
Analysis of Road Infrastructure and Traffic Factors Influencing Crash Frequency: Insights from Generalised Poisson Models †

 , ,
, ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Generalised Poisson (GP) Model
2.2. Negative Binomial (NB) Model
2.3. Model Structure
3. Data
4. Results
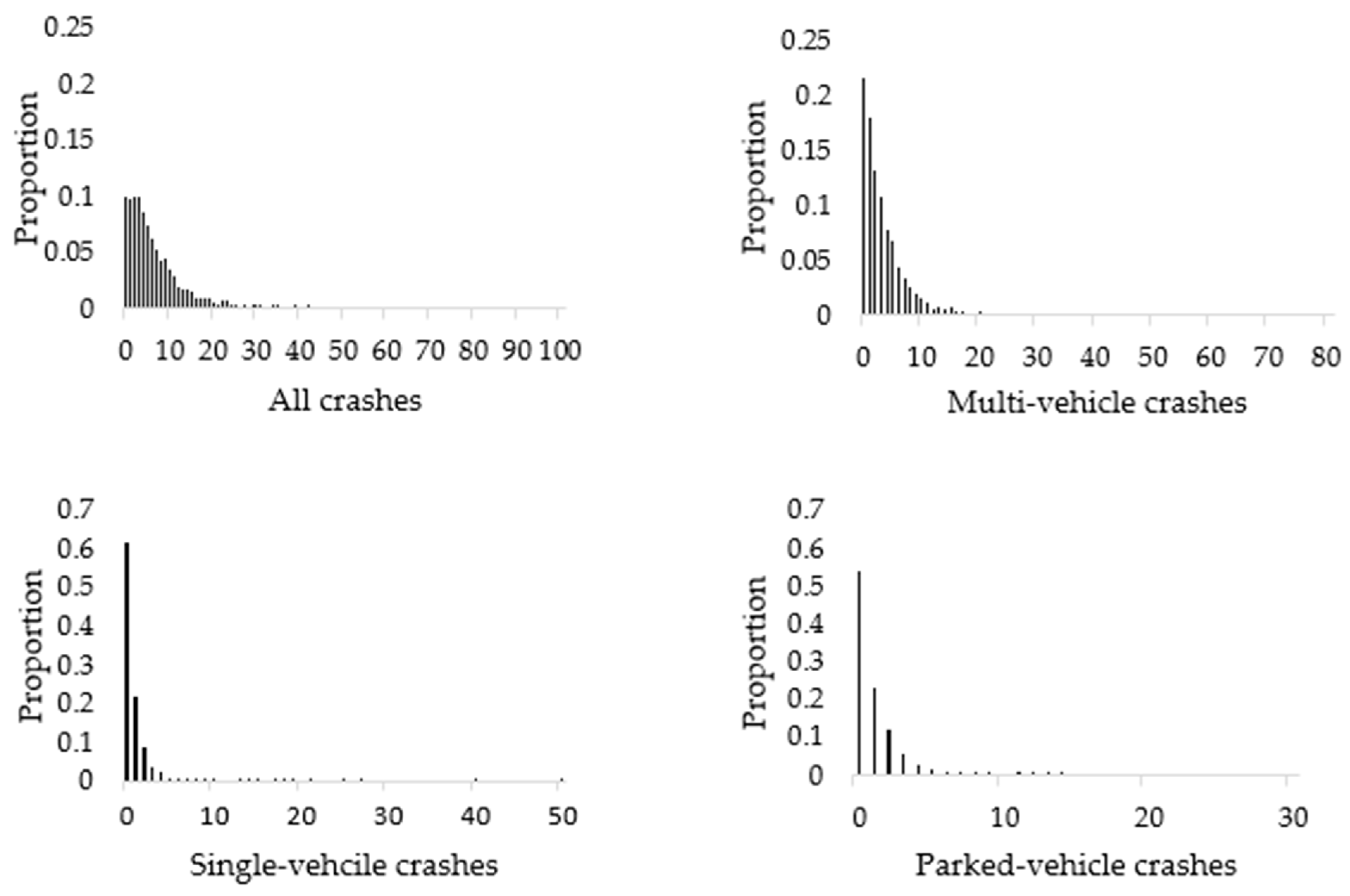
4.1. Exploratory Analysis
4.2. Modelling Results
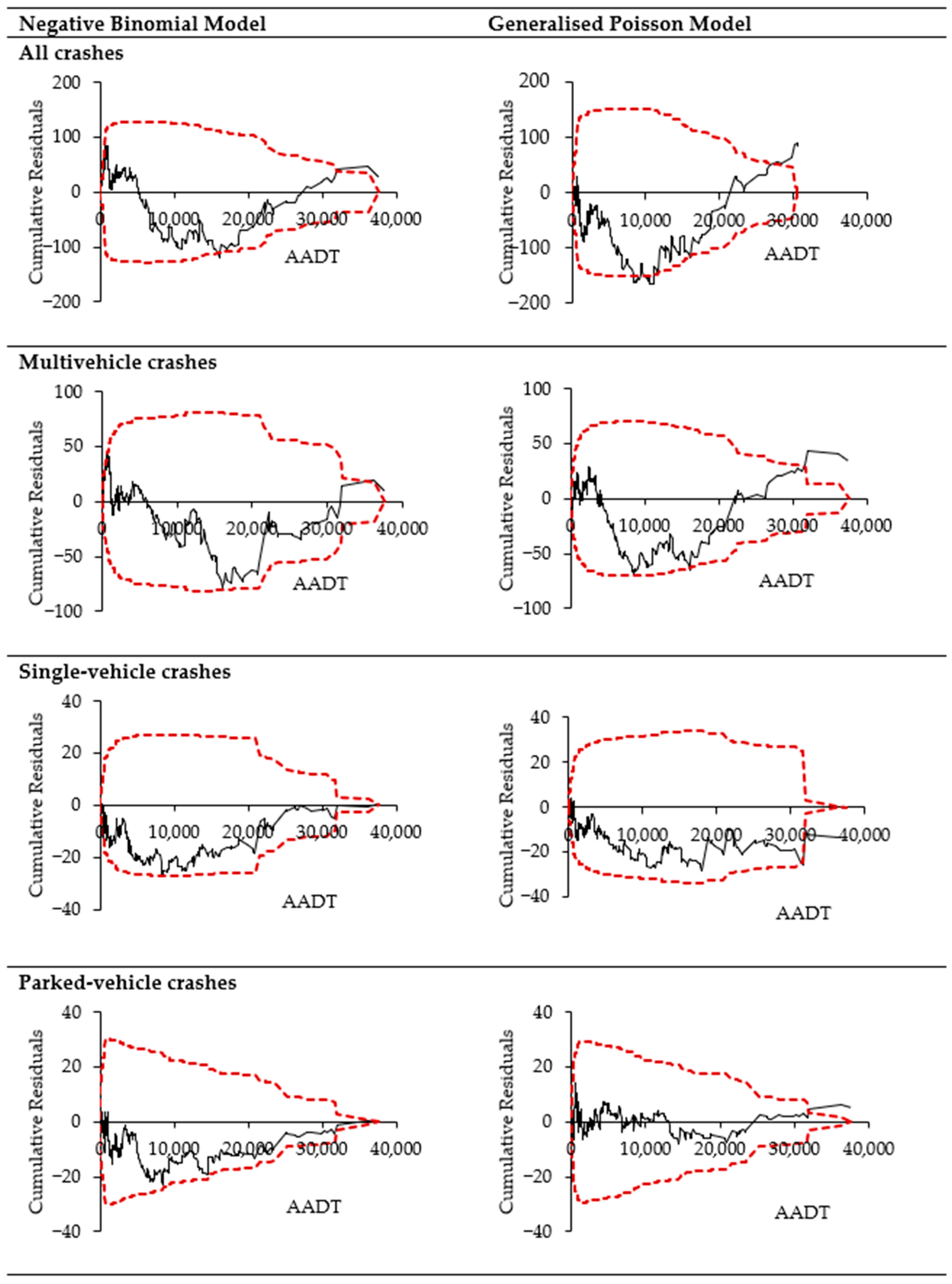
4.3. Goodness-of-Fit and Performance Evaluation
5. Discussion
5.1. Descriptive and Exploratory Analysis of Crash Data
5.2. Crash Frequency and Its Covariates
5.3. Performance Comparison
5.4. Practical Significance
5.5. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nassiri, H.; Mohamadian Amiri, A.; Najaf, P.; Mohamadian Amiri, A. Prediction of Roadway Accident Frequencies: Count Regressions versus Machine Learning Models. Sci. Iran. 2014, 21, 263–275. [Google Scholar]
- Swedish Parliament. Nollvisionen Och Det Trafiksäkra Samhället (Vision Zero and the Road Traffic Safety Society); Sveriges Riksdag: Stockholm, Sweden, 1997.
