
Bayesian Activity Estimation and Uncertainty Quantification of Spent Nuclear Fuel Using Passive Gamma Emission Tomography

 , ,
, ,
Abstract
:1. Introduction
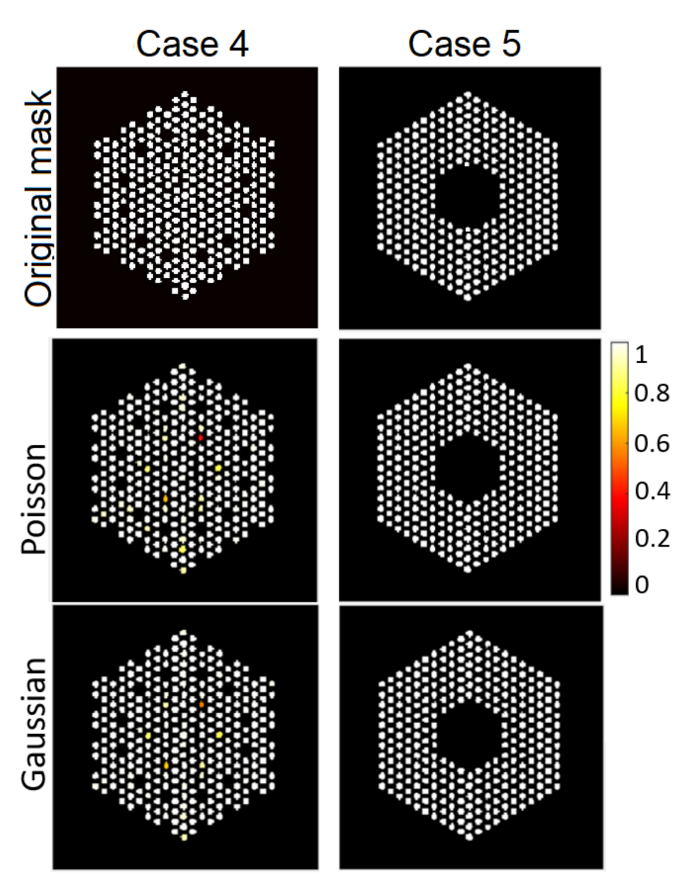
- We formulate the pin activity estimation problem within a Bayesian framework and assign a Bernoulli truncated-Gaussian (BtG) prior model to the intensity field to be estimated. To the best of our knowledge, no work attempted to sample from such a highly-multimodel joint posterior distribution using an SPA sampler. This allows for estimating the activity of spent-fuel, including the assessment of fuel rod presence/absence.
- We compare the performance of two different noise models for pin activity estimation from PGET sinograms simulated while accounting for pin self-attenuation (i.e., not simulated using a linear model).
- In addition to estimating the activity profile, the proposed algorithms allow the automated estimation of the crucial model hyperparameters, like regularization parameters, which might affect the resulting estimated activity.
2. Problem Formulation
3. Hierarchical Bayesian Model
3.1. Likelihood
3.2. Prior Distributions
3.3. Joint Posterior Distribution
4. Bayesian Inference
| Algorithm 1 Split and augmented—partially collapsed Gibbs sampling algorithm for activity estimation in PGET—version I. |
|
5. Simulations Using Synthetic Datasets
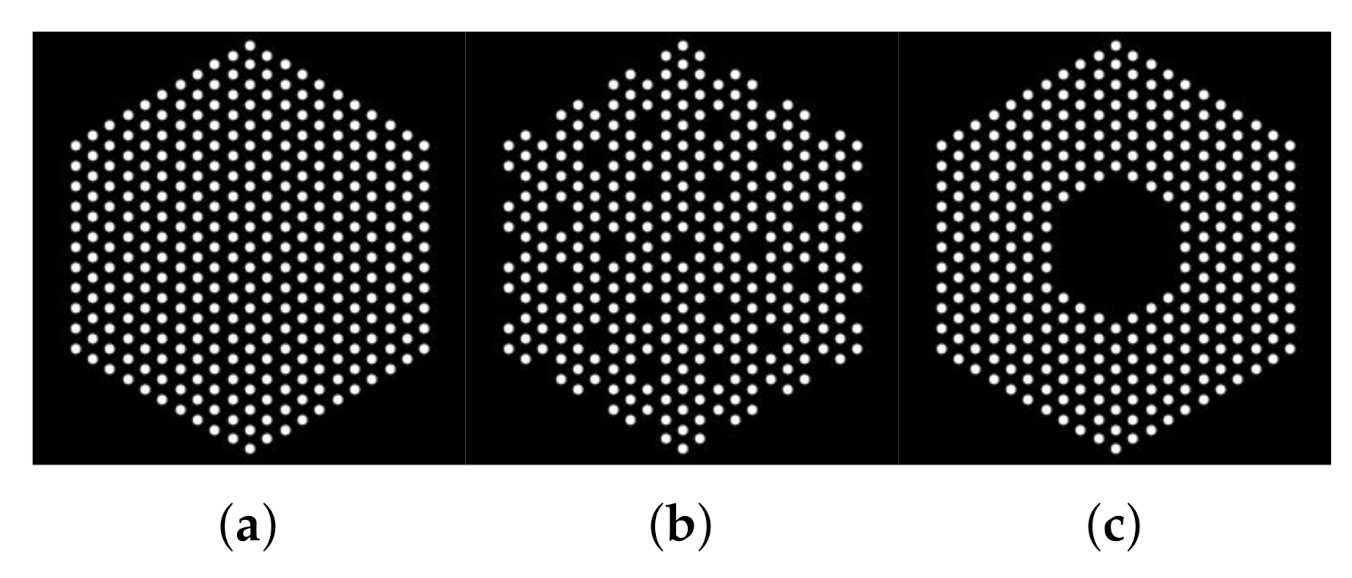
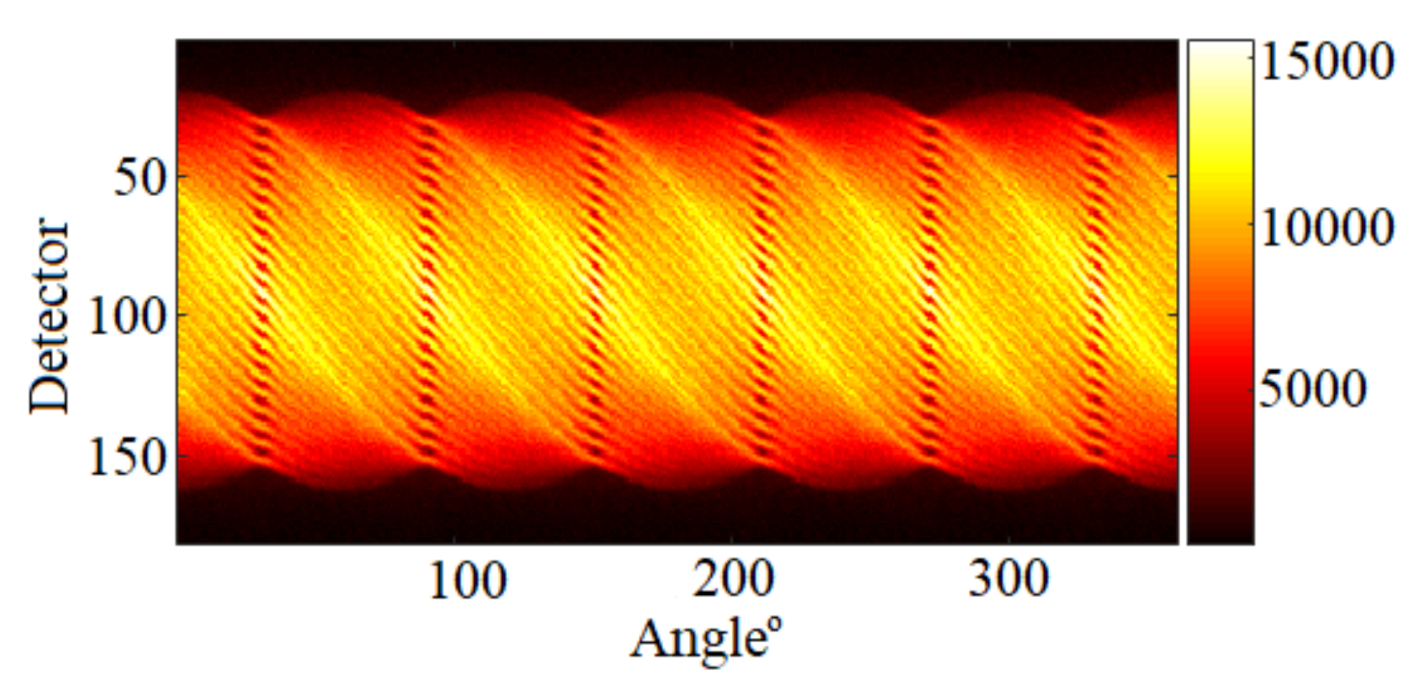
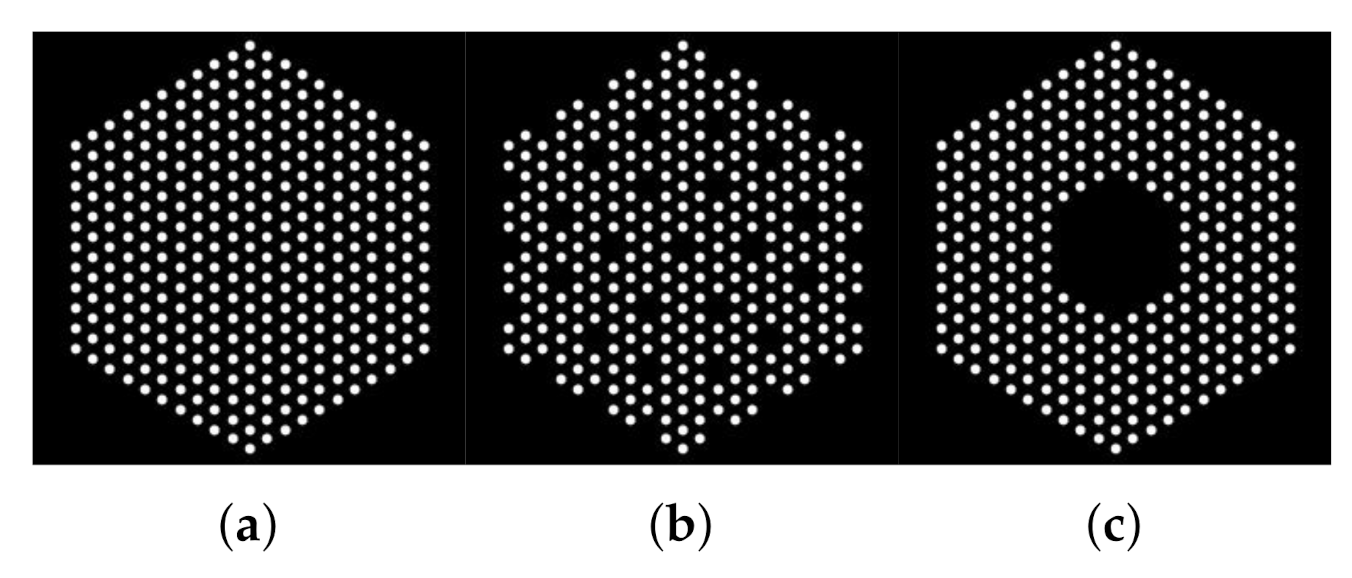
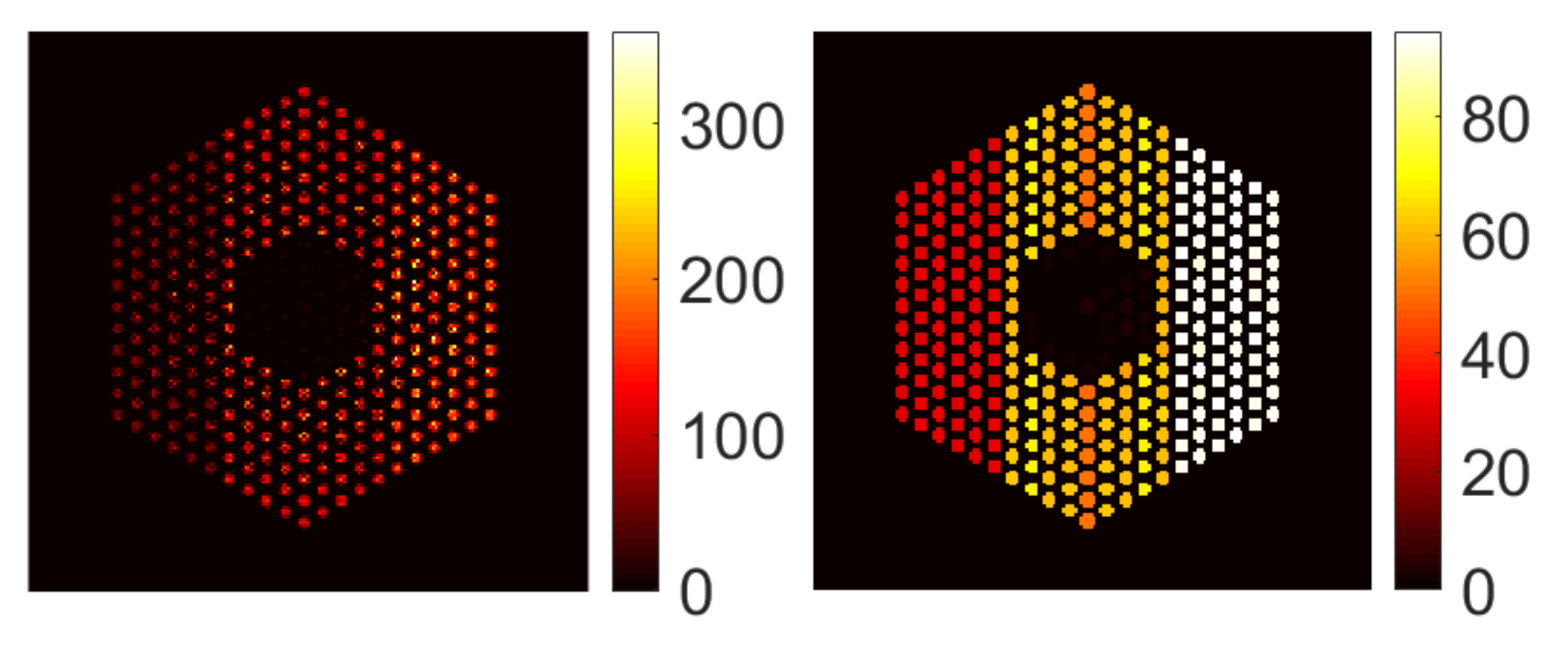
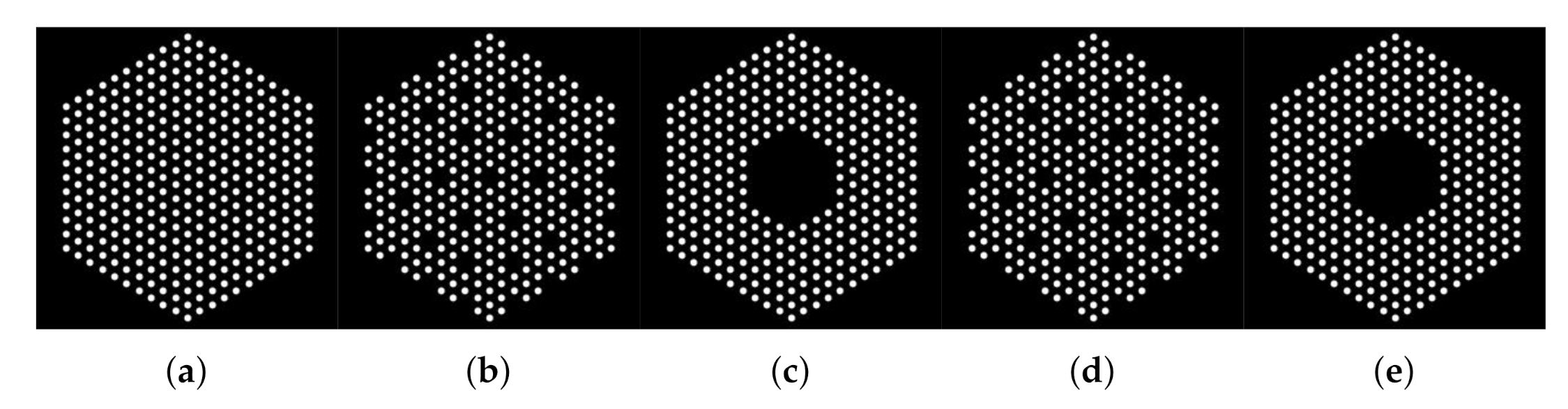
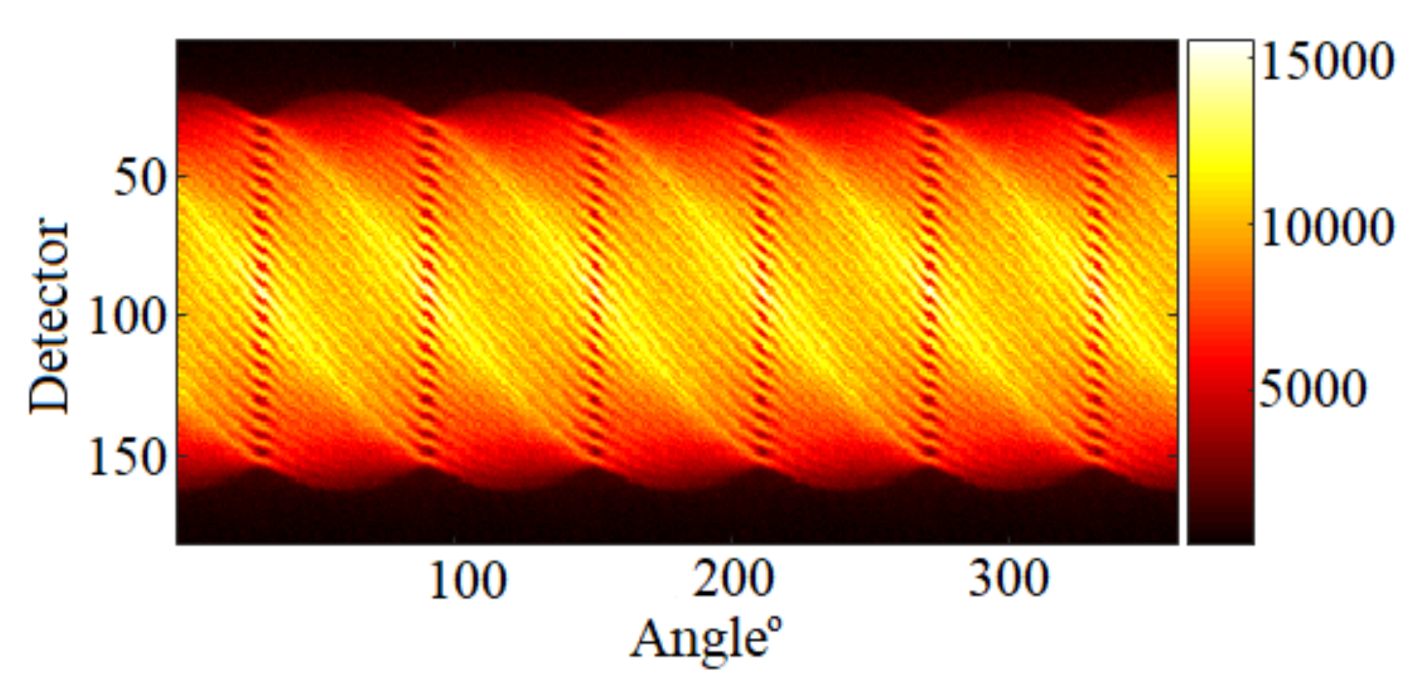
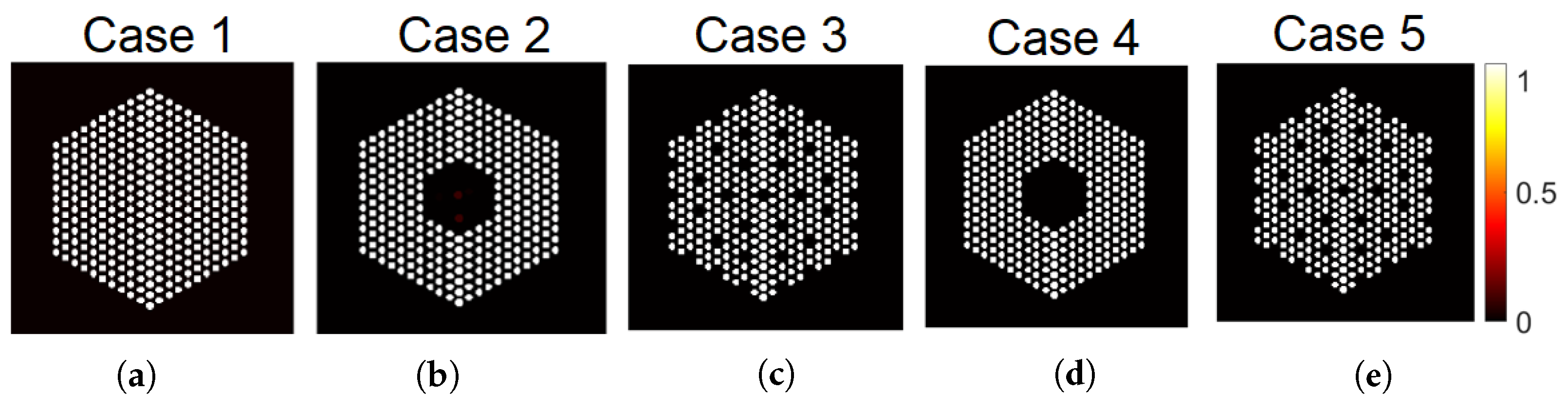
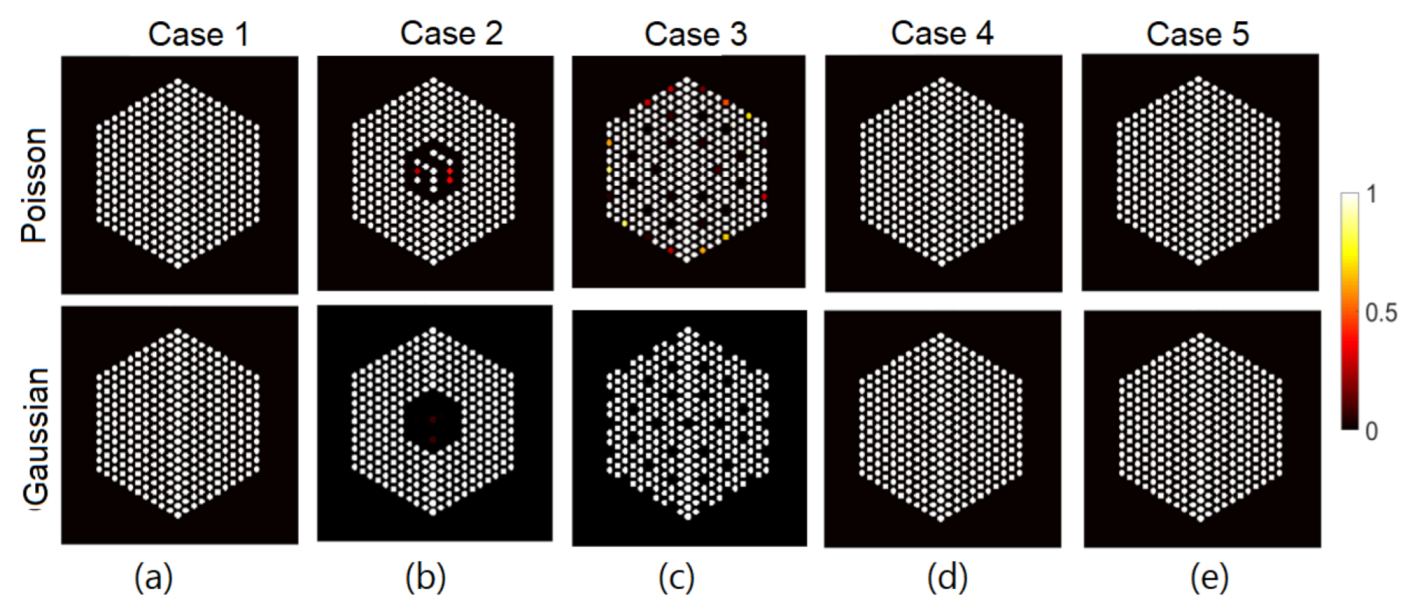
5.1. Data Creation
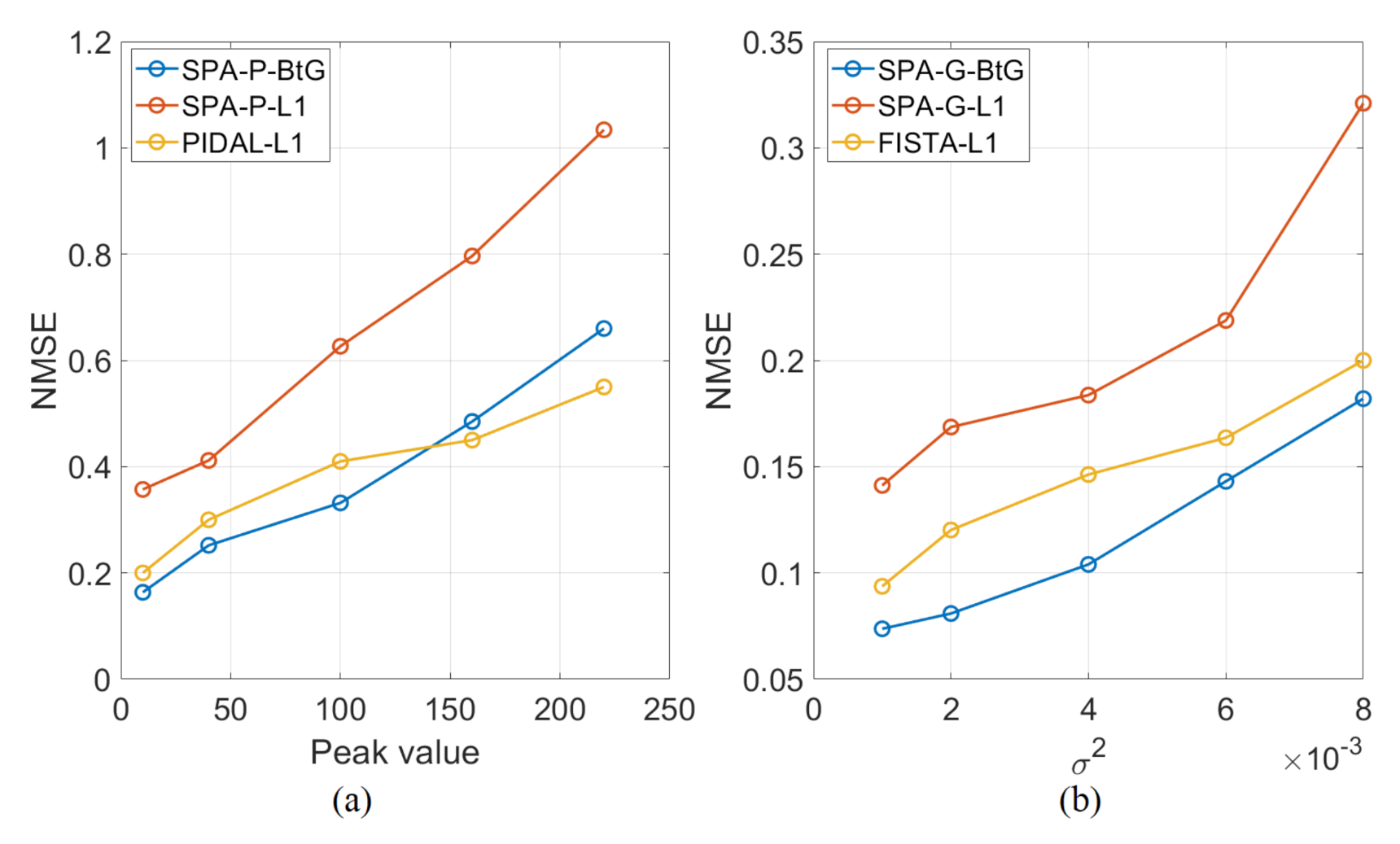
