
On Linear Coding over Finite Rings and Applications to Computing

Communication Theory Lab, School of Electrical Engineering, KTH Royal Institute of Technology, Stockholm 10044, Sweden
*
Author to whom correspondence should be addressed.
Entropy 2017, 19(5), 233; https://doi.org/10.3390/e19050233
Submission received: 6 January 2017
/
Revised: 24 April 2017
/
Accepted: 15 May 2017
/
Published: 20 May 2017
(This article belongs to the Special Issue Network Information Theory)
Abstract
:This paper presents a coding theorem for linear coding over finite rings, in the setting of the Slepian–Wolf source coding problem. This theorem covers corresponding achievability theorems of Elias (IRE Conv. Rec. 1955, 3, 37–46) and Csiszár (IEEE Trans. Inf. Theory 1982, 28, 585–592) for linear coding over finite fields as special cases. In addition, it is shown that, for any set of finite correlated discrete memoryless sources, there always exists a sequence of linear encoders over some finite non-field rings which achieves the data compression limit, the Slepian–Wolf region. Hence, the optimality problem regarding linear coding over finite non-field rings for data compression is closed with positive confirmation with respect to existence. For application, we address the problem of source coding for computing, where the decoder is interested in recovering a discrete function of the data generated and independently encoded by several correlated i.i.d. random sources. We propose linear coding over finite rings as an alternative solution to this problem. Results in Körner–Marton (IEEE Trans. Inf. Theory 1979, 25, 219–221) and Ahlswede–Han (IEEE Trans. Inf. Theory 1983, 29, 396–411, Theorem 10) are generalized to cases for encoding (pseudo) nomographic functions (over rings). Since a discrete function with a finite domain always admits a nomographic presentation, we conclude that both generalizations universally apply for encoding all discrete functions of finite domains. Based on these, we demonstrate that linear coding over finite rings strictly outperforms its field counterpart in terms of achieving better coding rates and reducing the required alphabet sizes of the encoders for encoding infinitely many discrete functions.
1. Introduction
The problem of source coding for computing considers the scenario where a decoder is interested in recovering a function of the message(s), other than the original message(s), that is (are) i.i.d. generated and independently encoded by the source(s). In rigorous terms:
Problem 1 (Source Coding for Computing).
Given and . For each consider a discrete memoryless source that randomly generates i.i.d. discrete data , where has a finite sample space and . For a discrete function what is the largest region , such that, and , there exists an , such that for all , there exist s encoders and one decoder with
where and
The region is called the achievable coding rate region for computing g. A rate tuple is said to be achievable for computing g (or simply achievable) if and only if . A region is said to be achievable for computing g (or simply achievable) if and only if .
If g is an identity function, the computing problem, Problem 1, is known as the Slepian–Wolf (SW) source coding problem. is then the SW region [1],
where is the complement of T in and is the random variable array . However, from [1] it is hard to draw conclusions regarding the structure (linear or not) of the encoders, as the corresponding mappings are chosen randomly among all feasible mappings. This limits the scope of their potential applications. As a consequence, linear coding over finite fields (LCoF), namely ’s are injectively mapped into some subsets of some finite fields and the ’s are chosen as linear mappings over these fields, is considered. It is shown that LCoF achieves the same encoding limit, the SW region [2,3]. Although it seems straightforward to study linear mappings over rings (non-field rings in particular), it has not been proved (nor denied) that linear encoding over non-field rings can be equally optimal.
For an arbitrary discrete function g, Problem 1 remains open in general, and obviously. Making use of Elias’ theorem on binary linear codes [2], Körner–Marton [4] shows that (“” is the modulo-two sum) contains the region
This region is not contained in the SW region for certain distributions. In other words, . Combining the standard random coding technique and Elias’ result, [5] shows that can be strictly larger than the convex hull of the union . However, the functions considered in these works are relatively simple. With a polynomial approach, [6,7] generalize the result of Ahlswede–Han ([5], Theorem 10) to the scenario of g being arbitrary. Making use of the fact that a discrete function is essentially a polynomial function (see Definition 2) over some finite field, an achievable region is given for computing an arbitrary discrete function. Such a region contains and can be strictly larger (depending on the precise function and distribution under consideration) than the SW region. Conditions under which is strictly larger than the SW region are presented in [6,8] from different perspectives, respectively. The cases regarding Abelian group codes are covered in [9,10,11].
