Abstract
(1) Background: The misuse of transformation technology using medical images is a critical problem that can endanger patients’ lives, and detecting manipulation via a deep learning model is essential to address issues of manipulated medical images that may arise in the healthcare field. (2) Methods: The dataset was divided into a real fundus dataset and a manipulated dataset. The fundus image manipulation detection model uses a deep learning model based on a Convolution Neural Network (CNN) structure that applies a concatenate operation for fast computation speed and reduced loss of input image weights. (3) Results: For real data, the model achieved an average sensitivity of 0.98, precision of 1.00, F1-score of 0.99, and AUC of 0.988. For manipulated data, the model recorded sensitivity of 1.00, precision of 0.84, F1-score of 0.92, and AUC of 0.988. Comparatively, five ophthalmologists achieved lower average scores on manipulated data: sensitivity of 0.71, precision of 0.61, F1-score of 0.65, and AUC of 0.822. (4) Conclusions: This study presents the possibility of addressing and preventing problems caused by manipulated medical images in the healthcare field. The proposed approach for detecting manipulated fundus images through a deep learning model demonstrates higher performance than that of ophthalmologists, making it an effective method.
1. Introduction
The advancement of image processing techniques using deep learning has led to a surge of research across various fields [1]. Among these techniques, image transformation technology employs an AI model to modify images through generation, alteration, and feature addition [2]. Such technology can facilitate the restoration of severely damaged images or enable digital mapping from satellite photographs, making it possible to augment deficient training datasets for deep learning models. Moreover, a research institute at the University of Lübeck in Germany published a paper on an AI system that demonstrated outstanding performance in cancer diagnosis by leveraging image transformation techniques [3]. In the study by Frid-Adar et al. [4], a Generative Adversarial Network (GAN) model was used to create synthetic medical images in order to address the difficulty of acquiring medical data. By using GAN-based data augmentation, the performance of a Convolutional Neural Network (CNN) for liver lesion classification was improved. They compared CNN performance when trained with both original and generated data, and finally validated the synthetic liver lesion images through specialist evaluation. Similarly, in the work of Lee et al. [5], research was carried out on generating mammography images via GAN to overcome limitations in medical research, such as anonymization of sensitive patient information and high labeling costs. Thus, image transformation technology has been applied to constructive purposes—especially in medical fields with limited data availability—leading to many studies on the manipulation or generation of medical images [4,5,6,7].
Although various approaches have been proposed to address difficulties in obtaining clinical data, few have focused on preventing the misuse of these techniques. Recently, image transformation technology has triggered numerous controversies under the name “Deep-Fake” [8,9]. This emerging possibility of misuse is especially concerning in the medical field, where the malicious use of transformation techniques poses a critical risk to patient safety. Furthermore, the abuse of image manipulation technology can lead to a variety of serious problems.
As of 2017, the precision medicine market stands at 47.47 billion USD, growing at an annual rate of 13.3%. Alongside the sector’s expansion, the number of clinical trial approvals required to validate the clinical efficacy of emerging medical products is steadily rising [10]. Image transformation technology could be misused to falsify patient eligibility or clinical conditions, thereby circumventing transparent testing and validation efforts [11]. Moreover, because Institutional Review Board (IRB) approval is mandatory for most medical research, it is possible for manipulated medical images to be inappropriately submitted for institutional clearance. With the rapid digitalization of societal systems, including healthcare reimbursement, the potential for manipulating or fabricating clinical images to claim unwarranted insurance coverage also increases [12]. In fact, advanced image transformation techniques that blur the distinction between real and artificially generated medical data can be exploited to fabricate or alter medical documentation [11,13].
Such manipulation technology affects not only the medical industry but also any sector that relies on image-based data, thereby posing significant social challenges. Although numerous studies on image transformation have emerged, relatively few have focused on detecting these fabricated images. Given the rising prevalence of fake images and the potentially fatal consequences of image manipulation in medicine, conducting research on the detection of manipulated images has become a critical priority.
In contrast to existing studies that focus primarily on image generation, several recent works have proposed models to detect manipulated medical images. For instance, Reichman et al. [14], introduced a CNN-based approach to identify GAN-generated alterations in CT scans, achieving strong performance in detecting both added and removed lesions. Similarly, Zhang et al. [15], proposed a two-stage cascade model combining patch-level anomaly detection and frequency-based global classification to effectively detect small-region GAN manipulations in medical images.
These studies demonstrate the growing interest in medical image forensics. However, most prior work has concentrated on CT or MRI scans. In contrast, our model specifically targets fundus images and demonstrates its effectiveness in clinical conditions through a comparison with ophthalmologists.
The clinical application of deep learning in medical imaging has been extensively studied, particularly in the context of classification and segmentation tasks using convolutional neural networks (CNNs) [16,17]. For example, Krizhevsky et al. demonstrated the power of CNNs in large-scale image classification through ImageNet [16], while Litjens et al. conducted a comprehensive review of deep learning applications in medical image analysis, highlighting its potential in various diagnostic tasks [17]. Our work builds upon this foundation by focusing specifically on the detection of manipulated fundus images.