- Belin, M.-Å.; Tillgren, P.; Vedung, E. Vision Zero—A Road Safety Policy Innovation. Int. J. Inj. Control Saf. Promot. 2012, 19, 171–179. [Google Scholar] [CrossRef]
- Al-Rousan, T.M.; Umar, A.A.; Al-Omari, A.A. Characteristics of Crashes Caused by Distracted Driving on Rural and Suburban Roadways in Jordan. Infrastructures 2021, 6, 107. [Google Scholar] [CrossRef]
- Chhotu, A.K.; Suman, S.K. Prediction of Fatalities at Northern Indian Railways’ Road–Rail Level Crossings Using Machine Learning Algorithms. Infrastructures 2023, 8, 101. [Google Scholar] [CrossRef]
- Pirdavani, A.; Brijs, T.; Bellemans, T.; Wets, G. Evaluation of Traffic Safety at Un-Signalized Intersections Using Microsimulation: A Utilisation of Proximal Safety Indicators. Adv. Transp. Stud. 2010, 22, 43–50. [Google Scholar]
- Nikolaou, D.; Dragomanovits, A.; Ziakopoulos, A.; Deliali, A.; Handanos, I.; Karadimas, C.; Kostoulas, G.; Frantzola, E.K.; Yannis, G. Exploiting Surrogate Safety Measures and Road Design Characteristics towards Crash Investigations in Motorway Segments. Infrastructures 2023, 8, 40. [Google Scholar] [CrossRef]
- Miaou, S.-P.; Lord, D. Modeling Traffic Crash-Flow Relationships for Intersections: Dispersion Parameter, Functional Form, and Bayes Versus Empirical Bayes Methods. Transp. Res. Rec. 2003, 1840, 31–40. [Google Scholar] [CrossRef]
- Pirdavani, A.; Brijs, T.; Bellemans, T.; Kochan, B.; Wets, G. Application of Different Exposure Measures in Development of Planning-Level Zonal Crash Prediction Models. Transp. Res. Rec. 2012, 2280, 145–153. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, J.; Li, X.; Fu, X.; Yang, C.; Jones, S. Localizing Safety Performance Functions for Two-Way STOP-Controlled (TWST) Three-Leg Intersections on Rural Two-Lane Two-Way (TLTW) Roadways in Alabama: A Geospatial Modeling Approach with Clustering Analysis. Accid. Anal. Prev. 2023, 179, 106896. [Google Scholar] [CrossRef]
- Kim, J.; Anderson, M.; Gholston, S. Modeling Safety Performance Functions for Alabama’s Urban and Suburban Arterials. Int. J. Traffic Transp. Eng. 2015, 4, 84–93. [Google Scholar]
- Jin, W.; Chowdhury, M.; Mahmud Khan, S.; Gerard, P. Investigating the Impacts of Crash Prediction Models on Quantifying Safety Effectiveness of Adaptive Signal Control Systems. J. Saf. Res. 2021, 76, 301–313. [Google Scholar] [CrossRef]
- Gitelman, V.; Carmel, R.; Doveh, E.; Hakkert, S. Exploring Safety Impacts of Pedestrian-Crossing Configurations at Signalized Junctions on Urban Roads with Public Transport Routes. Int. J. Inj. Control Saf. Promot. 2018, 25, 31–40. [Google Scholar] [CrossRef]
- El-Basyouny, K.; Sayed, T. Measuring Direct and Indirect Treatment Effects Using Safety Performance Intervention Functions. Saf. Sci. 2012, 50, 1125–1132. [Google Scholar] [CrossRef]
- Highway Safety Manual (HSM); AASHTO, American Association of State and Highway Transportation Officials: Washington DC, USA, 2010; ISBN 978-1-56051-477-0.
