
Prostitution Arrest Spatial Forecasting in an Era of Increasing Decriminalization


Abstract
1. Introduction
2. Background
2.1. Spatial Crime Forecasting
Potential for Bias in Predictive Policing
2.2. Commercial Sex in Urban Areas
3. Methods
3.1. Study Area and Data
3.2. Forecasting Prostitution
3.3. A Model for Predicting Locations of Prostitution Activity
3.3.1. Geocoding Masked Crime Data
3.3.2. Hexagonal Fishnet Aggregation
3.4. Model Generation
4. Results
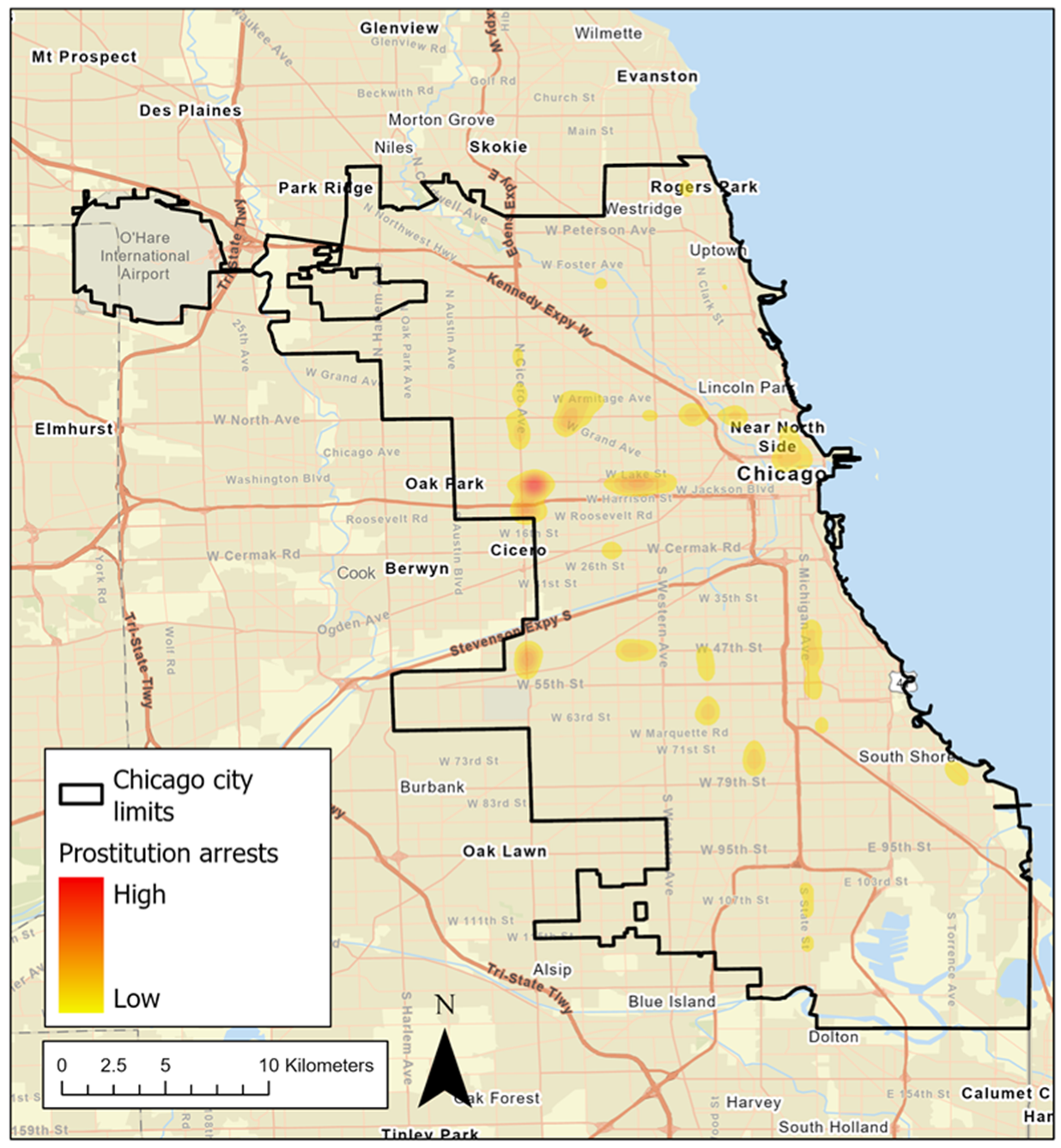
4.1. Spatial Footprint of Prostitution Arrests in Chicago
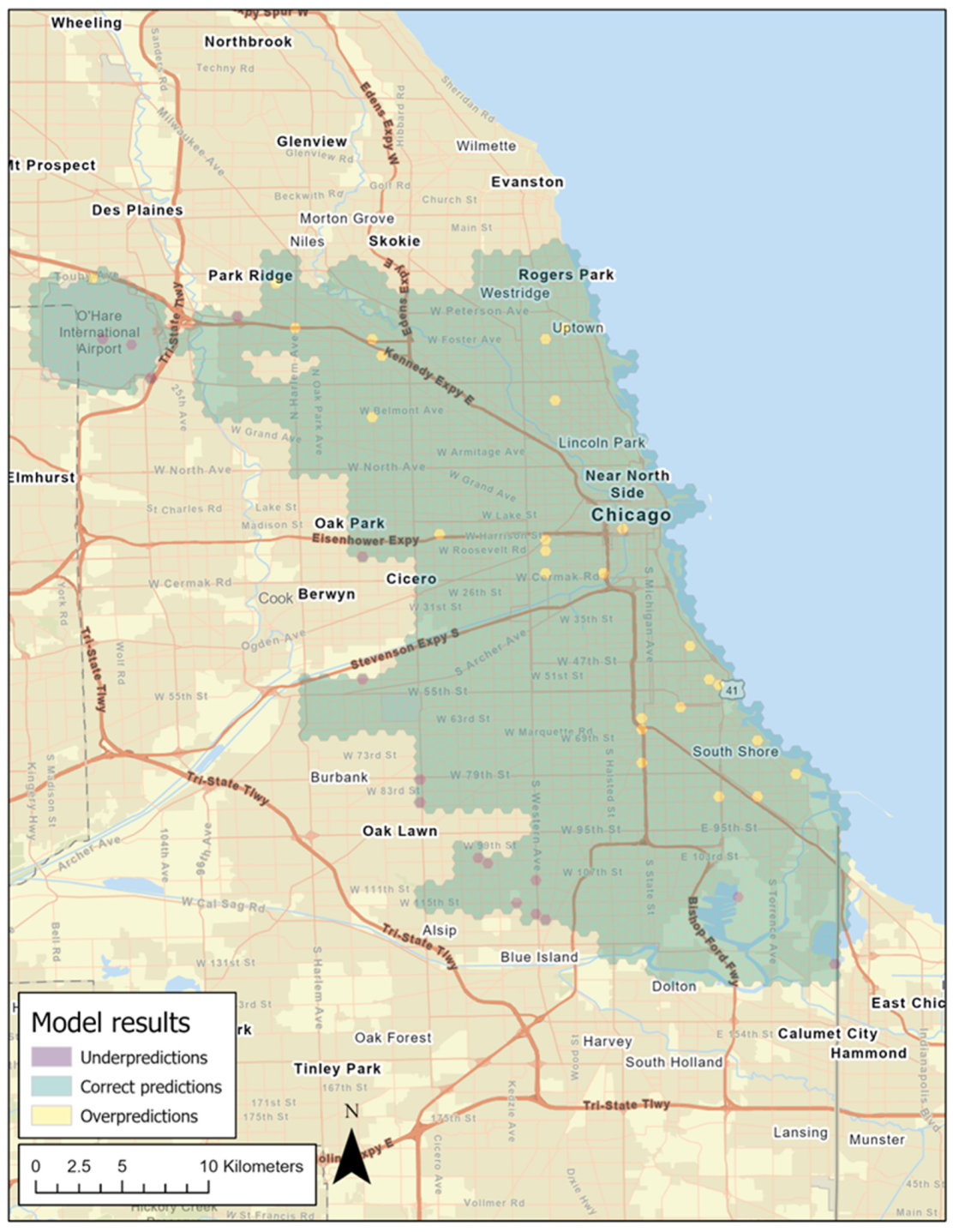
4.2. Model Performance
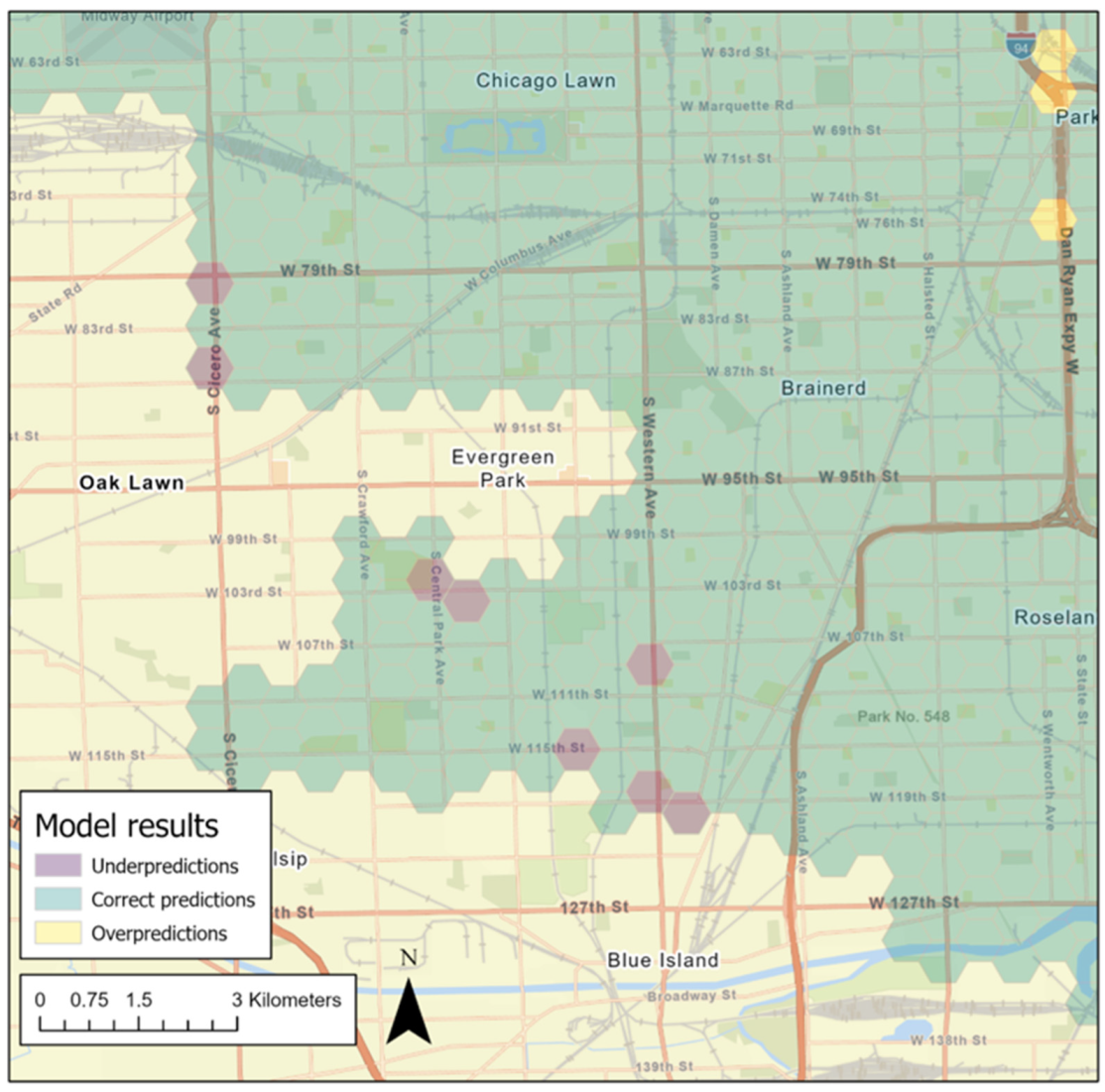
Model Residuals
5. Discussion
5.1. The Future of Decriminalization
5.2. Limitations and Future Work
5.3. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Perry, W.L. Predictive Policing: The Role of Crime Forecasting in Law Enforcement Operations; Rand Corporation: Santa Monica, CA, USA, 2013. [Google Scholar]
- Meijer, A.; Wessels, M. Predictive policing: Review of benefits and drawbacks. Int. J. Public Adm. 2019, 42, 1031–1039. [Google Scholar] [CrossRef]
- Mohammad, B.; Gerber, M. Area-Specific Crime Prediction Models. Available online: http://ieeexplore.ieee.org/abstract/document/7838222/ (accessed on 18 February 2022).