In this study, we propose a model designed to detect manipulated medical images in the healthcare domain. Specifically, we focus on detecting alterations in fundus images generated through a previously developed deep learning model and comparing the performance of our detection approach against expert evaluations by ophthalmologists.
2. Previous Research
In a previous study [18], we proposed a deep learning based medical image generation model to address the difficulties involved in securing adequate medical data, especially given the relative scarcity of abnormal lesion data compared to normal data, by focusing on fundus images.
This earlier work utilized the “Ocular Disease Intelligent Recognition” dataset from Kaggle [19] to compile training data for four categories of fundus images: normal, diabetic retinopathy, glaucoma, and macular degeneration. To ensure data consistency and quality, a systematic screening and preprocessing procedure was performed, yielding a final set of 356 high-quality fundus images.
The image generation model introduced in the previous study employed a Res U-Net architecture, which combines a U-Net structure with Residual Blocks (Figure 1). This approach effectively generated images that closely resembled the original data, outperforming the conventional U-Net. In the quantitative evaluation of image similarity (Table 1), the Res U-Net model excelled over the standard U-Net in three metrics—Root Mean Square Error (RMSE), Structural Similarity Index Map (SSIM), and Fréchet inception distance (FID)—showing a particularly remarkable eightfold improvement in FID, which indicates a notable enhancement in image quality.
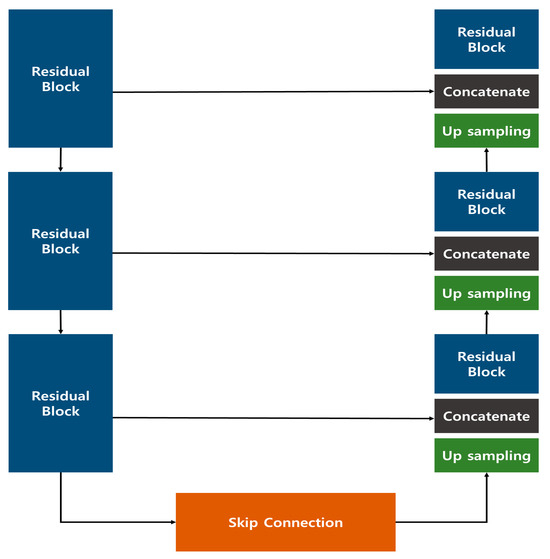
Figure 1.
Res U-Net Model Configuration proposed in the previous study [18].

Table 1.
Image similarity evaluation from the previous study [18].
Moreover, to verify the clinical effectiveness of the generated images, ophthalmologists were asked to assess them. The images produced by the Res U-Net model appeared visually very similar to genuine fundus images, to the extent that about 30% of the samples could not be reliably distinguished as original or regenerated. These findings suggest that the Res U-Net approach offers even greater potential than a conventional U-Net for clinical application as a reliable medical image generation model.
While our previous research confirmed the feasibility of generating fundus images through deep learning, it did not explore the possibility of these generated images being misused. Recognizing the mounting social concerns over deepfake technology and its potential malicious use in healthcare, we extended our work to investigate methods for detecting deep learning– manipulated fundus images.
3. Data Configuration
For the detection of manipulated fundus images in this study, we used real and manipulated fundus images derived from over 6000 raw images in the “Ocular Disease Intelligent Recognition” dataset [19] previously employed in our work. In the study, a total of 4 lesions were selected including three major blindness diseases, diabetic retinopathy, glaucoma, and macular degeneration, and normal. The selection process and manipulation method of the data used in the study were described in a previous study [18]. Additionally, to develop a detection model capable of handling various manipulation techniques, we included manipulated images generated by a Cycle GAN in our training. This step was taken to prevent an artificially inflated detection performance that might occur if the manipulated images were solely derived from the original image features. Moreover, since clinical settings may present a broad spectrum of manipulated data, we assembled the model’s dataset using a variety of image sources. For Cycle GAN training, we used Kaggle’s “MESSIDOR-2 DR Grades” and “Glaucoma Detection” datasets, both of which consist of fundus images and accompanying physician annotations [20,21].
Table 2 summarizes the dataset used to train and test our deep learning model for detecting manipulated fundus images. For the Normal category, we used 350 real images and 214 manipulated images; for Glaucoma, 203 real images and 125 manipulated; for Diabetic Retinopathy, 398 real images and 147 manipulated; and for Macular Degeneration, 217 real images and 129 manipulated. In total, we used 1168 real images and 615 manipulated images. Among these, the test set consisted of randomly selected data: 90 real images and 10 manipulated images for each category, including Normal and all three disease groups.
Table 2.
Composition of the fundus image manipulation detection dataset.
