Abstract
In this article, the Lagrange expansion of the second kind is used to generate a novel zero-truncated Katz distribution; we refer to it as the Lagrangian zero-truncated Katz distribution (LZTKD). Notably, the zero-truncated Katz distribution is a special case of this distribution. Along with the closed form expression of all its statistical characteristics, the LZTKD is proven to provide an adequate model for both underdispersed and overdispersed zero-truncated count datasets. Specifically, we show that the associated hazard rate function has increasing, decreasing, bathtub, or upside-down bathtub shapes. Moreover, we demonstrate that the LZTKD belongs to the Lagrangian distribution of the first kind. Then, applications of the LZTKD in statistical scenarios are explored. The unknown parameters are estimated using the well-reputed method of the maximum likelihood. In addition, the generalized likelihood ratio test procedure is applied to test the significance of the additional parameter. In order to evaluate the performance of the maximum likelihood estimates, simulation studies are also conducted. The use of real-life datasets further highlights the relevance and applicability of the proposed model.
1. Introduction
In probability theory, positive discrete distributions called “zero-truncated distributions” are used to model data that exclude zero counts. For instance, the number of times a voter casts a ballot during the general election, the number of journal articles published in various disciplines, the number of stressful events reported by patients, and the length of hospital stay, which must be at least one day. Various zero-truncated discrete distributions, such as the zero-truncated Poisson distribution (ZTPD) (see [1]), zero-truncated negative-binomial distribution (see [2]), zero-truncated Katz distribution (ZTKD) (see [3]), zero-truncated generalized negative-binomial distribution (ZTGNBD) (see [4]), zero-truncated generalized Poisson distribution (see [5]), intervened Poisson distribution (IPD) (see [6]), intervened generalized Poisson distribution (IGPD) (see [7]), a generalization of the Poisson–Sujatha distribution (AGPSD) (see [8]), and zero-truncated discrete Lindley distribution (ZTDLD) (see [9]), have been proposed in the literature to model such count data. In spite of the abundance of practical situations with counting data without zero categories, there is a notable sparseness of zero-truncated discrete distributions in the scientific literature, in contrast to the vast number of classical discrete distributions.
Since the early 1970s, researchers studying discrete distributions seem to have focused more on “Lagrangian distributions”, so named because they are connected to the Lagrange expansions (see [10,11]). The authors in [12] considered the possibility of using Lagrangian distributions to address inferential problems in a random mapping theory. A study in [13] showed that, in certain circumstances, all the discrete Lagrangian distributions converged to the Gaussian distribution and the inverse Gaussian distribution. The authors in [14] proposed certain mixture distributions based on Lagrangian distributions. Recently, Lagrangian distributions were used for turbulent collisional fluid–particle flows (see [15]). A unified method for creating the class of “quasi” distributions, which includes the quasi-binomial, quasi-Polya, quasi-hypergeometric, and several new quasi-distributions, was presented in [16] using the Lagrange expansions. As a result, the distributions arose from Lagrange expansions and have gained traction from both theoretical and applied perspectives.
The Lagrangian distributions of the first kind () and the Lagrangian distributions of the second kind () were the first divisions of the class of Lagrangian distributions. The authors in [13] were the first to present and study the . Several Lagrangian distributions have been constructed using the , but four fundamental distributions, which are the generalized negative binomial distribution, the generalized geometric series distribution, the generalized Poisson distribution, and the generalized logarithmic series distribution, are of particular note and have proven to be very useful in practical applications (see [4]). The authors in [17] defined a Lagrangian Katz distribution (LKD) using the . The author in [18] showed that the LKD was a subclass of the generalized Polya–Eggenberger family of distributions. The authors in [19] obtained the LKD as a limiting distribution of the Markov–Polya distribution. The authors in [20] discussed the application of the LKD to time series data.
On the other hand, the authors in [21,22] conducted extensive research on the . The Geeta distribution and its characteristics were derived in [23] based on the . The authors in [24] proposed the Dev distribution and some of its applications in queuing theory by using the . Ref. [25] proposed the Harish distribution and inferred some of its characteristics, with applications in the branching process and queuing theory based on the . Furthermore, the authors in [18] also used the to create the generalized LKD of type two. The competence of the distributions proposed based on the profoundly attracted our team, and as a result, we suggested the Lagrangian version of the ZTPD, the zero-truncated binomial distribution, and the IPD (see [26,27,28]). Moreover, the authors in [24] demonstrated that every member of the was also a member of the . Thus, the authors observed from the literature that several members of both and were based on various variants of classical discrete distributions that have thoroughly been explored in the literature. Analogously, we were motivated to fill the sparseness of zero-truncated discrete distributions by considering the probability-generating function (PGF) of the ZTKD and generalizing it through the and so we named the new distribution LZTKD.
