

Recent Advances in Large Language Models for Healthcare



Abstract
1. Introduction
- We analyze major large language model (LLM) architectures such as ChatGPT, Bloom, and LLaMA, which are composed of billions of parameters and have demonstrated impressive capabilities in natural language understanding and generation.
- We present recent trends in the medical datasets used to train such models. We classify these datasets according to different criteria, such as their size, source (e.g., patient files, scientific articles), and subject matter.
- We highlight the potential of LLMs to improve patient care through applications like assisted diagnosis, accelerate medical research by analyzing literature at scale, and optimize the efficiency of health systems through automation.
- We discuss key challenges for practically applying LLMs in medicine, particularly important ethical issues around privacy, confidentiality, and the risk of algorithmic biases negatively impacting patient outcomes or exacerbating health inequities. Addressing these challenges will be critical to ensuring that LLMs can safely and equitably benefit public health.
2. Brief History of Large Language Models
3. Transformers and Their Architecture
3.1. The Attention Mechanism
- The query vector, q, represents the encoded sequence up to that point.
- The key vector, noted k, corresponds to a projection of the encoded entry under consideration.
- The value vector, v, contains the information relative to this same encoded entry.
- The Q matrix produces the q query vectors.
- Matrix K produces key vectors k.
- Matrix V generates value vectors v.
3.2. Self-Attention
3.3. Multi-Head Attention
3.4. Attention Hyperparameters
- The embedding size, which corresponds to the dimension of the vectors used to represent the input elements (words and tokens). Present throughout the model, this dimension also defines its capacity, called “model size”.
- The size of the queries (equal to that of the keys and values), i.e., the dimension of the vectors produced by the three linear layers generating the matrices of queries, keys, and values required for attentional calculations.
- The number of attentional heads, which determines the number of attentional processing blocks operating in parallel.
3.5. Positional Encoding
3.6. Transformers
4. LLMs’ Architecture
4.1. ChatGPT
4.2. PaLM
4.3. LLaMA
4.4. Bloom
4.5. StableLM
5. Applications of Transformer-Based LLMs in Healthcare
5.1. Text Analysis and Summarization
5.2. Diagnostic Assistance
5.3. Answering Medical Queries
5.4. Image Captioning
6. Analysis of Massive Medical Datasets
6.1. General Datasets
- MIMIC-III, known as “Medical Information Mart for Intensive Care III”, is a publicly accessible database focused on critical care [209]. It is an extensive and comprehensive health database that includes de-identified health-related data from more than 40,000 patients who were admitted to Beth Israel Deaconess Medical Center (BIDMC) in Boston between the years 2001 and 2012. The database encompasses a diverse array of information, including clinical notes, physiological waveforms, laboratory test results, medication details, procedures, diagnoses, and demographics. This extensive dataset holds immense value for medical research and healthcare analytics, as well as the creation and validation of machine learning models and clinical decision support systems. It provides a valuable resource for advancing medical knowledge and enhancing patient care. MIMIC-III is widely utilized by researchers and healthcare professionals for a range of studies, including predictive modeling [210,211], risk stratification [212], treatment outcomes analysis [213], and other medical research investigations [214,215]. The database offers valuable insights into patient care [216,217], facilitates the development of advanced healthcare technologies [218,219], and contributes to the enhancement of clinical practices and patient outcomes [220,221]. It is essential to emphasize the importance of ethical considerations and strict adherence to data usage policies when accessing and utilizing the MIMIC-III database to ensure proper handling and protection of patient information.
- MIMIC-CXR, referred to as “Medical Information Mart for Intensive Care—Chest X-ray”, is an expansion of the MIMIC-III database that specifically concentrates on chest X-ray images and related clinical data [222]. This publicly available dataset comprises de-identified chest X-ray images alongside their corresponding radiology reports for a substantial number of patients. A total of 377,110 images are available in the MIMIC-CXR dataset. These images are associated with 227,835 radiographic studies conducted at the Beth Israel Deaconess Medical Center in Boston. The contributors to the dataset utilized the ChexPert tool [223] to classify the free-text notes associated with each image into 14 different labels. This process categorized the textual information accompanying the images, providing additional context and information for research and analysis. MIMIC-CXR is a valuable dataset that plays a crucial role in training and evaluating machine learning models and algorithms focused on chest X-ray image analysis, radiology report processing, NLP, and various medical imaging tasks. Researchers and healthcare professionals rely on MIMIC-CXR to develop and validate AI-driven systems designed for automated diagnosis [224,225], disease detection [226,227], and image-captioning applications specifically tailored to chest X-ray images [205,228].
- MEDLINE is an extensive and highly regarded bibliographic database that encompasses life sciences and biomedical literature. It is curated and maintained by the National Library of Medicine (NLM) and is a component of the larger PUBMED system. MEDLINE contains more than 29 million references sourced from numerous academic journals, covering a wide range of disciplines including medicine, nursing, dentistry, veterinary medicine, healthcare systems, and preclinical sciences. MEDLINE is a widely utilized resource by researchers, healthcare professionals, and scientists seeking access to an extensive collection of scholarly articles and abstracts. It serves as a vital source of information for academic research, aiding in clinical decision-making [229,230], and keeping individuals informed about the latest developments in the medical and life sciences [231,232,233]. The database plays a crucial role in supporting evidence-based practice, enabling professionals to stay updated with the most recent advancements and discoveries in their respective fields. MEDLINE’s comprehensive coverage and wealth of information make it an essential tool for professionals and researchers across the medical and life sciences domains. In MEDLINE, the data commonly consist of bibliographic information such as article titles, author names, abstracts, publication sources, publication dates, and other pertinent details. This dataset is an essential and foundational resource for conducting research in the fields of medicine and life sciences, supporting diverse applications like NLP [234], information retrieval [235,236], data analysis [237], and more [238,239]. The wealth of information contained within MEDLINE enables researchers to explore and extract valuable insights, contributing to advancements in medical knowledge and facilitating a wide range of research endeavors within the healthcare and life sciences domains [240,241,242].
- ABBREV dataset, proposed by Stevenson et al. in 2009 [243], is a collection of acronyms and their corresponding long forms extracted from MEDLINE abstracts. Originally introduced by Liu et al. in 2001, this dataset has undergone automated reconstruction. The reconstruction process involves identifying the long forms of acronyms in MEDLINE and replacing them with their respective acronyms. The dataset is divided into three subsets, with each subset containing 100, 200, and 300 instances, respectively.
- The PUBMED dataset comprises over 36 million citations and abstracts of biomedical literature; while it does not provide full-text journal articles, it typically includes links to the complete texts when they are available from external sources. Maintained by the National Center for Biotechnology Information (NCBI), PUBMED is an openly accessible resource for the public. Serving as a comprehensive search engine, it enables users to explore a vast collection of articles from diverse biomedical and life science journals. PUBMED encompasses a wide range of subjects, spanning medicine, nursing, dentistry, veterinary medicine, biology, biochemistry, and various other fields within the biomedical domain. Within the PUBMED dataset, you can find a wealth of information, such as article titles, author names, abstracts, publication sources, publication dates, keywords, and MeSH terms (Medical Subject Headings). This extensive dataset is extensively used by researchers, healthcare professionals, and individuals within the academic and medical communities. PUBMED serves as a go-to platform for accessing the latest research and information in the vast field of biomedicine. It provides a comprehensive search engine that enables users to explore a diverse range of topics, including medicine, nursing, dentistry, veterinary medicine, biology, biochemistry, and more. By utilizing PUBMED, researchers and professionals can stay updated with the latest scientific literature, conduct literature reviews, and make evidence-based decisions in their respective fields.
- The NUBES dataset [244], short for “Negation and Uncertainty annotations in Biomedical texts in Spanish”, is a collection of sentences extracted from de-identified health records. These sentences are annotated to identify and mark instances of negation and uncertainty phenomena. To the best of our knowledge, the NUBES corpus is presently the most extensive publicly accessible dataset for studying negation in the Spanish language. It is notable for being the first corpus to include annotations for speculation cues, scopes, and events alongside negation.
- The NCBI disease corpus comprises a massive compilation of biomedical abstracts curated to facilitate NLP of literature concerning human pathologies [245]. Leveraging Medical Subject Headings assigned to articles within PUBMED, the corpus was constructed by annotating over 1.5 million abstracts that discuss one or more diseases according to controlled vocabulary terms. Spanning publications from 1953 to the present day, the breadth of the included abstracts encapsulates a wide spectrum of health conditions. Each is tagged with the relevant disease(s) addressed, permitting focused retrieval. Beyond these annotations, access is also provided to the original PUBMED records and associated metadata, such as publication dates. By manually linking this substantial body of literature excerpts to standardized disease descriptors, the corpus establishes an invaluable resource for information extraction, classification, and QA applications centered around exploring and interpreting biomedical writings covering an immense range of human ailments. The colossal scale and selection of peer-reviewed reports ensure the corpus offers deep pools of content for natural language models addressing real-world biomedical queries or aiding disease investigations through text-based analysis. Overall, it presents a comprehensive, expertly curated foundation for driving advancements in medical text mining.
- The CASI (Clinical Abbreviation Sense Inventory) dataset aims to facilitate the disambiguation of medical terminology through the provision of contextual guidance for commonly abbreviated terms. Specifically, it features 440 of the most prevalent abbreviations and acronyms uncovered among the 352,267 dictated clinical notes. For each entry, potential intended definitions, or “senses”, are enumerated based on an analysis of the medical contexts within which the shorthand appeared across the vast note compilation. By aggregating examples of appropriate abbreviation implementation in genuine patient encounters, the inventory helps correlate ambiguous clinical jargon with probable denotations. This aids in navigating the challenges inherent to interpreting abbreviated nomenclature pervasive throughout medical documentation, which is often polysemous. The dataset provides utility for natural language systems seeking to map abbreviations to intended clinical senses when processing narratives originating from authentic healthcare records.
- The MEDNLI dataset was conceived with the goal of advancing natural language inference (NLI) within clinical settings. As in NLI generally, the objective involves predicting the evidential relationship between a hypothesis and premise as true, false, or undetermined. To facilitate model progress, MEDNLI comprises a sizable corpus of 14,049 manually annotated sentence pairs. The data originate from MIMIC-III, necessitating initial access to extract the pairs, while retrieval is dependent on securing permission to access the source’s protected patients, MEDNLI balances this ethically with the availability of an extensive set. This supports valuable work on a key clinical NLP challenge: determining the inferential relationship between ideas expressed.
- The MEDICAT dataset comprises a vast repository of medical imaging data, matched materials, and granular annotations [246]. It contains over 217,000 images extracted from 131,410 open-access articles in PUBMED Central. Each image is accompanied by a caption and 7507 feature compound structures with delineated subfigures and subcaptions. The reference text comes from the S2ORC database. The collection also includes online citations for around 25,000 images in the ROCO subset. MEDICAT introduces a new method for annotating the constituent elements of complex images. It correlates over 2000 composite visualizations with their constituent subfigures and descriptive subcapitals. This refined partitioning at multiple intralimatic scales within individual elements far surpasses previous collections based on unitary image-caption couplings. MedICaT’s granular annotations lay the foundations for modeling intra-element semantic congruence, an essential capability for tackling the sophisticated challenges of visual language in biomedical imaging. With its vast scale and careful delineation of image substructures, MEDICAT provides a cutting-edge dataset to advance research at the intersection of vision, language, and clinical media understanding.
- The OPEN-I, the Indiana University Chest X-ray dataset, presents a sizable corpus of 7470 chest radiograph images paired with associated radiology reports [247]. Each clinical dictation encompasses discrete segments for impression, findings, tags, comparison, and indication. Notably, rather than using full reports as captions, this dataset strategically concatenates the impression and findings portions for each image, while impressions convey overarching diagnoses, findings provide specifics on visualized abnormalities and lesions. By combining these sections, the designated captions offer concise and comprehensive clinical overviews. With a sample size exceeding 7000 image–report duos, this collection equips researchers with ample training and evaluation materials. Distinct from simpler descriptors, the report snippets incorporated as captions encompass richer diagnostic particulars. This notation format furnishes target descriptions well-suited to nurturing technologies aimed at automating radiographic report generation directly from chest X-ray visuals.
- The MEDICAL ABSTRACTS dataset presents a robust corpus of 14,438 clinical case abstracts describing five categories of patient conditions, an integral resource for the supervised classification of biomedical language [248]. Unlike many datasets, each sample benefits from careful human annotation, providing researchers with a fully labeled collection that avoids ambiguity. The abstracts also emanate from real medical scenarios, imbuing the models with authentic representations. The collection divides examples into standardized training and test scores, enabling a rigorous and consistent evaluation of classification performance. At this scale, DL techniques can derive profound meaning from the distribution of terminology across different specialties. Automatic organization of vast quantities of documents according to disease status should lead to improved indexing, keyword assignment, and file routing. This fundamental resource enables investigators to cultivate methods that intelligently classify and route written summaries, streamlining discovery and care.
6.2. De-Identification Dataset
- The I2B2 2006 dataset serves two main objectives—deidentification of protected health information from medical records [249], and extraction of smoking-related data [250]. Regarding privacy, it focuses on removing personally identifiable information (PII) from clinical documents. This is important for enabling the ethical and lawful use of such records for research purposes by preserving patient anonymity. At the same time, the dataset facilitates the extraction of key smoking-related details from these records. This aspect is crucial for understanding impactful health behavior and risk factors. Researchers leverage this dual-purpose dataset to develop automated systems capable of both tasks through NLP. This significantly advances the application of NLP within healthcare to tackle real-world issues surrounding privacy and extracting meaningful insights from unstructured notes. The dataset is freely available to the research community. Overall, it serves an important role in propelling research at the intersection of privacy, smoking cessation, and NLP technologies for EMR.
- The I2B2 2008 Obesity dataset is a specialized collection aimed at facilitating the recognition and extraction of obesity-related information from medical records [251]. The dataset challenge centered on identifying various aspects of obesity within clinical notes, such as body mass index, weight, diet, physical activity levels, and related conditions. Researchers leverage this curated corpus to build models and algorithms capable of accurately detecting and extracting obesity-related data from unstructured notes. Key elements identified include BMI, weight measurements, dietary patterns, exercise habits, and associated medical conditions. By developing technologies to systematically organize this clinical information, researchers can gain deeper insights into obesity trends, risk factors, and outcomes. This contribution ultimately advances healthcare research and strategies for obesity treatment and prevention [252,253,254]. The specificity of the I2B2 2008 Obesity dataset in regards to this important public health issue has made it a valuable resource for the medical informatics community to progress solutions.
- The I2B2 2009 Medication dataset is a specialized corpus focused on extracting granular medication-related information from clinical notes [255]. The dataset challenge centered on precisely identifying and categorizing various facets of medications documented within notes, such as names, dosages, frequencies, administration routes, and intended uses. The corpus is meticulously annotated to demarcate and classify mentions of medications and associated attributes in the unstructured text [256]. Researchers leverage this resource to develop sophisticated NLP models tuned to accurately recognize and extract intricate medication details. Key elements identified and disambiguated include drug names, dosage amounts, dosing schedules, administration methods, and therapeutic purposes. By automatically organizing these clinical aspects at scale, the resulting NLP systems enable vital insights to support healthcare decision-making and research [257]. The specificity and detailed annotation of the dataset in mining this significant clinical domain has made it instrumental for advancing automatic extraction of medication information [258,259].