- Tom-Jack, Q.T.; Bernstein, J.M.; Loyola, L.C. The Role of Geoprocessing in Mapping Crime Using Hot Streets. ISPRS Int. J. Geo-Inf. 2019, 8, 540. [Google Scholar] [CrossRef]
- Fei, Y.; Yu, Z.; Zhuang, F.; Zhang, X.; Xiong, H. An Integrated Model for Crime Prediction Using Temporal and Spatial Factors. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1386–1391. [Google Scholar] [CrossRef]
- Wilpen, G.; Olligschlaeger, A. Crime Hot Spot Forecasting with Data from the Pittsburgh [Pennsylvania] Bureau of Police, 1990–1998: Version 1. ICPSR Interuniv. Consort. Political Soc. Res. 2015. [Google Scholar] [CrossRef]
- Andresen, M.A.; Ha, O.K.; Davies, G. Spatially Varying Unemployment and Crime Effects in the Long Run and Short Run. Prof. Geogr. 2021, 73, 297–311. [Google Scholar] [CrossRef]
- Mohler, G. Marked Point Process Hotspot Maps for Homicide and Gun Crime Prediction in Chicago. Int. J. Forecast. 2014, 30, 491–497. [Google Scholar] [CrossRef]
- Tomoya, O.; Amemiya, M. Applying Crime Prediction Techniques to Japan: A Comparison between Risk Terrain Modeling and other Methods. Eur. J. Crim. Policy Res. 2018, 24, 469–487. [Google Scholar] [CrossRef]
- Chen, X.; Cho, Y.; Jang, S.Y. Crime Prediction Using Twitter Sentiment and Weather. In Proceedings of the 2015 Systems and Information Engineering Design Symposium, Charlottesville, VA, USA, 24 April 2015; pp. 63–68. [Google Scholar] [CrossRef]
- Alves, G.; Luiz, G.A.; Ribeiro, H.V.; Francisco, A. Rodrigues Crime Prediction through Urban Metrics and Statistical Learning. Phys. A Stat. Mech. Its Appl. 2018, 505, 435–443. [Google Scholar] [CrossRef]
- Caskey, T.R.; Wasek, J.S.; Franz, A.Y. Deter and protect: Crime modeling with multi-agent learning. Complex Intell. Syst. 2018, 4, 155–169. [Google Scholar] [CrossRef]
- Groff, E.R.; Johnson, S.D.; Thornton, A. State of the art in agent-based modeling of urban crime: An overview. J. Quant. Criminol. 2019, 35, 155–193. [Google Scholar] [CrossRef]
- Grant, D.; Moak, S.C.; Berthelot, E.R. Predictability of Gun Crimes: A Comparison of Hot Spot and Risk Terrain Modelling Techniques. Polic. Soc. 2016, 26, 312–331. [Google Scholar] [CrossRef]
- Edward, H.; Huff, J.; Morstatter, F.; Grubesic, A.; Wallace, D. Hidden in Plain Sight: A Machine Learning Approach for Detecting Prostitution Activity in Phoenix, Arizona. Appl. Spat. Anal. Policy 2019, 12, 941–963. [Google Scholar] [CrossRef]
- Konstantopoulos, M.W.; Ahn, R.; Alpert, E.J.; Cafferty, E.; McGahan, A.; Williams, T.P.; Burke, T.F. An international comparative public health analysis of sex trafficking of women and girls in eight cities: Achieving a more effective health sector response. J. Urban Health 2013, 90, 1194–1204. [Google Scholar] [CrossRef] [PubMed]
- Dallas, S.; Basu, I.; Das, S.; Jana, S.; Jane, M. Rotheram-Borus Empowering Sex Workers in India to Reduce Vulnerability to HIV and Sexually Transmitted Diseases. Soc. Sci. Med. 2009, 69, 1157–1166. [Google Scholar] [CrossRef]
- Martine, S.; Buhariwala, P.; Hassan, M.; O’Campo, P. Helping Women Transition out of Sex Work: Study Protocol of a Mixed-Methods Process and Outcome Evaluation of a Sex Work Exiting Program. BMC Women’s Health 2020, 20, 227. [Google Scholar] [CrossRef]
- Kaitlin, C.; Knight, L.; Mengo, C. Trauma Bonding Perspectives From Service Providers and Survivors of Sex Trafficking: A Scoping Review. Trauma Violence Abus. 2021, 23, 969–984. [Google Scholar] [CrossRef]
- Elizabeth, H.; Hidalgo, J. Invisible Chains: Psychological Coercion of Human Trafficking Victims. Intercult. Hum. Rights Law Rev. 2006, 1, 185. [Google Scholar]
- Davy, D. Understanding the Support Needs of Human-Trafficking Victims: A Review of Three Human-Trafficking Program Evaluations. J. Hum. Traffick. 2015, 1, 318–337. [Google Scholar] [CrossRef]
- Turnbull, L.S.; Hendrix, E.H.; Dent, B.D. Atlas of Crime: Mapping the Criminal Landscape|Office of Justice Programs. 2000. Available online: https://www.ojp.gov/ncjrs/virtual-library/abstracts/atlas-crime-mapping-criminal-landscape (accessed on 20 February 2022).
