Abstract
The increasing number of online communities has led to the significant growth in digital data in multiple languages on the Internet. Consequently, language processing and information retrieval have become important fields in the era of the Internet. Stemming, a crucial preprocessing tool in natural language processing and information retrieval, has been extensively explored for high-resource languages like English, German, and French. However, more extensive studies regarding stemming in the context of the Hausa language, an international language that is widely spoken in West Africa and one of the fastest-growing languages globally, are required. This paper presents a rule-based model for stemming Hausa words. The proposed model relies on a set of rules derived from the analysis of Hausa word morphology and the rules for extracting stem forms. The rules consider the syntactic constraints, e.g., affixation rules, and performs a morphological analysis of the properties of the Hausa language, such as word formation and distribution. The proposed model’s performance is evaluated against existing models using standard evaluation metrics. The evaluation method employed Sirstat’s approach, and a language expert assessed the system’s results. The model is evaluated using the manual annotation of a set of 5077 total words used in the algorithm, including 2630 unique words and 3766 correctly stemmed Hausa words. The model achieves an overall accuracy of 98.66%, demonstrating its suitability for use in applications such as natural language processing and information retrieval.
1. Introduction
A language is a set of rules and symbols used to communicate ideas or spread information [1]. Natural language processing (NLP) in computer science aims to enable computers to understand and generate human language, facilitating human–computer interaction; NLP enables computers to express in plain language how people use language [2]. In [3], the authors describe Information retrieval (IR) as a process used to search and retrieve information from a large collection of data, such as databases, documents, or the web, to provide users with relevant information based on their search query. NLP caters to users who cannot learn new languages quickly, making human–computer interaction more accessible [4]. NLP assists computers in recognizing how humans use language [1]. NLP is vital due to user-generated content, with Hausa NLP (HNLP) being a growing field for the Hausa language [2].
Hausa is a Chadic language which belongs to the Afroasiatic phylum. Over 100 million individuals speak the language, with the majority of them living in Northern and Southern Nigeria and the Republic of Niger [5,6]. Two types of writing systems are being used in the Hausa language: Ajami and Boko. The Ajami, who employ adapted Arabic alphabets, were first recognized in the early 17th century. The colonial administration implemented the Latin-based Boko system in the 1930s. In the increasingly written Hausa literature, including books, novels, newspapers, and plays, the Boko system is the most widespread. Several high-level degrees (master’s and Ph.D.) in Hausa are available at institutions in the United States, the United Kingdom, and Germany, etc. [7].
The main dialects of Hausa can be divided into Eastern, Western, Northern, and Southern dialects. The Eastern Hausa dialects include Kananci, Dauranci, Gudduranci, Bausanci, and Hadejanci. The Eastern Hausa dialects include Kutebanci, Katsinanci, Arewanci, Sakkwatanci, and Kurwayanci. The bridge connecting Eastern and Western dialects is Katsina. The Northern Hausa dialects are known as Arewanci. Zazzaganci is the primary Southern dialect in Zaria. Standard Hausa is based on the Kananci dialect; it has been chosen as the language to be used for writing in books, newspapers, radio broadcasts, and television [2].
Researchers take different types of features (manual or automatic) from provided data to model a language. Numerous NLP applications exist, and each type of application may call for a particular set of features. For instance, a linguist might use stemmers to learn and develop new vocabulary [8]. HNLP focuses on Hausa’s unique challenges [6].
Stemming is reducing morphological differences in words to their root form. For instance, the words “maintain”, “maintaining”, and “maintenance” are matched with their root words through stemming; it aids vocabulary development [9]. Despite Hausa’s prevalence, there is little stemming research, making it a resource gap. This study proposes a rule-based stemming approach with reference lookup to improve Hausa stemming algorithms, addressing over-stemming and under-stemming issues [7,10].
This research seeks to enhance Hausa language processing, benefiting Hausa speakers and potentially advancing NLP for other under-resourced languages. The proposed stemming algorithm aims to accurately handle Hausa text and mitigate stemming challenges. In this study, a rule-based stemming approach with reference lookup will be employed to address these limitations. Additionally, the utilization of exceptional cases will be introduced to further refine the stemming algorithm tailored explicitly for Hausa text. The aim is to develop an improved stemming algorithm that can accurately handle Hausa language text and mitigate the issues of over-stemming and under-stemming.