An overview of the remaining study sections is provided below: Section 2 provides a brief summary of the Lagrange expansions. The construction of the LZTKD and its statistical features are explored in Section 3 and Section 4, respectively. In Section 5, it is established that the LZTKD belongs to the class. In Section 6, the maximum likelihood (ML) estimation approach is employed to explore the parameter estimation of the LZTKD. The significance of the additional parameter in the LZTKD is evaluated using the likelihood ratio test in Section 7. The simulation results based on the maximum likelihood estimates (MLEs) are included in Section 8. Section 9 provides an empirical illustration of the LZTKD, and Section 10 concludes the article.
2. Some Basic Preliminary Results
In this section, we go over some fundamental concepts, such as the Lagrange expansions at the basis of the and , as well as some distributions that belong to the and that have already been published in the literature.
2.1. Lagrange Expansions
Let us first present the Lagrange expansions described in [10,11]. These expansions are described as
and
where and , under the conditions that and are two analytic functions of z in [−1,1], which are differentiable with respect to z and such that .
These expansions are at the basis of our findings.
2.2. Lagrangian Distribution of the First Kind
Along with the Lagrange expansion given in Equation (1), under the following additional conditions:
The class of Lagrangian distributions given in Equation (3) is sometimes denoted as . The corresponding PGF of the PMF given in Equation (3) is indicated as
where .
The functions and are called the transformed function and transformer function, respectively. Some important members belonging to the available in the literature are discussed below.
- Generalized Katz Distribution
A special case of the includes the generalized Katz distribution (GKD) given in [4]. It is generated through the PGF of the Katz distribution (KD). That is, the PMF of the GKD is obtained by applying and in Equation (3). Hence, it is given by
where is the generalized binomial coefficient, that is, , , , and .
- Generalized Poisson distribution
A special case of the includes the generalized Poisson distribution (GPD) given in [4], which is generated through the PGF of the Poisson distribution. That is, the PMF of the GPD is obtained by applying and in Equation (3). It is thus given by
where and .
- Generalized Binomial Distribution
A special case of the includes the generalized binomial distribution (GBD) given in [4], which is generated through the PGF of the binomial distribution. That is, the PMF of the GBD is obtained by applying and in Equation (3). It is thus indicated as
where , and .
2.3. Lagrangian Distribution of the Second Kind
Along with the Lagrange expansion given in Equation (2), under the conditions , , , and
for in Equation (2), we can define the PMF of the (see [21,29]). Explicitly, it is given by
The class of Lagrangian distributions given in Equation (4) is sometimes denoted as .
The corresponding PGF is given by
where .
In this case, the functions and are also called the transformed function and transformer function, respectively. Numerous members of the are available in the literature, some of them are described below.
- Weighted Consul Distribution
A special case of the includes the weighted Consul distribution (WCD) given in [4], which is generated through the PGF of the binomial distribution and an analytic function. That is, the PMF of the WCD is obtained by applying and in Equation (4). It is given as
where and .
- Rectangular–Poisson Distribution
A special case of the includes the rectangular–Poisson distribution (RPD) given in [4], which is generated through the PGF of the rectangular distribution and the PGF of the Poisson distribution. That is, the PMF of the RPD is obtained by applying and in Equation (4). Hence, it is expressed as
where is an integer, , .
- Rectangular–Binomial Distribution
The rectangular–binomial distribution (RBD) given in [4] is a special case of the , which is generated by the PGF of the binomial and rectangular distributions, respectively. That is, the PMF of the RBD is obtained by applying and in Equation (4). It is thus obtained as
where is an integer, , , and .
Given the applications of the Lagrangian distributions generated with various PGFs, it is worthwhile to investigate other horizon Lagrangian distributions that make use of new PGFs. This serves as the amended study distribution, which is displayed below.
3. Lagrangian Zero-Truncated Katz Distribution (LZTKD)
In this section, we adopt the PMF of the given in Equation (4) to derive the PMF of the LZTKD. Here, we consider as the PGF of the KD with parameters and , and as the PGF of the ZTKD with parameters and to generate the LZTKD.
That is, we take
The analytic functions given in Equation (6) satisfy the conditions presented in Section 2.3. That is, we have
Then, under the transformation , the PMF of the given in Equation (4) can be derived as follows:
where = .
Hence, the definition of the LZTKD can be formalized as follows:
Definition 1.
with Assume that a random variable (RV) Y follows the LZTKD, with , , and . Then, the PMF of Y is given by
This distribution is denoted as LZTKD(), and one can write to inform that Y follows the LZTKD with the parameters , , and .
