
Multimodal Data Fusion for Tabular and Textual Data: Zero-Shot, Few-Shot, and Fine-Tuning of Generative Pre-Trained Transformer Models

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
- We propose an innovative method that transforms tabular data into textual narratives through a serialization process and integrates them into existing textual data. This process enriches the dataset, facilitating multimodal analysis for traffic safety.
- Utilizing GPT-4’s few-shot learning capabilities, we introduce new labels, such as “driver at fault”, “driver actions”, and “crash factors”, expanding the scope of analysis beyond crash severity to capture critical road safety dimensions.
- We classify consolidated text into distinct labels and compare various learning strategies—zero-shot, few-shot, and fine-tuning—to highlight their impact on model optimization and performance.
- We evaluate the effectiveness of a multimodal dataset versus a unimodal one, demonstrating the superiority of the multimodal approach in enhancing classification accuracy.
2. Related Work
2.1. Tabular Data in Crash Analysis
2.2. Textual Data and NLP in Crash Analysis
2.3. Multimodal Data Fusion: Bridging Structured and Unstructured Data
3. Methodology
3.1. Dataset
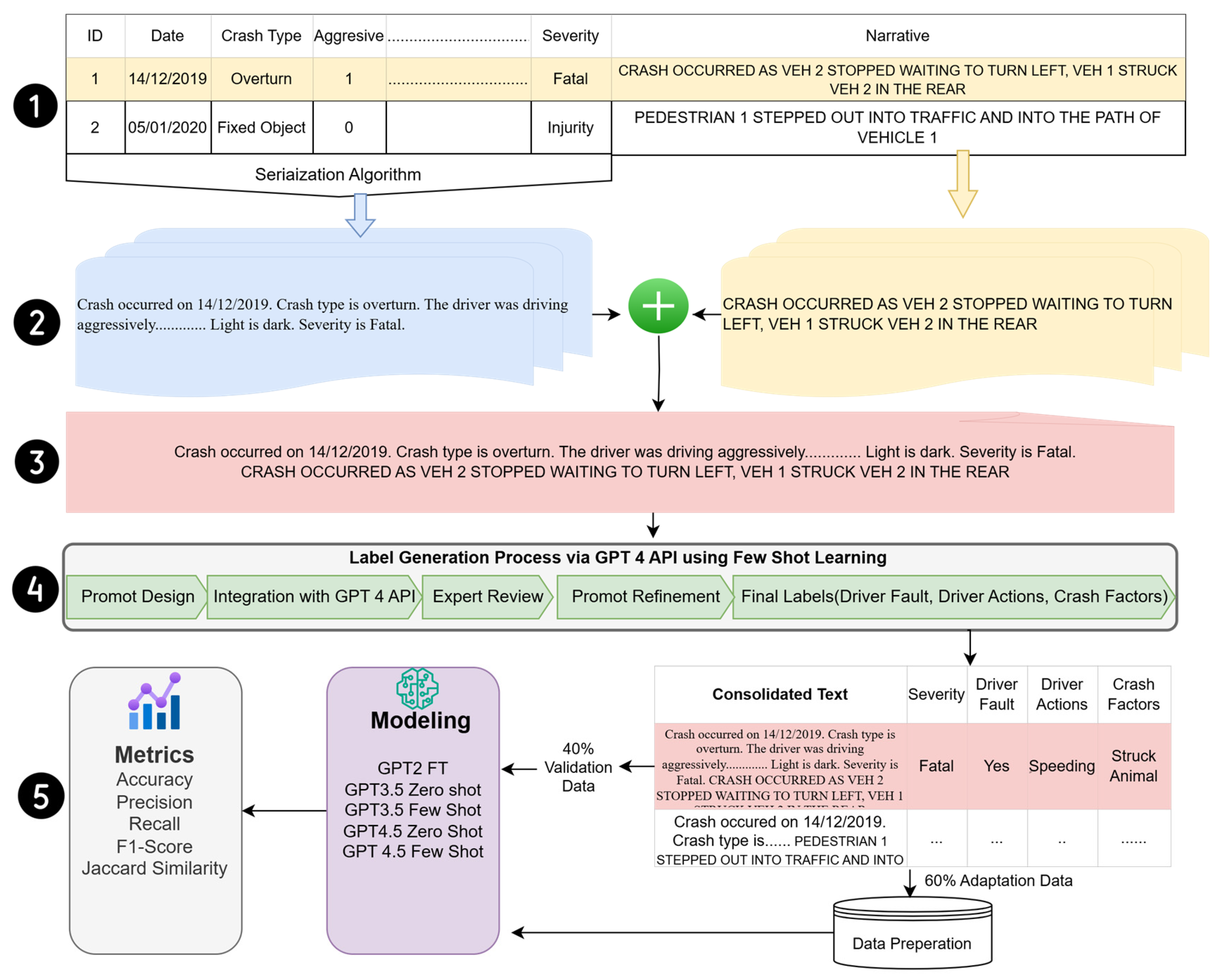
3.2. Multimodal Data Fusion (MDF) Framework
| Algorithm 1. MDF pseudocode. |
Input:
|
3.3. Data Preparation and Serialization (Tabular-to-Test Conversion)
| Algorithm 2. Data serialization process. |
| Input: A dataset with rows and columns (col_name, col_desc) Output: A list of text descriptions generated from the tabular data Begin Initialize text_list as an empty list For each record in the dataset do Initialize textDescription to an empty string For each (col_name, col_desc) pair in the record do Switch (col_name) Case patterns: Apply conversion logic based on col_name and col_desc Append the resulting string to textDescription // Cases cover different column names with specific logic for each // Example cases include “city”, “left_scene”, “acc_time”, etc. Default: Optionally handle unexpected or generic cases End Switch End For Append textDescription to text_list End For Return text_list End |
3.4. Label Generation via GPT Models
3.5. Dataset Creation
3.6. Modeling
3.6.1. Fine-Tuning (FT)
3.6.2. Prompt Engineering for Few-Shot and Zero-Shot Learning
3.7. Evaluation Metrics
3.8. Experiment Setup
- To evaluate whether integrating crash narrative information with tabular data enhances the accuracy of traffic crash classification models.
- To develop a novel framework for MDF using state-of-the-art LLMs.
- To test these methodologies on real-world traffic crash datasets.
3.9. Experiment 1: Comparative Analysis of Narrative, Tabular, and Fused Data Performance
3.9.1. Experimental Setup
- Tabular-only model: Relied solely on quantitative tabular data, such as environmental conditions, traffic statistics, and time of incidents, to evaluate the effectiveness of structured data in isolation.
- Narrative-only model: Focused exclusively on the unstructured crash narrative to assess the standalone value of unstructured data in the incident analysis.
- Fused (tabular + narrative) model: Combined both tabular and narrative data into a cohesive format to evaluate if this integrated approach could surpass the informational value of either data type alone, providing a richer, more nuanced context for analysis.
3.9.2. Model Evaluation and Results
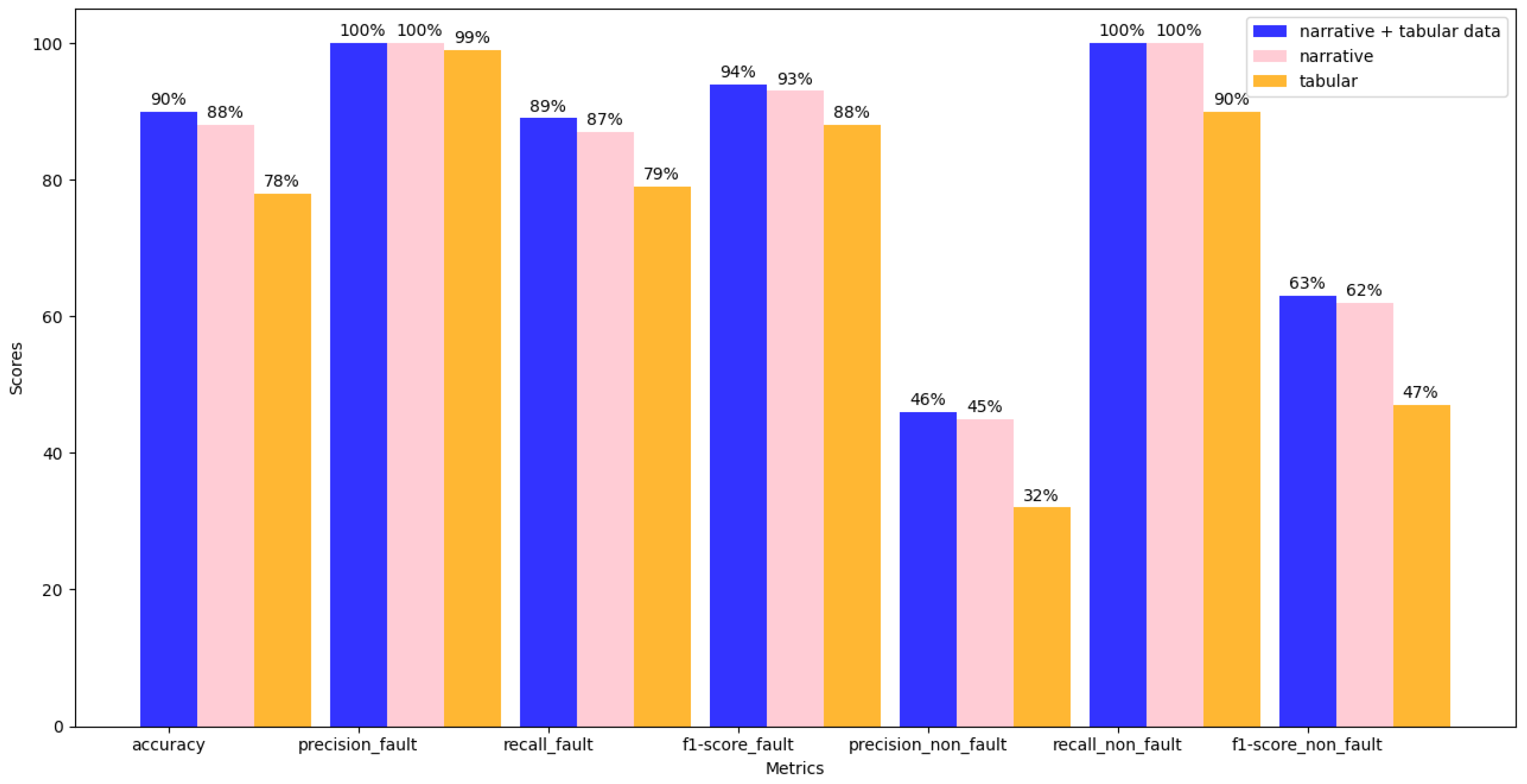
- Fused model: Achieved 90% accuracy and an F1-score of 94% for identifying drivers at fault. The model also demonstrated strong precision (100%) for detecting drivers at fault and recall (63%) for identifying drivers not at fault.
