
FedBirdAg: A Low-Energy Federated Learning Platform for Bird Detection with Wireless Smart Cameras in Agriculture 4.0


Abstract
1. Introduction
- We introduce an energy-aware metric to assess the operational efficiency of AuTs in agricultural applications.
- We develop a FL-based framework for the on-site training of a WSCN platform tailored for energy-efficient learning in the field. This framework is evaluated, using the introduced metric, against traditional centralized learning approaches in a bird detection use case for crop protection.
- By examining trade-offs between computational energy and transmission energy in complex scenarios with highly non-IID data, we aim to provide insights into optimizing energy use for autonomous agricultural devices.
2. Related Work
- Disease detection: IoT-enabled cameras capture images of crops, which are analyzed via AI models using image recognition/classification techniques to identify symptoms of diseases early on. This allows for timely interventions, reducing the spread of diseases and improving crop health [29,30,31,32,33].
- Water conservation: By tracking soil moisture and weather conditions, IoT devices feed data into AI systems that optimize irrigation schedules. This minimizes water usage while maintaining adequate hydration for crops, leading to better water conservation and reduced waste [36].
- Smart harvesting: IoT sensors continuously track environmental factors, providing real-time data that, when combined with AI models trained on historical datasets, can accurately identify the optimal time for harvesting. This approach maximizes yield quality while minimizing the risk of premature or delayed harvesting [37,38,39].
- Animal monitoring: IoT sensors, such as wearable devices, can monitor animal behavior, collecting data that track changes in key parameters indicative of health issues or other relevant conditions in livestock. These data, often represented as time series, can be used to train AI models capable of predicting diseases or classifying specific behaviors, enabling early intervention and improved herd management [40,41].
- Supply chain management: IoT devices monitor agricultural products throughout the supply chain, collecting data on conditions during transport and storage. AI analyzes this information to optimize logistics, manage inventory effectively, and reduce spoilage, ensuring that high-quality produce reaches consumers [42,43].
3. Methodology
3.1. QoSAuT: Quality of Service of an Autonomous Thing
