


Automated Foveal Avascular Zone Segmentation in Optical Coherence Tomography Angiography Across Multiple Eye Diseases Using Knowledge Distillation
 , ,
, ,
Abstract
1. Introduction
2. Methods
2.1. Background
2.2. Overview
2.3. Materials
2.4. Single-Condition FAZ Segmentation
2.5. Multi-Condition FAZ Segmentation via Knowledge Distillation for Intra-Modality Data
2.6. Knowledge Distillation for Inter-Modality Data
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Spaide, R.F.; Fujimoto, J.G.; Waheed, N.K.; Sadda, S.R.; Staurenghi, G. Optical Coherence Tomography Angiography. Prog. Retin. Eye Res. 2018, 64, 1–55. [Google Scholar] [CrossRef] [PubMed]
- Javed, A.; Khanna, A.; Palmer, E.; Wilde, C.; Zaman, A.; Orr, G.; Kumudhan, D.; Lakshmanan, A.; Panos, G.D. Optical Coherence Tomography Angiography: A Review of the Current Literature. J. Int. Med. Res. 2023, 51, 03000605231187933. [Google Scholar] [CrossRef]
- Rifai, O.M.; McGrory, S.; Robbins, C.B.; Grewal, D.S.; Liu, A.; Fekrat, S.; MacGillivray, T.J. The Application of Optical Coherence Tomography Angiography in Alzheimer’s Disease: A Systematic Review. Alzheimers Dement. 2021, 13, e12149. [Google Scholar] [CrossRef]
- Yap, T.E.; Balendra, S.I.; Almonte, M.T.; Cordeiro, M.F. Retinal Correlates of Neurological Disorders. Ther. Adv. Chronic Dis. 2019, 10, 2040622319882205. [Google Scholar] [CrossRef] [PubMed]
- Takase, N.; Nozaki, M.; Kato, A.; Ozeki, H.; Yoshida, M.; Ogura, Y. Enlargement of Foveal Avascular Zone in Diabetic Eyes Evaluated by En Face Optical Coherence Tomography Angiography. Retina 2015, 35, 2377–2383. [Google Scholar] [CrossRef]
- Lee, S.C.; Rusakevich, A.M.; Amin, A.; Tran, S.; Emami-Naeini, P.; Moshiri, A.; Park, S.S.; Yiu, G. Long-Term Retinal Vascular Changes in Age-Related Macular Degeneration Measured Using Optical Coherence Tomography Angiography. Ophthalmic Surg. Lasers Imaging Retin. 2022, 53, 529–536. [Google Scholar] [CrossRef]
- Parodi, M.; Visintin, F.; Della Rupe, P.; Ravalico, G. Foveal Avascular Zone in Macular Branch Retinal Vein Occlusion. Int. Ophthalmol. 1995, 19, 25–28. [Google Scholar] [CrossRef] [PubMed]
- Koulisis, N.; Kim, A.Y.; Chu, Z.; Shahidzadeh, A.; Burkemper, B.; de Koo, L.C.O.; Moshfeghi, A.A.; Ameri, H.; Puliafito, C.A.; Isozaki, V.L.; et al. Quantitative Microvascular Analysis of Retinal Venous Occlusions by Spectral Domain Optical Coherence Tomography Angiography. PLoS ONE 2017, 12, e0176404. [Google Scholar] [CrossRef]
- Reich, M.; Glatz, A.; Cakir, B.; Böhringer, D.; Lang, S.; Küchlin, S.; Joachimsen, L.; Lagreze, W.; Agostini, H.T.; Lange, C. Characterisation of Vascular Changes in Different Stages of Stargardt Disease Using Double Swept-Source Optical Coherence Tomography Angiography. BMJ Open Ophthalmol. 2019, 4, e000318. [Google Scholar] [CrossRef]
- Duffy, B.; Castellanos Canales, D.; Decker, N.; Yamaguchi, T.; Pearce, L.; Fawzi, A.A. Foveal Avascular Zone Enlargement Correlates with Visual Acuity Decline in Patients with Diabetic Retinopathy. Investig. Ophthalmol. Vis. Sci. 2024, 65, 955. [Google Scholar] [CrossRef]
- Balaratnasingam, C.; Inoue, M.; Ahn, S.; McCann, J.; Dhrami-Gavazi, E.; Yannuzzi, L.A.; Freund, K.B. Visual Acuity Is Correlated with the Area of the Foveal Avascular Zone in Diabetic Retinopathy and Retinal Vein Occlusion. Ophthalmology 2016, 123, 2352–2367. [Google Scholar] [CrossRef] [PubMed]
