
Methods for Parameter Estimation in Wine Fermentation Models


Abstract
1. Introduction
2. Materials and Methods
2.1. Fermentations
2.2. Fermentation Model
2.3. Parameter Estimation Methods
2.4. Numerical Integration Methods
2.5. Comparison of Parameter Estimation Methods
3. Results
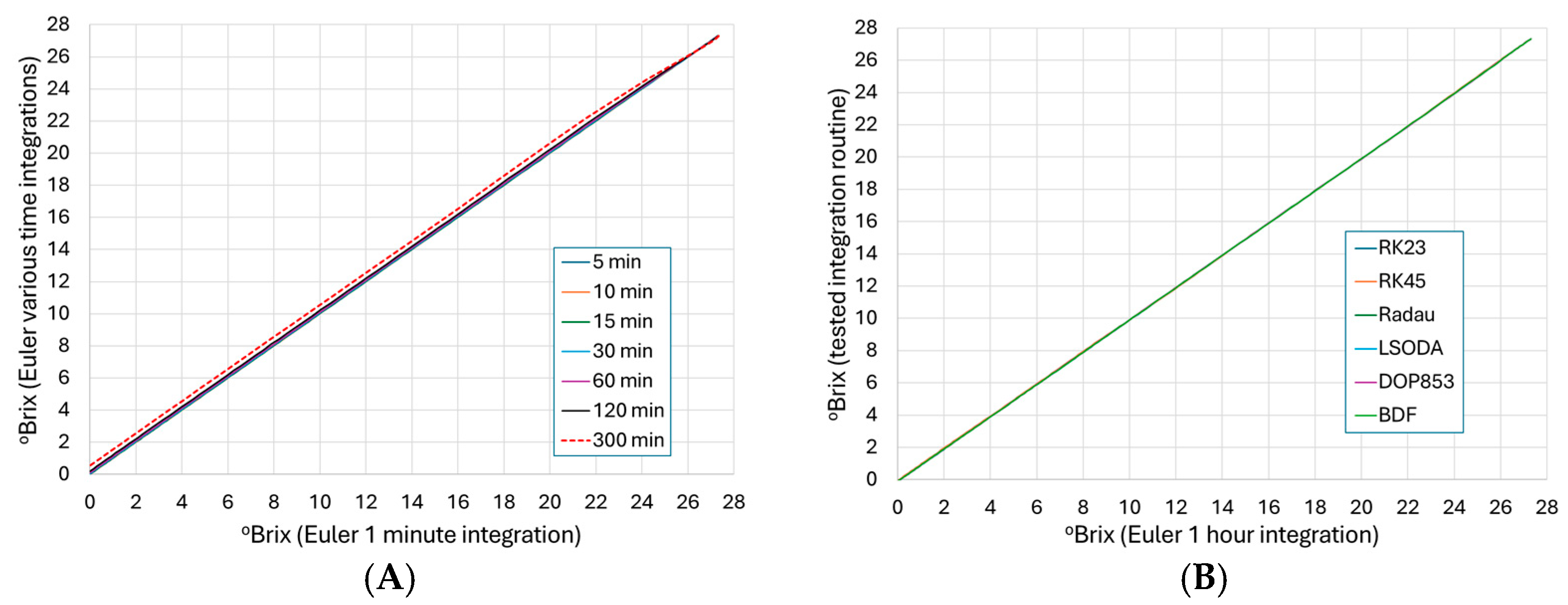
3.1. Analysis of Euler Integration Step Size
3.2. Analysis of Alternate Integration Methods
3.3. Analysis of Parameter Estimation Methods
3.4. Analysis of Fermentations
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Knoesen, A.; Boutlon, R. A Brief History of the Modeling, Control and Optimization of Wine. Fermentation, 2024; in submission. [Google Scholar]
- Boulton, R.B.; Singleton, V.L.; Bisson, L.F.; Kunkee, R.E. Principles and Practices of Winemaking; Chapman & Hall: New York, NY, USA; Springer: Boston, MA, USA, 1996; ISBN 0-412-06411-1. [Google Scholar] [CrossRef]
- Marín, M.R. Alcoholic Fermentation Modelling: Current State and Perspectives. Am. J. Enol. Vitic. 1999, 50, 166–178. [Google Scholar] [CrossRef]
- Bisson, L.F.; Butzke, C.E. Diagnosis and Rectification of Stuck and Sluggish Fermentations. Am. J. Enol. Vitic. 2000, 51, 168–177. [Google Scholar] [CrossRef]
- Nelson, J.; Boulton, R. Models for Wine Fermentation and Their Suitability for Commercial Applications. Fermentation 2024, 10, 269. [Google Scholar] [CrossRef]
- Pirt, S.J. Principles of Microbe and Cell Cultivation; Wiley: New York, NY, USA, 1975; ISBN 0470690380, 9780470690383. [Google Scholar]
- Aiba, S.; Humphrey, A.E.; Millis, N.F. Biochemical Engineering, 2nd ed.; Academic Press: New York, NY, USA, 1973; ISBN 0-12-045052-6.1. [Google Scholar]
- Bailey, J.E. Biochemical Engineering Fundamentals; McGraw Hill: New York, NY, USA, 1977; ISBN 0-07-003210-6. [Google Scholar]
- Boulton, R. The Prediction of Fermentation Behavior by a Kinetic Model. Am. J. Enol. Vitic. 1980, 31, 40–45. [Google Scholar] [CrossRef]
