
Feature Augmentation Based on Pixel-Wise Attention for Rail Defect Detection


Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
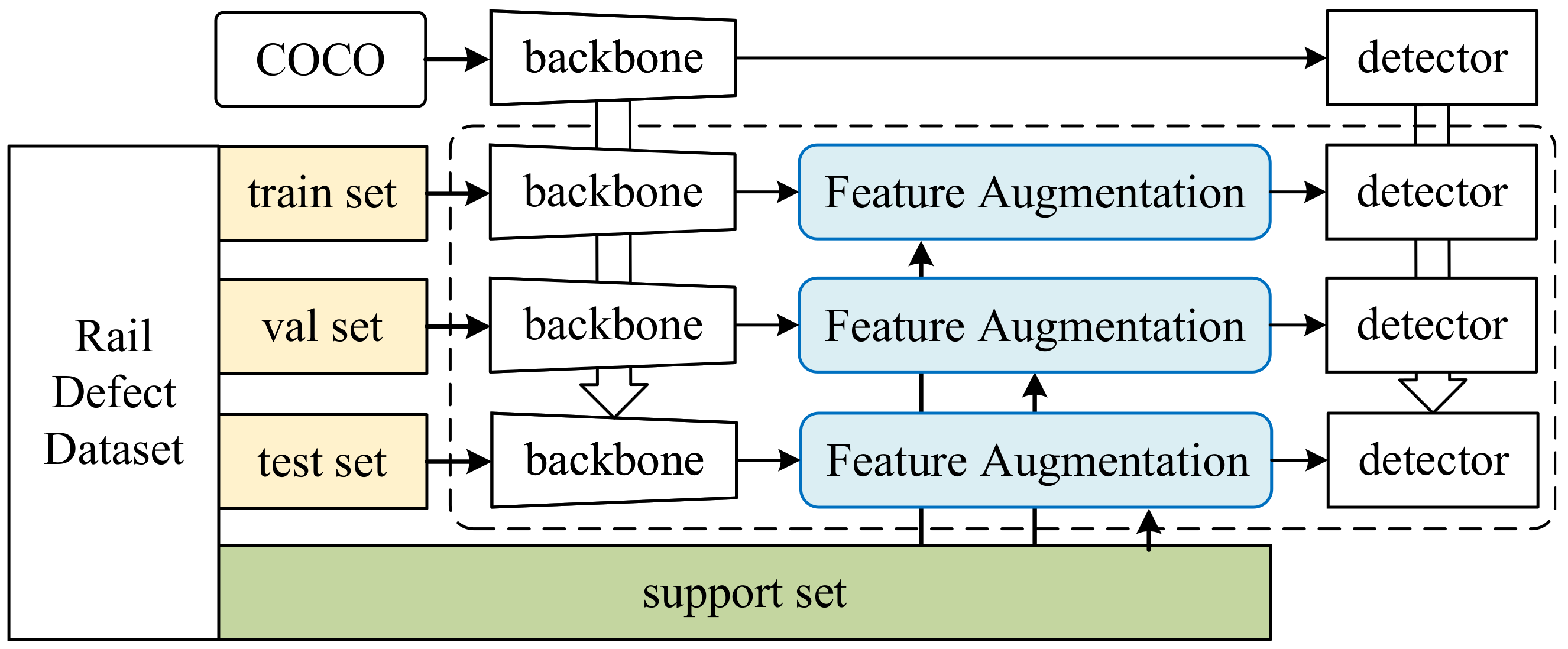
3.1. Dataset
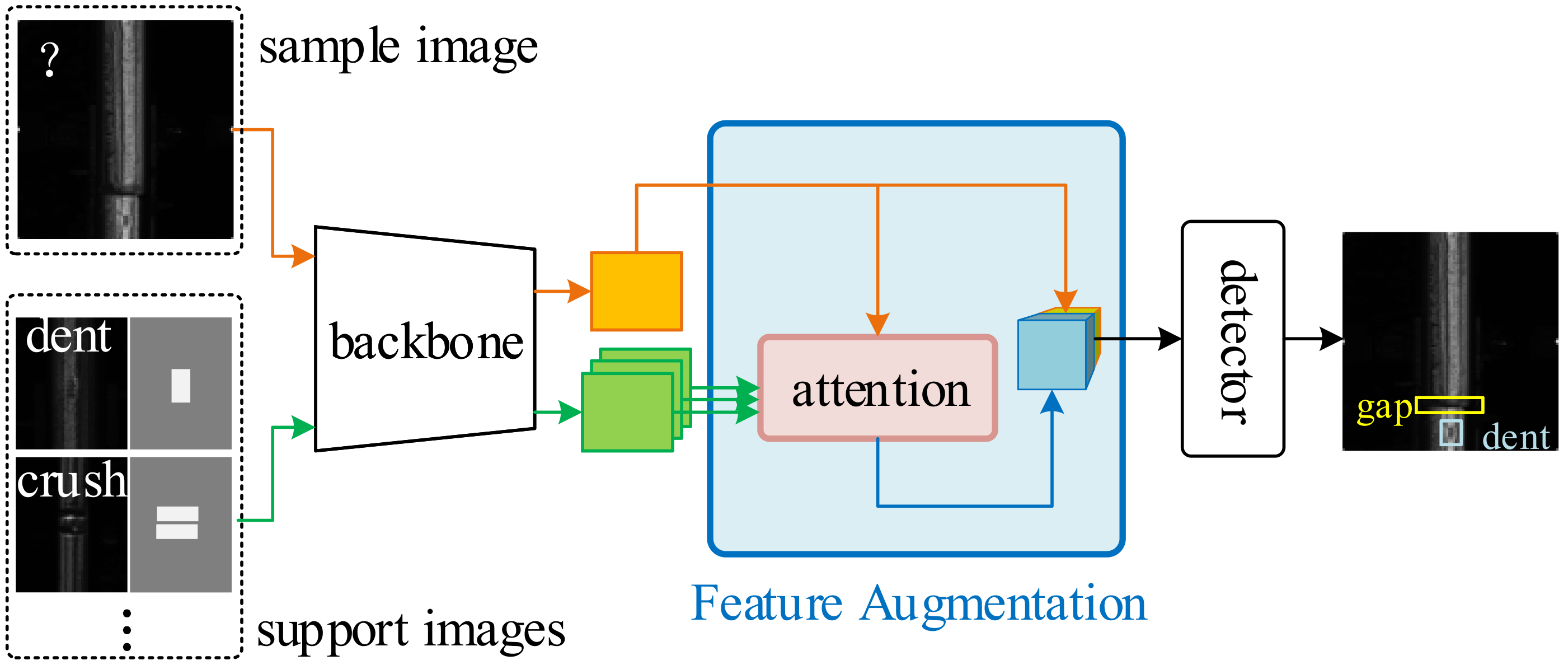
3.2. Model Architecture
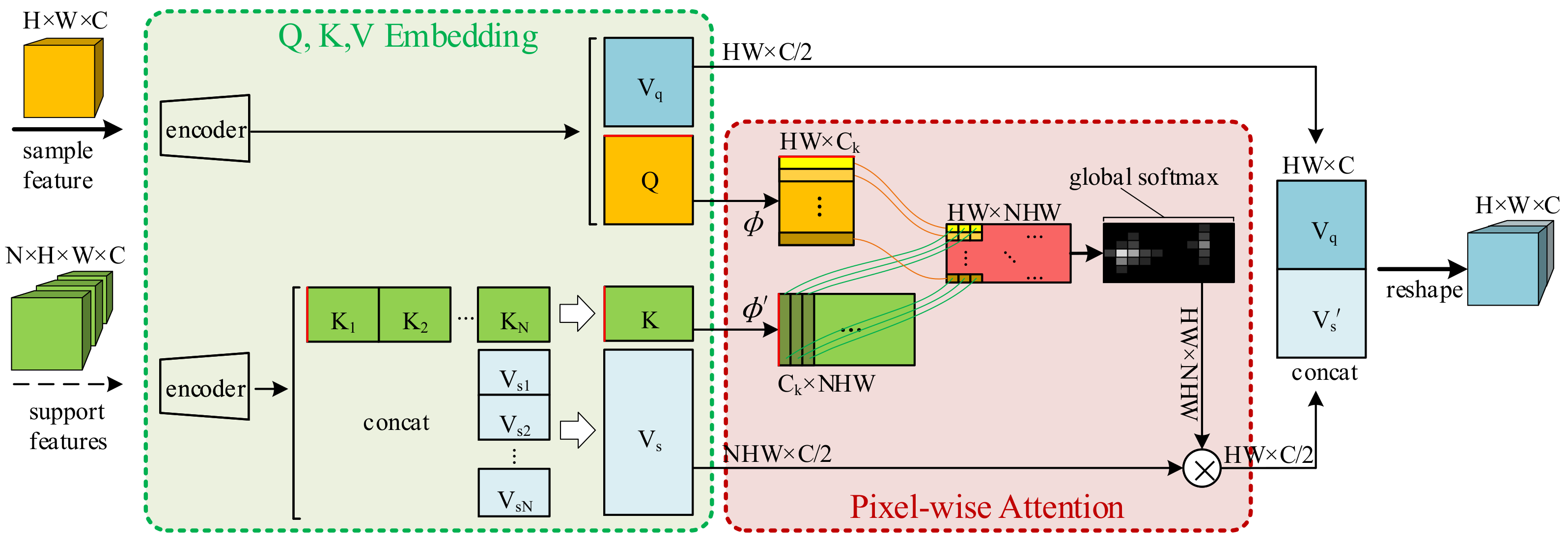
3.3. Feature Augmentation
4. Results
4.1. Experimental Settings
4.2. Detection Results
4.3. Ablation Study
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wei, X.; Yang, Z.; Liu, Y.; Wei, D.; Jia, L.; Li, Y. Railway track fastener defect detection based on image processing and deep learning techniques: A comparative study. Eng. Appl. Artif. Intell. 2019, 80, 66–81. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Lepetit, V.; Wohlhart, P.; Konolige, K. On pre-trained image features and synthetic images for deep learning. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Varma, M.; Lu, M.; Gardner, R.; Dunnmon, J.; Khandwala, N.; Rajpurkar, P.; Long, J.; Beaulieu, C.; Shpanskaya, K.; Fei-Fei, L.; et al. Automated abnormality detection in lower extremity radiographs using deep learning. Nat. Mach. Intell. 2019, 1, 578–583. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2204–2212. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; NeurIPS: San Diego, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Cross attention network for few-shot classification. arXiv 2019, arXiv:1910.07677. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8420–8429. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4013–4022. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Hu, H.; Bai, S.; Li, A.; Cui, J.; Wang, L. Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 10185–10194. [Google Scholar]
