
A Comparison of Convolutional Neural Network Transfer Learning Regression Models for Remote Photoplethysmography Signal Estimation




Abstract
1. Introduction
- Exploration of Transfer Learning: By leveraging pre-trained models, we aim to reduce the need for large datasets while still achieving high performance in estimating rPPG signals. This is particularly important given the limited availability of high-quality datasets for training deep learning models in this domain.
- Evaluation of Multiple Architectures: We rigorously assess different CNN architectures to identify which configurations yield the best performance for rPPG signal estimation. This comparative analysis not only highlights the strengths and weaknesses of each model but also provides insights into best practices for future research.
- Addressing Practical Limitations: Our work emphasizes the practical limitations associated with existing methods, including issues related to generalizability and robustness under varying conditions. By focusing on transfer learning and model adaptation, we provide a pathway for developing more reliable rPPG estimation techniques that can be deployed in real-world scenarios.
- Foundation for Future Research: The findings from our study serve as a foundation for further exploration into advanced techniques for rPPG signal extraction. By identifying effective models and methodologies, we pave the way for subsequent research aimed at enhancing the accuracy and applicability of non-invasive heart rate monitoring technologies.
2. State-of-the-Art
3. Materials and Methods
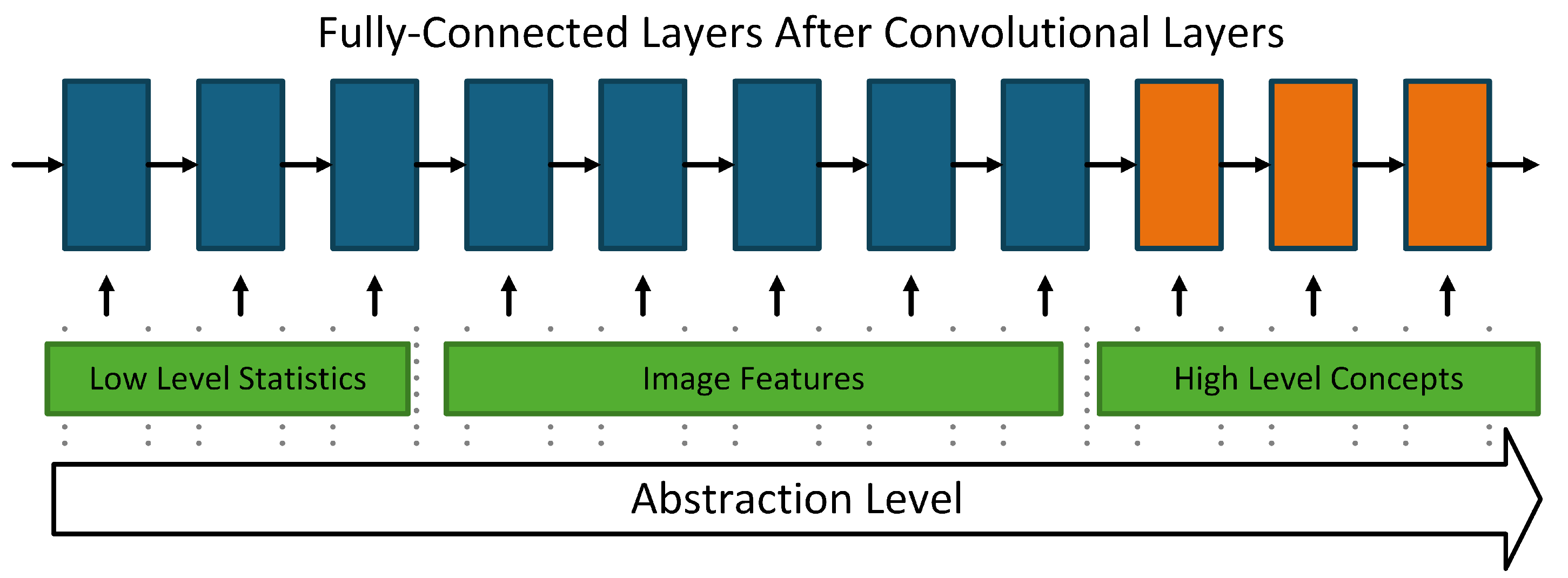
3.1. Neural Networks
- VGG (Visual Geometry Group): This CNN is known for its simplicity and uniform deep structure, using 3x3 convolutional filters and max-pooling for downsampling [38]. Variants like VGG16 and VGG19, with 16 and 19 layers, respectively, are widely used for image classification but are computationally intensive.
- ResNet (Residual Network): ResNet uses residual blocks with skip connections to mitigate vanishing gradients, enabling very deep networks like ResNet50 with 50 layers [39]. It excels in tasks such as image classification and object detection.
- Inception (GoogLeNet): This architecture introduces inception modules with parallel convolutional filters of varying sizes to capture multi-scale features efficiently [40]. Variants like InceptionV3 improve computational efficiency and performance.
- Xception: Inspired by Inception, Xception employs depthwise separable convolutions for efficient feature extraction, reducing parameters while maintaining accuracy [41].
- MobileNet: Designed for mobile and resource-constrained environments, MobileNet uses depthwise separable convolutions to achieve lightweight, efficient models [42].
- DenseNet: DenseNet introduces dense blocks with direct connections between layers, enhancing gradient flow and feature reuse while minimizing parameters [43]. The number in model names like DenseNet121 represents the total number of layers.
- NasNet: NasNet uses reinforcement learning to automate the design of efficient, high-performing models for various vision tasks [44].
- EfficientNet B0: EfficientNet [45] introduces a compound scaling method that balances network width, depth, and resolution using fixed scaling coefficients, enabling significantly higher accuracy with fewer parameters and FLOPs compared to architectures like ResNet and NASNet. The baseline model, EfficientNet-B0, designed using neural architecture search, employs mobile inverted bottleneck layers with squeeze-and-excitation optimization, offering a balance between accuracy and efficiency. Variants such as EfficientNet-B1 to B7 scale up these dimensions progressively, achieving state-of-the-art results in tasks like image classification and transfer learning while remaining computationally efficient.
- EfficientNet V2: EfficientNetV2 [46] builds on EfficientNet by introducing Fused-MBConv layers for improved training efficiency and hardware utilization, along with progressive learning that dynamically adjusts image sizes and regularization during training to enhance speed and accuracy. The EfficientNetV2 family includes variants such as B0, S, M, L, and XL, designed to scale across tasks with up to 11× faster training and 6.8× fewer parameters compared to EfficientNet. These improvements make EfficientNetV2 highly versatile and efficient for applications ranging from lightweight mobile tasks to large-scale data processing.