- The I2B2 2010 Relations dataset was specially curated to facilitate extracting and comprehending associations between medical entities in clinical texts. The dataset challenge centered on accurately identifying and categorizing relationship types expressed in clinical narratives, such as drug–drug interactions or dosage frequency links [260]. Annotations clearly define and classify the annotated relations, supporting the development of models precisely capable of recognizing and categorizing diverse medical connections. Advancements ultimately aim to bolster comprehension of treatment considerations and implications to elevate standards of care based on a complete view of patient context and interconnectivity [261,262].
- The I2B2 2011 coreference dataset has been specially designed to facilitate the resolution of coreferences in clinical notes [263]. The challenge of I2B2 2011 was to identify and resolve coreferences expressed in narratives, where different terms refer to the same real-world entity. Coreference annotations meticulously indicate these relationships in order to train models to discern and accurately link references to a common entity. Automatic identification of coreferential links improves understanding of complex clinical relationships. Further development of these technologies should enable the medical community to better understand patient histories, presentations, and treatments through the complete resolution of entities in clinical discussions.
- The I2B2 2012 Temporal Relations dataset was curated with a specific focus on aiding in the identification and understanding of temporally related elements present in clinical notes [264]. The dataset challenge centered on precisely identifying and categorizing the temporal relationships conveyed in narratives, with the goal of understanding when events or actions occurred relative to one another. The notes are meticulously annotated to delineate and classify these time-related connections, supporting the development of models that can accurately discern and organize temporal aspects. Key targets involve discerning whether certain phenomena preceded, followed, or co-occurred based on the documentation. The precise annotations of the dataset and the focus on this significant dimension continue to enable valuable progress on a fundamental but complex clinical modeling task [265].
- The I2B2 2014 Deidentification & Heart Disease dataset: This specialized collection addresses two primary objectives: privacy protection through de-identification and the extraction of heart disease information [266]. For de-identification, the task involves removing personally identifiable information (PII) from medical records while preserving anonymity. The datasets are annotated to highlight sensitive PII to remove. Researchers utilize this resource to develop and assess de-identification systems, ensuring ethical use of data for research by maintaining privacy [267] regarding heart disease extraction, annotations tag mentions, diagnostic details, treatments, and related clinical aspects within notes. Leveraging these guidelines supports building models accurately deriving insights into cardiovascular presentations and management [268].
- The I2B2 2018 dataset is divided into two pivotal tracks: Track 1, focusing on clinical trial cohort selection [269], and Track 2, centered around adverse drug events and medication [270]. Track 1 aims to accurately identify eligible patients for clinical trials using EMR data. The annotations mark records matching various eligibility criteria. Researchers use this resource to develop and evaluate ML models that can efficiently pinpoint suitable trial candidates, expediting the enrollment process. Regarding Track 2, the goal here is to detect and classify mentions of adverse drug reactions and medication information in notes. The annotations highlight such instances in clinical narratives. Researchers apply this dataset to advance NLP techniques specifically for precisely extracting and categorizing adverse events and medication details. This contributes to pharmacovigilance and patient safety.
6.3. Medical QA Datasets
- MEDQUAD dataset consolidates authoritative medical knowledge from across the NIH into a substantial question–answer resource. It contains 47,457 pairs compiled from 12 respected NIH websites focused on health topics (e.g., cancer.gov, niddk.nih.gov, GARD, and MEDLINEPlus Health Topics). These sources include the National Cancer Institute, the National Institute of Diabetes and Digestive and Kidney Diseases, and the Genetic and Rare Diseases Information Center databases. Questions fall under 37 predefined categories linked to diseases, drugs, diagnostic tests, and other clinical entities. Examples encompass queries about treatment, diagnosis, and side effects. By synthesizing verified content already maintained by leading NIH organizations, MEDQUAD constructs a rich collection of clinically important questions paired with validated responses. These address a diverse range of issues encountered in biomedical research and practice.
- MEDMCQA dataset contains over 194,000 authentic medical entrance exam multiple-choice questions designed to rigorously evaluate language understanding and reasoning abilities [161]. Sourced from the All India Institute of Medical Sciences (AIIMS) and National Eligibility cum Entrance Test (NEET) PG exams in India, the questions cover 2400 diverse healthcare topics across 21 medical subjects, with an average complexity mirrored in clinical practice. Each sample presents a question stem alongside the correct answer and plausible distractors, requiring models to comprehend language at a depth beyond simple retrieval. Correct selection demonstrates an understanding of semantics, concepts, and logical reasoning across topics. By spanning more than 10 specific reasoning skills, MEDMCQA comprehensively tests a model’s language and thought processes in a manner analogous to how human exam takers must demonstrate their clinical knowledge and judgment in order to gain entrance to postgraduate medical programs in India. The large scale, intricacy, and realism of these authentic medical testing scenarios establish MEDMCQA as a leading benchmark for developing assistive technologies with human-level reading comprehension, critical thinking, and decision-making skills. The dataset poses a major challenge that pushes the boundaries of language model abilities.
- The MEDQA-USMILE dataset, introduced by [161], provides 2801 question–answer pairs taken directly from the United States Medical Licensing Examination (USMLE). As the certification exam required to practice medicine in the United States, the USMLE assesses candidates on an extraordinarily broad and in-depth range of clinical skills. As such, it sets the bar for the level of medical acumen expected of MDs within the U.S. healthcare system. Using authentic samples from this rigorous assessment, MedQA USMILE offers insight into the comprehensive knowledge requirements and analytical abilities assessed. It reflects the extremely high standards of medical training and licensure in the USA. Although it is a preliminary size at present, the use of actual USMLE content gives the dataset validity as a test for medical QA systems looking for capabilities equivalent to those of junior doctors. These capabilities are essential for applications designed to help medical students in the USA. Thanks to its authentic test format and its link to the standards applicable to U.S. doctors, MedQA USMILE provides an important first benchmark, focused solely on the requirements of the U.S. system, and paves the way for more powerful aids for clinical training in the country.
- The MQP (Medical Question Pairs) dataset was compiled manually by MDs to provide examples of medical question pairs, whether similar or not [271]. From a random sample of 1524 authentic patient questions, MDs performed two labeling tasks. First, for each original question, they composed a reworded version retaining an equivalent underlying intention in order to generate a “similar pair”. At the same time, using overlapping terminology, they devised a “dissimilar pair” on a related but ultimately inapparent topic. This double-matching process produced, for each initial question, both a semantically coherent reworking and a variant that was superficially related but whose answer was not congruent. Only similar pairs are then used in MQP. By asking doctors to rewrite queries in different styles while retaining consistent meaning, the selected similar question instances give the models the ability to discern medical semantic substance beyond superficial correspondence. Their inclusion enables more rigorous evaluation and enhancement of a system’s comprehension capabilities at a deeper level.
- The CLINIQPARA dataset comprises a compendium of patient queries crafted with paraphrasing to progress medical QA from Electronic Health Records [272]. It presents 10,578 uniquely reworded questions sorted into 946 semantically distinct clusters anchored to shared clinical intent. Initially harvested from EMRs, the questions were aggregated to cultivate systems that generalize beyond surface forms to grasp the crux of related inquiries couched in diverse linguistic guises. By merging paraphrased variations tied to an identical underlying semantic substance, the inventory arm models have the prowess to discern core significance notwithstanding syntax. Equipped via CLINIQPARA, AI can learn how a single medical consultation may morph in phrasing while retaining essential import, empowering robust interrogation of noisily documented EMR contents. Its expansive scale and clustering by meaning establish it as paramount for advancing healthcare AI’s acuity in apprehending intent beneath variances in how patients may pose an identical essential query.
- The VQA-RAD dataset comprises 3515 manually crafted question–response pairs pertaining to 315 distinctive radiological images [273]. On average, approximately 11 inquiries are posed regarding each individual examination. The questions encapsulate a wide spectrum of clinical constructs and findings that a diagnosing radiologist may want to interrogate or validate within an imaging study. Example themes incorporate anatomical components, anomalies, measurements, diagnoses, and more. By aggregating thousands of question–answer annotations across hundreds of studies, VQA-RAD amasses a sizeable compendium to nurture visual QA (VQA) models. Its scale and granularity lend the resource considerable value to cultivating AI capable of helping radiologists unravel the semantics within medical visuals through an interactive query interface.
- PATHVQA is a seminal resource, representing the first VQA dataset curated specifically for pathology [274]. It contains 32,799 manually formulated questions broadly covering clinical and morphological issues pertinent to the specialty. These questions correlate to 4998 unique digitized tissue slides, averaging approximately 6–7 inquiries per image. PATHVQA aims to mirror the analytical and diagnostic cognition of pathologists when interpreting whole slide images.
- PUBMEDQA is an essential resource for advancing evidence-based QA in the biomedical field [275]. Its objective is to evaluate the ability of models to extract answers from PUBMED abstracts for clinical questions expressed in a yes/no/medium format. The dataset includes 1000 carefully selected questions, associated with expert annotations, which define the correct answer inferred from the literature for questions such as “Do preoperative statins reduce atrial fibrillation after coronary artery bypass grafting?”. In addition, 61,200 real-life but unlabeled questions enable semi-supervised techniques to develop learning. Over 211,000 artificially generated question–answer summaries are incorporated to deepen the learning pool.
- The VQA-MED-2018 dataset was the first of its kind created specifically for visual QA (VQA) using medical images [276]. It was introduced as part of the ImageCLEF 2018 challenge to allow the testing of VQA models in this new healthcare domain. An automatic rule-driven system first extracted captions from images, simplifying sentences and pinpointing response phrases to seed question formulation and candidate ranking. However, purely algorithmic derivation risks semantic inconsistencies or clinical irrelevance. Two annotators with medical experience thoroughly cross-checked each query and response twice. One round ensured semantic logic, while another judged clinical pertinence to associated visuals. This two-step validation by experienced clinicians guaranteed queries and answers not just made sense logically but genuinely applied to practice. As the pioneering dataset for medical VQA, it thus permits exploring how AI can interpret images and language in healthcare contexts. Thanks to its meticulously verified question–response sets grounded in actual medical images and language, VQA-MED-2018 laid the groundwork for advancing and benchmarking systems to help practitioners through image-based insights.
- The VQA-MED-2019 dataset represented the second iteration of questions and answers related to medical images as part of the ImageCLEF 2019 challenge [277]. Its design aimed to further the investigation started by its predecessor. Drawing inspiration from the question patterns observed in radiology contexts within VQA-RAD, it concentrated on the top four classes of inquiries typically encountered: imaging modalities, anatomical orientations, affected organs, and abnormalities. Some question types, like modality or plane, allowed for categorized responses and could thus be modeled as classification tasks. However, specifying abnormalities required generative models since possibilities were not fixed. This evaluation of different AI problem types paralleled the diverse thinking involved in analyzing scans. Questions also emulated natural consultations. By targeting the most common radiology question categories and building on lessons from previous work, VQA-MED-2019 enhanced the foundation for assessing and advancing systems meant to expedite diagnostic comprehension through combined vision and language processing.
- The VQA-MED-2020 dataset represented the third iteration of this influential initiative, presented as part of ImageCLEF 2020 to advance the answer to medical visual questions [278]. The core corpus consisted of diagnostically relevant images, whose diagnosis was derived directly from visual elements. The questions focused on abnormalities, with 330 frequent conditions selected to ensure minimum prevalence in systematically organized search patterns. This guided combination of visual and linguistic elements established the characteristic VQA assessment framework. In addition, VQA-MED-2020 enriched the landscape by introducing visual question generation, eliciting queries endogenously from radiographic content. Over 1001 associated images provided a basis for 2400 carefully constructed questions, first algorithmically designed and then manually refined. These interdependent tasks aimed to foster more nuanced understanding through contextual synergies between vision and language. By developing both explanatory and generative faculties, VQA-MED-2020 helped characterize key imaging subtleties while cultivating technologies better prepared to participate in clinical workflows. Its balanced approach to both established and emerging problem spaces iteratively honed assessment of progress towards diagnostically adroit interrogative and descriptive proficiencies—skills paramount to intuitively aiding radiographic decision-making.
- The RADVISDIAL dataset has led the way in the emerging field of visual dialog in medical imaging by introducing the first radiology dialog collection for iterative QA modeling [279]. Drawing on annotated cases from the MIMIC-CXR database accompanied by comprehensive reports, the dataset offered both simulated and authentic consultations. A silver set algorithmically generated multi-round interactions from plain text, while a gold standard captured 100 image-based discussions between expert radiologists under rigorous guidelines. Beyond simple question–answer pairs, this sequential format mimicked the richness of clinical dialogue, posing a more ecologically valid test of the systems’ contextual capabilities. The comparisons also revealed the importance of historical context for accuracy—an insight with implications for the development of conversational AI assistants. By establishing visual dialogue as a framework for evaluating the progress of models over a succession of queries, RADVISDIAL laid the foundation for the development of technologies that facilitate nuanced diagnostic reasoning through combined visual and linguistic questions and answers. Its dual-level design also provided a benchmark of synthetic and real-world performance as the field continues to advance. RADVISDIAL therefore opened the way to promising work on sequential and contextual modeling for visual dialogue tasks, such as doctor–patient or radiologist discussions.
