
Classification of Geometric Forms in Mosaics Using Deep Neural Network


Abstract
:1. Introduction
2. Related Work
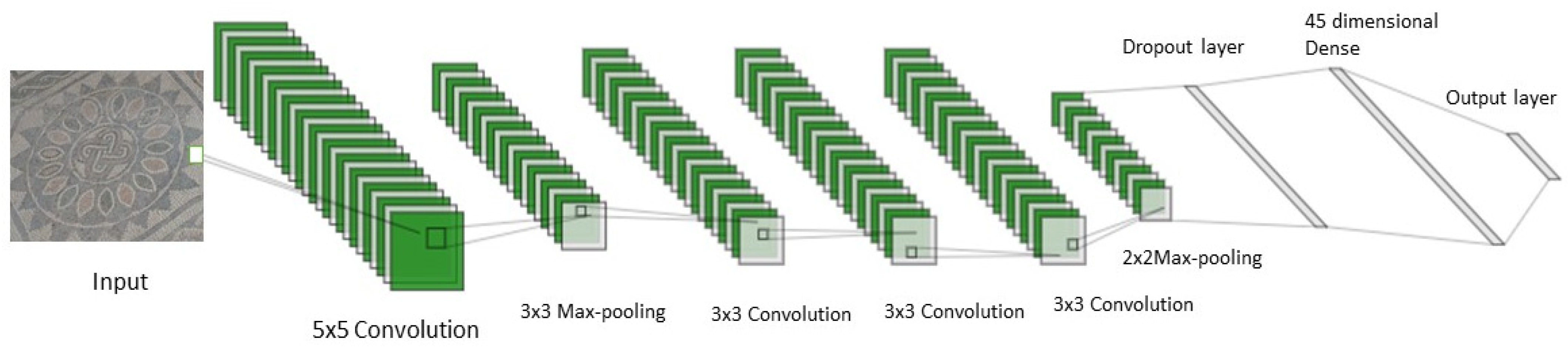
3. Proposed Method
4. Case Study
5. Experiments
5.1. Dataset
5.2. Evaluation Protocol
5.3. Results and Analysis
5.4. Comparison
6. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Barni, M.; Pelagotti, A.; Piva, A. Image processing for the Analyses and Conversation of Paintings: Opportunity and challenges. IEEE Signal Process. Mag. 2005, 22, 141–144. [Google Scholar] [CrossRef]
- Cornelis, B. Image processing for art Investigation. Electron. Lett. Comput. Image Anal. 2014, 14, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Johnson, C.R., Jr.; Hendriks, E.J.; Berezhony, I.; Brevdo, E.; Huges, S.M.; Daubechies, I.; Li, J.; Postma, E.; Wang, J.Z. Image processing for artist identification, Computerizes Analysis of Vincent van Gogh. IEEE Signal Process. Mag. 2008, 25, 37–48. [Google Scholar] [CrossRef]
- Bartolini, F.; Cappellini, V.; Del Mastio, A.; Piva, A. Applications of image processing technologies to fine arts. Opt. Metrol. Arts Multimed. 2003, 5146. [Google Scholar] [CrossRef]
- Berezhnoy, I.E.; Postma, E.O.; van den Herik, H.J. Computerized visual analysis of paintings. Proc. Int. Conf. Assoc. Hist. Comput. 2005, 28–32. Available online: https://repository.ubn.ru.nl/bitstream/handle/2066/32358/32358.pdf?sequence=1#page=29 (accessed on 14 August 2021).
- Teixiera, G.N.; Feitosa, R.Q.; Paciornik, S. Pattern Recognition Applied in Fine Art Authentication; Catholic University of Rio de Janeiro: Rio de Janeiro, Brazil, 2002; Available online: http://www.lvc.ele.puc-rio.br/users/raul_feitosa/publications/2002/Pattern%20recognition%20applied.pdf (accessed on 14 August 2021).
