
A Systematic Review of Machine-Learning Solutions in Anaerobic Digestion



Abstract
:1. Introduction
Research Questions
2. Materials and Methods
2.1. Research Design
2.2. Metadata Extraction
3. Results
3.1. Dataset and Data Pre-Processing
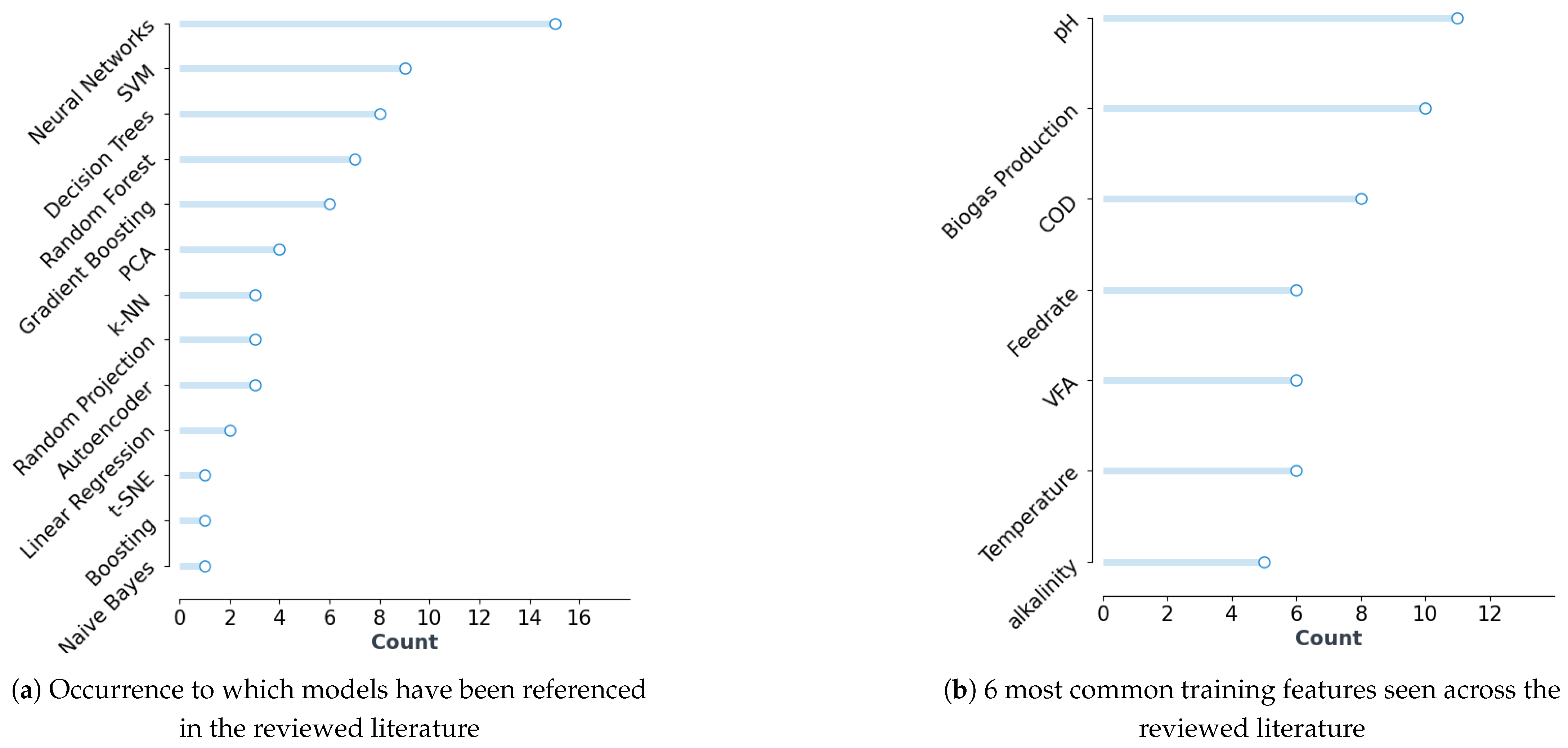
3.2. ML Techniques
3.2.1. Traditional Machine-Learning Methods
ANN
SVM
- represents the robustness with respect to fault i;
- is the VFA predicted by soft-sensors during the faulty event;
- is the real VFA in the normal operation of the process;
- N is the number of all faulty samples.