The present work proposes replacing the linear encoders over finite fields from Elias [2] and Csiszár [3] with linear encoders over finite rings in the case of the problems accounted for above. Achievability theorems related to linear coding over finite rings (LCoR) for SW data compression are presented, covering the results in [2,3] as special cases in the sense of characterizing the achievable region. In addition, it is proved that there always exists a sequence of linear encoders over some finite non-field rings that achieves the SW region for any scenario of SW. Therefore, the issue of optimality of linear coding over finite non-field rings for data compression is closed with respect to existence. Furthermore, we also consider LCoR as an alternative technique for the general computing problem, Problem 1. Results from Körner–Marton [4], Ahlswede–Han ([5], Theorem 10) and [7] are generalized to corresponding ring versions for encoding (pseudo) nomographic functions (over rings). Since any discrete function with a finite domain admits a nomographic presentation, we conclude that our results universally apply for encoding all discrete functions of finite domains. Finally, it is shown that our ring approach dominates its field counterpart in terms of achieving better coding rates and reducing alphabet sizes of the encoders for encoding some discrete function. The proof is done by taking advantage of the fact that the characteristic of a ring can be any positive integer while the characteristic of a field must be a prime. From this observation used in the proof, it is seen that there are actually infinite many such functions.
2. Rings, Ideals and Linear Mappings
We start by introducing some fundamental algebraic concepts and related properties. Readers who are already familiar with this material may still choose to go through quickly to identify our notation.
Definition 1.
The tuple is called a ring if the following criteria are met:
- 1.
- is an Abelian group ;
- 2.
- There exists a multiplicative identity , namely, , ;
- 3.
- , and ;
- 4.
- , and .
We often write for when the operations considered are known from the context. The operation “·” is usually written by juxtaposition, for , for all .
A ring is said to be commutative if , . In Definition 1, the identity of the group , denoted by 0, is called the zero. A ring is said to be finite if the cardinality is finite, and is called the order of . The set of integers modulo q is a commutative finite ring with respect to the modular arithmetic. For any ring , the set of all polynomials of s indeterminants over is an infinite ring.
Definition 2.
A polynomial function (Polynomial and polynomial function are distinct concepts.) of k variables over a finite ring is a function of the form
where and m and ’s are non-negative integers. The set of all the polynomial functions of k variables over ring is designated by .
Remark 1.
Polynomial and polynomial function are sometimes only defined over a commutative ring [12,13]. It is a very delicate matter to define them over a non-commutative ring [14,15], due to the fact that and can become different objects. We choose to define “polynomial functions” with Formula (5) because those functions are within the scope of this paper’s interest.
Proposition 1.
Given s rings , for any non-empty set , the Cartesian product (see [12]) forms a new ring with respect to the component-wise operations defined as follows:
.
Remark 2.
In Proposition 1, is called the direct product of . It can be easily seen that and are the zero and the multiplicative identity of , respectively.
Definition 3.
A non-zero element a of a ring is said to be invertible , if and only if there exists , such that . b is called the inverse of a, denoted by . An invertible element of a ring is called a unit.
Remark 3.
It can be proved that the inverse of a unit is unique. By definition, the multiplicative identity is the inverse of itself.
Let . The ring is a field if and only if is an Abelian group. In other words, all non-zero elements of are invertible. All fields are commutative rings. is a field if and only if q is a prime. All finite fields of the same order are isomorphic to each other ([16], p. 549). This “unique” field of order q is denoted by . It is necessary that q is a power of a prime. More details regarding finite fields can be found in ([16], Chapter 14.3).
