3.1. Panoptic DeepLab Trained on Cityscapes
Figure 2 presents the results of Panoptic Deeplab applied to the Cityscapes dataset. Cityscapes comprises a substantial variety of distinct labels. However, Panoptic Deeplab demonstrates its ability to successfully recognize and classify all of these labels, due to its efficient computational architecture, following thorough training.
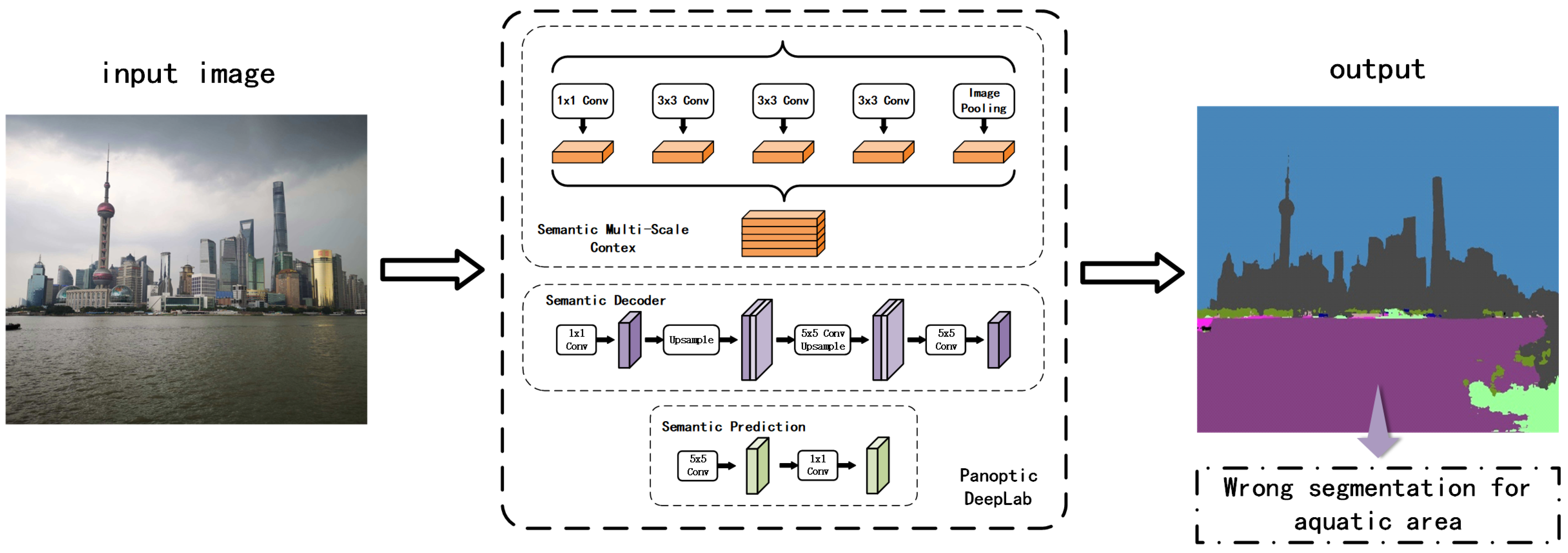
Figure 3 illustrates the structure of Panoptic DeepLab. Panoptic-DeepLab stands out in the realm of image segmentation with its innovative dual-atrous spatial pyramid pooling (ASPP) and dual-decoder modules [
42,
43]; this structure is specifically designed to tackle the intricacies of both semantic and instance segmentation tasks within the broader scope of panoptic segmentation. This advanced architecture is bolstered by a shared backbone [
44], which serves both segmentation tasks simultaneously. This not only optimizes computational resource usage but also ensures the extraction of rich feature representations that are equally beneficial for semantic and instance segmentation. A distinctive feature of Panoptic-DeepLab is its approach to instance segmentation through class-agnostic instance center regression. This method deviates from traditional top-down approaches [
45] that typically rely on region proposal networks. Instead, it directly predicts the center of each object instance and accurately computes the offset for each pixel within that instance, thus pinpointing its precise location [
46]. The semantic segmentation branch of Panoptic-DeepLab aligns with conventional semantic segmentation models, focusing on classifying each pixel into various categories, including “things” and “stuff”. Complementing these features is the model’s efficient merging operation. In summary, the main functionality of Panoptic-DeepLab is as follows:
The dual-ASPP and dual-decoder modules enable the network to handle the intricacies of both semantic segmentation (categorizing areas into broad classes) and instance segmentation (identifying individual object instances).
