

Inferior Alveolar Nerve Canal Segmentation on CBCT Using U-Net with Frequency Attentions
 ,
,
Abstract
:1. Introduction
2. Related Work
2.1. U-Shape Networks
2.2. Attention Mechanism
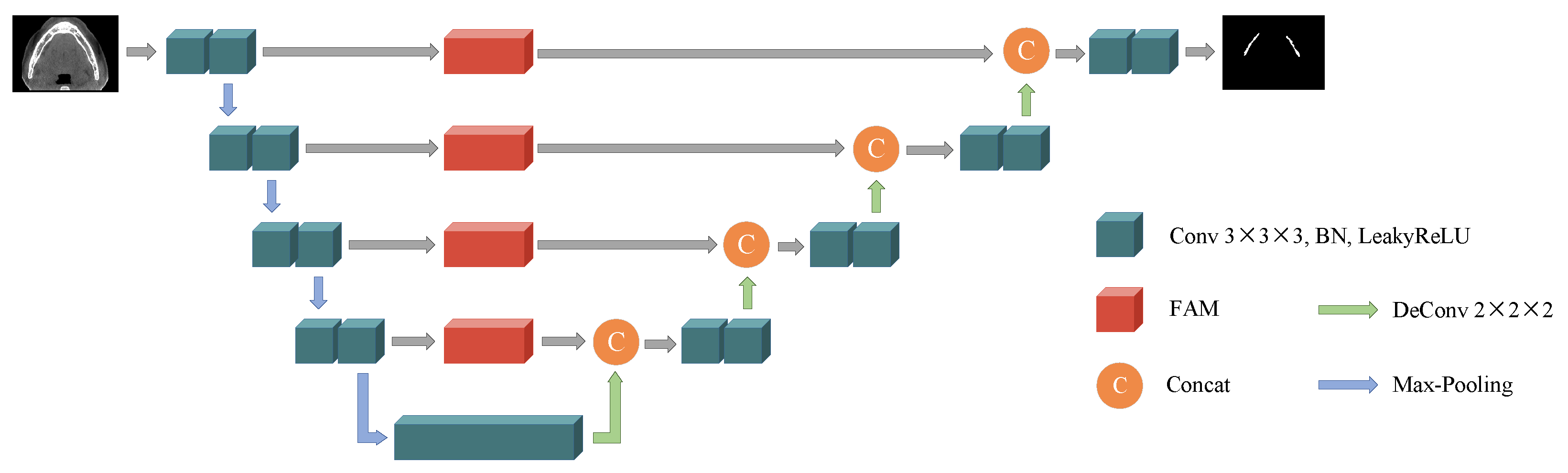
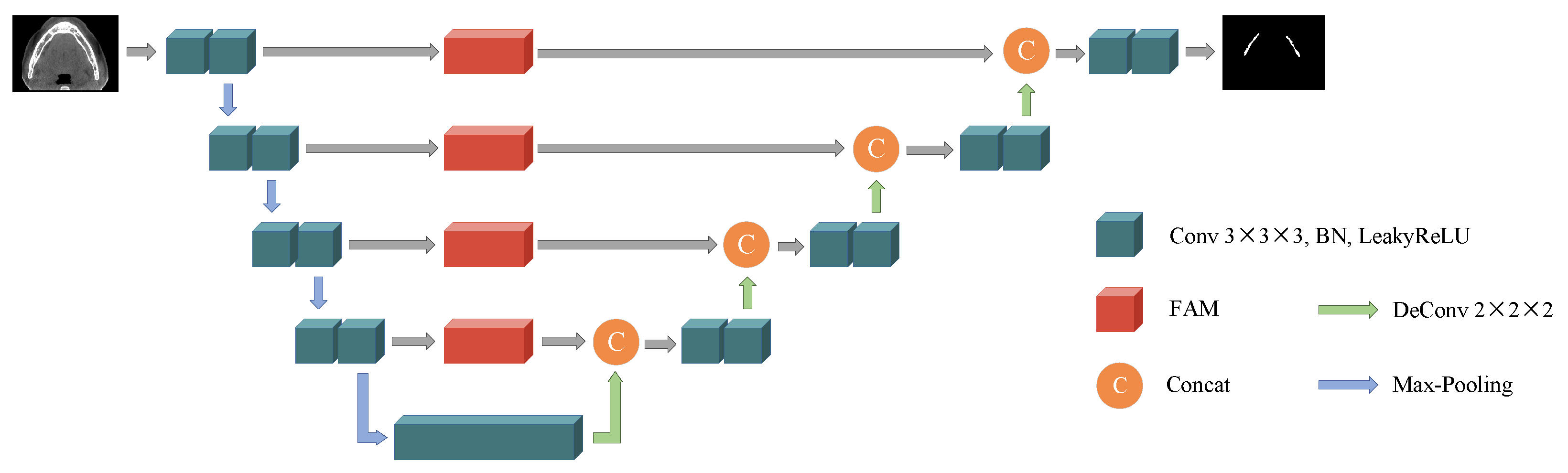
3. Frequency Attention UNet
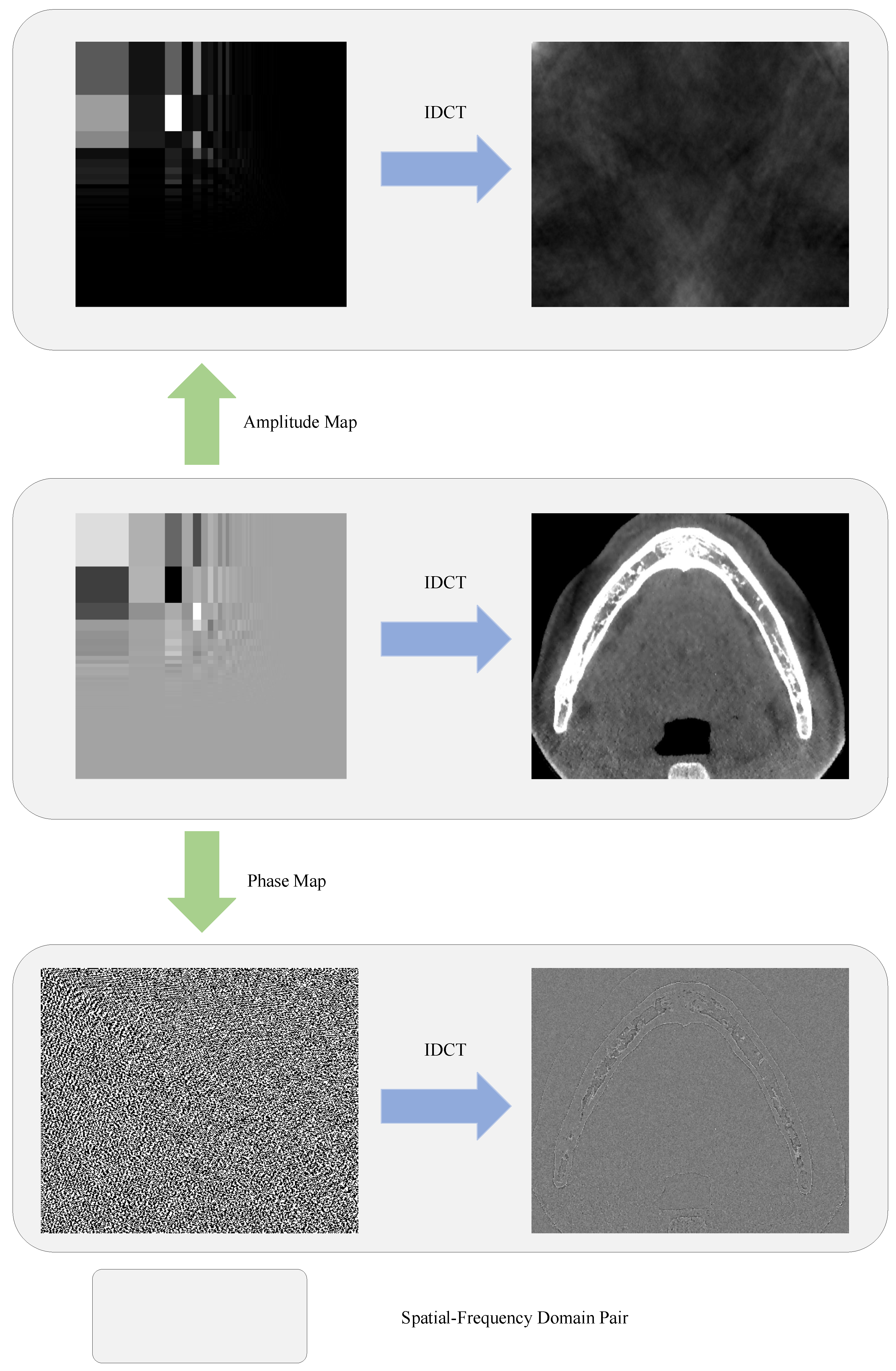
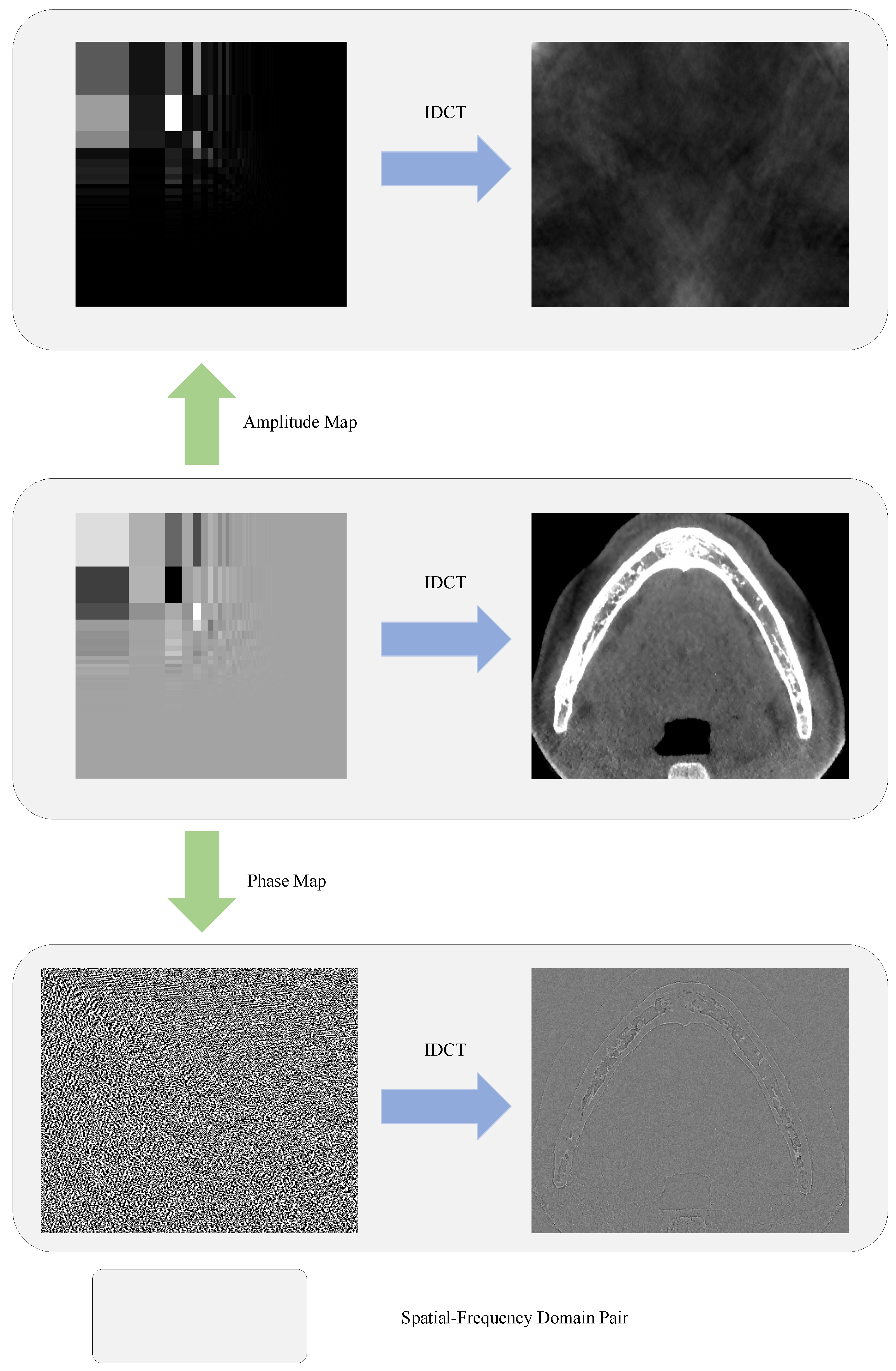
3.1. Discrete Cosine Transform Revisit
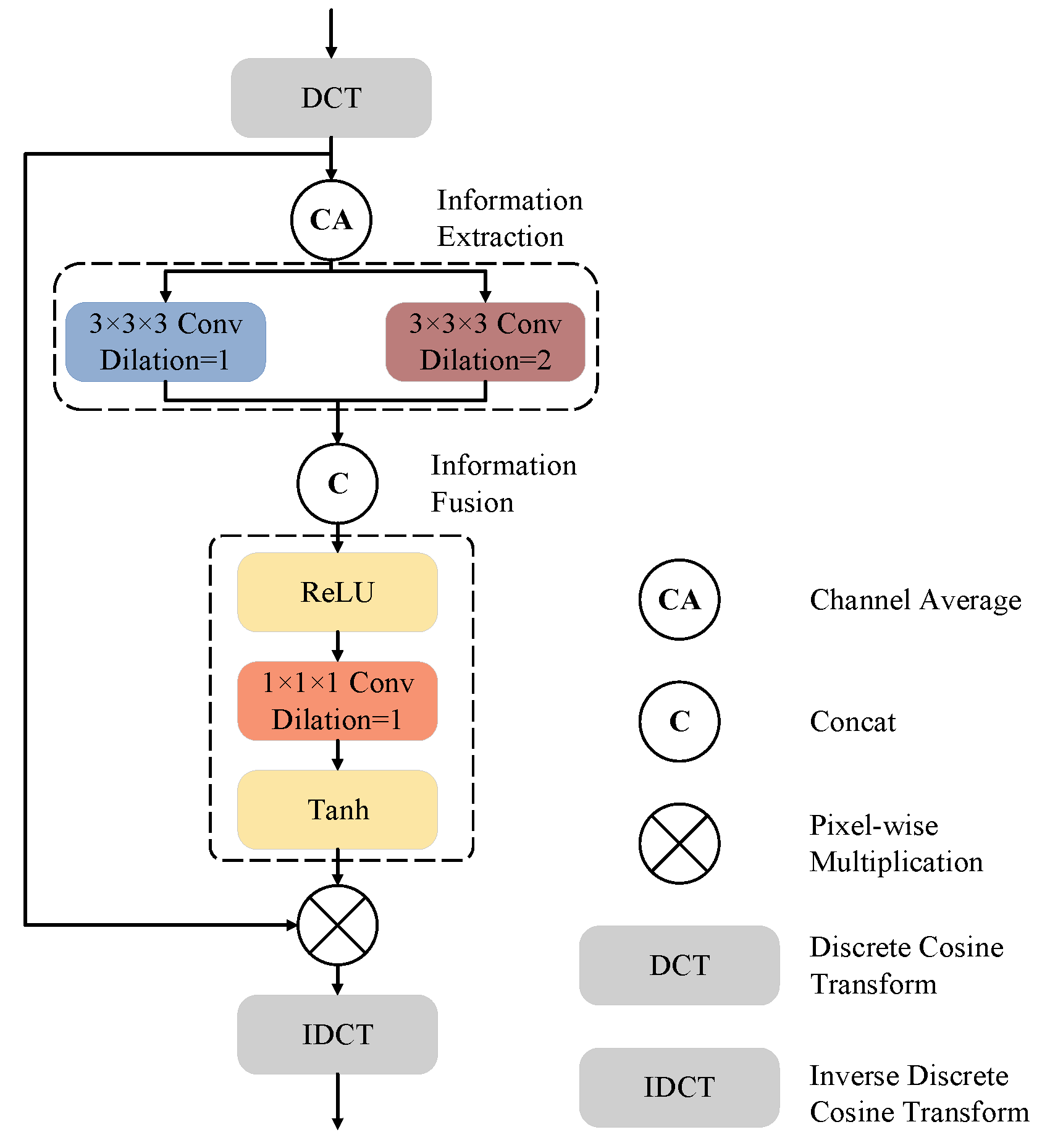
3.2. Frequency Attention Module
3.3. Loss Function
3.4. Evaluation Metrics
4. Experiment Results
4.1. Data
4.2. Implementations
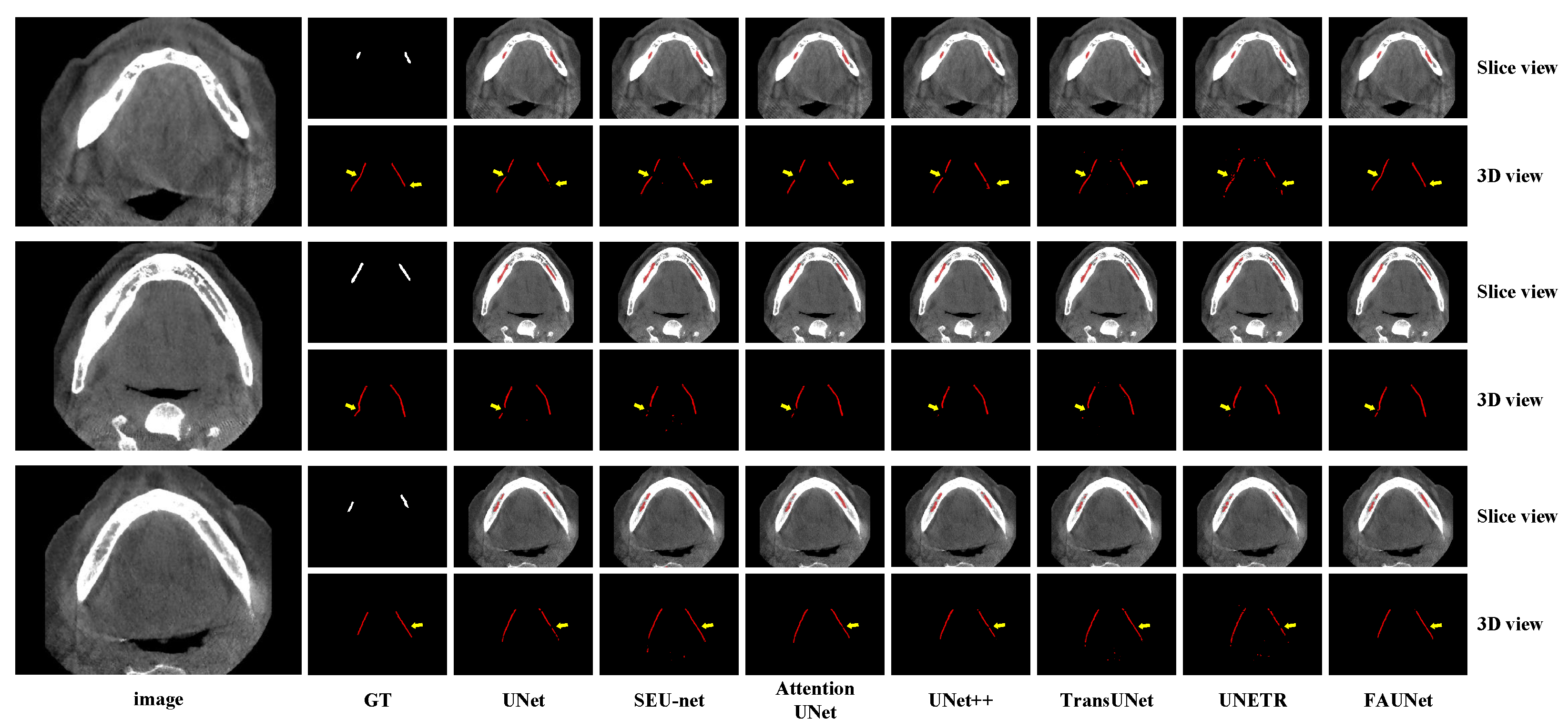
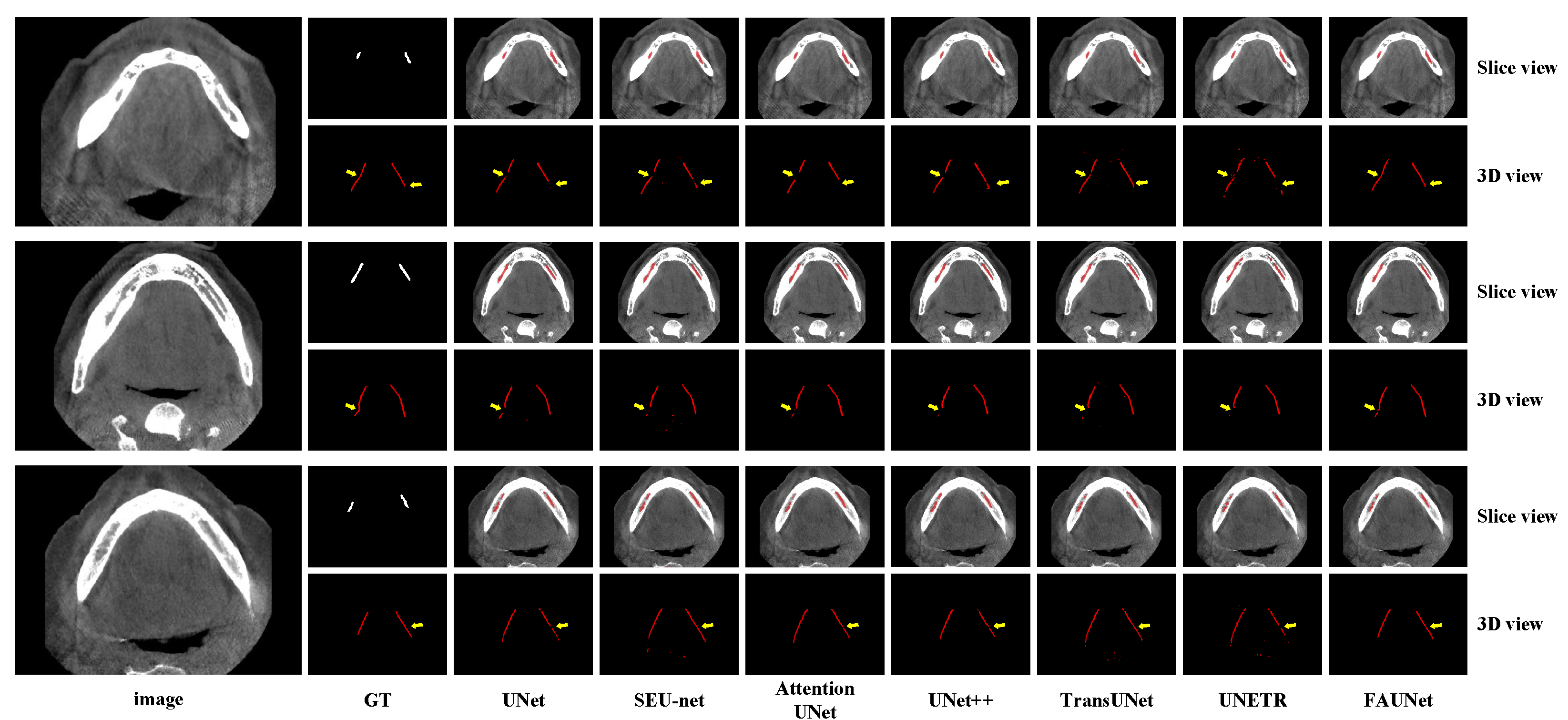
4.3. Results
5. Discussion
5.1. Spatial-Domain Attention versus Frequency-Domain Attention
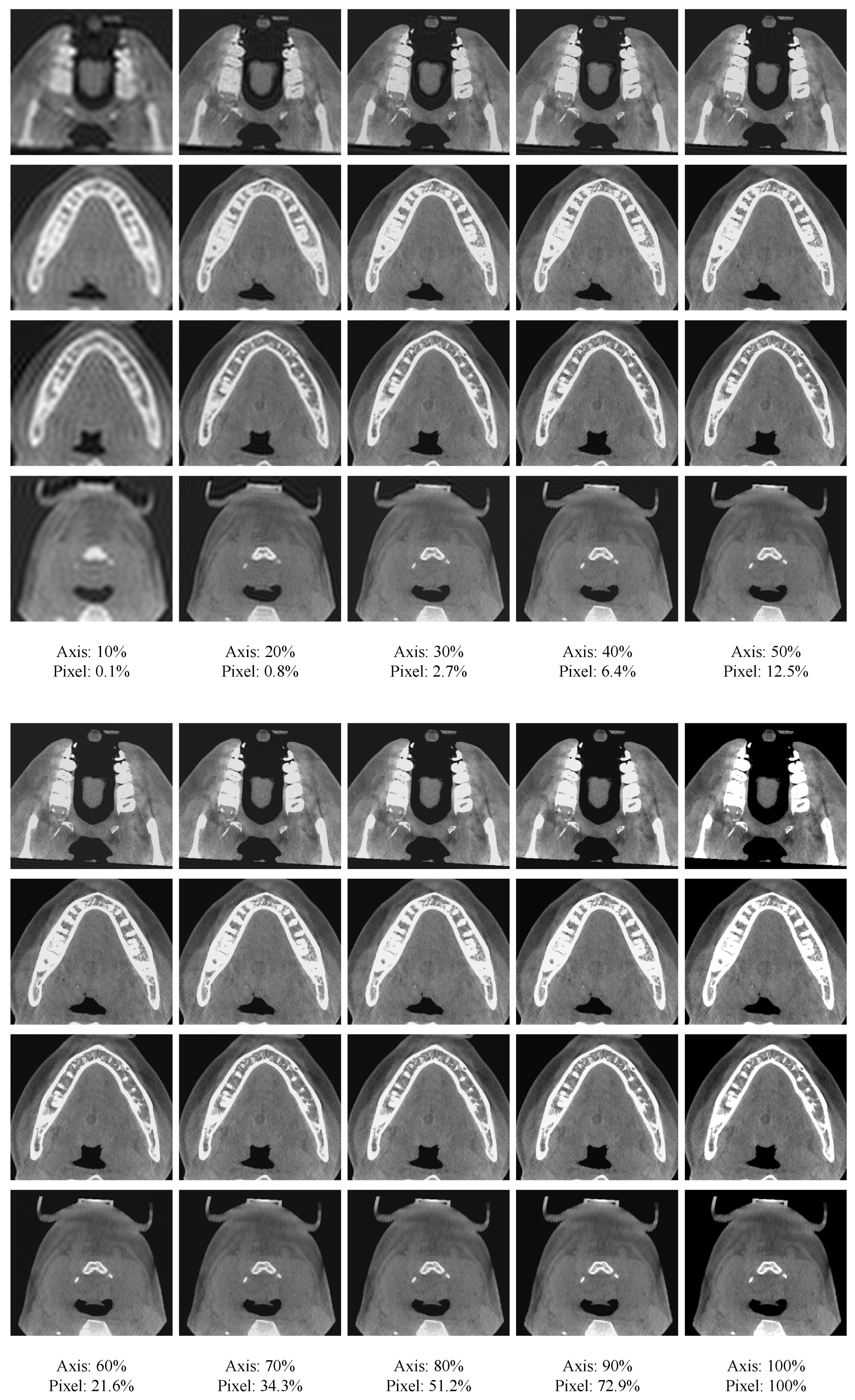
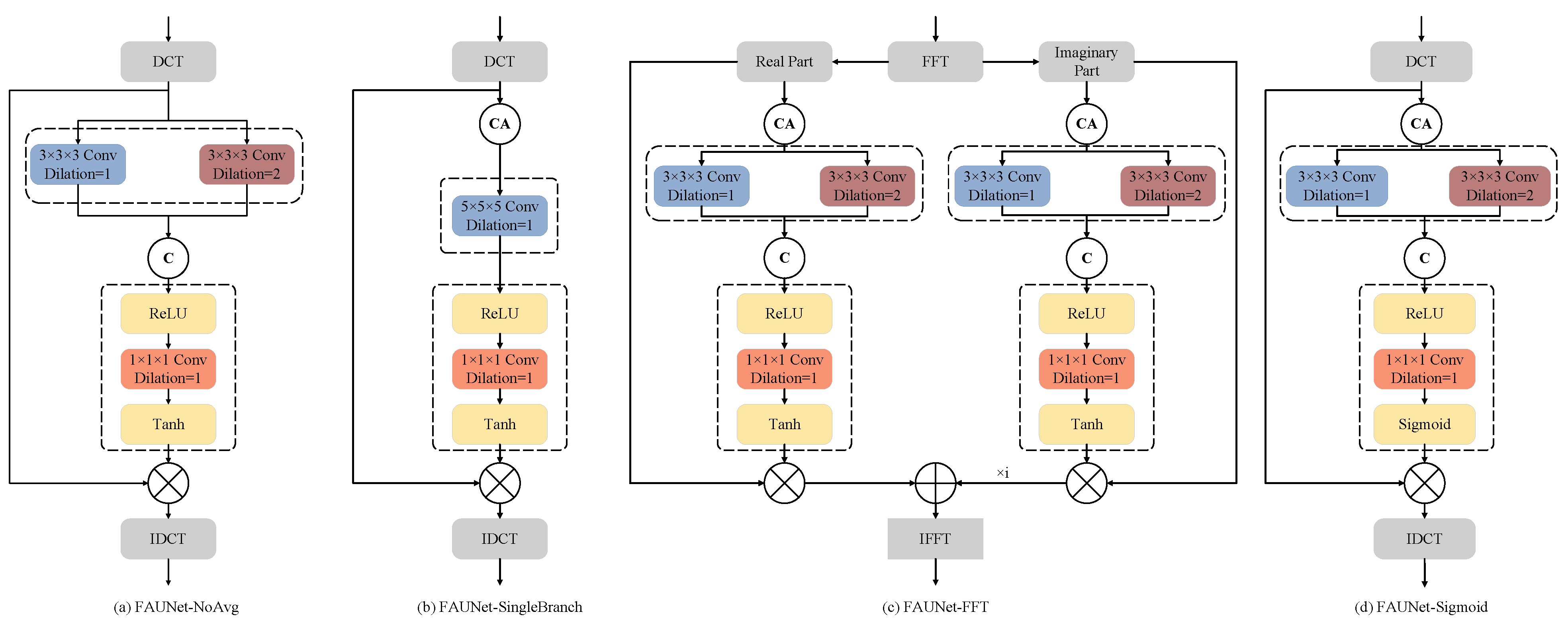
5.2. Ways to Generate Frequency-Domain Attention
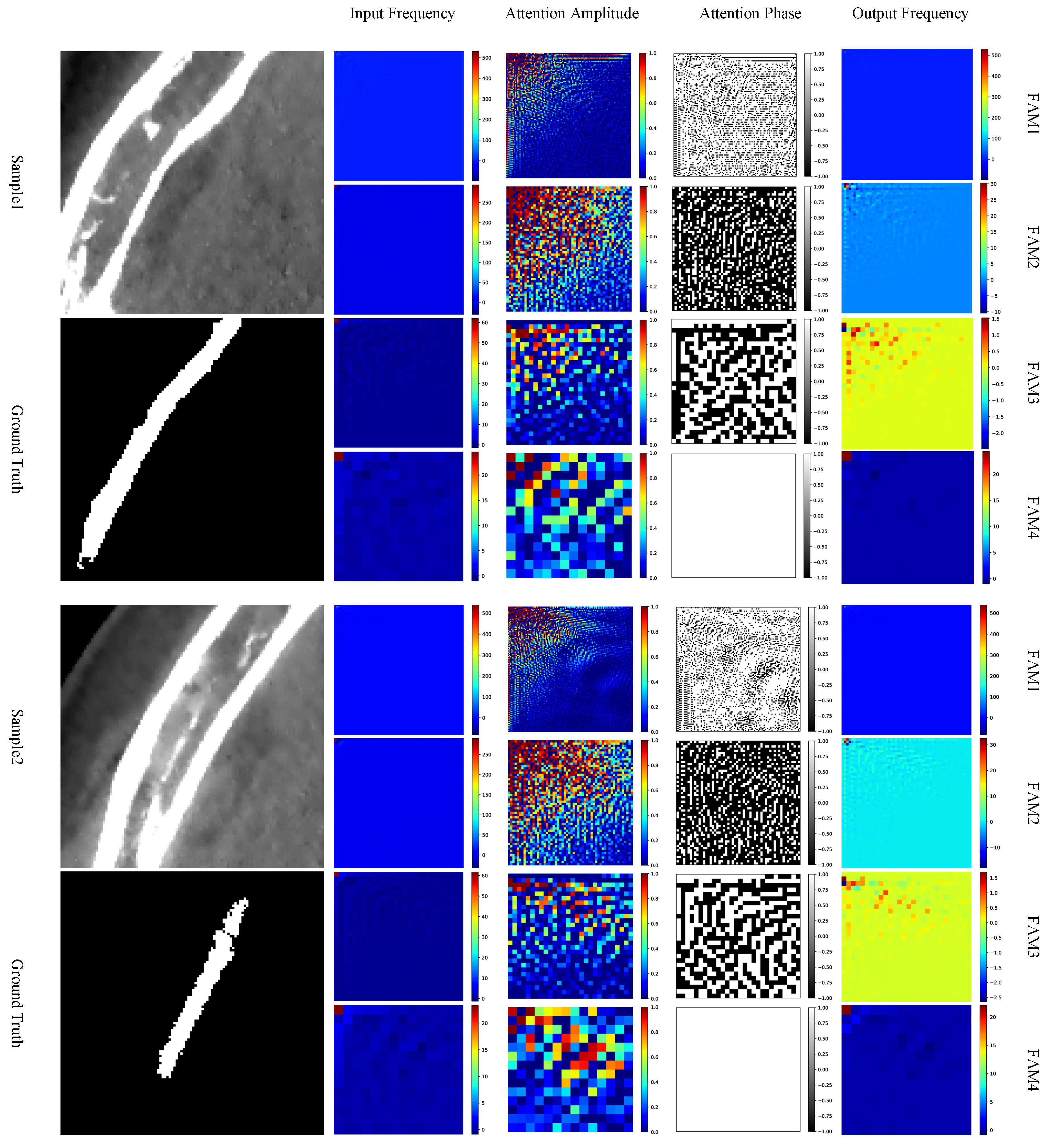
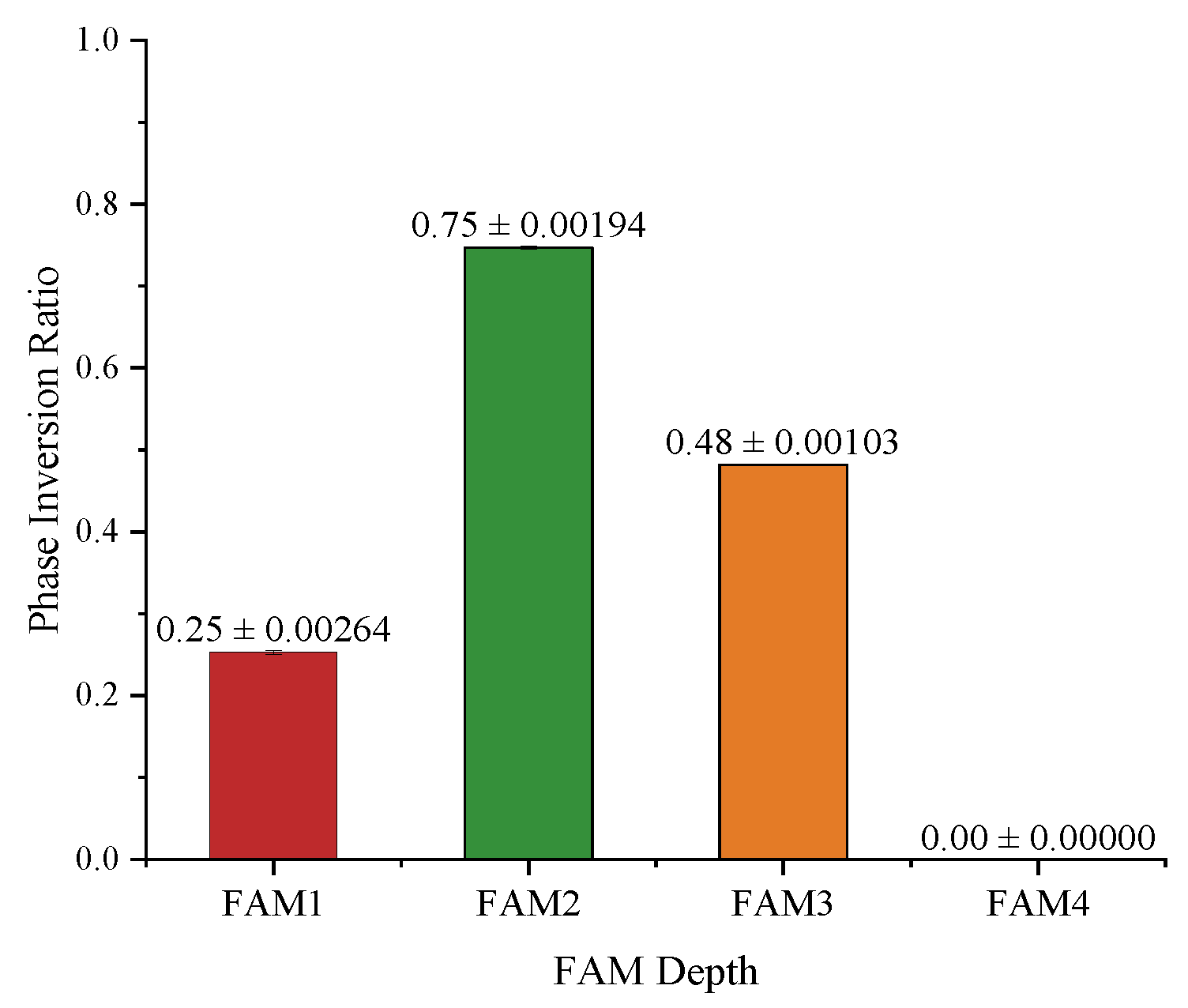
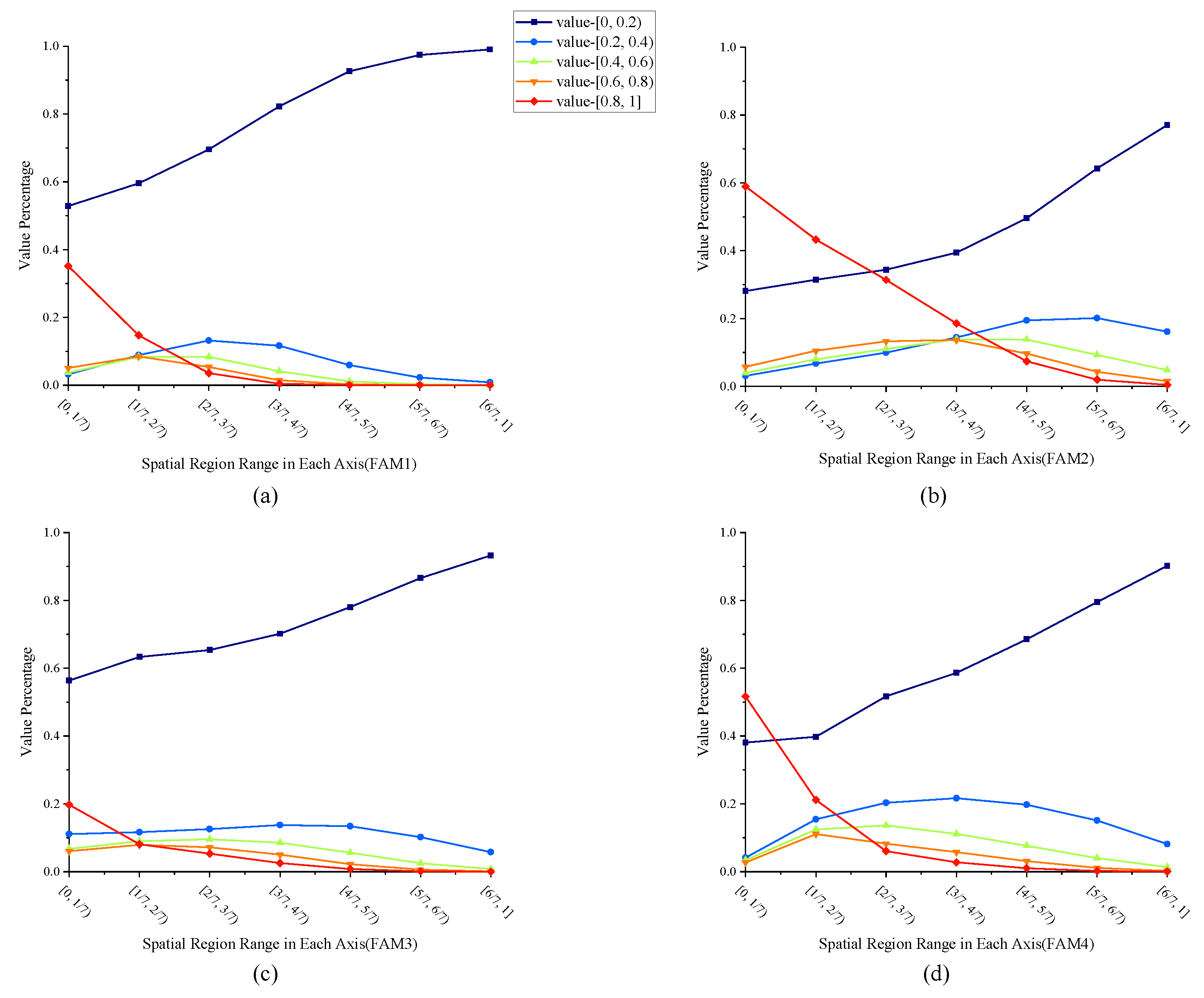
5.3. Analysis of Attention Maps
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alhassani, A.A.; AlGhamdi, A.S.T. Inferior alveolar nerve injury in implant dentistry: Diagnosis, causes, prevention, and management. J. Oral Implantol. 2010, 36, 401–407. [Google Scholar] [CrossRef]