- Coleman, M.C.; Fish, R.; Block, D.E. Temperature-Dependent Kinetic Model for Nitrogen-Limited Wine Fermentations. Appl. Environ. Microbiol. 2007, 73, 5875–5884. [Google Scholar] [CrossRef] [PubMed]
- Coleman, R.E.; Boulton, R.B. Alternative Estimation Routines for Modeling and Prediction of Commerical Wine Fermentations. In Proceedings of the 72nd American Society of Enology and Viticulture National Conference, Virtual, 24 June 2021. [Google Scholar]
- AWRI. Fermentation Simulator. Available online: https://www.awri.com.au/industry_support/winemaking_resources/wine_fermentation/awri-ferment-simulator/ (accessed on 18 May 2024).
- Nelson, J.N. The Digitization of Wine Fermentation. Ph.D. Thesis, University of California Davis, Davis, CA, USA, 2023. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. Scipy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, R.; Powell, M.J.D. A Rapidly Convergent Descent Method for Minimization. Comput. J. 1963, 6, 163–168. [Google Scholar] [CrossRef]
- Bard, Y. Comparison of Gradient Methods for the Solution of Nonlinear Parameter Estimation Problems. SIAM J. Numer. Anal. 1970, 7, 157–186. [Google Scholar] [CrossRef]
- Bard, Y. Nonlinear Parameter Estimation; Academic Press: New York, NY, USA, 1974; ISBN 0-12-078250-2. [Google Scholar]
- Abril-Pla, O.; Andreani, V.; Carroll, C.; Dong, L.; Fonnesbeck, C.J.; Kochurov, M.; Kumar, R.; Lao, J.; Luhmann, C.C.; Martin, O.A.; et al. Pymc: A Modern, and Comprehensive Probabilistic Programming Framework in Python. PeerJ Comput. Sci. 2023, 9, e1516. [Google Scholar] [CrossRef] [PubMed]
- Rahmadya. Particle Swarm. Available online: https://rahmadya.com/2020/05/31/particle-swarm-optimization-in-jupyter-notebook/ (accessed on 18 May 2024).
- Newville, M.; Stensitzki, T.; Allen, D.B.; Ingargiola, A. Lmfit: Non-Linear Least-Square Minimization and Curve-Fitting for Python (0.8.0). Zendo. 2014. Available online: https://zenodo.org/records/10998841 (accessed on 11 February 2024).
