


DIAG Approach: Introducing the Cognitive Process Mining by an Ontology-Driven Approach to Diagnose and Explain Concept Drifts

 , and
, and
Abstract
:1. Introduction
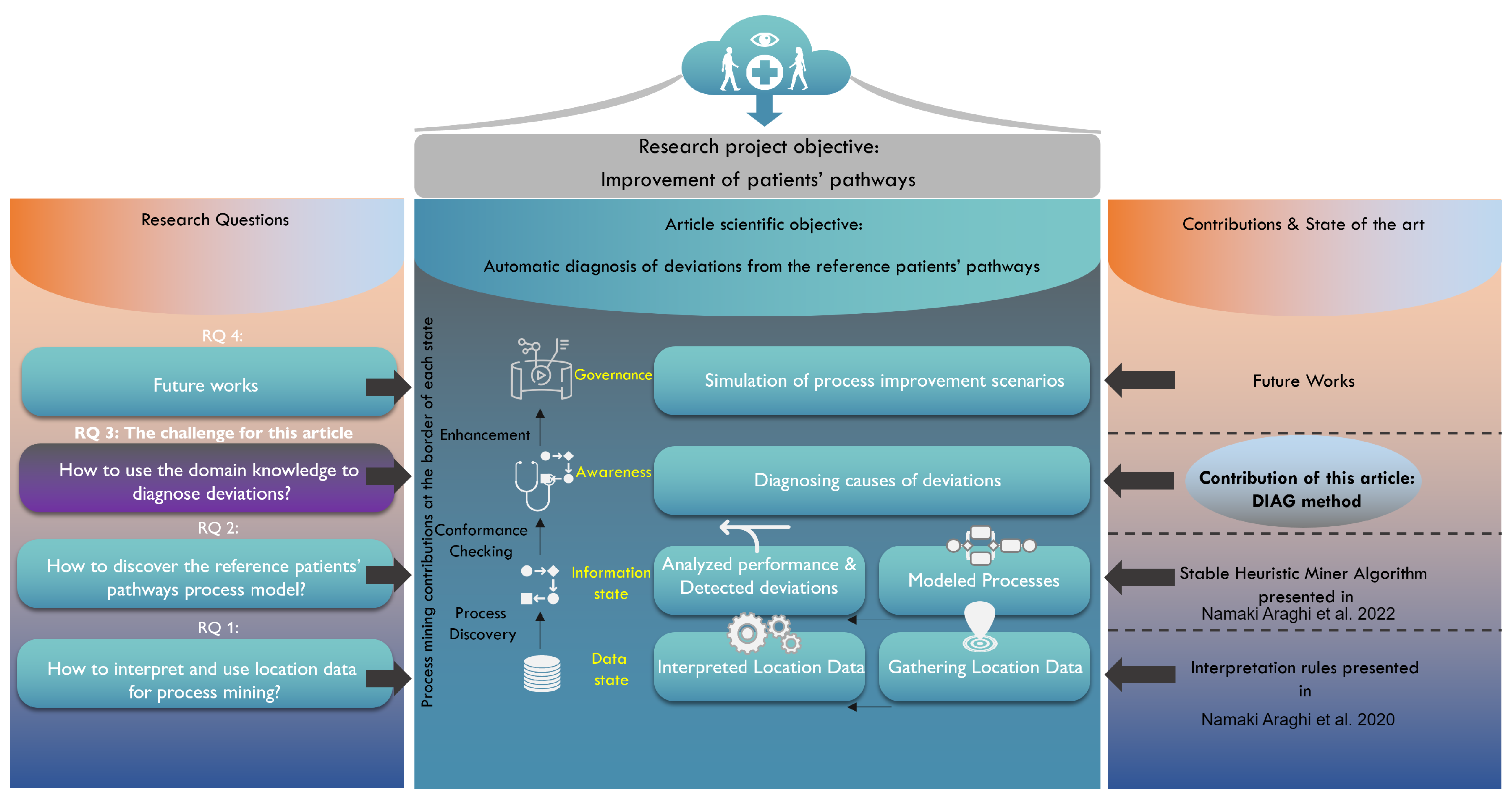
- “How to embed the domain knowledge into process mining applications in such a way that we can diagnose the causes of deviations and drifts from the reference patients’ pathways?” (RQ 3, c.f. Figure 1).
2. Background
2.1. Conformance Checking
2.2. Concept Drifts
- Change perspective: time, control flow, resource, data;
- Change analysis: online, offline;
- Change duration: momentary, permanent;
- Change type: sudden, gradual, recurring, incremental;
- Change dynamic: multi-order (i.e., process changes happen at different time periods).