The shared backbone allows for feature extraction that is beneficial for both segmentation tasks, maximizing the use of learned features.
The instance center regression facilitates the bottom-up approach for instance segmentation, identifying individual objects without needing region proposals.
The efficient merging operation combines the outputs of both segmentation tasks to create a cohesive panoptic segmentation map, integrating both “thing” (individual objects) and “stuff” (amorphous regions like grass or sky) categories.
In addition, Panoptic-DeepLab distinguishes itself with its simplicity, speed, efficiency, and state-of-the-art performance, setting a new benchmark in the field of panoptic segmentation. The architecture of the model is ingeniously crafted to be less complex yet robust, offering a simpler alternative to the more intricate two-stage methods commonly found in image segmentation. This simplicity not only facilitates ease of implementation and modification but also enhances its appeal for a broader range of applications. A key strength of Panoptic-DeepLab lies in its speed and efficiency, attributes that stem from its streamlined structure and the use of a shared backbone. This makes it particularly well suited for real-time applications, where quick processing is essential. In terms of performance, Panoptic-DeepLab excels, consistently achieving competitive or leading results across various renowned benchmarks, including Cityscapes, Mapillary Vistas, and COCO. This high level of performance is a testament to the model’s effectiveness in handling diverse segmentation tasks. Furthermore, its bottom-up approach in panoptic segmentation simplifies the process while maintaining high-quality output.
The performance of neural networks, particularly in the domain of computer vision, is fundamentally tied to the caliber and diversity of the training data they are exposed to. This principle is exemplified in the case of Panoptic DeepLab, a cutting-edge model in the field of panoptic segmentation. A key contributor to its success is the Cityscapes dataset, an extensive collection of stereo video sequences meticulously captured in street scenes from 50 different urban environments. This dataset is not just voluminous but rich in quality and variety, comprising high-quality pixel-level annotations of 5000 frames along with a substantial set of 20,000 frames with weaker annotations. This exhaustive dataset encompasses an extensive range of urban object classes, including cars, pedestrians, bicycles, and buildings, each presenting unique challenges in terms of segmentation and recognition.
Cityscapes’ detailed and diverse dataset serves as a crucial benchmark for the development and evaluation of advanced semantic segmentation algorithms. The dataset’s complexity and real-world variability make it an ideal proving ground for models intended for intricate tasks in computer vision, such as panoptic segmentation and object tracking. The depth and breadth of its data contribute significantly to the training of models, enabling them to learn and accurately identify a wide range of objects and scenarios typical of urban landscapes.
Trained on the Cityscapes dataset, Panoptic DeepLab has demonstrated exceptional proficiency, achieving state-of-the-art performance across several metrics. This high level of accuracy is particularly evident in the model’s panoptic segmentation of city views, where it successfully differentiates and segments a multitude of elements within dense urban scenes.
Table 1 clearly illustrates that the Cityscapes dataset encompasses a wide array of living-thing categories; however, it notably lacks labeled categories for aquatic environments. This limitation hinders its ability to efficiently process data related to aquatic areas, which, significantly, constitute the majority of the Earth’s surface.
3.2. WaSR
Cityscapes has established itself as a popular and valuable dataset for urban scene segmentation [
47]. It possesses inherent limitations, particularly in its applicability to environments beyond urban landscapes. One notable area where Cityscapes falls short is in the segmentation of aquatic environments [
48]—a domain vastly different from urban settings in terms of visual features and segmentation challenges [
49]. Recognizing this gap, researchers [
20] started to develop a specialized model tailored for aquatic environments, leading to the creation of the WaSR model.