Tree Models
3.2.2. Deep-Learning Methods
3.2.3. Time-Series Implementation
3.3. Feature Assessment
3.4. ML Techniques That Are Not Used in AD Applications but Can Be Found in Other Applied ML Fields
3.4.1. Reinforcement Learning Application
3.4.2. ML/IoT Practises
3.4.3. Explainable AI
4. Discussion
4.1. What Are the Identified Benefits of Implementing ML Techniques to Assist AD Operation?
4.2. What Challenges Are Faced in Applying ML to Improve the Autonomy of AD Applications?
4.3. ML Contributions to AD Practices
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AD | Anaerobic Digestion |
| MEC-AD | Microbial Electrochemical Cell—Anaerobic Digestion |
| BMP | Biochemical Methane Potential |
| COD | Chemical Oxygen Demand |
| VFA | Volatile Fatty Acids |
| TSS | Total Suspended Solids |
| TS | Total Solids |
| BOD | Biochemical Oxygen Demand |
| ML | Machine Learning |
| XAI | Explainable AI |
| DT | Decision Tree |
| PSO | Particle Swarm Optimisation |
| RSM | Response Surface Methodology |
| ANN | Artificial Neural Network |
| RNN | Recurrent Neural Network |
| ENN | Evolving Neural Network |
| ELM | Extreme Learning Machine |
| RBF | Radial Basis Function |
| GB | Gradient Boosting |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| RF | Random Forest |
| LSTM | Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| MLP | Multilayer Perceptron |
| ANFIS | Adaptive Neuro-Fuzzy Inference System |
| GA | Genetic Algorithm |
| RL | Reinforcement Learning |
| PCA | Principal Component Analysis |
| BOA | Bayesian Optimisation Algorithm |
References
- Induchoodan, T.G.; Haq, I.; Kalamdhad, A.S. 14—Factors affecting anaerobic digestion for biogas production: A review. In Advanced Organic Waste Management; Hussain, C., Hait, S., Eds.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 223–233. ISBN 978-0-323-85792-5. [Google Scholar]
- Cheon, A.; Sung, J.; Jun, H.; Jang, H.; Kim, M.; Park, J. Application of Various Machine Learning Models for Process Stability of Bio-Electrochemical Anaerobic Digestion. Processes 2022, 10, 158. [Google Scholar] [CrossRef]
- Cruz, I.A.; Chuenchart, W.; Long, F.; Surendra, K.C.; Andrade, L.R.S.; Bilal, M.; Liu, H.; Figueiredo, R.T.; Khanal, S.K.; Ferreira, L.F.R. Application of machine learning in anaerobic digestion: Perspectives and challenges. Bioresour. Technol. 2022, 345, 126433. [Google Scholar]
- Gupta, R.; Zhang, L.; Hou, J.; Zhang, Z.; Liu, H.; You, S.; Ok, Y.S.; Li, W. Review of explainable machine learning for anaerobic digestion. Bioresour. Technol. 2022, 369, 128468. [Google Scholar] [CrossRef]
- Dewasme, L. Brewery wastewater treatment plant key-component estimation using moving-window recurrent neural networks. IFAC-PapersOnLine 2020, 53, 16808–16813. [Google Scholar] [CrossRef]
- Özarslan, S.; Abut, S.; Atelge, M.R.; Kaya, M.; Unalan, S. Modeling and simulation of co-digestion performance with artificial neural network for prediction of methane production from tea factory waste with co-substrate of spent tea waste. Fuel 2021, 306, 121715. [Google Scholar] [CrossRef]
- Xiao, J.; Liu, C.; Ju, B.; Xu, H.; Sun, D.; Dang, Y. Estimation of in-situ biogas upgrading in microbial electrolysis cells via direct electron transfer: Two-stage machine learning modeling based on a NARX-BP hybrid neural network. Bioresour. Technol. 2021, 330, 124965. [Google Scholar] [CrossRef] [PubMed]
- Chiu, M.C.; Wen, C.Y.; Hsu, H.W.; Wang, W.C. Key wastes selection and prediction improvement for biogas production through hybrid machine learning methods. Sustain. Energy Technol. Assess. 2022, 52, 102223. [Google Scholar] [CrossRef]
- Mahmoodi-Eshkaftaki, M.; Ebrahimi, R. Integrated deep learning neural network and desirability analysis in biogas plants: A powerful tool to optimize biogas purification. Energy 2021, 231, 121073. [Google Scholar] [CrossRef]
- Bakht, A.; Nawaz, A.; Lee, M.; Lee, H. Ingredient analysis of biological wastewater using hybrid multi-stream deep learning framework. Comput. Chem. Eng. 2022, 168, 108038. [Google Scholar] [CrossRef]
- Karamichailidou, D.; Alexandridis, A.; Anagnostopoulos, G.; Syriopoulos, G.; Sekkas, O. Modeling biogas production from anaerobic wastewater treatment plants using radial basis function networks and differential evolution. Comput. Chem. Eng. 2022, 157, 107629. [Google Scholar] [CrossRef]