- Juodzbalys, G.; Wang, H.L.; Sabalys, G.; Sidlauskas, A.; Galindo-Moreno, P. Inferior alveolar nerve injury associated with implant surgery. Clin. Oral Implant. Res. 2013, 24, 183–190. [Google Scholar] [CrossRef]
- Tay, A.; Zuniga, J.R. Clinical characteristics of trigeminal nerve injury referrals to a university centre. Int. J. Oral Maxillofac. Surg. 2007, 36, 922–927. [Google Scholar] [CrossRef]
- Scarfe, W.C.; Farman, A.G.; Sukovic, P. Clinical applications of cone-beam computed tomography in dental practice. J.-Can. Dent. Assoc. 2006, 72, 75. [Google Scholar]
- Dalessandri, D.; Laffranchi, L.; Tonni, I.; Zotti, F.; Piancino, M.G.; Paganelli, C.; Bracco, P. Advantages of cone beam computed tomography (CBCT) in the orthodontic treatment planning of cleidocranial dysplasia patients: A case report. Head Face Med. 2011, 7, 1–9. [Google Scholar] [CrossRef]
- Zheng, Z.; Yan, H.; Setzer, F.C.; Shi, K.J.; Mupparapu, M.; Li, J. Anatomically constrained deep learning for automating dental CBCT segmentation and lesion detection. IEEE Trans. Autom. Sci. Eng. 2020, 18, 603–614. [Google Scholar] [CrossRef]
- Wang, H.; Minnema, J.; Batenburg, K.J.; Forouzanfar, T.; Hu, F.J.; Wu, G. Multiclass CBCT image segmentation for orthodontics with deep learning. J. Dent. Res. 2021, 100, 943–949. [Google Scholar] [CrossRef]
- Lahoud, P.; Diels, S.; Niclaes, L.; Van Aelst, S.; Willems, H.; Van Gerven, A.; Quirynen, M.; Jacobs, R. Development and validation of a novel artificial intelligence driven tool for accurate mandibular canal segmentation on CBCT. J. Dent. 2022, 116, 103891. [Google Scholar] [CrossRef]
