1. Introduction
Road crack detection and crack type classification are necessary to ensure road durability, traffic security and driver safety [
1]. In Morocco, roads are inspected every two years in order to plan the necessary maintenance and reconstruction efforts [
2].
In the past, the detection of road defects was performed visually by specialized agents stopping every 200 m along the road and taking images in order to verify the state of road damage, classify the different types of defects present (e.g., alligator cracking, longitudinal cracking, pothole, transverse cracking) [
2,
3] and then determine the surface condition indicator (ISU) [
2]. Such visual inspections are very time consuming, complex and risky for the inspectors. Since multi-functional road detection systems are safer and objective, the National Center for Road Studies and Research (CNER) acquired, in 2011, a road detection vehicle for the characterization of different road damage types (SMAC). The road condition recording is completed at a vehicle velocity of 100 km/h. The multifunctional pavement assessment vehicle is equipped with three front cameras and three macro cameras operating with high resolution. It also contains lighting equipment for ensuring sufficient brightness during recording at night and GPS/DGPS receivers to record the position of the vehicle [
2,
4].
There are many studies present in the literature describing road surface inspection systems. In 2017, Eisenbach et al., in [
5], used a multifunctional road detection vehicle with an inertial navigation system, laser sensors for evenness and texture measurement, a 2D laser range finder and two cameras. A majority of literature sources report, however, less sophisticated recording equipment being used for such purposes. In many cases, a smartphone mounted on a vehicle is used to acquire the pavement surface images [
6,
7,
8].
In Morocco, the image acquisition method for road defect detection has evolved, but the analysis of the data is still based on traditional image processing performed manually in the CNER laboratory using the image processing software “Argus” [
2,
4]. Since automatic image processing in the field of road infrastructure is very limited in our country, this paper proposes and evaluates a new method for automatic road crack detection using a convolutional neural network (CNN) [
9]. The proposed method allows us to classify the road cracks into three classes: longitudinal, alligator type crack or no crack [
1,
3]. In order to demonstrate the capabilities of the proposed CNN model, the results are also compared with the classification outcome of a pre-trained transfer learning model (Visual Geometry Group 19 [
10]).
In the literature, several deep learning algorithms for image processing were presented to detect road cracks [
8]. In 2016, Zhang et al., in [
6], proposed a method for crack detection from square image patches using ConvNets applied on a database of 500 images. Mandal et al., in [
7], presented a neural network algorithm based on YOLO V2 in 2018, using images obtained from a smartphone mounted on a vehicle. In the same year, Maeda et al., in [
8], demonstrated accuracies of 71% and 77% by applying MobileNet and Inception V2, respectively. In this case, an inference time of 1.5 s, by developing a large-scale image database taken by a vehicle-mounted smartphone, was used. In 2019, Fan et al., in [
11], achieved 99.92% accuracy when applying a deep learning algorithm for adaptive segmentation to extract cracks from the pavement surface. In the same year, a system that uses DCNN to detect and classify the pavement crack was developed [
12]. Another end-to-end CNN model called DeepCrack was applied by Zou et al. in [
13]. Although the results show that DeepCrack achieved an F1 score of over 87%, the model was sensitive to crack image noise. In 2020, Weidong et al., in [
14], used CrackSeg and Mei, in [
15], introduced a GoPro on the back of a vehicle in order to implement the ConnCrack method, which combines Wasserstein’s adversarial network and connectivity maps. Fan et al., in [
16], proposed an algorithm that uses an encoder–decoder architecture with hierarchical feature learning and dilated convolution (U-HDN), and Sheta et al., in [
17], achieved an average accuracy of 97.27% working on a lightweight convolutional neural network model used in real time. Fan et al., in [
18], proposed an ensemble of convolutional neural networks without a pooling layer using two public crack databases: CFD and AigleRN. The results indicated that a good crack detection from measured recording was achieved. In 2021, Fan et al., in [
19], built a new RAO-UNet pavement crack detection model using an encoder–decoder and achieved better performance in processing speed and detection accuracy. In the same year, Hacıefendioğlu et al., in [
20], deduced that the number of cracks detected at concrete road surfaces was independent of weather conditions during recording (sunny day and cloudy day) when they used a new approach based on fast pre-trained R-CNN.
