


Harvester Maintenance Prediction Tool: Machine Learning Model Based on Mechanical Features



Abstract
:1. Introduction
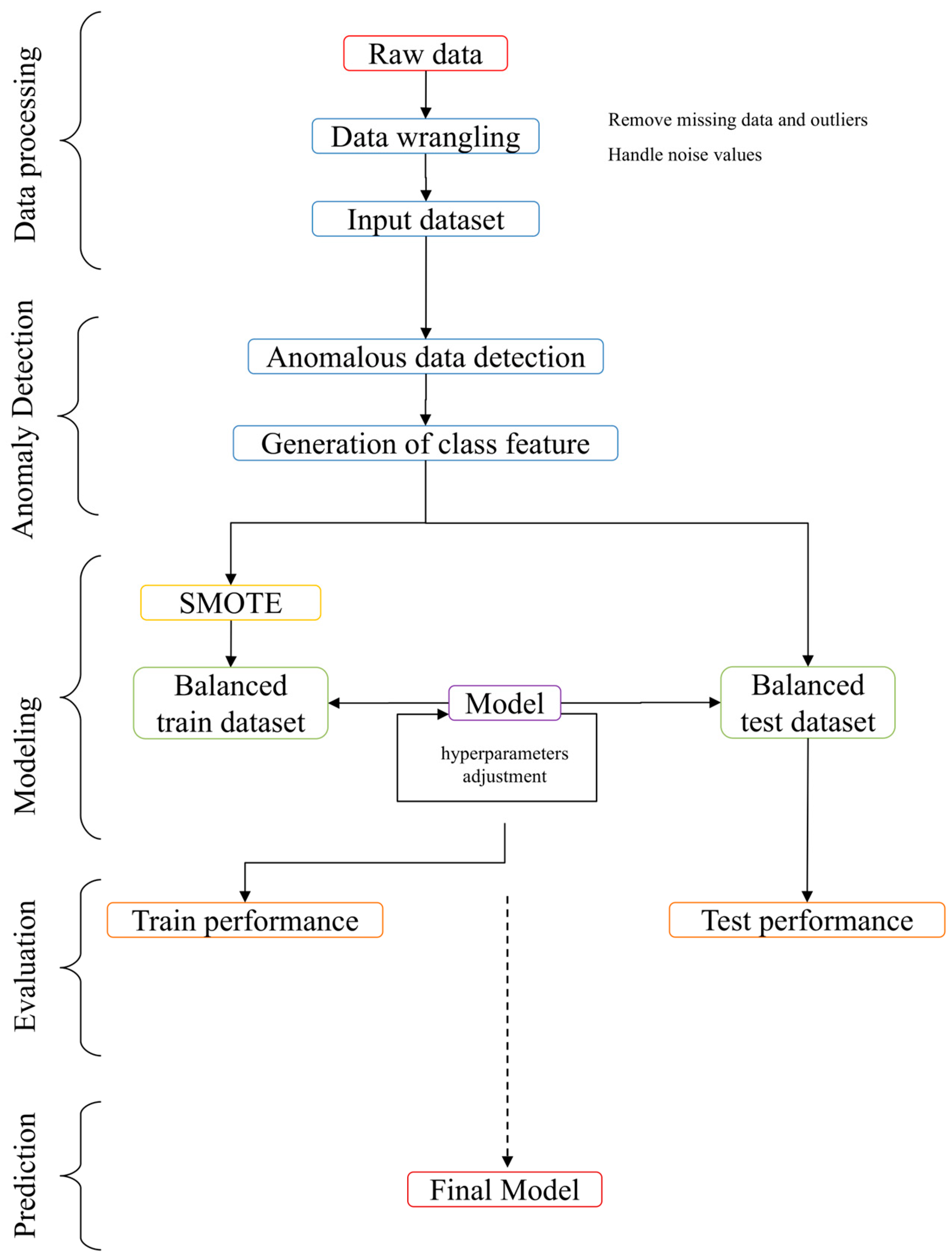
2. Materials and Methods
2.1. Data Processing
2.2. Unsupervised Machine Learning for the Identification of Data Anomalies
2.3. Modeling, Evaluation, and Prediction
3. Results
