
A Survey on AI-Driven Mouse Behavior Analysis Applications and Solutions



Abstract
1. Introduction
- RQ1: What applications can AI empower in the mice behavior analysis studies? (Answered in Section 3)
- RQ2: How to taxonomize the applications into AI tasks? (Answered in Section 3)
- RQ3: What methods are commonly used in artificial intelligence tasks related to mouse behavior analysis? (Answered in Section 4)
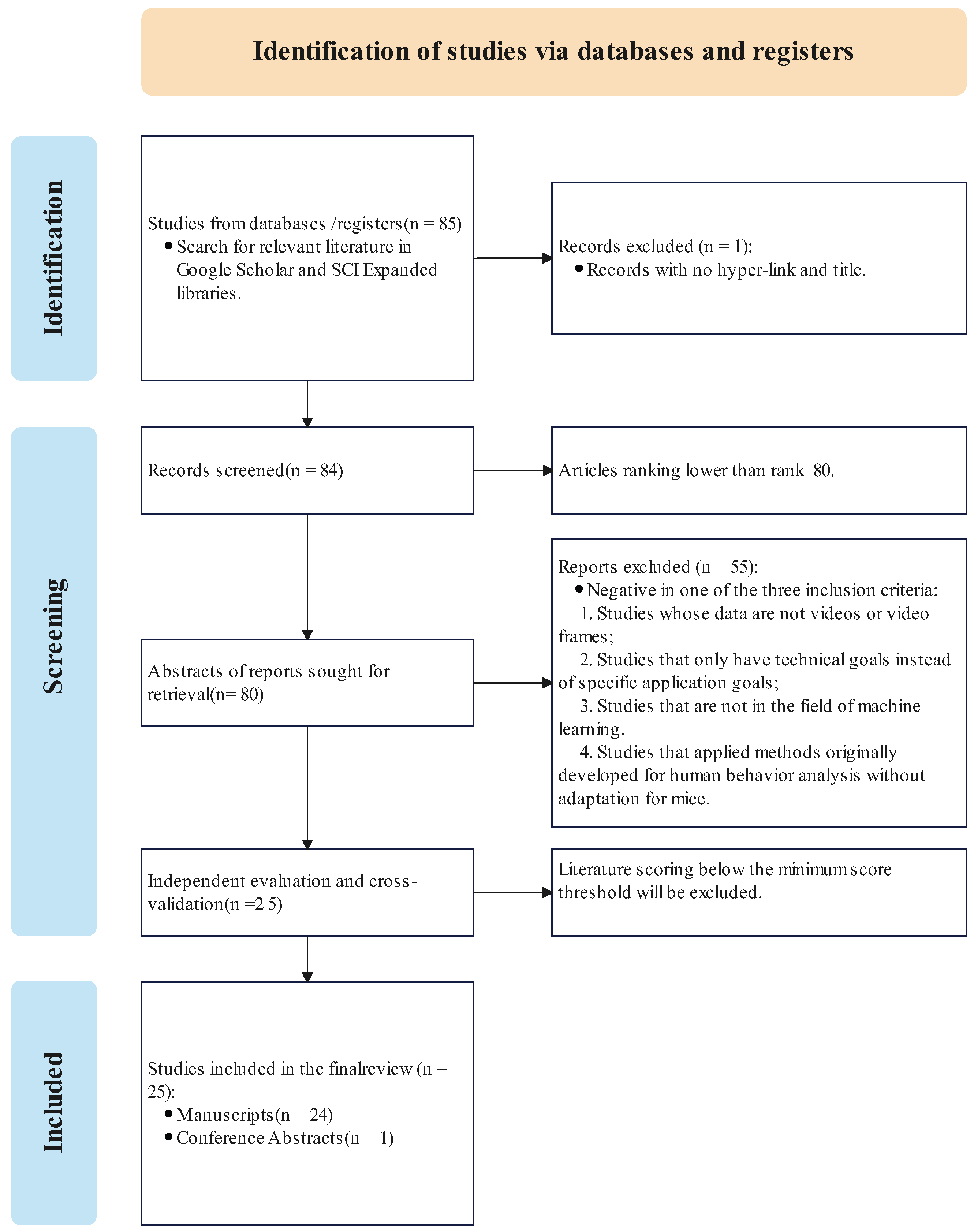
2. Survey Method
- Including studies whose data are videos or video frames;
- Including studies that have exact application goals instead of technical goals;
- Including studies in the field of machine learning;
- Excluding studies that applied methods originally developed for human behavior analysis without adaptation for mice.
- Excluding studies whose data are not videos or video frames;
- Excluding studies that only have technical goals instead of specific application goals;
- Excluding studies that are not in the field of machine learning.
3. Applications
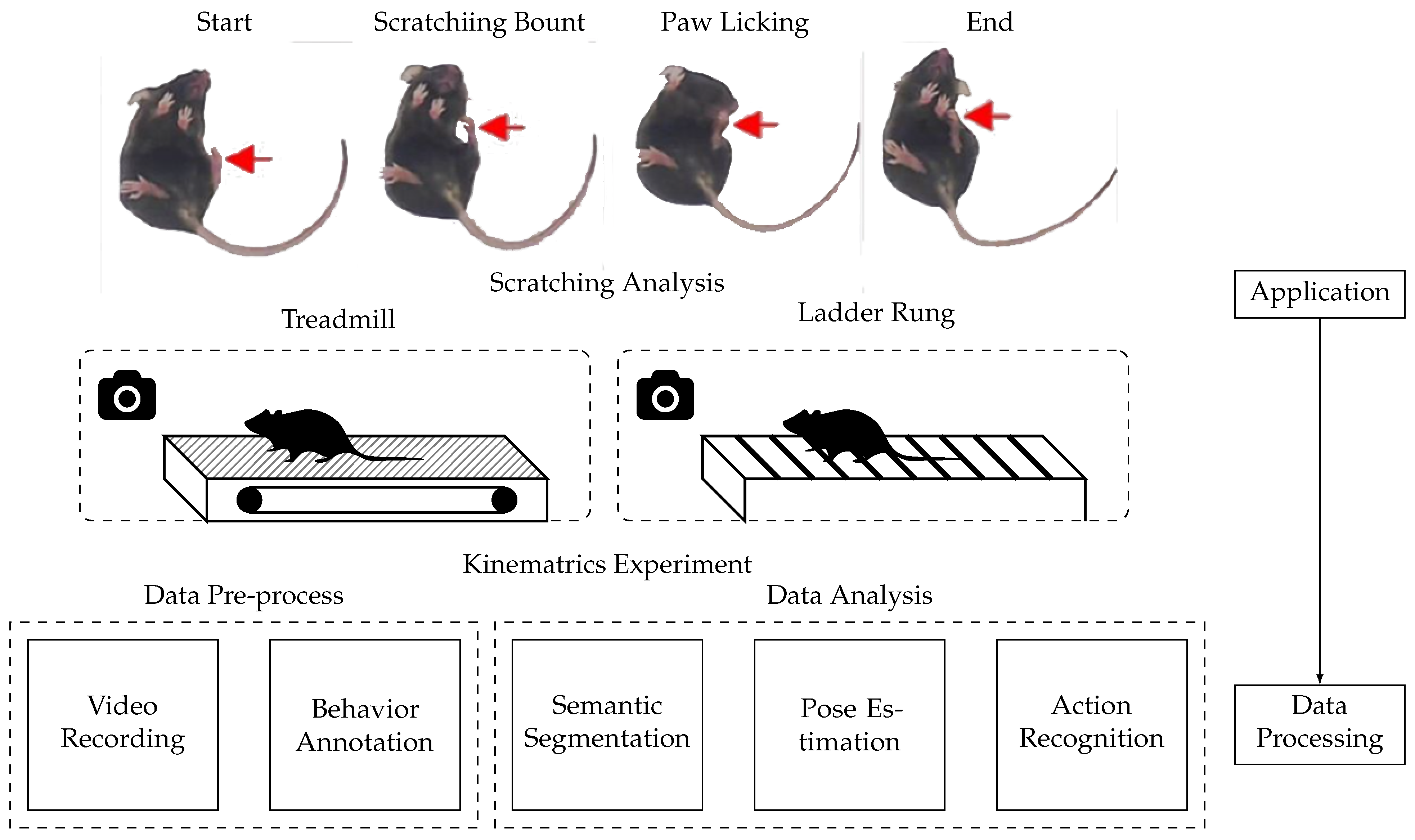
3.1. Disease Detection
3.2. External Stimuli Effective Assessment
3.3. Social Behavior Analysis
3.4. Neurobehavioral Assessment
3.5. AI Tasks Taxonomy
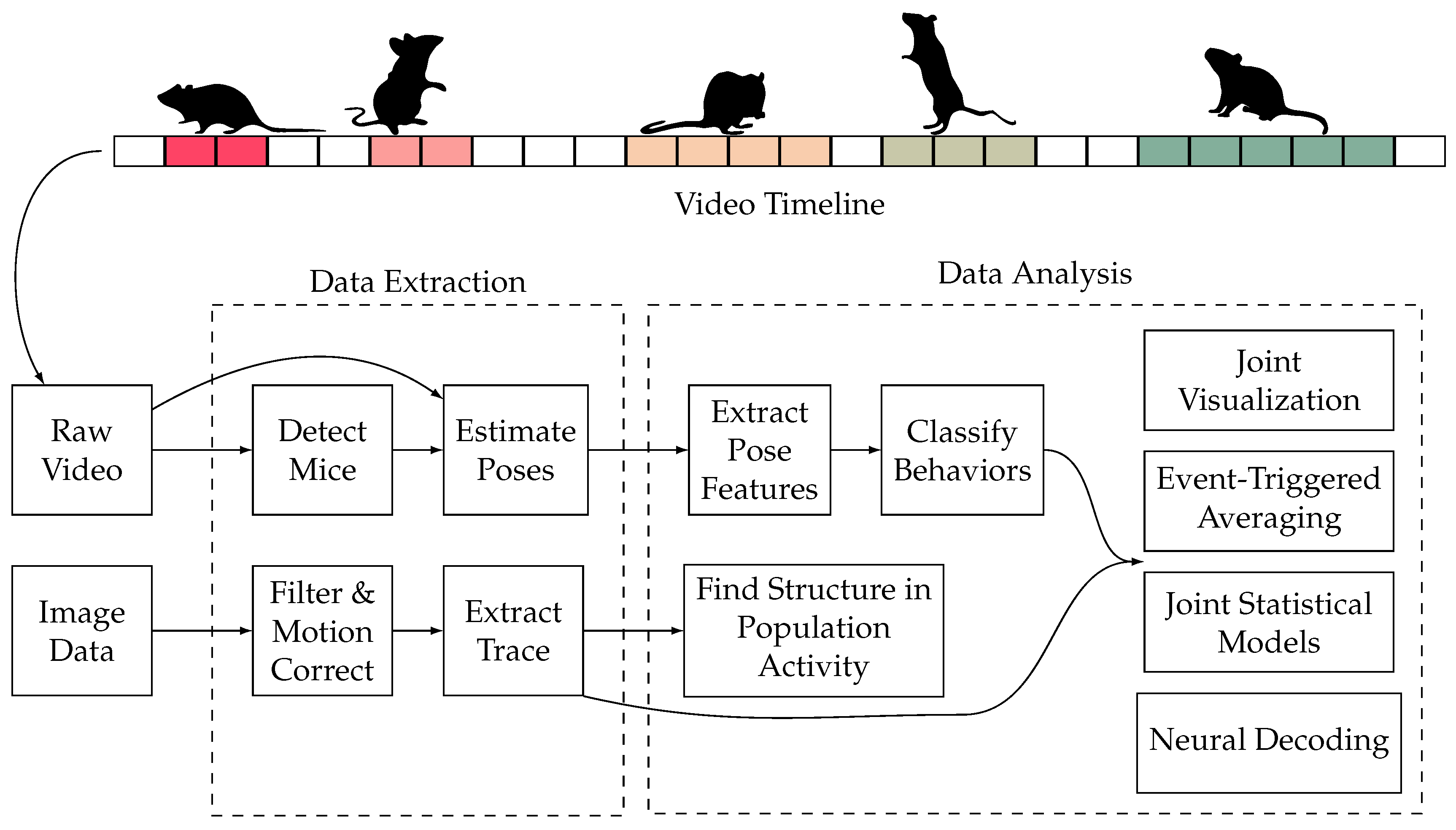
4. AI-Empowered Approaches
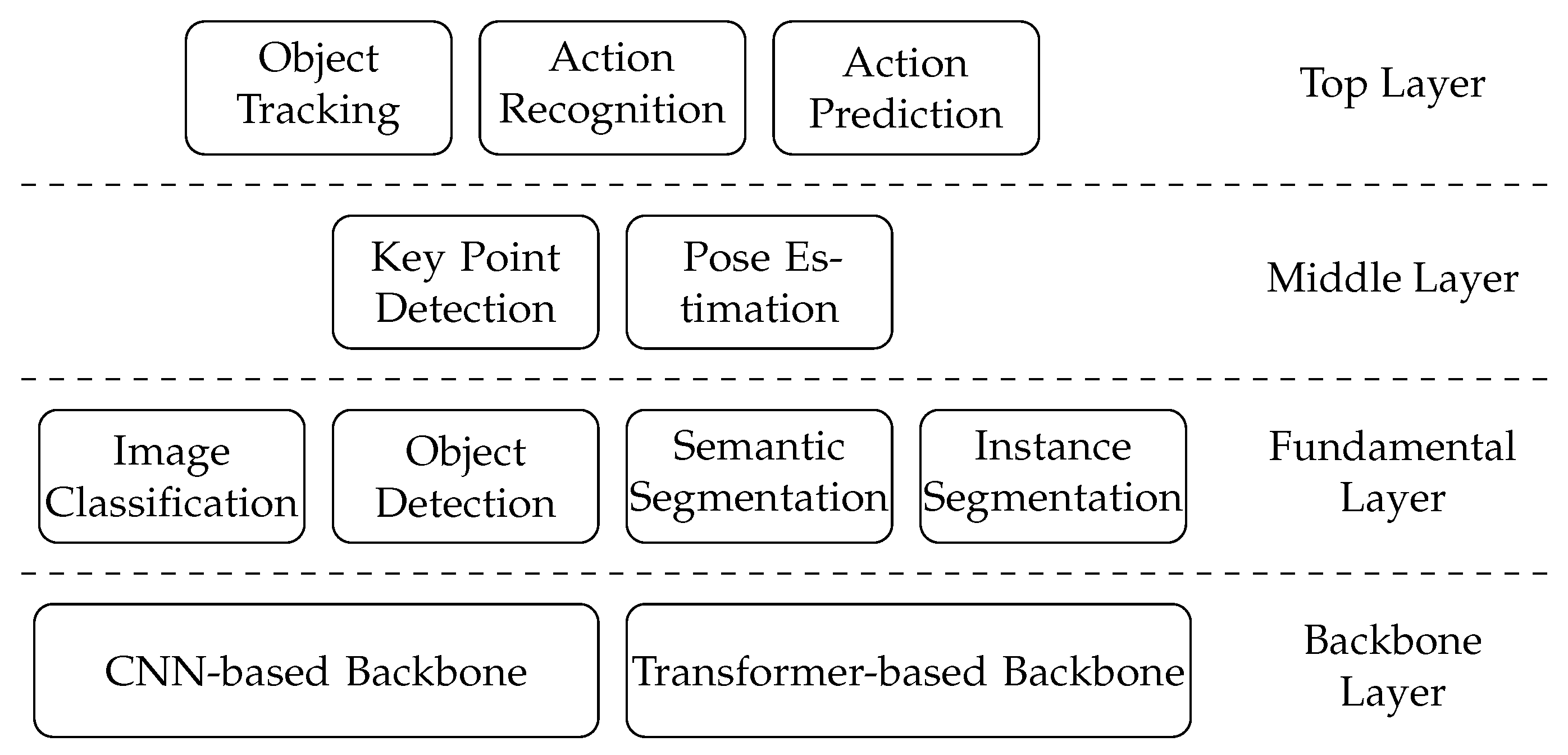
4.1. AI Pyramid
4.2. Backbone
4.3. Fundamental Layer Tasks
4.3.1. Image Classification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| AlexNet, C3D | Mice | Supervised learning | Private | The model can achieve an accuracy of 93.17% on Object Location Memory(OLM) and 95.34% on Novel Object Recognition Memory(NOR). | [49] |
| ResNet18 | Mice | Supervised learning | Private | The classification accuracy of this method can reach 92–96%, with a 5–10% false positive rate(FPR) and 4–6% false negative rate(FNR). | [52] |
| ResNet50 | Stomach | Semi-supervised learning | Private, Kvasir [65] | The classification accuracy stands at 92.57%, surpassing other state-of-the-art semi-supervised methods and exceeding the transfer learning-based classification method by 2.28%. | [61] |
| Transformer | Remote sensing | Self-supervised learning | Private | The S2FL model shows an Overall Accuracy(OA) of 69.63%, an Average Accuracy(AA) of 63.15%, and a kappa coefficient() of 0.63. | [62] |
| ResNet18 | Retina | Self-supervised learning | Ichallenge-AMD dataset [66], Ichallenge-PM dataset [67] | The model achieved AUC of 75.64, Accuracy of 87.09%, Precision of 83.96%, Recall of 75.64%, and F1-score of 78.51 on the Ichallenge-AMD Dataset. | [63] |
| ResNet18 | Dental caries | Self-supervised learning | Private | With just 18 annotations, the method can achieve a sensitivity of 45%, which is on par with human-level diagnostic performance. | [64] |
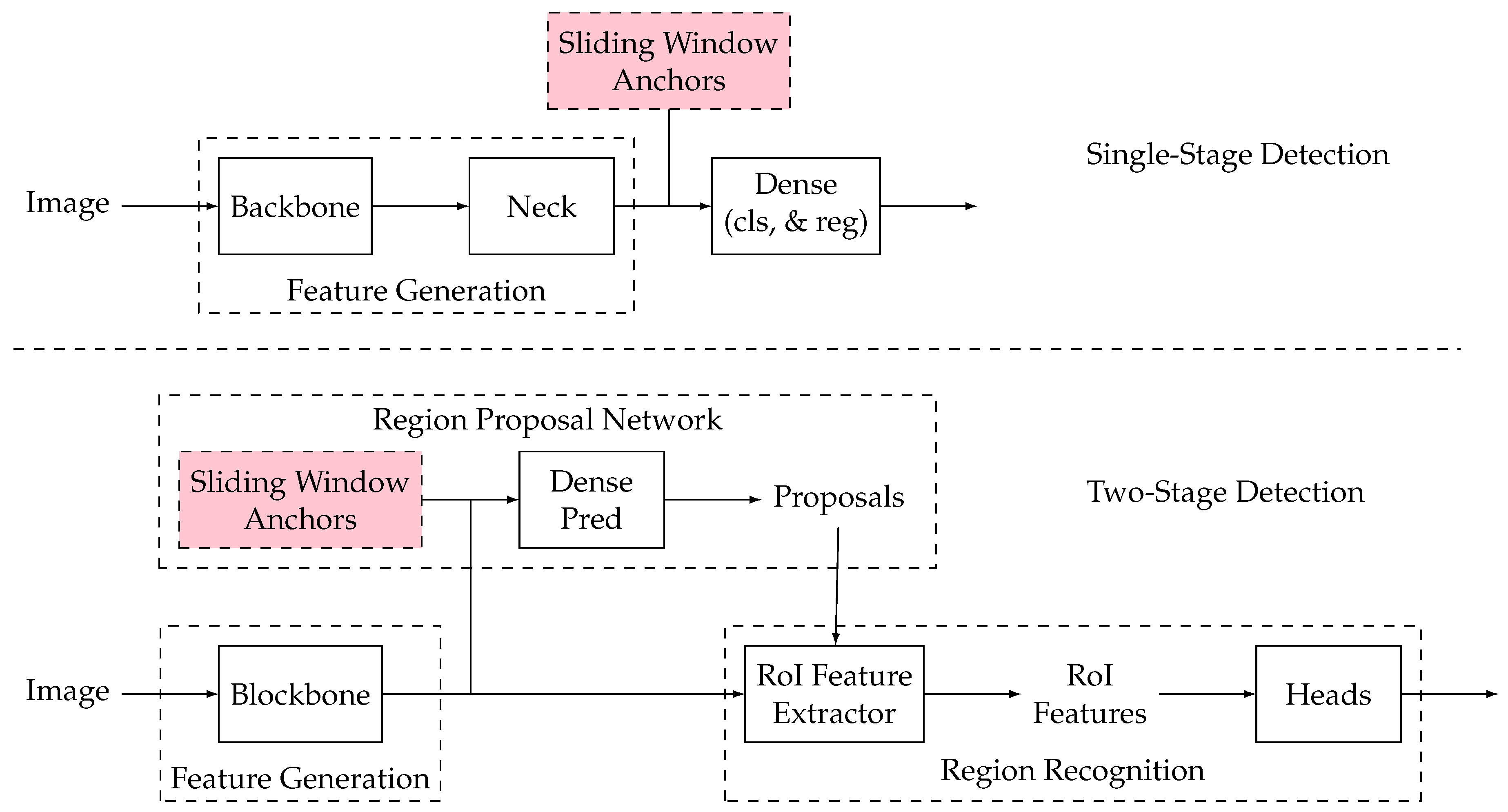
4.3.2. Object Detection
4.3.3. Semantic Segmentation
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| YoloV3 | Mice | CNN-based | Open Images dataset | Achieve a performance of 97.2% in terms of accuracy. | [26] |
| DCNN based on U-Net | Mice | CNN-based | MOST dataset | The framework notably enhanced U-Net’s segmentation efficacy, elevating somata accuracy from 0.927 to 0.996 and vessel accuracy from 0.886 to 0.971. | [74] |
| - | Mice | - | Private | Achieve an overall accuracy of 0.92 ± 0.05 (mean ± SD). | [11] |
| Context Encoding Network based on ResNet | Semantic segmentation framework | CNN-based | CIFAR-10 dataset | Achieve an error rate of 3.45%. | [76] |
| DCNN (VGG-16 or ResNet-101) | Semantic image segmentation model | CNN-based | PASCAL VOC 2012, PASCAL-Context, PASCALPerson-Part, and Cityscapes dataset | Reaching 79.7 percent mIOU. | [77] |
| DenseASPP, consists of a base network followed by a cascade of atrous convolution layers | Semantic image segmentation in autonomous driving | CNN-based | Cityscapes dataset | DenseASPP achieved mIoU class of 80.6, iIoU class of 57.9, mIoU category of 90.7, and iIoU category of 78.1 on the Cityscapes test set. | [78] |
| Transformer | Segmentation model | Transformer-based | ADE20K, Pascal Context, and Cityscapes dataset | Achieve new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. | [79] |
| Vision Transformer | Segmentation model | Transformer-based | ADE20K, Pascal Context, and Cityscapes dataset | Achieve a mean IoU of 53.63% on the ADE20K dataset. | [80] |
| Spatial-shift MLP (S2-MLP), containing only channel-mixing MLPs | Segmentation model | MLP-based | ImageNet-1K dataset | The S2-MLP-deep model achieves a top-1 accuracy of 80.7% and a top-5 accuracy of 95.4%. | [81] |
4.3.4. Instance Segmentation
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| Mask R-CNN | Mice | Top-down method | Private | SIPEC effectively identifies various behaviors of freely moving individual mice and socially interacting non-human primates in a three-dimensional space. | [28] |
| PDSL framework | - | Top-down method | PASCAL VOC 2012 [87], MS COCO [88] | The PDSL framework surpasses baseline models and attains leading-edge results on both the PASCAL VOC(49.7% mAP@0.50 score) and MS COCO datasets(13.1% mAP@0.50 score). | [82] |
| Mask R-CNN | Cell | Top-down method | Private | The proposed architecture significantly outperforms a cutting-edge Mask R-CNN method for cell detection and segmentation, delivering relative improvements in mean average precision of up to 23.88% and 23.17%, respectively. | [83] |
| ResNet101 | Human | Bottom-up method | MHPv2 [89], DensePose-COCO [90], PASCAL-Person-Part [91] | Achieve mAP@0.50 of 39.0% on MHPv2, 49.7% on DensePose-COCO, and 59.0% on PASCAL-Person-Part.The proposed model surpasses other bottom-up alternatives, offering significantly more efficient inference. | [84] |
