
Prediction of Extensibility and Toughness of Wheat-Flour Dough Using Bubble Inflation–Structured Light Scanning 3D Imaging Technology and the Enhanced 3D Vgg11 Model
Abstract
:1. Introduction
2. Materials and Methods
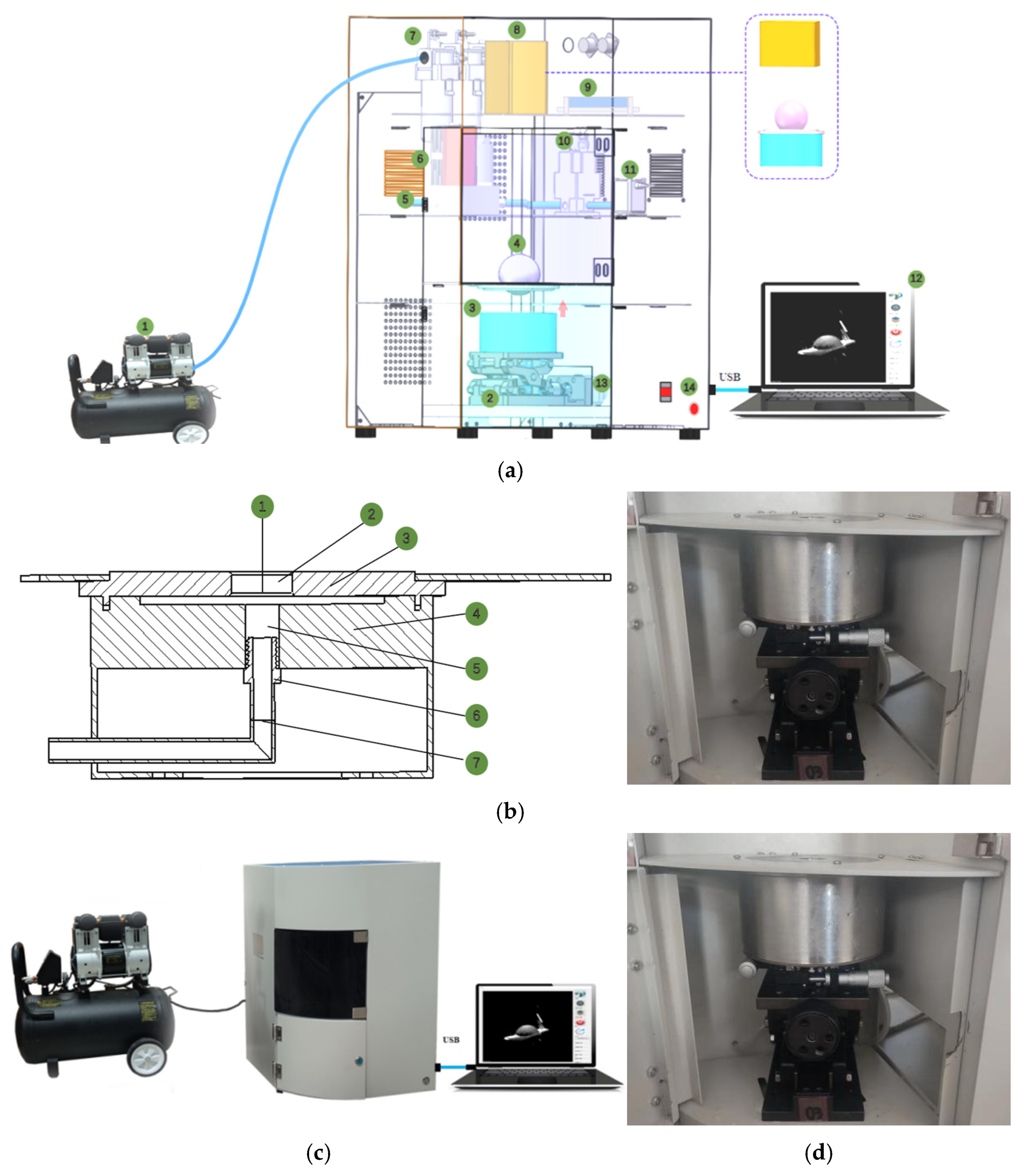
2.1. Self-Developed Data Acquisition System
2.2. Sample Preparation
2.3. Data Collection
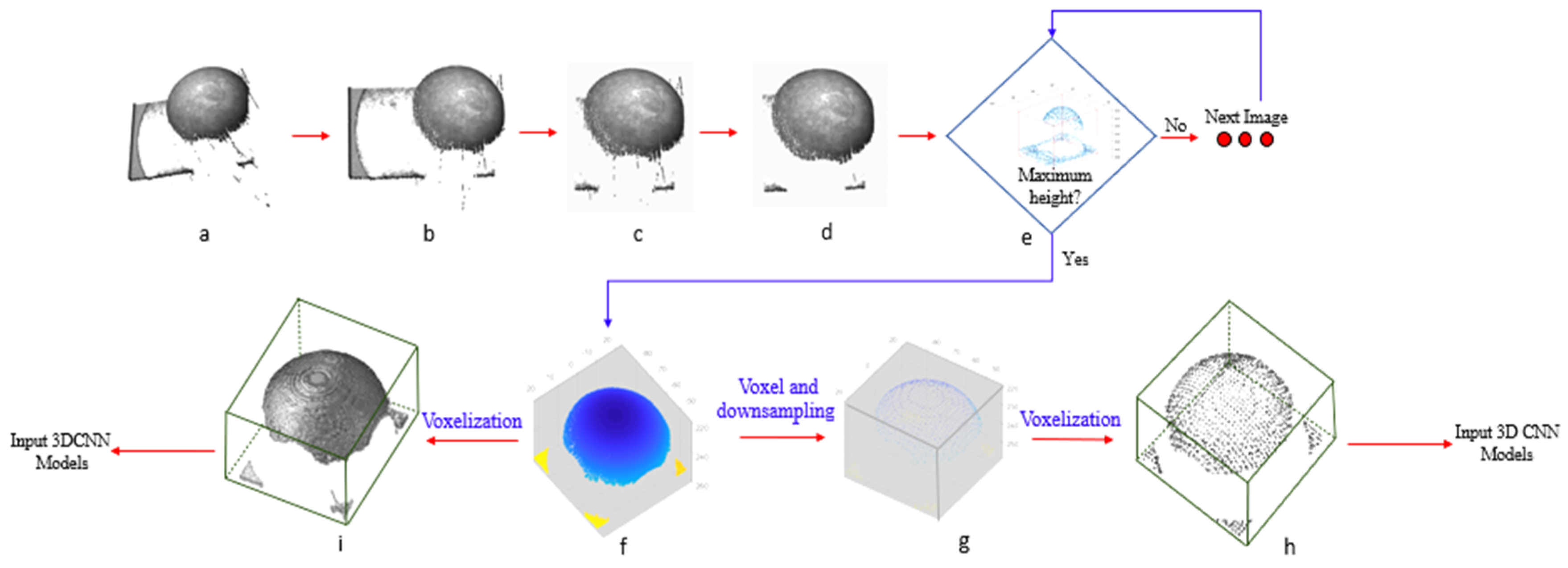
2.4. Point Cloud Image Preprocessing
2.5. The 3D CNN Model Design
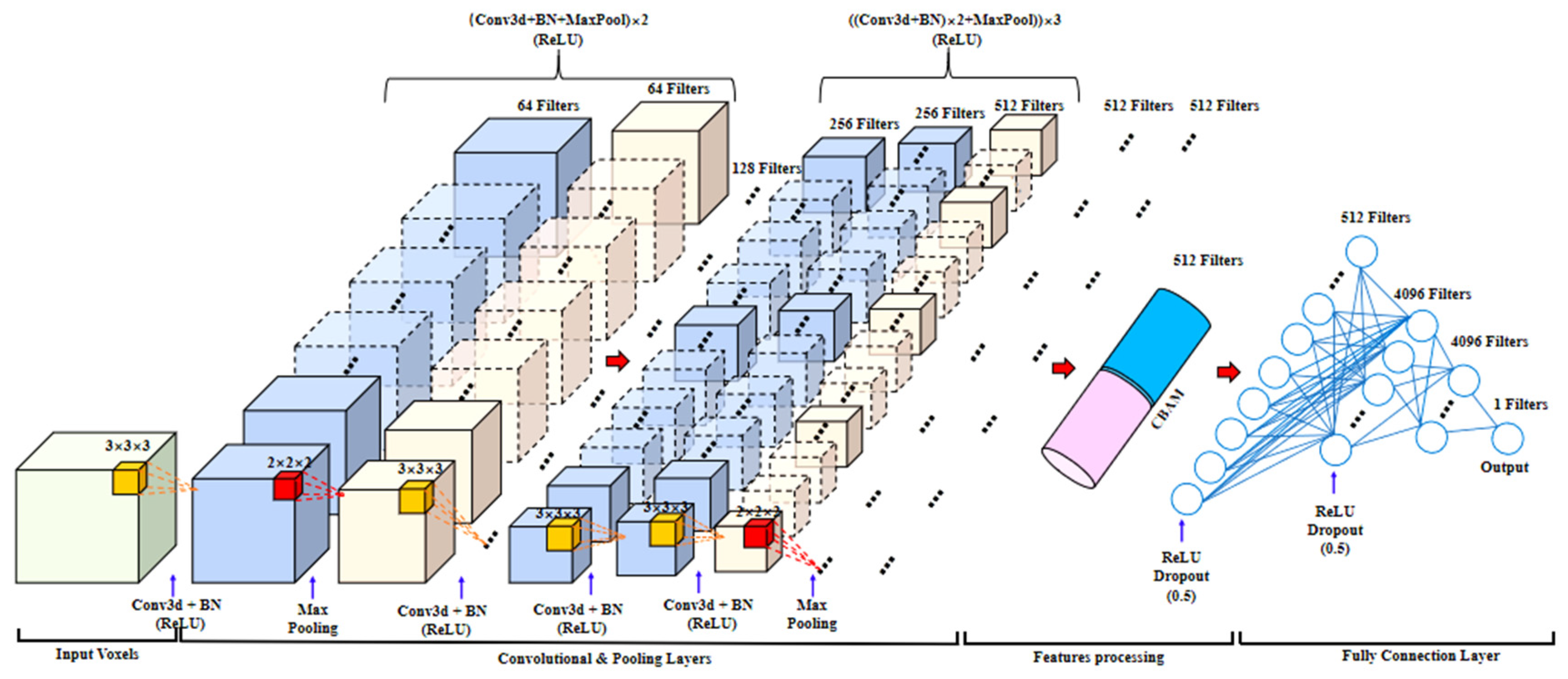
2.5.1. The 3D Vgg11 Model
- (1)
- Convolutional layer
- (2)
- Activation function
- (3)
- Pooling layer
- (4)
- Fully connected layer
2.5.2. Enhanced 3D Vgg11 Model
2.6. Network Training
2.7. Performance Evaluation of the Models
3. Results and Discussion
3.1. Statistics of Reference Extensibility and Toughness
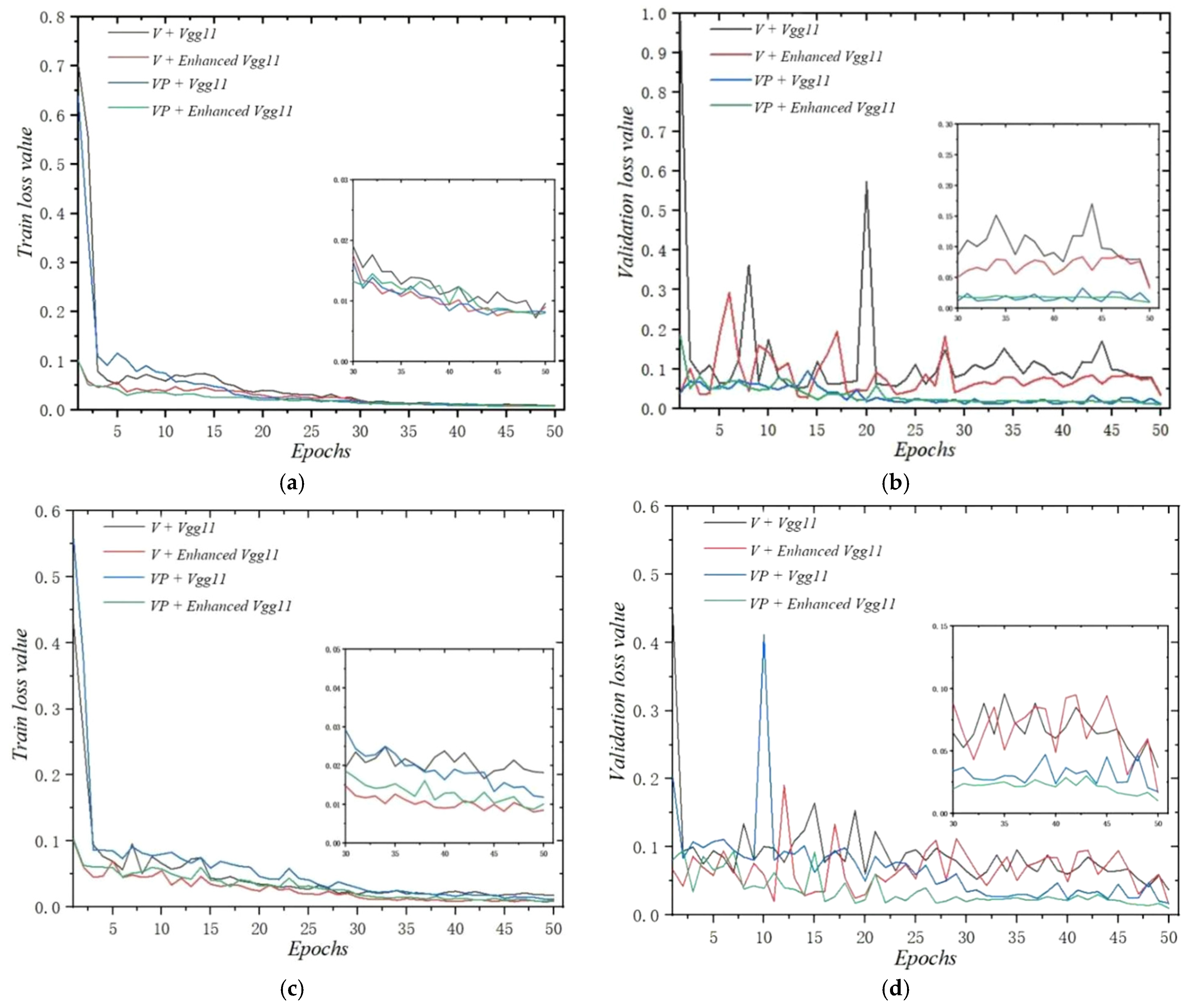
3.2. Training Analysis
3.3. Performance Comparison of Different Models
3.4. Comparison Between Two Different Data-Processing Methods
3.5. Analysis of Test Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luo, X.Z.; Yu, H.; An, J.; Wang, H.S.; Tang, X.Y. Determination of extensibility and toughness of wheat-four dough based on bubbles blown by sheeted dough and airffow-3D imaging technique. J. Cereal Sci. 2023, 113, 103754. [Google Scholar] [CrossRef]
- Cauvin, S.P.; Young, L.S. Technology of Breadmaking; Blackie Academic and Professional: London, UK, 1998. [Google Scholar]