2.3. Related Works
3. Proposal
- The DIAG meta-model is an ontology-based knowledge representation to engage domain-based semantics in the process mining analyses.
- The DIAG algorithm is a semantic-based algorithm that leverages the DIAG meta-model to generate meaningful insights and add the cognitive capability to process discovery.
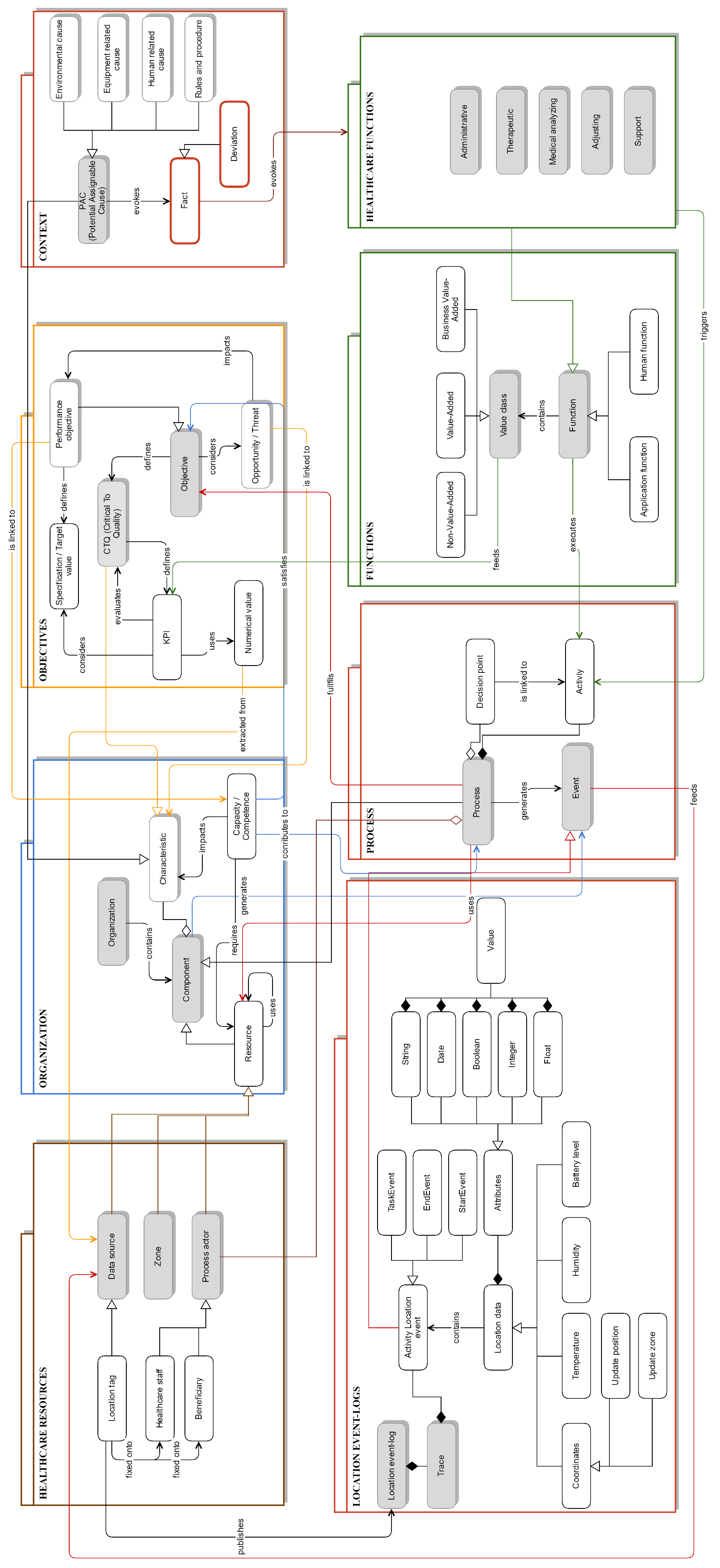
3.1. DIAG Meta-Model
3.2. DIAG Algorithm
| Algorithm 1 DIAG algorithm |
|
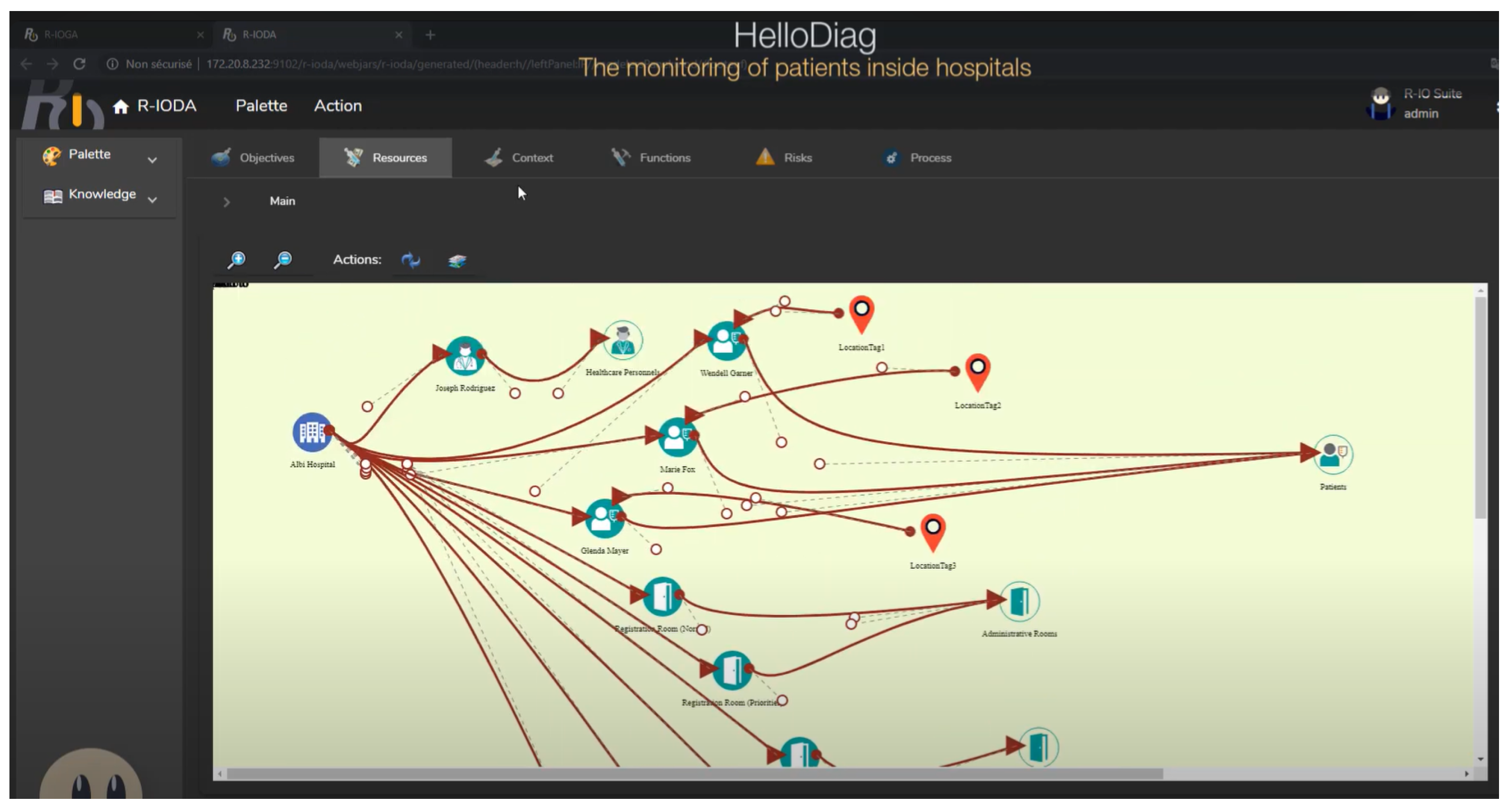
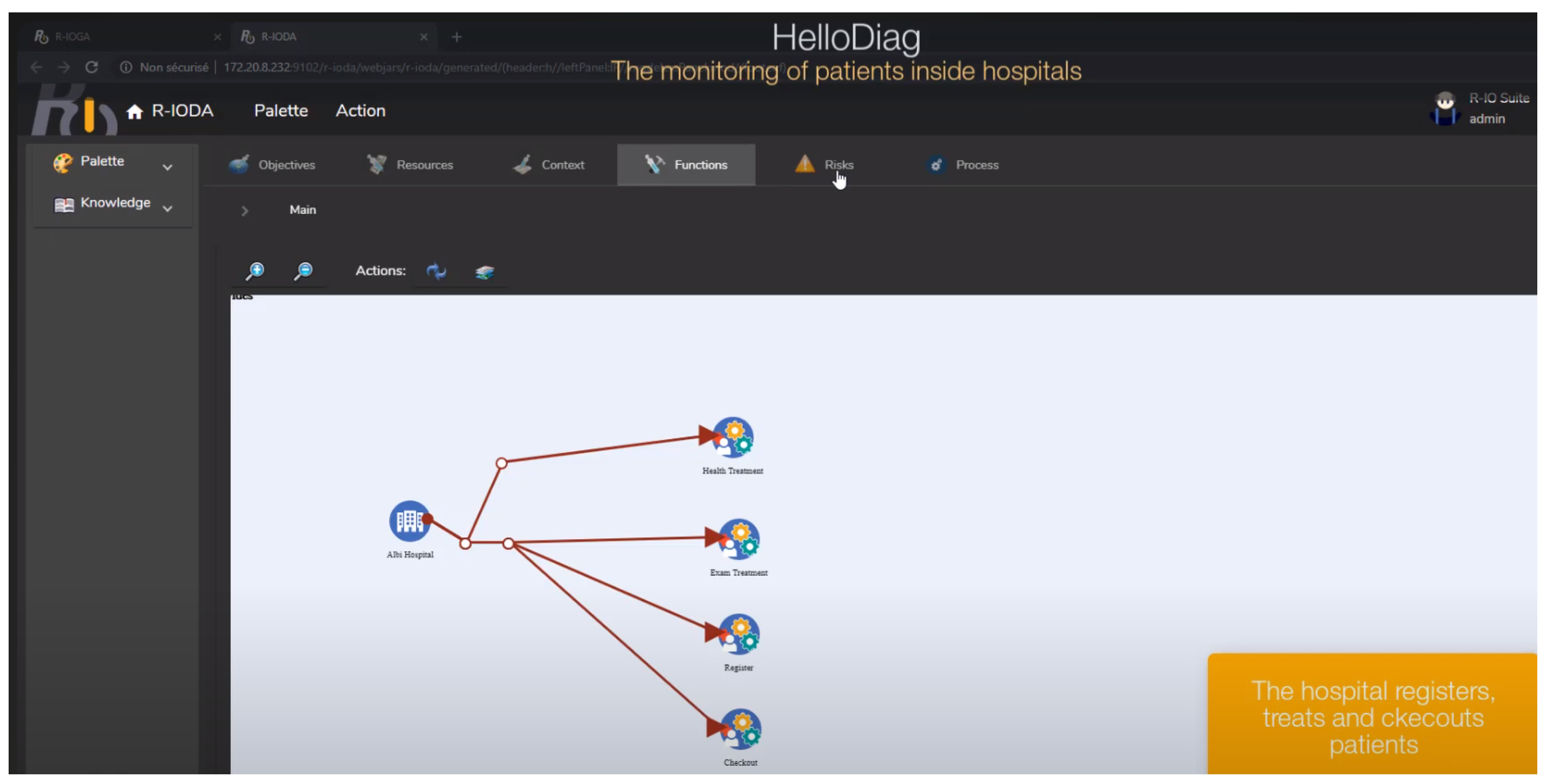
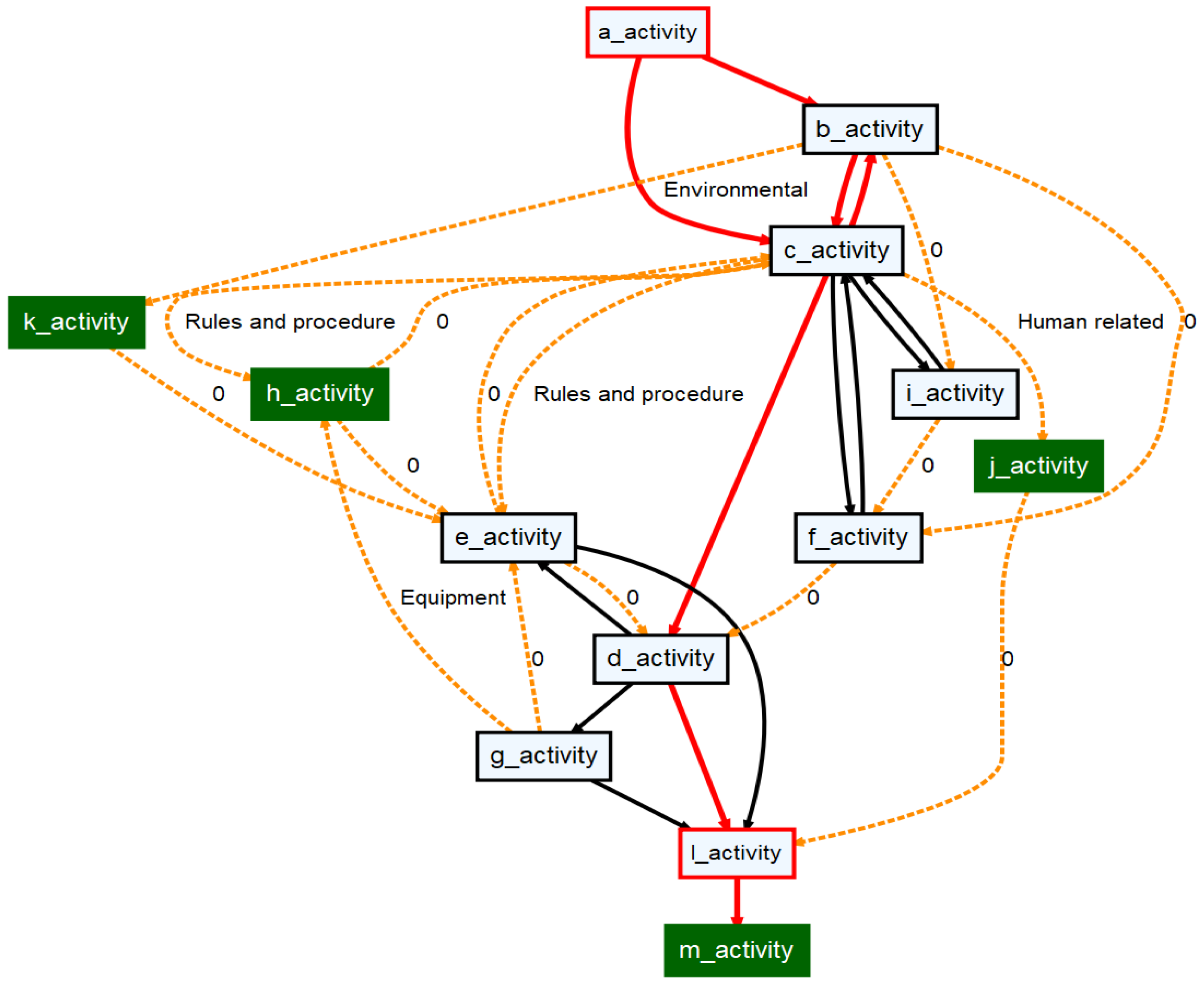
An Illustrative Example

4. Case Study
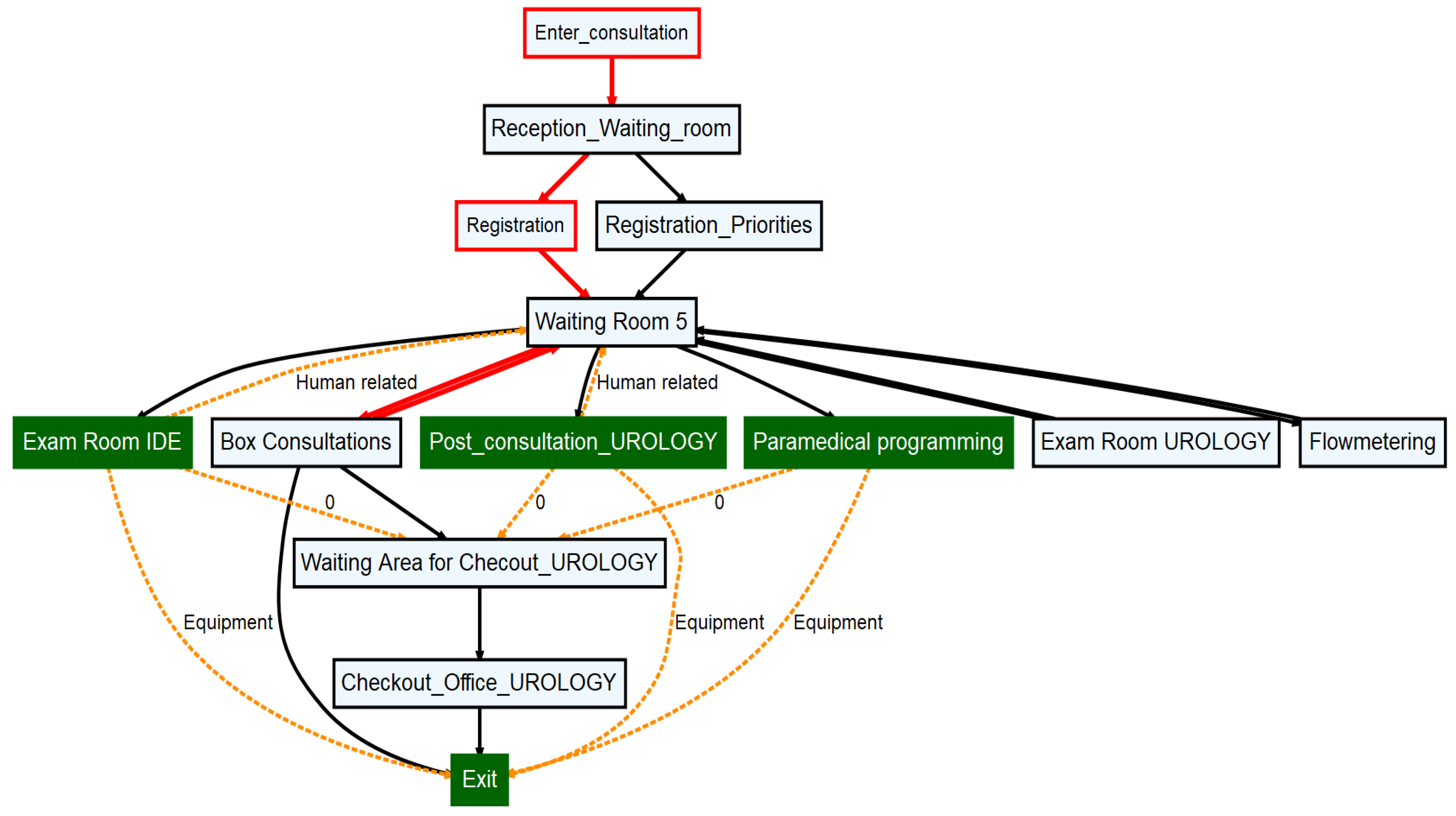
4.1. Presentation of the Case Study
4.2. Results and Analyses
- Stable activities and edges: These behaviors are shown in black. They are presenting the most common and normal behaviors.
- Activities and edges with high variations (unstable behaviors): These behaviors are shown in red. They correspond to observations with a higher level of variations than the upper control limit of the stability state.
- Drifts: These behaviors are represented by activities modeled in green and dashed edges. They illustrate unanticipated occurrences recorded in the event log.
5. Conclusions
