
Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search

Abstract
:1. Introduction
- We develop and integrate various building blocks of the 5G CS PHY of the gNB transmitter and UE receiver for realization on hardware. Along with the conventional baseband PHY operations, we design the gNB scheduler to broadcast the SS signals as per the 3GPP specifications.
- We demonstrate the design and FPGA implementation of signal processing blocks such as primary SS (PSS) and secondary SS (SSS) detection, demodulation reference signal (DMRS) detection, and cell identity (CI) estimation at UE as per 3GPP standard. Multiple instances of the detected PSS, SSS, and DMRS signals are used to detect the frame, sub-frame, and symbol boundaries in the received signal.
- To speed up the blind SS search, we propose a new PSS detection approach that explores a novel down-sampling approach resulting in a 60% reduction in on-chip memory and 50% lower search time.
- Via detailed performance analysis, we analyze the functional correctness, computational complexity, and latency of the proposed approach for different word lengths, signal-to-noise ratio (SNR), and down-sampling factors.
- We demonstrate the functionality of the proposed end-to-end 5G CS PHY on the GNU Radio and Universal Software Radio Peripheral (USRP) based radio frequency network-on-chip (RFNoC) platform from Ettus Research [27,28]. We demonstrate the 66% reduction in SS search time by efficiently utilizing the Field-Programmable Gate Array (FPGA) available on USRP compared to conventional GNU Radio-based software implementation.
2. Specifications of 5G CS and Literature Review
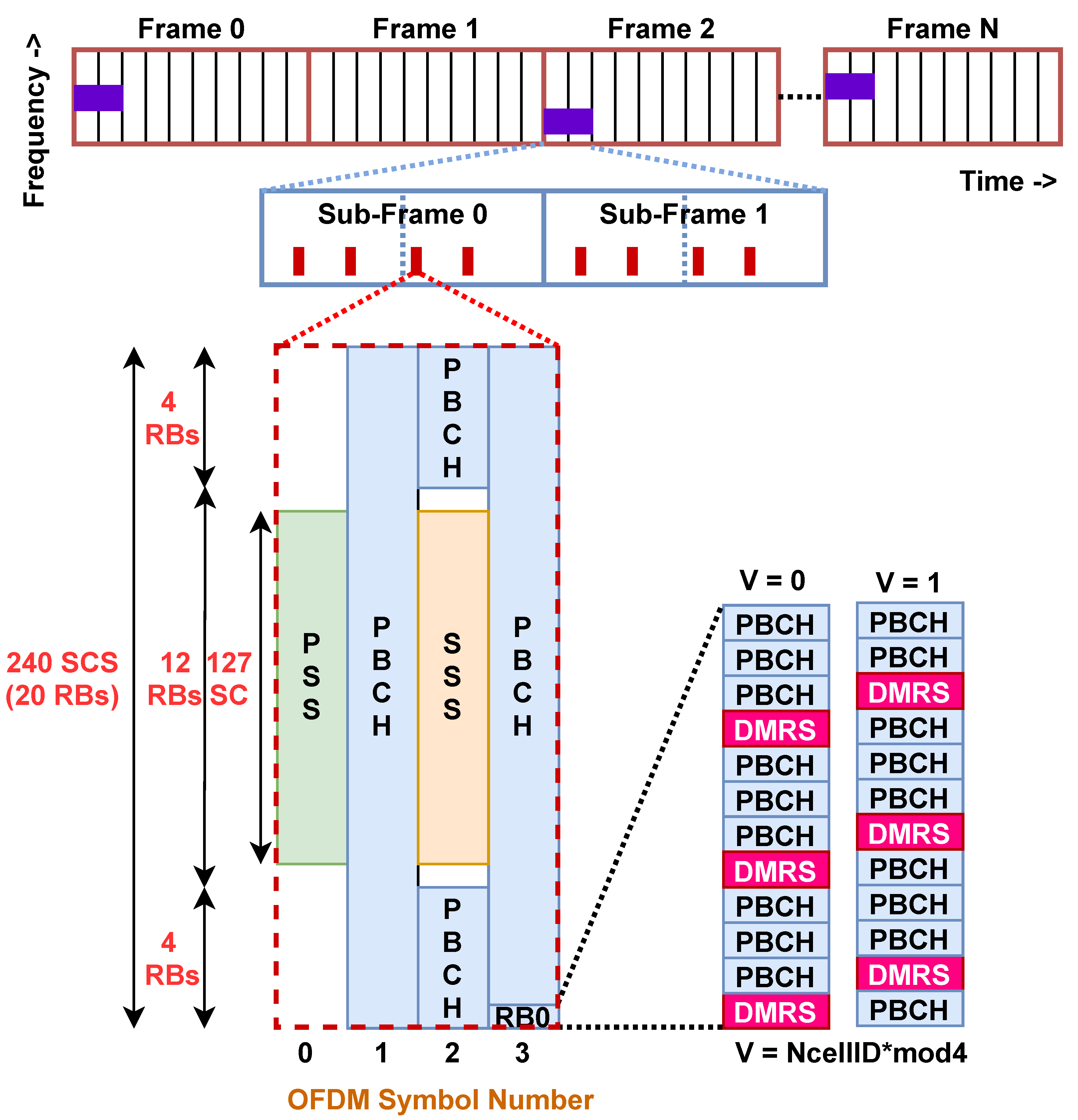
2.1. 5G CS PHY
2.2. Review: Mapping of 5G CS PHY on Hardware
3. Downlink Transmitter PHY for CS
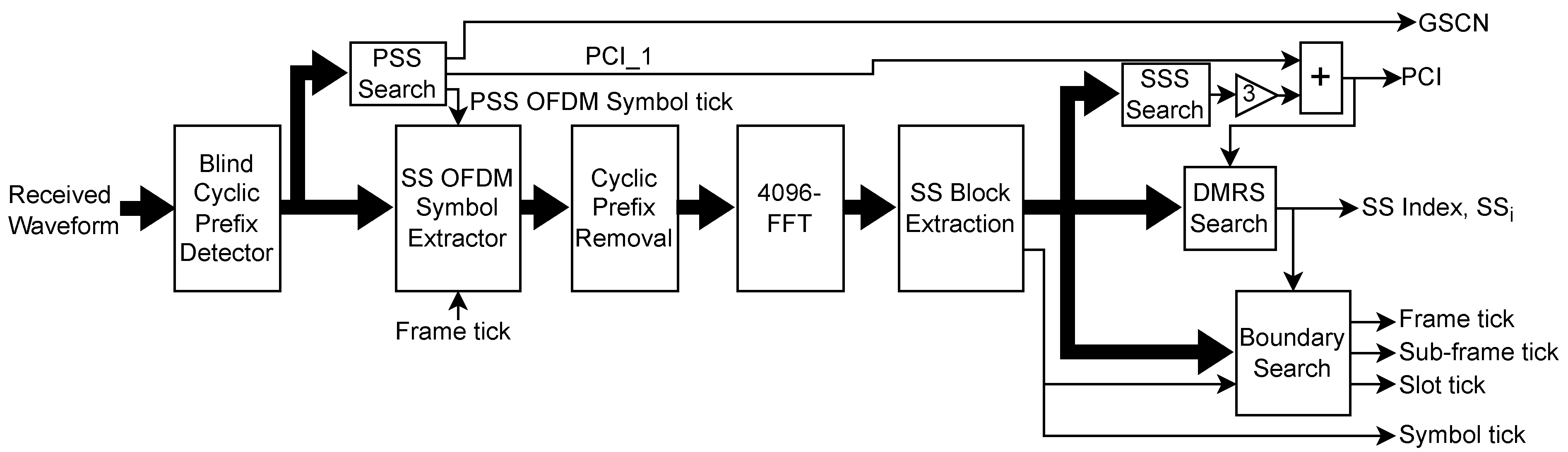
4. UE Receiver PHY for CS
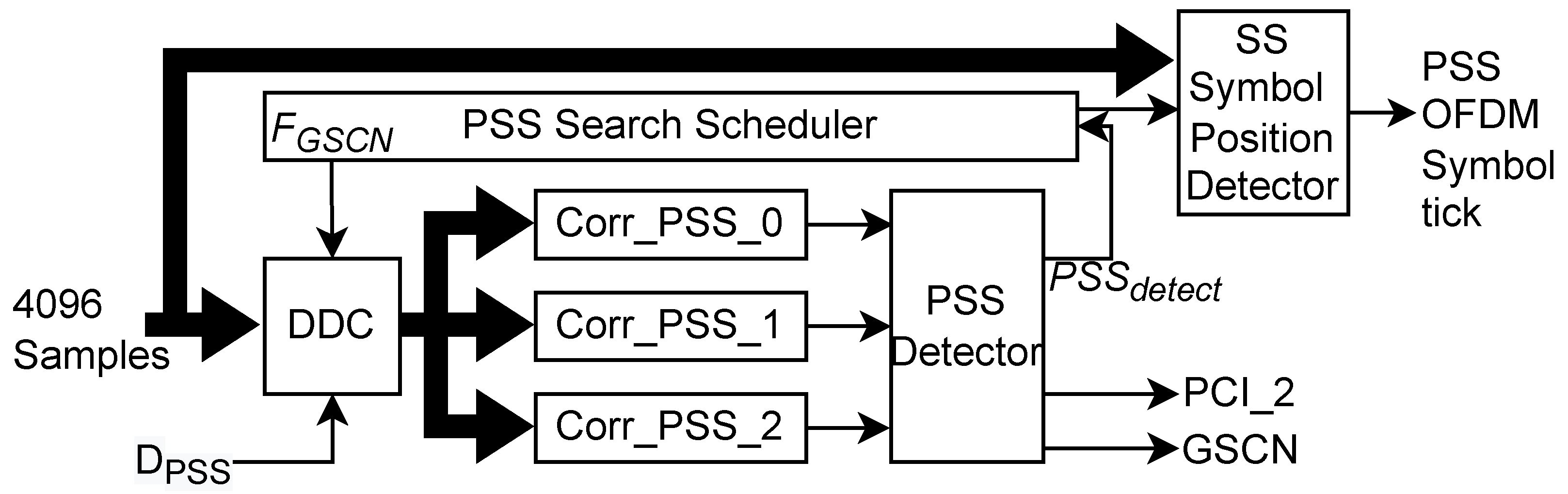
4.1. PSS Search
4.2. SSS Search
4.3. DMRS Search
4.4. Boundary Search
5. Performance and Complexity Analysis
5.1. PSS Search
5.2. SSS Search
5.3. DMRS Search
6. PHY Deployment on RFNoC Platform
7. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| 3GPP | 3rd Generation Partnership Project |
| AXI | ARM Extensible Interface |
| BPSK | Binary Phase Shift Keying |
| BS | Base Station |
| CI | Cell Identity |
| CS | Cell Search |
| DMRS | Demodulation Reference Signal |
| DPFL | Double Precision Floating Point |