Now, Figure 1 portrays the graphical representation of the PMF of the LZTKD for different parameter values of , , and . We see that it is monotonically decreasing for increasing values of the parameters and , and decreasing the value of the parameter as the value of y increases. In addition, this graph takes on a bell-shaped appearance as the value of y increases if both the and parameters increase but the parameter remains constant.
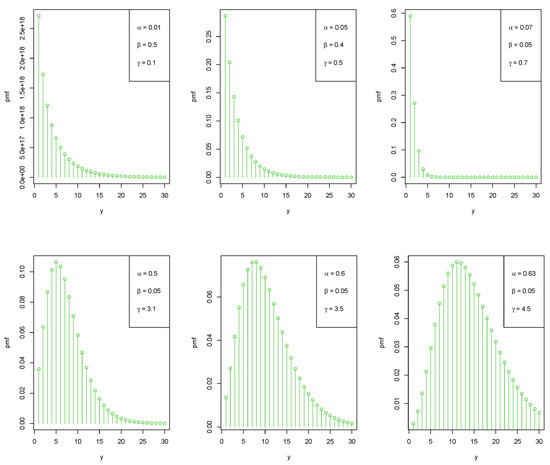
Figure 1.
Various shapes of the PMF of the LZTKD for different parameter values.
The hazard rate function (HRF) of the LZTKD is obtained by substituting the PMF in the following equation:
From Equation (8), it goes without saying that determining the closed-form expression of the HRF is more difficult. However, to determine the shape of the HRF, we sketched its graph. Figure 2 demonstrates that it has increasing, decreasing, bathtub, and upside-down bathtub shapes for various parameter values.
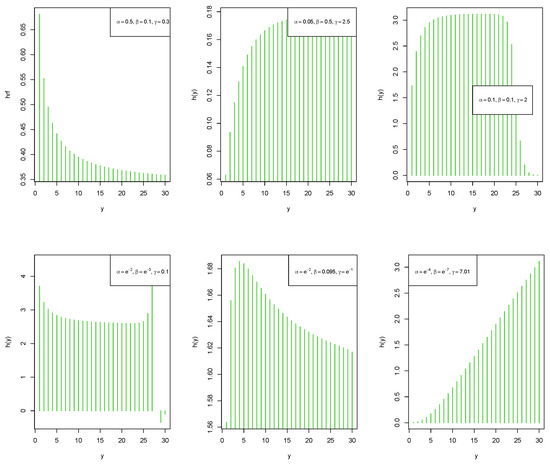
Figure 2.
Various shapes of the HRF of the LZTKD for different parameter values.
Proof.
For , the LZTKD defined with the PMF given in Equation (7) reduces to the ZTKD; the following PMF is obtained:
In this sense, the LZTKD is a generalization of the ZTKD. □
4. Mathematical Properties
In this section, we present some important mathematical properties of the LZTKD, including the median, mode, factorial moments, mean, variance, coefficient of variation (CV), index of dispersion (IOD), skewness, and kurtosis.
4.1. Median
Let Y be a RV following the LZTKD. The median of Y is then defined by the smaller integer such that , also written as
4.2. Mode
Let Y be a RV following the LZTKD. Then, the mode of Y, denoted by , exists in . It corresponds to the integer y for which the PMF has the greatest value. That is, we aim to solve and . First, we note that can also be written as
where .
Obviously, the inequality implies that
Moreover, the inequality implies that
4.3. Probability Generating Function
The Lagrangian transformation , when expanded in powers of u, provides the PGF of the given in Equation (5). That is,
where with .
Remark 1.
The moment-generating function (MGF) of a RV Y following the LZTKD is obtained by putting and in Equation (13). This yields
wherewith.
4.4. Distribution of Sample Sum
Let be n independently and identically distributed (iid) RVs following the LZTKD. Then, the distribution of the sample sum has the following PGF:
where with .
4.5. Factorial Moment
For any integer , the rth factorial moments of the LZTKD is calculated by successively differentiating in Equation (4) r times with respect to u, and by setting . Thus, we consider
and
Taking the first derivative with respect to u on both sides, we obtain
Then, taking second derivative with respect to u, we obtain
Proceeding like this, we obtain an rth derivative of the following form:
For , Equation (15) can be written as
We have and , which are substituted in Equation (16) to yield
4.6. Mean and Variance
The mean () and variance () for the LZTKD are now determined.
4.7. Index of Dispersion and Coefficient of Variation
A normalized measure of dispersion can be obtained by using the variance-to-mean relationship. This measure, the well-known IOD, is given by
Analogously, the CV of the RV Y has the following form:
The skewness and kurtosis coefficients of a distribution are frequently used to measure the degree of asymmetry and flatness, respectively. These coefficients are essential to characterize the shape of any distribution, but for the LZTKD, the expressions obtained for such measures were extensive and too lengthy. However, they can be calculated numerically. They are given in Table 1, as well as the mean, variance, CV, and IOD for particular values of the parameters.