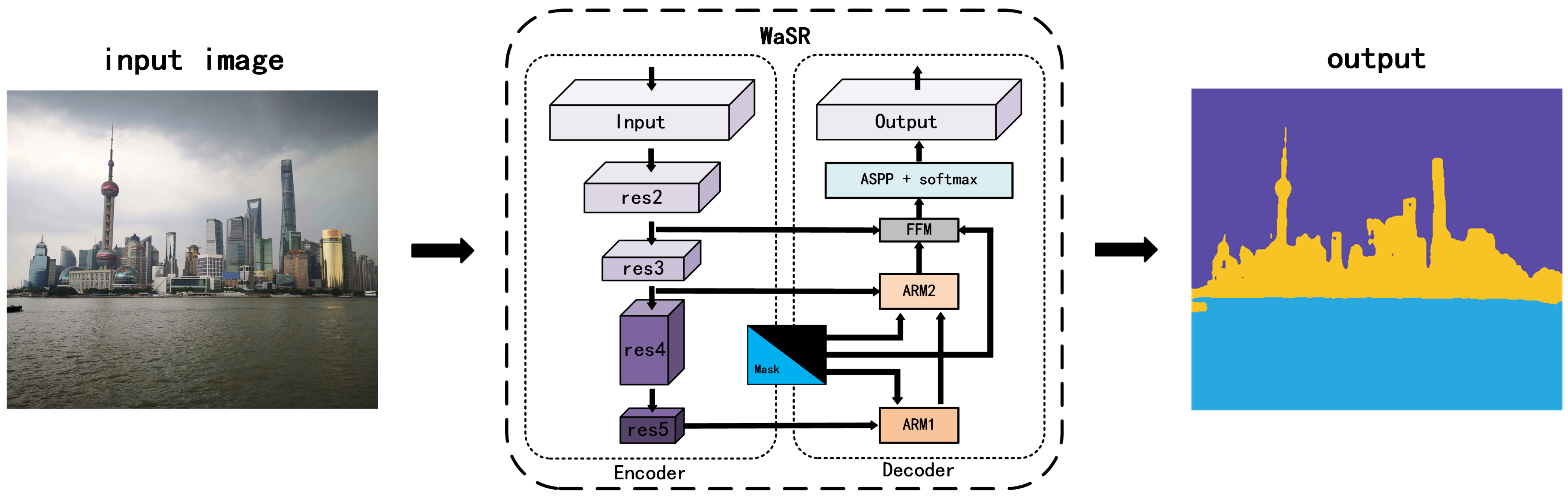
The WaSR network structure is a specialized deep learning architecture designed for maritime obstacle detection, with several distinctive features and functionalities. Below is a detailed breakdown of its network structure, functionalities, and advantages:
- 1.
Encoder–decoder architecture:
- (a)
Encoder: Based on ResNet101 with atrous convolutions for extracting rich visual features.
- (b)
Decoder: Integrates features from the encoder, upsampling them to construct the segmentation map. Includes multiple fusion modules for handling various water appearances.
- 2.
Fusion modules:
- 3.
Inertial measurement unit (IMU) integration:
- 4.
IMU feature channel encoding:
- (a)
Encoding methods: Drawing a horizon line, encoding a signed distance to the horizon, and creating a binary mask below the horizon.
- (b)
These encoded channels are fused into the decoder for improved segmentation accuracy.
The WaSR network is meticulously designed for precise semantic segmentation in maritime environments, a pivotal functionality for autonomous navigation and surveillance in marine settings. Its primary capability lies in its adeptness at distinguishing various elements within a maritime scene, such as water, sky, ships, and other pertinent objects. This specificity is crucial, as it directly informs navigation decisions for unmanned marine vehicles, ensuring safety and efficiency in navigation.
An essential aspect of WaSR’s functionality is its robustness in handling the complex appearances of water. Maritime environments are inherently dynamic, with varying conditions such as different lighting scenarios, reflections, and diverse water textures. WaSR’s sophisticated architecture can navigate these challenges, ensuring accurate segmentation even under these fluctuating conditions.
A standout feature of the WaSR network is its integration of data from an inertial measurement unit (IMU). This integration is not just a supplementary enhancement but a core aspect of its functionality. The IMU data play a critical role in accurately determining the horizon line and the camera’s orientation relative to the horizon. This is particularly vital in the ambiguous visual conditions often encountered at sea, such as foggy or glare-heavy scenarios. By fusing this inertial data with visual cues, WaSR achieves a higher level of precision in horizon detection and orientation, which is instrumental in correctly interpreting maritime scenes.
