

Research on Asphalt Pavement Surface Distress Detection Technology Coupling Deep Learning and Object Detection Algorithms
Abstract
1. Introduction
2. Hardware Selection and Algorithm Principles
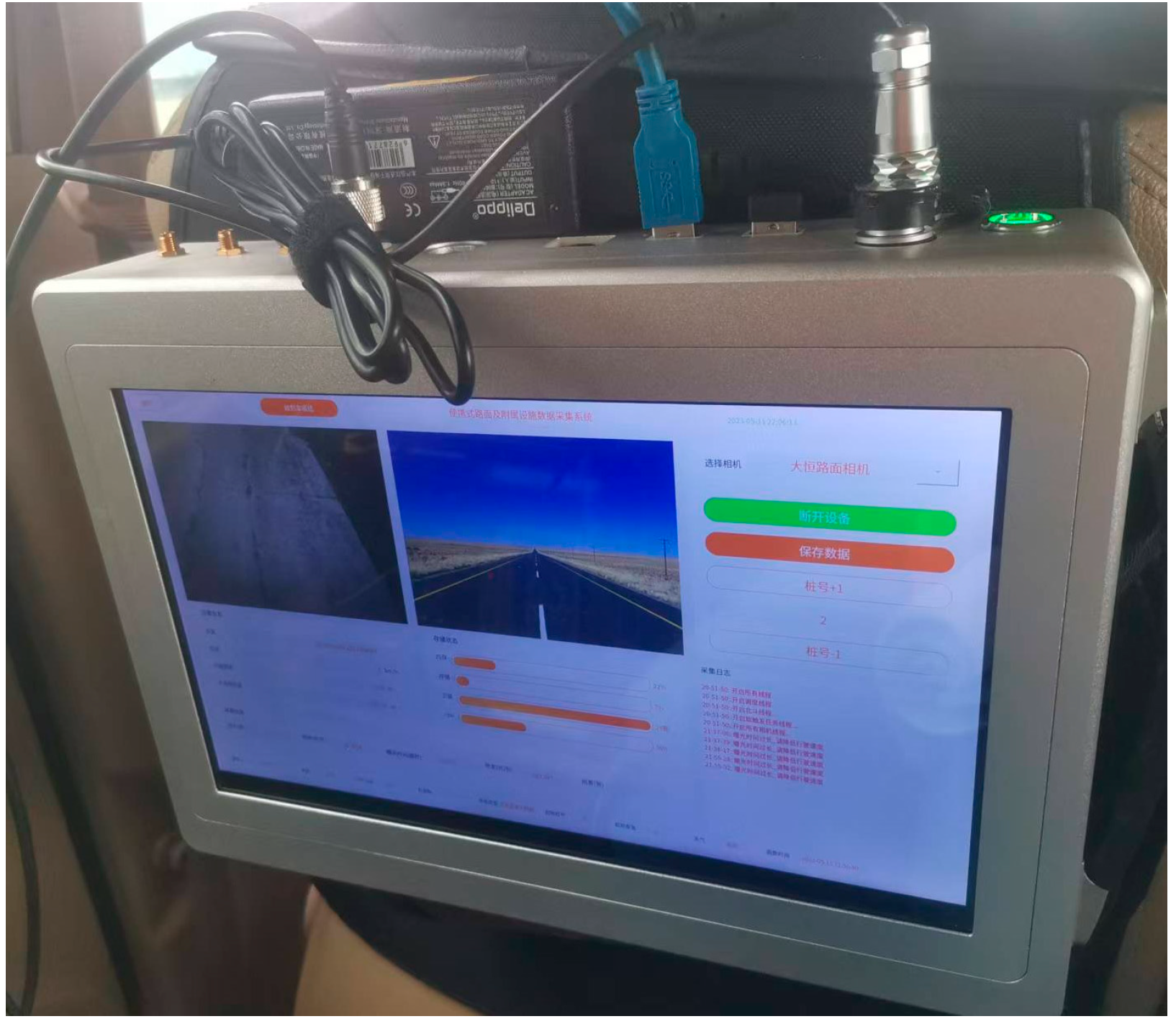
2.1. Hardware Selection
2.1.1. Hardware Platform
2.1.2. Camera Selection
