1. Introduction
Medical image analysis is an active research field focusing on computational methods for the extraction of clinically useful information from medical images. Research in medical image analysis critically depends on the availability of relevant medical image sets (datasets) for tasks, such as training, testing and validation of algorithms. It is widely accepted that solid medical image analysis research requires the use of sufficiently large datasets. This notion is rooted in classical statistical estimation [
1] and classification [
2] theories and is supported by the state-of-the-art machine learning theory [
3].
Obtaining relevant medical images is challenging and costly, as it requires the cooperation of medical professionals and institutes and alleviation of ethical, legal and often commercial conflicts. For example, making a clinical medical image available for research usually requires a collaborating clinical expert to obtain regulatory approvals, to find a relevant image in an institutional archive, to interpret the image and to remove identifying details. Thus, for research in medical image analysis, relevant images are usually in high demand and short supply. In a recent conference [
4], “the common theme from attendees was that everyone participating in medical image evaluation with machine learning is data starved”. Thus, typical dataset sizes in medical image analysis research are a far cry from the common perception of big data in healthcare [
5].
Since 2012, the deep learning paradigm has revolutionized the field of medical image analysis [
6], underscoring the significance of large image datasets. Thus, researchers are torn between the need for large image datasets, i.e., datasets containing medical images of many subjects, and the cost and effort required to obtain them.
In contrast to classical estimation, detection and classification problems, where sample size planning may yield to analysis [
1,
2,
7,
8,
9,
10,
11], the theoretical understanding of deep learning is limited. The trend is that increasing the training dataset size improves the performance of deep learning networks [
3,
12]. Small datasets are associated with overfitting and poor generalization performance on unseen data [
12]. In the presence of rare pathologies, small datasets are known to result in class imbalance and inadequate training [
4]. Yet, solid objective criteria for dataset size are difficult to obtain, especially in medical image analysis.
In practice, since dataset size is associated with research quality, the research community develops expectations regarding dataset size in medical image analysis. These evolving expectations are reflected in the peer-review process of reputable publication venues, implicitly setting ad-hoc thresholds on dataset size. Thus, a manuscript is accepted for publication or presentation in a reputable venue only if the dataset size is regarded by the referees as sufficiently large. Consequently, dataset sizes appearing in published articles reflect the implicit standard of the research community for dataset size. Since the standard is not static, researchers are often dismayed to discover that the dataset used in their current study, where the number of subjects was previously considered sufficiently large, is no longer up to expectations. This uncertainty leads to marginalization and loss of potentially valuable research.
The purpose of this research is to better understand the temporal trends in the implicit community expectations regarding dataset size. We hypothesize that these expectations grow over time, such that ever-increasing datasets are required for acceptance of a manuscript to a reputable venue. This study provides researchers, funding agencies, program committees and editors with guidelines regarding the community standards for dataset size in current and future medical image analysis research. For example, when preparing a research proposal for a funding agency, our results will allow the investigator to plan the dataset size and its evolution over the research period and to present a convincing justification for the requested dataset cost.
2. Methods
We scanned the proceedings of the annual MICCAI conference from 2011 to 2019 [
13,
14,
15,
16,
17,
18,
19,
20,
21], and carefully extracted the numbers of human subjects included in the datasets used. MICCAI, the acronym for Medical Image Computing and Computer-Assisted Intervention, is a leading conference in the field, with a rigorous peer-review process (typically at least three reviewers, double-blind).
Table 1 shows the number of submitted papers, the number of accepted papers (oral and posters) and the acceptance ratio per year (main conference only, excluding satellite events). We preferred monitoring a conference series rather than an archival journal since the conference review period is shorter than that of quality journals, implying a shorter sampling aperture, hence better temporal sampling.
We focused on studies involving three important imaging modalities: Magnetic Resonance Imaging (MRI), Computed Tomography (CT) and Functional MRI (fMRI). Taken together, this selection covers a substantial portion of the research articles in the MICCAI proceedings. Being well-established modalities, a good number of articles associated with each modality is found in each annual edition of the MICCAI proceedings, allowing meaningful statistical study.
We only considered datasets referring to human subjects rather than animal or other datasets. Given the stringent regulatory framework regarding human data [
22], we believe that the challenges and trade-offs associated with the collection and use of human medical data are unique and justify the exclusion of non-human datasets from this study. Nevertheless, in utero and post-mortem human datasets are included. We define the dataset size to be the number of distinct human subjects rather than the number of test images or similar data structures, as the number of human subjects better reflects the recruitment effort.
We examined each of the 2676 articles in the MICCAI 2011–2019 proceedings, found the 1215 relevant articles and extracted from each article the dataset size. No distinction was made between data used for training, validation, testing or any other use. With few exceptions, articles associated with several imaging modalities were considered with regard to one of the modalities, with preference to fMRI over CT and MRI.
Table 2 shows the number of relevant MICCAI articles, i.e., the articles included in our analysis, per year and imaging modality. The growth in 2018 and 2019 corresponds to the larger overall number of articles in the respective MICCAI conferences (see
Table 1).
To obtain an initial overview of dataset sizes in the MICCAI 2011–2019 conferences (
Section 3), for each year and modality, we present the average, geometric mean and median dataset sizes. In computing the average, to reduce the effect of outliers, we discarded the largest value and smallest value.
The statistical analysis (
Section 4 and
Section 5) had been carried out in two phases. Phase I (
Section 4) had been carried out before MICCAI 2019 took place. Statistical analysis of the 2011–2018 data was performed for each modality separately, using SPSS v.25 (IBM, Armonk NY, USA) and R v.3.6.0 25 (R-Foundation, Vienna, Austria).
p-values were corrected for multiple comparisons using the Benjamini–Hochberg (BH) procedure, with
p < 0.05 considered as significant. Phase I culminated in the release of predictions [
23] regarding dataset sizes in the then-upcoming MICCAI 2019 conference [
21].
In Phase II (
Section 5), the MICCAI 2019 statistics were extracted and compared to the corresponding Phase I predictions. The statistical analysis was then revised to include the 2019 data and cover the entire 2011–2019 period. Based on this analysis, we issue predictions regarding dataset sizes in the MICCAI 2020 conference (its analysis is beyond the scope of this research) and the MICCAI 2021 conference, noting that it has not yet taken place at the time of writing.
