Abstract
Business and science are using sentiment analysis to extract and assess subjective information from the web, social media, and other sources using NLP, computational linguistics, text analysis, image processing, audio processing, and video processing. It models polarity, attitudes, and urgency from positive, negative, or neutral inputs. Unstructured data make emotion assessment difficult. Unstructured consumer data allow businesses to market, engage, and connect with consumers on social media. Text data are instantly assessed for user sentiment. Opinion mining identifies a text’s positive, negative, or neutral opinions, attitudes, views, emotions, and sentiments. Text analytics uses machine learning to evaluate “unstructured” natural language text data. These data can help firms make money and decisions. Sentiment analysis shows how individuals feel about things, services, organizations, people, events, themes, and qualities. Reviews, forums, blogs, social media, and other articles use it. DD (data-driven) methods find complicated semantic representations of texts without feature engineering. Data-driven sentiment analysis is three-tiered: document-level sentiment analysis determines polarity and sentiment, aspect-based sentiment analysis assesses document segments for emotion and polarity, and data-driven (DD) sentiment analysis recognizes word polarity and writes positive and negative neutral sentiments. Our innovative method captures sentiments from text comments. The syntactic layer encompasses various processes such as sentence-level normalisation, identification of ambiguities at paragraph boundaries, part-of-speech (POS) tagging, text chunking, and lemmatization. Pragmatics include personality recognition, sarcasm detection, metaphor comprehension, aspect extraction, and polarity detection; semantics include word sense disambiguation, concept extraction, named entity recognition, anaphora resolution, and subjectivity detection.
1. Introduction
Sentiment analysis (SA) is gaining popularity in business and science, in which natural language processing (NLP), computational linguistics, text analysis, image processing, and video processing are used to extract and analyze subjective information from the web, social media, and other sources. It can identify positive, negative, or neutral data, and it can be modeled to focus on polarity, sentiments, urgency, and goals. Most global data are unstructured, making it difficult to assess people’s emotions. Google Play and App Store apps require user reviews and ratings to locate the best ones. Governments and businesses need unstructured consumer data to find information sources, and social media is an ideal tool for companies to market, communicate, and connect with consumers. SA quickly analyzes text data to understand the user’s perspective. Opinion mining (OM) involves identifying the text’s positive, negative, or neutral opinions, views, attitudes, perceptions, emotions, and sentiments. Text analytics uses machine learning algorithms to analyze “unstructured” natural language text data. These data can help companies to make decisions and generate more money by providing valuable insights. SA examines how individuals feel about goods, services, organizations, people, events, themes, and qualities. It is used in many real-life situations, such as review sites, forums, blogs, social media, and other writing forms. Research is developing Artificial Intelligence (AI) approaches for many tasks using supervised or unsupervised methods, such as Support Vector Machines (SVMs) and the Naive Bayes Algorithm. Deep learning (DL) algorithms may uncover complicated semantic representations of texts in data without feature engineering. Data-driven sentiment analysis comprises three levels: document, phrase, and aspect. Document-level sentiment analysis (DLSA) ranks documents by how they make people feel. Sentence-level sentiment analysis (SLSA) categorizes each phrase in a document, and subjectivity classification classifies sentences as opinionated or non-opinionated. Aspect-level sentiment analysis (ABSA) outperforms DLSA and SLSA, but linking the target and surrounding terms is difficult. Every minute, millions of individuals contribute comments, blogs, news articles, and other content to micro-blogging platforms for social networking purposes. Sentiment analysis examines written opinions and uses vocabulary to determine the tones of social media comments. Emotional contagion in social sciences can lead to synchronized behavior and the capacity to follow other people’s moods in real time, even if individuals are not paying attention to this information. Social networks promote happiness via emotional contagion.
2. Materials and Methods/Methodology
2.1. Domains of Our Study
2.1.1. YouTube Sentiment Analysis
Text data can be utilised for cost-effective sentiment analysis, frequently employing the Naive Bayes Algorithm, Support Vector Machines, and Accuracy Scores. Twitter sentiment research has shown that how individuals feel affects social, political, cultural, and economic events. Deep Learning for Hate Speech Detection in Tweets is one of the most helpful sentiment classification models, outperforming the top char/word methods.