3.1. Modeling in Default Mode
3.2. Tuned Model and Combined Models
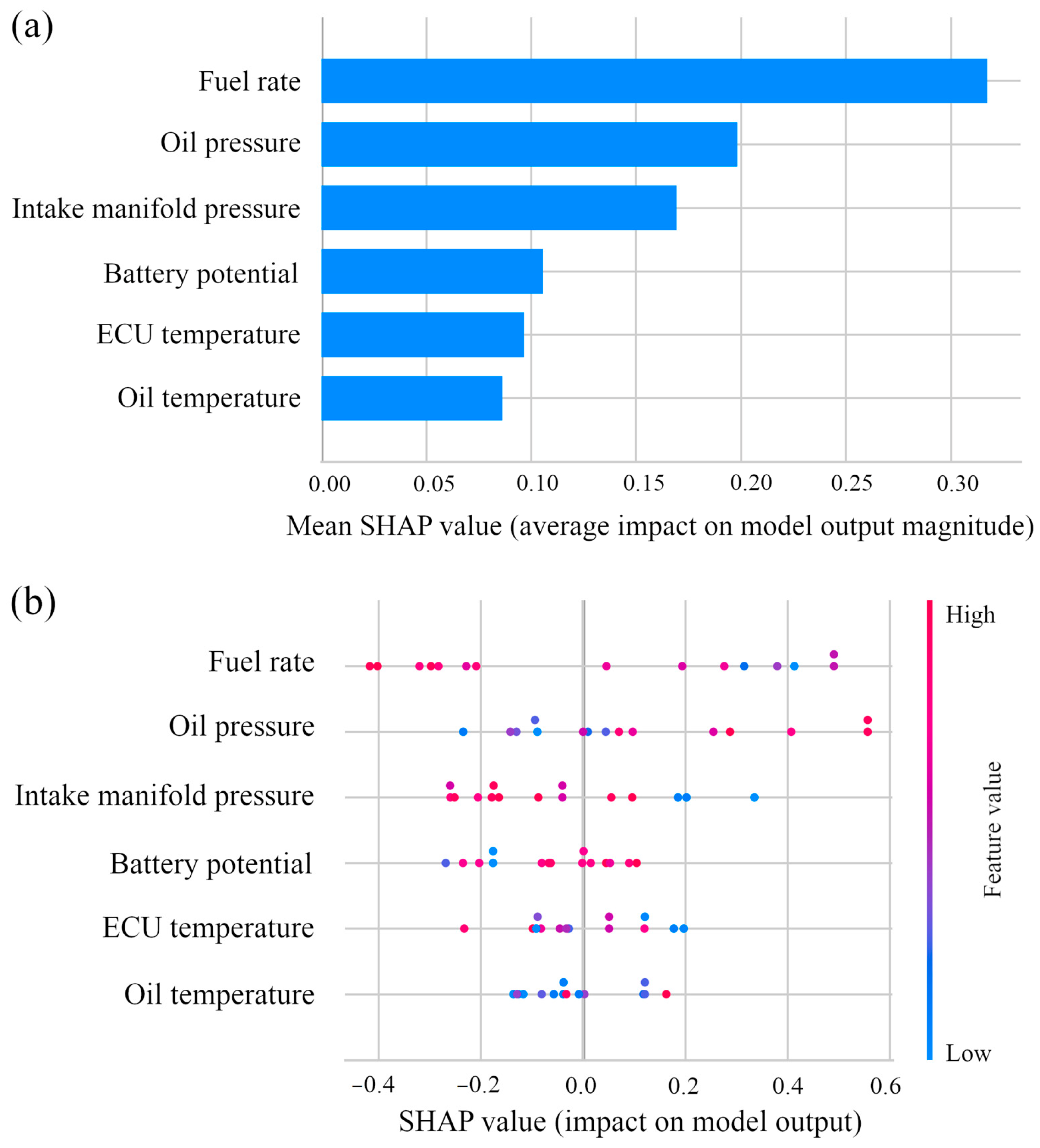
3.3. SHAP Dependence Analysis
4. Discussion
4.1. Predictive Models
4.2. Features and Their Effect on the Predictive Model
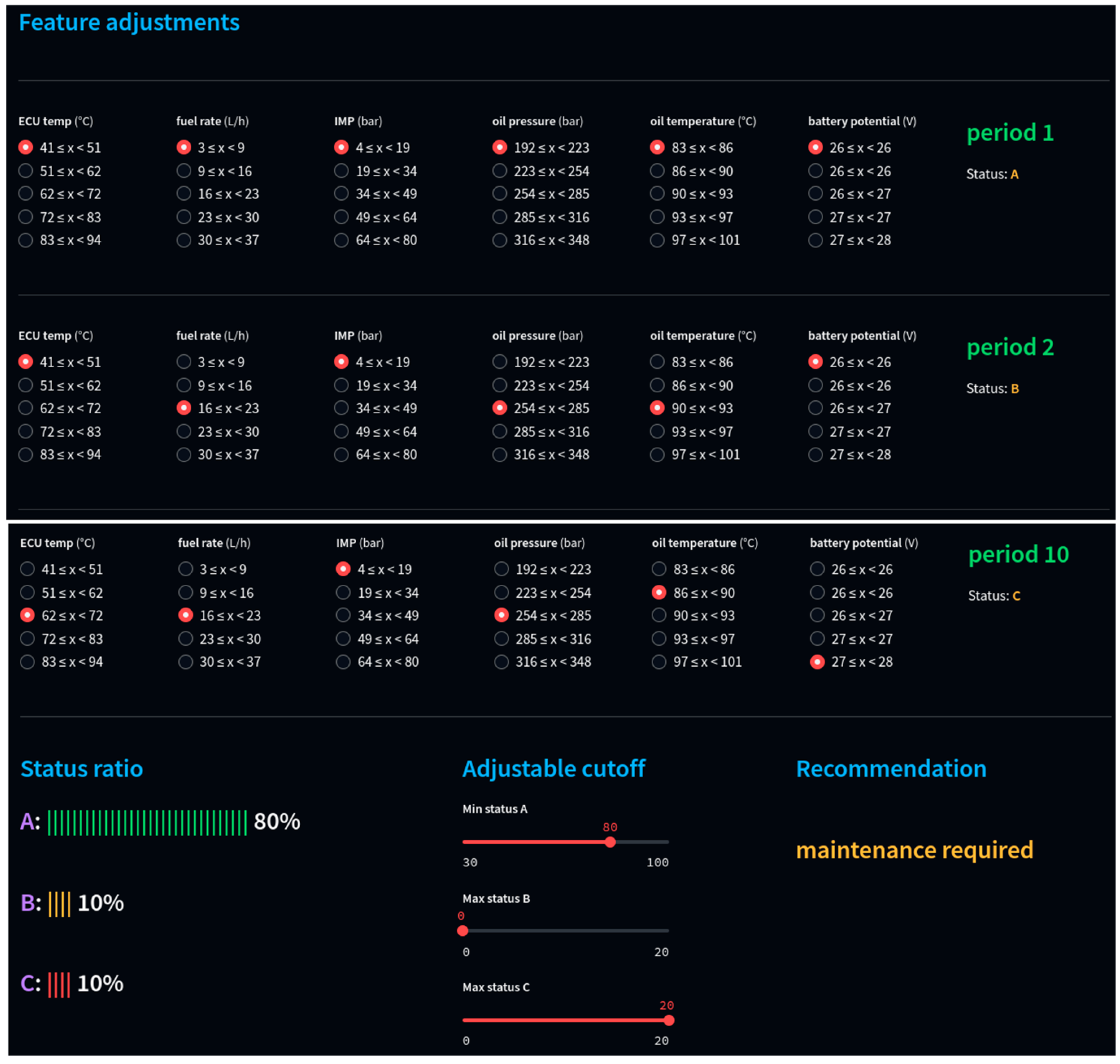
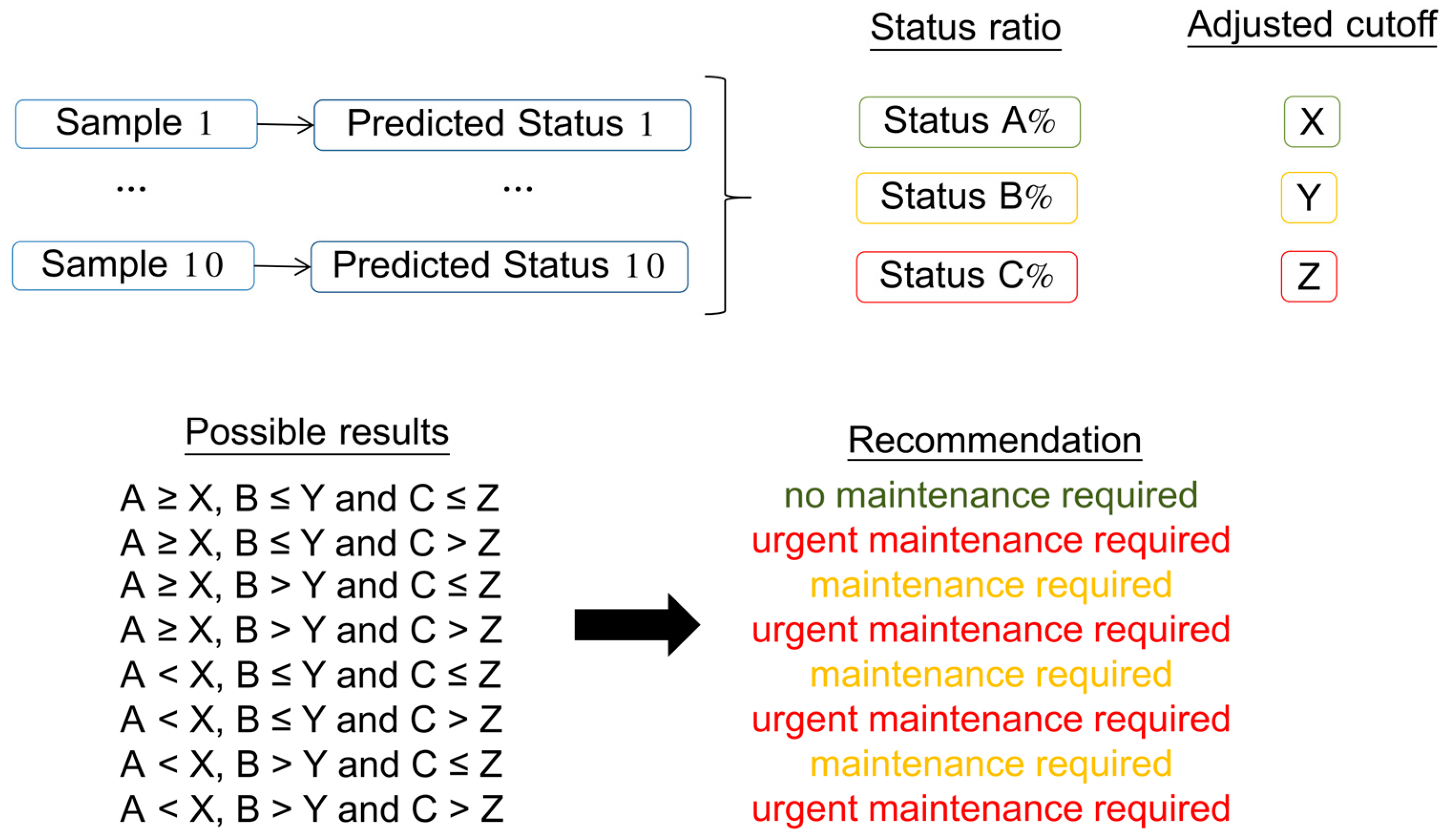
4.3. Harvester Maintenance Prediction Tool
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Food and Agriculture Organization of the United Nations. Global Forest Resources Assessment 2020; FAO: Rome, Italy, 2020. [Google Scholar]
- Brazilian Institute of Geography and Statistics. Vegetal Extraction and Forestry Production; Brazilian Institute of Geography and Statistics: Rio de Janeiro, Brazil, 2023.