- Trinh, M.; Kalloniatis, M.; Nivison-Smith, L. Radial Peripapillary Capillary Plexus Sparing and Underlying Retinal Vascular Impairment in Intermediate Age-Related Macular Degeneration. Investig. Ophthalmol. Vis. Sci. 2021, 62, 2. [Google Scholar] [CrossRef] [PubMed]
- Bresnick, G.H.; Condit, R.; Syrjala, S.; Palta, M.; Groo, A.; Korth, K. Abnormalities of the Foveal Avascular Zone in Diabetic Retinopathy. Arch. Ophthalmol. Chic. 1984, 102, 1286–1293. [Google Scholar] [CrossRef] [PubMed]
- Park, Y.G.; Kim, M.; Roh, Y.J. Evaluation of Foveal and Parafoveal Microvascular Changes Using Optical Coherence Tomography Angiography in Type 2 Diabetes Patients without Clinical Diabetic Retinopathy in South Korea. J. Diabetes Res. 2020, 2020, 6210865. [Google Scholar] [CrossRef]
- Stana, D.; Potop, V.; Istrate, S.L.; Eniceicu, C.; Mihalcea, A.R. Foveal Avascular Zone Area Measurements Using OCT Angiography in Patients with Type 2 Diabetes Mellitus Associated with Essential Hypertension. Rom. J. Ophthalmol. 2019, 63, 354–359. [Google Scholar] [CrossRef]
- Koutsiaris, A.G. A Blood Supply Pathophysiological Microcirculatory Mechanism for Long COVID. Life 2024, 14, 1076. [Google Scholar] [CrossRef]
- Gill, A.; Cole, E.D.; Novais, E.A.; Louzada, R.N.; de Carlo, T.; Duker, J.S.; Waheed, N.K.; Baumal, C.R.; Witkin, A.J. Visualization of Changes in the Foveal Avascular Zone in Both Observed and Treated Diabetic Macular Edema Using Optical Coherence Tomography Angiography. Int. J. Retin. Vitr. 2017, 3, 19. [Google Scholar] [CrossRef]
- Agarwal, A.; Bhatt, S.; Keshari, S.; Erckens, R.J.; Berendschot, T.T.J.M.; Webers, C.a.B.; Agrawal, R.; Bansal, R.; Gupta, V. Retinal Microvascular Alterations in Patients with Quiescent Posterior and Panuveitis Using Optical Coherence Tomography Angiography. Ocul. Immunol. Inflamm. 2022, 30, 1781–1787. [Google Scholar] [CrossRef]
- Smid, L.M.; Vermeer, K.A.; Missotten, T.O.A.R.; van Laar, J.A.M.; van Velthoven, M.E.J. Parafoveal Microvascular Alterations in Ocular and Non-Ocular Behҫet’s Disease Evaluated With Optical Coherence Tomography Angiography. Investig. Ophthalmol. Vis. Sci. 2021, 62, 8. [Google Scholar] [CrossRef]
- Hoshiyama, K.; Hirano, T.; Hirabayashi, K.; Wakabayashi, M.; Tokimitsu, M.; Murata, T. Morphological Changes in the Foveal Avascular Zone after Panretinal Photocoagulation for Diabetic Retinopathy Using OCTA: A Study Focusing on Macular Ischemia. Medicina 2022, 58, 1797. [Google Scholar] [CrossRef]
- Liao, D.; Zhou, Z.; Wang, F.; Zhang, B.; Wang, Y.; Zheng, Y.; Li, J. Changes in Foveal Avascular Zone Area and Retinal Vein Diameter in Patients with Retinal Vein Occlusion Detected by Fundus Fluorescein Angiography. Front. Med. 2023, 10. [Google Scholar] [CrossRef]
- Shoji, T.; Kanno, J.; Weinreb, R.N.; Yoshikawa, Y.; Mine, I.; Ishii, H.; Ibuki, H.; Shinoda, K. OCT Angiography Measured Changes in the Foveal Avascular Zone Area after Glaucoma Surgery. Br. J. Ophthalmol. 2022, 106, 80–86. [Google Scholar] [CrossRef] [PubMed]
- Sijilmassi, O. Quantitative Analysis of Different Foveal Avascular Zone Metrics in Healthy and Diabetic Subjects. Diabetology 2024, 5, 246–254. [Google Scholar] [CrossRef]