7. Foundation Models for Healthcare
7.1. Concept of FM
7.2. Clinical FMs
7.2.1. Clinical Language Models (CLaMs)
7.2.2. Foundation Models for EMR (FEMRs)
8. Discussion
8.1. Techniques for Mitigating Ethical Risks
8.2. Challenges and Future Perspectives
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DL | Deep Learning |
| LLM | Large Language Model |
| GPT | Generative Pre-trained Transformer |
| LLaMA | Large Language Model Meta AI |
| BLOOM | BigScience Large Open-science Open-access Multilingual Language Model |
| NLP | Natural Language Processing |
| RAG | Retrieval Augmented Generation |
| RL | Reinforcement Learning |
| RLHF | RL from Human Feedback |
| DPO | Direct Preference Optimization |
| PPO | Proximal Policy Optimization |
| GMAI | Generalist medical AI |
| RCT | Tandomized controlled trial |
| LDA | Latent Dirichlet allocation |
| GloVe | Global Vectors for Word Representation |
| BERT | Bidirectional Encoder Representations from Transformers |
| RoBERTa | Robustly Optimized BERT Approach |
| ELMo | Embeddings from Language Models |
| QA | Question Answering |
| T5 | Text-To-Text Transfer Transformer |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| BART | Bidirectional and Auto-Regressive Transformer |
| PaLM | Pathways Language Model |
| Flan-PaLM | Scaling Instruction-Fine-Tuned Language Models |
| EMRs | Electronic medical records |
| MD | Medical doctor |
| MLTL | Multilevel Transfer Learning Technique |
| LSTM | Long Short Term Memory |
| MIMIC | Medical Information Mart for Intensive Car |
| NLM | National Library of Medicine |
| NCBI | National Center for Biotechnology Information |
| MeSH | Medical Subject Headings |
| BIDMC | Beth Israel Deaconess Medical Center |
| NUBES | Negation and Uncertainty annotations in Biomedical texts in Spanish |
| CASI | Clinical Abbreviation Sense Inventory |
| NLI | Natural Language Inference |
| SNP | Single Nucleotide Polymorphism |
| I2B2 | Informatics for Integrating Biology and the Bedside |
| N2C2 | National Clinical Language Challenges |
| PII | Personally Identifiable Information |
| AIIMS | India Institute of Medical Sciences |
| NEET | National Eligibility cum Entrance Text |
| USMLE | United States Medical Licensing Examination |
| VQA | Visual Questions Answering |
| MQP | Medical Question Pairs |
| FM | Foundation model |
| CLaMs | Clinical Language Models |
| FEMRs | Foundation Models for EMRs |
| S2ORC | The Semantic Scholar Open Research Corpus |
| OPT | Open Pre-trained transformer Language Models |
| CLEF | Conference and Lab of the Evaluation Forum |
References
- Ye, J.; Chen, X.; Xu, N.; Zu, C.; Shao, Z.; Liu, S.; Cui, Y.; Zhou, Z.; Gong, C.; Shen, Y.; et al. A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models. arXiv 2023, arXiv:2303.10420. [Google Scholar]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Iroju, O.G.; Olaleke, J.O. A Systematic Review of Natural Language Processing in Healthcare. Int. J. Inf. Technol. Comput. Sci. 2015, 8, 44–50. [Google Scholar] [CrossRef]
- Hossain, E.; Rana, R.; Higgins, N.; Soar, J.; Barua, P.D.; Pisani, A.R.; Turner, K. Natural language Processing in Electronic Health Records in Relation to Healthcare Decision-making: A Systematic Review. Comput. Biol. Med. 2023, 155, 106649. [Google Scholar] [CrossRef] [PubMed]
- Singleton, J.; Li, C.; Akpunonu, P.D.; Abner, E.L.; Kucharska–Newton, A.M. Using Natural Language Processing to Identify Opioid Use Disorder in Electronic Health Record Data. Int. J. Med. Inform. 2023, 170, 104963. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Heacock, L.; Elias, J.; Hentel, K.D.; Reig, B.; Shih, G.; Moy, L. ChatGPT and other Large Language Models are Double-edged Swords. Radiology 2023, 307, e230163. [Google Scholar] [CrossRef] [PubMed]
- Christensen, L.; Haug, P.; Fiszman, M. MPLUS: A Probabilistic Medical Language Understanding System. In Proceedings of the ACL-02 Workshop on Natural Language Processing in the Biomedical Domain, Phildadelphia, PA, USA, 11 July 2002; pp. 29–36. [Google Scholar]
- Wang, D.Q.; Feng, L.Y.; Ye, J.G.; Zou, J.G.; Zheng, Y.F. Accelerating the Integration of ChatGPT and Other Large-scale AI Models Into Biomedical Research and Healthcare. MedComm-Future Med. 2023, 2, e43. [Google Scholar] [CrossRef]
- Schaefer, M.; Reichl, S.; ter Horst, R.; Nicolas, A.M.; Krausgruber, T.; Piras, F.; Stepper, P.; Bock, C.; Samwald, M. Large Language Models are Universal Biomedical Simulators. bioRxiv 2023. [Google Scholar] [CrossRef]
- Lederman, A.; Lederman, R.; Verspoor, K. Tasks as needs: Reframing the paradigm of clinical natural language processing research for real-world decision support. J. Am. Med. Inform. Assoc. 2022, 29, 1810–1817. [Google Scholar] [CrossRef]
- Zuheros, C.; Martínez-Cámara, E.; Herrera-Viedma, E.; Herrera, F. Sentiment Analysis based Multi-Person Multi-criteria Decision Making Methodology using Natural Language Processing and Deep Learning for Smarter Decision Aid. Case Study of Restaurant Choice using TripAdvisor Reviews. Inf. Fusion 2021, 68, 22–36. [Google Scholar] [CrossRef]
- Wang, Y.H.; Lin, G.Y. Exploring AI-healthcare Innovation: Natural Language Processing-based Patents Analysis for Technology-driven Roadmapping. Kybernetes 2023, 52, 1173–1189. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, Y.; Callcut, R.; Petzold, L. Integrating Physiological Time Series and Clinical Notes with Transformer for Early Prediction of Sepsis. arXiv 2022, arXiv:2203.14469. [Google Scholar]
- Harrer, S. Attention is Not All You Need: The Complicated Case of Ethically Using Large Language Models in Healthcare and Medicine. eBioMedicine 2023, 90, 104512. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Pan, S.; Li, Y.; Yang, X. Advancing Medical Imaging with Language Models: A Journey from n-grams to Chatgpt. arXiv 2023, arXiv:2304.04920. [Google Scholar]
- Pivovarov, R.; Elhadad, N. Automated Methods for the Summarization of Electronic Health Records. J. Am. Med. Inform. Assoc. 2015, 22, 938–947. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Costa, A.B.; Flores, M.G.; et al. A Large Language Model for Electronic Health Records. NPJ Digit. Med. 2022, 5, 194. [Google Scholar] [CrossRef] [PubMed]
- Tian, S.; Yang, W.; Le Grange, J.M.; Wang, P.; Huang, W.; Ye, Z. Smart Healthcare: Making Medical Care more Intelligent. Glob. Health J. 2019, 3, 62–65. [Google Scholar] [CrossRef]
- Iftikhar, L.; Iftikhar, M.F.; Hanif, M.I. Docgpt: Impact of Chatgpt-3 on Health Services as a Virtual Doctor. EC Paediatr. 2023, 12, 45–55. [Google Scholar]
- KS, N.P.; Sudhanva, S.; Tarun, T.; Yuvraaj, Y.; Vishal, D. Conversational Chatbot Builder–Smarter Virtual Assistance with Domain Specific AI. In Proceedings of the 2023 4th International Conference for Emerging Technology (INCET), Belgaum, India, 26–28 May 2023; pp. 1–4. [Google Scholar]
- Hunter, J.; Freer, Y.; Gatt, A.; Reiter, E.; Sripada, S.; Sykes, C. Automatic Generation of Natural Language Nursing shift Summaries in Neonatal Intensive Care: BT-Nurse. Artif. Intell. Med. 2012, 56, 157–172. [Google Scholar] [CrossRef] [PubMed]
- Abacha, A.B.; Yim, W.W.; Adams, G.; Snider, N.; Yetisgen-Yildiz, M. Overview of the MEDIQA-Chat 2023 Shared Tasks on the Summarization & Generation of Doctor-Patient Conversations. In Proceedings of the 5th Clinical Natural Language Processing Workshop, Toronto, ON, Canada, 14 July 2023; pp. 503–513. [Google Scholar]
- Thawkar, O.; Shaker, A.; Mullappilly, S.S.; Cholakkal, H.; Anwer, R.M.; Khan, S.; Laaksonen, J.; Khan, F.S. Xraygpt: Chest Radiographs Summarization Using Medical Vision-Language Models. arXiv 2023, arXiv:2306.07971. [Google Scholar]
- Phongwattana, T.; Chan, J.H. Automated Extraction and Visualization of Metabolic Networks from Biomedical Literature Using a Large Language Model. bioRxiv 2023. [Google Scholar] [CrossRef]
- Tian, S.; Jin, Q.; Yeganova, L.; Lai, P.T.; Zhu, Q.; Chen, X.; Yang, Y.; Chen, Q.; Kim, W.; Comeau, D.C.; et al. Opportunities and Challenges for ChatGPT and Large Language Models in Biomedicine and Health. Briefings Bioinform. 2024, 25, bbad493. [Google Scholar] [CrossRef] [PubMed]
- Pal, S.; Bhattacharya, M.; Lee, S.S.; Chakraborty, C. A Domain-Specific Next-Generation Large Language Model (LLM) or ChatGPT is Required for Biomedical Engineering and Research. Ann. Biomed. Eng. 2023, 52, 451–454. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wong, C.; Zhang, S.; Usuyama, N.; Liu, H.; Yang, J.; Naumann, T.; Poon, H.; Gao, J. Llava-med: Training a large language-and-vision Assistant for Biomedicine in One Day. arXiv 2023, arXiv:2306.00890. [Google Scholar]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in Medicine: An Overview of its Applications, Advantages, Limitations, Future Prospects, and Ethical Considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef] [PubMed]
- Moor, M.; Banerjee, O.; Abad, Z.S.H.; Krumholz, H.M.; Leskovec, J.; Topol, E.J.; Rajpurkar, P. Foundation Models for Generalist Medical Artificial Intelligence. Nature 2023, 616, 259–265. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Li, Z.; Zhang, K.; Dan, R.; Jiang, S.; Zhang, Y. Chatdoctor: A Medical Chat Model Fine-tuned on llama Model Using Medical Domain Knowledge. arXiv 2023, arXiv:2303.14070. [Google Scholar]
- Arif, T.B.; Munaf, U.; Ul-Haque, I. The future of Medical Education and Research: Is ChatGPT a Blessing or Blight in Disguise? Med. Educ. Online 2023, 28, 2181052. [Google Scholar] [CrossRef] [PubMed]
- Bahl, L.; Baker, J.; Cohen, P.; Jelinek, F.; Lewis, B.; Mercer, R. Recognition of Continuously Read Natural Corpus. In Proceedings of the ICASSP’78. IEEE International Conference on Acoustics, Speech, and Signal Processing, Tulsa, OK, USA, 10–12 April 1978; Volume 3, pp. 422–424. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the EMNLP, Doha, Qatar, 25–29 October 2014; Volume 14, pp. 1532–1543. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Zhuang, L.; Wayne, L.; Ya, S.; Jun, Z. A Robustly Optimized BERT Pre-training Approach with Post-training. In Proceedings of the 20th Chinese National Conference on Computational Linguistics, Huhhot, China, 13–15 August 2021; pp. 1218–1227. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A Pre-trained Biomedical Language Representation Model for Biomedical Text Mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Alsentzer, E.; Murphy, J.; Boag, W.; Weng, W.H.; Jindi, D.; Naumann, T.; McDermott, M. Publicly Available Clinical BERT Embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 7 June 2019; pp. 72–78. [Google Scholar]
- Piñeiro-Martín, A.; García-Mateo, C.; Docío-Fernández, L.; López-Pérez, M.d.C. Ethical Challenges in the Development of Virtual Assistants Powered by Large Language Models. Electronics 2023, 12, 3170. [Google Scholar] [CrossRef]
- Kim, T.; Bae, S.; Kim, H.A.; woo Lee, S.; Hong, H.; Yang, C.; Kim, Y.H. MindfulDiary: Harnessing Large Language Model to Support Psychiatric Patients’ Journaling. arXiv 2023, arXiv:2310.05231. [Google Scholar]
- Cazzato, G.; Capuzzolo, M.; Parente, P.; Arezzo, F.; Loizzi, V.; Macorano, E.; Marzullo, A.; Cormio, G.; Ingravallo, G. Chat GPT in Diagnostic Human Pathology: Will It Be Useful to Pathologists? A Preliminary Review with ‘Query Session’ and Future Perspectives. AI 2023, 4, 1010–1022. [Google Scholar] [CrossRef]
- Wu, P.Y.; Cheng, C.W.; Kaddi, C.D.; Venugopalan, J.; Hoffman, R.; Wang, M.D. Omic and Electronic Health Record Big Data Analytics for Precision Medicine. IEEE Trans. Biomed. Eng. 2016, 64, 263–273. [Google Scholar] [PubMed]
- Gupta, N.S.; Kumar, P. Perspective of Artificial Intelligence in Healthcare Data Management: A Journey Towards Precision Medicine. Comput. Biol. Med. 2023, 162, 107051. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Wright, A.P.; Patterson, B.L.; Wanderer, J.P.; Turer, R.W.; Nelson, S.D.; McCoy, A.B.; Sittig, D.F.; Wright, A. Using AI-Generated Suggestions from ChatGPT to Optimize Clinical Decision Support. J. Am. Med. Inform. Assoc. 2023, 30, 1237–1245. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Wright, A.P.; Patterson, B.L.; Wanderer, J.P.; Turer, R.W.; Nelson, S.D.; McCoy, A.B.; Sittig, D.F.; Wright, A. Assessing the Value of ChatGPT for Clinical Decision Support Optimization. MedRxiv 2023. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Hassan, R.; Mahmood, S.; Sanghera, R.; Barzangi, K.; El Mukashfi, M.; Shah, S. Trialling a Large Language Model (ChatGPT) in General Practice with the Applied Knowledge Test: Observational Study Demonstrating Opportunities and Limitations in Primary care. JMIR Med. Educ. 2023, 9, e46599. [Google Scholar] [CrossRef] [PubMed]
- Jo, E.; Epstein, D.A.; Jung, H.; Kim, Y.H. Understanding the Benefits and Challenges of Deploying Conversational AI Leveraging Large Language Models for Public Health Intervention. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–16. [Google Scholar]
- Lai, T.M.; Zhai, C.; Ji, H. KEBLM: Knowledge-Enhanced Biomedical Language Models. J. Biomed. Inform. 2023, 143, 104392. [Google Scholar] [CrossRef] [PubMed]
- Arsenyan, V.; Bughdaryan, S.; Shaya, F.; Small, K.; Shahnazaryan, D. Large Language Models for Biomedical Knowledge Graph Construction: Information Extraction from EMR Notes. arXiv 2023, arXiv:2301.12473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Radford, A. Improving Language Understanding by Generative Pre-Training. 2024. Available online: https://openai.com/research/language-unsupervised (accessed on 14 January 2024).
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Nassiri, K.; Akhloufi, M. Transformer Models used for Text-based Question Answering Systems. Appl. Intell. 2023, 53, 10602–10635. [Google Scholar] [CrossRef]
- Larochelle, H.; Hinton, G. Learning to Combine Foveal Glimpses with a Third-Order Boltzmann Machine. In Proceedings of the 23rd International Conference on Neural Information Processing Systems—Volume 1, NIPS’10, Vancouver, BC, Canada, 6–9 December 2010; pp. 1243–1251. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Cheng, J.; Dong, L.; Lapata, M. Long Short-Term Memory-Networks for Machine Reading. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 551–561. [Google Scholar]
- Parikh, A.; Täckström, O.; Das, D.; Uszkoreit, J. A Decomposable Attention Model for Natural Language Inference. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2249–2255. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A Deep Reinforced Model for Abstractive Summarization. In Proceedings of the 6th International Conference on Learning Representations, ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y. Convolutional Sequence to Sequence Learning. In Proceedings of the Thirty-fourth International Conference on Machine Learning, ICML, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Lin, Z.; Feng, M.; dos Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-attentive Sentence Embedding. In Proceedings of the 5th International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the Opportunities and Risks of Foundation Models. arXiv 2022, arXiv:2108.07258. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS’20), Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Alajrami, A.; Aletras, N. How does the Pre-training Objective affect what Large Language Models learn about Linguistic Properties? In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 131–147. [Google Scholar]
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and Applications of Large Language Models. arXiv 2023, arXiv:2307.10169. [Google Scholar]
- Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; et al. Constitutional AI: Harmlessness from AI Feedback. arXiv 2022, arXiv:2212.08073. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Lewkowycz, A.; Andreassen, A.; Dohan, D.; Dyer, E.; Michalewski, H.; Ramasesh, V.; Slone, A.; Anil, C.; Schlag, I.; Gutman-Solo, T.; et al. Solving Quantitative Reasoning Problems with Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 3843–3857. [Google Scholar]
- Wang, W.; Zheng, V.W.; Yu, H.; Miao, C. A survey of Zero-shot Learning: Settings, Methods, and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–37. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-consistency Improves Chain of Thought Reasoning in Language Models. arXiv 2023, arXiv:2203.11171. [Google Scholar]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Manning, C.D.; Ermon, S.; Finn, C. Direct preference optimization: Your language model is secretly a reward model. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–12 December 2024; Volume 36. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Tunstall, L.; Beeching, E.; Lambert, N.; Rajani, N.; Rasul, K.; Belkada, Y.; Huang, S.; von Werra, L.; Fourrier, C.; Habib, N.; et al. Zephyr: Direct Distillation of LM Alignment. arXiv 2023, arXiv:2310.16944. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059. [Google Scholar]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. arXiv 2022, arXiv:2210.11416. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Neelakantan, A.; Xu, T.; Puri, R.; Radford, A.; Han, J.M.; Tworek, J.; Yuan, Q.; Tezak, N.; Kim, J.W.; Hallacy, C.; et al. Text and Code Embeddings by Contrastive Pre-Training. arXiv 2022, arXiv:2201.10005. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling Language Modeling with Pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. Palm 2 Technical Report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Le Scao, T.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; Gallé, M.; et al. Bloom: A 176b-parameter Open-access Multilingual Language Model. arXiv 2023, arXiv:2211.05100. [Google Scholar]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Alpaca: A Strong, Replicable Instruction-following Model. Stanf. Cent. Res. Found. Models. 2023, 3, 7. Available online: https://crfm.stanford.edu/2023/03/13/alpaca.html (accessed on 24 January 2024).
