
Spatiotemporal Data Mining Problems and Methods


Abstract
:1. Introduction
2. Related Work
3. Spatiotemporal (ST) Data
3.1. Types of ST Data
- (1)
- Two different objects, , , are not allowed to be at the same time , at the same time point . For example, two different cars, a1, a2, are not allowed to be at the same time , at the same point , and to declare, for the same time and space, the theft of both of these cars. Thus, TheftCar(,,) ≠ TheftCar(,,).
- (2)
- An object is not allowed to be presented in two different places at the same time. Position(,,) ≠ Position(,,).
- (3)
- Can an object appear in the same place at two different times, only if a strictly defined time interval is defined? For example, Position(,,) = Potion(t2,,) when 0 ≤ t ≤ 100 s, so it is immovable. When t does not belong to the above interval, then it means that, probably, the object moved to another point, .
- (1)
- Each object has a unique position in space for a given moment in time.
- (2)
- Two objects have a unique and different position at a given moment in time.
- (3)
- An object can be considered to be at the same point at two different times, , , when a time interval t is defined where ≤ t and ≤ t, where in this case the object is considered stationary in this period of time.
- (1)
- TheftCar(,) ¬ Position(,,) ∧ Position(,,) ∧ ≠ .
- (2)
- Move(,,) ∧ ¬ move(,,) Position(,,).
- (3)
- Move(,,) ∧ ∧¬ move(,,) position(,,).
- (1)
- A polygon formed by a number of neighboring spatial points (,,,), with a set of events (ev1, ev2, ev3, ev4), respectively, cannot, with the number of these neighboring points, form another polygon at the same time () and determine its extent of the same event. So it can be formulated as follows:
- (2)
- Two polygons may consist of the same spatial points at the same time when they describe different events. Thus,
- (1)
- When we study the spatial extent of an event, at a specific moment in time, then the resulting polygon is unique.
- (2)
- Two or more polygons may be the same when, for the same spatial and temporal points, they studied a different event.
- (1)
- (, ,,) ∧ (,,, ) ∧ , where t is specific period of time.
- (2)
- () = (), if ∧ .
- (1)
- Two objects cannot have the same trajectory when moving at the same speed in the same amount of time.
- (2)
- Two trajectories are not considered similar when all their points are not exactly the same.
- (3)
- A trajectory does not consist of one point over a period of time.
- (1)
- Two objects can delete the same trajectory as long as they have different speeds for different amounts of time or same time period but different start time. For example, the faster object will clear the trajectory in a shorter time.
- (2)
- Two trajectories are considered similar when all their points are the same.
- (3)
- To be considered a trajectory, a trajectory must have more than one spatial point in a defined time interval.
- (1)
- Traj(,,,)∧Traj(,,,)∧∧, where and are the temporal and spatial starting points.
- (2)
- Traj(,,,)∧Traj(,,,)∧().
- (3)
- Traj(,,)Traj(,,) ∧.
- (4)
- Traj(,,)i.
- (1)
- In order to consider two or more spatial points as reference points, the times during which measurements were made at these points should have a constant difference between them, i.e., = + α and = + α, where α ∈ R.
- (2)
- A reference point can also be a time point. For example, at a time we measure the temperature in three large cities of Greece, for example, on 22 September, the temperature in Athens was 28 °C, in Heraklion 30 °C, and in Thessaloniki 26 °C. The reference point in this case is the time, so 22 September can capture data as a timestamp.
- (1)
- Measures(,)∧ti+ a, .
- (2)
- Measures(,)∧li+ a, .
- (1)
- Measurements taken in an area at unspecified times cannot be considered raster data.
- (2)
- Measurements made in a set of different areas for a given moment in time are not considered raster data.
- (1)
- Raster data are considered the measurements made at a spatial point , at regular time intervals, ,,, where =+ a and =+ a, with a ∈ R.
- (2)
- Raster data can also be considered the measurements made at a given time , in a group of areas, as long as these areas are related to each other in terms of some characteristics (for example, they are spatially adjacent).
- (1)
- + a, .
- (2)
- + a, .