- Anderrsen, R.S.; Bekes, F.; Gras, P.W.; Nikolov, A.; Wood, J.T. Wheat-flour dough extensibility as a discriminator for wheat varieties. J. Cereal Sci. 2004, 39, 195–203. [Google Scholar] [CrossRef]
- Nash, D.; Lanning, S.P.; Fox, P.; Martin, J.M.; Blake, N.K.; Souza, E.; Graybosch, R.A.; Giroux, M.J.; Talbert, L.E. Relationship of dough extensibility to dough strength in a spring wheat cross. Cereal Chem. 2006, 83, 255–258. [Google Scholar] [CrossRef]
- Hackenberg, S.; Jekle, M.; Becker, T. Mechanical wheat flour modification and its effect on protein network structure and dough rheology. Food Chem. 2008, 248, 296–303. [Google Scholar] [CrossRef]
- Munteanu, M.G.; Voicu, G.; Stefan, E.M.; Constantin, G.A. Determination of extensibility for certain types of pretzels dough. In Proceedings of the 8th International Conference on Thermal Equipment, Renewable Energy and Rural Development, Targoviste, Romania, 6–8 June 2019. [Google Scholar]
- Yang, Y.; Guan, E.; Zhang, L.; Li, M.; Bian, K. Mechanical action on the development of dough and its influence on rheological properties and protein network structure. Food Res. Int. 2022, 164, 112420. [Google Scholar] [CrossRef]
- Xu, H.H.; Wu, M.; Shang, N.; Wei, W.G.; Gao, F. Fortification of Wheat Bread with Edible Chrysanthemum (Chrysanthemum morifolium Ramat.): Unraveling the Mechanisms of Dough Rheology and Bread Quality Changes. Food Bioprocess Technol. 2023, 16, 82–97. [Google Scholar] [CrossRef]
- Yang, J.J.; Zhang, Y.Q.; Jiang, J.K.; Zhang, B.; Li, M.; Guo, B.L. Effects of Frozen Storage Time, Thawing Treatments, and Their Interaction on the Rheological Properties of Non-Fermented Wheat Dough. Foods 2023, 12, 4369. [Google Scholar] [CrossRef]