2.1.2. Sentiment Analysis of Online Customers Sites
This research examines how written comments and emotions affect consumer and citizen choices through text mining, sentiment analysis, views, and solutions.
2.1.3. Twitter Sentiment Analysis
Sentiment analysis is a technique used by businesses and in science to extract subjective information from web and social media sources using natural language processing, text and image analysis, and machine learning. It helps to identify the polarity, attitudes, and urgency of text and assesses the opinions, emotions, and sentiments of individuals. Unstructured consumer data can be used by firms to make informed decisions and improve marketing strategies. The process involves several layers of analysis, including syntactic, semantic, and pragmatic analyses.
2.1.4. Sentiment Analysis of Social Media
Microblogging platforms allow users to express their thoughts in various fields. Microblog data are both simple and hard to analyze. This study analyzes microblogging sentiment using social ties, formalizes sentiment analysis, and offers a supervised approach for noisy and short messages. Sentiment analysis uses NLP, text analysis, and statistics to identify the “emotional attitude” of a text. This study analyzes Twitter’s thoughts using text feature extraction and classification and emoji, picture, and voice processing.
3. Related Work
According to reference [1], Social media platforms are crucial due to their ability to generate a substantial volume of data in diverse formats. Carrying out sentiment analysis on social media is crucial as it provides valuable insights into people’s opinions and emotions. The work emphasizes the need for researchers to investigate social media analysis and its major issues, inspiring them to focus on sentiment analysis over social media.
The authors of [2] introduced social sensing and sentiment analysis paradigms, highlighting the usefulness of information that is shared on Online Social Networks (OSNs) in real-world applications. It also explains the sentiment analysis framework and presents two real-world applications for both social sensing and sentiment analysis.
The authors of reference [3] proposed a custom social media platform that automates the task of analyzing users’ reactions and sentiments on a post, generating reports based on the outcomes. The platform will have the ability to perform sentiment analysis on all user activities, which can aid admins in decision-making processes and identifying users who require special attention.
The authors of [4] discussed the potential of using social media data for profitable business research models, and how machine learning and NLP algorithms are being developed to analyze people’s opinions and attitudes. The focus of their study is on the prospects of deep learning and optimization-based methods in sentiment analysis and their effectiveness in improving learning models. Datasets and their characteristics are also examined.
The authors of [5] explored sentiment analysis and machine learning techniques applied to Twitter data related to Goods and Service Tax (GST) collected by web scraping. The study calculated the sentiments of positive, negative, and neutral tweets and used data visualization to find patterns. Machine learning was applied to predict future trends based on its current uses.
The authors of [6] discussed that Sentiment analysis is utilised by various industries, including management and social media marketing, to assess people’s emotions towards a specific subject matter. Using natural language processing to mine data for emotional signals and assess the polarity of the public perspective on the issue, this research focuses on a machine learning-based model that monitors public opinion on popular topics on Twitter.
The benefits, drawbacks and gaps have tabulated in Table 1.

Table 1.
Prior research and its gaps, with benefits and drawbacks.
4. Strategy for Bridging the Aforementioned Research GAPS
Our Primary Research
Sentiment analysis analyzes articles for positive or negative comments, questions, and requests. Natural language processing and information extraction extracts a writer’s feelings from their comments, queries, and demands. Sentiment analysis reveals a person’s or document’s tone. The rapid expansion of the internet and the exchange of public opinions are driving the current fascination with sentiment analysis. Online material is organized and unstructured. Evaluating these data to determine the public’s mood is tricky. Document-based sentiment analysis determines the writing’s tone. Sentence-based emotional analysis may also be used. Sentiment analysis may recognize words and phrases. Users or customers provide distinct facts or perspectives. Sentiment analysis determines an emotional goal. A paragraph’s goal must be determined even if it mentions several things. It expresses feeling. Negative emotions include disdain, rage, and horror (which denote a state of sorrow, dejection, or disappointment on the part of the writer). The emotions’ positivity, negativity, or objectivity are rated. This study improves the NLP model for textual sentiment detection. Videos, emoticons, and images are excluded from our context, (Table 2) accumulates the NLP methods of the study approach.