- ConvNeXt: ConvNeXt [47] is a modernized convolutional network architecture that builds upon the foundational ResNet design, incorporating features like larger kernels, LayerNorm, and depthwise convolutions inspired by vision transformers, while preserving the straightforward convolutional structure of ConvNets. This design emphasizes scalability and efficiency, with variants like ConvNeXt-Tiny and ConvNeXt-Base optimized for resource-constrained and balanced tasks, respectively, while larger models such as ConvNeXt-Large and ConvNeXt-XL focus on higher accuracy for complex and large-scale datasets.
3.2. Metrics
- Max Error (ME): The maximum error represents the largest absolute deviation between the predicted and true values, indicating the peak error in the prediction. A value of zero corresponds to perfect prediction with no deviation. Mathematically, it is defined as
- Explained Variance Score (EVS): This score reflects the proportion of variance in the true values captured by the predicted values, providing insight into the accuracy of the model’s predictions in explaining signal variance. A score of 1 indicates perfect overlap in variance, while lower values signify increasing error variance. It is defined as
- Mean Absolute Error (MAE): The mean absolute error represents the average absolute difference between predicted and true values, making it sensitive to the range of data values. A lower MAE is preferred, with zero indicating perfect accuracy. It is calculated as
- Mean Squared Error (MSE): A commonly used metric, MSE penalizes larger errors more heavily due to the squaring of differences, thus emphasizing substantial deviations. The optimal value is zero, representing no deviation between predicted and true values. It is expressed as
- R-squared Score (): The score quantifies the proportion of variance in the true values that is captured by the predictions, providing a measure of the goodness of fit. An value of 1 denotes a perfect fit, while values closer to zero indicate weaker predictive accuracy. It is defined aswhere represents the average (mean) of the true values over all observations.
- Mean Poisson Deviance (MPD): Poisson deviance is useful for measuring predicted values that represent expected counts or frequency, and it evaluates the extent to which predictions align with the distribution of the observed values. An MPD of zero implies perfect alignment with the true data distribution. It is defined as
4. Results
4.1. Dataset
Description of the System Architecture
- Base Model: Feature Extraction
- 1
- Input Image:
- The model accepts input images in the RGB format with dimensions 64 × 64 × 3 (64 pixels height and width, with three color channels).
- These images are processed as tensors for further computation.
- 2
- Known Architecture:
- The Base Model utilizes a predefined architecture (e.g., a convolutional neural network such as ResNet, VGG, …).
- The architecture consists of several convolutional and pooling layers, forming a feature extractor.
- These layers sequentially extract hierarchical features from the input image:
- –
- Lower layers capture low-level features (e.g., edges, corners).
- –
- Deeper layers encode high-level features (e.g., shapes, textures).
- Outputs from this block are passed to a pooling layer.
- Extension: Regression
- 1
- Average Pooling and Flatten:
- After feature extraction, the output feature maps from the base model undergo average pooling with a 2 × 2 kernel.
- Pooling reduces the spatial dimensions, summarizing feature information.
- A flattening layer converts the pooled feature maps into a 1D feature vector to be fed into the dense layers.
- 2
- Dense Layers:
- The flattened feature vector is passed through three fully connected layers, each with 128 units and a linear activation function.
- Regularization techniques are employed to prevent overfitting:
- –
- Dropout (0.5): Randomly drops 50% of the connections during training to promote generalization.
- –
- Batch Normalization: Stabilizes the learning process by normalizing activations at each layer.
- 3
- Output Layer:
- The final output layer consists of a single neuron with a linear activation function.
- This setup is typically used for regression tasks, where the model predicts a continuous scalar value.
- Training Objective
- The network appears to be designed for a regression task (e.g., predicting a numerical value based on input images).
- During training, the model optimizes a loss function (such as Mean Squared Error) to minimize the difference between the predicted and true output.
- Learning Rate: The learning rate determines how much the model’s parameters are adjusted after each training step. It directly affects how quickly the model converges and whether it stabilizes in an optimal state. Selecting the appropriate learning rate is crucial to preventing issues like underfitting or overfitting.
- Batch Size: Batch size refers to the number of training examples processed together in each iteration. It influences the speed of training, memory consumption, and the model’s ability to generalize. The optimal batch size depends on the hardware constraints and the characteristics of the dataset.
- Activation Functions: Activation functions introduce non-linearity into the network, allowing it to model complex relationships. Functions such as ReLU, sigmoid, and tanh determine how neurons respond to input signals, affecting both the network’s ability to learn intricate patterns and its training behavior.
- Dropout is a regularization technique that randomly deactivates a subset of neurons during the training process. This approach helps to prevent overfitting by encouraging the network to develop more robust features and reducing its dependence on specific neurons. The dropout rate determines the proportion of neurons that are deactivated in each forward pass through the network.
- NN Architecture: The architecture of a neural network defines the structure of its layers, including the types (e.g., convolutional layer, pooling layer, fully connected layer) and their connectivity. The architecture must be chosen based on the complexity of the task and the computational resources available to optimize both performance and efficiency.
- Advantages of the Proposed Model:
- Transfer Learning Ready: By using a “known architecture” in the base model, pre-trained weights from a well-established model can be leveraged to improve feature extraction.
- Regularization: Dropout and Batch Normalization ensure stability and reduce the likelihood of overfitting.