Limitations and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DIAG | Data, Information, Awareness, Governance |
| UCL | Upper Control Limit |
| CL | Central Line |
| LCL | Lower Control Limit |
| PAC | Potential Assignable Cause |
References
- Munoz-Gama, J.; Martin, N.; Fernandez-Llatas, C.; Johnson, O.A.; Sepúlveda, M.; Helm, E.; Galvez-Yanjari, V.; Rojas, E.; Martinez-Millana, A.; Aloini, D.; et al. Process mining for healthcare: Characteristics and challenges. J. Biomed. Inform. 2022, 127, 103994. [Google Scholar] [CrossRef] [PubMed]
- De Roock, E.; Martin, N. Process mining in healthcare—An updated perspective on the state of the art. J. Biomed. Inform. 2022, 127, 103995. [Google Scholar] [CrossRef] [PubMed]
- van der Aalst, W. Data Science in Action. In Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–23. [Google Scholar] [CrossRef]
- Namaki Araghi, S.; Fontaili, F.; Lamine, E.; Salatge, N.; Lesbegueries, J.; Pouyade, S.R.; Tancerel, L.; Benaben, F. A Conceptual Framework to Support Discovering of Patients’ Pathways as Operational Process Charts. In Proceedings of the 2018 IEEE/ACS 15th International Conference on Computer Systems and Applications (AICCSA), Aqaba, Jordan, 28 October–1 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Adams, J.N.; van Zelst, S.J.; Quack, L.; Hausmann, K.; van der Aalst, W.M.P.; Rose, T. A Framework for Explainable Concept Drift Detection in Process Mining. arXiv 2021, arXiv:2105.13155. [Google Scholar]
