Discovering Potential Correlations via Hypercontractivity †


Abstract
:1. Introduction
- We postulate a set of natural axioms that a measure of potential correlation from X to Y should satisfy (Section 2.1).
- We show that , our proposed measure of potential correlation, satisfies all the axioms we postulate (Section 2.2). In comparison, we prove that existing standard measures of correlation not only fail to satisfy the proposed axioms, but also fail to capture canonical examples of potential correlations captured by (Section 2.3). Another natural candidate is mutual information, but it is not clear how to interpret the value of mutual information as it is unnormalized, unlike all other measures of correlation which are between zero and one.
- Computation of the hypercontractivity coefficient from samples is known to be a challenging open problem. We in troduce a novel estimator to compute hypercontractivity coefficient from i.i.d. samples in a statistically consistent manner for continuous random variables, using ideas from importance sampling and kernel density estimation (Section 3).
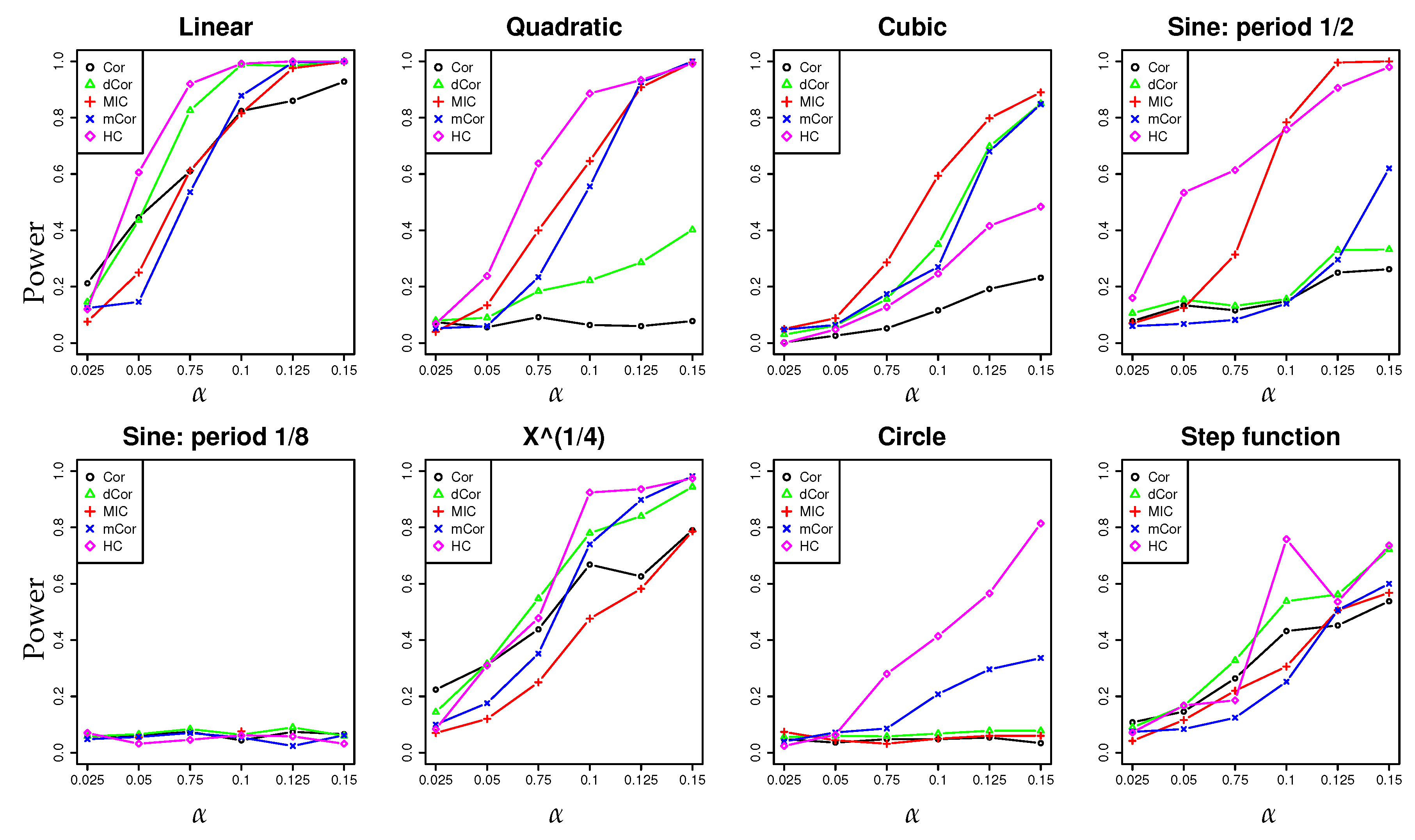
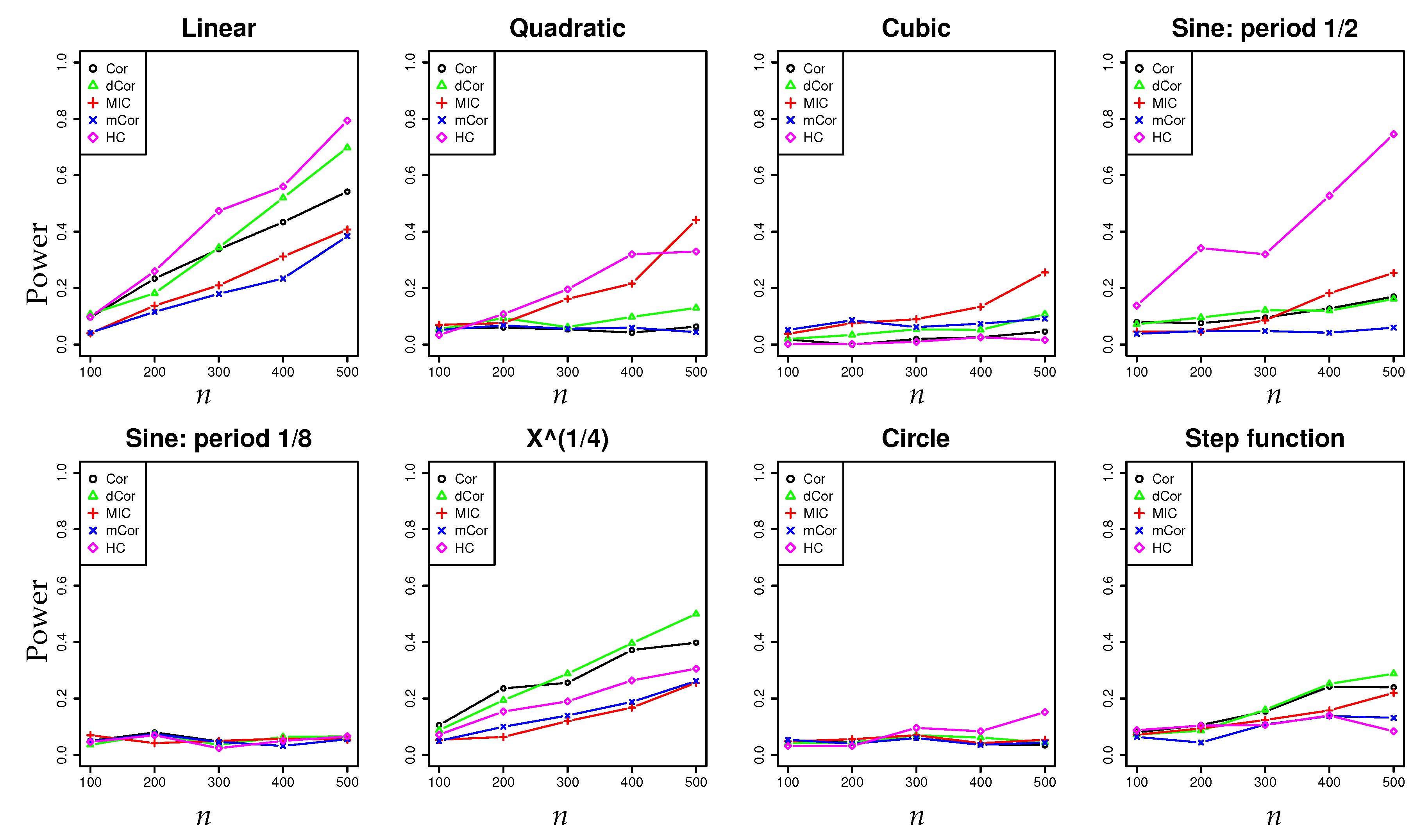
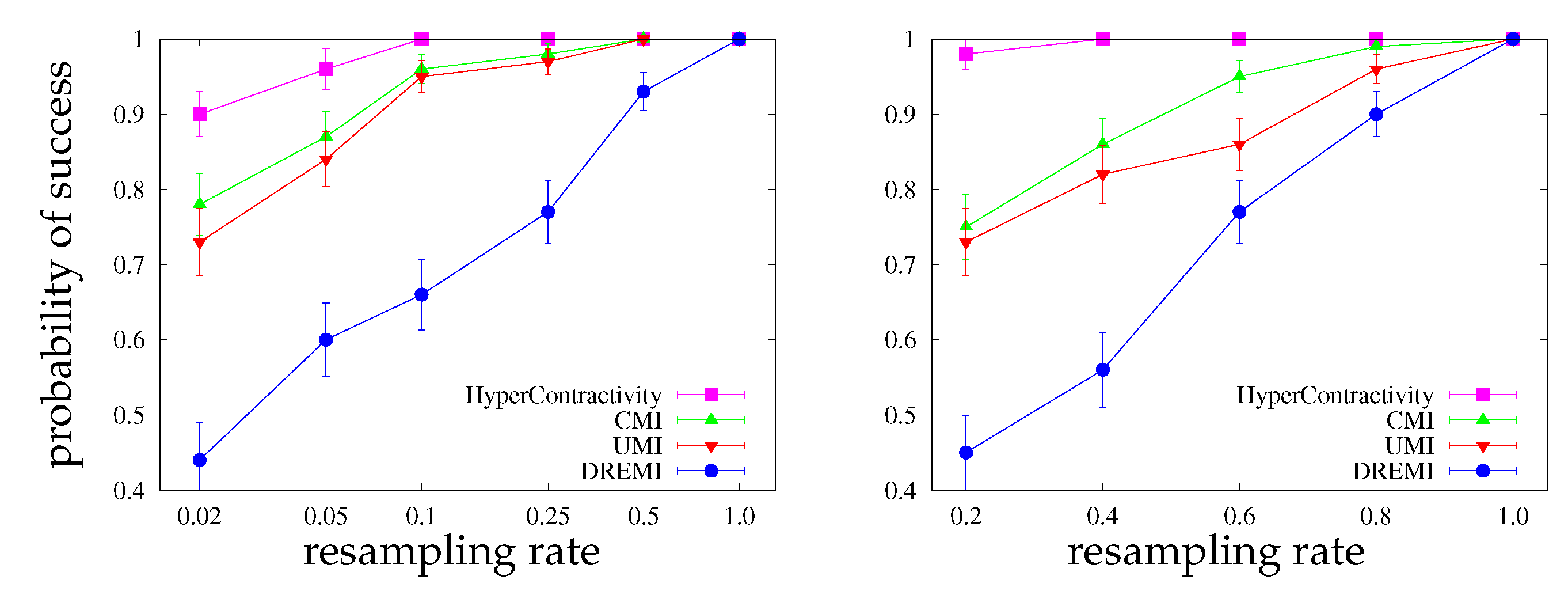
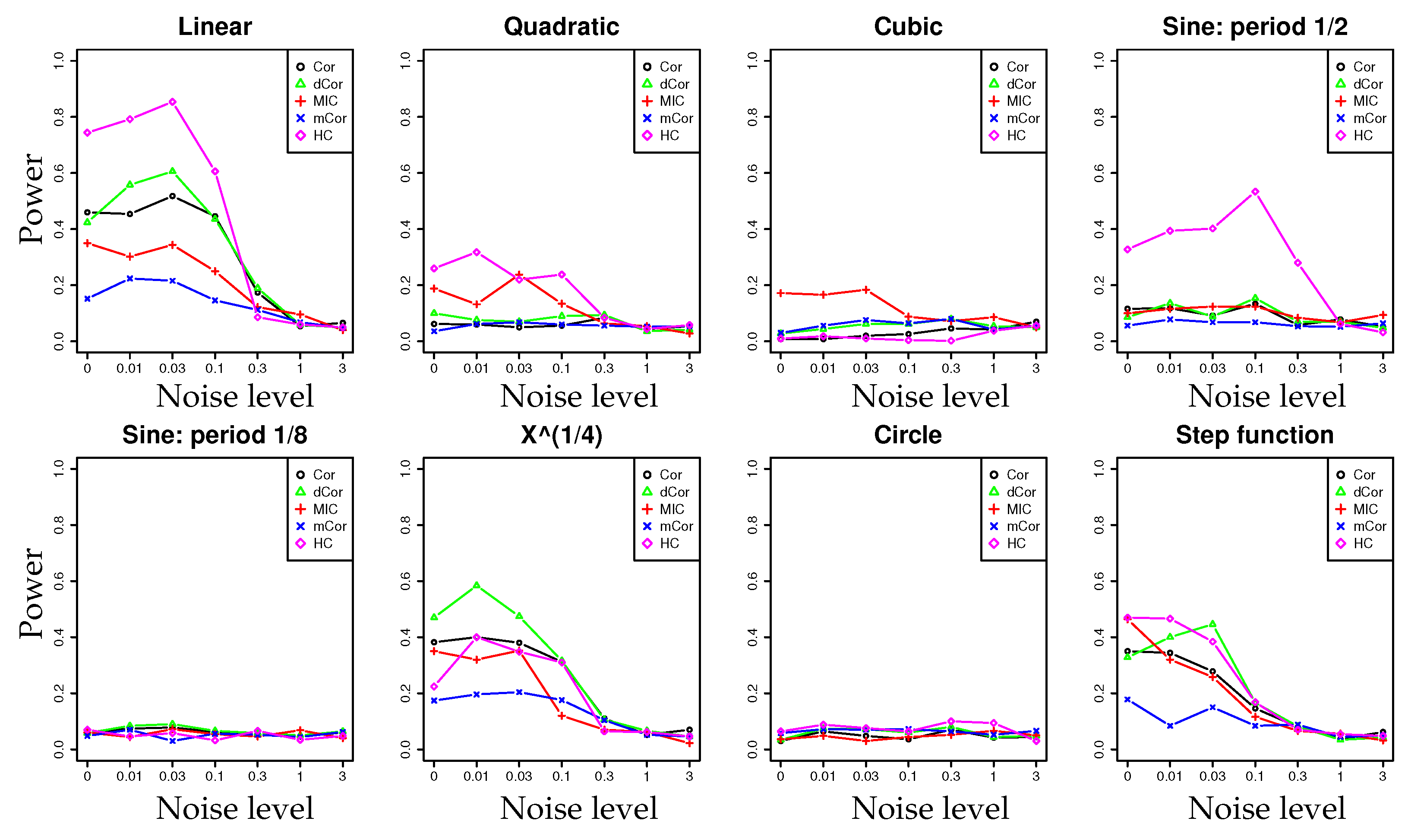
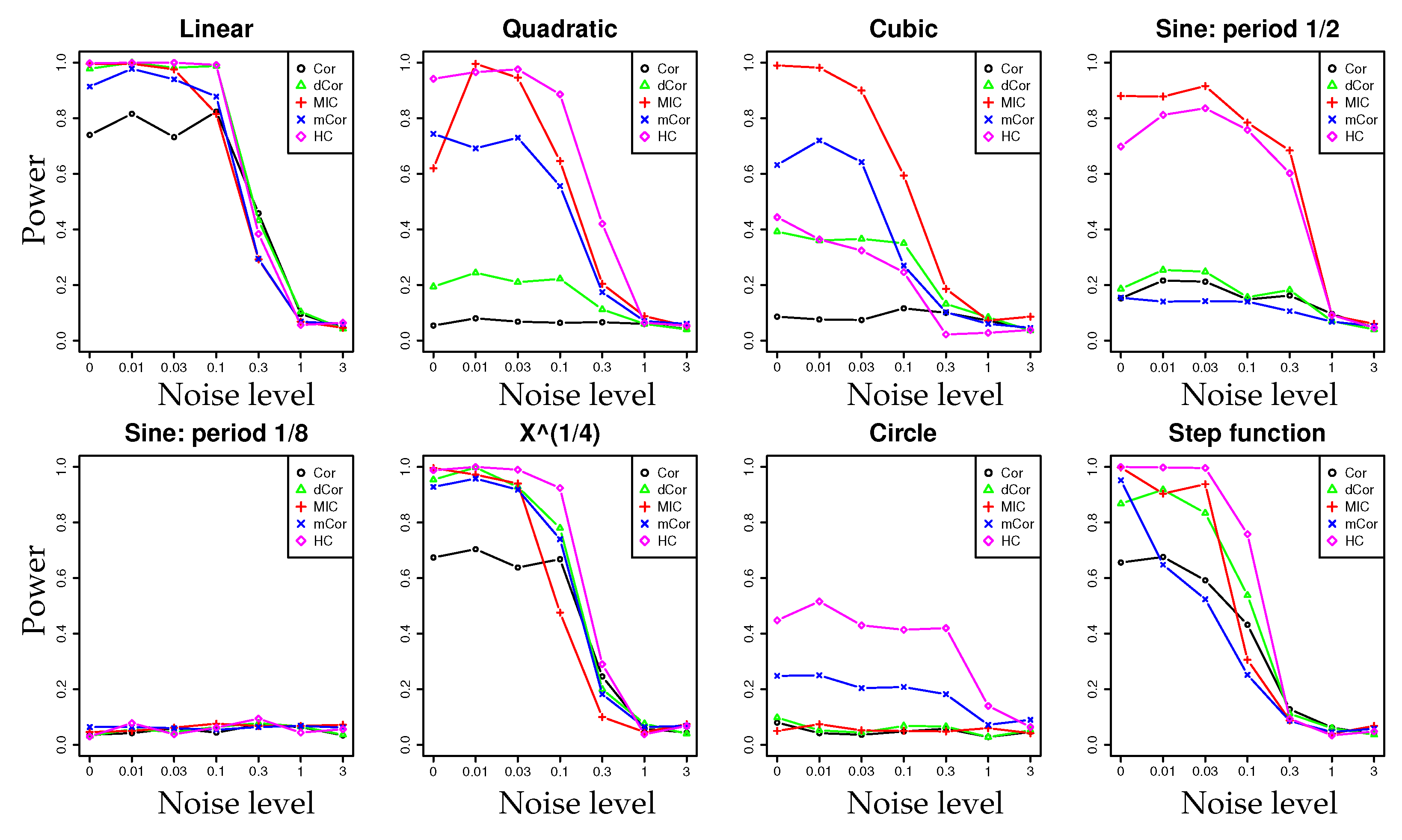
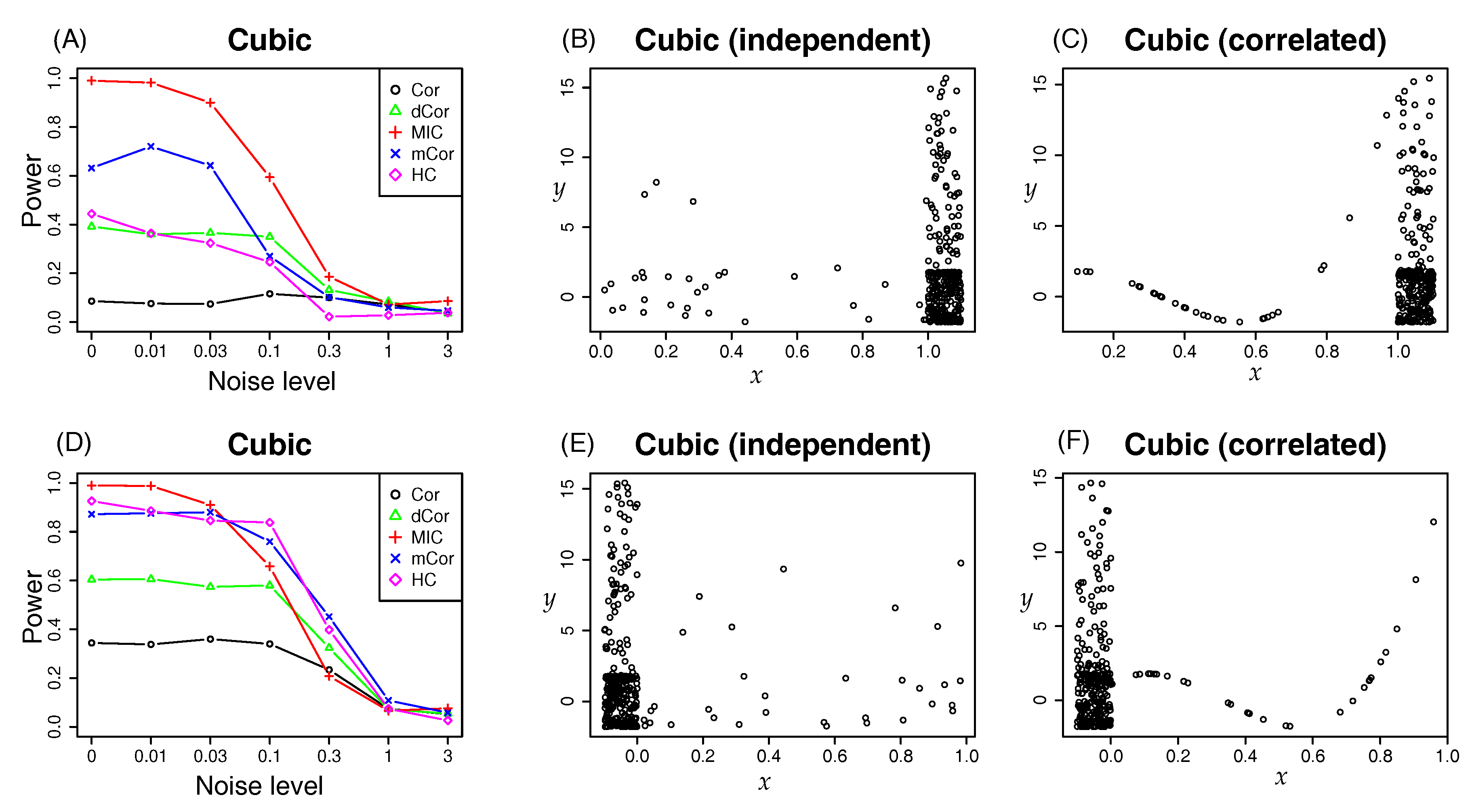
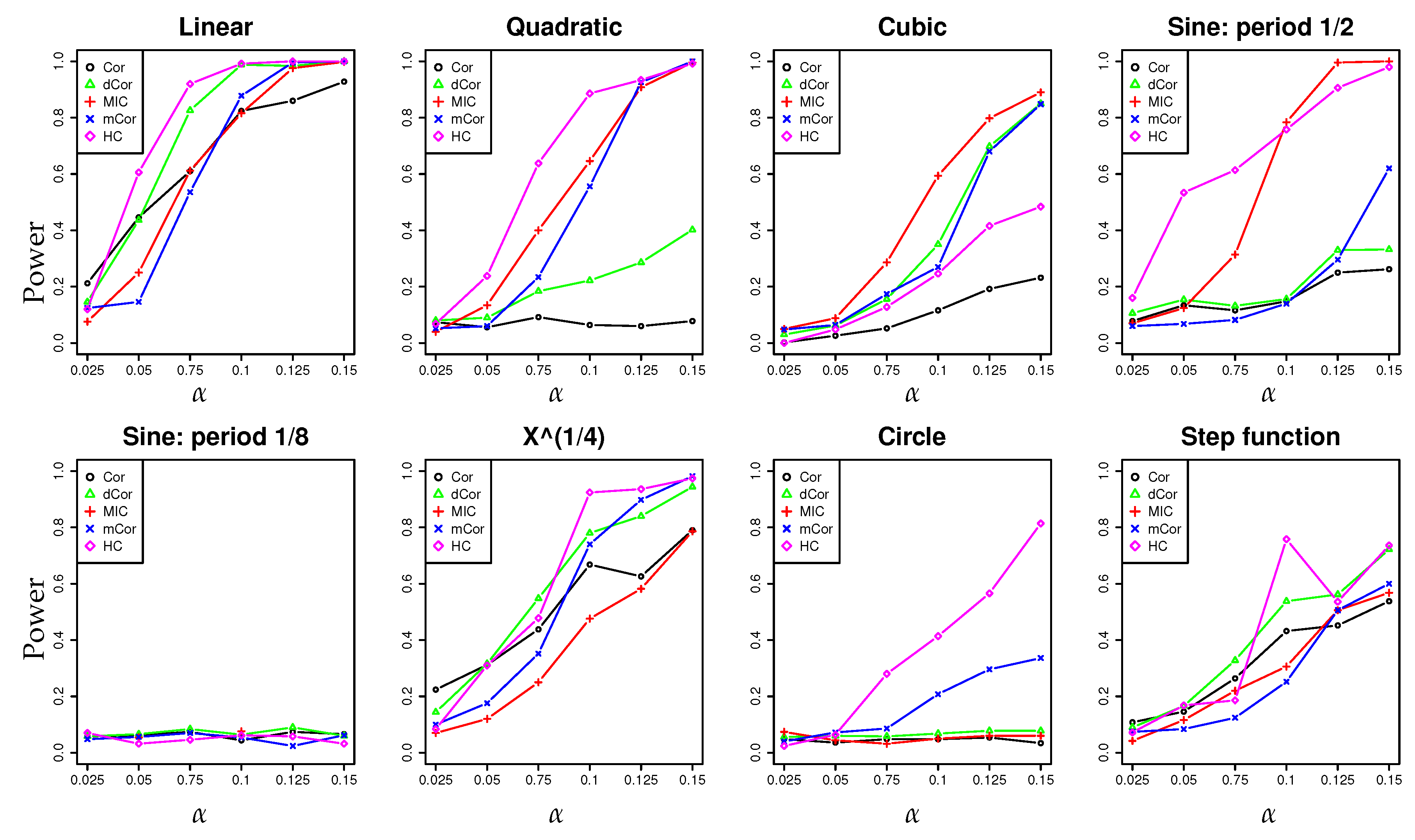
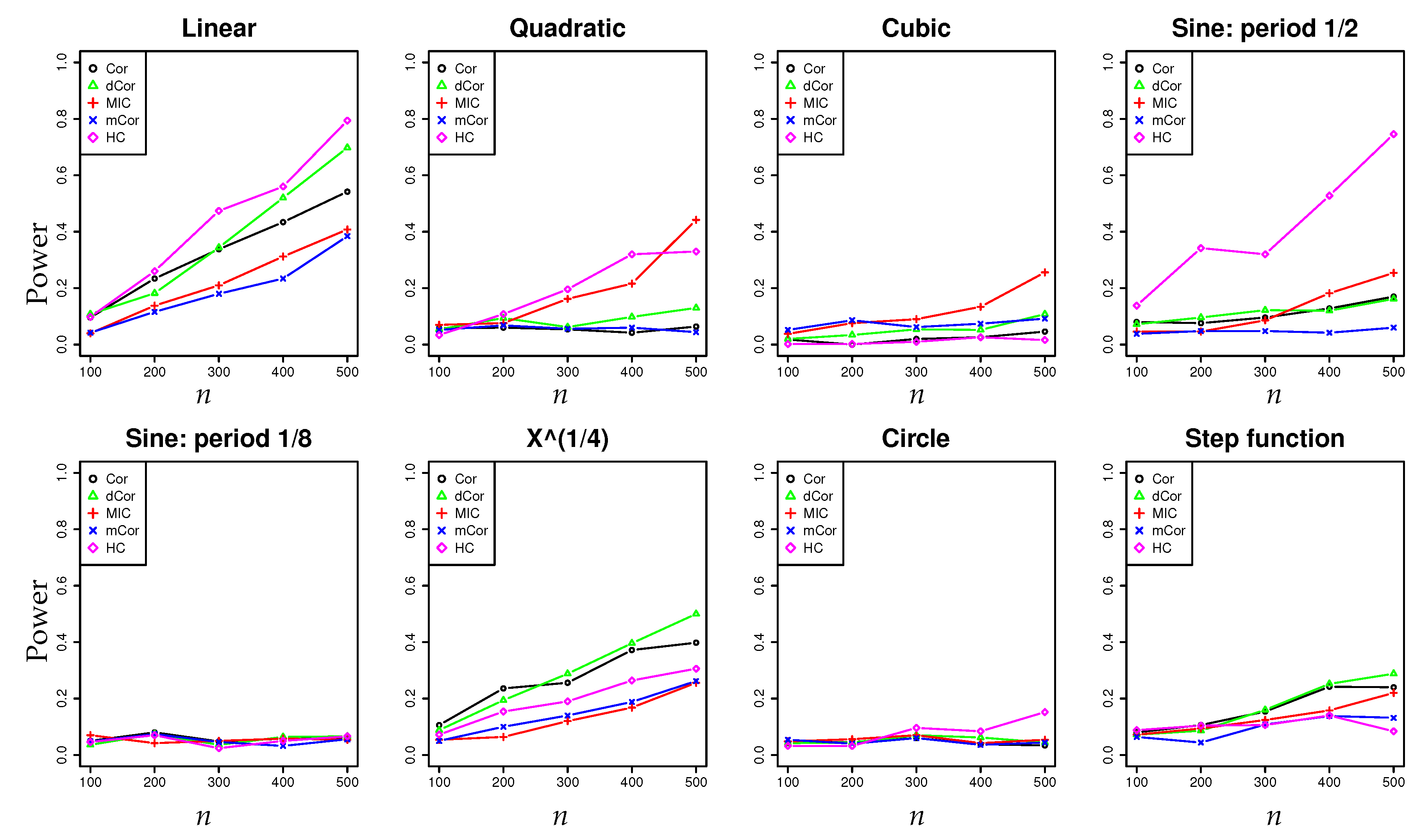
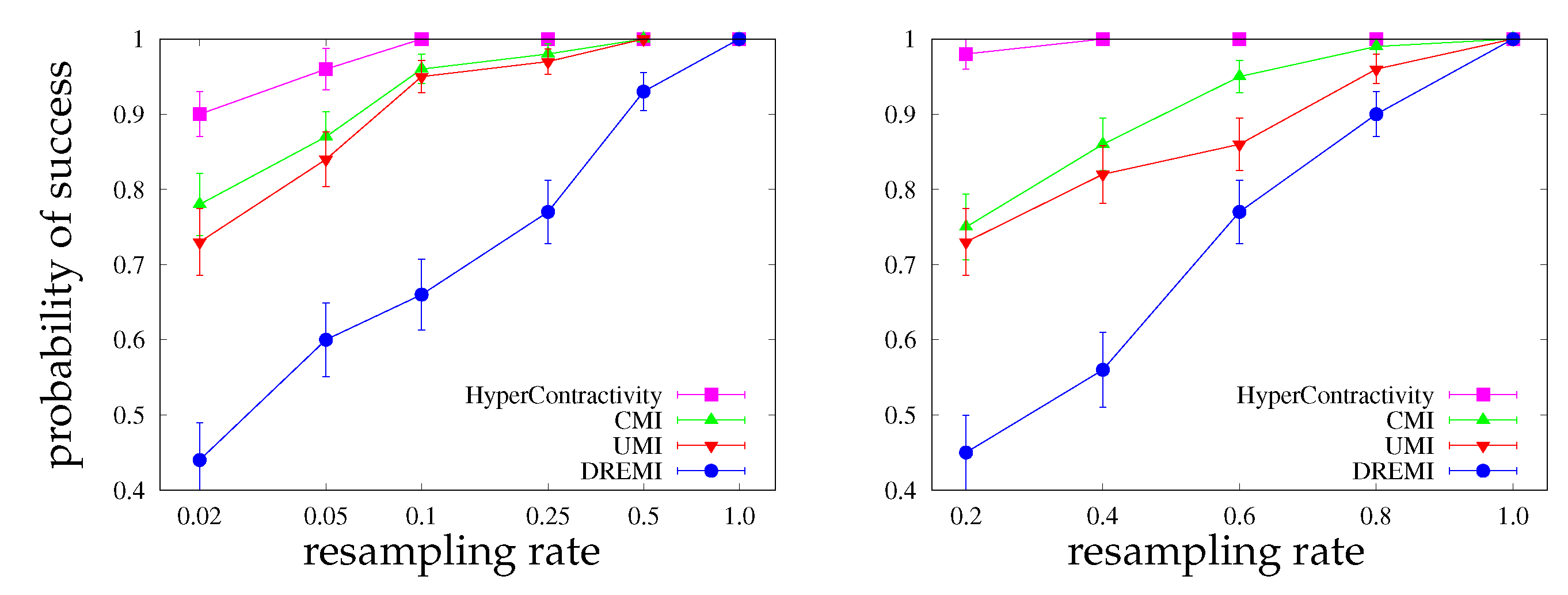
- In a series of synthetic experiments, we show empirically that our estimator for the hypercontractivity coefficient is statistically more powerful in discovering a potential correlation than existing correlation estimators; a larger power means a larger successful detection rate for a fixed false alarm rate (Section 4.1).