4.2. Exprimental Part
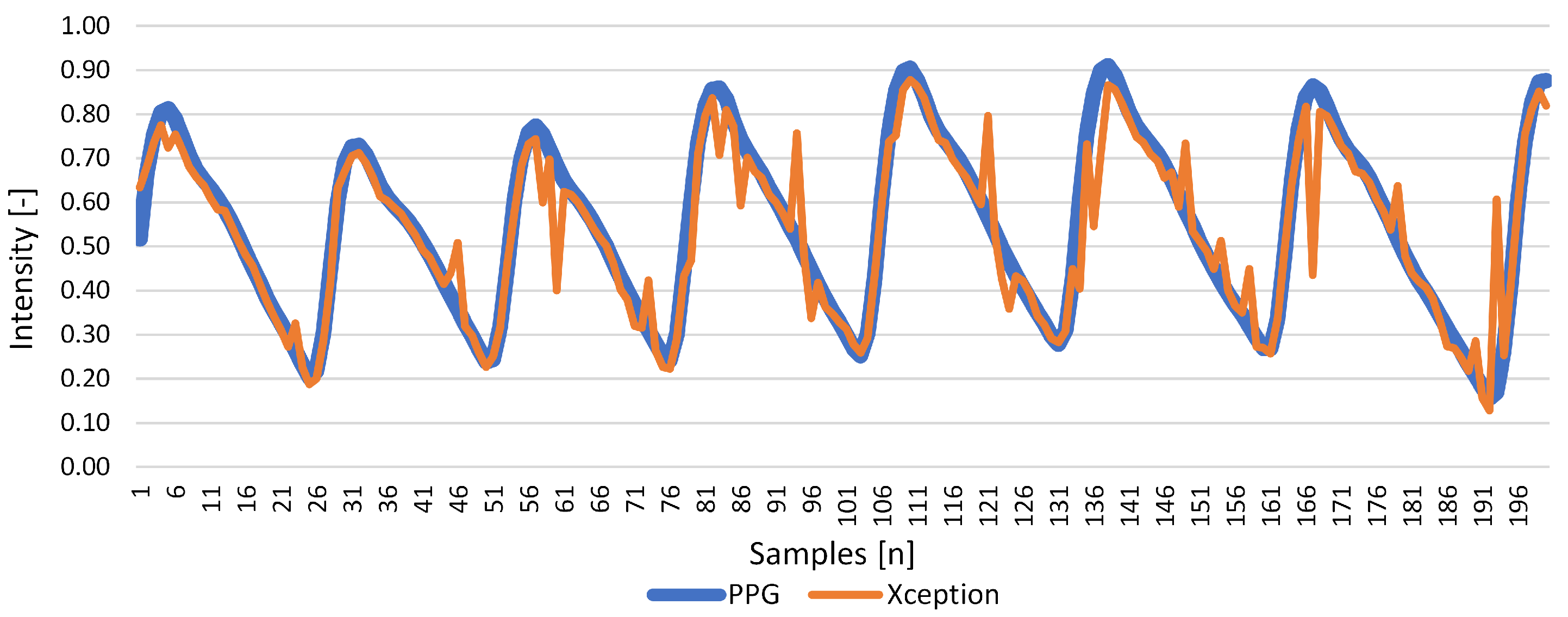
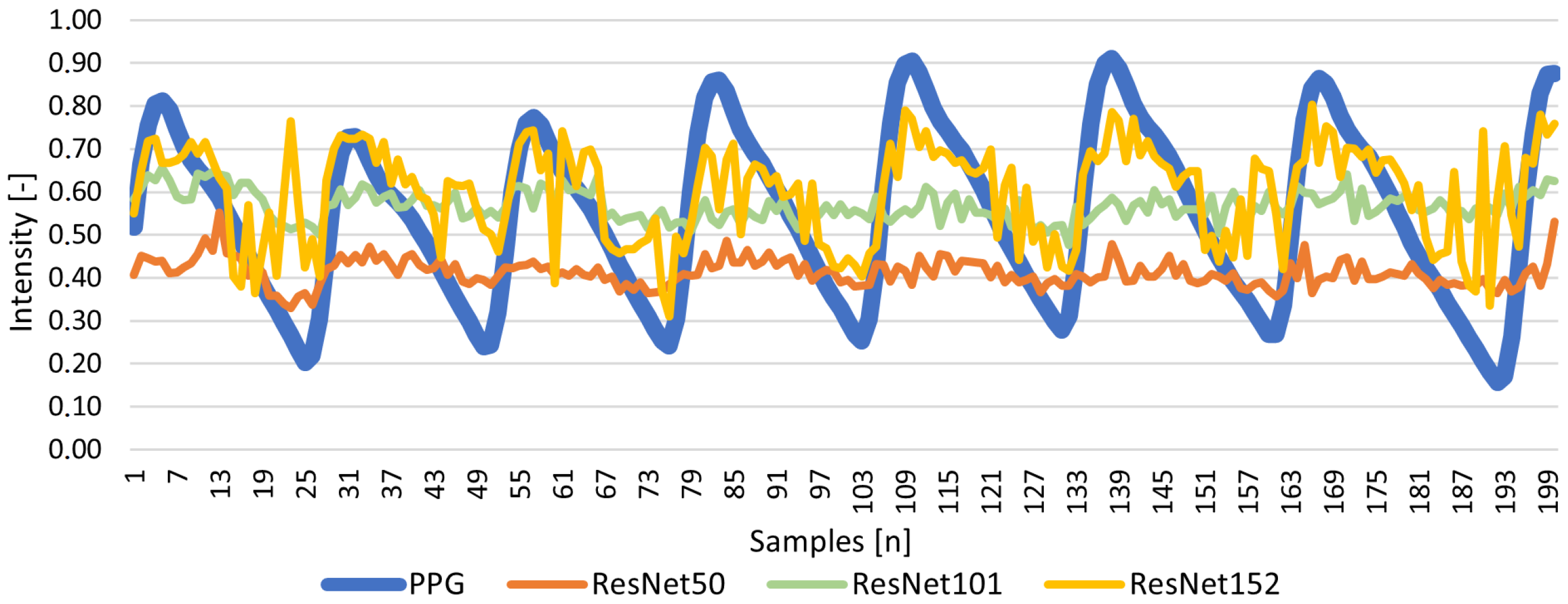
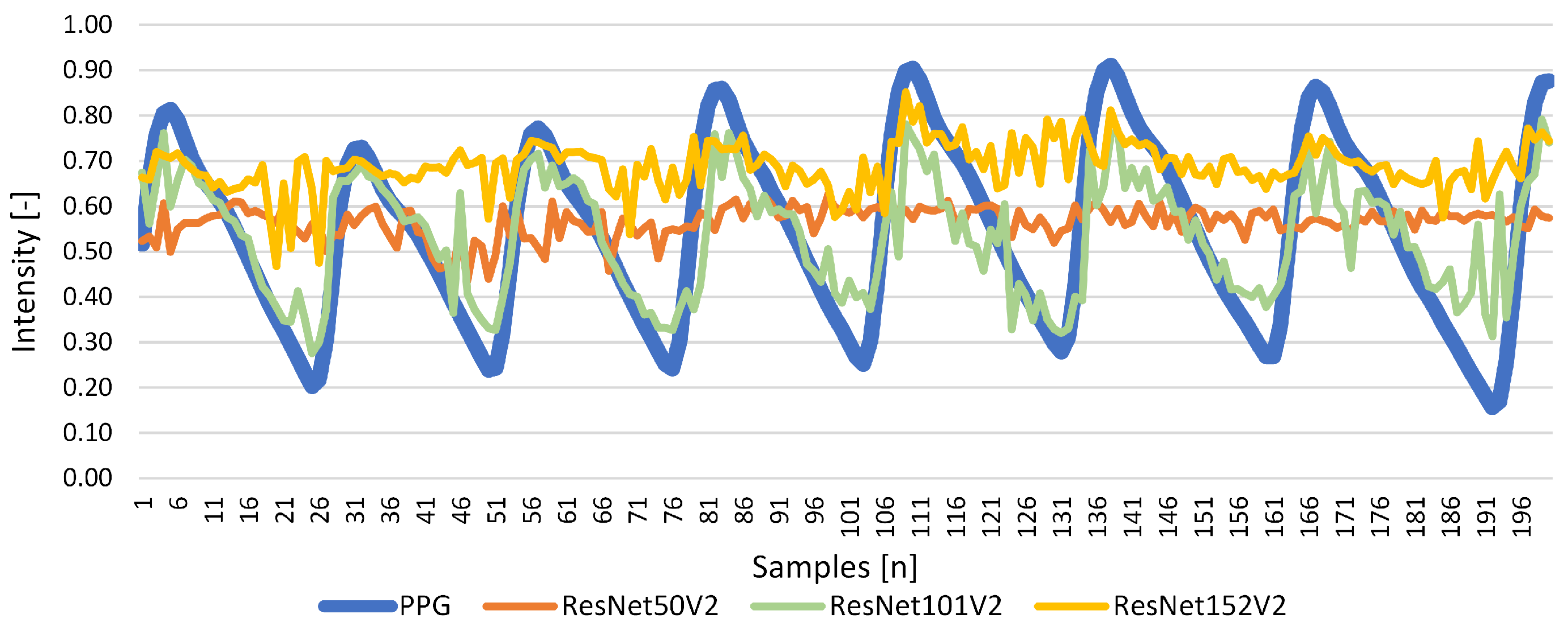
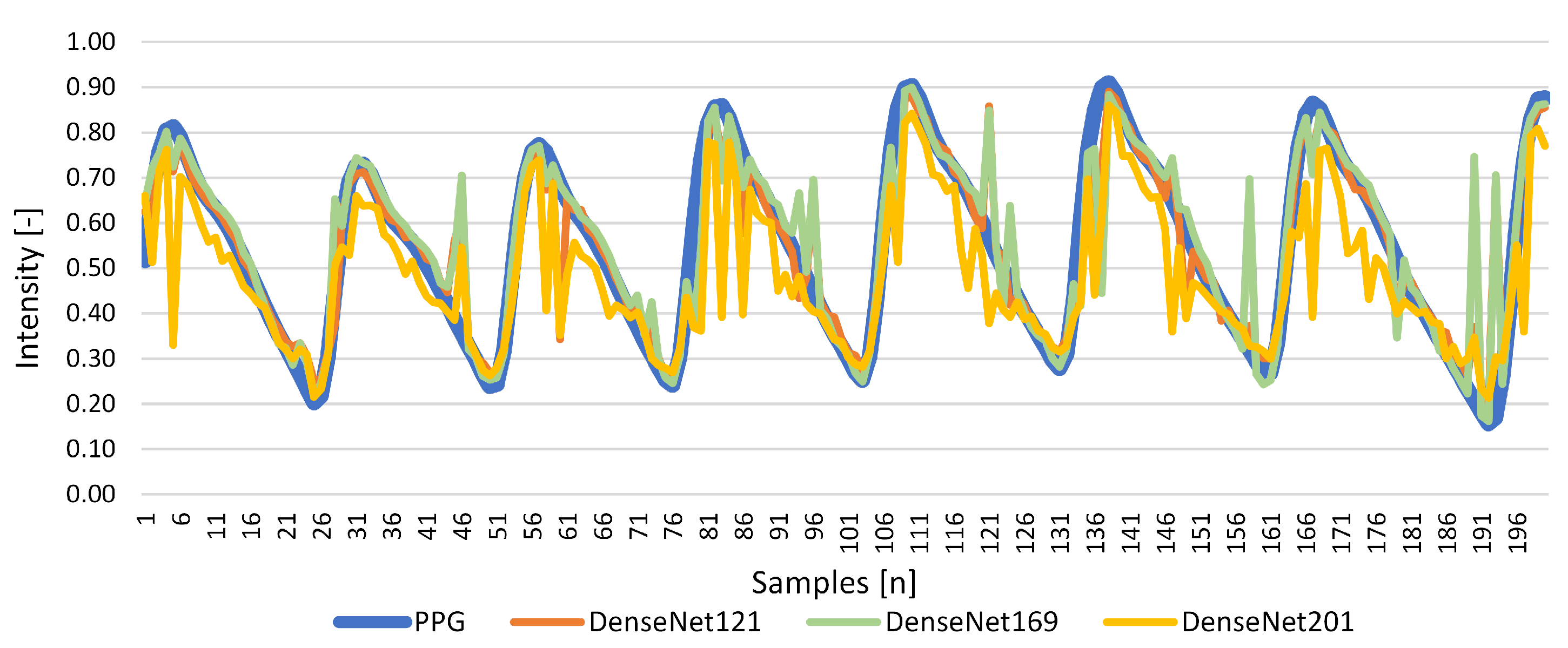