4. Statistical Analysis and Prediction—Phase I (2011–2018 Data)
As a preliminary test of the dataset growth hypothesis, we first divided the range of years into two categories: 2011–2014 and 2015–2018. The distributions of the dataset sizes in the two categories were similar and non-normal. A Mann–Whitney U test was carried out to determine if there were differences in dataset sizes between the two time-categories.
For MRI, the median numbers of subjects for 2011–2014 (26) and 2015–2018 (55.5) were statistically significantly different, U = 19.115, p < 0.001.
For CT, the median numbers of subjects for 2011–2014 (18.5) and 2015–2018 (36) were statistically significantly different, U = 8.311, p = 0.006.
For fMRI, the median numbers of subjects for 2011–2014 (37) and 2015–2018 (77) were statistically significantly different, U = 10.493, p = 0.003.
These results corroborate the dataset-growth hypothesis.
Returning to the full Phase-I year range, 2011–2018, we used the natural logarithm (ln) transformation to normalize dataset sizes. Linear regression established that the year (after 2010) could statistically significantly predict the natural logarithm of the dataset size. Throughout this research, in each regression analysis, the regression is based on the whole ensemble of dataset sizes, not on the empirical geometric means. The predictions for 2019 are of special interest since MICCAI 2019 had not yet taken place at the time these predictions were made.
For MRI, the model was statistically significant, F(1,566) = 38.720,
p < 0.001. The model explained 6.2% (adjusted R
2) of the variance in the natural logarithm of dataset sizes. The year was statistically significant (B = 0.189, CI = (0.129, 0.249),
p < 0.001), where B denotes slope and CI is its confidence interval. The regression equation is
where Ê(ln N) is the predicted mean of the natural logarithm of dataset sizes and y is the year. Returning to the original scale of MRI dataset sizes, we obtain
Here, Ĝ(N) is the predicted geometric mean of MRI dataset sizes. The annual growth rate of the predicted geometric mean is about 21%, corresponding to (e
0.189 − 1).
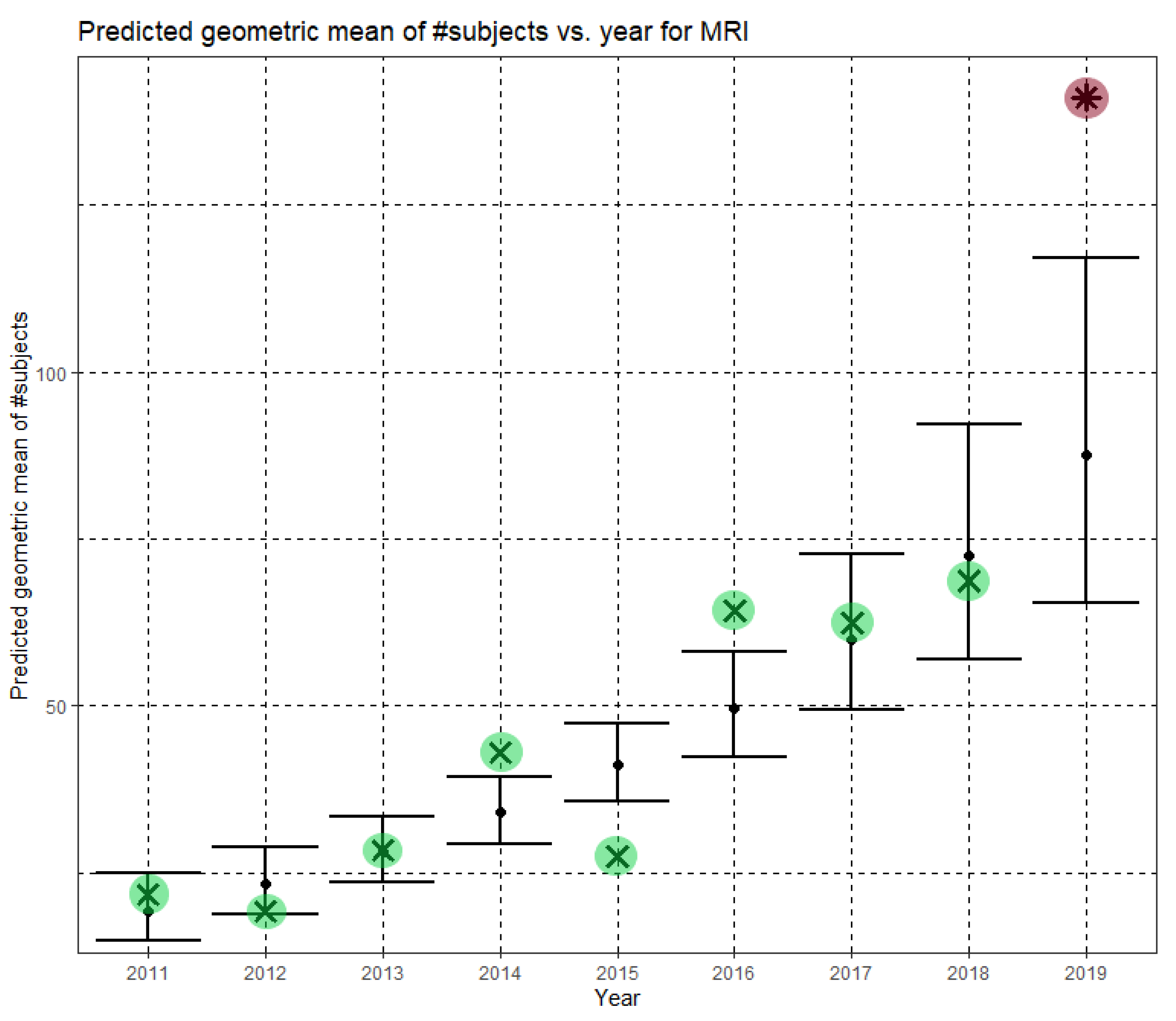
Figure 4 shows Ĝ(N) with its confidence interval for each of the years 2011–2019. The empirical geometric means, taken from
Table 3, are shown (in green) for comparison. We predicted the geometric mean of MRI dataset sizes in MICCAI 2019 to be 87.5, with a confidence interval of (65.5, 116.9). The empirical geometric mean for 2019 (in purple) became available later, in Phase II of this research.