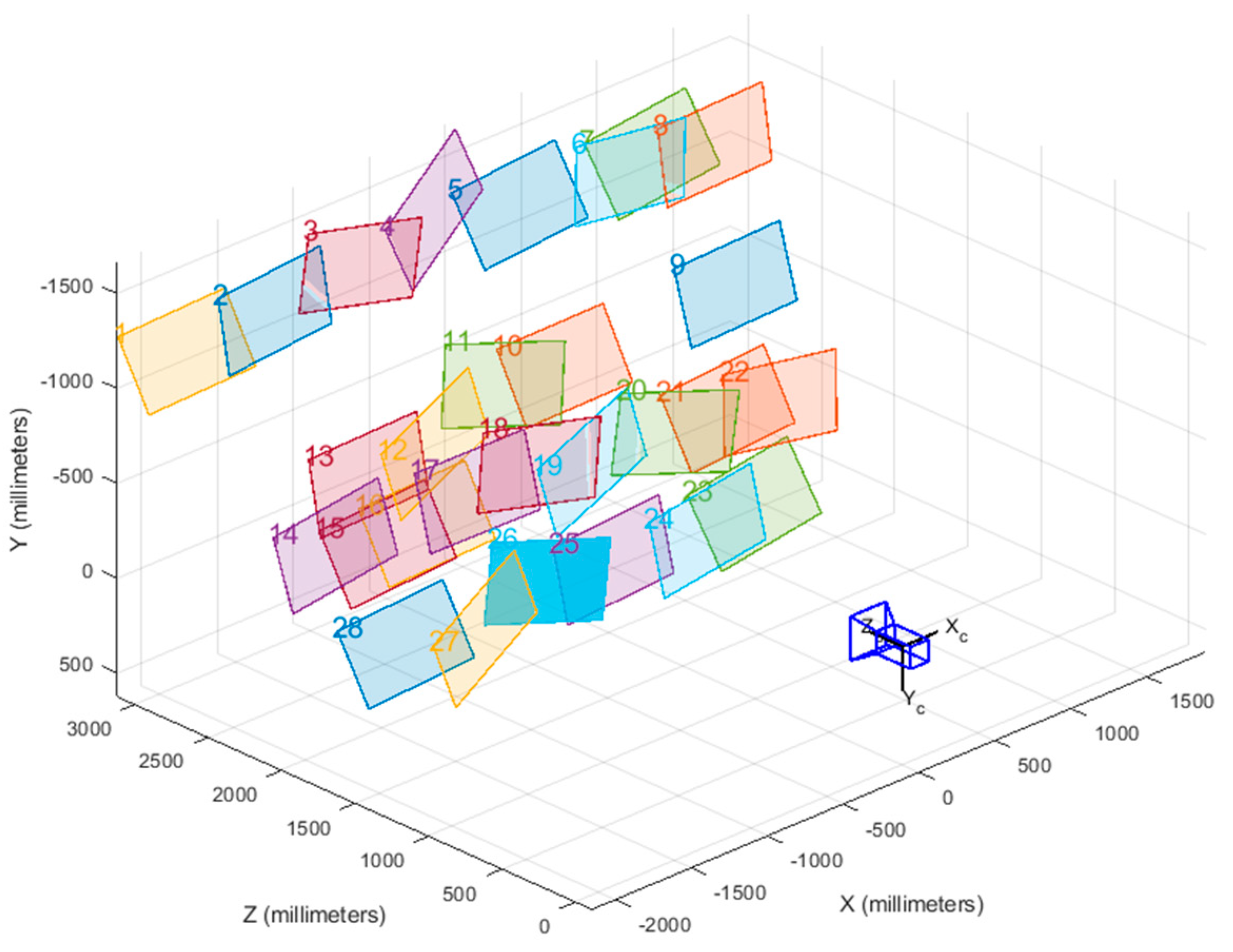
2.1.3. Positioning System
2.1.4. Movable Central Control System
2.1.5. Car Triangular Bracket
2.2. Algorithm Principle and Selection
2.2.1. Data Collection
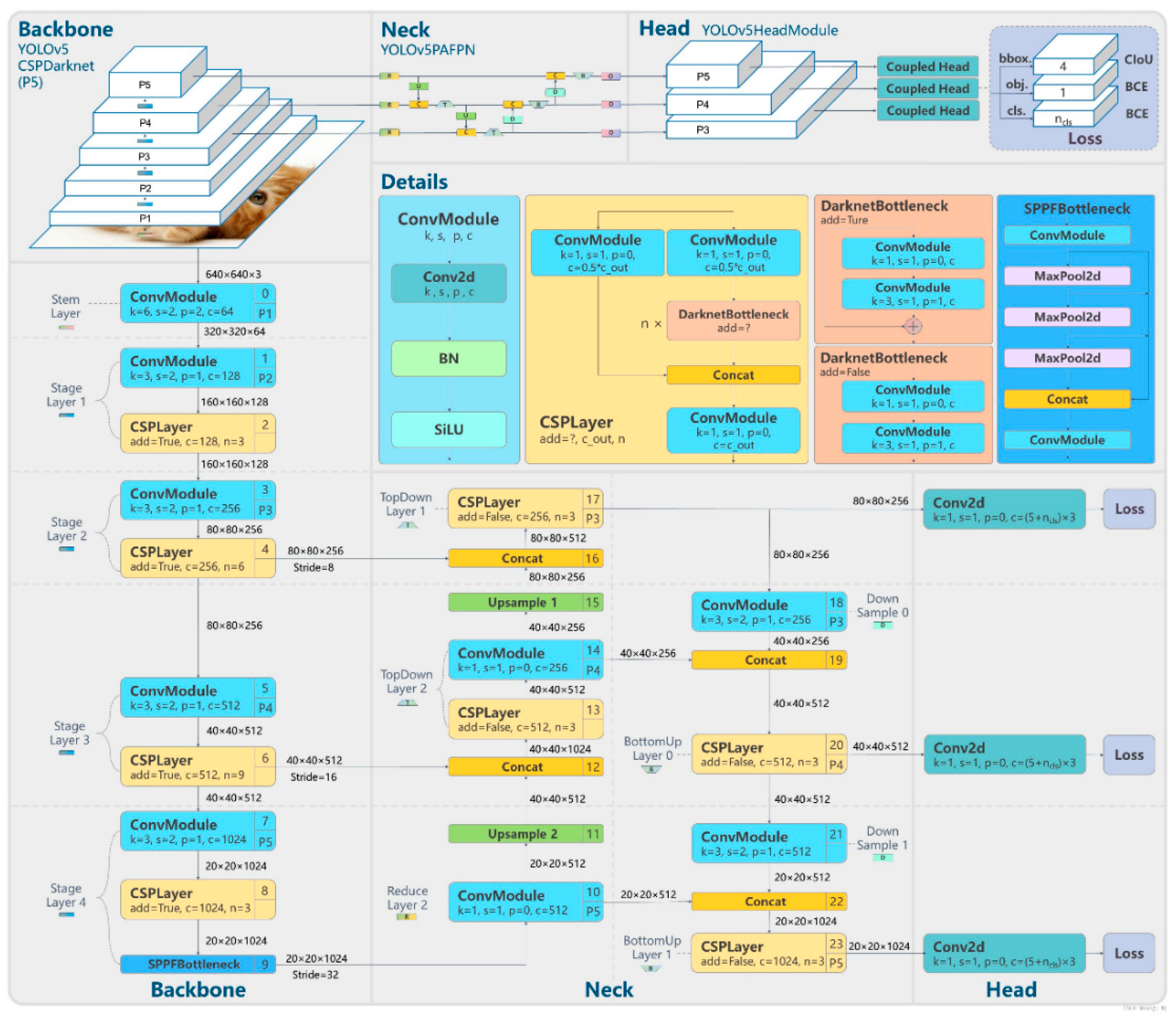
2.2.2. Object Detection Algorithms
3. Research on the Construction of Disease Datasets and Scheme Design
