1. Introduction
In recent years, location check-ins at Points-of-Interests (POIs) on social media has become a living habit. People love sharing their life on Facebook or Instagram. Whether it is traveling or tasting food, they will check-in or share photos to announce the locations. Then location-based Social Networks (LBSN) connecting user social relationships and their check-ins at POIs can be generated. LBSN enables location-aware recommendation applications, such as POI recommendation [
1,
2,
3,
4,
5,
6,
7] and potential customer recommendation [
8,
9].
Location promotion is one of the essential problems in LBSN [
10,
11], and the basic goal is to find the set of seeds (i.e., information
propagators) to maximize the number of users (i.e.,
customers) to visit the target POI [
10,
11,
12,
13,
14]. An effective location promotion algorithm can benefit the location service providers (e.g., restaurants and stores) to search the most influential promoters for targeted marketing. Another beneficial audience is users who are willing to be recruited as location promoters, i.e., they can earn money from the location service providers. In existing studies, however, both the selection of propagators and the estimation of customers rely on historical user-location interaction data (e.g., check-in records). The identified seeding propagators may not be influential in the future. In real practice, it is usually expected that the identified propagators can truly generate more users to visit the target POI (i.e., more customers) in the future, as discussed in existing studies [
10,
11,
15]. In other words, existing location promotion lacks predictability when finding propagators and customers.
To consider the predictability in location promotion, this paper proposes to solve two novel problems. The first is Targeted Propagator Discovery (TPD) while the second is Targeted Customer Discovery (TCD). The TPD problem is that given a target location that intends to initiate a promotion campaign, the goal is to predict which users are influential with respect to the target location during the upcoming promotion period. Specifically, we aim to find which users in LBSN can generate more users to visit the target location when the promotion campaign starts. To the best of our knowledge, we are the first attempt to deal with the problem of TPD. TPD has some differences from location promotion. TPD aims to find the set of users as propagators who will actually generate more other users visiting the target POI in the future, but conventional location promotion is to find the set of users who have a large influence on the target POI using historical check-in data in the past. Users who are influential in historical check-in data might not imply they will still be influential in the future, especially on activating other users to visit the target POI. Since POI holders usually have limited funding, accurately finding future propagators can bring more revenue for the target POI. On the other hand, the TCD problem is to predict which users will visit the target location during the upcoming promotion period. With TCD, the promotion initiator of the given POI can perform targeted marketing to boost the possibility of a user visiting. In addition, with TCD, the POI holders can first understand the common traits of the potential customers in advance so that the marketing strategy can be well constructed.
For the problem of TPD, it concerns the scenario that the POI holders, who aim to market or to promote sales, wonder which users are not only influential but also can attract more people to visit the POI in advance. Then POI holders can hire more influential people to market the POI that can increase the visited people to create more business opportunities. For example, a restaurant holder only has limited funds to employ three bloggers to advertise the restaurant. If we can find the potential candidates who have more attraction ability in the social network, by performing marketing based on these candidates, the POI will bring greater benefits to the restaurant holder. In other words, every venue would like to promote itself by recruiting some influential propagators under a limited budget. Therefore, it is crucial to devise a prediction-based method that can accurately identify such propagators for effective location promotion.
Moreover, for the problem of TCD, it concerns that the POI holders, who aim to advertise their POIs, want to perceive who the potential customers are when designing the promotion plan. The POI holders can analyze the potential customers to know the characteristics they have, and develop an effective marketing strategy that can successfully attract such potential customers. For example, if we can find the potential users who have a larger chance of visiting the restaurant, then the restaurant can send some discount coupons or send some mails to advertise the POI so that their probabilities of visiting the POI can be remarkably boosted. That said, not all users will be interested in the targeted POI, and our goal is to develop a prediction-based method to find those potential customers. By doing so, the POI holders can avoid putting resources on irrelevant users, and concentrate more on potential customers.