- Amura, A.; Aldini, A.; Pagnotta, S.; Salerno, E.; Tonazzini, A.; Triolo, P. Analysis of Diagnostic Images of Artworks and Feature Extraction: Design of a Methodology. J. Imaging 2021, 7, 53. [Google Scholar] [CrossRef]
- Daffara, C.; Ambrosini, D.; Di Biase, R.; Fontana, R.; Paoletti, D.; Pezzati, L.; Rossi, S. Imaging data integration for painting diagnostics. In Proceedings of the O3A: Optics for Arts, Architecture, and Archaeology II, Munich, Germany, 17–18 June 2009; Volume 7391. [Google Scholar] [CrossRef]
- Cappellini, V.; Barni, M.; Corsini, M.; Rosa, A.D.; Piva, A. Artshop: An art-oriented image processing tool for cultural heritage applications. J. Visual. Comput. Animat. 2003, 14, 149–158. [Google Scholar] [CrossRef]
- Milidiu, R.; Renteria, R. Projeto Pincelada; Pontifícia Universidade Católida do Rio de Janeiro: Rio de Janeiro, Brazil, 1998. [Google Scholar]
- Pei, S.-C.; Zeng, Y.-C.; Chang, C.-H. Virtual Restoration of Ancient Chinese Paintings Using Color contrast Enhancement and Lacuna Texture Synthesis; IEEE: Manhattan, NY, USA, 2004; Volume 13, pp. 416–429. [Google Scholar]
- Bellavia, F.V.; Colombo, C. Color correction for image stitching by monotone cubic spline interpolation. In Proceedings of the 7th Iberian Conference on Pattern Recognition and Image Analysis, Santiago de Compostela, Spain, 17–19 June 2015; Volume 9117, pp. 165–172. [Google Scholar] [CrossRef]
- Zhang, D.; Islam, M.; Lu, G. A review on automatic image annotation techniques. Pattern Recognit. 2012, 45, 346–362. [Google Scholar] [CrossRef]
- Cornelis, B.; Dooms, A.; Cornelis, J.; Schelkens, P. Digital canvas removal in paintings. Signal Process. 2012, 92, 1166–1171. [Google Scholar] [CrossRef]
- Yin, R.; Dunson, D.; Cornelis, B.; Brown, B.; Ocon, N.; Daubechies, I. Digital Cradle Removal in X-ray Images of Art Paintings. In Proceedings of the IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014. [Google Scholar]
- Cornelis, B.; Ruzic, T.; Gezels, E.; Dooms, A.; Pizurica, A.; Platisa, L.; Cornelis, J.; Martens, M.; De Mey, M.; Daubechies, I. Crack detection and in painting for virtual restoration of paintings: The case of the Ghent Altarpiece. Signal Process. 2013, 93, 605–619. [Google Scholar] [CrossRef]
- Cornelis, B.; Yang, Y.; Vogelstein, J.T.; Dooms, A.; Daubechies, I.; Dunson, D. Bayesian crack detection in ultra high resolution multimodal images of paintings. In Proceedings of the 18th International Conference on Digital Signal Processing (DSP), Santorini, Greece, 1–3 July 2013; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Cornelis, B.; Dooms, A.; Munteanu, A.; Cornelis, J.; Schelkens, P. Experimental study of canvas characterization for paintings. In Computer Vision and Image Analysis of Art; SPIE Press: San Jose, CA, USA, 2010. [Google Scholar]
- Barni, M.; Cappellini, V.; Mecocci, A. The use of different metrics in vector median filtering: Application to fine arts and paintings. In Proceedings of the 6th European Signal Processing Conference, Brussels, Belgium, 25–28 August 1992; pp. 1485–1488. [Google Scholar]
- Lu, C.S.; Chung, P.C.; Chen, C.F. Unsupervised texture segmentation via wavelet transformation. Pattern Recognit. 1997, 30, 729–742. [Google Scholar] [CrossRef]
- Chen, C.C.; Chen, C.C. Filtering methods for texture discrimination. Pattern Recognit. Lett. 1999, 20, 783–790. [Google Scholar] [CrossRef]
- Castellano, G.; Vessio, G. Deep learning approaches to pattern extraction and recognition in paintings and drawings: An overview. Neural Comput. Appl. 2021, 1–20. [Google Scholar] [CrossRef]
- Castellano, G.; Vessio, G. Deep convolutional embedding for digitized painting clustering. In Proceedings of the International Conference on Pattern Recognition, Virtual, Milan, 10–15 January 2021. [Google Scholar] [CrossRef]
- Stork, D.G. From Digital Imaging to Computer Image Analysis of Fine Art. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Huang, F., Wang, R.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- Basvaprasad, B.; Hegadi, R.S. A survey on traditional and graph theoretical technique for image segmentation. Inter. J. Comput. Appl. 2014, 957, 8887. [Google Scholar]