- Mendes, O.B.B.; Larocca, A.P.C.; Rodrigues Silva, K.; Pirdavani, A. Assessing the Performance of Highway Safety Manual (HSM) Predictive Models for Brazilian Multilane Highways. Sustainability 2023, 15, 10474. [Google Scholar] [CrossRef]
- Lu, J.; Haleem, K.; Alluri, P.; Gan, A.; Liu, K. Developing Local Safety Performance Functions versus Calculating Calibration Factors for SafetyAnalyst Applications: A Florida Case Study. Saf. Sci. 2014, 65, 93–105. [Google Scholar] [CrossRef]
- Persaud, B.; Saleem, T.; Faisal, S.; Lyon, C.; Chen, Y.; Sabbaghi, A. Adoption of Highway Safety Manual Predictive Technologies for Canadian Highways. In Proceedings of the 2012 Conference and Exhibition of the Transportation Association of Canada—Transportation: Innovations and Opportunities, Fredericton, NB, Canada, 14–17 October 2012. [Google Scholar]
- Kaaf, K.A.; Abdel-Aty, M. Transferability and Calibration of Highway Safety Manual Performance Functions and Development of New Models for Urban Four-Lane Divided Roads in Riyadh, Saudi Arabia. Transp. Res. Rec. 2015, 2515, 70–77. [Google Scholar] [CrossRef]
- Vieira Gomes, S. The Influence of the Infrastructure Characteristics in Urban Road Accidents Occurrence. Accid. Anal. Prev. 2013, 60, 289–297. [Google Scholar] [CrossRef]
- Khattak, M.W.; Pirdavani, A.; De Winne, P.; Brijs, T.; De Backer, H. Estimation of Safety Performance Functions for Urban Intersections Using Various Functional Forms of the Negative Binomial Regression Model and a Generalized Poisson Regression Model. Accid. Anal. Prev. 2021, 151, 105964. [Google Scholar] [CrossRef]
- Brijs, T.; Pirdavani, A. Urban and Suburban Arterials. In Safe Mobility: Challenges, Methodology and Solutions; Transport and Sustainability; Lord, D., Washington, S., Eds.; Emerald Publishing Limited: Bingley, UK, 2018; Volume 11, pp. 85–106. ISBN 978-1-78635-223-1. [Google Scholar]
- Liu, C.; Zhao, M.; Li, W.; Sharma, A. Multivariate Random Parameters Zero-Inflated Negative Binomial Regression for Analysing Urban Midblock Crashes. Anal. Methods Accid. Res. 2018, 17, 32–46. [Google Scholar] [CrossRef]
- Park, J.; Abdel-Aty, M. Evaluation of Safety Effectiveness of Multiple Cross Sectional Features on Urban Arterials. Accid. Anal. Prev. 2016, 92, 245–255. [Google Scholar] [CrossRef]
- Barua, S.; El-Basyouny, K.; Islam, M.T. Safety Performance Functions to Assess the Safety Risk of Urban Residential Collector Roads. In Proceedings of the Technical Session of the 2014 Conference of the Transportation Association of Canada, Montreal, QC, Canada, 28 September–1 October 2014. [Google Scholar]
- Khattak, M.W.; De Backer, H.; De Winne, P.; Brijs, T.; Pirdavani, A. Analysis of Factors Influencing Road Crashes in the Urban Areas: The Application of Generalised Poisson Model vs Negative Binomial Model. In Proceedings of the 6th International Symposium on Highway Geometric Design (ISHGD), Amsterdam, The Netherlands, 26–29 June 2022. [Google Scholar]
- Vieira Gomes, S.; Cardoso, J.L. Estimativa de Frequências de Acidentes Rodoviários em Meio Urbano Considerando Volumes de Tráfego de Peões; Departamento de Transportes Núcleo de Planeamento, Tráfego e Segurança, Laboratório Nacional de Engenharia Civil: Lisbon, Portugal, 2008. [Google Scholar]
- Potts, I.B.; Harwood, D.W.; Richard, K.R. Relationship of Lane Width to Safety on Urban and Suburban Arterials. Transp. Res. Rec. 2007, 2023, 63–82. [Google Scholar] [CrossRef]
- Rista, E.; Goswamy, A.; Wang, B.; Barrette, T.; Hamzeie, R.; Russo, B.; Bou-Saab, G.; Savolainen, P.T. Examining the Safety Impacts of Narrow Lane Widths on Urban/Suburban Arterials: Estimation of a Panel Data Random Parameters Negative Binomial Model. J. Transp. Saf. Secur. 2018, 10, 213–228. [Google Scholar] [CrossRef]
- Sharma, A.; Li, W.; Zhao, M.; Rilett, L. Safety and Operational Analysis of Lane Widths in Mid-Block Segments and Intersection Approaches in the Urban Environment in Nebraska; Research Reports; Nebraska Department of Transportation: Lincoln, NE, USA, 2015.