3.2. Properties of ST Data
3.3. Data Types Conversion
3.4. Data Instances
3.4.1. Data Instances Per Type
Points Instances
Trajectories Instances
Time Series Instances
Spatial Maps Instances
Raster Instances
3.4.2. Similarity between Cases Instances
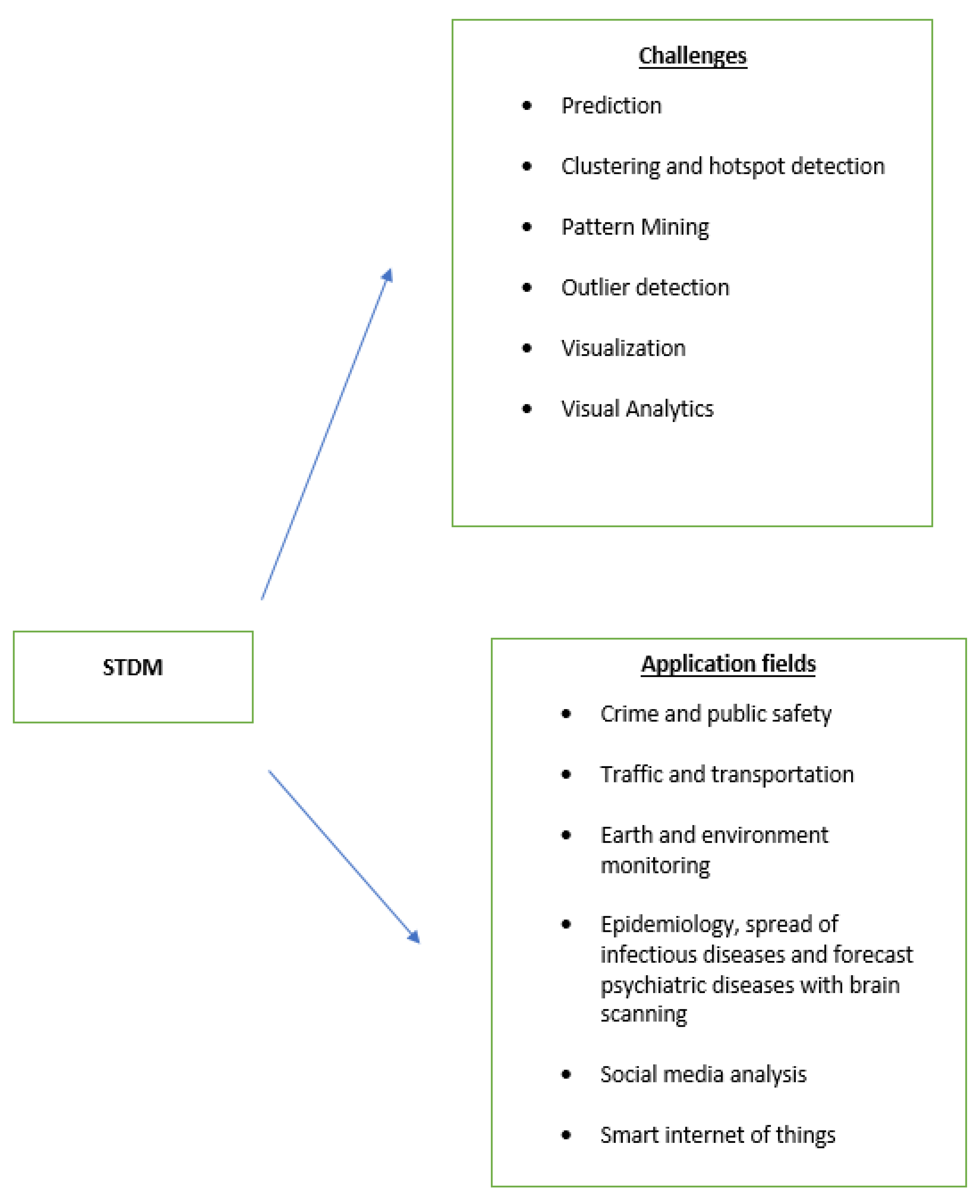
4. Problems and Methods
4.1. Clustering
4.2. Finding Dynamic ST Clusters
4.3. Predictive Learning
4.4. Frequency of Pattern Mining and Display of Patterns
4.5. Detection of Abnormalities
4.6. Identifying Time Points of Change in Behavior of Object to Study
4.7. Relationship Development
5. The Application of St Data in Various Fields Today
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Liu, Y.; Xiao, Y.; He, R. Spatial-temporal upsampling graph convolutional network for daily long-term traffic speed prediction. J. King Saud Univ.Comput. Inf. Sci. 2022, 34, 8996–9010. [Google Scholar] [CrossRef]
- Roddick, J.F.; Lees, B.G. Paradigms for Spatial and Spatio-Temporal Data Mining. In Geographic Data Mining and Knowledge Discovery; The Australian National University: Canberra, Australia, 2001; pp. 33–50. Available online: http://hdl.handle.net/1885/92749 (accessed on 1 November 2022).