- Shahsavar, M.M.; Akrami, M.; Gheibi, M.; Kavianpour, B.; Fathollahi-Fard, A.M.; Behzadian, K. Constructing a smart framework for supplying the biogas energy in green buildings using an integration of response surface methodology, artificial intelligence and petri net modelling. Energy Convers. Manag. 2021, 248, 114794. [Google Scholar] [CrossRef]
- Chen, J.W.; Chan, Y.J.; Arumugasamy, S.K.; Yazdi, S.K. Process modelling and optimisation of methane yield from palm oil mill effluent using response surface methodology and artificial neural network. J. Water Process Eng. 2023, 52, 103493. [Google Scholar] [CrossRef]
- Jeong, K.; Abbas, A.; Shin, J.; Son, M.; Kim, Y.M.; Cho, K.H. Prediction of biogas production in anaerobic co-digestion of organic wastes using deep learning models. Water Res. 2021, 205, 117697. [Google Scholar] [CrossRef] [PubMed]
- Cândido, D.; Bolsan, A.C.; Hollas, C.E.; Venturin, B.; Tápparo, D.C.; Bonassa, G.; Antes, F.G.; Steinmetz, R.L.R.; Bortoli, M.; Kunz, A. Integration of swine manure anaerobic digestion and digestate nutrients removal/recovery under a circular economy concept. J. Environ. Manag. 2022, 301, 113825. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, L.; Ren, Z.; Yu, Y.; Li, Y.; Pan, J.; Lu, Y.; Feng, L.; Zhang, W.; Han, Y. Plant-scale biogas production prediction based on multiple hybrid machine learning technique. Bioresour. Technol. 2022, 363, 127899. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; He, P.; Peng, W.; Lü, F.; Du, R.; Zhang, H. Exploring available input variables for machine learning models to predict biogas production in industrial-scale biogas plants treating food waste. J. Clean. Prod. 2022, 380, 135074. [Google Scholar] [CrossRef]
- Kazemi, P.; Bengoa, C.; Steyer, J.P.; Giralt, J. Data-driven techniques for fault detection in anaerobic digestion process. Process Saf. Environ. Prot. 2021, 146, 905–915. [Google Scholar] [CrossRef]
- Heydari, B.; Abdollahzadeh Sharghi, E.; Rafiee, S.; Mohtasebi, S.S. Use of artificial neural network and adaptive neuro-fuzzy inference system for prediction of biogas production from spearmint essential oil wastewater treatment in up-flow anaerobic sludge blanket reactor. Fuel 2021, 306, 121734. [Google Scholar] [CrossRef]
- Chong, D.J.S.; Chan, Y.J.; Arumugasamy, S.K.; Yazdi, S.K.; Lim, J.W. Optimisation and performance evaluation of response surface methodology (RSM), artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS) in the prediction of biogas production from palm oil mill effluent (POME). Energy 2023, 266, 126449. [Google Scholar] [CrossRef]
- Nguyen, V.T.; Ta, Q.T.H.; Nguyen, P.K.T. Artificial intelligence-based modeling and optimisation of microbial electrolysis cell-assisted anaerobic digestion fed with alkaline-pretreated waste-activated sludge. Biochem. Eng. J. 2022, 187, 108670. [Google Scholar] [CrossRef]
- Park, J.G.; Jun, H.B.; Heo, T.Y. Retraining prior state performances of anaerobic digestion improves prediction accuracy of methane yield in various machine learning models. Appl. Energy 2021, 298, 117250. [Google Scholar] [CrossRef]
- Wu, D.; Peng, X.; Li, L.; Yang, P.; Peng, Y.; Liu, H.; Wang, X. Commercial biogas plants: Review on operational parameters and guide for performance optimization. Fuel 2021, 303, 121282. [Google Scholar] [CrossRef]
- Kavzoglu, T. Determining optimum structure for artificial neural networks. In Proceedings of the 25th Annual Technical Conference and Exhibition of the Remote Sensing Society, Cardiff, UK, 8–10 September 1999; Remote Sensing Society: Nottingham, UK, 1999; pp. 675–682. [Google Scholar]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1310–1315. [Google Scholar]
- Sipper, M.; Moore, J.H. Conservation machine learning: A case study of random forests. Sci. Rep. 2021, 11, 3629. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Shu, K.; Wang, Z. Predicting energy use in construction using Extreme Gradient Boosting. PeerJ Comput. Sci. 2023, 9, e1500. [Google Scholar] [CrossRef] [PubMed]
- Pathak, S.; Mishra, I.; Swetapadma, A. An Assessment of Decision Tree-based Classification and Regression Algorithms. In Proceedings of the 2018 3rd International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 15–16 November 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2018; pp. 92–95. [Google Scholar] [CrossRef]
- Wilkinson, P. Non-Linear Regression with Decision Trees and Random Forest. Available online: https://towardsdatascience.com/non-linear-regression-with-decision-trees-and-random-forest-afae406df27d (accessed on 4 May 2023).