- Islamovic, A. Stability AI Launches the First of Its StableLM Suite of Language Models-Stability AI. 2023. Available online: https://stability.ai/news/stability-ai-launches-the-first-of-its-stablelm-suite-of-language-models (accessed on 24 January 2024).
- Conover, M.; Hayes, M.; Mathur, A.; Meng, X.; Xie, J.; Wan, J.; Shah, S.; Ghodsi, A.; Wendell, P.; Zaharia, M.; et al. Free dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM. 2023. Available online: https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm (accessed on 24 January 2024).
- Bowman, S.R. Eight Things to Know about Large Language Models. arXiv 2023, arXiv:2304.00612. [Google Scholar]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining. Briefings Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef]
- Bolton, E.; Hall, D.; Yasunaga, M.; Lee, T.; Manning, C.; Liang, P. Stanford CRFM introduces Pubmedgpt 2.7 b. 2022. Available online: https://hai.stanford.edu/news/stanford-crfm-introduces-pubmedgpt-27b (accessed on 24 January 2024).
- Xiong, H.; Wang, S.; Zhu, Y.; Zhao, Z.; Liu, Y.; Huang, L.; Wang, Q.; Shen, D. DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task. arXiv 2023, arXiv:2304.01097. [Google Scholar]
- Chen, Z.; Chen, J.; Zhang, H.; Jiang, F.; Chen, G.; Yu, F.; Wang, T.; Liang, J.; Zhang, C.; Zhang, Z.; et al. LLM Zoo: Democratizing ChatGPT. 2023. Available online: https://github.com/FreedomIntelligence/LLMZoo (accessed on 24 January 2024).
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Hou, L.; Clark, K.; Pfohl, S.; Cole-Lewis, H.; Neal, D.; et al. Towards Expert-level Medical Question Answering with Large Language Models. arXiv 2023, arXiv:2305.09617. [Google Scholar]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large Language Models Encode Clinical Knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Tu, T.; Azizi, S.; Driess, D.; Schaekermann, M.; Amin, M.; Chang, P.C.; Carroll, A.; Lau, C.; Tanno, R.; Ktena, I.; et al. Towards Generalist Biomedical AI. arXiv 2023, arXiv:2307.14334. [Google Scholar] [CrossRef]
- Driess, D.; Xia, F.; Sajjadi, M.S.M.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T.; et al. PaLM-E: An embodied multimodal language model. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Rabe, M.N.; Staats, C. Self-attention Does Not Need O(n2) Memory. arXiv 2022, arXiv:2112.05682. [Google Scholar]
- Korthikanti, V.A.; Casper, J.; Lym, S.; McAfee, L.; Andersch, M.; Shoeybi, M.; Catanzaro, B. Reducing activation recomputation in large transformer models. arXiv 2022, arXiv:2205.05198. [Google Scholar]
- Ainslie, J.; Lee-Thorp, J.; de Jong, M.; Zemlyanskiy, Y.; Lebron, F.; Sanghai, S. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 4895–4901. [Google Scholar]
- Gema, A.P.; Daines, L.; Minervini, P.; Alex, B. Parameter-Efficient Fine-Tuning of LLaMA for the Clinical Domain. arXiv 2023, arXiv:2307.03042. [Google Scholar]
- Wu, C.; Lin, W.; Zhang, X.; Zhang, Y.; Wang, Y.; Xie, W. PMC-LLaMA: Towards Building Open-source Language Models for Medicine. 2023; arXiv, arXiv:2304.14454. [Google Scholar]
- Shu, C.; Chen, B.; Liu, F.; Fu, Z.; Shareghi, E.; Collier, N. Visual Med-Alpaca: A Parameter-Efficient Biomedical LLM with Visual Capabilities. 2023. Available online: https://cambridgeltl.github.io/visual-med-alpaca/ (accessed on 24 January 2024).
- Guevara, M.; Chen, S.; Thomas, S.; Chaunzwa, T.L.; Franco, I.; Kann, B.; Moningi, S.; Qian, J.; Goldstein, M.; Harper, S.; et al. Large Language Models to Identify Social Determinants of Health in Electronic Health Records. arXiv 2023, arXiv:2308.06354. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Han, T.; Ma, S.; Zhang, J.; Yang, Y.; Tian, J.; He, H.; Li, A.; He, M.; Liu, Z.; et al. Summary of Chatgpt/gpt-4 Research and Perspective towards the Future of Large Language Models. Meta-Radiology 2023, 1, 100017. [Google Scholar] [CrossRef]
- Wagner, T.; Shweta, F.; Murugadoss, K.; Awasthi, S.; Venkatakrishnan, A.; Bade, S.; Puranik, A.; Kang, M.; Pickering, B.W.; O’Horo, J.C.; et al. Augmented Curation of Clinical Notes from a Massive EHR System Reveals Symptoms of Impending COVID-19 Diagnosis. eLife 2020, 9, e58227. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Wang, M.; Yu, F.; Yang, Y.; Walker, J.; Mostafa, J. A systematic review of Automatic Text Summarization for Biomedical Literature and EHRs. J. Am. Med. Inform. Assoc. 2021, 28, 2287–2297. [Google Scholar] [CrossRef] [PubMed]
- Gershanik, E.F.; Lacson, R.; Khorasani, R. Critical Finding Capture in the Impression Section of Radiology Reports. AMIA Annu. Symp. Proc. 2011, 2011, 465. [Google Scholar] [PubMed]
- Choi, E.; Xiao, C.; Stewart, W.; Sun, J. Mime: Multilevel Medical Embedding of Electronic Health Records for Predictive Healthcare. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Cai, X.; Liu, S.; Han, J.; Yang, L.; Liu, Z.; Liu, T. Chestxraybert: A Pretrained Language Model for Chest Radiology Report Summarization. IEEE Trans. Multimed. 2021, 25, 845–855. [Google Scholar] [CrossRef]
- Xie, Q.; Luo, Z.; Wang, B.; Ananiadou, S. A Survey for Biomedical Text Summarization: From Pre-trained to Large Language Models. arXiv 2023, arXiv:2304.08763. [Google Scholar]
- Sharma, A.; Feldman, D.; Jain, A. Team Cadence at MEDIQA-Chat 2023: Generating, Augmenting and Summarizing Clinical Dialogue with Large Language Models. In Proceedings of the 5th Clinical Natural Language Processing Workshop, Toronto, ON, Canada, 14 July 2023; pp. 228–235. [Google Scholar]
- Sushil, M.; Kennedy, V.E.; Mandair, D.; Miao, B.Y.; Zack, T.; Butte, A.J. CORAL: Expert-Curated Medical Oncology Reports to Advance Language Model Inference. arXiv 2024, arXiv:2308.03853. [Google Scholar] [CrossRef]
- Li, H.; Wu, Y.; Schlegel, V.; Batista-Navarro, R.; Nguyen, T.T.; Kashyap, A.R.; Zeng, X.; Beck, D.; Winkler, S.; Nenadic, G. PULSAR: Pre-training with Extracted Healthcare Terms for Summarizing Patients’ Problems and Data Augmentation with Black-box Large Language Models. arXiv 2023, arXiv:2306.02754. [Google Scholar]
- Park, G.; Yoon, B.J.; Luo, X.; Lpez-Marrero, V.; Johnstone, P.; Yoo, S.; Alexander, F. Automated Extraction of Molecular Interactions and Pathway Knowledge using Large Language Model, Galactica: Opportunities and Challenges. In Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 255–264. [Google Scholar]
- Kartchner, D.; Ramalingam, S.; Al-Hussaini, I.; Kronick, O.; Mitchell, C. Zero-Shot Information Extraction for Clinical Meta-Analysis using Large Language Models. In Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 396–405. [Google Scholar]
- Agrawal, M.; Hegselmann, S.; Lang, H.; Kim, Y.; Sontag, D. Large Language Models are Few-shot Clinical Information Extractors. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 1998–2022. [Google Scholar]
- Wu, J.; Shi, D.; Hasan, A.; Wu, H. KnowLab at RadSum23: Comparing Pre-trained Language Models in Radiology Report Summarization. In Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 535–540. [Google Scholar]
- Yan, A.; McAuley, J.; Lu, X.; Du, J.; Chang, E.Y.; Gentili, A.; Hsu, C.N. RadBERT: Adapting Transformer-based Language Models to Radiology. Radiol. Artif. Intell. 2022, 4, e210258. [Google Scholar] [CrossRef] [PubMed]
- Dash, D.; Thapa, R.; Banda, J.M.; Swaminathan, A.; Cheatham, M.; Kashyap, M.; Kotecha, N.; Chen, J.H.; Gombar, S.; Downing, L. Evaluation of GPT-3.5 and GPT-4 for Supporting Real-World Information Needs in Healthcare Delivery. arXiv 2023, arXiv:2304.13714. [Google Scholar]
- Li, H.; Gerkin, R.C.; Bakke, A.; Norel, R.; Cecchi, G.; Laudamiel, C.; Niv, M.Y.; Ohla, K.; Hayes, J.E.; Parma, V.; et al. Text-based Predictions of COVID-19 Diagnosis from Self-reported Chemosensory Descriptions. Commun. Med. 2023, 3, 104. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Zhang, D.; Tan, W.; Zhang, H. DeakinNLP at ProbSum 2023: Clinical Progress Note Summarization with Rules and Language ModelsClinical Progress Note Summarization with Rules and Languague Models. In Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 491–496. [Google Scholar]
- Macharla, S.; Madamanchi, A.; Kancharla, N. nav-nlp at RadSum23: Abstractive Summarization of Radiology Reports using BART Finetuning. In Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 541–544. [Google Scholar]
- Koga, S.; Martin, N.B.; Dickson, D.W. Evaluating the Performance of Large Language Models: ChatGPT and Google Bard in Generating Differential Diagnoses in Clinicopathological Conferences of Neurodegenerative Disorders. Brain Pathol. 2023, e13207, early view. [Google Scholar]
- Balas, M.; Ing, E.B. Conversational AI Models for Ophthalmic Diagnosis: Comparison of Chatbot and the Isabel pro Differential Diagnosis Generator. JFO Open Ophthalmol. 2023, 1, 100005. [Google Scholar] [CrossRef]
- Huang, H.; Zheng, O.; Wang, D.; Yin, J.; Wang, Z.; Ding, S.; Yin, H.; Xu, C.; Yang, R.; Zheng, Q.; et al. ChatGPT for Shaping the Future of Dentistry: The Potential of Multi-modal Large Language Model. Int. J. Oral Sci. 2023, 15, 29. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Chen, Y.J.; Zhou, Y.; Yin, J.J.; Gao, Y.J. The Artificial Intelligence Large Language Models and Neuropsychiatry Practice and Research Ethic. Asian J. Psychiatry 2023, 84, 103577. [Google Scholar] [CrossRef] [PubMed]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted Medical Education using Large Language Models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Eggmann, F.; Weiger, R.; Zitzmann, N.U.; Blatz, M.B. Implications of Large Language Models such as ChatGPT for Dental Medicine. J. Esthet. Restor. Dent. 2023, 35, 1098–1102. [Google Scholar] [CrossRef] [PubMed]
- Lehman, E.; Johnson, A. Clinical-t5: Large Language Models Built Using Mimic Clinical Text. 2023. Available online: https://www.physionet.org/content/clinical-t5/1.0.0/ (accessed on 24 January 2024).