Table 1.
Mean, variance, CV, IOD, skewness, and kurtosis of the LZTKD for different values of the parameters.
It is clear from this table that for and , the LZTKD exhibits overdispersion (IOD > 1) and for and , the LZTKD exhibits underdispersion (IOD < 1). When the parameter value of increases, the mean and variance of the LZTKD increases. Moreover, it is noteworthy that the LZTKD has various kurtosis levels and is mainly right-skewed.
5. Relationship Between and
In this section, we first examine the relationship between the and the . Secondly, we show that the LZTKD belongs to the .
Theorem 1.
Let and let X and Y be RVs with distributions into the and , respectively. Then, for all values of t.
Proof.
For the PMF of the given in Equation (3) with , we have
which belongs to the .
For the PMF of the given in Equation (4), we have
This completes the proof. □
To show the LZTKD belongs to the , we adopt the following equivalence theorem given in [24], also discussed in [4].
Theorem 2.
Let , , and be three analytical functions, which are successively differentiable for and such that and . Then, under the transformation , every member of the is a member of the by choosing
Proof.
The proof is not new; it is given in [4] and hence omitted. □
Proof.
The LZTKD belongs to the by choosing
□
Proof.
For the , the PMF can be rewritten as
It is the same PMF as the one of the zero-truncated generalized Katz distribution (ZTGKD). It is given in [4] and belongs to the . □
6. Estimation of the Parameters
In this section, we estimate the unknown parameters of the LZTKD by the method of the ML.
As a first remark, the model related to the LZTKD is a three-parameter model with parameters , , and . Let a random sample of size n be from the LZTKD and let the observed frequency be , , so that , where k is the largest of the observed value having nonzero frequencies. Then, the corresponding likelihood function is given by
Thus, the log-likelihood function is obtained as
where .
The maximization of with respect to the parameters gives their respective MLEs. They can also be obtained by considering the following differentiation approach. The score function associated with this log-likelihood function is
Now, by solving , =0, and simultaneously, we obtain the associated nonlinear log-likelihood equations. Consequently, these equations are given by
and
Thus, the solutions of these three equations give the MLEs.
In this research, we maximized the log-likelihood function to find the MLEs in the numerical optimization. The fitdistrplus package of RStudio software was used to fix a lower and upper bound for each parameter using the numerical optimization technique “L-BFGS-B”, see [30]. When there are uncertainties about the initial guesses and convergence of the algorithm, fitdistrplus is a highly useful tool that provides original solutions for the MLEs. In order to provide the algorithm with good starting values, we employed the prefit function of that package. Convergence is indicated using certain integer codes as one of the mledist function’s returning components, with “0” denoting a successful convergence and “1” denoting that the maximum number of iterations is used. As a result, a value of “10” indicates that the algorithm is degenerate, and a value of “100” shows that the algorithm made a mistake inside. One can click on the following link for further information about this package https://CRAN.R-project.org/package=fitdistrplus accessed on 3 January 2023. The corresponding R code is given in Appendix A.
7. Likelihood Ratio Test
In this section, we test the significance of an additional parameter included in the LZTKD using the generalized likelihood ratio test (GLRT) (see [31]).
More precisely, to test the significance of the parameter of the LZTKD, we consider the GLRT procedure. The null hypothesis is that follows the ZTKD against the alternative hypothesis that follows the LZTKD. In this setting, the test statistic is given by
where is the vector of MLEs of with no constraints, and is the vector of MLEs of under . The test statistic presented in Equation (19) is asymptotically distributed as the distribution with one degree of freedom.
8. Simulation Study
To evaluate the performance of the estimates obtained using the ML estimation approach, we ran a quick simulation exercise in this section. We simulated an LZTKD random sample using the inverse transformation method (see [32]). The following is the inverse transform algorithm for generating a value from the LZTKD:
- Step1:
- Generate a random number from the uniform distribution.
- Step2:
- , , .
- Step3:
- If , set and stop.
- Step4:
- , , .
- Step5:
- Go to Step 3.
In the above description, P is the probability that , and F is the probability that X is less than or equal to i.
The iteration process was repeated times and three parameter sets were considered. The specification of these sets was as follows:
(i) and .
(ii) , and .
(iii) , and .
Thus, we computed the average of the mean square error (MSE), and average absolute bias using the MLEs.
The average absolute bias of the simulated estimates was calculated as and the average MSE of the simulated estimates was calculated as , in which i is the number of iterations, and is the MLE of .
Table 2 provides a summary of the study for samples of sizes 50, 250, 500, and 1000. As the sample size increases and for the three parameter sets, it can be seen that the MSEs are in decreasing order, and the MLEs of the parameters become closer to their original parameter values, indicating their consistency property.