Fan et al., in [
21], proposed a deep residual convolutional neural network called Parallel ResNet for the purpose of detecting cracks at two publicly available datasets (CrackTree200 and CFD). Xu et al., in [
22], developed a new network called The LETNet for crack detection in pavements, which is very effective, especially when dealing with images of cracks recorded with a lot of noise and complex lighting conditions. Xu et al., in [
23], obtained good results by applying Faster R-CNN and Mask R-CNN on a database composed of only 130+ images.
Many studies presented in the literature describe powerful transfer learning algorithms for the detection and classification of road cracks, especially when a large dataset is involved (e.g., the pre-trained CNN architectures AlexNet [
24,
25,
26], VGG-16 [
27,
28,
29], ResNet [
24,
25,
26] SqueezeNet [
23], GoogleNet [
25,
26,
27] and VGG-19 [
10,
30]).
This paper addresses the following aspects of an automated crack detection method and an example of its application for road inspection purposes:
description of a novel inspection solution applied to Moroccan flexible pavement using a multifunctional pavement assessment system vehicle (SMAC) and deep neural networks for automatic crack detection and classification,
application of the classification method on a large dataset extracted from videos captured by high-resolution cameras mounted on a SMAC vehicle,
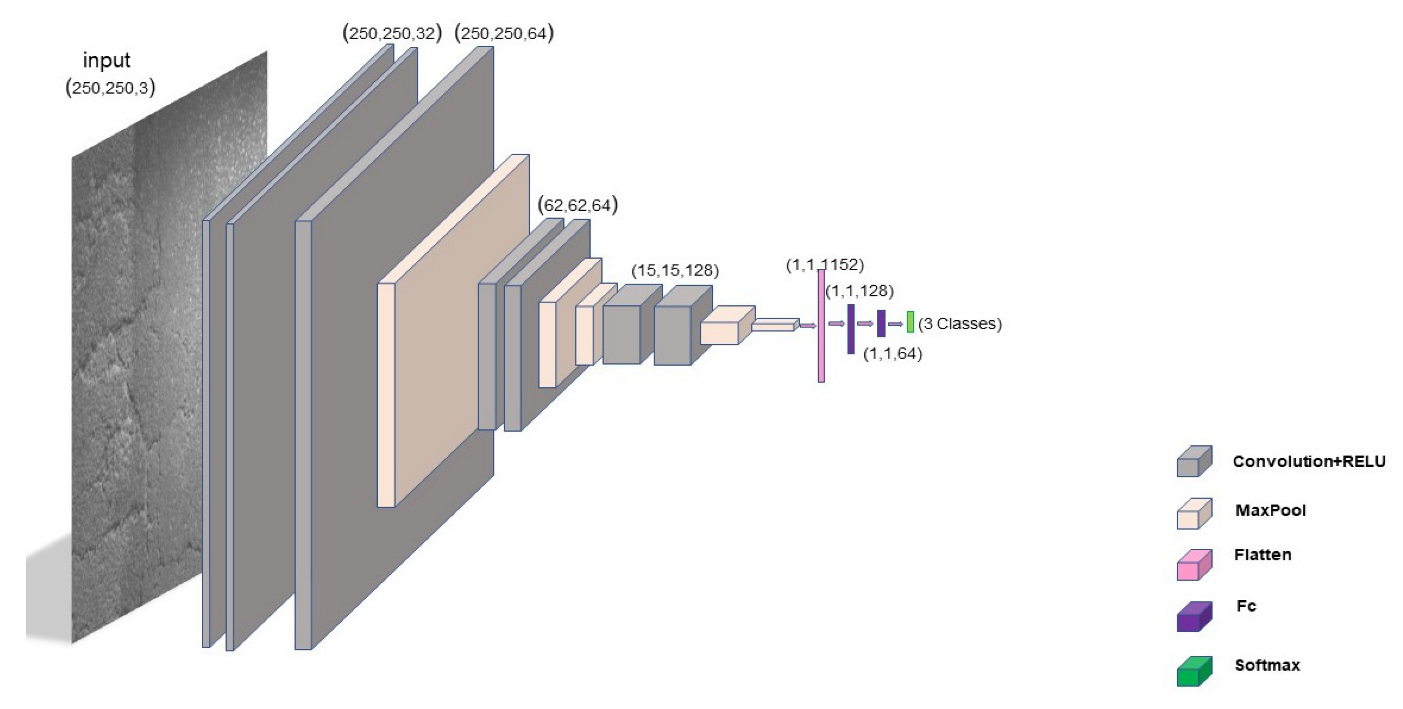
proposal and evaluation of a new method for automatic road crack detection using a convolutional neural network (CNN). The results are further compared with the outcome of a pre-trained transfer-learning VGG-19 model.