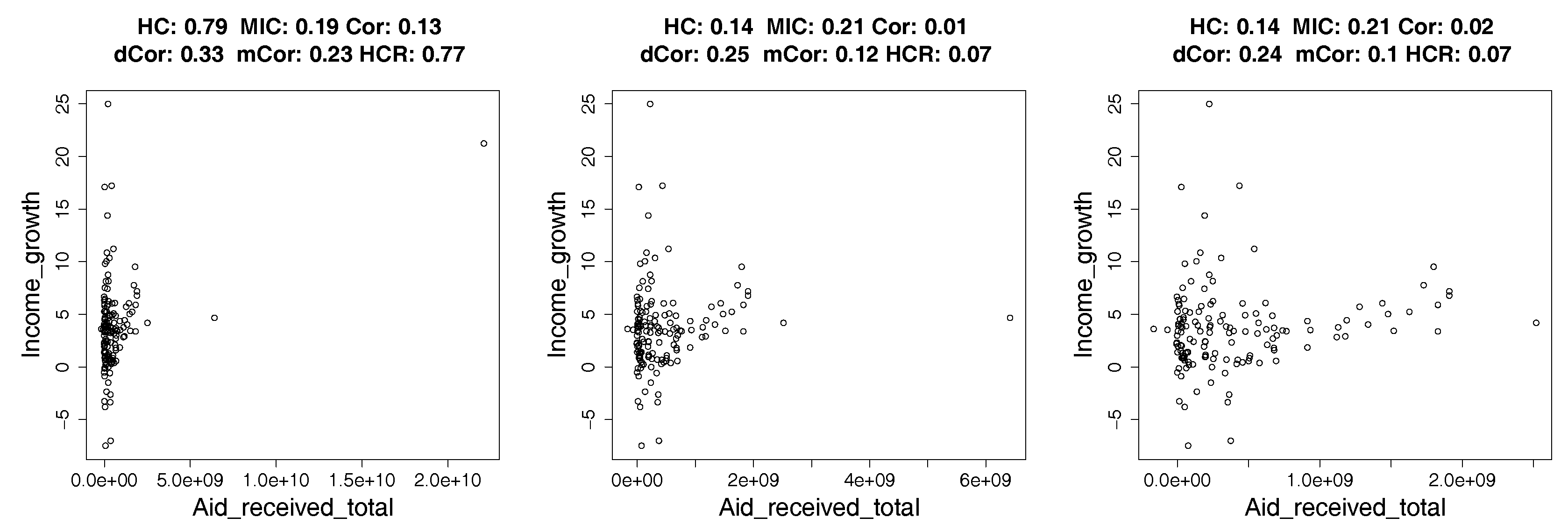
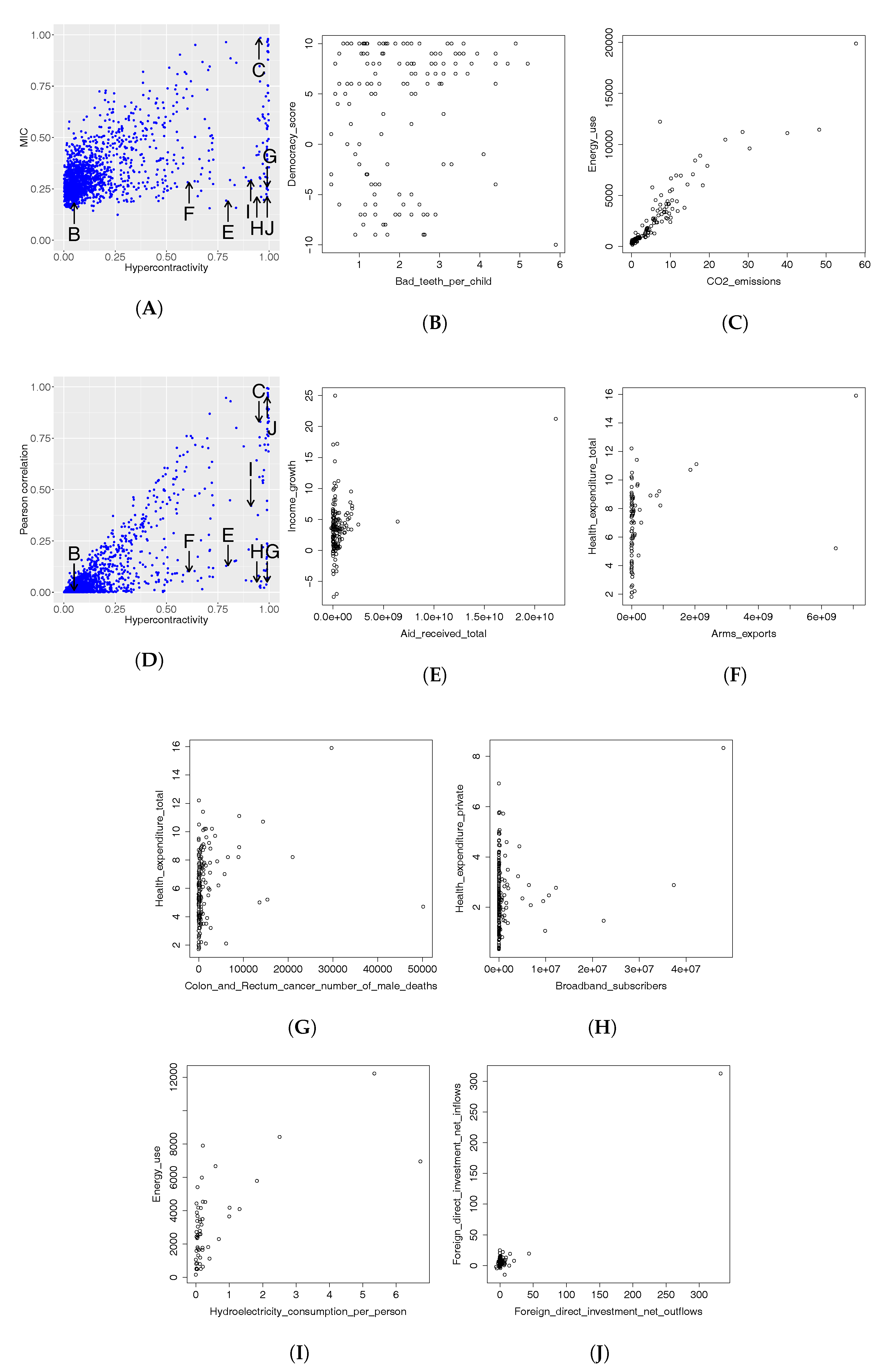
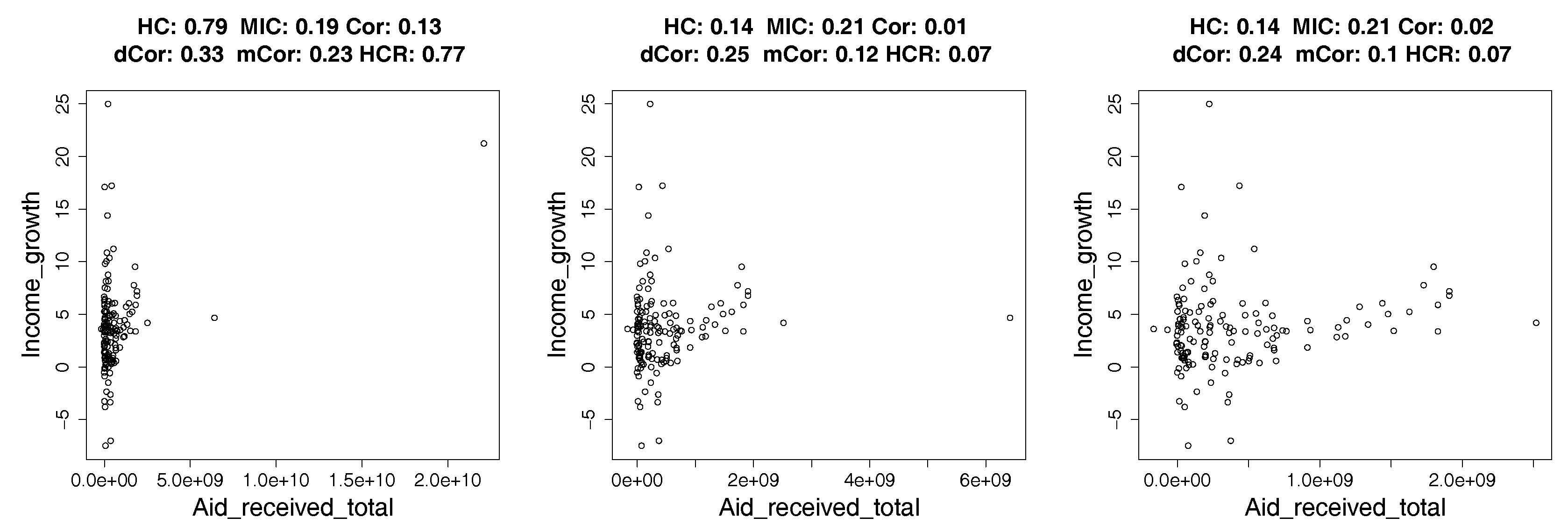
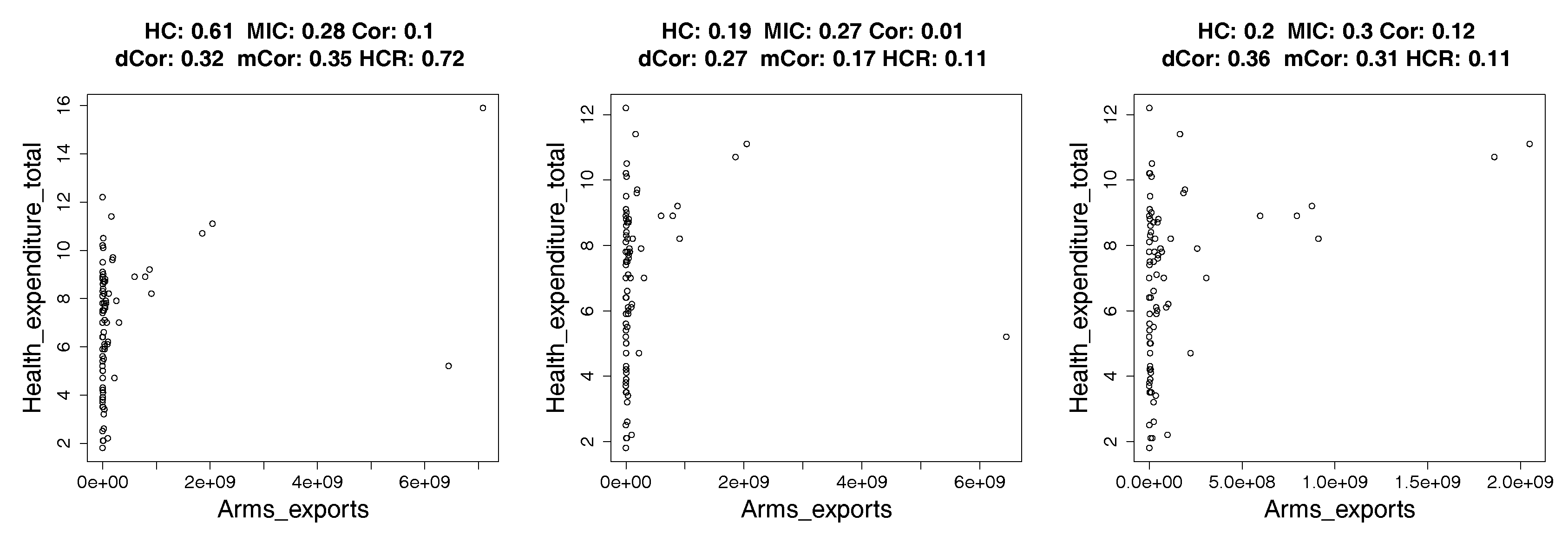
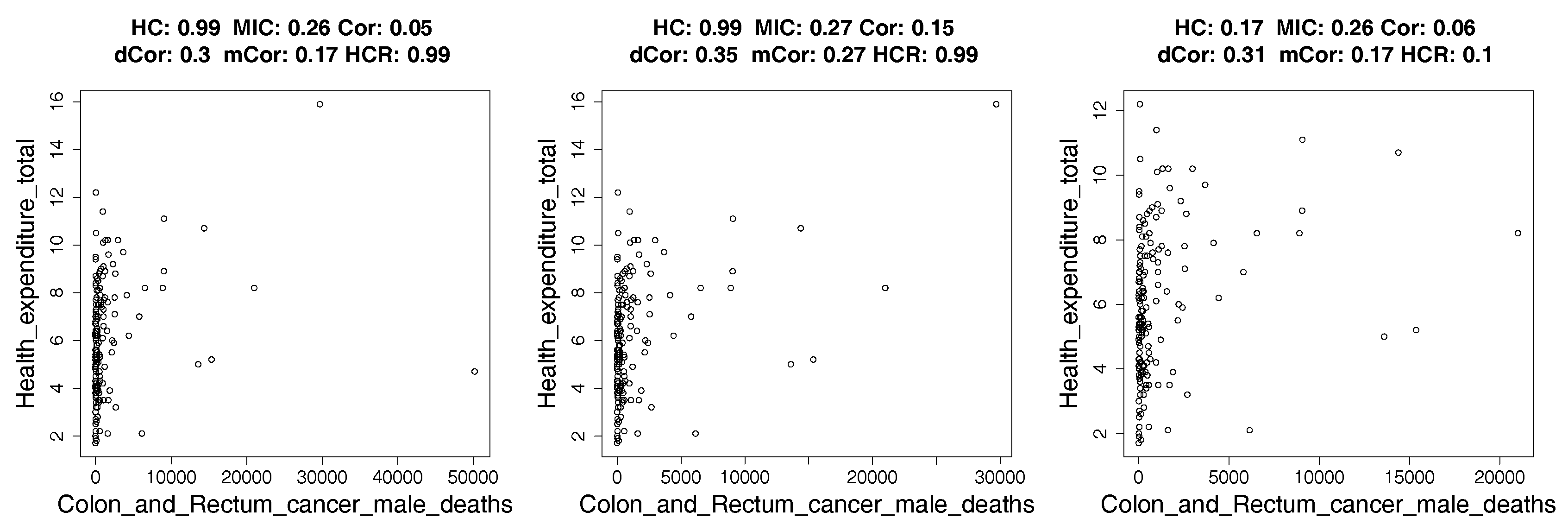
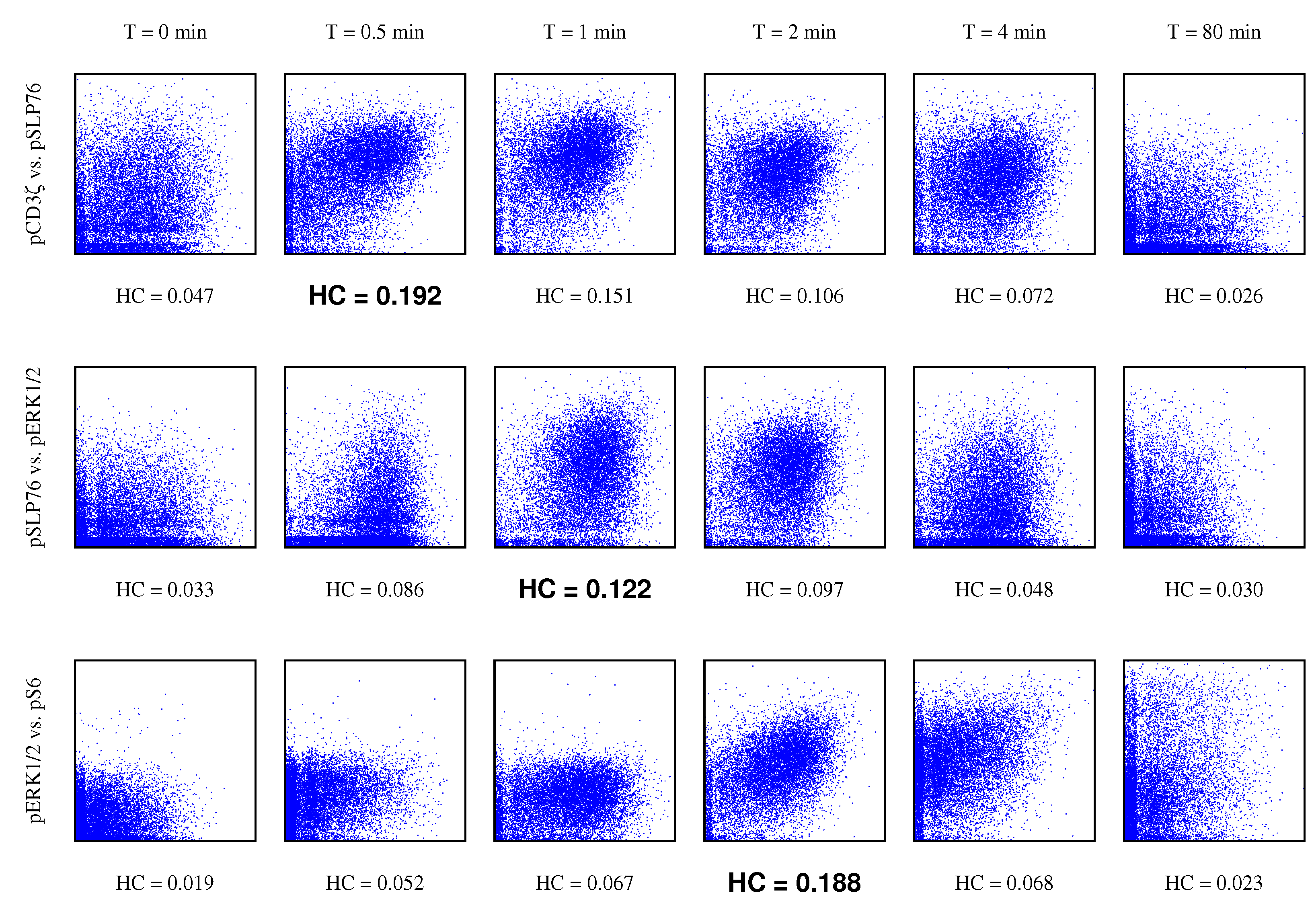
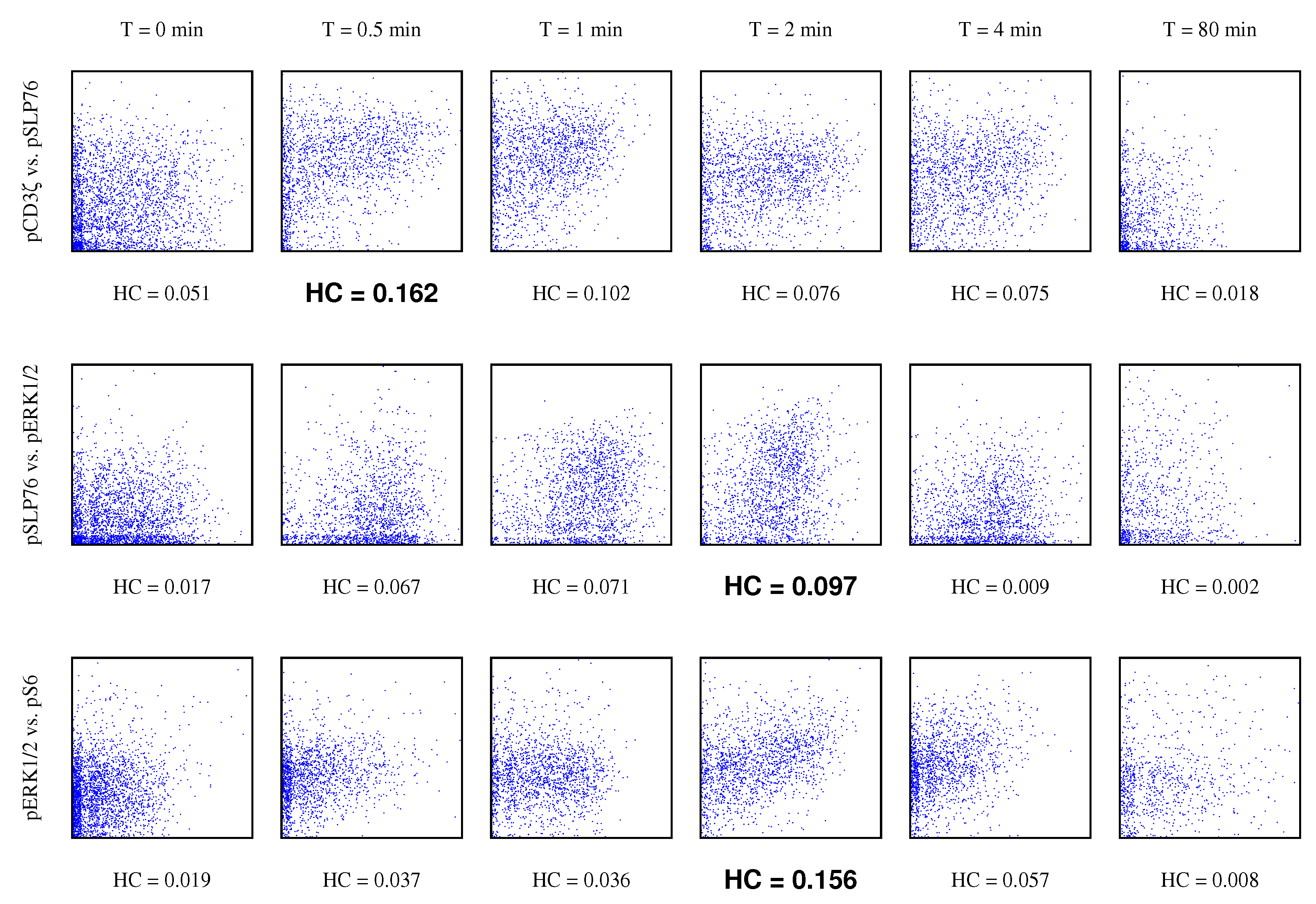
- We show applications of our estimator of hypercontractivity coefficient in two important datasets: In Section 4.2, we demonstrate that it discovers hidden potential correlations among various national indicators in WHO datasets, including how aid is potentially correlated with the income growth. In Section 4.3, we consider the following gene pathway recovery problem: we are given samples of four gene expressions time series. Assuming we know that gene A causes B, that B causes C, and that C causes D, the problem is to discover that these causations occur in the sequential order: A to B, and then B to C, and then C to D. We show empirically that the estimator of the hypercontractivity coefficient recovers this order accurately from a vastly smaller number of samples compared to other state-of-the art causal influence estimators.