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Malkomes, G.; Garnett, R. Automating Bayesian optimisation with Bayesian optimisation. Adv. Neural Inf. Process. Syst. 2018, 31, 5988–5997. [Google Scholar]
- Bahuleyan, H.; Mou, L.; Vechtomova, O.; Poupart, P. Variational attention for sequence-to-sequence models. arXiv 2017, arXiv:1712.08207. [Google Scholar]
- Pessuto, J.; Scopel, B.S.; Perondi, D.; Godinho, M.; Dettmer, A. Enhancement of biogas and methane production by anaerobic digestion of swine manure with addition of microorganisms isolated from sewage sludge. Process Saf. Environ. Prot. 2016, 104, 233–239. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, X.; Xing, W.; Li, R.; Yang, T. Responses of anaerobic digestion of food waste to coupling effects of inoculum origins, organic loads, and pH control under high load: Process performance and microbial characteristics. J. Environ. Manag. 2021, 279, 111772. [Google Scholar] [CrossRef]
- Duong-Trung, N.; Born, S.; Kim, J.W.; Schermeyer, M.T.; Paulick, K.; Borisyak, M.; Cruz-Bournazou, M.N.; Werner, T.; Scholz, R.; Schmidt-Thieme, L.; et al. When Bioprocess Engineering Meets Machine Learning: A Survey from the Perspective of Automated Bioprocess Development. Biochem. Eng. J. 2022, 190, 108764. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, P.M.D. Crop yield prediction using deep reinforcement learning model for sustainable agrarian applications. IEEE Access 2020, 8, 86886–86901. [Google Scholar] [CrossRef]
- Mocanu, E.; Mocanu, D.C.; Nguyen, P.H.; Liotta, A.; Webber, M.E.; Gibescu, M.; Slootweg, J.G. On-Line Building Energy optimisation Using Deep Reinforcement Learning. IEEE Trans. Smart Grid 2019, 10, 3698–3708. [Google Scholar] [CrossRef]
- Meegoda, J.N.; Li, B.; Patel, K.; Wang, L.B. A Review of the Processes, Parameters, and optimisation of Anaerobic Digestion. Int. J. Environ. Res. Public Health 2018, 15, 2224. [Google Scholar] [CrossRef]
- Hayes, C.F.; Rădulescu, R.; Bargiacchi, E.; Källström, J.; Macfarlane, M.; Reymond, M.; Verstraeten, T.; Zintgraf, L.M.; Dazeley, R.; Heintz, F.; et al. A Practical Guide to Multi-Objective Reinforcement Learning and Planning. Auton. Agents Multi-Agent Syst. 2022, 36, 26. [Google Scholar] [CrossRef]
- Pettigrew, L.; Delgado, A. Neural network-based reinforcement learning control for increased methane production in an anaerobic digestion system. In Proceedings of the 3rd IWA Specialized International Conference Ecotechnologies for Wastewater Treatment, Cambridge, UK, 27–30 June 2016; International Water Association: London, UK, 2016; pp. 1–4. [Google Scholar]
- Ayoub Shaikh, T.; Rasool, T.; Rasheed Lone, F. Towards leveraging the role of machine learning and artificial intelligence in precision agriculture and smart farming. Comput. Electron. Agric. 2022, 198, 107119. [Google Scholar] [CrossRef]
- Ahmed, I.; Jeon, G.; Piccialli, F. From Artificial Intelligence to Explainable Artificial Intelligence in Industry 4.0: A Survey on What, How, and Where. IEEE Trans. Ind. Inform. 2022, 18, 5031–5042. [Google Scholar] [CrossRef]
- He, B.; Zhao, Y.; Mao, W. Explainable artificial intelligence reveals environmental constraints in seagrass distribution. Ecol. Indic. 2022, 144, 109523. [Google Scholar] [CrossRef]
- Sarker, I.H. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef]
- Kaushal, A.; Shukla, M. Comparative analysis to highlight pros and cons of data mining techniques—Clustering, neural network and decision tree. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 651–656. [Google Scholar]
- Silva, A.J.; Pozzi, E.; Foresti, E.; Zaiat, M. The influence of the buffering capacity on the production of organic acids and alcohols from wastewater in anaerobic reactor. Appl. Biochem. Biotechnol. 2015, 175, 2258–2265. [Google Scholar] [CrossRef]
- Long, F.; Wang, L.; Cai, W.; Lesnik, K.; Liu, H. Predicting the performance of anaerobic digestion using machine learning algorithms and genomic data. Water Res. 2021, 199, 117182. [Google Scholar] [CrossRef] [PubMed]