The regression model was statistically significant for CT as well, F(1,221) = 21.273,
p < 0.001. The model explained 8.4% (adjusted R
2) of the variance in the natural logarithm of the dataset sizes. The year was statistically significant (B = 0.213, (CI = 0.122, 0.305),
p < 0.001). The regression equation is
Returning to the original scale of CT dataset sizes, we obtain
In Equation (4), Ĝ(N) is the predicted geometric mean of CT dataset sizes. Here, the annual growth rate of the predicted geometric mean is about 24%.
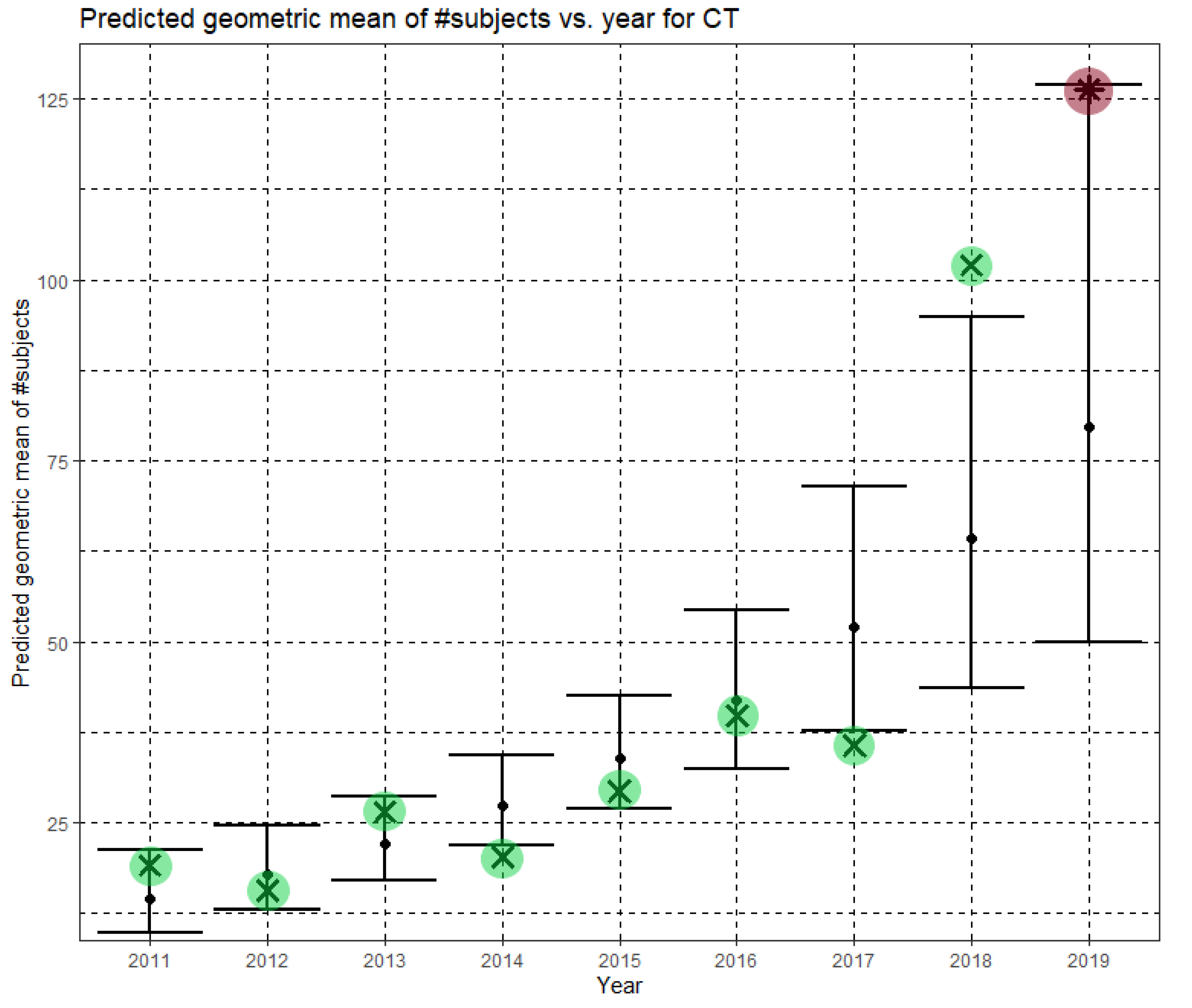
Figure 5 shows Ĝ(N) with its confidence interval for each of the years 2011–2019. The empirical geometric means, taken from
Table 4, are shown (in green) for comparison. We predicted the geometric mean of CT dataset sizes in the MICCAI 2019 conference to be 79.6 with a confidence interval of (49.9, 126.9). The empirical geometric mean for 2019 (in purple) became available later, in Phase II of this research.
Finally, for fMRI, the model was yet again statistically significant, F(1,114) = 27.130,
p < 0.001. The model explained 18.5% (adjusted R
2) of the variance in the natural logarithm of dataset sizes. The year was statistically significant (B = 0.271, CI = (0.168,0.374),
p < 0.001). The regression equation is
Returning to the original scale of fMRI dataset sizes, we obtain
In Equation (6), Ĝ(N) is the predicted geometric mean of fMRI dataset sizes. For fMRI, the annual growth rate of the predicted geometric mean is about 31%.
