
Discriminant Input Processing Scheme for Self-Assisted Intelligent Healthcare Systems

Abstract
:
1. Introduction
- To improve self-assistance services and diagnoses through emotion-based analysis and advanced technology in healthcare data.
- To assess emotional data in intelligent healthcare systems, the study has introduced DIPS, which uses cutting-edge processing methods.
- To enhance the accuracy of DIPS’s recommendations by identifying similar data patterns across multiple streams.
2. Related Works
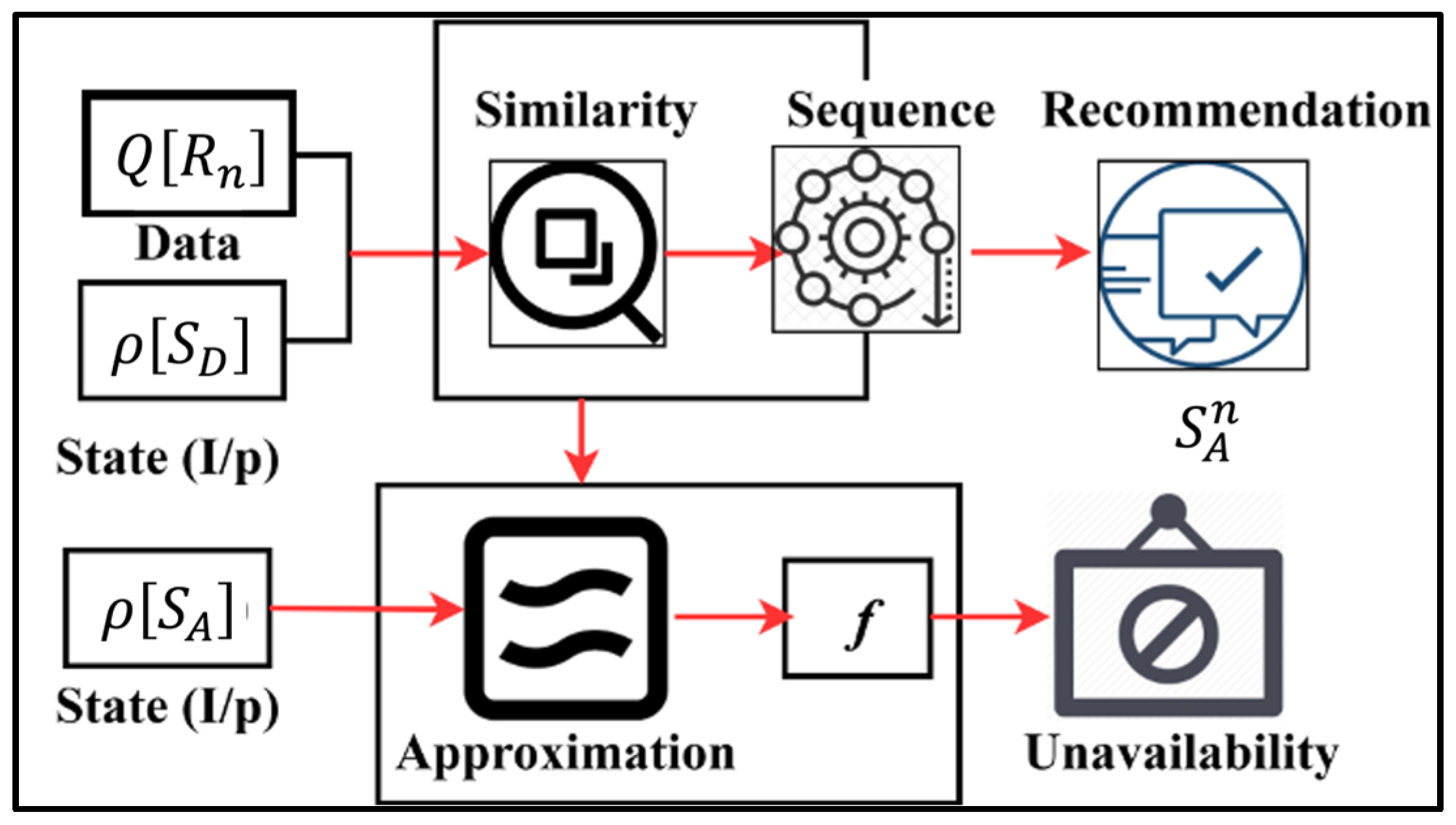
3. Discriminant Input Processing Scheme
3.1. Observation-Based Diagnosis
Preliminaries
| Algorithm 1. Observation-Based Diagnosis |
| Input: Initialize at initial analysis time : Stream distinction feature : Stream similarity feature : Segmented data for emotion analysis : Initial computation value Output: Compute: based on , Adjust: based on , Analyze: Emotion data function Swap: is based on feature-based analysis, and Deny: The access decision is based on and condition. Step 1: Compute based on if > 1 then for from 1 to do += compute_expression_1(j, , ) else for from 1 to (), do += compute_expression_2(, ) Step 2: Compute based on if > 1 then = compute_expression_3(, , ) else if <= 1 then = compute_expression_4(, , ) Step 3: Compute the emotion data function = compute1(, , ) = compute2(, ) Step 4: Feature-based analysis if Ab! = Ac then Pc follows 0 >= 1 condition else if == 1 then is swapped from = 1 instance Step 5: Access SA based on and condition if then Compute accuracy, false data, approximation, and data utilization ratio else Deny access to emotional data |
3.2. Similarity Checking
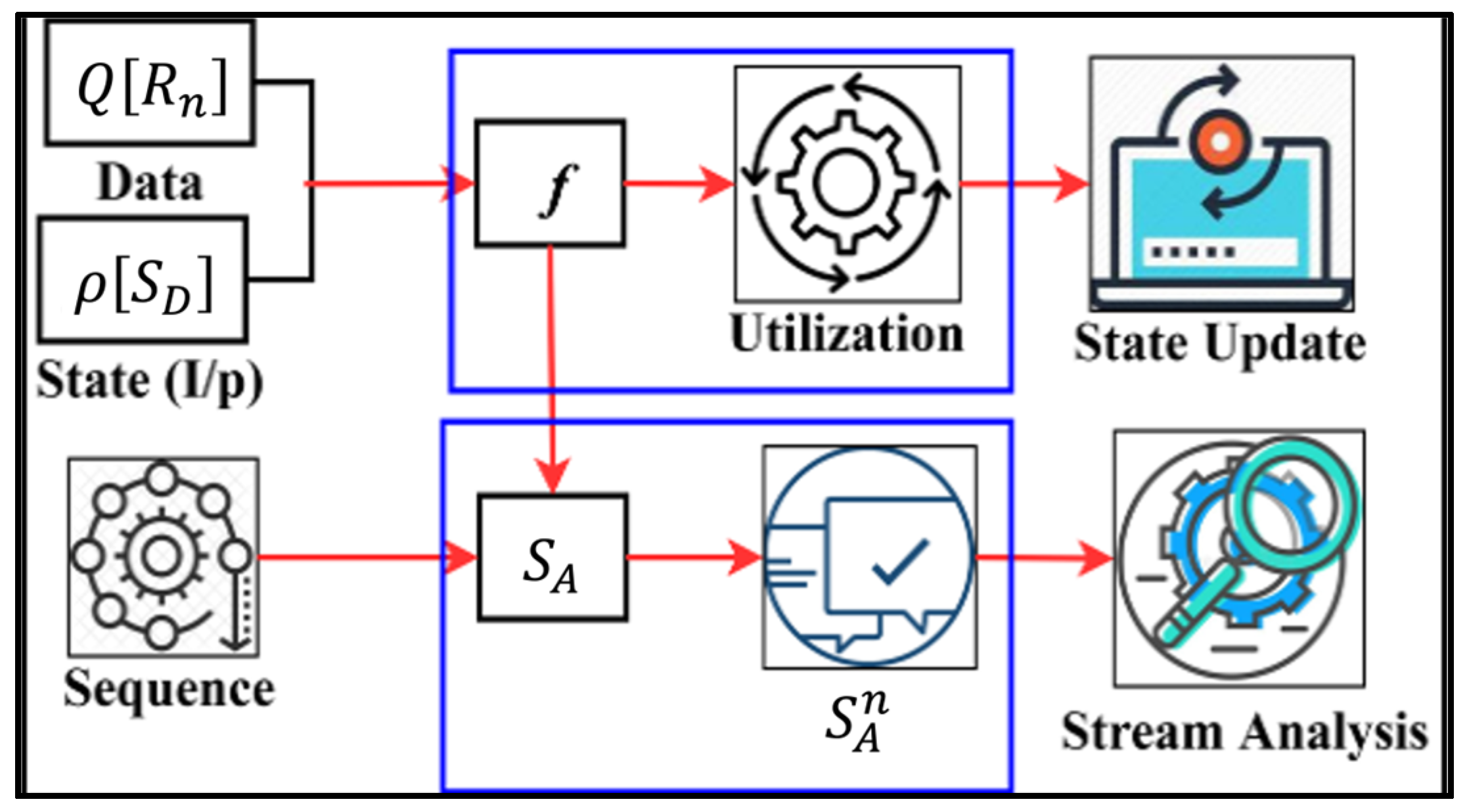
3.3. Transfer Learning for State Analysis
| Algorithm 2. Transfer Learning for State Analysis |
| Input: data instance: data_instance_1, data_instance_2,…, data_instance_n Output: SD: recommendation state sequence; SA: analysis state sequence Step 1: function TransferLearningForRecommendationState(input_data) return // Compute recommendation state sequence for each data instance R_i in input_data, do = compute_recommendation_state