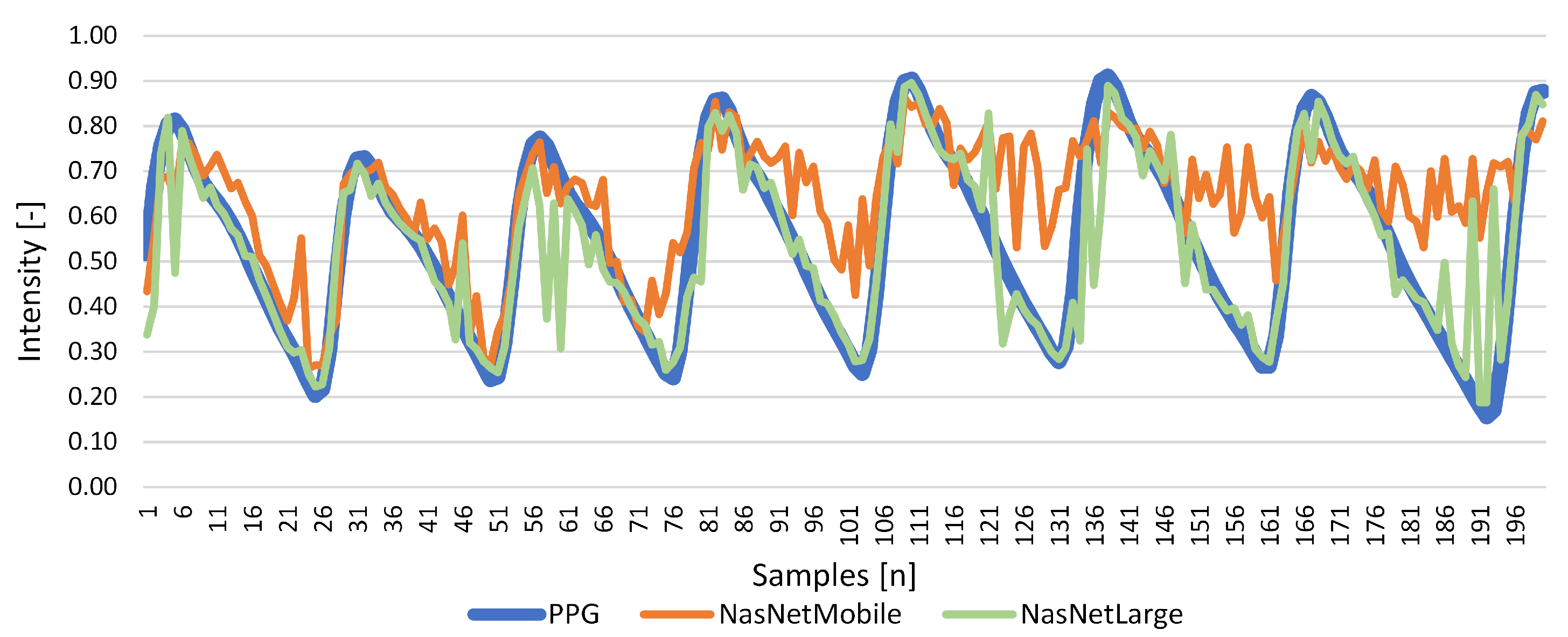
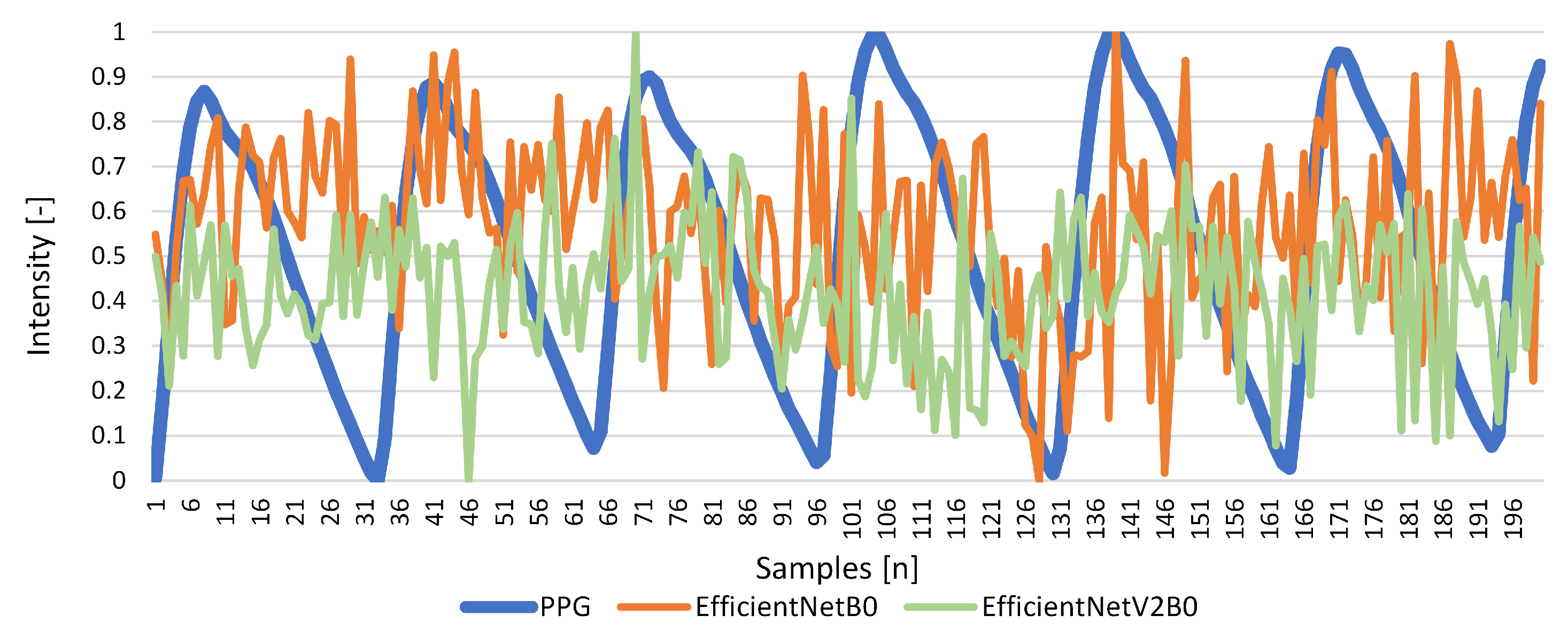
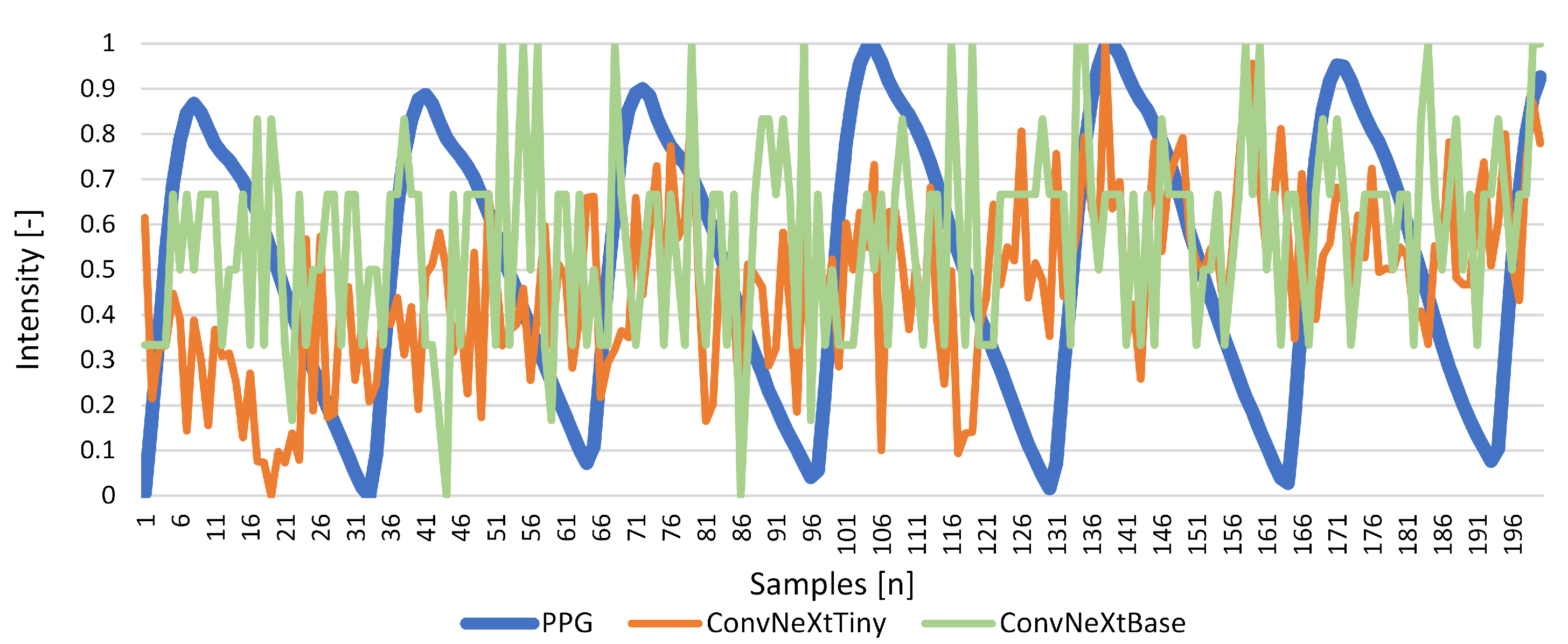
Results for Signal Reconstruction
5. Discussion and Conclusions
- Hyperparameter Optimization: Fine-tuning parameters such as learning rates, dropout rates, and layer configurations in DenseNet121 and other promising models to further improve performance and reduce prediction errors.