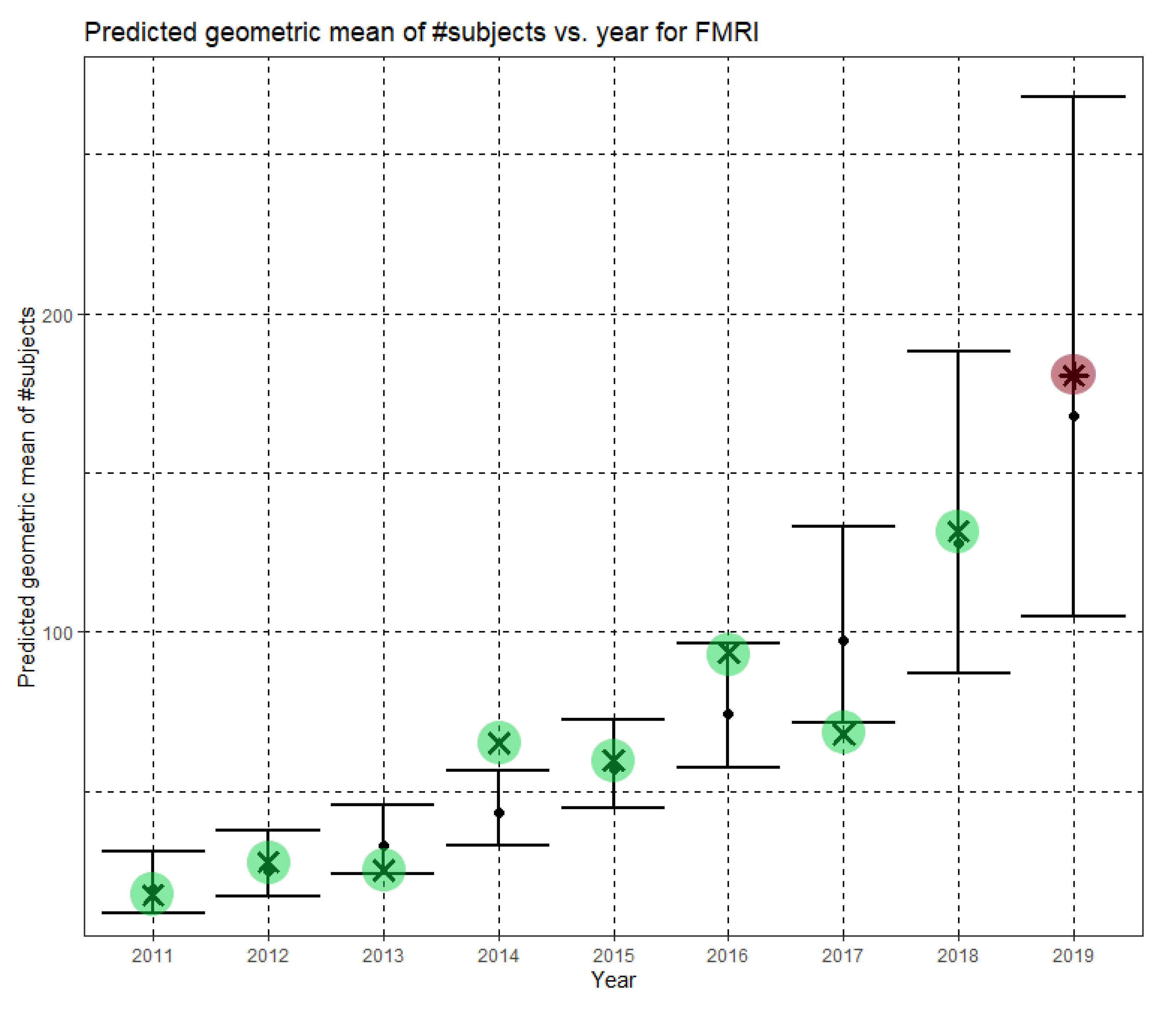
Figure 6 shows Ĝ(N) with its confidence interval for each of the years 2011–2019. The empirical geometric means, taken from
Table 5, are shown (in green) for comparison. We predicted the geometric mean of fMRI dataset sizes in the MICCAI 2019 conference to be 167.7, with a confidence interval of (104.9, 268.0). The empirical geometric mean for 2019 (in purple) became available later, in Phase II of this research.
The low adjusted R
2 values in this section (6.2% for MRI, 8.4% for CT and 18.5% for fMRI) and in the next section require clarification. The regression tasks in this research are unusual because for each imaging modality and for each value of the independent variable (year), there are many (10–187, see
Table 2) disparate values of the dependent variable (dataset size). The values themselves are radically different from each other, as dataset sizes encountered in MICCAI articles can be as small as one or as large as many thousands (where large external datasets are used). This implies a huge inherent variance of the dependent variable at each value of the independent variable. No single-valued hypothetic regression function, regardless of linearity or of any other property, can provide a single prediction at a specific value of the independent variable that simultaneously “explains” hugely different observations of the dependent variable at that point. This is the reason for the inevitably low adjusted R
2 values. The higher adjusted R
2 value for fMRI, compared to MRI and CT, follows from the scarcity of large external fMRI datasets, implying a smaller inherent variance that needs to be “explained”. Nevertheless, our models are statistically significant, and the predicted geometric means are pleasantly close to the empirical ones where the latter are available.
The Phase I analysis, including predictions regarding dataset sizes in MICCAI 2019, had been presented in [
23], before the MICCAI 2019 conference took place.
5. Statistical Analysis and Prediction—Phase II (2011–2019 Data)
Once the MICCAI 2019 proceedings became available, we extracted the dataset sizes and computed the empirical geometric means of dataset sizes for MRI, CT and fMRI (see the 2019 column in
Table 3,
Table 4 and
Table 5, respectively). The 2019 values are shown in purple in
Figure 4,
Figure 5 and
Figure 6. For CT and fMRI, the empirical geometric means are within the confidence intervals of the Phase I analysis. For MRI, the empirical geometric mean of dataset sizes exceeds the confidence interval, indicating dataset growth beyond the Phase I prediction.
Based on the Phase II year range 2011–2019, we updated the statistical analysis. Linear regression again established that the year (after 2010) can statistically significantly predict the natural logarithm of the dataset size. Here too, the regression is based on the whole ensemble of dataset sizes, not on the empirical geometric means. The predictions for 2020–2021 are of special interest since MICCAI 2021 has not yet taken place, and the MICCAI 2020 data has not yet been analyzed at the time of writing. For MRI, the Phase II model was statistically significant, F(1,753) = 104.727,
p < 0.001. The model explained 12.09% (adjusted R
2) of the variance in the natural logarithm of dataset sizes. The year was statistically significant (B = 0.240, CI = (0.194,0.286),
p < 0.001), where B denotes slope and CI is its confidence interval. The Phase II regression equation is
where Ê(ln N) is the predicted mean of the natural logarithm of dataset sizes, and y is the year. Returning to the original scale of MRI dataset sizes, we obtain
Here, Ĝ(N) is the Phase II prediction of the geometric mean of MRI dataset sizes. The annual growth rate of the predicted geometric mean is about 27%, corresponding to (e
0.240 − 1).
Figure 7 shows Ĝ(N) with its confidence interval for each of the years 2011–2021. The empirical geometric means for 2011–2019, taken from
Table 3, are shown (in green) for comparison. We predict the geometric mean of MRI dataset sizes in MICCAI 2020 to be 147.2, with a confidence interval of (116.9, 185.5). We predict the geometric mean of MRI dataset sizes in MICCAI 2021 to be 187.1, with a confidence interval of (142.8, 245.2).