- Python Package Index—Pypi. Python Software Foundation. Available online: https://pypi.org/ (accessed on 12 February 2024).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023; Available online: https://www.R-project.org/ (accessed on 1 December 2023).
- RStudio Team. Rstudio: Integrated Development Environment for R; RStudio, PBC: Boston, MA, USA, 2023; Available online: http://www.rstudio.com/ (accessed on 1 December 2023).
- Friendly, M.; Fox, J. Candisc: Visualization Generalized Canonical Correlation Analysis. R. Package Version 0.9.0. 2024. Available online: https://CRAN.R-project.org/package=heplots (accessed on 6 November 2021).
- Nelson, J.; Coleman, R.; Gravesen, P.; Silacci, M.; Velasquez, A.; Marinell, K. Analysis of a Commercial Red Wine Fermentation Dataset with a Wine Kinetic Model. Fermentation, 2024; in submission. [Google Scholar]
- Shyam, M.M.; Naik, N.; Gemson, R.M.O.; Ananthasayanam, M.R. Introduction to the Kalman Filter and Tuning Its Statistics for near Optimal Estimates and Cramer Rao Bound. arXiv 2015, arXiv:1503.04313. [Google Scholar] [CrossRef]
- Zheng, J.; Ma, L.; Wu, Y.; Ye, L.; Shen, F. Nonlinear Dynamic Soft Sensor Development with a Supervised Hybrid Cnn-Lstm Network for Industrial Processes. ACS Omega 2022, 7, 16653–16664. [Google Scholar] [CrossRef] [PubMed]
- Gu, X.; Wang, S. Bayesian Takagi–Sugeno–Kang Fuzzy Model and Its Joint Learning of Structure Identification and Parameter Estimation. IEEE Trans Ind. Inform. 2018, 14, 5327–5337. [Google Scholar] [CrossRef]
- Moya Almeida, V.; Diezma Iglesias, B.; Correa Hernando, E.C. Artificial Neural Networks and Gompertz Functions for Modelling and Prediction of Solvents Produced by the S. Cerevisiae Safale S04 Yeast. Fermentation 2021, 7, 217. [Google Scholar] [CrossRef]
- Florea, A.; Sipos, A.; Stoisor, M.-C. Applying Ai Tools for Modeling, Predicting and Managing the White Wine Fermentation Process. Fermentation 2022, 8, 137. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| ID | Vintage | Cultivar | Inoculum (g/L) | Temperature (°C) 1 | Yeast | Volume (kL) |
|---|---|---|---|---|---|---|
| 417A | 2018 | Chardonnay | 0.258 | 18.95 | VL1 | 9.16 |