- k = AuT index.
- = QoSAuT of the trained AuT k.
- = accuracy gained via the model in k from the training, evaluated on unseen test data.
- = number of training rounds of k.
- = number of data frames sent via k in one training round.
- = computational cost * of one training round in k.
- = computational cost * of inference by the trained model in k.
- = transmission cost * of 1 byte by k.
- = size (in bytes) of one data frame sent and/or received via k.
- = the maximum portion of the battery capacity we are willing to allocate ** for training.
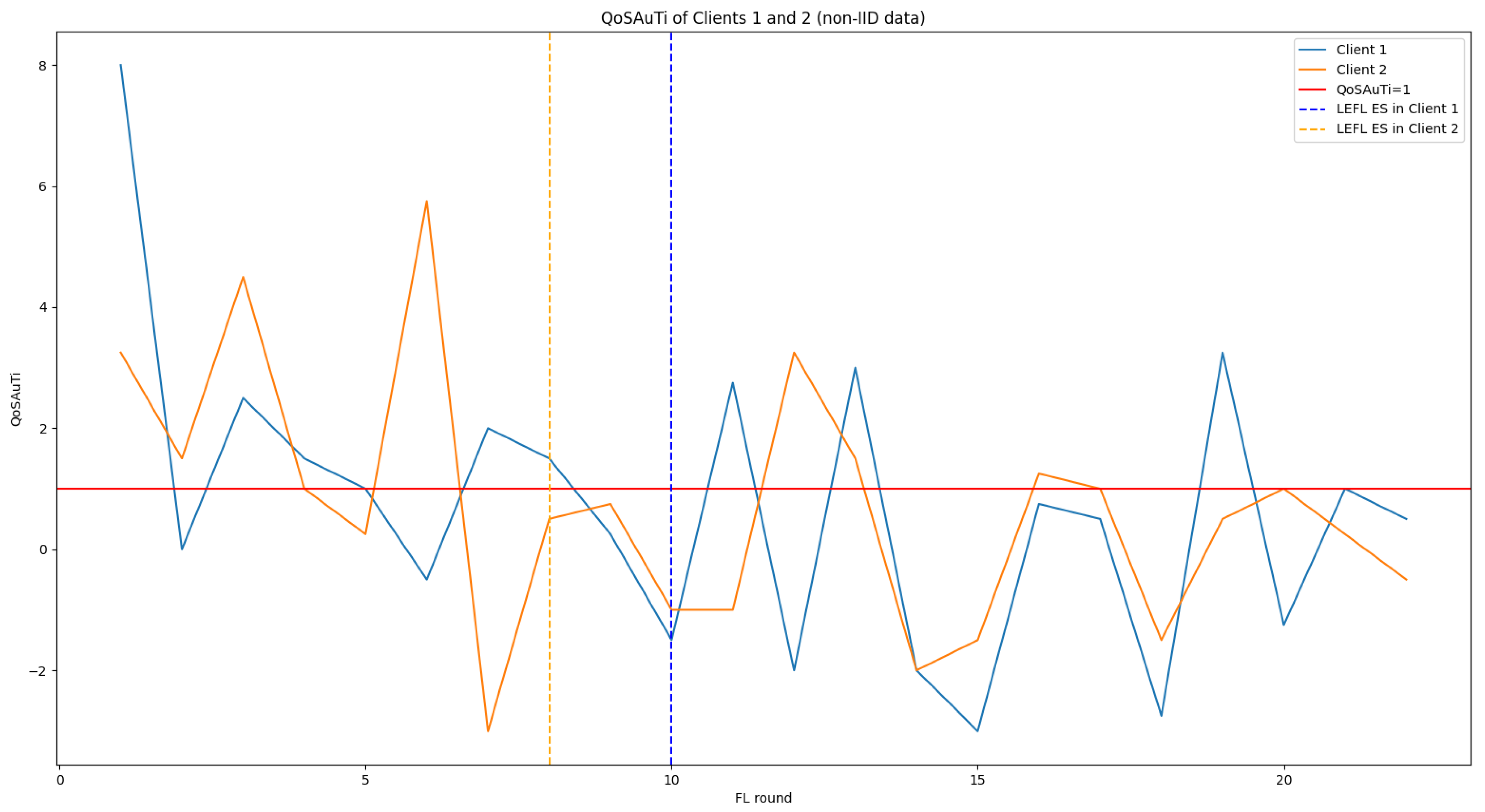
3.2. LEFL: A Low-Energy Federated Learning Framework
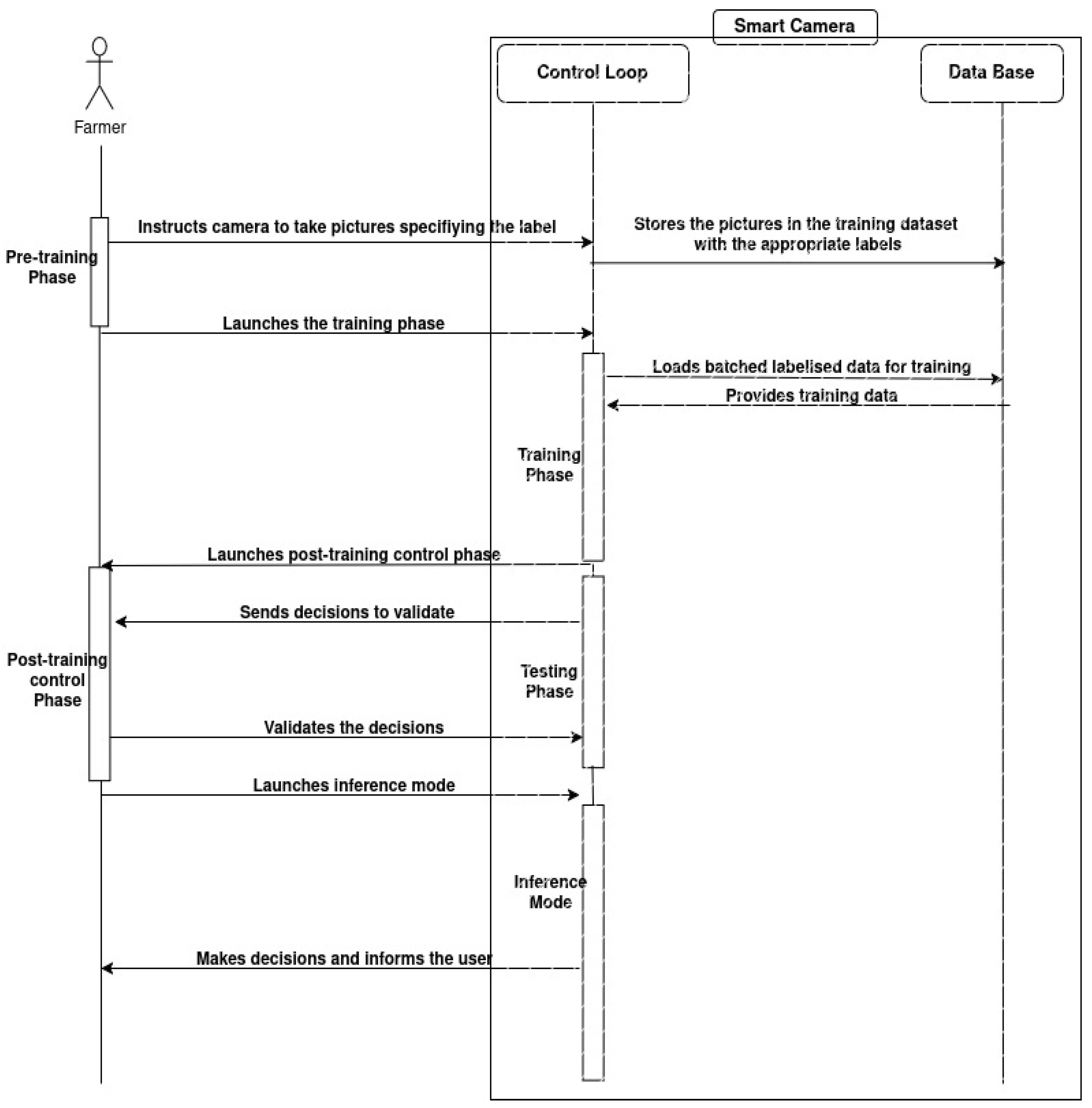
3.3. Bird Detection Scenario
4. Implementation
4.1. Hardware
4.2. Software
- = factor defined in Formula (1).
- = gained accuracy in the round, i, via the trained model in k.
- = number of weights sent in the round, i, via k.
- = computational cost of the round, i, in k.
- = inference cost of the model in k.
- = transmission cost of 1 byte via k.
| Algorithm 1 Computing . |
if then return False end if return Q |
| Algorithm 2 LEFL ES Algorithm. |
while False do if then && else break end if end while |
4.3. Data
4.3.1. Dataset Overview
4.3.2. Data Distribution for Training
4.3.3. Data Distribution over Clients
- During the training phase, both crop fields monitored via the cameras were equally likely to attract either bird species (homogeneous distribution). To replicate this scenario in our study, we split the training data between the two clients (cameras) in a balanced manner, ensuring an even representation of both bird species across the datasets. This data distribution over clients is called identically independent distribution (IID), meaning the data samples across all clients are independently drawn from the same probability distribution. ().
- During the training phase, one crop field is more likely to attract pigeons, while the other tends to attract crows. To simulate this scenario, we distribute the training data unequally between the two clients, assigning images showcasing more pigeons to the first client and images showcasing more crows to the second. This ensures a heterogeneous data distribution across the clients. Such a distribution is termed non-identically independent distribution (non-IID), indicating that data samples on each client are drawn from distinct probability distributions ().
5. Results
5.1. Benchmark Preparation