- Narrative-only model: Showed slightly lower performance with 88% accuracy and an F1-score of 93%. Precision for detecting drivers at fault remained at 100%, but Recall for not-at-fault drivers dropped to 62%.
- Tabular-only model: Performed the weakest, particularly in identifying drivers not at fault, with an accuracy of 78% and a precision of only 32%. This model had difficulty capturing contextual information, resulting in lower Recall and F1-scores.
3.10. Experiment 2: Multimodal Data Framework (MDF) Modeling and Evaluation
3.10.1. Fine-Tuning with GPT-2
3.10.2. Prompt Engineering Using Few-Shot and Zero-Shot Learning (GPT-3.5 and GPT-4.5)
4. Analysis and Results
4.1. Model Performance Evaluation: Baseline vs. Advanced Models
4.1.1. Baseline Model: GPT-2 Fine-Tuned (FT)
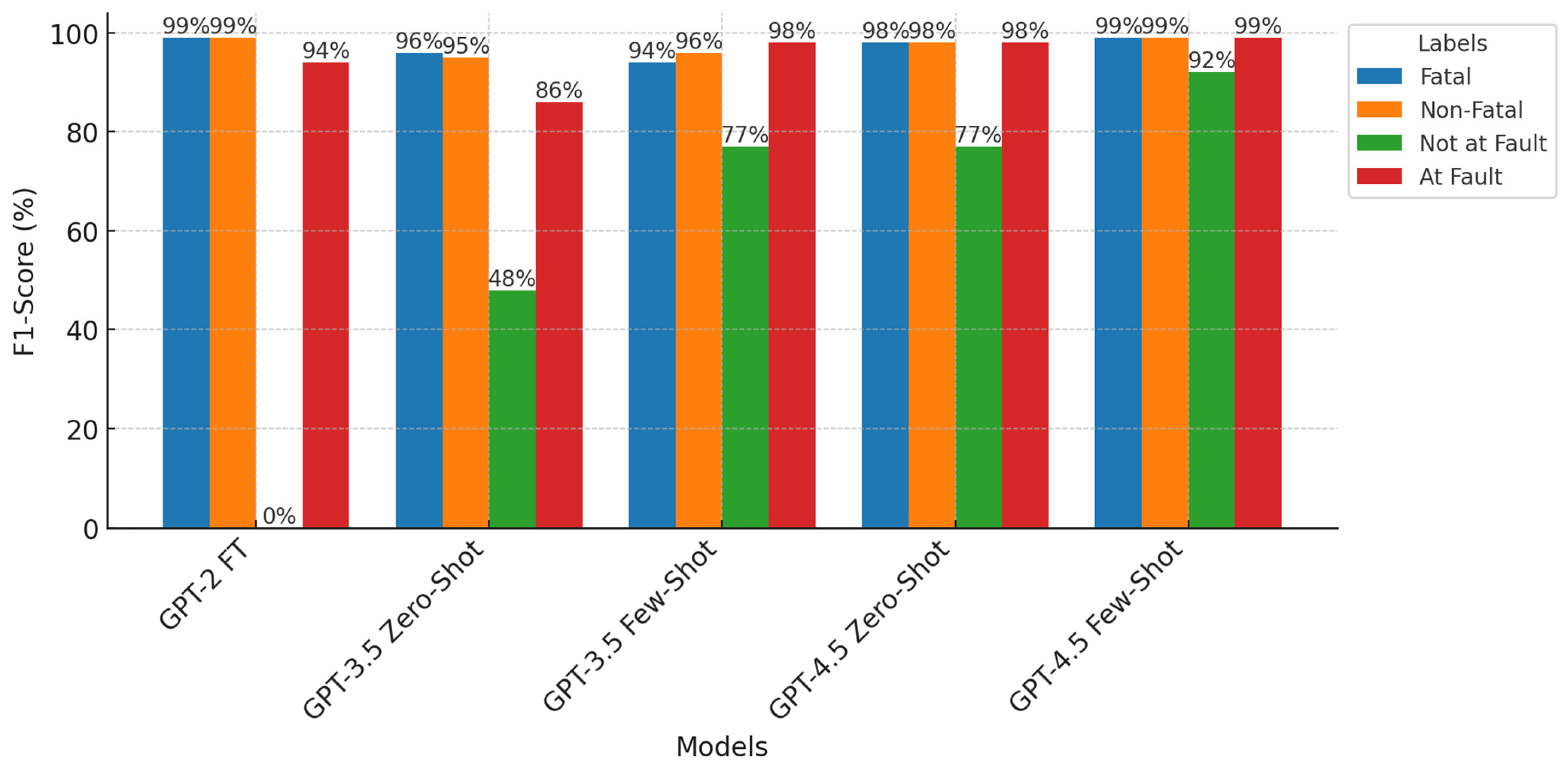
4.1.2. Advanced Models Through Prompt Engineering: GPT-3.5 and GPT-4.5 (Few-Shot and Zero-Shot)
4.1.3. Summary of Baseline vs. Advanced Models
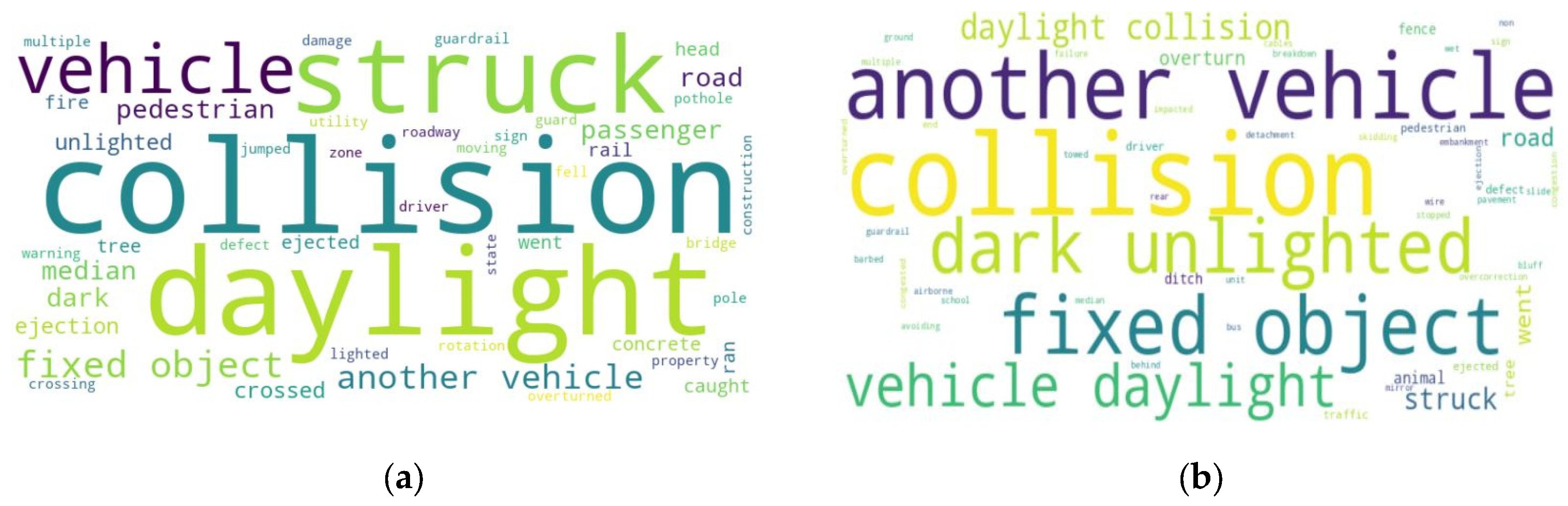
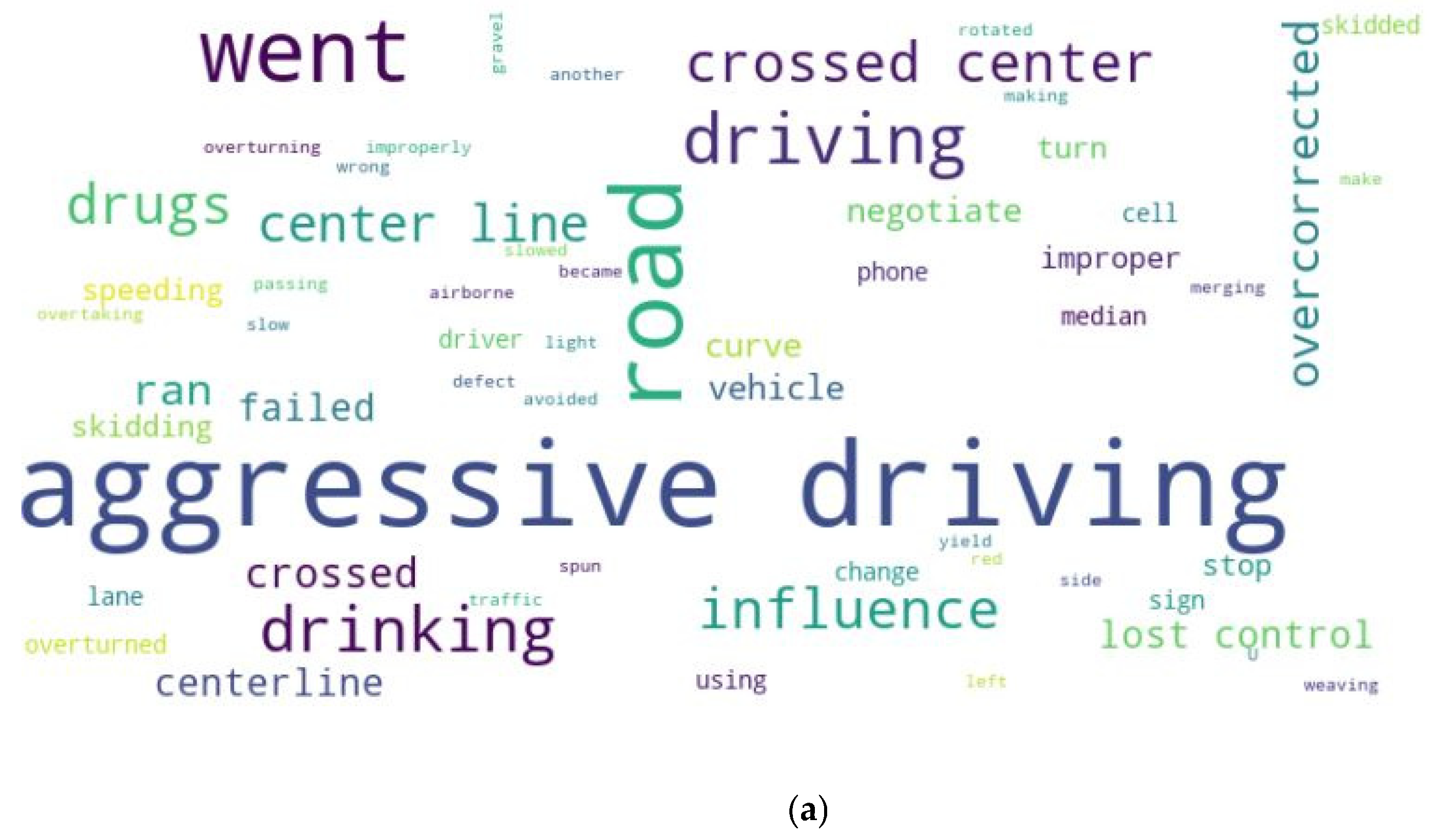
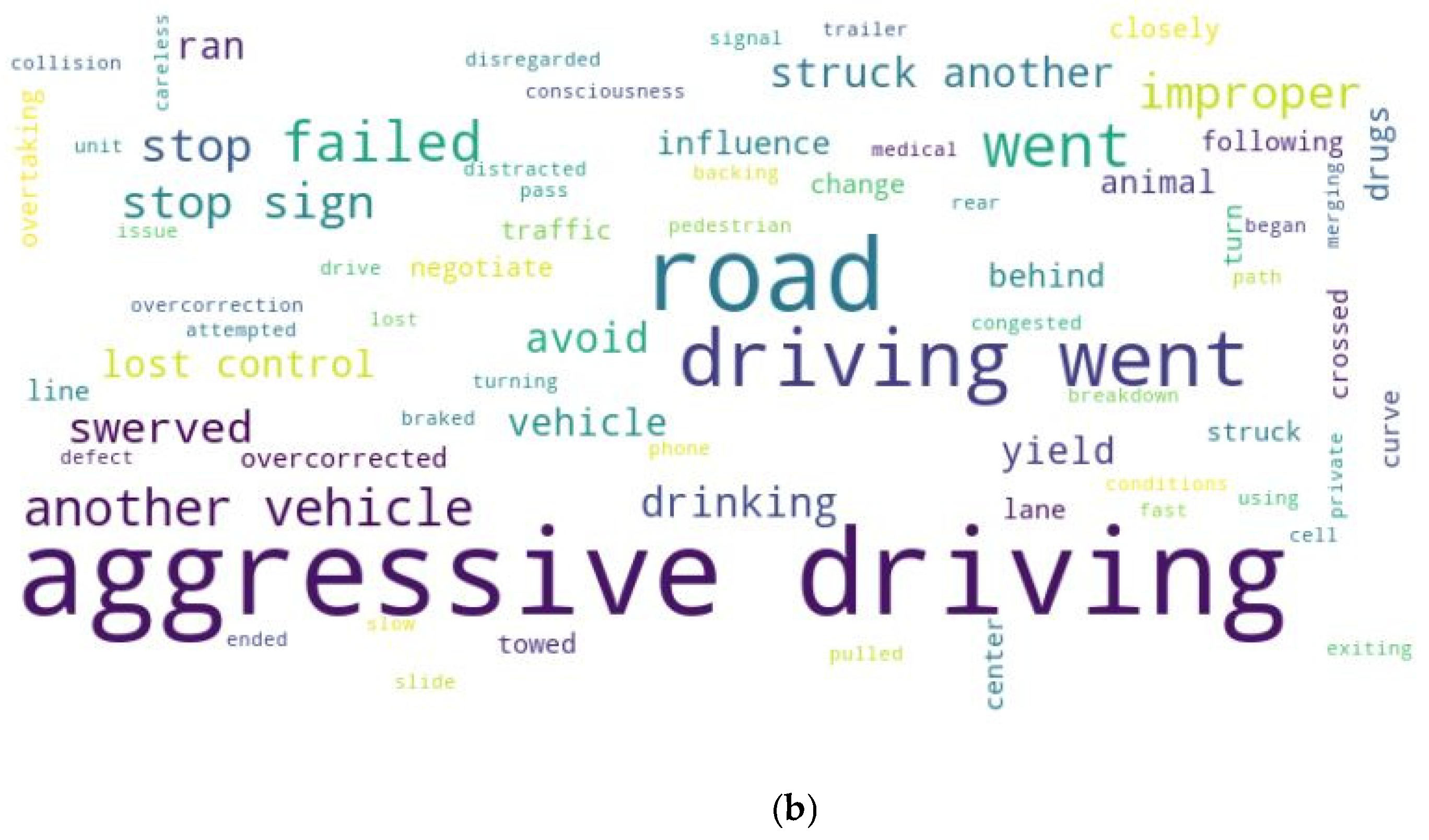
4.2. Enhancing Traffic Crash Prediction and Insights via MDF
Insights from Tabular and Narrative Data Fusion
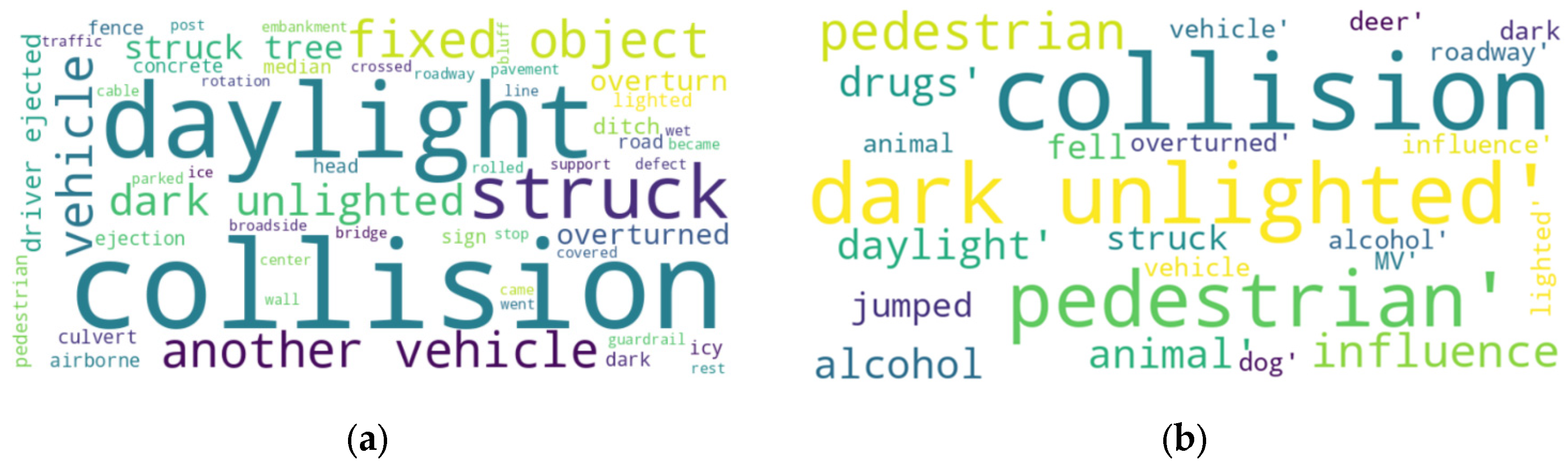
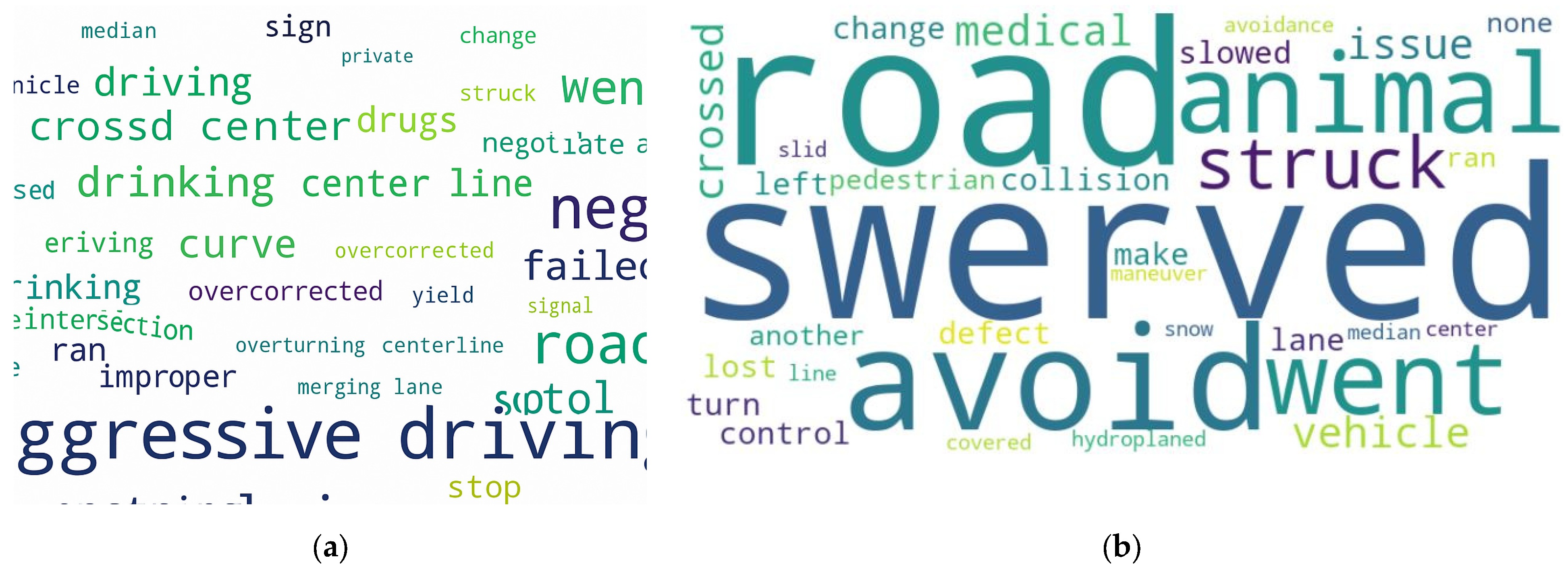
4.3. Case Studies: Enhancing Crash Prediction and Factor Extraction with Multimodal Data
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| API | Application programming interface |
| DUI | Driving Under the Influence |
| EHR | Electronic Health Record |
| FS | Few-shot |
| FT | Fine-tuning |
| GPT | Generative Pre-Trained Transformer |
| LLM | Large Language Model |
| MDF | Multimodal Data Fusion |
| ML | Machine learning |
| NLP | Natural language processing |
| SMOTE | Synthetic Minority Over-sampling Technique |
| ZS | Zero-shot |
References
- Mannering, F.L.; Bhat, C.R. Analytic Methods in Accident Research: Methodological Frontier and Future Directions. Anal. Methods Accid. Res. 2014, 1, 1–22. [Google Scholar]
- Saket, B.; Endert, A.; Demiralp, Ç. Task-Based Effectiveness of Basic Visualizations. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2505–2512. [Google Scholar] [PubMed]
- Roberts, P.L.D.; Jaffe, J.S.; Trivedi, M.M. Multiview, Multimodal Fusion of Acoustic and Optical Data for Classifying Marine Animals. J. Acoust. Soc. Am. 2011, 130, 2452. [Google Scholar]
- Gu, X.; Wang, Z.; Jin, I.; Wu, Z. Advancing Multimodal Data Fusion in Pain Recognition: A Strategy Leveraging Statistical Correlation and Human-Centered Perspectives. arXiv 2024, arXiv:2404.00320. [Google Scholar]
- Zhang, Y.-D.; Dong, Z.; Wang, S.-H.; Yu, X.; Yao, X.; Zhou, Q.; Hu, H.; Li, M.; Jiménez-Mesa, C.; Ramirez, J. Advances in Multimodal Data Fusion in Neuroimaging: Overview, Challenges, and Novel Orientation. Inf. Fusion. 2020, 64, 149–187. [Google Scholar]
- Shen, W.; Wang, J.; Han, J. Entity Linking with a Knowledge Base: Issues, Techniques, and Solutions. IEEE Trans. Knowl. Data Eng. 2014, 27, 443–460. [Google Scholar]
- Hegselmann, S.; Buendia, A.; Lang, H.; Agrawal, M.; Jiang, X.; Sontag, D. Tabllm: Few-Shot Classification of Tabular Data with Large Language Models. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 25–27 April 2023; pp. 5549–5581. [Google Scholar]
- Olugbade, S.; Ojo, S.; Imoize, A.L.; Isabona, J.; Alaba, M.O. A Review of Artificial Intelligence and Machine Learning for Incident Detectors in Road Transport Systems. Math. Comput. Appl. 2022, 27, 77. [Google Scholar] [CrossRef]
- Haghshenas, S.S.; Guido, G.; Vitale, A.; Astarita, V. Assessment of the Level of Road Crash Severity: Comparison of Intelligence Studies. Expert. Syst. Appl. 2023, 234, 121118. [Google Scholar]
- Yang, Y.; Wang, K.; Yuan, Z.; Liu, D. Predicting Freeway Traffic Crash Severity Using XGBoost-Bayesian Network Model with Consideration of Features Interaction. J. Adv. Transp. 2022, 2022, 4257865. [Google Scholar] [CrossRef]
- Valcamonico, D.; Baraldi, P.; Amigoni, F.; Zio, E. A Framework Based on Natural Language Processing and Machine Learning for the Classification of the Severity of Road Accidents from Reports. Proc. Inst. Mech. Eng. O J. Risk Reliab. 2022, 238, 957–971. [Google Scholar] [CrossRef]
- Arteaga, C.; Paz, A.; Park, J. Injury Severity on Traffic Crashes: A Text Mining with an Interpretable Machine-Learning Approach. Saf. Sci. 2020, 132, 104988. [Google Scholar] [CrossRef]