- Cipriano, M.; Allegretti, S.; Bolelli, F.; Pollastri, F.; Grana, C. Improving segmentation of the inferior alveolar nerve through deep label propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21137–21146. [Google Scholar]
- Issa, J.; Olszewski, R.; Dyszkiewicz-Konwińska, M. The effectiveness of semi-automated and fully automatic segmentation for inferior alveolar canal localization on CBCT scans: A systematic review. Int. J. Environ. Res. Public Health 2022, 19, 560. [Google Scholar] [CrossRef]
- Di Bartolomeo, M.; Pellacani, A.; Bolelli, F.; Cipriano, M.; Lumetti, L.; Negrello, S.; Allegretti, S.; Minafra, P.; Pollastri, F.; Nocini, R.; et al. Inferior alveolar canal automatic detection with deep learning CNNs on CBCTs: Development of a novel model and release of open-source dataset and algorithm. Appl. Sci. 2023, 13, 3271. [Google Scholar] [CrossRef]
- Jindanil, T.; Marinho-Vieira, L.E.; de Azevedo-Vaz, S.L.; Jacobs, R. A unique artificial intelligence-based tool for automated CBCT segmentation of mandibular incisive canal. Dentomaxillofacial Radiol. 2023, 52, 20230321. [Google Scholar] [CrossRef] [PubMed]