| ResNet50 | - | Top-down method | LVIS [92] | Achieve a mask AP of 39.7% on MS COCO, and improve the baseline method by about 1% AP on LVIS. The proposed framework sets new standards in instance segmentation, excelling in both speed and accuracy, and is notably simpler than current methods. | [85] |
| ResNet | - | Bottom-up method | COCO2017, Cityscapes [93] | The average segmentation accuracy on COCO2017 and Cityscapes reaches 56% and 47.3% respectively, marking an increase of 4.4% and 7.4% over the performance of the original SOLO network. | [86] |
4.4. Middle Layer Tasks
4.4.1. Key Point Detection
4.4.2. Pose Estimation
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| Hourglass network | Mice | 2D | Parkinson’s Disease Mouse Behaviour | Achieve RMSE of 2.84 pixels and the mean PCK score of 97.80%. The superior performance over the other stateof-the-art methods in terms of PCK@0.2 score. | [98] |
| ResNet, ASPP | Mice | 2D | Private | The average PCK was 9%, 6%, and 2% higher than those of CPM, Stacked Hourglass, and DeepLabCut, with superior performance at various thresholds. | [99] |
| Structured forests | Mice | 3D | Private | Achieve a 24.9% failure rate in 3D pose estimation for laboratory mice, outperforming the adapted Cascaded Pose Regression and Deep Neural Networks. | [42] |
| HRNet | Human | 2D | COCO, MPII human pose estimation, and PoseTrack dataset | Achieves a 92.3 PCKh@0.5 score | [101] |
| HigherHRNet | Human | 2D | COCO dataset | The model attains a groundbreaking performance on the COCO test-dev with an AP of 70.5%, and it outperforms all existing top-down approaches on the CrowdPose test, achieving an AP of 67.6%. | [102] |
| Lite-HRNet | Human | 2D | COCO and MPII human pose estimation datasets | Achieves a 87.0 PCKh @0.5 score. | [103] |
| ResNet-152 | Human | 3D | Human3.6M and CMU Panoptic datasets | The model reaches cutting-edge performance on the Human3.6M dataset, with a mean error of 20.8 mm. | [104] |
| ResNet-50 | Human | 3D | InterHand and Human3.6M datasets | Outperforms state-of-the-art by 4.23mm and achieves MPJPE 26.9 mm | [105] |
| ResNet-50 | Human | 3D | MPII, MuPoTs-3D, and RenderedH datasets | The model surpasses the performance of the same whole-body model and remains comparable to that of expert models. It is less resource-intensive than an ensemble of experts and is capable of achieving real-time performance. | [106] |
4.5. Top Layer Tasks
4.5.1. Object Tracking
4.5.2. Action Recognition
4.5.3. Action Prediction
5. Discussion
5.1. Limitation of AI Technology
5.2. Strength and Challenges of Constructing a Mouse Behavior Analysis Platform Framework
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| CRNN | Convolutional Recurrent Neural Network |
| FC | Fully Connected |
| SVMs | Support Vector Machines |
| KNN | K-nearest Neighbours |
| MARS | Mouse Action Recognition System |
| RPN | Region Propose Network |
| ROI | Region of Interest |
| IoU | Intersection over Union |
| GCN | Graph Convolution Network |
References
- Manavalan, B.; Basith, S.; Shin, T.H.; Lee, D.Y.; Wei, L.; Lee, G. 4mCpred-EL: An Ensemble Learning Framework for Identification of DNA N4-methylcytosine Sites in the Mouse Genome. Cells 2019, 8, 1332. [Google Scholar] [CrossRef] [PubMed]
- Koehler, C.C.; Hall, L.M.; Hellmer, C.B.; Ichinose, T. Using Looming Visual Stimuli to Evaluate Mouse Vision. J. Vis. Exp. 2019, 148, 59766. [Google Scholar] [CrossRef]
- Taherzadeh, G.; Yang, Y.; Xu, H.; Xue, Y.; Liew, A.W.C.; Zhou, Y. Predicting Lysine-Malonylation Sites of Proteins Using Sequence and Predicted Structural Features. J. Comput. Chem. 2018, 39, 1757–1763. [Google Scholar] [CrossRef] [PubMed]
- Pearson, B.L.; Defensor, E.B.; Blanchard, D.C.; Blanchard, R.J. C57BL/6J Mice Fail to Exhibit Preference for Social Novelty in the Three-Chamber Apparatus. Behav. Brain Res. 2010, 213, 189–194. [Google Scholar] [CrossRef] [PubMed]
- Kulesskaya, N.; Voikar, V. Assessment of Mouse Anxiety-like Behavior in the Light–Dark Box and Open-Field Arena: Role of Equipment and Procedure. Physiol. Behav. 2014, 133, 30–38. [Google Scholar] [CrossRef]
- Seo, M.K.; Jeong, S.; Seog, D.H.; Lee, J.A.; Lee, J.H.; Lee, Y.; McIntyre, R.S.; Park, S.W.; Lee, J.G. Effects of Liraglutide on Depressive Behavior in a Mouse Depression Model and Cognition in the Probe Trial of Morris Water Maze Test. J. Affect. Disord. 2023, 324, 8–15. [Google Scholar] [CrossRef] [PubMed]
- Bohnslav, J.P.; Wimalasena, N.K.; Clausing, K.J.; Dai, Y.Y.; Yarmolinsky, D.A.; Cruz, T.; Kashlan, A.D.; Chiappe, M.E.; Orefice, L.L.; Woolf, C.J.; et al. DeepEthogram, a Machine Learning Pipeline for Supervised Behavior Classification from Raw Pixels. eLife 2021, 10, e63377. [Google Scholar] [CrossRef] [PubMed]
- Egnor, S.R.; Branson, K. Computational Analysis of Behavior. Annu. Rev. Neurosci. 2016, 39, 217–236. [Google Scholar] [CrossRef] [PubMed]
- Rezaei Miandoab, A.; Bagherzadeh, S.A.; Meghdadi Isfahani, A.H. Numerical study of the effects of twisted-tape inserts on heat transfer parameters and pressure drop across a tube carrying Graphene Oxide nanofluid: An optimization by implementation of Artificial Neural Network and Genetic Algorithm. Eng. Anal. Bound. Elem. 2022, 140, 1–11. [Google Scholar] [CrossRef]
- Alexandrov, V.; Brunner, D.; Menalled, L.B.; Kudwa, A.; Watson-Johnson, J.; Mazzella, M.; Russell, I.; Ruiz, M.C.; Torello, J.; Sabath, E.; et al. Large-Scale Phenome Analysis Defines a Behavioral Signature for Huntington’s Disease Genotype in Mice. Nat. Biotechnol. 2016, 34, 838–844. [Google Scholar] [CrossRef] [PubMed]