Table 2.
NLP approach.
5. The Sentiment as Determined Using the NLP Method
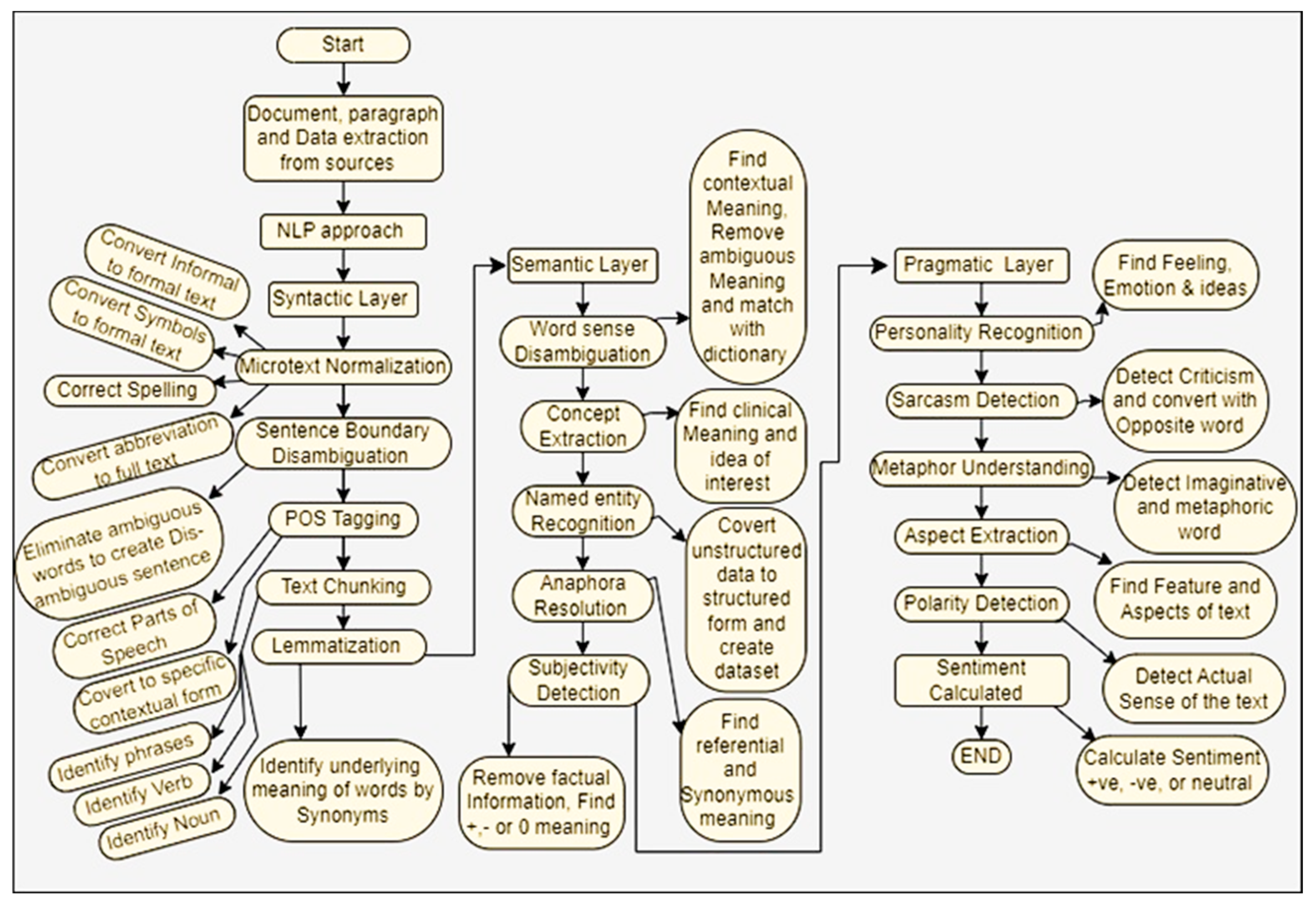
5.1. Syntactic Layer as per Figure 1
5.1.1. S-1: Microtext Normalization
Based on [7], this study highlights the need to translate plain English into formal language, emotions, and acronyms before applying NLP techniques. Microtext normalization, similar to spelling correction, is necessary due to frequent and severe spelling mistakes. Lexicon-based spelling correction algorithms cannot normalize microtext, as non-standard words are used intentionally.