- Batch size: For our simulation, we adopted a classic batch learning scheme, also referred to as offline learning. In this approach, the training dataset is divided into smaller batches. The model processes one batch at a time, updating its weights only after completing the forward and backward passes for each batch. A large batch size helps the model learn faster but may require more memory and computational resources. Given the constraints of working on resource-limited devices and a small training dataset of 92 samples, we selected a small batch size of 16 samples.
- Base learning rate: The learning rate controls how much to change the model in response to the error each time the model weights are updated. A low learning rate allows the model to learn more fine-grained patterns in the data, but it requires more iterations to converge, leading to higher computational costs. Conversely, a high learning rate can accelerate convergence, but it may risk overshooting optimal values and potentially leading to poor model performance. Given the small size of our dataset, which is more prone to quick convergence, we used a low base learning rate of in conjunction with the Adaptive Moment Estimation (Adam) Optimizer.
- Optimizer: We employed the Adam optimizer, which dynamically adjusts the learning rate for each parameter during training. The optimizer reduces the risk of overfitting on our small dataset while maintaining good generalization performance. Small updates to the weights ensure that the model does not memorize training examples too quickly.
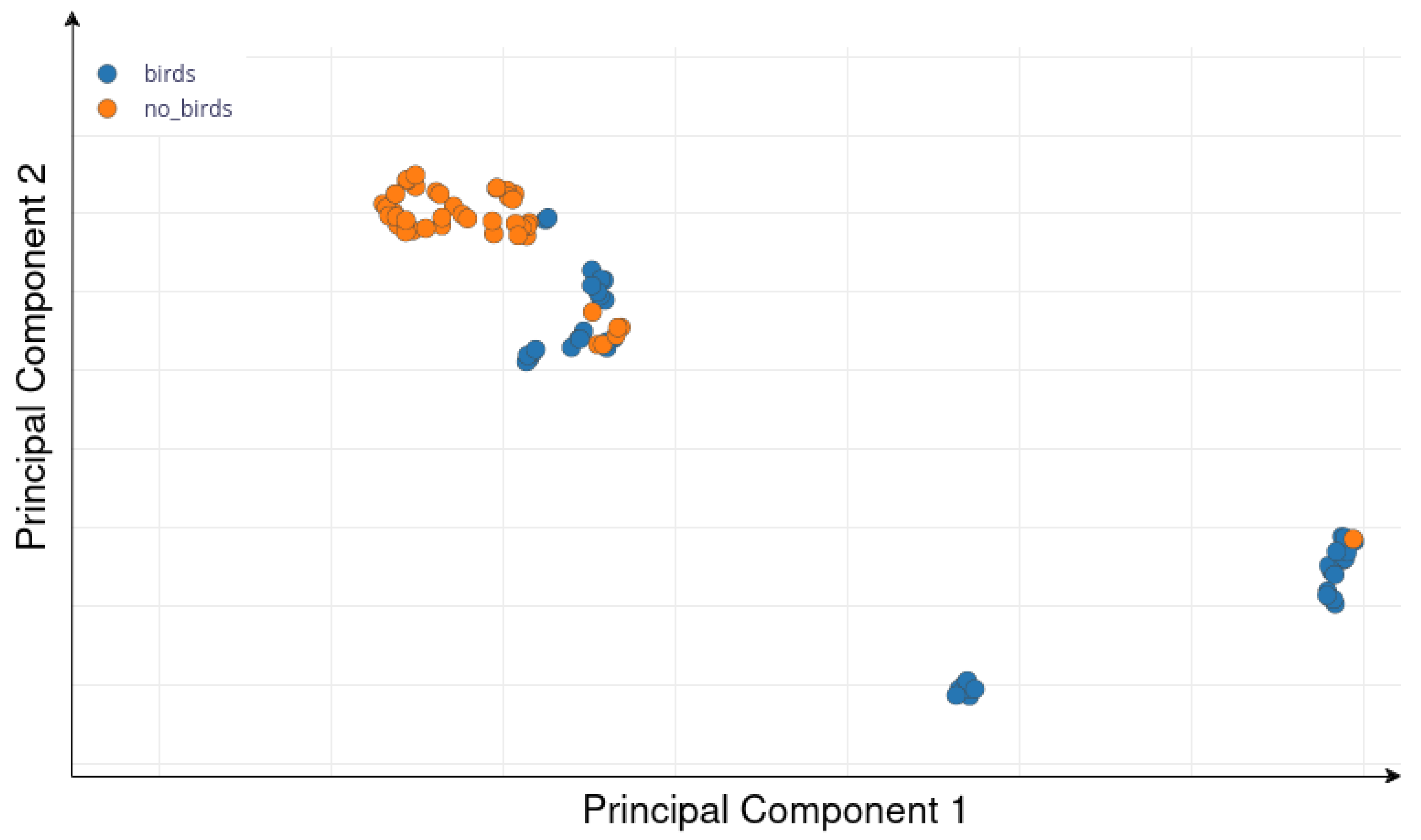
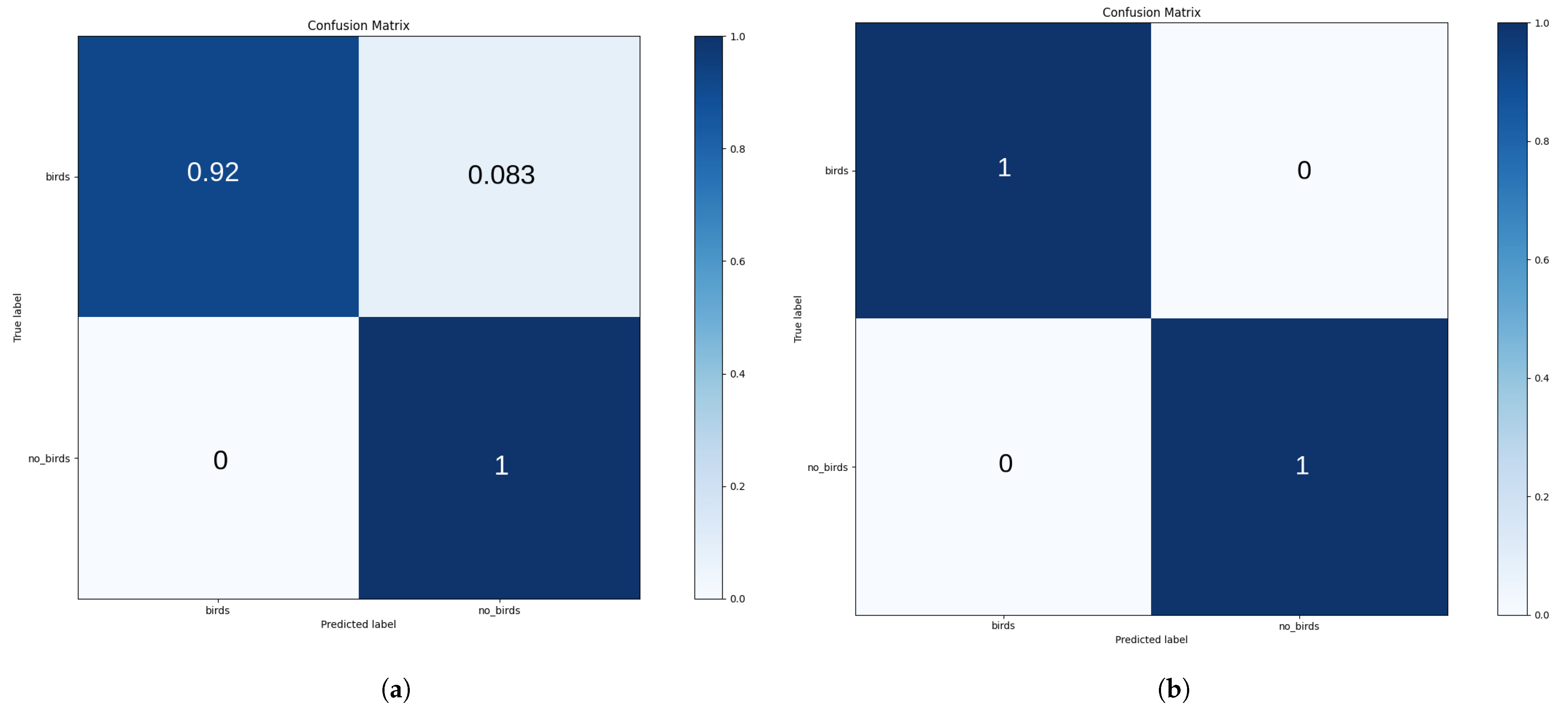
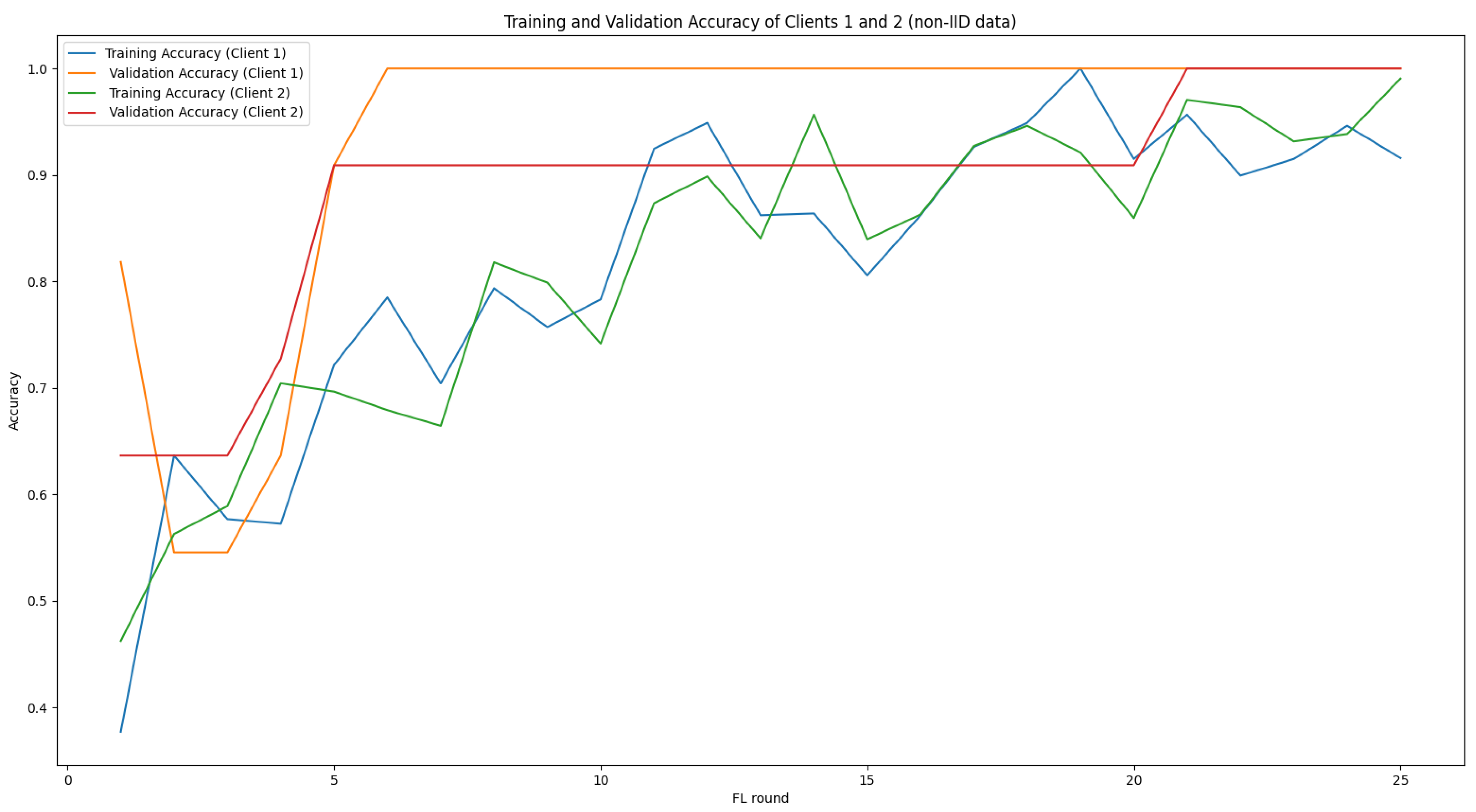
- Number of epochs: In one epoch, the model trains on the entire dataset. Too few epochs may lead to underfitting, while too many can result in overfitting. Given our small dataset, which has limited variability and is not very sparse in the feature space (Figure 6), a small number of epochs is sufficient to achieve model convergence. As shown in Figure 7, the model begins to overfit after the 11th epoch, with the validation accuracy plateauing while the training accuracy continues to rise. Based on this observation, we set the number of epochs to 11 to balance sufficient training while preventing overfitting. The model begins to overfit after a relatively small number of epochs, likely due to the limited size of the training dataset and the low diversity of samples, particularly those labeled as .