The Phase II regression model was statistically significant for CT as well, F(1,318) = 63.700,
p < 0.001. The model explained 16.4% (adjusted R
2) of the variance in the natural logarithm of dataset sizes. The year was statistically significant (B = 0.266, (CI = 0.200, 0.331),
p < 0.001). The Phase II regression equation is
Returning to the original scale of CT dataset sizes, we obtain
In Equation (10), Ĝ(N) is the Phase II predicted geometric mean of CT dataset sizes. Here, the annual growth rate of the predicted geometric mean is about 30%.
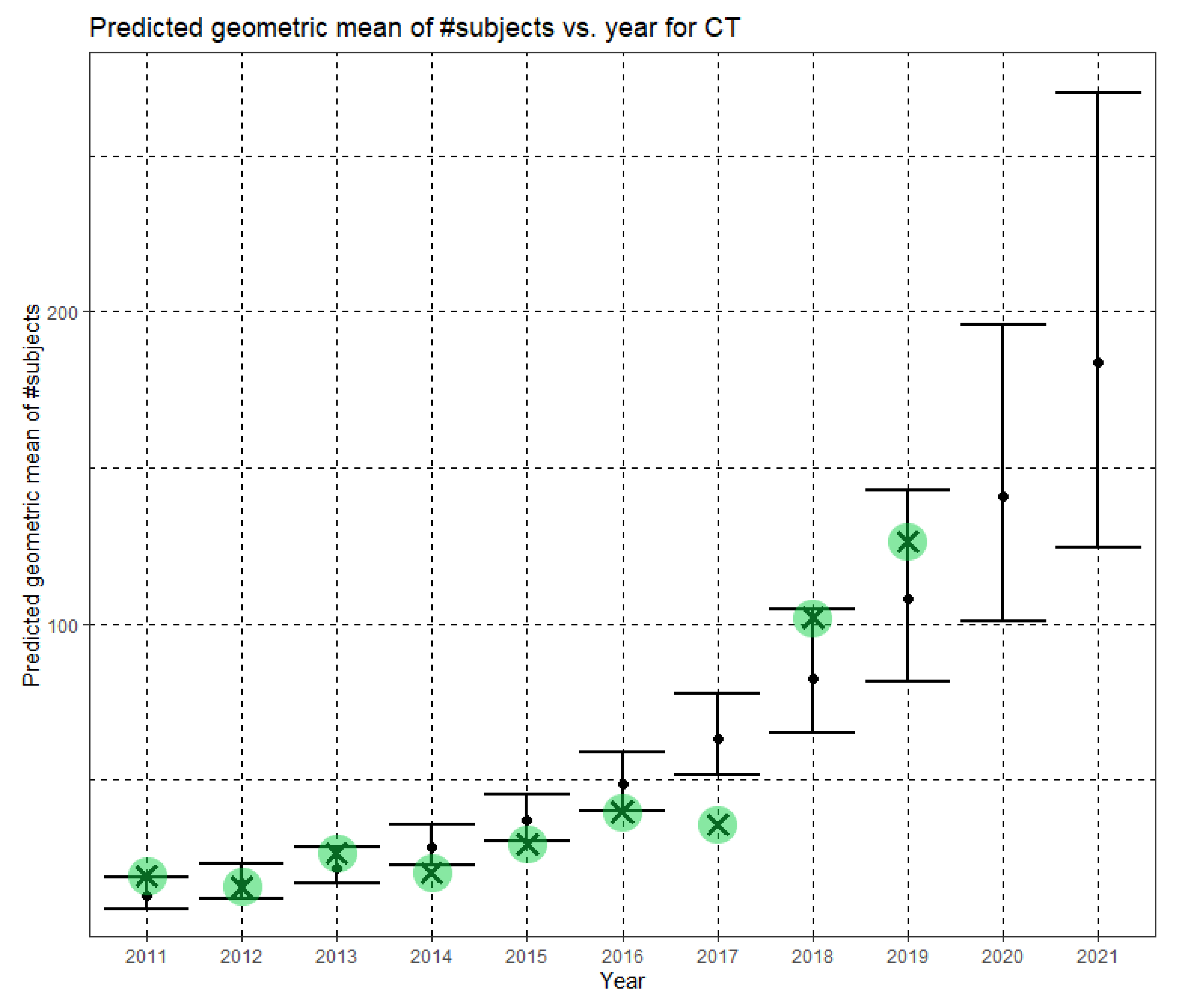
Figure 8 shows Ĝ(N) with its confidence interval for each of the years 2011–2021. The empirical geometric means for 2011–2019, taken from
Table 4, are shown (in green) for comparison. We predict the geometric mean of CT dataset sizes in MICCAI 2020 to be 140.7, with a confidence interval of (101.1, 196.0). We predict the geometric mean of CT dataset sizes in MICCAI 2021 to be 183.6, with a confidence interval of (124.7, 270.2).
Finally, for fMRI, the Phase II model was yet again statistically significant, F(1,138) = 42.545,
p < 0.001. The model explained 23.0% (adjusted R
2) of the variance in the natural logarithm of dataset sizes. The year was statistically significant (B = 0.277, CI = (0.193,0.361),
p < 0.001). The Phase II regression equation is
Returning to the original scale of fMRI dataset sizes, we obtain
In Equation (12), Ĝ(N) is the Phase II predicted geometric mean of fMRI dataset sizes. For fMRI, the annual growth rate of the predicted geometric mean is about 32%.