Table 2.
The simulation for different parameter values , and .
9. Applications
9.1. Presentation
The purpose of this section is to demonstrate the LZTKD’s empirical relevance. To this end, two COVID-19 datasets were considered. In the first COVID-19 dataset, daily newly reported cases were included, while in the second COVID-19 dataset, daily deaths were included. Since the outbreak’s detection, almost every country has reported at least one new positive case and death each day. To the best of our knowledge, zero-truncated distributions are the most suitable statistical model in this case. In order to show how the LZTKD might be useful, we compared the fits of the various competing distributions, which are presented in Table 3. To evaluate these datasets numerically, we used RStudio software version 4.2.1.
Table 3.
The considered competitive distributions.
The HRF of the datasets was determined using a graphical technique based on the total time on test (TTT) plot. If a TTT plot is convex, concave, convex then concave, or concave then convex, the corresponding HRF has a decreasing, increasing, bathtub shape, or an upside-down bathtub shape, respectively (see [33]).
9.2. Daily New Cases of COVID-19 Dataset
Here, we considered a dataset of daily newly reported COVID-19 instances from Algeria in East Africa, recorded between 13 June 2022 to 3 October 2022. These data are accessible at http://covid19.who.int/data, (accessed on 20 October 2022). The dataset is: 2 10 6 9 12 4 3 4 10 8 13 9 10 5 8 11 13 11 14 18 10 13 19 17 17 21 26 18 11 17 29 25 28 36 32 21 42 55 49 63 46 72 67 77 94 86 98 93 87 80 92 111 120 125 131 108 113 102 122 106 134 148 142 133 128 112 92 83 94 81 74 89 77 72 54 48 30 19 41 37 32 55 46 21 17 18 15 13 18 15 10 7 12 10 9 14 15 7 3 3 6 7 6 5 7 4 8 5 8 6 5 3 3.
The descriptive measures of this dataset, which include sample size (n), minimum (), first quartile (), median (), third quartile (), maximum (), and interquartile range (), are given in Table 4.
Table 4.
Descriptive statistics for the COVID-19 dataset from Algeria.
In addition, Figure 3 shows the corresponding empirical TTT plot. It revealed an upside-down bathtub shape HRF.
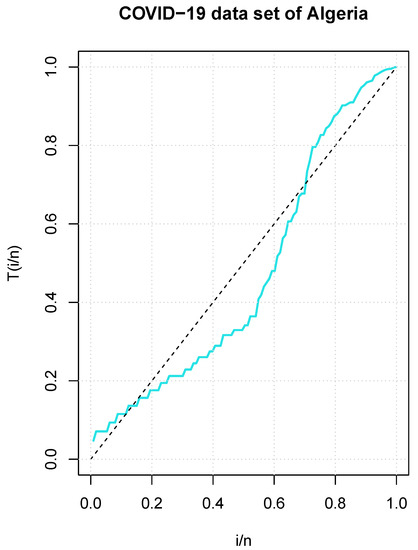
Figure 3.
TTT plot for the COVID-19 dataset from Algeria.
We compared the competitive distributions to the LZTKD employing the statistical techniques provided, namely the negative log-likelihood (−), Akaike information criterion (AIC), Bayesian information criterion (BIC), and value. Table 5 displays the corresponding MLEs, model adequacy measures, and values. As it can be seen in this table, the model adequacy measures and value of the LZTKD are lower than those of the other studied distributions. The suggested model is therefore the most suitable one to model the provided dataset.
Table 5.
MLEs, model adequacy measures, and values for the COVID-19 dataset from Algeria.
In the case of the GLRT, the calculated value based on the test statistic given in Equation (19) was (p-value ). As a result, at any level , the null hypothesis is rejected in favor of the alternative hypothesis. Hence, we conclude that the additional parameter in the LZTKD is significant in light of the test procedure outlined in Section 7.
