Abstract
Infrared (IR) images record the temperature radiation distribution of the object being captured. The hue and color difference in the image reflect the caloric and temperature difference, respectively. However, due to the thermal diffusion effect, the target information in IR images can be relatively large and the objects’ boundaries are blurred. Therefore, IR images may undergo some image enhancement operations prior to use in relevant application scenarios. Furthermore, Infrared Enhancement (IRE) algorithms have a negative impact on the watermarking information embedded into the IR image in most cases. In this paper, we propose a novel multi-scale robust watermarking model under IRE attack, called IEWNet. This model trains a preprocessing module for extracting image features based on the conventional Undecimated Dual Tree Complex Wavelet Transform (UDTCWT). Furthermore, we consider developing a noise layer with a focus on four deep learning and eight classical attacks, and all of these attacks are based on IRE algorithms. Moreover, we add a noise layer or an enhancement module between the encoder and decoder according to the application scenarios. The results of the imperceptibility experiments on six public datasets prove that the Peak Signal to Noise Ratio (PSNR) is usually higher than 40 dB. The robustness of the algorithms is also better than the existing state-of-the-art image watermarking algorithms used in the performance evaluation comparison.
1. Introduction
In nature, all objects are capable of radiating infrared (IR) light. Furthermore, an IR image records the thermal radiation properties of the object. Thermal radiation properties are not visible to the human visual system, but the object can be imaged at any time based on the released energy. Moreover, it can be applied in some application environments such as disease screening [1], biotracking [2], robotic systems [3], disaster detection [4], and military [5].
However, IR images only record the temperature information of the object, IR images contain a limited amount of information. Additionally, the object exchanges heat with the surrounding environment, so, IR images always have the disadvantage of blurred edges. Therefore, IR images need to undergo a pre-processing step before further use. Infrared Enhancement (IRE) is one of the common pre-processing methods for IR images. It facilitates the subsequent image processing tasks by highlighting the edge information of the IR image, enhancing the contrast of the image pixels or removing the noise interference of the IR image. Initially, IR images were treated as two-dimensional arrays consisting of temperature values, and then various mathematical operations were applied to directly process the infrared images for better visualization. Later, image processing algorithms increasingly used frequency domain transforms. The infrared image is also decomposed into high-frequency, medium-frequency, and low-frequency subbands. The mathematical operations applied to the frequency domain subbands result in better IRE performance. With the popularization of machine learning, neural network models have become a hot research topic for IRE algorithms. Neural networks can intelligently learn the connection between the original IR image and the enhanced IR image. Nowadays, more and more algorithms combine frequency domain transform with neural network to enhance IR images.
There are three main categories for IRE algorithms: spatial domain, frequency domain, and hybrid domain-based methods [6]. Histogram Equalization (HE) algorithm is a common spatial domain IRE algorithm. Paul et al. [7] proposed the IRE algorithm based on fuzzy disparity HE algorithm. They obtained fuzzy disparity histogram based on the contextual information of the pixels. Then, they cropped and equalized the histogram of the IR image based on the extreme values of the different regions’ histograms. Wan et al. [8] used the particle wandering optimization algorithm to compute the entropy value of the local pixel blocks. This entropy value was applied to optimize the histogram of the local image, which in turn enhanced local details and overall contrast of the IR image. To avoid the problem of IR over-enhancement, Paul et al. [9] used logarithmic and power formulas to calculate the histogram.
With the development of science and technology, machine learning-based IRE algorithms in the spatial domain have become a hot research topic. Bhattacharya et al. [10] proposed an IRE model based on concise Convolutional Neural Networks (CNN). They applied 3 × 3 and 5 × 5 convolutional kernels to extract image features and added the classical Rectified Linear Unit (ReLU) activation function to refine the structure of the model. Kuang et al. [11] presented a novel deep learning model based on Generative Adversarial Network (GAN) for IRE task. The GAN model consumes more time and resources during the training process, but it has improved the enhancement effect of IR images.
In the literature, there are plenty of frequency domain transforms-based methods for IRE and image processing tasks. These transforms usually decompose original images to extract different features and reconstruct these features back to the original image with low error. Qi et al. [12] removed most of the noise information and weak signals using Fast Fourier Transform (FFT) domain for IR images. Zhao et al. [13] enhanced the IR image at smoothing transform scales and finally synthesized the complete IRE image. The hybrid domain-based IRE algorithms combine the previous two categories of IRE algorithms in both spatial and frequency domains. Wu et al. [14] enhanced the global contrast and local contrast of the IR image based on the histograms of the high-frequency and low-frequency subbands, respectively. Ein-shoka et al. [15] combined Discrete Wavelet Transform (DWT) with HE algorithm, and then they processed the histograms with the high-pass adaptive function.
The IRE algorithm enhances the contrast, edges, contours, and other features of the IR image. This improves the utility value of IR images, but at the same time, it also attacks the watermarked images. Therefore, this paper introduces a novel IR image robust watermarking algorithm under infrared enhancement attack. The encoder and decoder of the proposed algorithm use multi-scale structure to improve the robustness and imperceptibility of the algorithm. The algorithm applied two noise networks based on traditional and machine learning IRE algorithms to improve the robustness against IRE attacks. This is of great help in infrared image processing in industrial, scientific, and military fields.
In this paper, we propose an image watermarking auto-encoder model against the IRE attack based on conventional UDTCWT [16]. The proposed model improves the correct rate of watermark extraction from watermarked IRE images by adding the noise layer or enhancement module. The encoder and decoder of the model adopt the multi-scale neural network structure, and an attention mechanism is added after each of their convolutional layers to improve the feature’s extraction capability. The watermarked IR image output from the encoder is fed into the trained noise layer or enhancement module to simulate the effect of IRE attack, where the noise layer and enhancement module are used to simulate traditional and machine learning IRE algorithms, respectively. Finally, the decoder extracts the previously embedded watermark information in the IRE image. The main contributions of this work are as follows:
- We employ a multi-scale neural network structure to embed image watermarks of different scales onto the original IR image of the corresponding scale. The proposed model is able to select the appropriate watermark embedding location among features at different scales.
- We add a noise layer between the encoder and decoder to cope with the traditional IRE attack. The noise layer is used to simulate the principle of eight traditional IRE attacks. It is applied as the alternative to the eight traditional IRE attacks in the flow of the algorithm. This makes the proposed algorithm more robust against traditional IRE attacks.
- For machine learning IRE attacks where the specific structure is known, we train an enhancement sub-network to improve robustness. The enhancement sub-network is able to replace the role of four machine learning-based IRE algorithms in the IEWNet. The structure of the enhancement module is referenced to four classical IRE neural networks.
The rest of the paper is structured as follows: Section 2 introduces the research background of image robust watermarking algorithms. Section 3 describes the research work that is closely related to the proposed algorithm. Section 4 presents in detail the structure of the proposed auto-encoder, loss function, and training process. The experimental results that prove the relevant performance of the proposed algorithm are shown in Section 5. Finally, Section 6 and Section 7 summarize the strengths and weaknesses of the proposed algorithm and provides an outlook for future research work.
2. Background
IRE plays a very important role in improving the quality of IR images. However, IR images often have a significant connection with the research results of a group or enterprise. In order to prevent undesirable behavior such as data leakage, groups or companies that are copyright owners often embed digital watermarks into their IR images. Some companies want to produce important work equipment at low cost. They steal infrared images of industrial equipment to imitate the equipment and claim that the infrared image belongs to them. Other organizations enhance infrared images to prevent copyright holders from proving the origin of the image and to confuse the ownership of the image. The processing of watermarked IR images by IRE affects the extraction of digital watermarks, which in turn affects the copyright protection of IR images. Therefore, the image watermarking algorithm that can resist IRE attacks is necessary. The watermarking algorithm seeks the ability to resist image attacks, so we should consider a robust watermarking algorithm.
Image robust watermarking algorithms can also be categorized into three categories: spatial domain, frequency domain, and hybrid domain-based algorithms [17]. In recent years, image watermarking algorithms based on machine learning in the spatial domain are more common. Wang et al. [18] proposed a Deep Neural Network (DNN) model which contains encoder, discriminator, detector, and decoder. Singh et al. [19] incorporated a denoising module in a CNN-based auto-encoder for image watermarking. Boujerfaoui et al. [20] proposed an end-to-end DNN for print-shooting attacks, called Cam-Unet.
Apart from neural networks, image watermarking algorithms in the spatial domain based on traditional methods are also available. Xiao et al. [21] proposed a watermarking algorithm for screen-shooting images based on the matrix operation for screen image watermarking algorithm. Hasan et al. [22] applied Pascal’s triangle algorithm to look for the watermark embedding location. For the frequency domain-based algorithm, Peng et al. [23] extracted features in the Discrete Non-separable Shearlet Transform (DNST) domain of the image using Pseudo-Zernike Moments (PZM). The statistical model is then applied to compute several parameters to represent the extracted features. Zeng at al. [24] proposed a medical image watermarking algorithm based on KAZE features with Discrete Cosine Transform (DCT). Furthermore, Kumar et al. [25] combined DCT with DWT and then embedded both image watermarks in the frequency domain. DWT can also be applied in conjunction with the Walsh Hadamard Transform (WHT) and Singular Value Decomposition (SVD), and this frequency domain-based algorithm can be used to achieve robust and imperceptible image watermarking algorithms in the Y-channel of YCbCr images [26]. Devi et al. [27] proposed the H-Grey adaptive image watermarking embedding algorithm based on DWT and SVD in both frequency domains. Su et al. [28] employed Graph Based Transform (GBT) to count the distribution of stable features in the image.
Further, recent hybrid domain-based robust watermarking algorithms are often made by combining traditional frequency domain transforms and CNN. Zhang et al. [29] proposed a hybrid domain image auto-encoder based on FFT with diffusion model. Gorbal et al. [30] proposed a high-capacity image watermarking algorithm by combining the Nondownsampled Contour Wave Transform (NCWT), DWT, and DNN.
3. Related Work
In this paper, the machine learning model based on multi-scale feature extraction and the enhancement module are the two main prominent innovations of the proposed algorithm. The multi-scale algorithm can extract important features of the image more comprehensively, whereas the enhancement module can help the decoder to extract watermarking information more accurately after the watermarked IR image is processed by the machine learning-based IRE algorithm. In this section, the existing multi-scale-based algorithms are introduced along with the existing CNN-based IRE models.