5.2. Quantitative Analysis
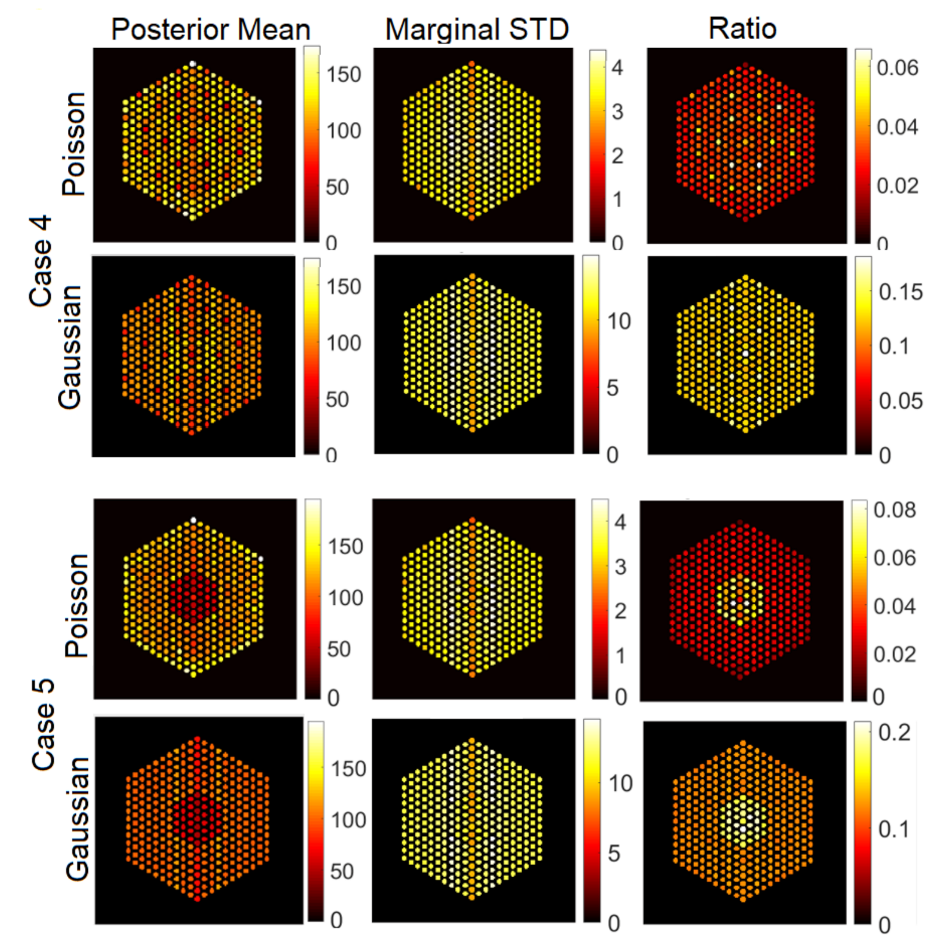
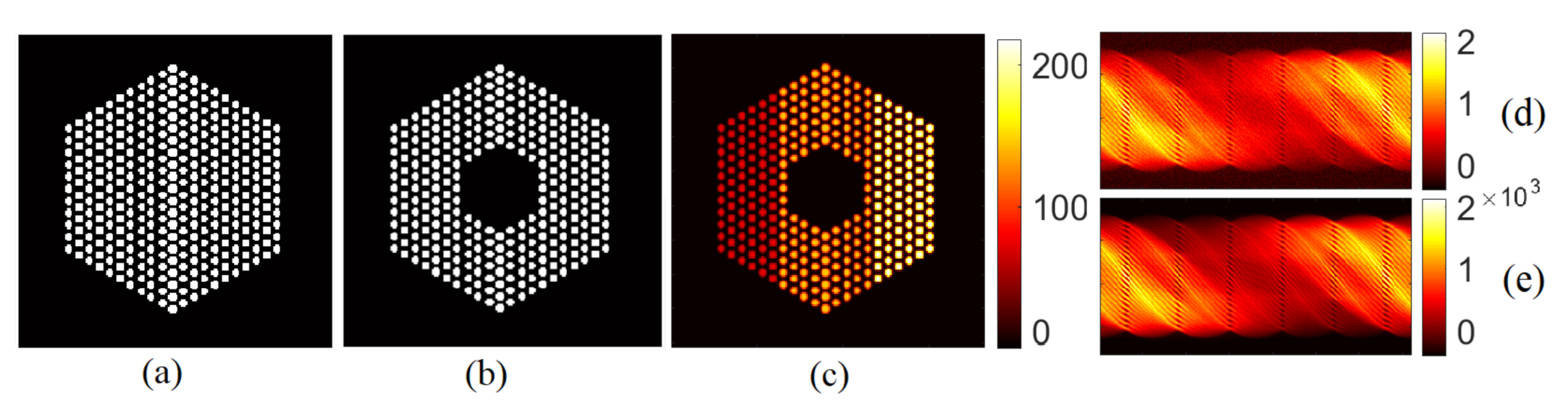
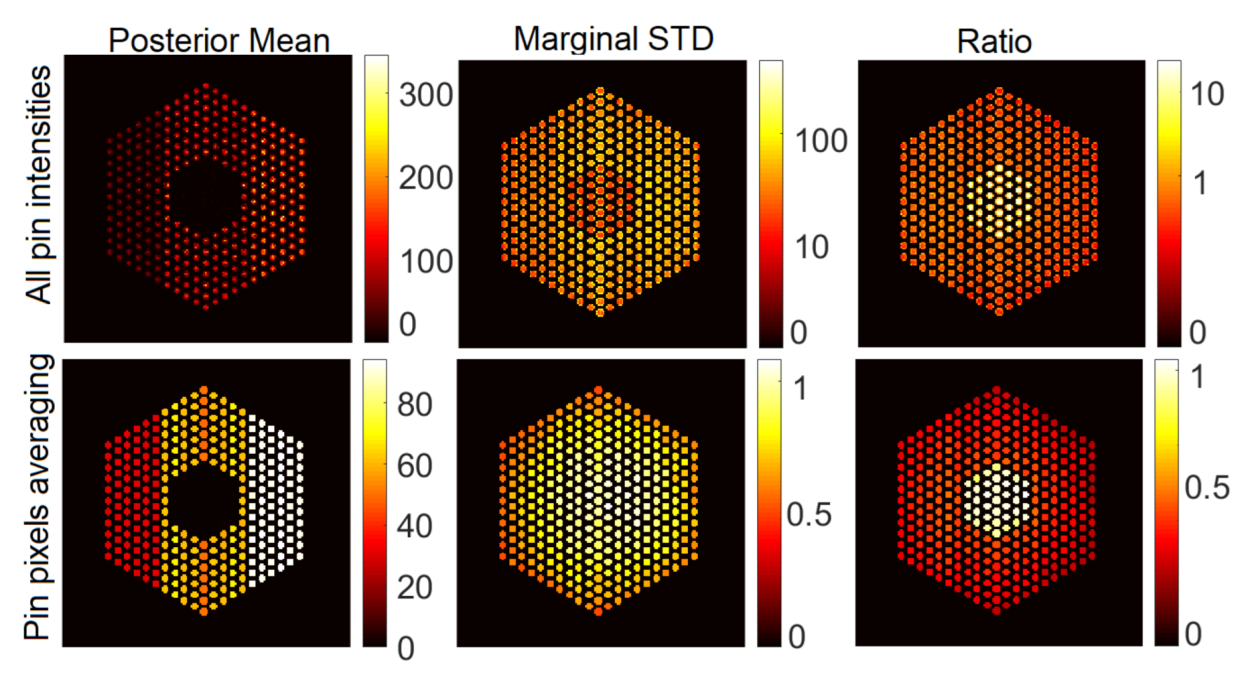
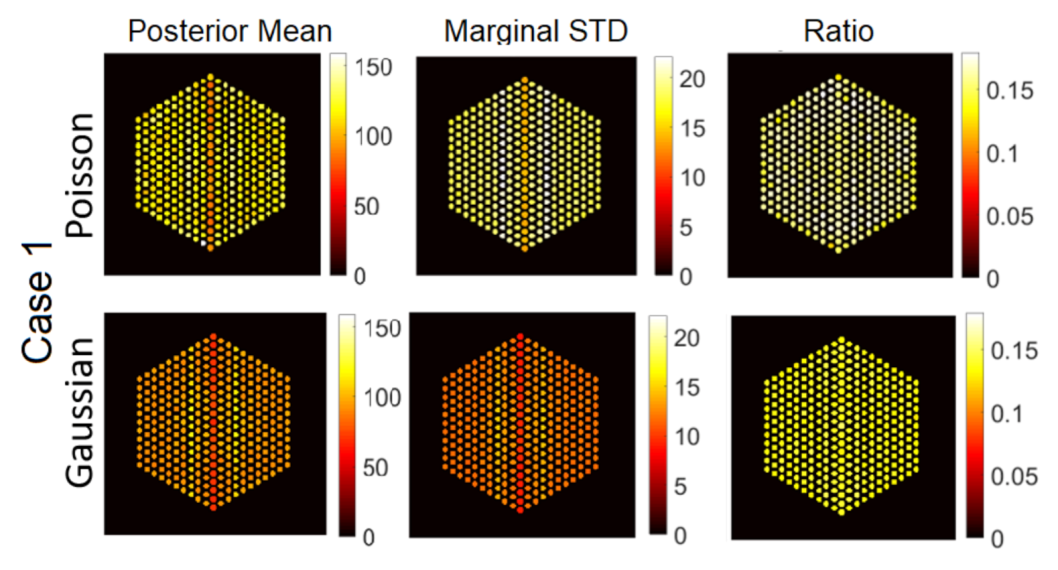
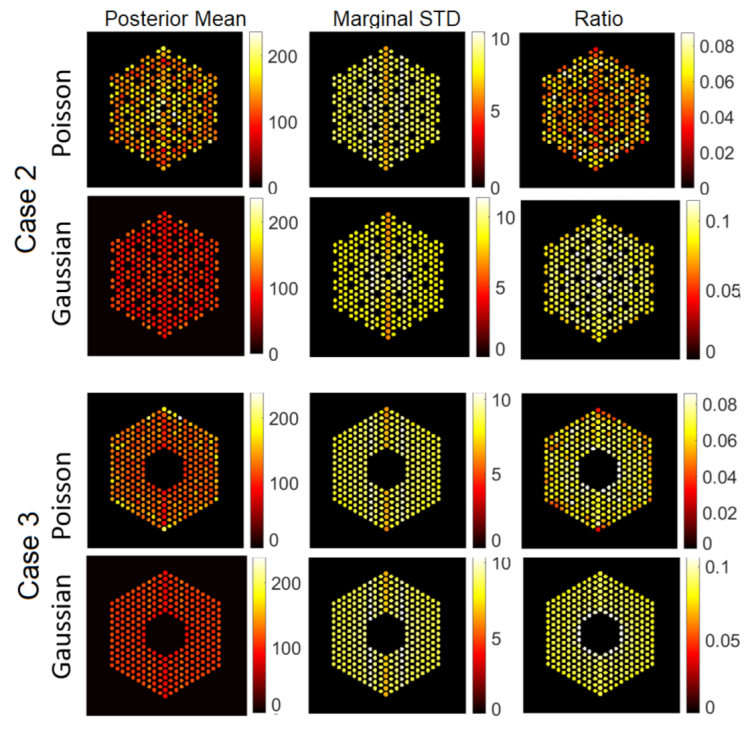
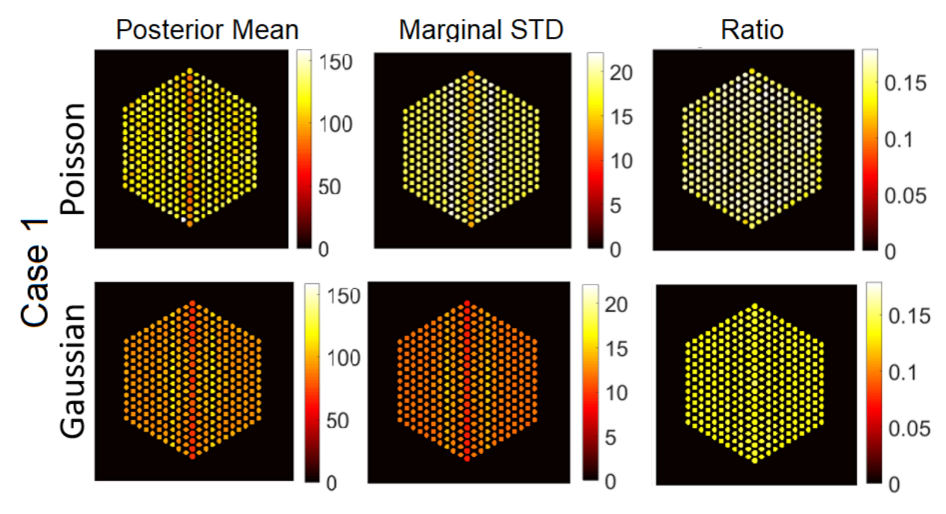
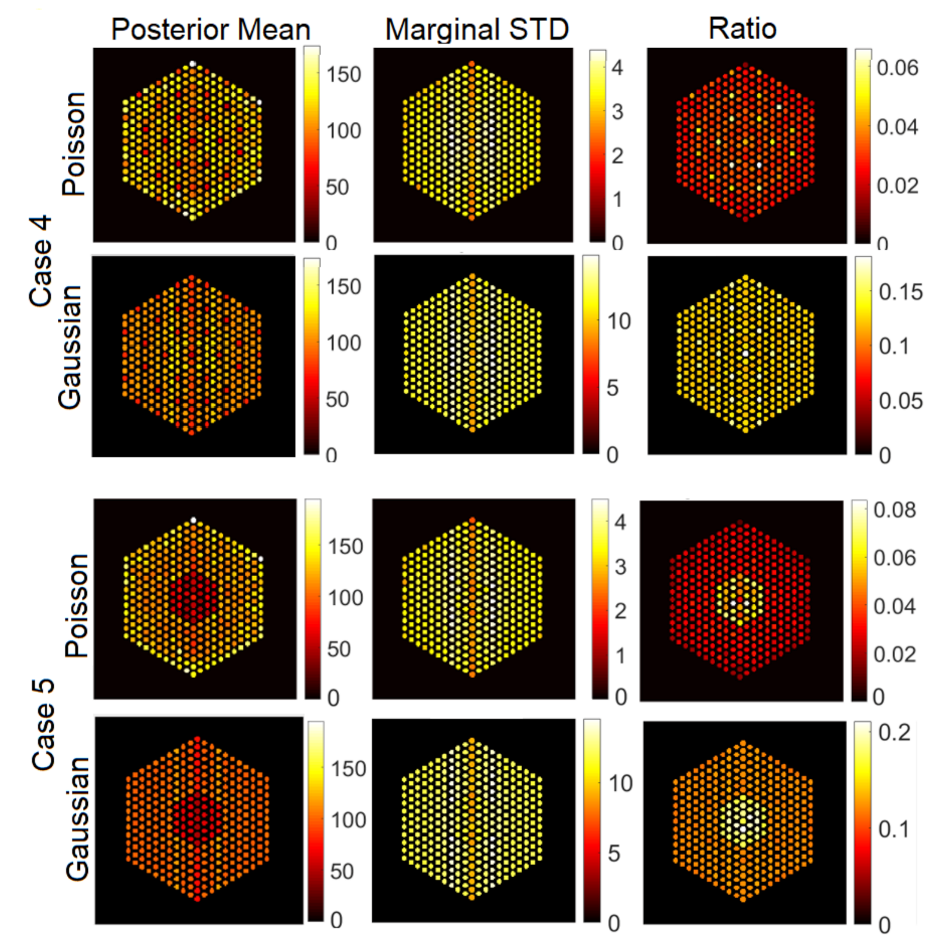
5.3. Qualitative Analysis
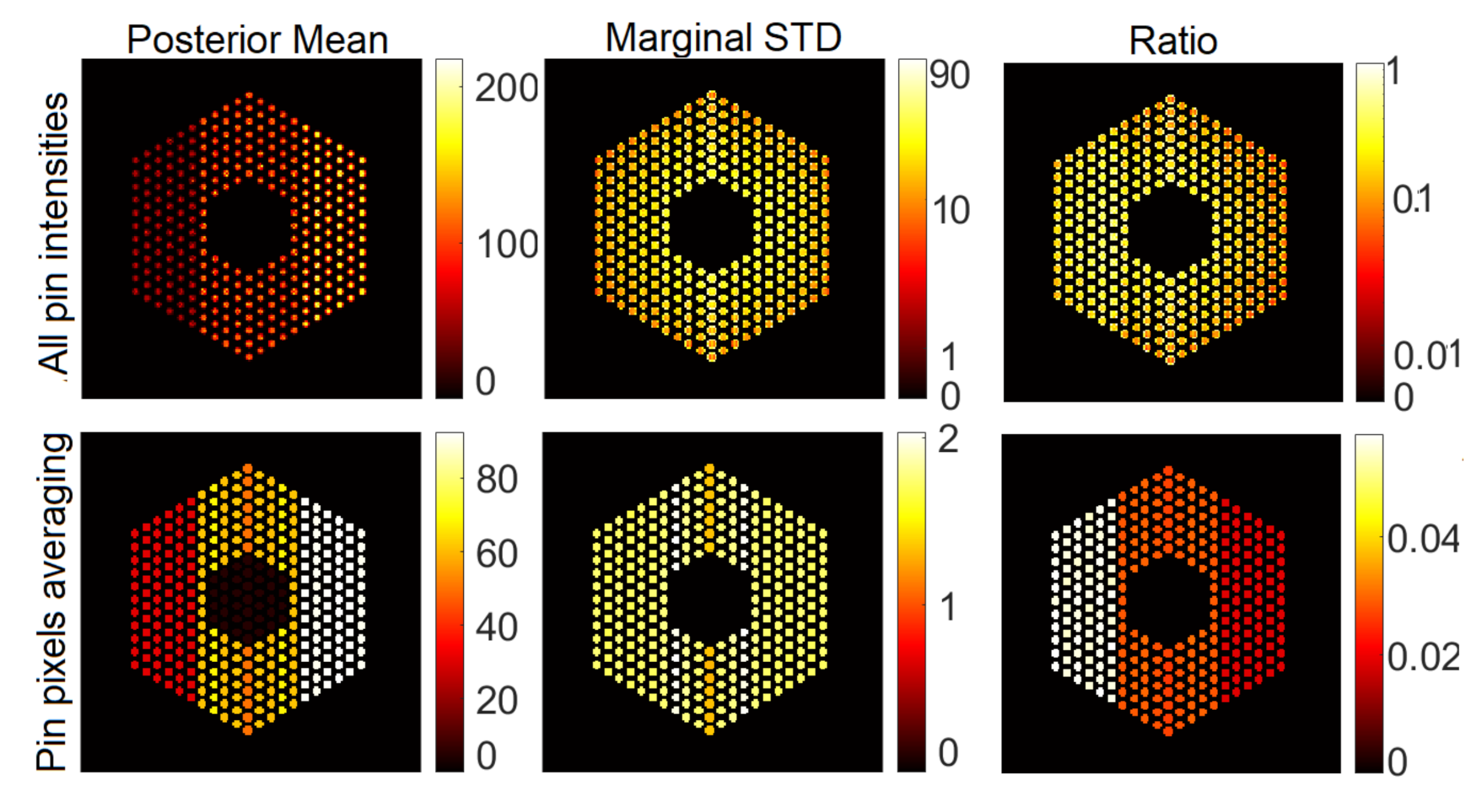
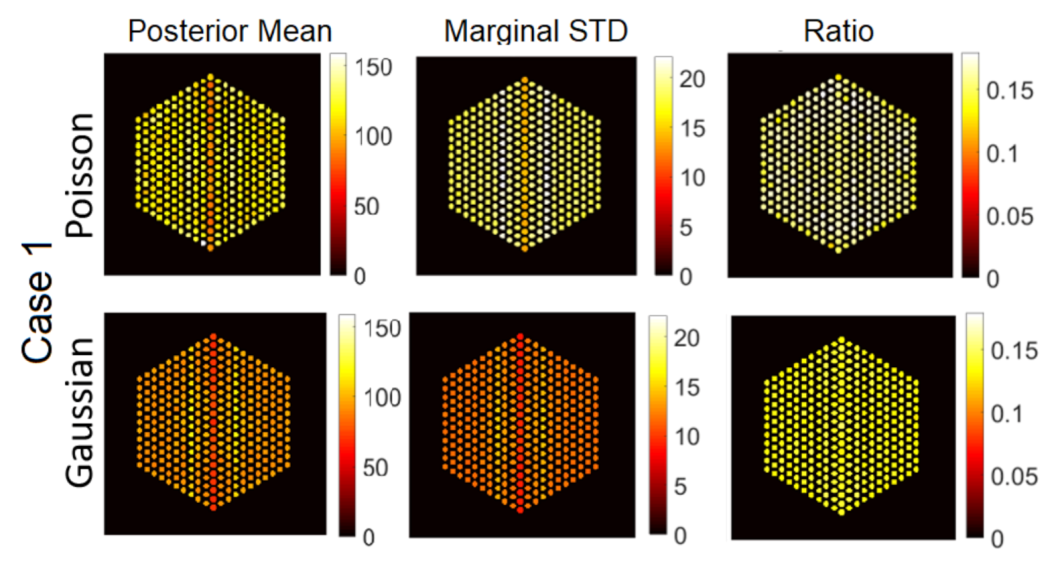
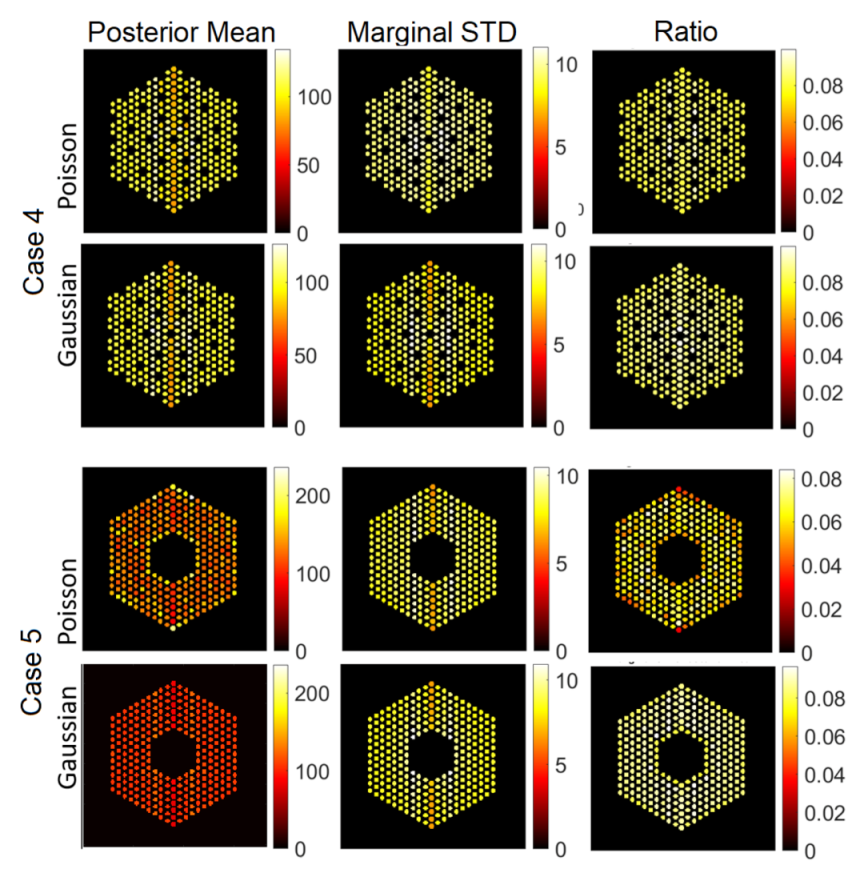
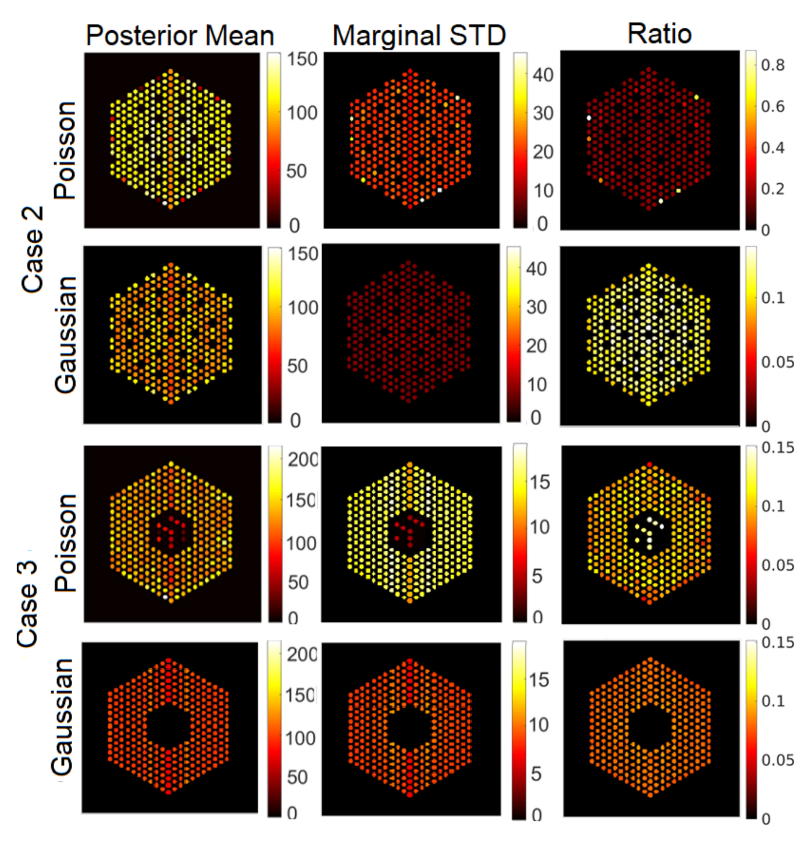
5.3.1. The Proposed Method
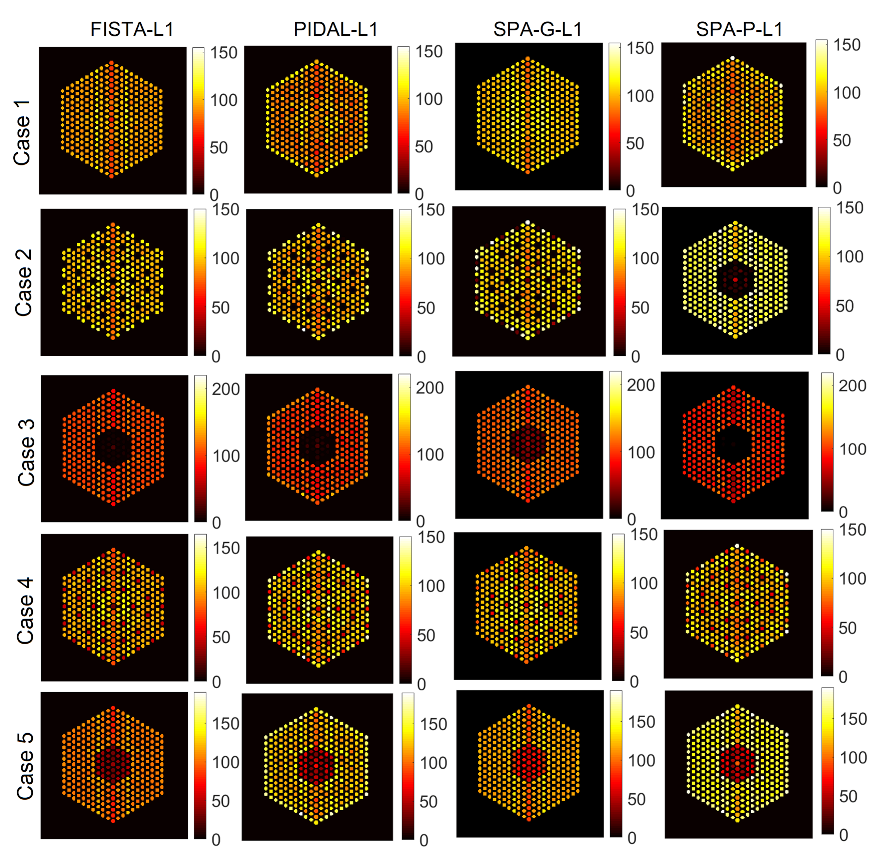
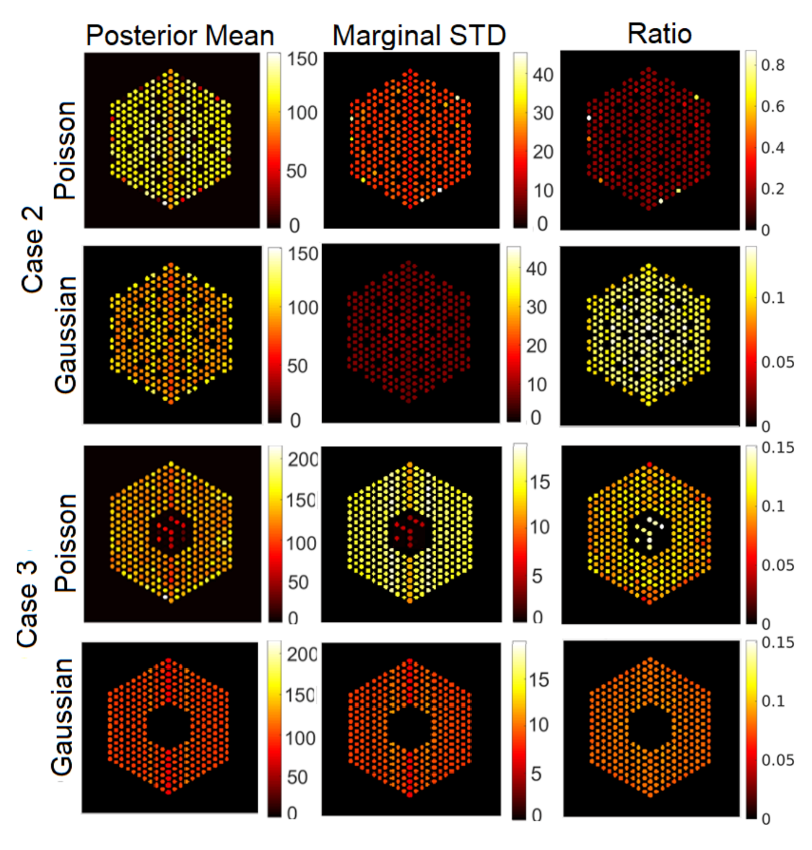
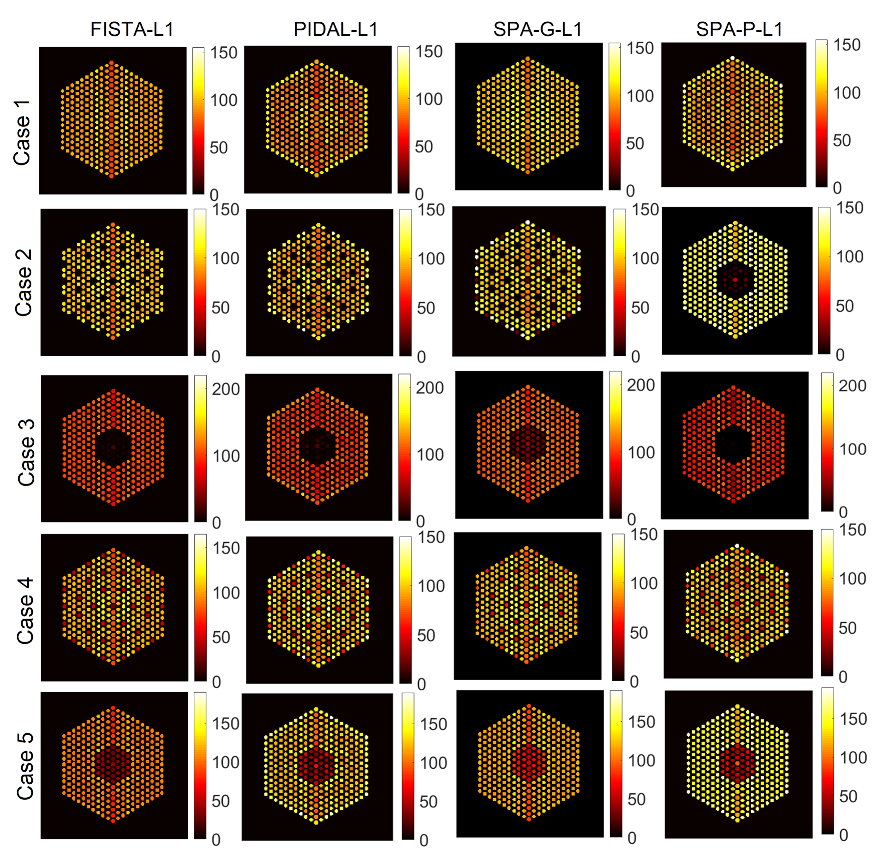
5.3.2. Comparison with Existing Methods
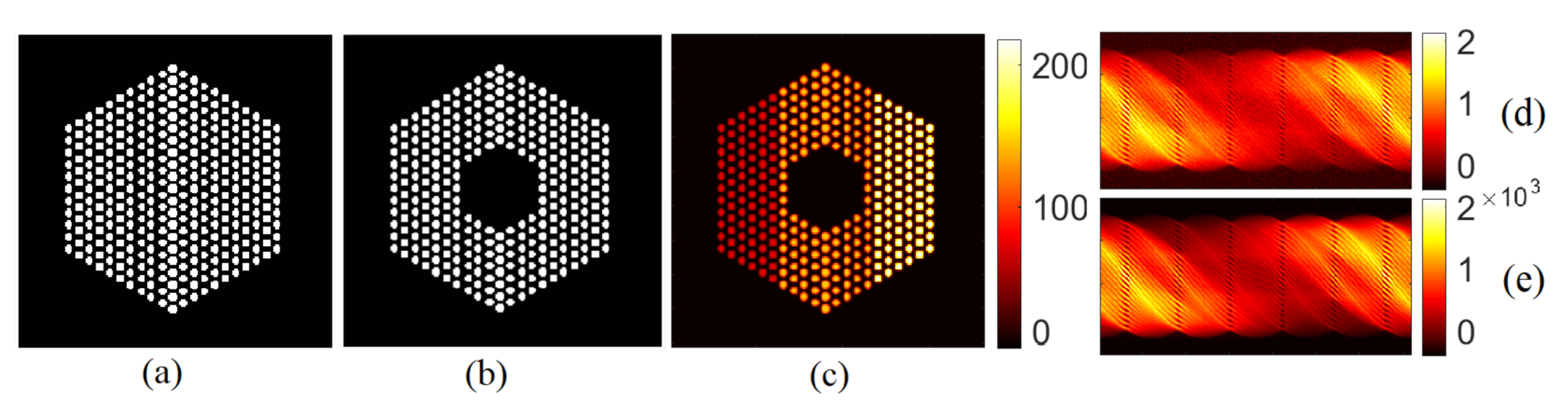
6. Simulations Using Realistic Datasets
6.1. The IDEAL Response Matrix
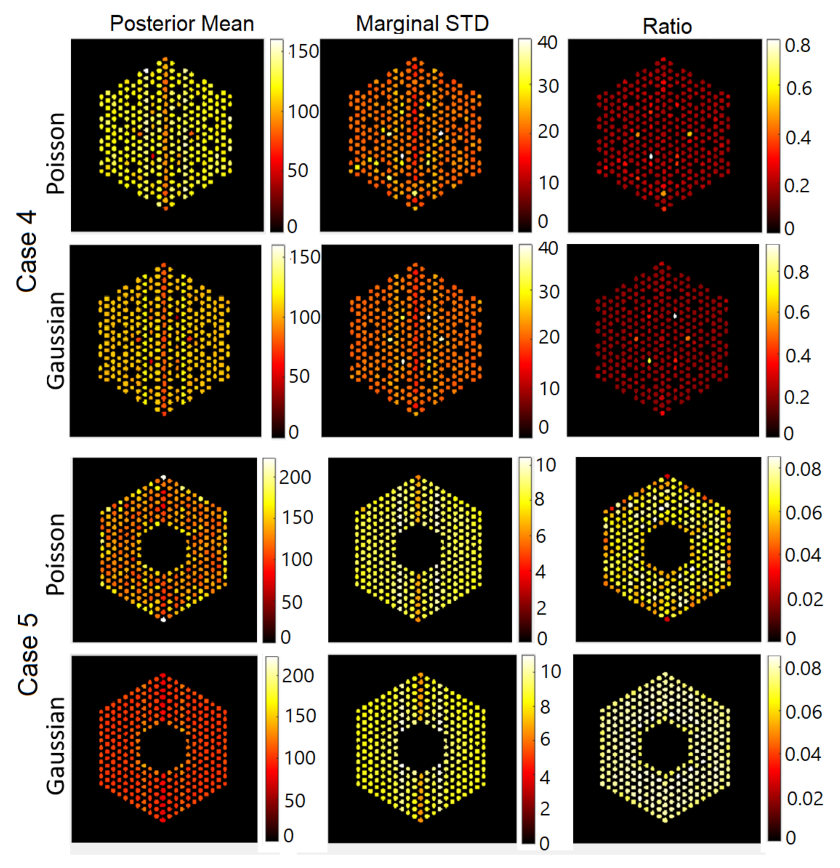
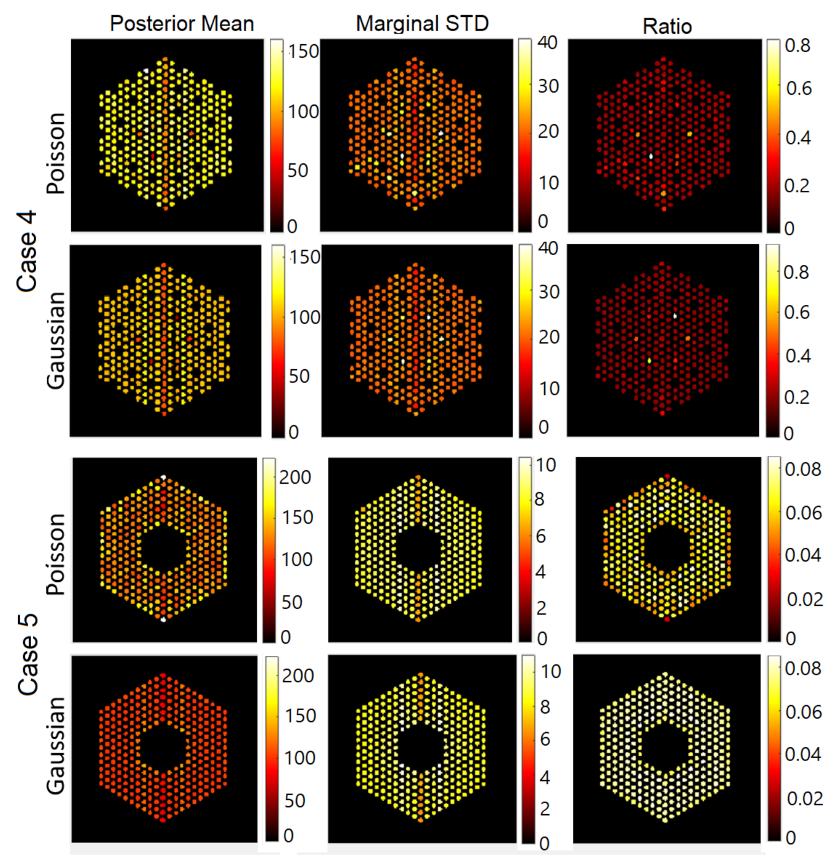
6.1.1. Results Using the Proposed Approach
6.1.2. Comparison with Existing Methods
6.2. The FULL Response Matrix
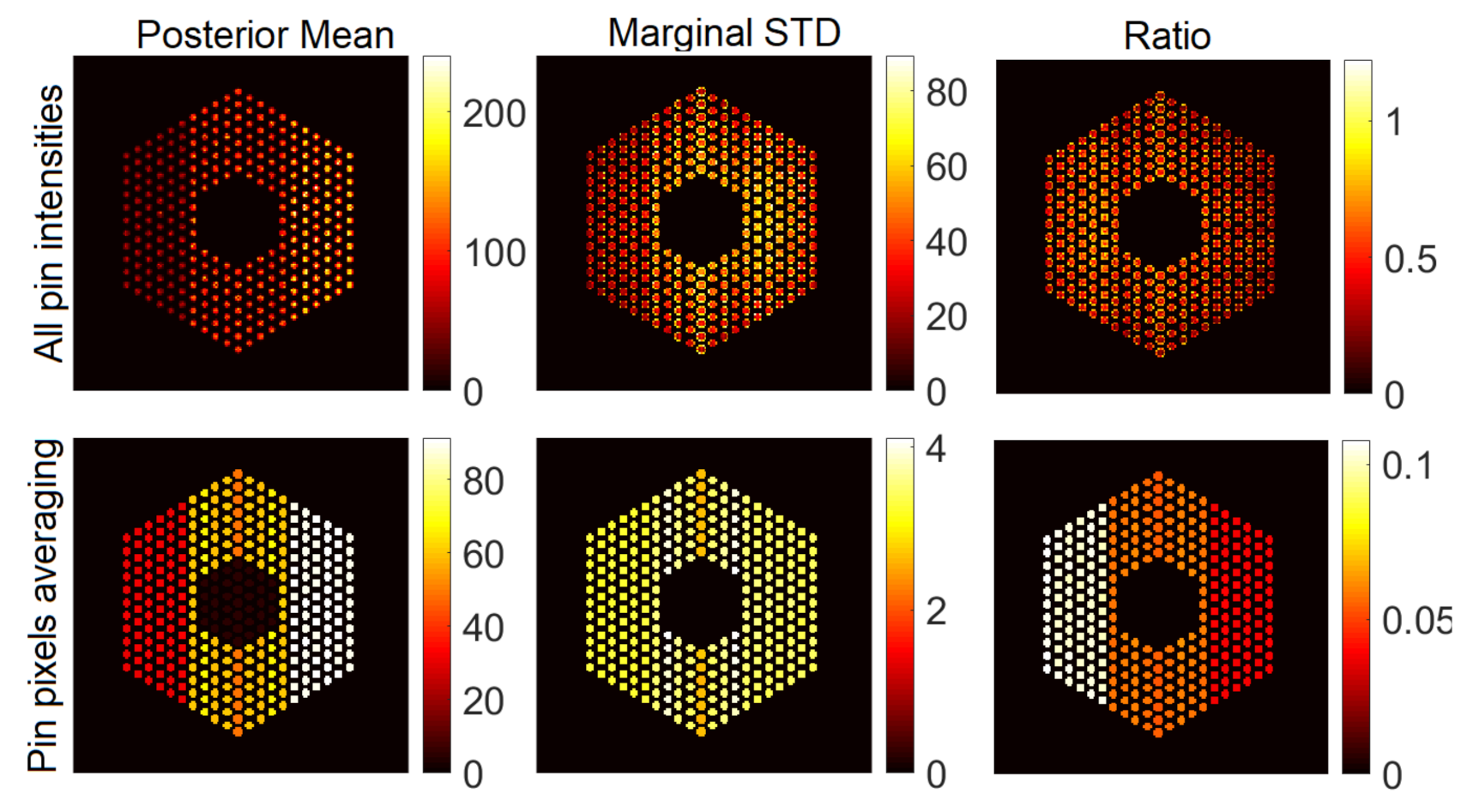
6.2.1. Results Using the Proposed Approach
6.2.2. Comparison with Existing Methods
6.3. The EMPIRICAL Response Matrix
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1 Split and augmented—partially collapsed Gibbs sampling algorithm for activity estimation in PGET—version II. |
|
References
- Firmage, E.B. The treaty on the non-proliferation of nuclear weapons. Am. J. Int. Law 1969, 63, 711–746. [Google Scholar] [CrossRef]
- White, T.; Mayorov, M.; Deshmukh, N.; Miller, E.; Smith, L.E.; Dahlberg, J.; Honkamaa, T. SPECT reconstruction and analysis for the inspection of spent nuclear fuel. In Proceedings of the 2017 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), Atlanta, GA, USA, 21–28 October 2017; pp. 1–2. [Google Scholar]
