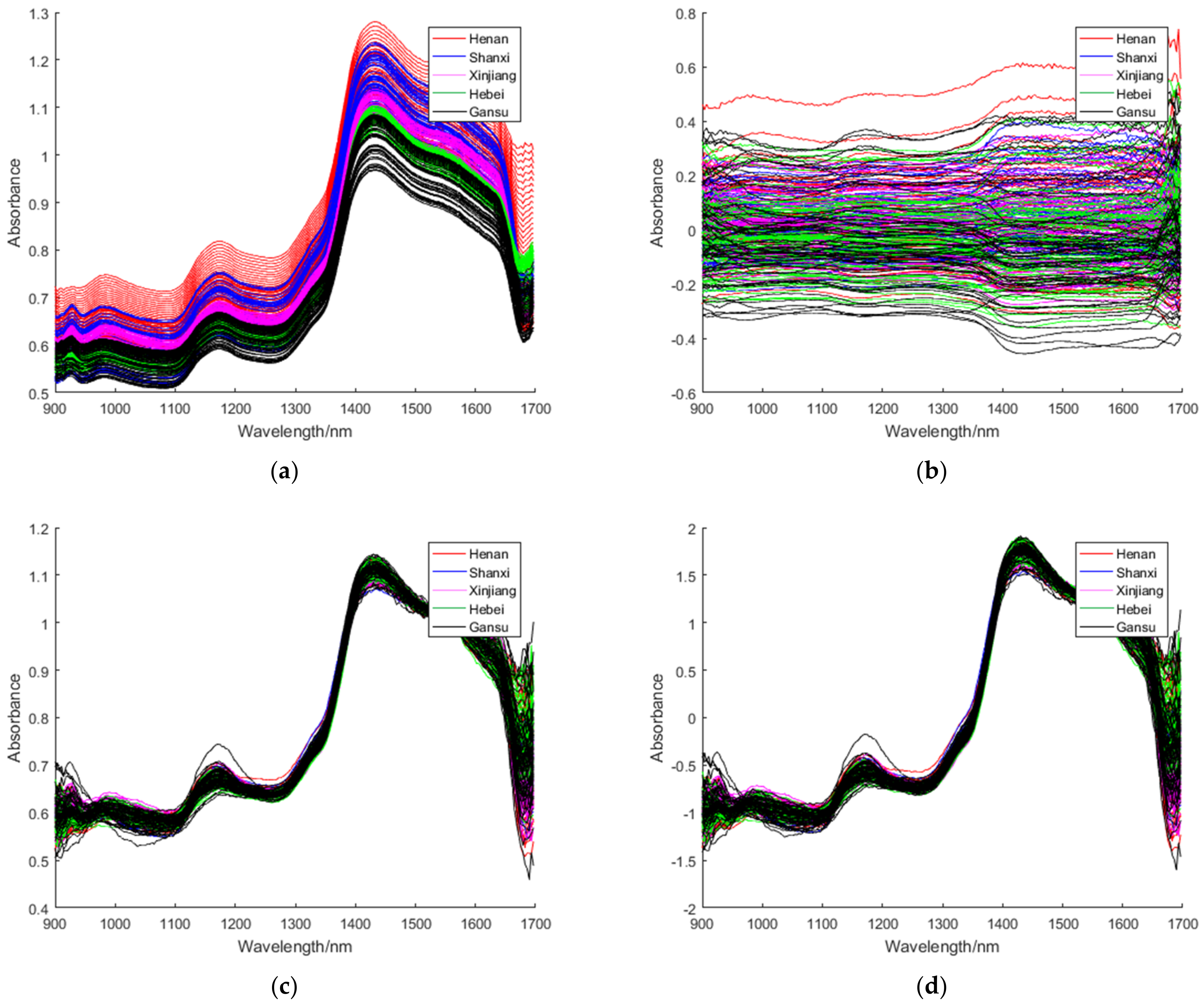
3.2. Spectral Preprocessing
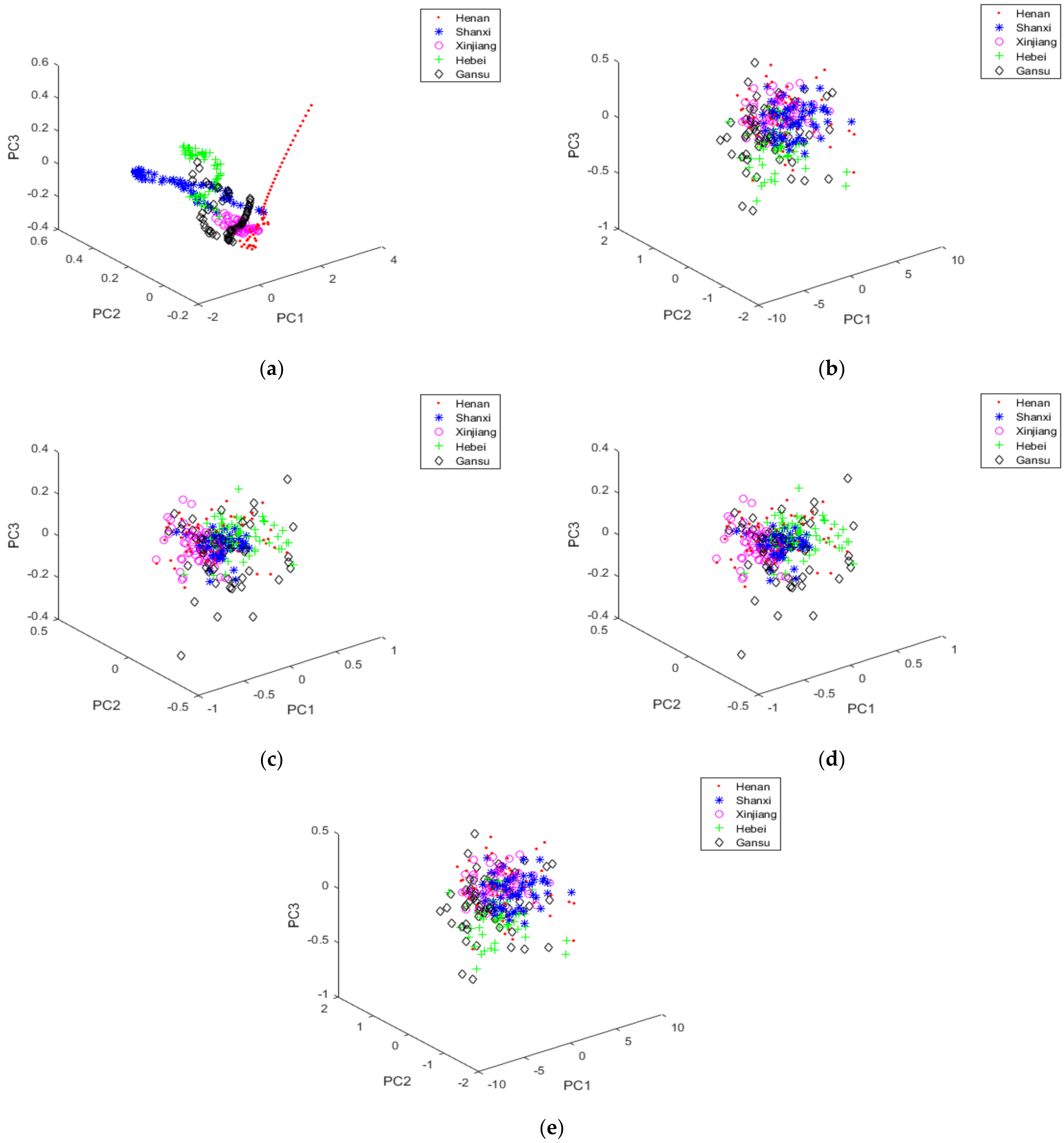
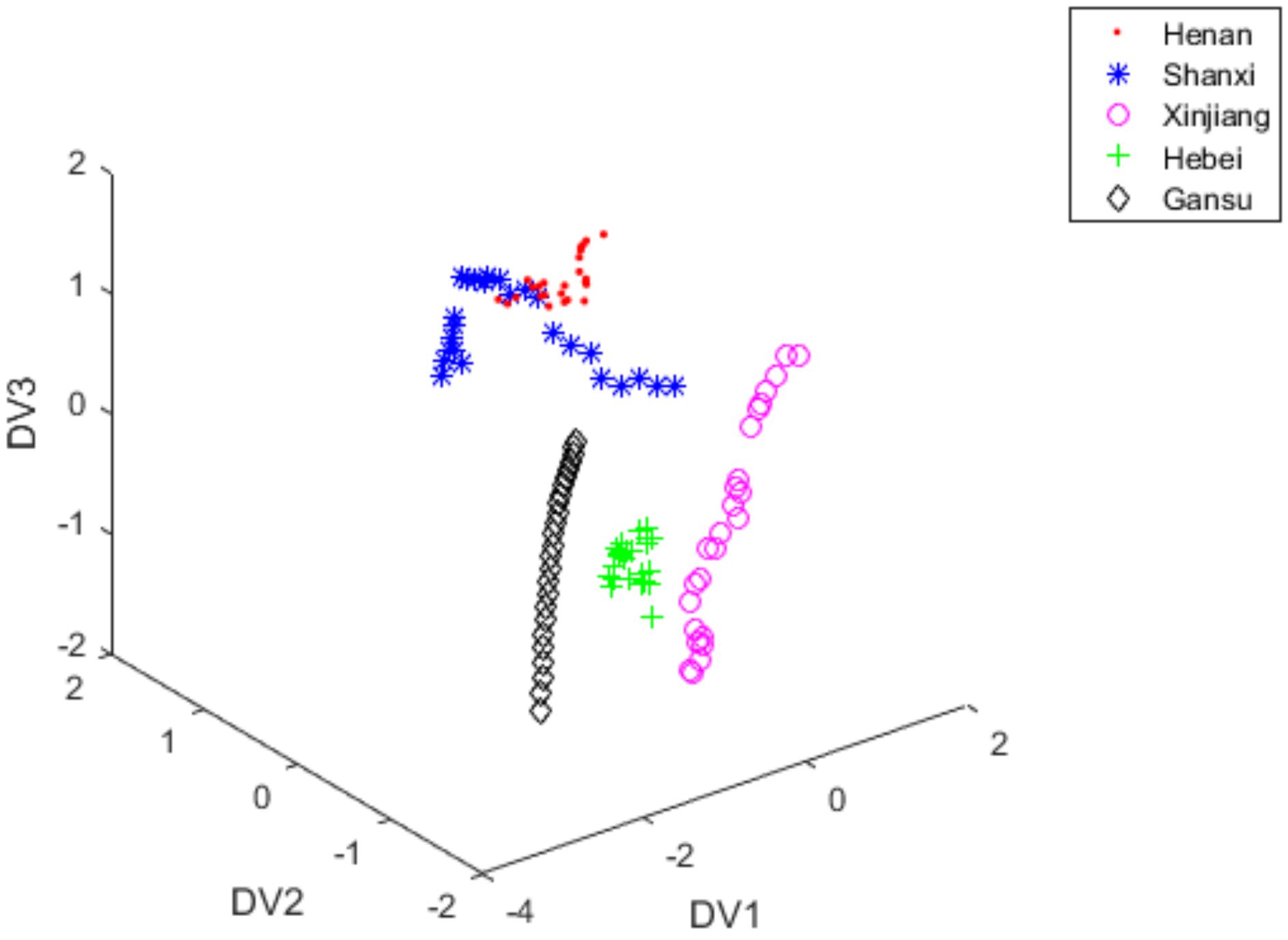
3.3. Classification with PCA + LDA
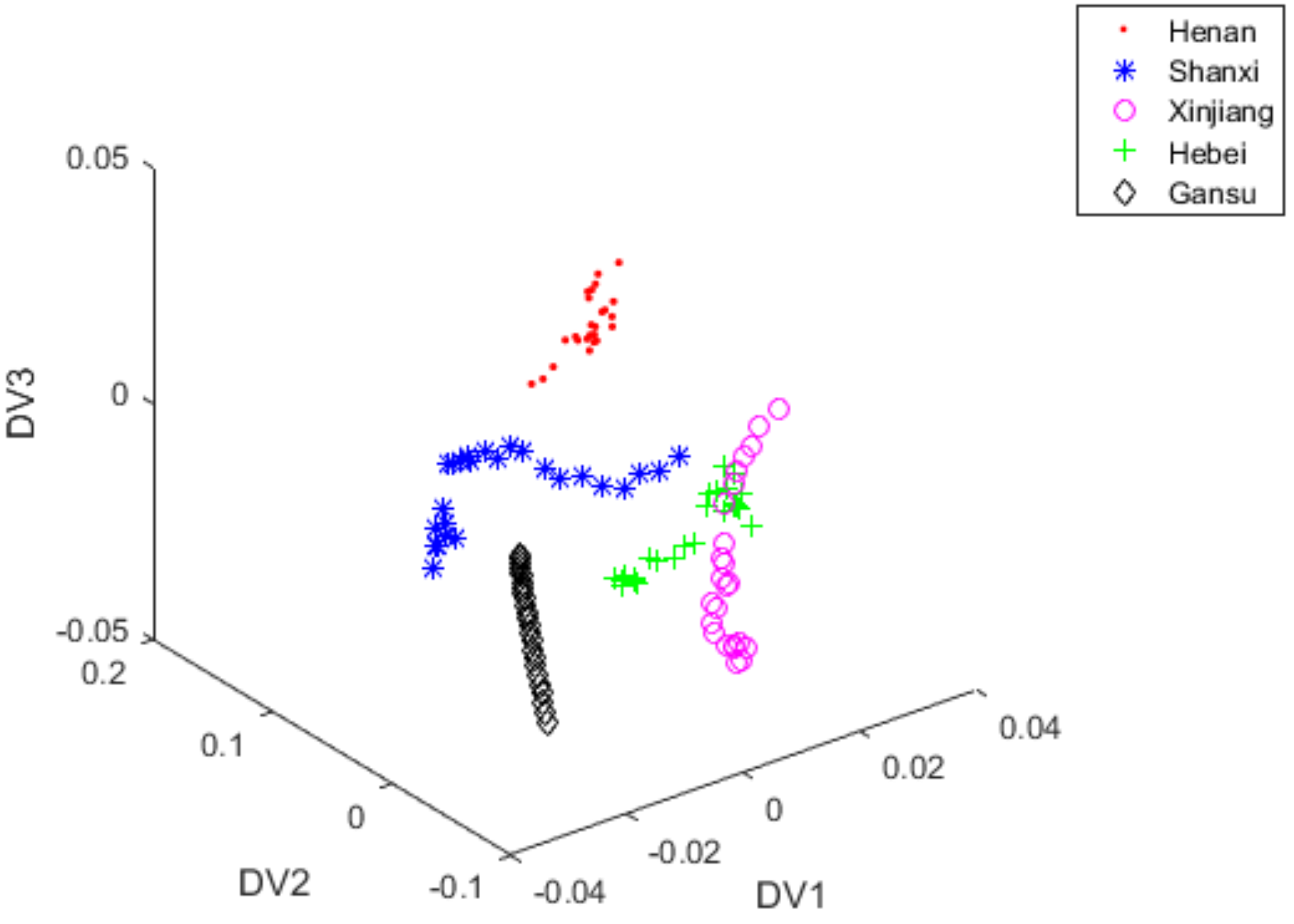
3.4. Classification with iLDA
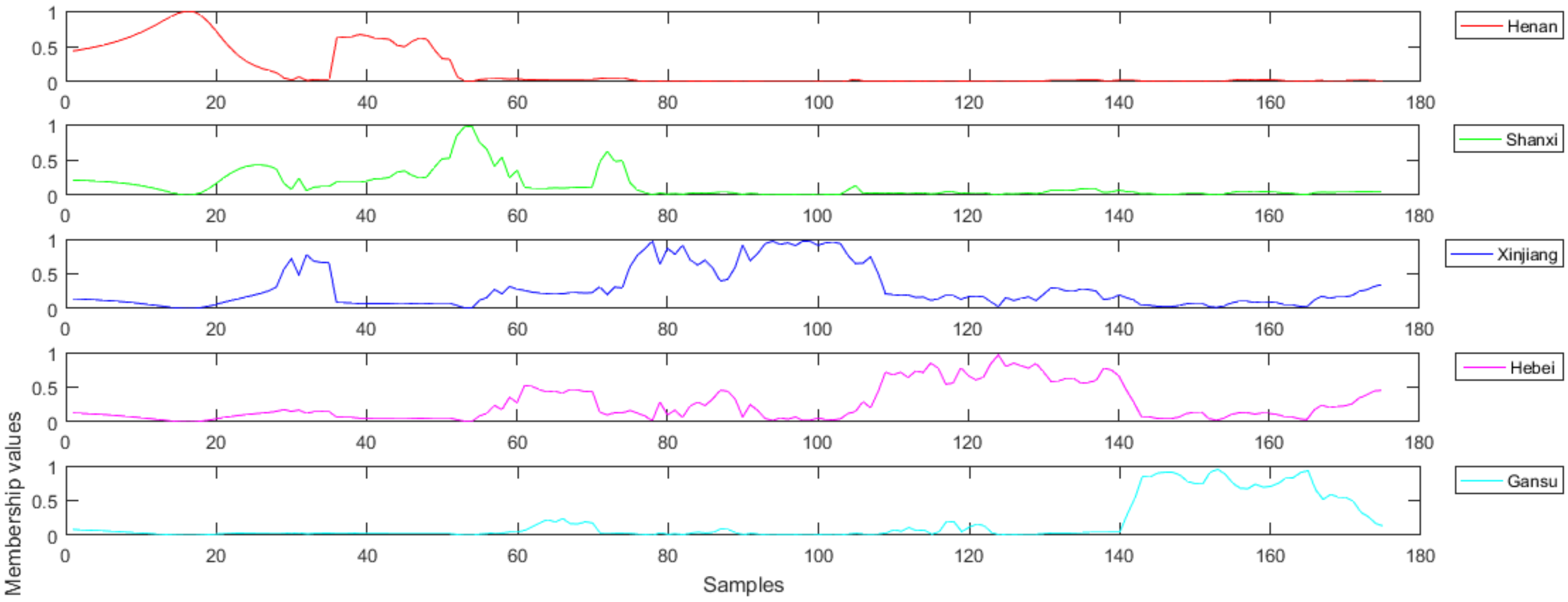
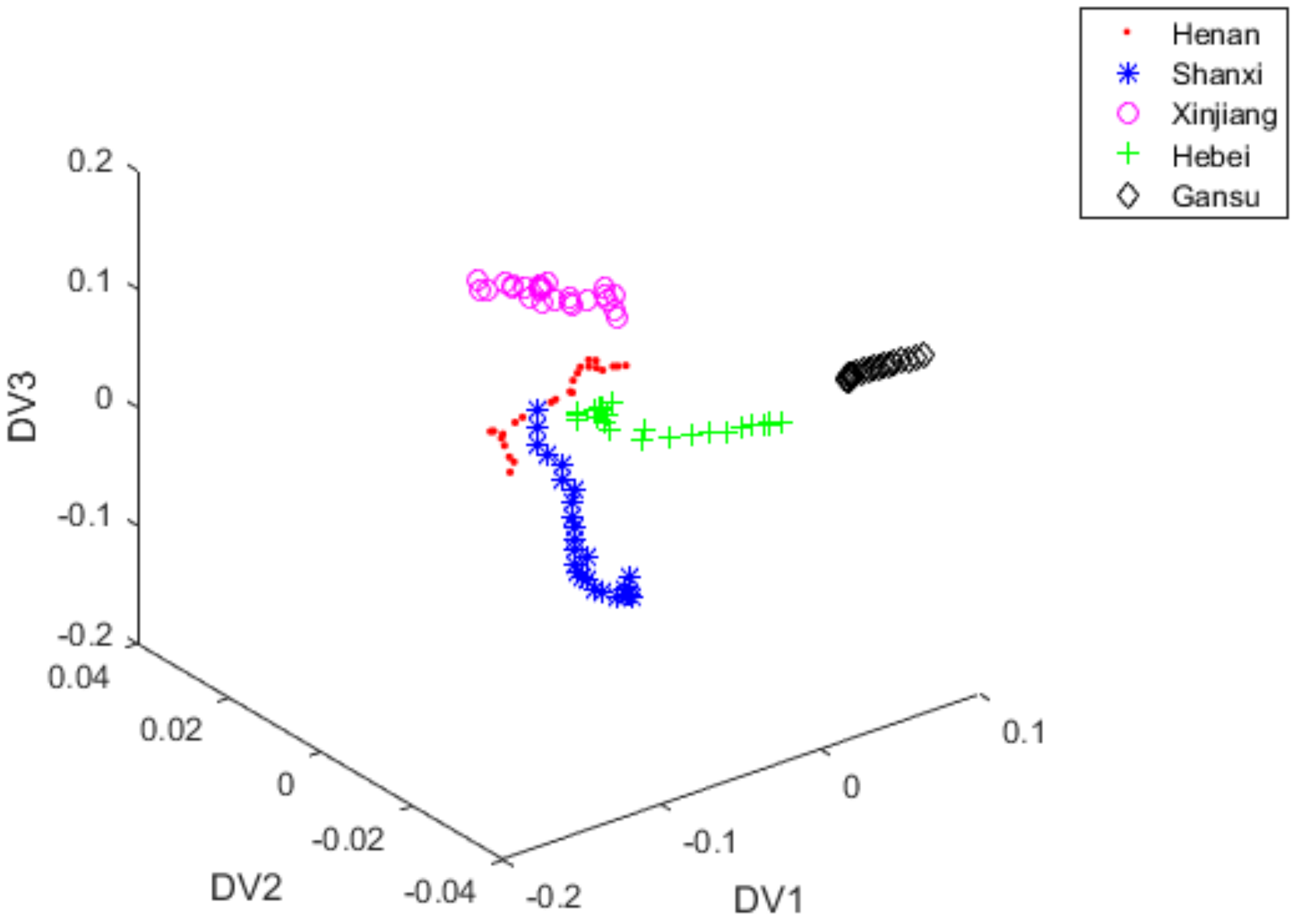
3.5. Classification with FiLDA
3.6. Classification Results of KNN
3.7. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, J.; Hou, Y.; Chang, N. Determination of amino acid content and principal component analysis of Shanxi jujube. Food Res. Dev. 2021, 42, 141–145. [Google Scholar]
- Mairemu, S.Y. Establishment of near infrared spectroscopy for Jun jujube sugar of different mature period. Anhui Agric. Sci. Bull. 2017, 23, 143–145. [Google Scholar]
- Wang, H.Q.; Zhang, H.H.; Zhuo, S.P.; Zhang, Z.; Li, H.F. Identification of jujube fruit species based on dielectric properties. Food Sci. Technol. 2014, 7, 304–308. [Google Scholar]
- Chen, Q.S.; Chen, M.; Liu, Y.; Wu, J.Z.; Wang, X.Y.; Ouyang, Q.; Chen, X.H. Application of FT-NIR spectroscopy for simultaneous estimation of taste quality and taste-related compounds content of black tea. Food Sci. Technol. Mysore. 2018, 55, 4363–4368. [Google Scholar] [CrossRef]
- Jiang, H.; Chen, Q.S. Chemometric models for the quantitative descriptive sensory properties of green tea (Camellia sinensis L.) using Fourier transform near infrared (FT-NIR) spectroscopy. Food Anal. Method. 2015, 8, 954–962. [Google Scholar] [CrossRef]