- Khodadadi, A.; Shirazi, M.; Geedipally, S.; Lord, D. Evaluating Alternative Variations of Negative Binomial–Lindley Distribution for Modelling Crash Data. Transp. A Transp. Sci. 2023, 19, 2062480. [Google Scholar] [CrossRef]
- Geedipally, S.R.; Lord, D.; Dhavala, S.S. The Negative Binomial-Lindley Generalized Linear Model: Characteristics and Application Using Crash Data. Accid. Anal. Prev. 2012, 45, 258–265. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, Z.; Lord, D. Estimating Dispersion Parameter of Negative Binomial Distribution for Analysis of Crash Data: Bootstrapped Maximum Likelihood Method. Transp. Res. Rec. 2007, 2019, 15–21. [Google Scholar] [CrossRef]
- Lord, D.; Mannering, F. The Statistical Analysis of Crash-Frequency Data: A Review and Assessment of Methodological Alternatives. Transp. Res. Part A Policy Pract. 2010, 44, 291–305. [Google Scholar] [CrossRef]
- Saha, K.; Paul, S. Bias-Corrected Maximum Likelihood Estimator of the Negative Binomial Dispersion Parameter. Biometrics 2005, 61, 179–185. [Google Scholar]
- Hardin, J.W.; Hilbe, J. Generalized Linear Models and Extensions, 2nd ed.; Stata Press: College Station, TX, USA, 2007; ISBN 978-1-59718-014-6. [Google Scholar]
- Lord, D.; Geedipally, S.R.; Guikema, S.D. Extension of the Application of Conway-Maxwell-Poisson Models: Analysing Traffic Crash Data Exhibiting Underdispersion. Risk Anal. 2010, 30, 1268–1276. [Google Scholar] [CrossRef]
- Lord, D. Modeling Motor Vehicle Crashes Using Poisson-Gamma Models: Examining the Effects of Low Sample Mean Values and Small Sample Size on the Estimation of the Fixed Dispersion Parameter. Accid. Anal. Prev. 2006, 38, 751–766. [Google Scholar] [CrossRef]
- Maher, M.J.; Summersgill, I. A Comprehensive Methodology for the Fitting of Predictive Accident Models. Accid. Anal. Prev. 1996, 28, 281–296. [Google Scholar] [CrossRef]
- Park, B.-J.; Lord, D.; Hart, J.D. Bias Properties of Bayesian Statistics in Finite Mixture of Negative Binomial Regression Models in Crash Data Analysis. Accid. Anal. Prev. 2010, 42, 741–749. [Google Scholar] [CrossRef]
- Pew, T.; Warr, R.L.; Schultz, G.G.; Heaton, M. Justification for Considering Zero-Inflated Models in Crash Frequency Analysis. Transp. Res. Interdiscip. Perspect. 2020, 8, 100249. [Google Scholar] [CrossRef]
- Lord, D.; Washington, S.; Ivan, J.N. Further Notes on the Application of Zero-Inflated Models in Highway Safety. Accid. Anal. Prev. 2007, 39, 53–57. [Google Scholar] [CrossRef]
- Consul, P.C.; Famoye, F. Generalized Poisson Regression Model. Commun. Stat. Theory Methods 1992, 21, 89–109. [Google Scholar] [CrossRef]
- Zamani, H.; Ismail, N. Functional Form for the Generalised Poisson Regression Model. Commun. Stat. Theory Methods 2012, 41, 3666–3675. [Google Scholar] [CrossRef]
- Ismail, N.; Jemain, A.A. Handling Overdispersion with Negative Binomial and Generalised Poisson Regression Models. Casualty Actuar. Soc. Forum 2007, 2007, 103–158. Available online: https://www.casact.org/sites/default/files/database/forum_07wforum_07w109.pdf (accessed on 1 January 2024).