5.2. FL Preparation
- Batch size per client: In our FL scenario, each client is assigned 42 samples for training, which represents half of the base training dataset, as there are two clients. To accommodate this, we adjust the batch size by halving it. This results in a batch size of 8 samples per client.
- Base learning rate: Since we halved the batch size, we also reduced the learning rate by half to maintain learning behavior aligning with our benchmark. We set the base learning rate to for each client.
- Optimizer: We kept the same optimizer as the benchmark (Adam) for both clients.
- Number of epochs per federated round: To maintain global control over the learning convergence, we ensured that each client performed one training pass per federated round. Therefore, we set the number of epochs to 1 for each client.
- Aggregation algorithm: Since we simulated a use case where both cameras monitor crop fields with equal importance and the training data are distributed equally across the clients, ensuring that no client has more weight than the other, we used the classic FedAvg algorithm with equal weights for all clients. The formula below illustrates the algorithm, with being the global weight at round and and being the local weights after round t of clients 1 and 2, respectively.
5.3. LEFL’s Performance
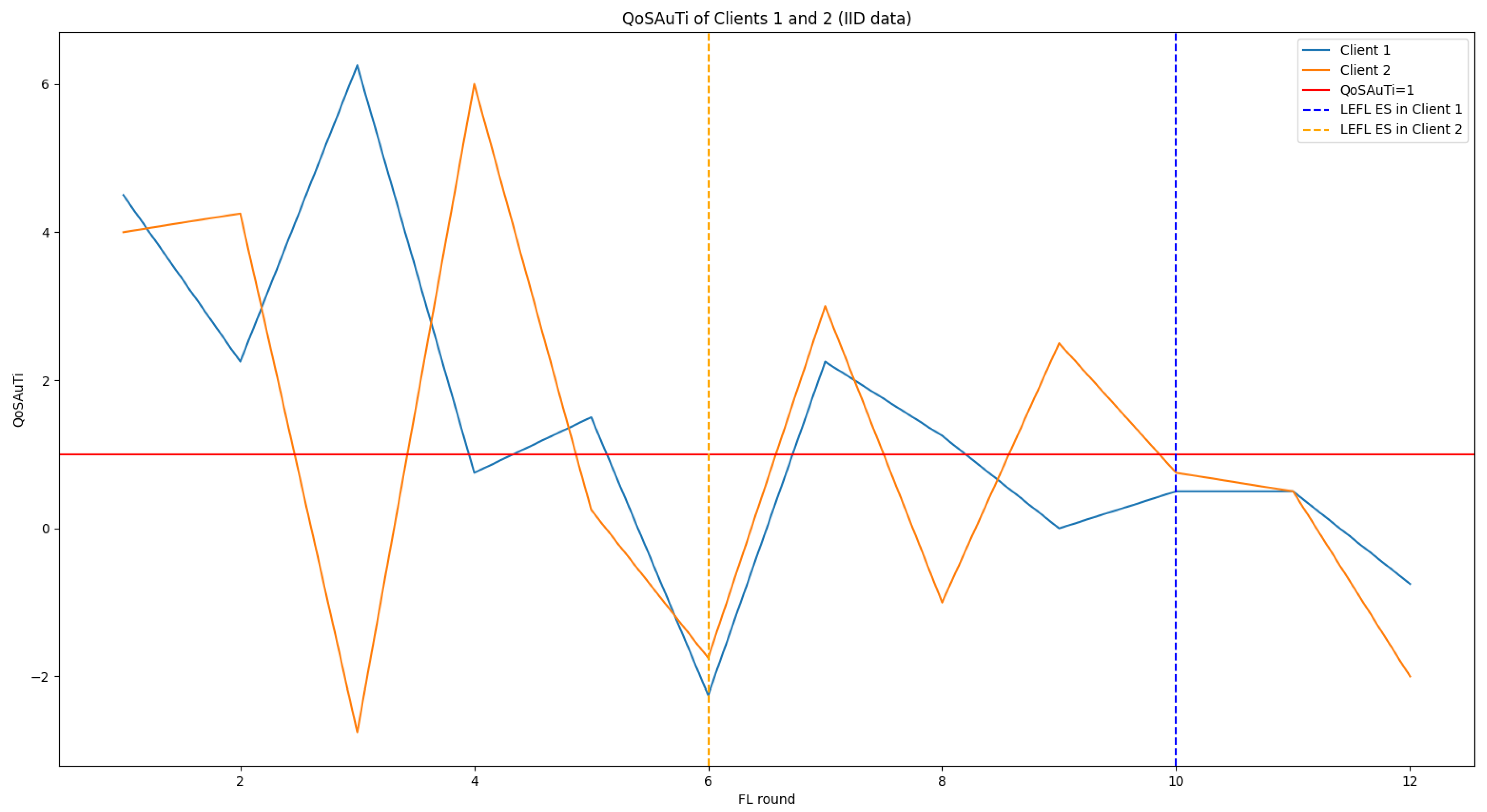
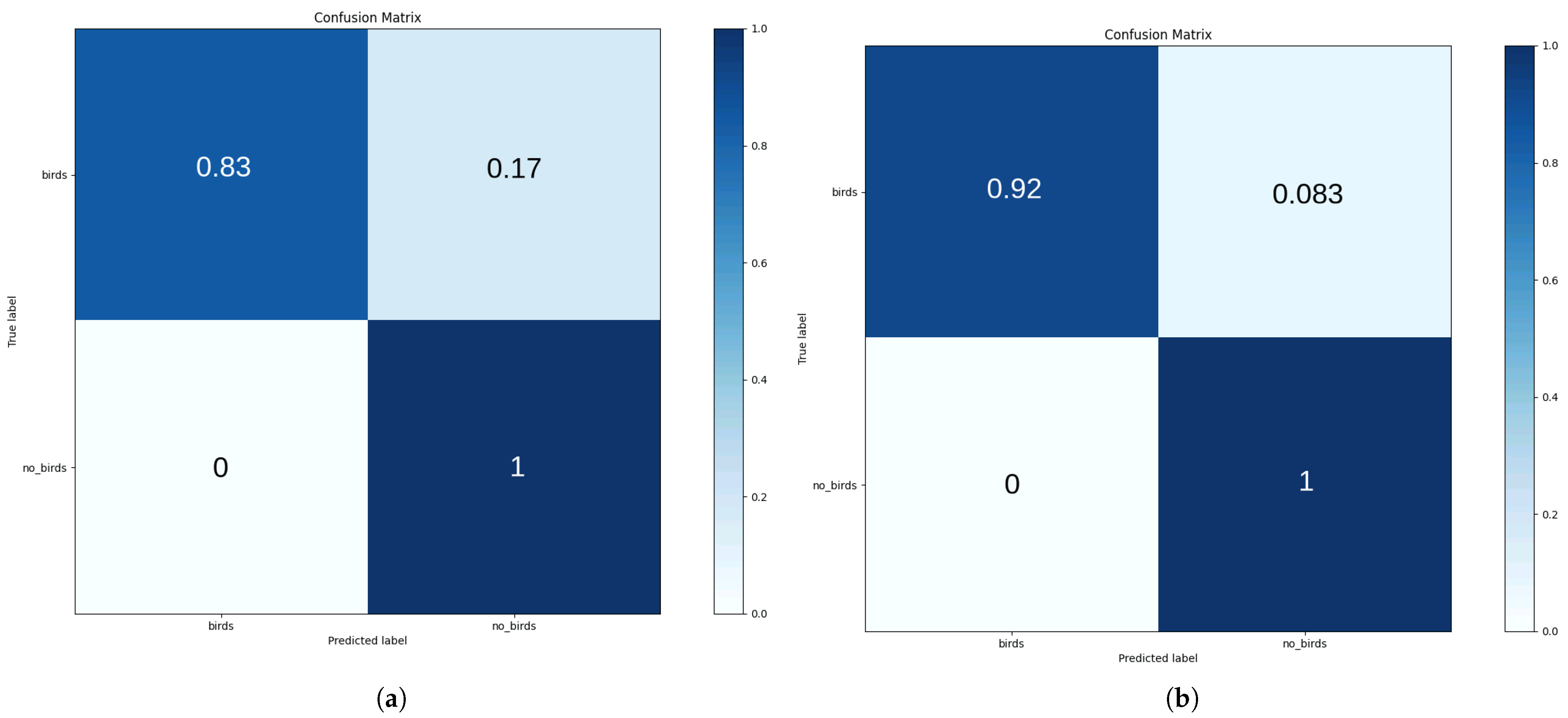
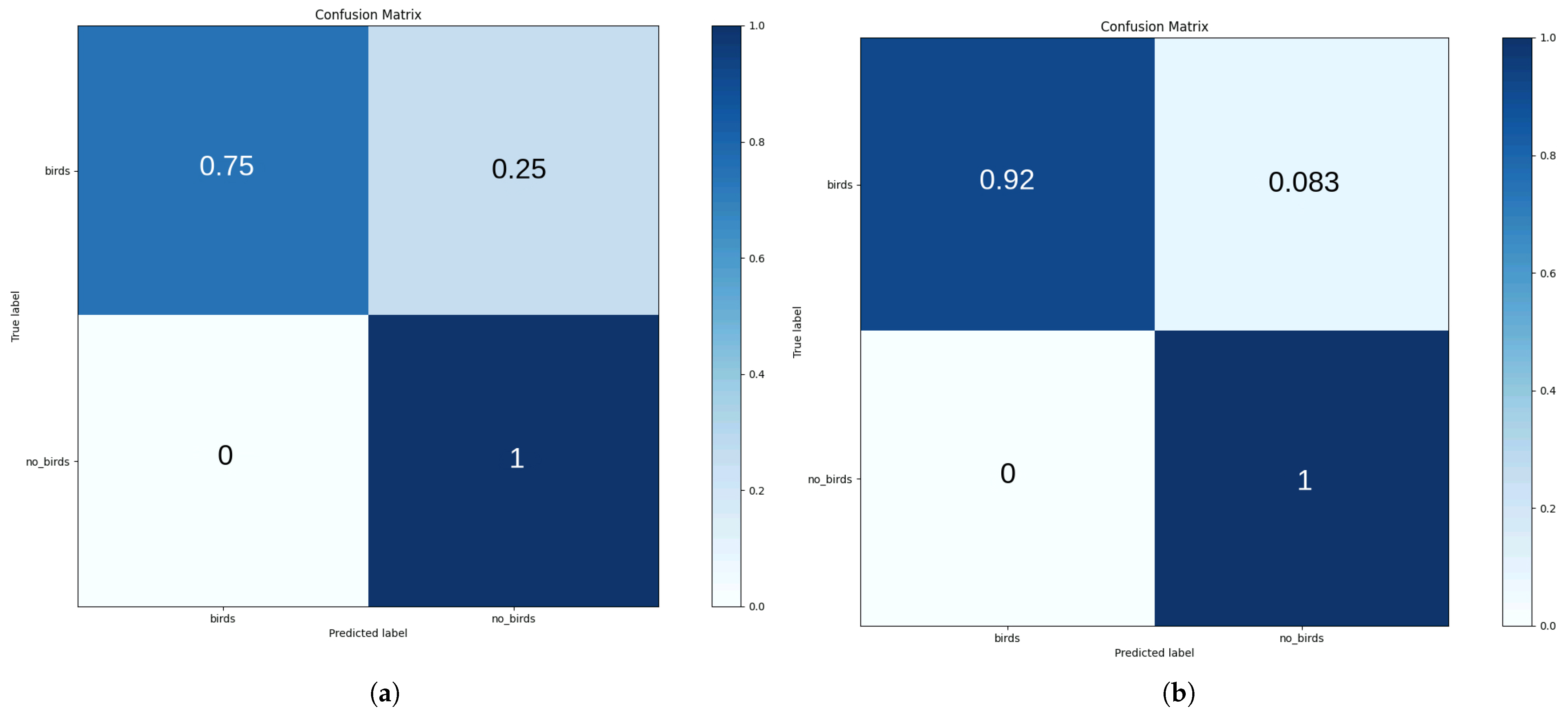
5.3.1. LEFL’s Performance on IID Data
5.3.2. LEFL’s Performance on Non-IID Data
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Basso, B.; Antle, J. Digital agriculture to design sustainable agricultural systems. Nat. Sustain. 2020, 3, 254–256. [Google Scholar] [CrossRef]
- Wakchaure, M.; Patle, B.; Mahindrakar, A. Application of AI techniques and robotics in agriculture: A review. Artif. Intell. Life Sci. 2023, 3, 100057. [Google Scholar] [CrossRef]
- Eli-Chukwu, N.C. Applications of Artificial Intelligence in Agriculture: A Review. Eng. Technol. Appl. Sci. Res. 2019, 9, 4377–4383. [Google Scholar] [CrossRef]