- Santana, J.S.; Valente, D.S.M.; Queiroz, D.M.; Coelho, A.L.F.; Barbosa, I.A.; Momin, A. Automated Detection of Young Eucalyptus Plants for Optimized Irrigation Management in Forest Plantations. AgriEngineering 2024, 6, 3752–3767. [Google Scholar] [CrossRef]
- ISO 6814:2009; International Standardization for Organization Machinery for Forestry—Mobile and Self-Propelled Machinery—Terms, Definitions and Classification. ISO: Geneva, Switzerland, 2009.
- Prinz, R.; Spinelli, R.; Magagnotti, N.; Routa, J.; Asikainen, A. Modifying the Settings of CTL Timber Harvesting Machines to Reduce Fuel Consumption and CO2 Emissions. J. Clean. Prod. 2018, 197, 208–217. [Google Scholar] [CrossRef]
- Shan, C.; Bi, H.; Watt, D.; Li, Y.; Strandgard, M.; Ghaffariyan, M.R. A New Model for Predicting the Total Tree Height for Stems Cut-to-Length by Harvesters in Pinus Radiata Plantations. J. For. Res. 2021, 32, 21–41. [Google Scholar] [CrossRef]
- Spinelli, R.; Conrado de Arruda Moura, A.; Manoel da Silva, P. Decreasing the Diesel Fuel Consumption and CO2 Emissions of Industrial In-Field Chipping Operations. J. Clean. Prod. 2018, 172, 2174–2181. [Google Scholar] [CrossRef]
- Liski, E.; Jounela, P.; Korpunen, H.; Sosa, A.; Lindroos, O.; Jylhä, P. Modeling the Productivity of Mechanized CTL Harvesting with Statistical Machine Learning Methods. Int. J. For. Eng. 2020, 31, 253–262. [Google Scholar] [CrossRef]
- Lundbäck, M.; Häggström, C.; Nordfjell, T. Worldwide Trends in Methods for Harvesting and Extracting Industrial Roundwood. Int. J. For. Eng. 2021, 32, 202–215. [Google Scholar] [CrossRef]
- Noordermeer, L.; Sørngård, E.; Astrup, R.; Næsset, E.; Gobakken, T. Coupling a Differential Global Navigation Satellite System to a Cut-to-Length Harvester Operating System Enables Precise Positioning of Harvested Trees. Int. J. For. Eng. 2021, 32, 119–127. [Google Scholar] [CrossRef]
- Olivera, A.; Visser, R. Using the Harvester On-Board Computer Capability to Move towards Precision Forestry. N. Z. J. For. Sci. 2016, 60, 3–7. [Google Scholar]
- Jankovský, M.; Merganič, J.; Allman, M.; Ferenčík, M.; Messingerová, V. The Cumulative Effects of Work-Related Factors Increase the Heart Rate of Cabin Field Machine Operators. Int. J. Ind. Ergon. 2018, 65, 173–178. [Google Scholar] [CrossRef]
- Felipe Maldaner, L.; de Paula Corrêdo, L.; Fernanda Canata, T.; Paulo Molin, J. Predicting the Sugarcane Yield in Real-Time by Harvester Engine Parameters and Machine Learning Approaches. Comput. Electron. Agric. 2021, 181, 105945. [Google Scholar] [CrossRef]
- Simões, D.; Fenner, P.T.; Esperancini, M.S.T. Produtividade e Custos do Feller-Buncher e Processador Florestal em Povoamento de Eucalipto de Primeiro Corte. Ciênc. Florest. 2014, 24, 621–630. [Google Scholar] [CrossRef]
- Paccola, J.E. Manutenção e Operação de Equipamentos Móveis; JAC: São José dos Campos, Brazil, 2017. [Google Scholar]
- Drożyner, P.; Mikołajczak, P. Maintenance of Vehicles, Machines and Equipment in View of the ISO9001 Requirements. Eksploat. Niezawodn. 2007, 4, 55–58. [Google Scholar]
- Clarotti, C.; Lannoy, A.; Odin, S.; Procaccia, H. Detection of Equipment Aging and Determination of the Efficiency of a Corrective Measure. Reliab. Eng. Syst. Saf. 2004, 84, 57–64. [Google Scholar] [CrossRef]
- Khodabakhshian, R. A Review of Maintenance Management of Tractors and Agricultural Machinery: Preventive Maintenance Systems. Agric. Eng. Int. CIGR J. 2013, 15, 147–159. [Google Scholar]
- Maktoubian, J.; Taskhiri, M.S.; Turner, P. Intelligent Predictive Maintenance (IPdM) in Forestry: A Review of Challenges and Opportunities. Forests 2021, 12, 1495. [Google Scholar] [CrossRef]
- Kemmerer, J.; Labelle, E.R. Using Harvester Data from On-Board Computers: A Review of Key Findings, Opportunities and Challenges. Eur. J. For. Res. 2021, 140, 1–17. [Google Scholar] [CrossRef]
- Strandgard, M.; Walsh, D.; Acuna, M. Estimating Harvester Productivity in Pinus Radiata Plantations Using Stanford Stem Files. Scand. J. For. Res. 2013, 28, 73–80. [Google Scholar] [CrossRef]
- Munis, R.A.; Almeida, R.O.; Camargo, D.A.; da Silva, R.B.G.; Wojciechowski, J.; Simões, D. Machine Learning Methods to Estimate Productivity of Harvesters: Mechanized Timber Harvesting in Brazil. Forests 2022, 13, 1068. [Google Scholar] [CrossRef]