- Namaki Araghi, S.; Fontanili, F.; Lamine, E.; Salatge, N.; Benaben, F. Interpretation of Patients’ Location Data to Support the Application of Process Mining Notations. In HEALTHINF 2020-13th International Conference on Health Informatics; SCITEPRESS-Science and Technology Publications: Setúbal, Portugal, 2020; Volume 5, pp. 472–481. [Google Scholar] [CrossRef]
- Yang, W.; Su, Q. Process mining for clinical pathway: Literature review and future directions. In Proceedings of the 2014 11th International Conference on Service Systems and Service Management (ICSSSM), Beijing, China, 25–27 June 2014; pp. 1–5. [Google Scholar]
- Namaki Araghi, S.; Fontanili, F.; Lamine, E.; Okongwu, U.; Benaben, F. Stable Heuristic Miner: Applying statistical stability to discover the common patient pathways from location event logs. Intell. Syst. Appl. 2022, 14, 200071. [Google Scholar] [CrossRef]
- Namaki Araghi, S. A Methodology for Business Process Discovery and Diagnosis Based on Indoor Location Data: Application to Patient Pathways Improvement. Ph.D. Thesis, Ecole des Mines d’Albi-Carmaux, Albi, France, 2019. Albi-FRANCE. [Google Scholar]