- Tang, F.Y.; Ng, D.S.; Lam, A.; Luk, F.; Wong, R.; Chan, C.; Mohamed, S.; Fong, A.; Lok, J.; Tso, T.; et al. Determinants of Quantitative Optical Coherence Tomography Angiography Metrics in Patients with Diabetes. Sci. Rep. 2017, 7, 2575. [Google Scholar] [CrossRef]
- Krawitz, B.D.; Mo, S.; Geyman, L.S.; Agemy, S.A.; Scripsema, N.K.; Garcia, P.M.; Chui, T.Y.P.; Rosen, R.B. Acircularity Index and Axis Ratio of the Foveal Avascular Zone in Diabetic Eyes and Healthy Controls Measured by Optical Coherence Tomography Angiography. Vis. Res. 2017, 139, 177–186. [Google Scholar] [CrossRef]
- Choi, J.; Kwon, J.; Shin, J.W.; Lee, J.; Lee, S.; Kook, M.S. Quantitative Optical Coherence Tomography Angiography of Macular Vascular Structure and Foveal Avascular Zone in Glaucoma. PLoS ONE 2017, 12, e0184948. [Google Scholar] [CrossRef]
- Kwon, J.; Choi, J.; Shin, J.W.; Lee, J.; Kook, M.S. Glaucoma Diagnostic Capabilities of Foveal Avascular Zone Parameters Using Optical Coherence Tomography Angiography According to Visual Field Defect Location. J. Glaucoma 2017, 26, 1120. [Google Scholar] [CrossRef]
- Živković, M.L.J.; Lazić, L.; Zlatanovic, M.; Zlatanović, N.; Brzaković, M.; Jovanović, M.; Barišić, S.; Darabus, D.-M. The Influence of Myopia on the Foveal Avascular Zone and Density of Blood Vessels of the Macula—An OCTA Study. Medicina 2023, 59, 452. [Google Scholar] [CrossRef]
- Piao, H.; Guo, Y.; Zhang, H.; Sung, M.S.; Park, S.W. Acircularity and Circularity Indexes of the Foveal Avascular Zone in High Myopia. Sci. Rep. 2021, 11, 16808. [Google Scholar] [CrossRef]
- Sui, J.; Li, H.; Bai, Y.; He, Q.; Sun, Z.; Wei, R. Morphological Characteristics of the Foveal Avascular Zone in Pathological Myopia and Its Relationship with Macular Structure and Microcirculation. Graefes Arch. Clin. Exp. Ophthalmol. 2024, 262, 2121–2133. [Google Scholar] [CrossRef]
- Koutsiaris, A.G.; Batis, V.; Liakopoulou, G.; Tachmitzi, S.V.; Detorakis, E.T.; Tsironi, E.E. Optical Coherence Tomography Angiography (OCTA) of the Eye: A Review on Basic Principles, Advantages, Disadvantages and Device Specifications. Clin. Hemorheol. Microcirc. 2023, 83, 247–271. [Google Scholar] [CrossRef] [PubMed]
- Karn, P.K.; Abdulla, W.H. On Machine Learning in Clinical Interpretation of Retinal Diseases Using OCT Images. Bioengineering 2023, 10, 407. [Google Scholar] [CrossRef]
- Akinniyi, O.; Rahman, M.M.; Sandhu, H.S.; El-Baz, A.; Khalifa, F. Multi-Stage Classification of Retinal OCT Using Multi-Scale Ensemble Deep Architecture. Bioengineering 2023, 10, 823. [Google Scholar] [CrossRef]
- Xue, S.; Wang, H.; Guo, X.; Sun, M.; Song, K.; Shao, Y.; Zhang, H.; Zhang, T. CTS-Net: A Segmentation Network for Glaucoma Optical Coherence Tomography Retinal Layer Images. Bioengineering 2023, 10, 230. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Gandhi, J.S.; Stangos, A.N.; Campa, C.; Broadbent, D.M.; Harding, S.P. Automated Segmentation of Foveal Avascular Zone in Fundus Fluorescein Angiography. Investig. Ophthalmol. Vis. Sci. 2010, 51, 3653–3659. [Google Scholar] [CrossRef] [PubMed]
- Yoon, J.M.; Lim, C.Y.; Noh, H.; Nam, S.W.; Jun, S.Y.; Kim, M.J.; Song, M.Y.; Jang, H.; Kim, H.J.; Seo, S.W.; et al. Enhancing Foveal Avascular Zone Analysis for Alzheimer’s Diagnosis with AI Segmentation and Machine Learning Using Multiple Radiomic Features. Sci. Rep. 2024, 14, 1841. [Google Scholar] [CrossRef]