4. Manipulated Fundus Image Detection Model
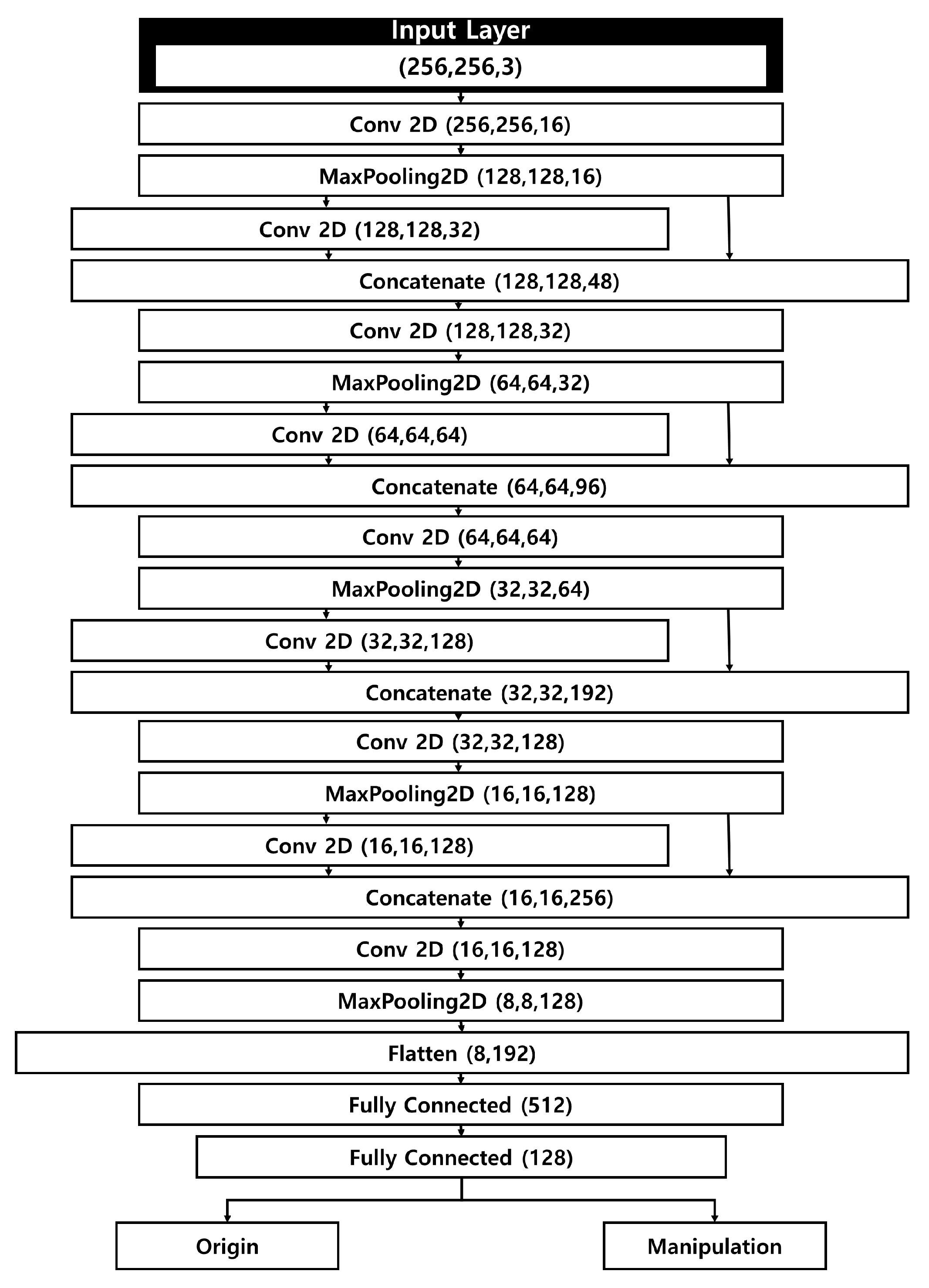
Our manipulated fundus image detection model takes as input both genuine fundus images, sized 256 × 256 × 3, and manipulated images generated by a separate manipulation model. The size of the input data was selected as 256 × 256 × 3 to quickly determine manipulated in consideration of the computational efficiency of the deep learning model. The model architecture is a CNN that incorporates a Concatenate operation to achieve fast computation while mitigating the loss of weight information from the input images. Its relatively simple structure allows for rapid yet precise detection.
Figure 2 illustrates the structure of the detection model. Apart from the first layer and the final flattening layer, the network comprises four layers, each containing two 2D convolutional layers, a concatenate layer, and a pooling layer. As input images move through the pooling and convolutional layers, the model extracts salient features of the fundus images. Similar to the contraction path in U-Net, the feature map size is halved at each stage, while the number of channels is doubled. Unlike U-Net, which connects encoder and decoder features, our method performs feature connections within the encoder to reduce information loss by preserving fine-grained features during initial extraction. To address the issue of weight loss that grows with each additional deep-learning layer, the model integrates a concatenate layer that connects to the previous pooling layer.