- White, T.; Mayorov, M.; Lebrun, A.; Peura, P.; Honkamaa, T.; Dahlberg, J.; Keubler, J.; Ivanov, V.; Turunen, A. Application of passive gamma emission tomography (PGET) for the verification of spent nuclear fuel. In Proceedings of the INMM 59th Annual Meeting, Baltimore, MD, USA, 22–26 July 2018. [Google Scholar]
- Mayorov, M.; White, T.; Lebrun, A.; Brutscher, J.; Keubler, J.; Birnbaum, A.; Ivanov, V.; Honkamaa, T.; Peura, P.; Dahlberg, J. Gamma emission tomography for the inspection of spent nuclear fuel. In Proceedings of the 2017 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), Atlanta, GA, USA, 21–28 October 2017; pp. 1–2. [Google Scholar]
- Bélanger-Champagne, C.; Peura, P.; Eerola, P.; Honkamaa, T.; White, T.; Mayorov, M.; Dendooven, P. Effect of gamma-ray energy on image quality in passive gamma emission tomography of spent nuclear fuel. IEEE Trans. Nucl. Sci. 2018, 66, 487–496. [Google Scholar] [CrossRef]
- Virta, R.; Backholm, R.; Bubba, T.A.; Helin, T.; Moring, M.; Siltanen, S.; Dendooven, P.; Honkamaa, T. Fuel rod classification from Passive Gamma Emission Tomography (PGET) of spent nuclear fuel assemblies. arXiv 2020, arXiv:2009.11617. [Google Scholar]
- Backholm, R.; Bubba, T.A.; Bélanger-Champagne, C.; Helin, T.; Dendooven, P.; Siltanen, S. Simultaneous reconstruction of emission and attenuation in passive gamma emission tomography of spent nuclear fuel. arXiv 2019, arXiv:1905.03849. [Google Scholar] [CrossRef] [Green Version]
- Figueiredo, M.A.; Bioucas-Dias, J.M. Restoration of Poissonian images using alternating direction optimization. IEEE Trans. Image Process. 2010, 19, 3133–3145. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A. Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 2010, 19, 2345–2356. [Google Scholar] [CrossRef] [Green Version]