2. Axiomatic Approach to Measure Potential Correlations
2.1. Axioms for Potential Correlation
- is defined for any pair of non-constant random variables X and Y.
- .
- iff X and Y are statistically independent.
- For bijective Borel-measurable functions , .
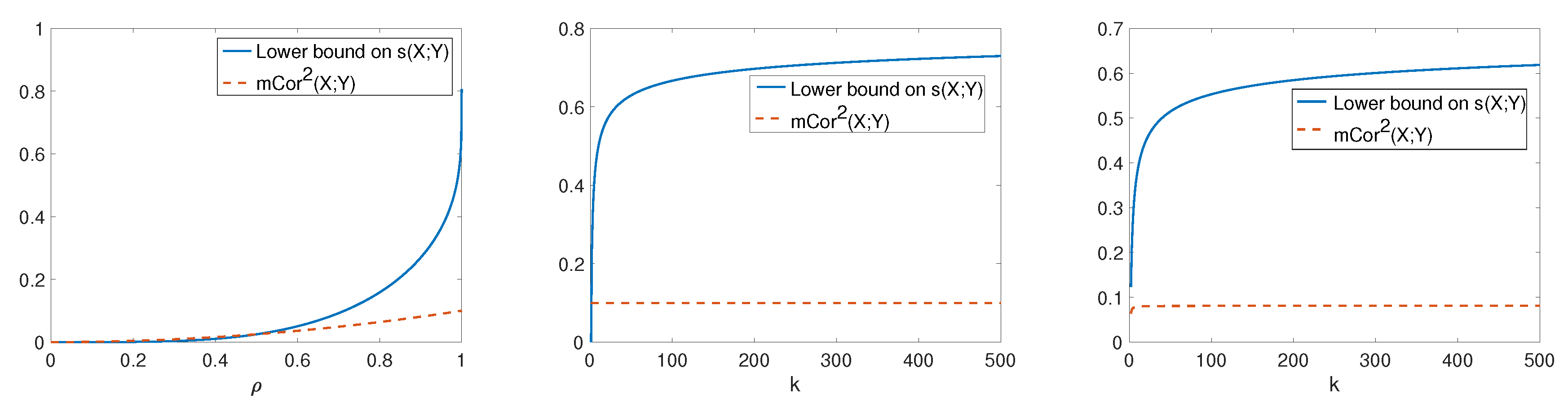
- If , then , where is the Pearson correlation coefficient.
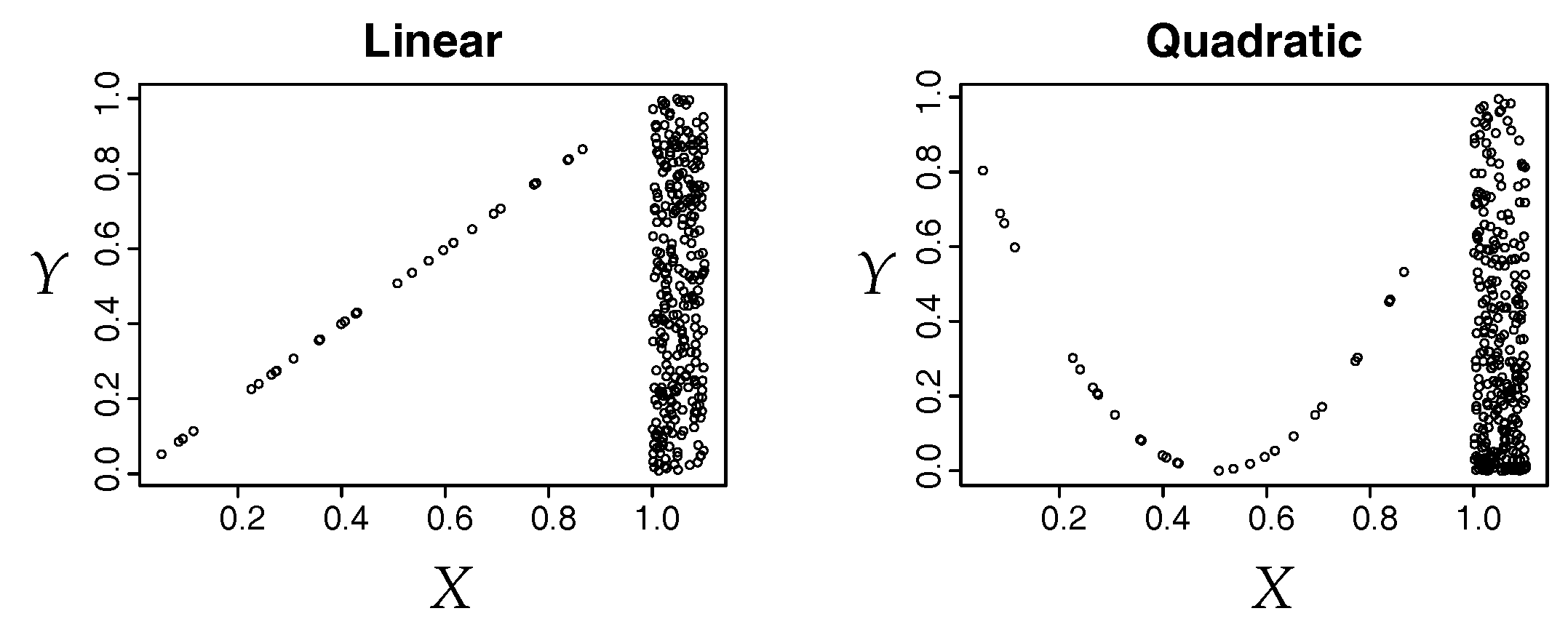
- if there exists a subset such that for a pair of continuous random variables , for a Borel-measurable and non-constant continuous function f.
- 6’.
- if for Borel-measurable functions f or g, or .
- 7’.
- .
2.2. The Hypercontractivity Coefficient Satisfies All Axioms
2.3. Standard Correlation Coefficients Violate the Axioms
2.4. Mutual Information Violates the Axioms
- Practically, mutual information is unnormalized, i.e., . Hence, it provides no absolute indication of the strength of the dependence.
- Mathematically, we are looking for a quantity that tensorizes, i.e., does not change when there are many i.i.d. copies of the same pair of random variables.