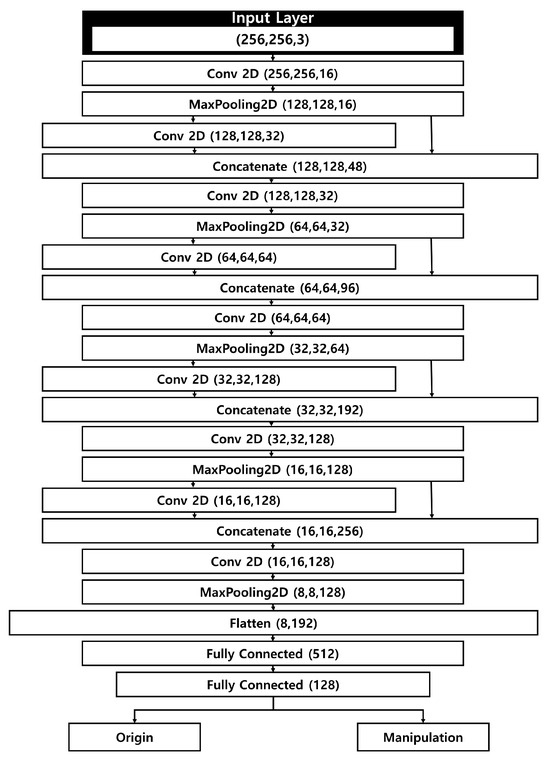
Figure 2.
Structure of the fundus image manipulation detection model.
After completing the operations in the fifth layer, the tensor assumes a shape of 8 × 8 × 128, which is then passed on to the flattening layer. Here, the data are converted into a one-dimensional array, forming a flattened matrix of 8192 elements. Through subsequent fully connected layers, the number of elements in the flattened matrix is progressively reduced. Ultimately, the model classifies each fundus image as either genuine or manipulated. The model consists of five convolutional layers with kernel sizes of 3 × 3 and stride of 1, each followed by batch normalization and ReLU activation. Dropout of 0.3 was applied to mitigate overfitting.
Our detection model is designed to minimize feature loss during the convolution process, which is critical because detecting manipulated images hinges on both raw pixel values and the differences among them. Consequently, the concatenate layer helps preserve these essential feature values.
Developed to prevent the misuse of image generation technologies in healthcare, this detection model can rapidly determine whether medical data have been manipulated, and it is engineered to handle various types of manipulated content that may appear in actual clinical practice.
5. Results
5.1. Performance of the Manipulated Fundus Image Detection Model
In this study, we used 1168 real fundus images and 615 manipulated fundus images to verify the detection performance of the fundus image manipulation detection model. Of these, 808 real fundus images and 575 manipulated fundus images were used for model training, while 360 real fundus images and 40 manipulated fundus images were used for model testing. In the case of the test data, the same number was constructed in all lesions for comparison of the results with the detection test by an ophthalmologist to be described later.
To quantitatively evaluate the fundus image manipulation detection model, four metrics derived from the confusion matrix were used: sensitivity, precision, F1-score, and Area Under the Curve (AUC). Sensitivity indicates how well an AI model identifies true positives in statistical classification; in a study such as this one, aimed at detecting manipulated data, incorrect classification results can cause serious problems, thus sensitivity is indispensable. Precision represents how accurately the model’s predicted positives match actual positives, and by calculating precision, we can establish the reliability of the AI model’s classification performance. This must be computed to improve and enhance the model’s classification performance. The F1-score, which is the harmonic mean of precision and sensitivity, is used to reduce distortions that may arise between the two metrics. In this study, since the number of manipulated data points is smaller than that of real data, a group-based quantitative evaluation is necessary, and thus the F1-score is used. Lastly, the AUC is widely employed in classification studies as it provides a comprehensive performance metric over all possible classification thresholds.
Table 3 shows the sensitivity, precision, and F1-score results for the fundus image manipulation detection model. For real data, the model achieved an average sensitivity of 0.98, precision of 1.00, and F1-score of 0.99 across the four lesion types (Normal, Glaucoma, Diabetic Retinopathy, and Macular Degeneration). These results demonstrate that the model performs excellently in identifying real fundus images without manipulation.
Table 3.
Results of the fundus image manipulation detection model (Sensitivity, Precision, F1-Score).
For manipulated data, the model achieved sensitivity = 1.00, precision = 0.84, and F1-score = 0.92. Among the four lesions, detection performance for Normal and Diabetic Retinopathy was relatively lower in precision and F1-score, likely due to the high similarity between manipulated and real images. Nevertheless, all metrics remained high, with Glaucoma and Macular Degeneration showing strong detection results.
Table 4 presents the AUC scores, with Normal at 0.989, Diabetic Retinopathy at 0.978, and both Glaucoma and Macular Degeneration at 0.994. Despite minor variations across categories, the model consistently achieved AUC values above 0.97, confirming its ability to accurately distinguish between real and manipulated fundus images.
Table 4.
Results of the fundus image manipulation detection model (AUC).