- Afonso, M.; Bioucas-Dias, J.; Figueiredo, M.A. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2010, 20, 681–695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carrillo, R.E.; McEwen, J.D.; Wiaux, Y. Sparsity averaging reweighted analysis (SARA): A novel algorithm for radio-interferometric imaging. Mon. Not. R. Astron. Soc. 2012, 426, 1223–1234. [Google Scholar] [CrossRef] [Green Version]
- Carrillo, R.E.; McEwen, J.D.; Van De Ville, D.; Thiran, J.P.; Wiaux, Y. Sparsity averaging for compressive imaging. IEEE Signal Process. Lett. 2013, 20, 591–594. [Google Scholar] [CrossRef] [Green Version]
- Eldaly, A.K.; Altmann, Y.; Akram, A.; Perperidis, A.; Dhaliwal, K.; McLaughlin, S. Patch-based sparse representation for bacterial detection. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 657–661. [Google Scholar]
- Eldaly, A.K.; Altmann, Y.; Perperidis, A.; Krstajić, N.; Choudhary, T.R.; Dhaliwal, K.; McLaughlin, S. Deconvolution and restoration of optical endomicroscopy images. IEEE Trans. Comput. Imaging 2018, 4, 194–205. [Google Scholar] [CrossRef] [Green Version]
- Eldaly, A.K.; Altmann, Y.; Perperidis, A.; McLaughlin, S. Deconvolution of irregularly subsampled images. In Proceedings of the 2018 IEEE Statistical Signal Processing Workshop (SSP), Freiburg im Breisgau, Germany, 10–13 June 2018; pp. 303–307. [Google Scholar]
- Tachella, J.; Altmann, Y.; Pereyra, M.; McLaughlin, S.; Tourneret, J.Y. Bayesian restoration of high-dimensional photon-starved images. In Proceedings of the 2018 IEEE 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 747–751. [Google Scholar]