- Guo, M.; Zhao, M.; Cheong, A.M.Y.; Dai, H.; Lam, A.K.C.; Zhou, Y. Automatic Quantification of Superficial Foveal Avascular Zone in Optical Coherence Tomography Angiography Implemented with Deep Learning. Vis. Comput. Ind. Biomed. Art 2019, 2, 21. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar]
- Liang, Z.; Zhang, J.; An, C. Foveal Avascular Zone Segmentation of Octa Images Using Deep Learning Approach with Unsupervised Vessel Segmentation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1200–1204. [Google Scholar]
- Meng, Y.; Lan, H.; Hu, Y.; Chen, Z.; Ouyang, P.; Luo, J. Application of Improved U-Net Convolutional Neural Network for Automatic Quantification of the Foveal Avascular Zone in Diabetic Macular Ischemia. J. Diabetes Res. 2022, 2022, 4612554. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Mirshahi, R.; Anvari, P.; Riazi-Esfahani, H.; Sardarinia, M.; Naseripour, M.; Falavarjani, K.G. Foveal Avascular Zone Segmentation in Optical Coherence Tomography Angiography Images Using a Deep Learning Approach. Sci. Rep. 2021, 11, 1031. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Nice, France, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Thisanke, H.; Deshan, C.; Chamith, K.; Seneviratne, S.; Vidanaarachchi, R.; Herath, D. Semantic Segmentation Using Vision Transformers: A Survey. Eng. Appl. Artif. Intell. 2023, 126, 106669. [Google Scholar] [CrossRef]
- Philippi, D.; Rothaus, K.; Castelli, M. A Vision Transformer Architecture for the Automated Segmentation of Retinal Lesions in Spectral Domain Optical Coherence Tomography Images. Sci. Rep. 2023, 13, 517. [Google Scholar] [CrossRef]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do Vision Transformers See Like Convolutional Neural Networks? In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Online, 6–14 December 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, G.; Qiao, S.; Liu, M.; Qu, L.; Han, N.; Wu, T.; Yuan, G.; Wu, T.; Peng, Y. Imbalanced Data Classification: Using Transfer Learning and Active Sampling. Eng. Appl. Artif. Intell. 2023, 117, 105621. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531v1. [Google Scholar]
- Habib, G.; Saleem, T.J.; Kaleem, S.M.; Rouf, T.; Lall, B. A Comprehensive Review of Knowledge Distillation in Computer Vision. Int. J. Innov. Res. Comput. Sci. Technol. 2024, 12, 106–112. [Google Scholar]
- Linderman, R.; Salmon, A.E.; Strampe, M.; Russillo, M.; Khan, J.; Carroll, J. Assessing the Accuracy of Foveal Avascular Zone Measurements Using Optical Coherence Tomography Angiography: Segmentation and Scaling. Transl. Vis. Sci. Technol. 2017, 6, 16. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Bai, J.; Al-Sabaawi, A.; Santamaría, J.; Albahri, A.S.; Al-dabbagh, B.S.N.; Fadhel, M.A.; Manoufali, M.; Zhang, J.; Al-Timemy, A.H.; et al. A Survey on Deep Learning Tools Dealing with Data Scarcity: Definitions, Challenges, Solutions, Tips, and Applications. J. Big Data 2023, 10, 46. [Google Scholar] [CrossRef]
- Gani, H.; Naseer, M.; Yaqub, M. How to Train Vision Transformer on Small-Scale Datasets? In Proceedings of the 33rd British Machine Vision Conference, London, UK, 21–24 November 2022.