| 417B | 2019 | Riesling | 0.243 | 13.85 | VL1 | 5.43 |
| 450 | 2020 | Cabernet Sauvignon | 0.247 | 25.85 | BDX | 11.30 |
| 457 | 2020 | Cabernet Sauvignon | 0.242 | 29.15 | BO213 | 11.53 |
| 486 | 2020 | Syrah | 0.321 | 27.25 | M2 | 9.82 |
| 489 | 2020 | Cabernet Sauvignon | 0.243 | 27.95 | FX10 | 13.57 |
| 571 | 2019 | Sauvignon blanc | 0.240 | 13.35 | VL3 | 4.54 |
| 823 | 2020 | Sauvignon blanc | 0.270 | 14.25 | VL3 | 4.38 |
| 826 | 2020 | Pinot noir | 0.211 | 24.65 | RC212 | 2.55 |
| 829 | 2019 | Muscat | 0.265 | 13.65 | VL3 | 4.11 |
| Euler Integration Step Size (minutes) | |||||||
|---|---|---|---|---|---|---|---|
| 5 | 10 | 15 | 30 | 60 | 120 | 300 | |
| RSME | 0.006 | 0.014 | 0.022 | 0.046 | 0.095 | 0.195 | 0.513 |
| MAE | 0.006 | 0.014 | 0.021 | 0.044 | 0.091 | 0.186 | 0.489 |
| %RAE | 0.07 | 0.16 | 0.25 | 0.15 | 1.05 | 2.16 | 5.61 |
| Numerical Integration Method | ||||||
|---|---|---|---|---|---|---|
| RK23 | RK45 | Radau | LSODA | DOP853 | BDF | |
| RSME | 0.102 | 0.066 | 0.092 | 0.097 | 0.094 | 0.096 |
| MAE | 0.097 | 0.057 | 0.088 | 0.093 | 0.090 | 0.092 |
| %RAE | 1.13 | 0.66 | 1.02 | 1.08 | 1.05 | 1.07 |
| ID: | 417A | 417B | 450 | 457 | 486 | 489 | 571 | 823 | 826 | 829 |
|---|---|---|---|---|---|---|---|---|---|---|
| Root Mean Squared Error (RMSE) | ||||||||||
| B | 0.481 | 0.079 | 0.446 | 0.314 | 0.516 | 0.268 | 0.077 | 0.240 | 0.338 | 0.104 |
| BO-SMC | 0.499 | 0.167 | 0.487 | 0.324 | 0.515 | 0.312 | 0.090 | 0.252 | 0.338 | 0.140 |
| DE | 0.477 | 0.112 | 0.456 | 0.314 | 0.510 | 0.303 | 0.082 | 0.241 | 0.326 | 0.137 |
| GA | 0.479 | 0.129 | 0.485 | 0.328 | 0.512 | 0.306 | 0.090 | 0.243 | 0.330 | 0.144 |
| PSO | 0.480 | 0.129 | 0.469 | 0.318 | 0.523 | 0.309 | 0.115 | 0.260 | 0.361 | 0.161 |
| MDGS | 0.487 | 0.151 | 0.500 | 0.350 | 0.555 | 0.363 | 0.131 | 0.270 | 0.373 | 0.181 |
| mean | 0.484 | 0.128 | 0.474 | 0.325 | 0.522 | 0.310 | 0.098 | 0.251 | 0.344 | 0.145 |
| Lag Time (hours) | ||||||||||
| ID: | 417A | 417B | 450 | 457 | 486 | 489 | 571 | 823 | 826 | 829 |
| Method | Mean ± %RSD | |||||||||
| B | 41.7 ± 12.5 | 68.0 ± 1.9 | 13.1 ± 3.7 | 27.9 ± 3.9 | 20.9 ± 2.4 | 12.9 ± 5.0 | 62.6 ± 1.6 | 63.4 ± 5.2 | 16.8 ± 6.4 | 46.9 ± 2.2 |
