

Evaluating Segmentation-Based Deep Learning Models for Real-Time Electric Vehicle Fire Detection



Abstract
1. Introduction
- A dedicated dataset for electric vehicle (EV) fire detection was constructed and meticulously labeled. It can serve as foundational data for advancing object detection research.
- This is the first study to apply segmentation techniques in real time for EV fire detection and conduct a comprehensive performance comparison.
- The latest YOLO model, YOLOv11-Seg, was applied for the first time in deep learning-based fire detection research, representing a significant innovation in this domain.
2. Literature Review
2.1. Existing Fire Detection Research Based on Object Detection
2.2. One-Stage Object Models
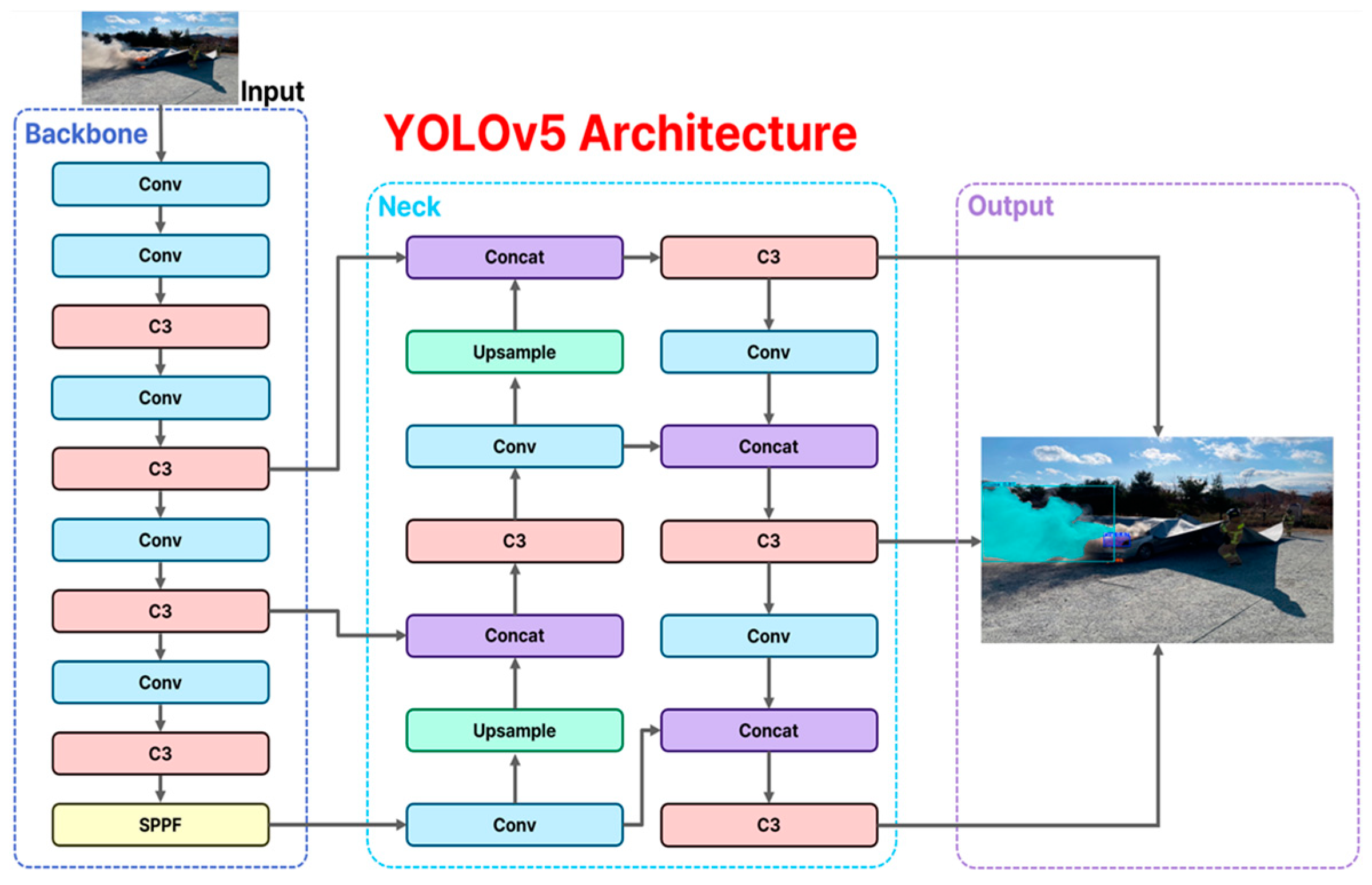
2.2.1. YOLOv5-Seg
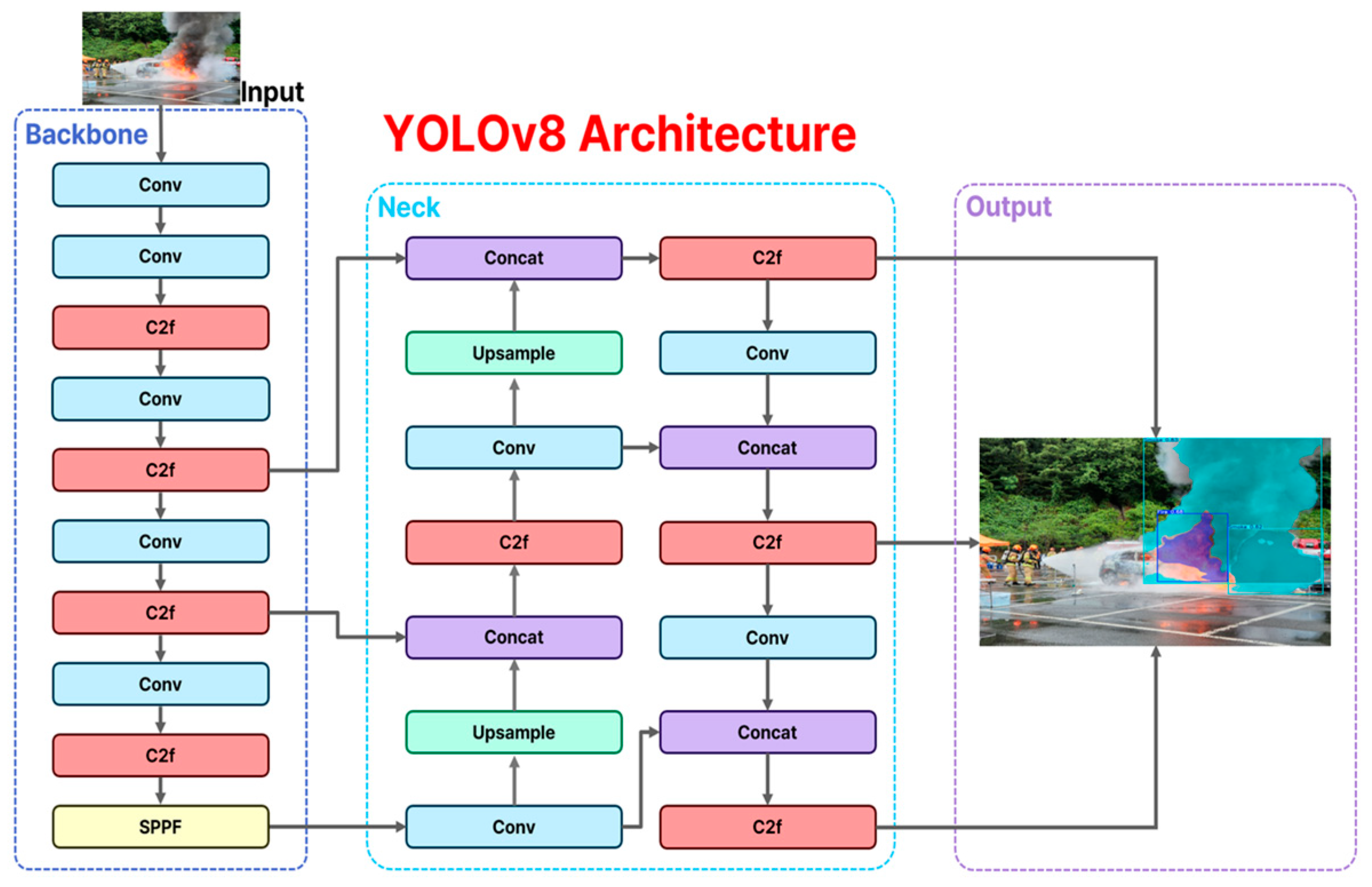
2.2.2. YOLOv8-Seg
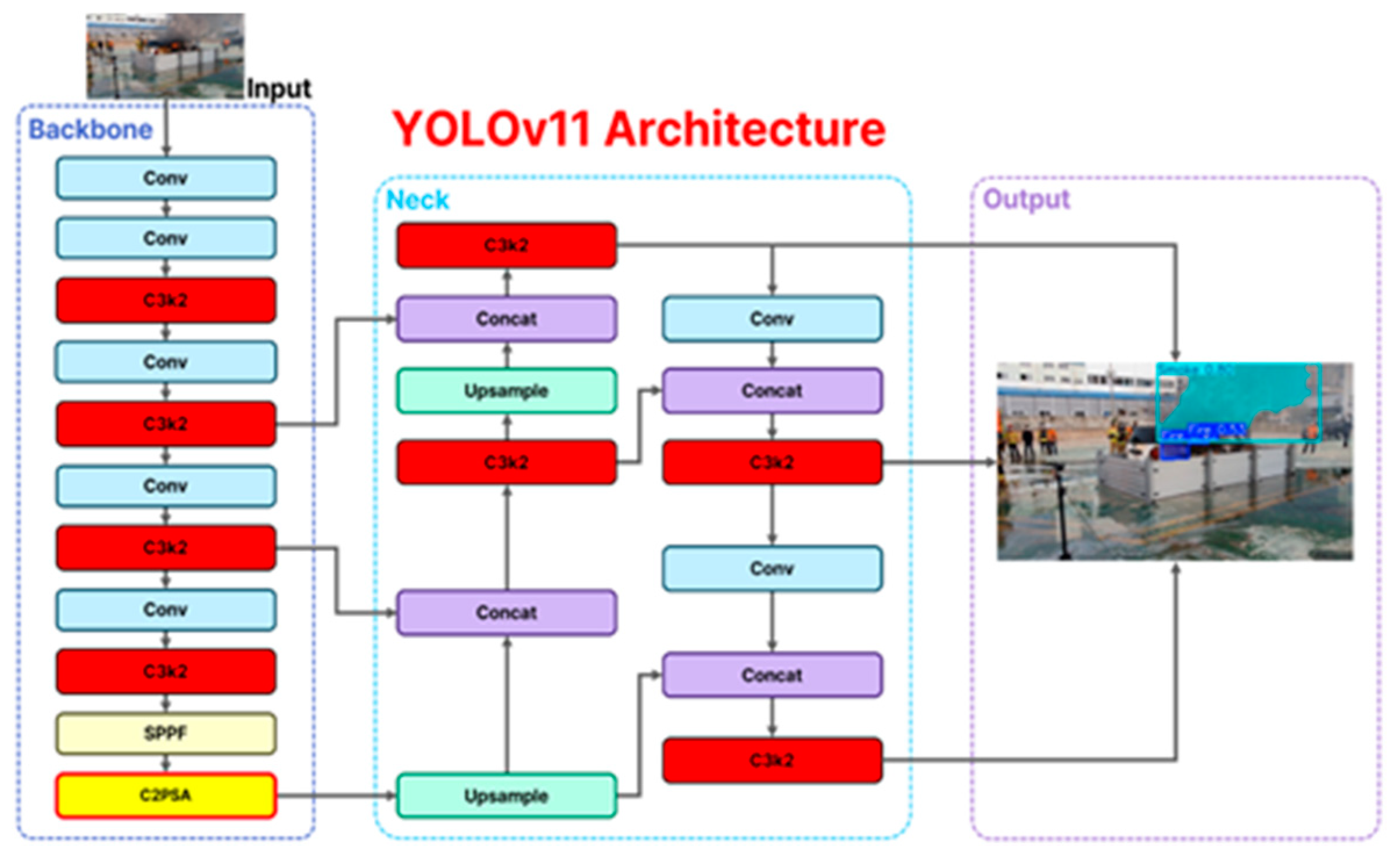
2.2.3. YOLOv11-Seg
2.3. Multi-Stage Object Models
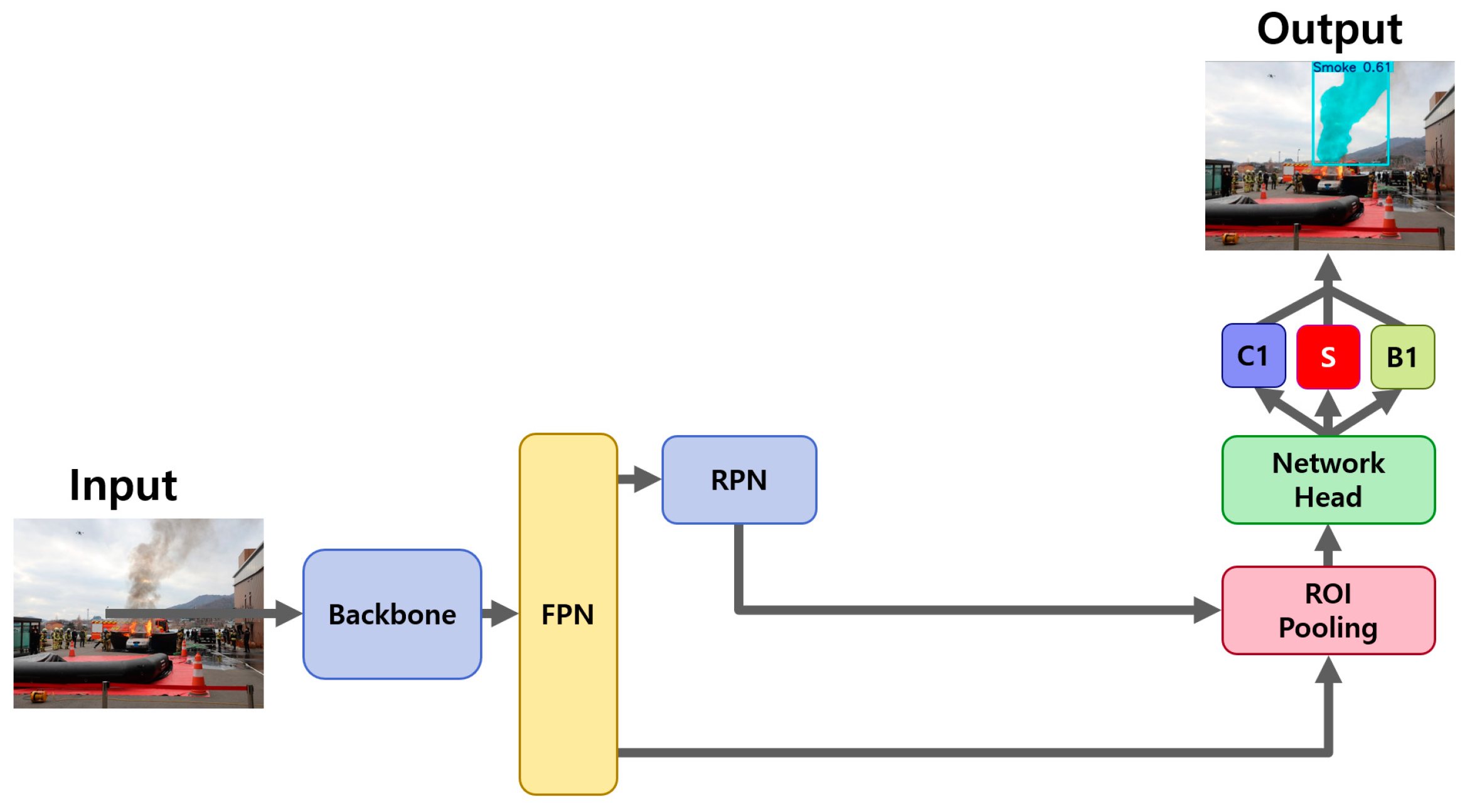
2.3.1. Mask R-CNN
2.3.2. Cascade Mask R-CNN
2.4. Bounding Box and Segmentation Labeling
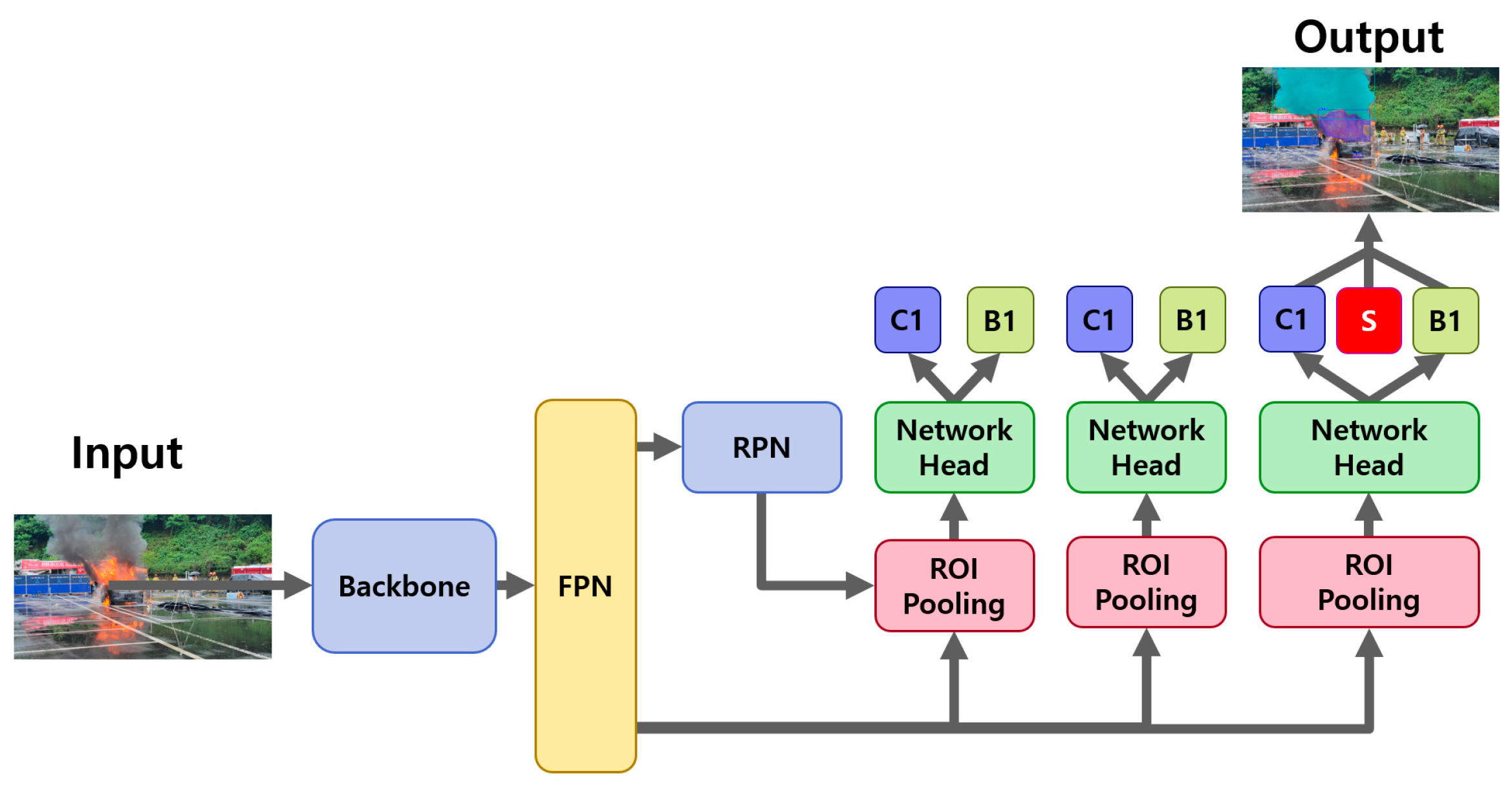
3. Research Methods
- Data collection: Videos of electric vehicle (EV) fires were collected from the Internet. A total of 60 videos encompassing the entire combustion process from ignition to the peak fire stage were investigated.