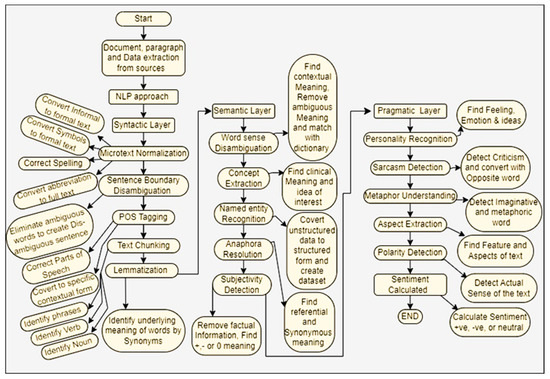
Figure 1.
Model/blueprint sentiment as determined using the NLP method.
Figure 1.
Model/blueprint sentiment as determined using the NLP method.
5.1.2. S-2: Sentence Boundary Disambiguation
Sentence boundary disambiguation (SBD) is a critical task in NLP that is carried out to identify the boundaries between sentences. It is necessary for machine translation, text summarization, and speech recognition. SBD can be performed using statistical models, rule-based approaches, or a combination of both. Despite being challenging, advances in ML and NLP techniques have made it possible to achieve high levels of accuracy [8].
5.1.3. S-3: POS Tagging
Part-of-speech (POS) tagging is a technique used in NLP to classify words in a corpus based on their part of speech. It considers the definition and context of the word to determine its classification [9].
5.1.4. S-4: Text Chunking
Text chunking, also known as shallow parsing, follows POS tagging to structure the phrases in a text by grouping the words into “chunks”. This involves identifying the components of a sentence such as noun groups and verb groups without describing their internal structures or functions in detail. Chunking works in addition to POS tagging [10].
5.1.5. S-5: Lemmatization
Lemmatization is a pre-processing method in NLP that breaks a word down to its underlying meaning to identify commonalities. It involves identifying lemmas, which are the base forms of words. For example, “better” would be converted to “good” by a lemmatization algorithm [11].
5.2. Semantic Layer as per Figure 1
5.2.1. S-1: Word Sense Disambiguation
Word sense disambiguation is used in NLP to identify a word’s meaning in context. NLP systems face challenges in recognizing words due to ambiguity. This is due to variations in word definitions across different dictionaries and text corpuses [12].
5.2.2. S-2: Concept Extraction
The text describes a delay in the camera’s focusing ability. The second part mentions the use of concept extraction in NLP to extract clinical information from the text for decision making and quality improvement in healthcare [13].
5.2.3. S-3: Named Entity Recognition
Named entity recognition categorizes data using natural language processing. It is an area of AI that automates significant data classification for unstructured text and datasets [14].
5.2.4. S-4: Anaphora Resolution
The process of analyzing the connection between an anaphor (also known as a repeated reference) and its antecedent is referred to as anaphora resolution (i.e., the previous mention of the entity). Since it typically requires an interpretation that extends beyond the boundaries of individual sentences, the process is interesting [15].
5.2.5. S-5: Subjectivity Detection
According to [16], subjectivity identification in NLP involves removing factual or neutral information from online evaluations. It is a component of sentiment analysis and classifies text as either subjectively positive or negative, or objectively neutral.
5.3. Pragmatics Layer as per Figure 1
5.3.1. S-1: Personality Recognition
The research presented in [17] indicates the importance of automated personality detection systems in social networks. The complex nature of style traits in creative works, such as blogs and posts, present challenges for personality-based sentiment analysis. Various personality models, such as MBTI and the Big Five Factor Personality Model, are used in cyber personality research.
5.3.2. S-2: Sarcasm Detection
Sarcasm detection is a subcategory of sentiment analysis in the field of natural language processing (NLP). Unlike sentiment analysis, sarcasm detection specifically aims to identify sarcasm within a text rather than determine the overall sentiment. Thus, the primary goal of sarcasm detection is to determine if a given text contains any sarcastic remarks [18].
