


Efficient Wheat Head Segmentation with Minimal Annotation: A Generative Approach


Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
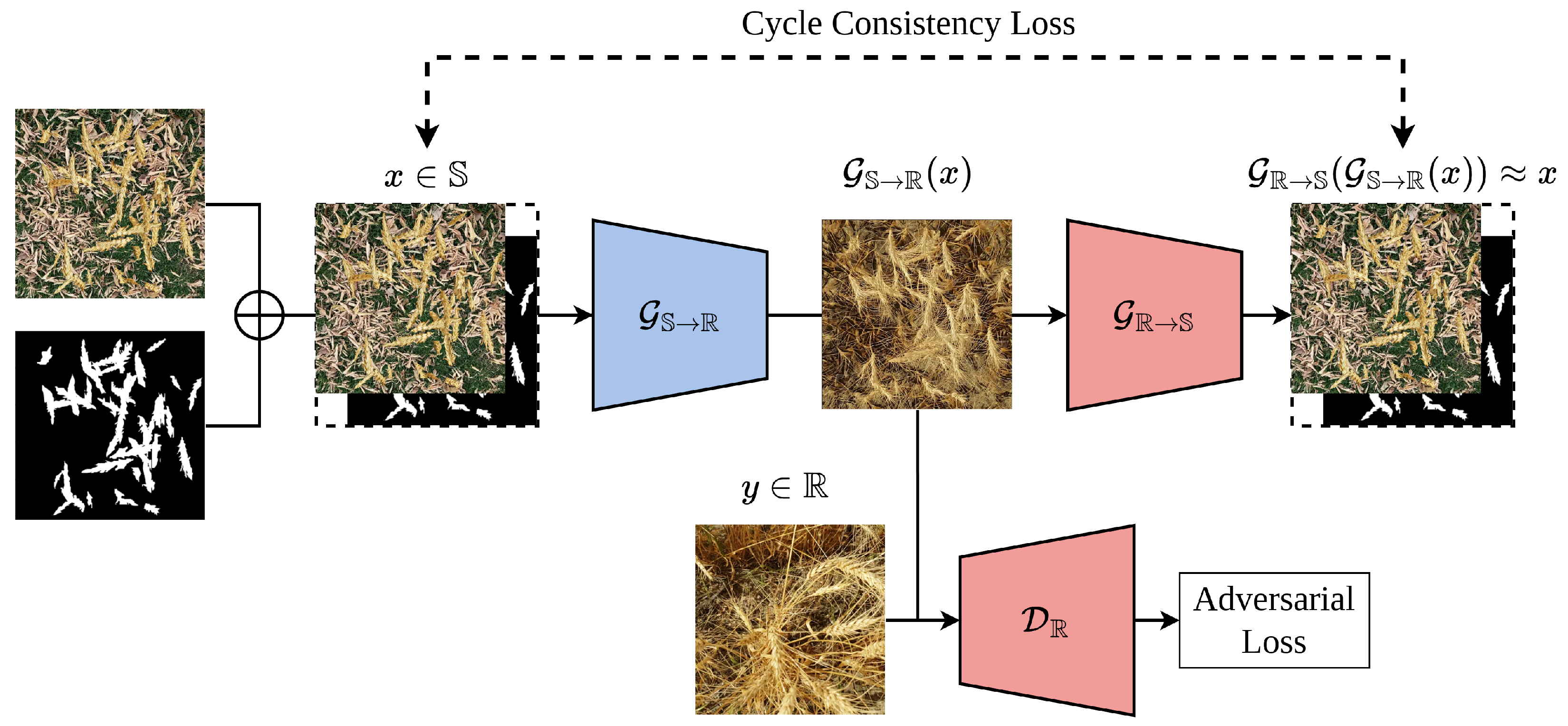
2.2. Model Architecture
2.3. Pseudo Labelling
2.4. Experiments
3. Results
3.1. Synthesization of Wheat Head Images
3.2. Evaluation of Wheat Head Segmentation Model Trained with Generated Wheat Head Images
4. Discussion
4.1. Synthetic Image Generation
4.2. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Network |
| GWHD | Global Wheat Head Detection |
| CycleGAN | Cycle-Consistent Generative Adversarial Networks |
References
- Hao, S.; Zhou, Y.; Guo, Y. A Brief Survey on Semantic Segmentation with Deep Learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for Data: Ground Truth from Computer Games. In European Conference on Computer Vision (ECCV), Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; LNCS; Springer International Publishing: Cham, Switzerland, 2016; Volume 9906, pp. 102–118. [Google Scholar]
- Mardanisamani, S.; Maleki, F.; Hosseinzadeh Kassani, S.; Rajapaksa, S.; Duddu, H.; Wang, M.; Shirtliffe, S.; Ryu, S.; Josuttes, A.; Zhang, T.; et al. Crop lodging prediction from UAV-acquired images of wheat and canola using a DCNN augmented with handcrafted texture features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Jia, B.; He, H.; Ma, F.; Diao, M.; Jiang, G.; Zheng, Z.; Cui, J.; Fan, H. Use of a Digital Camera to Monitor the Growth and Nitrogen Status of Cotton. Sci. World J. 2014, 2014, 602647. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Y.; Liang, L.; Wang, L.; She, J.; Wu, M. Identification of cash crop diseases using automatic image segmentation algorithm and deep learning with expanded dataset. Comput. Electron. Agric. 2020, 177, 105712. [Google Scholar] [CrossRef]
- Behmann, J.; Mahlein, A.K.; Rumpf, T.; Römer, C.; Plümer, L. A review of advanced machine learning methods for the detection of biotic stress in precision crop protection. Precis. Agric. 2015, 16, 239–260. [Google Scholar] [CrossRef]
- Al-Tamimi, N.; Langan, P.; Bernád, V.; Walsh, J.; Mangina, E.; Negrao, S. Capturing crop adaptation to abiotic stress using image-based technologies. Open Biol. 2022, 12, 210353. [Google Scholar] [CrossRef] [PubMed]
- David, E.; Serouart, M.; Smith, D.; Madec, S.; Velumani, K.; Liu, S.; Wang, X.; Pinto, F.; Shafiee, S.; Tahir, I.S.; et al. Global wheat head detection 2021: An improved dataset for benchmarking wheat head detection methods. Plant Phenomics 2021, 2021, 1–9. [Google Scholar] [CrossRef]
- Fourati, F.; Mseddi, W.S.; Attia, R. Wheat head detection using deep, semi-supervised and ensemble learning. Can. J. Remote Sens. 2021, 47, 198–208. [Google Scholar] [CrossRef]
- Najafian, K.; Ghanbari, A.; Stavness, I.; Jin, L.; Shirdel, G.H.; Maleki, F. A Semi-Self-Supervised learning approach for wheat head detection using extremely small number of labeled samples. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 1342–1351. [Google Scholar]