- Dedey, K.B.; Grenier, D.; Blondel, L.; Diascorn, Y.; Morel, M.; Lucas, T. Observation of the microstructure of a biextended hydrated dough and hydrated gluten under large strain and extremely low strain-rates: Results of an initial study. J. Cereal Sci. 2023, 110, 103629. [Google Scholar] [CrossRef]
- Charalambides, M.N.; Wanigasooriya, L.; Williams, G.J. Biaxial deformation of dough using the bubble inflation technique. II. Numerical modelling. Rheol. Acta 2002, 41, 541–548. [Google Scholar] [CrossRef]
- He, K.; Jing, B.; Tang, X. Combination of airflow and multi-point laser ranging technique for the prediction of total volatile basic nitrogen content in beef. J. Food Meas. Charact. 2022, 16, 3095–3105. [Google Scholar] [CrossRef]
- Sun, Q.M.; Luo, X.Z.; He, K.; Jing, B.W.; Tang, X.Y. Assessment of kiwifruit firmness by using airflow and laser technique. J. Texture Stud. 2023, 54, 237–244. [Google Scholar] [PubMed]
- Zhang, Y.S.; Yu, H.; Zhang, H.Y.; Tang, X.Y. Bread staling prediction with a multiobjective particle swarm optimization-based bread constitutive modeling method. J. Texture Stud. 2023, 54, 498–509. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Xiong, L.; Gao, X.; Hou, Y.; He, M.; Tang, X. Determination of beef tenderness based on airflow pressure combined with structural light three dimensional (3D) vision technology. Meat Sci. 2023, 202, 109206. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Hu, Q.; Dai, D.; Zhang, C.; Deng, Y. Beef tenderness detection based on pulse air-puff combined with structural light 3D imaging. Trans. Chin. Soc. Agric. Mach. 2020, 51, 324–331. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar] [CrossRef]
- Han, X.; Huang, X.; Sun, S.; Wang, M. 3DDACNN: 3D dense attention convolutional neural network for point cloud based object recognition. Artif. Intell. Rev. 2022, 55, 6655–6671. [Google Scholar]
- Zhang, X.; Lin, T.; Xu, J.; Luo, X.; Ying, Y. Deep Spectra: An end-to-end deep learning approach for quantitative spectral analysis. Anal. Chim. Acta 2019, 1058, 48–57. [Google Scholar] [CrossRef]
- Du, J.; Zhang, N.; Teng, X.; Wang, Y.; Law, C.L.; Fang, D. Evaluation of vegetable sauerkraut quality during storage based on convolution neural network. Food. Res. Int. 2023, 164, 112420. [Google Scholar]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. Comput. Anal. Images Patterns 2017, 10424, 95–107. [Google Scholar] [CrossRef]
- Boulch, A.; Le Saux, B.; Audebert, N. Unstructured point cloud semantic labeling using deep segmentation networks. In Eurographics Workshop on 3D Object Retrieval; Euro Graphics Association: Lyon, France, 2017; pp. 17–24. [Google Scholar] [CrossRef]
- Kengpol, A.; Tabkosai, P. Hybrid deep learning cost evaluation using CNN with ANN for the plastic injection industry. Neural Comput. Appl. 2023, 35, 23153–23175. [Google Scholar]
- Zhuang, W.M.; Wang, E.M.; Zhang, H.L. Prediction of compressive mechanical properties of three-dimensional mesoscopic aluminium foam based on deep learning method. Mech. Mater. 2023, 182, 104684. [Google Scholar]