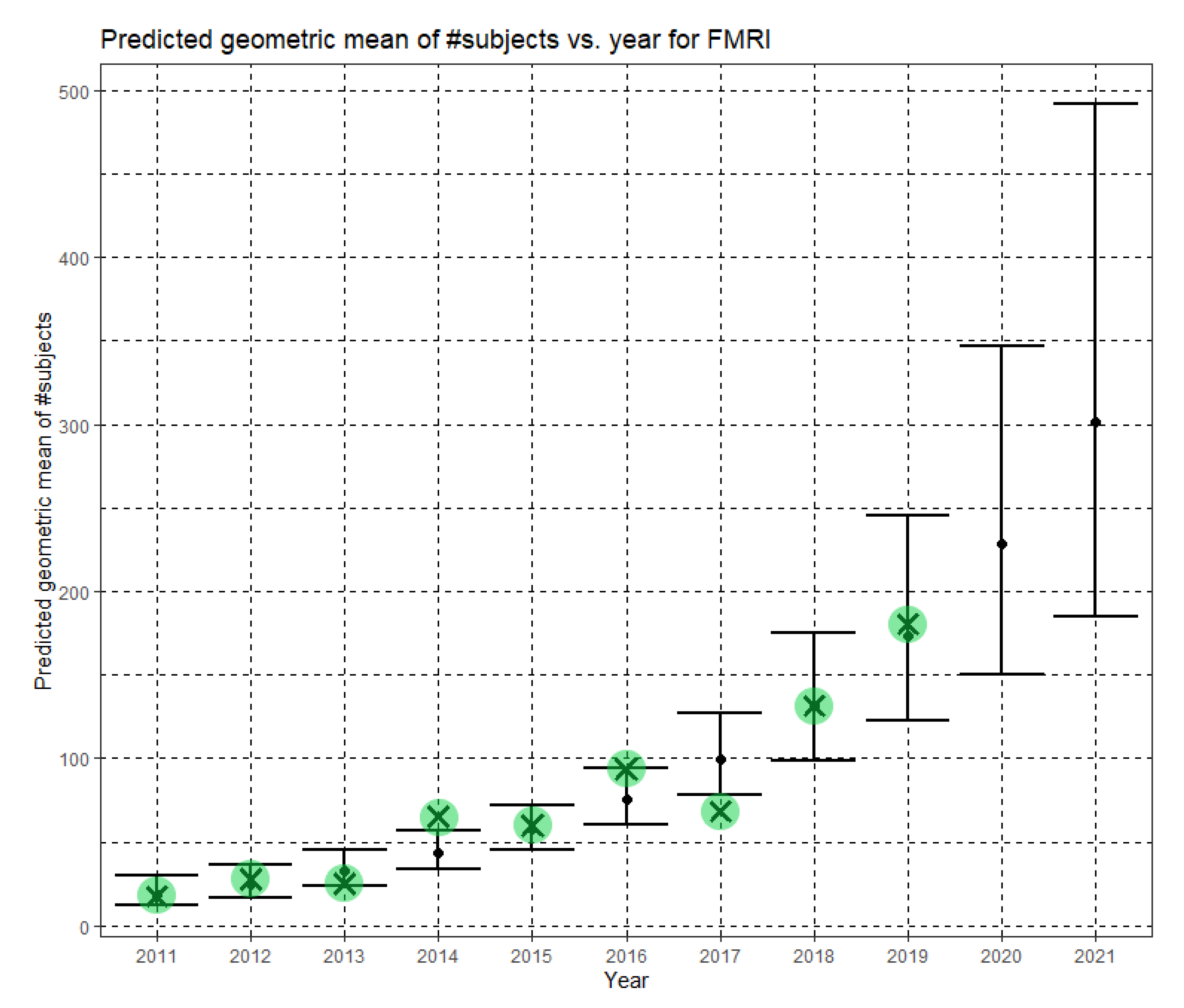
Figure 9 shows Ĝ(N) with its confidence interval for each of the years 2011–2021. The empirical geometric means for 2011–2019, taken from
Table 5, are shown (in green) for comparison. We predict the geometric mean of fMRI dataset sizes in MICCAI 2020 to be 228.5, with a confidence interval of (150.6, 346.6). We predict the geometric mean of fMRI dataset sizes in MICCAI 2021 to be 301.4, with a confidence interval of (184.6, 492.1).
6. Discussion
To our knowledge, this research is the first attempt to quantify the evolving, implicit standards of the research community regarding dataset size in medical image analysis research. Compared to common computer vision tasks, acquiring datasets for medical image analysis is difficult and expensive. For example, while annotation of the ImageNet dataset [
25] was based on low-cost crowdsourcing using the Amazon Mechanical Turk, the gold standard for most medical image analysis tasks is reading by a highly qualified radiologist. Therefore, the marginal cost of enlarging a computer vision dataset is often negligible, but the cost of expanding a medical image analysis dataset can be prohibitive. Thus, prior to this research, dataset growth in medical image analysis research was not obvious, and the growth rate could not be deduced from other domains.
In Phase I of this research, we scanned all the 2136 articles published in the MICCAI proceedings from 2011 to 2018. We extracted the dataset sizes from 907 papers relying on human data from three prevalent imaging modalities: MRI, CT and fMRI. Going through so many papers required substantial effort and expertise because dataset size is often not explicitly reported. It is sometimes distributed in different parts of an article or provided as a reference to another publication.
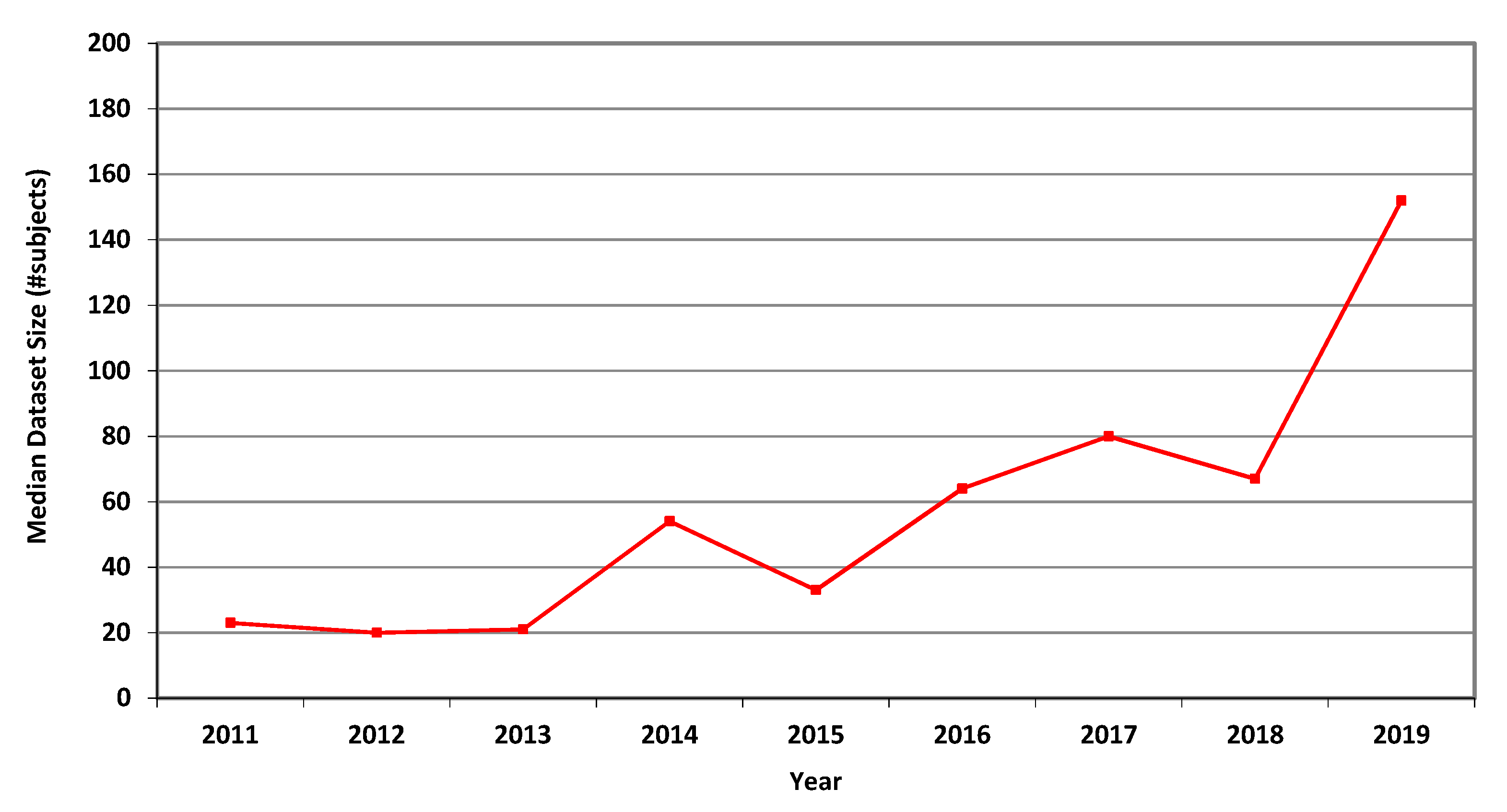