This paper is structured as follows: the dataset and methods used are described in
Section 2. The results of the two deep learning models for crack detection and classification are evaluated and discussed in
Section 3. Finally, the main conclusions are summarized in the last section,
Section 4.
3. Results
The performance of the two deep learning models for crack detection and classification was evaluated on a database of 3287 Moroccan road images. The number of parameters for each model is listed in
Table 3. The program is currently implemented in Python code.
The results confirm that the CNN model used requires a lower number of parameters compared with the VGG-19 pre-trained model. As listed in
Table 3, the VGG-19 model contains a four-times higher number of parameters than the CNN. We expect that having more parameters significantly extends the classification time. Additionally, the number of parameters in the VGG-19 model strongly indicates higher complexity of the model compared with the CNN model. In this study, the number of training epochs is set to 40. A larger value of training epochs may extend the training time and lead to overfitting of the models.
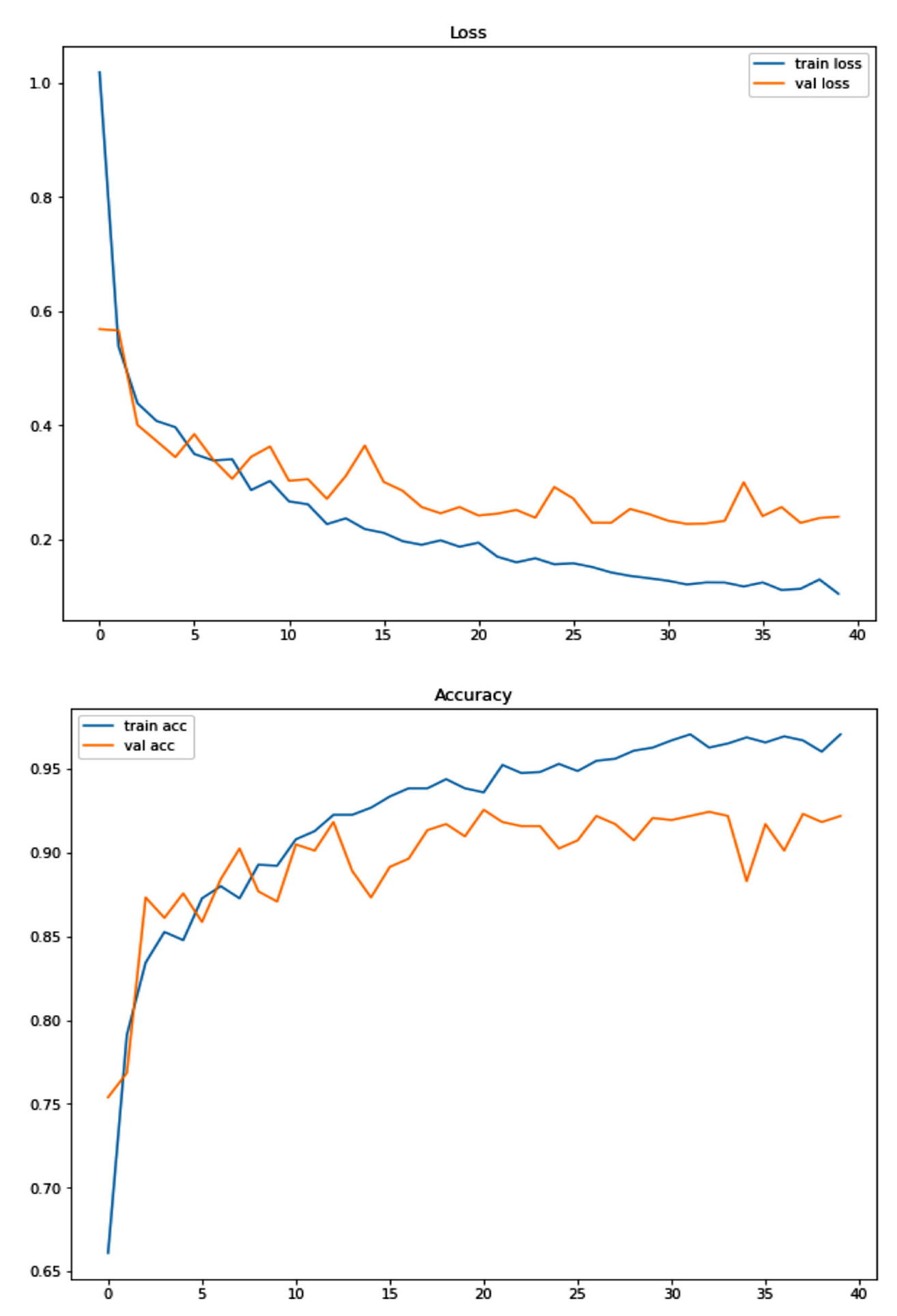
Figure 5 and
Figure 6 summarize the results of the training and validation of the two networks, CNN and VGG-19. The Loss function, observed during training and validation phases, measures the rate of error in the model and, therefore, the performance of the model. The VGG model converged to the minimum loss value of 10.47% at the 40th epoch, and reached the minimum loss value of the validation of 22.72% at the 32nd epoch. The lowest loss value of the proposed CNN model in training is 12.65% at the 40th epoch and, in validation, is 18.65% at epoch 34/40.