return SD Step 1: function TransferLearningForStateAnalysis(input_data) return // Compute analysis state sequence for each data instance in input_data, do = compute_analysis_state return Step 2a: Update state analysis for each in do if false_data_detected () then = update_state_analysis return Step 3: function MainTransferLearning(input_data) return = TransferLearningForRecommendationState(input_data) = TransferLearningForStateAnalysis(input_data) return Step 4: Compute final output final_output = compute_final_output return final_output |
4. Results and Discussion
4.1. Dataset Description
4.2. Accuracy Comparison
4.3. False Rate Comparison
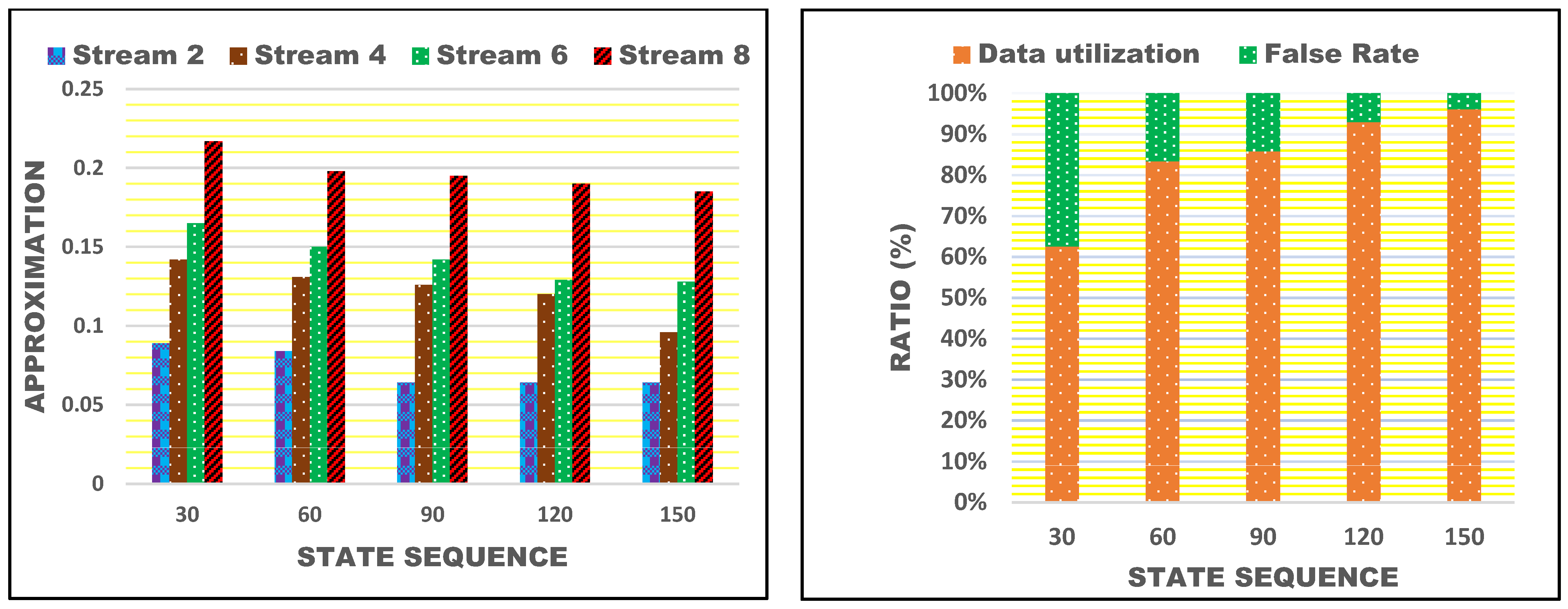
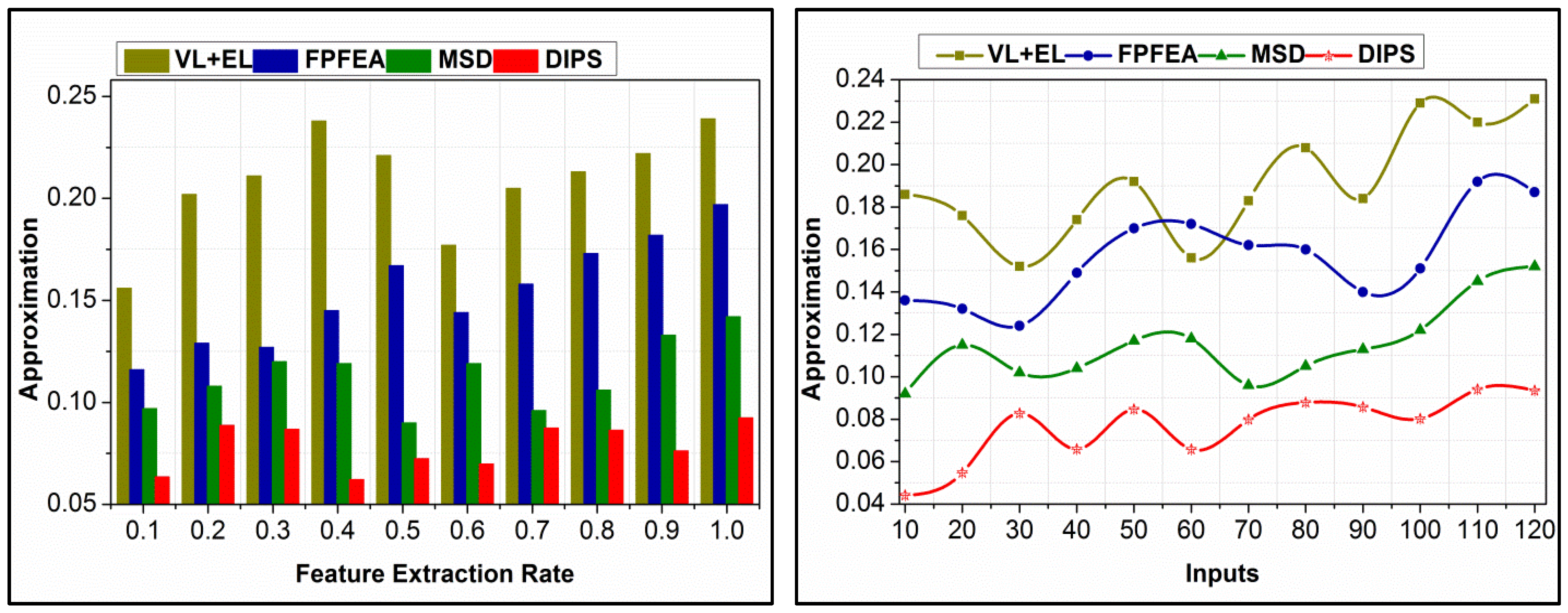
4.4. Approximation Comparison
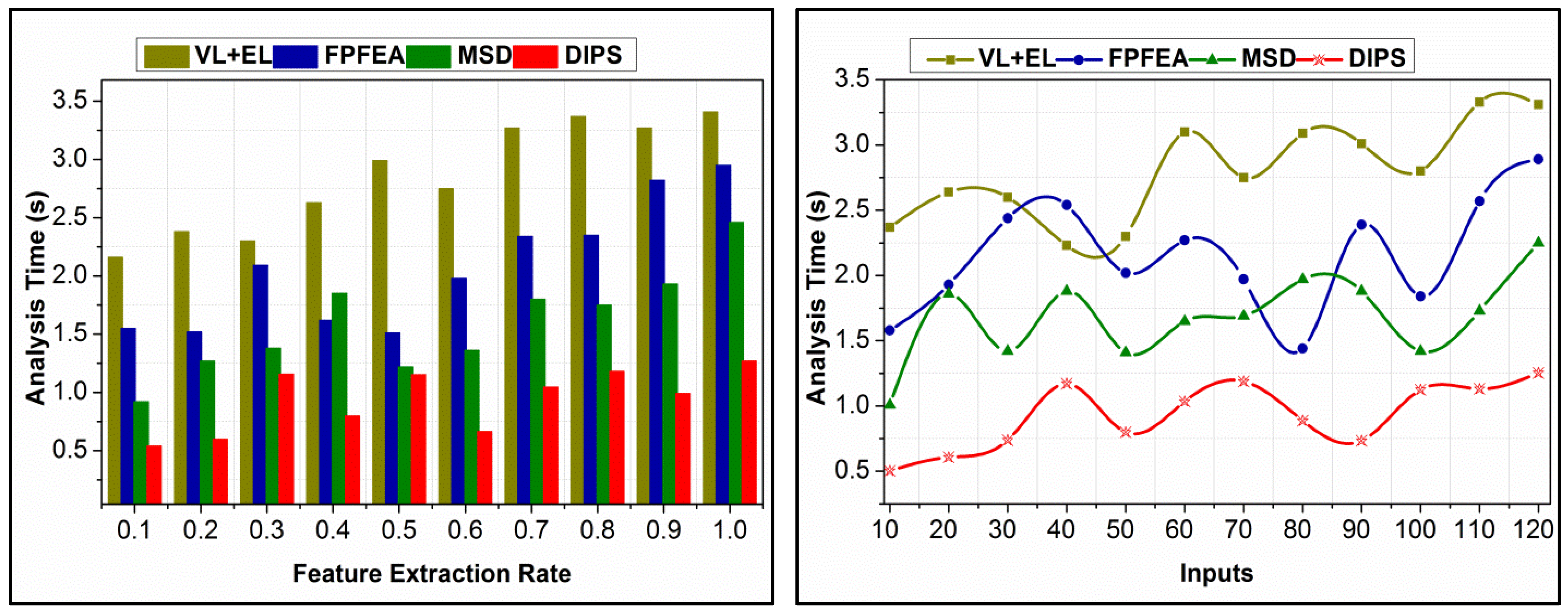
4.5. Analysis Time Comparison
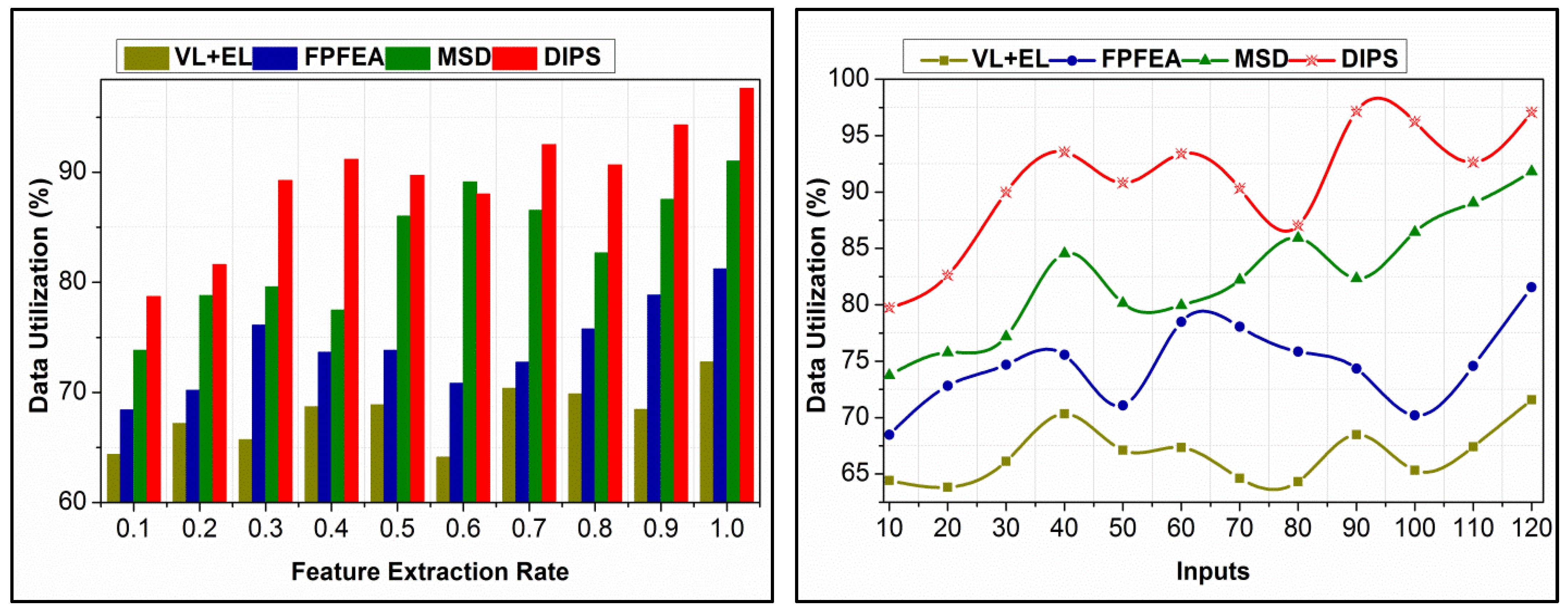
4.6. Data Utilization Comparison
5. Conclusions and Future Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, S.; Liu, H.; Hou, Z.; Li, X.; Wu, Z. EEG-Based Hardware-Oriented Lightweight 1D-CNN Emotion Classifier. In Proceedings of the 15th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2023; pp. 210–213. [Google Scholar]
- Lyu, S.; Cheung, R.C. Efficient Multiple Channels EEG Signal Classification Based on Hierarchical Extreme Learning Machine. Sensors 2023, 23, 8976. [Google Scholar] [CrossRef] [PubMed]
- Kute, S.S.; Tyagi, A.K.; Aswathy, S.U. Industry 4.0 challenges in e-healthcare applications and emerging technologies. Intell. Interact. Multimed. Syst. e-Healthc. Appl. 2022, 265–290. [Google Scholar]
- Dobre, G.C. Social Interactions in Immersive Virtual Environments: People, Agents, and Avatars. Doctoral Dissertation, Goldsmiths, University of London, London, UK, 2023. [Google Scholar]
- Lv, Z.; Poiesi, F.; Dong, Q.; Lloret, J.; Song, H. Deep learning for intelligent human–computer interaction. Appl. Sci. 2022, 12, 11457. [Google Scholar] [CrossRef]
- Li, B.; Lima, D. Facial expression recognition via ResNet-50. Int. J. Cogn. Comput. Eng. 2021, 2, 57–64. [Google Scholar] [CrossRef]