- Munis, R.A.; Almeida, R.O.; Camargo, D.A.; da Silva, R.B.G.; Wojciechowski, J.; Simões, D. Tactical Forwarder Planning: A Data-Driven Approach for Timber Forwarding. Forests 2023, 14, 1782. [Google Scholar] [CrossRef]
- Almeida, R.O.; da Silva, R.B.G.; Simões, D. Cut-to-Length Harvesting Prediction Tool: Machine Learning Model Based on Harvest and Weather Features. Forests 2024, 15, 1398. [Google Scholar] [CrossRef]
- Leal, R.D.; da Silva, T.; Nicodemo, A.C.; Almeida, R.O.; Munis, R.A.; da Silva, R.B.G.; Simões, D. Harvesters’ Productivity Prediction in Brazilian Eucalyptus Plantations: Development of a Model from Machine Learning. Int. J. For. Eng. 2025, 36, 58–66. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; da Rosa Righi, R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive Maintenance in the Industry 4.0: A Systematic Literature Review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Yan, J.; Wang, X. Unsupervised and Semi-Supervised Learning: The Next Frontier in Machine Learning for Plant Systems Biology. Plant J. 2022, 111, 1527–1538. [Google Scholar] [CrossRef]
- Quatrini, E.; Costantino, F.; Di Gravio, G.; Patriarca, R. Machine Learning for Anomaly Detection and Process Phase Classification to Improve Safety and Maintenance Activities. J. Manuf. Syst. 2020, 56, 117–132. [Google Scholar] [CrossRef]
- Ayvaz, S.; Alpay, K. Predictive Maintenance System for Production Lines in Manufacturing: A Machine Learning Approach Using IoT Data in Real-Time. Expert Syst. Appl. 2021, 173, 114598. [Google Scholar] [CrossRef]
- Mokhtari, S.; Abbaspour, A.; Yen, K.K.; Sargolzaei, A. A Machine Learning Approach for Anomaly Detection in Industrial Control Systems Based on Measurement Data. Electronics 2021, 10, 407. [Google Scholar] [CrossRef]
- Kumar, N.; Gangola, S.; Bhatt, P.; Jeena, N.; Khwairakpam, R. Soil Genesis, Survey and Classification. In Mycorrhizosphere and Pedogenesis; Varma, A., Choudhary, D.K., Eds.; Springer Singapore: Singapore, 2019; pp. 139–150. ISBN 978-981-13-6479-2. [Google Scholar]
- Momesso, L.; Crusciol, C.A.C.; Soratto, R.P.; Vyn, T.J.; Tanaka, K.S.; Costa, C.H.M.; Neto, J.F.; Cantarella, H. Impacts of Nitrogen Management on No-Till Maize Production Following Forage Cover Crops. Agron. J. 2019, 111, 639–649. [Google Scholar] [CrossRef]
- MacLeod, A.; Korycinska, A. Detailing Köppen–Geiger Climate Zones at Sub-National to Continental Scale: A Resource for Pest Risk Analysis. EPPO Bull. 2019, 49, 73–82. [Google Scholar] [CrossRef]
- Xavier, A.C.F.; Martins, L.L.; Rudke, A.P.; de Morais, M.V.B.; Martins, J.A.; Blain, G.C. Evaluation of Quantile Delta Mapping as a Bias-Correction Method in Maximum Rainfall Dataset from Downscaled Models in São Paulo State (Brazil). Int. J. Climatol. 2022, 42, 175–190. [Google Scholar] [CrossRef]
- Stephens, T. Gplearn: Genetic Programming in Python. with a Scikit-Learn Inspired API. Available online: https://github.com/trevorstephens/gplearn (accessed on 20 November 2024).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. In Proceedings of the KDD ’19: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the NIPS ’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4766–4775. [Google Scholar]
- Shi, M.; Xu, J.; Liu, S.; Xu, Z. Productivity-Based Land Suitability and Management Sensitivity Analysis: The Eucalyptus E. urophylla × E. grandis Case. Forests 2022, 13, 340. [Google Scholar] [CrossRef]
- Priyanka; Rajat; Avtar, R.; Malik, R.; Musthafa, M.; Rathore, V.S.; Kumar, P.; Singh, G. Forest Plantation Species Classification Using Full-Pol-Time-Averaged SAR Scattering Powers. Remote Sens. Appl. Soc. Environ. 2023, 29, 100924. [Google Scholar] [CrossRef]
- Shi, L.; Qin, Y.; Zhang, J.; Wang, Y.; Qiao, H.; Si, H. Multi-Class Classification of Agricultural Data Based on Random Forest and Feature Selection. J. Inf. Technol. Res. 2022, 15, 1–17. [Google Scholar] [CrossRef]
- Abioye, E.A.; Hensel, O.; Esau, T.J.; Elijah, O.; Abidin, M.S.Z.; Ayobami, A.S.; Yerima, O.; Nasirahmadi, A. Precision Irrigation Management Using Machine Learning and Digital Farming Solutions. AgriEngineering 2022, 4, 70–103. [Google Scholar] [CrossRef]