- Lienhart, R.; Maydt, J. An extended set of haar-like features for rapid object detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 1, p. 1. [Google Scholar]
- Mizuno, K.; Terachi, Y.; Takagi, K.; Izumi, S.; Kawaguchi, H.; Yoshimoto, M. Architectural study of HOG feature extraction processor for real-time object detection. In Proceedings of the 2012 IEEE Workshop on Signal Processing Systems, Quebec City, QC, Canada, 17–19 October 2012; pp. 197–202. [Google Scholar]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Zhao, Y.; Xiang, J.; Zhang, C.; Chen, Z. Review of object detection methods based on SVM. Control Decis. 2014, 29, 193–200. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 391–405. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Durand, T.; Mordan, T.; Thome, N.; Cord, M. WILDCAT: Weakly Supervised Learning of Deep ConvNets for Image Classification, Pointwise Localization and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 642–651. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Xu, B.; Liang, H.; Liang, R.; Chen, P. Locate Globally, Segment Locally: A Progressive Architecture With Knowledge Review Network for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3004–3012. [Google Scholar]
- Sun, L.; Zhao, C.; Yan, Z.; Liu, P.; Duckett, T.; Stolkin, R. A novel weakly-supervised approach for RGB-D-based nuclear waste object detection. IEEE Sens. J. 2018, 19, 3487–3500. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, W.; Wang, X.; Zhang, C.; Yang, X. Factors in finetuning deep model for object detection with long-tail distribution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 864–873. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Chen, Y.C.; Zhu, X.; Zheng, W.S.; Lai, J.H. Person re-identification by camera correlation aware feature augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 392–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Fu, Y.; Zhang, Y.; Jiang, Y.G.; Xue, X.; Sigal, L. Multi-level semantic feature augmentation for one-shot learning. IEEE Trans. Image Process. 2019, 28, 4594–4605. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Northcutt, C.G.; Athalye, A.; Mueller, J. Pervasive label errors in test sets destabilize machine learning benchmarks. arXiv 2021, arXiv:2103.14749. [Google Scholar]
- Choi, J.; Elezi, I.; Lee, H.J.; Farabet, C.; Alvarez, J.M. Active Learning for Deep Object Detection via Probabilistic Modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 10264–10273. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 20 June 2021).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, Y.; Yang, T.; Zhang, X.; Meng, G.; Xiao, X.; Sun, J. Detnas: Backbone search for object detection. Adv. Neural Inf. Process. Syst. 2019, 32, 6642–6652. [Google Scholar]
- ultralytics. YOLOv5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 7 September 2021).