- Bazi, Y.; Bruzzone, L.; Melgani, F. Image thresholding based on the EM algorithm and the generalized Gaussian distribution. Pattern Recognit. 2007, 40, 619–634. [Google Scholar] [CrossRef]
- Davies, E.R. Chapter 4—Thresholding Techniques. In Computer and Machine Vision, 4th ed.; Davies, E.R., Ed.; Academic Press: Cambridge, MA, USA, 2012; pp. 82–110. [Google Scholar] [CrossRef]
- Callara, A.L.; Magliaro, C.; Ahluwalia, A.; Vanello. A Smart Region-Growing Algorithm for Single-Neuron Segmentation From Confocal and 2-Photon Datasets. Front. Neuroinform. 2020, 14, 8–12. [Google Scholar] [CrossRef] [Green Version]
- Maeda, J.; Ishikawa, C.; Novianto, S.; Tadehara, N.; Suzuki, Y. Rough and accurate segmentation of natural color images using fuzzy region-growing algorithm. In Proceedings of the 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000. [Google Scholar]
- Peng, B.; Zhang, L.; Zhang, D. A survey of graph theoretical approaches to image segmentation. Pattern Recognit. 2013, 46, 1020–1038. [Google Scholar] [CrossRef] [Green Version]
- Magzhan, K.; Matjani, H. A review and evaluations of shortes path algorithm. Int. J. Sci. Technol. Res. 2013, 2, 99–104. [Google Scholar]
- Yi, F.; Moon, I. Image segmentation: A survey of graph-cut methods. In Proceedings of the IEEE International Conference on Systems and Informatics, Yantai, China, 19–20 May 2012. [Google Scholar]
- Han, P.; Li, Z.; Gong, J. Effects of Aggregation Methods on Image Classification. In Technology for Earth Obs. Geospatial; Li, D., Shan, J., Gong, J., Eds.; Springer: Boston, MA, USA, 2010; pp. 271–288. [Google Scholar] [CrossRef]
- Guedj, B.; Rengot, J. Non-linear Aggregation of Filters to Improve Image Denoising. In Advances in Intelligent Systems and Computing; Arai, K., Kapoor, S., Bhatia, R., Eds.; Springer: Cham, Switzerland, 2020; Volume 1229. [Google Scholar] [CrossRef]
- Hao, X.; Zhang, G.; Ma, S. Deep learning. Int. J. Semant. Comput. 2020, 10, 417–439. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, M.; Mukherjee, H.; Obaidullah, S.M.; Santosh, K.C.; Das, N.; Roy, K. Identifying the presence of graphical texts in scene images using CNN. In Proceedings of the 2019 International Conference on Document Analysis and Recognition, Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Castellano, G.; Vessio, G. A Brief Overview of Deep Learning Approaches to Pattern Extraction and Recognition in Paintings and Drawings. In Proceedings of the 25th International Conference on Pattern Recognition Workshops, Milan, Italy, 10–11 January 2021. [Google Scholar] [CrossRef]
- Castellano, G.; Lella, E.; Vessio, G. Visual link retrieval and knowledge discovery in painting datasets. Multimed. Tools Appl. 2021, 80, 6599–6616. [Google Scholar] [CrossRef]
- Sharma, D.; Gupta, N.; Chattopadhyay, C.; Mehta, S. Daniel: A deep architecture for automatic analysis and retrieval of building floor plans. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 Novmber 2017; pp. 420–425. [Google Scholar]
- Osuna-Coutiño, J.D.J.; Martinez-Carranza, J. Structure extraction in urbanized aerial images from a single view using a CNN-based approach. Int. J. Remote Sens. 2020, 41, 8256–8280. [Google Scholar] [CrossRef]
- Ziran, Z.; Marinai, S. Object detection in floor plan images. In IAPR Workshop on Artificial Neural Networks in Pattern Recognition; Springer: Cham, Switzerland, 2018; pp. 383–394. [Google Scholar]
- Gómez-Ríos, A.; Tabik, S.; Luengo, J.; Shihavuddin, A.S.M.; Krawczyk, B.; Herrera, F. Towards highly accurate coral texture images classification using deep convolutional neural networks and data augmentation. Expert Syst. Appl. 2019, 118, 315–328. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Chen, Q.; Gu, G.; Tao, T.; Zhang, L.; Hu, Y.; Wei, Y.; Zuo, C. Fringe pattern analysis using deep learning. Adv. Photonics 2019, 1, 025001. [Google Scholar] [CrossRef] [Green Version]
- Sandelin, F. Semantic and Instance Segmentation of Room Features in Floor Plans Using Mask R-CNN. Master’s Thesis, Uppsala Universitet, Uppsala, Sweden, 2019. Available online: http://uu.diva-portal.org/smash/record.jsf?pid=diva2%3A1352780&dswid=8811 (accessed on 14 August 2021).