- Zheng, J.; Huang, L.; Li, S.; Lajoie, S.P.; Chen, Y.; Hmelo-Silver, C.E. Self-regulation and emotion matter: A case study of instructor interactions with a learning analytics dashboard. Comput. Educ. 2021, 161, 104061. [Google Scholar] [CrossRef]
- Chuah, S.H.W.; Yu, J. The future of service: The power of emotion in human-robot interaction. J. Retail. Consum. Serv. 2021, 61, 102551. [Google Scholar] [CrossRef]
- Correia, A.I.; Castro, S.L.; MacGregor, C.; Müllensiefen, D.; Schellenberg, E.G.; Lima, C.F. Enhanced recognition of vocal emotions in individuals with naturally good musical abilities. Emotion 2022, 22, 894. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.X.; Dixon, M.L.; Goldin, P.R.; Spiegel, D.; Gross, J.J. The neural separability of emotion reactivity and regulation. Affect. Sci. 2023, 4, 617–629. [Google Scholar] [CrossRef]
- Murphy, J.M.; Bennett, J.M.; de la Piedad Garcia, X.; Willis, M.L. Emotion recognition and traumatic brain injury: A systematic review and meta-analysis. Neuropsychol. Rev. 2021, 32, 1–17. [Google Scholar] [CrossRef]
- Duriez, P.; Guy-Rubin, A.; Kaya Lefèvre, H.; Gorwood, P. Morphing analysis of facial emotion recognition in anorexia nervosa: Association with physical activity. Eat. Weight. Disord. -Stud. Anorex. Bulim. Obes. 2021, 27, 1053–1061. [Google Scholar] [CrossRef]
- Iwakabe, S.; Nakamura, K.; Thoma, N.C. Enhancing emotion regulation. Psychother. Res. 2023, 33, 918–945. [Google Scholar] [CrossRef] [PubMed]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Jahangir, R.; Teh, Y.W.; Hanif, F.; Mujtaba, G. Deep learning approaches for speech emotion recognition: State of the art and research challenges. Multimed. Tools Appl. 2021, 80, 23745–23812. [Google Scholar] [CrossRef]
- Christ, N.M.; Elhai, J.D.; Forbes, C.N.; Gratz, K.L.; Tull, M.T. A machine learning approach to modeling PTSD and difficulties in emotion regulation. Psychiatry Res. 2021, 297, 113712. [Google Scholar] [CrossRef] [PubMed]
- Meng, W.; Cai, Y.; Yang, L.T.; Chiu, W.Y. Hybrid Emotion-aware Monitoring System based on Brainwaves for Internet of Medical Things. IEEE Internet Things J. 2021, 8, 16014–16022. [Google Scholar] [CrossRef]