- Expanding Signal Scope: Extending the system to extract additional physiological signals such as blood pressure and respiratory rate. This expansion will increase the clinical utility of the system, enabling comprehensive health monitoring in a non-contact manner.
- Real-Time Applications: Developing a standalone system optimized for real-time operation on handheld devices. This step will involve adapting the architecture to handle resource constraints while maintaining accuracy, paving the way for portable and scalable monitoring solutions.
- Addressing Variability in Input Data: Exploring techniques to improve the robustness of the system under diverse conditions, including varying lighting, skin tones, and motion artifacts. This may involve integrating data augmentation strategies or employing domain adaptation techniques to enhance model generalization.
- Benchmarking with Larger Datasets: Testing the system on larger and more diverse datasets to validate its scalability and reliability. Incorporating datasets with real-world variability will ensure the robustness of the model in practical applications.
- Investigating Lightweight Architectures: Exploring more efficient neural network architectures tailored for edge computing, such as MobileNet variants or transformer-based models optimized for smaller datasets.
- Clinical Integration: Collaborating with medical professionals to evaluate the system in clinical environments, particularly for applications in telemedicine, neonatal care, and ICU monitoring.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANNMS | Adaptive Neural Network Model Selection |
| CNN | Convolutional Neural Network |
| EVS | Explained Variance Score |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| ME | Max Error |
| MPD | Mean Poisson Deviance |
| MSE | Mean Squared Error |
| NN | Neural Network |
| PPG | Photoplethysmography |
| PPGI | Photoplethysmography Imagining |
| rPPG | remote Photoplethysmography |
| SGD | Stochastic Gradient Descent |
| VGG | Visual Geometry Group |
| V4V | Vision for Vitals |
References
- Novita, D.; Adikusuma, F.W.; Rohadi, N.; Wibawa, B.M.; Trisanto, A.; Defi, I.R.; Fauziah, S.R. Development of contactless human vital signs monitoring device with remote-photoplethysmography using adaptive region-of-interest and hybrid processing methods. Intell.-Based Med. 2024, 10, 100160. [Google Scholar] [CrossRef]
- Sun, Y.; Thakor, N. Photoplethysmography revisited: From contact to noncontact, from point to imaging. IEEE Trans. Biomed. Eng. 2016, 63, 463–477. [Google Scholar] [CrossRef] [PubMed]
- Allen, J. Photoplethysmography and its application in clinical physiological measurement. Physiol. Meas. 2007, 28, R1–39. [Google Scholar] [CrossRef] [PubMed]
- Blanik, N.; Abbas, A.K.; Venema, B.; Blazek, V.; Leonhardt, S. Hybrid optical imaging technology for long-term remote monitoring of skin perfusion and temperature behavior. J. Biomed. Opt. 2014, 19, 016012. [Google Scholar] [CrossRef]
- Rubins, U.; Marcinkevics, Z.; Muckle, R.A.; Henkuzena, I.; Roze, A.; Grabovskis, A. Remote photoplethysmography for assessment of oral mucosa. In Proceedings of the Clinical and Preclinical Optical Diagnostics II (2019), Munich, Germany, 23–25 June 2019; Paper 11073_50. Optica Publishing Group: Washington, DC, USA, 2019; p. 11073_50. [Google Scholar] [CrossRef]
- Schraven, S.P.; Kossack, B.; Strüder, D.; Jung, M.; Skopnik, L.; Gross, J.; Hilsmann, A.; Eisert, P.; Mlynski, R.; Wisotzky, E.L. Continuous intraoperative perfusion monitoring of free microvascular anastomosed fasciocutaneous flaps using remote photoplethysmography. Sci. Rep. 2023, 13, 1532. [Google Scholar] [CrossRef] [PubMed]
- Premkumar, S.; Hemanth, D.J. Intelligent remote photoplethysmography-based methods for heart rate estimation from face videos: A survey. Informatics 2022, 9, 57. [Google Scholar] [CrossRef]
- Park, S.; Youn, H.; Lee, S.; Kwon, S. A Study on the Implementation of Temporal Noise-Robust Methods for Acquiring Vital Signs. IEEE Access 2024, 12, 24700–24713. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, X.; Zhang, Y. Lightweight and interpretable convolutional neural network for real-time heart rate monitoring using low-cost video camera under realistic conditions. Biomed. Signal Process. Control 2024, 87, 105461. [Google Scholar] [CrossRef]
- Gao, H.; Zhang, C.; Pei, S.; Wu, X. LSTM-based real-time signal quality assessment for blood volume pulse analysis. Biomed. Opt. Express 2023, 14, 1119–1136. [Google Scholar] [CrossRef]
- Fontes, L.; Machado, P.; Vinkemeier, D.; Yahaya, S.; Bird, J.J.; Ihianle, I.K. Enhancing stress detection: A comprehensive approach through rPPG analysis and deep learning techniques. Sensors 2024, 24, 1096. [Google Scholar] [CrossRef]
- Patel, P.; Biradar, V. Monitoring physiological and mental well-being through video-based vital parameter measurement: A review. Int. J. Innov. Res. Technol. Sci. IJCTET 2024, 12, 79–86. [Google Scholar]