- Vono, M.; Dobigeon, N.; Chainais, P. Bayesian image restoration under Poisson noise and log-concave prior. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1712–1716. [Google Scholar]
- Vono, M.; Dobigeon, N.; Chaináis, P. Split-and-augmented Gibbs sampler—Application to large-scale inference problems. IEEE Trans. Signal Process. 2019, 67, 1648–1661. [Google Scholar] [CrossRef] [Green Version]
- Pereyra, M. Proximal markov chain monte carlo algorithms. Stat. Comput. 2016, 26, 745–760. [Google Scholar] [CrossRef] [Green Version]
- Durmus, A.; Moulines, E.; Pereyra, M. Efficient bayesian computation by proximal markov chain monte carlo: When langevin meets moreau. SIAM J. Imaging Sci. 2018, 11, 473–506. [Google Scholar] [CrossRef]
- Iyengar, A.S.; Hausladen, P.; Yang, J.; Fabris, L.; Hu, J.; Lacy, J.; Athanasiades, A. Detection of Fuel Pin Diversion via Fast Neutron Emission Tomography; Technical Report; Oak Ridge National Lab.(ORNL): Oak Ridge, TN, USA, 2017. [Google Scholar]
- Fang, M.; Altmann, Y.; Della Latta, D.; Salvatori, M.; Di Fulvio, A. Quantitative imaging and automated fuel pin identification for passive gamma emission tomography. Sci. Rep. 2021, 11, 1–11. [Google Scholar] [CrossRef]
- Newstadt, G.E.; Hero, A.O.; Simmons, J. Robust spectral unmixing for anomaly detection. In Proceedings of the 2014 IEEE Workshop on Statistical Signal Processing (SSP), Gold Coast, QLD, Australia, 29 June–2 July 2014; pp. 109–112. [Google Scholar]
- Ishwaran, H.; Rao, J.S. Spike and slab variable selection: Frequentist and Bayesian strategies. Ann. Stat. 2005, 33, 730–773. [Google Scholar] [CrossRef] [Green Version]
- George, E.I.; McCulloch, R.E. Variable selection via Gibbs sampling. J. Am. Stat. Assoc. 1993, 88, 881–889. [Google Scholar] [CrossRef]