- Lytridis, C.; Kaburlasos, V.G.; Pachidis, T.; Manios, M.; Vrochidou, E.; Kalampokas, T.; Chatzistamatis, S. An Overview of Cooperative Robotics in Agriculture. Agronomy 2021, 11, 1818. [Google Scholar] [CrossRef]
- Farooq, M.S.; Riaz, S.; Abid, A.; Umer, T.; Zikria, Y.B. Role of IoT Technology in Agriculture: A Systematic Literature Review. Electronics 2020, 9, 319. [Google Scholar] [CrossRef]
- Banđur, D.; Jakšić, B.; Banđur, M.; Jović, S. An analysis of energy efficiency in Wireless Sensor Networks (WSNs) applied in smart agriculture. Comput. Electron. Agric. 2019, 156, 500–507. [Google Scholar] [CrossRef]
- Raghunathan, V.; Schurgers, C.; Park, S.; Srivastava, M. Energy-aware wireless microsensor networks. IEEE Signal Process. Mag. 2002, 19, 40–50. [Google Scholar] [CrossRef]
- Jawad, H.; Nordin, R.; Gharghan, S.; Jawad, A.; Ismail, M. Energy-Efficient Wireless Sensor Networks for Precision Agriculture: A Review. Sensors 2017, 17, 1781. [Google Scholar] [CrossRef]
- Sahota, H.; Kumar, R.; Kamal, A.; Huang, J. An energy-efficient wireless sensor network for precision agriculture. In Proceedings of the IEEE Symposium on Computers and Communications, Riccione, Italy, 22–25 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 347–350. [Google Scholar] [CrossRef]
- Hemmati, A.; Rahmani, A.M. The Internet of Autonomous Things applications: A taxonomy, technologies, and future directions. Internet Things 2022, 20, 100635. [Google Scholar] [CrossRef]
- Singh, R.; Gill, S.S. Edge AI: A survey. Internet Things Cyber-Phys. Syst. 2023, 3, 71–92. [Google Scholar] [CrossRef]
- Kukreja, N.; Shilova, A.; Beaumont, O.; Huckelheim, J.; Ferrier, N.; Hovland, P.; Gorman, G. Training on the Edge: The why and the how. arXiv 2019, arXiv:1903.03051. [Google Scholar]
- Shi, Y.; Yang, K.; Jiang, T.; Zhang, J.; Letaief, K.B. Communication-Efficient Edge AI: Algorithms and Systems. arXiv 2020, arXiv:2002.09668. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated Learning on Non-IID Data: A Survey. arXiv arXiv:cs.LG/2106.06843, 2021.