- Vilnrotter, F.M.; Nevatia, R.; Price, K.E. Structural analysis of natural textures. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 1986; Volume 1, pp. 76–89. [Google Scholar]
- Adami, A.; Fassi, F.; Fregonese, L.; Piana, M. Image-Based Techniques For the Survey of Mosaics in the St Mark’s Basilica in Venice. Virtual Archaeol. Rev. 2018, 9, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Doria, E.; Picchio, F. Techniques For Mosaics Documentation Through Photogrammetry Data Acquisition. The Byzantine Mosaics Of The Nativity Church. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 5, 2. [Google Scholar]
- Fioretti, G.; Acquafredda, P.; Calò, S.; Cinelli, M.; Germanò, G.; Laera, A.; Moccia, A. Study and Conservation of the St. Nicola’s Basilica Mosaics (Bari, Italy) by Photogrammetric Survey: Mapping of Polychrome Marbles, Decorative Patterns and Past Restorations. Stud. Conserv. 2020, 65, 160–171. [Google Scholar] [CrossRef]
- Fazio, L.; Lo Brutto, M.; Dardanelli, G. Survey and virtual reconstruction of ancient roman floors in an archaeological context. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 511–518. [Google Scholar] [CrossRef] [Green Version]
- Zitova, B.; Flusser, J.; Łroubek, F. An application of image processing in the medieval mosaic conservation. Pattern Anal. Appl. 2004, 7, 18–25. [Google Scholar] [CrossRef] [Green Version]
- Felicetti, A.; Paolanti, M.; Zingaretti, P.; Pierdicca, R.; Malinverni, E.S. Mo.Se.: Mosaic image segmentation based on deep cascading learning. Virtual Archaeol. Rev. 2021, 12. [Google Scholar] [CrossRef]
- Benyoussef, L.; Derrode, S. Analysis of ancient mosaic images for dedicated applications. In Digital Imaging for Cultural Heritage Preservation—Analysis, Restoration, and Reconstruction of Ancient Artworks; Filippo., S., Sebastiano, B., Giovanni, G., Eds.; CRC Press: Boca Raton, FL, USA, 2017; 523p. [Google Scholar]
- Falomir, Z.; Museros, L.; Gonzalez-Abril, L.; Velasco, F. Measures of similarity between qualitative descriptions of shape, colour and size applied to mosaic assembling. J. Vis. Commun. Image Represent. 2013, 24, 388–396. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, M.; Mukherjee, H.; Obaidullah, S.M.; Santosh, K.C.; Das, N.; Roy, K. LWSINet: A deep learning-based approach towards video script identification. Multimed. Tools Appl. 2021, 1–34. [Google Scholar] [CrossRef]
- Ghosh, M.; Roy, S.S.; Mukherjee, H.; Obaidullah, S.M.; Santosh, K.C.; Roy, K. Understanding movie poster: Transfer-deep learning approach for graphic-rich text recognition. Vis. Comput. 2021, 1–20. [Google Scholar] [CrossRef]
- Gherardini, F.; Santachiara, M.; Leali, F. Enhancing heritage fruition through 3D virtual models and augmented reality: An application to Roman artefacts. Virtual Archaeol. Rev. 2019, 10, 67–79. [Google Scholar] [CrossRef]
- Santachiara, M.; Gherardini, F.; Leali, F. An Augmented Reality Application for the Visualization and the Pattern Analysis of a Roman Mosaic. In IOP Conference Series: Materials Science and Engineering, Kuala Lumpur, Malaysia, 13–14 August 2018; IOP Publishing: Bristol, UK, 2018; Volume 364, p. 012094. [Google Scholar]