- Najafian, K.; Ghanbari, A.; Sabet Kish, M.; Eramian, M.; Shirdel, G.H.; Stavness, I.; Jin, L.; Maleki, F. Semi-Self-Supervised Learning for Semantic Segmentation in Images with Dense Patterns. Plant Phenomics 2023, 5, 0025. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Li, E.; Liang, Z. Detection of apple lesions in orchards based on deep learning methods of cyclegan and yolov3-dense. J. Sens. 2019, 2019. [Google Scholar] [CrossRef]
- Li, Y.; Zhan, X.; Liu, S.; Lu, H.; Jiang, R.; Guo, W.; Chapman, S.; Ge, Y.; Solan, B.; Ding, Y.; et al. Self-supervised plant phenotyping by combining domain adaptation with 3D plant model simulations: Application to wheat leaf counting at seedling stage. Plant Phenomics 2023, 5, 0041. [Google Scholar] [CrossRef]
- Panda, S.S.; Ames, D.P.; Panigrahi, S. Application of vegetation indices for agricultural crop yield prediction using neural network techniques. Remote Sens. 2010, 2, 673–696. [Google Scholar] [CrossRef]
- Rawat, S.; L Chandra, A.; Desai, S.V.; Balasubramanian, V.; Ninomiya, S.; Guo, W. How Useful is Image-Based Active Learning for Plant Organ Segmentation? Plant Phenomics 2022, 2022, 1–11. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the ICML 2013 Workshop: Challenges in Representation Learning (WREPL), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. International Conference on Learning Representations (ICLR). arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization methods for large-scale machine learning. Siam Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Torbunov, D.; Huang, Y.; Yu, H.; Huang, J.; Yoo, S.; Lin, M.; Viren, B.; Ren, Y. UVCGAN: UNet Vision Transformer Cycle-consistent GAN for unpaired image-to-image translation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2023; pp. 702–712. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Trained On | Tested on | Tested on | Tested on | |||
|---|---|---|---|---|---|---|---|
| Dice | IoU | Dice | IoU | Dice | IoU | ||
| A | 0.709 | 0.566 | 0.368 | 0.274 | 0.407 | 0.275 | |
| B | 0.811 | 0.686 | 0.578 | 0.440 | 0.644 | 0.511 | |
| C | + | 0.834 | 0.720 | 0.796 | 0.687 | 0.836 | 0.754 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Myers, J.; Najafian, K.; Maleki, F.; Ovens, K. Efficient Wheat Head Segmentation with Minimal Annotation: A Generative Approach. J. Imaging 2024, 10, 152. https://doi.org/10.3390/jimaging10070152
Myers J, Najafian K, Maleki F, Ovens K. Efficient Wheat Head Segmentation with Minimal Annotation: A Generative Approach. Journal of Imaging. 2024; 10(7):152. https://doi.org/10.3390/jimaging10070152
Chicago/Turabian StyleMyers, Jaden, Keyhan Najafian, Farhad Maleki, and Katie Ovens. 2024. "Efficient Wheat Head Segmentation with Minimal Annotation: A Generative Approach" Journal of Imaging 10, no. 7: 152. https://doi.org/10.3390/jimaging10070152
APA StyleMyers, J., Najafian, K., Maleki, F., & Ovens, K. (2024). Efficient Wheat Head Segmentation with Minimal Annotation: A Generative Approach. Journal of Imaging, 10(7), 152. https://doi.org/10.3390/jimaging10070152