- Ripoll, G.; Lobón, S.; Joy, M. Use of visible and near infrared reflectance spectra to predict lipid peroxidation of light lamb meat and discriminate dam’s feeding systems. Meat Sci. 2018, 143, 24–29. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.J.; Zareef, M.; He, P.H.; Sun, H.; Chen, Q.S.; Li, H.H.; Xu, D.L. Evaluation of matcha tea quality index using portable NIR spectroscopy coupled with chemometric algorithms. J. Sci. Food Agric. 2019, 99, 5019–5027. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, H.; Liu, G.H.; Mei, C.L.; Huang, Y.H. Identification of radix puerariae starch from different geographical origins by FT-NIR spectroscopy. Int. J. Food Prop. 2017, 20, 1567–1577. [Google Scholar] [CrossRef]
- Tan, B.; Xiao, T.F.; Liu, Q.L.; Li, G.; Huang, C.X.; Li, G. Nondestructive detection experiment of typical economic fruit near-infrared diffuse reflection and its spectral data analysis. Hubei Agric. Sci. 2020, 59, 154–158. [Google Scholar]
- Lei, S.Z.; Yao, H.G. Applications of near infrared spectrum technique for non-destructive measurement of fruit quality. Chinese J. Spectrosc. Lab. 2009, 26, 775–779. [Google Scholar]
- Shang, J.; Zhang, Y.; Meng, Q.L. Nondestructive identification of apple varieties by VIS/NIR spectroscopy. Storage. Process 2019, 19, 8–14. [Google Scholar]
- Zhan, Y.; Peng, Y.F.; Peng, H.G.; Luo, H.P. Application of near-infrared spectroscopy nondestructive testing of jujube in south xinjiang sugar content. J. Agric. Mech. Res. 2014, 36, 179–183. [Google Scholar]
- Wu, X.H.; Wu, B.; Sun, J.; Li, M. Rapid discrimination of apple varieties via near-infrared reflectance spectroscopy and fast allied fuzzy c-means clustering. Int. J. Food Eng. 2014, 11, 23–30. [Google Scholar] [CrossRef]