- Braz, G.H.R.; Fernandez-Gonzalez, N.; Lema, J.M.; Carballa, M. Organic overloading affects the microbial interactions during anaerobic digestion in sewage sludge reactors. Chemosphere 2019, 222, 323–332. [Google Scholar] [CrossRef] [PubMed]
- Basile, A.; Zampieri, G.; Kovalovszki, A.; Karkaria, B.; Treu, L.; Patil, K.R.; Campanaro, S. Modelling of microbial interactions in anaerobic digestion: From black to glass box. Curr. Opin. Microbiol. 2023, 75, 102363. [Google Scholar] [CrossRef] [PubMed]
- Begum, S.; Anupoju, G.R.; Sridhar, S.; Bhargava, S.K.; Jegatheesan, V.; Eshtiaghi, N. Evaluation of single and two-stage anaerobic digestion of landfill leachate: Effect of pH and initial organic loading rate on volatile fatty acid (VFA) and biogas production. Bioresour. Technol. 2018, 251, 364–373. [Google Scholar] [CrossRef] [PubMed]
- Erdirencelebi, D.; Yalpir, S. Adaptive network fuzzy inference system modeling for the input selection and prediction of anaerobic digestion effluent quality. Appl. Math. Model. 2011, 35, 3821–3832. [Google Scholar] [CrossRef]
- Pattnaik, B.S.; Pattanayak, A.S.; Udgata, S.K.; Panda, A.K. Machine learning-based soft sensor model for BOD estimation using intelligence at the edge. Complex Intell. Syst. 2021, 7, 961–976. [Google Scholar] [CrossRef]
- Luca, A.R.; Ursuleanu, T.F.; Gheorghe, L.A.; Grigorovici, R.; Iancu, S.; Hlusneac, M.; Grigorovici, A. Impact of quality, type, and volume of data used by deep learning models in the analysis of medical images. Inform. Med. Unlocked 2022, 29, 100911. [Google Scholar] [CrossRef]
- Asmaul, H.; Ethel, M.; Jigmey, G.; Zulfikar, A.; Zeyar, A.; Azim, M.A. Transfer learning: A friendly introduction. J. Big Data 2022, 9, 102. [Google Scholar]
- Kirkegaard, R.H.; McIlroy, S.J.; Kristensen, J.M.; Nierychlo, M.; Karst, S.M.; Dueholm, M.S.; Albertsen, M.; Nielsen, P.H. The impact of immigration on microbial community composition in full-scale anaerobic digesters. Sci. Rep. 2017, 7, 9343. [Google Scholar] [CrossRef]
- Akanksha, K.; Vivek, M.; Krishna Prakasha, K.; Acharya, V. Automated retraining of machine learning models. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 445–452. [Google Scholar]
- Simeonov, I.; Chorukova, E. Neural networks modeling of two biotechnological processes. In Proceedings of the 2004 2nd International IEEE Conference on ‘Intelligent Systems’, Proceedings (IEEE Cat. No.04EX791), Varna, Bulgaria, 22–24 June 2004; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2004; Volume 1, pp. 331–336. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Research Question | Rationale |
|---|---|---|
| RQ1 | How is ML being practically used in the field of AD? | This question aims to detail particular applications where the components of an AD system have been used to train ML models and outlines the role these models play in AD operation. |
| RQ2 | What ML techniques have been selected in the reviewed literature? | This research question was selected to understand how researchers have selected and compared different ML techniques and if this relates to the application domain and data structure. |
| RQ3 | What are the identified benefits of implementing ML techniques to assist with AD operation? | This aims to provide an up-to-date understanding of the advantages of particular ML techniques have over traditional statistical approaches. |
| RQ4 | What challenges are faced in applying ML to improve the autonomy of AD applications and systems? | This question looks at the challenges/considerations which should be addressed in order to remove the need for human-in-the-loop operation. |
| RQ5 | What ML techniques have been successful in comparable process applications? | The rationale behind this research question is to identify potential ML techniques that have been successful in other fields but have not yet been applied in AD. |
| Sub-Category | Keyword |
|---|---|
| Machine learning | ‘machine learning’, ‘learning’, ‘performance’, ‘prediction’, ‘intelligence’ |
| AD/MEC-AD/Waste Water | ‘gas’, ‘methane’, ‘anaerobic’, ‘digestion’, ‘waste’, ‘treatment’ |