We take advantage of social relations and user-POI interactions in LBSN to make predictions in both TPD and TCD problems. While existing studies estimate the number of activated users via information propagation [
11,
16,
17], we think such simulation-based influence estimation cannot reflect the potential of a user becoming influential, i.e., affecting other users to visit the target POI. Therefore, we propose a network embedding method,
LBSN2vec, to depict users and their interactions with POIs. The idea is to jointly embed users in the social network as well as their check-in records at POIs into a low-dimensional space. The embedding space is expected to preserve user preferences as well as user–user interactions in visiting POIs. In the embedding space, two users close to each other can reflect that: (a) they have similar preferences of POI visiting, and (b) they have higher potential to affect one another. That is, one of them visiting a new POI tends to give higher motivation for the other also to visit that POI. In addition, since check-in records are also used in learning embeddings, the embedding vectors of users and POIs are comparable. And the distance between a user and a POI can imply user preference in visiting that POI. A closer distance between a user and a POI can reflect that the user has a higher desire to visit the POI. Consequently, for a given POI, we propose some similarity measures to retrieve influential users as propagators and potential users as customers.
Here we would like to elaborate the underlying reasons that we adopt the embedding learning approach to solve the proposed tasks. To better motivate the proposed method, we create
Table 1 to systematically compare the neural network embedding-based approach with the simple statistical scoring heuristics in different aspects. First, both our TPD and TCD tasks aim to predict the future behaviors of users with respect to the given targeted POI. Existing node scoring measurements, such as the weighted neighborhood size and the number of involved geodesics, mainly rely on a variety of statistical calculations, less regarding predictability. The proposed embedding learning methods can better model how users interact with POIs, and thus properly work for predicting future propagators and customers. Second, the statistical methods, such as the number of geodesics ending in targeted POI, multiplying the neighborhood size or centrality score, cannot model the semantic behaviors of users. That said, although two users could have totally different visited POIs, these POIs can belong to similar types. If we do not model the semantic behaviors of users via exploiting their high-order interactions in the check-in graph, the user influence and user’s predictability to the target POI cannot be well learned. The proposed embedding learning method is to better depict the high-order semantic relationships between users and items in the vector space. This is the main reason that we adopt the embedding learning method. Third, in addition to representing users by their visited POIs, we think the POIs can also be depicted by those users who visit there. Rather than quantitatively considering POIs in a statistical manner, we jointly project users and locations into their common embedding space so that we can estimate and exploit their distances to better distinguish their affinity to the targeted POIs.
Below summarizes the contributions of this paper.
We formulate two novel problems: Targeted Propagator Discovery (TPD) and Targeted Customer Discovery (TCD). To the best of our knowledge, we are the first study that proposes the problem of TPD.
We propose a network embedding model, LBSN2vec, to jointly learn the feature representations of POIs and users based on the social network and user-POI check-in data in LBSN. A more effective variant, PLBSN2vec, is also presented to further boost the predictability of the embedding space.
Experiments were conducted on a large-scale Instagram dataset to examine the performance of LBSN2vec and PLBSN2vec. The results exhibit that LBSN2vec can outperform well-known network embedding methods in both TPD and TCD tasks.
This paper is organized as below. We first present the problem formulation in
Section 2. Then we describe the proposed LBSN2vec and PLBSN2vec in
Section 3.
Section 4 demonstrates the experimental setup and presents a discussion of the results.
Section 5 concludes this work.
2. Related Work
The relevant studies can be divided into two categories, location promotion and network representation learning in graphs. We will first describe both, and discuss their comparisons with our work.
Location Promotion in LBSNs. Location promotion is to find a set of users as seeding promotors such that the number of influenced users visiting the targeted POI can be maximized. There are several typical methods in this research direction. Likhyani et al. [
10] developed the model named LoCaTe to quantify the influence of a location and a user by modeling user-location interaction patterns, and categorical and temporal semantics between users and locations. Liao et al. [
12] aim at modeling how users interact with each other via their friendships, and accordingly devise a user proximity score for recommending companions for an activity. Bouros et al. [
13] incorporate the geographical region information into the identification of influential users, and develop a new LBSN influence propagation method to achieve the goal. POI2Vec [
14] is designed to predict users who will visit a given location within a future period. POI sequential transition and user preference are used to learn the representation of POI so that potential visitors can be effectively predicted. Zhu et al. [
11] also aim to select a set of seeding users and expect them to attract most other users to visit a given location. Its novelty is the modeling of user mobility from check-in records so that the location-aware propagation probabilities can be better derived.