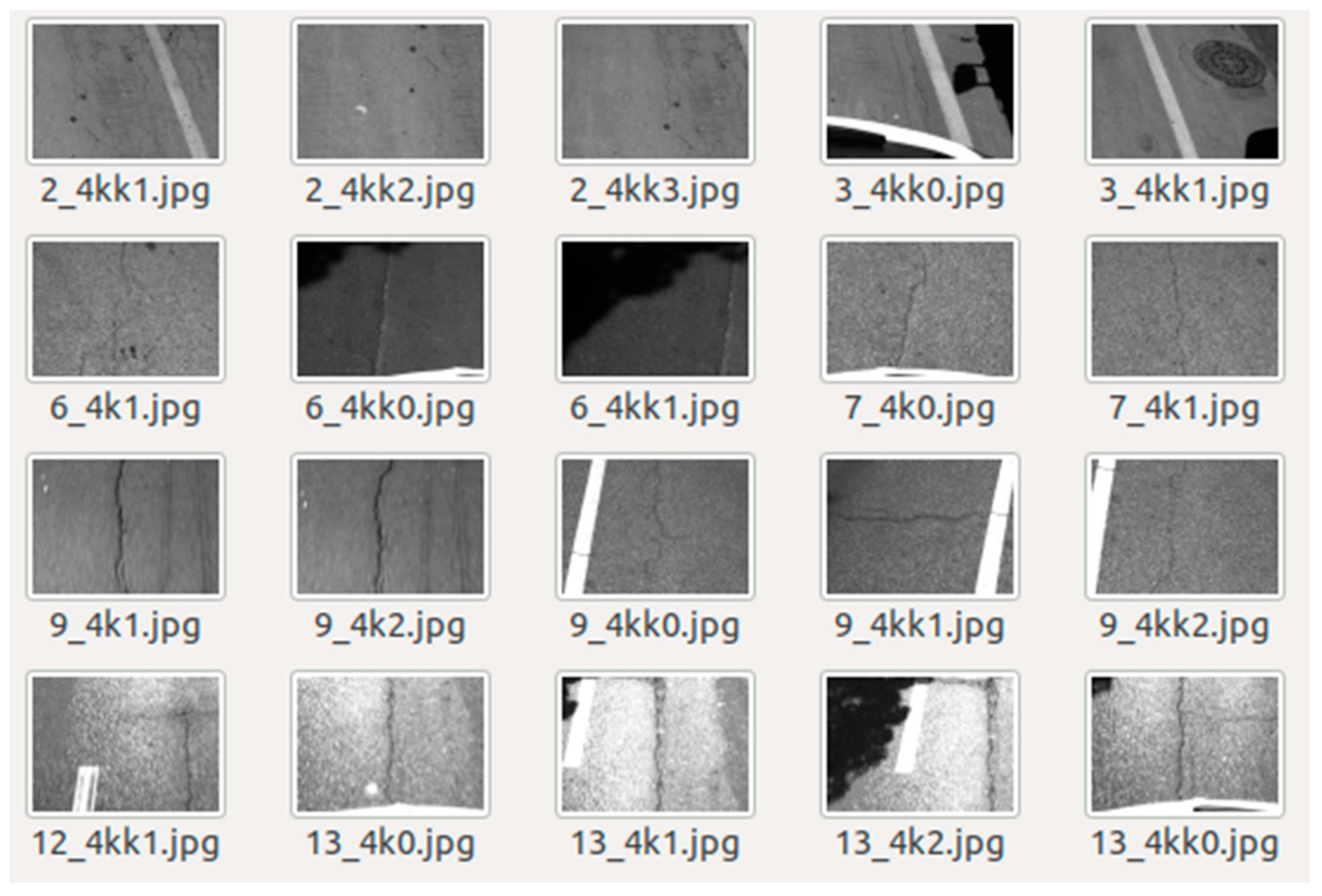
3.1. Construction of Road Disease Detection Dataset
3.2. Model Training Design
3.2.1. Platform Environment Deployment
3.2.2. Dataset Preparation
3.2.3. Training Parameter Adjustments
3.3. Methods for Analyzing Test Results
- (1)
- Recall detection rate
- (2)