| Criteria Type | Point | Rationale |
|---|---|---|
| Inclusion 1 | Date of publication is after 2018 | This criterion ensured that the studies considered were recent and focuses on the most up-to-date techniques and technologies in ML and sensing. |
| Inclusion 2 | Poses an application of ML in comparable research applications | The studies being considered were relevant to the research question and use ML in comparable contexts. |
| Exclusion 1 | Does not present primary research or is a review paper | This review considered primary research studies rather than reviews to ensure the depth of analysis required to answer the research question was met. |
| Exclusion 2 | Duplicate of a previously evaluated document | Meta-analysis conducted was based on unique work and not incorrectly skewed by duplicated studies. |
| Exclusion 3 | Paper does not show the application of ML algorithms with subject-relevant datasets | The studies being considered should be based on empirical data rather than pure theory. |
| Data Extraction Point | Field | Description | Research Context |
|---|---|---|---|
| DEP01 | Study Number | The number assigned to the included papers for reference | For documentation purposes, to facilitate easy identification and reference to the individual studies within this review |
| DEP02 | Paper Title | Title of publication | For documentation purposes to provide a brief overview of the study’s focus and scope |
| DEP03 | Publication Year | The year in which the paper was published | To allow chronological development of the research topic to be traced over time |
| DEP04 | Journal | The publication venue | To identify which outlets have predominantly published in this field |
| DEP05 | Research Field | Context of work (waste water, anaerobic digestion, MEC-AD) | RQ1 |
| DEP06 | Application Domain | The role played by ML | RQ1 |
| DEP07 | Data Source and Description | Where the dataset was obtained: Extracted from literature, provided by industrial scale operation, data collected for study purpose | RQ2 |
| DEP08 | Experimental Scale | The size of AD operation from which data were collected | RQ1 |
| DEP09 | Performance Optimisation | How the ML optimised the overall AD operation | RQ1 |
| DEP10 | Variable Structure | Variables referenced in study dataset | RQ2 |
| DEP11 | Machine-Learning Algorithm(s) | What machine-learning algorithms have been applied to an AD context | RQ2 |
| DEP12 | Listed Optimal Model | The best-performing model identified in the given study domain | RQ2 |
| DEP13 | Feature Engineering Methods | Pre-processing methods applied to dataset for viable ML training | RQ2 |
| DEP14 | Highlighted Benefits | Benefits that ML has brought to the specified AD operation | RQ3 |
| DEP15 | Challenges/Limitations | Highlighted challenges and limitations encountered when implementing ML solutions in the AD application domain | RQ4 |
| Paper Number | Title | Year | Journal |
|---|---|---|---|
| P1 | Brewery wastewater treatment plant key-component estimation using moving-window recurrent neural networks [5] | 2020 | IFAC |
| P2 | Modelling and simulation of co-digestion performance with artificial neural network for prediction of methane production from tea factory waste with co-substrate of spent tea waste [6] | 2021 | Fuel |
| P3 | Estimation of in situ biogas upgrading in microbial electrolysis cells via direct electron transfer [7] | 2021 | Bioresource Technology |
| P4 | Key waste selection and prediction improvement for biogas production through hybrid machine-learning methods [8] | 2022 | Sustainable Energy Technologies and Assessments |
| P5 | Integrated deep-learning neural network and desirability analysis in biogas plants [9] | 2020 | Energy |
| P6 | Ingredient analysis of biological wastewater using hybrid multi-stream deep-learning framework [10] | 2022 | Computers and Chemical Engineering |
| P7 | Modelling biogas production from anaerobic wastewater treatment plants using radial basis function networks and differential evolution [11] | 2021 | Computers and Chemical Engineering |