The main difference between our work and existing studies in this category is two-fold. First, past methods on location promotion utilize historical check-in records to find the most influential users who can attract the most other users to visit a targeted location. The influence of users is estimated based on historical data. However, these methods cannot predict whether the identified influential users can truly visit the location in the future. In other words, these methods are not to predict the
future influence of users for location promotion. Second, although the method proposed by Zhu et al. [
11] can effectively predict whether a user will visit the targeted location in the future, it is not to identify the influential users who can better serve as seeding promotors, attracting more users to visit the targeted location. In short, our work is the first work that predicts future user influence that can bring more other users to visit the targeted location in the future. Note that the main difference between the proposed propagators and the so-called influencers in existing studies is that previous influencers are identified based on only the social network structure via diffusion simulation. The identified influencers cannot be ensured to have the same influence in the future. That said, the mining of influencers in the literature does not consider the predictability. We argue that for real applications, the predictability of whether influencers can truly activate more users should be taken into account. We treat the influencers with predictability as propagators to be detected in our work.
Network Representation Learning in Graphs. Network representation learning, also known as node embedding learning, aims to generate a low-dimensional vector for each node in a graph. The goal is to preserve the neighborhood proximity between nodes in the embedding vectors of nodes. Two nodes that share similar neighbors are supposed to have similar vectors in the embedding space. There are three typical studies in network representation learning, node2vec [
18], LINE [
19], and GraphGAN [
20]. The node2vec proposes to sample the neighbors of a particular node via a hybrid BFS and DFS mechanism, and apply the Skip-gram model [
21] to generate the embedding vectors. LINE aims to preserve both the local and global network structures, i.e., the first- and second-order pairwise proximities, for nodes in the embedding space. GraphGAN applies generative adversarial networks (GAN) for network representation learning. Given a node in a network, the generative model is to fit its connectivity distribution over all nodes, and produces fake embeddings to make the discriminative model wrong. The discriminative model aims to determine whether the generated node embedding is true or artificial, i.e., generated by the generative model. In our experiments, we will compare the proposed methods with these three models of network presentation learning.
The differences between the proposed LBSN2vec and existing graph embedding methods consist of three parts. First, our LBSN2vec is able to effectively exploit two graphs, i.e., the social network and the check-in network, to generate the node embeddings by jointly considering social neighborhood and check-in neighborhood. However, the existing method takes advantage of only the social network. Being able to incorporate multi-model information in a united framework is the key to LBSN2vec. Second, in LBSN2vec, we introduce a penalization mechanism to avoid the random walk traversing the same node so that nodes with higher distinguishability can be sampled. Such a penalization cannot be achieved by existing methods. Third, in the experiments, we have found that when having our extensive design from existing methods, LBSN2vec and its variant PLBSN2vec can improve the performance on both tasks of TPD and TCD.
Recent Advances in LBSN. Recent advances in mining location-based social networks focus on recommendation point-of-interests for users. Das et al. [
22] classify immediate and distant social relationships based on check-in data for better POI recommendation. A hierarchical attention mechanism (HAM) [
23], which effectively selects the more representative LBSN data instances for training, is devised to perform efficient personalized POI recommendation. DSPR [
24] further leverages user preferences and real-time demand, along with an attention-based recurrent neural network, for POI recommendation. While labeled data are scarce in practice, a semi-supervised learning framework HisRect [
25] is developed to take advantage of unlabeled data to recommend the next POIs. SACRA is a self-attentive prospective customer recommendation framework [
26] that makes comparisons between users’ check-ins by adversarial training so that POI recommendation can be more robust. Li et al. [
27] further combine metric learning and few-shot learning to fully utilize user check-ins and better learn the semantic matching between users and POIs. GGLR [
28] is a graph-based geographical latent representation model to capture non-linear geographical influences based on the user-POI check-in graph.