- Wang, Z.; Wang, P.; Liu, K.; Wang, P.; Fu, Y.; Lu, C.-T.; Aggarwal, C.C.; Pei, J.; Zhou, Y. A Comprehensive Survey on Data Augmentation. arXiv 2024, arXiv:2405.09591. [Google Scholar]
- Goyal, M.; Mahmoud, Q.H. A Systematic Review of Synthetic Data Generation Techniques Using Generative AI. Electronics 2024, 13, 3509. [Google Scholar] [CrossRef]
- Gui, J.; Chen, T.; Zhang, J.; Cao, Q.; Sun, Z.; Luo, H.; Tao, D. A Survey on Self-Supervised Learning: Algorithms, Applications, and Future Trends. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9052–9071. [Google Scholar] [CrossRef]
- Kim, H.E.; Cosa-Linan, A.; Santhanam, N.; Jannesari, M.; Maros, M.E.; Ganslandt, T. Transfer Learning for Medical Image Classification: A Literature Review. BMC Med. Imaging 2022, 22, 69. [Google Scholar] [CrossRef]
- Mei, X.; Liu, Z.; Robson, P.M.; Marinelli, B.; Huang, M.; Doshi, A.; Jacobi, A.; Cao, C.; Link, K.E.; Yang, T.; et al. RadImageNet: An Open Radiologic Deep Learning Research Dataset for Effective Transfer Learning. Radiol. Artif. Intell. 2022, 4, e210315. [Google Scholar] [CrossRef]
- Schäfer, R.; Nicke, T.; Höfener, H.; Lange, A.; Merhof, D.; Feuerhake, F.; Schulz, V.; Lotz, J.; Kiessling, F. Overcoming Data Scarcity in Biomedical Imaging with a Foundational Multi-Task Model. Nat. Comput. Sci. 2024, 4, 495–509. [Google Scholar] [CrossRef] [PubMed]
- Jafarigol, E.; Trafalis, T. A Review of Machine Learning Techniques in Imbalanced Data and Future Trends. arXiv 2023, arXiv:2310.07917. [Google Scholar]
- Araf, I.; Idri, A.; Chairi, I. Cost-Sensitive Learning for Imbalanced Medical Data: A Review. Artif. Intell. Rev. 2024, 57, 80. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble Deep Learning: A Review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Zhao, L.; Qian, X.; Guo, Y.; Song, J.; Hou, J.; Gong, J. MSKD: Structured Knowledge Distillation for Efficient Medical Image Segmentation. Comput. Biol. Med. 2023, 164, 107284. [Google Scholar] [CrossRef]