Moreover, the network’s ability to incorporate IMU data for horizon estimation and to adaptively respond to various sea states showcases its advanced approach to maritime scene understanding [
50,
51]. This results in a significant reduction in false positives, a common challenge in water segmentation due to the reflective and dynamic nature of marine environments. The WaSR network presents several substantial advantages that set it apart in the field of maritime obstacle detection and navigation. These advantages underscore its potential as a transformative tool for a wide array of maritime applications.
One of the primary advantages of the WaSR network is its remarkable capability to reduce false positives. In the context of maritime environments, where the reflective and dynamic nature of water often leads to visual ambiguities [
52,
53], reducing false positives is crucial. Traditional segmentation methods can struggle with differentiating between actual obstacles and reflections or other water-related phenomena [
54,
55,
56]. WaSR, with its sophisticated fusion of visual and inertial data, excels in accurately distinguishing between these elements. This precision is particularly beneficial in ensuring the safety and efficiency of autonomous marine navigation, where accurate detection of obstacles is vital.
Another significant advantage of WaSR is its impressive generalization capabilities. The network has been tested and has shown commendable performance across various datasets and hardware setups. This ability to generalize ensures that WaSR is not limited to the specific conditions or environments it was trained, making it a versatile and robust tool for maritime obstacle detection. Whether deployed on different types of unmanned surface vehicles or in varied geographical locations, WaSR maintains a consistent level of accuracy and reliability.
Additionally, WaSR is exceptionally robust in challenging conditions. Maritime environments can be highly unpredictable, with factors like fog, glare, and varying light conditions often impeding visibility [
57,
58,
59]. WaSR’s design and integration of IMU data make it adept at navigating these challenges, ensuring accurate segmentation even in less-than-ideal visual conditions. This robustness enhances the network’s applicability in real-world scenarios, where such conditions are commonplace.
Figure 4 illustrates the main procedure of the WaSR model, showcasing the intricate process of how the model handles aquatic imagery. The model’s procedure involves a series of steps that include initial segmentation, feature extraction, and refinement stages, each meticulously designed to address the unique challenges posed by water bodies. The WaSR network presents several substantial advantages that set it apart in the field of maritime obstacle detection and navigation. These advantages underscore its potential as a transformative tool for a wide array of maritime applications.
A primary limitation of the WaSR model is its specialization for maritime environments, which inherently restricts its effectiveness in nonmaritime contexts as shown in
Table 2, which only includes three different items, obstacle, water, and sky. Its algorithms and data processing techniques are optimized for water, sky, and marine obstacles shown in
Figure 5, which means it might not yield the same level of accuracy or reliability in terrestrial or aerial environments. This specialization, while a strength in marine settings, limits its versatility across diverse environmental applications, especially for large and complex terrestrial environments.
Another significant challenge is the requirement for substantial training data [
60,
61,
62,
63]. To achieve its high level of accuracy, WaSR needs to be trained on extensive datasets that comprehensively cover various maritime scenarios and conditions. Gathering such large and diverse datasets can be resource-intensive and may not be feasible for all applications, especially those with limited access to maritime environments or those operating under constrained research budgets. The model’s demand for significant computational resources is also a drawback. To process complex datasets and perform real-time segmentation and detection, WaSR requires powerful processing capabilities. This requirement can pose a barrier to its deployment on systems with limited computational power or in scenarios where minimizing power consumption is critical, such as on unmanned, battery-operated marine vehicles.
In terms of operational limitations, the WaSR model shows sensitivity to lighting conditions, particularly in low-light environments. Its performance can decrease under such conditions, as the visual sensors may not capture enough detail to accurately differentiate between various elements in the scene. This sensitivity could be a hindrance in operations conducted during nighttime or in areas with poor visibility [
64,
65,
66]. Lastly, the model’s ability to detect small obstacles is an area of concern, especially in safety-critical applications. While WaSR excels in identifying larger objects, it may sometimes miss smaller obstacles, which, in a maritime setting, can be just as hazardous as larger ones. This limitation necessitates additional caution and possibly supplementary detection systems to ensure comprehensive safety in navigation.