- Noh, J.; Lee, S.; Ham, B. HVPR: Hybrid voxel-point representation for single-stage 3D object detection. In Proceedings of the 2021 IEEE/CVF Conference Computer Vision Patten Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14605–14614. [Google Scholar] [CrossRef]
- Shi, S.; Guo, C.; Jiang, J.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; Volume 131, pp. 10529–10538. [Google Scholar] [CrossRef]
- Song, Z.; Wei, H.; Jia, C.; Xia, Y.; Li, X.; Zhang, C. VP-Net: Voxels as Points for 3D Object Detection. IEEE Trans. Geosci. Remote 2023, 61, 5701912. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Meng, X.Z.; Li, Y.J.; Wang, G.C.; Meng, T.S. Face recognition algorithm incorporating CBAM and Siamese neural network. Opt. Precis. Eng. 2023, 31, 3192–3202. [Google Scholar]
- Han, X.; Zhao, C.J.; Wu, H.R.; Zhu, H.J.; Zhang, Y. Image classification method for tomato leaf deficient nutrient elements based on attention mechanism and multi-scale feature fusion. Trans. CSAE 2021, 37, 177–188. [Google Scholar]
- Lin, S.; Liu, M.; Tao, Z.Y. Detection of underwater treasures using attention mechanism and improved YOLOv5. Trans. CSAE 2021, 37, 307–314. [Google Scholar]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-scale Image Recognition. arXiv, 2014. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar] [CrossRef]