- Ippolito, A.; Cigola, M. Handbook of Research on Emerging Technologies for Digital Preservation and Information Modeling; Information Science Reference: Hersey, PA, USA, 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Dimension | #Parameters |
|---|---|---|
| Convolution 1 | 196 × 196 × 32 | 2432 |
| Max-pool | 3 × 3 | - |
| Convolution 2 | 63 × 63 × 16 | 4624 |
| Convolution 3 | 61 × 61 × 16 | 2320 |
| Convolution 4 | 59 × 59 × 16 | 2320 |
| Max-pool | 2 × 2 | - |
| Dense 1 | 45 | 605,565 |
| Dense 2 | 5 | 230 |
| Total | 617,491 |
| #Fold | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| 5 | 91.40 | 0.9348 | 0.8912 | 0.9100 |
| 7 | 89.68 | 0.9108 | 0.8475 | 0.8714 |
| 10 | 93.61 | 0.9529 | 0.9236 | 0.9367 |
| 12 | 89.19 | 0.9159 | 0.8879 | 0.8960 |
| Epoch | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| 200 | 0.941 | 0.9563 | 0.9252 | 0.9395 |
| 300 | 96.81 | 0.9742 | 0.9599 | 0.9667 |
| 400 | 95.82 | 0.9658 | 0.9505 | 0.9578 |
| 500 | 97.05 | 0.9645 | 0.9658 | 0.9651 |
| 600 | 93.37 | 0.9459 | 0.9189 | 0.9313 |
| 700 | 91.89 | 0.947 | 0.9067 | 0.9246 |
| Batch | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| 50 | 97.05 | 0.9760 | 0.9632 | 0.9693 |
| 100 | 97.05 | 0.9645 | 0.9658 | 0.9651 |
| 150 | 93.61 | 0.9472 | 0.9253 | 0.9354 |
| 200 | 90.37 | 0.9021 | 0.8913 | 0.8966 |
| 250 | 92.87 | 0.9438 | 0.9002 | 0.9184 |
| Circles | Leaves | Octagons | Squares | Triangles | |
|---|---|---|---|---|---|
| Circles | 97.08 | 0 | 0 | 0.019 | 0.009 |
| Leaves | 0 | 94.11 | 0 | 0 | 0.058 |
| Octagons | 0.012 | 0 | 97.46 | 0 | 0.012 |
| Squares | 0.056 | 0 | 0 | 94.33 | 0 |
| Triangles | 0.007 | 0 | 0.007 | 0 | 98.54 |
| Network | Accuracy (%) | Precision | Recall | F-Score |
|---|---|---|---|---|
| VGG19 | 93.90 | 0.9409 | 0.9278 | 0.9343 |
| MobileNetV2 | 89.78 | 0.9056 | 0.8860 | 0.8956 |
| ResNet50 | 84.67 | 0.8478 | 0.8408 | 0.8442 |
| InceptionV3 | 78.55 | 0.7720 | 0.7803 | 0.7761 |
| Proposed | 97.05 | 0.9645 | 0.9658 | 0.9651 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghosh, M.; Obaidullah, S.M.; Gherardini, F.; Zdimalova, M. Classification of Geometric Forms in Mosaics Using Deep Neural Network. J. Imaging 2021, 7, 149. https://doi.org/10.3390/jimaging7080149
Ghosh M, Obaidullah SM, Gherardini F, Zdimalova M. Classification of Geometric Forms in Mosaics Using Deep Neural Network. Journal of Imaging. 2021; 7(8):149. https://doi.org/10.3390/jimaging7080149
Chicago/Turabian StyleGhosh, Mridul, Sk Md Obaidullah, Francesco Gherardini, and Maria Zdimalova. 2021. "Classification of Geometric Forms in Mosaics Using Deep Neural Network" Journal of Imaging 7, no. 8: 149. https://doi.org/10.3390/jimaging7080149
APA StyleGhosh, M., Obaidullah, S. M., Gherardini, F., & Zdimalova, M. (2021). Classification of Geometric Forms in Mosaics Using Deep Neural Network. Journal of Imaging, 7(8), 149. https://doi.org/10.3390/jimaging7080149