- Geuther, B.; Chen, M.; Galante, R.J.; Han, O.; Lian, J.; George, J.; Pack, A.I.; Kumar, V. High-Throughput Visual Assessment of Sleep Stages in Mice Using Machine Learning. Sleep 2022, 45, zsab260. [Google Scholar] [CrossRef] [PubMed]
- Vogel-Ciernia, A.; Matheos, D.P.; Barrett, R.M.; Kramár, E.A.; Azzawi, S.; Chen, Y.; Magnan, C.N.; Zeller, M.; Sylvain, A.; Haettig, J.a. The neuron-specific chromatin regulatory subunit BAF53b is necessary for synaptic plasticity and memory. Nat. Neurosci. 2015, 16, 552–561. [Google Scholar] [CrossRef]
- Kalueff, A.V.; Stewart, A.M.; Song, C.; Berridge, K.C.; Graybiel, A.M.; Fentress, J.C. Neurobiology of Rodent Self-Grooming and Its Value for Translational Neuroscience. Nat. Rev. Neurosci. 2016, 17, 45–59. [Google Scholar] [CrossRef] [PubMed]
- Houle, D.; Govindaraju, D.R.; Omholt, S. Phenomics: The next Challenge. Nat. Rev. Genet. 2010, 11, 855–866. [Google Scholar] [CrossRef]
- Lee, K.; Park, I.; Bishayee, K.; Lee, U. Machine-Learning Based Automatic and Real-Time Detection of Mouse Scratching Behaviors. IBRO Rep. 2019, 6, S414–S415. [Google Scholar] [CrossRef]
- Sakamoto, N.; Haraguchi, T.; Kobayashi, K.; Miyazaki, Y.; Murata, T. Automated Scratching Detection System for Black Mouse Using Deep Learning. Front. Physiol. 2022, 13, 939281. [Google Scholar] [CrossRef] [PubMed]
- Viglione, A.; Sagona, G.; Carrara, F.; Amato, G.; Totaro, V.; Lupori, L.; Putignano, E.; Pizzorusso, T.; Mazziotti, R. Behavioral Impulsivity Is Associated with Pupillary Alterations and Hyperactivity in CDKL5 Mutant Mice. Hum. Mol. Genet. 2022, 31, 4107–4120. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Xiong, J.; Ye, A.Y.; Cranfill, S.L.; Cannonier, T.; Gautam, M.; Zhang, M.; Bilal, R.; Park, J.E.; Xue, Y.; et al. Scratch-AID, a Deep Learning-Based System for Automatic Detection of Mouse Scratching Behavior with High Accuracy. eLife 2022, 11, e84042. [Google Scholar] [CrossRef]
- Weber, R.Z.; Mulders, G.; Kaiser, J.; Tackenberg, C.; Rust, R. Deep Learning-Based Behavioral Profiling of Rodent Stroke Recovery. BMC Biol. 2022, 20, 232. [Google Scholar] [CrossRef] [PubMed]
- Aljovic, A.; Zhao, S.; Chahin, M.; De La Rosa, C.; Van Steenbergen, V.; Kerschensteiner, M.; Bareyre, F.M. A Deep Learning-Based Toolbox for Automated Limb Motion Analysis (ALMA) in Murine Models of Neurological Disorders. Commun. Biol. 2022, 5, 131. [Google Scholar] [CrossRef]
- Cai, H.; Luo, Y.; Yan, X.; Ding, P.; Huang, Y.; Fang, S.; Zhang, R.; Chen, Y.; Guo, Z.; Fang, J.; et al. The Mechanisms of Bushen-Yizhi Formula as a Therapeutic Agent against Alzheimer’s Disease. Sci. Rep. 2018, 8, 3104. [Google Scholar] [CrossRef]
- Iino, Y.; Sawada, T.; Yamaguchi, K.; Tajiri, M.; Ishii, S.; Kasai, H.; Yagishita, S. Dopamine D2 Receptors in Discrimination Learning and Spine Enlargement. Nature 2020, 579, 555–560. [Google Scholar] [CrossRef] [PubMed]
- Merlini, M.; Rafalski, V.A.; Rios Coronado, P.E.; Gill, T.M.; Ellisman, M.; Muthukumar, G.; Subramanian, K.S.; Ryu, J.K.; Syme, C.A.; Davalos, D.; et al. Fibrinogen Induces Microglia-Mediated Spine Elimination and Cognitive Impairment in an Alzheimer’s Disease Model. Neuron 2019, 101, 1099–1108.e6. [Google Scholar] [CrossRef] [PubMed]
- Wotton, J.M.; Peterson, E.; Anderson, L.; Murray, S.A.; Braun, R.E.; Chesler, E.J.; White, J.K.; Kumar, V. Machine Learning-Based Automated Phenotyping of Inflammatory Nocifensive Behavior in Mice. Mol. Pain 2020, 16, 174480692095859. [Google Scholar] [CrossRef] [PubMed]
- Kathote, G.; Ma, Q.; Angulo, G.; Chen, H.; Jakkamsetti, V.; Dobariya, A.; Good, L.B.; Posner, B.; Park, J.Y.; Pascual, J.M. Identification of Glucose Transport Modulators In Vitro and Method for Their Deep Learning Neural Network Behavioral Evaluation in Glucose Transporter 1–Deficient Mice. J. Pharmacol. Exp. Ther. 2023, 384, 393–405. [Google Scholar] [CrossRef] [PubMed]
- Vidal, A.; Jha, S.; Hassler, S.; Price, T.; Busso, C. Face Detection and Grimace Scale Prediction of White Furred Mice. Mach. Learn. Appl. 2022, 8, 100312. [Google Scholar] [CrossRef]
- Abdus-Saboor, I.; Fried, N.T.; Lay, M.; Burdge, J.; Swanson, K.; Fischer, R.; Jones, J.; Dong, P.; Cai, W.; Guo, X.; et al. Development of a Mouse Pain Scale Using Sub-second Behavioral Mapping and Statistical Modeling. Cell Rep. 2019, 28, 1623–1634.e4. [Google Scholar] [CrossRef] [PubMed]
- Marks, M.; Jin, Q.; Sturman, O.; Von Ziegler, L.; Kollmorgen, S.; Von Der Behrens, W.; Mante, V.; Bohacek, J.; Yanik, M.F. Deep-Learning-Based Identification, Tracking, Pose Estimation and Behaviour Classification of Interacting Primates and Mice in Complex Environments. Nat. Mach. Intell. 2022, 4, 331–340. [Google Scholar] [CrossRef] [PubMed]
- Torabi, R.; Jenkins, S.; Harker, A.; Whishaw, I.Q.; Gibb, R.; Luczak, A. A Neural Network Reveals Motoric Effects of Maternal Preconception Exposure to Nicotine on Rat Pup Behavior: A New Approach for Movement Disorders Diagnosis. Front. Neurosci. 2021, 15, 686767. [Google Scholar] [CrossRef]
- Martins, T.M.; Brown Driemeyer, J.P.; Schmidt, T.P.; Sobieranski, A.C.; Dutra, R.C.; Oliveira Weber, T. A Machine Learning Approach to Immobility Detection in Mice during the Tail Suspension Test for Depressive-Type Behavior Analysis. Res. Biomed. Eng. 2022, 39, 15–26. [Google Scholar] [CrossRef]
- Wang, J.; Karbasi, P.; Wang, L.; Meeks, J.P. A Layered, Hybrid Machine Learning Analytic Workflow for Mouse Risk Assessment Behavior. Eneuro 2023, 10, ENEURO.0335–22.2022. [Google Scholar] [CrossRef] [PubMed]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless Pose Estimation of User-Defined Body Parts with Deep Learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef]