- Chipman, H. Bayesian variable selection with related predictors. Can. J. Stat. 1996, 24, 17–36. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, C.M.; Chang, J.; Lucas, J.E.; Nevins, J.R.; Wang, Q.; West, M. High-dimensional sparse factor modeling: Applications in gene expression genomics. J. Am. Stat. Assoc. 2008, 103, 1438–1456. [Google Scholar] [CrossRef] [Green Version]
- Kail, G.; Tourneret, J.Y.; Hlawatsch, F.; Dobigeon, N. Blind deconvolution of sparse pulse sequences under a minimum distance constraint: A partially collapsed Gibbs sampler method. IEEE Trans. Signal Process. 2012, 60, 2727–2743. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Mailhes, C.; Tourneret, J.Y. P- and T-wave delineation in ECG signals using a Bayesian approach and a partially collapsed Gibbs sampler. IEEE Trans. Biomed. Eng. 2010, 57, 2840–2849. [Google Scholar]
- Kail, G.; Tourneret, J.Y.; Hlawatsch, F.; Dobigeon, N. A partially collapsed Gibbs sampler for parameters with local constraints. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 3886–3889. [Google Scholar]
- Ge, D.; Idier, J.; Le Carpentier, E. A new MCMC algorithm for blind Bernoulli-Gaussian deconvolution. In Proceedings of the 2008 IEEE 16th European Signal Processing Conference, Lausanne, Switzerland, 25–29 August 2008; pp. 1–5. [Google Scholar]
- Robert, C.; Casella, G. Monte Carlo Statistical Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Eldaly, A.K.; Altmann, Y.; Akram, A.; McCool, P.; Perperidis, A.; Dhaliwal, K.; McLaughlin, S. Bayesian Bacterial Detection Using Irregularly Sampled Optical Endomicroscopy Images. Med. Image Anal. 2019, 57, 18–31. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.S. The collapsed Gibbs sampler in Bayesian computations with applications to a gene regulation problem. J. Am. Stat. Assoc. 1994, 89, 958–966. [Google Scholar] [CrossRef]