9.3. Daily Death Cases of COVID-19 Dataset
Here, we considered a dataset of daily death cases of COVID-19 instances from Bosnia and Herzegovina in Europe, recorded between 2 August 2020 to 28 June 2021. These data are accessible at http://covid19.who.int/data, (accessed on 20 October 2022). The dataset is: 11 12 11 11 6 5 10 8 6 17 22 6 5 11 2 9 6 9 12 8 10 6 5 11 13 11 11 9 3 4 11 11 7 9 3 12 4 9 5 6 5 6 4 6 9 20 11 11 5 6 6 6 8 12 12 6 7 2 12 14 13 5 10 6 2 9 15 5 5 13 1 1 8 11 11 14 8 2 4 11 20 14 20 14 6 15 18 21 36 21 30 22 14 32 37 41 44 55 33 20 73 46 72 49 58 49 41 75 69 47 64 56 40 27 66 52 35 51 62 34 44 61 46 46 39 53 57 30 60 69 70 48 51 48 38 55 66 54 38 34 42 28 53 86 46 40 23 22 30 23 48 26 22 14 14 31 48 32 37 16 21 20 25 28 15 26 12 18 20 23 14 23 12 15 19 14 5 19 28 22 16 20 17 9 19 13 8 16 14 16 9 13 21 19 15 13 11 4 20 19 14 13 17 16 12 9 18 17 11 9 17 8 20 29 29 26 28 19 12 38 48 37 28 36 42 33 63 53 35 57 44 44 48 73 67 62 77 76 58 50 99 74 80 76 88 40 84 66 99 80 84 82 60 47 82 79 76 60 86 49 33 68 87 57 82 39 39 39 69 68 46 48 39 28 15 59 60 23 26 28 21 23 28 50 31 15 23 26 19 25 19 16 10 12 9 14 19 18 16 10 17 11 11 20 17 33 29 42 21 4 12 49 7 6 6 9 3 4 39 74 18 4 4 3 6 5 3 2 2 1 2.
The descriptive measures of the real dataset, which include n, , , , , , and are given in Table 6.
Table 6.
Descriptive statistics for the COVID-19 dataset from Bosnia and Herzegovina.
In addition, Figure 4 shows an empirical TTT plot for the COVID-19 dataset from Bosnia and Herzegovina and it shows an increasing HRF.
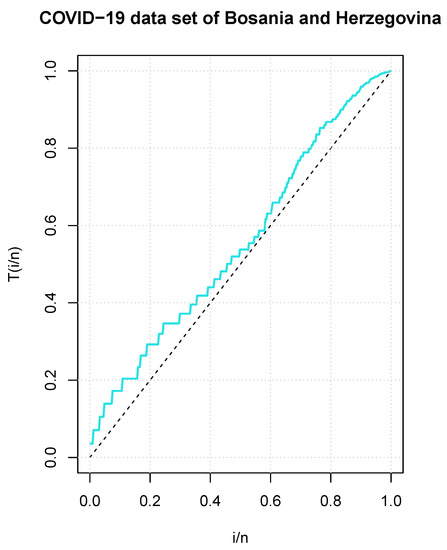
Figure 4.
TTT plot for the COVID-19 dataset from Bosnia and Herzegovina.
We used well-established statistical measures to compare the competitive distributions to the LZTKD, including the , AIC, BIC, and value. Table 7 displays the corresponding MLEs, model adequacy measures, and values. It is observed that the LZTKD’s model adequacy measures and value are lower than those of the other distributions studied. Because of this, the suggested model is the best choice for modeling the considered dataset.
Table 7.
MLEs, model adequacy measures and values for the Bosnia and Herzegovina COVID-19 dataset.
In the case of the GLRT, the calculated value based on the test statistic given in Equation (19) was (p-value ). As a result, at any level , the null hypothesis is rejected in favor of the alternative hypothesis. Hence, we conclude that the additional parameter in the LZTKD is significant in light of the test procedure outlined in Section 7.
10. Concluding Remarks
In this article, we proposed a novel zero-truncated Lagrangian distribution called the “LZTKD” using the Lagrange expansion of the second kind. We demonstrated that the ZTKD was a special case of the LZTKD. We looked at the shape properties of the PMF and HRF of the LZTKD. The expressions for the factorial moments, generating functions, mean, and median were derived. Using the equivalence theorem of the class of Lagrangian distributions, we demonstrated that the LZTKD belonged to the . Subsequently, the ML method was employed to estimate the model parameters for the LZTKD. Using the GLRT procedure, we tested the significance of the additional parameter included in the LZTKD. Simulated studies were conducted to show the effectiveness of MLEs. Two actual datasets were used to validate the results, which proved that the LZTKD offered a superior fit compared to competing models. The LZTKD may also act as a baseline distribution for the hurdle model’s development. If the bivariate version of the LZTKD and the corresponding regression model are constructed, this research may go in a new direction. This task requires a lot of improvements and research, which we leave for further study.
Author Contributions
Conceptualization, D.S.S., C.C., M.M., R.M. and M.R.I.; methodology, D.S.S., C.C., M.M., R.M. and M.R.I.; software, D.S.S., C.C., M.M., R.M. and M.R.I.; validation, D.S.S., C.C., M.M., R.M. and M.R.I.; formal analysis, D.S.S., C.C., M.M., R.M. and M.R.I.; investigation, D.S.S., C.C., M.M., R.M. and M.R.I.; resources, D.S.S., C.C., M.M., R.M. and M.R.I.; data curation, D.S.S., C.C., M.M., R.M. and M.R.I.; writing—original draft preparation, D.S.S., C.C., M.M., R.M. and M.R.I.; writing—review and editing, D.S.S., C.C., M.M., R.M. and M.R.I.; visualization, D.S.S., C.C., M.M., R.M. and M.R.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets are available in the application section.