- Bermudez Contreras, E.; Sutherland, R.J.; Mohajerani, M.H.; Whishaw, I.Q. Challenges of a Small World Analysis for the Continuous Monitoring of Behavior in Mice. Neurosci. Biobehav. Rev. 2022, 136, 104621. [Google Scholar] [CrossRef]
- Gharagozloo, M.; Amrani, A.; Wittingstall, K.; Hamilton-Wright, A.; Gris, D. Machine Learning in Modeling of Mouse Behavior. Front. Neurosci. 2021, 15, 700253. [Google Scholar] [CrossRef] [PubMed]
- Van Dam, E.A.; Noldus, L.P.; Van Gerven, M.A. Deep Learning Improves Automated Rodent Behavior Recognition within a Specific Experimental Setup. J. Neurosci. Methods 2020, 332, 108536. [Google Scholar] [CrossRef]
- Robie, A.A.; Seagraves, K.M.; Egnor, S.E.R.; Branson, K. Machine Vision Methods for Analyzing Social Interactions. J. Exp. Biol. 2017, 220, 25–34. [Google Scholar] [CrossRef] [PubMed]
- Segalin, C.; Williams, J.; Karigo, T.; Hui, M.; Zelikowsky, M.; Sun, J.J.; Perona, P.; Anderson, D.J.; Kennedy, A. The Mouse Action Recognition System (MARS) Software Pipeline for Automated Analysis of Social Behaviors in Mice. eLife 2021, 10, e63720. [Google Scholar] [CrossRef]
- Agbele, T.; Ojeme, B.; Jiang, R. Application of Local Binary Patterns and Cascade AdaBoost Classifier for Mice Behavioural Patterns Detection and Analysis. Procedia Comput. Sci. 2019, 159, 1375–1386. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhou, F.; Zhao, A.; Li, X.; Li, L.; Tao, D.; Li, X.; Zhou, H. Multi-View Mouse Social Behaviour Recognition with Deep Graphic Model. IEEE Trans. Image Process. 2021, 30, 5490–5504. [Google Scholar] [CrossRef]
- Sheets, A.L.; Lai, P.L.; Fisher, L.C.; Basso, D.M. Quantitative Evaluation of 3D Mouse Behaviors and Motor Function in the Open-Field after Spinal Cord Injury Using Markerless Motion Tracking. PLoS ONE 2013, 8, e74536. [Google Scholar] [CrossRef]
- Burgos-Artizzu, X.P.; Dollár, P.; Lin, D.; Anderson, D.J.; Perona, P. Social Behavior Recognition in Continuous Video. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1322–1329. [Google Scholar] [CrossRef]
- Salem, G.; Krynitsky, J.; Hayes, M.; Pohida, T.; Burgos-Artizzu, X. Three-Dimensional Pose Estimation for Laboratory Mouse From Monocular Images. IEEE Trans. Image Process. 2019, 28, 4273–4287. [Google Scholar] [CrossRef] [PubMed]
- Winters, C.; Gorssen, W.; Ossorio-Salazar, V.A.; Nilsson, S.; Golden, S.; D’Hooge, R. Automated Procedure to Assess Pup Retrieval in Laboratory Mice. Sci. Rep. 2022, 12, 1663. [Google Scholar] [CrossRef]
- Hong, W.; Kennedy, A.; Burgos-Artizzu, X.P.; Zelikowsky, M.; Navonne, S.G.; Perona, P.; Anderson, D.J. Automated Measurement of Mouse Social Behaviors Using Depth Sensing, Video Tracking, and Machine Learning. Proc. Natl. Acad. Sci. USA 2015, 112, E5351–E5360. [Google Scholar] [CrossRef]
- Tanas, J.K.; Kerr, D.D.; Wang, L.; Rai, A.; Wallaard, I.; Elgersma, Y.; Sidorov, M.S. Multidimensional Analysis of Behavior Predicts Genotype with High Accuracy in a Mouse Model of Angelman Syndrome. Transl. Psychiatry 2022, 12, 426–434. [Google Scholar] [CrossRef] [PubMed]
- Yamamoto, M.; Motomura, E.; Yanagisawa, R.; Hoang, V.A.T.; Mogi, M.; Mori, T.; Nakamura, M.; Takeya, M.; Eto, K. Evaluation of Neurobehavioral Impairment in Methylmercury-Treated KK-Ay Mice by Dynamic Weight-Bearing Test: Neurobehavioral Disorders in Methylmercury-Treated Mice. J. Appl. Toxicol. 2019, 39, 221–230. [Google Scholar] [CrossRef] [PubMed]
- Delanogare, E.; Bullich, S.; Barbosa, L.A.D.S.; Barros, W.D.M.; Braga, S.P.; Kraus, S.I.; Kasprowicz, J.N.; Dos Santos, G.J.; Guiard, B.P.; Moreira, E.L.G. Metformin Improves Neurobehavioral Impairments of Streptozotocin-treated and Western Diet-fed Mice: Beyond Glucose-lowering Effects. Fundam. Clin. Pharmacol. 2023, 37, 94–106. [Google Scholar] [CrossRef] [PubMed]
- McMackin, M.Z.; Henderson, C.K.; Cortopassi, G.A. Neurobehavioral Deficits in the KIKO Mouse Model of Friedreich’s Ataxia. Behav. Brain Res. 2017, 316, 183–188. [Google Scholar] [CrossRef]
- Ren, Z.; Annie, A.N.; Ciernia, V.; Lee, Y.J. Who Moved My Cheese? Automatic Annotation of Rodent Behaviors with Convolutional Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1277–1286. [Google Scholar] [CrossRef]
- Jiang, Z.; Crookes, D.; Green, B.D.; Zhao, Y.; Ma, H.; Li, L.; Zhang, S.; Tao, D.; Zhou, H. Context-Aware Mouse Behavior Recognition Using Hidden Markov Models. IEEE Trans. Image Process. 2019, 28, 1133–1148. [Google Scholar] [CrossRef]
- Tong, M.; Yu, X.; Shao, J.; Shao, Z.; Li, W.; Lin, W. Automated Measuring Method Based on Machine Learning for Optomotor Response in Mice. Neurocomputing 2020, 418, 241–250. [Google Scholar] [CrossRef]
- Cai, L.X.; Pizano, K.; Gundersen, G.W.; Hayes, C.L.; Fleming, W.T.; Holt, S.; Cox, J.M.; Witten, I.B. Distinct Signals in Medial and Lateral VTA Dopamine Neurons Modulate Fear Extinction at Different Times. eLife 2020, 9, e54936. [Google Scholar] [CrossRef] [PubMed]
- Jhuang, H.; Garrote, E.; Yu, X.; Khilnani, V.; Poggio, T.; Steele, A.D.; Serre, T. Correction: Corrigendum: Automated Home-Cage Behavioural Phenotyping of Mice. Nat. Commun. 2012, 3, 654. [Google Scholar] [CrossRef]