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. arXiv 2018, arXiv:1806.00582. [Google Scholar]
- Zhao, Z.; Feng, C.; Hong, W.; Jiang, J.; Jia, C.; Quek, T.Q.S.; Peng, M. Federated Learning with Non-IID Data in Wireless Networks. IEEE Trans. Wirel. Commun. 2022, 21, 1927–1942. [Google Scholar] [CrossRef]
- Restrepo-Arias, J.F.; Branch-Bedoya, J.W.; Awad, G. Image classification on smart agriculture platforms: Systematic literature review. Artif. Intell. Agric. 2024, 13, 1–17. [Google Scholar] [CrossRef]
- Liu, G.; Zhong, K.; Li, H.; Chen, T.; Wang, Y. A state of art review on time series forecasting with machine learning for environmental parameters in agricultural greenhouses. Inf. Process. Agric. 2024, 11, 143–162. [Google Scholar] [CrossRef]
- Jha, K.; Doshi, A.; Patel, P.; Shah, M. A comprehensive review on automation in agriculture using artificial intelligence. Artif. Intell. Agric. 2019, 2, 1–12. [Google Scholar] [CrossRef]
- Xu, J.; Gu, B.; Tian, G. Review of agricultural IoT technology. Artif. Intell. Agric. 2022, 6, 10–22. [Google Scholar] [CrossRef]
- Qazi, S.; Khawaja, B.A.; Farooq, Q.U. IoT-Equipped and AI-Enabled Next Generation Smart Agriculture: A Critical Review, Current Challenges and Future Trends. IEEE Access 2022, 10, 21219–21235. [Google Scholar] [CrossRef]
- Muhammed, D.; Ahvar, E.; Ahvar, S.; Trocan, M.; Montpetit, M.J.; Ehsani, R. Artificial Intelligence of Things (AIoT) for smart agriculture: A review of architectures, technologies and solutions. J. Netw. Comput. Appl. 2024, 228, 103905. [Google Scholar] [CrossRef]
- Kumar, S.; Chowdhary, G.; Udutalapally, V.; Das, D.; Mohanty, S.P. gCrop: Internet-of-Leaf-Things (IoLT) for Monitoring of the Growth of Crops in Smart Agriculture. In Proceedings of the 2019 IEEE International Symposium on Smart Electronic Systems (iSES) (Formerly iNiS), Rourkela, India, 16–18 December 2019; pp. 53–56. [Google Scholar] [CrossRef]
- T, M.; Makkithaya, K.; G, N.V. A Federated Learning-Based Crop Yield Prediction for Agricultural Production Risk Management. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), New Delhi, India, 11–13 February 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Yu, C.; Shen, S.; Zhang, K.; Zhao, H.; Shi, Y. Energy-Aware Device Scheduling for Joint Federated Learning in Edge-assisted Internet of Agriculture Things. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Idoje, G.; Dagiuklas, T.; Iqbal, M. Federated Learning: Crop classification in a smart farm decentralised network. Smart Agric. Technol. 2023, 5, 100277. [Google Scholar] [CrossRef]
- Jiang, P.; Chen, Y.; Liu, B.; He, D.; Liang, C. Real-Time Detection of Apple Leaf Diseases Using Deep Learning Approach Based on Improved Convolutional Neural Networks. IEEE Access 2019, 7, 59069–59080. [Google Scholar] [CrossRef]
- Antico, T.M.; Moreira, L.F.R.; Moreira, R. Evaluating the Potential of Federated Learning for Maize Leaf Disease Prediction. In Proceedings of the Anais do XIX Encontro Nacional de Inteligência Artificial e Computacional (ENIAC 2022), Sociedade Brasileira de Computação—SBC, 2022, ENIAC 2022, Campinas, Brazil, 28 November–1 December; 2022. [Google Scholar] [CrossRef]
- Khan, F.S.; Khan, S.; Mohd, M.N.H.; Waseem, A.; Khan, M.N.A.; Ali, S.; Ahmed, R. Federated learning-based UAVs for the diagnosis of Plant Diseases. In Proceedings of the 2022 International Conference on Engineering and Emerging Technologies (ICEET), Kuala Lumpur, Malaysia, 27–28 October 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Patros, P.; Ooi, M.; Huang, V.; Mayo, M.; Anderson, C.; Burroughs, S.; Baughman, M.; Almurshed, O.; Rana, O.; Chard, R.; et al. Rural AI: Serverless-Powered Federated Learning for Remote Applications. IEEE Internet Comput. 2023, 27, 28–34. [Google Scholar] [CrossRef]
- Deng, F.; Mao, W.; Zeng, Z.; Zeng, H.; Wei, B. Multiple Diseases and Pests Detection Based on Federated Learning and Improved Faster R-CNN. IEEE Trans. Instrum. Meas. 2022, 71, 3523811. [Google Scholar] [CrossRef]
- Vincent, D.R.; Deepa, N.; Elavarasan, D.; Srinivasan, K.; Chauhdary, S.H.; Iwendi, C. Sensors Driven AI-Based Agriculture Recommendation Model for Assessing Land Suitability. Sensors 2019, 19, 3667. [Google Scholar] [CrossRef]
- Murugamani, C.; Shitharth, S.; Hemalatha, S.; Kshirsagar, P.R.; Riyazuddin, K.; Naveed, Q.N.; Islam, S.; Mazher Ali, S.P.; Batu, A. Machine Learning Technique for Precision Agriculture Applications in 5G-Based Internet of Things. Wirel. Commun. Mob. Comput. 2022, 2022, 6534238. [Google Scholar] [CrossRef]
- Dahane, A.; Benameur, R.; Kechar, B.; Benyamina, A. An IoT Based Smart Farming System Using Machine Learning. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Cheng, Z.; Zhang, F. Flower End-to-End Detection Based on YOLOv4 Using a Mobile Device. Wirel. Commun. Mob. Comput. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Hsu, C.W.; Huang, Y.H.; Huang, N.F. Real-time Dragonfruit’s Ripeness Classification System with Edge Computing Based on Convolution Neural Network. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Republic of Korea, 12–15 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 177–182. [Google Scholar] [CrossRef]
- Paul, P.B.; Biswas, S.; Bairagi, A.K.; Masud, M. Data-Driven Decision Making for Smart Cultivation. In Proceedings of the 2021 IEEE International Symposium on Smart Electronic Systems (iSES), Jaipur, India, 18–22 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 249–254. [Google Scholar] [CrossRef]