3.1. Multi-Scale-Based Methods
Multi-scale algorithms are the mature technique in the image processing region. The Gaussian pyramid downsamples the image sequentially from the largest resolution to obtain a series of progressively smaller scales. Olkkonen et al. [31] proposed Gaussian pyramid transforms which can be applied for both 2D and 3D images. This frequency domain transform not only decomposes the image to extract features, but also reconstructs the obtained features into the original image with relatively low error. Yan et al. [32] applied Gaussian pyramid to the visible and IR image fusion algorithm. The algorithm first decomposes the visible and IR images into two scales. The first scale contains the number of subbands equal to the level of image decomposition. The second scale uses the Gaussian blurring algorithm to obtain the detailed features and base features of the image. The algorithm filters and combines the high- and low-frequency information of two images and finally produces a high-quality fused image. In order to reconstruct the Gaussian pyramid low-scale image in the maximum extent of the high-scale original image, the researchers proposed the Laplace pyramid algorithm. Gaussian pyramid performs Gaussian blurring before downsampling, then the low-level scale image contains only low-frequency information. The Laplace pyramid helps to reconstruct the resolution of the degraded image into a high-resolution image by calculating the difference with the high-level scale image to obtain the high-frequency information. Lai et al. [33] proposed a CNN for super-resolution tasks based on Laplace pyramid. Each low-scale image of the Laplace pyramid is fed into the network to predict the corresponding high-scale image. Furthermore, the network applies the Charbonnier loss function with high accuracy to supervise the training of the network. The algorithm combines the traditional Laplace pyramid with novel machine learning algorithms, which makes the algorithm outperform several classical machine learning super-resolution models in terms of speed and capacity. Multi-scale algorithms are also used in machine learning-based robust image watermarking algorithms. Qin et al. [34] proposed an end-to-end machine learning model for print-shooting attacks. The algorithm builds a deep noise simulation network after the encoder to learn the process of the image being printed and photographed. The model’s encoder processes the input image into tensors of different sizes through a convolutional operation, and then the input image is downsampled into different degrees to concatenate these tensors. This encoder based on multi-scale algorithm enhances the quality of the watermarked image and implies that the imperceptibility of the first algorithm is improved. Moreover, Rai et al. [35] also introduced a multi-scale algorithm in the model’s decoder and the watermarking information output from each scale is supervised by the baseline truth values during model training. The tensors generated by the multi-scale algorithm in the encoder are also fused with each other through downsampling and upsampling operations. The downsampling operation serves to reduce the training cost, prevent overfitting, and increase the sensory range while generating multiple scales. The upsampling operation is able to preserve some of the detailed features of the previous scale. This two-way propagation multi-scale algorithm is able to refer to the features of other scales during the training process of each scale, which in turn improves the accuracy of model training. The proposed IEWNet model structure is based on the multi-scale machine learning model structure presented by Rai et al. [35].
3.2. Infrared Enhancement-Based Networks
In recent years, machine learning-based IRE algorithms have become more and more common. The IRE-based CNN model introduced by Choi et al. [36] is applied to refine the task of nighttime target recognition in the field of autonomous driving. The network structure consists of a total of four convolutional layers with two 3 × 3 convolutional layers, one 5 × 5 convolutional layer, and one 7 × 7 convolutional layer. A ReLU activation function is set between each two convolutional layers to mitigate the problems of gradient vanishing and overfitting. Furthermore, Lee et al. [37] proposed a CNN-based IRE model for target detection based on luminance domain and residual structure. The model is fed with low-quality luminance images, and the output is trained with a high-quality baseline true value image. The feature extraction module first extracts the initial features of the luminance image using two 3 × 3 convolutional layers. Then, the mapping module performs dimensionality reduction using 1 × 1 convolutional layers and enhances the reduced features with nonlinear mapping. After the extension module expands the dimensionality of the features, the image reconstruction module outputs a high-quality image based on the residual structure. Moreover, Kuang et al. [38] introduced an IRE-based DNN for removing noise interference in IR image. The network applies hopping connections several times to prevent the loss of image information, and consists of denoising network and conditional discriminator. The denoising network consists of eight convolutional layers and eight inverse convolutional layers where each convolutional kernel has a size of 4 × 4, whereas the conditional discriminator consists of five 4 × 4 convolutional layers. Unlike normal discriminators that only input true and false images, the conditional discriminator also adds noise images as input. Additionally, Zhong et al. [39] employed three branches for feature extraction module to extract features from IR images, where each branch contains one or two convolutional layers and a ReLU activation function. The features of the three branches are concatenated into a tensor which is then fed into the image enhancement module. The image enhancement module first processes the input tensor using eight 3 × 3 convolutional layers, and the results of each convolutional layer are finally combined together. After dimensionality reduction by a 5 × 5 convolutional layer, the current tensor is applied for residual computation with the feature extraction module. Finally, the image enhancement module outputs the IRE image with one convolutional layer. In this paper, the proposed enhancement module is constructed with special reference to the above-mentioned IRE-based networks in the process of introducing the noise layer of the model. This will improve the robustness of the proposed algorithm against IRE attacks. The models proposed by [37,38,39,40] are referred to as, in order, Thermal Image Enhancement using CNN (TEN), Brightness-Based CNN (BCNN), Optical Noise Removal Deep CNN (ONRDCNN), and Auto-Driving CNN (ACNN) in the experimental results of Section 4.
4. Materials and Methods
In order to improve the ability of infrared image robust watermarking algorithms to resist IRE attacks, this paper constructs a multi-scale self-encoder based on infrared images for both traditional and machine learning IRE attacks. The infrared image datasets for the algorithm include GTOT [40], Road-Scene [41], TNO [42], LasHeR [43], RGBT210 [44], and RGBT234 [45].
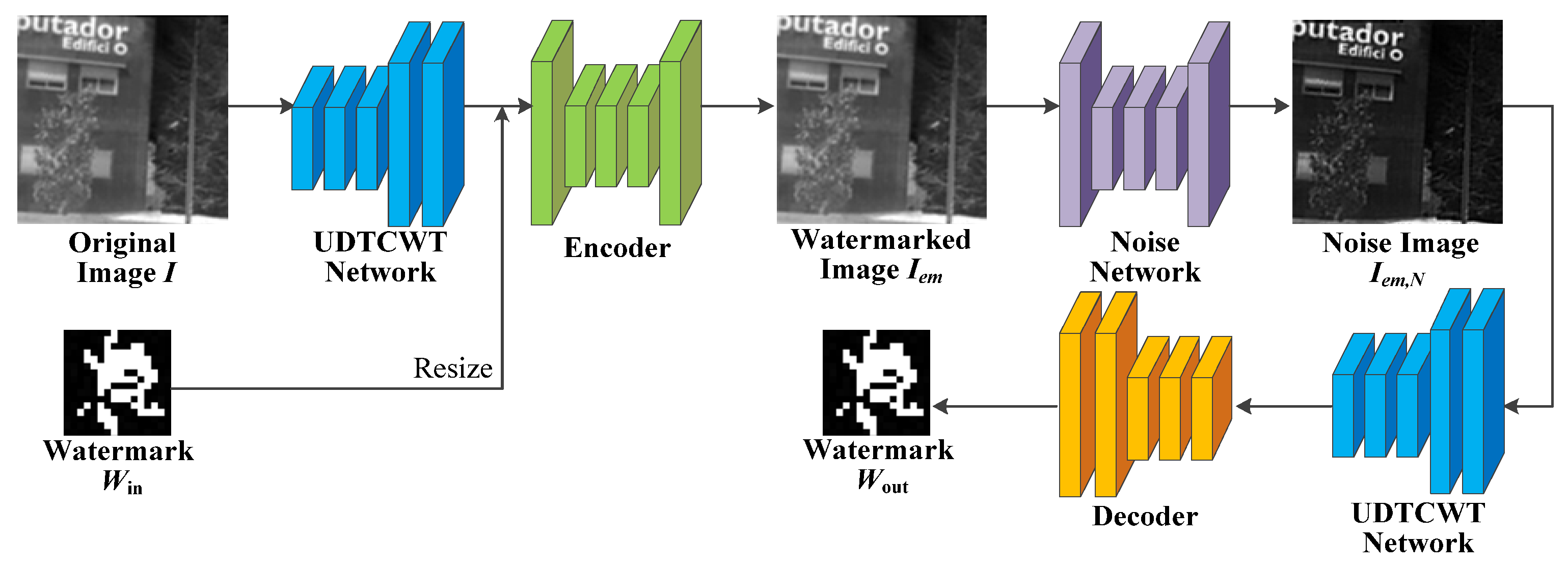
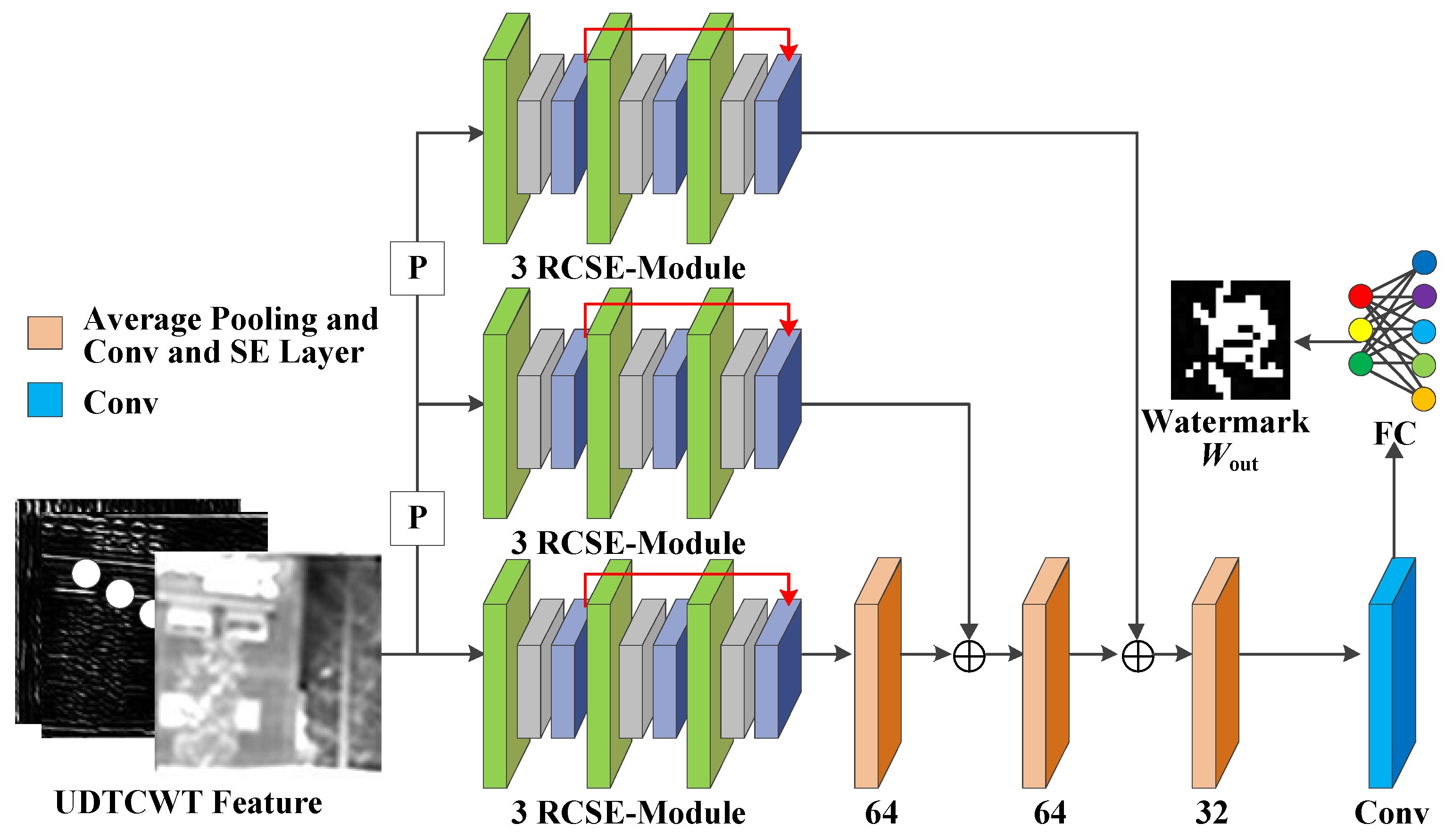
The proposed IRE robust watermarking network (IEWNet) uses the encoder–decoder structure to embed and extract the watermarking information, respectively. Before the watermarked image is fed to the decoder, the noise layer or enhancement module simulates traditional or machine learning IRE algorithms to process the watermarked image. This section first introduces the network structure of the proposed IEWNet. Next, the details of training IEWNet are described in terms of loss function and training process. The general architecture of the proposed IEWNet is shown in Figure 1. The original infrared image is first input to the UDTCWT [16] network for preprocessing and is embedded with the watermark Win by the encoder . Then, the noise network outputs the watermarked image Iem as the noisy image . Finally, the UDTCWT [16] network and the decoder extract the watermarking information from the noisy image .