3.3. Model Fusion
In our endeavor to refine segmentation for both aquatic and terrestrial environments, we innovated a fusion model that capitalizes on the distinct strengths of the WaSR and Panoptic DeepLab models. This model is designed to overcome each system’s specific limitations when dealing with complex environmental scenes that include both land and water.
The aquatic model excels in segmenting aquatic areas but falls short in providing intricate details for land segments. Conversely, Panoptic DeepLab, trained with the extensive Cityscapes dataset, offers comprehensive labeling for land features but cannot segment aquatic regions effectively. Our fusion model aims to harness these disparate capabilities for a more robust segmentation solution.
The process begins with a standard preprocessing step where an input image is resized to a uniform dimension, making it compatible with analysis by the two models. The aquatic model processes the image to segment it into three categories: aquatic, sky, and other. Following this, we employ a custom mask that filters out the ‘sky’ and ‘other’ segments, isolating the aquatic region in the image. Concurrently, Panoptic DeepLab performs its segmentation, producing detailed split instance graphs based on its terrestrial-focused training labels. However, it is important to note that Panoptic DeepLab’s output for aquatic areas is not reliable due to the absence of such labels in its training set.
The challenge then lies in effectively merging these outputs to produce a cohesive segmented map. To address this, our fusion model initially discards the aquatic segment from Panoptic DeepLab’s output, acknowledging its inherent inaccuracy. We replace this segment with the aquatic mask generated by the aquatic result, ensuring precise delineation of water bodies. However, a critical issue arises in extracting nonaquatic segments from Panoptic DeepLab’s output, given its inaccuracy in classifying aquatic regions. To resolve this, we introduce an innovative color-based tag finder. This tool analyzes the RGB output from the WaSR model, focusing on identifying the blue hues that correspond to aquatic areas. By accurately pinpointing these regions, we can seamlessly integrate the detailed land segmentation from Panoptic DeepLab with the aquatic segmentation from the other model.
Through this sophisticated fusion approach, our model effectively combines the detailed terrestrial segmentation of Panoptic DeepLab with the precise aquatic delineation of WaSR. This results in a comprehensive and accurate representation of both land and water environments, significantly enhancing the capabilities of environmental segmentation and analysis.
Our novel fusion model adeptly merges the segmentation capabilities of Panoptic DeepLab and WaSR, resulting in a system that can accurately segment both land and aquatic areas by utilizing the strengths of both models. The comprehensive structure and workflow of this fusion model are depicted in
Figure 1, illustrating how the outputs of the two models are integrated to achieve superior segmentation performance.
In our fusion model, a critical component is the color-based tag finder, whose structure and function are detailed in
Figure 6. This finder is tasked with processing the RGB images from the label classification results of the aquatic elaboration. These images are then converted into LAB value images, a format that significantly enhances color differentiation, making it easier to isolate specific color ranges. The finder operates by pinpointing and extracting the areas that match the predefined aquatic color values. The resulting mask, as shown in
Figure 6b, uses black to denote the extracted aquatic area. This mask is a pivotal element in the fusion process, allowing us to overlay it onto the combined output of WaSR and Panoptic DeepLab, effectively replacing inaccurately segmented areas.
The fusion process itself is visually elucidated in
Figure 7. Here, we demonstrate how the extracted mask image from
Figure 6 and the output from Panoptic DeepLab are blended. In this synthesis, the split map from Panoptic DeepLab automatically aligns with the corresponding areas on the mask. Simultaneously, the remaining areas in the mask, representing aquatic segments, are overlaid onto the final output map. This method ensures that the final output not only maintains WaSR’s high accuracy in identifying aquatic areas but also benefits from the diverse and precise labeling of terrestrial features provided by Cityscapes.
Moreover, we introduced a color modification step for the extracted labeled areas. This alteration is implemented to enhance the visual distinction of these areas, making it easier to observe and analyze the segmented results. By modifying the color of these areas, we provide a clearer visual demarcation, which is especially useful in applications requiring quick identification and differentiation of various segments.
In summary, our fusion model represents a significant advancement in environmental segmentation, combining the aquatic accuracy of the aquatic model result with the extensive land labeling capabilities of Panoptic DeepLab. The model not only achieves high accuracy in segmenting diverse environments but also presents the results in a visually intuitive manner, enhancing both the usability and applicability of the segmented data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}