- Li, M.; Cui, C.; Liu, Q.; Deng, R.; Yao, T.; Lionts, M.; Huo, Y. Dataset Distillation in Medical Imaging: A Feasibility Study. arXiv 2024, arXiv:2407.14429. [Google Scholar]
- Qin, D.; Bu, J.; Liu, Z.; Shen, X.; Zhou, S.; Gu, J.; Wang, Z.; Wu, L.; Dai, H. Efficient Medical Image Segmentation Based on Knowledge Distillation. IEEE Trans. Med. Imaging 2021, 40, 3820–3831. [Google Scholar] [CrossRef]
- Xing, X.; Hou, Y.; Li, H.; Yuan, Y.; Li, H.; Meng, M.Q.-H. Categorical Relation-Preserving Contrastive Knowledge Distillation for Medical Image Classification. In Proceedings of the 24th International Conference on Medical Image Computing and Computer Assisted Intervention, Strasbourg, France, 27 September–1 October 2021. [Google Scholar]
- Du, S.; Bayasi, N.; Hamarneh, G.; Garbi, R. MDViT: Multi-Domain Vision Transformer for Small Medical Image Segmentation Datasets. In Proceedings of the 26th International Conference on Medical Image Computing and Computer Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023. [Google Scholar]
- Camino Benech, A.; Wang, Z.; Basu Bal, A.; Benmansour, F.; Carano, R.; Ferrara, D. Deep Learning Segmentation of Foveal Avascular Zone (FAZ) in Optical Coherence Tomography Angiography (OCTA) of Nonproliferative Diabetic Retinopathy. Investig. Ophthalmol. Vis. Sci. 2023, 64, 1125. [Google Scholar]
- Cunningham, H.; Ewart, A.; Riggs, L.; Huben, R.; Sharkey, L. Sparse Autoencoders Find Highly Interpretable Features in Language Models. arXiv 2023, arXiv:2309.08600. [Google Scholar]
- Alam, M.N.; Yamashita, R.; Ramesh, V.; Prabhune, T.; Lim, J.I.; Chan, R.V.P.; Hallak, J.; Leng, T.; Rubin, D. Contrastive Learning-Based Pretraining Improves Representation and Transferability of Diabetic Retinopathy Classification Models. Sci. Rep. 2023, 13, 6047. [Google Scholar] [CrossRef] [PubMed]
- Hervella, Á.S.; Rouco, J.; Novo, J.; Ortega, M. Multimodal Image Encoding Pre-Training for Diabetic Retinopathy Grading. Comput. Biol. Med. 2022, 143, 105302. [Google Scholar] [CrossRef] [PubMed]