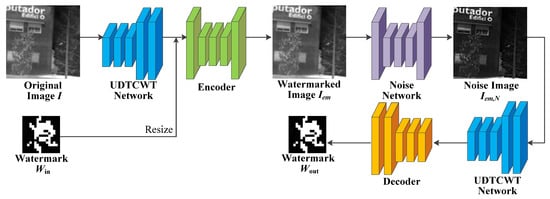
Figure 1.
General network architecture of IEWNet.
4.1. Network Architecture
The proposed network consists of four sub-modules in total: UDTCWT [16] network , encoder , noise network , and decoder . The network takes the original IR image as an input, and the UDTCWT [16] network works with the encoder to obtain the watermarked image . After the noise network outputs the noisy image , the UDTCWT [16] network works with the decoder to obtain the extracted watermarking information .
- (1)
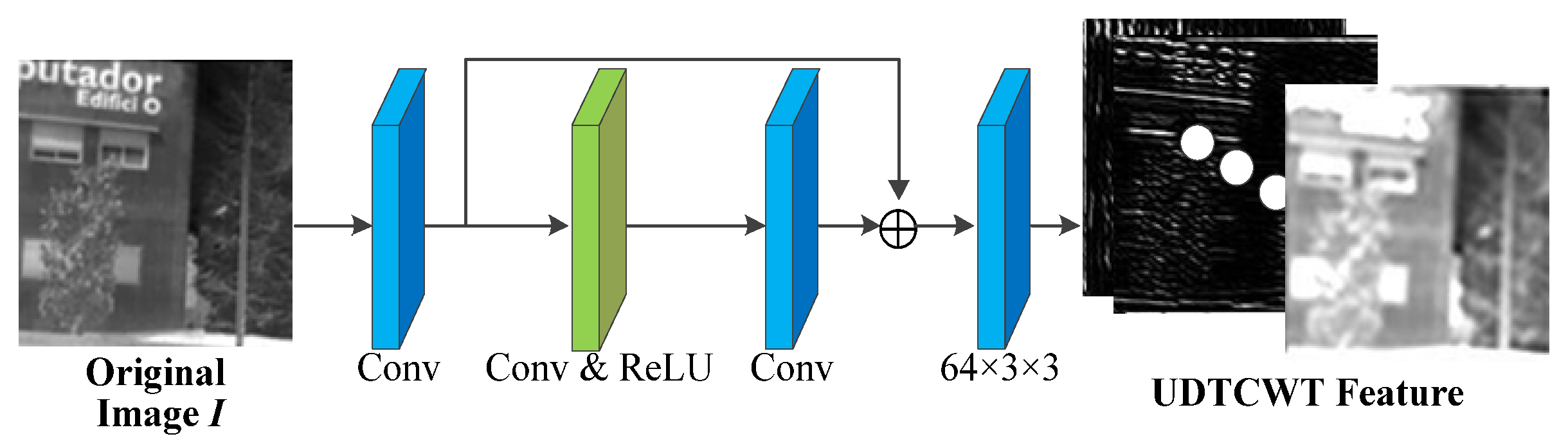
- UDTCWT [16] Network : To make the frequency domain transform more suitable for incorporation into the proposed IEWNet, we train a small CNN with subbands of the UDTCWT [1] decomposition as targets. The main structure of UDTCWT [16] network is shown in Figure 2. The network structure starts with the convolutional layer, followed by a residual structure consisting of a convolutional layer and a ReLU activation function. The final output from a convolutional layer is a 28-dimensional tensor. The convolutional kernel size is 3 × 3 and has 64 dimensions.
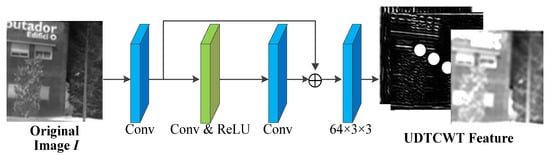 Figure 2. Network structure diagram for the UDTCWT [1] network U.
Figure 2. Network structure diagram for the UDTCWT [1] network U.
- (2)
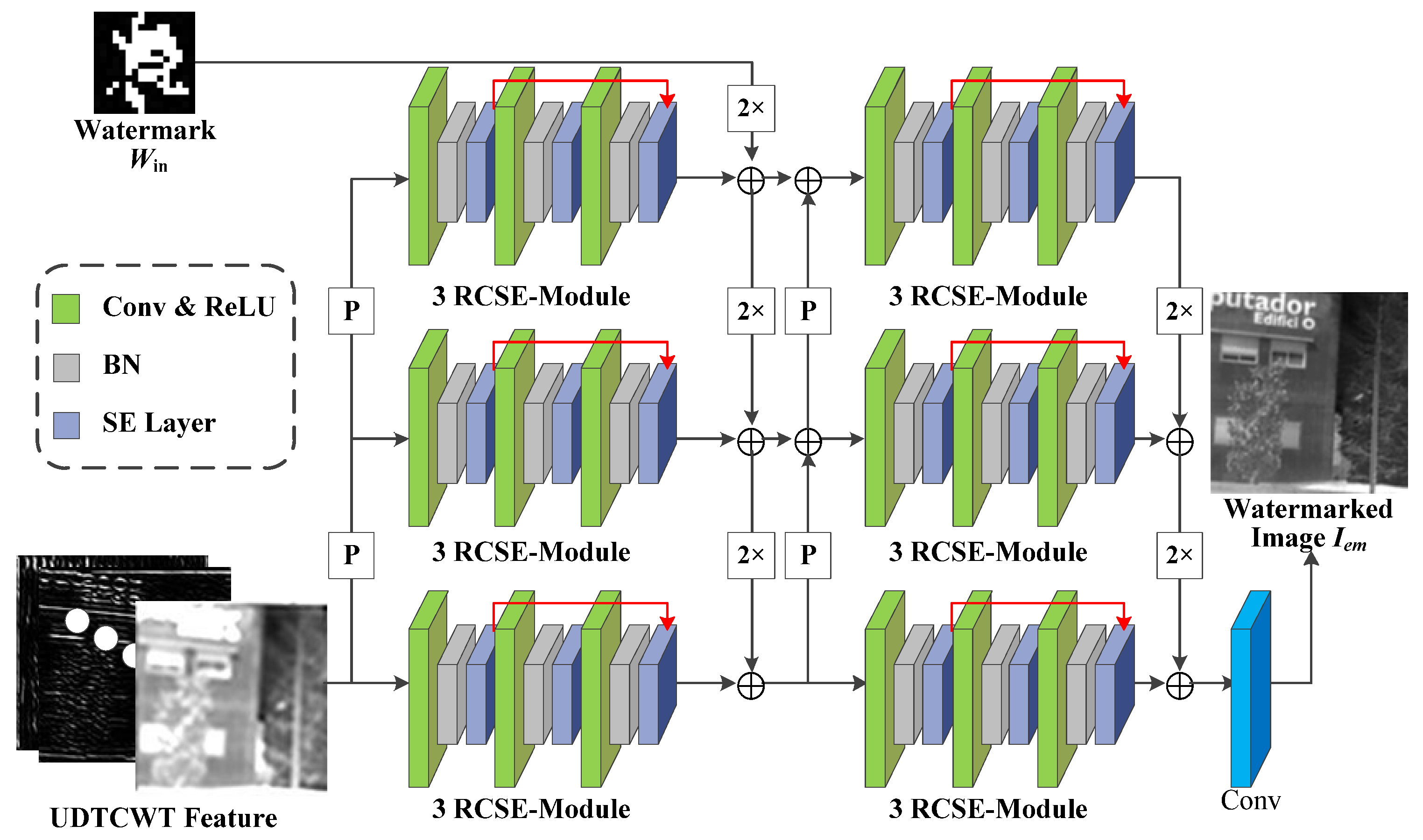
- Encoder : Figure 3 shows the network structure for the encoder , where “P” stands for 2 × 2 average pooling operation, “2×” stands for 64 × 3 × 3 doubly expanded convolutional layers, and (+) indicates the addition operation used to sum the features at each scale. Encoder aims to encode the input UDTCWT [16] features with the original IR image into a fixed dimensional tensor and to extract multi-scale image features while reducing the dimensionality of the input. The structure of encoder is generally divided into three scales. On the one hand, the UDTCWT [16] subnet extracts features after one or two 1/2 downsampling to form three dimensionality-decreasing features. On the other hand, a doubly extended convolutional layer can scale the watermarked image to twice or four times its size. Then, their sizes at these three scales will be in equal relationship. This will facilitate the combination of features at different scales with the help of downsampling and upsampling operations as illustrated in Figure 3. The inter-scale feature fusion will preserve more features from the original image during the model training process, which will improve the imperceptibility of the encoder . The Residual Convolutional SE (RCSE) module is a residual network structure consisting of three SE-Conv sub-blocks. The structure of the SE-Conv sub-blocks is based on channel attention module proposed by Cao et al. [46]. The ReLU activation function is capable of applying nonlinear operations on the model weights. The BN operation reduces the covariate bias of the model weights. After the tensor is processed sequentially by the 3 × 3 convolutional layer, ReLU activation function, and BN operation, the channel attention module is able to adjust the weights of the image watermark’s feature in different channels according to the important relationship between the channels. The attention module first reduces the dimension of the tensor to one dimension using the global average pooling algorithm. Then, two sets of Fully Connected (FC) layers with activation functions adjust the one-dimensional tensor. Finally, the output of the attention module is multiplied by the input tensor to achieve the final result. After the encoder obtains the sum of the features at each scale, it outputs the watermarked IR image through a 64-dimensional 3 × 3 convolutional layer.