- Lara-Doña, A.; Torres-Sanchez, S.; Priego-Torres, B.; Berrocoso, E.; Sanchez-Morillo, D. Automated Mouse Pupil Size Measurement System to Assess Locus Coeruleus Activity with a Deep Learning-Based Approach. Sensors 2021, 21, 7106. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Available online: http://arxiv.org/abs/1506.02640 (accessed on 8 June 2015).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. arXiv 2016, arXiv:1603.06937. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Du, W.; Rao, N.; Yong, J.; Wang, Y.; Hu, D.; Gan, T.; Zhu, L.; Zeng, B. Improving the Classification Performance of Esophageal Disease on Small Dataset by Semi-supervised Efficient Contrastive Learning. J. Med. Syst. 2022, 46, 4. [Google Scholar] [CrossRef] [PubMed]
- Xue, Z.; Yu, X.; Yu, A.; Liu, B.; Zhang, P.; Wu, S. Self-Supervised Feature Learning for Multimodal Remote Sensing Image Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5533815. [Google Scholar] [CrossRef]
- Li, X.; Hu, X.; Qi, X.; Yu, L.; Zhao, W.; Heng, P.A.; Xing, L. Rotation-Oriented Collaborative Self-Supervised Learning for Retinal Disease Diagnosis. IEEE Trans. Med. Imaging 2021, 40, 2284–2294. [Google Scholar] [CrossRef]
- Taleb, A.; Rohrer, C.; Bergner, B.; De Leon, G.; Rodrigues, J.A.; Schwendicke, F.; Lippert, C.; Krois, J. Self-Supervised Learning Methods for Label-Efficient Dental Caries Classification. Diagnostics 2022, 12, 1237. [Google Scholar] [CrossRef]
- Pogorelov, K.; Randel, K.R.; Griwodz, C.; Lange, T.D.; Halvorsen, P. KVASIR: A Multi-Class Image Dataset for Computer Aided Gastrointestinal Disease Detection. In Proceedings of the Acm on Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017. [Google Scholar]
- Fu, H.; Li, F.; Orlando, J.; Bogunovic, H.; Sun, X.; Liao, J.; Xu, Y.; Zhang, S.; Zhang, X. Adam: Automatic detection challenge on age-related macular degeneration. IEEE Dataport 2020. [Google Scholar] [CrossRef]
- Fang, H.; Li, F.; Wu, J.; Fu, H.; Sun, X.; Orlando, J.I.; Bogunović, H.; Zhang, X.; Xu, Y. PALM: Open Fundus Photograph Dataset with Pathologic Myopia Recognition and Anatomical Structure Annotation. arXiv 2023, arXiv:2305.07816. [Google Scholar]
- Hu, Y.; Ding, Z.; Ge, R.; Shao, W.; Huang, L.; Li, K.; Liu, Q. AFDetV2: Rethinking the Necessity of the Second Stage for Object Detection from Point Clouds. Proc. Aaai Conf. Artif. Intell. 2022, 36, 969–979. [Google Scholar] [CrossRef]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Sun, G.; Hua, Y.; Hu, G.; Robertson, N. Efficient One-Stage Video Object Detection by Exploiting Temporal Consistency. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; Volume 13695, pp. 1–16. [Google Scholar] [CrossRef]
- Zhou, J.; Feng, K.; Li, W.; Han, J.; Pan, F. TS4Net: Two-stage Sample Selective Strategy for Rotating Object Detection. Neurocomputing 2022, 501, 753–764. [Google Scholar] [CrossRef]
- Zhou, Q.; Li, X.; He, L.; Yang, Y.; Cheng, G.; Tong, Y.; Ma, L.; Tao, D. TransVOD: End-to-End Video Object Detection with Spatial-Temporal Transformers. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7853–7869. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Wu, X.; Tao, Y.; He, G.; Liu, D.; Fan, M.; Yang, S.; Gong, H.; Xiao, R.; Chen, S.; Huang, J. Boosting Multilabel Semantic Segmentation for Somata and Vessels in Mouse Brain. Front. Neurosci. 2021, 15, 610122. [Google Scholar] [CrossRef] [PubMed]
- Webb, J.M.; Fu, Y.H. Recent Advances in Sleep Genetics. Curr. Opin. Neurobiol. 2021, 69, 19–24. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7242–7252. [Google Scholar] [CrossRef]
- Yu, T.; Li, X.; Cai, Y.; Sun, M.; Li, P. S2-MLP: Spatial-Shift MLP Architecture for Vision. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3615–3624. [Google Scholar] [CrossRef]
- Shen, Y.; Cao, L.; Chen, Z.; Zhang, B.; Su, C.; Wu, Y.; Huang, F.; Ji, R. Parallel detection-and-segmentation learning for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8198–8208. [Google Scholar]
- Korfhage, N.; Mühling, M.; Ringshandl, S.; Becker, A.; Schmeck, B.; Freisleben, B. Detection and Segmentation of Morphologically Complex Eukaryotic Cells in Fluorescence Microscopy Images via Feature Pyramid Fusion. PLoS Comput. Biol. 2020, 16, e1008179. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Wang, W.; Liu, S.; Yang, Y.; Van Gool, L. Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1622–1631. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. SOLO: A Simple Framework for Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8587–8601. [Google Scholar] [CrossRef] [PubMed]
- Li, B.r.; Zhang, J.k.; Liang, Y. PaFPN-SOLO: A SOLO-based Image Instance Segmentation Algorithm. In Proceedings of the 2022 Asia Conference on Algorithms, Computing and Machine Learning (CACML), Hangzhou, China, 25–27 March 2022; pp. 557–564. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zhao, J.; Li, J.; Cheng, Y.; Zhou, L.; Sim, T.; Yan, S.; Feng, J. Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018. [Google Scholar]
- Güler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense Human Pose Estimation In The Wild. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Xia, F.; Wang, P.; Chen, X.; Yuille, A.L. Joint Multi-person Pose Estimation and Semantic Part Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6080–6089. [Google Scholar] [CrossRef]
- Gupta, A.; Dollár, P.; Girshick, R. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA 15–20 June 2019. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wen, J.; Chi, J.; Wu, C.; Yu, X. Human Pose Estimation Based Pre-training Model and Efficient High-Resolution Representation. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 8463–8468. [Google Scholar] [CrossRef]
- Gong, F.; Li, Y.; Yuan, X.; Liu, X.; Gao, Y. Human Elbow Flexion Behaviour Recognition Based on Posture Estimation in Complex Scenes. IET Image Process. 2023, 17, 178–192. [Google Scholar] [CrossRef]