- Wu, X.H.; Wu, B.; Sun, J.; Li, M.; Du, H. Discrimination of apples using near infrared spectroscopy and sorting discriminant analysis. Int. J. Food Prop. 2016, 19, 1016–1028. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Hao, L.; Chen, Q.; Huang, X.; Sun, Z.; Fang, Z. Identification of egg’s freshness using NIR and support vector data description. J. Food Eng. 2010, 98, 408–414. [Google Scholar] [CrossRef]
- Teye, E.; Huang, X.; Takrama, J.; Haiyang, G. Integrating NIR spectroscopy and electronic tongue together with chemometric analysis for accurate classification of cocoa bean varieties. J. Food Process Eng. 2014, 37, 560–566. [Google Scholar] [CrossRef]
- Xing, Z.; Hou, X.; Tang, Y.; He, R.; Mintah, B.K.; Dabbour, M. Monitoring of polypeptide content in the solid-state fermentation process of rapeseed meal using NIRS and chemometrics. J. Food Process Eng. 2018, 41, e12853. [Google Scholar] [CrossRef]
- Guo, Z.; Barimah, A.O.; Shujat, A.; Zhang, Z.; Chen, Q. Simultaneous quantification of active constituents and antioxidant capability of green tea using NIR spectroscopy coupled with swarm intelligence algorithm. LWT-Food Sci. Technol. 2020, 129, 109510. [Google Scholar] [CrossRef]
- Cai, J.R.; Chen, Q.S.; Wan, X.M.; Zhao, J.W. Determination of total volatile basic nitrogen (TVB-N) content and warner-bratzler shear force (WBSF) in pork using Fourier transform near infrared (FT-NIR) spectroscopy. Food Chem. 2011, 126, 1354–1360. [Google Scholar] [CrossRef]