- Precision detection rate
- (3)
- False-negative rate
- (4)
- Test results
4. Analysis of Asphalt Pavement Surface Damage Detection Technology
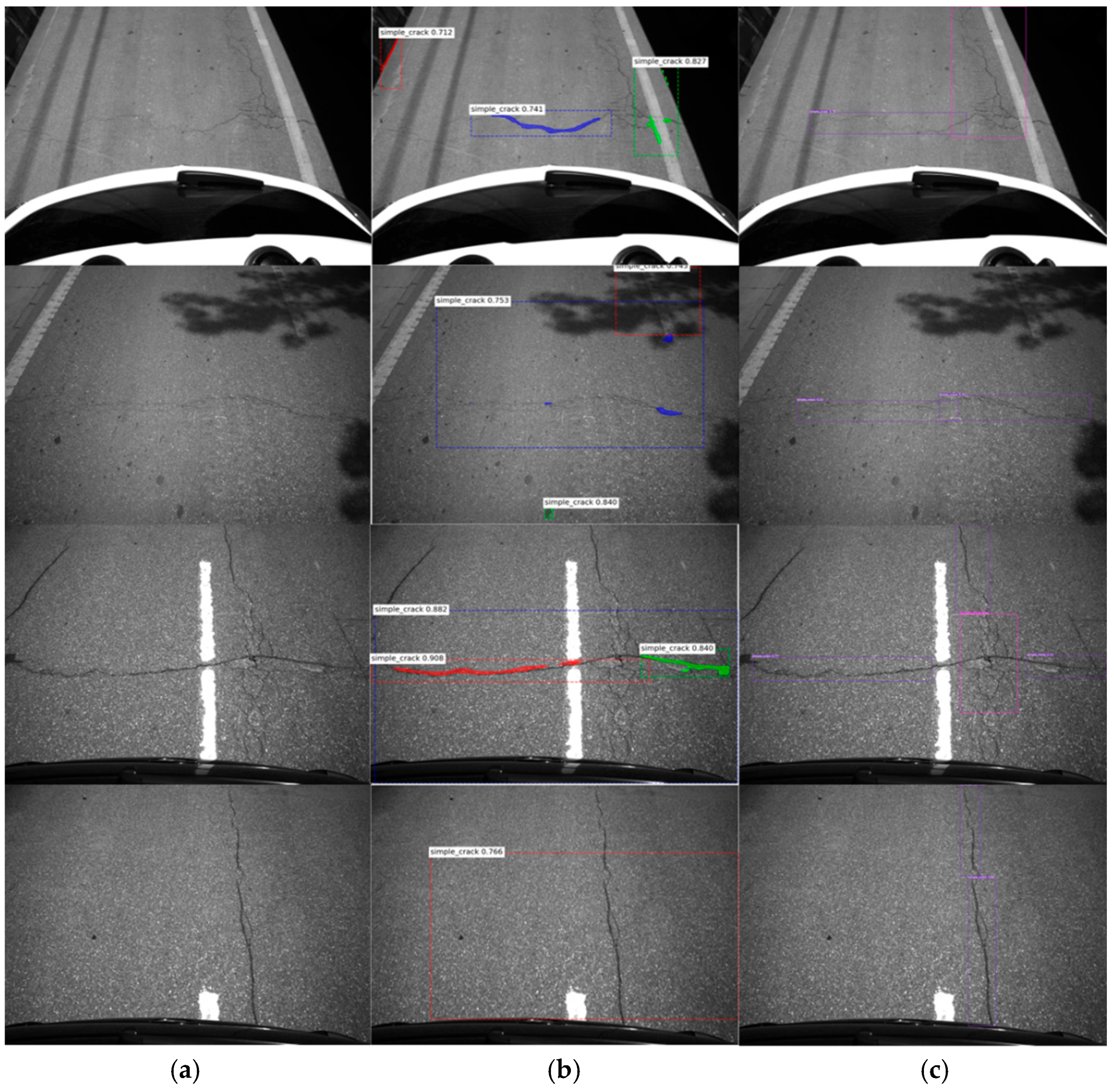
4.1. Demonstration and Analysis of the Experimental Results of Object Detection Algorithm
4.2. Analysis of Camera Calibration Algorithms
4.3. Measurement Index Table
4.4. Analysis of Broken Geometry Information Measurement Algorithm
5. Conclusions
- (1)
- Through the hardware selection and design process, a lightweight and portable pavement distress detection device was assembled, offering an efficient and practical solution for on-site pavement inspection.