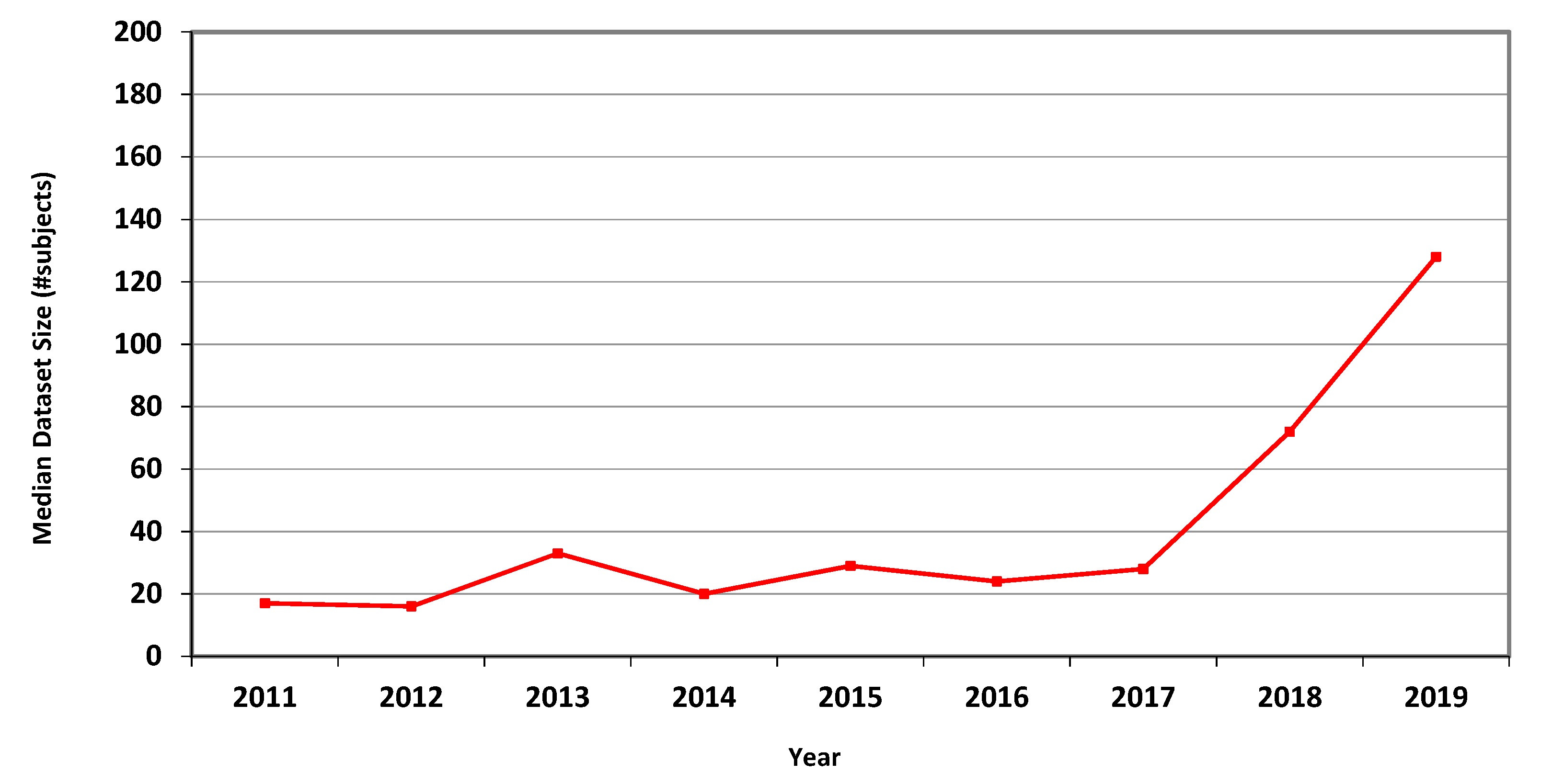
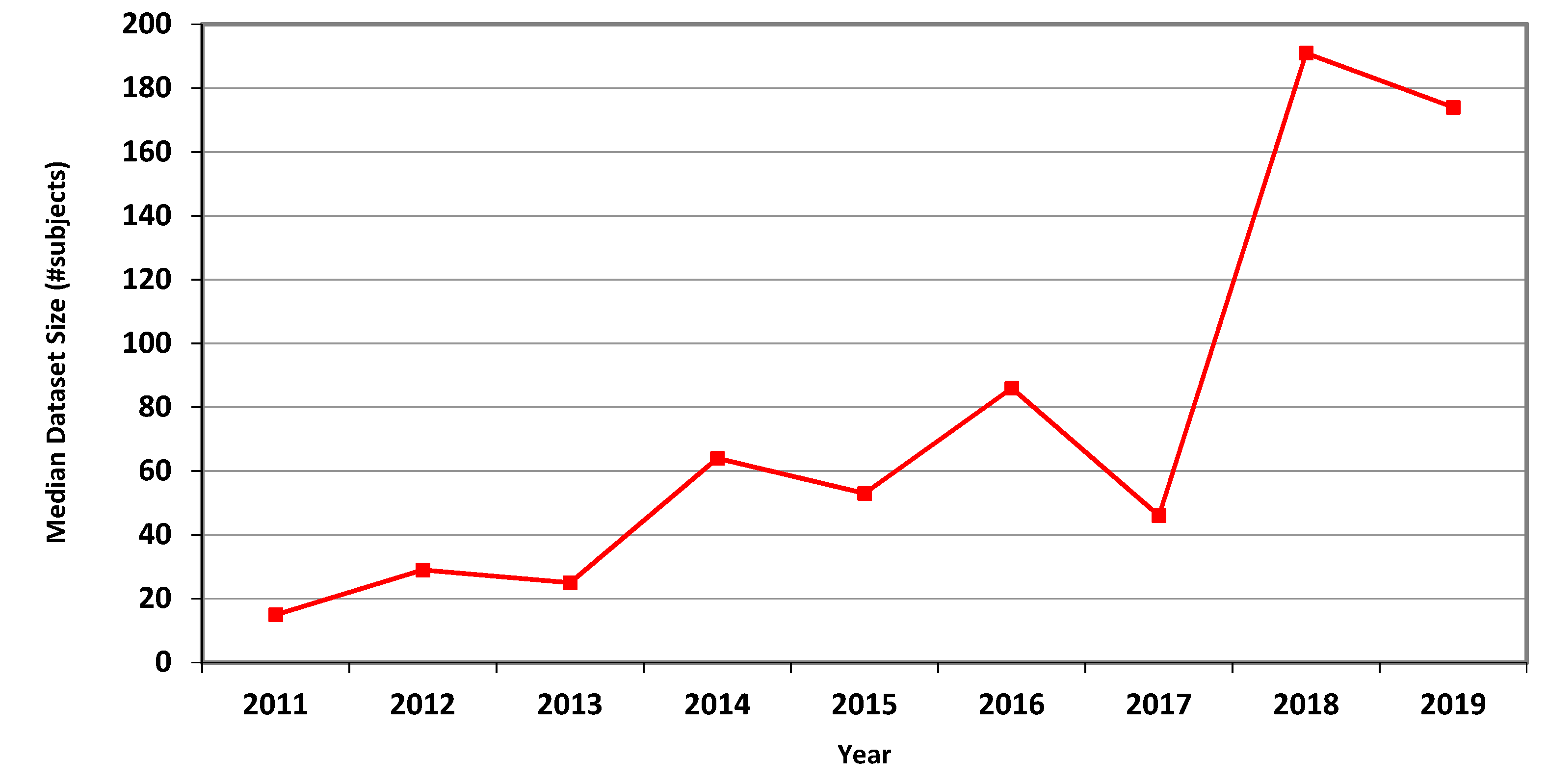
Table 3,
Table 4 and
Table 5 and
Figure 1,
Figure 2 and
Figure 3 describe the data. Human dataset size in MRI-related research nearly trebled from 2011 to 2018, while the CT and fMRI datasets grew at even faster rates. Similar trends are observed in the median, geometric mean and average values, though the average numbers are substantially higher than the median and geometric mean measures due to the occasional use of very large open datasets.
Still in Phase I, statistical analysis using the Mann–Whitney U test corroborated the dataset growth hypothesis for all three modalities. Furthermore, regression analysis revealed statistically significant exponential growth in the geometric mean of the dataset sizes, albeit with large variability. The predicted annual growth rates of the geometric mean of the number of subjects in the datasets were about 21% for MRI, 24% for CT and 31% for fMRI.
For the MICCAI 2019 conference, which had not yet taken place during Phase I of this research, we predicted the geometric mean of the number of subjects in the datasets to be 87.5 with a confidence interval of (65.5, 116.9) for MRI related articles, 79.6 with a confidence interval of (49.9, 126.9) for CT and 167.7 with a confidence interval of (104.9, 268.0) for fMRI.
Phase II of this research incorporated the MICCAI 2019 data. The empirical geometric means in the MICCAI 2019 proceedings were 141.1 for MRI, 126.2 for CT and 180.5 for fMRI. For CT and fMRI, the empirical MICCAI 2019 values are within the confidence intervals of the Phase I predictions. For MRI, they are even beyond the confidence interval of the Phase I prediction. Based on analysis of the MICCAI 2019 data, we updated the regression models. The Phase II annual growth rates of the geometric mean of the number of subjects