- Chamard, S. The history of crime mapping and its use by American police departments. In Alaska Justice Forum; the Justice Center at University of Alaska Anchorage: Anchorage, AK, USA, 2006; Volume 23, No. 3; pp. 4–8. [Google Scholar]
- Lawrence, E.C.; Felson, M. Social Change and Crime Rate Trends: A Routine Activity Approach. Am. Sociol. Rev. 1979, 44, 588–608. [Google Scholar] [CrossRef]
- Brantingham, P.J.; Brantingham, P.L. Environmental Criminolog|Office of Justice Programs. 1981. Available online: https://www.ojp.gov/ncjrs/virtual-library/abstracts/environmental-criminology (accessed on 20 February 2022).
- Spelman, W. Problem-Oriented Policing; U.S. Department of Justice, National Institute of Justice: Washington, DC, USA, 1987. [Google Scholar]
- Ourania, K.; Ristea, A.; Araujo, A.; Leitner, M. A Systematic Review on Spatial Crime Forecasting. Crime Sci. 2020, 9, 7. [Google Scholar] [CrossRef]
- Weisburd, D. Hot Spots Policing Experiments and Criminal Justice Research: Lessons from the Field. Ann. Am. Acad. Political Soc. Sci. 2005, 599, 220–245. [Google Scholar] [CrossRef]
- Wilpen, G.; Harries, R. Introduction to Crime Forecasting. Int. J. Forecast. 2003, 19, 551–555. [Google Scholar] [CrossRef]
- Bao, W.; Yin, P.; Bertozzi, A.L.; Brantingham, P.J.; Osher, S.J.; Xin, J. Deep Learning for Real-Time Crime Forecasting and Its Ternarization. Chin. Ann. Math. Ser. B 2019, 40, 949–966. [Google Scholar] [CrossRef]
- Brown, M. A Modelling the Spatial Distribution of Suburban Crime. Econ. Geogr. 1982, 58, 247–261. [Google Scholar] [CrossRef]
- Qi, W.; Jin, G.; Zhao, X.; Feng, Y.; Huang, J. CSAN: A Neural Network Benchmark Model for Crime Forecasting in Spatio-Temporal Scale. Knowl.-Based Syst. 2020, 189, 105120. [Google Scholar] [CrossRef]
- Arya, A.; Hofkens, T.L.; Pianta, R.C. Absenteeism in the First Decade of Education Forecasts Civic Engagement and Educational and Socioeconomic Prospects in Young Adulthood. J. Youth Adolesc. 2020, 49, 1835–1848. [Google Scholar] [CrossRef]
- Charlie, C.; Cesario, E.; Talia, D.; Vinci, A. A Data-Driven Approach for Spatio-Temporal Crime Predictions in Smart Cities. In Proceedings of the 2018 IEEE International Conference on Smart Computing (SMARTCOMP), Taormina, Italy, 17–24 June 2018. [Google Scholar] [CrossRef]
- Erica, R.; Galster, G. Neighborhood Disinvestment, Abandonment, and Crime Dynamics. J. Urban Aff. 2015, 37, 367–396. [Google Scholar] [CrossRef]
- John, M.M.; Hipp, J.R.; Gil, C. The Effects of Immigrant Concentration on Changes in Neighborhood Crime Rates. J. Quant. Criminol. 2013, 29, 191–215. [Google Scholar] [CrossRef]
- Kubrin, C.E.; Hiromi, I. Why Some Immigrant Neighborhoods Are Safer than Others: Divergent Findings from Los Angeles and Chicago. ANNALS Am. Acad. Political Soc. Sci. 2012, 641, 148–173. [Google Scholar] [CrossRef]
- Julian, C.; Louderback, E.R.; Vildosola, D.; Sen, S.R. Crime in an Affluent City: Spatial Patterns of Property Crime in Coral Gables, Florida. Eur. J. Crim. Policy Res. 2020, 26, 547–570. [Google Scholar] [CrossRef]
- Heaven, W.D. Predictive Policing Algorithms Are Racist. They Need to Be Dismantled. MIT Technology Review. Available online: https://www.technologyreview.com/2020/07/17/1005396/predictive-policing-algorithms-racist-dismantled-machine-learning-bias-criminal-justice/ (accessed on 29 September 2022).
- Siegel, E. How to Fight Bias with Predictive Policing. Scientific American Blog Network. Available online: https://blogs.scientificamerican.com/voices/how-to-fight-bias-with-predictive-policing/ (accessed on 29 September 2022).