- Ning, F.; Shi, Y.; Cai, M.; Xu, W. Various realization methods of machine-part classification based on deep learning. Journal of Intelligent Manufacturing. J. Intell. Manuf. 2020, 31, 2019–2032. [Google Scholar]
- Bonin, M.D.; Silva, S.; Bünger, L.; Ross, D.; Feijó, G.L.D.; Gomes, R.D.; Rennó, F.P.; de Almeida Santana, M.H.; de Rezende, F.M.; Ítavo, L.C.; et al. Predicting the shear value and intramuscular fat in meat from Nellore cattle using Vis-NIR spectroscopy. Meat. Sci. 2013, 163, 108077. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Patil, S.P.; Arya, S.S. Influence of additive proteins, extruded and germinated flour on gluten free dough rheological parameters and flatbread characteristics: A mixture design approach. J. Microbiol. Biotechnol. Food Sci. 2019, 8, 1198–1204. [Google Scholar]
- Khuzwayo, T.A.; Taylor, J.R.N.; Taylor, J. Influence of dough sheeting, flour pre-gelatinization and zein inclusion on maize bread dough functionality. LWT—Food. Sci. Technol. 2020, 121, 108993. [Google Scholar] [CrossRef]
- Soronja-Simovic, D.; Zahorec, J.; Seres, Z.; Maravic, N.; Mozina, S.S.; Luskar, L.; Lukovic, J. Challenges in determination of rheological properties of wheat dough supplemented with industrial by-products: Carob pod flour and sugar beet fibers. J. Food Meas. Charact. 2020, 15, 914–922. [Google Scholar] [CrossRef]
 ” is feature mapping; “⊗” represents the multiplication of the values of two channels.
” is feature mapping; “⊗” represents the multiplication of the values of two channels.
” is feature mapping; “⊗” represents the multiplication of the values of two channels.