- Huang, X.Y.; Xu, H.X.; Wu, L.; Dai, H.; Yao, L.Y.; Han, F.K. A data fusion detection method for fish freshness based on computer vision and near-infrared spectroscopy. Anal. Method 2016, 8, 2929–2935. [Google Scholar] [CrossRef]
- Wu, X.H.; Fu, H.J.; Tian, X.Y.; Wu, B.; Sun, J. Prediction of pork storage time using Fourier transform near infrared spectroscopy and adaboost ULDA. J. Food Process Eng. 2017, 40, e12566. [Google Scholar] [CrossRef]
- Fan, Y.; Qiu, Z.; Chen., J.; Wu, X.; He, Y. Identification of varieties of dried red jujubes with near-infrared hyperspectral imaging. Spectrosc. Spectr. Anal. 2017, 37, 836–840. [Google Scholar]
- Zhang, J.C.; Zhang, X.; Bai, T.C.; Shi, L.Z. Jujube species identification based on near infrared spectroscopy and PLS-DA. Sci. Technol. Food Ind. 2017, 38, 68–71, 76. [Google Scholar]
- Luo, H.P.; Wang, L.; Guo, L.; Xuan, Z.Y. The research to detection the moisture content of southern jujube rapidly with near infrared spectroscopy. Int. Acad. Annu. Meet China Agric. Mach. Soc. 2012, 14, 25–28. [Google Scholar]
- Guo, W.C.; Gu, J.S.; Liu, D.Y.; Shang, L. Peach variety identification using near-infrared diffuse reflectance spectroscopy. Comput. Electron. Agric. 2016, 123, 297–303. [Google Scholar] [CrossRef]
- Cao, F.; Wu, D.; He, Y. Soluble solids content and pH prediction and varieties discrimination of grapes based on visible–near infrared spectroscopy. Comput. Electron. Argic. 2010, 71, 15–18. [Google Scholar] [CrossRef]