- Sükei, E.; Rumetshofer, E.; Schmidinger, N.; Mayr, A.; Schmidt-Erfurth, U.; Klambauer, G.; Bogunović, H. Multi-Modal Representation Learning in Retinal Imaging Using Self-Supervised Learning for Enhanced Clinical Predictions. Sci. Rep. 2024, 14, 26802. [Google Scholar] [CrossRef]
- Zhou, Y.; Chia, M.A.; Wagner, S.K.; Ayhan, M.S.; Williamson, D.J.; Struyven, R.R.; Liu, T.; Xu, M.; Lozano, M.G.; Woodward-Court, P.; et al. A Foundation Model for Generalizable Disease Detection from Retinal Images. Nature 2023, 622, 156–163. [Google Scholar] [CrossRef]
- Wu, R.; Zhang, C.; Zhang, J.; Zhou, Y.; Zhou, T.; Fu, H. MM-Retinal: Knowledge-Enhanced Foundational Pretraining with Fundus Image-Text Expertise. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco, 6–10 October 2024. [Google Scholar]
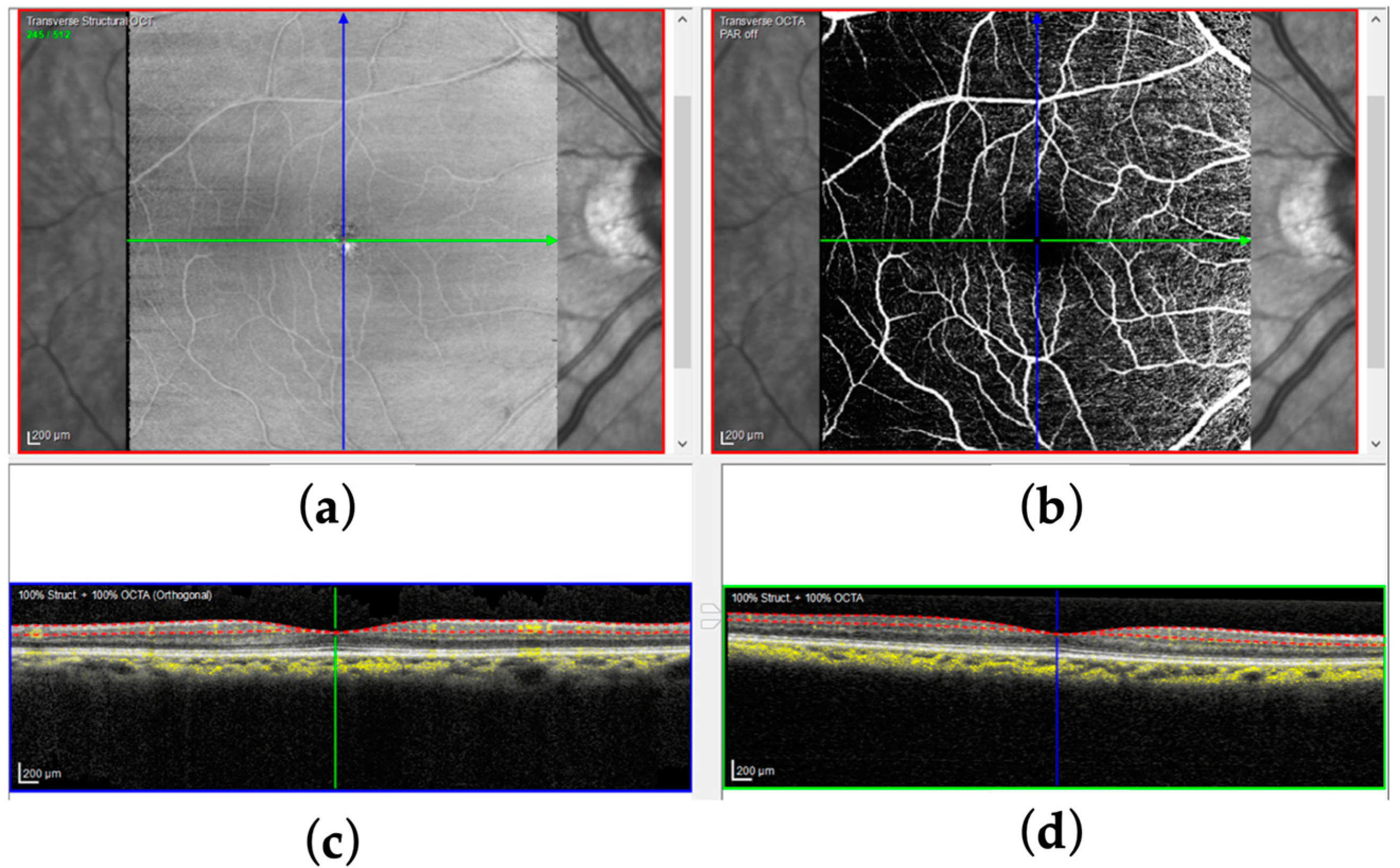

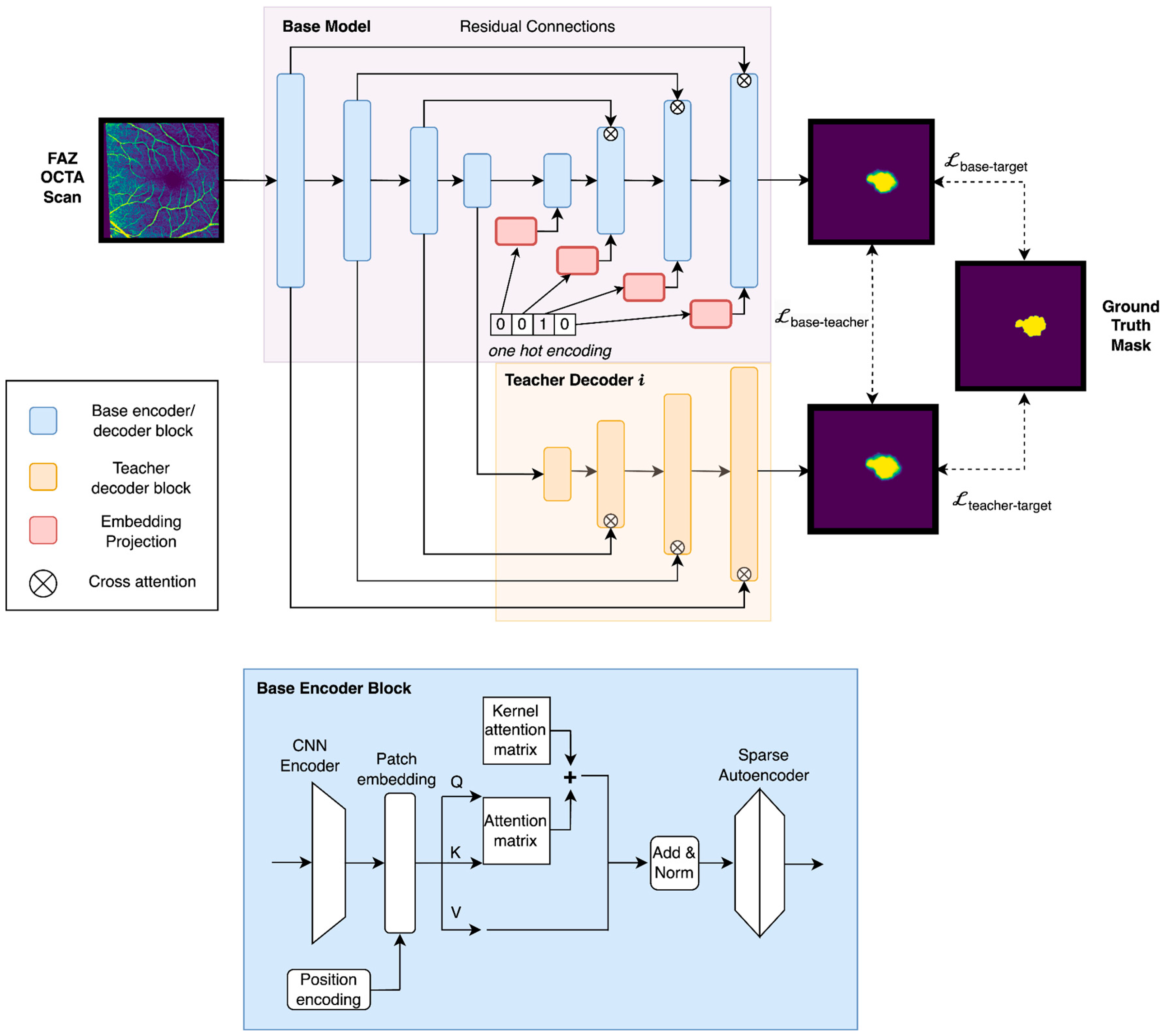


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Healthy | ALZ | AMD | DR | Mean | |
|---|---|---|---|---|---|---|
| Single-condition Model | Without pretraining | 86.4 | 80.6 | 82.8 | 79.6 | 82.0 |
| With pretraining | 86.6 | 83.1 | 82.8 | 80.8 | 83.1 | |
| Multi-condition Model | Without pretraining | 85.4 | 83.7 | 82.9 | 83.3 | 83.7 |
| With pretraining | 88.0 | 83.9 | 81.3 | 84.4 | 83.8 |
| Model | Healthy | ALZ | AMD | DR | Mean | |
|---|---|---|---|---|---|---|
| Single-condition Model | Without pretraining | 85.3 | 81.3 | 83.9 | 81.2 | 81.1 |
| With pretraining | 86.4 | 84.1 | 85.4 | 81.0 | 84.2 | |
| Multi-condition Model | Without pretraining | 86.2 | 84.0 | 82.3 | 82.5 | 83.5 |
| With pretraining | 87.1 | 84.1 | 82.3 | 83.3 | 83.9 |
| Model | Healthy | ALZ | AMD | DR | |
|---|---|---|---|---|---|
| Single-condition Model | With/without pretraining | 0.005 | <0.001 | 0.94 | <0.001 |
| With/without 2 annotations | <0.001 | 0.006 | <0.001 | <0.001 | |
| Multi-condition Model | With/without pretraining | <0.001 | 0.21 | <0.001 | <0.001 |