- Varani, M.; Mattetti, M.; Molari, G.; Biglia, A.; Comba, L. Correlation between Power Harrow Energy Demand and Tilled Soil Aggregate Dimensions. Biosyst. Eng. 2023, 225, 54–68. [Google Scholar] [CrossRef]
- Pitla, S.K.; Lin, N.; Shearer, S.A.; Luck, J.D. Use of Controller Area Network (CAN) Data To Determine Field Efficiencies of Agricultural Machinery. Appl. Eng. Agric. 2014, 30, 829–838. [Google Scholar] [CrossRef]
- Grzesiek, A.; Zimroz, R.; Śliwiński, P.; Gomolla, N.; Wyłomańska, A. A Method for Structure Breaking Point Detection in Engine Oil Pressure Data. Energies 2021, 14, 5496. [Google Scholar] [CrossRef]
- Lima, F.B.F.D.; Silva, M.A.D.; Silva, R.P.D. Quality of Mechanical Soybean Harvesting at Two Travel Speeds. Eng. Agrícola 2017, 37, 1171–1182. [Google Scholar] [CrossRef]
- Rostek, E.; Babiak, M.; Wróblewski, E. The Influence of Oil Pressure in the Engine Lubrication System on Friction Losses. Procedia Eng. 2017, 192, 771–776. [Google Scholar] [CrossRef]
- Wu, J.-D.; Huang, C.-K.; Chang, Y.-W.; Shiao, Y.-J. Fault Diagnosis for Internal Combustion Engines Using Intake Manifold Pressure and Artificial Neural Network. Expert Syst. Appl. 2010, 37, 949–958. [Google Scholar] [CrossRef]
- Wu, J.-D.; Huang, C.-K. An Engine Fault Diagnosis System Using Intake Manifold Pressure Signal and Wigner–Ville Distribution Technique. Expert Syst. Appl. 2011, 38, 536–544. [Google Scholar] [CrossRef]
- Maksum, H.; Purwanto, W. Pressure Analysis of the Ideal Intake Manifold with the Vibration Parameters at the Diesel Engine. J. Phys. Conf. Ser. 2019, 1317, 012109. [Google Scholar] [CrossRef]
- Kim, H.; Shon, J.; Lee, K. A Study of Fuel Economy and Exhaust Emission According to Engine Coolant and Oil Temperature. J. Therm. Sci. Technol. 2013, 8, 255–268. [Google Scholar] [CrossRef]
- Ponce-Bobadilla, A.V.; Schmitt, V.; Maier, C.S.; Mensing, S.; Stodtmann, S. Practical Guide to SHAP Analysis: Explaining Supervised Machine Learning Model Predictions in Drug Development. Clin. Transl. Sci. 2024, 17, e70056. [Google Scholar] [CrossRef]
- Xi, B.; Li, E.; Fissha, Y.; Zhou, J.; Segarra, P. LGBM-Based Modeling Scenarios to Compressive Strength of Recycled Aggregate Concrete with SHAP Analysis. Mech. Adv. Mater. Struct. 2024, 31, 5999–6014. [Google Scholar] [CrossRef]
- Basu, S.; Munafo, A.; Ben-Amor, A.; Roy, S.; Girard, P.; Terranova, N. Predicting Disease Activity in Patients with Multiple Sclerosis: An Explainable Machine-Learning Approach in the Mavenclad Trials. CPT Pharmacomet. Syst. Pharmacol. 2022, 11, 843–853. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B. Explainable Artificial Intelligence (XAI) for Interpreting the Contributing Factors Feed into the Wildfire Susceptibility Prediction Model. Sci. Total Environ. 2023, 879, 163004. [Google Scholar] [CrossRef]
- Bai, S.; Yuan, Y.; Niu, K.; Zhou, L.; Zhao, B.; Wei, L.; Liu, L.; Liu, Y.; Pang, Z.; Wang, F.; et al. Design and Implementation of the Remote Operation and Maintenance Platform for the Combine Harvester. Appl. Sci. 2022, 12, 7637. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, B.; Zhou, L.; Wang, J.; Niu, K.; Wang, F.; Wang, R. Research on Comprehensive Operation and Maintenance Based on the Fault Diagnosis System of Combine Harvester. Agriculture 2022, 12, 893. [Google Scholar] [CrossRef]
- Yang, L.; Ye, Z.; Lee, C.-G.; Yang, S.; Peng, R. A Two-Phase Preventive Maintenance Policy Considering Imperfect Repair and Postponed Replacement. Eur. J. Oper. Res. 2019, 274, 966–977. [Google Scholar] [CrossRef]
- Çınar, Z.M.; Abdussalam Nuhu, A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine Learning in Predictive Maintenance towards Sustainable Smart Manufacturing in Industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Gerasimov, Y.; Seliverstov, A.; Syunev, V. Industrial Round-Wood Damage and Operational Efficiency Losses Associated with the Maintenance of a Single-Grip Harvester Head Model: A Case Study in Russia. Forests 2012, 3, 864–880. [Google Scholar] [CrossRef]
- Da Silva, C.A.G.; Rodrigues de Sá, J.L.; Menegatti, R. Diagnostic of Failure in Transmission System of Agriculture Tractors Using Predictive Maintenance Based Software. AgriEngineering 2019, 1, 132–144. [Google Scholar] [CrossRef]