- Xu, H.; Liu, Y.; Shu, C.-M.; Bai, M.; Motalifu, M.; He, Z.; Wu, S.; Zhou, P.; Li, B. Cause Analysis of Hot Work Accidents Based on Text Mining and Deep Learning. J. Loss Prev. Process Ind. 2022, 76, 104747. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5999–6009. [Google Scholar]
- Tian, S.; Li, L.; Li, W.; Ran, H.; Ning, X.; Tiwari, P. A Survey on Few-Shot Class-Incremental Learning. Neural Netw. 2024, 169, 307–324. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. Adv. Neural Inf. Process Syst. 2020, 33, 1877–1901. [Google Scholar]
- Song, Y.; Wang, T.; Mondal, S.K.; Sahoo, J.P. A Comprehensive Survey of Few-Shot Learning: Evolution, Applications, Challenges, and Opportunities. ACM Comput. Surv. 2023, 55, 271. [Google Scholar] [CrossRef]
- Brown, D.E. Text Mining the Contributors to Rail Accidents. IEEE Trans. Intell. Transp. Syst. 2016, 17, 346–355. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. ACM Comput. Surv. 2021, 53, 63. [Google Scholar] [CrossRef]
- Ashqar, H.I.; Alhadidi, T.I.; Elhenawy, M.; Jaradat, S. Factors Affecting Crash Severity in Roundabouts: A Comprehensive Analysis in the Jordanian Context. Transp. Eng. 2024, 17, 100261. [Google Scholar] [CrossRef]
- Hussain, Q.; Alhajyaseen, W.K.M.; Brijs, K.; Pirdavani, A.; Brijs, T. Innovative Countermeasures for Red Light Running Prevention at Signalized Intersections: A Driving Simulator Study. Accid. Anal. Prev. 2020, 134, 105349. [Google Scholar] [PubMed]
- Fisa, R.; Musukuma, M.; Sampa, M.; Musonda, P.; Young, T. Effects of Interventions for Preventing Road Traffic Crashes: An Overview of Systematic Reviews. BMC Public. Health 2022, 22, 513. [Google Scholar]
- Pourpanah, F.; Abdar, M.; Luo, Y.; Zhou, X.; Wang, R.; Lim, C.P.; Wang, X.-Z.; Wu, Q.M.J. A Review of Generalized Zero-Shot Learning Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4051–4070. [Google Scholar]
- Xu, W.; Xian, Y.; Wang, J.; Schiele, B.; Akata, Z. Attribute Prototype Network for Zero-Shot Learning. Adv. Neural Inf. Process Syst. 2020, 33, 21969–21980. [Google Scholar]
- Cao, W.; Wu, Y.; Sun, Y.; Zhang, H.; Ren, J.; Gu, D.; Wang, X. A Review on Multimodal Zero-Shot Learning. WIREs Data Min. Knowl. Discov. 2023, 13, e1488. [Google Scholar] [CrossRef]
- Teoh, J.R.; Dong, J.; Zuo, X.; Lai, K.W.; Hasikin, K.; Wu, X. Advancing Healthcare through Multimodal Data Fusion: A Comprehensive Review of Techniques and Applications. PeerJ Comput. Sci. 2024, 10, e2298. [Google Scholar] [CrossRef]
- Ye, J.; Hai, J.; Song, J.; Wang, Z. Multimodal Data Hybrid Fusion and Natural Language Processing for Clinical Prediction Models. medRxiv 2023. [Google Scholar] [CrossRef]
- Luo, X.; Jia, N.; Ouyang, E.; Fang, Z. Introducing Machine-learning-based Data Fusion Methods for Analyzing Multimodal Data: An Application of Measuring Trustworthiness of Microenterprises. Strateg. Manag. J. 2024, 45, 1597–1629. [Google Scholar] [CrossRef]
- Zou, Z.; Gan, H.; Huang, Q.; Cai, T.; Cao, K. Disaster Image Classification by Fusing Multimodal Social Media Data. ISPRS Int. J. Geoinf. 2021, 10, 636. [Google Scholar] [CrossRef]
- Lord, D.; Mannering, F. The Statistical Analysis of Crash-Frequency Data: A Review and Assessment of Methodological Alternatives. Transp. Res. Part. A Policy Pr. 2010, 44, 291–305. [Google Scholar]
- Savolainen, P.T.; Mannering, F.L.; Lord, D.; Quddus, M.A. The Statistical Analysis of Highway Crash-Injury Severities: A Review and Assessment of Methodological Alternatives. Accid. Anal. Prev. 2011, 43, 1666–1676. [Google Scholar]
- Delen, D.; Sharda, R.; Bessonov, M. Identifying Significant Predictors of Injury Severity in Traffic Accidents Using a Series of Artificial Neural Networks. Accid. Anal. Prev. 2006, 38, 434–444. [Google Scholar]
- Erdogan, S.; Yilmaz, I.; Baybura, T.; Gullu, M. Geographical Information Systems Aided Traffic Accident Analysis System Case Study: City of Afyonkarahisar. Accid. Anal. Prev. 2008, 40, 174–181. [Google Scholar] [CrossRef] [PubMed]
- Ashqar, H.I.; Shaheen, Q.H.Q.; Ashur, S.A.; Rakha, H.A. Impact of Risk Factors on Work Zone Crashes Using Logistic Models and Random Forest. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 1815–1820. [Google Scholar]
- Theofilatos, A.; Chen, C.; Antoniou, C. Comparing Machine Learning and Deep Learning Methods for Real-Time Crash Prediction. Transp. Res. Rec. 2019, 2673, 169–178. [Google Scholar] [CrossRef]
- Iranitalab, A.; Khattak, A. Comparison of Four Statistical and Machine Learning Methods for Crash Severity Prediction. Accid. Anal. Prev. 2017, 108, 27–36. [Google Scholar] [CrossRef] [PubMed]
- Santos, K.; Dias, J.P.; Amado, C. A Literature Review of Machine Learning Algorithms for Crash Injury Severity Prediction. J. Saf. Res. 2022, 80, 254–269. [Google Scholar] [CrossRef]