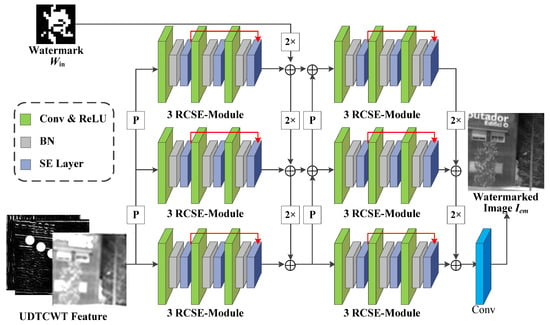 Figure 3. Network structure diagram for the encoder E.
Figure 3. Network structure diagram for the encoder E.
- (3)
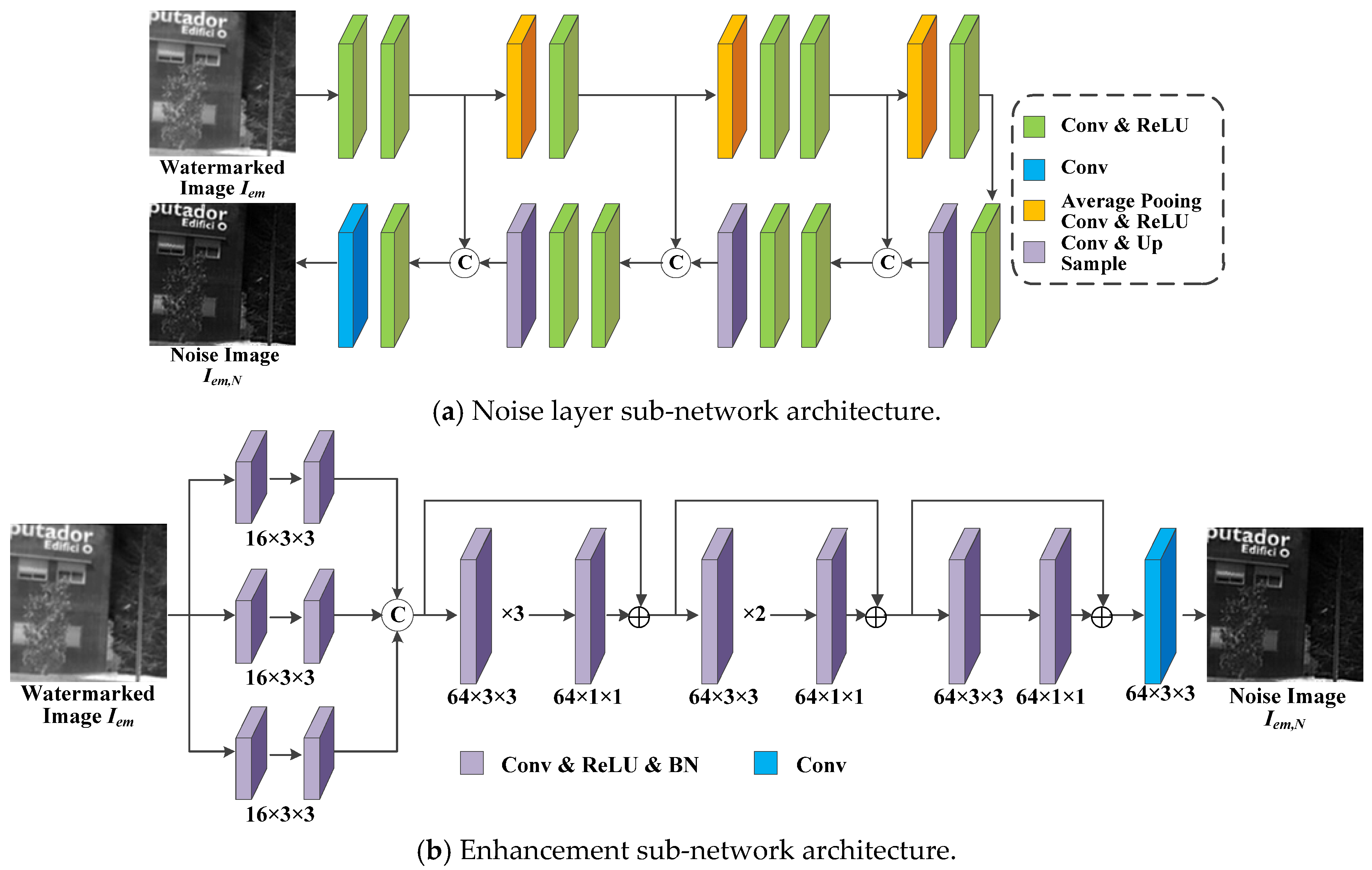
- Noisy Network : In order to learn some patterns of IRE attacks, we set up the noise network between the encoder and decoder to simulate these attack methods. IRE attacks are categorized into traditional-based methods and machine learning-based methods. For traditional-based methods, we choose eight attacks for IRE images as the target for model training. These attacks include HE, mean filter, median filter, and Sobel operator, and there are also four IRE attacks provided by the GitHub public repository: Adaptive Histogram Partition and Brightness Correction (AHPBC) [47], Discrete Wavelet Transform and Event triggered Particle Swarm Optimization (DWT-EPSO), DeepVIP [48], and Adaptive Non-local Filter and Local Contrast (ANFLC) [49]. The code for these algorithms is all using Matlab. Figure 4 illustrates the results of eight traditional IRE algorithms.
 Figure 4. Example for eight traditional-based IRE attacks. (a) Orginal image. (b) HE. (c) Mean filter. (d) Median filter. (e) Sobel operator. (f) AHPBC. (g) DWT-EPSO. (h) DeepVIP. (i) ANFLC.
Figure 4. Example for eight traditional-based IRE attacks. (a) Orginal image. (b) HE. (c) Mean filter. (d) Median filter. (e) Sobel operator. (f) AHPBC. (g) DWT-EPSO. (h) DeepVIP. (i) ANFLC.
The noise layer in Figure 5a is applied to machine learn these eight conventional IRE algorithms. The noise layer refers to Unet [50] and uses 2 × 2 maximum pooling with the doubled expansion of the convolutional layer for upsampling and downsampling operations. Furthermore, it uses combination of convolutional layers and ReLU activation functions to continuously extract the desired features. Based on the basic idea of the four IRE-based models [36,37,38,39] introduced in the details of Section 3.2 in constructing the enhancement network, the proposed enhancement sub-network first extracts features from different receptive fields by three different sizes of convolutional kernels, where the convolutional kernels are 7 × 7, 5 × 5, and 3 × 3. The extracted features are sequentially processed by three residual structures, and each residual structure consists of four, three, and two convolutional blocks, respectively. Each convolutional block includes a convolutional layer, a ReLU activation function and a BN operation. The specific structure of the model is shown in Figure 5b.
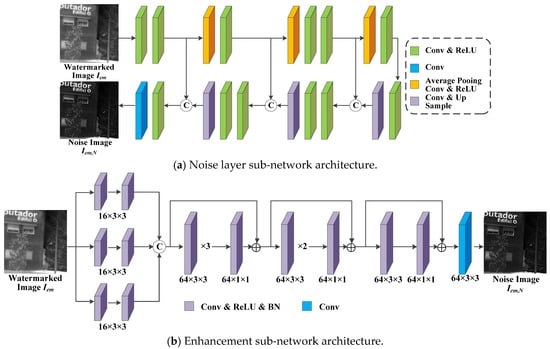
Figure 5.
Network architecture diagram (a,b) for the proposed noise network N.
- (4)
- Decoder : Figure 6 illustrates the structure of decoder . Decoder decodes the noisy image and maps the features flowing through the other sub-networks to the watermark information. Unlike the encoder , the decoder has only one residual convolution module per scale. Both the encoder and the decoder have exactly the same structure for their residual convolution modules. The first scale undergoes two 2 × 2 average pooling operations with SE-Conv blocks to match the features of the other two scales in turn. To obtain the mapping of the features to the watermark image , the decoder applies a FC layer at the end. We choose the scale with the smallest size to output the watermark image , because the FC layer maps each weight of the model. If the number of weights in the feature tensor is too large, the difficulty of model training increases substantially.