Although these are successful proposals for point-of-interest recommendation for users, none of them discuss how to apply advanced neural network and representation learning methods for discovering influential propagators and predicting potential customers. We believe existing methods can accurately predict the next POIs. Since our problem is significantly different from POI recommendation, i.e., estimating the future influence of users regarding a targeted location in our work, a novelty of our work can be the first to adopt representation learning for predicting propagators and customers in location-based social networks.
3. Problem Formulation
In this section, we formulate the problem of Targeted Propagator Discovery and Targeted Customer Discovery. The Targeted Propagator Discovery aims to find the set of users who will generate more people to visit the target POI in the future. Moreover, the aim of Targeted Customer Discovery is to find the set of users who will visit the target POI in the future.
We first present the notations. Let be a social network, where U is the set of users and , . Also let represent a check-in record, which means user u visits POI p at the time t. We denote a check-in network as , where , P is the set of POIs and , where and .
Problem 1 (Targeted Propagator Discovery, TPD): Given an LBSN containing social network and check-in network , a target POI and the current time , the goal of TPD is to find the k users who will generate more people to visit POI p in the time period .
Problem 2 (Targeted Customer Discovery, TCD): Given an LBSN with social network and check-in network , a target POI and the current time , the goal of TCD aims to find a set of users who will visit POI p in the time period .
4. The Proposed Method
The proposed method consists of two parts. The first is to learn the embedding vectors of users and POIs in
Section 3, which describe how we generate “contexts” of nodes in the social network and the check-in network, and how we learn the embeddings, respectively. That said, we will learn a mapping function
from users and POI nodes in
and
and output the
d-dimensional embedding vectors. The second is a scoring function to estimate the similarity between users and POIs so that both TPD and TCD can be solved in
Section 3.
The main properties preserved by LBSN2vec are two parts. First, the similarity between users with regard to their check-in POIs is preserved by LBSN2vec. Two users possessing more visited check-in POIs tend to be close to each other in the embedding space generated by LBSN2vec. Such a property cannot be well preserved by existing graph embedding methods. Second, since LBSN2vec jointly considers neighboring users and visited POIs to be the context of a node, the mix of two diverse contexts can better deal with the data sparsity of either part. That said, our LBSN2vec can preserve or alleviate the sparsity property in location-based social network data.
4.1. Random Walk Mechanism
We take advantage of the skip-gram model [
21] to learn the feature representation of users and POIs. Let
be the set of user
u’s neighbors in graph
. To have the contexts in the skip-gram model, we generate
through a devised random walk mechanism. Below we first present the probability associated with each edge, then describe the random walk mechanism.
We consider that nodes with strong social connections with each other tend to be treated as neighbors. Thus we introduce two
affinity scores to quantify the social strength between users
i and
j. The first is
social affinity , defined as:
where
is the social network,
is the neighborhood of user
i in
. The second is
co-visiting affinity , defined as:
where
is the check-in network,
is the neighborhood of user
i in
.
Since
shows the affinity based on user-POI interactions, if there are more co-visited POIs between users,
gets higher. Two users are more likely to possess similar POI visiting preferences in the future. On the other hand,
shows the affinity based on the social network. If two users have more common friends,
gets higher, i.e., the two users are more likely to affect each other. Then we define the edge weight (probability)
between users
i and
j in the social network by combining social affinity and co-visiting affinity, given by:
where
is the edge set of social network
.