- Cipriano, M.; Allegretti, S.; Bolelli, F.; Di Bartolomeo, M.; Pollastri, F.; Pellacani, A.; Minafra, P.; Anesi, A.; Grana, C. Deep segmentation of the mandibular canal: A new 3D annotated dataset of CBCT volumes. IEEE Access 2022, 10, 11500–11510. [Google Scholar] [CrossRef]
- Morgan, N.; Van Gerven, A.; Smolders, A.; de Faria Vasconcelos, K.; Willems, H.; Jacobs, R. Convolutional neural network for automatic maxillary sinus segmentation on cone-beam computed tomographic images. Sci. Rep. 2022, 12, 7523. [Google Scholar] [CrossRef] [PubMed]
- Urban, R.; Haluzová, S.; Strunga, M.; Surovková, J.; Lifková, M.; Tomášik, J.; Thurzo, A. AI-assisted CBCT data management in modern dental practice: Benefits, limitations and innovations. Electronics 2023, 12, 1710. [Google Scholar] [CrossRef]
- Preda, F.; Morgan, N.; Van Gerven, A.; Nogueira-Reis, F.; Smolders, A.; Wang, X.; Nomidis, S.; Shaheen, E.; Willems, H.; Jacobs, R. Deep convolutional neural network-based automated segmentation of the maxillofacial complex from cone-beam computed tomography: A validation study. J. Dent. 2022, 124, 104238. [Google Scholar] [CrossRef] [PubMed]
- Fu, W.; Zhu, Q.; Li, N.; Wang, Y.; Deng, S.; Chen, H.; Shen, J.; Meng, L.; Bian, Z. Clinically Oriented CBCT Periapical Lesion Evaluation via 3D CNN Algorithm. J. Dent. Res. 2024, 103, 5–12. [Google Scholar] [CrossRef] [PubMed]