- Afsharnia, F.; Marzban, A.; Asoodar, M.; Abdeshahi, A. Preventive Maintenance Optimization of Sugarcane Harvester Machine Based on FT-Bayesian Network Reliability. Int. J. Qual. Reliab. Manag. 2020, 38, 722–750. [Google Scholar] [CrossRef]
- Lopes, E.S.; de Oliveira, D.; Sampietro, J.A. Influence of Wheeled Types of a Skidder on Productivity and Cost of the Forest Harvesting. Floresta 2013, 44, 53–62. [Google Scholar] [CrossRef]
- Santos, L.N.d.; Fernandes, H.C.; Silva, R.M.F.; Silva, M.L.d.; Souza, A.P.d. Evaluation of Costs of Harvester in Cut and Processing of Eucalyptus Wood. Rev. Árvore 2017, 41, e410501. [Google Scholar] [CrossRef]
- Leite, E.d.S.; Fernandes, H.C.; Minette, L.J.; Leite, H.G.; Guedes, I.L. Modelagem Técnica e de Custos Do Harvester No Corte de Madeira de Eucalipto No Sistema de Toras Curtas. Sci. For. 2013, 41, 205–215. [Google Scholar]
- Fernandes, H.C.; Burla, E.R.; Da Silva Leite, E.; Minette, L.J. Avaliação Técnica e Econômica de um “Harvester” em Diferentes Condições de Terreno e Produtividade da Floresta. Sci. For. 2013, 41, 145–151. [Google Scholar]
- Fiedler, N.C.; Carmo, F.C.d.A.d.; Minette, L.J.; Souza, A.P.d. Operational Analysis of Mechanical Cut-to-Lenght Forest Harvesting System. Rev. Árvore 2017, 41, e410301. [Google Scholar] [CrossRef]
- Cavassin Diniz, C.C.; Da Silva Lopes, E.; De Magalhães Miranda, G.; Soares Koehler, H.; Kremer Custodio de Souza, E. Analysis of Indicators and Cost of World Class Maintenance (WCM) in Forest Machines. Floresta 2019, 49, 533. [Google Scholar] [CrossRef]
- Diniz, C.C.C.; Lopes, E.S.; Koehler, H.S.; Miranda, G.M.; Paccola, J. Comparative Analysis of Maintenance Models in Forest Machines. Floresta Ambient. 2020, 27, e20170994. [Google Scholar] [CrossRef]
- Cantú, R.P.; LeBel, L.; Gautam, S. A Context Specific Machine Replacement Model: A Case Study of Forest Harvesting Equipment. Int. J. For. Eng. 2017, 28, 124–133. [Google Scholar] [CrossRef]
- Bassoli, H.M.; Batistela, G.C.; Fenner, P.T.; Simões, D. Custo Anual Uniforme Equivalente de Máquinas de Colheita de Madeira: Uma Abordagem Estocástica. Pesqui. Florest. Bras. 2020, 40, 1–10. [Google Scholar] [CrossRef]
- Rodrigues, T.A.; Silva, M.L.d.; Fernandes, H.C.; Leite, E.d.S.; Schettini, B.L.S.; Silva, A.A.; Minette, L.J. The Optimal Replacement Time for Harvesters: An Economic Analysis. Rev. Árvore 2024, 48, e4812. [Google Scholar] [CrossRef]
- Streamlit—A Faster Way to Build and Share Data Apps. Available online: https://streamlit.io (accessed on 1 November 2024).
- Lee, C.; Lin, J.; Prokop, A.; Gopalakrishnan, V.; Hanna, R.N.; Papa, E.; Freeman, A.; Patel, S.; Yu, W.; Huhn, M.; et al. StarGazer: A Hybrid Intelligence Platform for Drug Target Prioritization and Digital Drug Repositioning Using Streamlit. Front. Genet. 2022, 13, 868015. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Model |
|---|---|
| Used with a linear complexity in the number of samples to approximate the solution of a kernelized One-Class SVM. | One-Class SVM |
| Uses the same technique as the One-Class SVM, but adds stochastic gradient descent. | SGD One-Class SVM |
| Fits a robust estimate of covariance to the data by discarding points outside the central mode and fitting an ellipse to the core data points. | Elliptic Envelope |
| “Isolates” observations by randomly splitting values and performing recursive partitioning. The path length, a measure of normality in the decision function, is determined by the number of splits needed to isolate a sample. | Isolation Forest |
| Determines the degree of outlierness of the data by computing a score known as the local outlier factor. It calculates a data point’s local density deviance in relation to its neighbors. | Local Outlier Factor |
| Amber Warning Lamp | Red Stop Lamp | Anomaly | Instances | Class |
|---|---|---|---|---|
| no | no | no | 8430 | A |
| yes | no | no | 3623 | B |
| no | yes | no | 19 | C |
| yes | yes | no | 7 | C |
| no | no | yes | 65 | B |
| yes | no | yes | 68 | A |
| no | yes | yes | 0 | A |
| yes | yes | yes | 0 | B |
| Description | Model | Group |
|---|---|---|
| A linear combination of the attributes is anticipated to be the target value. | Linear Methods | 1 |