- (2)
- By integrating the YOLOv5 object detection algorithm with convolutional deep learning techniques, a model was trained using 85,511 pavement sample images. The final statistical results show an overall false-negative rate of 1.13%, a recall rate of 97.35%, and a precision rate of 98.30%, demonstrating the model’s high accuracy and reliability.
- (3)
- Algorithm validation and analysis confirmed that the distress geometry measurement algorithm can accurately extract physical spatial parameters using only the calibration-generated index table and the semantic segmentation-derived distress mask. The study concludes that the developed pavement distress detection device has significant potential for practical engineering applications.
6. Prospect
- (1)
- This study utilizes a monocular camera, which effectively identifies two-dimensional pavement distresses, such as transverse and longitudinal cracks, alligator cracking, block cracking, and patched areas. However, it currently lacks the capability to accurately detect three-dimensional distresses, such as potholes and subsidence. In the future, a stereo camera system could be implemented, incorporating existing equipment algorithms and advanced technical approaches to enable comprehensive pavement distress detection.
- (2)
- This study focuses solely on pavement distress detection for asphalt surfaces. Given the distinct differences between cement and asphalt pavement distresses, future research could explore established distress recognition methodologies to develop an automated detection system for cement pavement distresses.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 15th IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Ravi, R.; Habib, A.; Bullock, D. Pothole Mapping and Patching Quantity Estimates using LiDAR-Based Mobile Mapping Systems. Transp. Res. Rec. J. Transp. Res. Board 2020, 2674, 124–134. [Google Scholar] [CrossRef]
- Fakhri, S.A.; Satari Abrovi, M.; Zakeri, H.; Safdarinezhad, A.; Fakhri, A. Pavement crack detection through a deep-learned asymmetric encoder-decoder convolutional neural network. Int. J. Pavement Eng. 2023, 24, 2255359. [Google Scholar] [CrossRef]
- Sami, A.A.; Sakib, S.; Deb, K.; Sarker, I.H. Improved YOLOv5-Based Real-Time Road Pavement Damage Detection in Road Infrastructure Management. Algorithms 2023, 16, 452. [Google Scholar] [CrossRef]
- Hedeya, M.A.; Samir, E.; El-Sayed, E.; El-Sharkawy, A.A.; Abdel-Kader, M.F.; Moussa, A.; Abdel-Kader, R.F. A Low-Cost Multi-sensor Deep Learning System for Pavement Distress Detection and Severity Classification. In Proceedings of the 8th International Conference on Advanced Machine Learning and Technologies and Applications (AMLTA2022), Cairo, Egypt, 5–7 May 2022; pp. 21–33. [Google Scholar]
- Matarneh, S.; Elghaish, F.; Al-Ghraibah, A.; Abdellatef, E.; Edwards, D.J. An automatic image processing based on Hough transform algorithm for pavement crack detection and classification. Smart Sustain. Built Environ. 2023. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Zhang, A.A.; Shang, J.; Li, B.; Hui, B.; Gong, H.; Li, L.; Zhan, Y.; Ai, C.; Niu, H.; Chu, X.; et al. Intelligent pavement condition survey: Overview of current researches and practices. J. Road Eng. 2024, 4, 257–281. [Google Scholar] [CrossRef]