- Frame extraction and preprocessing: Non-fire footage was manually removed from the videos, and the remaining footage was converted into frame-by-frame images. Consecutive or duplicate frames were subsequently excluded, yielding a final dataset of 3000 images.
- Labeling for segmentation: The extracted images were labeled for segmentation using RoboFlow.
- Model application: The labeled images were processed using segmentation models, including YOLOv5-Seg, YOLOv8-Seg, YOLOv11-Seg, Mask R-CNN, and Cascade Mask R-CNN.
- Training, validation, and testing: The models were trained and validated using the constructed dataset, and the inference results were analyzed using a designated test dataset.
3.1. Production of Datasets
3.2. Data Preprocessing
3.3. Experimental Environment and Parameter Settings
3.4. Model Evaluation Metrics
4. Experimental Analysis
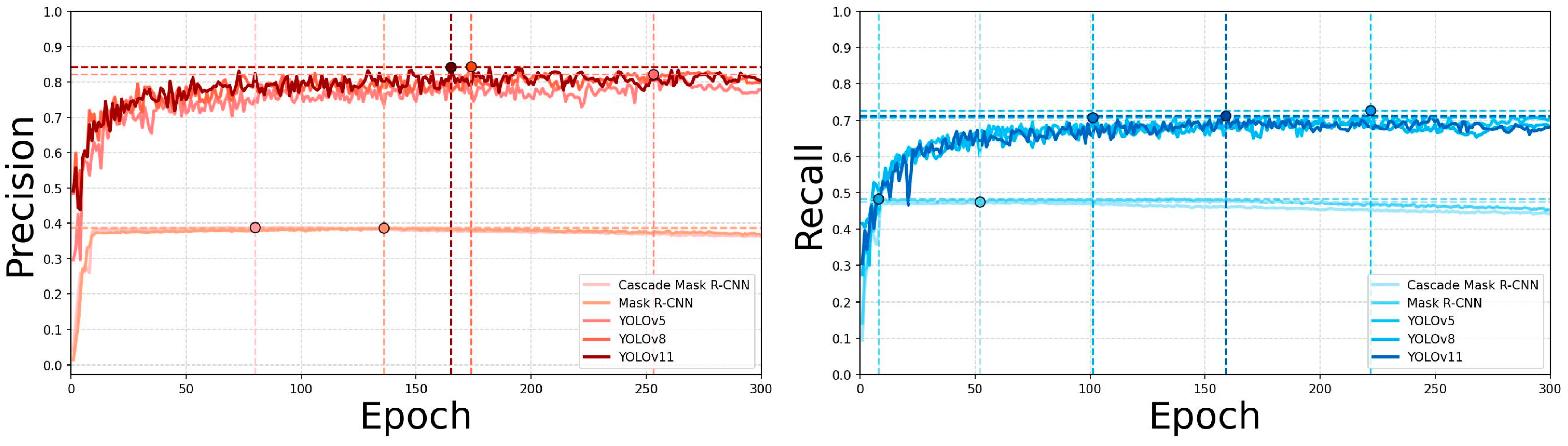
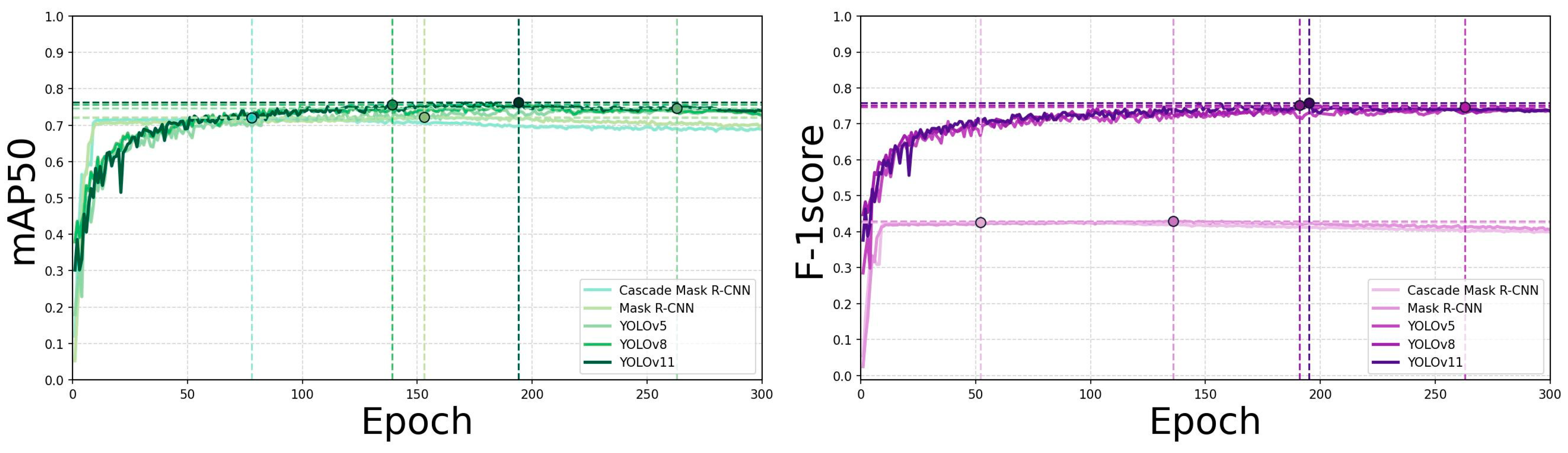
4.1. Training and Validation Results of Electric Vehicle Fire Detection Model
4.2. EV Fire Detection Model Test and Inference Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Challa, R.; Kamath, D.; Anctil, A. Well-to-wheel greenhouse gas emissions of electric versus combustion vehicles from 2018 to 2030 in the US. J. Environ. Manag. 2022, 308, 114592. [Google Scholar] [CrossRef]