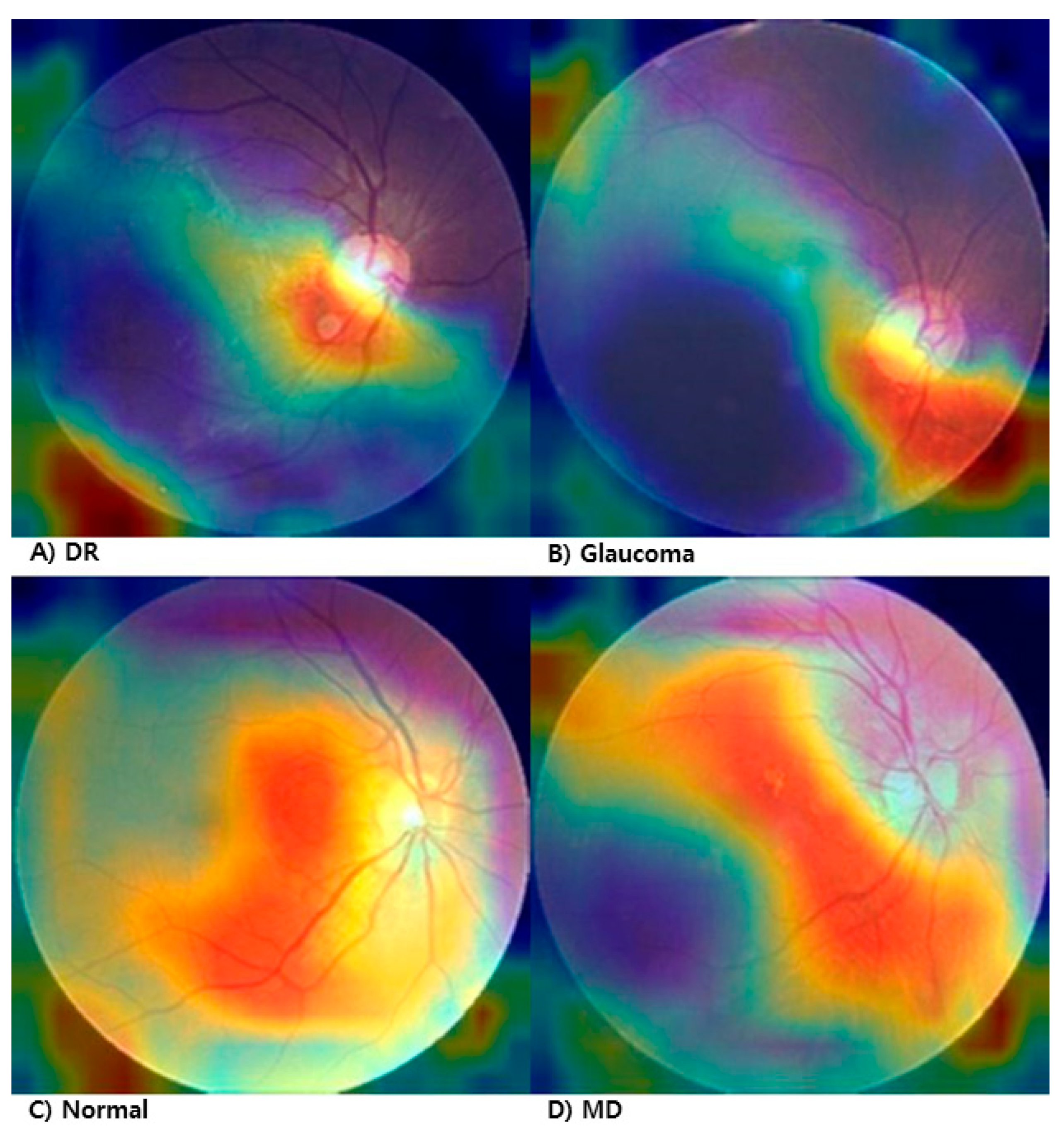
To enhance the explainability of the proposed fundus image manipulation detection model, we applied Grad-CAM (Gradient-weighted Class Activation Mapping) to visualize which regions of the input image the model attends to when making predictions. Figure 3 shows the Grad-CAM results applied to manipulated fundus images across four lesion types: diabetic retinopathy (DR), glaucoma, macular degeneration (MD), and normal.
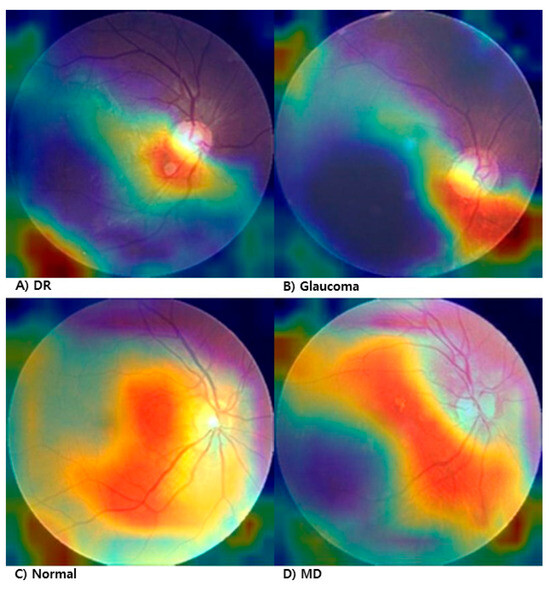
Figure 3.