- Wang, S.; Cai, B.; Wang, W.; Li, Z.; Hu, W.; Yan, B.; Liu, X. Automated detection of pavement distress based on enhanced YOLOv8 and synthetic data with textured background modeling. Transp. Geotech. 2024, 48, 101304. [Google Scholar] [CrossRef]
- Yuan, B.; Sun, Z.; Pei, L.; Li, W.; Zhao, K. Shuffle Attention-Based Pavement-Sealed Crack Distress Detection. Sensors 2024, 24, 5757. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Wang, C.; Chu, X. Research Progress on Pavement Damage Image Recognition. J. Jilin Univ. Technol. (Eng. Ed.) 2002, 32, 91–97. [Google Scholar]
- Li, L.; Sun, L.; Chen, C. Edge Detection Method for Pavement Damage Image Processing. J. Tongji Univ. (Nat. Sci. Ed.) 2011, 39, 688–692. [Google Scholar]
- Shi, L.; Dang, L.; Yang, L.; Shi, S. Pavement Damage Image Recognition Method Based on Manifold Feature Fusion. Comput. Appl. Softw. 2016, 33, 150–152 + 96. [Google Scholar]
- Zhang, Y.; Li, Q.; Xue, F.; Yu, L. Design of Pavement Crack Detection System Based on Jetson TX2. Highway 2023, 68, 337–344. [Google Scholar]
- Chen, H.; Wang, J. Infrared Asphalt Pavement Crack Detection Method Based on Improved YOLOv5. Telev. Technol. 2023, 47, 43–50. [Google Scholar]
- Zhou, Y.; Zhang, J.; Cao Ji Liu, Y.; Zhang, H. Research on Pavement Pothole Detection Error Compensation Algorithm Based on 3D Laser Technology. J. Highw. Transp. Technol. 2023, 40, 17–24. [Google Scholar]
- Wu, C.; Ti, J.; Ma, J. Digitalization of Asphalt Pavement Maintenance Information Based on Holographic 3D Detection Technology. Guangdong Highw. Transp. 2023, 49, 1–7. [Google Scholar]
- Chen, M.; Zhang, M.; Liu, Z.; Han, Y.; Gu, S. Design and Implementation of a Lightweight Portable Intelligent Pavement Distress Detection System. Eng. Qual. 2022, 40, 74–79. [Google Scholar]
- Chen, X.; Gao, H.; Yang, Z.; Kong, T.; Che, R. Research on Pavement Crack Detection and Recognition Based on Improved Yolov5s. Softw. Guide 2014. [Google Scholar]
- Wang, Y.; Zhou, C.; Wang, Y.; Li, W. Digital Research on Pavement Distress Based on Improved YOLOv8 Algorithm. Highway 2024, 69, 350–356. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone Network | Model Depth | The Width of the Interstory Passage | Parameter Size/KB |
|---|---|---|---|
| YOLOv5s | 0.33 | 0.5 | 14,468 |
| YOLOv5m | 0.67 | 0.75 | 42,367 |
| YOLOv5l | 1.0 | 1.0 | 93,086 |
| YOLOv5x | 1.33 | 1.25 | 173,370 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Dong, Y.; Hou, Y.; Cheng, X.; Xie, P.; Di, K. Research on Asphalt Pavement Surface Distress Detection Technology Coupling Deep Learning and Object Detection Algorithms. Infrastructures 2025, 10, 72. https://doi.org/10.3390/infrastructures10040072
Zhang H, Dong Y, Hou Y, Cheng X, Xie P, Di K. Research on Asphalt Pavement Surface Distress Detection Technology Coupling Deep Learning and Object Detection Algorithms. Infrastructures. 2025; 10(4):72. https://doi.org/10.3390/infrastructures10040072
Chicago/Turabian StyleZhang, Hong, Yuanshuai Dong, Yun Hou, Xiangjun Cheng, Peiwen Xie, and Keming Di. 2025. "Research on Asphalt Pavement Surface Distress Detection Technology Coupling Deep Learning and Object Detection Algorithms" Infrastructures 10, no. 4: 72. https://doi.org/10.3390/infrastructures10040072
APA StyleZhang, H., Dong, Y., Hou, Y., Cheng, X., Xie, P., & Di, K. (2025). Research on Asphalt Pavement Surface Distress Detection Technology Coupling Deep Learning and Object Detection Algorithms. Infrastructures, 10(4), 72. https://doi.org/10.3390/infrastructures10040072