| FFT | Fast Fourier Transform |
| FPGA | Field Programmable Gate Array |
| GSCN | Global Synchronization Channel Number |
| HPFL | Half Precision Floating Point |
| IA | Initial Access |
| LTE | Long Term Evolution |
| MAC | Medium Access Control |
| MSI | Minimum System Information |
| OFDM | Orthogonal Frequency Division Multiplexing |
| PBCH | Physical Broadcast Control Channel |
| PCI | Physical Cell ID |
| PHY | Physical Layer |
| PRACH | Physical Random Access Channel |
| PRBS | Pseudo-random Binary Sequence |
| PSS | Primary Synchronization Signal |
| QPSK | Quadrature Phase Shift Keying |
| RB | Resource Block |
| RFNoC | Radio Frequency Network on Chip |
| SCS | Sub-carrier Spacing |
| SNR | Signal to Noise Ratio |
| SoC | System on Chip |
| SPFL | Single Precision Floating Point |
| SS | Synchronization Signal |
| SSB | Synchronization Signal Burst |
| SSS | Secondary Synchronization Signal |
| UE | User Equipment |
| USRP | Universal Software Radio Peripheral |
| WL | Word Length |
| ZSoC | Zynq System on Chip |
References
- Won, S.; Choi, S.W. Three Decades of 3GPP Target Cell Search through 3G, 4G, and 5G. IEEE Access 2020, 8, 116914–116960. [Google Scholar] [CrossRef]
- Lien, S.Y.; Shieh, S.L.; Huang, Y.; Su, B.; Hsu, Y.L.; Wei, H.Y. 5G New Radio: Waveform, Frame Structure, Multiple Access, and Initial Access. IEEE Commun. Mag. 2017, 55, 64–71. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S. NR—The New 5G Radio-Access Technology. In Proceedings of the 2018 IEEE 87th Vehicular Technology Conference (VTC Spring), Porto, Portugal, 3–6 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Jeon, J. NR Wide Bandwidth Operations. IEEE Commun. Mag. 2018, 56, 42–46. [Google Scholar] [CrossRef]
- Zaidi, A.A.; Baldemair, R.; Moles-Cases, V.; He, N.; Werner, K.; Cedergren, A. OFDM Numerology Design for 5G New Radio to Support IoT, eMBB, and MBSFN. IEEE Commun. Stand. Mag. 2018, 2, 78–83. [Google Scholar] [CrossRef]
- Lin, X.; Li, J.; Baldemair, R.; Cheng, J.F.T.; Parkvall, S.; Larsson, D.C.; Koorapaty, H.; Frenne, M.; Falahati, S.; Grovlen, A.; et al. 5G New Radio: Unveiling the Essentials of the Next Generation Wireless Access Technology. IEEE Commun. Stand. Mag. 2019, 3, 30–37. [Google Scholar] [CrossRef]
- Won, S.; Choi, S.W. A Tutorial on 3GPP Initial Cell Search: Exploring a Potential for Intelligence Based Cell Search. IEEE Access 2021, 9, 100223–100263. [Google Scholar] [CrossRef]