- Wahab, L.; Jiang, H. A Comparative Study on Machine Learning Based Algorithms for Prediction of Motorcycle Crash Severity. PLoS ONE 2019, 14, e0214966. [Google Scholar] [CrossRef]
- Hwang, Y.; Song, J. Recent Deep Learning Methods for Tabular Data. Commun. Stat. Appl. Methods 2023, 30, 215–226. [Google Scholar] [CrossRef]
- Chen, J.; Tao, W.; Jing, Z.; Wang, P.; Jin, Y. Traffic Accident Duration Prediction Using Multi-Mode Data and Ensemble Deep Learning. Heliyon 2024, 10, e25957. [Google Scholar]
- Dingus, T.A.; Guo, F.; Lee, S.; Antin, J.F.; Perez, M.; Buchanan-King, M.; Hankey, J. Driver Crash Risk Factors and Prevalence Evaluation Using Naturalistic Driving Data. Proc. Natl. Acad. Sci. USA 2016, 113, 2636–2641. [Google Scholar] [CrossRef]
- Adanu, E.K.; Li, X.; Liu, J.; Jones, S. An Analysis of the Effects of Crash Factors and Precrash Actions on Side Impact Crashes at Unsignalized Intersections. J. Adv. Transp. 2021, 2021, 6648523. [Google Scholar] [CrossRef]
- Ma, Z.; Zhao, W.; Steven, I.; Chien, J.; Dong, C. Exploring Factors Contributing to Crash Injury Severity on Rural Two-Lane Highways. J. Saf. Res. 2015, 55, 171–176. [Google Scholar]
- Osman, M.; Paleti, R.; Mishra, S.; Golias, M.M. Analysis of Injury Severity of Large Truck Crashes in Work Zones. Accid. Anal. Prev. 2016, 97, 261–273. [Google Scholar] [PubMed]
- Jaradat, S.; Nayak, R.; Paz, A.; Elhenawy, M. Ensemble Learning with Pre-Trained Transformers for Crash Severity Classification: A Deep NLP Approach. Algorithms 2024, 17, 284. [Google Scholar] [CrossRef]
- Jaradat, S.; Alhadidi, T.I.; Ashqar, H.I.; Hossain, A.; Elhenawy, M. Exploring Traffic Crash Narratives in Jordan Using Text Mining Analytics. arXiv 2024, arXiv:2406.09438. [Google Scholar]
- Das, S.; Sun, X.; Dadashova, B.; Rahman, M.A.; Sun, M. Identifying Patterns of Key Factors in Sun Glare-Related Traffic Crashes. Transp. Res. Rec. 2021, 2676, 165–175. [Google Scholar] [CrossRef]
- Khadka, A.; Parkin, J.; Pilkington, P.; Joshi, S.K.; Mytton, J. Completeness of Police Reporting of Traffic Crashes in Nepal: Evaluation Using a Community Crash Recording System. Traffic Inj. Prev. 2022, 23, 79–84. [Google Scholar] [CrossRef]
- Muni, K.M.; Ningwa, A.; Osuret, J.; Zziwa, E.B.; Namatovu, S.; Biribawa, C.; Nakafeero, M.; Mutto, M.; Guwatudde, D.; Kyamanywa, P.; et al. Estimating the Burden of Road Traffic Crashes in Uganda Using Police and Health Sector Data Sources. Inj. Prev. 2021, 27, 208. [Google Scholar] [CrossRef]
- Kim, J.; Trueblood, A.B.; Kum, H.-C.; Shipp, E.M. Crash Narrative Classification: Identifying Agricultural Crashes Using Machine Learning with Curated Keywords. Traffic Inj. Prev. 2021, 22, 74–78. [Google Scholar] [CrossRef]
- Zhang, X.; Green, E.; Chen, M.; Souleyrette, R.R. Identifying Secondary Crashes Using Text Mining Techniques. J. Transp. Saf. Secur. 2020, 12, 1338–1358. [Google Scholar]
- Boggs, A.M.; Wali, B.; Khattak, A.J. Exploratory Analysis of Automated Vehicle Crashes in California: A Text Analytics & Hierarchical Bayesian Heterogeneity-Based Approach. Accid. Anal. Prev. 2020, 135, 105354. [Google Scholar]
- Chandraratna, S.; Stamatiadis, N.; Stromberg, A. Crash Involvement of Drivers with Multiple Crashes. Accid. Anal. Prev. 2006, 38, 532–541. [Google Scholar]
- Adetiloye, T.; Awasthi, A. Multimodal Big Data Fusion for Traffic Congestion Prediction. In Multimodal Analytics for Next-Generation Big Data Technologies and Applications; Springer: Cham, Switzerland, 2019; pp. 319–335. [Google Scholar] [CrossRef]
- Jaradat, S.; Nayak, R.; Paz, A.; Ashqar, H.I.; Elhenawy, M. Multitask Learning for Crash Analysis: A Fine-Tuned LLM Framework Using Twitter Data. Smart Cities 2024, 7, 2422–2465. [Google Scholar] [CrossRef]
- Rahman, S.; Khan, S.; Porikli, F. A Unified Approach for Conventional Zero-Shot, Generalized Zero-Shot, and Few-Shot Learning. IEEE Trans. Image Process. 2018, 27, 5652–5667. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Koubaa, A. GPT-4 vs. GPT-3.5: A Concise Showdown. Preprints 2023. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized Autoregressive Pretraining for Language Understanding. In Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 5753–5763. [Google Scholar]
- Sammoudi, M.; Habaybeh, A.; Ashqar, H.I.; Elhenawy, M. Question-Answering (QA) Model for a Personalized Learning Assistant for Arabic Language. arXiv 2024, arXiv:2406.08519. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 6 April 2024).