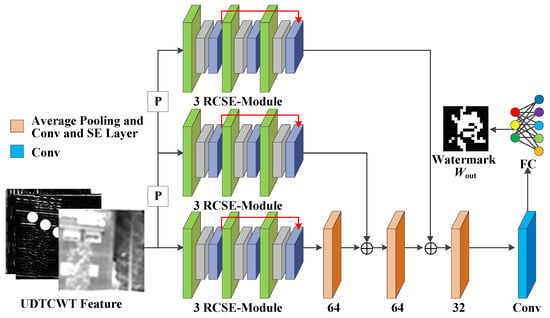 Figure 6. Network architecture for the decoder D.
Figure 6. Network architecture for the decoder D.
4.2. Loss Function
All four subnets of IEWNet apply the L2 loss function, which is the Mean Squared Error (MSE) loss function. , , , and denote the network weights of UDTCWT [1] network , encoder , noise network , and decoder , respectively. The UDTCWT [1] network will model the decomposition process of the UDTCWT [1] transform. Furthermore, it is more suitable as a network model for joint training with other networks. The loss function for UDTCWT [1] network is calculated as follows:
The encoder loss minimizes the error between the original IR image and the watermarked IR image . Equation (2) introduces loss function of the encoder .
In order to learn the principles of multiple IRE algorithms, the loss function of the noise network will make the outputs of the noise layer and enhancement module be closer to these IRE algorithms. The structure of the noise layer and the enhancement module are different, however, they both use the same loss function as shown in Equation (3).
In this case, is the IRE image produced by traditional and machine learning IRE algorithms based on the original image .
The loss function of the decoder continuously improves the similarity between the output watermark and the input watermark during the training process. The UDTCWT [1] network also helps decoder to extract more features of the watermarked IR image . Equation (4) calculates the error between the input watermark and the output watermark .
Finally, the loss function of the proposed IEWNet during joint training is
where is the hyperparameter that controls the percentage of the equilibrium loss function.
4.3. Training Process
The UDTCWT [16] network and the noise network of the proposed IEWNet work separately for network training. The encoder and the decoder are jointly trained together. For the network training, we use six public IR images datasets: GTOT [40], Road-Scene [41], TNO [42], LasHeR [43], RGBT210 [44], and RGBT234 [45]. These datasets include IR images of different times, locations and targets. The number of images in the training and testing sets is 80% and 20% of the whole dataset, respectively. The size of all IR images are scaled or randomly cropped to 128 × 128. Training UDTCWT [16] network requires that the original IR image is first decomposed into 28 subbands by using UDTCWT [16] transform. The loss function makes the output of the network closer and closer to these 28 subbands. The noise layer of the noise network is trained based on the IRE image generated by the traditional-based IRE algorithms. On the other hand, the enhancement sub-network, is trained on the randomly selected dataset from references [36,37,38,39]. The loss function used in the training process for both networks of the noise network is .
We jointly train the encoder and decoder while keeping the network weights of the UDTCWT [16] network and the noise network unchanged. The original IR image is first preliminarily extracted with features by the UDTCWT [16] network . The watermarked IR image is fed into the noise layer to simulate the process of traditional-based IRE algorithms. These features and the original image watermark are used as carriers by encoder to generate the watermarked IR image . The watermarked IR image is fed into the noise layer to simulate the process of the eight traditional-based IRE algorithms, or it can be applied as an input carrier for the enhancement sub-network to simulate the result of the four machine learning-based IRE algorithms [36,37,38,39]. The output of the noise networks FN results in the noisy image . The UDTCWT [16] network also extracts roughly the features of the noisy image and these features are used by the extraction of the final image watermark . The joint training applies the loss function as a supervised metric for the training to obtain the encoder and decoder that the algorithm expects.
5. Experimental Results
This section first describes the dataset used, software and hardware needed for the proposed algorithm. Then, it lists the performance evaluation, imperceptibility experimental results and robustness of the UDTCWT [16] transform.
5.1. Datasets and Experimental Configuration
To verify the effectiveness and generalization of the proposed IEWNet, we select six public IR image datasets in Figure 7: GTOT [40], Road-Scene [41], TNO [42], LasHeR [43], RGBT210 [44] and RGBT234 [45]. These datasets include human infrared images in both indoor and outdoor environments. And the infrared images of outdoor environments are also available for buildings and vehicles in the city as well as in the field. These infrared images are taken during the day and night. They cover lots of situations in time and space. They form a total training set for model training. These datasets have both visible and IR images at the corresponding time. Since our model is proposed to overcome IRE attacks, we only consider IR images from these six datasets. First, the IR images are randomly filtered, cropped or scaled and then the image size is adjusted to 128 × 128. Figure 7 illustrates sample images from six datasets. In order to ensure good model training effect, we control the ratio of the number of infrared images between the training set and the test set at 4:1. and with reference to the number of images in various datasets, this paper screens different numbers of infrared images for each dataset. The training set of the six datasets has 80, 160, 80, 160, 160, 160, and 80 images, respectively. The number of images in the test set is set to be 1/4 of the training set. The watermarking information is an image consisting of a 256-bit with 0,1 sequence. In training the enhancement module of the noise network , 100 IR images are randomly selected from the four algorithms presented in [36,37,38,39] as the training set. The settings of this training set are consistent with the six datasets. Figure 8 illustrates five IR images from the training set of the augmented sub-network. All experiments are conducted on a computer Dell OptiPlex 7070 with an Intel(R) Core(TM) i7-9700 CPU processor and with NVIDIA GeForce GTX 1660 graphics card from Randrock, Texas, USA. Furthermore, we use MATLAB R2016a and PyCharm 2020.3.3 to build our proposed network. In experiments, our model is trained on 100 epochs using Stochastic Gradient Descent (SGD) with a momentum of 0.9, a batch size of 1, and the initialization learning rate and weight decay rate are set to 0.001.

Figure 7.
Sample IR images from the six datasets. (a) GTOT, (b) Road-Scene, (c) TNO, (d) LasHeR, (e) RGBT210, (f) RGBT234.

Figure 8.
Training set of IR images for the augmented sub-network. The first row is the original IR image. The second row is the enhanced infrared image.
5.2. UDTCWT
The UDTCWT [1] extracts high-frequency subbands at different scales from the IR image in a total of six directions at ±15°, ±45°, and ±75°. In this paper, the application of the secondary UDTCWT [16] transform produces two scales. We take the second original IR image in Figure 9 to train UDTCWT [1] network , and all the high-frequency (HF) and low-frequency (LF) subbands are shown in Figure 9.

Figure 9.
All subbands resulting (a–d) from the secondary UDTCWT [16] decomposition of an IR image.
5.3. Imperceptibility Comparison
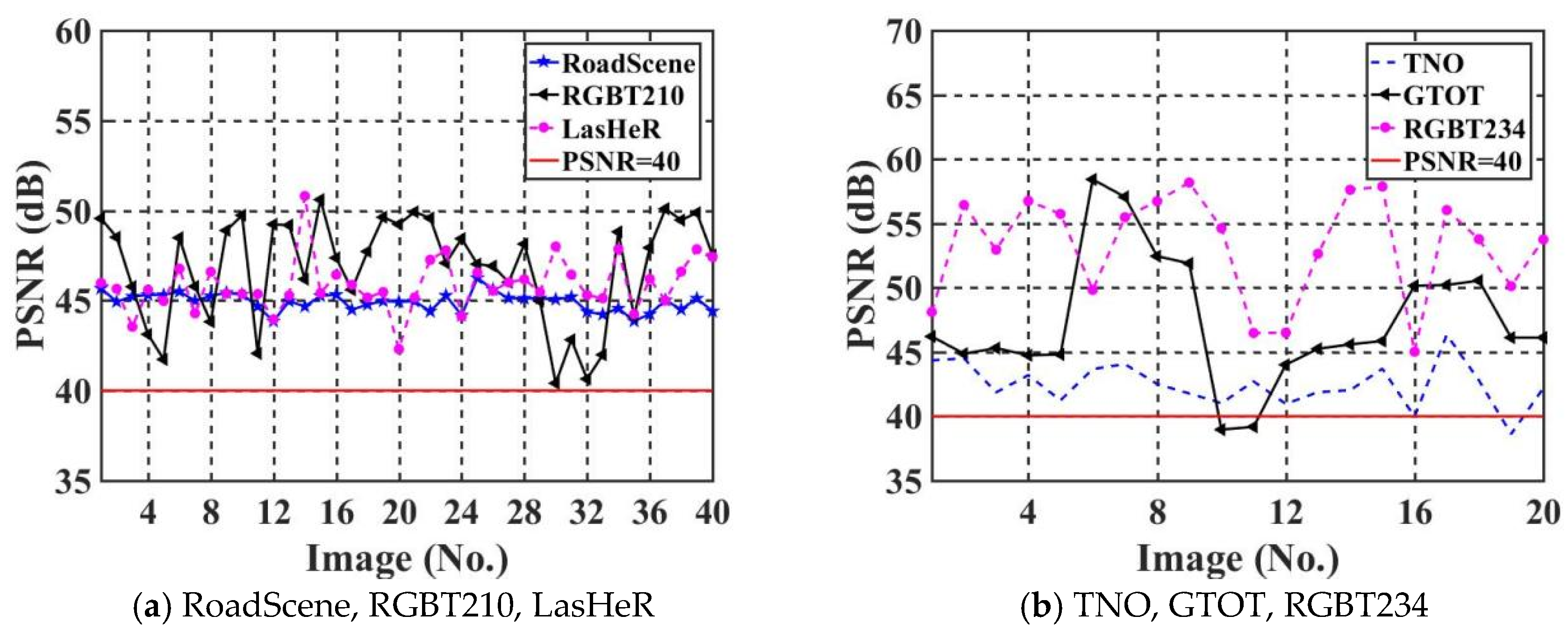
The imperceptibility of the proposed algorithm is evaluated by using PSNR. The PSNR value quantifies the degree of loss in image quality. The higher the PSNR value is, the higher the quality of the watermarked IR image , and the watermarked IR image tended to be more similar to the original IR image . Figure 10 shows PSNR values of the test set for six IR images datasets, where the horizontal and vertical coordinates of each graph represent the image serial number and the corresponding PSNR value of the image, respectively. We choose PSNR = 40 as the standard line for evaluating image quality.
where “length()” denotes the length of the image. “width()” denotes the width of the image. “Size()” is the area of the image. The experimental results demonstrated in Figure 10 prove that nearly all the PSNR values of the watermarked images are greater than 40. This proves that the proposed IEWNet network has a good imperceptibility.