- Ndue, K.; Baylie, M.M.; Goda, P. Determinants of Rural Households’ Intensity of Flood Adaptation in the Fogera Rice Plain, Ethiopia: Evidence from Generalised Poisson Regression. Sustainability 2023, 15, 11025. [Google Scholar] [CrossRef]
- Wu, P.; Li, J.; Pian, Y.; Li, X.; Huang, Z.; Xu, L.; Li, G.; Li, R. How Determinants Affect Transfer Ridership between Metro and Bus Systems: A Multivariate Generalized Poisson Regression Analysis Method. Sustainability 2022, 14, 9666. [Google Scholar] [CrossRef]
- Yadav, B.; Jeyaseelan, L.; Jeyaseelan, V.; Durairaj, J.; George, S.; Selvaraj, K.G.; Bangdiwala, S.I. Can Generalized Poisson Model Replace Any Other Count Data Models? An Evaluation. Clin. Epidemiol. Glob. Health 2021, 11, 100774. [Google Scholar] [CrossRef]
- Famoye, F.; Wulu, J.T.; Singh, K.P. On the Generalised Poisson Regression Model with an Application to Accident Data. J. Data Sci. 2004, 2, 287–295. [Google Scholar] [CrossRef]
- Greene, W. Functional Forms for the Negative Binomial Model for Count Data. Econ. Lett. 2008, 99, 585–590. [Google Scholar] [CrossRef]
- Joe, H.; Zhu, R. Generalized Poisson Distribution: The Property of Mixture of Poisson and Comparison with Negative Binomial Distribution. Biom. J. 2005, 47, 219–229. [Google Scholar] [CrossRef]
- Hubert, P.C., Jr.; Lauretto, M.S.; Stern, J.M. FBST for Generalized Poisson Distribution. AIP Conf. Proc. 2009, 1193, 210–217. [Google Scholar] [CrossRef]
- Yang, Z.; Hardin, J.W.; Addy, C.L.; Vuong, Q.H. Testing Approaches for Overdispersion in Poisson Regression versus the Generalized Poisson Model. Biom. J. 2007, 49, 565–584. [Google Scholar] [CrossRef]
- Ye, F.; Wang, Y. Performance Evaluation of Various Missing Data Treatments in Crash Severity Modeling. Transp. Res. Rec. 2018, 2672, 149–159. [Google Scholar] [CrossRef]
- Oh, J.; Lyon, C.; Washington, S.; Persaud, B.; Bared, J. Validation of FHWA Crash Models for Rural Intersections: Lessons Learned. Transp. Res. Rec. 2003, 1840, 41–49. [Google Scholar] [CrossRef]
- McFadden, D. Conditional Logit Analysis of Qualitative Choice Behavior. In Frontiers in Econometrics; Academic Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Hauer, E. The Art of Regression Modeling in Road Safety; Springer International Publishing: Cham, Switzerland, 2015; ISBN 978-3-319-12528-2. [Google Scholar]
- Chen, H.Y.; Ivers, R.Q.; Martiniuk, A.L.C.; Boufous, S.; Senserrick, T.; Woodward, M.; Stevenson, M.; Williamson, A.; Norton, R. Risk and Type of Crash among Young Drivers by Rurality of Residence: Findings from the DRIVE Study. Accid. Anal. Prev. 2009, 41, 676–682. [Google Scholar] [CrossRef]
- Dong, B.; Ma, X.; Chen, F.; Chen, S. Investigating the Differences of Single-Vehicle and Multivehicle Accident Probability Using Mixed Logit Model. J. Adv. Transp. 2018, 2018, e2702360. [Google Scholar] [CrossRef]
- Kononov, J.; Bailey, B.; Allery, B.K. Relationships between Safety and Both Congestion and Number of Lanes on Urban Freeways. Transp. Res. Rec. 2008, 2083, 26–39. [Google Scholar] [CrossRef]
- Box, P.C. Angle Parking Issues Revisited, 2001. ITE J. 2002, 72, 36–47. [Google Scholar]
- Moran, M.E. What’s Your Angle? Analysing Angled Parking via Satellite Imagery to Aid Bike-Network Planning. Environ. Plan. B Urban Anal. City Sci. 2021, 48, 1912–1925. [Google Scholar] [CrossRef]
- Boelaert, F. Afwegingskader Voor Het Invoeren van 30 km/u op Gewest- en Gemeentewegen Binnen de Bebouwde Kom; Vlaamse Overheid, Departement Mobiliteit en Openbare, Werken; Agentschap Wegen en Verkeer. 2021. Available online: https://assets.vlaanderen.be/image/upload/v1638886808/Afwegingskader_3050_hsjju2.pdf (accessed on 1 January 2024).
- Intini, P.; Berloco, N.; Ranieri, V.; Colonna, P. Geometric and Operational Features of Horizontal Curves with Specific Regard to Skidding Proneness. Infrastructures 2020, 5, 3. [Google Scholar] [CrossRef]
- Williams, K.M.; Stover, V.G.; Dixon, K.K.; Demosthenes, P. Access Management Manual; Transportation Research Board (TRB): Washington, DC, USA, 2014; ISBN 0-309-29541-6. [Google Scholar]
- Harwood, D.W.; Council, F.M.; Hauer, E.; Hughes, W.E.; Vogt, A. Prediction of the Expected Safety Performance of Rural Two-Lane Highways; Federal Highway Administration: Washington, DC, USA, 2000; p. 1997.