| P8 | Constructing a smart framework for supplying the biogas energy in green buildings using an integration of response surface methodology, artificial intelligence, and petri-net modelling [12] | 2021 | Energy Conversion and Management |
| P9 | Process modelling and optimisation of methane yield from palm oil mill effluent using response surface methodology and artificial neural network [13] | 2023 | Journal of Water Process Engineering |
| P10 | Prediction of biogas production in anaerobic co-digestion of organic wastes using deep-learning models [14] | 2021 | Water Research |
| P11 | Integration of swine manure anaerobic digestion and digestate nutrients removal/recovery under a circular economy concept [15] | 2021 | Journal of Environmental Management |
| P12 | Plant-scale biogas production prediction based on multiple hybrid machine-learning technique [16] | 2022 | Bioresource Technology |
| P13 | Exploring available input variables for machine-learning models to predict biogas production in industrial-scale biogas plants treating food waste [17] | 2022 | Journal of Cleaner Production |
| P14 | Data-driven techniques for fault detection in anaerobic digestion process [18] | 2020 | Process Safety and Environmental Protection |
| P15 | Use of artificial neural network and adaptive neuro-fuzzy inference system for prediction of biogas production from spearmint essential oil wastewater treatment in up-flow anaerobic sludge blanket reactor [19] | 2021 | Fuel |
| P16 | Optimisation and performance evaluation of response surface methodology(RSM), artificial neural network (ANN), and adaptive neuro-fuzzy inference system (ANFIS) in the prediction of biogas production from palm oil mill effluent (POME) [20] | 2022 | Energy |
| P17 | Artificial intelligence-based modelling and optimisation of microbial electrolysis cell-assisted anaerobic digestion fed with alkaline-pretreated waste-activated sludge [21] | 2022 | Biochemical Engineering Journal |
| P18 | Retraining prior state performances of anaerobic digestion improves prediction accuracy of methane yield in various machine-learning models [22] | 2021 | Applied Energy |
| Paper Number | Data Source | Dataset Length |
|---|---|---|
| P1 | Industrial-scale AD facility | 19-day (10-day training, 9-day cross-validation) |
| P2 | Lab data from AD experiment with tea factory waste | 49-day bmp test |
| P3 | Two datasets used from previous research | 71-day and 138-day datasets, operating under a continuously fed artificial waste stream |
| P4 | Open source data from Industrial-scale AD facility | 1340-day |
| P5 | Lab experiment | 24-day bmp test running co-digestion of food and animal waste |
| P6 | Industrial wastewater plant | 5-day (10second interval with live sensors) |
| P7 | Data provided by industrial paper mill | 389-day (75%, 25% training cross-validation) |
| P8 | AD operating with palm oil mill effluent | Not explicitly stated |
| P10 | Data provided by full-scale municipal wastewater treatment plant | 731-day and 27-day (used to demonstrate the use of DL for AD process optimisation) |
| P11 | Concept modelled on SISTRATES® waste management system | - |
| P12 | Industrial food-waste treatment plant | - |
| P13 | Industrial food-waste treatment plant | 360-day |
| P14 | Data provided using simulated dataset using benchmark simulation model from international water association | - |
| P15 | Lab experiment treating synthetic spearmint essential oil wastewater with continuously fed reactor | 141-day |
| P16 | Industrial scale palm oil mill effluent AD facility | - |
| P17 | Data extracted from lab-based study reported in the literature | 20-day batch experiment |
| P18 | Lab-based AD reactor (working volume 18L), operating under varied COD-based OLRs using food waste | 630 day |
| Paper Number | Models Listed | Optimal Model/Hybrid Optimisation | Application Domain | KPI Metrics |
|---|---|---|---|---|
| P1 | RBF-ANN | Application of moving window (MV-RBF-ANN) | Hybrid model development of an ANN to provide time-series prediction of parameters such as VFA and biogas composition. | - |