- ultralytics. YOLOv6. 2022. Available online: https://github.com/meituan/YOLOv6 (accessed on 30 July 2022).
- Li, B.; Yang, B.; Liu, C.; Liu, F.; Ji, R.; Ye, Q. Beyond Max-Margin: Class Margin Equilibrium for Few-shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7363–7372. [Google Scholar]
- Han, G.; He, Y.; Huang, S.; Ma, J.; Chang, S.F. Query adaptive few-shot object detection with heterogeneous graph convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 3263–3272. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Santur, Y.; Karaköse, M.; Akin, E. A new rail inspection method based on deep learning using laser cameras. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017; pp. 1–6. [Google Scholar]
- Santur, Y.; Karaköse, M.; Akın, E. Condition monitoring approach using 3D modelling of railway tracks with laser cameras. In Proceedings of the International Conference on Advanced Technology &Sciences (ICAT’16), Konya, Turkey, 1–3 September 2016; Volume 132, p. 135. [Google Scholar]
- Santur, Y.; Karaköse, M.; Akın, E. Learning based experimental approach for condition monitoring using laser cameras in railway tracks. Int. J. Appl. Math. Electron. Comput. 2016, 1–5. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 4 Class Division | 8 Class Division |
|---|---|
| gap: gaps left between successive rails on a railway track dirt: paint, or mud that covers the surface of the rail unknown: unrecognized features | |
| damage | general damage: displacement of parent metal from the rail surface dent: tear of the lateral planes of the rail surface crush: big/severe wear of the lateral planes of the rail surface scratch: small/mild wear of the lateral planes of the rail surface slant: tear of the lateral planes of the rail surface |
| Model | Backbone | mAP@.5 | mAP@.5:.95 |
|---|---|---|---|
| 8 defect classes | |||
| YOLOv5 + FA (ours) | s | 0.8462 | 0.3724 |
| YOLOv5 + FA (ours) | s6 | 0.8643 | 0.4232 |
| YOLOv6 + FA (ours) | s | 0.8714 | 0.3911 |
| YOLOv5 [42] | s | 0.8371 | 0.3206 |
| YOLOv5 [42] | s6 | 0.8316 | 0.3476 |
| YOLOv6 [43] | s | 0.8417 | 0.3595 |
| Faster R-CNN [4] | R50 | 0.8351 | 0.3447 |
| Faster R-CNN [4] | R101 | 0.8402 | 0.3366 |
| AL-MDN [37] | VGG16 | 0.8545 | 0.3772 |
| DyHead [38] | RetinaNet | 0.8513 | 0.3817 |
| DyHead [38] | F R50 | 0.8527 | 0.3833 |
| DyHead [38] | F R101 | 0.8535 | 0.3851 |
| 4 defect classes | |||
| YOLOv5 + FA (ours) | s | 0.8856 | 0.4557 |
| YOLOv5 + FA (ours) | s6 | 0.8992 | 0.4979 |
| YOLOv6 + FA (ours) | s | 0.8878 | 0.5011 |
| YOLOv5 [42] | s | 0.8989 | 0.4622 |
| YOLOv5 [42] | s6 | 0.8966 | 0.4659 |
| YOLOv6 [43] | s | 0.8981 | 0.4730 |
| Faster R-CNN [4] | R50 | 0.8779 | 0.4642 |
| Faster R-CNN [4] | R101 | 0.8916 | 0.4760 |
| AL-MDN [37] | VGG16 | 0.8947 | 0.4861 |
| DyHead [38] | RetinaNet R50 | 0.8941 | 0.4903 |
| DyHead [38] | F R50 | 0.8965 | 0.4967 |
| DyHead [38] | F R101 | 0.8932 | 0.4839 |
| Model | Backbone | mAP@.5 | mAP@.5:.95 | FPS |
|---|---|---|---|---|
| 8 defect classes | ||||