- Sánchez, M.T.; Haba, M.J.D.L.; Benítez-López, M.; Fernández-Novales, J.; Garrido-Varo, A.; Perez-Marin, D. Non-destructive characterization and quality control of intact strawberries based on NIR spectral data. J. Food Eng. 2012, 110, 102–108. [Google Scholar] [CrossRef]
- Pérez-Marín, D.; Paz, P.; Guerrero, J.M.; Garrido-Varo, A.; Sánchez, M.T. Miniature handheld NIR sensor for the on-site non-destructive assessment of post-harvest quality and refrigerated storage behavior in plums. J. Food Eng. 2010, 99, 294–302. [Google Scholar] [CrossRef]
- Yan, C.; Fan, L. Feature extraction using fuzzy maximum margin criterion. Neurocomputing 2012, 86, 52–58. [Google Scholar]
- Huang, P.; Yang, Z.J.; Chen, C.K. Fuzzy local discriminant embedding for image feature extraction. Comput. Elect. Eng. 2015, 46, 231–240. [Google Scholar] [CrossRef]
- Xie, J.; Li, J.; Wang, H.; Zeng, W.; Guo, P. The methods for two-dimensional fiber spectra extraction. In Proceedings of the 2016 12th International Conference on Computational Intelligence and Security (CIS), Wuxi, China, 16–19 December 2016; pp. 487–491. [Google Scholar]
- Liu, Z.B. An improved LDA algorithm and its application to face recognition. Comput. Eng. Sci. 2011, 33, 89–93. [Google Scholar]
- Huang, Y.; Guan, Y. On the linear discriminant analysis for large number of classes. Eng. Appl. Artif. Intell. 2015, 43, 15–26. [Google Scholar] [CrossRef]
- Liang, J.F.; Wu, W.; Chen, D.W. Identification of liquor authenticity based on FTIR with PCA- LDA. Sci. Technol. Food Ind. 2016, 37, 309–312. [Google Scholar]
- Yang, Z.; Wang, N.; Ullah, N.; Liang, Y.; Yang, X.; Cheng, Z. Quality of jujube beverage fermented by lactic acid based on electronic nose analysis. Acta. Agric. Boreali Occiden Sin. 2015, 24, 149–156. [Google Scholar]
