
Adversarial Robustness for Deep Learning-Based Wildfire Prediction Models



Abstract
:1. Introduction
1.1. Existing DNN Solutions to Wildfire Smoke Detection
1.2. Challenges in Adapting DNN Solutions to Wildfire Smoke Detection
1.3. Contributions
- We propose WARP, consisting of global and local model-agnostic evaluation methods for model robustness, tailored to wildfire smoke detection.
- We compare the robustness of DNN-based wildfire detection models across two major neural network architectures, namely CNNs and transformers, and provide detailed insights into specific vulnerabilities of those models.
- We propose data augmentation approaches for potential model improvement based on the above findings.
2. Preliminaries
2.1. Problem Statement
2.2. Adversarial Robustness
Given a test input and a perturbation , compare how differs from .
3. Materials and Methods
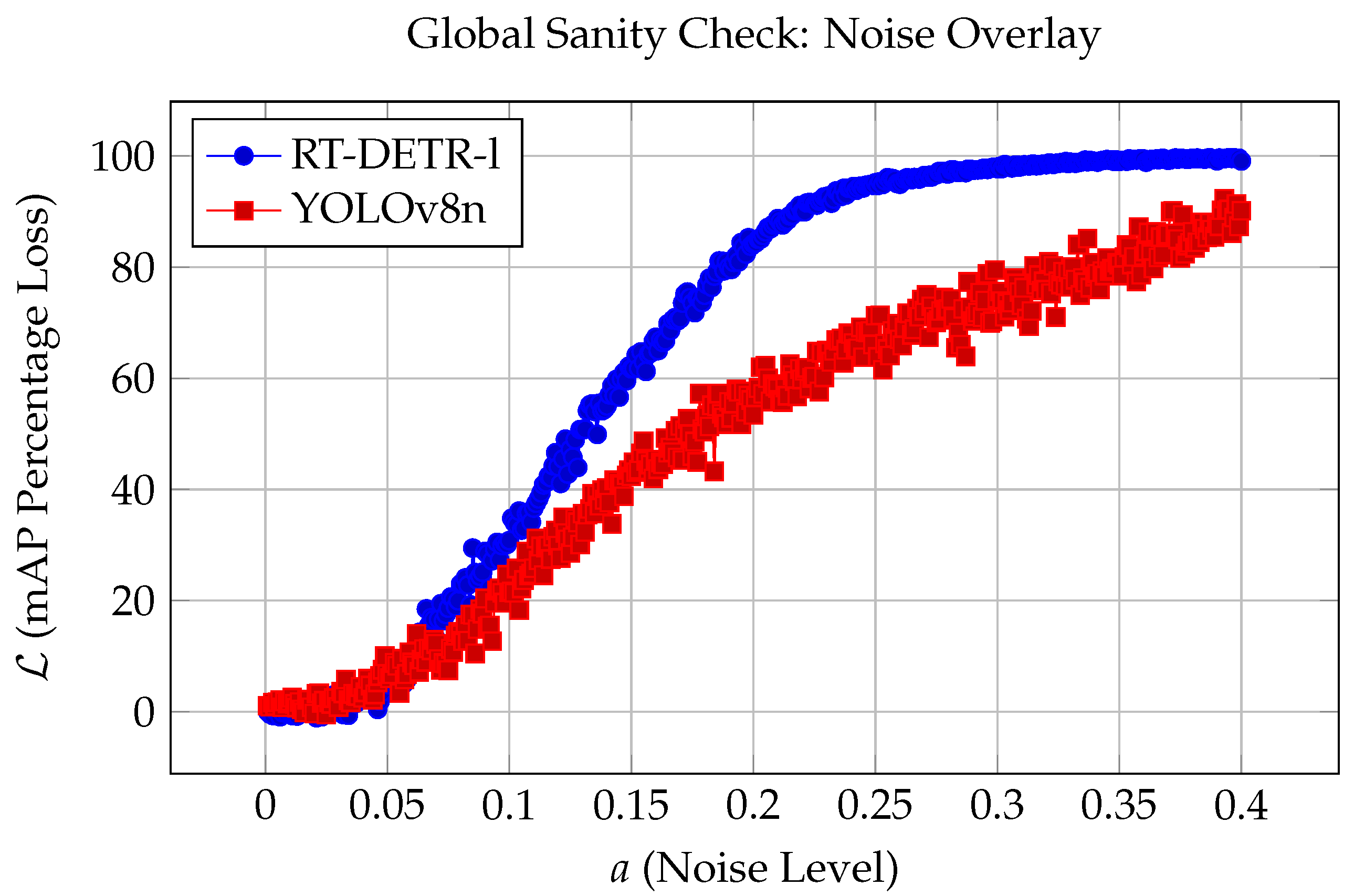
3.1. Global Sanity Check: Noise Overlay
3.2. Local Deception Test: Noise Patch
3.2.1. Classification Flip Probabilities
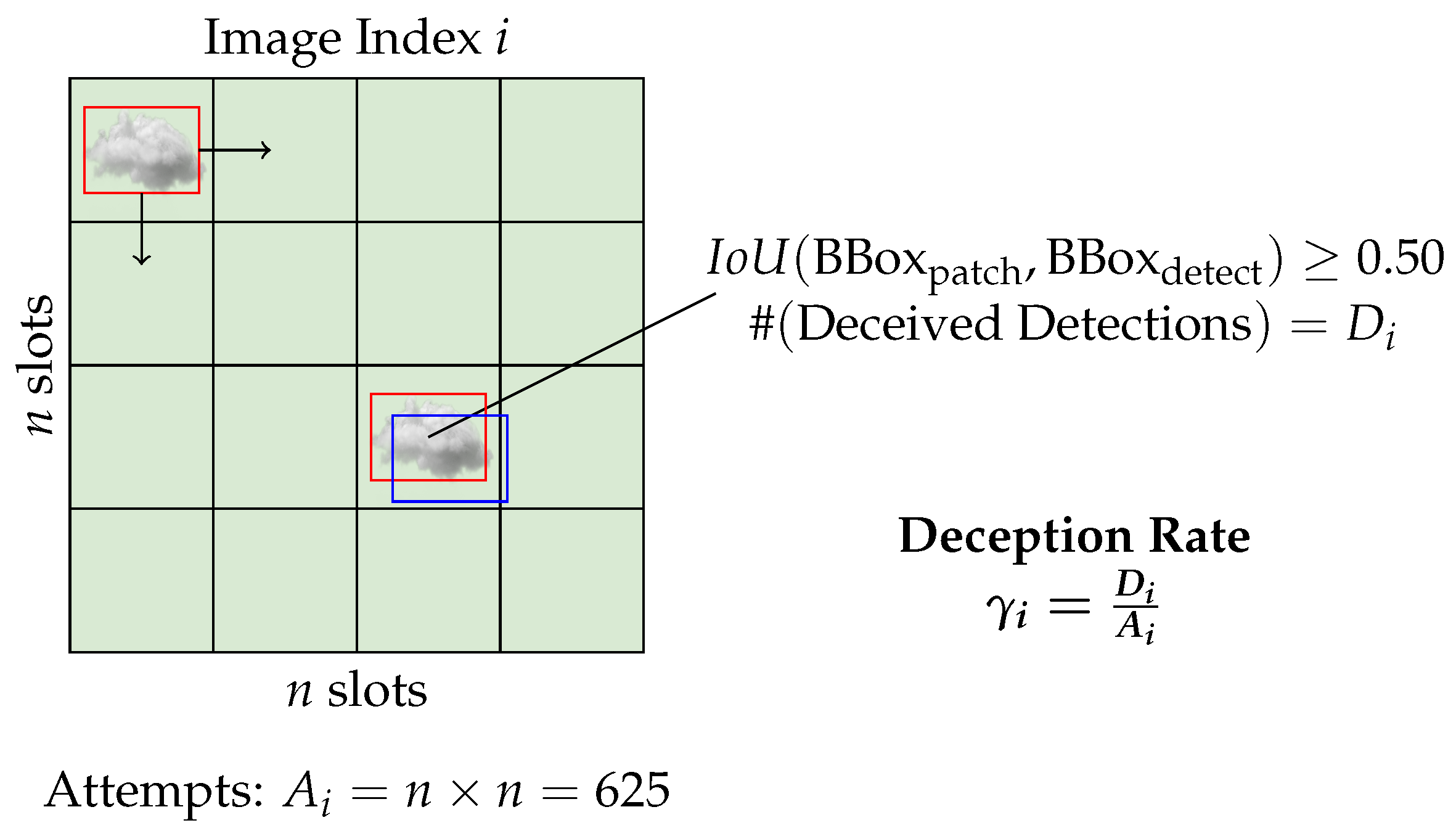
3.2.2. Localization Deception Rate
3.3. Data Collection and Preparation
3.4. Object Detection Framework
- For a CNN-based real-time object detection model, we choose YOLOv8, the 8th generation model of the YOLO (You Only Look Once) framework. It is a popular real-time object detection framework and is publically available on the Ultralytics API [33].