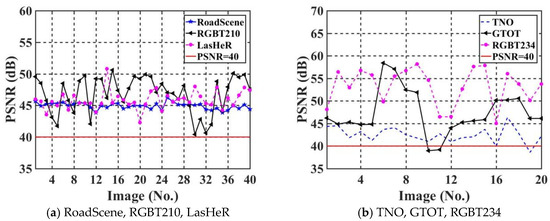
Figure 10.
Comparison of PSNR values for the six test sets (a,b).
5.4. Robustness Comparison
Imperceptibility is an indicator that evaluates the difference between the carrier after embedding the watermarked information and the original carrier as perceived by the human eye. If the difference between the two carriers is very small, most of the index values of imperceptibility will be larger. The smaller the difference between the watermarked infrared image and the original infrared image is, the better the imperceptibility of the watermarking algorithm is proved to be.
5.4.1. Ablation Study
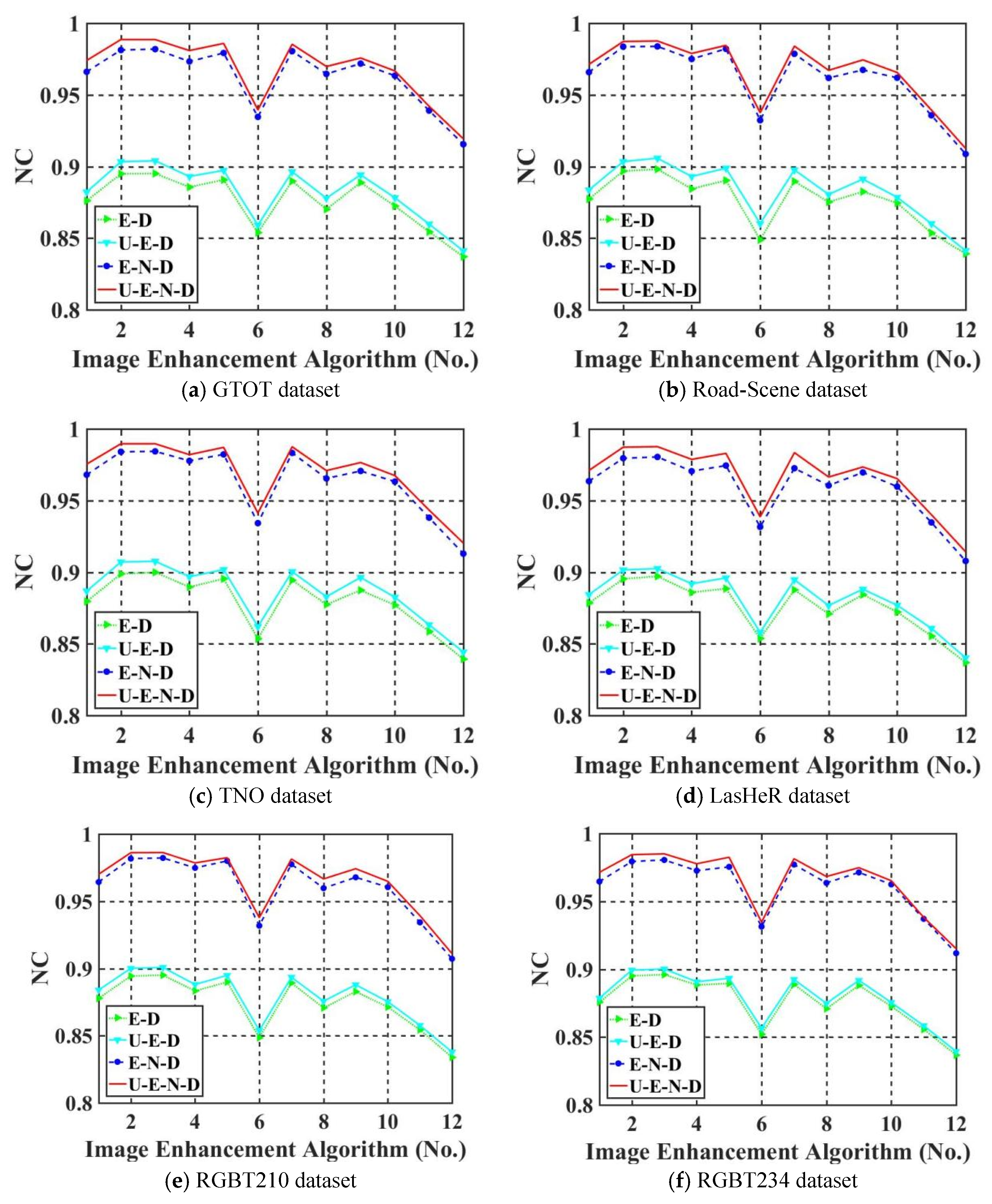
To verify the effectiveness of the proposed model components, we conduct a series of experiments according to the impact of UDTCWT [16] network and noise network on robustness. First, we remove UDTCWT [16] network and noise network from the proposed framework IEWNet, and then we test the robustness of the remaining structures against IRE attacks. Figure 11a–f shows Normalized Correlation (NC) values (as calculated in Equation (7)) of thewatermark extraction for different model structures on the six test datasets, respectively. The horizontal axis of the images represents the eight traditional-based IRE algorithms and four machine learning-based IRE algorithms in order.
where “cov” and “” denote the formulas for covariance and variance, respectively.
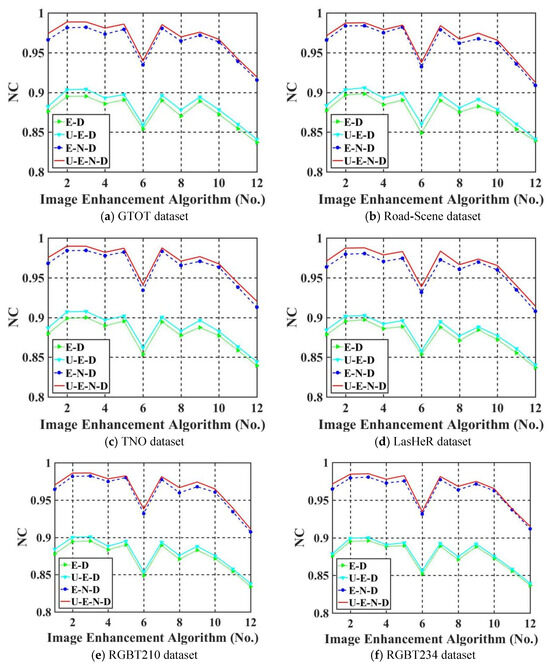
Figure 11.
Comparison of average NC values for different model structures (a–f).
The structure U-E-N-D represents the complete structure of the proposed IEWNet model. E-D represents the encoder–decoder structure. E-N-D indicates the proposed IEWNet model after removing the UDTCWT [16] network from its structure. U-E-D indicates the proposed IEWNet model after removing the noise network . Figure 11 demonstrates that the noise network improves a lot of the IRE attack’s robustness. The UDTCWT [16] network also slightly enhances the NC value of watermark extraction (0 ≤ NC ≤ 1). The higher NC value is, the closer the image watermark to is.
5.4.2. Comparative Study
A total of eight traditional-based IRE algorithms and four machine learning-based IRE algorithms are applied to test the robustness effect of the proposed IEWNet. The experiments use the same six datasets presented in Section 5.1. Furthermore, we compare our experimental results with four recent image robust watermarking algorithms: Cao et al. [46], Singh et al. [19], Anand [51], and Niu et al. [52], as shown in Table 1.

Table 1.
Bit Error Ratio (BER) values of the traditional-based IRE attacks for six IR image datasets.
In order to verify the robustness of the algorithm from different perspectives, we use BER as a criterion in this section. The BER value indicates how many proportions of pixels of the embedded watermark and extracted watermark are different. Table 1 compares the average BER values for the six test sets. For the GTOT [40] dataset, the average BER value of IEWNet for all attacks is 1.50% and it outperforms the average BER values of the other comparing algorithms [18,46,51,52], which are: 2.25%, 1.81%, 2.53%, and 2.64%, respectively. The experimental results of the proposed model on Road-Scene [41] dataset show that the average BER value is about 1.62%. The average BER values of the algorithms used for comparison are 1.95%, 2.39%, 2.68%, and 2.83%, respectively. The robustness of IEWNet on the TNO [42] dataset (1.41%) is also better than Cao et al. [46] (1.73%), Singh et al. [20] (2.16%), Anand [51] (2.47%), and Niu et al. [52] (2.59%). For the LasHeR [43] dataset, the average BER value of IEWNet is 1.65% and it also outperforms the average BER values of the other four algorithms [18,46,51,52], which are: 2.41%, 1.99%, 2.71%, and 2.85%, respectively. The experimental results of the RGBT210 [44] dataset show that average BER value of our algorithm is about 1.70%. The average BER values of the algorithms used for comparison [18,46,51,52] are 2.45%, 1.99%, 2.74%, and 2.88%. The robustness of IEWNet on the RGBT234 [45] dataset (1.41%) is also better than Cao et al. [46] (1.99%), Singh et al. [19] (2.36%), Anand [51] (2.62%), and Niu et al. [52] (2.71%).
Table 2 shows the BER values of machine learning-based IRE attacks for the six IR image test sets. The experimental results demonstrate that the proposed IEWNet exhibits the lowest average BER value and the best robustness on all datasets.
Table 2.
BER values for machine learning-based IRE attacks on the six IR image datasets.