- Chakrapani, A. On the Design Details of SS/PBCH, Signal Generation and PRACH in 5G-NR. IEEE Access 2020, 8, 136617–136637. [Google Scholar] [CrossRef]
- Omri, A.; Shaqfeh, M.; Ali, A.; Alnuweiri, H. Synchronization Procedure in 5G NR Systems. IEEE Access 2019, 7, 41286–41295. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S.; Sköld, J. Chapter 16—Initial Access. In 5G NR: The Next Generation Wireless Access Technology; Dahlman, E., Parkvall, S., Sköld, J., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 311–334. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, Q.; Zhao, X.; Bai, J.; Wang, Z. A Scheme for improving 5G Cell Search Performance. In Proceedings of the 2023 5th International Conference on Communications, Information System and Computer Engineering (CISCE), Guangzhou, China, 14–16 April 2023; pp. 141–145. [Google Scholar] [CrossRef]
- Wang, S.D.; Wang, H.M.; Wang, W.; Leung, V.C.M. Detecting Intelligent Jamming on Physical Broadcast Channel in 5G NR. IEEE Commun. Lett. 2023, 27, 1292–1296. [Google Scholar] [CrossRef]
- Zhang, Z. Novel PRACH Scheme for 5G Networks Based on Analog Bloom Filter. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Schreiber, G.; Tavares, M. 5G New Radio Physical Random Access Preamble Design. In Proceedings of the 2018 IEEE 5G World Forum (5GWF), Silicon Valley, CA, USA, 9–11 July 2018; pp. 215–220. [Google Scholar] [CrossRef]
- Yin, J.L.; Lee, M.C.; Hsiao, W.H.; Huang, C.C. A Novel Network Resolved and Mobile Assisted Cell Search Method for 5G Cellular Communication Systems. IEEE Access 2022, 10, 75331–75342. [Google Scholar] [CrossRef]
- 3GPP. NR: Physical Channels and Modulation; Technical Specification (TS) 36.211, Version 17.0; 3rd Generation Partnership Project (3GPP): Valbonne, France, 2022. [Google Scholar]
- 3GPP. NR: Physical Layer: General Description; Technical Specification (TS) 36.201, Version 17.0.0; 3rd Generation Partnership Project (3GPP): Valbonne, France, 2022. [Google Scholar]
- 3GPP. NR: Physical Layer Procedures for Control; Technical Specification (TS) 36.213, Version 17.2.0; 3rd Generation Partnership Project (3GPP): Valbonne, France, 2022. [Google Scholar]