- For a transformer-based real-time object detector, we choose RT-DETR (Real-Time Detection-Transformer), which can be viewed as a real-time variant of DETR used by [3]. RT-DETR overcomes the computation-costly limitations of transformers by sacrificing minimal accuracy for speed by prioritizing and selectively extracting object queries that overlap the ground truth bounding boxes by a certain IoU [34].
4. Results
4.1. Post-Training
4.2. Results of Global Sanity Check
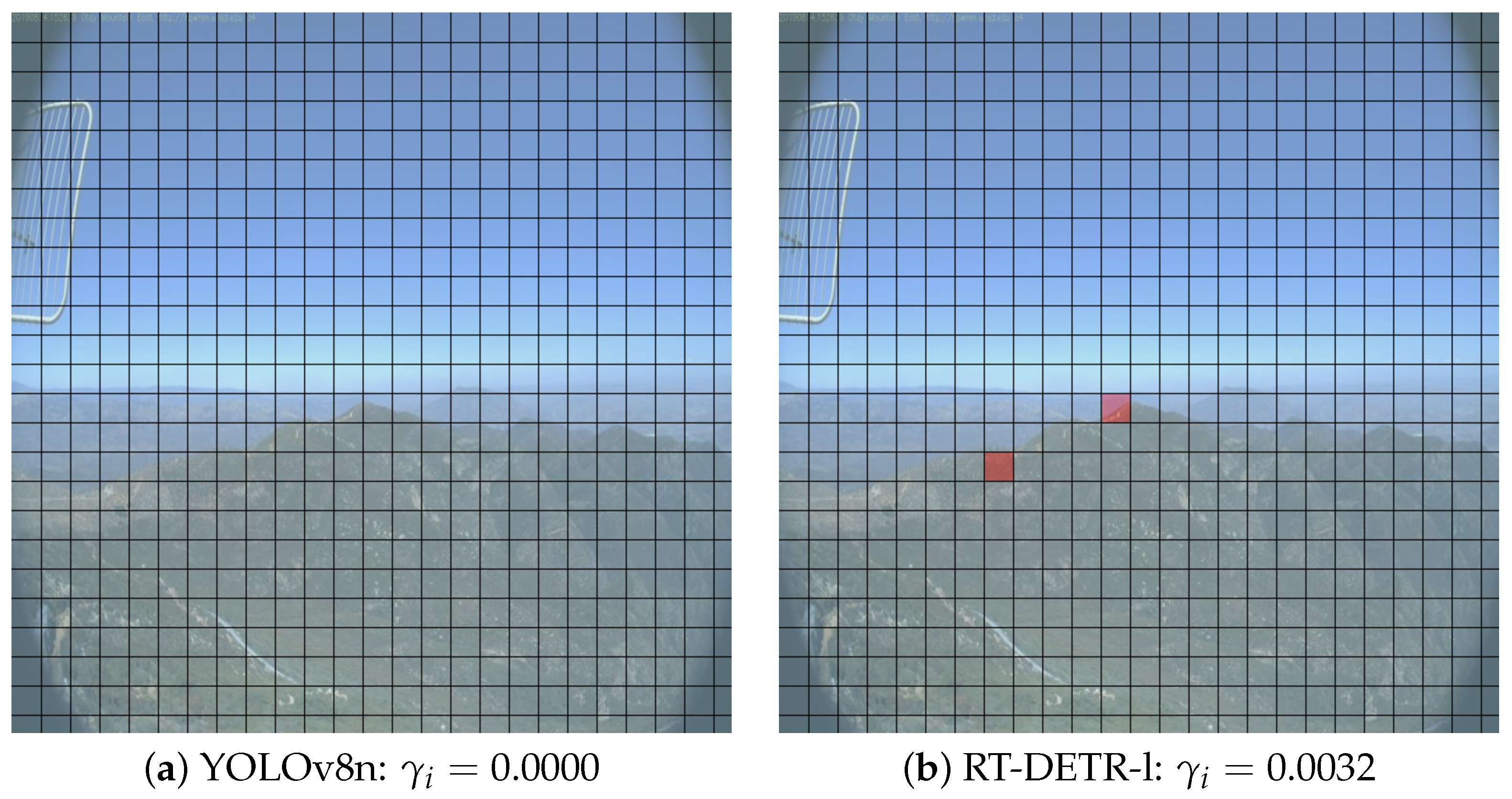
4.3. Results of Local Deception Test
4.3.1. Result of Classification Flip Probabilities
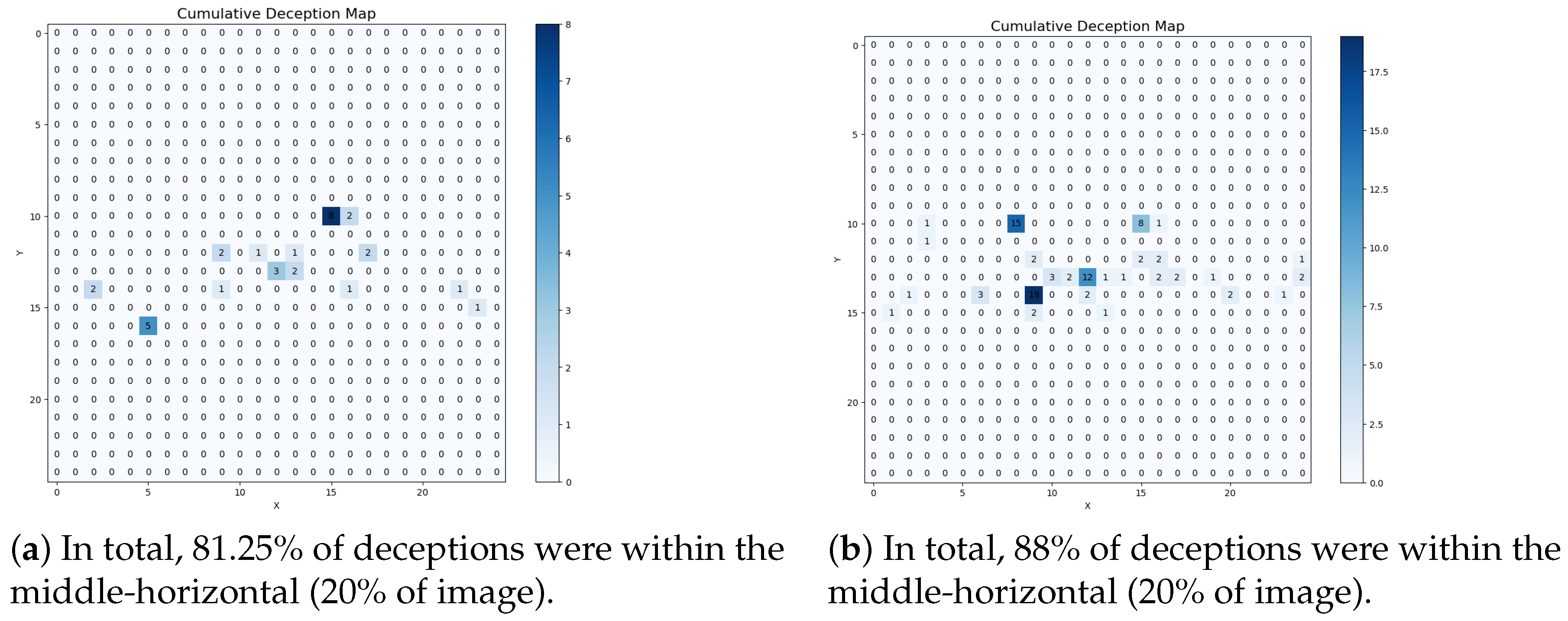
4.3.2. Results of Localized Deception Rate
5. Discussion
- The global sanity check revealed that the transformer-based RT-DETR-l model was substantially more vulnerable to global noise injection compared to the CNN-based YOLOv8, even at noise levels barely visible to the human eye. This is a notable contrast from other studies [35,36] which suggest that transformers trained on Big Data (i.e., CIFAR-10, MNIST, etc.) are more robust than CNNs against global noise. The current results may be an artifact of the severe data shortage in wildfire detection. Thus, as more data augmentation techniques (such as those from WARP) create more diverse adversarial examples, transformers will most likely overtake CNNs in terms of global noise robustness.