Grad-CAM visualization of manipulated fundus images. (A) Diabetic Retinopathy (DR), (B) Glaucoma, (C) Normal, (D) Macular Degeneration.
In the DR image (Figure 3A), the model strongly focuses on the lower central region, likely responding to irregularities in tissue texture and vascular distribution. In the glaucoma image (Figure 3B), the model concentrates on the optic disc area, suggesting sensitivity to structural deformation or local brightness variation. In the normal image (Figure 3C), although there is no pathological lesion, the model selectively attends to a localized pattern anomaly, indicating high sensitivity to subtle texture differences introduced by manipulation. In the MD image (Figure 3D), the attention is primarily centered on the macular region.
These results demonstrate that the model effectively identifies manipulation-relevant regions depending on the lesion type, contributing to its clinical reliability and interpretability.
5.2. Detection Results of Manipulated Fundus Images by Ophthalmologists
In this study, to verify whether the fundus image manipulation detection model can function effectively in actual clinical settings, we conducted a detection test for manipulated fundus images with ophthalmologists. For each lesion, the data requested comprised 45 original fundus images and 5 manipulated fundus images, and the ophthalmologists were asked to identify manipulated images from a randomly mixed set. A total of five ophthalmologists participated, each affiliated with a different institution. Because the detection of manipulated fundus images takes place in diverse clinical environments, it is possible to compare and rigorously evaluate the clinical effectiveness of the fundus image manipulation detection model.
The detection of the manipulated image by the ophthalmologist was delivered through e-mail due to the limitation of distance, and the transmitted data is an Excel file that records 200 actual and manipulated images and detection contents. Detection proceeded with an image with a size of 256 × 256 × 3, which is the image size input to the deep learning model, and in the case of the manipulated image, it is marked as ‘0’ in the Excel file. The detection time was not set separately, and it took an average of 7 days. In detecting manipulated fundus images, no patient information for the manipulated images was provided, and the same procedure was applied for the real fundus images. This was intended to minimize the impact that missing patient information could have on the ophthalmologists’ detection of manipulated fundus images. Each metric was expressed as an average of the detection scores of the five ophthalmologists. This is because it is more important to grasp the average detection ability than to assess each ophthalmologist’s individual capacity for detecting manipulated images.
Table 5 presents the sensitivity, precision, and F1-score results for ophthalmologists in detecting fundus images. For real data, ophthalmologists achieved an average sensitivity of 0.93, precision of 0.96, and F1-score of 0.95 across all lesion types. While these metrics are relatively high, they are still lower than those of the proposed manipulation detection model.
Table 5.
Detection results of manipulated fundus images by ophthalmologists (Sensitivity, Precision, F1-Score).
In detecting manipulated images, ophthalmologists recorded a sensitivity of 0.71, precision of 0.61, and F1-score of 0.65 on average. Notably, the detection performance for glaucoma and diabetic retinopathy was significantly lower compared to the model, indicating challenges in recognizing these manipulated images without automated support.
Table 6 shows the AUC results for ophthalmologists. Normal achieved an AUC of 0.895, diabetic retinopathy 0.788, macular degeneration 0.844, and glaucoma showed the lowest performance at 0.762. These AUC values are consistently lower than those achieved by the proposed model, highlighting the advantage of deep learning-based detection for subtle manipulations.
Table 6.
Detection results of the fundus image manipulation detection model by ophthalmologists (AUC).
6. Discussion
In this study, we conducted research on the possibility of detecting manipulated medical images using a deep learning model, aiming to resolve the issue of medical image manipulation that can arise in the healthcare domain. We performed our experiments based on fundus images generated by a previously studied deep learning model, and then compared and verified the results of the manipulation detection model with those of 5 ophthalmologists.
The proposed fundus image manipulation detection model demonstrated consistently strong performance across both real and manipulated datasets. For real data, the model achieved an average sensitivity of 0.98, precision of 1.00, F1-score of 0.99, and AUC of 0.988 across four lesion types. In the manipulated data, sensitivity was 1.00, precision 0.84, F1-score 0.92, and AUC remained high at 0.988, indicating that all lesion categories exceeded a 97% detection rate.
Despite slightly lower precision and F1-scores for Normal and Diabetic Retinopathy in manipulated data, the AUC remained consistently high across all lesion types. This suggests that the model performs robustly regardless of the manipulation method (e.g., CycleGAN, Res U-Net), confirming its ability to accurately detect tampered fundus images.
To further assess clinical utility, model performance was compared with that of ophthalmologists. For real data, ophthalmologists achieved an average sensitivity of 0.93, precision of 0.96, F1-score of 0.95, and AUC of 0.822. In contrast, for manipulated data, their performance dropped to a sensitivity of 0.71, precision of 0.61, F1-score of 0.65, and AUC of 0.822. While the performance for real data was similar to the model, the results for manipulated data showed average differences of −0.29 in sensitivity, −0.23 in precision, −0.27 in F1-score, and −0.166 in AUC, demonstrating a clear advantage of the proposed model in detecting tampered images.