- Zhang, Z.; Liu, J.; Long, K. Low-Complexity Cell Search With Fast PSS Identification in LTE. IEEE Trans. Veh. Technol. 2012, 61, 1719–1729. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S.; Sköld, J. Chapter 5—NR Overview. In 5G NR: The Next Generation Wireless Access Technology; Dahlman, E., Parkvall, S., Sköld, J., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 57–71. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S.; Sköld, J. Chapter 4—LTE—An Overview. In 5G NR: The Next Generation Wireless Access Technology; Dahlman, E., Parkvall, S., Sköld, J., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 39–55. [Google Scholar] [CrossRef]
- Enescu, M.; Yuk, Y.; Vook, F.; Ranta-aho, K.; Kaikkonen, J.; Hakola, S.; Farag, E.; Grant, S.; Manolakos, A. PHY Layer. In 5G New Radio: A Beam-Based Air Interface; John Wiley & Sons: Hoboken, NJ, USA, 2020; pp. 95–260. [Google Scholar] [CrossRef]
- Chong, D.; Ko, G.; Kim, B.K.; Do, J.H.; Lee, J. Efficient PBCH DMRS Sequence Detection for Fast Synchronization Process of 5G NR Systems. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, M.; Hu, D.; He, L.; Wu, J. Deep-Learning-Based Initial Access Method for Millimeter-Wave MIMO Systems. IEEE Wirel. Commun. Lett. 2022, 11, 1067–1071. [Google Scholar] [CrossRef]
- Ahmadi, S. Chapter 3—New Radio Access Physical Layer Aspects (Part 1). In 5G NR; Ahmadi, S., Ed.; Academic Press: Cambridge, MA, USA, 2019; pp. 285–409. [Google Scholar] [CrossRef]
- Bishop, J.; Chareau, J.M.; Bonavitacola, F. Implementing 5G NR Features in FPGA. In Proceedings of the 2018 European Conference on Networks and Communications (EuCNC), Ljubljana, Slovenia, 18–21 June 2018; pp. 373–379. [Google Scholar] [CrossRef]
- Braun, M.; Pendlum, J. A flexible data processing framework for heterogeneous processing environments: RF Network-on-Chip™. In Proceedings of the 2017 International Conference on FPGA Reconfiguration for General-Purpose Computing (FPGA4GPC), Hamburg, Germany, 9–10 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Reddy, K.M.; Darak, S.J.; Praveen, M.D. Novel Framework for Enabling Hardware Acceleration in GNU Radio. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Vook, F.W.; Ghosh, A.; Diarte, E.; Murphy, M. 5G New Radio: Overview and Performance. In Proceedings of the 2018 52nd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; pp. 1247–1251. [Google Scholar] [CrossRef]