2. Literature Review
2.1. Natural Language Processing (NLP)
Natural language processing (NLP) is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, particularly with how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of “understanding” the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents, as well as categorize and organize the documents themselves [11].
Natural language processing (NLP) caters to those users who do not have enough time to learn new languages or become proficient in them because not all users are familiar with machine-specific language. In reality, NLP is a branch of AI and linguistics that aims to help computers comprehend sentences or words written in human languages. It was created to make the user’s work easier and to fulfill their desire to speak naturally to the computer [4].
A few of the researched tasks of NLP are automatic summarization (which produces an understandable summary of a set of text and provides summaries or detailed information of text of a known type), Co-Reference Resolution (refers to a sentence or larger set of text that determines all words that refer to the same object), Discourse Analysis (the task of identifying the discourse structure of connected text, i.e., the study of text in relation to social context), machine translation (automated translation of text from one language to another), morphological segmentation (which refers to breaking words into individual meaning-bearing morphemes), Named Entity Recognition (used for information extraction to recognize and classify name entities), Optical Character Recognition (OCR is used for automatic text recognition by translating printed and handwritten text into machine-readable format), Part of Speech Tagging (describes a sentence and determines the part of speech for each word), and so on [1,4].
2.2. Morphology
The beginnings of words, or morphology, are called morphemes (the smallest meaningful constituent of a linguistic expression). For instance, the word “pre-cancelation” can be broken down morphologically into three distinct morphemes: the prefix “pre”, the root “cancella”, and the suffix “ation”. For the most part, morphemes always have the same meaning, so humans can break down any unknown word into morphemes to comprehend its meaning. For instance, the suffix “-ed” can be used to indicate that a verb’s action occurred in the past. Lexical morphemes are words that cannot be broken up and have meaning on their own (e.g., table, chair). Grammatical morphemes are the words (such as -ed, -ing, -est, -ly, and -ful) that are combined with the lexical morpheme (e.g., worked, consulting, smallest, likely, use) [4].
The grammatical morphemes that are used in conjunction are referred to as bound morphemes (-ed, -ing, etc.). Inflectional and derivational morphemes are two categories of bound morphemes. The various grammatical categories, such as tense, gender, person, mood, aspect, definiteness, and animacy, change when inflectional morphemes are added to a word. For instance, the root park becomes parked when the inflectional morpheme “ed” is added. When combined with a word, derivative morphemes alter the semantic meaning of that word. For instance, the word “normalize” becomes a verb when the bound morpheme “ize” is added to the root “normal”; therefore, the word “normalize” was previously an adjective (normal) [4].
2.3. Stemmer
Stemmer is a system that accepts inflected words as input and produces root words as output. The inflected word may be singular, plural, or have additional affixes. The correct word with the correct dictionary meaning is the root word [12].
2.4. Application of Stemming Algorithm
Stemming is a necessary preprocessing step for applications such as information extraction (IE), information retrieval (IR), text classification (TC), text clustering (TClu), question answering (QA), text summarizations (TS), machine translation (MT), text segmentation (TS), indexing (Ind), automatic speech recognition (ASR), and language generation. For many NLP applications, stemming enhances performance by lowering the time and space complexity [13].
The purpose of stemming is to return the derived and inflected words from a commonly written word form to their basic form (the root or stem). Moreover, a stem can be described as a morpheme or a group of concatenated morphemes that can take an affix [1]. Text stemming is an intricate and important step in many query systems, in indexing, in web search engines, and in IR systems, as well as in document classification and linguistic feature extraction. By truncating redundant terms, it has the advantage of lowering the amount of storage needed. In fact, it improves the likelihood of a match when comparing documents and streamlining the vocabulary process [14].
A stemming algorithm is a computerized strategy for reducing all words with the same root form to the same form by removing any affixes or infixes from those words. Stemming programs are sometimes known as “stemmers” or “stemming algorithms” [7]. One of the benefits of stemming is that it improves information retrieval (IR) performance by offering morphological variations in key phrases to match documents to the provided query. The terms in the request might have several different variations.