Theorem 1
(Wedderburn’s little theorem [12]). Let be a finite ring. is a field if and only if all non-zero elements of are invertible.
Remark 4.
Wedderburn’s little theorem guarantees commutativity for a finite ring if all of its non-zero elements are invertible. Hence, a finite ring is either a field or at least one of its elements has no inverse. However, a finite commutative ring is not necessary a field, e.g., is not a field if q is not a prime.
Definition 4
([16]). The characteristic of a finite ring is defined to be the smallest positive integer m, such that , where 0 and 1 are the zero and the multiplicative identity of , respectively. The characteristic of is often denoted by .
Remark 5.
Clearly, . For a finite field , is always the prime such that for some integer n ([12], Proposition 2.137).
Proposition 2.
Let be a finite field. For any , if and only if m is the smallest positive integer such that .
Proof.
Since ,
The statement is proved. ☐
Definition 5.
A subset of a ring is said to be a left ideal of , denoted by , if and only if
- 1.
- is a subgroup of ;
- 2.
- and , .
If condition 2 is replaced by
- 3.
- and , ,
then is called a right ideal of , denoted by . is a trivial left (right) ideal, usually denoted by 0.
The cardinality is called the order of a finite left (right) ideal .
Remark 6.
Let be a non-empty set of elements of some ring . It is easy to verify that is a right ideal and is a left ideal. Furthermore, and if is a unit for some .
It is well-known that if , then is divided into disjoint cosets which are of equal size (cardinality). For any coset , , . The set of all cosets forms a left module over , denoted by . Similarly, becomes a right module over if [17]. Of course, can also be considered as a quotient group [12]. However, its structure is well richer than simply being a quotient group.
Proposition 3.
Let () be a ring and . For any , (or ) if and only if and (or ), .
Proof.
We prove for the case only, and the case follows from a similar argument. Let () be the coordinate function assigning every element in its ith component. Then , where . Moreover, for any
where for all feasible i, we have that
where has the ith coordinate being 1 and others being 0. If , then by definition. Therefore, . Consequently, . Since is a homomorphism, we also have that for all feasible i. The other direction is easily verified by definition. ☐
Remark 7.
It is worthwhile to point out that Proposition 3 does not hold for infinite index set, namely, , where I is not finite.
For any , Proposition 3 states that any left (right) ideal of is a Cartesian product of some left (right) ideals of , . Let be a left (right) ideal of ring (). We define to be the left (right) ideal of .
Let be the transpose of a vector (or matrix) .
Definition 6.
A mapping given as:
where t stands for transposition and for all feasible i and j, is called a left linear mapping over ring . Similarly,
defines a right linear mapping over ring . If , then f is called a left ( right ) linear function over .
From now on, left linear mapping (function) or right linear mapping (function) are simply called linear mapping (function). This will not lead to any confusion since the intended use can usually be clearly distinguished from the context.
Remark 8.
The mapping f in Definition 6 is called linear in accordance with the definition of linear mapping (function) over a field. In fact, the two structures have several similar properties. Moreover, (11) is equivalent to
where is an matrix over and for all feasible i and j. is named the coefficient matrix. It is easy to prove that a linear mapping is uniquely determined by its coefficient matrix, and vice versa. The linear mapping f is said to be trivial , denoted by 0, if is the zero matrix , i.e., for all feasible i and j.
It should be noted that an interesting approach to coding over an Abelian group was presented in [9,10,11]. However, we emphasize that even if group, field and ring are closely related algebraic structures, the definition of the group encoder in [11] and the linear encoder in [3] and in the present work are in general fundamentally different (although there is an overlap in special cases). To highlight in more detail the difference between linear encoding (this work and [3]) and encoding over a group, as in [11], which is a nonlinear operation in general, take the Abelian group , the field of order 4 and the matrix ring as examples.