- Abd-Alhalem, S.M.; Marie, H.S.; El-Shafai, W.; Altameem, T.; Rathore, R.S.; Hassan, T.M. Cervical cancer classification based on a bilinear convolutional neural network approach and random projection. Eng. Appl. Artif. Intell. 2024, 127, 107261. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and sIgnal Processing (ICASSP), Virtual, 4–9 May 2020; pp. 1055–1059. [Google Scholar]
- Chen, Y.; Wang, K.; Liao, X.; Qian, Y.; Wang, Q.; Yuan, Z.; Heng, P.A. Channel-Unet: A spatial channel-wise convolutional neural network for liver and tumors segmentation. Front. Genet. 2019, 10, 1110. [Google Scholar] [CrossRef]
- Cai, S.; Tian, Y.; Lui, H.; Zeng, H.; Wu, Y.; Chen, G. Dense-UNet: A novel multiphoton in vivo cellular image segmentation model based on a convolutional neural network. Quant. Imaging Med. Surg. 2020, 10, 1275. [Google Scholar] [CrossRef]
- Kitrungrotsakul, T.; Chen, Q.; Wu, H.; Iwamoto, Y.; Hu, H.; Zhu, W.; Chen, C.; Xu, F.; Zhou, Y.; Lin, L.; et al. Attention-RefNet: Interactive attention refinement network for infected area segmentation of COVID-19. IEEE J. Biomed. Health Inform. 2021, 25, 2363–2373. [Google Scholar] [CrossRef] [PubMed]
- Song, H.; Wang, Y.; Zeng, S.; Guo, X.; Li, Z. OAU-net: Outlined Attention U-net for biomedical image segmentation. Biomed. Signal Process. Control 2023, 79, 104038. [Google Scholar] [CrossRef]