- Wei, Y.; Lin, L.; Yang, X.; Li, D.; Fu, H.; Yang, T. NIR fiber technology combined with pattern recognition forrapid identification of melamine adulteration in milk. China Dairy Ind. 2016, 44, 48–51. [Google Scholar]
- Ye, J.P. Characterization of a family of algorithms for generalized discriminant analysis on undersampled problems. J. Mach. Learn. Res. 2005, 6, 483–502. [Google Scholar]
- Shen, Y.; Wu, X.; Wu, B.; Tan, Y.; Liu, J. Qualitative analysis of lambda-cyhalothrin on Chinese cabbage using mid-infrared spectroscopy combined with fuzzy feature extraction algorithms. Agriculture 2021, 11, 275. [Google Scholar] [CrossRef]
- Xiong, C.C.; Li, L.; Wang, T.Y. Establishment of a cinnamon habitat model based on near infrared spectroscopy. Northwest Pharm. J. 2016, 31, 221–225. [Google Scholar]
- Yu, M.; Li, S.; Yang, F.; Zheng, Y.; Li, P.; Jiang, L.; Liu, X. Identification on different origins of citri reticulatae pericarpium using near infrared spectroscopy combined with optimized spectral pretreatments. J. Instrum. Anal. 2021, 40, 65–71. [Google Scholar]
- Chen, J.; Jonsson, P. A simple method for reconstructing a high-quality NDVI time-series data set based on the savitzky-golay filter. Remote Sens. Environ. 2004, 91, 332–344. [Google Scholar] [CrossRef]
- Chen, S.Y.; Zhao, Q.M.; Dong, D.M. Application of near infrared spectroscopy combined with comparative principal component analysis for pesticide residue detection in fruit. Spectrosc. Spectr. Anal. 2020, 40, 917–921. [Google Scholar]