- By ([11], Example 2), the Abelian group encoder encodes the source based on a Slepian–Wolf like scheme. Namely, two binary linear encoders encode and separately as two binary sources. Therefore, the lengths of the codewords from encoding and can even be different, and the encoder is in general a highly nonlinear device.
- On the other hand, the linear encoder over either or simply outputs a linear combination of the vector , namely for some matrix over or .
- However, if one requires that the codewords from encoding and be of the same length in (1), then the output from encoding is the same as for some matrix over ring (a specific product ring whose multiplication is significantly different from those of or ). In other words, in this quite specific special case, the encoder becomes linear over a product ring of modulo integers, which is a sub-class of the completely general ring structures considered in this paper.
We also note that in some source network problems, linear codes appear superior to others [3]. For instance, for encoding the modulo-two sum of binary symmetric sources, linear coding over or achieves the optimal Körner–Marton region [4] (the case will be established in later sections), while coding over G achieves the sub-optimal Slepian–Wolf region ([11], p. 1509). To avoid any remaining confusion, we in Appendix D present additional details regarding the differences between linear coding, as in the present work and in [3], and coding over an Abelian group, as in [11].
Let be an matrix over ring and , . For the system of linear equations
let be the set of all solutions, namely . It is obvious that if f is trivial, i.e., is the zero matrix. If is a field, then is a subspace of . We conclude this section with a lemma regarding the cardinalities of and in the following.
Lemma 1.
For a finite ring and a linear function
we have
where . In particular, if is invertible for some , then .
Proof.
It is obvious that the image by definition. Moreover, , the pre-images satisfy and . Therefore, , i.e., . Moreover, if is a unit, then , thus, . ☐
3. Linear Coding over Finite Rings
In this section, we will present a coding rate region achieved with LCoR for the SW source coding problem, i.e., g is an identity function in Problem 1. This region is exactly the SW region if all the rings considered are fields. However, being field is not necessary as seen in Section 5, where the issue of optimality is addressed.
Before proceeding, a subtlety needs to be cleared out. It is assumed that a source generates data taking values from a finite sample space , while does not necessarily admit any algebraic structure. We have to either assume that is with a certain algebraic structure, for instance is a ring, or injectively map elements of into some algebraic structure. In our subsequent discussions, we assume that is mapped into a finite ring of order at least by some injection . Hence, can simply be treated as a subset for a fixed . When required, can also be selected to obtain desired outcomes.
To facilitate our discussion, the following notation is used. For , ( and resp.) is defined to be the Cartesian product
where is a realization of . If , we denote the marginal of p with respect to by , i.e., , define the support
For simplicity, is defined to be
( is implicitly assumed), and for any and . For any , let
where and is a random variable with sample space .
Theorem 2.
is achievable with linear coding over the finite rings . In exact terms, , there exists , for all , there exist linear encoders (left linear mappings to be more precise) () and a decoder ψ, such that
where , as long as
Proof.
The proof is given in Section 4. ☐
The following is a concrete example providing some insight into this theorem.
Example 1.
Consider the single source scenario, where and , specified as follows.
Obviously, contains 3 non-trivial ideals , and , and and admit the distributions
![Entropy 19 00233 i001]() respectively. In addition, is a constant. Thus, by Theorem 2, rate is achievable if
In other words,
is achievable with linear coding over ring . Obviously, is just the region . Optimality is claimed.
respectively. In addition, is a constant. Thus, by Theorem 2, rate is achievable if
In other words,
is achievable with linear coding over ring . Obviously, is just the region . Optimality is claimed.
| 0 | 1 | 2 | 3 | 4 | 5 | |

Additionally, we would like to point out that some of the inequalities defining (22) are not active for specific scenarios. Two classes of these scenarios are discussed in the following theorems. The first, Theorem 3, is for scenarios where rings considered are product rings, while the second, Theorem 4, is for cases of lower triangle matrix rings (similarly, readers can consider usual matrix rings, which are often non-commutative, if interested).