- Van Dyk, D.A.; Park, T. Partially collapsed Gibbs samplers: Theory and methods. J. Am. Stat. Assoc. 2008, 103, 790–796. [Google Scholar] [CrossRef]
- Doucet, A.; Godsill, S.J.; Robert, C.P. Marginal maximum a posteriori estimation using Markov chain Monte Carlo. Stat. Comput. 2002, 12, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Robert, C. The Bayesian Choice: From Decision-Theoretic Foundations to Computational Implementation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Goorley, J.T.; James, M.R.; Booth, T.E.; Brown, F.B.; Bull, J.S.; Cox, L.J.; Durkee, J.W., Jr.; Elson, J.S.; Fensin, M.L.; Forster, R.A., III; et al. Initial MCNP6 Release Overview-MCNP6 Version 1.0; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2013. [Google Scholar]
- Gelman, A.; Stern, H.S.; Carlin, J.B.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Pereyra, M.; Mieles, L.V.; Zygalakis, K.C. Accelerating proximal Markov chain Monte Carlo by using an explicit stabilized method. SIAM J. Imaging Sci. 2020, 13, 905–935. [Google Scholar] [CrossRef]
- Vidal, A.F.; De Bortoli, V.; Pereyra, M.; Durmus, A. Maximum Likelihood Estimation of Regularization Parameters in High-Dimensional Inverse Problems: An Empirical Bayesian Approach Part I: Methodology and Experiments. SIAM J. Imaging Sci. 2020, 13, 1945–1989. [Google Scholar] [CrossRef]
- Papandreou, G.; Yuille, A.L. Gaussian sampling by local perturbations. Adv. Neural Inf. Process. Syst. 2010, 23, 1858–1866. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
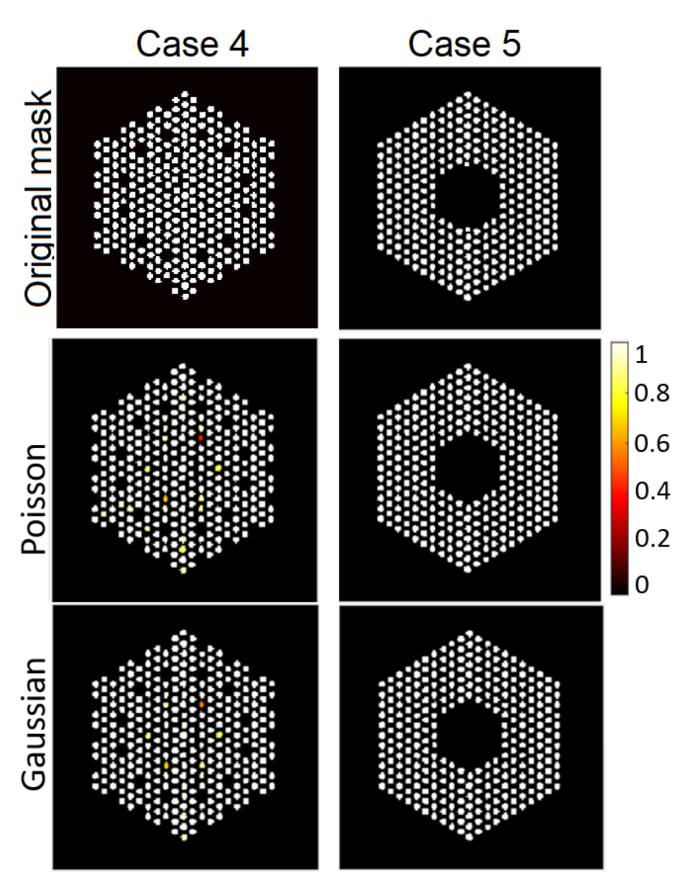{kind=link}
{kind=link}
| SPA-P-BtG | SPA-G-BtG | SPA-P- | SPA-G- | PIDAL- | FISTA- | Ground Truth | |
|---|---|---|---|---|---|---|---|