- Russo, F.; Busiello, M.; Dell Acqua, G. Safety Performance Functions for Crash Severity on Undivided Rural Roads. Accid. Anal. Prev. 2016, 93, 75–91. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Variable | Min | Max | Mean | Standard Deviation (SD) |
|---|---|---|---|---|
| (a) Crash frequency | ||||
| All crashes | 0 | 90 | 7.54 | 10.29 |
| Multi-vehicle crashes | 0 | 71 | 3.99 | 6.39 |
| Single-vehicle crashes | 0 | 40 | 0.83 | 2.16 |
| Parked-vehicle crashes | 0 | 13 | 0.93 | 1.45 |
| (b) Traffic and road infrastructure variables | ||||
| Segment length (km) | 0.05 | 1.557 | 0.12 | 0.10 |
| Traffic volume (AADT) | 35 | 31,783 | 4894.09 | 6715.03 |
| Lane width (m) | 2.5 | 5 | 3.51 | 0.53 |
| Number of lanes | 1 = 748 sites (30.39%), 2 = 1051 sites (42.71%), 3 and 3+ = 662 sites (26.90%) | |||
| Parking type | No parking = 733 sites (29.78%), Parallel parking = 1564 sites (63.55%), Perpendicular & angle parking = 164 sites (6.66%) | |||
| Parking arrangement | No parking = 733 sites (29.78%) One-sided parking = 719 sites (29.22%) Two-sided parking = 949 sites (38.60%) Two-sided parking on each road = 59 sites (2.40%) | |||
| Divide/Undivided | Divided sites = 566 sites (23.00%), Undivided = 1895 sites (77.00%) | |||
| Speed | 30 km/h or below = 493 sites (20.03%), 50 km/h = 1768 sites (71.84%), 70 km/h and above = 200 sites (8.13%) | |||
| All Crashes | Multi-Vehicle Crashes | Single-Vehicle Crashes | Parked-Vehicle Crashes | ||
|---|---|---|---|---|---|
| Coef. (St. Err.) | Coef. (St. Err.) | Coef. (St. Err.) | Coef. (St. Err.) | ||
| Generalised Poisson Model | |||||
| Intercept | 1.714 *** (0.240) | 1.148 *** (0.287) | −0.678 (0.494) | 1.267 *** (0.407) | |
| Ln (Length) | 0.474 *** (0.026) | 0.557 *** (0.032) | 0.565 *** (0.051) | 0.642 *** (0.047) | |
| Ln (AADT) | 0.578 *** (0.017) | 0.591 *** (0.021) | 0.501 *** (0.036) | 0.551 ** (0.027) | |
| No of Lanes Base: one lane | Two lanes | −0.267 *** (0.054) | −0.352 *** (0.065) | - | −0.163 * (0.092) |
| Three or more lanes | −0.386 *** (0.073) | −0.387 *** (0.088) | - | −0.570 *** (0.139) | |
| Lane width | −0.113 *** (0.043) | −0.141 *** (0.051) | - | −0.081 * (0.074) | |
| Parking Type Base: No parking | Parallel Parking | 0.323 *** (0.042) | 0.528 *** (0.052) | −0.318 *** (0.075) | 0.949 * (0.094) |
| Others a | 0.350 *** (0.081) | 0.633 *** (0.096) | −0.344 ** (0.168) | 1.133 *** (0.137) | |
| Speed Base: 30 km/h | 50 km/h | −0.148 *** (0.045) | −0.160 *** (0.053) | - | −0.176 ** (0.073) |
| 70 km/h or more | −0.773 *** (0.084) | −0.839 *** (0.102) | −0.555 *** (0.149) | −1.377 *** (0.209) | |
| Divided roadway Base: undivided | −0.312 *** (0.051) | −0.292 *** (0.062) | −0.286 *** (0.094) | −0.411 *** (0.102) | |
| Dispersion | 0.565 (0.010) | 0.507 (0.012) | 0.231 (0.019) | 0.227 (0.018) | |
| All Crashes | Multi-Vehicle Crashes | Single-Vehicle Crashes | Parked-Vehicle Crashes | ||
|---|---|---|---|---|---|
| Coef. (St. Err.) | Coef. (St. Err.) | Coef. (St. Err.) | Coef. (St. Err.) | ||
| Negative Binomial Model | |||||