- Ma, C.; Wu, Z.; Wang, J.; Xu, S.; Wei, Y.; Liu, Z.; Jiang, X.; Guo, L.; Cai, X.; Zhang, S.; et al. ImpressionGPT: An Iterative Optimizing Framework for Radiology Report Summarization with ChatGPT. arXiv 2023, arXiv:2304.08448. [Google Scholar]
- Liu, Z.; Zhong, A.; Li, Y.; Yang, L.; Ju, C.; Wu, Z.; Ma, C.; Shu, P.; Chen, C.; Kim, S.; et al. Radiology-GPT: A Large Language Model for Radiology. arXiv 2023, arXiv:2306.08666. [Google Scholar]
- Li, C.; Zhang, Y.; Weng, Y.; Wang, B.; Li, Z. Natural Language Processing Applications for Computer-Aided Diagnosis in Oncology. Diagnostics 2023, 13, 286. [Google Scholar] [CrossRef] [PubMed]
- Joseph, S.A.; Chen, L.; Trienes, J.; Göke, H.L.; Coers, M.; Xu, W.; Wallace, B.C.; Li, J.J. FactPICO: Factuality Evaluation for Plain Language Summarization of Medical Evidence. arXiv 2024, arXiv:2402.11456. [Google Scholar]
- Van Veen, D.; Van Uden, C.; Attias, M.; Pareek, A.; Bluethgen, C.; Polacin, M.; Chiu, W.; Delbrouck, J.B.; Zambrano Chaves, J.; Langlotz, C.; et al. RadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models. In Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 449–460. [Google Scholar]
- Den Hamer, D.M.; Schoor, P.; Polak, T.B.; Kapitan, D. Improving Patient Pre-screening for Clinical Trials: Assisting Physicians with Large Language Models. arXiv 2023, arXiv:2304.07396. [Google Scholar]
- Cascella, M.; Montomoli, J.; Bellini, V.; Bignami, E. Evaluating the Feasibility of ChatGPT in Healthcare: An Analysis of Multiple Clinical and Research Scenarios. J. Med. Syst. 2023, 47, 33. [Google Scholar] [CrossRef] [PubMed]
- Tang, L.; Peng, Y.; Wang, Y.; Ding, Y.; Durrett, G.; Rousseau, J. Less Likely Brainstorming: Using Language Models to Generate Alternative Hypotheses. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 12532–12555. [Google Scholar]
- Chen, S.; Wu, M.; Zhu, K.Q.; Lan, K.; Zhang, Z.; Cui, L. LLM-empowered Chatbots for Psychiatrist and Patient Simulation: Application and Evaluation. arXiv 2023, arXiv:2305.13614. [Google Scholar]
- Kleesiek, J.; Wu, Y.; Stiglic, G.; Egger, J.; Bian, J. An Opinion on ChatGPT in Health Care—Written by Humans Only. J. Nucl. Med. 2023, 64, 701–703. [Google Scholar] [CrossRef] [PubMed]
- Jackson, R.G.; Patel, R.; Jayatilleke, N.; Kolliakou, A.; Ball, M.; Gorrell, G.; Roberts, A.; Dobson, R.J.; Stewart, R. Natural Language Processing to Extract Symptoms of Severe Mental Illness from Clinical Text: The Clinical Record Interactive Search Comprehensive Data Extraction (CRIS-CODE) project. BMJ Open 2017, 7, e012012. [Google Scholar] [CrossRef] [PubMed]
- Liang, S.; Hartmann, M.; Sonntag, D. Cross-domain German Medical Named Entity Recognition using a Pre-Trained Language Model and Unified Medical Semantic Types. In Proceedings of the 5th Clinical Natural Language Processing Workshop, Toronto, ON, Canada, 14 July 2023; pp. 259–271. [Google Scholar]
- Harskamp, R.E.; De Clercq, L. Performance of ChatGPT as an AI-assisted Decision Support Tool in Medicine: A Proof-of-concept Study for Interpreting Symptoms and Management of Common Cardiac Conditions (AMSTELHEART-2). Acta Cardiol. 2024, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Rao, A.; Kim, J.; Kamineni, M.; Pang, M.; Lie, W.; Dreyer, K.J.; Succi, M.D. Evaluating GPT as an Adjunct for Radiologic Decision Making: GPT-4 Versus GPT-3.5 in a Breast Imaging Pilot. J. Am. Coll. Radiol. 2023, 20, 990–997. [Google Scholar] [CrossRef] [PubMed]
- Lyu, C.; Wu, M.; Wang, L.; Huang, X.; Liu, B.; Du, Z.; Shi, S.; Tu, Z. Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration. arXiv 2023, arXiv:2306.09093. [Google Scholar]
- Drozdov, I.; Forbes, D.; Szubert, B.; Hall, M.; Carlin, C.; Lowe, D.J. Supervised and Unsupervised Language Modelling in Chest X-ray Radiological Reports. PLoS ONE 2020, 15, e0229963. [Google Scholar] [CrossRef] [PubMed]
- Nath, C.; Albaghdadi, M.S.; Jonnalagadda, S.R. A Natural Language Processing Tool for Large-scale Data Extraction from Echocardiography Reports. PLoS ONE 2016, 11, e0153749. [Google Scholar] [CrossRef] [PubMed]
- Naseem, U.; Bandi, A.; Raza, S.; Rashid, J.; Chakravarthi, B.R. Incorporating Medical Knowledge to Transformer-based Language Models for Medical Dialogue Generation. In Proceedings of the 21st Workshop on Biomedical Language Processing, Dublin, Ireland, 26 May 2022; pp. 110–115. [Google Scholar]
- Zhou, H.Y.; Yu, Y.; Wang, C.; Zhang, S.; Gao, Y.; Pan, J.; Shao, J.; Lu, G.; Zhang, K.; Li, W. A Transformer-based Representation-Learning Model with Unified Processing of Multimodal Input for Clinical Diagnostics. Nat. Biomed. Eng. 2023, 7, 743–755. [Google Scholar] [CrossRef] [PubMed]
- Biswas, S. ChatGPT and the future of medical writing. Radiology 2023, 307, e223312. [Google Scholar] [CrossRef] [PubMed]
- Shortliffe, E.H. Computer Programs to Support Clinical decision making. JAMA 1987, 258, 61–66. [Google Scholar] [CrossRef] [PubMed]
- Szolovits, P.; Pauker, S.G. Categorical and probabilistic reasoning in medicine revisited. Artif. Intell. 1993, 59, 167–180. [Google Scholar] [CrossRef]
- Yasunaga, M.; Leskovec, J.; Liang, P. LinkBERT: Pretraining Language Models with Document Links. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 8003–8016. [Google Scholar]
- Yasunaga, M.; Bosselut, A.; Ren, H.; Zhang, X.; Manning, C.D.; Liang, P.S.; Leskovec, J. Deep Bidirectional Language-Knowledge Graph Pretraining. Adv. Neural Inf. Process. Syst. 2022, 35, 37309–37323. [Google Scholar]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Trans. Comput. Healthc. (HEALTH) 2021, 3, 1–23. [Google Scholar] [CrossRef]
- Jin, D.; Pan, E.; Oufattole, N.; Weng, W.H.; Fang, H.; Szolovits, P. What Disease does this Patient have? A Large-scale Open Domain Question Answering Dataset from Medical Exams. Appl. Sci. 2021, 11, 6421. [Google Scholar] [CrossRef]
- Pal, A.; Umapathi, L.K.; Sankarasubbu, M. MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering. In Proceedings of the Conference on Health, Inference, and Learning, Virtual Event, 7–8 April 2022; Volume 174, pp. 248–260. [Google Scholar]
- Zhu, X.; Chen, Y.; Gu, Y.; Xiao, Z. SentiMedQAer: A Transfer Learning-Based Sentiment-Aware Model for Biomedical Question Answering. Front. Neurorobot. 2022, 16, 773329. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Zhang, Y. Datlmedqa: A Data Augmentation and Transfer Learning based Solution for Medical Question Answering. Appl. Sci. 2021, 11, 11251. [Google Scholar] [CrossRef]
- Black, S.; Biderman, S.; Hallahan, E.; Anthony, Q.; Gao, L.; Golding, L.; He, H.; Leahy, C.; McDonell, K.; Phang, J.; et al. GPT-NeoX-20B: An Open-Source Autoregressive Language Model. In Proceedings of the BigScience Episode #5—Workshop on Challenges & Perspectives in Creating Large Language Models, Virtual, 27 May 2022; pp. 95–136. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. Opt: Open Pre-trained Transformer Language Models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Rosol, M.; Gasior, J.S.; Laba, J.; Korzeniewski, K.; Młyńczak, M. Evaluation of the Performance of GPT-3.5 and GPT-4 on the Medical Final Examination. Sci. Rep. 2023, 13, 20512. [Google Scholar] [CrossRef] [PubMed]
- Nori, H.; King, N.; McKinney, S.M.; Carignan, D.; Horvitz, E. Capabilities of gpt-4 on Medical Challenge Problems. arXiv 2023, arXiv:2303.13375. [Google Scholar]
- Nashwan, A.J.; Abujaber, A.A.; Choudry, H. Embracing the Future of Physician-patient Communication: GPT-4 in Gastroenterology. Gastroenterol. Endosc. 2023, 1, 132–135. [Google Scholar] [CrossRef]
- Meskó, B.; Topol, E.J. The Imperative for Regulatory Oversight of Large Language Models (or Generative AI) in Healthcare. NPJ Digit. Med. 2023, 6, 120. [Google Scholar] [CrossRef] [PubMed]
- Shin, D. The Effects of Explainability and Causability on Perception, Trust, and Acceptance: Implications for Explainable AI. Int. J. Hum.-Comput. Stud. 2021, 146, 102551. [Google Scholar] [CrossRef]
- Khowaja, S.A.; Khuwaja, P.; Dev, K. ChatGPT Needs SPADE (Sustainability, PrivAcy, Digital divide, and Ethics) Evaluation: A Review. arXiv 2023, arXiv:2305.03123. [Google Scholar]
- Ferrara, E. Should Chatgpt be Biased? Challenges and Risks of Bias in Large Language Models. arXiv 2023, arXiv:2304.03738. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Zakka, C.; Shad, R.; Chaurasia, A.; Dalal, A.R.; Kim, J.L.; Moor, M.; Fong, R.; Phillips, C.; Alexander, K.; Ashley, E.; et al. Almanac—Retrieval-Augmented Language Models for Clinical Medicine. NEJM AI 2024, 1, AIoa2300068. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, T.; Liang, P. Evaluating Verifiability in Generative Search Engines. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 7001–7025. [Google Scholar]
- Jin, Q.; Leaman, R.; Lu, Z. Retrieve, Summarize, and Verify: How will ChatGPT impact information seeking from the medical literature? J. Am. Soc. Nephrol. 2023, 34, 10–1681. [Google Scholar] [CrossRef] [PubMed]
- Parisi, A.; Zhao, Y.; Fiedel, N. TALM: Tool Augmented Language Models. arXiv 2022, arXiv:2205.12255. [Google Scholar]
- Jin, Q.; Yang, Y.; Chen, Q.; Lu, Z. GeneGPT: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics 2024, 40, btae075. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Hu, S.; Lin, Y.; Chen, W.; Ding, N.; Cui, G.; Zeng, Z.; Huang, Y.; Xiao, C.; Han, C.; et al. Tool Learning with Foundation Models. arXiv 2023, arXiv:2304.08354. [Google Scholar]
- Gao, L.; Madaan, A.; Zhou, S.; Alon, U.; Liu, P.; Yang, Y.; Callan, J.; Neubig, G. PAL: Program-aided language models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every Picture Tells a Story: Generating Sentences from Images. In Proceedings of the Computer Vision—ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part IV 11. pp. 15–29. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and Generating Simple Image Descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef]
- Li, S.; Kulkarni, G.; Berg, T.; Berg, A.; Choi, Y. Composing Simple Image Descriptions using Web-scale N-grams. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning, Portland, OR, USA, 23–24 June 2011; pp. 220–228. [Google Scholar]