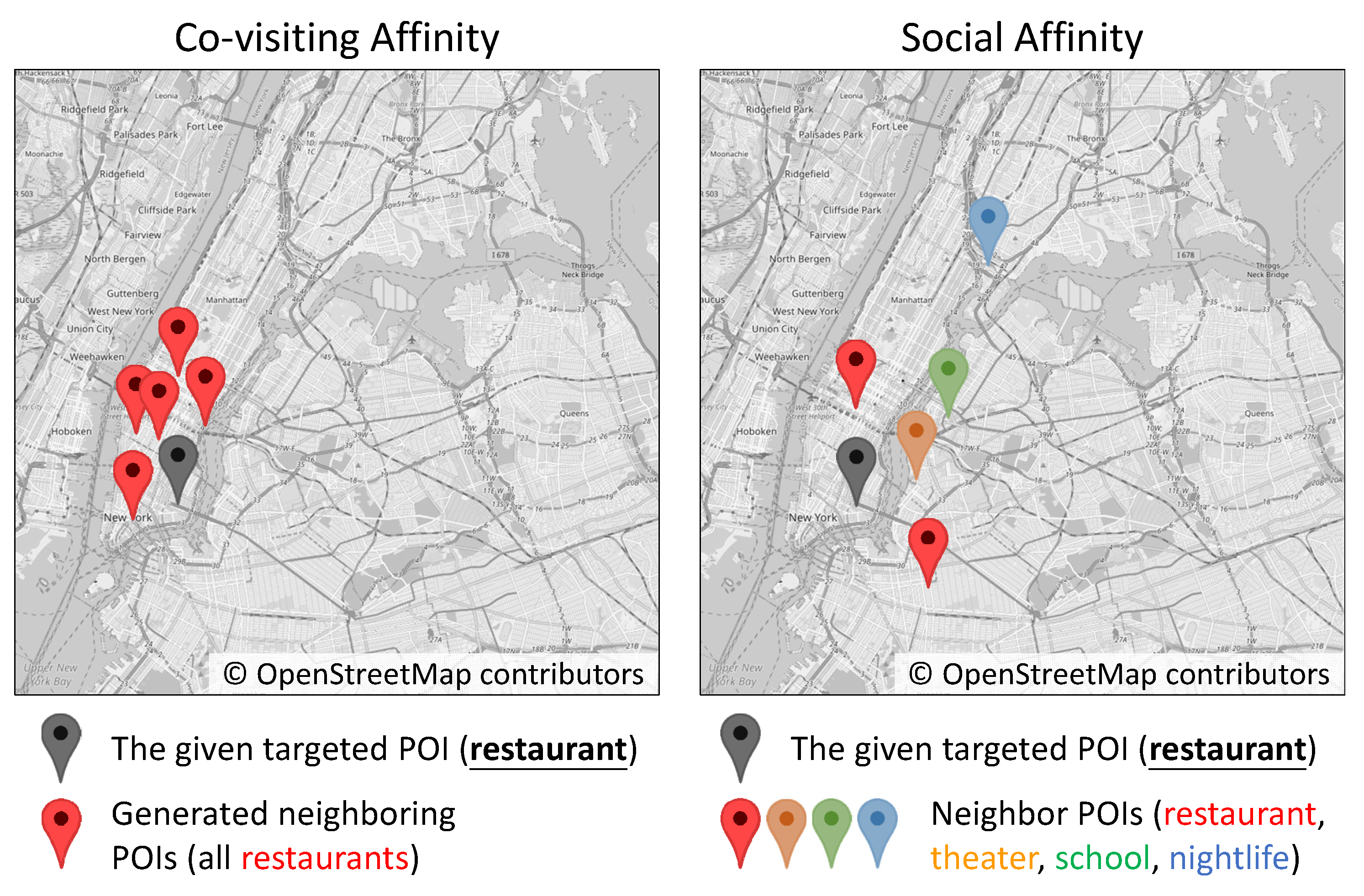
Here we present examples to demonstrate the derived neighboring POIs sampled by random walks of co-visiting affinity and social affinity, in
Figure 1, in which different colors mean various venue categories. We can find that the random walk by co-visiting affinity tends to collect neighbors with the same category as the target POI. The random walk by social affinity has a higher potential to bring neighbors with diverse venue categories. Hence, we would like to have both effects so that the representation learning can generate similar embeddings that not only encode similar categories but also distinguish from each other due to different social interests.
We also propose a penalization-based LBSN2vec (PLBSN2vec) by adding a penalty parameter in the random walk: a return parameter
(
) and a parameter
effect. The return parameter
is the penalty value to avoid traversing the same nodes. In addition, we think that near-by nodes of a user tend to have similar preferences. Hence, we let those close to each other have a high possibility of being traversed as the neighbors. Given the starting user
u, the next user
n, and the previous user
r, we devise the penalty weight
as:
where
is the shortest path length between
n and
r. Lower values of return parameter
make the walk have a lower opportunity to repeat the previous user. By contrast, a larger return parameter
will increase the chance of walking back to the previously traversed users. In addition, longer paths between nodes get a larger penalty in
, which will decrease the probability.