2.5. Hypercontractivity Ribbon
2.6. Multidimensional X and Y
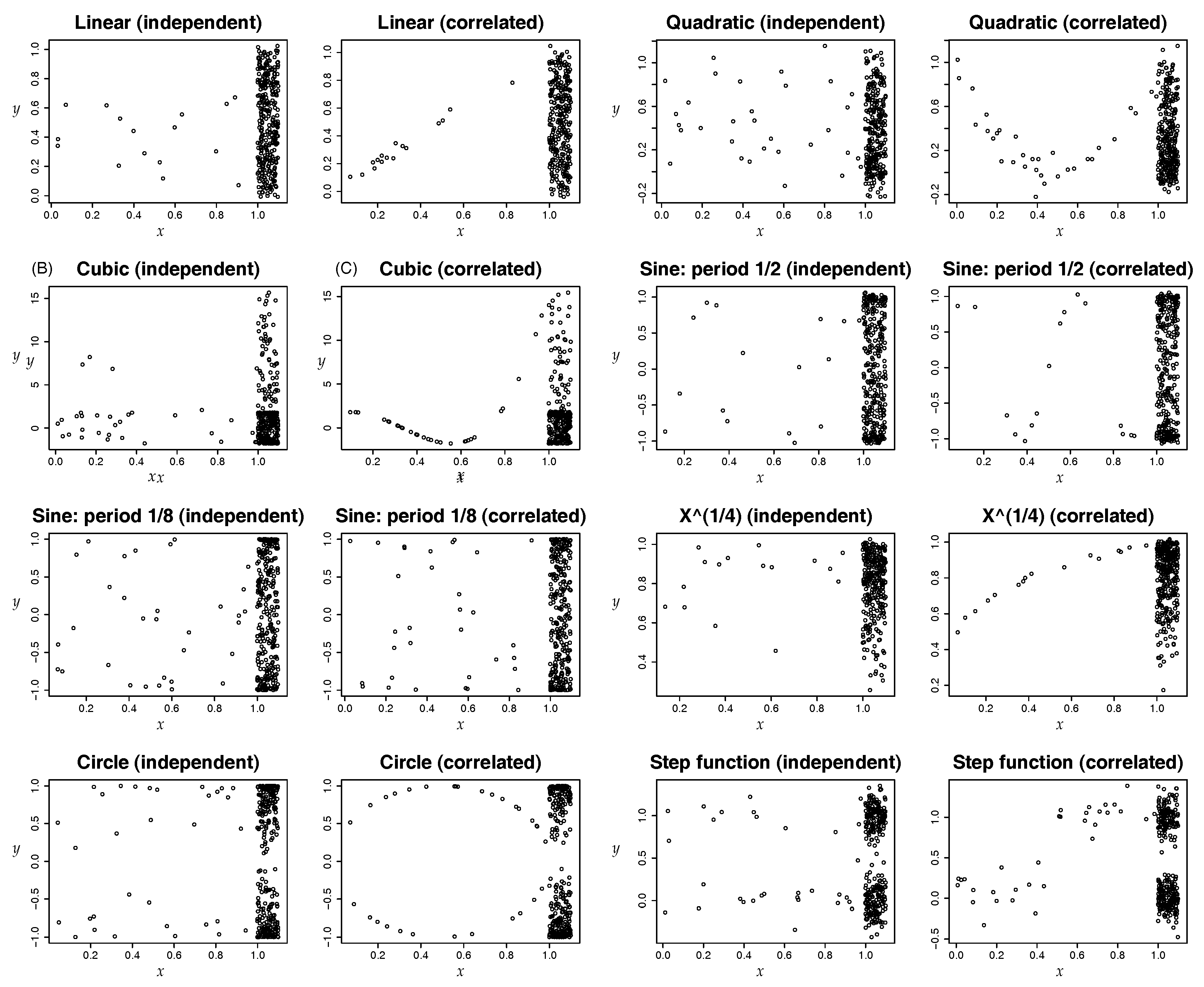
2.7. Noisy, Discrete, Noisy and Discrete Potential Correlation
3. Estimator of the Hypercontractivity Coefficient from Samples
Consistency of Estimation
4. Experimental Results
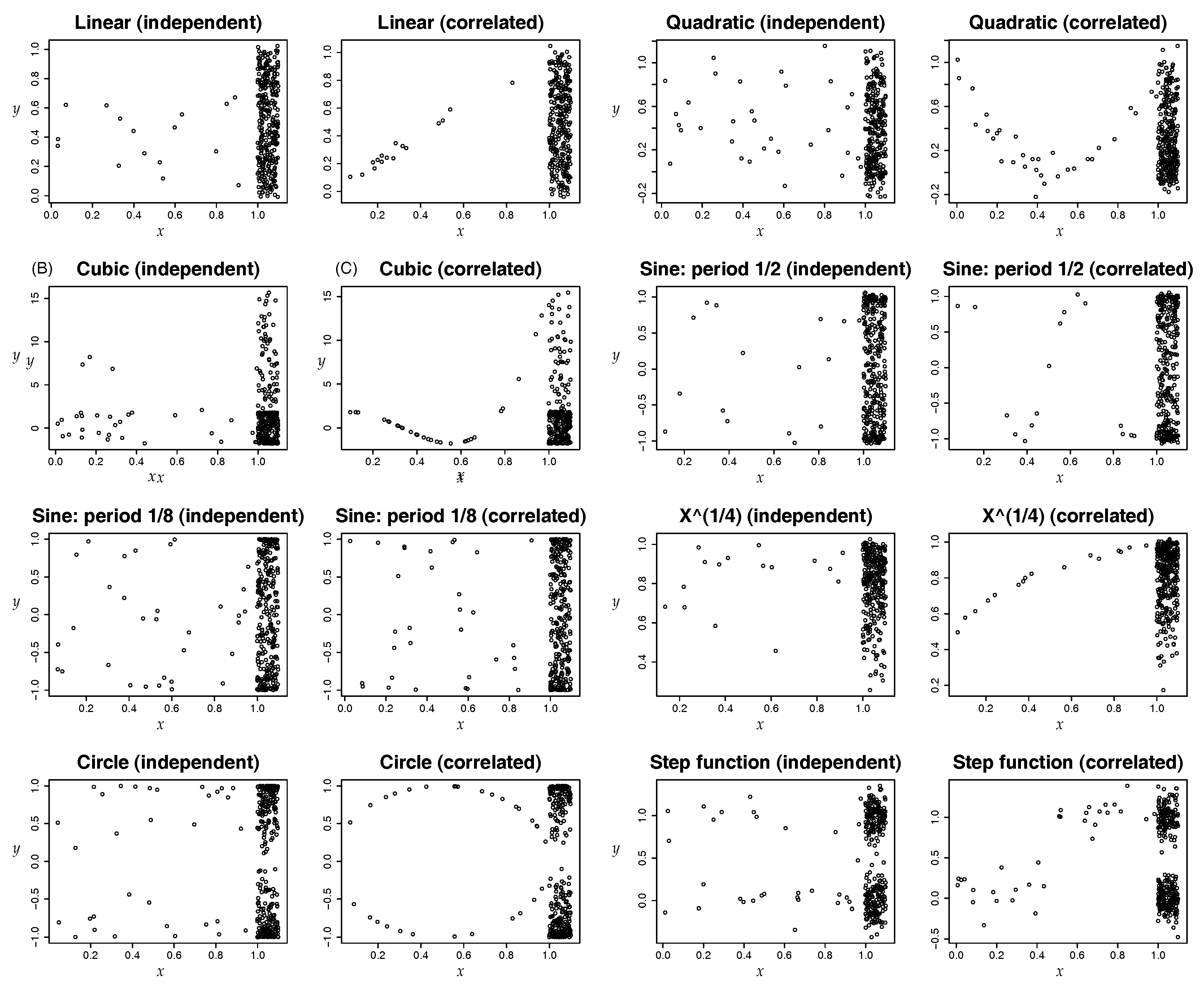
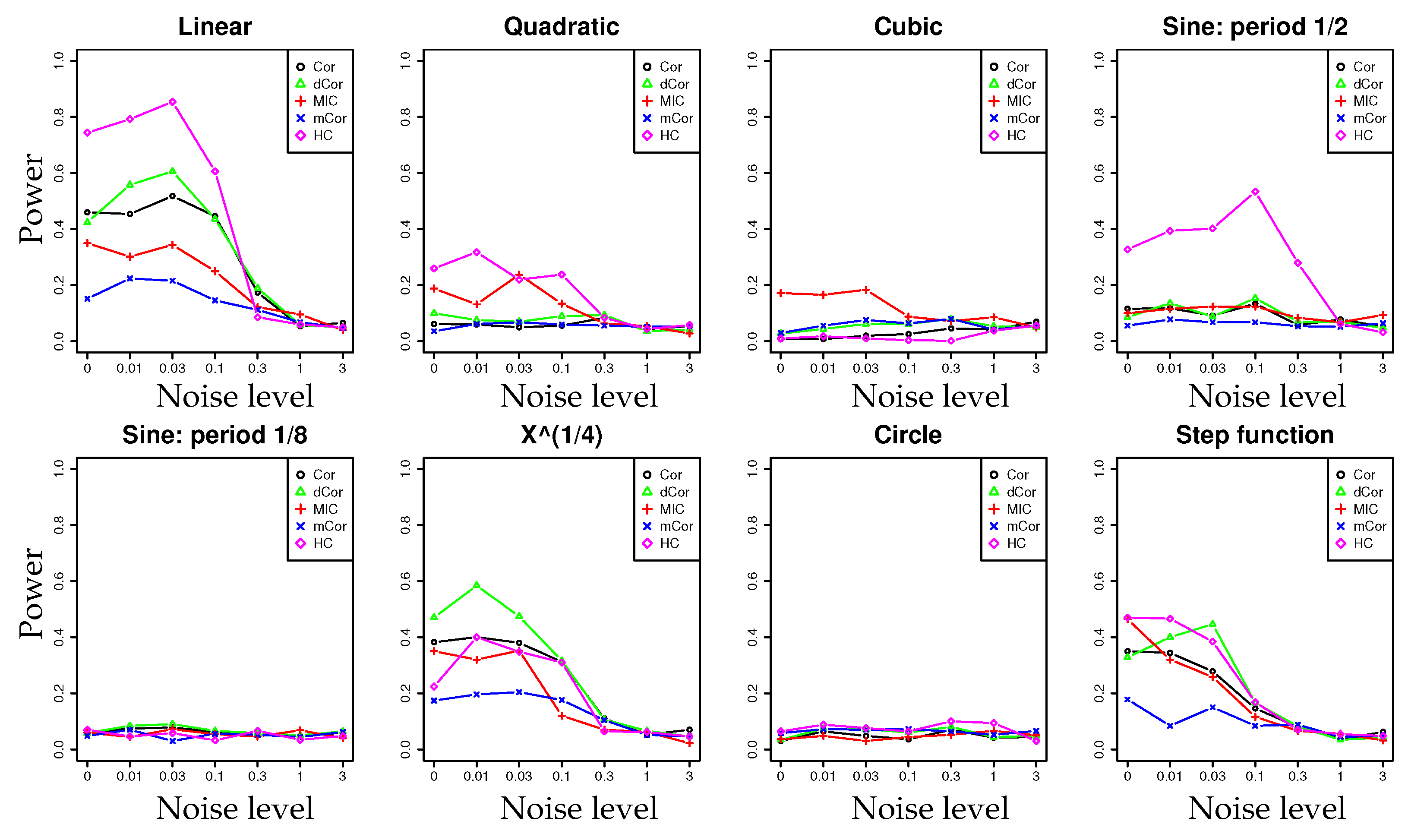
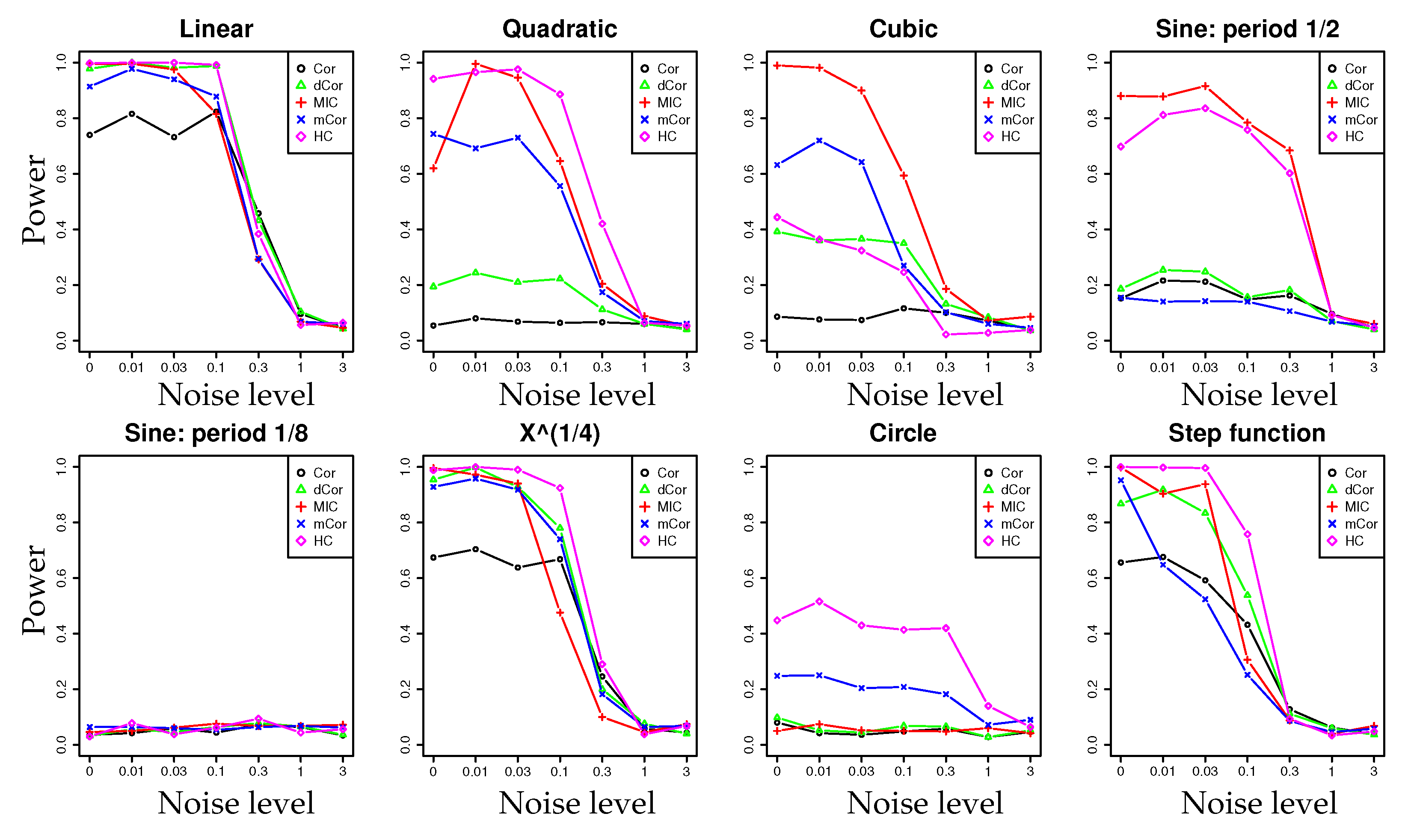
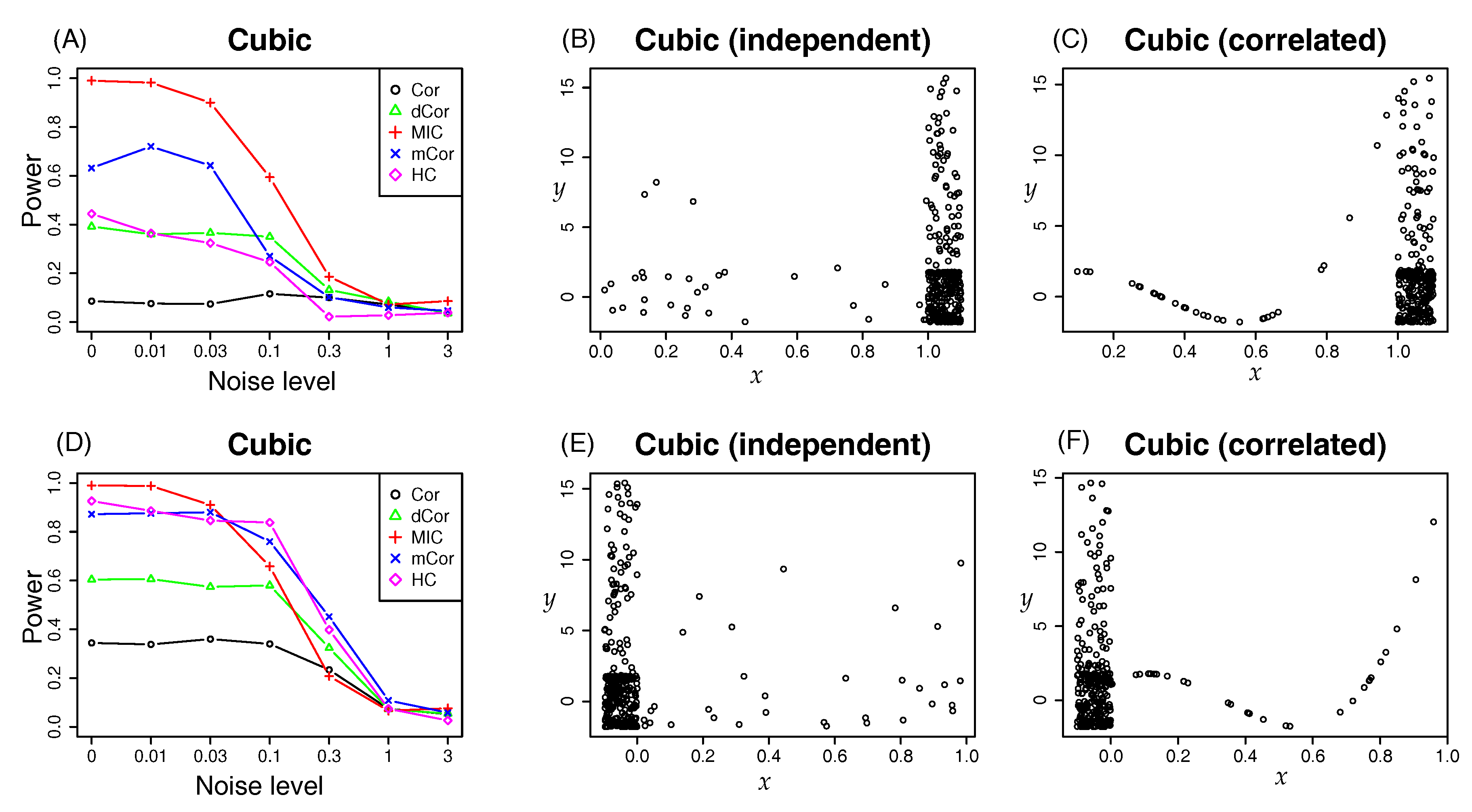
4.1. Synthetic Data: Power Test on Potential Correlation
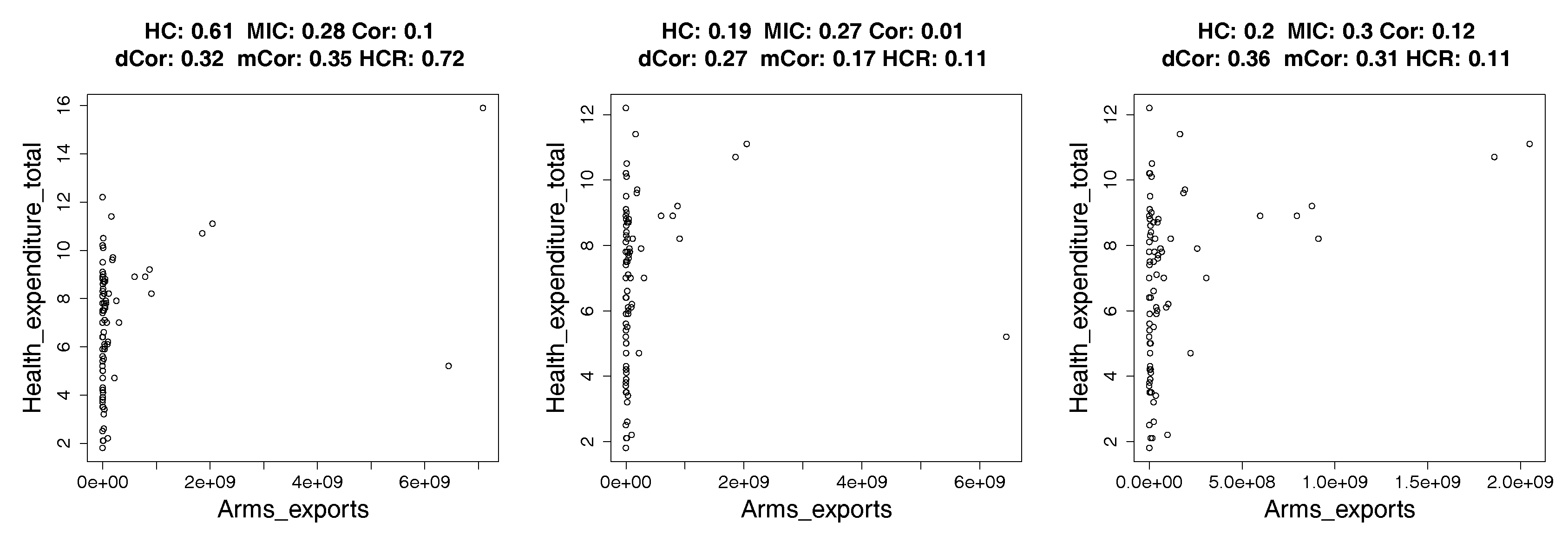
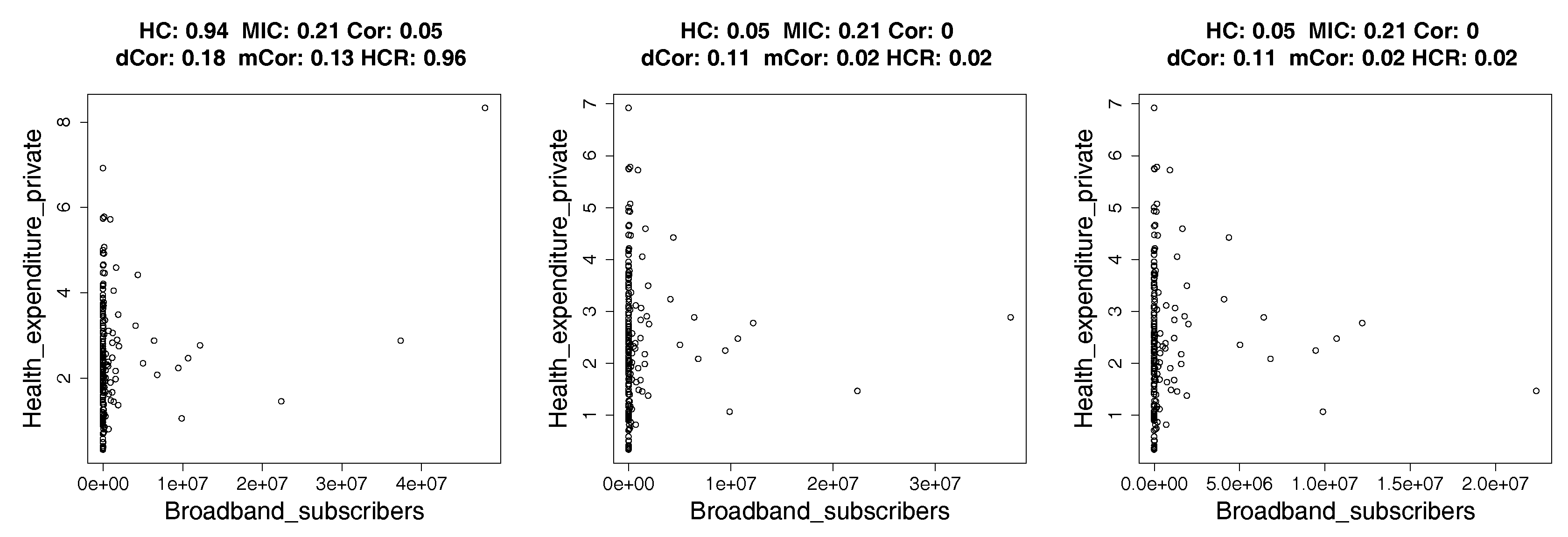
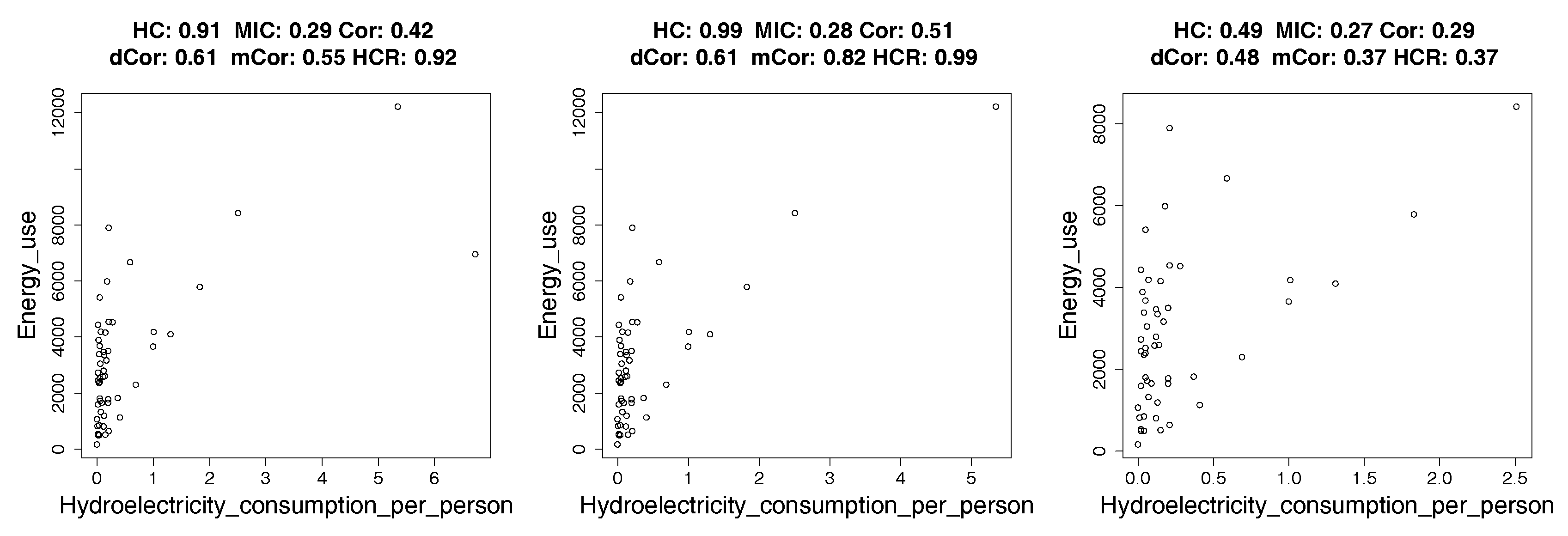
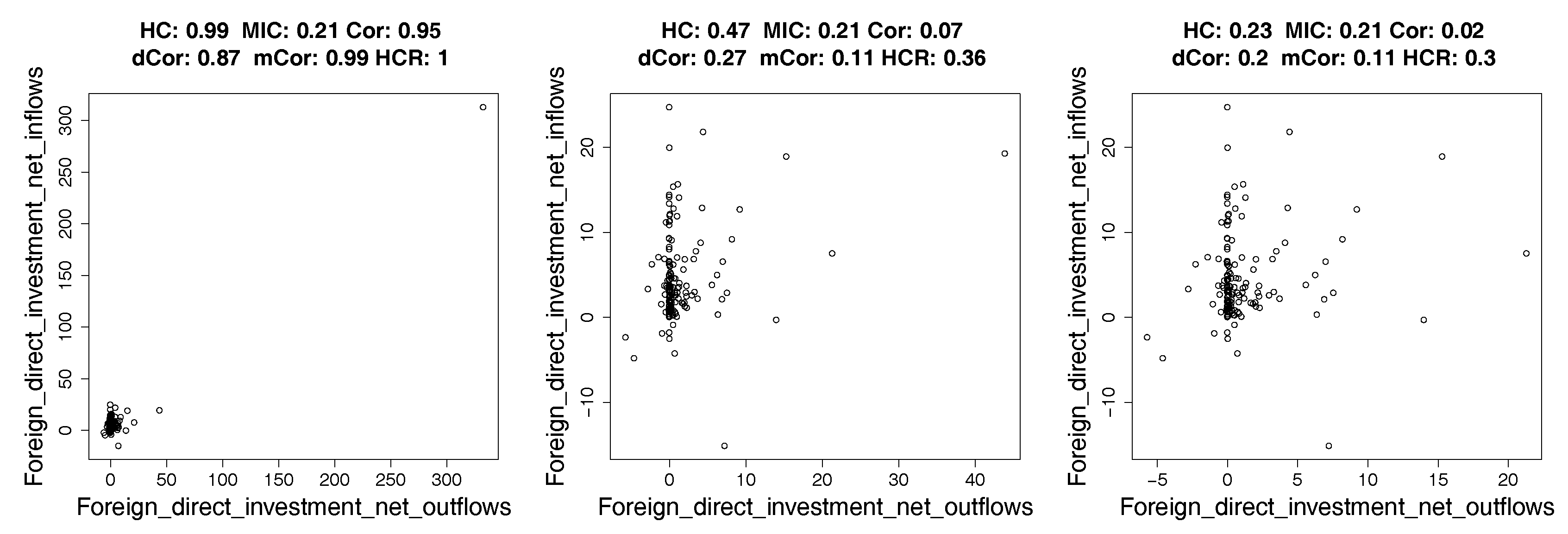
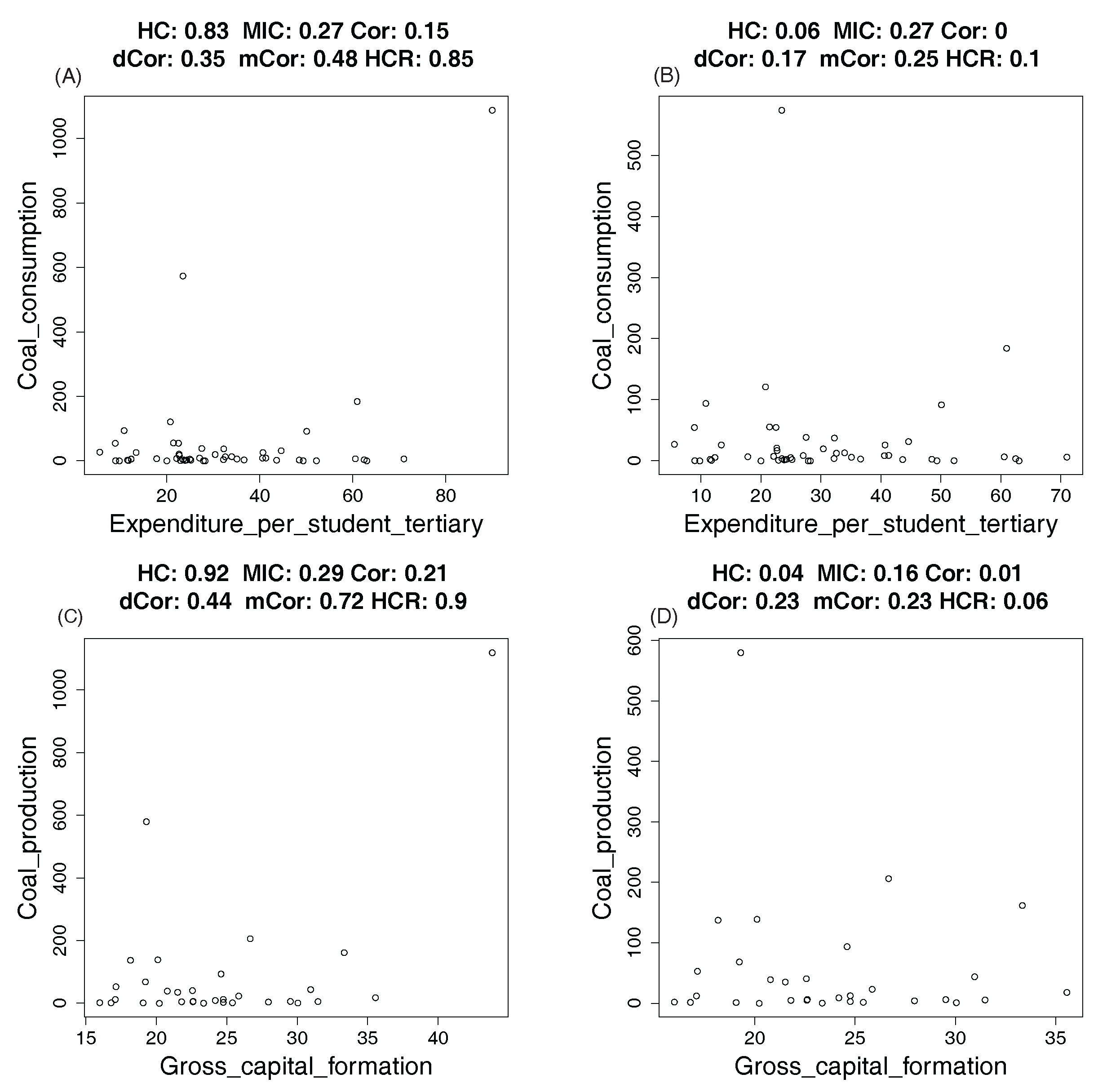
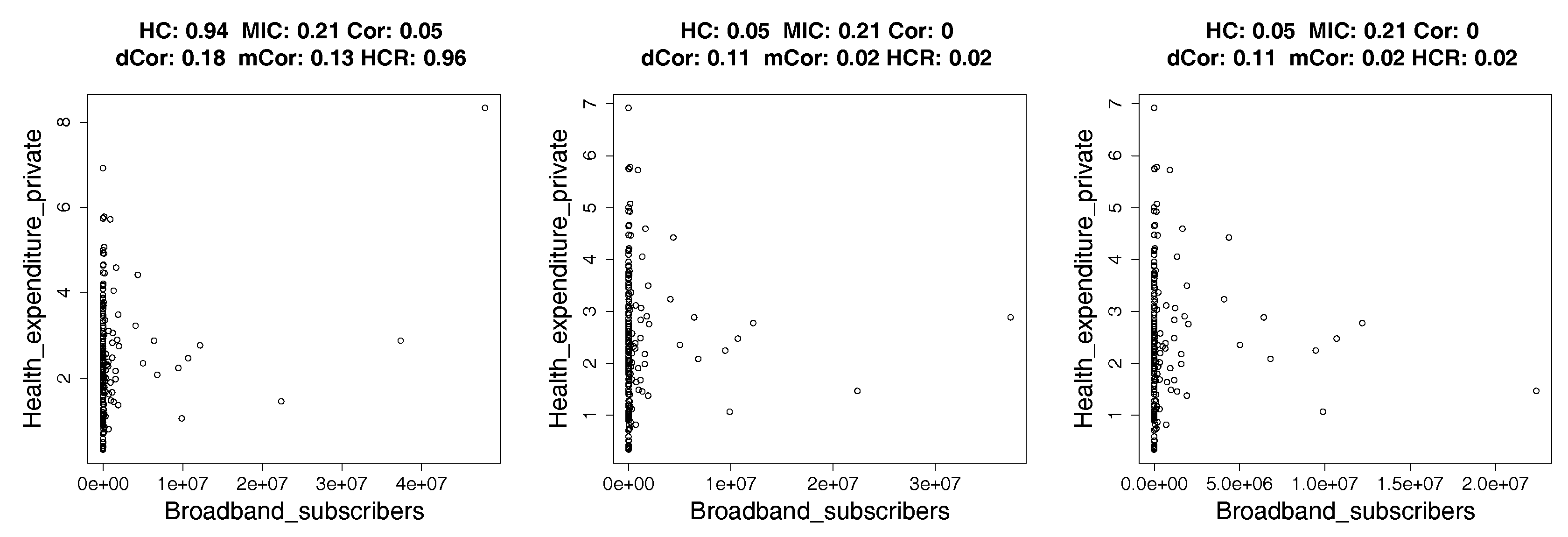
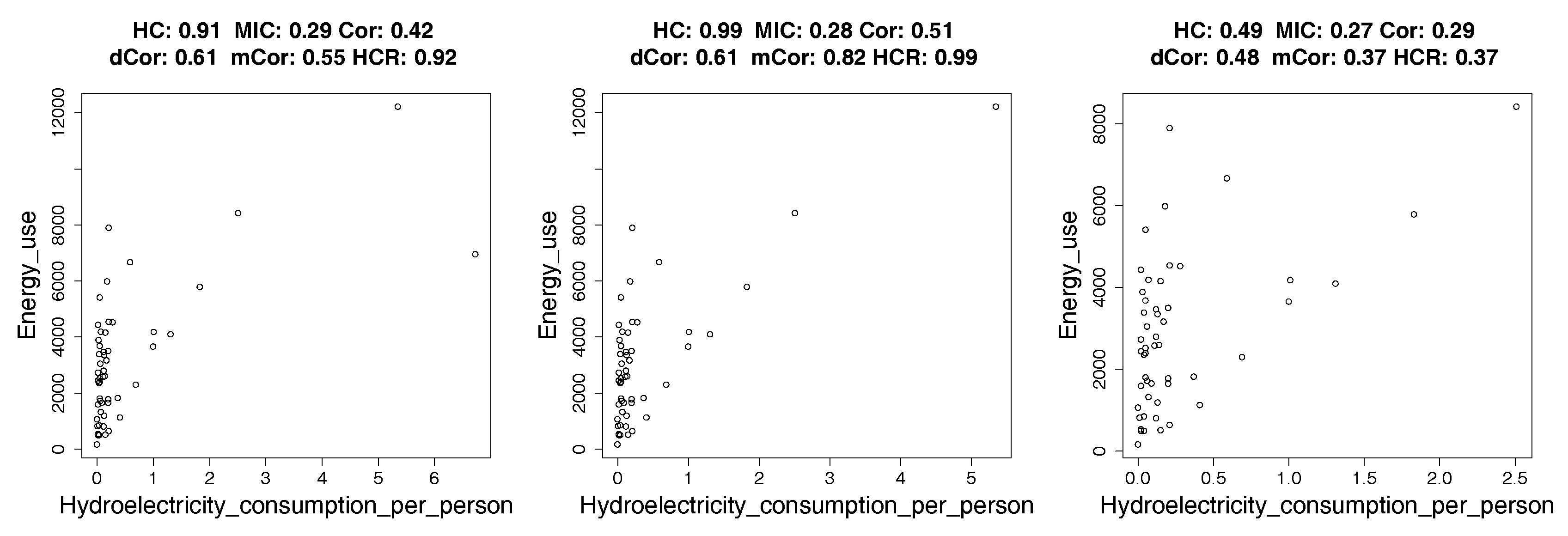
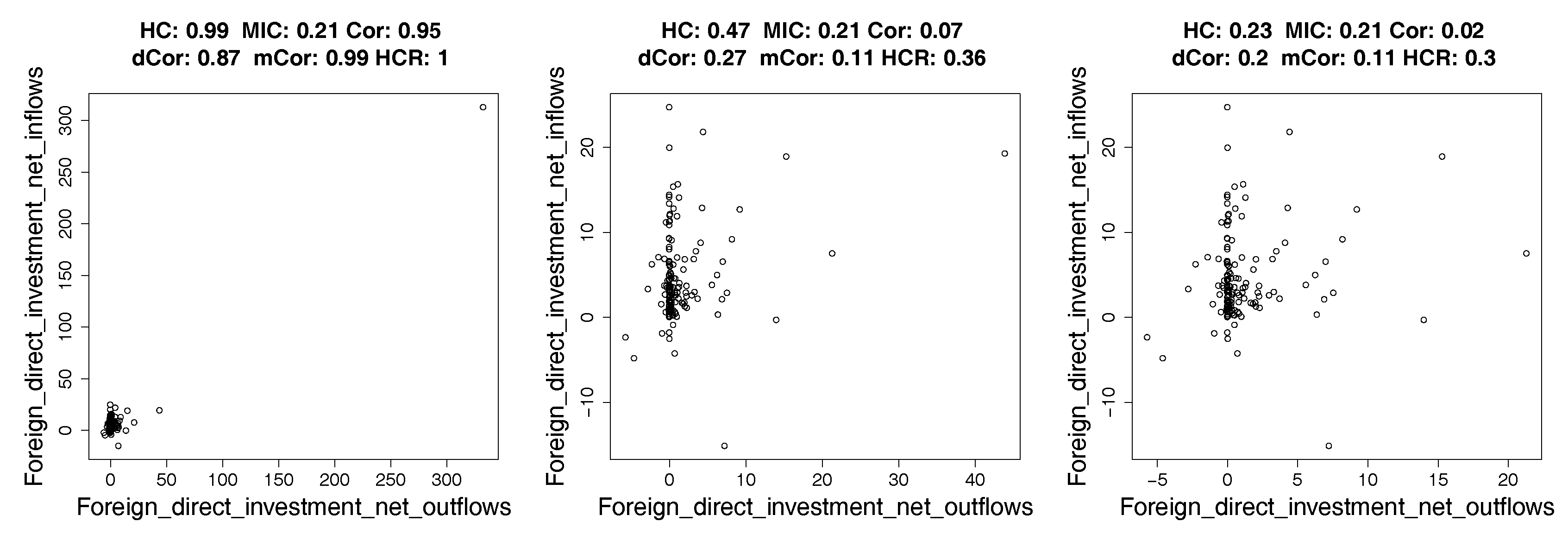
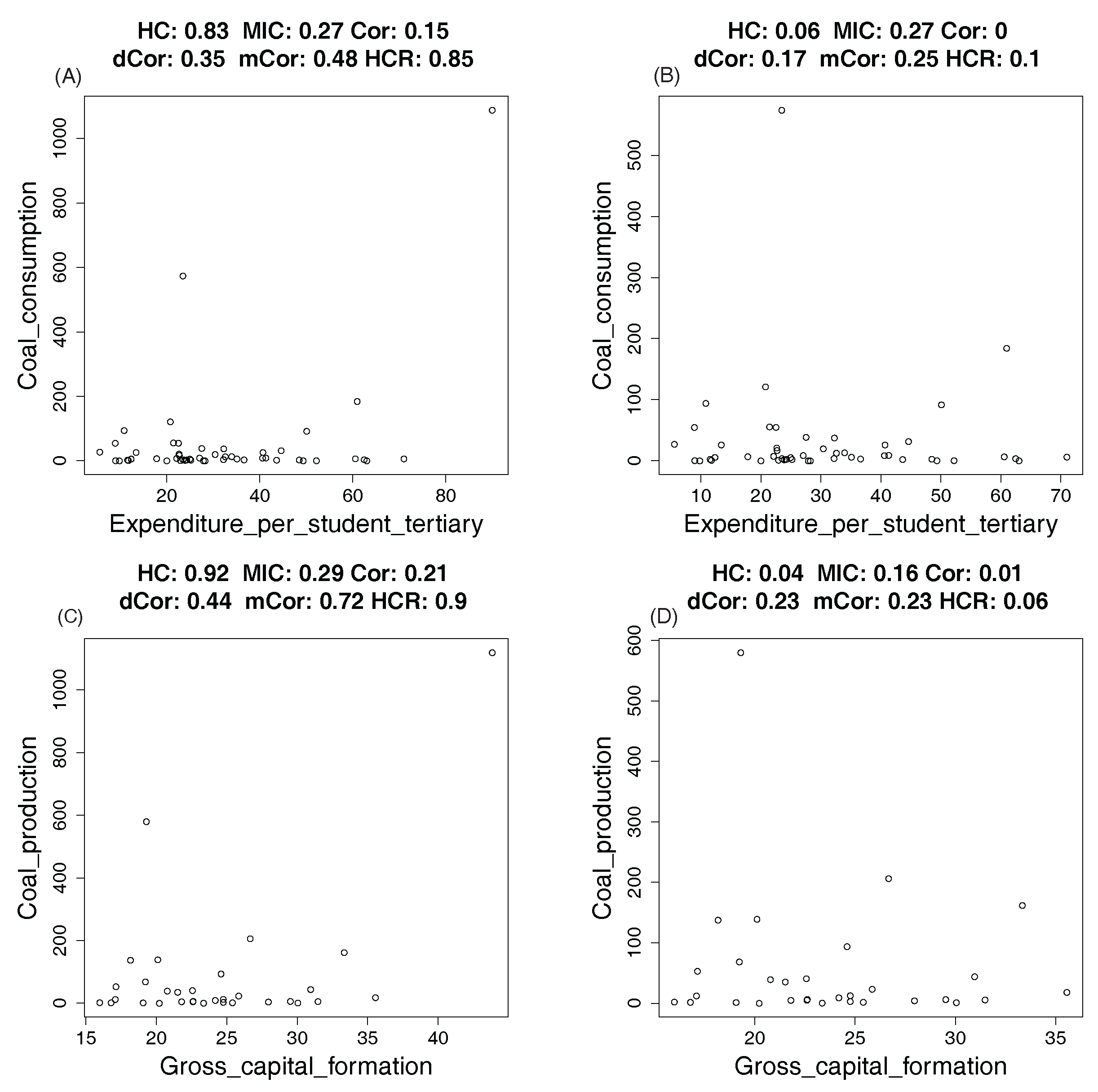
4.2. Real Data: Correlation between Indicators of WHO Datasets
4.2.1. How Hypercontractivity Changes as We Remove Outliers
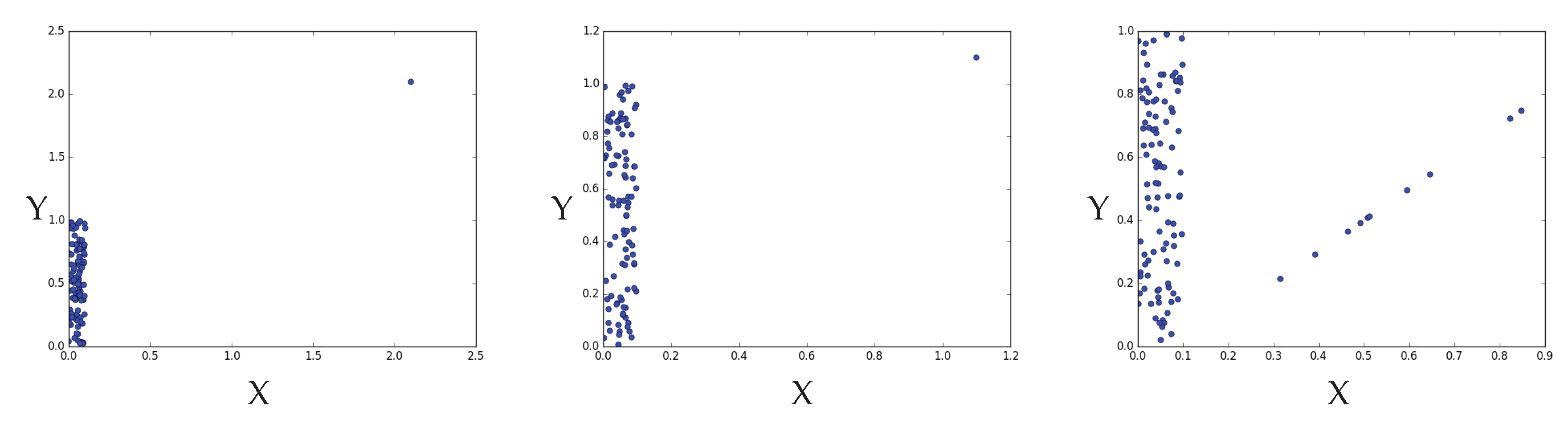
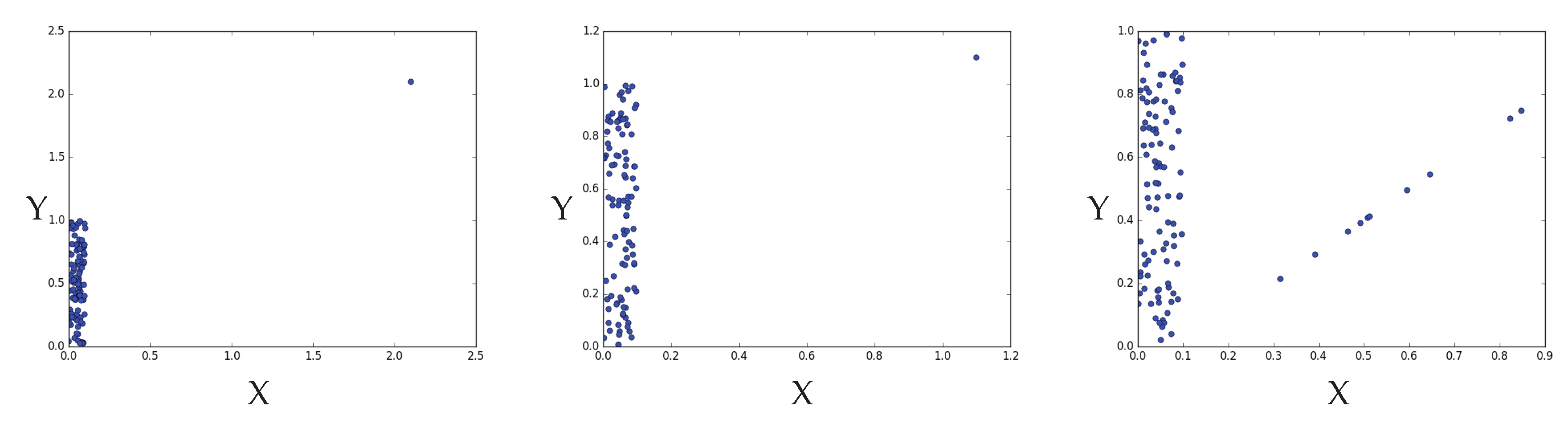
4.2.2. Hypercontractivity Detecting an Outlier
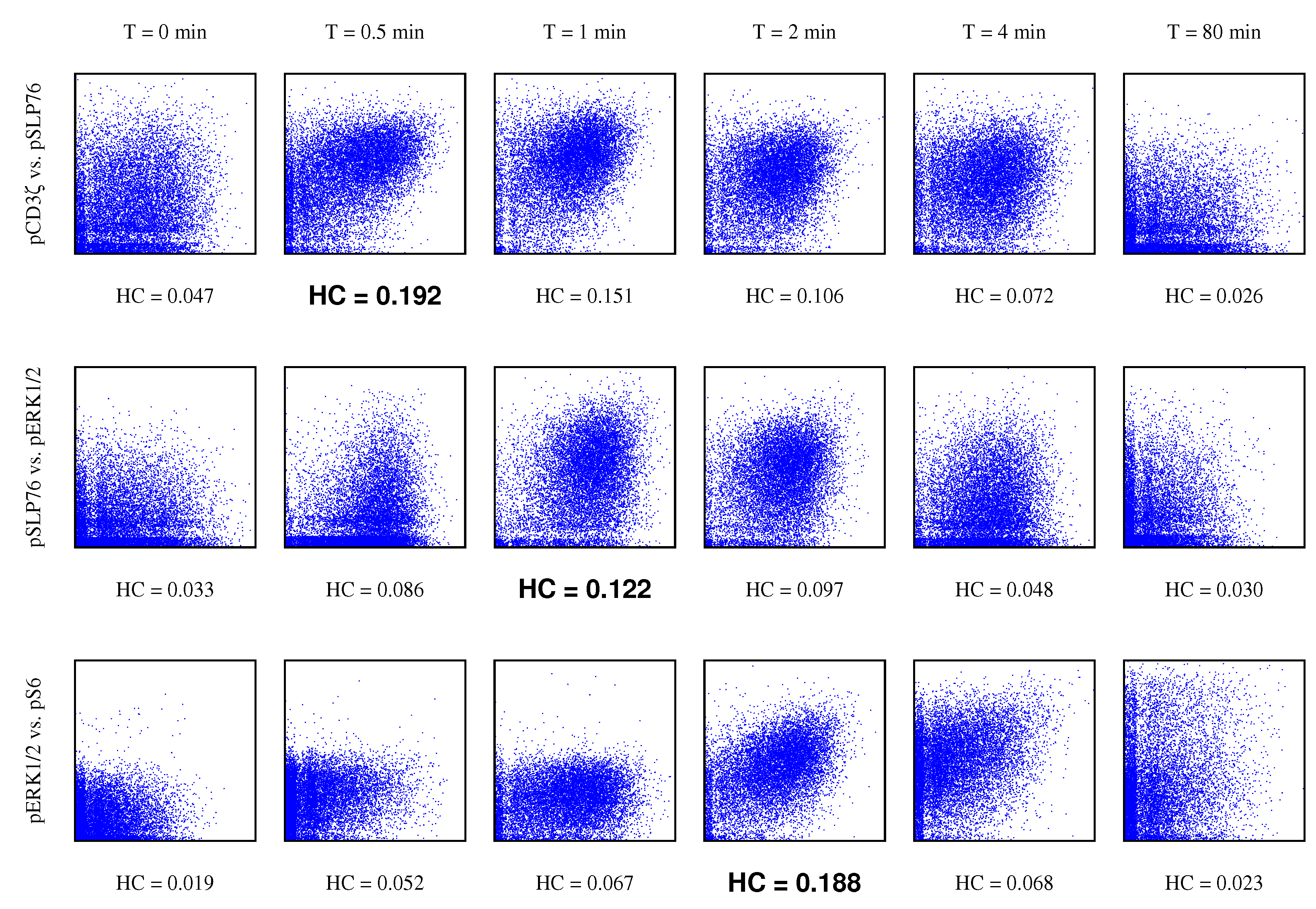
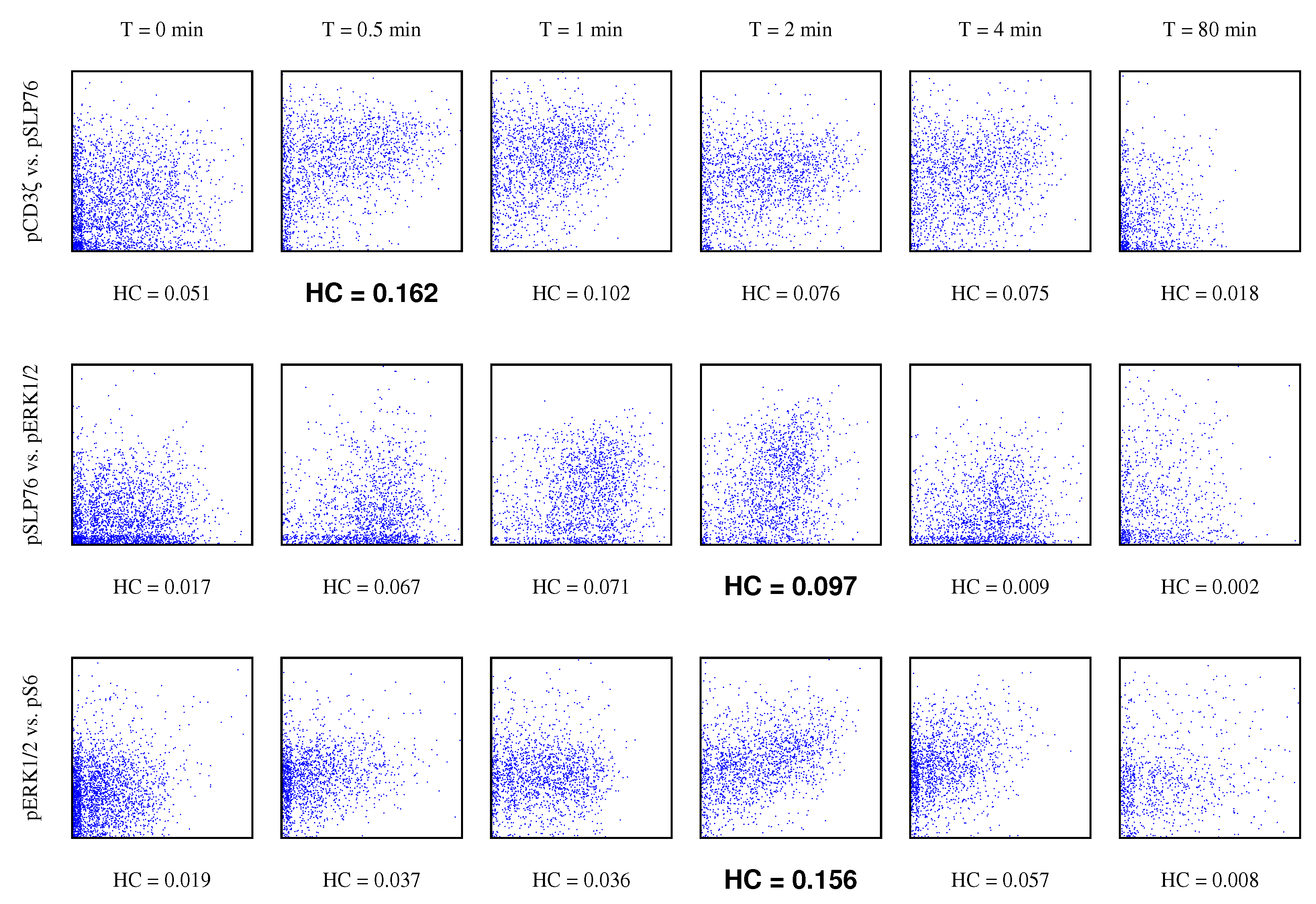
4.3. Gene Pathway Recovery From Single Cell Data
5. Proofs
5.1. Proof of Proposition 1
- 1.
- is defined for any pair of non-constant random variables because and are defined for any random variables X, Y by Theorem 1.
- 2.
- because the output of a function F is in by the condition on F.
- 3.
- If X and Y are statistically independent, . By the condition on F, it follows that . If , by the condition on F, , which implies that X and Y are statistically independent.
- 4.
- for any bijective Borel-measurable functions because = and by Theorem 1.
- 5.
- For with Pearson correlation , . Hence, .
- 6’
- If for a non-constant function f, it follows that because if is discrete, and otherwise, . HenceSimilarly, . Hence, . Likewise, we can show that if .
- 7’
- because .
5.2. Proof of Theorem 1
- For any non-constant random variable X, s.t. . Hence, is defined for any pair of non-constant random variables X and Y.
- Since mutual information is non-negative, . By data processing inequality, for any , . Hence, .
- If X and Y are independent, for any U, . Hence, . If X and Y are dependent, , which implies that .
- For any bijective functions ,Similarly, . Hence,
- By Theorem 3.1 in [33], for jointly Gaussian with correlation coefficient ,for . Equivalently,which implies that . To show that , let for . ConsiderHence, . An alternative proof is provided in [24].
- To prove that satisfies Axiom 6, we first show the following lemma.
5.3. Proof of Theorem 2
5.4. Proof of Proposition 2
5.5. Noisy Rare Correlation in Example 1
5.6. Noisy Discrete Rare Correlation in Example 3
5.7. Proof of Proposition 4
5.8. Proof of Theorem 3