- Yao, B.Z.; Yang, X.; Lin, L.; Lee, M.W.; Zhu, S.C. I2t: Image Parsing to Text Description. Proc. IEEE 2010, 98, 1485–1508. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: Lessons Learned from the 2015 MSCOCO Image Captioning Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 652–663. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Karpathy, A.; Fei-Fei, L. Densecap: Fully Convolutional Localization Networks for Dense Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4565–4574. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Hierarchy Parsing for Image Captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2621–2629. [Google Scholar]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Auto-Encoding Scene Graphs for Image Captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10685–10694. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring Visual Relationship for Image Captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to Look: Adaptive Attention via a Visual Sentinel for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Li, X.; Jiang, S. Know More Say Less: Image Captioning Based on Scene graphs. IEEE Trans. Multimed. 2019, 21, 2117–2130. [Google Scholar] [CrossRef]
- Chunseong Park, C.; Kim, B.; Kim, G. Attend to You: Personalized Image Captioning with Context Sequence Memory Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 895–903. [Google Scholar]
- Yang, Z.; Yuan, Y.; Wu, Y.; Cohen, W.W.; Salakhutdinov, R.R. Review Networks for Caption Generation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Wang, Y.; Lin, Z.; Shen, X.; Cohen, S.; Cottrell, G.W. Skeleton Key: Image Captioning by Skeleton-Attribute Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7272–7281. [Google Scholar]
- Wang, Q.; Chan, A.B. CNN+ CNN: Convolutional Decoders for Image Captioning. arXiv 2018, arXiv:1805.09019. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-Memory Transformer for Image Captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked Cross Attention for Image-Text Matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 201–216. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled Transformer for Image Captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8928–8937. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and Top-down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Alsharid, M.; Sharma, H.; Drukker, L.; Chatelain, P.; Papageorghiou, A.T.; Noble, J.A. Captioning Ultrasound Images Automatically. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; Proceedings, Part IV 22. Springer: Berlin/Heidelberg, Germany, 2019; pp. 338–346. [Google Scholar]
- Alsharid, M.; El-Bouri, R.; Sharma, H.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. A Curriculum Learning based Approach to Captioning Ultrasound Images. In Proceedings of the Medical Ultrasound, and Preterm, Perinatal and Paediatric Image Analysis: First International Workshop, ASMUS 2020, and 5th International Workshop, PIPPI 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 4–8 October 2020; Proceedings 1. Springer: Berlin/Heidelberg, Germany, 2020; pp. 75–84. [Google Scholar]
- Alsharid, M.; El-Bouri, R.; Sharma, H.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. A Course-focused Dual Curriculum for Image Captioning. In Proceedings of the IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 716–720. [Google Scholar]
- Aswiga, R.; Shanthi, A. A Multilevel Transfer Learning Technique and LSTM Framework for Generating Medical Captions for Limited CT and DBT Images. J. Digit. Imaging 2022, 35, 564–580. [Google Scholar] [CrossRef] [PubMed]
- Selivanov, A.; Rogov, O.Y.; Chesakov, D.; Shelmanov, A.; Fedulova, I.; Dylov, D.V. Medical Image Captioning via Generative Pretrained Transformers. Sci. Rep. 2023, 13, 4171. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 37, pp. 2048–2057. [Google Scholar]
- Alsharid, M.; Cai, Y.; Sharma, H.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. Gaze-Assisted Automatic Captioning of Fetal Ultrasound Videos using Three-way Multi-modal Deep Neural Networks. Med. Image Anal. 2022, 82, 102630. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; He, Y.; Wang, Y.; Li, Y.; Wang, W.; Luo, P.; Wang, Y.; Wang, L.; Qiao, Y. VideoChat: Chat-Centric Video Understanding. arXiv 2024, arXiv:2305.06355. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.w.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a Freely Accessible Critical Care Database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Zhang, J.; Wang, G.; Yao, R.; Ren, C.; Chen, G.; Jin, X.; Guo, J.; Liu, S.; Zheng, H.; et al. Machine Learning Prediction Models for Mechanically Ventilated Patients: Analyses of the MIMIC-III Database. Front. Med. 2021, 8, 662340. [Google Scholar] [CrossRef] [PubMed]
- Khope, S.R.; Elias, S. Simplified & Novel Predictive Model using Feature Engineering over MIMIC-III Dataset. Procedia Comput. Sci. 2023, 218, 1968–1976. [Google Scholar]
- Huang, H.; Liu, Y.; Wu, M.; Gao, Y.; Yu, X. Development and Validation of a Risk Stratification Model for Predicting the Mortality of Acute Kidney Injury in Critical Care Patients. Ann. Transl. Med. 2021, 9, 323. [Google Scholar] [CrossRef]
- Li, D.; Gao, J.; Hong, N.; Wang, H.; Su, L.; Liu, C.; He, J.; Jiang, H.; Wang, Q.; Long, Y.; et al. A Clinical Prediction Model to Predict Heparin Treatment Outcomes and Provide Dosage Recommendations: Development and Validation Study. J. Med. Internet Res. 2021, 23, e27118. [Google Scholar] [CrossRef] [PubMed]
- Khope, S.; Elias, S. Strategies of Predictive Schemes and Clinical Diagnosis for Prognosis Using MIMIC-III: A Systematic Review. Healthcare 2023, 11, 710. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Cai, L.; Liu, Y.; Zhang, J.; Ou, X.; Xu, J. Machine Learning Algorithms for Prediction of Ventilator Associated Pneumonia in Traumatic Brain Injury Patients from the MIMIC-III Database. Heart Lung 2023, 62, 225–232. [Google Scholar] [CrossRef] [PubMed]
- Geri, G.; Ferrer, L.; Tran, N.; Celi, L.A.; Jamme, M.; Lee, J.; Vieillard-Baron, A. Cardio-Pulmonary-Renal Interactions in ICU Patients. Role of Mechanical Ventilation, Venous Congestion and Perfusion Deficit on Worsening of Renal Function: Insights from the MIMIC-III Database. J. Crit. Care 2021, 64, 100–107. [Google Scholar] [CrossRef] [PubMed]
- Kurniati, A.P.; Hall, G.; Hogg, D.; Johnson, O. Process Mining in Oncology Using the MIMIC-III Dataset. J. Phys. Conf. Ser. 2018, 971, 012008. [Google Scholar] [CrossRef]
- McWilliams, C.J.; Lawson, D.J.; Santos-Rodriguez, R.; Gilchrist, I.D.; Champneys, A.; Gould, T.H.; Thomas, M.J.; Bourdeaux, C.P. Towards a Decision Support Tool for Intensive Care Discharge: Machine Learning Algorithm Development Using Electronic Healthcare Data from MIMIC-III and Bristol, UK. BMJ Open 2019, 9, e025925. [Google Scholar] [CrossRef] [PubMed]
- Ding, E.Y.; Albuquerque, D.; Winter, M.; Binici, S.; Piche, J.; Bashar, S.K.; Chon, K.; Walkey, A.J.; McManus, D.D. Novel Method of Atrial Fibrillation Case Identification and Burden Estimation Using the MIMIC-III Electronic Health Data Set. J. Intensive Care Med. 2019, 34, 851–857. [Google Scholar] [CrossRef]
- Aldughayfiq, B.; Ashfaq, F.; Jhanjhi, N.Z.; Humayun, M. Capturing Semantic Relationships in Electronic Health Records Using Knowledge Graphs: An Implementation Using MIMIC III Dataset and GraphDB. Healthcare 2023, 11, 1762. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.L.; Hong, L.; Yuan, S.Q.; Xu, X.M.; Wei, J.R.; Yin, H.Y. Association Between Glucocorticoid Use and All-cause Mortality in Critically Ill Patients with Heart Failure: A Cohort Study Based on the MIMIC-III Database. Front. Pharmacol. 2023, 14, 1118551. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.; Pollard, T.J.; Berkowitz, S.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.y.; Mark, R.G.; Horng, S. MIMIC-CXR, a De-identified Publicly Available Database of Chest Radiographs with Free-Text Reports. Sci. Data 2019, 6, 317. [Google Scholar] [CrossRef] [PubMed]
- Kwiatkowski, T.; Palomaki, J.; Redfield, O.; Collins, M.; Parikh, A.; Alberti, C.; Epstein, D.; Polosukhin, I.; Devlin, J.; Lee, K.; et al. Natural Questions: A Benchmark for Question Answering Research. Trans. Assoc. Comput. Linguist. 2019, 7, 453–466. [Google Scholar] [CrossRef]
- Irmici, G.; Cè, M.; Caloro, E.; Khenkina, N.; Della Pepa, G.; Ascenti, V.; Martinenghi, C.; Papa, S.; Oliva, G.; Cellina, M. Chest X-ray in Emergency Radiology: What Artificial Intelligence Applications Are Available? Diagnostics 2023, 13, 216. [Google Scholar] [CrossRef] [PubMed]
- van Sonsbeek, T.; Worring, M. Towards Automated Diagnosis with Attentive Multi-modal Learning Using Electronic Health Records and Chest X-rays. In Proceedings of the Multimodal Learning for Clinical Decision Support and Clinical Image-Based Procedures: 10th International Workshop, ML-CDS 2020, and 9th International Workshop, CLIP 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 4–8 October 2020; Proceedings 9. pp. 106–114. [Google Scholar]
- Lin, M.; Hou, B.; Mishra, S.; Yao, T.; Huo, Y.; Yang, Q.; Wang, F.; Shih, G.; Peng, Y. Enhancing Thoracic Disease Detection Using Chest X-rays from PubMed Central Open Access. Comput. Biol. Med. 2023, 159, 106962. [Google Scholar] [CrossRef] [PubMed]
- Glocker, B.; Jones, C.; Bernhardt, M.; Winzeck, S. Algorithmic Encoding of Protected Characteristics in Chest X-ray Disease Detection Models. eBioMedicine 2023, 89, 104467. [Google Scholar] [CrossRef] [PubMed]
- Park, H.; Kim, K.; Park, S.; Choi, J. Medical Image Captioning Model to Convey More Details: Methodological Comparison of Feature Difference Generation. IEEE Access 2021, 9, 150560–150568. [Google Scholar] [CrossRef]
- Légaré, F.; Turcotte, S.; Stacey, D.; Ratté, S.; Kryworuchko, J.; Graham, I.D. Patients’ Perceptions of Sharing in Decisions: A Systematic Review of Interventions to Enhance Shared Decision Making in Routine Clinical Practice. Patient-Patient Outcomes Res. 2012, 5, 1–19. [Google Scholar] [CrossRef]
- Barradell, A.C.; Gerlis, C.; Houchen-Wolloff, L.; Bekker, H.L.; Robertson, N.; Singh, S.J. Systematic Review of Shared Decision-making Interventions for People Living with Chronic Respiratory Diseases. BMJ Open 2023, 13, e069461. [Google Scholar] [CrossRef]