| Intercept | 2.150 *** (0.257) | 1.436 *** (0.314) | −0.380 (0.498) | 1.580 *** (0.425) | |
| Ln (Length) | 0.624 *** (0.031) | 0.664 *** (0.037) | 0.597 *** (0.057) | 0.720 *** (0.053) | |
| Ln (AADT) | 0.584 *** (0.018) | 0.504 *** (0.022) | 0.554 *** (0.035) | 0.443 ** (0.029) | |
| No of Lanes Base: one lane | Two lanes | −0.287 *** (0.060) | −0.394 *** (0.074) | - | −0.213 ** (0.096) |
| Three or more lanes | −0.300 ** (0.085) | −0.325 *** (0.104) | - | −0.501 *** (0.143) | |
| Lane width | −0.181 *** (0.047) | −0.192 *** (0.057) | - | −0.140 * (0.076) | |
| Parking Type Base: No parking | Parallel Parking | 0.330 *** (0.048) | 0.529 *** (0.059) | −0.458 *** (0.081) | 1.005 *** (0.092) |
| Others a | 0.459 *** (0.090) | 0.755 *** (0.108) | −0.586 *** (0.180) | 1.251 *** (0.142) | |
| Speed Base: 30 km/h | 50 km/h | −0.084 * (0.049) | −0.107 ** (0.060) | - | −0.132 ** (0.078) |
| 70 km/h or more | −0.863 *** (0.090) | −0.906 *** (0.109) | −0.471 ** (0.161) | −1.302 *** (0.190) | |
| Divided roadways Base: undivided | −0.320 *** (0.061) | −0.367 *** (0.074) | −0.385 *** (0.104) | −0.364 *** (0.106) | |
| Dispersion | 0.491 (0.022) | 0.626 (0.033) | 0.753 (0.086) | 0.587 (0.063) | |
| All Crashes | Multi-Vehicle Crashes | Single-Vehicle Crashes | Parked-Vehicle Crashes | |||||
|---|---|---|---|---|---|---|---|---|
| GP | NB | GP | NB | GP | NB | GP | NB | |
| AIC | 10,775.80 | 10,656.22 | 8678.63 | 8611.67 | 3985.96 | 4015.46 | 4593.96 | 4599.03 |
| BIC | 10,842.39 | 10,722.81 | 8745.21 | 8678.25 | 4052.491 | 4081.99 | 4660.54 | 4665.61 |
| Pseudo R2 | 0.069 | 0.084 | 0.078 | 0.092 | 0.093 | 0.087 | 0.088 | 0.086 |
| MPB | 0.058 | 0.029 | 0.084 | 0.064 | 0.001 | 0.013 | 0.008 | 0.052 |
| MAD | 0.778 | 0.779 | 0.447 | 0.451 | 0.126 | 0.132 | 0.155 | 0.176 |
| MSPE | 1.872 | 1.728 | 0.726 | 0.699 | 0.385 | 0.450 | 0.054 | 0.061 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khattak, M.W.; De Backer, H.; De Winne, P.; Brijs, T.; Pirdavani, A. Analysis of Road Infrastructure and Traffic Factors Influencing Crash Frequency: Insights from Generalised Poisson Models. Infrastructures 2024, 9, 47. https://doi.org/10.3390/infrastructures9030047
Khattak MW, De Backer H, De Winne P, Brijs T, Pirdavani A. Analysis of Road Infrastructure and Traffic Factors Influencing Crash Frequency: Insights from Generalised Poisson Models. Infrastructures. 2024; 9(3):47. https://doi.org/10.3390/infrastructures9030047
Chicago/Turabian StyleKhattak, Muhammad Wisal, Hans De Backer, Pieter De Winne, Tom Brijs, and Ali Pirdavani. 2024. "Analysis of Road Infrastructure and Traffic Factors Influencing Crash Frequency: Insights from Generalised Poisson Models" Infrastructures 9, no. 3: 47. https://doi.org/10.3390/infrastructures9030047
APA StyleKhattak, M. W., De Backer, H., De Winne, P., Brijs, T., & Pirdavani, A. (2024). Analysis of Road Infrastructure and Traffic Factors Influencing Crash Frequency: Insights from Generalised Poisson Models. Infrastructures, 9(3), 47. https://doi.org/10.3390/infrastructures9030047