Stemming is the most basic sort of language processing employed in information retrieval systems, and it has shown to be more useful in languages with complicated morphology and a high number of variations for a single word [3]. Though text stemming began in the late sixties [15], it has experienced tremendous growth in recent years, and a large number of techniques and algorithms have been proposed to handle this task. However, designing completely unsupervised, language independent stemmers is a great challenge.
According to [16], before assigning a term to an index, stemming is normally performed by eliminating any associated suffixes and prefixes (affixes) from the term. The stemming procedure eventually increases the number of retrieved documents in an IR system since the stem of a word indicates a larger notion than the original phrase. Before applying any related algorithm, text clustering, categorization, and summarization, each requires this conversion as part of the preprocessing.
Most morphological forms of words have similar semantic interpretations and can be regarded as equivalents for IR applications. Because the meaning is the same but the word form differs, it is important to match each word form to its base form. Several stemming algorithms have been developed to accomplish this. Each algorithm tries to map morphological variants of a word, such as “introduction”, “introducing”, and “introducing”, to the term “introduce”. Some algorithms may just map them to “introduce”, which is allowed as long as they all map to the same word form, also known as the stem form. As a result, stems, rather than the original words, represent the essential terms in a query or document. The goal is to lower the total number of distinct terms in a document or query, which reduces the final output’s processing time [16].
2.5. Stemming Errors
Recognizing the types of errors a stemmer may produce is the first step in measuring the effectiveness of a given stemmer. These types of errors can aid in determining when and why they occurred, as well as their impact on stemmer performance. 1. Under-stemming errors (USEs): under-stemming a word involves deleting too little of a word; this happens when a stemming algorithm fails to reduce words to their common stem, resulting in similar words being treated as separate entities. [8]. 2. Over-stemming errors (OSEs): this occurs when a stemming algorithm excessively reduces words to their stems, resulting in different words being mapped to the same stem or when a stemmer removes too many letters from a word, resulting in a stem that is not a valid word [7]. 3. Mis-stemming errors (MSEs): The term “mis-stemming errors” refers to those errors in which the stripped characters do not make proper affixes [8].
2.6. Stemming Algorithms
Statistical: These stemmers rely on strategies and thorough research. For instance, Melucci proposed a model based on finite-state automata in which transitions between states are controlled by the probability function [15]. The types are as follows:
- o
- N-Gram method;
- o
- HMM method;
- o
- YASS method.
Truncating: These methods are related to removing a word’s suffixes or prefixes (commonly referred to as “affixes”), as the name indicates. A term is shortened at the nth sign using this simplest stemmer. In this system, terms shorter than n are kept in their current form. Short words have a higher likelihood of being stemmed [15]. The types include the following:
- o
- Lovin’s stemmer;
- o
- Porter’s stemmer;
- o
- HUSK stemmer/PAICE;
- o
- Dawson stemmer.
3. Related Work
In a study conducted by [17], entitled “An Improved Hausa Word Stemming Algorithm”, Hausa words were stemmed using a reference lookup and an affix-stripping approach involving conflation; the researcher also added additional root words to the previous paper, and the ability to handle previously unresearched words has improved the base research. The system was evaluated by the researcher using the Sirsat evaluation method, and the results were 96.9% for the Correctly Stemmed Word Factor (CSWF), Index Compression Factor (74.76%), Words Stemmed Factor (WSF) 70.44%, and average word conflation factor (59.47%). By adding the use of stop words and improving the root words, additional work can be performed to cover a wider range of Hausa words.
Ref. [7] conducted a study on “A Word Stemming Algorithm for the Hausa Language”. The researchers modified Porter’s stemmer’s algorithm using some rules to create a system for stemming Hausa text that is context-sensitive, iterative in nature, and can handle Hausa’s exceptional cases. The developed Hausa stemmer follows these rules: check length, stop words list, masculine and feminine gender markers, prefix list, suffix list, infix rule, and dictionary check, which achieved an accuracy of 73.8% for implementation with 2573 words extracted from 4 different articles in the Hausa Leadership newspaper. Because their proposed method lacked a large number of exceptional cases, it contained 26.2% of over- and under-stemming errors. Additionally, it is only available in Hausa.