- Wu, X.H.; Zhou, H.X.; Wu, B.; Fu, H.J. Determination of apple varieties by near infrared reflectance spectroscopy coupled with improved possibilistic Gath–Geva clustering algorithm. J. Food Process Preserv. 2020, 44, e14561. [Google Scholar] [CrossRef]
- Dixon, S.J.; Brereton, R.G. Comparison of performance of five common classifiers represented as boundary methods: Euclidean distance to centroids, linear discriminant analysis, quadratic discriminant analysis, learning vector quantization and support vector machines, as dependent on data structure. Chemometr. Intell. Lab. Syst. 2009, 95, 1–17. [Google Scholar]
- Dogantekin, E.; Dogantekin, A.; Avci, D. An automatic diagnosis system based on thyroid gland: ADSTG. Expert. Syst. Appl. 2010, 37, 6368–6372. [Google Scholar] [CrossRef]
- Dixon, S.J. Application of classification methods when group sizes are unequal by incorporation of prior probabilities to three common approaches: Application to simulations and mouse urinary chemosignals. Chemometr. Intell. Lab. Syst. 2009, 99, 111–120. [Google Scholar] [CrossRef]
- Wu, B.; Wang, D.Z.; Ji, G. Classification of vinegars based on orthogonal linear discriminant analysis and electronic nose technology. Food Ferment. Ind. 2020, 46, 263–268. [Google Scholar]
- Wu, L.G.; He, J.G.; Liu, G.S.; Wang, S.L.; He, X.G. Detection of common defects on jujube using Vis-NIR and NIR hyperspectral imaging. Postharvest Biol. Technol. 2016, 112, 134–142. [Google Scholar] [CrossRef]