- Gilbertson, A. Data-Informed Predictive Policing Was Heralded As Less Biased. Is It? The Markup. Available online: https://themarkup.org/the-breakdown/2020/08/20/does-predictive-police-technology-contribute-to-bias (accessed on 20 February 2022).
- Jeffrey, B.P.; Valasik, M.; Mohler, G.O. Does Predictive Policing Lead to Biased Arrests? Results from a Randomized Controlled Trial. Stat. Public Policy 2018, 5, 1–6. [Google Scholar] [CrossRef]
- Kiana, A.; Drobina, E.; Prioleau, D.; Richardson, B.; Purves, D.; Gilbert, J.E. A Review of Predictive Policing from the Perspective of Fairness. Artif. Intell. Law 2022, 33, 1–17. [Google Scholar] [CrossRef]
- Bulman, G. Law Enforcement Leaders and the Racial Composition of Arrests. Econ. Inq. 2019, 57, 1842–1858. [Google Scholar] [CrossRef]
- Huff, J. Understanding Police Decisions to Arrest: The Impact of Situational, Officer, and Neighborhood Characteristics on Police Discretion. J. Crim. Justice 2021, 75, 101829. [Google Scholar] [CrossRef]
- Patrick, J.C.; Napolitano, L.; Keating, J. We Never Call the Cops and Here Is Why: A Qualitative Examination of Legal Cynicism in Three Philadelphia Neighborhoods. Criminology 2007, 45, 445–480. [Google Scholar] [CrossRef]
- Gaurav, H.; Chawla, M.; Rasool, A. A Clustering Based Hotspot Identification Approach For Crime Prediction. Procedia Comput. Sci. Int. Conf. Comput. Intell. Data Sci. 2020, 167, 1462–1470. [Google Scholar] [CrossRef]
- Samuel, L.; Persson, P. Human Trafficking and Regulating Prostitution; SSRN Scholarly Paper; Social Science Research Network: Rochester, NY, USA, 2021. [Google Scholar] [CrossRef]
- Hayes-Smith, R.; Shekarkhar, Z. Why Is Prostitution Criminalized? An Alternative Viewpoint on the Construction of Sex Work. Contemp. Justice Rev. 2010, 13, 43–55. [Google Scholar] [CrossRef]
- Dempsey, M. Madden Decriminalizing Victims of Sex Trafficking. Am. Crim. Law Rev. 2015, 52, 207. [Google Scholar]
- U.S. Department of State. The Link between Prostitution and Sex Trafficking. Bureau of Public Affairs. 2004. Available online: https://2001-2009.state.gov/r/pa/ei/rls/38790.htm (accessed on 20 February 2022).
- Scott, C.; Shah, M. Decriminalizing Indoor Prostitution: Implications for Sexual Violence and Public Health. Rev. Econ. Stud. 2018, 85, 1683–1715. [Google Scholar] [CrossRef]
- Raphael, J. Decriminalization of Prostitution: The Soros Effect. Dign. A J. Anal. Exploit. Violence 2018, 3, 1. [Google Scholar] [CrossRef]
- Ella, C.; Bowers, K. Human Trafficking for Sex, Labour and Domestic Servitude: How Do Key Trafficking Types Compare and What Are Their Predictors? Crime Law Soc. Chang. 2019, 72, 9–34. [Google Scholar] [CrossRef]
- Erin, A.; Adamo, K. Decreasing Human Trafficking through Sex Work Decriminalization. AMA J. Ethics 2017, 19, 122–126. [Google Scholar] [CrossRef]
- Svitlana, B. Prostitution and Human Trafficking for Sexual Exploitation. Gend. Issues 2007, 24, 46–50. [Google Scholar] [CrossRef]
- Cassandra, E.D.; Das, J. Human Trafficking and Country Borders. Int. Crim. Justice Rev. 2017, 27, 278–288. [Google Scholar] [CrossRef]
- Josh, M.; Fewer, J.R. People in Cook County Are Being Charged with Crimes. Why Are Black People Making up a Larger Share of Defendants? Better Gov. Assoc. Available online: https://www.bettergov.org/news/fewer-people-in-cook-county-are-being-charged-with-crimes-why-are-black-people-making-up-a/ (accessed on 1 December 2021).
- Shmueli, G. To explain or to predict? Stat. Sci. 2020, 25, 289–310. [Google Scholar]
- Chicago Data Portal. 2017. Available online: https://data.cityofchicago.org/ (accessed on 20 February 2022).