- Lagen, S.; Wanuga, K.; Elkotby, H.; Goyal, S.; Patriciello, N.; Giupponi, L. New Radio Physical Layer Abstraction for System-Level Simulations of 5G Networks. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Ji, W.; Wu, Z.; Zheng, K.; Zhao, L.; Liu, Y. Design and Implementation of a 5G NR System Based on LDPC in Open Source SDR. In Proceedings of the 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Henarejos, P.; Ángel Vázquez, M. Decoding 5G-NR Communications VIA Deep Learning. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3782–3786. [Google Scholar] [CrossRef]
- Sybis, M.; Wesolowski, K.; Jayasinghe, K.; Venkatasubramanian, V.; Vukadinovic, V. Channel Coding for Ultra-Reliable Low-Latency Communication in 5G Systems. In Proceedings of the 2016 IEEE 84th Vehicular Technology Conference (VTC-Fall), Montreal, QC, Canada, 18–21 September 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Gamage, H.; Rajatheva, N.; Latva-aho, M. Channel coding for enhanced mobile broadband communication in 5G systems. In Proceedings of the 2017 European Conference on Networks and Communications (EuCNC), Oulu, Finland, 12–15 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Tewari, A.; Singh, N.; Darak, S.J.; Kizheppatt, V.; Jafri, M.S. Reconfigurable Wireless PHY with Dynamically Controlled Out-of-Band Emission on Zynq SoC. In Proceedings of the 65TH IEEE International Midwest Symposium on Circuits and Systems (MWSCAS 2022), Fukuoka, Japan, 7–10 August 2022; pp. 1–6. [Google Scholar]
- Zhang, L.; Ijaz, A.; Xiao, P.; Molu, M.M.; Tafazolli, R. Filtered OFDM Systems, Algorithms, and Performance Analysis for 5G and Beyond. IEEE Trans. Commun. 2018, 66, 1205–1218. [Google Scholar] [CrossRef]
- Hong, W.; Choi, J.; Park, D.; Kim, M.s.; You, C.; Jung, D.; Park, J. mmWave 5G NR Cellular Handset Prototype Featuring Optically Invisible Beamforming Antenna-on-Display. IEEE Commun. Mag. 2020, 58, 54–60. [Google Scholar] [CrossRef]
- Herranz, C.; Zhang, M.; Mezzavilla, M.; Martin-Sacristán, D.; Rangan, S.; Monserrat, J.F. A 3GPP NR Compliant Beam Management Framework to Simulate End-to-End MmWave Networks. In Proceedings of the 21st ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, New York, NY, USA, 28 October–2 November 2018; pp. 119–125. [Google Scholar] [CrossRef]
- Mehrabi, M.; Mohammadkarimi, M.; Ardakani, M.; Jing, Y. Decision Directed Channel Estimation Based on Deep Neural Network k-Step Predictor for MIMO Communications in 5G. IEEE J. Sel. Areas Commun. 2019, 37, 2443–2456. [Google Scholar] [CrossRef]