in the datasets are about 27% for MRI, 30% for CT and 32% for fMRI. In slight analogy to Moore’s law, these estimated growth rates can provide researchers, review boards and funding agencies with a tentative roadmap regarding dataset sizes in future medical image analysis studies.
This study estimated dataset growth in medical image analysis research by analyzing the annual MICCAI conference proceedings. The extension to prominent journals in the field is an interesting topic for future research. Note, however, that the review period for conferences is short, identical for all papers and synchronized by the common submission and reviewing timeline. For reputable journals, the review period is longer, different between papers and unsynchronized. These differences raise substantial analysis challenges. Comparative dataset growth analysis across different scientific domains is an additional interesting future research topic. For example, ImageNet currently contains more than 14 million images. We assume that the growth rate in a particular field depends on the data acquisition and annotation cost in that field.
The perception that “everyone participating in medical image evaluation with machine learning is data starved” [
4] is not surprising given the exponentially increasing expectations regarding dataset size. Transfer learning [
26] and data augmentation [
27] are two popular and often successful strategies to alleviate the shortage of data, see [
28]. Recently, Generative Adversarial Networks (GAN) have been used to create large sets of “fake” but credible new medical images based on a limited collection of genuine images, see [
29]. If accepted by the research community, this strategy may bridge the gap between demand and supply of medical images for use in research and development.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}