| BO-SMC | 35.2 ± 0.3 | 63.2 ± 2.0 | 15.3 ± 8.7 | 25.6 ± 1.5 | 18.5 ± 0.9 | 10.8 ± 3.6 | 62.9 ± 2.2 | 58.1 ± 0.5 | 7.6 ± 9.9 | 50.3 ± 0.0 |
| DE | 35.7 ± 0.0 | 72.0 ± 0.0 | 11.3 ± 0.0 | 25.3 ± 0.0 | 18.8 ± 0.0 | 9.8 ± 0.0 | 65.2 ± 0.0 | 63.3 ± 0.0 | 6.5 ± 0.0 | 50.5 ± 0.3 |
| GA | 33.7 ± 8.1 | 69.2 ± 3.6 | 14.9 ± 19.7 | 26.8 ± 4.2 | 18.7 ± 2.7 | 9.3 ± 4.7 | 64.2 ± 3.8 | 61.0 ± 2.6 | 6.4 ± 14.7 | 52.8 ± 1.9 |
| PSO | 36.4 ± 3.0 | 70.2 ± 4.4 | 10.6 ± 10.9 | 25.8 ± 3.1 | 20.1 ± 0.9 | 10.3 ± 8.7 | 69.3 ± 6.7 | 64.5 ± 10.2 | 4.6 ± 87.3 | 51.8 ± 6.6 |
| MDGS | 36.3 ± 10.8 | 68.1 ± 3.0 | 13.3 ± 24.4 | 25.9 ± 6.3 | 19.8 ± 3.7 | 10.5 ± 23.4 | 64.9 ± 4.7 | 56.4 ± 3.7 | 7.4 ± 38.5 | 49.9 ± 10.9 |
| Initial Nitrogen (mg/L) | ||||||||||
| ID: | 417A | 417B | 450 | 457 | 486 | 489 | 571 | 823 | 826 | 829 |
| Method | Mean ± %RSD | |||||||||
| B | 131 ± 9.3 | 158 ± 1.0 | 126 ± 0.2 | 209 ± 4.5 | 320 ± 0.6 | 214 ± 2.4 | 164 ± 1.3 | 145 ± 2.4 | 238 ± 3.4 | 189 ± 0.7 |
| BO-SMC | 144 ± 0.5 | 136 ± 1.2 | 149 ± 4.3 | 230 ± 2.2 | 327 ± 0.7 | 243 ± 1.9 | 156 ± 1.9 | 135 ± 0.3 | 305 ± 2.9 | 182 ± 0.0 |
| DE | 145 ± 0.0 | 150 ± 0.0 | 132 ± 0.0 | 226 ± 0.0 | 333 ± 0.0 | 233 ± 0.0 | 161 ± 0.1 | 141 ± 0.0 | 294 ± 0.0 | 182 ± 0.3 |
| GA | 139 ± 5.1 | 143 ± 3.3 | 148 ± 8.7 | 244 ± 6.3 | 332 ± 2.2 | 230 ± 1.4 | 158 ± 3.8 | 137 ± 2.3 | 291 ± 3.4 | 188 ± 1.2 |
| PSO | 143 ± 1.5 | 145 ± 4.3 | 133 ± 0.4 | 232 ± 4.8 | 350 ± 0.0 | 235 ± 1.9 | 169 ± 6.0 | 143 ± 7.1 | 282 ± 7.8 | 185 ± 6.2 |
| MDGS | 150 ± 5.8 | 145 ± 1.9 | 139 ± 6.3 | 235 ± 9.3 | 322 ± 3.5 | 227 ± 7.7 | 161 ± 5.3 | 136 ± 4.4 | 293 ± 6.6 | 184 ± 4.6 |
| Specific Maintenance Rate (1/h) | ||||||||||
| ID: | 417A | 417B | 450 | 457 | 486 | 489 | 571 | 823 | 826 | 829 |
| Method | Mean ± %RSD | |||||||||
| B | 0.169 ± 13.7 | 0.129 ± 2.0 | 0.300 ± 0.6 | 0.224 ± 8.8 | 0.081 ± 1.9 | 0.200 ± 4.9 | 0.144 ± 2.7 | 0.143 ± 6.0 | 0.126 ± 7.1 | 0.121 ± 1.7 |
| BO-SMC | 0.175 ± 1.1 | 0.159 ± 2.0 | 0.256 ± 6.4 | 0.217 ± 4.2 | 0.084 ± 2.3 | 0.180 ± 4.4 | 0.154 ± 3.5 | 0.153 ± 0.4 | 0.101 ± 8.3 | 0.124 ± 0.1 |
| DE | 0.171 ± 0.0 | 0.133 ± 0.1 | 0.300 ± 0.0 | 0.221 ± 0.0 | 0.079 ± 0.0 | 0.196 ± 0.0 | 0.146 ± 0.4 | 0.143 ± 0.0 | 0.111 ± 0.0 | 0.124 ± 0.6 |