| Classifiers that have closed-form solutions that are easy to compute, are inherently multiclass, and have no hyperparameters to tune. | Discriminant Analysis | 2 |
| The decision function benefits from using a subset of training points in high-dimensional spaces. The choice of kernel function is likewise open to the individual. | SVM | 3 |
| Known as nonparametric and non-generalizing machine learning techniques, the Euclidean distance, or the separation between the new location and the samples under study, serves as the foundation for the prediction. | K nearest Neighbors | 4 |
| Algorithms that use the Bayes theorem with the “naive” presumption that, given the value of the class variable, each pair of characteristics is conditionally independent. | Naive Bayes | 5 |
| A nonparametric supervised approach that learns decision rules to forecast a target feature’s value. | Decision Tree | 6 |
| The generality and ruggedness of the final model can be improved via a single estimator by combining the outputs of many estimators through a learning process. | Ensemble | 7 |
| One or more nonlinear (hidden) layers that may train and run nonlinear models in real time may be included in the input and output layers. | Artificial Neural Network | 8 |
| Group | F1 | Rec | Prec | Acc | MCC |
|---|---|---|---|---|---|
| Linear Methods | 0.52 | 0.57 | 0.64 | 0.57 | 0.37 |
| Discriminant Analysis | 0.74 | 0.76 | 0.76 | 0.74 | 0.63 |
| SVM | 0.52 | 0.61 | 0.65 | 0.57 | 0.42 |
| K Nearest Neighbors | 0.74 | 0.76 | 0.77 | 0.73 | 0.63 |
| Naive Bayes | 0.50 | 0.58 | 0.68 | 0.60 | 0.42 |
| Decision Tree | 0.90 | 0.90 | 0.90 | 0.90 | 0.86 |
| Ensemble | 0.80 | 0.81 | 0.81 | 0.80 | 0.71 |
| Artificial Neural Network | 0.69 | 0.73 | 0.77 | 0.70 | 0.61 |
| Group | Model | F1 | Rec | Prec | Acc | MCC |
|---|---|---|---|---|---|---|
| 1 | Ridge | 0.75 | 0.76 | 0.76 | 0.75 | 0.64 |
| 2 | Linear Discriminant Analysis | 0.75 | 0.76 | 0.76 | 0.74 | 0.63 |
| 3 | SVM rbf Kernel | 0.56 | 0.65 | 0.68 | 0.60 | 0.49 |
| 4 | K Nearest Neighbors | 0.76 | 0.79 | 0.82 | 0.76 | 0.69 |
| 5 | Multinomial Naive Bayes | 0.72 | 0.73 | 0.74 | 0.72 | 0.59 |
| 6 | CART | 0.90 | 0.90 | 0.90 | 0.90 | 0.86 |
| 7 | Random Forest | 0.93 | 0.93 | 0.93 | 0.93 | 0.90 |
| 8 | Multilayer Perceptron with 2 Layers | 0.72 | 0.75 | 0.78 | 0.72 | 0.63 |
| F1 | Rec | Prec | Acc | MCC | Mode | Meta Learning | Final Model |
|---|---|---|---|---|---|---|---|
| 0.933 | 0.933 | 0.933 | 0.933 | 0.900 | Default | Not applicable | Random Forest |
| 0.905 | 0.905 | 0.905 | 0.905 | 0.857 | Default | Not applicable | CART |
| 0.923 | 0.923 | 0.928 | 0.923 | 0.888 | Voting | Not applicable | CART × Random Forest |
| 0.927 | 0.928 | 0.934 | 0.928 | 0.896 | Stacking | Nearest Neighbors | CART × Random Forest |
| 0.928 | 0.929 | 0.934 | 0.929 | 0.896 | Stacking | Random Forest | CART × Random Forest |
| 0.927 | 0.928 | 0.934 | 0.928 | 0.896 | Stacking | Random Forest | Random Forest × CART |
| 0.927 | 0.928 | 0.933 | 0.928 | 0.896 | Stacking | Logistic Regression | Random Forest × CART |
| 0.927 | 0.928 | 0.933 | 0.928 | 0.896 | Stacking | Nearest Neighbors | Random Forest × CART |
| 0.926 | 0.928 | 0.933 | 0.928 | 0.895 | Stacking | Logistic Regression | CART × Random Forest |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almeida, R.O.; da Silva, R.B.G.; Simões, D. Harvester Maintenance Prediction Tool: Machine Learning Model Based on Mechanical Features. AgriEngineering 2025, 7, 97. https://doi.org/10.3390/agriengineering7040097
Almeida RO, da Silva RBG, Simões D. Harvester Maintenance Prediction Tool: Machine Learning Model Based on Mechanical Features. AgriEngineering. 2025; 7(4):97. https://doi.org/10.3390/agriengineering7040097
Chicago/Turabian StyleAlmeida, Rodrigo Oliveira, Richardson Barbosa Gomes da Silva, and Danilo Simões. 2025. "Harvester Maintenance Prediction Tool: Machine Learning Model Based on Mechanical Features" AgriEngineering 7, no. 4: 97. https://doi.org/10.3390/agriengineering7040097
APA StyleAlmeida, R. O., da Silva, R. B. G., & Simões, D. (2025). Harvester Maintenance Prediction Tool: Machine Learning Model Based on Mechanical Features. AgriEngineering, 7(4), 97. https://doi.org/10.3390/agriengineering7040097