- Alpi, K.M.; Martin, C.L.; Plasek, J.M.; Sittig, S.; Smith, C.A.; Weinfurter, E.V.; Wells, J.K.; Wong, R.; Austin, R.R. Characterizing Terminology Applied by Authors and Database Producers to Informatics Literature on Consumer Engagement with Wearable Devices. J. Am. Med. Inform. Assoc. 2023, 30, 1284–1292. [Google Scholar] [CrossRef]
- Yuan, P.; Qi, G.; Hu, X.; Qi, M.; Zhou, Y.; Shi, X. Characteristics, Likelihood and Challenges of Road Traffic Injuries in China before COVID-19 and in the Postpandemic Era. Humanit. Soc. Sci. Commun. 2023, 10, 2. [Google Scholar] [CrossRef]
- Rohanian, O.; Nouriborji, M.; Kouchaki, S.; Clifton, D.A. On the Effectiveness of Compact Biomedical Transformers. Bioinformatics 2023, 39, btad103. [Google Scholar] [CrossRef] [PubMed]
- Jimeno Yepes, A.J.; Verspoor, K. Classifying Literature Mentions of Biological Pathogens as Experimentally Studied Using Natural Language Processing. J. Biomed. Semant. 2023, 14, 1. [Google Scholar] [CrossRef] [PubMed]
- Gupta, V.; Dixit, A.; Sethi, S. An Improved Sentence Embeddings based Information Retrieval Technique using Query Reformulation. In Proceedings of the 2023 International Conference on Advancement in Computation & Computer Technologies (InCACCT), Gharuan, India, 5–6 May 2023; pp. 299–304. [Google Scholar]
- Bascur, J.P.; Verberne, S.; van Eck, N.J.; Waltman, L. Academic Information Retrieval using Citation Clusters: In-Depth Evaluation based on Systematic Reviews. Scientometrics 2023, 128, 2895–2921. [Google Scholar] [CrossRef]
- Bramley, R.; Howe, S.; Marmanis, H. Notes on the Data Quality of Bibliographic Records from the MEDLINE Database. Database 2023, 2023, baad070. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.L.; Rotemberg, V.; Lester, J.C.; Novoa, R.A.; Chiou, A.S.; Daneshjou, R. Evaluation of Diagnosis Diversity in Artificial Intelligence Datasets: A Scoping Review. Br. J. Dermatol. 2023, 188, 292–294. [Google Scholar] [CrossRef]
- Lunge, S.B.; Shetty, N.S.; Sardesai, V.R.; Karagaiah, P.; Yamauchi, P.S.; Weinberg, J.M.; Kircik, L.; Giulini, M.; Goldust, M. Therapeutic Application of Machine Learning in Psoriasis: A Prisma Systematic Review. J. Cosmet. Dermatol. 2023, 22, 378–382. [Google Scholar] [CrossRef]
- Ernst, P.; Siu, A.; Milchevski, D.; Hoffart, J.; Weikum, G. DeepLife: An Entity-aware Search, Analytics and Exploration Platform for Health and Life Sciences. In Proceedings of the ACL-2016 System Demonstrations, Berlin, Germany, 7–12 August 2016; pp. 19–24. [Google Scholar]
- Chen, Y.; Elenee Argentinis, J.; Weber, G. IBM Watson: How Cognitive Computing Can Be Applied to Big Data Challenges in Life Sciences Research. Clin. Ther. 2016, 38, 688–701. [Google Scholar] [CrossRef] [PubMed]
- Haynes, R.; McKibbon, K.; Walker, C.; Mousseau, J.; Baker, L.; Fitzgerald, D.; Guyatt, G.; Norman, G. Computer Searching of the Medical Literature. An Evaluation of MEDLINE Searching Systems. Ann. Intern. Med. 1985, 103, 812–816. [Google Scholar] [CrossRef] [PubMed]
- Stevenson, M.; Guo, Y.; Alamri, A.; Gaizauskas, R. Disambiguation of Biomedical Abbreviations. In Proceedings of the BioNLP 2009 Workshop, Boulder, CO, USA, 4–5 June 2009; pp. 71–79. [Google Scholar]
- Lima Lopez, S.; Perez, N.; Cuadros, M.; Rigau, G. NUBes: A Corpus of Negation and Uncertainty in Spanish Clinical Texts. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 5772–5781. [Google Scholar]
- Doğan, R.I.; Leaman, R.; Lu, Z. NCBI Disease Corpus: A Resource for Disease Name Recognition and Concept Normalization. J. Biomed. Inform. 2014, 47, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, S.; Wang, L.L.; Bogin, B.; Mehta, S.; van Zuylen, M.; Parasa, S.; Singh, S.; Gardner, M.; Hajishirzi, H. MedICaT: A Dataset of Medical Images, Captions, and Textual References. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 2112–2120. [Google Scholar]
- Demner-Fushman, D.; Kohli, M.D.; Rosenman, M.B.; Shooshan, S.E.; Rodriguez, L.; Antani, S.; Thoma, G.R.; McDonald, C.J. Preparing a Collection of Radiology Examinations for Distribution and Retrieval. J. Am. Med. Inform. Assoc. 2016, 23, 304–310. [Google Scholar] [CrossRef] [PubMed]
- Schopf, T.; Braun, D.; Matthes, F. Evaluating Unsupervised Text Classification: Zero-Shot and Similarity-Based Approaches. In Proceedings of the 2022 6th International Conference on Natural Language Processing and Information Retrieval, New York, NY, USA, 11–12 July 2023; pp. 6–15. [Google Scholar]
- Uzuner, O.; Luo, Y.; Szolovits, P. Evaluating the State-of-the-Art in Automatic De-identification. J. Am. Med. Inform. Assoc. 2007, 14, 550–563. [Google Scholar] [CrossRef] [PubMed]
- Uzuner, Z.; Goldstein, I.; Luo, Y.; Kohane, I. Identifying Patient Smoking Status from Medical Discharge Records. J. Am. Med. Inform. Assoc. 2008, 15, 14–24. [Google Scholar] [CrossRef] [PubMed]
- Uzuner, O. Recognizing Obesity and Comorbidities in Sparse Data. J. Am. Med. Inform. Assoc. 2009, 16, 561–570. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Luo, Y.; Stone, D.; Zong, N.; Wen, A.; Yu, Y.; Rasmussen, L.V.; Wang, F.; Pathak, J.; Liu, H.; et al. Integration of NLP2FHIR Representation with Deep Learning Models for EHR Phenotyping: A Pilot Study on Obesity Datasets. AMIA Summits Transl. Sci. Proc. 2021, 2021, 410. [Google Scholar] [PubMed]
- Hong, N.; Wen, A.; Stone, D.J.; Tsuji, S.; Kingsbury, P.R.; Rasmussen, L.V.; Pacheco, J.A.; Adekkanattu, P.; Wang, F.; Luo, Y.; et al. Developing a FHIR-based EHR Phenotyping Framework: A Case Study for Identification of Patients with Obesity and Multiple Comorbidities from Discharge Summaries. J. Biomed. Inform. 2019, 99, 103310. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Mao, C.; Luo, Y. Clinical Text Classification with Rule-based Features and Knowledge-guided Convolutional Neural Networks. BMC Med. Inform. Decis. Mak. 2019, 19, 31–39. [Google Scholar] [CrossRef] [PubMed]
- Uzuner, O.; Solti, I.; Cadag, E. Extracting Medication Information from Clinical Text. J. Am. Med. Inform. Assoc. 2010, 17, 514–518. [Google Scholar] [CrossRef] [PubMed]
- Uzuner, O.; Solti, I.; Xia, F.; Cadag, E. Community Annotation Experiment for Ground Truth Generation for the I2B2 Medication Challenge. J. Am. Med. Inform. Assoc. 2010, 17, 519–523. [Google Scholar] [CrossRef] [PubMed]
- Houssein, E.H.; Mohamed, R.E.; Ali, A.A. Heart Disease Risk Factors Detection from Electronic Health Records using Advanced NLP and Deep Learning Techniques. Sci. Rep. 2023, 13, 7173. [Google Scholar] [CrossRef]
- Doan, S.; Collier, N.; Xu, H.; Duy, P.H.; Phuong, T.M. Recognition of Medication Information from Discharge Summaries using Ensembles of Classifiers. BMC Med. Inform. Decis. Mak. 2012, 12, 36. [Google Scholar] [CrossRef]
- Fu, S.; Chen, D.; He, H.; Liu, S.; Moon, S.; Peterson, K.J.; Shen, F.; Wang, L.; Wang, Y.; Wen, A.; et al. Clinical Concept Extraction: A Methodology Review. J. Biomed. Inform. 2020, 109, 103526. [Google Scholar] [CrossRef] [PubMed]
- Uzuner, O.; South, B.R.; Shen, S.; DuVall, S.L. 2010 i2b2/VA Challenge on Concepts, Assertions, and Relations in Clinical Text. J. Am. Med. Inform. Assoc. 2011, 18, 552–556. [Google Scholar] [CrossRef] [PubMed]
- Naseem, U.; Thapa, S.; Zhang, Q.; Hu, L.; Masood, A.; Nasim, M. Reducing Knowledge Noise for Improved Semantic Analysis in Biomedical Natural Language Processing Applications. In Proceedings of the 5th Clinical Natural Language Processing Workshop, Toronto, ON, Canada, 14 July 2023; pp. 272–277. [Google Scholar]
- Moscato, V.; Napolano, G.; Postiglione, M.; Sperlì, G. Multi-task Learning for Few-shot Biomedical Relation Extraction. Artif. Intell. Rev. 2023, 56, 13743–13763. [Google Scholar] [CrossRef]
- Uzuner, O.; Bodnari, A.; Shen, S.; Forbush, T.; Pestian, J.; South, B.R. Evaluating the State of the Art in Coreference Resolution for Electronic Medical Records. J. Am. Med. Inform. Assoc. 2012, 19, 786–791. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Rumshisky, A.; Uzuner, O. Evaluating Temporal Relations in Clinical Text: 2012 I2B2 Challenge. J. Am. Med. Inform. Assoc. 2013, 20, 806–813. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Rumshisky, A.; Uzuner, O. Annotating Temporal Information in Clinical Narratives. J. Biomed. Inform. 2013, 46, S5–S12. [Google Scholar] [CrossRef]
- Kumar, V.; Stubbs, A.; Shaw, S.; Uzuner, O. Creation of a New Longitudinal Corpus of Clinical Narratives. J. Biomed. Inform. 2015, 58, S6–S10. [Google Scholar] [CrossRef]
- Stubbs, A.; Uzuner, Ö. Annotating Longitudinal Clinical Narratives for De-identification: The 2014 i2b2/UTHealth Corpus. J. Biomed. Inform. 2015, 58, S20–S29. [Google Scholar] [CrossRef] [PubMed]
- Stubbs, A.; Kotfila, C.; Uzuner, O. Automated Systems for the De-identification of Longitudinal Clinical Narratives: Overview of 2014 I2B2/UTHealth Shared Task Track 1. J. Biomed. Inform. 2015, 58, S11–S19. [Google Scholar] [CrossRef] [PubMed]
- Stubbs, A.; Filannino, M.; Soysal, E.; Henry, S.; Uzuner, O. Cohort Selection for Clinical Trials: N2C2 2018 Shared Task Track 1. J. Am. Med. Inform. Assoc. 2019, 26, 1163–1171. [Google Scholar] [CrossRef]
- Henry, S.; Buchan, K.; Filannino, M.; Stubbs, A.; Uzuner, O. 2018 N2C2 Shared Task on Adverse Drug Events and Medication Extraction in Electronic Health Records. J. Am. Med. Inform. Assoc. 2019, 27, 3–12. [Google Scholar] [CrossRef] [PubMed]
- McCreery, C.H.; Katariya, N.; Kannan, A.; Chablani, M.; Amatriain, X. Effective Transfer Learning for Identifying Similar Questions: Matching User Questions to COVID-19 FAQs. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 23–27 August 2020; pp. 3458–3465. [Google Scholar]
- Soni, S.; Roberts, K. A Paraphrase Generation System for EHR Question Answering. In Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy, 1 August 2019; pp. 20–29. [Google Scholar]
- Lau, J.J.; Gayen, S.; Ben Abacha, A.; Demner-Fushman, D. A dataset of Clinically Generated Visual Questions and Answers about Radiology Images. Sci. Data 2018, 5, 180251. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. PathVQA: 30000+ Questions for Medical Visual Question Answering. arXiv 2020, arXiv:2003.10286. [Google Scholar]