In another study conducted by [10] on “Stemming Hausa Text: Using Affix-Stripping Rules and Reference Lookup”, the authors stemmed Hausa text using 78 affix-stripping rules applied in 4 steps and a reference lookup consisting of 1500 Hausa root words. The researchers examine the influence of reference lookup on the stemmer’s strength and accuracy by calculating the over-stemming index, under-stemming index, stemmer weight, incorrectly stemmed words factor, and average word conflation factor. The proposed system employs two approaches. The first method, HSTEMV1, only includes affix-stripping rules, whereas HSTEMV2 also includes a reference lookup in addition to the affix-stripping rules. Researchers discovered that using Paice’s assessment approach, reference lookup, helped reduce both over- and under-stemming errors. A comparison of HStemV1 and HStemV2 based on stemming weight reveals that a reference lookup weakens the power of an affix-stripping stemmer.
4. Method
We propose to develop a new stemming algorithm for the Hausa language that addresses the issues of over-stemming and under-stemming. Our approach will involve introducing the use of exceptional cases, developing a Hausa words dataset for stemming, and improving the performance of the previously developed Hausa word stemming algorithms.
4.1. Data Collection
The primary dataset for this research comprised Hausa texts extracted from newspapers such as Leadership Hausa, BBC Hausa, and AfriHausa. A substantial volume of text was manually gathered, organized, and processed. An online tool (https://www.tracemyip.org/tools) was used to remove irrelevant characters and duplicate words during the data cleaning phase, which was followed by further preprocessing.
4.1.1. Text Preprocessing
Text data contain noise in various forms, like emotions, punctuations, and text in different cases. Text preprocessing is a method to clean the text data and enable it to feed data to the model. Text preprocessing is the process of applying any sort of computation to shapeless raw data to change them into a format that can be handled more quickly and efficiently in another procedure. Some of the preprocessing steps are as follows:
- Remove special characters: In this step, all the punctuation from the text is removed; the string library of Python version 2.0 contains some predefined list of punctuations such as “!” $% & ’() *+, -. /:; [ ]—’.
- Lowering case: This is one of the most common preprocessing steps where the text is converted into the same case, preferably lower case.
- Tokenization: This is the first step in the preprocessing of both phases used to tokenize a sequence of text or document into sentences and change sentences into words [18].
- Remove stop words: Stop word removal is also another step of preprocessing used to frequently remove words in the text that are not relevant or have no impact on determining classifying sentiments [18]. Examples of stop words: “a”, “abin”, “akan”, “ake”, “amma”, “an”, “ana”, “ba”, “babu”, “bai”, “ban”, “baya”, “bayan”, “bisa”, “can”, “ce”, “cewa”, “ci”, “cikin”, “da”, “dab”, “daga”, “dai”, “dama”, “dan”, “daya”, “din”, “domin”, “don”, “duba”, “duk”, “dukkan”, “fa”, “fi”, “fiye”, “ga”, “gaba”, “gaban”, “haka”, “hakan”.
4.1.2. Checking for Exceptional Cases
Exceptional cases are words that have different stemming rules than similar words. For example, Hausa verbs ending in “a” are the root forms, and all others are derived forms. This rule is sometimes inconsistent, as there are others (exceptional cases) ending in “e”, “o”, “i”, or “u” as the root forms. The same is true for pluralization in Hausa nouns; nouns ending in “a” are usually considered plural. For example, “mata” (women) comes from “mace” (woman), and “yara” (boys) comes from “yaro” (boy). But, in some cases, words ending in “u” are plurals, like, for instance, the word “kujeru” (chairs) from “kujera” (chair). Therefore, there are also singular words ending in “a”. Hence, most Hausa stemming errors are a result of these inconsistencies. Examples of such words are dandano, Yartsana, dansanda, Tabarma, Magani, Nishadi, Bahaya, etc.
For example, in Table 1, words beginning with the prefix “ma” and ending with the suffixes “ci” or “nci” follow a rule that removes the prefix “ma” and the suffix “ci” or “nci”. Although the words in Table 1 share a similar structure, each requires a unique rule to be stemmed accurately.

Table 1.
Treatment of Exceptional Cases.