- Zang, Y.; Fan, C.; Zheng, Z.; Yang, D. Pose Estimation at Night in Infrared Images Using a Lightweight Multi-Stage Attention Network. Signal Image Video Process. 2021, 15, 1757–1765. [Google Scholar] [CrossRef]
- Hong, F.; Lu, C.; Liu, C.; Liu, R.; Jiang, W.; Ju, W.; Wang, T. PGNet: Pipeline Guidance for Human Key-Point Detection. Entropy 2020, 22, 369. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Jiang, Z.; Liu, Z.; Chen, F.; Chen, L.; Tong, L.; Yang, Z.; Wang, H.; Fei, M.; Li, L.; et al. Structured Context Enhancement Network for Mouse Pose Estimation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2787–2801. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, R.; Wang, Z.; Wang, S.; Zhu, J. Detection of Key Points in Mice at Different Scales via Convolutional Neural Network. Symmetry 2022, 14, 1437. [Google Scholar] [CrossRef]
- Topham, L.K.; Khan, W.; Al-Jumeily, D.; Hussain, A. Human Body Pose Estimation for Gait Identification: A Comprehensive Survey of Datasets and Models. ACM Comput. Surv. 2023, 55, 1–42. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar] [CrossRef]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5385–5394. [Google Scholar] [CrossRef]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-HRNet: A Lightweight High-Resolution Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10435–10445. [Google Scholar] [CrossRef]
- Iskakov, K.; Burkov, E.; Lempitsky, V.; Malkov, Y. Learnable Triangulation of Human Pose. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October –2 November 2019; pp. 7717–7726. [Google Scholar] [CrossRef]
- He, Y.; Yan, R.; Fragkiadaki, K.; Yu, S.I. Epipolar Transformers. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7779–7788. [Google Scholar]
- Weinzaepfel, P.; Brégier, R.; Combaluzier, H.; Leroy, V.; Rogez, G. DOPE: Distillation of Part Experts for Whole-Body 3D Pose Estimation in the Wild. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12371, pp. 380–397. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Wang, F.; Luo, L.; Zhu, E.; Wang, S. Multi-Object Tracking with a Hierarchical Single-Branch Network. In MultiMedia Modeling; Þór Jónsson, B., Gurrin, C., Tran, M.T., Dang-Nguyen, D.T., Hu, A.M.C., Huynh Thi Thanh, B., Huet, B., Eds.; Springer International Publishing: Cham, Switzerland, 2022; Volume 13142, pp. 73–83. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Vaquero, V.; Del Pino, I.; Moreno-Noguer, F.; Sola, J.; Sanfeliu, A.; Andrade-Cetto, J. Dual-Branch CNNs for Vehicle Detection and Tracking on LiDAR Data. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6942–6953. [Google Scholar] [CrossRef]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; ˇCehovin Zajc, L.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 3–53. [Google Scholar]
- Kristan, M.; Berg, A.; Zheng, L.; Rout, L.; Zhou, L. The Seventh Visual Object Tracking VOT2019 Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 445–461. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Jiang, J.; Yang, X.; Li, Z.; Shen, K.; Jiang, F.; Ren, H.; Li, Y. MultiBSP: Multi-Branch and Multi-Scale Perception Object Tracking Framework Based on Siamese CNN. Neural Comput. Appl. 2022, 34, 18787–18803. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Le, V.A.; Murari, K. Recurrent 3D Convolutional Network for Rodent Behavior Recognition. In Proceedings of the ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1174–1178. [Google Scholar] [CrossRef]
- Kramida, G.; Aloimonos, Y.; Parameshwara, C.M.; Fermuller, C.; Francis, N.A.; Kanold, P. Automated Mouse Behavior Recognition Using VGG Features and LSTM Networks. In Proceedings of the Visual Observation and Analysis of Vertebrate And Insect Behavior, Cancun, Mexico, 4 December 2016; pp. 1–3. [Google Scholar]
- Zong, M.; Wang, R.; Chen, X.; Chen, Z.; Gong, Y. Motion Saliency Based Multi-Stream Multiplier ResNets for Action Recognition. Image Vis. Comput. 2021, 107, 104108. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, D.; Xiong, Z. Two-Stream Action Recognition-Oriented Video Super-Resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8798–8807. [Google Scholar] [CrossRef]
- He, J.Y.; Wu, X.; Cheng, Z.Q.; Yuan, Z.; Jiang, Y.G. DB-LSTM: Densely-connected Bi-directional LSTM for Human Action Recognition. Neurocomputing 2021, 444, 319–331. [Google Scholar] [CrossRef]
- Fayyaz, M.; Bahrami, E.; Diba, A.; Noroozi, M.; Adeli, E.; Van Gool, L.; Gall, J. 3D CNNs with Adaptive Temporal Feature Resolutions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4729–4738. [Google Scholar] [CrossRef]
- Li, S.; Li, W.; Cook, C.; Gao, Y. Deep Independently Recurrent Neural Network (IndRNN). arXiv 2020, arXiv:1910.06251. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Neural Networks for High Performance Skeleton-Based Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1963–1978. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Constructing Stronger and Faster Baselines for Skeleton-Based Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1474–1488. [Google Scholar] [CrossRef] [PubMed]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal Multiplier Networks for Video Action Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7445–7454. [Google Scholar] [CrossRef]
- Majd, M.; Safabakhsh, R. Correlational Convolutional LSTM for Human Action Recognition. Neurocomputing 2020, 396, 224–229. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef]