- Dhote, S.; Baskar, S.; Shakeel, P.M.; Dhote, T. Cloud computing assisted mobile healthcare systems using distributed data analytic model. IEEE Trans. Big Data 2023, 1–12. [Google Scholar] [CrossRef]
- Li, M.; Xie, L.; Lv, Z.; Li, J.; Wang, Z. Multistep Deep System for Multimodal Emotion Detection with Invalid Data in the Internet of Things. IEEE Access 2020, 8, 187208–187221. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Subasi, A. A new fractal pattern features a generation function-based emotion recognition method using EEG. Chaos Solitons Fractals 2021, 144, 110671. [Google Scholar] [CrossRef]
- Ahamed, F. Smart Aging: Utilization of Machine Learning and the Internet of Things for Independent Living. Doctoral Dissertation, Western Sydney University, Kingswood, Australia, 2021. [Google Scholar]
- Fei, Z.; Yang, E.; Li, D.D.-U.; Butler, S.; Ijomah, W.; Li, X.; Zhou, H. Deep convolution network-based emotion analysis towards mental health care. Neurocomputing 2020, 388, 212–227. [Google Scholar] [CrossRef]
- Du, Y.; Du, W.; Lin, D.; Ai, M.; Li, S.; Zhang, L. Recent progress on hydrogel-based piezoelectric devices for biomedical applications. Micromachines 2023, 14, 167. [Google Scholar] [CrossRef]
- Subasi, A.; Tuncer, T.; Dogan, S.; Tanko, D.; Sakoglu, U. EEG-based emotion recognition using tunable Q wavelet transform and rotation forest ensemble classifier. Biomed. Signal Process. Control 2021, 68, 102648. [Google Scholar] [CrossRef]
- Kao, F.-C.; Ho, H.-H.; Chiu, P.-Y.; Hsieh, M.-K.; Liao, J.-C.; Lai, P.-L.; Huang, Y.-F.; Dong, M.-Y.; Tsai, T.-T.; Lin, Z.H. Self-assisted wound healing using piezoelectric and triboelectric nanogenerators. Sci. Technol. Adv. Mater. 2022, 23, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Dheeraj, K.; Ramakrishnudu, T. Negative emotions detection on online mental-health related patients texts using the deep learning with MHA-BCNN model. Expert Syst. Appl. 2021, 182, 115265. [Google Scholar] [CrossRef]