The results of our study are listed in
Table 4 and
Table 5. To compare the performance of the new CNN model with the VGG-19 model, a variety of evaluation metrics, such as accuracy, precision, recall and F1-score, are calculated. These measures use the notions of positive and negative.
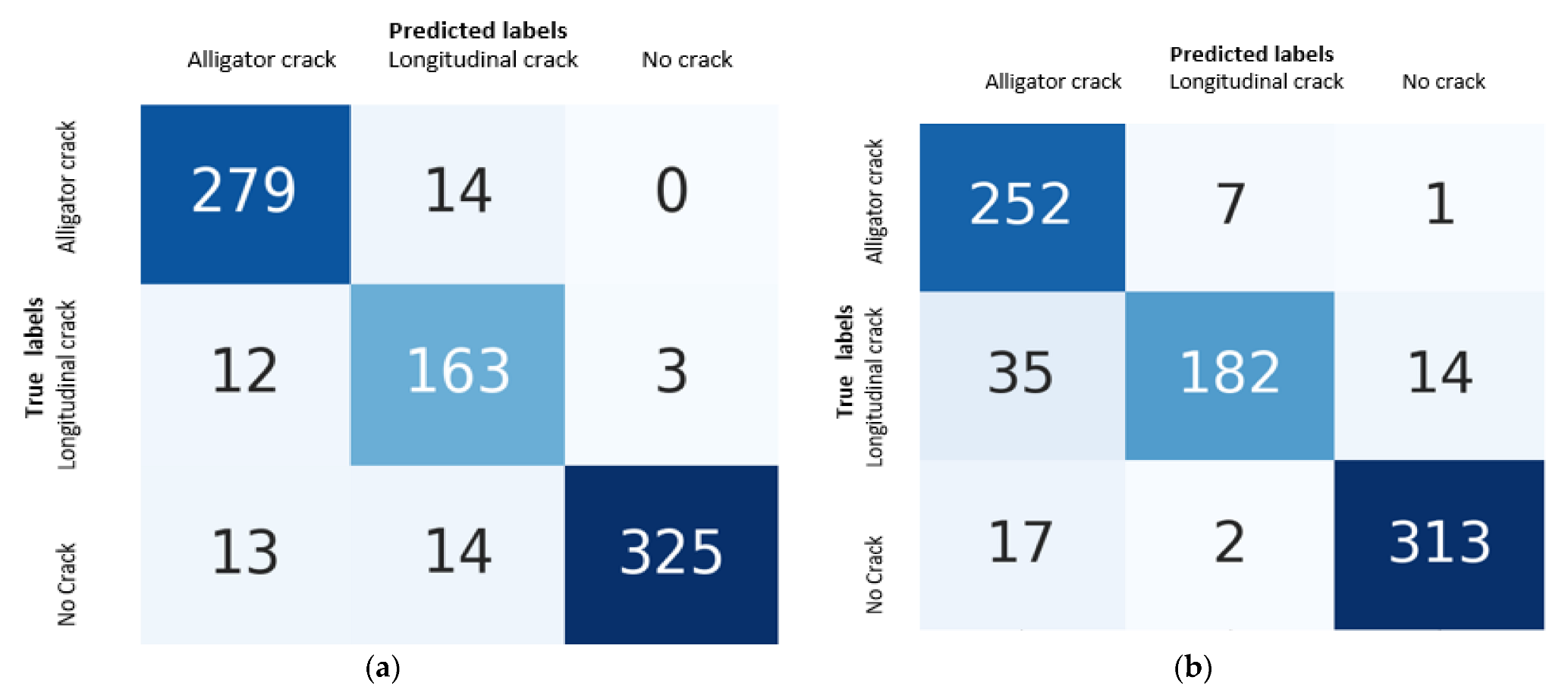
Table 4 shows the values of true positives (TP), true negatives (TN), false positives (FP) and false negatives (TN) calculated from the results of the confusion matrices obtained after testing the two models, CNN and VGG-19, shown in
Figure 7.