- Qiao, Q.; Zhao, F.; Liu, Z.; He, X.; Hao, H. Life cycle greenhouse gas emissions of electric vehicles in China: Combining the vehicle cycle and fuel cycle. Energy 2019, 177, 222–233. [Google Scholar] [CrossRef]
- Sun, P.; Bisschop, R.; Niu, H.; Huang, X. A review of battery fires in electric vehicles. Fire Technol. 2020, 56, 1361–1410. [Google Scholar] [CrossRef]
- Dorsz, A.; Lewandowski, M. Analysis of fire hazards associated with the operation of electric vehicles in enclosed structures. Energies 2021, 15, 11. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, J.; Cong, B.; Han, X.; Yin, S. Characterization and assessment of fire evolution process of electric vehicles placed in parallel. Process Saf. Environ. Prot. 2022, 166, 524–534. [Google Scholar] [CrossRef]
- La Scala, A.; Loprieno, P.; Foti, D.; La Scala, M. The mechanical response of structural elements in enclosed structures during electric vehicle fires: A computational study. Energies 2023, 16, 7233. [Google Scholar] [CrossRef]
- Kiasari, M.M.; Aly, H.H. Enhancing Fire Protection in Electric Vehicle Batteries Based on Thermal Energy Storage Systems Using Machine Learning and Feature Engineering. Fire 2024, 7, 296. [Google Scholar] [CrossRef]
- EV Universe. EV Fires. Available online: https://www.evuniverse.io/p/ev-fires (accessed on 5 December 2024).