Acknowledgments
The editors and the unknown reviewers are to be thanked for their insightful comments, which helped to substantially improve the current version of our work.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LZTKD | Lagrangian zero-truncated Katz distribution |
| ZTPD | Zero-truncated Poisson distribution |
| ZTKD | Zero-truncated Katz distribution |
| IPD | Intervened Poisson distribution |
| ZTDLD | Zero-truncated discrete Lindley Distribution |
| LD | Lagrangian distribution of the first kind |
| LD | Lagrangian distribution of the second kind |
| LKD | Lagrangian Katz distribution |
| GKD | Generalized Katz distribution |
| KD | Katz distribution |
| GPD | Generalized Poisson distribution |
| GBD | Generalized binomial distribution |
| RPD | Rectangular Poisson distribution |
| WCD | Weighted Consul distribution |
| RBD | Rectangular binomial distribution |
| ZTGKD | Zero-truncated generalized Katz distribution |
| AGPSD | A generalization of the Poisson–Sujatha distribution |
| PMF | Probability mass function |
| HRF | Hazard rate function |
| IOD | Index of dispersion |
| PGF | Probability-generating function |
| MGF | Moment-generating function |
| CV | Coefficient of variation |
| iid | Independent and identically distributed |
| RV | Random variable |
| ML | Maximum likelihood |
| MLEs | Maximum likelihood estimates |
| GLRT | Generalized likelihood ratio test |
| MSE | Mean squared error |
| TTT | Total time on test |
| AIC | Akaike information criterion |
| BIC | Bayesian information criterion |
| Interquartile range | |
| Median | |
| Minimum | |
| Maximum | |
| First quartile | |
| Second quartile | |
| SE | Standard error |
Appendix A
The R code for the MLEs of the LZTKD is given by
library(fitdistrplus)
dfn <- function(y, alpha, beta, gamma){
d <- ((1-(beta/(1-alpha)))/(1-(1-alpha)^(gamma/alpha)))
* (alpha)^y*(1-alpha)^(gamma+(beta*y))/alpha
* (choose(((gamma+(beta*y))/alpha)+y-1,x)-choose((((beta*y))/alpha)+y-1,y))
return(d)
}
pfn <- function(q,alpha,beta,gamma){
cumsum(dfn(q,alpha,beta,gamma))
}
#
pfn(x,0.03,0.4,2)
#
pre <- prefit(x, “fn”, “mle”, list(alpha=0.01, beta=0.01, gamma=0.02),
lower=c(0, 0, 0), upper=c(1, 1, Inf))
fit.fn <- fitdist(x, “fn”,
start=list(alpha=pre$alpha, beta=pre$beta, gamma=pre$gamma),
optim.method=“L-BFGS-B”, lower=c(0, 0, 0), upper=c(1, 1, Inf),
discrete=TRUE)
summary(fit.fn)
gofstat(fit.fn).
References
- Cohen, A.C. Estimating parameters in a conditional Poisson distribution. Biometrics 1960, 16, 203–211. [Google Scholar] [CrossRef]
- Grogger, J.T.; Carson, R.T. Models for Truncated Counts. J. Appl. Econom. 1991, 6, 225–238. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kemp, A.W.; Kotz, S. Univariate Discrete Distributions; John Wiley & Sons: New York, NY, USA, 2005. [Google Scholar]
- Consul, P.C.; Famoye, F. Lagrangian Probability Distributions; Birkhäuser: New York, NY, USA, 2006. [Google Scholar]
- Consul, P.C.; Famoye, F. The truncated generalized Poisson distribution and its estimation. Commun. Stat. Theory Methods 1989, 18, 3635–3648. [Google Scholar] [CrossRef]
- Shanmugam, R. An intervened Poisson distribution and its medical application. Biometrics 1985, 41, 1025–1029. [Google Scholar] [CrossRef] [PubMed]
- Scollnik, D.P.M. On the intervened generalized Poisson distribution. Commun. Stat. Theory Methods 2006, 35, 953–963. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K. A generalization of Poisson-Sujatha distribution and its applications to ecology. Int. J. Biomath. 2019, 12, 1–11. [Google Scholar] [CrossRef]
- Hussain, T. A zero truncated discrete distribution: Theory and applications to count data. Pak. J. Stat. Oper. Res. 2020, 16, 167–190. [Google Scholar] [CrossRef]
- Jenson, J.L.W. Sur une identité d’ Abel et sur d’autres formules analogues. Acta Math. 1902, 26, 307–318. [Google Scholar] [CrossRef]