- Zhong, B.; Pan, X.; Love, P.E.D.; Ding, L.; Fang, W. Deep Learning and Network Analysis: Classifying and Visualizing Accident Narratives in Construction. Autom. Constr. 2020, 113, 103089. [Google Scholar] [CrossRef]
- Alhadidi, T.I.; Jaber, A.; Jaradat, S.; Ashqar, H.I.; Elhenawy, M. Object Detection Using Oriented Window Learning Vi-Sion Transformer: Roadway Assets Recognition. arXiv 2024, arXiv:2406.10712. [Google Scholar]
- Elhenawy, M.; Abdelhay, A.; Alhadidi, T.I.; Ashqar, H.I.; Jaradat, S.; Jaber, A.; Glaser, S.; Rakotonirainy, A. Eyeballing Combinatorial Problems: A Case Study of Using Multimodal Large Language Models to Solve Traveling Salesman Problems. In Proceedings of the Intelligent Systems, Blockchain, and Communication Technologies (ISBCom 2024), Sharm El-Sheikh, Egypt, 10–11 May 2025; Springer: Cham, Switzerland, 2025; pp. 341–355. [Google Scholar] [CrossRef]
- Gilardi, F.; Alizadeh, M.; Kubli, M. Chatgpt Outperforms Crowd-Workers for Text-Annotation Tasks. arXiv 2023, arXiv:2303.15056. [Google Scholar]
- Yin, P.; Neubig, G.; Yih, W.; Riedel, S. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. arXiv 2020, arXiv:2005.08314. [Google Scholar]
- Li, Y.; Li, J.; Suhara, Y.; Doan, A.; Tan, W.-C. Deep Entity Matching with Pre-Trained Language Models. arXiv 2020, arXiv:2004.00584. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Hou, Y.; Li, G.; Wang, H.; Xu, H.; Xiang, Y.; Tang, B. Multimodal Data Matters: Language Model Pre-Training over Structured and Unstructured Electronic Health Records. IEEE J. Biomed. Health Inf. 2023, 27, 504–514. [Google Scholar] [CrossRef]
- Jaotombo, F.; Adorni, L.; Ghattas, B.; Boyer, L. Finding the Best Trade-off between Performance and Interpretability in Predicting Hospital Length of Stay Using Structured and Unstructured Data. PLoS ONE 2023, 18, e0289795. [Google Scholar] [CrossRef]
- Oliaee, A.H.; Das, S.; Liu, J.; Rahman, M.A. Using Bidirectional Encoder Representations from Transformers (BERT) to Classify Traffic Crash Severity Types. Nat. Lang. Process. J. 2023, 3, 100007. [Google Scholar] [CrossRef]
- Varotto, G.; Susi, G.; Tassi, L.; Gozzo, F.; Franceschetti, S.; Panzica, F. Comparison of Resampling Techniques for Imbalanced Datasets in Machine Learning: Application to Epileptogenic Zone Localization from Interictal Intracranial EEG Recordings in Patients with Focal Epilepsy. Front. Neuroinform. 2021, 15, 715421. [Google Scholar]
- Ambati, N.S.R.; Singara, S.H.; Konjeti, S.S.; Selvi, C. Performance Enhancement of Machine Learning Algorithms on Heart Stroke Prediction Application Using Sampling and Feature Selection Techniques. In Proceedings of the 2022 International Conference on Augmented Intelligence and Sustainable Systems (ICAISS), Trichy, India, 24–26 November 2022; pp. 488–495. [Google Scholar]
- Gong, L.; Jiang, S.; Bo, L.; Jiang, L.; Qian, J. A Novel Class-Imbalance Learning Approach for Both within-Project and Cross-Project Defect Prediction. IEEE Trans. Reliab. 2019, 69, 40–54. [Google Scholar]
- Ekambaram, V.; Jati, A.; Nguyen, N.H.; Dayama, P.; Reddy, C.; Gifford, W.M.; Kalagnanam, J. TTMs: Fast Multi-Level Tiny Time Mixers for Improved Zero-Shot and Few-Shot Forecasting of Multivariate Time Series. arXiv 2024, arXiv:2401.03955. [Google Scholar]
- Osborne, J.W. Best Practices in Data Cleaning: A Complete Guide to Everything You Need to Do Before and After Collecting Your Data; Sage Publications: New York, NY, USA, 2012; ISBN 1452289670. [Google Scholar]
- Zhu, Q.; Chen, X.; Jin, Q.; Hou, B.; Mathai, T.S.; Mukherjee, P.; Gao, X.; Summers, R.M.; Lu, Z. Leveraging Professional Radiologists’ Expertise to Enhance LLMs’ Evaluation for Radiology Reports. arXiv 2024, arXiv:2401.16578. [Google Scholar]
- Shi, D.; Chen, X.; Zhang, W.; Xu, P.; Zhao, Z.; Zheng, Y.; He, M. FFA-GPT: An Interactive Visual Question Answering System for Fundus Fluorescein Angiography. Res. Sq. 2023. [Google Scholar] [CrossRef]
- Rezapour, M.M.M.; Khaled, K. Utilizing Crash and Violation Data to Assess Unsafe Driving Actions. J. Sustain. Dev. Transp. Logist. 2017, 2, 35–46. [Google Scholar]
- Moomen, M.; Rezapour, M.; Ksaibati, K. An Analysis of Factors Influencing Driver Action on Downgrade Crashes Using the Mixed Logit Analysis. J. Transp. Saf. Secur. 2022, 14, 2111–2136. [Google Scholar] [CrossRef]
- Sirrianni, J.; Sezgin, E.; Claman, D.; Linwood, S.L. Medical Text Prediction and Suggestion Using Generative Pretrained Transformer Models with Dental Medical Notes. Methods Inf. Med. 2022, 61, 195–200. [Google Scholar] [CrossRef] [PubMed]
- Lajkó, M.; Horváth, D.; Csuvik, V.; Vidács, L. Fine-Tuning Gpt-2 to Patch Programs, Is It Worth It? In Proceedings of the International Conference on Computational Science and Its Applications, Malaga, Spain, 4–7 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 79–91. [Google Scholar]
- Nguyen-Mau, T.; Le, A.-C.; Pham, D.-H.; Huynh, V.-N. An Information Fusion Based Approach to Context-Based Fine-Tuning of GPT Models. Inf. Fusion. 2024, 104, 102202. [Google Scholar] [CrossRef]
- Yin, C.; Du, K.; Nong, Q.; Zhang, H.; Yang, L.; Yan, B.; Huang, X.; Wang, X.; Zhang, X. PowerPulse: Power Energy Chat Model with LLaMA Model Fine-tuned on Chinese and Power Sector Domain Knowledge. Expert. Syst. 2024, 41, e13513. [Google Scholar] [CrossRef]
- He, K.; Pu, N.; Lao, M.; Lew, M.S. Few-Shot and Meta-Learning Methods for Image Understanding: A Survey. Int. J. Multimed. Inf. Retr. 2023, 12, 14. [Google Scholar] [CrossRef]
- Park, G.; Hwang, S.; Lee, H. Low-Resource Cross-Lingual Summarization through Few-Shot Learning with Large Language Models. arXiv 2024, arXiv:2406.04630. [Google Scholar]
- Ono, D.; Dickson, D.W.; Koga, S. Evaluating the Efficacy of Few-shot Learning for GPT-4Vision in Neurodegenerative Disease Histopathology: A Comparative Analysis with Convolutional Neural Network Model. Neuropathol. Appl. Neurobiol. 2024, 50, e12997. [Google Scholar] [CrossRef]
- Loukas, L.; Stogiannidis, I.; Malakasiotis, P.; Vassos, S. Breaking the Bank with ChatGPT: Few-Shot Text Classification for Finance. arXiv 2023, arXiv:2308.14634. [Google Scholar]
- Pornprasit, C.; Tantithamthavorn, C. Fine-Tuning and Prompt Engineering for Large Language Models-Based Code Review Automation. Inf. Softw. Technol. 2024, 175, 107523. [Google Scholar] [CrossRef]
- Ashqar, H.I.; Alhadidi, T.I.; Elhenawy, M.; Khanfar, N.O. The Use of Multimodal Large Language Models to Detect Objects from Thermal Images: Transportation Applications. arXiv 2024, arXiv:2406.13898. [Google Scholar]
- Rouzegar, H.; Makrehchi, M. Generative AI for Enhancing Active Learning in Education: A Comparative Study of GPT-3.5 and GPT-4 in Crafting Customized Test Questions. arXiv 2024, arXiv:2406.13903. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Data Type | Model/Method | Learning Type | Labels/Tasks | Evaluation Metrics | Key Contributions | Limitation Compared to the Study |
|---|---|---|---|---|---|---|---|
| Arteaga et al. [12] | Narrative only | Gradient Boosting + SHAP | Supervised ML | Injury Severity | Accuracy, AUC, SHAP | Used interpretable ML to predict severity from crash text | No multimodal fusion; limited to severity prediction from text only |