” is feature mapping; “⊗” represents the multiplication of the values of two channels.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Datasets | Number of Samples | Minimum | Maximum | Mean Value | Standard Deviation |
|---|---|---|---|---|---|---|
| Extensibility (cm) | Calibration set | 204 | −106.065 | −19.140 | −67.078 | 18.588 |
| Validation set | 51 | −106.065 | −19.140 | −65.916 | 18.774 | |
| Test set | 51 | −101.625 | −23.815 | −71.913 | 18.463 | |
| Toughness (g) | Calibration set | 204 | 29.9 | 288.725 | 115.711 | 67.003 |
| Validation set | 51 | 32.17 | 251.51 | 118.868 | 60.278 | |
| Test set | 51 | 34.17 | 288.725 | 120.456 | 64.448 |
| Indicators | Method | Models | Calibration Set | Validation Set | Training Time/s (Each Epoch) | Evaluating Time/s (Each Epoch) | Occupies Space (Each Data Point) | ||
|---|---|---|---|---|---|---|---|---|---|
| Rc | RMSEC | Rv | RMSEV | ||||||
| Extensibility | V | MobileNet | 0.941 | 0.086 | 0.449 | 0.208 | 87.22 | 17.34 | 156 KB |
| ResNet18 | 0.916 | 0.085 | 0.588 | 0.187 | 664.51 | 43.02 | |||
| Vgg11 | 0.921 | 0.098 | 0.591 | 0.188 | 86.38 | 16.15 | |||
| E-Vgg11 | 0.927 | 0.095 | 0.629 | 0.181 | 84.76 | 15.99 | |||
| VP | MobileNet | 0.883 | 0.100 | 0.464 | 0.191 | 86.92 | 15.00 | 12 KB | |
| ResNet18 | 0.903 | 0.092 | 0.523 | 0.184 | 635.00 | 39.70 | |||
| Vgg11 | 0.906 | 0.091 | 0.882 | 0.102 | 82.16 | 6.48 | |||
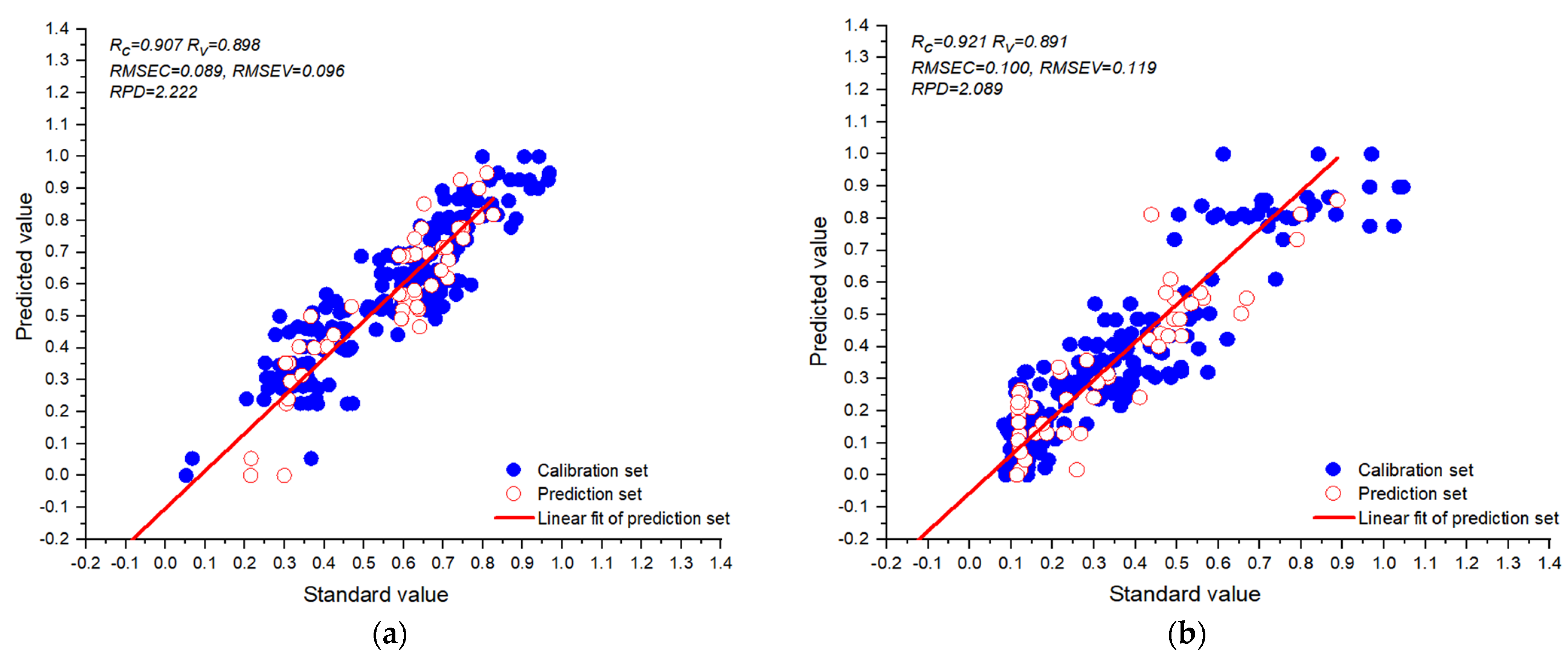
| E-Vgg11 | 0.907 | 0.089 | 0.898 | 0.096 | 82.23 | 15.03 | |||
| Toughness | V | MobileNet | 0.793 | 0.154 | 0.435 | 0.264 | 92.19 | 17.12 | 156 KB |
| ResNet18 | 0.710 | 0.178 | 0.650 | 0.243 | 690.41 | 46.45 | |||
| Vgg11 | 0.835 | 0.135 | 0.681 | 0.192 | 92.79 | 16.05 | |||
| E-Vgg11 | 0.933 | 0.092 | 0.802 | 0.158 | 77.30 | 14.87 | |||
| VP | MobileNet | 0.935 | 0.091 | 0.485 | 0.249 | 80.49 | 16.49 | 12 KB | |
| ResNet18 | 0.946 | 0.083 | 0.845 | 0.152 | 666.07 | 43.02 | |||
| Vgg11 | 0.904 | 0.109 | 0.886 | 0.132 | 73.42 | 14.82 | |||