- Carmona, J.; van Dongen, B.; Weidlich, M. Conformance Checking: Foundations, Milestones and Challenges. In Process Mining Handbook; Lecture Notes in Business Information Processing; van der Aalst, W.M.P., Carmona, J., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 155–190. [Google Scholar] [CrossRef]
- Rodriguez-Fernandez, V.; Trzcionkowska, A.; Gonzalez-Pardo, A.; Brzychczy, E.; Nalepa, G.J.; Camacho, D. Conformance Checking for Time-Series-Aware Processes. IEEE Trans. Ind. Inform. 2021, 17, 871–881. [Google Scholar] [CrossRef]
- Van der Aalst, W.; Adriansyah, A.; van Dongen, B. Replaying history on process models for conformance checking and performance analysis. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 182–192. [Google Scholar] [CrossRef]
- Carmona, J.; van Dongen, B.; Solti, A.; Weidlich, M. Conformance Checking; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Burattin, A.; Maggi, F.M.; Sperduti, A. Conformance checking based on multi-perspective declarative process models. Expert Syst. Appl. 2016, 65, 194–211. [Google Scholar] [CrossRef]
- Gatta, R.; Vallati, M.; Fernandez-Llatas, C.; Martinez-Millana, A.; Orini, S.; Sacchi, L.; Lenkowicz, J.; Marcos, M.; Munoz-Gama, J.; Cuendet, M.; et al. Clinical Guidelines: A Crossroad of Many Research Areas. Challenges and Opportunities in Process Mining for Healthcare. In Business Process Management Workshops; Lecture Notes in Business Information Processing; Di Francescomarino, C., Dijkman, R., Zdun, U., Eds.; Springer: Cham, Switzerland, 2019; pp. 545–556. [Google Scholar] [CrossRef]
- Dunzer, S.; Stierle, M.; Matzner, M.; Baier, S. Conformance checking: A state-of-the-art literature review. In Proceedings of the 11th International Conference on Subject-Oriented Business Process Management: S-BPM ONE 2019, Seville, Spain, 26–28 June 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Asare, E.; Wang, L.; Fang, X. Conformance Checking: Workflow of Hospitals and Workflow of Open-Source EMRs. IEEE Access 2020, 8, 139546–139566. [Google Scholar] [CrossRef]
- Benevento, E.; Pegoraro, M.; Antoniazzi, M.; Beyel, H.H.; Peeva, V.; Balfanz, P.; van der Aalst, W.M.P.; Martin, L.; Marx, G. Process Modeling and Conformance Checking in Healthcare: A COVID-19 Case Study. In Process Mining Workshops; Lecture Notes in Business Information Processing; Montali, M., Senderovich, A., Weidlich, M., Eds.; Springer: Cham, Switzerland, 2023; pp. 315–327. [Google Scholar] [CrossRef]