Table 7 shows the results of a bootstrap comparison between an ophthalmologist and a manipulated image detection model. We applied bootstrap resampling (n = 10,000) to estimate a 95% confidence interval for sensitivity, precision, and F1 scores. Bootstrap comparison is one of the statistical methods, which is a technique for performing statistical estimation by repeatedly extracting samples from a given data. This method is particularly useful when the sample size is small or the distribution of data is uncertain.
Table 7.
Comparison of bootstrap between ophthalmologist and manipulated image detection model (Sensitivity, Precision, F1-Score).
Bootstrap comparison results show significantly higher performance than ophthalmologists on all performance indicators (sensitivity, precision, F1 score) in the manipulation data results. This means that the model is more effective in detecting manipulation data.
The Fleiss’ kappa coefficient between ophthalmologists was calculated as 0.0399, which showed a low level of agreement. This means that evaluators have different opinions on the same item. It appears that factors such as missing patient information or the relatively low quality of certain fundus images played a role. Because detection was conducted without knowledge of image manipulation using a deep learning model, the lack of clear criteria for manipulation detection also seems to have contributed to the low detection rate.
In addition to our proposed model, recent studies have explored manipulation detection in medical images. Reichman et al. introduced a CNN-based framework for detecting GAN-generated tampering in CT scans, achieving an AUC of 0.941 in identifying both added and removed lesions. Zhang et al. proposed a two-stage cascade model that combines patch-level anomaly detection with frequency-domain classification, reporting over 99% accuracy in detecting small-region GAN manipulations. Similarly, Sharafudeen et al. [22] developed a deep learning model to detect tampered lung CT scans generated using CT-GANs. Their approach achieved an accuracy of 91.57%, sensitivity of 91.42%, and specificity of 97.20% in distinguishing between tampered and original images. Furthermore, Albahli et al. [23] proposed MedNet, a model based on EfficientNetV2-B4, to detect fake lung CT images. Their model achieved an accuracy of 85.49% in identifying manipulated images.
While many of these methods focus on CT and MRI images, our model specifically targets fundus image manipulation. It achieved a high AUC of 0.988 across various lesion types, outperforming ophthalmologists (AUC 0.822) in real-world evaluation scenarios. This highlights the clinical utility and domain-specific strength of the proposed approach.
Through this study, we confirmed that the fundus image manipulation detection model shows excellent performance, but there are several limitations, which we plan to address in future research. First, we utilized three open datasets to train the fundus image manipulation detection model and used data manipulated through Cycle GAN and Res U-Net. Although we used three datasets and two manipulation methods for application in real clinical environments, it is necessary to employ datasets gathered from actual multicenter settings rather than only open datasets, and to conduct research with a broader variety of manipulated data than those presented here. Second, our research is limited to detecting manipulation in fundus images among medical imaging data. Because medical imaging data can be acquired in numerous ways, issues with manipulated medical data can occur in any field, so it is important to establish manipulation detection technologies for various areas. Third, the relatively low detection performance by ophthalmologists may have been caused by the low quality of certain manipulated fundus images. This means that manipulated images must be generated at the same level of image quality as those collected in actual clinical settings, and through this, accurate comparison of detection performance becomes possible. Fourth, in this study, we did not evaluate large-scale state-of-the-art image classification models such as ResNet, EfficientNet, or Vision Transformers. While these models are widely used, they require relatively large computational resources and memory, which differs from the design goal of our lightweight manipulation detection model. We also acknowledge the value of conducting ablation analysis to assess the contribution of specific architectural components. Although such experiments were not included in this study, the use of concatenation layers and preprocessing steps was based on empirical performance improvements observed during preliminary testing. In future work, we plan to conduct quantitative comparisons with high-performance classification models and include formal ablation studies on architectural variations.
7. Conclusions
This study proposed a lightweight CNN-based deep learning model for detecting manipulated fundus images in the medical domain. The model was trained and evaluated using a dataset composed of real and synthetically manipulated images generated via CycleGAN and Res U-Net. The model achieved high performance across multiple metrics, with an average AUC of 0.988, demonstrating robustness in detecting tampered images.
Comparison with five ophthalmologists revealed that the model significantly outperformed human experts in detecting manipulated data, especially for challenging cases such as glaucoma and diabetic retinopathy. While ophthalmologists showed comparable performance on real data, their detection ability dropped considerably on manipulated images.
These findings suggest that the proposed model is effective in distinguishing between real and altered fundus images, regardless of manipulation method. The system presents a promising approach for supporting clinical decision-making and preventing the misuse of synthetic medical data. Future work will focus on expanding the dataset using multicenter real-world images and comparing performance with larger state-of-the-art classification models such as ResNet, EfficientNet, and Vision Transformers.