- He, H.; Wen, C.K.; Jin, S.; Li, G.Y. Deep Learning-Based Channel Estimation for Beamspace mmWave Massive MIMO Systems. IEEE Wirel. Commun. Lett. 2018, 7, 852–855. [Google Scholar] [CrossRef]
- Chun, C.J.; Kang, J.M.; Kim, I.M. Deep Learning-Based Channel Estimation for Massive MIMO Systems. IEEE Wirel. Commun. Lett. 2019, 8, 1228–1231. [Google Scholar] [CrossRef]
- Larsen, L.M.P.; Checko, A.; Christiansen, H.L. A Survey of the Functional Splits Proposed for 5G Mobile Crosshaul Networks. IEEE Commun. Surv. Tutor. 2019, 21, 146–172. [Google Scholar] [CrossRef]
- Koutsopoulos, I. The Impact of Baseband Functional Splits on Resource Allocation in 5G Radio Access Networks. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Rony, R.I.; Lopez-Aguilera, E.; Garcia-Villegas, E. Optimization of 5G Fronthaul Based on Functional Splitting at PHY Layer. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Drozdenko, B.; Zimmermann, M.; Dao, T.; Leeser, M.; Chowdhury, K. High-level hardware-software co-design of an 802.11a transceiver system using Zynq SoC. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 682–683. [Google Scholar]
- Drozdenko, B.; Zimmermann, M.; Dao, T.; Chowdhury, K.; Leeser, M. Hardware-Software Codesign of Wireless Transceivers on Zynq Heterogeneous Systems. IEEE Trans. Emerg. Top. Comput. 2018, 6, 566–578. [Google Scholar] [CrossRef]
- Garg, S.; Agrawal, N.; Darak, S.J.; Sikka, P. Spectral coexistence of candidate waveforms and DME in air-to-ground communications: Analysis via hardware software co-design on Zynq SoC. In Proceedings of the 2017 IEEE/AIAA 36th Digital Avionics Systems Conference (DASC), St. Petersburg, FL, USA, 17–21 September 2017; pp. 1–6. [Google Scholar]
- Pham, T.H.; Fahmy, S.A.; McLoughlin, I.V. An End-to-End Multi-Standard OFDM Transceiver Architecture Using FPGA Partial Reconfiguration. IEEE Access 2017, 5, 21002–21015. [Google Scholar] [CrossRef]
- Drozdova, V.G.; Kalachikov, A.A. SDR Based Evaluation of the Initial Cell Search In 5G NR OpenAirInterface Implementation. In Proceedings of the 2021 XV International Scientific-Technical Conference on Actual Problems of Electronic Instrument Engineering (APEIE), Novosibirsk, Russia, 19–21 November 2021; pp. 248–251. [Google Scholar] [CrossRef]