- Chen, X.; Faghmous, J.H.; Khandelwal, A.; Kumar, V. Clustering dynamic spatio-temporal patterns in the presence of noise and missing data. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Ghazi, A.-N.; Chawla, S.; Gudmundsson, J. Dimensionality reduction for long duration and complex spatio-temporal queries. In Proceedings of the 2007 ACM Symposium on Applied Computing, Seoul, Republic of Korea, 11–15 March 2007. [Google Scholar]
- Atluri, G.; Padmanabhan, K.; Fang, G.; Steinbach, M.; Petrella, J.R.; Lim, K.; MacDonald, A., III; Samatova, N.F.; Doraiswamy, P.M.; Kumar, V. Complex biomarker discovery in neuroimaging data: Finding a needle in a haystack. NeuroImage Clin. 2013, 3, 123–131. [Google Scholar] [CrossRef] [Green Version]
- Bellec, P.; Perlbarg, V.; Jbabdi, S.; Pélégrini-Issac, M.; Anton, J.L.; Doyon, J.; Benali, H. Identification of large-scale networks in the brain using fMRI. Neuroimage 2006, 29, 1231–1243. [Google Scholar] [CrossRef]
- Geetha, R.; Sumathi, N.; Sathiyabama, S.; Tiruchengode, T.T. A survey of spatial, temporal and spatio-temporal data mining. J. Comput. Appl. 2008, 1, 31–33. [Google Scholar]
- She, X.; Dash, S.; Kim, D.; Mukhopadhyay, S. A heterogeneous spiking neural network for unsupervised learning of spatiotemporal patterns. Front. Neurosci. 2021, 14, 1406. [Google Scholar] [CrossRef]
- Bogorny, V.; Renso, C.; de Aquino, A.R.; de Lucca Siqueira, F.; Alvares, L.O. Constant—A conceptual data model for semantic trajectories of moving objects. Trans. GIS 2014, 18, 66–88. [Google Scholar] [CrossRef]
- Alt, H.; Godau, M. Computing the Fréchet distance between two polygonal curves. Int. J. Comput. Geom. Appl. 1995, 5, 75–91. [Google Scholar] [CrossRef]
- Atluri, G.; Karpatne, A.; Kumar, V. Spatio-temporal data mining: A survey of problems and methods. ACM Comput. Surv. (CSUR) 2018, 51, 1–41. [Google Scholar] [CrossRef]
- Blumensath, T.; Jbabdi, S.; Glasser, M.F.; Van Essen, D.C.; Ugurbil, K.; Behrens, T.E.; Smith, S.M. Spatially constrained hierarchical parcellation of the brain with resting-state fMRI. Neuroimage 2013, 76, 313–324. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Jin, G.; Deng, X.; Wu, F. Multidimensional measurement of poverty and its spatio-temporal dynamics in China from the perspective of development geography. J. Geogr. Sci. 2021, 31, 130–148. [Google Scholar] [CrossRef]
- Anselin, L. The Moran scatterplot as an ESDA tool to assess local instability in spatial. In Spatial Analytical Perspectives on GIS; Routledge: Oxford, UK, 1996; pp. 111–126. [Google Scholar]
- Alam, M.M.; Torgo, L.; Bifet, A. A survey on spatio-temporal data analytics systems. ACM Comput. Surv. 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Anselin, L. Local indicators of spatial association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Taha, B.M.; Yu, Q.R.; Liu, Y. Fast multivariate spatio-temporal analysis via low rank tensor learning. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Karpatne, A.; Faghmous, J.; Kawale, J.; Styles, L.; Blank, M.; Mithal, V.; Chen, X.; Khandelwal, A.; Boriah, S.; Steinhaeuser, K.; et al. Earth science applications of sensor data. In Managing and Mining Sensor Data; Springer: Boston, MA, USA, 2013; pp. 505–530. [Google Scholar]
- Wang, Z.; Peng, Z.; Wang, S.; Song, Q. Personalized Long-Distance Fuel-Efficient Route Recommendation through Historical Trajectories Mining. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022. [Google Scholar]
- Atluri, G.; Steinbach, M.; Lim, K.O.; Kumar, V.; MacDonald III, A. Connectivity cluster analysis for discovering discriminative subnetworks in schizophrenia. Hum. Brain Mapp. 2015, 36, 756–767. [Google Scholar] [CrossRef]
- Gatrell, A.C.; Bailey, T.C.; Diggle, P.J.; Rowlingson, B.S. Spatial point pattern analysis and its application in geographical epidemiology. Trans. Inst. Br. Geogr. 1996, 21, 256–274. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Mining: The Textbook; Springer: New York, NY, USA, 2015; Volume 1. [Google Scholar]
- Alon, J.; Sclaroff, S.; Kollios, G.; Pavlovic, V. Discovering clusters in motion time-series data. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 1. [Google Scholar]