- Riordan, J. Combinatorial Identities; John Wiley & Sons: New York, NY, USA, 1968. [Google Scholar]
- Berg, K.; Nowicki, K. Statistical inference for a class of modified power series distribution with applications to random mapping theory. J. Stat. Plan. Inference 1991, 28, 247–261. [Google Scholar] [CrossRef]
- Consul, P.C.; Shenton, L.R. Use of Lagrange expansion for generating generalized probability distributions. SIAM J. Appl. Math. 1972, 23, 239–248. [Google Scholar] [CrossRef]
- Li, S.; Famoye, F.; Lee, C. On certain mixture distributions based on Lagrangian probability models. J. Probab. Stat. Sci. 2008, 6, 91–100. [Google Scholar]
- Innocenti, A.R.; Fox, O.; Chibbaro, S. A Lagrangian probability density function model for collisional turbulent fluid-particle flows. J. Fluid Mech. 2019, 862, 449–489. [Google Scholar] [CrossRef]
- Li, S.; Black, D.; Lee, C.; Famoye, F. Dependence Models Arising from the Lagrangian Probability Distributions. Commun. Stat. Theory Methods 2010, 29, 1729–1742. [Google Scholar] [CrossRef]
- Consul, P.C.; Famoye, F. Lagrngian Katz family of distributions. Commun. Stat. Theory Methods 1996, 25, 415–434. [Google Scholar] [CrossRef]
- Janardan, K.G. Generalized Polya- Eggenberger family of distributions and its relation to Lagrangian Katz family. Commun. Stat. Theory Methods 1998, 27, 2423–2443. [Google Scholar] [CrossRef]
- Gathy, M.; Lefevre, C. On Markov-Pólya Distribution and the Katz Family of Distributions. Commun. Stat. Theory Methods 2011, 40, 267–278. [Google Scholar] [CrossRef]
- Kim, H.; Lee, S. On first-order integer-valued autoregressive process with Katz family innovations. J. Stat. Comput. Simul. 2017, 87, 546–562. [Google Scholar] [CrossRef]
- Janardan, K.G. A wider class of Lagrange distributions of the second kind. Commun. Stat. Theory Methods 1997, 26, 2087–2097. [Google Scholar] [CrossRef]
- Consul, P.C.; Famoye, F. On Lagrangian distribution of the second kind. Commun. Stat. Theory Methods 2001, 30, 165–178. [Google Scholar] [CrossRef]
- Consul, P.C. Geeta distribution and its properties. Commun. Stat. Theory Methods 1990, 19, 3051–3068. [Google Scholar] [CrossRef]
- Consul, P.C.; Famoye, F. DEV Probability Distribution and some of its Applications. Adv. Appl. Stat. 2005, 5, 17–30. [Google Scholar]
- Consul, P.C.; Famoye, F. Harish Probability Distribution and its Applications. J. Stat. Theory Appl. 2006, 5, 17–30. [Google Scholar]
- Irshad, M.R.; Chesneau, C.; Shibu, D.S.; Monisha, M.; Maya, R. Lagrangian Zero Truncated Poisson Distribution: Properties Regression Model and Applications. Symmetry 2022, 14, 1775. [Google Scholar] [CrossRef]
- Irshad, M.R.; Chesneau, C.; Shibu, D.S.; Monisha, M.; Maya, R. A Novel Generalization of Zero-Truncated Binomial Distribution by Lagrangian Approach with Applications for the COVID-19 Pandemic. Stats 2022, 5, 1004–1028. [Google Scholar] [CrossRef]
- Irshad, M.R.; Monisha, M.; Chesneau, C.; Maya, R.; Shibu, D.S. A Novel Flexible Class of Intervened Poisson Distribution by Lagrangian Approach. Stats 2023, 6, 150–168. [Google Scholar] [CrossRef]
- Janardan, K.G.; Rao, B.R. Lagrangian distributions of second kind and weighted distributions. SIAM J. Appl. Math. 1983, 43, 302–313. [Google Scholar] [CrossRef]
- Delignette-Muller, M.L.; Dutang, C. fitdistrplus: An R Package for Fitting Distributions. J. Stat. Softw. 2015, 64, 1–34. [Google Scholar] [CrossRef]
- Rao, C.R. Minimum variance and the estimation of several parameters. Math. Proc. Camb. Philos. Soc. 1947, 43, 280–283. [Google Scholar] [CrossRef]
- Ross, S. Simulation, 5th ed.; Academic Press: Cambridge, MA, USA, 2013; pp. 5–38. [Google Scholar] [CrossRef]
- Aarset, M.V. How to identify a bathtub hazard rate. IEEE Trans Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).