- Wang, J.; Nakano, K.; Ohashi, S. Nondestructive detection of internal insect infestation in jujubes using visible and near-infrared spectroscopy. Postharvest Biol. Technol. 2010, 59, 272–279. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNV | MSC | MC | S-G Smoothing | S-G Filter | |
|---|---|---|---|---|---|
| PCA + LDA | 47.2% | 44.0% | 44.6% | 45.6% | 75.2% |
| PCA + iLDA | 50.1% | 44.0% | 47.2% | 58.4% | 77.6% |
| PCA + FiLDA | 52.5% | 68.5% | 62.5% | 75.0% | 94.4% |
| n_training | n_test | PCA + LDA | PCA + iLDA | PCA + FiLDA |
|---|---|---|---|---|
| 150 | 150 | 77.3% | 79.3% | 92.0% |
| 175 | 125 | 75.2% | 77.6% | 94.4% |
| 200 | 100 | 75.0% | 76.0% | 90.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Z.; Wu, X.; Yang, Y.; Wu, B.; Fu, H. Discrimination of the Red Jujube Varieties Using a Portable NIR Spectrometer and Fuzzy Improved Linear Discriminant Analysis. Foods 2022, 11, 763. https://doi.org/10.3390/foods11050763
Qi Z, Wu X, Yang Y, Wu B, Fu H. Discrimination of the Red Jujube Varieties Using a Portable NIR Spectrometer and Fuzzy Improved Linear Discriminant Analysis. Foods. 2022; 11(5):763. https://doi.org/10.3390/foods11050763
Chicago/Turabian StyleQi, Zuxuan, Xiaohong Wu, Yangjian Yang, Bin Wu, and Haijun Fu. 2022. "Discrimination of the Red Jujube Varieties Using a Portable NIR Spectrometer and Fuzzy Improved Linear Discriminant Analysis" Foods 11, no. 5: 763. https://doi.org/10.3390/foods11050763
APA StyleQi, Z., Wu, X., Yang, Y., Wu, B., & Fu, H. (2022). Discrimination of the Red Jujube Varieties Using a Portable NIR Spectrometer and Fuzzy Improved Linear Discriminant Analysis. Foods, 11(5), 763. https://doi.org/10.3390/foods11050763