- Pane, E.S.; Wibawa, A.D.; Purnomo, M.H. Improving the accuracy of EEG emotion recognition by combining valence lateralization and ensemble learning with tuning parameters. Cogn. Process. 2019, 20, 405–417. [Google Scholar] [CrossRef] [PubMed]
- Anjum, M.; Shahab, S.; Dimitrakopoulos, G.; Guye, H.F. An In-Vehicle Behaviour-Based Response Model for Traffic Monitoring and Driving Assistance in the Context of Smart Cities. Electronics 2023, 12, 1644. [Google Scholar] [CrossRef]
- Upreti, K.; Mahaveerakannan, R.; Dinkar, R.R.; Maurya, S.; Reddy, V.; Thangadurai, N. An Experimental Evaluation of Hybrid Learning Methodology based Internet of Things Assisted Health Care Monitoring System. Res. Sq. 2021. preprint. [Google Scholar]
- Gong, L.; Chen, W.; Zhang, D. An Attention-Based Multi-Domain Bi-Hemisphere Discrepancy Feature Fusion Model for EEG Emotion Recognition. IEEE J. Biomed. Health Inform. 2024. online ahead of print. [Google Scholar] [CrossRef]
- Kamble, K.S.; Sengupta, J. Multi-channel EEG-based affective emotion identification using a dual-stage filtering approach. In Data Analytics for Intelligent Systems: Techniques and Solutions; IOP Publishing: Bristol, UK, 2024; pp. 1–3. [Google Scholar]
- Available online: https://ascertain-dataset.github.io/ (accessed on 5 March 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Proposed Method | Application Used | Outcomes | Limitations |
|---|---|---|---|---|
| Meng et al. [17] | Emotion-aware healthcare monitoring system | Internet of Medical Things, EEG | High efficiency and accuracy of emotions | Scalability and generalizability of the hybrid emotion-aware monitoring system, especially for diverse patient populations and real-world implementation |
| Dhote et al. [18] | Mobile healthcare apps using distributed cloud technologies | Distributed Data Analytics and Organization Model, federated learning | Effective service rollout, improved data organization | Early service and recommendation problems |
| Li et al. [19] | Multistep deep (MSD) emotion detection system | Deep learning, imputation method | Improved performance by eliminating invalid data | Generalization of the multistep deep system across different IoT environments and additional validation of emotion detection under diverse conditions |