Author Contributions
Conceptualization, H.-J.S. and Y.-S.K.; methodology, H.-J.S. and Y.-S.K.; software, H.-J.S. and J.-H.H.; validation, Y.-S.C.; formal analysis, H.-J.S. and J.-H.H.; investigation, H.-J.S. and Y.-S.K.; resources, H.-J.S. and J.-H.H.; data curation, H.-J.S. and J.-H.H.; writing—original draft preparation, H.-J.S.; writing—review and editing, H.-J.S. and Y.-S.K.; visualization, H.-J.S.; supervision, Y.-S.K.; project administration, Y.-S.K.; funding acquisition, Y.-S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by a grant of the Information and Communications Promotion Fund through the National IT Industry Promotion Agency (NIPA), funded by the Ministry of Science and ICT (MSIT), Republic of Korea.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this study, “Ocular Disease Intelligent Recognition”, “MESSIDOR-2 DR Grades”, “Glaucoma Detection”, is publicly available from Kaggle and does not involve directly identifiable patient data.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Dhamo, H.; Farshad, A.; Laina, I.; Navab, N.; Hager, G.D.; Tombari, F.; Rupprecht, C. Semantic image manipulation using scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5213–5222. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Uzunova, H.; Ehrhardt, J.; Jacob, F.; Frydrychowicz, A.; Handels, H. Multi-scale gans for memory-efficient generation of high resolution medical images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; pp. 112–120. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef]
- Lee, H.S.; Song, H.J.; Her, Y.D. A Study on the Image Generation with Residual U-Net Generator of CycleGAN in Digital Breast Tomography. J. Knowl. Inf. Technol. Syst. 2023, 18, 1633–1641. [Google Scholar]
- Iqbal, T.; Ali, H. Generative adversarial network for medical images (MI-GAN). J. Med. Syst. 2018, 42, 231. [Google Scholar] [CrossRef] [PubMed]
- Fan, C.; Lin, H.; Qiu, Y. U-Patch GAN: A medical image fusion method based on GAN. J. Digit. Imaging 2023, 36, 339–355. [Google Scholar] [CrossRef] [PubMed]
- Westerlund, M. The emergence of deepfake technology: A review. Technol. Innov. Manag. Rev. 2019, 9, 39–52. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 61, 131–148. [Google Scholar] [CrossRef]
- Number of Clinical Trial Registrations by Location, Disease, Phase of Development, Age and Sex of Trial Participants (1999–2024). Available online: https://www.who.int/observatories/global-observatory-on-health-research-and-development/monitoring/number-of-trial-registrations-by-year-location-disease-and-phase-of-development (accessed on 22 April 2025).
- Kim, H.; Jung, D.C.; Choi, B.W. Exploiting the vulnerability of deep learning-based artificial intelligence models in medical imaging: Adversarial attacks. J. Korean Soc. Radiol. 2019, 80, 259–273. [Google Scholar] [CrossRef]
- Significance and Characteristics of Health Insurance System. Available online: https://www.nhis.or.kr/nhis/policy/wbhada01000m01.do (accessed on 22 April 2025).
- Mirsky, Y.; Mahler, T.; Shelef, I.; Elovici, Y. {CT-GAN}: Malicious Tampering of 3D Medical Imagery using Deep Learning. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 461–478. [Google Scholar]
- Reichman, B.; Jing, L.; Akin, O.; Tian, Y. Medical Image Tampering Detection: A New Dataset and Baseline. In Pattern Recognition, ICPR International Workshops and Challenges: Virtual Event, 10–15 January 2021; Proceedings, Part I; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 266–277. [Google Scholar]
- Zhang, J.; Huang, X.; Liu, Y.; Han, Y.; Xiang, Z. GAN-Based Medical Image Small Region Forgery Detection via a Two-Stage Cascade Framework. PLoS ONE 2024, 19, e0290303. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. IEEE Trans. Med. Imaging 2017, 35, 1153–1172. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.S. A Study on the Performance Comparison of the Fundus Image Generation Model. Math. Stat. Eng. Appl. 2022, 71, 527–537. [Google Scholar]
- Ocular Disease Recognition: Right and Left Eye Fundus Photographs of 5000 Patients. Available online: https://www.kaggle.com/andrewmvd/ocular-disease-recognition-odir5k (accessed on 22 April 2025).
- MESSIDOR-2 DR Grades: Adjudicated DR Severity, DME, and Gradability for the MESSIDOR-2 Fundus Dataset. Available online: https://www.kaggle.com/google-brain/messidor2-dr-grades (accessed on 22 April 2025).
- Glaucoma Detection: OCT Scans. Available online: https://www.kaggle.com/sshikamaru/glaucoma-detection (accessed on 22 April 2025).
- Sharafudeen, M.J.; Chandra Sekaran, V.S. Leveraging Vision Attention Transformers for Detection of Artificially Synthesized Dermoscopic Lesion Deepfakes Using Derm-CGAN. Diagnostics 2023, 13, 825. [Google Scholar] [CrossRef] [PubMed]
- Albahli, S.; Nawaz, M. MedNet: Medical Deepfakes Detection Using an Improved Deep Learning Approach. Multimed. Tools Appl. 2023, 83, 48357–48375. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).