| GA | 0.183 ± 8.0 | 0.147 ± 5.7 | 0.261 ± 11.3 | 0.192 ± 12.7 | 0.079 ± 6.9 | 0.198 ± 2.1 | 0.151 ± 7.8 | 0.150 ± 3.9 | 0.115 ± 8.8 | 0.116 ± 2.4 |
| PSO | 0.176 ± 2.9 | 0.144 ± 9.0 | 0.300 ± 0.0 | 0.210 ± 9.6 | 0.067 ± 1.8 | 0.194 ± 1.7 | 0.134 ± 12.2 | 0.140 ± 10.7 | 0.123 ± 19.2 | 0.122 ± 13.2 |
| MDGS | 0.162 ± 10.1 | 0.141 ± 4.0 | 0.281 ± 7.3 | 0.207 ± 19.2 | 0.091 ± 16.9 | 0.209 ± 17.3 | 0.142 ± 11.0 | 0.149 ± 9.1 | 0.114 ± 17.8 | 0.120 ± 9.9 |
| Viability Constant (L/g/h) | ||||||||||
| ID: | 417A | 417B | 450 | 457 | 486 | 489 | 571 | 823 | 826 | 829 |
| Method | Mean ± %RSD | |||||||||
| B | 20.2 ± 3.2 | 29.3 ± 2.9 | 27.9 ± 0.4 | 19.3 ± 2.6 | 22.4 ± 1.1 | 18.5 ± 1.9 | 18.3 ± 2.9 | 23.7 ± 4.7 | 25.8 ± 2.0 | 15.8 ± 1.8 |
| BO-SMC | 17.4 ± 0.3 | 25.0 ± 2.4 | 26.4 ± 0.2 | 17.9 ± 0.2 | 21.4 ± 0.6 | 17.1 ± 0.3 | 18.3 ± 2.0 | 23.8 ± 0.7 | 20.0 ± 1.8 | 16.6 ± 0.1 |
| DE | 17.3 ± 0.0 | 29.3 ± 0.1 | 26.5 ± 0.0 | 17.9 ± 0.0 | 21.7 ± 0.0 | 17.0 ± 0.0 | 18.8 ± 0.9 | 23.8 ± 0.0 | 19.6 ± 0.0 | 16.5 ± 0.6 |
| GA | 17.2 ± 0.4 | 25.6 ± 4.4 | 26.3 ± 0.4 | 18.0 ± 1.8 | 21.8 ± 1.5 | 17.2 ± 0.9 | 18.6 ± 6.7 | 23.3 ± 2.4 | 19.4 ± 1.5 | 17.0 ± 1.6 |
| PSO | 17.0 ± 1.8 | 26.0 ± 12.2 | 26.4 ± 0.7 | 18.0 ± 1.3 | 22.4 ± 1.8 | 16.8 ± 2.1 | 20.8 ± 9.9 | 24.8 ± 2.2 | 19.7 ± 2.6 | 16.6 ± 9.1 |
| MDGS | 17.5 ± 3.5 | 28.8 ± 3.8 | 26.6 ± 2.3 | 18.2 ± 3.9 | 20.7 ± 8.7 | 16.8 ± 5.0 | 21.6 ± 9.9 | 24.5 ± 11.7 | 19.4 ± 3.1 | 17.9 ± 6.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coleman, R.; Nelson, J.; Boulton, R. Methods for Parameter Estimation in Wine Fermentation Models. Fermentation 2024, 10, 386. https://doi.org/10.3390/fermentation10080386
Coleman R, Nelson J, Boulton R. Methods for Parameter Estimation in Wine Fermentation Models. Fermentation. 2024; 10(8):386. https://doi.org/10.3390/fermentation10080386
Chicago/Turabian StyleColeman, Robert, James Nelson, and Roger Boulton. 2024. "Methods for Parameter Estimation in Wine Fermentation Models" Fermentation 10, no. 8: 386. https://doi.org/10.3390/fermentation10080386
APA StyleColeman, R., Nelson, J., & Boulton, R. (2024). Methods for Parameter Estimation in Wine Fermentation Models. Fermentation, 10(8), 386. https://doi.org/10.3390/fermentation10080386