| Tuncer et al. [20] | Automatic emotion recognition system using EEG | EEG, facial patterns, iterative selector | High accuracy in emotion classification | The fractal pattern feature generation method’s scalability and robustness across different EEG data sources and neurological conditions |
| Ahamed [21] | Smart ageing with fall detection and dementia diagnosis | Biometric security, fall detection, dementia diagnosis | 99% accuracy in fall detection, 93% accuracy in dementia diagnosis | Generalizability and effectiveness of innovative ageing solutions across diverse contexts and further validation of machine learning algorithms |
| Fei et al. [22] | Emotion analysis framework using Deep CNN | Analysis of the emotions of patients in healthcare | Increased accuracy in predicting emotions | Additional validation of the emotion analysis framework in clinical settings and its performance across demographic groups |
| Du et al. [23] | Hydrogel-based wearable and implantable devices | Hydrogel structure, piezoelectric capabilities | Flexible and stretchable devices, biomedical applications | Translating hydrogel-based piezoelectric devices to practical biomedical applications, including challenges related to stability and biocompatibility |
| Subasi et al. [24] | EEG-based emotion recognition with noise reduction | Discrete Wavelet Transforms, tunable Q wavelet transform | Maximized classification accuracy | Generalization of EEG-based emotion recognition to real-world scenarios and diverse datasets |
| Kao et al. [25] | Piezoelectric and triboelectric nanogenerators for wound healing | Piezoelectric and triboelectric materials | Potential use in wound healing, external electric field | Challenges in implementing self-assisted wound healing using nanogenerators, including biocompatibility and device performance |
| Dheeraj et al. [26] | Text-based emotion recognition using multi-head attention and BCNN | Multi-head attention, bidirectional convolutional neural network | Identification of negative next-based emotions, examination of mental-health-related questions | Generalizability of the deep learning model for negative emotion detection in mental-health-related texts, including biases in training data |