- An analysis of the classification flip probabilities revealed that both CNN- and transformer-based models are sensitive to local noise injection. A single noise–injected grid (out of 625 total) resulted in flip probabilities of ≈50% and ≈34% in the smoke-positive prediction for the CNN and transformer models, respectively. These results underscore the need for further model training using data augmentation techniques. While transformers performed better during this test in our study, [37,38] suggest that transformers are not necessarily stronger at patch perturbations than CNNs. Because this seems to be a continuity even for Big Data models, more research is recommended for this adversarial attack.
- An analysis of the localization deception rate revealed areas within the images that were particularly vulnerable to local noise injection. Detailed analysis suggests that human annotation bias may cause to over-focus on the middle-horizontal region, offering insights for future data augmentation strategies to enhance model robustness. This is consistent with DNN behavior in other fields [39], highlighting the need to consider not only the visual characteristics of the target objects but also its spatiotemporal context for true unbiased training.
- Gaussian-distributed Noise
- –
- Gaussian noise with should be introduced into training data, which should reduce precision degradation when encountering global noise, especially among speed-optimized transformers. It will also improve data variety and quantity.
- Cloud PNG-Patch
- –
- Clouds and smoke overlap most in the middle-horizontal strip of the images. Given that most false positives occur in this zone, cloud PNG patches should be placed in this zone to help models distinguish the two.
- –
- Furthermore, cloud PNG patches should also be placed into the upper areas (areas depicting the sky) to add spatial variety to local noise patches.
- Collages/Mosaic
- –
- An effective solution to combat false positives extensively used by [3] is to use collages. This is because collages allow models to easily compare between smoke-positive and smoke-negative images. Since CNNs suffered from local perturbation classification, collages of images between classes should be implemented into training data.
- –
- Furthermore, certain collage techniques such as the YOLOv4-style mosaic [40] has the added benefit of introducing object size variety in the data. This is particularly useful for small object detection.
- –
- However, collages inevitably make the already-small smoke object even smaller. Especially for speed-optimized transformers, which have a known weakness to small objects, crucial smoke features must be extracted first. The below augmentation strategy seeks to offer a potential solution.
- 2 × 2 Crops
- –
- –
- Furthermore, since the crops will result in a smaller-sized image, when resized to the target image size (640 × 640 pixels), the image, and by extension, smoke, will appear larger. This may help models better extract the subtle features of smoke, offering a solution to the problem discussed in the previous augmentation strategy.