- Yoneda, S.; Sawahashi, M.; Nagata, S. Comparisons of Physical Cell ID Detection Methods with Carrier Frequency Offset Compensation for Millimeter-Wave Bands. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Word Length | |||
|---|---|---|---|---|
| 1 | 6 | 10 | ||
| Execution Time (ms) | SPFL (32 bits) | 29.3 | 19.2 | 19.1 |
| Fixed Point {32,2} | 13.3 | 6.9 | 6.85 | |
| Fixed Point {24,2} | 13.3 | 6.8 | 6.84 | |
| On Chip Memory (18 KB BRAMs) | SPFL (32 bits) | 156 | 108 | 100 |
| Fixed Point {32,2} | 144 | 106 | 96 | |
| Fixed Point {24,2} | 108 | 82 | 80 | |
| Embedded Multipliers (DSP48s) | SPFL (32 bits) | 137 | 137 | 137 |
| Fixed Point {32,2} | 107 | 107 | 107 | |
| Fixed Point {24,2} | 104 | 104 | 104 | |
| 6-input Look-Up-Table (LUT) | SPFL (32 bits) | 42.7 K | 42.6 K | 42.6 K |
| Fixed Point {32,2} | 41.5 K | 41.3 K | 41.3 K | |
| Fixed Point {24,2} | 31.1 K | 30.9 K | 30.9 K | |
| Parameters | SPFL | HPFL | Fixed Point {24,2} | Fixed Point {16,2} |
|---|---|---|---|---|
| Execution Time (μs) | 33.4 | 18.8 | 16.6 | 16.6 |
| On Chip Memory (18 KiloBytes BRAMs) | 58 | 49 | 44 | 31 |
| Embedded Multipliers (DSP48s) | 651 | 573 | 573 | 558 |
| 6-input Look-Up-Table (LUT) | 84,052 | 33,696 | 32,574 | 28,878 |
| Parameters | SPFL | HPFL | Fixed Point {16,2} | Fixed Point {8,2} |
|---|---|---|---|---|
| Execution Time (μs) | 6.7 | 6.1 | 2.1 | 1.9 |
| On Chip Memory (18 KiloBytes BRAMs) | 83 | 60 | 60 | 42 |
| Embedded Multipliers (DSP48s) | 85 | 71 | 70 | 66 |
| 6-input Look-Up-Table (LUT) | 50,311 | 39,956 | 38,933 | 28,069 |
| Platform | ||||
|---|---|---|---|---|
| 1 | 6 | 10 | 14 | |
| GNU Radio | 27.6 | 17.9 | 15.3 | 13.6 |
| RFNoC | 9.54 | 8 | 7.2 | 6.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lodhi, K.; Chhillar, J.; Darak, S.J.; Sharma, D. Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search. Chips 2023, 2, 223-242. https://doi.org/10.3390/chips2040014
Lodhi K, Chhillar J, Darak SJ, Sharma D. Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search. Chips. 2023; 2(4):223-242. https://doi.org/10.3390/chips2040014
Chicago/Turabian StyleLodhi, Khalid, Jayant Chhillar, Sumit J. Darak, and Divisha Sharma. 2023. "Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search" Chips 2, no. 4: 223-242. https://doi.org/10.3390/chips2040014
APA StyleLodhi, K., Chhillar, J., Darak, S. J., & Sharma, D. (2023). Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search. Chips, 2(4), 223-242. https://doi.org/10.3390/chips2040014