- Zang, T.; Zhu, Y.; Zhu, J.; Xu, Y.; Liu, H. MPAN: Multi-parallel Attention Network for Session-Based Recommendation. Neurocomputing 2022, 471, 230–241. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Wan, H.; Li, X.; Cong, G. Learning Dynamics and Heterogeneity of Spatial-Temporal Graph Data for Traffic Forecasting. IEEE Trans. Knowl. Data Eng. 2022, 34, 5415–5428. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, C.; Yu, D.; Guan, L.; Wang, D.; Hu, Z.; Liu, X. MTSCANet: Multi Temporal Resolution Temporal Semantic Context Aggregation Network. IET Comput. Vis. 2023, 17, 366–378. [Google Scholar] [CrossRef]

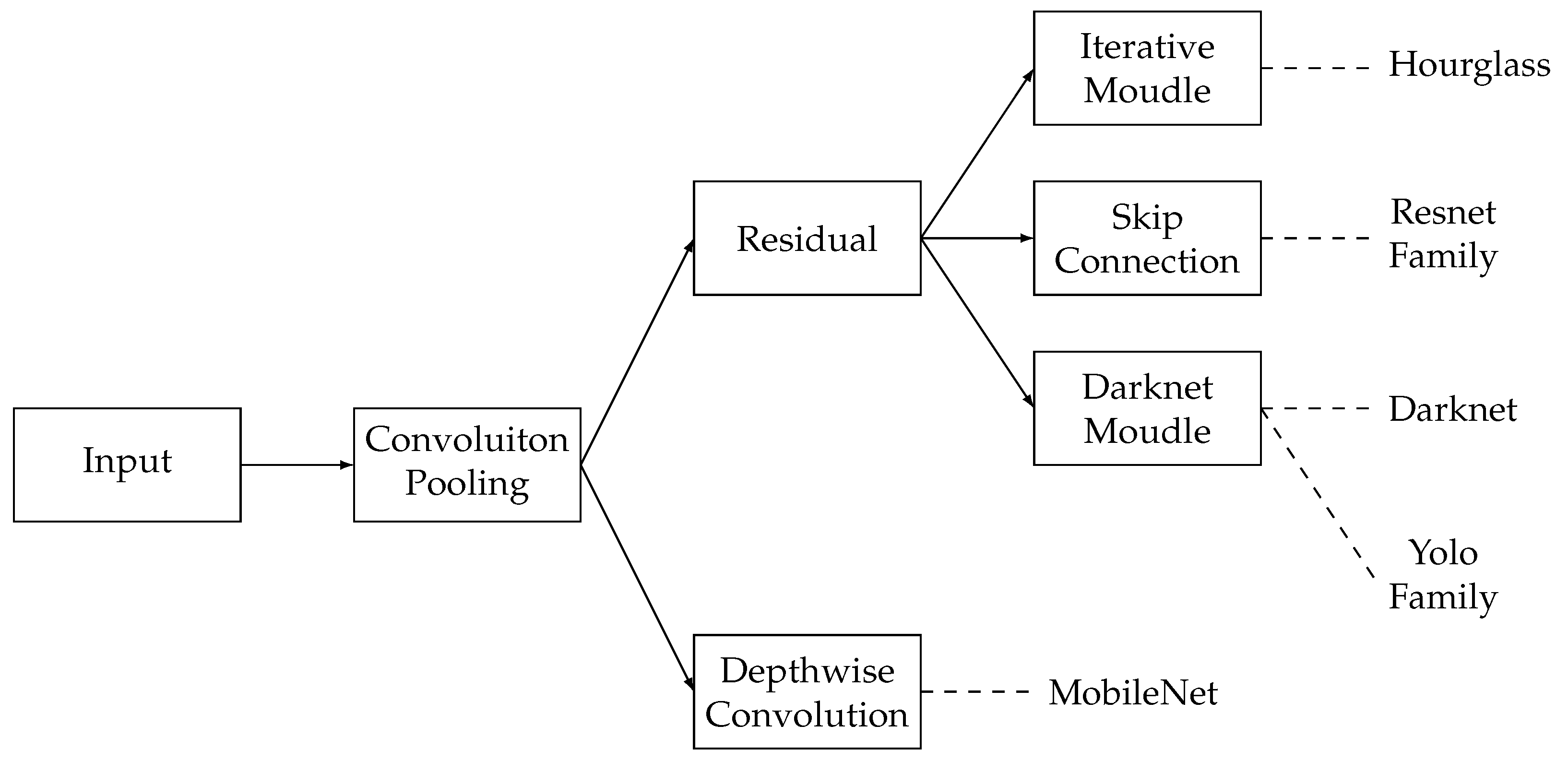
| Application | AI Method | AI Task | Data Attribute | Literature |
|---|---|---|---|---|
| Neurobehavioral Assessment | CNN | Semantic Segmentation, Key Point Detection | SV-T | [51] |
| CNN | Image Classification | SV-T | [49] | |
| CNN | Image Classification | SV-T | [52] | |
| XGBoost, HMM | Semantic Segmentation, Action Recognition | SV-T | [11] | |
| SVM,HMM | Semantic Segmentation, Image Classification | SV-F | [53] | |
| SFV-SAN+HMM | Action Prediction | SV-F | [50] | |
| SOLOv2 | Semantic Segmentation | SV-F | [54] | |
| Social Behavior Analysis | Cascade AdaBoost | Object Detection, Action Recognition | SV-S | [38] |
| Random Forest | Pose Estimation, Action Recognition | MV-TFS | [44] | |
| DeepLabCut | Pose Estimation, Action RecognitionObject Tracing | SV-T | [43] | |
| MLVAE | Action Recognition, Key Point Detection | MV-TS | [39] | |
| PCA, K-Means | Action Recognition | MV-TS | [45] | |
| XGBoost | Object Detection, Pose Estimation, Action recognition | MV-TF | [37] | |
| External Stimuli Effective Assessment | DeepLabCut | Key Point Detection, Action Recognition | MV-B | [24] |
| DeepLabCut | Pose Estimation | SV-B | [25] | |
| YOLO, Dilated CNN | Object Detection, Semantic Segmentation, Image Classification | SV-F | [26] | |
| PCA, SVM | Action Recognition | SV-T | [27] | |
| Mask R-CNN | Instance Segmentation, Key Point Detection, Object Tracing, Action Recognition | SV-T | [28] | |
| CNN, RNN | Action Recognition | SV-T | [29] | |
| CNN | Object Detection, Action Recognition | SV-F | [30] | |
| DeepLabCut | Object Tracing, Action Recognition | SV-T | [31] | |
| Disease Detection | CRNN | Semantic Segmentation, Action Recognition | SV-B | [18] |
| CRNN | Semantic Segmentation, Action Recognition | SV-T | [16] | |
| DeepLabCut | Key Point Detection, Pose Estimation | MV-BS | [19] | |
| DeepLabCut | Key Point Detection, Pose Estimation | SV-S | [20] |
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| YoloV3 | Mice | One-stage | Open Images dataset | A mean intersection over union (IoU) score of 0.87. | [26] |
| Inspection ResNetV2 with Faster R-CNN | Mice | Two-stage | Private | Approximately 95%. accuracy | [30] |
| Inspection ResNetV2 with ImageNet pre-trained weights | Mice | Two-stage | Behavior Ensemble and Neural Trajectory Observatory (BENTO) | 0.902 mean average precision(mAP) and 0.924 mean average recall(mAR) in pose estimation metrics. | [37] |
| Point Cloud Voxelization, 3D Feature Extractor, backbone(AFDet) and the Anchor-Free Detector | Object detection from point clouds | One-stage, anchor-free | Waymo Open Dataset, nuScenes Dataset | Accuracy: 73.12, latency: 60.06 ms. | [68] |
| YOLOv5, the feature fusion layer, and the multiscale detection layer | Industrial defect detection | Two-stage, anchor-based | VOC2007, NEU-DET, Enriched-NEU-DET | 83.3% mAP. | [69] |
| The location prior network (LPN) and the size prior network (SPN) | Video object detection | One-stage | ImageNet VID | 54.1 AP and 60.1 APl. | [70] |
| ResNet backbone, a FPN, an ARM cascade network with rotated IoU prediction branch, and the two-stage sample selective strategy | Rotating object detection | Two-stage | UAV-ROD | 96.65 mAP and 98.84 accuracy under the plane category. | [71] |
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| CNN | Mice | 2D | Private | Achieve the recognition rate of 94.89% and the false detection rate of 7.38%. | [51] |
| ResNet-50 | Mice | 2D | Private | Achieve 98% agreement with human observers per second in small videos. | [24] |
| ResNet-50 | Mice | 2D | Private | A 98% accuracy when compared baseline to animals at 3 dpi. | [19] |
| ResNet-50 | Mice | 2D | Private | An accuracy of 86.7% | [43] |
| ResNet-50 | Mice | 2D | Private | Predict the injury status with 98% accuracy and the recovery status with 94% accuracy. | [20] |
| SHNet, MaskedNet | Human | multi-person | MPII, COCO2017 | Achieves high accuracy on all 16 joint points, comparable to that of the latest models. | [94] |
| AlphaPose | Human | multi-person | Private, Halpe-FullBody136 | Detection precision is improved by 5.6%, and the false detection rate is reduced by 13% | [95] |
| LMANet | Human | single-person | Private, MPII, AI Challenger | PCKh value is 83.0935 | [96] |
| PGNet | Human | single-person | COCO | Improve the accuracy of the COCO dataset by 0.2% | [97] |
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| Mask R-CNN | Mice | - | Private | SIPEC: SegNet is designed to robustly segment animals even in challenging conditions such as occlusions, varying scales, and rapid movements. It facilitates the tracking of animal identities within a session, ensuring accurate and consistent identification despite these complexities. | [28] |
| ResNet | Mice | - | Private | DeepLabCut can estimate the positions of mouse body parts. | [31] |
| ResNet | Mice | - | Private | Automated tracking of a dam and a single pup was implemented using DeepLabCut, which was then integrated with automated behavioral classification in Simple Behavioral Analysis (SimBA). Their automated procedure estimated retrieval success with an accuracy of 86.7%, whereas accuracies of “approach”, “carry” and “digging” were estimated at respectively 99.3%, 98.6% and 85.0%. | [43] |