- U.S. Census Bureau. 2015–2019 American Community Survey 5-Year Public Use Microdata Samples; U.S. Census Bureau: Washington, DC, USA, 2020.
- Esri. Esri Demographics Data Axle. 2021. Available online: https://doc.arcgis.com/en/esri-demographics/data/business.htm (accessed on 20 February 2022).
- U.S. Census Bureau. TIGER/Line Shapefiles; U.S. Census Bureau: Washington, DC, USA, 2019.
- Cook County GIS. 2022. Available online: https://hub-cookcountyil.opendata.arcgis.com/datasets/5ec856ded93e4f85b3f6e1bc027a2472_0/about (accessed on 20 February 2022).
- Edward, H.; Nelson, J.R.; Grubesic, T.H. Unmasking Mased Address Data: A Medoid Geocoding Solution. MethodsX, 2022; in press. [Google Scholar]
- Bruno, C.; Branco, P.; Pereira, S. Crime Prediction Using Regression and Resources Optimization. In Progress in Artificial Intelligence, edited by Francisco Pereira, Penousal Machado, Ernesto Costa, and Amílcar Cardoso, 513–524; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Ae, C.S.; Paturu, V.A.; Yuan, S.; Pathak, R.; Atluri, V.; Adam, N.R. Crime Prediction Model Using Deep Neural Networks. In Proceedings of the 20th Annual International Conference on Digital Government Research, DG.O 2019, Dubai, United Arab Emirates, 18–20 June 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Sweeney, L. Chicago’s “Decriminalization” of Sex Work. Loyala University School of Law. 2021. Available online: http://blogs.luc.edu/compliance/?p=4195 (accessed on 20 February 2022).
- Steans Family Foundation|North Lawndale History. 2009. Available online: http://www.steansfamilyfoundation.org/lawndale_history.shtml (accessed on 20 February 2022).
- Kozol, J. Savage Inequalities: Children in America’s Schools; Crown: New York, NY, USA, 2012. [Google Scholar]
- Mack, E.A.; Grubesic, T.H. Forecasting broadband provision. Inf. Econ. Policy 2009, 21, 297–311. [Google Scholar] [CrossRef]
- Angelos, M.; Rovolis, A.; Stamou, M. Property Valuation with Artificial Neural Network: The Case of Athens. J. Prop. Res. 2013, 30, 128–143. [Google Scholar] [CrossRef]
- Tang, Y.; Qiu, F.; Wang, B.; Wu, D.; Jing, L.; Sam, Z. A Deep Relearning Method Based on the Recurrent Neural Network for Land Cover Classification. GISci. Remote Sens. 2022, 29, 1344–1366. [Google Scholar] [CrossRef]
- Black, W.R. Spatial Interaction Modeling Using Artificial Neural Networks. J. Transp. Geogr. 1995, 3, 159–166. [Google Scholar] [CrossRef]
- Cory, P.H.; Ratcliffe, J.H. Testing for Temporally Differentiated Relationships among Potentially Criminogenic Places and Census Block Street Robbery Counts. Criminology 2015, 53, 457–483. [Google Scholar] [CrossRef]
- Yorghos, A.; Sönmez, S.; Shattell, M.; Kronenfeld, J. Sex Work in Trucking Milieux: Lot Lizards, Truckers, and Risk. Nurs. Forum 2012, 47, 140–152. [Google Scholar] [CrossRef][Green Version]
- Duque Richard, B. Black Health Matters Too… Especially in the Era of COVID-19: How Poverty and Race Converge to Reduce Access to Quality Housing, Safe Neighborhoods, and Health and Wellness Services and Increase the Risk of Co-Morbidities Associated with Global Pandemics. J. Racial Ethn. Health Disparities 2021, 8, 1012–1025. [Google Scholar] [CrossRef] [PubMed]
- Mark, B.; Slocum, T.L.A.; Loeber, R. Illegal Behavior, Neighborhood Context, and Police Reporting by Victims of Violence. J. Res. Crime Delinq. 2013, 50, 75–103. [Google Scholar] [CrossRef]
- Grubesic, T.H.; Pridemore, W.A. Alcohol outlets and clusters of violence. Int. J. Health Geogr. 2011, 10, 1–12. [Google Scholar] [CrossRef]
- Grubesic, T.H.; Murray, A.T.; Pridemore, W.A.; Tabb, L.P.; Liu, Y.; Wei, R. Alcohol beverage control, privatization and the geographic distribution of alcohol outlets. BMC Public Health 2012, 12, 1–10. [Google Scholar] [CrossRef]
- Wei, R.; Grubesic, T.H.; Kang, W. Spatiotemporal patterns of alcohol outlets and violence: A spatially heterogeneous Markov chain analysis. Environ. Plan. B Urban Anal. City Sci. 2021, 48, 2151–2166. [Google Scholar] [CrossRef]
- Polaris. On-Ramps, Intersections, and Exit Routes. The Polaris Project. 2018. Available online: https://polarisproject.org/on-ramps-intersections-and-exit-routes/ (accessed on 20 February 2022).