5.5. Watermark Capacity Test
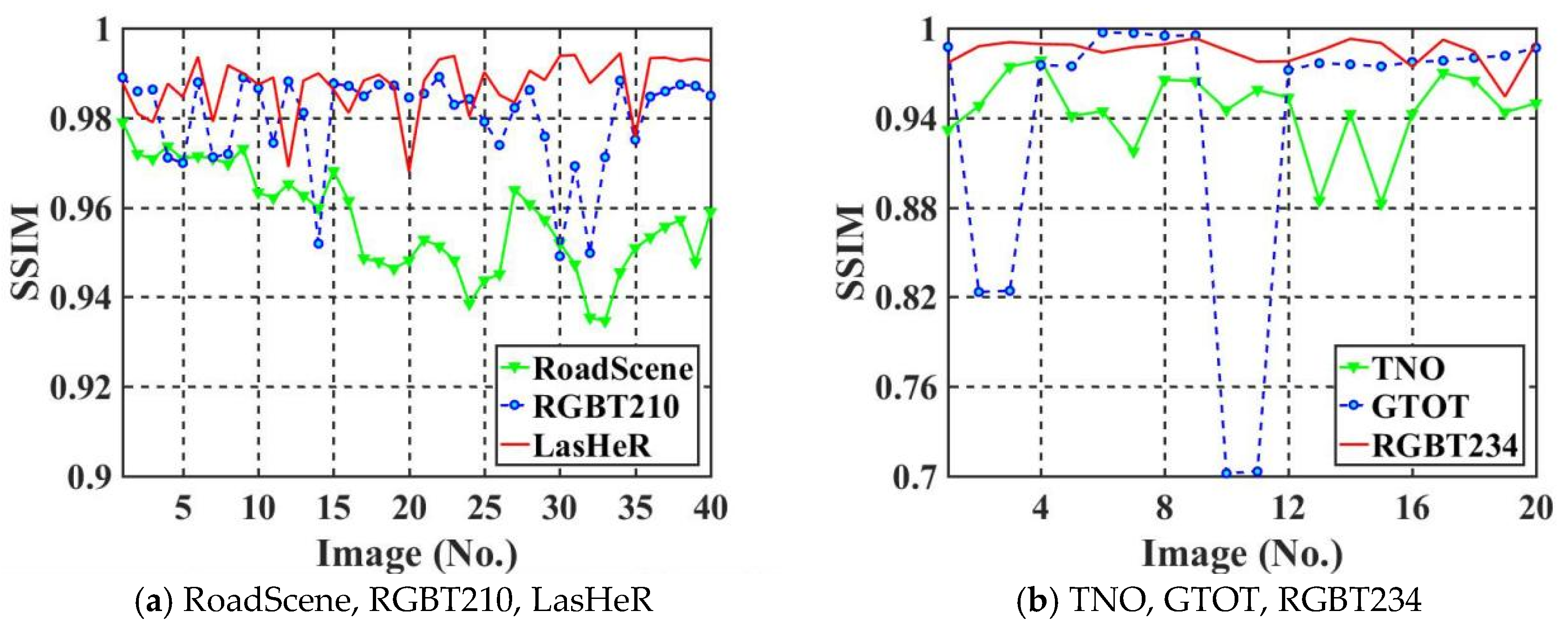
This section tests the watermark capacity of the proposed algorithm using six infrared image datasets. The watermark capacity is increased to 1024 bits. In order to demonstrate more fully the imperceptibility of the algorithm, we use Structural Similarity Index Measure (SSIM) to test the imperceptibility of the six IR images datasets. The computation of SSIM is shown in Equation (8).
where “mean” indicates the mean. And ; . The SSIM values for each test set are shown in Figure 12.
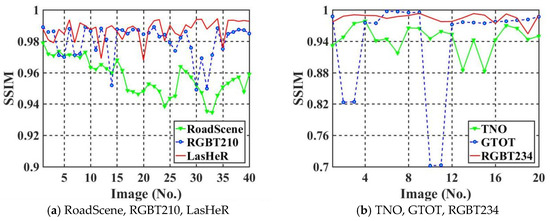
Figure 12.
Comparison of SSIM values for different watermark capacities (a,b).
After observing Figure 12 and all the IR images in the test set, we can find that the more smoothed the regions are in the IR images, the worse the imperceptibility of the watermarked IR images. Those IR images with very low PSNR or SSIM have much smoother regions than other IR images. Also, the brightness of the IR images does not affect PSNR and SSIM to the same degree. Thus, a too large difference in brightness between individual images and others can also lead to oscillations in the results.
With the watermark capacity of 1024 bits, Table 3 calculates the average BER values for the six IR datasets. The experimental results prove that the test sets GTOT and TNO with a small number of IR images have good robustness. The RGBT234 test set has some IR images with many texture features. This makes it slightly less robust than the previous two test sets. The robustness of the other three test sets is relatively close.
Table 3.
Average BER value (%) for 1024-bit watermark capacity.
6. Discussion
IR images captured by existing IR image acquisition devices are difficult to use directly in industrial production and daily life. Therefore, IRE algorithms are often applied to process IR images. However, since IR image acquisition is expensive, IR images also need copyright protection. Previous research works usually use infrared images as the carrier to embed watermarking information without considering the effect of IRE attacks on watermarked images. The proposed algorithm is able to extract the watermark information after the watermarked IR image is enhanced. This is very helpful for industrial scenarios. In this paper, only IRE algorithm is targeted to improve the robustness of the algorithm. In future research work, more complex IR image processing algorithms should be considered. And more investigation should be done to improve the algorithm for the combined attack of multiple IR processing algorithms.
7. Conclusions
Due to the limitations of IR images, IRE algorithms are often used to improve the quality of IR images. However, these have a negative impact on the watermarking information embedded in IR images. In this paper, we propose an image robust watermarking auto-encoder network against IRE for both traditional-based and machine learning-based IRE attacks, namely IEWNet. The network employs UDTCWT [1] network to help the encoder and decoder to pre-extract the features from IR image. The multi-scale network structure used by the encoder and decoder is capable of extracting the features of the infrared image and the watermarking information at different scales. This is more conducive to discovering regions of the infrared image that are more suitable for embedding the watermark information. And the encoder also combines the original image and the watermarking information at the same scale, making the algorithm imperceptible. The network learns traditional and machine learning-based IRE algorithms to shape the noise layer and enhancement module, respectively. They can learn the laws of IRE attacks to help IEWNet extract image watermark information more accurately. However, the number and variety of IRE algorithms are very large, and they have different principles.
There is currently no proposed algorithm that can determine which IRE algorithm the enhanced IR image is sourced from, so an algorithm that can quickly and accurately analyze the type of IRE needs to be investigated in the future. And in future work, we should categorize the wide variety of IRE algorithms more precisely. Networks constructed based on these categories with different simulated IRE algorithms have the potential to achieve better imperceptibility and robustness. And there are other processing methods for infrared images in industrial scenarios, such as the special noise generated in the process of transmission. Developing novel and practical algorithms based on more complex industrial scenes in real life will be of great help to industrial production and scientific research.
Author Contributions
Conceptualization L.L. and S.Z.; software, Y.B.; formal analysis, Y.B.; supervision, J.L.; writing—original draft, Y.B. and L.L.; writing—review and editing, J.L. and T.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant No. 62471264, grant No. 62172132).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset available on request from the authors. The datasets used in this paper include GTOT, Road-Scene, TNO, LasHeR, RGBT210 and RGBT234. These datasets are available for download with links in their references or on the official website of the author’s team. https://github.com/mmic-lcl/Datasets-and-benchmark-code. The datasets are allowed to be used in non-commercial activities.
Acknowledgments
The authors would like to thank all the anonymous reviewers for their helpful comments and suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IR | Infrared |
| IRE | Infrared Enhancement |
| UDTCWT | Undecimated Dual Tree Complex Wavelet Transform |
| PSNR | Peak Signal to Noise Ratio |
| HE | Histogram Equalization |
| CNN | Convolutional Neural Networks |
| ReLU | Rectified Linear Unit |
| GAN | Generative Adversarial Network |
| FFT | Fast Fourier Transform |
| DWT | Discrete Wavelet Transform |
| DNN | Deep Neural Network |
| DNST | Discrete Non-separable Shearlet Transform |
| PZM | Pseudo-Zernike Moments |
| DCT | Discrete Cosine Transform |
| WHT | Walsh Hadamard Transform |
| SVD | Singular Value Decomposition |
| GBT | Graph Based Transform |
| NCWT | Nondownsampled Contour Wave Transform |
| TEN | Thermal Image Enhancement using CNN |
| BCNN | Brightness-Based CNN |
| ONRDCNN | Optical Noise Removal Deep CNN |
| ACNN | Auto-Driving CNN |
| AHPBC | Adaptive Histogram Partition and Brightness Correction |
| DWT-EPSO | Discrete Wavelet Transform and Event triggered Particle Swarm Optimization |
| ANFLC | Adaptive Non-local Filter and Local Contrast |
| SGD | Stochastic Gradient Descent |
| HF | high-frequency |
| LF | low-frequency |
| NC | Normalized Correlation |
| SSIM | Structural Similarity Index Measure |
References
- Hildebrandt, C.; Raschner, C.; Ammer, K. An Overview of Recent Application of Medical Infrared Thermography in Sports Medicine in Austria. Sensors 2021, 10, 4700–4715. [Google Scholar] [CrossRef] [PubMed]
- Gong, J.; Fan, G.; Yu, L.; Havlicek, J.P.; Chen, D.; Fan, N. Joint Viewidentity Manifold for Infrared Target Tracking and Recognition. Comput. Vis. Image Underst. 2014, 118, 211–224. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar] [CrossRef]
- Arrue, B.C.; Ollero, A.; de Dios, J.R.M. An Intelligent System for False Alarm Reduction in Infrared Forest-fire Detection. IEEE Intell. Syst. 2000, 15, 64–73. [Google Scholar] [CrossRef]
- Goldberg, A.C.; Fischer, T.; Derzko, Z.I. Application of Dual-band Infrared Focal Plane Arrays to Tactical and Strategic Military Problems. In Proceedings of the International Symposium on Optical Science and Technology, Seattle, WA, USA, 7–11 July 2002; Society of Photo-Optical Instrumentation Engineers: Bellingham, WA, USA, 2003; Volume 4820, pp. 500–514. [Google Scholar] [CrossRef]
- Janani, V.; Dinakaran, M. Infrared Image Enhancement Techniques—A Review. In Proceedings of the Second International Conference on Current Trends in Engineering and Technology-ICCTET, Coimbatore, India, 8 July 2014; pp. 167–173. [Google Scholar] [CrossRef]
- Paul, A.; Sutradhar, T.; Bhattacharya, P.; Maity, S.P. Infrared Images Enhancement Using Fuzzy Dissimilarity Histogram Equalization. Optik 2021, 247, 167887. [Google Scholar] [CrossRef]
- Wan, M.; Gu, G.; Maldague, X.; Qian, W.; Ren, K.; Chen, Q. Particle Swarm Optimization-based Local Entropy Weighted Histogram Equalization for Infrared Image Enhancement. Infrared Phys. Technol. 2018, 91, 164–181. [Google Scholar] [CrossRef]
- Paul, A.; Sutradhar, T.; Bhattacharya, P.; Maity, S.P. Adaptive Clip-limit-based Bi-histogram Equalization Algorithm for Infrared Image Enhancement. Appl. Opt. 2020, 59, 9032–9041. [Google Scholar] [CrossRef]