Theorem 3.
Suppose () is a (finite) product ring of finite rings ’s, and the sample space satisfies for all feasible i and l. Given injections and let
where is defined as
We have that
where , is achievable with linear coding over . Moreover, .
Proof.
The proof is found in Section 4. ☐
Let be a finite ring and
where m is a positive integer. It is easy to verify that is a ring with respect to matrix operations. Moreover, is a left ideal of if and only if
Let be the set of all left ideals of the form
Theorem 4.
Let () be a finite ring such that . For any injections , let
where is defined as
We have that
where , is achievable with linear coding over . Moreover, .
Proof.
The proof is found in Section 4. ☐
Remark 9.
Remark 10.
Without much effort, one can see that ( and , respectively) in Theorem 2 (Theorem 3 and Theorem 4, respectively) depends on Φ via random variables ’s whose distributions are determined by Φ. For each , there exist distinct injections from to a ring of order at least . Let be the convex hull of a set . By a straightforward time sharing argument, we have that
is achievable with linear coding over .
Remark 11.
From Theorem 5, one will see that (22) and (36) are the same when all the rings are fields. Actually, both are identical to the SW region. However, (36) can be strictly larger than (22) (see Section 5), when not all the rings are fields. This implies that, in order to achieve the desired rate, a suitable injection is required. However, be reminded that taking the convex hull in (36) is not always needed for optimality as shown in Example 1. A more sophisticated elaboration on this issue is found in Section 5.
The rest of this section provides key supporting lemmata and concepts used to prove Theorems 2–4. The final proofs are presented in Section 4.
Lemma 2.
Let be two distinct sequences, where is a finite ring, and assume that . If is a random linear mapping chosen uniformly at random, i.e., generate the coefficient matrix of f by independently choosing each entry of from uniformly at random, then
where .
Proof.
Let , where is a random linear function. Then
since the ’s are independent from each other. The statement follows from Lemma 1, which ensures that . ☐
Remark 12.
In Lemma 2, if is a field and , then because every non-zero is a unit. Thus, .
Definition 7
([18]). Let be a discrete random variable with sample space . The set of strongly -typical sequencesof length n with respect to X is defined to be
where is the number of occurrences of x in the sequence .
The notation is sometimes replaced by when the length n and the random variable X referred to are clear from the context.
Now we conclude this section with the following lemma. It is a crucial part for our proofs of the achievability theorems. It generalizes the classic conditional typicality lemma ([19], Theorem 15.2.2), yet at the same time distinguishes our argument from the one for the field version.
Lemma 3.
Let be a jointly random variable whose sample space is a finite ring . For any , there exists , such that, and ,
where
and is a random variable with sample space .
Proof.
Define the mapping by
Assume that , and let
By definition, , where ,
Moreover,
For fixed , the number of strongly -typical sequences such that is strongly -typical is strictly upper bounded by if n is large enough and is small. Therefore,
☐
Remark 13.
We acknowledge an anonymous reviewer of our paper [20] for suggesting the proof for Lemma 3 given above. Our original proof was presented as a special case of a more general result in [21]. The techniques behind the two proofs are quite different, however the full generality of our original proof is appreciated better in non-i.i.d. scenarios, as in [21].
Remark 14.
Assume that , then is equivalent to .
4. Proof of the Achievability Theorems
4.1. Proof of Theorem 2
As mentioned, can be seen as a subset of for a fixed . In this section, we assume that has sample space , which makes sense since is injective.
Let and , , where n is the length of the data sequences. If , then (this implies that for some small constant and large enough n), . We claim that is achievable by linear coding over .
Encoding:
For every , randomly generate a matrix based on a uniform distribution, i.e., independently choose each entry of uniformly at random from . Define a linear encoder such that
Obviously the coding rate of this encoder is .
Decoding:
Subject to observing () from the ith encoder, the decoder claims that is the array of the encoded data sequences, if and only if:
- ; and
- , if , then , for some j.