4.1.3. Root Words
A root words dictionary contains a list of Hausa root words that can be used to verify a word after it has undergone affixation. If the word is found in the root words dictionary, the algorithm will consider it to be a correctly stemmed word. If not, the algorithm will apply certain rules until the word is found in the dictionary., e.g., {“ADAN—Adana, Adani”, “ADDAB—Addaba”, “AF—Afa, Afu, Afi, xan’afi”, “AGAZ—agaza, agazari, agaji”, “AIK—aika, aiki, aika-aika”, “AIBAT—aibata, aibu, aibi”, “AIWAT—aiwata, aiwatar”, “BA—ba, bai, bayar”, “BA’ANT—ba’anta”, “BABANT—banbance”, “BADDAL—baddala”, “BAD—bada, badada, badi, badini”, “BAIBAY—baibaye, baibaya”, etc.} [19].
4.1.4. Affix-Stripping Rules
Affix-stripping rules are rules that remove affixes from words to obtain their root or stem. Affixes are morphemes that are attached to words to change their meaning or function. For example, the suffix “-ing” is an affix that can be attached to verbs to form the present participle. The affix-stripping rule for “-ing” would be to remove the suffix, leaving the verb stem “run” [20]. Table 2 shows some rules applied in this research.
Table 2.
Examples of some applied rules in this research.
4.2. Proposed Model
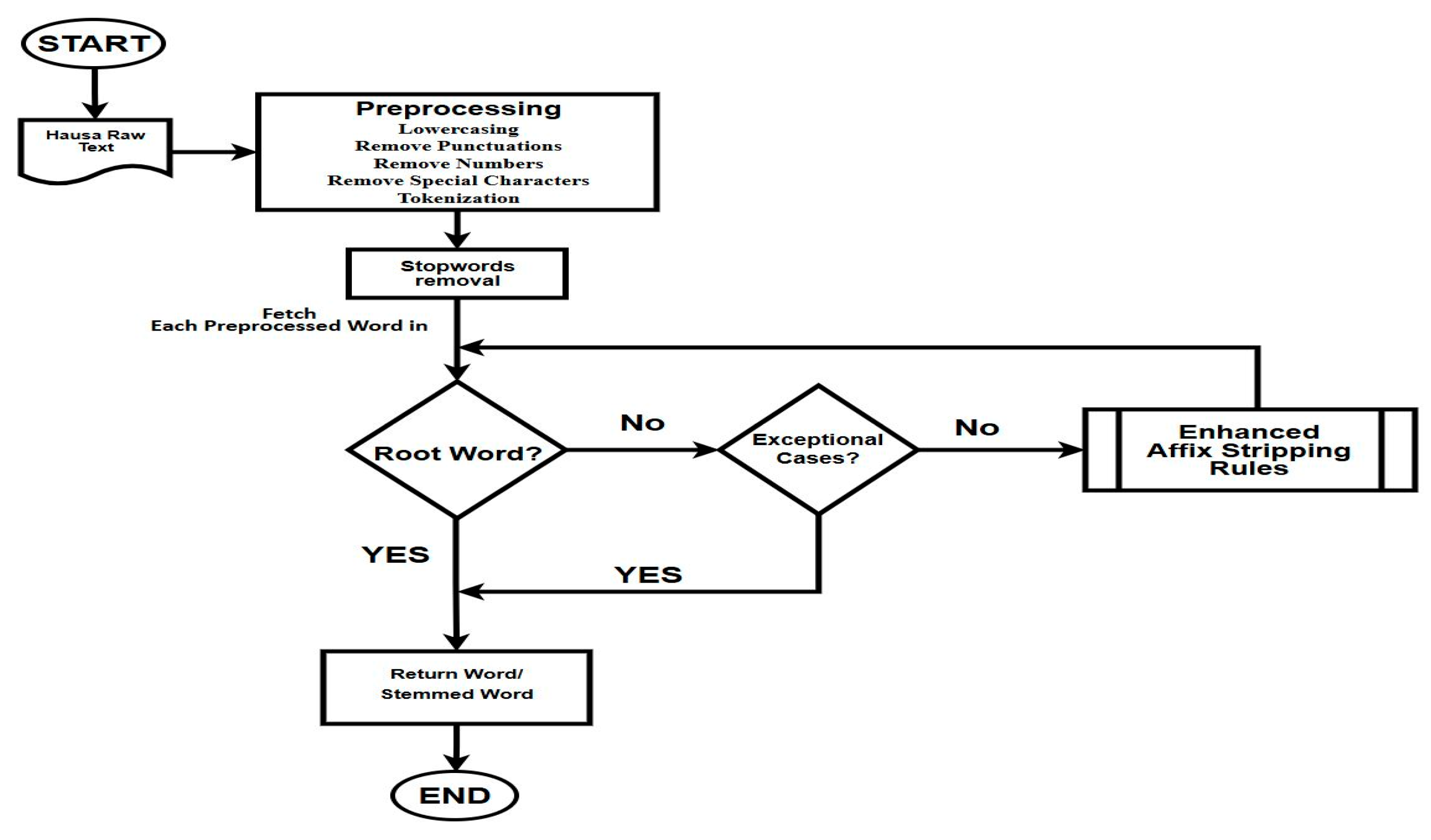
The proposed model is clearly illustrated in Figure 1, it consists of several stages, including data preprocessing, removal of stop words, elimination of exceptional words, application of stemming steps with enhanced affix stripping rules, and a reference lookup stage.