Then we present the random walk mechanism. Formally, given the current node
c, we simulate a random walk of length
l. Let
be the
i-th node in the random walk. For LBSN2vec, we define the conditional probability of the next node
n given the current node
c:
where
Z is the normalizing constant. After simulating the random walk with length
l and window size
w, we can obtain the neighbors of a node, which are considered as the so-called “contexts” in the skip-gram model.
4.2. Embedding Learning
This section presents the embedding learning of LBSN2vec and PLBSN2vec based on the skip-gram model architecture. We adopt a three-layer neural network [
21,
29], consisting of an input layer, a hidden layer, and an output layer. We consider the matrix
f from the input layer to the hidden layer to be the projection matrix, and there is a difference matrix (denoted as
) between the hidden and output layers. Let
be the mapping function from node
to its embedding vector, where
f is the projection matrix of size
, and
d is the dimensionality of embeddings (
). The output layer (denoted by
y) is the vector of size
. We apply the softmax function to define the conditional probability of user
given the input user
as:
where
. Skip-gram is the model that predicts the context based on the given word (node). We replace the context with the neighbors generated through the random walk mechanism in
Section 3. The training objective
O is to maximize the conditional probability of neighborhood given the user, given by:
where
is the neighborhood of user
u.
can be generated based on either social network
or check-in network
. We optimize the objective function by stochastic gradient descent (SGD).
4.3. Making Prediction via Similarity
For the TPD task, we aim to find a set of users who will generate more people to visit the given POI. We consider quantifying two factors to determine whether a user will visit the given POI. One is user preference
, given by:
where
. The other is POI preference
, given by:
where
,
is the embedding vector, and
is the cosine similarity to compute the relation between two input vectors. Two users with similar preferences will have similar embedding vectors. So user preference is devised to depict the tendency of being influential between users. Moreover, if the similarity between the embedding vectors of a user and a POI is high, we consider that the user has a higher chance of visiting the POI. Hence, POI preference is designed to estimate the POI visiting potential/desire of a user.
To find the future targeted propagators, we develop a
contagion scoring measure by combining user preference and POI preference.
For the TPD task, we rank all users’ contagion scores, and select the top-K users as the discovered propagators, i.e., those that can generate the most people to visit the given POI.
For the TCD task, we devise a
visiting scoring measure considering POI preference:
Then we rank all users’ scores, and select the top-K users as the potential customers for the given POI.
The novelty of our similarity-based measures lies in its inductive predictability on LBSN. First, measuring the similarity to identify targeted propagators and potential customers is an unsupervised learning approach. Since we do not have any label data about future propagators and customers, the similarity-based unsupervised method can properly generate the results without supervision information. This would be especially useful for location promotion because we cannot have the labeled promotion data before campaigns.
5. Experimental Evaluation
We conduct experiments to examine whether the proposed LBSN2vec and PLBSN2vec can better model user preferences and user-POI interactions in TPD and TCD tasks, comparing with well-known network embedding methods. Collected Instagram data are used for the experiments (the dataset can be crawled via Instagram API:
https://www.instagram.com/developer/—due to the privacy issue established by Instagram, we cannot provide the data for download). The dataset contains check-in records and user–user followships collected in New York City from Jan 2012 to Nov 2015. There are 994,412 user-POI check-ins and 1,048,575 followship relations. We randomly select 200 POIs and repeat the random selection up to 50 times for the experiments. We use the first 80% chronological check-ins for training and the remaining 20% for testing. We compare LBSN2vec and PLBSN2vec with several well-known network embedding methods: node2vec [
18], LINE [
19], and GraphGAN [
20]. They all map nodes in a network to embedding vectors. The embedding vectors derived from all these methods are fed into the proposed scoring function for both TPD and TCD tasks. We should notice that the difference between our LBSN2vec and PLBSN2vec lies in that the former considers only
as the random walk probability while the latter further imposes the penalized parameters.