- Arablouei, R.; Wang, L.; Currie, L.; Yates, J.; Alvarenga, F.A.; Bishop-Hurley, G.J. Animal behavior classification via deep learning on embedded systems. Comput. Electron. Agric. 2023, 207, 107707. [Google Scholar] [CrossRef]
- Mao, A.; Huang, E.; Gan, H.; Liu, K. FedAAR: A Novel Federated Learning Framework for Animal Activity Recognition with Wearable Sensors. Animals 2022, 12, 2142. [Google Scholar] [CrossRef] [PubMed]
- Aliahmadi, A.; Nozari, H.; Ghahremani-Nahr, J. AIoT-based Sustainable Smart Supply Chain Framework. Int. J. Innov. Manag. Econ. Soc. Sci. 2022, 2, 28–38. [Google Scholar] [CrossRef]
- Durrant, A.; Markovic, M.; Matthews, D.; May, D.; Enright, J.; Leontidis, G. The role of cross-silo federated learning in facilitating data sharing in the agri-food sector. Comput. Electron. Agric. 2022, 193, 106648. [Google Scholar] [CrossRef]
- Chabot, D.; Francis, C.M. Computer-automated bird detection and counts in high-resolution aerial images: A review. J. Field Ornithol. 2016, 87, 343–359. [Google Scholar] [CrossRef]
- Akçay, H.G.; Kabasakal, B.; Aksu, D.; Demir, N.; Öz, M.; Erdoğan, A. Automated Bird Counting with Deep Learning for Regional Bird Distribution Mapping. Animals 2020, 10, 1207. [Google Scholar] [CrossRef]
- Wäldchen, J.; Mäder, P. Machine learning for image based species identification. Methods Ecol. Evol. 2018, 9, 2216–2225. [Google Scholar] [CrossRef]
- Hong, S.J.; Han, Y.; Kim, S.Y.; Lee, A.Y.; Kim, G. Application of Deep-Learning Methods to Bird Detection Using Unmanned Aerial Vehicle Imagery. Sensors 2019, 19, 1651. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.; Jeon, H.; Smith, A. Bird Detection in Agriculture Environment using Image Processing and Neural Network. In Proceedings of the 2019 6th International Conference on Control, Decision and Information Technologies (CoDIT), Paris, France, 23–26 April 2019; pp. 1658–1663. [Google Scholar] [CrossRef]
- Li, C.; Zhang, B.; Hu, H.; Dai, J. Enhanced Bird Detection from Low-Resolution Aerial Image Using Deep Neural Networks. Neural Process. Lett. 2018, 49, 1021–1039. [Google Scholar] [CrossRef]
- Mashuk, F.; Sattar, A.; Sultana, N. Machine Learning Approach for Bird Detection. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 818–822. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.J. Federated Learning for Smart Healthcare: A Survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, S.; Lu, Q.; Dai, W.; Chen, M.; Liu, X.; Pirttikangas, S.; Shi, Y.; Zhang, W.; Herrera-Viedma, E. A Survey on Federated Learning and its Applications for Accelerating Industrial Internet of Things. arXiv 2021, arXiv:2104.10501. [Google Scholar]
- Pandya, S.; Srivastava, G.; Jhaveri, R.; Babu, M.R.; Bhattacharya, S.; Maddikunta, P.K.R.; Mastorakis, S.; Piran, M.J.; Gadekallu, T.R. Federated learning for smart cities: A comprehensive survey. Sustain. Energy Technol. Assess. 2023, 55, 102987. [Google Scholar] [CrossRef]
- Žalik, K.R.; Žalik, M. A Review of Federated Learning in Agriculture. Sensors 2023, 23, 9566. [Google Scholar] [CrossRef] [PubMed]
- Saha, R.; Misra, S.; Deb, P.K. FogFL: Fog-Assisted Federated Learning for Resource-Constrained IoT Devices. IEEE Internet Things J. 2021, 8, 8456–8463. [Google Scholar] [CrossRef]
- Kumar, A.; Srirama, S.N. Fog Enabled Distributed Training Architecture for Federated Learning. In Big Data Analytics; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 78–92. [Google Scholar] [CrossRef]
- Kumar, P.; Gupta, G.P.; Tripathi, R. PEFL: Deep Privacy-Encoding-Based Federated Learning Framework for Smart Agriculture. IEEE Micro 2022, 42, 33–40. [Google Scholar] [CrossRef]
- Friha, O.; Ferrag, M.A.; Shu, L.; Maglaras, L.; Choo, K.K.R.; Nafaa, M. FELIDS: Federated learning-based intrusion detection system for agricultural Internet of Things. J. Parallel Distrib. Comput. 2022, 165, 17–31. [Google Scholar] [CrossRef]
- Abu-Khadrah, A.; Ali, A.M.; Jarrah, M. An Amendable Multi-Function Control Method using Federated Learning for Smart Sensors in Agricultural Production Improvements. ACM Trans. Sens. Netw. 2023. [Google Scholar] [CrossRef]
- Sachidananda, V.; Khelil, A.; Suri, N. Quality of information in wireless sensor networks: A survey. Citeseer 2010. [Google Scholar]
- Dong, K.; Zhou, C.; Ruan, Y.; Li, Y. MobileNetV2 Model for Image Classification. In Proceedings of the 2020 2nd International Conference on Information Technology and Computer Application (ITCA), Guangzhou, China, 18–20 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 476–480. [Google Scholar] [CrossRef]
- Gupta, J.; Pathak, S.; Kumar, G. Deep Learning (CNN) and Transfer Learning: A Review. J. Phys. Conf. Ser. 2022, 2273, 012029. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. arXiv 2016, arXiv:1605.08695. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Fernandez-Marques, J.; Gao, Y.; Sani, L.; Li, K.H.; Parcollet, T.; de Gusmão, P.P.B.; et al. Flower: A Friendly Federated Learning Research Framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]
- Stuecke, J. Top 7 Open-Source Frameworks for Federated Learning. 2024. Available online: https://www.apheris.com/resources/blog/top-7-open-source-frameworks-for-federated-learning/ (accessed on 13 December 2024).
- Niu, Z.; Dong, H.; Qin, A.K.; Gu, T. FLrce: Resource-Efficient Federated Learning with Early-Stopping Strategy. arXiv 2023, arXiv:2310.09789. [Google Scholar]
- Sausse, C.; Barbu, C.; Bertrand, M.; Thibord, J.B. Dégâts d’oiseaux à la levée: Vers un changement de méthode? Phytoma 2022, 35–38. [Google Scholar]
- Ferreboeuf, H. The Shift Project, Lean ICT Report. 2018. Available online: https://theshiftproject.org/en/article/lean-ict-our-new-report/ (accessed on 12 December 2024).