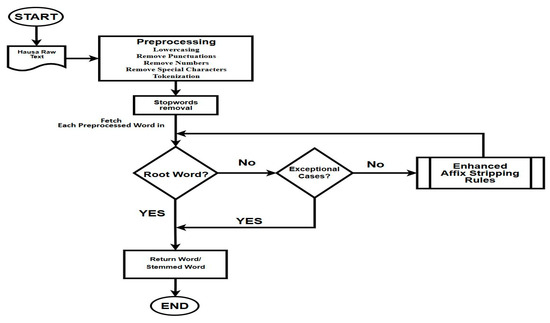
Figure 1.
Architecture of the Proposed Model.
4.3. Algorithm
The stemmer algorithm (Algorithm 1) was developed based on the affix-stripping rules approach. It comprises the following steps:
| Algorithm 1. Processing Sequence of the Stemmer |
| Input: Hausa raw text (α) Output: Stemmed word (W) Variables: - α: Input raw text - W: Stemmed word - N: Number of words in α - i: Current word index - word: Current word being processed - lookup_table: Table of known word stems - exception_table: Table of exceptional cases - min_word_length (2): Minimum word length for processing 1. Start 2. Read α 3. Preprocessing stage α ← StripIrrelevantCharacters(α) α ← ConvertToLowercase(α) α ← TokenizeWords(α) α ← RemoveStopWords(tokens) N ← Count(tokens) i ← 1 4. While i ≤ N, do steps 5-10 a. word ← tokens [i] 5. If Length(word) ≥ min_word_length, then Proceed to step 6 Else Increment i by 1 Continue to step 4 6. If a word is in lookup_table, then W ← LookupStem(lookup_table, word) Increment i by 1 Continue to step 4 Else Proceed to step 7 7. If a word is in exception_table, then W ← LookupStem(exception_table, word) Increment i by 1 Continue to step 4 Else Proceed to step 8 8. Apply affix stemming rules to the word If a word is stemmed (W found), then Increment i by 1 Continue to step 4 Else Proceed to step 9 9. If i = N, then Proceed to step 10 Else Increment i by 1 Continue to step 4 10. End |
5. Results and Discussion
This study used a collection of words obtained from a Hausa online newspaper as the primary data source for evaluating the proposed stemmer. The collection of words was pre-processed and used to test the proposed stemmer’s ability to accurately identify and extract the base form of words in the Hausa language. The results of the proposed stemmer were compared with previous algorithms developed by [7,10,17] as presented in Table 3, Table 4 and Table 5. The comparison provided insight into the proposed stemmer’s performance in relation to existing state-of-the-art methods, allowing for a comprehensive evaluation of its effectiveness. Table 3 presents a comparative analysis between the models of [7,10,17], and the improved stemmer. Table 4 summarizes the results, while Table 5 provides a comparative analysis of the affixes used [10,17], and proposed model.
Table 3.
Comparative analysis of [7,10,17] and improved model.
Table 4.
Summary of the result table.
Table 5.
Comparative analysis of Bimba, Siraj, and Bari affixes.