- (a)
- There exist finite constants such that the ratio of the optimal and the true satisfies for every .
- (b)
- There exist finite constants such that the KL divergence .
5.9. Proof of Lemma 2
5.10. Proof of Lemma 3
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pearson, K. Note on Regression and Inheritance in the Case of Two Parents. Proc. R. Soc. Lond. 1895, 58, 240–242. [Google Scholar] [CrossRef]
- Hirschfeld, H. A Connection between Correlation and Contingency. Math. Proc. Camb. Philos. Soc. 1935, 31, 520–524. [Google Scholar] [CrossRef]
- Gebelein, H. Das statistische Problem der Korrelation als Variations-und Eigenwertproblem und sein Zusammenhang mit der Ausgleichsrechnung. J. Appl. Math. Mech. 1941, 21, 364–379. [Google Scholar] [CrossRef]
- Rényi, A. On measures of dependence. Acta Math. Hung. 1959, 10, 441–451. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting Novel Associations in Large Data Sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Krishnaswamy, S.; Spitzer, M.H.; Mingueneau, M.; Bendall, S.C.; Litvin, O.; Stone, E.; Pe’er, D.; Nolan, G.P. Conditional density-based analysis of T cell signaling in single-cell data. Science 2014, 346, 1250689. [Google Scholar] [CrossRef] [PubMed]
- Tishby, N.; Pereira, F.C.; Bialek, W. The Information Bottleneck Method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing, Champaign, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Dhillon, I.S.; Mallela, S.; Kumar, R. A Divisive Information-Theoretic Feature Clustering Algorithm for Text Classification. J. Mach. Learn. Res. 2003, 3, 1265–1287. [Google Scholar]
- Bekkerman, R.; El-Yaniv, R.; Tishby, N.; Winter, Y. Distributional Word Clusters vs. Words for Text Categorization. J. Mach. Learn. Res. 2003, 3, 1183–1208. [Google Scholar]
- Anantharam, V.; Gohari, A.A.; Kamath, S.; Nair, C. On Maximal Correlation, Hypercontractivity, and the Data Processing Inequality studied by Erkip and Cover. arXiv, 2013; arXiv:1304.6133. [Google Scholar]
- Davies, E.B.; Gross, L.; Simone, B. Hypercontractivity: A Bibliographic Review. In Ideas and Methods in Quantum and Statistical Physics (Oslo, 1988); Cambridge University Press: Cambridge, UK, 1992; pp. 370–389. [Google Scholar]
- Nelson, E. Construction of quantum fields from Markoff fields. J. Funct. Anal. 1973, 12, 97–112. [Google Scholar] [CrossRef]
- Kahn, J.; Kalai, G.; Linial, N. The Influence of Variables on Boolean Functions. In Proceedings of the IEEE Computer Society SFCS ’88 29th Annual Symposium on Foundations of Computer Science, White Plains, NY, USA, 24–26 October 1988; pp. 68–80. [Google Scholar]
- O’Donnell, R. Analysis of Boolean Functions; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bonami, A. Étude des coefficients de Fourier des fonctions de Lp(G). Annales de l’institut Fourier 1970, 20, 335–402. (In French) [Google Scholar] [CrossRef]