- Janet, H.; Kotiswaran, P.; Shamir, H.; Thomas, C. From the International to the Local in Feminist Legal Responses to Rape, Prostitution/Sex Work, and Sex Trafficking: Four Studies in Contemporary Governance Feminism. Harv. J. Law Gend. 2006, 29, 335. [Google Scholar]
- Riccardo, C.; Sviatschi, M.M. The Effect of Adult Entertainment Establishments on Sex Crime: Evidence from New York City. Econ. J. 2022, 132, 147–198. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Source |
|---|---|---|
| Crimes | Location-masked spatial crime data, from 2001 to the present. Updated weekly. | Chicago open data |
| Problem landlords | Building Code Scofflaw list. Identifies buildings with “serious and chronic code violations”. | Chicago open data |
| Bus stops | Chicago Transit Authority-generated bus stop shapefile | Chicago open data |
| Hospitals | Hospital locations | Chicago open data |
| Liquor stores | Location of liquor stores (all businesses with the NAICS code 445310) | Esri |
| Bars/strip clubs | Location of bars/strip clubs (all businesses with the NAICS code 722410) | Esri |
| Police stations | Police station locations | Chicago open data |
| Pedestrian paths | Total length of pedestrian paths | Chicago open data |
| Roads | Total length of roads, count of intersections, divided by road type (primary, secondary, and tertiary). | Chicago open data |
| Parks | Total park acreage | Chicago open data |
| Schools | Total school acreage | Chicago open data |
| Water features | Total waterway/water feature acreage | Chicago open data |
| Population | Count of the population | ACS |
| Ethnicity/race | Percentage of population that is black, white, Hispanic, Asian, Native American, or all others combined. | ACS |
| Educational attainment | Percentage of population that has a high school diploma or equivalent, and the percentage with a Bachelor’s degree | ACS |
| Household income | Median household income | ACS |
| Coefficient | Estimate | p-Value |
|---|---|---|
| Problem landlords | 0.85 | <0.001 |
| Bus stops | 0.15 | <0.001 |
| Hospitals (1st order) | −0.82 | 0.02 |
| Hospitals (2nd order) | −0.65 | 0.1 |
| Liquor stores | 0.28 | 0.007 |
| Bars/strip clubs | 0.01 | <0.001 |
| Police stations (1st order) | 0.88 | 0.122 |
| Police stations (2nd order) | 0.55 | 0.11 |
| School acreage | −0.02 | 0.25 |
| Park acreage | −0.01 | 0.35 |
| Pedestrian path length | 0.05 | 0.09 |
| Road length (primary—1st order) | 0.02 | <0.001 |
| Road length (primary—2nd order) | 0.39 | <0.001 |
| Road length (secondary) | 0.27 | <0.001 |
| Road intersection count | 0.33 | <0.001 |
| Percent black | 1.35 | <0.001 |
| Median household income | −0.01 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Helderop, E.; Grubesic, T.H.; Roe-Sepowitz, D.; Sefair, J.A. Prostitution Arrest Spatial Forecasting in an Era of Increasing Decriminalization. Urban Sci. 2023, 7, 2. https://doi.org/10.3390/urbansci7010002
Helderop E, Grubesic TH, Roe-Sepowitz D, Sefair JA. Prostitution Arrest Spatial Forecasting in an Era of Increasing Decriminalization. Urban Science. 2023; 7(1):2. https://doi.org/10.3390/urbansci7010002
Chicago/Turabian StyleHelderop, Edward, Tony H. Grubesic, Dominique Roe-Sepowitz, and Jorge A. Sefair. 2023. "Prostitution Arrest Spatial Forecasting in an Era of Increasing Decriminalization" Urban Science 7, no. 1: 2. https://doi.org/10.3390/urbansci7010002
APA StyleHelderop, E., Grubesic, T. H., Roe-Sepowitz, D., & Sefair, J. A. (2023). Prostitution Arrest Spatial Forecasting in an Era of Increasing Decriminalization. Urban Science, 7(1), 2. https://doi.org/10.3390/urbansci7010002