| Adanu et al. [42] | Tabular | Random Forest + TF-IDF | Supervised ML | Precrash Actions, Injury Severity | Marginal Effects, Log-Likelihood, AIC, Pseudo R² | Introduced behavioral pathway analysis linking precrash actions to crash severity using path modeling | No narrative data used; no multimodal or LLM-based modeling; focused on indirect effects, not prediction |
| Dingus et al. [41] | Narrative only | Manual Analysis | Descriptive | Crash Causality | None | Provided insight into human error, impairment, distraction | No automation or computational modeling |
| Liu et al. [69] | Structured + unstructured (EHR) | MedM-PLM (Pre-Trained Multimodal Language Model with Cross-Modal Transformer Module) | Self-supervised pretraining + fine-tuned supervised learning | Medication Recommendation, 30-Day Readmission, ICD Coding | Accuracy, F1, AUC (per task) | Novel cross-modal fusion of clinical notes and codes; pretraining over both modalities captures richer patient representations | Focused on general clinical decision support; does not address LOS or crash-specific applications directly |
| Jaotombo et al. [70] | Tabular + clinical notes | Ensemble ML (AutoGluon), BioClinicalBERT, Fusion via LDA Topic Modeling) | Supervised ML | Prolonged Hospital Length of Stay (binary classification) | ROC AUC, PRC AUC, F1, Accuracy | Demonstrated that combining structured and unstructured data significantly boosts both performance (ROC AUC) and interpretability | Domain-specific (ICU/healthcare); does not use few-shot or generative LLMs; limited to discharge notes only |
| Ye et al. [27] | Tabular + narrative | Hybrid Fusion (BERT, RoBERTa, ClinicalBERT) | Supervised ML | Injury Diagnosis | Accuracy, F1-Score (Macro and Weighted), Top-k Accuracy | Proposed a hybrid fusion method integrating structured EHR and narrative clinical notes for enhanced injury prediction | Domain is healthcare; no use of few-/zero-shot LLMs or generative approaches |
| Oliaee et al. [71] | Unstructured crash narrative data (750,000+ reports from Louisiana, 2011–2016) | Fine-tuned BERT (transformer-based language model) for multi-label classification | Supervised learning | Multi-class classification of crash severity (5 levels: KABCO scale) | Accuracy, Weighted F1, AUROC, Macro F1 | First large-scale application of a fine-tuned BERT model on a statewide crash narrative dataset for severity classification; demonstrated strong predictive capability and scalability | Uses only unstructured data (narratives); does not integrate structured crash data; lacks multimodal fusion or cross-modal interaction modeling present in this study |
| This study (2025) | Fused tabular + narrative | GPT-2, GPT-3.5, GPT-4.5 | Few-shot, zero-shot, fine-tuning | Severity, driver fault, driver actions, crash factors | Accuracy, F1-Score, Jaccard Index | First to fuse structured and unstructured crash data for LLMs using an MDF framework; enables scalable multi-label classification via few-shot and zero-shot learning across diverse traffic safety tasks | Most previous studies in traffic safety rely on a single data source without data fusion and typically use fine-tuning without exploring zero-shot or few-shot learning. While data fusion has been considered in other domains, few have compared zero-shot, few-shot, and fine-tuning approaches across prediction and information retrieval tasks |
| Class | Severity | ||
|---|---|---|---|
| Fatal | Non-Fatal | Total | |
| Training set | 357 | 299 | 571 |
| Testing set | 204 | 177 | 381 |
| Total | 476 | 476 | 952 |
| Role | Instruction |
|---|---|
| System Prompt | Your role is to categorize accident details into specific labels. For each accident description provided, you need to determine (1) if the driver was at fault (yes or no), (2) what actions the driver took that contributed to the accident (such as speeding, ran off road), and (3) what external factors were involved (such as collision, tree, animal, overcorrection, embankment). Please format your response in JSON, following this structure exactly:{\“driver_fault\”: \“yes/no\”,\“driver_action\”: [\“action1\”, \“action2\”,…], \“factors\”: [\“factor1\”, \“factor2\”, …]\n}NOTE: Ensure your response strictly follows this JSON template without including any additional text. |
| User Input | Your role is to categorize accident details into specific labels. For each accident description provided, you need to determine (1) if the driver was at fault (yes or no), (2) what actions the driver took that contributed to the accident (such as speeding, ran off the road), and (3) what external factors were involved (e.g., collision, tree, animal, overcorrection, embankment). Please format your response in JSON, following this structure exactly: {“driver_fault”: “yes/no”, “driver_action”: [“action1”, “action2”, …], “factors”: [“factor1”, “factor2”, …]} |
| Assistance Output | {“driver_fault”: “yes”, “driver_action”: [“aggressive driving”, “went off-road”], “factors”: [“collision with fixed object”, “daylight”, “sliding”, “struck bluff”, “struck tree”]} |
| Driver at Fault | Yes | No | Total |
|---|---|---|---|
| Training set | 554 | 17 | 571 |
| Testing set | 337 | 44 | 381 |
| Total | 891 | 61 | 952 |
| Consolidated Crash Data (Tabular + Narrative) | Severity | Driver Fault | Driver Actions | Crash Factors |
|---|---|---|---|---|
| Narrative 1: The accident was reported by Missouri State Highway Patrol-Troop A, county JACKSON in city LEES SUMMIT. The driver was at the scene after the accident. The accident occurred before the intersection on street IS 470, ERM EAST IS 470 MILE 100 in East direction. The vehicle collided with Fixed Object. The vehicle went off road. The light conditions were Daylight. The driver was driving aggressively. The accident happened on day Sun. The narrative by the reporters is as follows: CRASH OCCURRED AS VEH1 TRAVELED OFF THE ROADWAY, STRUCK A SIGN AND A FENCE. ASSISTED BY CPL C S KUTZNER /462/. | 0 | Yes | [‘aggressive driving’, ‘went off-road’] | [‘collision with fixed object’, ‘daylight’, ‘struck sign’, ‘struck fence’] |
| Narrative 2: The accident was reported by Missouri State Highway Patrol-Troop C, county LINCOLN in city MOSCOW MILLS. The driver was at the scene after the accident. The accident occurred before the intersection on street US 61, PVT ANDERSON ROAD in South direction. The vehicle collided with Pedestrian. The light conditions were Dark-Unlighted. The pedestrian had done drugs. The vehicle was a commercial motor vehicle. The accident happened on day Thu. The narrative by the reporters is as follows: FATALITY REPORT- VEHICLE 1 WAS SOUTHBOUND ON HIGHWAY 61. PEDESTRIAN 1 WAS IN LANE 1. VEHICLE 1 STRUCK THE PEDESTRIAN. PEDESTRIAN 1 WAS PRONOUNCED ON SCENE AT 2251 HOURS ON 8/29/2019 BY LINCOLN COUNTY CORONER KELLY WALTERS. ASSISTED BY MSGT. J. L. DECKER (240), CPL. A. H. MICHAJLICZENKO (769), TPR. W. H. ABEL (132), AND TPR. J. L. HUGHES (879). | 1 | No | [] | [‘collision with pedestrian’, ‘dark-unlighted’, ‘pedestrian under influence of drugs’] |
| Hyperparameter | Value |
|---|---|
| Batch_size: Number of training examples processed in one iteration | 16 |
| Num_train_epochs: Number of times the entire training dataset is processed | 40 |
| Save_steps: Frequency of saving the model’s parameters during training | 50,000 |
| Block_size: Size of text blocks during training, managing memory | 256 |