Considering a positive class, true positive (TP) is the number of testing images that are correctly classified. True negative (TN) is the number of the negative testing images correctly classified as negatives. False positive (FP) is the number of negative images that are tested and classified as positive. False negative (FN) is the number of positive images that are classified as negative after the test.
In our study, four metrics are used for the evaluation of the proposed networks, which are: accuracy, recall, precision and F1-score. According to Equation (4), the accuracy is defined as the ratio of correctly classified images to the total number of tested images.
Recall is defined as the ratio of positive images correctly identified as positive to the total number of True positive and False negative images, as given by the following Equation (5).
Precision is the ratio of positive images correctly classified as positive to the total number of true positive and false positive according to the following relation:
Finally, the F1-score measures accuracy by using the values of precision and recall based on the following relation:
The values of precision, recall and F1-score of each class in our image dataset are listed in
Table 4. It is observed that the highest F1-score value results for the no crack class are 95.58% for CNN and 94.83% for VGG-19. Both models are most accurate in detecting the no crack class. Moreover, both models are more accurate in the detection of alligator cracks than in the detection of longitudinal cracks. This finding can be explained by the lower number of images of the longitudinal crack class in the database. In our case, the CNN model performs better than the VGG model in detecting all classes.
According to the summarized results in
Table 6, both models show high F1-score values. It means that both models have successfully detected and classified the images into alligator crack, longitudinal crack and no crack. The CNN model performs with an F1-score value of 93.19%, which is higher than the F1-score value of the VGG model (90.76%). The above results show that the proposed CNN network performs better than the pre-trained VGG-19 network.
The results of the proposed models deliver similar performance levels as many studies presented in the literature for solving road crack detection and classification problems, such as using SVM [
6], YOLO V2 [
7] MobileNet and Inception V2 [
8]. However, the comparison with other deep learning algorithms is partially valid due to the fact that different databases for training are used.
4. Conclusions
In this research, we have proposed a methodology for pavement image crack detection and classification utilizing an artificial neural network, particularly, convolutional neural networks applied for the classification of recordings from Moroccan pavement inspection. The performance of two models was evaluated for the detection and classification of cracks in pavement structures. We used a database of 3287 high-definition images extracted from videos captured by high-resolution cameras mounted on the SMAC vehicle. We found that the accuracy and F1-score of the CNN model are slightly higher compared with those of the VGG-19 model, while the complexity and training duration of the latter, caused by a larger network size, are significantly higher. This indicates that the crack detection and classification are more accurately achieved with the CNN model, even though it contains fewer convolution layers than the VGG-19 pre-trained model. The proposed CNN model requires a smaller number of parameters compared to the pre-trained model, resulting in better performance.
The results showed that the F1-score result of the alligator cracks, 93.45% for CNN and 89.34% for VGG-19, is larger than the results of longitudinal cracks: 88.53% for CNN and 86.24% for VGG-19. It is concluded that while the database used in this work is relatively large, a larger dataset of pavement images with a higher amount of longitudinal cracks would certainly increase the detection precision of the longitudinal crack class.
All the results indicated that the proposed CNN and pre-trained model VGG-19 can be used for automatic detection and classification in Moroccan flexible pavement. Our research also demonstrates the benefit of deep learning models in Moroccan road inspection.
In future work, we are planning to investigate the road crack classification performance of other deep learning algorithms on larger databases in order to detect and classify additional pavement damage types.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}