- Agarwal, D.; McGregor, A.; Phillips, J.M.; Venkatasubramanian, S.; Zhu, Z. Spatial scan statistics: Approximations and performance study. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Aggarwal, C.C. Spatial outlier detection. In Outlier Analysis; Springer: Cham, Switzerland, 2017; pp. 345–368. [Google Scholar]
- Birant, D.; Alp, K. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Rakesh, A.; Srikant, R. Mining sequential patterns. In Proceedings of the Eleventh International Conference on Data Engineering, Washington, DC, USA, 6–10 March 1995; IEEE: Piscataway, NJ, USA, 1995. [Google Scholar]
- Aoki, M. State Space Modeling of Time Series; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Brosius, L.S.; Anthony, K.W.; Treat, C.C.; Lenz, J.; Jones, M.C.; Bret-Harte, M.S.; Grosse, G. Spatiotemporal patterns of northern lake formation since the LaSTGlacial Maximum. Quat. Sci. Rev. 2021, 253, 106773. [Google Scholar] [CrossRef]
- Atluri, G.; Steinbach, M.; Lim, K.O.; III, A.M.; Kumar, V. Discovering groups of time series with similar behavior in multiple small intervals of time. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2014. [Google Scholar]
- Boriah, S.; Mithal, V.; Garg, A.; Kumar, V.; Steinbach, M.S.; Potter, C.; Klooster, S.A. A Comparative Study of Algorithms for Land Cover Change. In Proceedings of the Conference on Intelligent Data Understanding, Mountain View, CA, USA, 5–6 October 2010. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Sá, A.C.; Pereira, J.M.; Charlton, M.E.; Mota, B.; Barbosa, P.M.; Stewart Fotheringham, A. The pyrogeography of sub-Saharan Africa: A study of the spatial non-stationarity of fire–environment relationships using GWR. J. Geogr. Syst. 2011, 13, 227–248. [Google Scholar] [CrossRef] [Green Version]
- Bassett, D.S.; Bullmore, E. Small-world brain networks. Neuroscientist 2006, 12, 512–523. [Google Scholar] [CrossRef]
- Gao, N.; Xue, H.; Shao, W.; Zhao, S.; Qin, K.K.; Prabowo, A.; Rahaman, M.S.; Salim, F.D. Generative adversarial networks for spatio-temporal data: A survey. ACM Trans. Intell. Syst. Technol. TIST 2022, 13, 1–25. [Google Scholar] [CrossRef]
- Andreou, E.; Eric, G. Detecting multiple breaks in financial market volatility dynamics. J. Appl. Econom. 2002, 17, 579–600. [Google Scholar] [CrossRef]
- Scherg, M.; Berg, P.; Nakasato, N.; Beniczky, S. Taking the EEG back into the brain: The power of multiple discrete sources. Front. Neurol. 2019, 10, 855. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Jiannong, C.; Philip, Y. Deep learning for spatio-temporal data mining: A survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 3681–3700. [Google Scholar] [CrossRef]
- Bishop, C.M. Novelty detection and neural network validation. IEE Proc. Vis. Image Signal Process. 1994, 141, 217–222. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, H.; Zhang, B.; Jin, J.; Lyu, Y. SPEMI: Normalizing spatial imbalance with spatial eminence transformer for citywide region embedding. In Proceedings of the 5th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Seattle, WA, USA, 1 November 2022. [Google Scholar]
- Agrawal, S.; Atluri, G.; Karpatne, A.; Haltom, W.; Liess, S.; Chatterjee, S.; Kumar, V. Tripoles: A new class of relationships in time series data. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Liang, X.; Guan, Q.; Clarke, K.C.; Chen, G.; Guo, S.; Yao, Y. Mixed-cell cellular automata: A new approach for simulating the spatio-temporal dynamics of mixed land use structures. Landsc. Urban Plan. 2021, 205, 103960. [Google Scholar] [CrossRef]
- Bu, Y.; Chen, L.; Fu, A.W.C.; Liu, D. Efficient anomaly monitoring over moving object trajectory streams. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009. [Google Scholar]
- Carney, N. All lives matter, but so does race: Black lives matter and the evolving role of social media. Humanit. Soc. 2016, 40, 180–199. [Google Scholar] [CrossRef]