| P2 | ANN | No comparison listed | Determining co-digestion ratio of 2 waste streams to maximise methane yield. | R2 |
| P3 | ANN, Linear regression, Tree, SVM, Ensemble, Gaussian Process Regression | Hybrid ANN (NARX-BP ANN) | Predicting methane production from biogas upgrading in MECs via direct electron transfer (DET) | RMSE, R2, MSE, MAE |
| P4 | RF, XGBoost, DT, SVM, Linear regression, LSTM, KNN | Hybrid RF+LSTM | Analysing the key components in wastes streams to improve biogas generation predictions | MSE, RMSE, MAE |
| P5 | DNN | No comparison listed | Prediction of biogas response to slurry properties | R2, AR2, MSR |
| P6 | DNN, LSTM, CNN | DNN-LSTM hybrid | Analysis of waste stream ingredients to inform purification controls | RMSE, CORR |
| P7 | SVM, GP, linear/quadratic regression, CART, MLP, RBF-ANN | RBF-ANN (trained with systematic fuzzy means) hybrid | Modelling biogas production in a wastewater plant using industrial-scale data | MAE, R2 |
| P8 | RT, RF, ANN, ANFIS | ANFIS | Forecasting accumulated biogas production | CORR, MAE, RMSE, RAE, RRSE |
| P9 | BDD-RSM, ANN | ANN | Modelling methane and hydrogen sulfide production | RSME, R2 |
| P10 | LSTM variations | DA–LSTM–VSN | Forecasting downstream methane production | R2, NRMSE, MAE(%) |
| P11 | DT | No comparison given | Implementation of classification to assist human-in-the-loop decision-making in AD control operations. | - |
| P12 | ELM hybrid variations using SMOTER and GA | SMOTER-GA-ELM | Forecasting biogas production | R2, MAE |
| P13 | XGBoost, RF ANN, SVM | RF | Forecasting up to 10 days of downstream biogas production using data concerning feedstock properties | R2, RMSE |
| P14 | ENN, ELM, SVM | SVM | Predicting total VFA for use in a system fault detection framework | NRMSE, R2 |
| P15 | ANN, ANFIS | BP-ANN | Modelling biogas production using data from a lab-scale UASB reactor | R2, RMSE, RRMSE(%) |
| P16 | RSM, ANFIS, ANN | ANFIS | Prediction of biogas production/methane yield and optimisation of controllable parameters to maximise gas production/methane yield. | R2, MSE, MAE |
| P17 | RSM, ANN, PSO | No comparison given | Use of an ANN (tuned using RSM) to generate biogas predictions. PSO was used to optimise the potential difference applied to the MEC electrodes to maximise the energy output | MSE |
| P18 | RNN, XGBoost, RF, SVR | RNN | 1-step ahead with retraining method to predict AD biogas production using data detailing prior state in the time-series data | RMSE |
| Evaluated ML Methods | Paper Number |
|---|---|
| Traditional ML | P2, P3, P4, P7, P8, P11, P13, P14, P15, P16, P17, P18 |
| Deep Learning | P4, P5, P6, P10, P18 |
| Traditional ML with NovelModification | P1, P9, P12 |
| Paper Number | DNN Points of Interest | Output Context | Loss Metric | Hyperparamter Optimisation |
|---|---|---|---|---|
| P4 |
| Biogas production | MSE | Grid search Cross-Validation |
| P5 |
| Biogas compound (%) prediction | MSE | GA |
| P10 |
| Gas prediction | MSE | BOA |
| P18 |
| Methane Yield | RMSE | 10-fold cross-validation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rutland, H.; You, J.; Liu, H.; Bull, L.; Reynolds, D. A Systematic Review of Machine-Learning Solutions in Anaerobic Digestion. Bioengineering 2023, 10, 1410. https://doi.org/10.3390/bioengineering10121410
Rutland H, You J, Liu H, Bull L, Reynolds D. A Systematic Review of Machine-Learning Solutions in Anaerobic Digestion. Bioengineering. 2023; 10(12):1410. https://doi.org/10.3390/bioengineering10121410
Chicago/Turabian StyleRutland, Harvey, Jiseon You, Haixia Liu, Larry Bull, and Darren Reynolds. 2023. "A Systematic Review of Machine-Learning Solutions in Anaerobic Digestion" Bioengineering 10, no. 12: 1410. https://doi.org/10.3390/bioengineering10121410
APA StyleRutland, H., You, J., Liu, H., Bull, L., & Reynolds, D. (2023). A Systematic Review of Machine-Learning Solutions in Anaerobic Digestion. Bioengineering, 10(12), 1410. https://doi.org/10.3390/bioengineering10121410