- –
- Finally, crops that do not include smoke introduce negative samples. Generally speaking, negative samples will help reduce false positives.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| WARP | Wildfire Adversarial Robustness Protocol |
| DNN | Deep Neural Network |
| CNN | Convolutional Neural Network |
| YOLO | You Only Look Once |
| LSTM | Long Short Term Memory |
| mAP | mean Average Precision |
| NEMO | NEvada sMOke detection benchmark |
| DETR | DEtection TRansformer |
| IoU | Intersection over Union |
| HPWREN | High-Performance Wireless Research and Education Network |
| RT-DETR | Real-Time DETR |
| COCO | Common Objections in COntext |
| FRCNN | Faster Region-based Convolutional Neural Network |
| RNet | RetinaNet |
Appendix A
References
- Salas, E.B. Number of Fatalities Due to Natural Disasters U.S. 2023. 2024. Available online: https://www.statista.com/statistics/216831/fatalities-due-to-natural-disasters-in-the-united-states/ (accessed on 29 September 2024).
- The Department of Forestry and Protection. Palisades Fire. 2025. Available online: https://www.fire.ca.gov/ (accessed on 18 January 2025).
- Yazdi, A.; Qin, H.; Jordan, C.B.; Yang, L.; Yan, F. Nemo: An open-source transformer-supercharged benchmark for fine-grained wildfire smoke detection. Remote Sens. 2022, 14, 3979. [Google Scholar] [CrossRef]
- Fernandes, A.M.; Utkin, A.B.; Lavrov, A.V.; Vilar, R.M. Development of neural network committee machines for automatic forest fire detection using lidar. Pattern Recognit. 2004, 37, 2039–2047. [Google Scholar] [CrossRef]
- Govil, K.; Welch, M.L.; Ball, J.T.; Pennypacker, C.R. Preliminary results from a wildfire detection system using deep learning on remote camera images. Remote Sens. 2020, 12, 166. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- National Interagency Fire Center. Wildfires and Acres. 2023. Available online: https://www.nifc.gov/fire-information/statistics/wildfires (accessed on 18 September 2024).
- ALERTWildfire. Available online: https://www.alertwildfire.org/ (accessed on 18 September 2024).
- Gonçalves, A.M.; Brandão, T.; Ferreira, J.C. Wildfire Detection with Deep Learning—A Case Study for the CICLOPE Project. IEEE Access 2024, 12, 82095–82110. [Google Scholar] [CrossRef]
- Jindal, P.; Gupta, H.; Pachauri, N.; Sharma, V.; Verma, O.P. Real-time wildfire detection via image-based deep learning algorithm. In Soft Computing: Theories and Applications: Proceedings of SoCTA 2020; Springer: Singapore, 2021; Volume 2, pp. 539–550. [Google Scholar]
- Jeong, M.; Park, M.; Nam, J.; Ko, B.C. Light-weight student LSTM for real-time wildfire smoke detection. Sensors 2020, 20, 5508. [Google Scholar] [CrossRef]
- Fernandes, A.M.; Utkin, A.B.; Chaves, P. Automatic Early Detection of Wildfire Smoke with Visible Light Cameras Using Deep Learning and Visual Explanation. IEEE Access 2022, 10, 12814–12828. [Google Scholar] [CrossRef]
- Al-Smadi, Y.; Alauthman, M.; Al-Qerem, A.; Aldweesh, A.; Quaddoura, R.; Aburub, F.; Mansour, K.; Alhmiedat, T. Early wildfire smoke detection using different yolo models. Machines 2023, 11, 246. [Google Scholar] [CrossRef]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Hochreiter, S. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Pan, Z.; Gao, H.; He, N.; Gao, T. An efficient model for real-time wildfire detection in complex scenarios based on multi-head attention mechanism. J.-Real-Time Image Process. 2023, 20, 66. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Cho, S.H.; Kim, S.; Choi, J.H. Transfer learning-based fault diagnosis under data deficiency. Appl. Sci. 2020, 10, 7768. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 18 September 2024).