- Oliart, E.; Rojas, E.; Capurro, D. Are we ready for conformance checking in healthcare? Measuring adherence to clinical guidelines: A scoping systematic literature review. J. Biomed. Inform. 2022, 130, 104076. [Google Scholar] [CrossRef]
- Soliman-Junior, J.; Tzortzopoulos, P.; Baldauf, J.P.; Pedo, B.; Kagioglou, M.; Formoso, C.T.; Humphreys, J. Automated compliance checking in healthcare building design. Autom. Constr. 2021, 129, 103822. [Google Scholar] [CrossRef]
- Elkhawaga, G.; Abuelkheir, M.; Barakat, S.I.; Riad, A.M.; Reichert, M. CONDA-PM—A Systematic Review and Framework for Concept Drift Analysis in Process Mining. Algorithms 2020, 13, 161. [Google Scholar] [CrossRef]
- Sato, D.M.V.; De Freitas, S.C.; Barddal, J.P.; Scalabrin, E.E. A Survey on Concept Drift in Process Mining. ACM Comput. Surv. 2021, 54, 189:1–189:38. [Google Scholar] [CrossRef]
- Bose, R.P.J.C.; van der Aalst, W.M.P.; Žliobaitė, I.; Pechenizkiy, M. Dealing With Concept Drifts in Process Mining. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 154–171. [Google Scholar] [CrossRef] [PubMed]
- ManojKumarM, V.; Thomas, L.; Basava, A. Capturing the Sudden Concept Drift in Process Mining. In ATAED@Petri Nets/ACSD; 2015; Available online: https://api.semanticscholar.org/CorpusID:18068152 (accessed on 26 November 2023).