5.3.3. S-3: Metaphor Understanding
When we refer to an NLP metaphor, we are talking about a story that is both relevant and symbolic. Such a tale assists us in navigating through the conscious resistance of the client and enables them to establish connections on a deeper level [19].
5.3.4. S-4: Aspect Extraction
The field of “aspect extraction” within natural language processing has received considerable attention in research. This area focuses on identifying the characteristics of text to gather information. An example of this is aspect-based sentiment analysis (ABSA), which requires the identification of aspects before the sentiment can be analyzed [20].
5.3.5. S-5: Polarity Detection
Initially, polarity detection was focused on the binary classification problem of determining whether a text has a positive or negative sentiment. However, modern research has shifted towards using a float L1, +1 to quantify the intensity of polarity. With the exponential growth of user-generated content (UGC) on the web, natural language processing (NLP) has become crucial for information aggregation, although computer systems still have limitations in their ability to comprehend this vast amount of data [21].
6. Algorithms for Textual Sentiment Analysis
6.1. Understanding Language
According to [22], high-level symbolic abilities, which are currently lacking in the bulk of natural language processing systems, are necessary to comprehend natural language. A great majority of current NLP systems lack the sophisticated symbolic capabilities required for natural language interpretation:
#1. Dynamic binding creation and propagation;
#2. Recursive and component structure manipulation;
#3. Lexical, semantic, and episodic memory acquisition access;
#4. Control over various learning/processing modules and information flow between such units;
#5. The grounding of fundamental linguistic structures in perceptual and motor experiences, such as objects and actions;
#6. Illustration of an abstract idea;
#7. Language occupies a space between perception and cognition; it is a transparent material that allows anything we transmit through it to color and sharpen the outside environment.
6.2. Tf-idf Weighting Scheme
According to [23]:
- I.
- Tf-idf:
- tf = term frequency;
- df = document frequency;
- idf = inverse document frequency.
- II.
- Replace one hot encoding with tf-idf weight:
- tf = tf(t,D) = log[freq (t,D)] + 1;
- idf = idf(t) = log(n/N);
- n = number of documents;
- N = number of documents contain term, t.
6.3. Word Embeddings
According to [24], the embeddings of a word are d-dimensional vectors that represent semantic information.
- I.
- CBOW tries to predict a context word when given a word (the goal is to calculate the embedding of the word w);
- II.
- One may construct one’s own:
- (a)
- Make a random d-dimensional word with embedded word forms.
- (b)
- Create a powerful neural network that takes as input words that are randomly selected. These embeddings are to be trained and improved upon by embedding.
- (c)
- Make a loss function.
- (d)
- To train the network, backpropagate the mistake to the input layer.
- (e)
- The foundation is backpropagation, which is excellent for anybody wanting to design their own word embedding technique in Python. Otherwise, utilize Gensim, a fantastic word2vec package that employs the CBOW model.
6.4. Initial Stages of Text Processing
According to [25], these initial stages of text processing are often followed by more advanced techniques, such as sentiment analysis, topic modeling, and text classification, which can extract more complex and nuanced information from the text [26,27,28]:
Tokenization;
- Cut the character sequence into word tokens.
Normalization;
- Map the text and query the term to the same form.
Stemming;
- One may wish to use different forms of a root to match authorization.
Stop-words;
- One may omit very common words (or not), such as the, a, to, and of.
7. Conclusions
Google Assistant, Amazon Alexa, and Apple Siri are popular due to technology. Voice recognition, NLP, and speech synthesis enable communication. Voice assistants can call, search, play music, and more. Consumer research sentiment analysis in NLP can uncover customer purchase patterns, preferences, and feedback, providing valuable insights into consumer behavior. Social media has significantly facilitated sentiment analysis, enabling marketers and salespeople to tailor their strategies to match customer behaviors. NLP algorithms are used by email providers to categorize emails by tone, with many being sent to the spam folder. Automated email sorting saves time. NLP’s analysis of public opinion is beneficial for financial traders and corporations, as it tracks world news and may increase corporate revenues using data. The rise of fake news on social media has become a global concern, causing worry and stress among people. NLP algorithms can help to evaluate the linguistic reliability of information, which is especially useful during times of worldwide pandemics or natural disasters such as cyclones. Effective writing is crucial for successful communication through email or blog posts. The use of proper grammar and spelling is important for engaging readers, and NLP has popularized grammar and spell checks to enhance writing quality. Grammarly is a user-friendly tool that enables the faster and more accurate writing of essays and emails. Google’s autocomplete feature offers suggestions for text searches, making the process quicker and more convenient. The feature uses NLP and language analysis to generate the suggested search terms, allowing users to select from a list instead of typing out the entire query.