| Case 1 | 2.00 | 1.49 | 2.244 | 1.65 | 1.512 | 1.524 | 1.51 |
| Case 2 | 2.44 | 1.54 | 2.89 | 1.72 | 1.47 | 1.513 | 1.70 |
| Case 3 | 2.10 | 1.58 | 2.37 | 1.77 | 1.49 | 1.624 | 1.70 |
| Case 4 | 2.25 | 1.61 | 1.68 | 1.83 | 1.57 | 1.68 | 1.70 |
| Case 5 | 2.16 | 1.65 | 2.47 | 1.80 | 1.69 | 1.69 | 1.70 |
| Method | SPA-P-BtG | SPA-G-BtG | SPA-P- | SPA-G- | PIDAL- | FISTA- |
|---|---|---|---|---|---|---|
| Computation time (min) | 50 | 60 | 45 | 55 | 75 | 3 |
| Uncertainty maps | Yes | Yes | Yes | Yes | No | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eldaly, A.K.; Fang, M.; Di Fulvio, A.; McLaughlin, S.; Davies, M.E.; Altmann, Y.; Wiaux, Y. Bayesian Activity Estimation and Uncertainty Quantification of Spent Nuclear Fuel Using Passive Gamma Emission Tomography. J. Imaging 2021, 7, 212. https://doi.org/10.3390/jimaging7100212
Eldaly AK, Fang M, Di Fulvio A, McLaughlin S, Davies ME, Altmann Y, Wiaux Y. Bayesian Activity Estimation and Uncertainty Quantification of Spent Nuclear Fuel Using Passive Gamma Emission Tomography. Journal of Imaging. 2021; 7(10):212. https://doi.org/10.3390/jimaging7100212
Chicago/Turabian StyleEldaly, Ahmed Karam, Ming Fang, Angela Di Fulvio, Stephen McLaughlin, Mike E. Davies, Yoann Altmann, and Yves Wiaux. 2021. "Bayesian Activity Estimation and Uncertainty Quantification of Spent Nuclear Fuel Using Passive Gamma Emission Tomography" Journal of Imaging 7, no. 10: 212. https://doi.org/10.3390/jimaging7100212
APA StyleEldaly, A. K., Fang, M., Di Fulvio, A., McLaughlin, S., Davies, M. E., Altmann, Y., & Wiaux, Y. (2021). Bayesian Activity Estimation and Uncertainty Quantification of Spent Nuclear Fuel Using Passive Gamma Emission Tomography. Journal of Imaging, 7(10), 212. https://doi.org/10.3390/jimaging7100212