- Martinez-Millana, A.; Lizondo, A.; Gatta, R.; Vera, S.; Salcedo, V.T.; Fernandez-Llatas, C. Process Mining Dashboard in Operating Rooms: Analysis of Staff Expectations with Analytic Hierarchy Process. Int. J. Environ. Res. Public Health 2019, 16, 199. [Google Scholar] [CrossRef]
- Augusto, A.; Conforti, R.; Dumas, M.; La Rosa, M. Split Miner: Discovering Accurate and Simple Business Process Models from Event Logs. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Pulsanong, W.; Porouhan, P.; Tumswadi, S.; Premchaiswadi, W. Using inductive miner to find the most optimized path of workflow process. In Proceedings of the 2017 15th International Conference on ICT and Knowledge Engineering (ICT&KE), Bangkok, Thailand, 22–24 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Namaki Araghi, S. LivingLabHospital_Interpreted Location Event Logs. Available online: https://data.mendeley.com/datasets/v5kc7chhpv/1 (accessed on 26 November 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distinguished Characteristics | Challenges |
|---|---|
| D1: Exhibit Substantial Variability | C1: Design Dedicated / Tailored Methodologies and Frameworks |
| D2: Value the Infrequent Behaviour | C2: Discover Beyond Discovery |
| D3: Use Guidelines and Protocols | C3: Mind the Concept Drift |
| D4: Break the glass | C4: Deal with Reality |
| D5: Consider Data at Multiple Abstraction Levels | C5: Do it Yourself |
| D6: Involve a Multidisciplinary Team | C6: Pay Attention to Data Quality |
| D7: Focus on the Patient | C7: Take Care of Privacy and Security |
| D8: Think about White-box Approaches | C8: Look at the Process through the Patient’s Eyes |
| D9: Generate Sensitive and Low-Quality Data | C9: Complement HISs with the Process Perspective |
| D10: Handle Rapid Evolutions and New Paradigms | C10: Evolve in Symbiosis with the Development in the Healthcare Domain |
| Activity | Deviation | PAC |
|---|---|---|
| c | j | Human-related |
| b | k | Environmental |
| c | h | Rules and procedure |
| j | i | Human-related |
| c | e | Rules and procedure |
| g | h | Equipment |
| ... | ... | ... |
| Activity | Deviation | PAC |
|---|---|---|
| Enter_consultation | Box Consultation | Rules and procedure |
| Reception_Waiting_room | Registration_Priorities | Rules and procedure |
| Registration | Reception_Waiting_room | Rules and procedure |
| Waiting_room 5 | Registration | Rules and procedure |
| Waiting_room 5 | Exam Room UROLOGY | Rules and procedure |
| Box_Consultation | Waiting_room 5 | Human-related |
| Box_Consultation | Registration | Environmental |
| Checkout_Office_UROLOGY | Registration | Rules and procedure |
| Paramedical programming | Exit | Equipment |
| Flowmetering | Waiting_room 5 | Human-related |
| Post_consultation | Box_Consultation | Rules and procedure |
| Post_consultation | Waiting_room 5 | Human-related |
| Post_consultation | Exit | Equipment |
| Exit | Checkout_Office_UROLOGY | Rules and procedure |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Namaki Araghi, S.; Fontanili, F.; Sarkar, A.; Lamine, E.; Karray, M.-H.; Benaben, F. DIAG Approach: Introducing the Cognitive Process Mining by an Ontology-Driven Approach to Diagnose and Explain Concept Drifts. Modelling 2024, 5, 85-98. https://doi.org/10.3390/modelling5010006
Namaki Araghi S, Fontanili F, Sarkar A, Lamine E, Karray M-H, Benaben F. DIAG Approach: Introducing the Cognitive Process Mining by an Ontology-Driven Approach to Diagnose and Explain Concept Drifts. Modelling. 2024; 5(1):85-98. https://doi.org/10.3390/modelling5010006
Chicago/Turabian StyleNamaki Araghi, Sina, Franck Fontanili, Arkopaul Sarkar, Elyes Lamine, Mohamed-Hedi Karray, and Frederick Benaben. 2024. "DIAG Approach: Introducing the Cognitive Process Mining by an Ontology-Driven Approach to Diagnose and Explain Concept Drifts" Modelling 5, no. 1: 85-98. https://doi.org/10.3390/modelling5010006
APA StyleNamaki Araghi, S., Fontanili, F., Sarkar, A., Lamine, E., Karray, M.-H., & Benaben, F. (2024). DIAG Approach: Introducing the Cognitive Process Mining by an Ontology-Driven Approach to Diagnose and Explain Concept Drifts. Modelling, 5(1), 85-98. https://doi.org/10.3390/modelling5010006