- Bhattacharya, P.; Riechen, J.; Zolzer, U. Infrared Image Enhancement in Maritime Environment with Convolutional Neural Networks. In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Funchal, Portugal, 27–29 January 2018; Volume 4, pp. 37–46. [Google Scholar] [CrossRef]
- Kuang, X.; Sui, X.; Liu, Y.; Chen, Q.; Gu, G. Single Infrared Image Enhancement Using a Deep Convolutional Neural Network. Neurocomputing 2019, 332, 119–128. [Google Scholar] [CrossRef]
- Qi, Y.; He, R.; Lin, H. Novel Infrared Image Enhancement Technology Based on The Frequency Compensation Approach. Infrared Phys. Technol. 2016, 76, 521–529. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, Y.; Feng, H.; Xu, Z.; Li, Q. Infrared Image Enhancement Through Saliency Feature Analysis Based on Multi-scale Decomposition. Infrared Phys. Technol. 2014, 62, 86–93. [Google Scholar] [CrossRef]
- Wu, W.; Yang, X.; Li, H.; Liu, K.; Jian, L.; Zhou, Z. A Novel Scheme for Infrared Image Enhancement by Using Weighted Least Squares Filter and Fuzzy Plateau Histogram Equalization. Multimed. Tools Appl. 2017, 76, 24789–24817. [Google Scholar] [CrossRef]
- Ein-shoka, A.A.; Faragallah, O.S. Quality Enhancement of Infrared Images Using Dynamic Fuzzy Histogram Equalization and High Pass Adaptation in DWT. Optik 2018, 160, 146–158. [Google Scholar] [CrossRef]
- Hilla, P.R.; Anantrasirichai, N.; Achim, A.; Al-Mualla, M.E.; Bull, D.R. Undecimated Dual-Tree Complex Wavelet Transforms. Signal Process. Image Commun. 2015, 35, 61–70. [Google Scholar] [CrossRef]
- Sharma, S.; Zou, J.; Fang, G.; Shukla, P.; Cai, W. A Review of Image Watermarking for Identity Protection and Verification. Multimed. Tools Appl. 2024, 83, 31829–31891. [Google Scholar] [CrossRef]
- Wang, G.; Ma, Z.; Liu, C.; Yang, X.; Fang, H.; Zhang, W.; Yu, N. MuST: Robust Image Watermarking for Multi-Source Tracing. In Proceedings of the 38th AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5364–5371. [Google Scholar] [CrossRef]
- Singh, H.K.; Singh, A.K. Digital Image Watermarking Using Deep Learning. Multimed. Tools Appl. 2024, 83, 2979–2994. [Google Scholar] [CrossRef]
- Boujerfaoui, S.; Douzi, H.; Harba, R.; Ros, F. Cam-Unet: Print-Cam Image Correction for Zero-Bit Fourier Image Watermarking. Sensors 2024, 24, 3400. [Google Scholar] [CrossRef]
- Xiao, X.; Zhang, Y.; Hua, Z.; Xia, Z.; Weng, J. Client-Side Embedding of Screen-Shooting Resilient Image Watermarking. IEEE Trans. Inf. Forensics Secur. 2024, 19, 5357–5372. [Google Scholar] [CrossRef]
- Hasan, M.K.; Kamil, S.; Shafiq, M.; Yuvaraj, S.; Kumar, E.S.; Vincent, R.; Nafi, N.S. An Improved Watermarking Algorithm for Robustness and Imperceptibility of Data Protection in the Perception Layer of Internet of Things. Pattern Recognit. Lett. 2021, 152, 283–294. [Google Scholar] [CrossRef]
- Peng, F.; Wang, X.; Li, Y.; Niu, P. Statistical Learning Based Blind Image Watermarking Approach. Knowl.-Based Syst. 2024, 297, 111971. [Google Scholar] [CrossRef]
- Zeng, C.; Liu, J.; Li, J.; Cheng, J.; Zhou, J.; Nawaz, S.A.; Xiao, X.; Bhatti, U.A. Multi-watermarking Algorithm for Medical Image Based on KAZE-DCT. J. Ambient. Intell. Humaniz. Comput. 2024, 15, 1735–1743. [Google Scholar] [CrossRef]
- Kumar, C. Hybrid Optimization for Secure and Robust Digital Image Watermarking with DWT, DCT and SPIHT. Multimed. Tools Appl. 2024, 83, 31911–31932. [Google Scholar] [CrossRef]
- Kumar, S.; Verma, S.; Singh, B.K.; Kumar, V.; Chandra, S.; Barde, C. Entropy Based Adaptive Color Image Watermarking Technique in YCbCr Color Space. Multimed. Tools Appl. 2024, 83, 13725–13751. [Google Scholar] [CrossRef]
- Devi, K.J.; Singh, P.; Bilal, M.; Nayyar, A. Enabling Secure Image Transmission in Unmanned Aerial Vehicle Using Digital Image Watermarking with H-Grey Optimization. Expert Syst. Appl. 2024, 236, 121190. [Google Scholar] [CrossRef]
- Su, Q.; Hu, F.; Tian, X.; Su, L.; Cao, S. A Fusion-domain Intelligent Blind Color Image Watermarking Scheme Using Graph-based Transform. Opt. Laser Technol. 2024, 177, 111191. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, X.; Martin, A.V.; Bearfield, C.X.; Brun, Y.; Guan, H. Robust Image Watermarking using Stable Diffusion. arXiv 2024, arXiv:2401.04247. [Google Scholar]
- Gorbal, M.; Shelke, R.D.; Joshi, M. An Image Watermarking Scheme: Combining the Transform Domain and Deep Learning Modality with an Improved Scrambling Process. Int. J. Comput. Appl. 2024, 46, 310–323. [Google Scholar] [CrossRef]
- Olkkonen, H.; Pesola, P. Gaussian Pyramid Wavelet Transform for Multiresolution Analysis of Images. Graph. Models Image Process. 1996, 58, 394–398. [Google Scholar] [CrossRef]
- Yan, L.; Hao, Q.; Cao, J.; Saad, R.; Li, K.; Yan, Z.; Wu, Z. Infrared and Visible Image Fusion Via Octave Gaussian Pyramid Framework. Sci. Rep. 2021, 11, 1235. [Google Scholar] [CrossRef]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar] [CrossRef]
- Qin, C.; Li, X.; Zhang, Z.; Li, F.; Zhang, X.; Feng, G. Print-Camera Resistant Image Watermarking with Deep Noise Simulation and Constrained Learning. IEEE Trans. Multimed. 2024, 26, 2164–2177. [Google Scholar] [CrossRef]
- Rai, M.; Goyal, S.; Pawar, M. An Optimized Deep Fusion Convolutional Neural Network-Based Digital Color Image Watermarking Scheme for Copyright Protection. Circuits Syst. Signal Process. 2023, 42, 4019–4050. [Google Scholar] [CrossRef]
- Choi, Y.; Kim, N.; Hwang, S.; Kweon, I.S. Thermal Image Enhancement using Convolutional Neural Network. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 223–230. [Google Scholar] [CrossRef]
- Lee, K.; Lee, J.; Lee, J.; Hwang, S.; Lee, S. Brightness-Based Convolutional Neural Network for Thermal Image Enhancement. IEEE Access. 2017, 5, 26867–26879. [Google Scholar] [CrossRef]
- Kuang, X.; Sui, X.; Liu, Y.; Chen, Q.; Gu, G. Single Infrared Image Optical Noise Removal Using a Deep Convolutional Neural Network. IEEE Photonics J. 2017, 10, 7800615. [Google Scholar] [CrossRef]
- Zhong, S.; Fu, L.; Zhang, F. Infrared Image Enhancement Using Convolutional Neural Networks for Auto-Driving. Appl. Sci. 2023, 13, 12581. [Google Scholar] [CrossRef]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning Collaborative Sparse Representation for Grayscale-thermal Tracking. IEEE Trans. Image Process. 2016, 25, 5743–5756. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Ma, J. DRF: Disentangled Representation for Visible and Infrared Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 5006713. [Google Scholar] [CrossRef]
- Toet, A. The TNO Multiband Image Data Collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef]
- Li, C.; Xue, W.; Jia, Y.; Qu, Z.; Luo, B.; Tang, J.; Sun, D. LasHeR: A Large-scale High-diversity Benchmark for RGBT Tracking. IEEE Trans. Image Process. 2021, 31, 392–404. [Google Scholar] [CrossRef]
- Li, C.; Zhao, N.; Lu, Y.; Zhu, C.; Tang, J. Weighted Sparse Representation Regularized Graph Learning for RGB-T Object Tracking. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1856–1864. [Google Scholar] [CrossRef]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T Object Tracking: Benchmark and Baseline. Pattern Recognit. 2019, 96, 106977. [Google Scholar] [CrossRef]
- Cao, F.; Guo, D.; Wang, T.; Yao, H.; Li, J.; Qin, C. Universal Screen-shooting Robust Image Watermarking with Channel-attention in DCT Domain. Expert Syst. Appl. 2024, 238, 122062. [Google Scholar] [CrossRef]
- Wan, M.; Gu, G.; Qian, W.; Ren, K.; Chen, Q.; Maldague, X. Infrared Image Enhancement Using Adaptive Histogram Partition and Brightness Correction. Remote Sens. 2018, 10, 682. [Google Scholar] [CrossRef]
- Qi, J.; Abera, D.E.; Fanose, M.N.; Wang, L.; Cheng, J. A Deep Learning and Image Enhancement Based Pipeline for Infrared and Visible Image Fusion. Neurocomputing 2024, 578, 127353. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, H.; Wang, Y. Infrared Image Enhancement Based on Adaptive Non-local Filter and Local Contrast. Optik 2023, 292, 171407. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Niomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention MICCAI International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Anand, A. A Dimensionality Reduction-based Approach for Secured Color Image Watermarking. Soft Comput. 2024, 28, 5137–5154. [Google Scholar] [CrossRef]
- Niu, P.; Wang, F.; Wang, X. SVD-UDWT Difference Domain Statistical Image Watermarking Using Vector Alpha Skew Gaussian Distribution. Circuits Syst. Signal Process. 2024, 43, 224–263. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).