- Beckner, W. Inequalities in Fourier analysis. Ann. Math. 1975, 102, 159–182. [Google Scholar] [CrossRef]
- Gross, L. Hypercontractivity and logarithmic Sobolev inequalities for the Clifford-Dirichlet form. Duke Math. J. 1975, 42, 383–396. [Google Scholar] [CrossRef]
- Ahlswede, R.; Gács, P. Spreading of sets in product spaces and hypercontraction of the Markov operator. Ann. Probab. 1976, 4, 925–939. [Google Scholar] [CrossRef]
- Mossel, E.; Oleszkiewicz, K.; Sen, A. On reverse hypercontractivity. Geom. Funct. Anal. 2013, 23, 1062–1097. [Google Scholar] [CrossRef]
- Nair, C.; (Chinese University of Hong Kong, Hong Kong, China); Kamath, S.; (PDT Partners, Princeton, NJ, USA). Personal communication, 2016.
- Alemi, A.A.; Fischer, I.; Dillion, J.V.; Murphy, K. Deep variational information bottleneck. arXiv, 2017; arXiv:1612.0041. [Google Scholar]
- Achille, A.; Soatto, S. Information Dropout: Learning Optimal Representations Through Noisy Computation. arXiv, 2016; arXiv:1611.01353. [Google Scholar]
- Nair, C. An extremal inequality related to hypercontractivity of Gaussian random variables. In Proceedings of the Information Theory and Applications Workshop, San Diego, CA, USA, 9–14 February 2014. [Google Scholar]
- Gao, W.; Kannan, S.; Oh, S.; Viswanath, P. Conditional Dependence via Shannon Capacity: Axioms, Estimators and Applications. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2780–2789. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, DC, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Srivastava, N.; Salakhutdinov, R.R. Multimodal learning with deep boltzmann machines. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2222–2230. [Google Scholar]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep canonical correlation analysis. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1247–1255. [Google Scholar]
- Makur, A.; Zheng, L. Linear Bounds between Contraction Coefficients for f-Divergences. arXiv, 2017; arXiv:1510.01844. [Google Scholar]
- Witsenhausen, H.S. On Sequences of Pairs of Dependent Random Variables. SIAM J. Appl. Math. 1975, 28, 100–113. [Google Scholar] [CrossRef]
- Bell, C. Mutual information and maximal correlation as measures of dependence. Ann. Math. Stat. 1962, 33, 587–595. [Google Scholar] [CrossRef]
- Nair, C. Equivalent Formulations of Hypercontractivity Using Information Measures. In Proceedings of the 2014 International Zurich Seminar on Communications, Zurich, Switzerland, 26–28 February 2014. [Google Scholar]
- Chechik, G.; Globerson, A.; Tishby, N.; Weiss, Y. Information Bottleneck for Gaussian Variables. J. Mach. Learn. Res. 2005, 6, 165–188. [Google Scholar]
- Michaeli, T.; Wang, W.; Livescu, K. Nonparametric Canonical Correlation Analysis. In Proceedings of the ICML’16 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1967–1976. [Google Scholar]