- Chen, P.Y.; Hsieh, C.J. Adversarial Robustness for Machine Learning; Academic Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Szegedy, C. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- HPRWEN. The HPWREN Fire Ignition Images Library for Neural Network Training. 2023. Available online: https://www.hpwren.ucsd.edu/FIgLib/ (accessed on 18 September 2024).
- Wang, L.; Zhang, H.; Zhang, Y.; Hu, K.; An, K. A Deep Learning-Based Experiment on Forest Wildfire Detection in Machine Vision Course. IEEE Access 2023, 11, 32671–32681. [Google Scholar] [CrossRef]
- Oh, S.H.; Ghyme, S.W.; Jung, S.K.; Kim, G.W. Early wildfire detection using convolutional neural network. In International Workshop on Frontiers of Computer Vision; Springer: Singapore, 2020; pp. 18–30. [Google Scholar]
- Wei, C.; Xu, J.; Li, Q.; Jiang, S. An intelligent wildfire detection approach through cameras based on deep learning. Sustainability 2022, 14, 15690. [Google Scholar] [CrossRef]
- Ultralytics. Ultralytics YOLO Docs. 2024. Available online: https://docs.ultralytics.com/ (accessed on 18 September 2024).
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Mahmood, K.; Mahmood, R.; Van Dijk, M. On the robustness of vision transformers to adversarial examples. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 7838–7847. [Google Scholar]
- Shao, R.; Shi, Z.; Yi, J.; Chen, P.Y.; Hsieh, C.J. On the adversarial robustness of vision transformers. arXiv 2021, arXiv:2103.15670. [Google Scholar]
- Fu, Y.; Zhang, S.; Wu, S.; Wan, C.; Lin, Y. Patch-fool: Are vision transformers always robust against adversarial perturbations? arXiv 2022, arXiv:2203.08392. [Google Scholar]
- Gu, J.; Tresp, V.; Qin, Y. Are vision transformers robust to patch perturbations? In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 404–421. [Google Scholar]
- Dhar, S.; Shamir, L. Systematic biases when using deep neural networks for annotating large catalogs of astronomical images. Astron. Comput. 2022, 38, 100545. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Testing |
|---|---|---|
| 2704 | 337 | 1661 |
| mAP | mAP50 | Parameter Size | mAP-to-Param Ratio | |
|---|---|---|---|---|
| YOLOv8n | 39.0 | 72.0 | 3.2 M | |
| RT-DETR-l | 32.2 | 69.7 | 33 M | |
| NEMO-DETR | 42.3 | 79.0 | 41 M | |
| NEMO-FRCNN | 29.5 | 69.3 | 43 M | |
| NEMO-RNet | 28.9 | 68.8 | 32 M |
| TP | FN | |||
|---|---|---|---|---|
| YOLOv8n | 1496 | 165 | ||
| RT-DETR-l | 1102 | 559 |
| 0.0000 | 0.0016 | 0.0032 | 0.0048 | |
|---|---|---|---|---|
| YOLOv8n | 1629 | 32 | 0 | 0 |
| RT-DETR-l | 1570 | 85 | 5 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ide, R.; Yang, L. Adversarial Robustness for Deep Learning-Based Wildfire Prediction Models. Fire 2025, 8, 50. https://doi.org/10.3390/fire8020050
Ide R, Yang L. Adversarial Robustness for Deep Learning-Based Wildfire Prediction Models. Fire. 2025; 8(2):50. https://doi.org/10.3390/fire8020050
Chicago/Turabian StyleIde, Ryo, and Lei Yang. 2025. "Adversarial Robustness for Deep Learning-Based Wildfire Prediction Models" Fire 8, no. 2: 50. https://doi.org/10.3390/fire8020050
APA StyleIde, R., & Yang, L. (2025). Adversarial Robustness for Deep Learning-Based Wildfire Prediction Models. Fire, 8(2), 50. https://doi.org/10.3390/fire8020050