Author Contributions
Conceptualization, M.R. and A.M.S.; methodology, M.R. and S.T.; writing—original draft preparation, M.R. and A.M.S.; writing—review and editing, M.R., A.M.S. and N.S.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No data Availability.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rajput, L.; Gupta, S. Sentiment Analysis Using Latent Dirichlet Allocation for Aspect Term Extraction. J. Comput. Mech. Manag. 2023, 2, 8–13. [Google Scholar]
- Ducange, P.; Fazzolari, M. Social sensing and sentiment analysis: Using social media as useful information source. In Proceedings of the 2017 International Conference on Smart Systems and Technologies (SST), Osijek, Croatia, 18–20 October 2017. [Google Scholar]
- Tanna, D.; Dudhane, M.; Sardar, A.; Deshpande, K.; Deshmukh, N. Sentiment Analysis on social media for Emotion Classification. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020. [Google Scholar]
- Saxena, P.; Sharma, S. Systematic Literature Review for Sentiment Analysis Using Big Data social media Streams. In Proceedings of the 2022 5th International Conference on Contemporary Computing and Informatics (IC3I), Uttar Pradesh, India, 14–16 December 2022. [Google Scholar]
- Dansana, D.; Adhikari, J.D.; Mohapatra, M.; Sahoo, S. An approach to analyse and Forecast Social media data using Machine Learning and Data Analysis. In Proceedings of the 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 13–14 March 2020. [Google Scholar]
- Sathya, V.; Venkataramanan, A.; Tiwari, A.; PS, D.D. Ascertaining Public Opinion Through Sentiment Analysis. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019. [Google Scholar]
- Satapathy, R.; Guerreiro, C.; Chaturvedi, I.; Cambria, E. Phonetic-Based Microtext Normalization for Twitter Sentiment Analysis. In Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Pallavi, B.G.; Kumar, E.R.; Karnati, R.; Kumar, R.A. LSTM Based Named Entity Chunking and Entity Extraction. In Proceedings of the 2022 First International Conference on Artificial Intelligence Trends and Pattern Recognition (ICAITPR), Hyderabad, India, 10–12 March 2022. [Google Scholar]
- Kowsher, M.; Tahabilder, A.; Sarker, M.M.; Sanjid, M.Z.; Prottasha, N.J. Lemmatization Algorithm Development for Bangla Natural Language Processing. In Proceedings of the 2020 Joint 9th International Conference on Informatics, Electronics & Vision (ICIEV) and 2020 4th International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Kitakyushu, Japan, 26–29 August 2020. [Google Scholar]
- Smelyakov, K.; Karachevtsev, D.; Kulemza, D.; Samoilenko, Y.; Patlan, O.; Chupryna, A. Effectiveness of Preprocessing Algorithms for Natural Language Processing Applications. In Proceedings of the 2020 IEEE International Conference on Problems of Infocommunications. Science and Technology (PIC S&T), Kharkiv, Ukraine, 6–9 October 2020; pp. 187–191. [Google Scholar]
- Khin, N.P.P.; Lynn, K.T. Medical concept extraction: A comparison of statistical and semantic methods. In Proceedings of the 18th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Kanazawa, Japan, 26–28 June 2017. [Google Scholar]
- Shatalov, O.; Ryabova, N. Named Entity Recognition Problem for Long Entities in English Texts. In Proceedings of the 2021 IEEE 16th International Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 22–25 September 2021. [Google Scholar]
- Dahou, A.H.; Abdelmoazz, M.; Cheragui, M.A. Arabic Anaphora Resolution System Using New Features: Pronominal and Verbal Cases. In Analysis and Application of Natural Language and Speech Processing; Springer: Cham, Switzerland, 2023; pp. 101–121. [Google Scholar]