| Faster R-CNN, ResNet-50 | Human | Single-branch | MOT16 [107], MOT20 [108] | Compared to the previous best tracker, it has improved by 1.6%/2.6% MOTA on MOT16/MOT20, Respectively. The specific values are 50.4% and 51.5%. | [109] |
| DNN | Vehicle | Multi-branch | Kitti [110] | In the Vehicle Tracking task, for MOTA, Recall, Prec. MT, PT, ML The values are 39.7%, 63.6%, 83.0%, 29.5%, 54.6%, and 15.8%, respectively. | [111] |
| ResNet50 | - | Multi-branch | VOT-2018 [112], VOT-2019 [113], OTB-100 [114], UAV123 [115], GOT10k [116], LASOT [117] | MultiBSP demonstrates robust tracking capabilities and achieves state-of-the-art performance. The effectiveness of each module and the overall tracking stability are validated through both qualitative and quantitative analyses.For the OTB100 and UAV123 tasks, the precision scores are 0.930 and 0.837, respectively. On the VOT2018 task, the results of EAO and R were 0.453 and 0.169. For LaSOT, its accuracy is 0.524. | [118] |
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| Hourglass network | Mice | video-based | Private | Provide a robust computational pipeline for the analysis of social behavior in pairs of interacting mice. Precision and Recall of MARS classifiers was comparable to that of human annotators for both attack and close investigation, and slightly below human performance for mounting. | [37] |
| 3D ConvNet, LSTM network | Mice | video-based | Private | Obtain accuracy on par with human assessment | [121] |
| LSTM | Mice | video-based | Private | Producing errors of 3.08%, 14.81%, and 7.4% on the training, validation, and testing sets respectively | [122] |
| 2D CNN | Human | video-based | UCF101 and HMDB51 datasets | Outperforms other compared state-of-the-art models. The accuracy on the UCF101 dataset is 93.5% and 66.7% on the HMDB51 dataset. | [123] |
| 2D CNN | Human | video-based | UCF101 and HMDB51 datasets | Improve the recognition performance of LR video from 42.81% to 53.59% on spatial stream and from 56.54% to 61.5% on temporal stream. | [124] |
| RNN | Human | video-based | UCF101 and HMDB51 datasets | The accuracy of the proposed model DB-LSTM on the datasets UCF101 and HMDB51 is 97.3% and 81.2%. | [125] |
| 3D CNN | Human | video-based | Kinetics-600, Kinetics-400, mini-Kinetics, Something-Something V2, UCF101, and HMDB51 datasets | SGS decreases the computation cost (GFLOPS) between 33% and 53% without compromising accuracy. | [126] |
| RNN | Human | skeleton-based | Penn Treebank (PTB-c), and NTU RGB+D datasets | Performs much better than the traditional RNN, LSTM, and Transformer models on sequential MNIST classification, language modeling, and action recognition tasks. With a deep densely connected IndRNN, the performance is further improved to 84.88% and 90.34% for CS and CV. | [127] |
| CNN | Human | skeleton-based | NTU RGB+D, the SYSU Human-Object Interaction, the UWA3D, the Northwestern-UCLA, and the SBU Kinect Interaction datasets | Two models were proposed, namely VA-RNN and VA-CNN. The accuracy on NTU-CV is 88.7% and 94.3%, respectively. | [128] |
| GCN | Human | skeleton-based | NTU RGB+D 60 and 120 datasets | The best performance of the model EfficientGCN-B4 are 92.1% and 96.1% for X-sub and X-view benchmark, respectively. | [129] |
| Architecture | Type | Category | Dataset | Performance | Reference |
|---|---|---|---|---|---|
| RNN with LSTM | Mice | long-term | COCO, MPII | PCKh value is 92.3 in MPII and AP value is 75.5 in COCO | [122] |
| hidden Markov model (HVV) | Mice | long-term | Private, JHuang’s datasets | Achieve weighted average accuracy of 96.5% (using visual and context features) and 97.9% (incorporated with IDT and TDD features) | [50] |
| MultiParallel Attention Network (MPAN) | Recommendation | short-term | YOOCHOSE and DIGENTICA | On the YOOCHOOSE dataset, two metrics Recall@20 And MRR@20. The values are: 72.58% and 33.06%. On the DIGENTICA dataset, these two values are: 52.01% and 17.58%. | [133] |
| Spatial-Temporal Graph Neural Network (ASTGNN) | Traffic forecasting | long-term | Caltrans Performance Measurement System (PeMS) | The best MAE, RMSE, MAPE were obtained on different datasets of PEMS, especially on the PEMS07 dataset, with values of 19.26%, 32.75%, and 8.54%, respectively. | [134] |
| Multi-temporal resolution pyramid structure model (MTSCANet) | Videos | temporal semantic context | THUMOS14, ActivityNet-1.3, HACS | An average mAP of 47.02% on THUMOS14, an average mAP of 34.94% on ActivityNet-1.3 and an average mAP of 28.46% on HACS | [135] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, C.; Chen, Y.; Ma, C.; Hao, S.; Song, J. A Survey on AI-Driven Mouse Behavior Analysis Applications and Solutions. Bioengineering 2024, 11, 1121. https://doi.org/10.3390/bioengineering11111121
Guo C, Chen Y, Ma C, Hao S, Song J. A Survey on AI-Driven Mouse Behavior Analysis Applications and Solutions. Bioengineering. 2024; 11(11):1121. https://doi.org/10.3390/bioengineering11111121
Chicago/Turabian StyleGuo, Chaopeng, Yuming Chen, Chengxia Ma, Shuang Hao, and Jie Song. 2024. "A Survey on AI-Driven Mouse Behavior Analysis Applications and Solutions" Bioengineering 11, no. 11: 1121. https://doi.org/10.3390/bioengineering11111121
APA StyleGuo, C., Chen, Y., Ma, C., Hao, S., & Song, J. (2024). A Survey on AI-Driven Mouse Behavior Analysis Applications and Solutions. Bioengineering, 11(11), 1121. https://doi.org/10.3390/bioengineering11111121