Error:
Assume that () is the original data sequence generated by the ith source. It is readily seen that an error occurs if and only if one of the following events occurs:
- E1:
- ;
- E2:
- There exists , such that , .
Error Probability:
By the joint asymptotic equipartition principle (AEP) ([18], Theorem 6.9), , .
Additionally, for , let
We have
where and , since goes over all possible non-trivial left ideals. Consequently,
where
- (52) is from the fact that (disjoint union);
- (54) is from Lemmas 2 and 3, as well as the fact that every left ideal of is a Cartesian product of some left ideals of , (see Proposition 3). At the same time, is required to be sufficiently small;
- (55) is due to the facts that the number of non-empty subsets of is and the number of non-trivial left ideals of the finite ring is less than , which is the number of non-empty subsets of .
Thus, , when , from (55), since for sufficiently large n and small , .
Therefore, as and .
4.2. Proof of Theorem 3
The proof follows almost the same steps as in proving Theorem 2, except that the performance analysis only focuses on sequences () such that
for some . Let be any two such sequences satisfying for some . Based on the special structure of and , it is easy to verify that for all . (This causes the difference between (22) and (29).) In addition, it is obvious that by their definitions.
4.3. Proof of Theorem 4
The proof is similar to that for Theorem 2, except that it only focuses on sequences () such that satisfies for some . Let be any two such sequences such that for some . It is easily seen that if and only if (This causes the difference between (22) and (35).) In addition, it is obvious that by their definitions.
5. Optimality
Obviously, Theorem 2 specializes to its field counterpart if all rings considered are fields, as summarized in the following theorem.
Theorem 5.
Proof.
In Theorem 2, random variable admits a sample space of cardinality 1 for all , since the only non-trivial left ideal of is itself for all feasible i. Thus, . Consequently,
which is the SW region . Therefore, region (36) is also the SW region.
If is a field, then obviously it has no proper non-trivial left (right) ideal. Conversely, , implies that , such that . Similarly, , such that . Moreover, . Hence, . b is the inverse of a. By Wedderburn’s little theorem, is a field. ☐
One important question to address is whether linear coding over finite non-field rings can be equally optimal for data compression. Hereby, we claim that, for any SW scenario, there always exist linear encoders over some finite non-field rings which achieve the data compression limit. Therefore, optimality of linear coding over finite non-field rings for data compression is established in the sense of existence.
5.1. Existence Theorem I: Single Source
For any single source scenario, the assertion that there always exists a finite ring , such that is in fact the SW region
is equivalent to the existence of a finite ring and an injection , such that
where .
Theorem 6.
Remark 15.
Examples of such a non-field ring in the above theorem include
( is a ring with respect to matrix addition and multiplication) and , where p is any prime. For any single source scenario, one can always choose to be either or . Consequently, optimality is attained.
Proof of Theorem 6.
Notice that the random variable depends on the injection , so does its entropy . Obviously , since the sample space of the random variable contains only one element. Therefore,
Consequently, (59) is equivalent to
since . By Lemma A1, there exists injection such that (62) holds if . The statement follows. ☐
Up to isomorphism, there are exactly 4 distinct rings of order for a given prime p. They include 3 non-field rings, , and , in addition to the field . It has been proved that, using linear encoders over the last three, optimality can always be achieved in the single source scenario. Actually, the same holds true for all multiple sources scenarios.
5.2. Existence Theorem II: Multiple Sources
Theorem 7.
Let be s finite rings with . If is isomorphic to either
- 1.
- a field, i.e., contains no proper non-trivial left (right) ideal; or
- 2.
- a ring containing one and only one proper non-trivial left ideal and ,
Remark 16.
It is obvious that Theorem 7 includes Theorem 6 as a special case. In fact, its proof resembles the one of Theorem 6. Examples of ’s include all finite fields, and , where p is a prime. However, Theorem 7 does not guarantee that all rates, except the vertexes , in the polytope of the SW region are “directly” achievable for the multiple sources case. A time sharing scheme is required in our current proof. Nevertheless, all rates are “directly” achievable if ’s are fields or if . This is partially the reason that the two theorems are stated separately.