- Khummongkol, R.; Samart, A.; Chitthong, S.; Yokota, M. The Prototype Development of Thai Language Understanding based on Mental Image Directed Semantic Theory. In Proceedings of the 2021 25th International Computer Science and Engineering Conference (ICSEC), Chiang Rai, Thailand, 18–20 November 2021. [Google Scholar]
- Paik, J.H. A novel TF-IDF weighting scheme for effective ranking. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013. [Google Scholar]
- Cobos, R.; Jurado, F.; Blazquez-Herranz, A. A Content Analysis System That Supports Sentiment Analysis for Subjectivity and Polarity Detection in Online Courses. IEEE Rev. Iberoam. Tecnol. Aprendiz. 2019, 14, 177–187. [Google Scholar] [CrossRef]
- KN, P.K.; Gavrilova, M.L. Latent Personality Traits Assessment from Social Network Activity Using Contextual Language Embedding. IEEE Trans. Comput. Soc. Syst. 2022, 9, 638–649. [Google Scholar]
- Manohar, M.Y.; Kulkarni, P. Improvement sarcasm analysis using NLP and corpus-based approach. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017. [Google Scholar]
- Florou, E.; Perifanos, K.; Goutsos, D. Neural Embeddings for Metaphor Detection in a Corpus of Greek Texts. In Proceedings of the 9th International Conference on Information, Intelligence, Systems and Applications (IISA), Zakynthos, Greece, 23–25 July 2018. [Google Scholar]
- Vargas, D.S.; Pessutto, L.R.C.; Moreira, V.P. Simple Unsupervised Similarity-Based Aspect Extraction. In Computational Linguistics and Intelligent Text Processing; Springer: Cham, Switzerland, 2023; pp. 619–631. [Google Scholar]
- Putra, S.J.; Gunawan, M.N.; Khalil, I.; Mantoro, T. Sentence boundary disambiguation for Indonesian language. In Proceedings of the 19th International Conference on Information Integration and Web-based Applications & Services, Salzburg, Austria, 4–6 December 2017. [Google Scholar]
- Wang, B.; Wang, A.; Chen, F.; Wang, Y.; Kuo, C.C.J. Evaluating word embedding models: Methods and experimental results. APSIPA Trans. Signal Inf. Process. 2019, 8, e19. [Google Scholar] [CrossRef]
- Mangmang, G.B.; Feliscuzo, L.; Maravillas, E.A. Descriptive Feedback on Interns’ Performance using a text mining approach. In Proceedings of the 14th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Chiang Mai, Thailand, 30 October–1 November 2019. [Google Scholar]
- Zhonghua, C.; Goyal, S.B.; Zhonghua, C.; Goyal, S.B.; Rajawat, A.S. Smart contracts attribute-based access control model for security & privacy of IoT system using blockchain and edge computing. J. Supercomput. 2024, 80, 1396–1425. [Google Scholar] [CrossRef]
- Barhanpurkar, K.; Mandlik, N.; Rajawat, A.S.; Goyal, S.B.; Mihaltan, T.C.; Verma, C.; Raboaca, M.S. Unveiling the Post-Covid Economic Impact Using NLP Techniques. In Proceedings of the 2023 15th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Bucharest, Romania, 29–30 June 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Pant, P.; Rajawat, A.S.; Goyal, S.B.; Kemat, B.B.; Mihălţan, T.C.; Verma, C.; Răboacă, M.S. Machine Learning Techniques for Analysis of Mars Weather Data. In Proceedings of the 2023 15th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Bucharest, Romania, 29–30 June 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Kumar, S.; Gupta, U.; Singh, A.K.; Singh, A.K. Artificial Intelligence: Revolutionizing Cyber Security in the Digital Era. J. Comput. Mech. Manag. 2023, 2, 31–42. [Google Scholar]
- Randhawa, P.; Shanthagiri, V.; Kumar, A. Recognition of violent activity response using machine learning methods with wearable sensors. J. Adv. Res. Dyn. Control. Syst. 2019, 11, 592–601. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).