- Sevilla, J.; Heim, L.; Hobbhahn, M.; Besiroglu, T.; Ho, A.; Villalobos, P. Estimating Training Compute of Deep Learning Models. 2022. Available online: https://epoch.ai/blog/estimating-training-compute (accessed on 18 December 2024).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Liao, F.; Zhou, F.; Chai, Y. Neuromorphic vision sensors: Principle, progress and perspectives. J. Semicond. 2021, 42, 013105. [Google Scholar] [CrossRef]
- Ghosh-Dastidar, S.; Adeli, H. Spiking neural networks. Int. J. Neural Syst. 2009, 19, 295–308. [Google Scholar] [CrossRef]
- Hareb, D.; Martinet, J. EvSegSNN: Neuromorphic Semantic Segmentation for Event Data. arXiv 2024, arXiv:2406.14178. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Use Case | IoT Device(s)/ Dataset(s) | AI Model(s) | FL Improvement(s) |
|---|---|---|---|---|
| [31] | Disease detection | UAVs | EfficientNet-B3 | Communication overhead, data privacy |
| [32] | Weed detection | Hyperspectral Camera | Custom CNN | Fault tolerance, data sovereignty |
| [43] | Supply chain data management | Remote sensors, weather and soil data | Custom CNN, LSTM RNN | Data privacy |
| [26] | Crop yield prediction | Sensors, Cameras | ResNet-16, ResNet-28 | Data privacy, data sovereignty |
| [30] | Maize leaf disease prediction | Cameras | AlexNet, SqueezeNet, ResNet-18, VGG-11, ShuffleNet | Data privacy |
| [57] | Intrusion detection | ToN-IoT dataset | GRU RNN | Data privacy |
| [41] | Automated animal activity recognition | Wearable sensors | CMI-Net | Data privacy |
| [58] | Securing agricultural IoT infrastructures | CSE-CIC-IDS2018, MQTTset, and InSDN datasets | Custom DNN, CNN, and RNN | Data privacy |
| [59] | Improving agricultural production | Smart sensors | Custom ML algorithm | Sensor control and adaptability |
| [28] | Crop classification | Climatic features | Gaussian Naive Bayes | Model accuracy |
| [33] | Disease and pest detection | Apple orchard images | ResNet-101 | Model training speed |
| Our work | Bird detection | Smart cameras | MobileNetV2 | Energy efficiency, knowledge sharing |
| QoSAuT | Quality of Service | Interpretation |
|---|---|---|
| Good | The AuT learned at a relatively low energy cost. | |
| Average | The AuT learned near the limit of energy optimization. | |
| Bad | The AuT learned but at a relatively high energy cost. | |
| Very bad | The AuT did not learn. | |
| Disastrous | Theoretically impossible as the training must improve the model’s accuracy. |
| Device | CPU | GPU/NPU | Memory | MobileNetV2 Performance (FPS) | Wireless Communication | Training Energy Cost (Power) | Price (USD) |
|---|---|---|---|---|---|---|---|
| Raspberry Pi 4 | Quad-core Cortex-A72 @ 1.5 GHz | VideoCore VI GPU (32 GFLOPS) | 1–8 GB LPDDR4 | 3–4 | Wi-Fi 5 (802.11ac), Bluetooth 5.0 | 3.4 W | 50 |
| Jetson Nano | Quad-core Cortex-A57 @ 1.43 GHz | 128 CUDA cores (1.8 TOPS) | 4 GB LPDDR4 | 10–12 | External USB Wi-Fi adapter required | 5–10 W | 99 |
| Google Coral Dev Board | ARM Cortex-A53 | Edge TPU (4 TOPS) | 1 GB LPDDR4 | 50–60 | Wi-Fi 5 (802.11ac), Bluetooth 4.1 | 2 W | 129 |
| Radxa Zero | Quad-core Cortex-A55 @ 1.4 GHz | Mali-G52 (0.6 TOPS NPU) | 1–8 GB LPDDR4 | 2–3 | Wi-Fi 5 (802.11ac) (only in advanced model), No wireless in basic model | 3 W | 40 |
| BeagleBone AI | Dual-core Cortex-A15 @ 1.5 GHz | PowerVR SGX544 + C66x DSP | 1 GB DDR3L | 5–6 | External USB Wi-Fi adapter required | 7 W | 120 |
| Model | Top-1 Accuracy | Model Size | Latency (CPU) | Energy Consumption | Notable Strengths |
|---|---|---|---|---|---|
| MobileNetV2 | 71.8% | 14 MB | 20 ms | Moderate | Lightweight, efficient for edge devices. |
| EfficientNet-B0 | 77.1% | 20 MB | 24 ms | Moderate-High | Higher accuracy; more resource-demanding. |
| SqueezeNet | 58.1% | 4.8 MB | 18 ms | Low | Extremely lightweight, lower accuracy. |
| ShuffleNet V2 | 69.4% | 8 MB | 22 ms | Low | Faster on mobile CPUs, good trade-off. |
| Feature | TensorFlow | PyTorch |
|---|---|---|
| Ease of Use | High-level API with extensive documentation | Dynamic computational graph, more flexible |
| Performance on edge devices | Optimized for edge deployment with TensorFlow Lite | Requires optimizations for edge deployment |
| Model deployment | Easy integration with TensorFlow Lite for mobile/edge | Model conversion needed for deployment |
| Resource efficiency | Highly optimized for low-resource devices | May require more resources for similar tasks |
| Framework | Ease of Use | Communication Efficiency | Energy Efficiency | Edge Adaptability | Observations |
|---|---|---|---|---|---|
| Flower | High | Optimized | High | Excellent | Lightweight, flexible, and edge-focused, DL framework-agnostic |
| TensorFLow FL (TFF) | Moderate | Moderate | Moderate | Good | Focused on TensorFlow-based implementations |
| PySyft | Moderate | Good | Moderate | Moderate | Emphasizes security but less edge-specific |
| FedML | Moderate | Optimized | High | Good | Versatile but more complex for lightweight systems |
| LEAF | Low | Basic | Low | Limited | Designed primarily for academic purposes where performance is not the primary focus |
| Subset | All | ||
|---|---|---|---|
| Training () | 34 | 35 | 69 |
| Validation () | 11 | 12 | 23 |
| Testing () | 12 | 11 | 23 |
| Total () | 57 | 58 | 115 |
| Paper | Dataset Size | Data Type |
|---|---|---|
| [29] | 2029 | Images |
| [30] | 3852 | Images |
| [31] | 5400 | Images |
| [32] | 104,544 | Hypervoxels |
| Our work | 115 | Images |
| Client | (Mostly Pigeons) | (Mostly Crows) | Total | |
|---|---|---|---|---|
| Client 1 | 13 | 10 | 23 | 46 |
| Client 2 | 13 | 9 | 24 | 46 |
| Client | (Mostly Pigeons) | (Mostly Crows) | Total | |
|---|---|---|---|---|
| Client 1 | 26 | 0 | 20 | 46 |
| Client 2 | 0 | 19 | 27 | 46 |
| Scenario | LEFL | FL-to-Convergence | Remote Benchmark |
|---|---|---|---|
| Test Accuracy | 0.91 | 0.96 | 0.96 |
| 1.55 | 1.40 | 0.09 | |
| 2.56 | 1.40 | 0.09 |
| Scenario | LEFL | FL-to-Convergence | Remote Benchmark |
|---|---|---|---|
| Test Accuracy | 0.87 | 0.96 | 0.96 |
| 1.44 | 0.77 | 0.09 | |
| 1.80 | 0.77 | 0.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benhoussa, S.; De Sousa, G.; Chanet, J.-P. FedBirdAg: A Low-Energy Federated Learning Platform for Bird Detection with Wireless Smart Cameras in Agriculture 4.0. AI 2025, 6, 63. https://doi.org/10.3390/ai6040063
Benhoussa S, De Sousa G, Chanet J-P. FedBirdAg: A Low-Energy Federated Learning Platform for Bird Detection with Wireless Smart Cameras in Agriculture 4.0. AI. 2025; 6(4):63. https://doi.org/10.3390/ai6040063
Chicago/Turabian StyleBenhoussa, Samy, Gil De Sousa, and Jean-Pierre Chanet. 2025. "FedBirdAg: A Low-Energy Federated Learning Platform for Bird Detection with Wireless Smart Cameras in Agriculture 4.0" AI 6, no. 4: 63. https://doi.org/10.3390/ai6040063
APA StyleBenhoussa, S., De Sousa, G., & Chanet, J.-P. (2025). FedBirdAg: A Low-Energy Federated Learning Platform for Bird Detection with Wireless Smart Cameras in Agriculture 4.0. AI, 6(4), 63. https://doi.org/10.3390/ai6040063