Sirsat’s evaluation method was utilized to gauge the performance of this stemmer. A set of 2630 unique words was analyzed, and the results of the proposed system were assessed by a language expert. To evaluate the system further, a collection of 5077 words from various articles in the Hausa online newspaper was employed. Among the total 5077 words, 3766 were correctly stemmed, resulting in an accuracy rate of 98.66%. However, 51 words were observed to have been either over-stemmed or under-stemmed, indicating stemming errors. The system demonstrated a word stemmed factor (WSF) of 75.18%, as well as a CSWF (Correctly Stemmed Word Factor) of 98.66% and AWCF (Accuracy of Word Classification Factor) of 63.62%.
6. Conclusions
In conclusion, this research proposes an improved Hausa language stemming model to enhance the information retrieval and indexing of Hausa text. Despite the rapid growth of online communities, Hausa has received little attention in stemming research, making this work valuable for under-resourced languages. The proposed model achieved a high accuracy rate of 98.66% in stemming correctly, showcasing its potential. However, challenges remain due to Hausa’s complex morphological rules. This research contributes to linguistic studies, promoting inclusivity and accessibility in the digital world for less-studied languages. It underscores the importance of addressing linguistic diversity in language processing in hopes of inspiring further research and more inclusive language technologies.
7. Future Work
The future research efforts will be directed towards augmenting the dataset to encompass a comprehensive compilation of Hausa lexicons in their myriad forms, while concurrently enhancing the precision of the stemmer. Furthermore, future work will entail the integration of a Hausa API as a reference lookup dictionary, with the objective of optimizing the stemmer’s performance.
Author Contributions
Conceptualization, M.A.B.; methodology, M.A.B. & B.S.B.; software, M.A.B. & B.S.B.; validation, M.A.B. & B.S.B.; formal analysis, M.A.B., B.S.B., H.A.U. and I.S.A.; investigation, M.A.B.; resources, M.A.B. & B.S.B.; data curation, M.A.B.; writing—original draft preparation, M.A.B.; writing—review and editing, M.A.B., B.S.B., H.A.U. and I.S.A.; visualization, M.A.B., B.S.B., H.A.U. and I.S.A.; supervision, B.S.B. and H.A.U.; project administration, B.S.B. and H.A.U. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article.
Acknowledgments
All praise and gratitude go to Almighty Allah (SWT) for the gift of existence, knowledge, and growth. I am deeply thankful to my parents, siblings, friends, and colleagues for their unwavering support. Special appreciation goes to my supervisor, Hadiza Ali Umar, and other mentors, including Bello Shehu Bello, Yahuza Bello, Malam Mustapha Lawal Bari, Malam Khamis Hassan, and Umar Lawan, for their invaluable guidance and encouragement throughout this research. I also extend heartfelt thanks to the Computer Science department staff, my course mates, and university faculty for their immense support, making this journey a rewarding and memorable experience.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| API | Application Programming Interface |
| ASR | Automatic Speech Recognition |
| AWCF | Average Words Conflation Factor |
| CSWF | Correctly Stemmed Words Factor |
| HMM | Hidden Markov Model |
| HNLP | Hausa Natural Language Processing |
| IE | Information Extraction |
| IND | Indexing |
| IR | Information Retrieval |
| MSE | Mis Stemming Errors |
| MT | Machine Translation |
| NER | Name Entity Recognition |
| NLP | Natural Language Processing |
| NLTK | Natural Language Toolkit |
| OCR | Optical Character Recognition |
| OSE | Over Stemming Errors |
| POS | Part of Speech |
| QA | Question Answering |
| TC | Text Classification |