- Zhang, S.; Yang, Q.; Gao, Y.; Gao, D. Real-time fire detection method for electric vehicle charging stations based on machine vision. World Electr. Veh. J. 2022, 13, 23. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Nath, N.D.; Behzadan, A.H.; Paal, S.G. Deep learning for site safety: Real-time detection of personal protective equipment. Autom. Constr. 2020, 112, 103085. [Google Scholar] [CrossRef]
- Mody, S.; Mehta, H.; Mantri, P.; Ali, B.; Khivasara, A. Safety Gear Equipment Detection for Warehouse and Construction Sites Using YOLOv5. Int. Res. J. Eng. Technol. 2021, 9, 3885–3895. [Google Scholar]
- Wei, Y.; Liu, X. Dangerous goods detection based on transfer learning in X-ray images. Neural Comput. Appl. 2020, 32, 8711–8724. [Google Scholar] [CrossRef]
- Mohapatra, A.; Trinh, T. Early wildfire detection technologies in practice—A review. Sustainability 2022, 14, 12270. [Google Scholar] [CrossRef]
- Lee, J.; Jeong, K.; Jung, H. Development of a Forest Fire Detection System Using a Drone-based Convolutional Neural Network Model. Int. J. Fire Sci. Eng. 2023, 37, 30–40. [Google Scholar]
- Bouguettaya, A.; Zarzour, H.; Taberkit, A.M.; Kechida, A. A review on early wildfire detection from unmanned aerial vehicles using deep learning-based computer vision algorithms. Signal Process. 2022, 190, 108309. [Google Scholar] [CrossRef]
- Gonçalves, L.A.O.; Ghali, R.; Akhloufi, M.A. YOLO-Based Models for Smoke and Wildfire Detection in Ground and Aerial Images. Fire 2024, 7, 140. [Google Scholar] [CrossRef]
- Maillard, S.; Khan, M.S.; Cramer, A.; Sancar, E.K. Wildfire and Smoke Detection Using YOLO-NAS. In Proceedings of the 2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), Mt Pleasant, MI, USA, 13–14 April 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Kwon, H.J.; Lee, B.H.; Jeong, H.Y. A Study on Improving YOLO-Based Object Detection Model Performance for Smoke and Flame Occurring from Various Materials. J. Korean Inst. Electr. Electron. Mater. Eng. 2024, 37, 261–273. [Google Scholar]
- Cao, X.; Su, Y.; Geng, X.; Wang, Y. YOLO-SF: YOLO for fire segmentation detection. IEEE Access 2023, 11, 111079–111092. [Google Scholar] [CrossRef]
- Zhao, C.; Hu, W.; Meng, D.; Mi, W.; Wang, X.; Wang, J. Full-scale experimental study of the characteristics of electric vehicle fires process and response measures. Case Stud. Therm. Eng. 2024, 53, 103889. [Google Scholar] [CrossRef]
- Khan, F.; Xu, Z.; Sun, J.; Khan, F.M.; Ahmed, A.; Zhao, Y. Recent advances in sensors for fire detection. Sensors 2022, 22, 3310. [Google Scholar] [CrossRef]
- Brzezinska, D.; Bryant, P. Performance-based analysis in evaluation of safety in car parks under electric vehicle fire conditions. Energies 2022, 15, 649. [Google Scholar] [CrossRef]
- Guede-Fernández, F.; Martins, L.; de Almeida, R.V.; Gamboa, H.; Vieira, P. A deep learning based object identification system for forest fire detection. Fire 2021, 4, 75. [Google Scholar] [CrossRef]
- Zhang, L.; Li, J.; Zhang, F. An efficient forest fire target detection model based on improved YOLOv5. Fire 2023, 6, 291. [Google Scholar] [CrossRef]
- He, Y.; Hu, J.; Zeng, M.; Qian, Y.; Zhang, R. DCGC-YOLO: The Efficient Dual-Channel Bottleneck Structure YOLO Detection Algorithm for Fire Detection. IEEE Access 2024, 12, 65254–65265. [Google Scholar] [CrossRef]
- Catargiu, C.; Cleju, N.; Ciocoiu, I.B. A Comparative Performance Evaluation of YOLO-Type Detectors on a New Open Fire and Smoke Dataset. Sensors 2024, 24, 5597. [Google Scholar] [CrossRef]
- Wang, D.; Qian, Y.; Lu, J.; Wang, P.; Hu, Z.; Chai, Y. FS-YOLO: Fire-Smoke Detection Based on Improved YOLOv7. Multimed. Syst. 2024, 30, 215–227. [Google Scholar] [CrossRef]
- Wang, D.; Qian, Y.; Lu, J.; Wang, P.; Yang, D.; Yan, T. EA-YOLO: Efficient Extraction and Aggregation Mechanism of YOLO for Fire Detection. Multimed. Syst. 2024, 30, 287–299. [Google Scholar] [CrossRef]
- Ultralytics. Ultralytics/YOLOv5: V7.0—YOLOv5 SOTA Real-Time Instance Segmentation. Available online: https://github.com/ultralytics/yolov5 (accessed on 28 November 2023).
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 27 November 2023).