Remark 17.
Theorem 7 also includes Theorem 5 as a special case. However, Theorem 5 admits a simpler proof compared to the one for Theorem 7.
Proof of Theorem 7.
It suffices to prove that, for any satisfies
for some set of injections , where . Let be the set of injections, where, if
- (i)
- is a field, is any injection;
- (ii)
- satisfies 2, is the injection such thatwhen . The existence of is guaranteed by Lemma A1.
If , then
for all and . As a consequence,
for all . Thus, . ☐
By Theorems 5–7, we draw the conclusion that
Corollary 1.
For any SW scenario, there always exists a sequence of linear encoders over some finite rings (fields or non-field rings) which achieves the data compression limit, the SW region.
In fact, LCoR can be optimal even for rings beyond those stated in the above theorems (see Example 1). We classify some of these scenarios in the remaining parts of this section.
5.3. Product Rings
Theorem 8.
Let () be a set of finite rings of equal size, and for all feasible i. If the coding rate is achievable with linear encoders over (), then is achievable with linear encoders over .
Proof.
By definition, is a convex combination of coding rates which are achieved by different linear encoding schemes over (), respectively. To be more precise, there exist and positive numbers with , such that . Moreover, there exist injections (), where , such that
where , and is a random variable with sample space . To show that is achievable with linear encoders over , it suffices to prove that is achievable with linear encoders over for all feasible j. Let . For all and with (), we have
where . By (72), it can be easily seen that
Meanwhile, let , , (Note:
for all .) and . It can be verified that () is a function of , hence, . Consequently,
which implies that by Theorem 3. We therefore conclude that is achievable with linear encoders over for all feasible j, so is . ☐
Obviously, in Theorem 8 are of the same size. Inductively, one can verify the following without any difficulty.
Theorem 9.
Let be any finite index set, () be a set of finite rings of equal size, and for all feasible i. If the coding rate is achievable with linear encoders over (), then is achievable with linear encoders over .
Remark 18.
There are delicate issues to the situation Theorem 9 (Theorem 8) illustrates. Let () be the set of all symbols generated by the ith source. The hypothesis of Theorem 9 (Theorem 8) implicitly implies the alphabet constraint for all feasible i and l.
Let be s finite rings each of which is isomorphic to either
- a ring containing one and only one proper non-trivial left ideal whose order is , e.g., and (p is a prime); or
- a ring of a finite product of finite field(s) and/or ring(s) satisfying 1), e.g., (p and ’s are prime) and ( and are non-negative, ’s are prime and ’s are power of primes).
Theorems 7 and 9 ensure that linear encoders over ring are always optimal in any applicable (subject to the condition specified in the corresponding theorem) SW coding scenario. As a very special case, , where p is a prime, is always optimal in any (single source or multiple sources) scenario with alphabet size less than or equal to p. However, using a field or product rings is not necessary. As shown in Theorem 6, neither nor is (isomorphic to) a product of rings nor a field. It is also not required to have a restriction on the alphabet size (see Theorem 7), even for product rings (see Example 1 for a case of ).
5.4. Trivial Case: Uniform Distributions
The following theorem is trivial, however we include it for completeness.
Theorem 10.
Regardless which set of rings is chosen, as long as for all feasible i, region (22) is the SW region if is a uniform distribution.
Proof.
If p is uniform, then, for any and , is uniformly distributed on . Moreover, and are independent, so are and . Therefore, and . Consequently,
Region (22) is the SW region. ☐
Remark 19.
When p is uniform, it is obvious that the uncoded strategy (all encoders are one-to-one mappings) is optimal in the SW source coding problem. However, optimality stated in Theorem 10 does not come from deliberately fixing the linear encoding mappings, but generating them randomly.