- Chen, G.; Liu, Y.; Qian, J.; Zhang, J.; Yin, X.; Cui, L.; Dai, Y. DSEU-net: A novel deep supervision SEU-net for medical ultrasound image segmentation. Expert Syst. Appl. 2023, 223, 119939. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Xu, K.; Qin, M.; Sun, F.; Wang, Y.; Chen, Y.K.; Ren, F. Learning in the frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1740–1749. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8 September 2018; pp. 801–818. [Google Scholar]
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hofmann, F.; D’Anastasi, M.; et al. Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3D conditional random fields. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016; Proceedings, Part II 19. Springer: Berlin/Heidelberg, Germany, 2016; pp. 415–423. [Google Scholar]
- Wang, C.; MacGillivray, T.; Macnaught, G.; Yang, G.; Newby, D. A two-stage 3D Unet framework for multi-class segmentation on full resolution image. arXiv 2018, arXiv:1804.04341. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; Springer: Cham, Switzerland, 2021; pp. 272–284. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Wu, M.; Liu, Z. Less is More: Contrast Attention Assisted U-Net for Kidney, Tumor and Cyst Segmentations. In International Challenge on Kidney and Kidney Tumor Segmentation; Springer: Berlin/Heidelberg, Germany, 2021; pp. 46–52. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’in fully convolutional networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2018; pp. 421–429. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Cheng, J.; Tian, S.; Yu, L.; Gao, C.; Kang, X.; Ma, X.; Wu, W.; Liu, S.; Lu, H. ResGANet: Residual group attention network for medical image classification and segmentation. Med. Image Anal. 2022, 76, 102313. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. Sa-unet: Spatial attention u-net for retinal vessel segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1236–1242. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Probability | Settings |
|---|---|---|
| Elastic deformation | 0.3 | , |
| Zooming | 0.3 | zooming scale factor . |
| Rotation | 0.3 | rotation angle for each plane. |
| Axis flip | 0.5 (each axis) | \ |
| Contrast adjustment | 0.2 | |
| Scale intensity adjustment | 0.2 | factors |
| Method | Dice (%) | HD95 | ASSD | SD (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| UNet [13] * | 67.00 | / | / | / | / | / |
| UNet | 73.16 | 22.05 | 3.60 | 78.53 | 22.93 | 363.5 |
| Attention UNet | 72.60 | 26.03 | 3.63 | 78.07 | 23.02 | 366.5 |
| SEU-net | 71.94 | 40.13 | 6.28 | 76.19 | 25.29 | 436.3 |
| UNet++ | 74.10 | 16.99 | 2.65 | 79.74 | 26.64 | 1282.3 |
| UNet3+ | 69.78 | 19.83 | 3.00 | 75.36 | 20.40 | 2622.8 |
| UNETR | 55.99 | 95.73 | 12.08 | 54.61 | 101.62 | 419.6 |
| TransUNet | 71.53 | 37.03 | 5.53 | 75.61 | 68.47 | 272.4 |
| FAUNet | 75.55 | 16.98 | 2.63 | 81.35 | 22.93 | 363.6 |
| Method | Dice (%) | HD95 | ASSD | SD (%) |
|---|---|---|---|---|