| Do_sample: Binary flag for using sampling during text generation | True |
| Max_length: Maximum length of the generated output | 600 |
| Top_k: Considers the top-k most likely next words during text generation | 1 |
| Top_p: Influences text diversity by setting a probability threshold for word selection | 1 |
| Role | Instruction |
|---|---|
| System | Given the details of the crash answer the following questions. Return the response in the mentioned JSON format mentioned after the questions. Is it fatal or not fatal? (fatality) Ideal response: If it is fatal then return ‘1’ if it is not fatal then return ‘0’ Is it the driver’s fault? (driver_fault) Ideal response: If it is the driver’s fault then return ‘yes’ otherwise ‘no’ What were the driver’s actions? (driver_actions) Ideal response: What were the driver’s actions that caused the crash? e.g., overspeeding, drinking and driving, drugs, overturning etc. Return a list of the driver’s actions in a JSON list. What were the factors that caused the crash? (factors) Ideal response: What were the factors that caused the crash? e.g., struck a tree, struck a pedestrian, embankment, dark light conditions, etc. Return a list of the factors in a JSON list. JSON TEMPLATE {\n\“fatality\” : <integer>, “driver_fault\” : <string>, \“driver_actions\” : <list>, \“factors\” : <list>\n} NOTE: Strictly follow the template as mentioned above and restrain from adding any preambles or filler text. |
| User | CRASH DETAILS: The crash was reported by Missouri State Highway Patrol-Troop C, county JEFFERSON. The driver was at the scene after the crash. The crash occurred after the intersection on street MO 21, ERM NORTH MO 21 MILE 1780 in North direction. The vehicle collided with Fixed Object. The vehicle went off road. The light conditions were Dark-Unlighted The driver’s age was over 64. The driver was driving aggressively. The vehicle was a truck. The vehicle was a pickup vehicle. The crash happened on day Wed. The narrative by the reporters is as follows: VEHICLE 1 WAS TRAVELING NORTHBOUND ON MO-21. DRIVER 1 CHANGED LANES AND LOST CONTROL OF VEHICLE 1 ON THE WET PAVEMENT. DRIVER 1 ATTEMPTED TO RECOVER VEHICLE 1 AND VEHICLE 1 TRAVELED OFF THE LEFT SIDE OF THE ROADWAY AND STRUCK A ROCK BLUFF. VEHICLE 1 CONTINUED SPINNING, EJECTING DRIVER 1 INTO THE ROADWAY. DRIVER 1 PRONOUNCED AT 0644 HOURS ON 10302019 BY EMS PERSONNEL. ASSISTED BY MSGT C ARBUTHNOT (694). |
| Assistance | “ {\“fatality\” : 1, \“driver_fault\” : \“no\”, \“driver_actions\” : [], \“factors\” : [‘collision with pedestrian’, ‘dark-unlighted’, ‘pedestrian under influence of alcohol’]} |
| Role | Instruction |
|---|---|
| System | Given the details of the crash answer the following questions. Return the response in the mentioned JSON format mentioned after the questions. 1. Is it fatal or not fatal? (fatality) Ideal response: If it is fatal then return ‘1’ if it is not fatal then return ‘0’ 2. Is it the driver’s fault? (driver_fault) Ideal response: If it is the driver’s fault then return ‘yes’ otherwise ‘no’ 3. What were the driver’s actions? (driver_actions) Ideal response: What were the driver’s actions that caused the crash? e.g., overspeeding, drinking and driving, drugs, overturning etc. Return a list of the driver’s actions in a JSON list. 4. What were the factors that caused the crash? (factors) Ideal response: What were the factors that caused the crash? e.g., struck a tree, struck a pedestrian, embankment, dark light conditions, etc. Return a list of the factors in a JSON list. JSON TEMPLATE {\n\“fatality\”: <integer>,\n\“driver_fault\” : <string>,\n\“driver_actions\” : <list>,\n\“factors\” : <list>\n} NOTE: Strictly follow the template as mentioned above and restrain from adding any preambles or filler text. |
| User | Narrative (Text) |
| Hyperparameter | Value |
|---|---|
| Temperature: Controls text randomness | 0 |
| Top_p: Influences text diversity by setting a probability threshold for word selection | 1 |
| Frequency_penalty: Adjusts the likelihood of selecting common words during generation | 0 |
| Presence_penalty: Influences the inclusion of specified tokens in the generated text | 0 |
| Label | Class | Accuracy | Precision | Recall | F1-Score | Jaccard Score |
|---|---|---|---|---|---|---|
| Severity | Non-Fatal | 99% | 98% | 100% | 99% | - |
| Fatal | 100% | 98% | 99% | - | ||
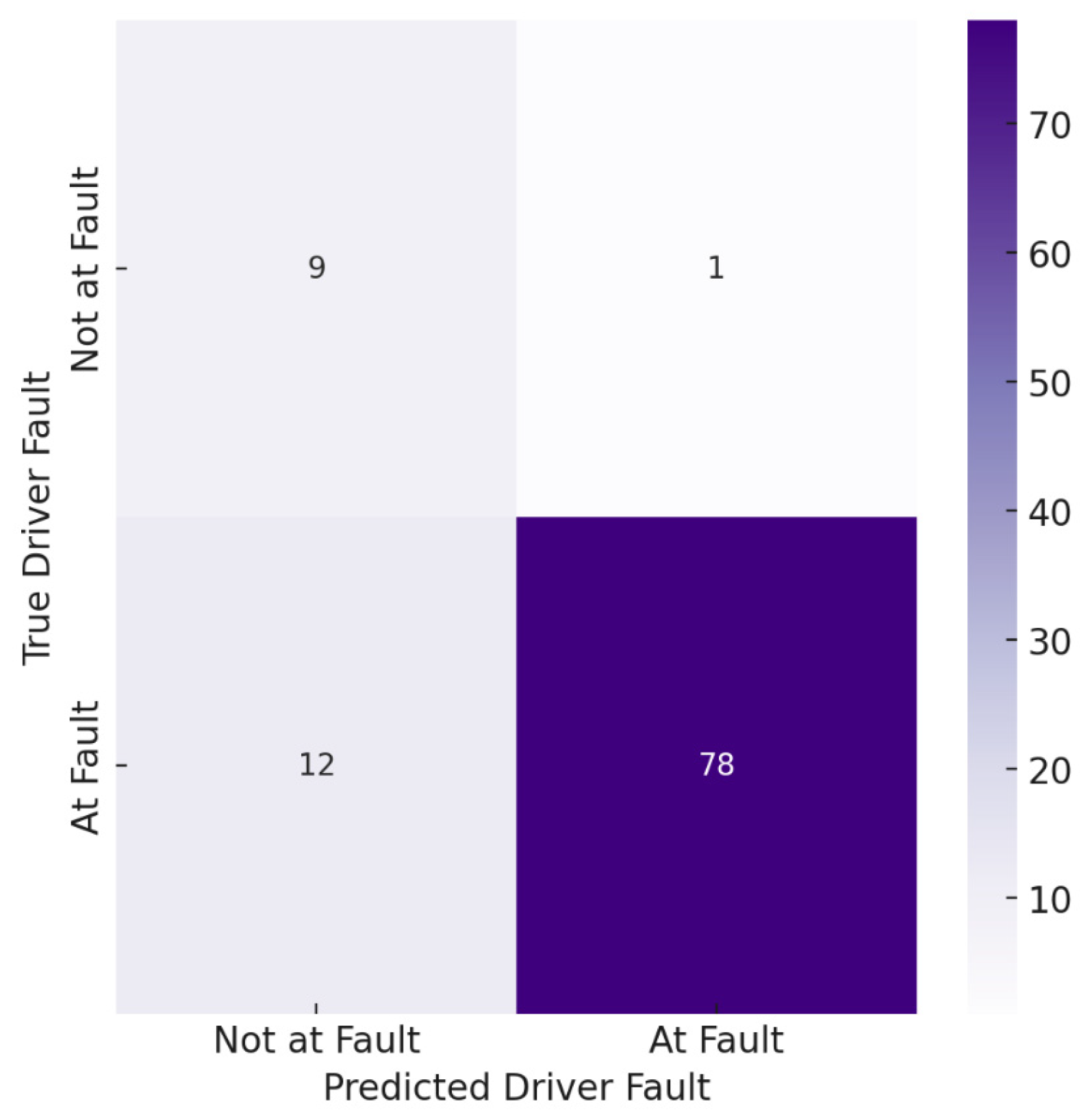
| Driver Fault | Not at Fault | 88% | 0% | 0% | 0% | - |
| At Fault | 88% | 100% | 94% | - | ||
| Driver Actions | - | - | - | - | - | 72.2 |
| Crash Factors | - | - | - | - | - | 79.7 |
| Model | Label | Class | Accuracy | Precision | Recall | F1-Score | Jaccard Score |
|---|---|---|---|---|---|---|---|
| GPT-3.5 Zero-Shot | Severity | Non-Fatal | 99% | 98% | 92% | 95% | - |
| Fatal | 93% | 99% | 96% | - | |||
| GPT-3.5 Zero-Shot | Severity | Non-Fatal | 96% | 98% | 93% | 96% | |
| Fatal | 94% | 99% | 96% | ||||
| GPT-4.5 Zero-Shot | Severity | Non-Fatal | 98% | 98% | 99% | 98% | |
| Fatal | 99% | 98% | 99% | ||||
| GPT-4.5 Zero-Shot | Severity | Non-Fatal | 99% | 98% | 100% | 99% | |
| Fatal | 100% | 98% | 99% | ||||
| GPT-3.5 Zero-Shot | Driver Fault | Non-Fatal | 78% | 33% | 89% | 48% | |
| Fatal | 98% | 77% | 86% | ||||
| GPT-3.5 Zero-Shot | Driver Fault | Non-Fatal | 96% | 97% | 64% | 77% | |
| Fatal | 95% | 100% | 98% | ||||
| GPT-4.5 Zero-Shot | Driver Fault | Non-Fatal | 96% | 97% | 64% | 77% | |
| Fatal | 95% | 100% | 98% | ||||
| GPT-4.5 Zero-Shot | Driver Fault | Non-Fatal | 98% | 97% | 86% | 92% | |
| Fatal | 98% | 100% | 99% | ||||
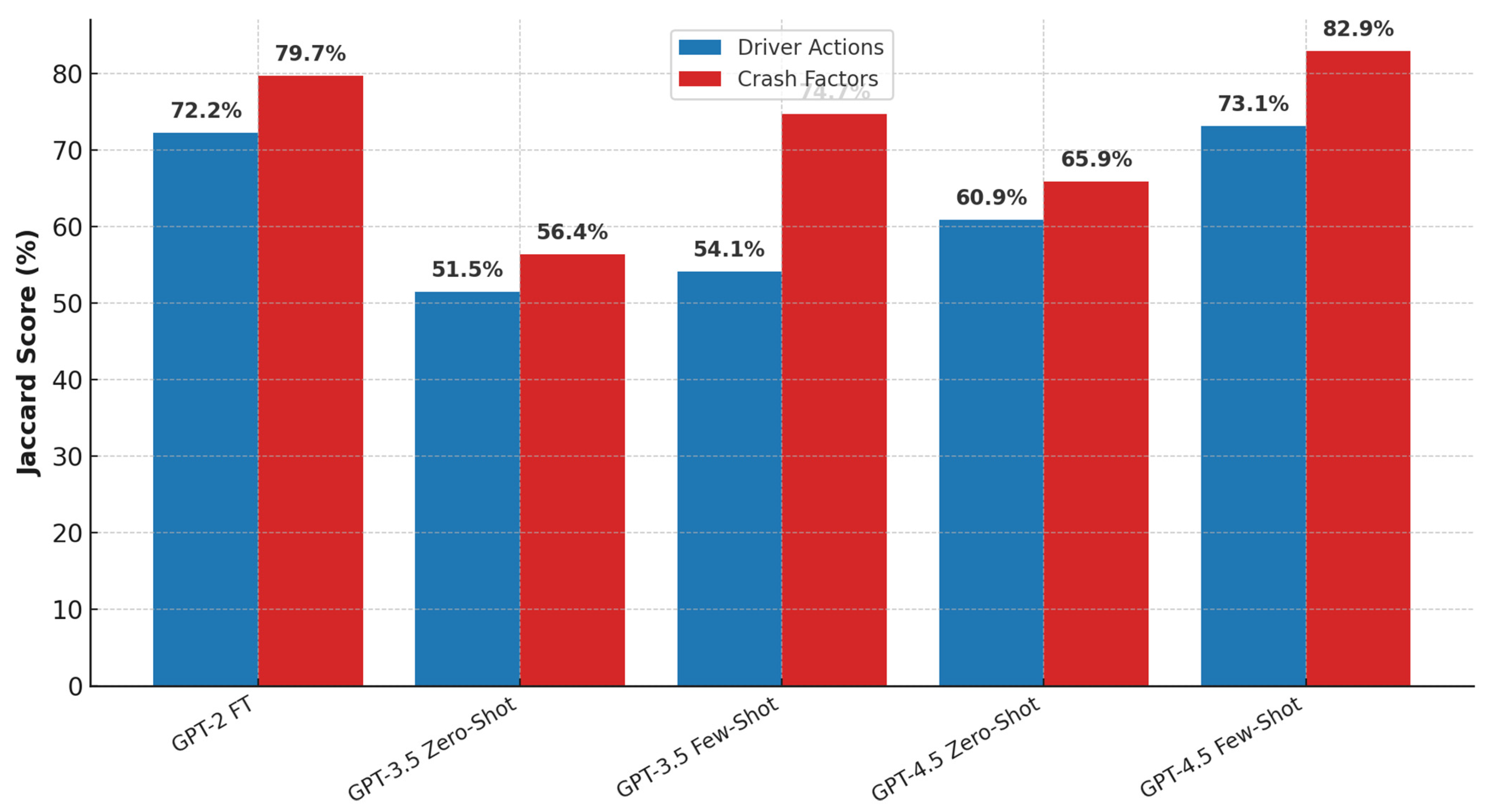
| GPT-3.5 Zero-Shot | Driver Actions | 51.5% | |||||
| GPT-3.5 Few-Shot | Driver Actions | 54.1% | |||||
| GPT-4.5 Zero-Shot | Driver Actions | 60.9% | |||||
| GPT-4.5 Few-Shot | Driver Actions | 73.1% | |||||
| GPT-3.5 Zero-Shot | Crash Factors | 56.4% | |||||
| GPT-3.5 Few-Shot | Crash Factors | 74.7% | |||||
| GPT-4.5 Zero-Shot | Crash Factors | 65.9% | |||||
| GPT-4.5 Few-Shot | Crash Factors | 82.9% |
| Consolidated Crash Data (Tabular + Narrative) | Severity | Driver Fault | Driver Actions | Crash Factors |
|---|---|---|---|---|
| The crash was reported by Missouri State Highway Patrol-Troop E, county MADISON. The driver was at the scene after the crash. on street CRD 447, CRD 422 The crash happened due to Overturn. The light conditions were Daylight. The driver’s age was under 21. The driver’s age was under 25. The driver was driving aggressively. The vehicle was an all-terminal vehicle. The crash happened on day Thu. The narrative by the reporters is as follows: CRASH OCCURRED AS DRIVER 1 LOST CONTROL ON THE ROADWAY, OVERTURNED, AND TRAVELED OFF THE RIGHT SIDE OF THE ROADWAY. | 0 | yes | [‘aggressive driving’, ‘lost control’, ‘went off-road’] | [‘overturn’] |
| The crash was reported by Missouri State Highway Patrol-Troop A, county JACKSON in city LEES SUMMIT. The driver was at the scene after the crash. on street IS 470, ERM EAST IS 470 MILE 100 The vehicle collided with Fixed Object. The vehicle went off road. The light conditions were Daylight. The driver was driving aggressively. The crash happened on day Sun. The narrative by the reporters is as follows: CRASH OCCURRED AS VEH1 TRAVELED OFF THE ROADWAY, STRUCK A SIGN AND A FENCE. ASSISTED BY CPL C S KUTZNER /462/. | 0 | yes | [‘aggressive driving’, ‘went off-road’] | [‘collision with fixed object’, ‘struck sign’, ‘struck fence’] |