- Tsoukatos, I.; Dimitrios, G. Efficient mining of spatiotemporal patterns. In International Symposium on Spatial and Temporal Databases; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Cao, H.; Mamoulis, N.; Cheung, D.W. Mining frequent spatio-temporal sequential patterns. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; IEEE: Piscataway, NJ, USA, 2005. [Google Scholar]
- Arnold, A.; Liu, Y.; Abe, N. Temporal causal modeling with graphical granger methods. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007. [Google Scholar]
- Hamed, A.; Sengstock, C.; Gertz, M. Eventweet: Online localized event detection from twitter. In Proceedings of the VLDB Endowment, Trento, Italy, 26–30 August 2013; Volume 6, pp. 1326–1329. [Google Scholar]
- Trasarti, R.; Pinelli, F.; Nanni, M.; Giannotti, F. Mining mobility user profiles for car pooling. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011. [Google Scholar]
- Giannotti, F.; Nanni, M.; Pinelli, F.; Pedreschi, D. Trajectory pattern mining. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007. [Google Scholar]
- Steinbach, M.; Tan, P.N.; Kumar, V.; Potter, C.; Klooster, S.; Torregrosa, A. Data mining for the discovery of ocean climate indices. In Proceedings of the Fifth Workshop on Scientific Data Mining, Canberra, Australia, 3 December 2002. [Google Scholar]
- Shekhar, S.; Zhang, P.; Huang, Y.; Vatsavai, R.R. Trends in Spatial Data Mining. Data Mining: Next Generation Challenges and Future Directions; MIT Press: Cambridge, MA, USA, 2003; pp. 357–380. [Google Scholar]
- Bernaola-Galván, P.; Ivanov, P.C.; Amaral, L.A.N.; Stanley, H.E. Scale invariance in the nonstationarity of human heart rate. Phys. Rev. Lett. 2001, 87, 168105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, X.; Matijaš, M.; Suykens, J.A. Hinging hyperplanes for time-series segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1279–1291. [Google Scholar] [CrossRef] [PubMed]
- Davidson, I.; Gilpin, S.; Carmichael, O.; Walker, P. Network discovery via constrained tensor analysis of fmri data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Xu, Y.; Cai, X.; Wang, E.; Liu, W.; Yang, Y.; Yang, F. Dynamic Traffic Correlations Based Spatio-Temporal Graph Convolutional Network for Urban Traffic Prediction. Inf. Sci. 2022, 621, 580–595. [Google Scholar] [CrossRef]
- Kong, X.; Gao, H.; Alfarraj, O.; Ni, Q.; Zheng, C.; Shen, G. Huad: Hierarchical urban anomaly detection based on spatio-temporal data. IEEE Access 2020, 8, 26573–26582. [Google Scholar] [CrossRef]
- Deng, L.; Lian, D.; Huang, Z.; Chen, E. Graph convolutional adversarial networks for spatiotemporal anomaly detection. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2416–2428. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Features | Spatial Data Mining | Spatiotemporal Data Mining |
|---|---|---|
| Definition | Extraction of information and relationships from geographical data stored in a spatial database | Extraction of information from the spatiotemporal data to identify the pattern of the data |
| Data | Needs space information within the data such as location coordinates, etc. | Needs space and time information |
| Conceptual basis, Rules | Based on rules like association rules, discriminant rules, characteristic rules, etc. | Based on finding patterns in the data by clustering, association, prediction and data comparison |
| Application | Determining the hotspot of any event | Register situation changes over a period of time and predicts a future state |
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koutsaki, E.; Vardakis, G.; Papadakis, N. Spatiotemporal Data Mining Problems and Methods. Analytics 2023, 2, 485-508. https://doi.org/10.3390/analytics2020027
Koutsaki E, Vardakis G, Papadakis N. Spatiotemporal Data Mining Problems and Methods. Analytics. 2023; 2(2):485-508. https://doi.org/10.3390/analytics2020027
Chicago/Turabian StyleKoutsaki, Eleftheria, George Vardakis, and Nikolaos Papadakis. 2023. "Spatiotemporal Data Mining Problems and Methods" Analytics 2, no. 2: 485-508. https://doi.org/10.3390/analytics2020027
APA StyleKoutsaki, E., Vardakis, G., & Papadakis, N. (2023). Spatiotemporal Data Mining Problems and Methods. Analytics, 2(2), 485-508. https://doi.org/10.3390/analytics2020027