| TClu | Text Clustering |
| TS | Text Segmentation |
| TS | Text Summarizations |
| USE | Under Stemming Errors |
| WSF | Word Stemmed Factor |
| YASS | Yet Another Suffix Stripper |
References
- Alshalabi, H.; Tiun, S.; Omar, N.; AL-Aswadi, F.N.; Ali Alezabi, K. Arabic Light-Based Stemmer Using New Rules. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 6635–6642. [Google Scholar] [CrossRef]
- Zakari, R.Y.; Lawal, Z.K.; Abdulmumin, I. A Systematic Literature Review of Hausa Natural Language Processing. Int. J. Comput. Inf. Technol. 2021, 10, 173–179. [Google Scholar] [CrossRef]
- Xu, J.; Croft, W.B. Corpus-Based Stemming Using Cooccurrence of Word Variants. ACM Trans. Inf. Syst. 1998, 16, 61–81. [Google Scholar] [CrossRef]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of the Art, Current Trends and Challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Inuwa-Dutse, I. The First Large Scale Collection of Diverse Hausa Language Datasets. arXiv 2021, arXiv:2102.06991. [Google Scholar]
- Rakhmanov, O.; Schlippe, T. Sentiment Analysis for {H}ausa: Classifying Students{’} Comments. In Proceedings of the 1st Annual Meeting of the ELRA/ISCA Special Interest Group on Under-Resourced Languages, Marseille, France, 20–25 June 2022; pp. 98–105. [Google Scholar]
- Bashir, M.; Rozaimee, A.B.; Malini, W.; Isa, B.W. A Word Stemming Algorithm for Hausa Language. IOSR J. Comput. Eng. 2015, 17, 2278–2661. [Google Scholar] [CrossRef]
- Jabbar, A.; Iqbal, S.; Tamimy, M.I.; Hussain, S.; Akhunzada, A. Empirical Evaluation and Study of Text Stemming Algorithms. Artif. Intell. Rev. 2020, 53, 5559–5588. [Google Scholar] [CrossRef]
- Jabbar, A.; Iqbal, S.; Ilahi, M. High Performance Stemming Algorithm to Handle Multi-Level Inflections in Urdu Language. Research Square 2022. [Google Scholar] [CrossRef]
- Bimba, A.; Idris, N.; Khamis, N.; Noor, N.F.M. Stemming Hausa Text: Using Affix-Stripping Rules and Reference Look-Up. Lang. Resour. Eval. 2016, 50, 687–703. [Google Scholar] [CrossRef]
- Yalçin, O.G. Natural Language Processing. In Applied Neural Networks with TensorFlow 2: API Oriented Deep Learning with Python; Apress: Berkeley, CA, USA, 2021; pp. 187–213. ISBN 978-1-4842-6513-0. [Google Scholar]
- Kaur, P. Review on Stemming Techniques. Int. J. Adv. Res. Comput. Sci. 2018, 9, 64–68. [Google Scholar] [CrossRef]
- Jabbar, A.; Iqbal, S.; Akhunzada, A.; Abbas, Q. An Improved Urdu Stemming Algorithm for Text Mining Based on Multi-Step Hybrid Approach. J. Exp. Theor. Artif. Intell. 2018, 30, 703–723. [Google Scholar] [CrossRef]
- Bichi, A.A.; Samsudin, R.; Hassan, R. Automatic Construction of Generic Stop Words List for Hausa Text. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 1501–1507. [Google Scholar] [CrossRef]
- Memon, S.; Mallah, G.A.; Memon, K.N.; Shaikh, A.; Aasoori, S.K.; Dehraj, F.U.H. Comparative Study of Truncating and Statistical Stemming Algorithms. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 563–568. [Google Scholar] [CrossRef]
- Jivani, A.G. A Comparative Study of Stemming Algorithms. Int. J. Circuit Theory Appl. 2011, 2, 1930–1938. [Google Scholar]
- Musa, S.; Obunadike, G.N.; Yakubu, M.M. An Improved Hausa Word Stemming Algorithm. Fudma J. Sci. 2022, 6, 291–295. [Google Scholar] [CrossRef]
- Wayessa, N.; Abas, S. Multi-Class Sentiment Analysis from Afaan Oromo Text Based on Supervised Machine Learning Approaches. Int. J. Res. Stud. Sci. Eng. Technol. 2020, 7, 10–18. [Google Scholar]
- Newman, P.; Newman, R.M. Hausa-English/English-Hausa, Ƙamusun Hausa: Hausa-Ingilishi/Ingilishi-Hausa; Bayero University Press: Kano, Nigeria, 2020; 627p, ISBN 978-978-98446-6-1. [Google Scholar]
- Sharipov, M.; Salaev, U. Uzbek Affix Finite State Machine for Stemming. arXiv 2022, arXiv:2205.10078. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).