- Ultralytics. YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 28 November 2023).
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Alkhammash, E.H. Multi-Classification Using YOLOv11 and Hybrid YOLO11n-MobileNet Models: A Fire Classes Case Study. Fire 2025, 8, 17. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Roboflow. Smart Polygon Annotation with Roboflow Annotate. Available online: https://docs.roboflow.com/annotate/use-roboflow-annotate/smart-polygon (accessed on 27 November 2023).
- Dumitriu, A.; Tatui, F.; Miron, F.; Ionescu, R.T.; Timofte, R. Rip Current Segmentation: A Novel Benchmark and YOLOv8 Baseline Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1261–1271. [Google Scholar]
- Padilla, R.; Netto, S.L.; da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Dataset |
|---|---|
| Object Type | Fire, Smoke |
| Datasets Format | YOLO, COCO-MMdetection |
| Division | Train (80%):val(10%):test(10%) = 8:1:1 |
| Quantities | Train (2400):val(300):test(300) = Total(3000) |
| Scenes | On the road (19), above-ground parking (26), above-ground parking (charging) (4), underground parking (3), underground parking (charging) (1), open lots and others (6) |
| Vehicle type | Passenger cars (55), buses (4), trucks (1) |
| Public Dataset | None |
| Hyperparameters | Hardware | ||
|---|---|---|---|
| YOLOv5-seg, YOLOv8-seg, and YOLOv11-seg | |||
| Parameters | Details | Name | Version |
| Epochs | 300 | Pytorch | 2.2 |
| Batch size | 16 | CUDA | 12.3 |
| Image size (Pixels) | 640 × 640 | CPU | 12 core |
| Optimizer algorithm | SGD | RAM | 96 |
| learning rate | 0.01 | GPU | NVIDIA V100 |
| Mask R-CNN and Cascade R-CNN | |||
| Parameters | Details | Name | Version |
| Epochs | 300 | Pytorch | 1.11 |
| Batch size | 16 | CUDA | 11.6 |
| Image size (Pixels) | 640 × 640 | CPU | 12 core |
| Optimizer algorithm | AdamW | RAM | 96 |
| learning rate | 0.01 | GPU | NVIDIA V100 |
| Model | Class | Precision | Recall | F1-Score | mAP50 | FPS |
|---|---|---|---|---|---|---|
| Mask R-CNN | Fire | 0.418 | 0.504 | 0.457 | 0.771 | 29.10 |
| Smoke | 0.390 | 0.483 | 0.432 | 0.688 | ||
| Total | 0.404 | 0.494 | 0.445 | 0.730 | ||
| Cascade Mask_R-CNN | Fire | 0.430 | 0.506 | 0.465 | 0.790 | 20.10 |
| Smoke | 0.397 | 0.472 | 0.431 | 0.700 | ||
| Total | 0.414 | 0.489 | 0.448 | 0.745 | ||
| YOLOv5-Seg | Fire | 0.755 | 0.727 | 0.741 | 0.758 | 67.11 |
| Smoke | 0.795 | 0.678 | 0.732 | 0.713 | ||
| Total | 0.775 | 0.703 | 0.737 | 0.736 | ||
| YOLOv8-Seg | Fire | 0.836 | 0.677 | 0.741 | 0.757 | 111.11 |
| Smoke | 0.801 | 0.689 | 0.748 | 0.731 | ||
| Total | 0.818 | 0.683 | 0.744 | 0.744 | ||
| YOLOv11-Seg | Fire | 0.781 | 0.702 | 0.739 | 0.766 | 136.99 |
| Smoke | 0.793 | 0.676 | 0.730 | 0.722 | ||
| Total | 0.787 | 0.689 | 0.735 | 0.744 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, H.; Choi, S.; Woo, W.; Jung, H. Evaluating Segmentation-Based Deep Learning Models for Real-Time Electric Vehicle Fire Detection. Fire 2025, 8, 66. https://doi.org/10.3390/fire8020066
Kwon H, Choi S, Woo W, Jung H. Evaluating Segmentation-Based Deep Learning Models for Real-Time Electric Vehicle Fire Detection. Fire. 2025; 8(2):66. https://doi.org/10.3390/fire8020066
Chicago/Turabian StyleKwon, Heejun, Sugi Choi, Wonmyung Woo, and Haiyoung Jung. 2025. "Evaluating Segmentation-Based Deep Learning Models for Real-Time Electric Vehicle Fire Detection" Fire 8, no. 2: 66. https://doi.org/10.3390/fire8020066
APA StyleKwon, H., Choi, S., Woo, W., & Jung, H. (2025). Evaluating Segmentation-Based Deep Learning Models for Real-Time Electric Vehicle Fire Detection. Fire, 8(2), 66. https://doi.org/10.3390/fire8020066