- Álvarez Casado, C.; Nguyen, L.; Silvén, O.; Bordallo López, M. Assessing the feasibility of remote photoplethysmography through videocalls: A study of network and computing constraints. In Image Analysis. SCIA 2023; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2023; pp. 586–598. [Google Scholar]
- Svoboda, L.; Sperrhake, J.; Nisser, M.; Zhang, C.; Notni, G.; Proquitté, H. Contactless heart rate measurement in newborn infants using a multimodal 3D camera system. Front. Pediatr. 2022, 10, 897961. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.J.; Lin, L.C.; Yang, S.T.; Hwang, K.S.; Liao, C.T.; Ho, W.H. High-reliability non-contact photoplethysmography imaging for newborn care by a generative artificial intelligence. IEEE Access 2023, 11, 90801–90810. [Google Scholar] [CrossRef]
- Park, J.; Seok, H.S.; Kim, S.S.; Shin, H. Photoplethysmogram analysis and applications: An integrative review. Front. Physiol. 2021, 12, 808451. [Google Scholar] [CrossRef] [PubMed]
- Wu, B.F.; Chu, Y.W.; Huang, P.W.; Chung, M.L. Neural Network Based Luminance Variation Resistant Remote-Photoplethysmography for Driver’s Heart Rate Monitoring. IEEE Access 2019, 7, 57210–57225. [Google Scholar] [CrossRef]
- Revanur, A.; Li, Z.; Ciftci, U.A.; Yin, L.; Jeni, L.A. The First Vision For Vitals (V4V) Challenge for Non-Contact Video-Based Physiological Estimation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2760–2767. [Google Scholar] [CrossRef]
- Pediaditis, M.; Farmaki, C.; Schiza, S.; Tzanakis, N.; Galanakis, E.; Sakkalis, V. Contactless respiratory rate estimation from video in a real-life clinical environment using Eulerian magnification and 3D CNNs. In Proceedings of the 2022 IEEE International Conference on Imaging Systems and Techniques (IST), Virtual, 21–23 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, H.; Huang, J.; Wang, G.; Lu, H.; Wang, W. Surveillance Camera-based Cardio-respiratory Monitoring for Critical Patients in ICU. In Proceedings of the 2022 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), Ioannina, Greece, 27–30 September 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Molinaro, N.; Schena, E.; Silvestri, S.; Bonotti, F.; Aguzzi, D.; Viola, E.; Buccolini, F.; Massaroni, C. Contactless vital signs monitoring from videos recorded with digital cameras: An overview. Front. Physiol. 2022, 13, 801709. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Gebhart, I.; Kühmstedt, P.; Rosenberger, M.; Notni, G. Enhanced contactless vital sign estimation from real-time multimodal 3D image data. J. Imaging 2020, 6, 123. [Google Scholar] [CrossRef]
- Wang, W.; Weiss, S.; den Brinker, A.C.; Wuelbern, J.H.; Tormo, A.G.i.; Pappous, I.; Sénégas, J. Fundamentals of Camera-PPG Based Magnetic Resonance Imaging. IEEE J. Biomed. Health Inform. 2022, 26, 4378–4389. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.S.; Hwang, G.; Ryu, M.; Lee, S.J. LSTC-rPPG: Long Short-Term Convolutional Network for Remote Photoplethysmography. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 6015–6023. [Google Scholar] [CrossRef]
- Xiong, J.; Ou, W.; Yao, Y.; Liu, Y.; Gao, Z.; Liu, Z.; Gou, J. STGNet: Spatio-temporal graph neural networks considering inherent properties of physiological signals for camera-based remote photoplethysmography. Biomed. Signal Process. Control. 2024, 98, 106690. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.; Sim, J.Y. DSE-NN: Deeply Supervised Efficient Neural Network for Real-Time Remote Photoplethysmography. Bioengineering 2023, 10, 1428. [Google Scholar] [CrossRef]
- Zhao, C.; Cao, P.; Hu, M.; Huang, B.; Chen, H.; Li, J. WTC3D: An Efficient Neural Network for Noncontact Pulse Acquisition in Internet of Medical Things. IEEE Trans. Ind. Inform. 2024; early access. 1–10. [Google Scholar] [CrossRef]
- Chavlis, S.; Poirazi, P. Drawing inspiration from biological dendrites to empower artificial neural networks. Curr. Opin. Neurobiol. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef]
- Mallak, A. Comprehensive Machine and Deep Learning Fault Detection and Classification Approaches of Industry 4.0 Mechanical Machineries: With Application to a Hydraulic Test Rig. Ph.D. Thesis, Universität Siegen, Siegen, Germany, 2021. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Santoro, A.; Marris, L.; Akerman, C.J.; Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci. 2020, 21, 335–346. [Google Scholar] [CrossRef] [PubMed]
- Jais, I.; Ismail, A.R.; Qamrun Nisa, S. Adam Optimization Algorithm for Wide and Deep Neural Network. Knowl. Eng. Data Sci. 2019, 2, 41. [Google Scholar] [CrossRef]
- Masters, D.; Luschi, C. Revisiting Small Batch Training for Deep Neural Networks. arXiv 2018, arXiv:1804.07612. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Salman, S.; Liu, X. Overfitting Mechanism and Avoidance in Deep Neural Networks. arXiv 2019, arXiv:1901.06566. [Google Scholar] [CrossRef]
- Keras. Keras Applications. Available online: https://keras.io/api/applications/ (accessed on 17 December 2024).