We choose three common measures in the information retrieval field as the evaluation metrics [
30]: (a) Precision@N, (b) Recall@N, and (c) NDCG@N:
where
is the top-N predicted ranking, and
top-N ground-truth ranking. Furthermore,
and
. Precision aims at examining whether a method can accurately rank the ground truth at the top position while Recall is used to quantify whether all of the ground truth can be retrieved in the ranking list. The measures of precision and recall are trade-offs between each other. They must be seen together to understand the effectiveness of a model. As for NDCG, it is to estimate how the predicted ranking is close to the ground-truth ranking, which cannot be captured by Precision and Recall.
For all methods, we use the same default parameters listed below if they have the settings: the embedding dimension , the number of walks per node = 10, the walk length , and the neighborhood size . In our PLBSN2vec methods, we set the return parameter and chose the user-POI weighting parameter by default.
Results of TPD. We present the results of Precision@N (
) in
Figure 2. The results of Precision@10, Recall@10, and NDCG@10 are also shown in
Table 2. It can be apparently found that LBSN2vec and PLBSN2vec outperform the other embedding methods by varying
N. In addition, as
N gets increased, PLBSN2vec is able to stably have the higher Precision values. Among the competing methods, we find that GraphGAN has the worst performance, as it cannot capture the contagion between users and POIs. We think our methods lead to better performance because two key factors are considered. One is the modeling of user–user contagion, and the other is user-POI visiting preference. Such two factors can be better modeled into the embedding vectors of our proposed LBSN2vec and PLBSN2vec.
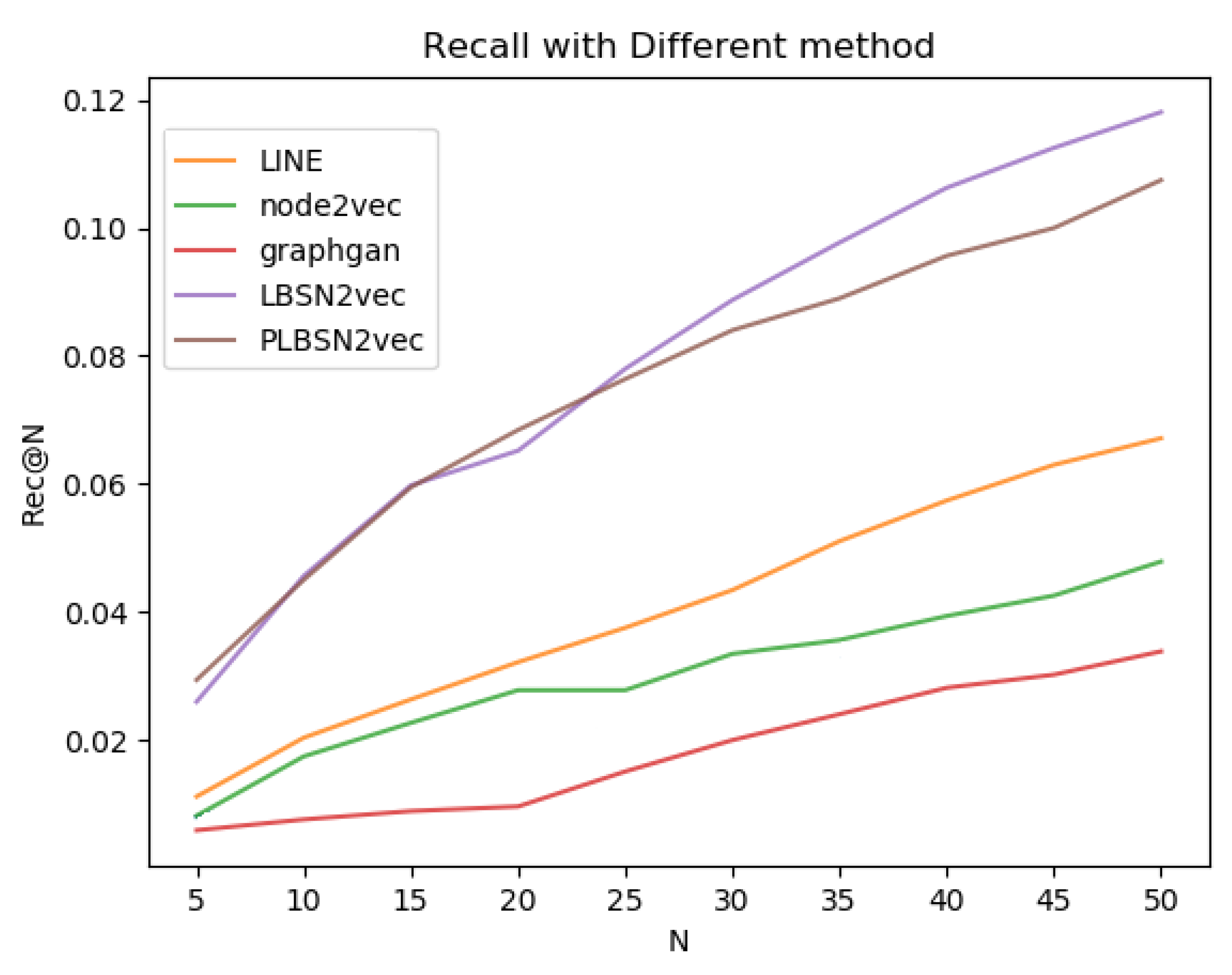
Results of TCD. In TCD, we believe the promotion initiator would care more about whether all potential customers can be found. Hence, we report Recall@N in this part.
Figure 3 shows the results in Recall@N by varying
N. We can see the Recall values with different embedding methods. Our LBSN2vec and PLBSN2vec are able to significantly outperform the other network embedding methods. We think the superiority of our methods comes from the derived embedding space that better utilizes the information between user–user interactions and user-POI visiting records in location-based social networks, which is crucial in modeling the potential of future POI visiting.