| YOLOv5 + FA (ours) | s | 0.757 | 0.365 | 34.36 |
| YOLOv5 + FA (ours) | s6 | 0.726 | 0.369 | 34.25 |
| YOLOv6 + FA (ours) | s | 0.740 | 0.377 | 52.99 |
| YOLOv5 [42] | s | 0.657 | 0.317 | 52.36 |
| YOLOv5 [42] | s6 | 0.680 | 0.346 | 48.54 |
| YOLOv6 [43] | s | 0.674 | 0.325 | 72.51 |
| Faster R-CNN [4] | R50 | 0.719 | 0.333 | 8.49 |
| Faster R-CNN [4] | R101 | 0.726 | 0.322 | 9.00 |
| AL-MDN [37] | VGG16 | 0.744 | 0.362 | 5.98 |
| DyHead [38] | RetinaNet R50 | 0.741 | 0.367 | 38.41 |
| DyHead [38] | F R50 | 0.741 | 0.367 | 8.23 |
| DyHead [38] | F R101 | 0.741 | 0.367 | 7.36 |
| 4 defect classes | ||||
| YOLOv5s + FA (ours) | s | 0.796 | 0.357 | 41.49 |
| YOLOv5s6 + FA (ours) | s6 | 0.818 | 0.391 | 32.79 |
| YOLOv6 + FA (ours) | s | 0.835 | 0.393 | 54.31 |
| YOLOv5 [42] | s | 0.816 | 0.336 | 56.34 |
| YOLOv5 [42] | s6 | 0.804 | 0.386 | 56.18 |
| YOLOv6 [43] | s | 0.827 | 0.383 | 72.33 |
| Faster R-CNN [4] | R50 | 0.808 | 0.387 | 14.48 |
| Faster R-CNN [4] | R101 | 0.820 | 0.373 | 9.76 |
| AL-MDN [37] | VGG16 | 0.816 | 0.381 | 6.27 |
| DyHead [38] | RetinaNet R50 | 0.802 | 0.377 | 40.67 |
| DyHead [38] | F R50 | 0.809 | 0.381 | 7.75 |
| DyHead [38] | F R101 | 0.810 | 0.389 | 6.51 |
| Method | Feature Generation Approach | mAP@.5 | mAP@.5:.95 |
|---|---|---|---|
| YOLOv5s + FA | random selection | 0.758 | 0.371 |
| YOLOv5s + FA | random selection (2) | 0.757 | 0.369 |
| YOLOv5s + FA | add & norm | 0.743 | 0.356 |
| YOLOv5s + FA | add & norm (2) | 0.729 | 0.344 |
| YOLOv5s + FA | average | 0.760 | 0.372 |
| YOLOv5s + FA | average (2) | 0.757 | 0.366 |
| Method | w/ Mask | w/o Mask | ||
|---|---|---|---|---|
| mAP@.5 | mAP@.5:.95 | mAP@.5 | mAP@.5:.95 | |
| YOLOv5s + FA | 0.757 | 0.365 | 0.748 | 0.345 |
| YOLOv5s6 + FA | 0.726 | 0.369 | 0.716 | 0.354 |
| Method | Backbone | mAP@.5 | mAP@.5:.95 | FPS |
|---|---|---|---|---|
| Faster R-CNN [4] | R50 | 0.719 | 0.333 | 8.49 |
| Faster R-CNN [4] + FA | R50 | 0.727 | 0.346 | 8.13 |
| RetinaNet [46] | R50 | 0.687 | 0.328 | 24.26 |
| RetinaNet [46] + FA | R50 | 0.696 | 0.337 | 20.98 |
| SSD [27] | VGG16 | 0.684 | 0.321 | 21.78 |
| SSD [27] + FA | VGG16 | 0.698 | 0.342 | 19.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Li, H.; Hou, Z.; Song, H.; Liu, J.; Dai, P. Feature Augmentation Based on Pixel-Wise Attention for Rail Defect Detection. Appl. Sci. 2022, 12, 8006. https://doi.org/10.3390/app12168006
Li H, Li H, Hou Z, Song H, Liu J, Dai P. Feature Augmentation Based on Pixel-Wise Attention for Rail Defect Detection. Applied Sciences. 2022; 12(16):8006. https://doi.org/10.3390/app12168006
Chicago/Turabian StyleLi, Hongjue, Hailang Li, Zhixiong Hou, Haoran Song, Junbo Liu, and Peng Dai. 2022. "Feature Augmentation Based on Pixel-Wise Attention for Rail Defect Detection" Applied Sciences 12, no. 16: 8006. https://doi.org/10.3390/app12168006
APA StyleLi, H., Li, H., Hou, Z., Song, H., Liu, J., & Dai, P. (2022). Feature Augmentation Based on Pixel-Wise Attention for Rail Defect Detection. Applied Sciences, 12(16), 8006. https://doi.org/10.3390/app12168006