| E-Vgg11 | 0.921 | 0.100 | 0.891 | 0.119 | 56.79 | 14.47 | |||
| Indicators | Methods | Models | Rp | MAE | RPD |
|---|---|---|---|---|---|
| Extensibility | V | MobileNet | 0.760 | 0.193 | 1.539 |
| Resnet18 | 0.685 | 0.155 | 1.373 | ||
| Vgg11 | 0.766 | 0.140 | 1.556 | ||
| E-Vgg11 | 0.766 | 0.138 | 1.556 | ||
| VP | MobileNet | 0.868 | 0.147 | 2.014 | |
| Resnet18 | 0.857 | 0.159 | 1.941 | ||
| Vgg11 | 0.888 | 0.127 | 2.175 | ||
| E-Vgg11 | 0.893 | 0.117 | 2.222 | ||
| Toughness | V | MobileNet | 0.735 | 0.189 | 1.475 |
| Resnet18 | 0.602 | 0.210 | 1.252 | ||
| Vgg11 | 0.699 | 0.162 | 1.398 | ||
| E-Vgg11 | 0.743 | 0.180 | 1.494 | ||
| VP | MobileNet | 0.735 | 0.197 | 1.475 | |
| Resnet18 | 0.747 | 0.131 | 1.504 | ||
| Vgg11 | 0.785 | 0.171 | 1.614 | ||
| E-Vgg11 | 0.878 | 0.128 | 2.089 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Niu, C.; Zhu, Z.; Hou, Y.; Jiang, H.; Tang, X. Prediction of Extensibility and Toughness of Wheat-Flour Dough Using Bubble Inflation–Structured Light Scanning 3D Imaging Technology and the Enhanced 3D Vgg11 Model. Foods 2025, 14, 1295. https://doi.org/10.3390/foods14081295
Luo X, Niu C, Zhu Z, Hou Y, Jiang H, Tang X. Prediction of Extensibility and Toughness of Wheat-Flour Dough Using Bubble Inflation–Structured Light Scanning 3D Imaging Technology and the Enhanced 3D Vgg11 Model. Foods. 2025; 14(8):1295. https://doi.org/10.3390/foods14081295
Chicago/Turabian StyleLuo, Xiuzhi, Changhe Niu, Zhaoshuai Zhu, Yuxin Hou, Hong Jiang, and Xiuying Tang. 2025. "Prediction of Extensibility and Toughness of Wheat-Flour Dough Using Bubble Inflation–Structured Light Scanning 3D Imaging Technology and the Enhanced 3D Vgg11 Model" Foods 14, no. 8: 1295. https://doi.org/10.3390/foods14081295
APA StyleLuo, X., Niu, C., Zhu, Z., Hou, Y., Jiang, H., & Tang, X. (2025). Prediction of Extensibility and Toughness of Wheat-Flour Dough Using Bubble Inflation–Structured Light Scanning 3D Imaging Technology and the Enhanced 3D Vgg11 Model. Foods, 14(8), 1295. https://doi.org/10.3390/foods14081295