- Cruz, A.C.; Luvisi, A.; De Bellis, L.; Ampatzidis, Y. X-FIDO: An Effective Application for Detecting Olive Quick Decline Syndrome with Deep Learning and Data Fusion. Front. Plant Sci. 2017, 8, 1741. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. [Google Scholar] [CrossRef]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. arXiv 2018, arXiv:1707.07012. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Hyperparameter | Value |
|---|---|---|
| Epochs | 250 | |
| Learning Rate | 0.0001 | |
| Batch size | 128 | |
| Convolutional Neural Network | Activation | ReLU |
| Pooling size | 2 × 2 | |
| Pooling method | “max” | |
| Dropout rate | 0.5 | |
| Loss function | MSE |
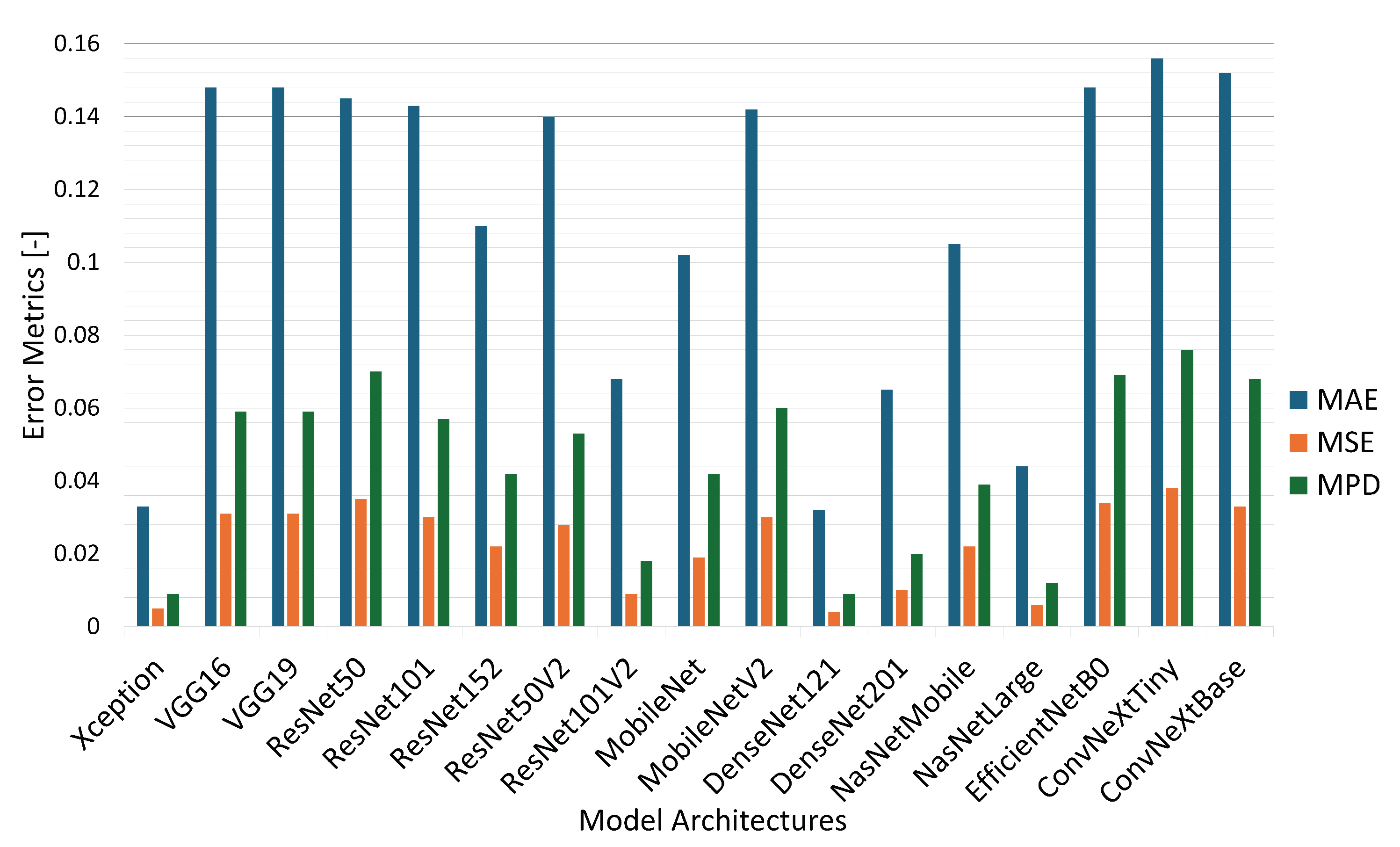
| Architecture | ME | EVS | MAE | MSE | R2 | MPD |
|---|---|---|---|---|---|---|
| (Best Value) | 0 | 1 | 0 | 0 | ±1 | 0 |
| Xception | 0.493 | 0.848 | 0.033 | 0.005 | 0.844 | 0.009 |
| VGG16 | 0.561 | 0.000 | 0.148 | 0.031 | −0.002 | 0.059 |
| VGG19 | 0.553 | 0.000 | 0.148 | 0.031 | 0.000 | 0.059 |
| ResNet50 | 0.605 | 0.180 | 0.145 | 0.035 | −0.152 | 0.070 |
| ResNet101 | 0.582 | 0.067 | 0.143 | 0.030 | 0.029 | 0.057 |
| ResNet152 | 0.537 | 0.288 | 0.110 | 0.022 | 0.288 | 0.042 |
| ResNet50V2 | 0.458 | 0.099 | 0.140 | 0.028 | 0.097 | 0.053 |
| ResNet101V2 | 0.548 | 0.700 | 0.068 | 0.009 | 0.700 | 0.018 |
| ResNet152V2 | 0.567 | 0.174 | 0.135 | 0.032 | −0.029 | −1.000 |
| MobileNet | 0.602 | 0.383 | 0.102 | 0.019 | 0.368 | 0.042 |
| MobileNetV2 | 0.609 | 0.096 | 0.142 | 0.030 | 0.006 | 0.060 |
| DenseNet121 | 0.526 | 0.855 | 0.032 | 0.004 | 0.855 | 0.009 |
| DenseNet169 | 0.539 | 0.810 | 0.042 | 0.006 | 0.810 | −1.000 |
| DenseNet201 | 0.529 | 0.739 | 0.065 | 0.010 | 0.663 | 0.020 |
| NasNetMobile | 1.473 | 0.332 | 0.105 | 0.022 | 0.267 | 0.039 |
| NasNetLarge | 0.535 | 0.802 | 0.044 | 0.006 | 0.792 | 0.012 |
| EfficientNetB0 | 0.511 | 0.040 | 0.148 | 0.034 | −0.024 | 0.069 |
| EfficientNetV2B0 | 1.146 | −0.103 | 0.558 | 0.348 | −9.574 | −1.000 |
| ConvNeXtTiny | 0.525 | 0.000 | 0.156 | 0.038 | −0.150 | 0.076 |
| ConvNeXtBase | 0.478 | 0.000 | 0.152 | 0.033 | −0.001 | 0.068 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sturekova, J.; Kamencay, P.; Sykora, P.; Hlavata, R. A Comparison of Convolutional Neural Network Transfer Learning Regression Models for Remote Photoplethysmography Signal Estimation. AI 2025, 6, 24. https://doi.org/10.3390/ai6020024
Sturekova J, Kamencay P, Sykora P, Hlavata R. A Comparison of Convolutional Neural Network Transfer Learning Regression Models for Remote Photoplethysmography Signal Estimation. AI. 2025; 6(2):24. https://doi.org/10.3390/ai6020024
Chicago/Turabian StyleSturekova, Jana, Patrik Kamencay, Peter Sykora, and Roberta Hlavata. 2025. "A Comparison of Convolutional Neural Network Transfer Learning Regression Models for Remote Photoplethysmography Signal Estimation" AI 6, no. 2: 24. https://doi.org/10.3390/ai6020024
APA StyleSturekova, J., Kamencay, P., Sykora, P., & Hlavata, R. (2025). A Comparison of Convolutional Neural Network Transfer Learning Regression Models for Remote Photoplethysmography Signal Estimation. AI, 6(2), 24. https://doi.org/10.3390/ai6020024