| Pane et al. [27] | Ensemble learning and lateralization approach | EEG-based emotion recognition, hybrid feature extraction, random forest | Improved emotion recognition accuracy | Generalization of the EEG emotion recognition method to diverse datasets and emotion categories |
| Anjum et al. [28] | Behavior-based response model for smart city traffic | Regression model, cloud computing | Real-time insights for drivers, congestion reduction | Scalability and real-world applicability of the behavior-based response model for traffic monitoring, including data privacy challenges |
| Upreti et al. [29] | Cloud-based model for smart city traffic analysis | Cloud computing, regression model | Real-time insights for drivers, traffic assistance | Generalizability of the IoT-assisted healthcare monitoring system to diverse settings and need for further validation in clinical environments |
| Notation | Definition |
|---|---|
| At | Recorded input and analysis time |
| Recorded input from the input device | |
| Analysis of the recorded input | |
| Emotion data received | |
| Count of the verified input sequence | |
| Varying emotion data sequence | |
| Process condition | |
| Stream similarity | |
| Stream distinction | |
| State analysis | |
| Feature extraction | |
| Feature extraction rate | |
| Iterative computations | |
| Recorded sequence input | |
| Mapping for maximizing accuracy | |
| nu | Input processing improvement |
| Requesting users through services | |
| Feature-based accuracy maximization |
| Streams | Feature Extraction | Data Utilization (%) | Similarity (%) |
|---|---|---|---|
| 1 | 0.16 | 63.5 | 55.82 |
| 2 | 0.25 | 71.69 | 63.25 |
| 3 | 0.31 | 68.25 | 59.87 |
| 4 | 0.38 | 75.36 | 74.25 |
| 5 | 0.42 | 73.98 | 68.25 |
| 6 | 0.39 | 82.69 | 78.21 |
| 7 | 0.58 | 89.54 | 81.36 |
| 8 | 0.69 | 92.64 | 89.25 |
| 9 | 0.97 | 97.57 | 90.81 |
| Inputs | State Sequences | Unavailability | False Rate |