| With/without 2 annotations | <0.001 | 0.09 | 0.03 | 0.001 | |
| Single-condition/Multi-condition Model | <0.001 | <0.001 | <0.001 | <0.001 | |
| Model | Healthy | ALZ | AMD | DR | |
|---|---|---|---|---|---|
| Single-condition Model | With/without pretraining | 0.3 | 1.8 | 0.0 | 0.86 |
| With/without 2 annotations | −1.1 | 0.3 | 0.8 | 1.2 | |
| Multi-condition Model | With/without pretraining | 3.2 | 0.1 | −0.7 | 0.6 |
| With/without 2 annotations | 0.6 | 0.2 | −0.2 | −0.3 | |
| Single-condition/Multi-condition Model | 1.7 | 2.6 | 1.3 | 0.5 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Racioppo, P.; Alhasany, A.; Pham, N.V.; Wang, Z.; Corradetti, G.; Mikaelian, G.; Paulus, Y.M.; Sadda, S.R.; Hu, Z. Automated Foveal Avascular Zone Segmentation in Optical Coherence Tomography Angiography Across Multiple Eye Diseases Using Knowledge Distillation. Bioengineering 2025, 12, 334. https://doi.org/10.3390/bioengineering12040334
Racioppo P, Alhasany A, Pham NV, Wang Z, Corradetti G, Mikaelian G, Paulus YM, Sadda SR, Hu Z. Automated Foveal Avascular Zone Segmentation in Optical Coherence Tomography Angiography Across Multiple Eye Diseases Using Knowledge Distillation. Bioengineering. 2025; 12(4):334. https://doi.org/10.3390/bioengineering12040334
Chicago/Turabian StyleRacioppo, Peter, Aya Alhasany, Nhuan Vu Pham, Ziyuan Wang, Giulia Corradetti, Gary Mikaelian, Yannis M. Paulus, SriniVas R. Sadda, and Zhihong Hu. 2025. "Automated Foveal Avascular Zone Segmentation in Optical Coherence Tomography Angiography Across Multiple Eye Diseases Using Knowledge Distillation" Bioengineering 12, no. 4: 334. https://doi.org/10.3390/bioengineering12040334
APA StyleRacioppo, P., Alhasany, A., Pham, N. V., Wang, Z., Corradetti, G., Mikaelian, G., Paulus, Y. M., Sadda, S. R., & Hu, Z. (2025). Automated Foveal Avascular Zone Segmentation in Optical Coherence Tomography Angiography Across Multiple Eye Diseases Using Knowledge Distillation. Bioengineering, 12(4), 334. https://doi.org/10.3390/bioengineering12040334