- Simon, N.; Tibshirani, R. Comment on “Detecting Novel Associations In Large Data Sets” by Reshef Et Al, Science 16 December 2011. arXiv, 2014; arXiv:stat.ME/1401.7645. [Google Scholar]
- Gorfine, M.; Heller, R.; Heller, Y. Comment on Detecting Novel Associations in Large Data Sets. Available online: http://emotion.technion.ac.il/~gorfinm/filesscience6.pdf (accessed on 30 October 2017).
- Hastings, C.; Mosteller, F.; Tukey, J.W.; Winsor, C.P. Low Moments for Small Samples: A Comparative Study of Order Statistics. Ann. Math. Stat. 1947, 18, 413–426. [Google Scholar] [CrossRef]
- McBean, E.A.; Rovers, F. Statistical Procedures for Analysis of Environmental Monitoring Data and Assessment; Prentice-Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Rustum, R.; Adeloye, A.J. Replacing outliers and missing values from activated sludge data using Kohonen self-organizing map. J. Environ. Eng. 2007, 133, 909–916. [Google Scholar] [CrossRef]
- Kumar, G. Binary Rényi Correlation: A Simpler Proof of Witsenhausen’s Result and a Tight Lower Bound. Available online: http://www.gowthamiitm.com/research/Witsenhausen_simpleproof.pdf (accessed on 30 October 2017).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cor | dCor | mCor | MIC | HC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | Function | Dep | Indep | Dep | Indep | Dep | Indep | Dep | Indep | Dep | Indep | ||
| 1 | Linear | 0.05 | 0.03 | 0.03 | 0.00 | 0.19 | 0.11 | 0.06 | 0.04 | 0.21 | 0.17 | 0.18 | 0.08 |
| 2 | Quadratic | 0.10 | 0.10 | 0.00 | 0.01 | 0.09 | 0.10 | 0.07 | 0.02 | 0.21 | 0.18 | 0.08 | 0.04 |
| 3 | Cubic | 0.10 | 0.00 | 0.02 | 0.00 | 0.16 | 0.08 | 0.09 | 0.03 | 0.26 | 0.17 | 0.11 | 0.04 |
| 4 | sin() | 0.05 | 0.03 | 0.00 | 0.00 | 0.10 | 0.06 | 0.03 | 0.01 | 0.20 | 0.18 | 0.10 | 0.04 |
| 5 | sin() | 0.10 | 0.00 | 0.00 | 0.00 | 0.07 | 0.08 | 0.03 | 0.03 | 0.18 | 0.22 | 0.03 | 0.03 |
| 6 | 0.05 | 0.01 | 0.01 | 0.00 | 0.12 | 0.07 | 0.02 | 0.01 | 0.20 | 0.20 | 0.12 | 0.04 | |
| 7 | Circle | 0.10 | 0.00 | 0.00 | 0.00 | 0.09 | 0.05 | 0.01 | 0.03 | 0.16 | 0.17 | 0.06 | 0.01 |
| 8 | Step func. | 0.10 | 0.03 | 0.00 | 0.00 | 0.13 | 0.07 | 0.04 | 0.02 | 0.20 | 0.17 | 0.11 | 0.04 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.; Gao, W.; Kannan, S.; Oh, S.; Viswanath, P. Discovering Potential Correlations via Hypercontractivity. Entropy 2017, 19, 586. https://doi.org/10.3390/e19110586
Kim H, Gao W, Kannan S, Oh S, Viswanath P. Discovering Potential Correlations via Hypercontractivity. Entropy. 2017; 19(11):586. https://doi.org/10.3390/e19110586
Chicago/Turabian StyleKim, Hyeji, Weihao Gao, Sreeram Kannan, Sewoong Oh, and Pramod Viswanath. 2017. "Discovering Potential Correlations via Hypercontractivity" Entropy 19, no. 11: 586. https://doi.org/10.3390/e19110586