|---|---|---|---|
| 20 | 39 | 0.073 | 0.04 |
| 40 | 96 | 0.096 | 0.08 |
| 80 | 128 | 0.15 | 0.21 |
| 120 | 153 | 0.22 | 0.38 |
| Emotion | State Sequence | |||||||
|---|---|---|---|---|---|---|---|---|
| 40 | 80 | 120 | 160 | |||||
| Accuracy | False Rate | Accuracy | False Rate | Accuracy | False Rate | Accuracy | False Rate | |
| Anger | 59.32 | 0.08 | 63.41 | 0.071 | 71.4 | 0.065 | 86.5 | 0.061 |
| Sad/Crying | 61.3 | 0.07 | 66.47 | 0.062 | 70.06 | 0.06 | 77.5 | 0.052 |
| Happy/Smiling | 67.3 | 0.063 | 74.6 | 0.059 | 78.2 | 0.056 | 90.07 | 0.054 |
| Mood Change | 81.3 | 0.043 | 86.51 | 0.039 | 90.39 | 0.039 | 94.19 | 0.035 |
| Miscellaneous | 80.4 | 0.058 | 83.62 | 0.051 | 86.1 | 0.048 | 90.39 | 0.048 |
| Metrics | VL + EL | FPFEA | MSD | DIPS |
|---|---|---|---|---|
| Accuracy (%) | 69.68 | 78.34 | 89.47 | 95.059 |
| False Rate | 0.365 | 0.255 | 0.158 | 0.0843 |
| Approximation | 0.239 | 0.197 | 0.142 | 0.0925 |
| Analysis Time (s) | 3.41 | 2.95 | 2.46 | 1.269 |
| Data Utilization (%) | 72.78 | 81.23 | 91.01 | 97.624 |
| Metrics | VL + EL | FPFEA | MSD | DIPS |
|---|---|---|---|---|
| Accuracy (%) | 68.48 | 75.67 | 85.74 | 95.429 |
| False Rate | 0.374 | 0.281 | 0.195 | 0.0921 |
| Approximation | 0.231 | 0.187 | 0.152 | 0.0935 |
| Analysis Time (s) | 3.31 | 2.89 | 2.25 | 1.254 |
| Data Utilization (%) | 71.58 | 81.57 | 91.81 | 97.072 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Medani, M.; Alsubai, S.; Min, H.; Dutta, A.K.; Anjum, M. Discriminant Input Processing Scheme for Self-Assisted Intelligent Healthcare Systems. Bioengineering 2024, 11, 715. https://doi.org/10.3390/bioengineering11070715
Medani M, Alsubai S, Min H, Dutta AK, Anjum M. Discriminant Input Processing Scheme for Self-Assisted Intelligent Healthcare Systems. Bioengineering. 2024; 11(7):715. https://doi.org/10.3390/bioengineering11070715
Chicago/Turabian StyleMedani, Mohamed, Shtwai Alsubai, Hong Min, Ashit Kumar Dutta, and Mohd Anjum. 2024. "Discriminant Input Processing Scheme for Self-Assisted Intelligent Healthcare Systems" Bioengineering 11, no. 7: 715. https://doi.org/10.3390/bioengineering11070715