Limitations. Here we would like to discuss the limitations of the proposed methods for effectively solving TPD and TCD tasks. First, the proposed embedding learning methods, LBSN2vec and PLBSN2vec, are based on historical check-in records, i.e., existing interactions between users and POIs. If users tend to visit some particular POIs, it would be possible that the recommended propagators and potential customers, with respect to one of these POIs, can to some extent be similar. In other words, the “filter bubble” effect could happen. We would leave the solution to filter bubble as future work because there is a critical challenge in striking a balance between having accurate predictions and fair recommendations. Second, the embedding learning-based approach via a neural network requires a rich set of user-POI interactions to generate effective representations. While it is common to have some popular POI types and popular POIs, it would be natural to have better performance for popular venues and types. Third, different POIs have a variety of behaviors of users. Some are frequently visited by similar groups of users, and some are visited by various types of users. No matter which types of POIs are given, our proposed method can recommend proper propagators and customers. Due to the requirement of rich data for better prediction performance, we think our method may be less suitable for venues visited by users with diverse behaviors.
6. Conclusions and Discussion
In this paper, we propose two novel problems, Targeted Propagator Discovery (TPD) and Targeted Customer Discovery (TCD), in the context of location promotion. To the best of knowledge, we are the first to find future potential propagators in location-based social networks. We propose two network embedding methods, LBSN2vec and PLBSN2vec, along with a modified random walk mechanism based on the Skip-gram model. We also devise two scoring functions with the estimation of user preference and POI preference for TPD and TCD tasks. Experiments conducted on a large-scale Instagram dataset exhibit superior performance, compared to several well-known network embedding methods.
While effectively solving both TPD and TCD tasks by the proposed LBSN2vec and PLBSN2vec, two implications should be discussed. First, one may concern that the spatio-temporal footprints of users can be obtained and revealed by the POI holders who are performing the algorithms, leading to the issue of privacy leakage. We should highlight that the POI holders can only access the discovered propagators and potential customers. The original data and the footprints of general users are still maintained by the service providers who have an obligation to keep the prediction results confidential. Therefore, every POI holder cannot trace users. Second, one may also think that the POI holder can directly contact the recommended targeted propagators. Such an action could happen indeed. Here our algorithms leave the mechanism design on how to contact propagators and potential customers to the service providers. Whether and how the users react to being propagators or receiving the discount coupons should also be properly devised.







{kind=link}
{kind=link}
{kind=link}