- Jin, Q.; Dhingra, B.; Liu, Z.; Cohen, W.; Lu, X. PubMedQA: A Dataset for Biomedical Research Question Answering. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 7 November 2019; pp. 2567–2577. [Google Scholar]
- Hasan, S.A.; Ling, Y.; Farri, O.; Liu, J.; Müller, H.; Lungren, M. Overview of Imageclef 2018 MMedical Domain Visual Question Answering Task. In Proceedings of the CLEF Conference and Labs of the Evaluation Forum-Working Notes, Avignon, France, 10–14 September 2018. [Google Scholar]
- Ben Abacha, A.; Hasan, S.A.; Datla, V.V.; Demner-Fushman, D.; Müller, H. Vqa-med: Overview of the Medical Visual Question Answering Task at Imageclef 2019. In Proceedings of the CLEF Conference and Labs of the Evaluation Forum-Working Notes, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Ben Abacha, A.; Sarrouti, M.; Demner-Fushman, D.; Hasan, S.A.; Müller, H. Overview of the vqa-med task at imageclef 2021: Visual question answering and generation in the medical domain. In Proceedings of the CLEF Conference and Labs of the Evaluation Forum-Working Notes, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Kovaleva, O.; Shivade, C.; Kashyap, S.; Kanjaria, K.; Wu, J.; Ballah, D.; Coy, A.; Karargyris, A.; Guo, Y.; Beymer, D.B.; et al. Towards Visual Dialog for Radiology. In Proceedings of the 19th SIGBioMed. Workshop on Biomedical Language Processing, Online, 9 July 2020; pp. 60–69. [Google Scholar]
- Esser, P.; Chiu, J.; Atighehchian, P.; Granskog, J.; Germanidis, A. Structure and Content-guided Video Synthesis with Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 7346–7356. [Google Scholar]
- Jumper, J.M.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Zídek, A.; Potapenko, A.; et al. Highly Accurate Protein Structure Prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Gupta, A.; Zhang, Z.; Wang, G.; Dou, Y.; Chen, Y.; Fei-Fei, L.; Anandkumar, A.; Zhu, Y.; Fan, L. VIMA: General Robot Manipulation with Multimodal Prompts. arXiv 2023, arXiv:2210.03094. [Google Scholar]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.O.; Ricke, J.; et al. ChatGPT makes Medicine easy to Swallow: An Exploratory Case Study on Simplified Radiology Reports. Eur. Radiol. 2023, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wornow, M.; Xu, Y.; Thapa, R.; Patel, B.; Steinberg, E.; Fleming, S.; Pfeffer, M.A.; Fries, J.; Shah, N.H. The Shaky Foundations of Large Language Models and Foundation Models for Electronic Health Records. NPJ Digit. Med. 2023, 6, 135. [Google Scholar] [CrossRef] [PubMed]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. J. Priv. Confidentiality 2016, 7, 17–51. [Google Scholar] [CrossRef]
- Kerrigan, G.; Slack, D.; Tuyls, J. Differentially Private Language Models Benefit from Public Pre-training. In Proceedings of the Second Workshop on Privacy in NLP, Online, 16–20 November 2020; pp. 39–45. [Google Scholar]
- Röösli, E.; Bozkurt, S.; Hernandez-Boussard, T. Peeking into a black box, the fairness and generalizability of a MIMIC-III benchmarking model. Sci. Data 2022, 9, 24. [Google Scholar] [CrossRef] [PubMed]
- Hassija, V.; Chamola, V.; Mahapatra, A.; Singal, A.; Goel, D.; Huang, K.; Scardapane, S.; Spinelli, I.; Mahmud, M.; Hussain, A. Interpreting black-box models: A review on explainable artificial intelligence. Cogn. Comput. 2024, 16, 45–74. [Google Scholar] [CrossRef]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Wen, Y.; Wang, Z.; Sun, J. MindMap: Knowledge Graph Prompting Sparks Graph of Thoughts in Large Language Models. arXiv 2023, arXiv:2308.09729. [Google Scholar]
- Zack, T.; Lehman, E.; Suzgun, M.; Rodriguez, J.A.; Celi, L.A.; Gichoya, J.; Jurafsky, D.; Szolovits, P.; Bates, D.W.; Abdulnour, R.E.E.; et al. Assessing the potential of GPT-4 to perpetuate racial and gender biases in health care: A model evaluation study. Lancet Digit. Health 2024, 6, e12–e22. [Google Scholar] [CrossRef] [PubMed]
- Feng, Q.; Du, M.; Zou, N.; Hu, X. Fair Machine Learning in Healthcare: A Review. arXiv 2024, arXiv:2206.14397. [Google Scholar]
- Kumar, A.; Agarwal, C.; Srinivas, S.; Li, A.J.; Feizi, S.; Lakkaraju, H. Certifying LLM Safety against Adversarial Prompting. arXiv 2024, arXiv:2309.02705. [Google Scholar]
- Yuan, J.; Tang, R.; Jiang, X.; Hu, X. Large language models for healthcare data augmentation: An example on patient-trial matching. AMIA Annu. Symp. Proc. 2023, 2023, 1324. [Google Scholar] [PubMed]
- Lai, T.; Shi, Y.; Du, Z.; Wu, J.; Fu, K.; Dou, Y.; Wang, Z. Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models. arXiv 2023, arXiv:2307.11991. [Google Scholar]
- Kim, K.; Oh, Y.; Park, S.; Byun, H.K.; Kim, J.S.; Kim, Y.B.; Ye, J.C. RO-LLaMA: Generalist LLM for Radiation Oncology via Noise Augmentation and Consistency Regularization. arXiv 2023, arXiv:2311.15876. [Google Scholar]
- Allenspach, S.; Hiss, J.A.; Schneider, G. Neural multi-task learning in drug design. Nat. Mach. Intell. 2024, 6, 124–137. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef]
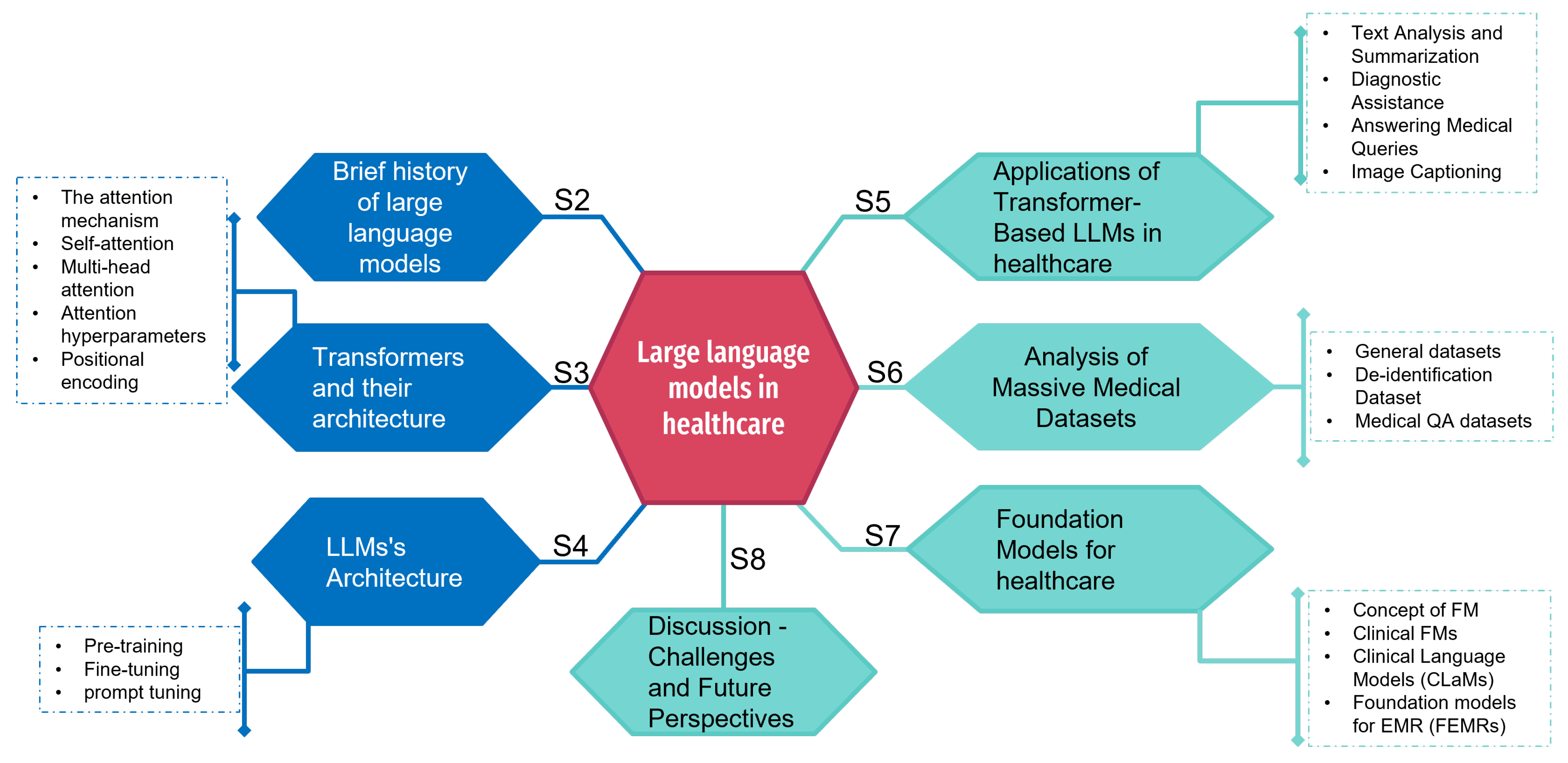






{kind=link}
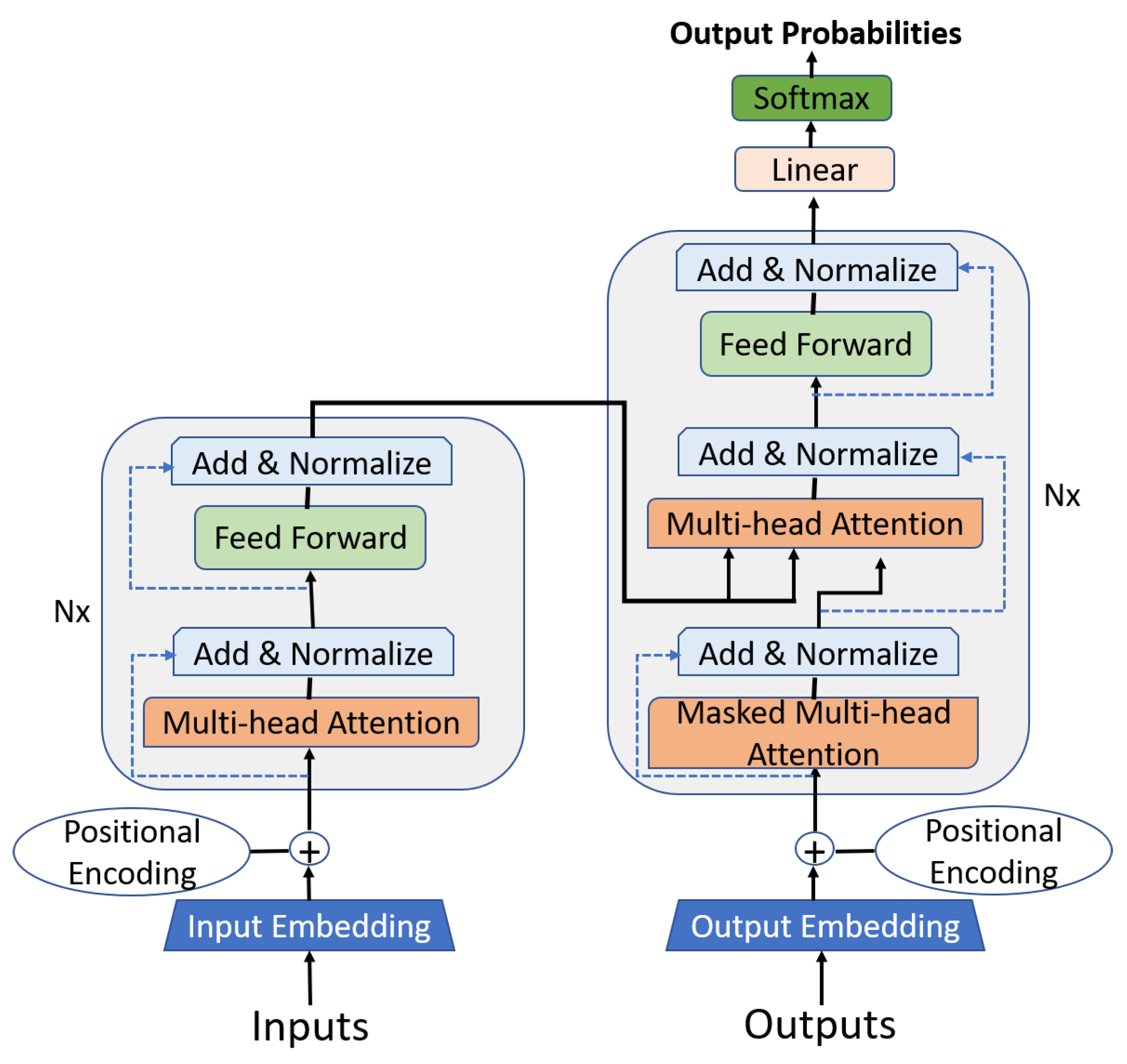{kind=link}
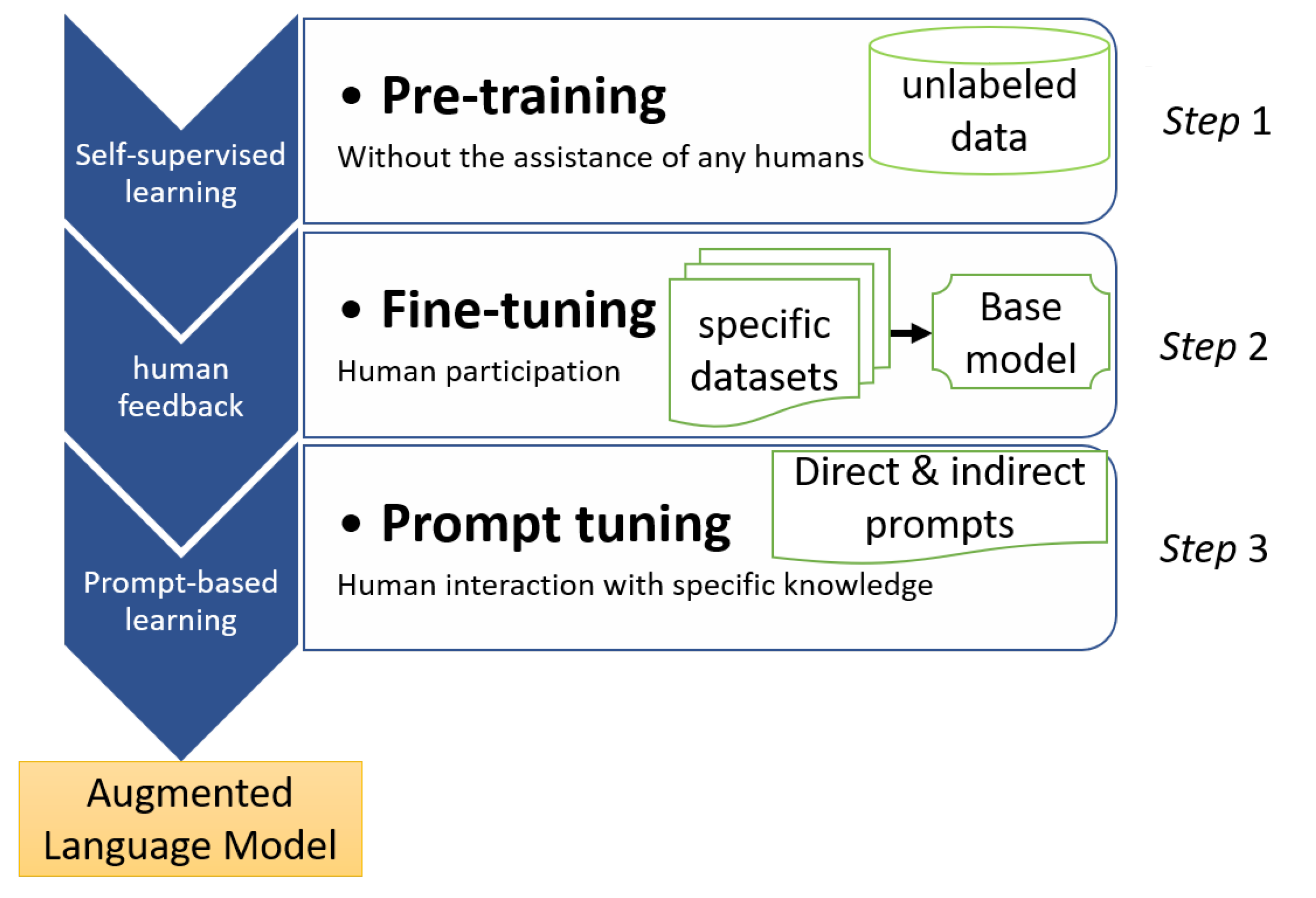{kind=link}
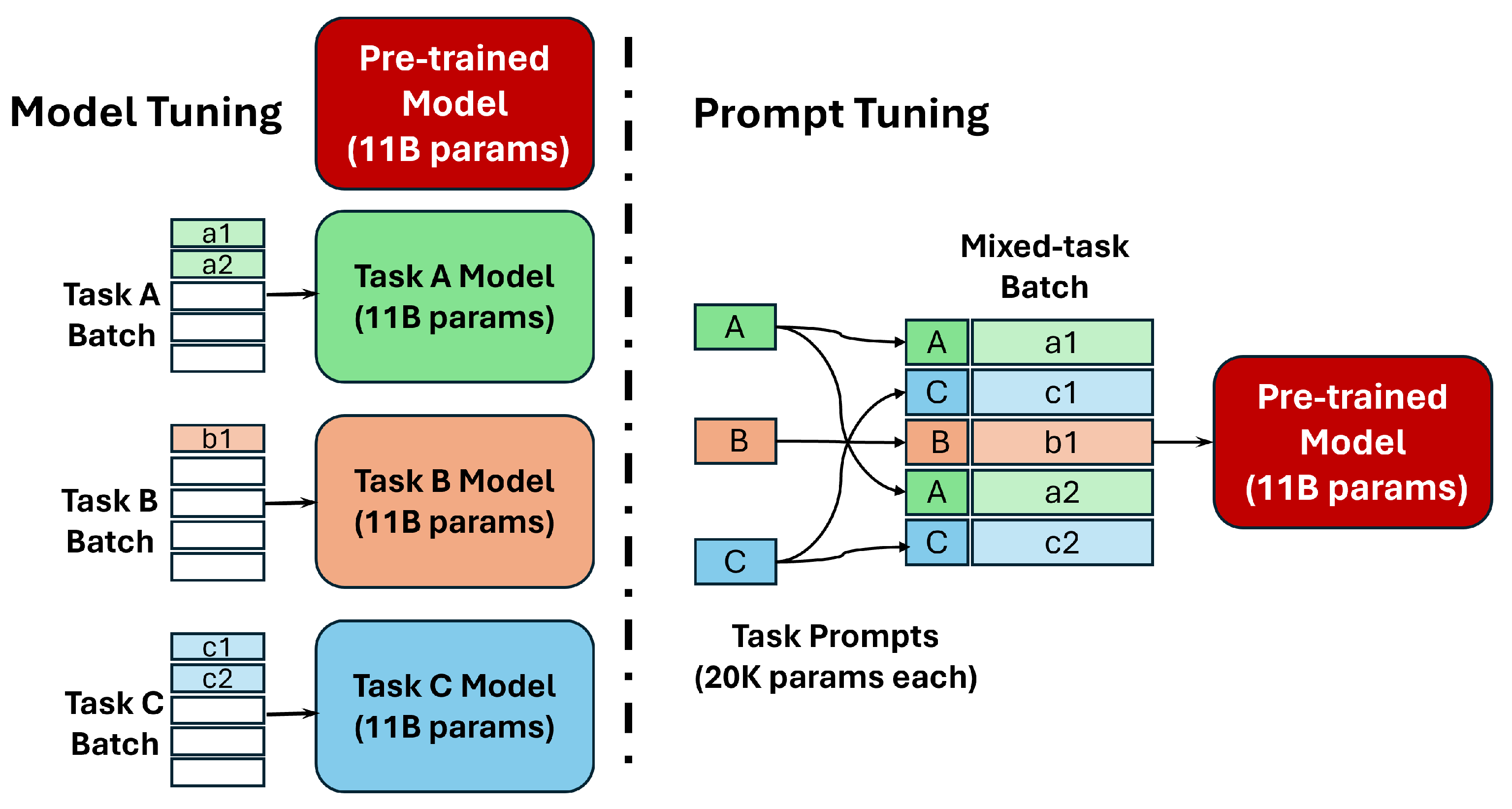{kind=link}
{kind=link}
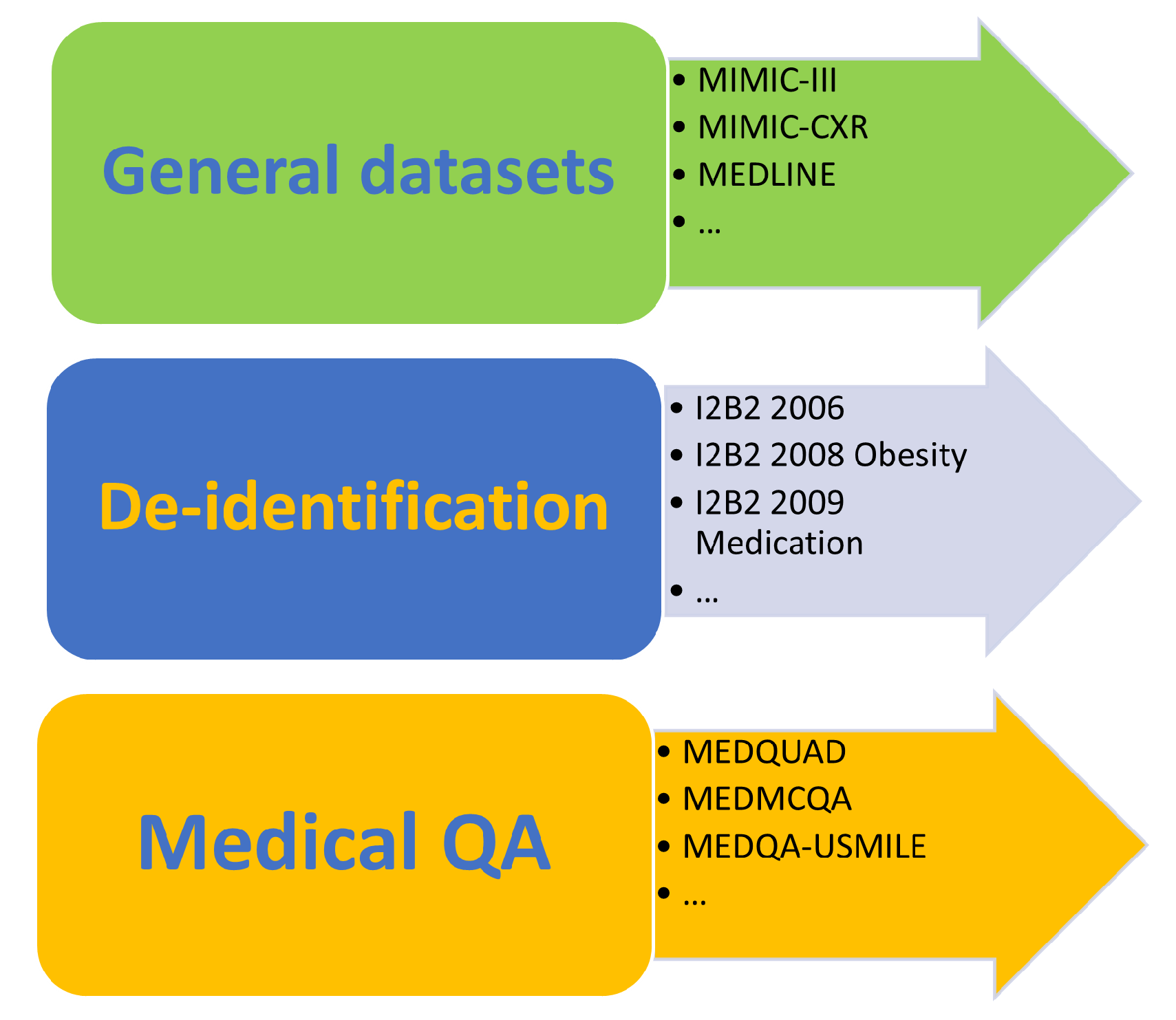{kind=link}
| Architectures | Models | Parameters |
|---|---|---|
| Autoencoders (Encoder Only) | BERT | 110 M |
| RoBERTa | 125 M | |
| Autoregressors (Decoder Only) | GPT-3 | 175 B |
| GPT-4 | 1.76 T | |
| Bloom | 176 B | |
| PaLM | 540 B | |
| LLaMA | from 7 to 70 B | |
| StableLM | from 15 to 65 B | |
| Sequence-to-Sequence (Encoder–Decoder) | T5 | 220 M |
| BART | 139 M |
| Version | Year | Number of Parameters | Healthcare Applications | Advances/Particularities in Healthcare |
|---|---|---|---|---|
| GPT | 2018 | 110 M | Basic medical text generation. | A leader in automatic NLP, but limited in its ability to understand complex medical terminology. |
| GPT-2 | 2019 | 1.5 Bn | Improvements in medical text generation, first drafts of medical article summaries. | Improved consistency in text generation, but still with limits in terms of precision and specific medical context. |
| GPT-3 | 2020 | 175 Bn | Search summaries, assistance in interpreting medical data, generation of medical QA. | Enhanced ability to understand and generate complex medical texts, useful for literature analysis and health consulting applications. |
| GPT-4 | 2023 | Unknown | In-depth analysis of clinical cases, integration into assisted diagnosis systems, personalized health advice. | Significant advancement in language understanding and accuracy, and the ability to integrate textual and visual data for more comprehensive analyses. |
| Dataset | Domain | Size | Data Type |
|---|---|---|---|
| MIMIC-III | Intensive care | Over 58,000 patients | Structured and unstructured clinical data |
| MIMIC-CXR | Radiology | Over 380,000 images | Medical images (X-rays) |
| MEDLINE | Biomedical | Over 25 million abstracts | Biomedical article abstracts |
| ABBREV | Biomedical | 6205 abbreviations | Abbreviation list |
| PUBMED | Biomedical | Over 30 million abstracts | Article abstracts |
| NUBES | Spanish biomedical | 30,000 phrases | Phrases |
| NCBI | Disease | 11,223 documents | Texts |
| CASI | Terminology | 6300 entries | Abbreviation senses |
| MEDNLI | Clinical reasoning | 10,000 sentence pairs | Sentence pairs |
| MEDICAT | Clinical trials | 30,000 trials | Semi-structured clinical trial descriptions |
| OPEN-I | Adverse drug reactions | Over 1 million ADRs | Doctor narratives about ADRs |
| MEDICAL ABSTRACTS | Biomedical | Over 400,000 abstracts | Scientific paper abstracts |
| Dataset | Domain | Size | Data Type |
|---|---|---|---|
| I2B2 2006 | De-identification | 347 documents | Medical records |
| I2B2 2008 Obesity | Phenotyping | 571 documents | Medical records focused on obesity |
| I2B2 2009 Medication | Relation extraction | 402 documents | Medical records |
| I2B2 2010 Relations | Relation extraction | 947 documents | Medical records |
| I2B2 2011 coreference | Coreference resolution | 970 documents | Medical records |
| I2B2 2012 Temporal | Temporal relation extraction | 2000 medical encounters | Medical records |
| I2B2 2014 Deidentification | Heart Disease dataset | Focused on cardiovascular diseases | Medical records |
| I2B2 2018 | Benchmarking | Hierarchical clinical document classification | Clinical case notes |
| Dataset | Domain | Size | Data Type |
|---|---|---|---|
| MEDQUAD | QA | 11,230 questions | Clinical questions and answers |
| MEDMCQA | QA | 1310 question–answer pairs | Clinical questions and answers |
| MEDQA-USMLE | QA | 500+ question–answer pairs | Clinical vignettes and questions |
| MQP | QA | 1000 question pairs | Clinical question pairs |
| CLINIQA-PARA | Paraphrasing | 8130 paraphrase pairs | Clinical texts |
| VQA-RAD | Image QA | 6000 question–image pairs | Radiological images and questions |
| PATHVQA | Pathology image QA | Over 14,000 image–question pairs | Pathology images and questions |
| PUBMEDQA | Abstract QA | Over 13,000 question–abstract pairs | Biomedical abstracts and questions |
| VQA-MED-2018, 2019, 2020 | Visual QA | Over 8000 image–question–answer triples each year | Medical images, questions, and answers |
| RADVISDIAL | Conversational agent for radiology | Over 1500 dialogues | Text-based dialogues in radiology domain |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nassiri, K.; Akhloufi, M.A. Recent Advances in Large Language Models for Healthcare. BioMedInformatics 2024, 4, 1097-1143. https://doi.org/10.3390/biomedinformatics4020062
Nassiri K, Akhloufi MA. Recent Advances in Large Language Models for Healthcare. BioMedInformatics. 2024; 4(2):1097-1143. https://doi.org/10.3390/biomedinformatics4020062
Chicago/Turabian StyleNassiri, Khalid, and Moulay A. Akhloufi. 2024. "Recent Advances in Large Language Models for Healthcare" BioMedInformatics 4, no. 2: 1097-1143. https://doi.org/10.3390/biomedinformatics4020062
APA StyleNassiri, K., & Akhloufi, M. A. (2024). Recent Advances in Large Language Models for Healthcare. BioMedInformatics, 4(2), 1097-1143. https://doi.org/10.3390/biomedinformatics4020062