| The crash was reported by Missouri State Highway Patrol-Troop D, county BARRY. The driver was at the scene after the crash. on street RT C, CRD 1120 The vehicle struck another vehicle. The vehicle went off road. The light conditions were Daylight. The driver was driving aggressively. The vehicle was a truck. The vehicle was a pickup vehicle. The crash happened on day Mon. The narrative by the reporters is as follows: THIS IS TROOP D’S 110TH FATALITY CRASH FOR 2019. CRASH OCCURRED AS VEHICLE #1 LOST CONTROL OF VEHICLE ON THE ICE COVERED ROADWAY. VEHICLE #1 RAN OFF THE RIGHT SIDE OF ROADWAY, AND STRUCK A PEDESTRIAN THAT WAS STANDING NEAR VEHICLE #2, THAT HAD CRASH PRIOR TO THIS INCIDENT. THE PEDESTRIAN WAS PRONOUNCED BY BARRY COUNTY DEPUTY CORONER GARY SWEARINGEN, AT 15:10 HOURS ON SCENE. | 1 | yes | [‘aggressive driving’, ‘lost control’, ‘went off-road’] | [‘collision with another vehicle’, ‘icy road’, ‘struck pedestrian’] |
| The crash was reported by Missouri State Highway Patrol-Troop C, county ST. LOUIS. The driver was at the scene after the crash. on street IS 270, ERM SOUTH IS 270 MILE 156 The cause of crash was Other Non Collision. The light conditions were Daylight. The driver’s age was over 55. The driver’s age was over 64. The vehicle had a defect. The crash happened on day Fri. The narrative by the reporters is as follows: BOTH VEHICLES WERE TRAVELING SOUTHBOUND I-270, VEHICLE #1 TIRE BLEW OUT, DRIVER #1 LOST CONTROL OF VEHICLE #1 AND STRUCK VEHICLE #2. | 0 | no | [‘lost control due to tire blowout’] | [‘vehicle defect’, ‘collision with another vehicle’] |
| The crash was reported by Missouri State Highway Patrol-Troop C, county ST. LOUIS in city FENTON. The driver was at the scene after the crash. The crash occurred after the intersection on street MO 30, CO SUMMIT RD TO MO30W in the West direction. The vehicle collided with Pedestrian. The light conditions were Dark-Unlighted. The pedestrian was drinking and driving. The pedestrian had done drugs. The driver’s age was under 25. The crash happened on day Thu. The narrative by the reporters is as follows: PEDESTRIAN 1 WAS ATTEMPTING TO CROSS THE ROADWAY AND WAS STRUCK BY VEHICLE 1. PEDESTRIAN 1 WAS PRONOUNCED ON SCENE BY FENTON FIRE DISTRICT PERSONNEL AT 2331 HOURS. ASSISTED TPR. J. S. HUSKEY (1265). | 1 | no | [] | [‘collision with pedestrian’, ‘dark-unlighted’, ‘pedestrian under influence of alcohol and drugs’] |
| Case | Consolidated Crash Data (Tabular + Narrative) | Ground Truth | Tabular Pred. | Narrative Pred. | Combined Pred. | Tabular Factors | Narrative Factors | Combined Factors |
|---|---|---|---|---|---|---|---|---|
| Example 1: Fault Change Due to Combined Data | The accident was reported by Missouri State Highway Patrol-Troop C, county JEFFERSON. The driver was at the scene after the accident. On street IS 55, ERM NORTH IS 55 MILE 1892 in the north direction. The vehicle collided with a fixed object. The vehicle went off-road. The light conditions were daylight. The driver’s age was over 55. The driver’s age was over 64. The accident happened on a Friday. The narrative by the reporters is as follows: VEHICLE 1 WAS TRAVELING NORTH ON INTERSTATE 55 IN LANE 3. Driver 1 swerved to the left to avoid a collision with an unknown vehicle that was changing lanes. Vehicle 1 traveled off the left side of the road and impacted the concrete median barrier with its front left side. | No | Yes | No | No | Collision with fixed object; daylight | Swerved to avoid collision; collision with concrete median barrier | Collision with fixed object; daylight; swerved to avoid collision; collision with concrete |
| Example 2: Fault Change Due to Combined Data | The accident was reported by Missouri State Highway Patrol-Troop A, county PETTIS. The driver was at the scene after the accident. On street RT H, BRIDGE W0535 in the north direction. The vehicle collided with a fixed object. The vehicle went off-road. The light conditions were daylight. The driver’s age was over 55. The accident happened on a Wednesday. The narrative by the reporters is as follows: CRASH OCCURRED AS DRIVER 1 SWERVED TO AVOID A DEER IN THE ROADWAY AND STRUCK A BRIDGE RAIL. Assisted by Trooper W. C. Grose /280/ and Pettis County Sheriff’s Department. | No | Yes | No | No | Collision with fixed object; daylight; animal in roadway | Swerved to avoid deer; struck bridge rail | Collision with fixed object; daylight; swerved to avoid deer; struck bridge rail |
| Example 3: Additional Factors in Combined Data | The accident was reported by Missouri State Highway Patrol-Troop H, county ANDREW. The driver was at the scene after the accident. On street IS 29, ERM SOUTH IS 29 MILE 512. The vehicle collided with a pedestrian. The light conditions were dark-unlighted. The pedestrian was drinking and driving. The pedestrian had done drugs. The driver’s age was over 55. The driver’s age was over 64. The vehicle was a commercial motor vehicle. The accident happened on a Thursday. The narrative by the reporters is as follows: FATALITY REPORT—NEXT OF KIN NOTIFIED—CRASH OCCURRED AS VEHICLE 1 WAS SOUTHBOUND IN THE DRIVING LANE OF I-29, AND PEDESTRIAN 1 WAS WALKING SOUTHBOUND IN THE DRIVING LANE OF I-29. Vehicle 1 struck pedestrian 1 with its front passenger fender. Vehicle 1 came to a controlled stop just south of the crash scene. Pedestrian 1 was pronounced deceased on 8/22/2019 at 2130 h by Andrew County Coroner Doug Johnson. Assisted by Chief CVO M.A. McCartney (W003), Sgt. H.A. Sears (1200), Cpl. R.P. Dudeck (516), Cpl. S.J. Cool (546), Tpr. R.A. Allee (465), Andrew County Sheriff’s Office, and Buchanan County Sheriff’s Office. | No | No | No | No | Collision with pedestrian; dark, unlit; pedestrian under influence of alcohol and drugs | Collision with pedestrian; pedestrian in driving lane | Collision with pedestrian; dark, unlit; pedestrian under influence of alcohol; collision with pedestrian; pedestrian in driving lane |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaradat, S.; Elhenawy, M.; Nayak, R.; Paz, A.; Ashqar, H.I.; Glaser, S. Multimodal Data Fusion for Tabular and Textual Data: Zero-Shot, Few-Shot, and Fine-Tuning of Generative Pre-Trained Transformer Models. AI 2025, 6, 72. https://doi.org/10.3390/ai6040072
Jaradat S, Elhenawy M, Nayak R, Paz A, Ashqar HI, Glaser S. Multimodal Data Fusion for Tabular and Textual Data: Zero-Shot, Few-Shot, and Fine-Tuning of Generative Pre-Trained Transformer Models. AI. 2025; 6(4):72. https://doi.org/10.3390/ai6040072
Chicago/Turabian StyleJaradat, Shadi, Mohammed Elhenawy, Richi Nayak, Alexander Paz, Huthaifa I. Ashqar, and Sebastien Glaser. 2025. "Multimodal Data Fusion for Tabular and Textual Data: Zero-Shot, Few-Shot, and Fine-Tuning of Generative Pre-Trained Transformer Models" AI 6, no. 4: 72. https://doi.org/10.3390/ai6040072
APA StyleJaradat, S., Elhenawy, M., Nayak, R., Paz, A., Ashqar, H. I., & Glaser, S. (2025). Multimodal Data Fusion for Tabular and Textual Data: Zero-Shot, Few-Shot, and Fine-Tuning of Generative Pre-Trained Transformer Models. AI, 6(4), 72. https://doi.org/10.3390/ai6040072