| Attention UNet | 72.60 | 26.03 | 3.63 | 78.07 |
| Attention UNet + DCT | 73.38 | 29.31 | 4.44 | 78.14 |
| SEU-net | 71.94 | 40.13 | 6.28 | 76.19 |
| SEU-net + DCT | 72.49 | 21.08 | 3.31 | 77.69 |
| FAUNet − DCT | 74.72 | 18.11 | 2.80 | 80.16 |
| FAUNet | 75.55 | 16.98 | 2.63 | 81.35 |
| Method | Dice (%) | HD95 | ASSD | SD (%) |
|---|---|---|---|---|
| UNet | 73.16 | 22.05 | 3.60 | 78.53 |
| FAUNet | 75.55 | 16.98 | 2.63 | 81.35 |
| FAUNet-NoAvg | 74.10 | 20.47 | 3.14 | 79.09 |
| FAUNet-SingleBranch | 74.54 | 17.59 | 2.75 | 79.92 |
| FAUNet-Sigmoid | 74.89 | 16.56 | 2.93 | 80.41 |
| FAUNet-FFT | 74.70 | 19.58 | 2.94 | 79.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Yang, D.; Zhang, M.; Liu, G.; Zhang, Q.; Li, X. Inferior Alveolar Nerve Canal Segmentation on CBCT Using U-Net with Frequency Attentions. Bioengineering 2024, 11, 354. https://doi.org/10.3390/bioengineering11040354
Liu Z, Yang D, Zhang M, Liu G, Zhang Q, Li X. Inferior Alveolar Nerve Canal Segmentation on CBCT Using U-Net with Frequency Attentions. Bioengineering. 2024; 11(4):354. https://doi.org/10.3390/bioengineering11040354
Chicago/Turabian StyleLiu, Zhiyang, Dong Yang, Minghao Zhang, Guohua Liu, Qian Zhang, and Xiaonan Li. 2024. "Inferior Alveolar Nerve Canal Segmentation on CBCT Using U-Net with Frequency Attentions" Bioengineering 11, no. 4: 354. https://doi.org/10.3390/bioengineering11040354