So far, we have only shown that there exist linear encoders over finite non-field rings that are equally good as their field counterparts. In next section, Problem 1 is considered with an arbitrary g. It will be demonstrated that linear coding over finite non-field rings can strictly outperform its field counterpart for encoding some discrete functions, and there are infinitely many such functions.
6. Application: Source Coding for Computing
The problem of Source Coding for Computing, Problem 1, with an arbitrary g is addressed in this section. Some advantages of LCoR (compared to LCoF) will be demonstrated. We begin with establishing the following theorem which can be recognized as a generalization of Körner–Marton [4].
Theorem 11.
Let be a finite ring, and
and ’s are functions mapping to . Then
where and .
Proof.
By Theorem 2, , there exists a large enough n, an matrix and a decoder , such that , if . Let () be the encoder of the ith source. Upon receiving from the ith source, the decoder claims that , where , is the function, namely , subject to computation. The probability of decoding error is
Therefore, all , where , is achievable, i.e., . ☐
Corollary 2.
In Theorem 11, let . We have
if either of the following conditions holds:
- 1.
- is isomorphic to a finite field;
- 2.
- is isomorphic to a ring containing one and only one proper non-trivial left ideal with , and
Proof.
If either (1) or (2) holds, then it is guaranteed that
in Theorem 11. The statement follows. ☐
Remark 20.
By Lemma A2, examples of non-field rings satisfying (2) in Corollary 2 includes
- (1)
- with satisfying
- (2)
Interested readers can figure out even more explicit examples deduced from Lemma A1.
Remark 21.
We claim that there are functions g for which LCoR outperforms LCoF; in fact, there are infinite many such g’s. To prove this, some definitions are required for the mechanics of our argument.
Definition 8.
Let and be two functions. If there exist bijections , , and , such that
then and are said to be equivalent(via and ν).
Definition 9.
Given function , and let . The restriction of g on is defined to be the function such that .
Lemma 4.
Let and Ω be some finite sets. For any discrete function there always exist a finite ring (field) and a polynomial function such that
for some injections () and .
Proof.
There are several possible proofs of this lemma. One is provided in Appendix B. ☐
Remark 22.
Up to equivalence, a function can be presented in many different formats. For example, the function defined on (with ordering ) can either be seen as on or be treated as the restriction of defined on to the domain .
Lemma 4 implies that any discrete function defined on a finite domain is equivalent to a restriction of some polynomial function over some finite ring (field). As a consequence, we can restrict Problem 1 to all polynomial functions. This polynomial approach offers valuable insight into the general problem, because the algebraic structure of a polynomial function is clearer than that of an arbitrary function. We often call in Lemma 4 a polynomial presentation of g. On the other hand, the given by (78) is named a nomographic function over (by terminology borrowed from [22]), it is said to be a nomographic presentation of g if g is equivalent to a restriction of it.
Lemma 5.
Let and Ω be some finite sets. For any discrete function , there exists a nomographic function over some finite ring (field) such that
for some injections () and .
Proof.
There are several proofs of this lemma. One is provided in Appendix B. ☐
Lemma 5 advances Lemma 4 by claiming that a discrete function with a finite domain is always equivalent to a restriction of some nomographic function. From this, it is seen that Theorem 11 and Corollary 2 have presented a universal solution to Problem 1.
Given some finite ring , let of format (78) be a nomographic presentation of g. We say that the region given by (79) is achievable for computing g in the sense of Körner–Marton. From Theorem 13 given later, we know that might not be the largest achievable region one can obtain for computing g. However, still captures the ability of linear coding over when used for computing g. In other words, is the region purely achieved with linear coding over for computing g. On the other hand, regions from Theorem 13 are achieved by combining the linear coding and the standard random coding techniques. Therefore, it is reasonable to compare LCoR with LCoF in the sense of Körner–Marton.
We show that linear coding over finite rings, non-field rings in particular, strictly outperforms its field counterpart, LCoF, in the following example.
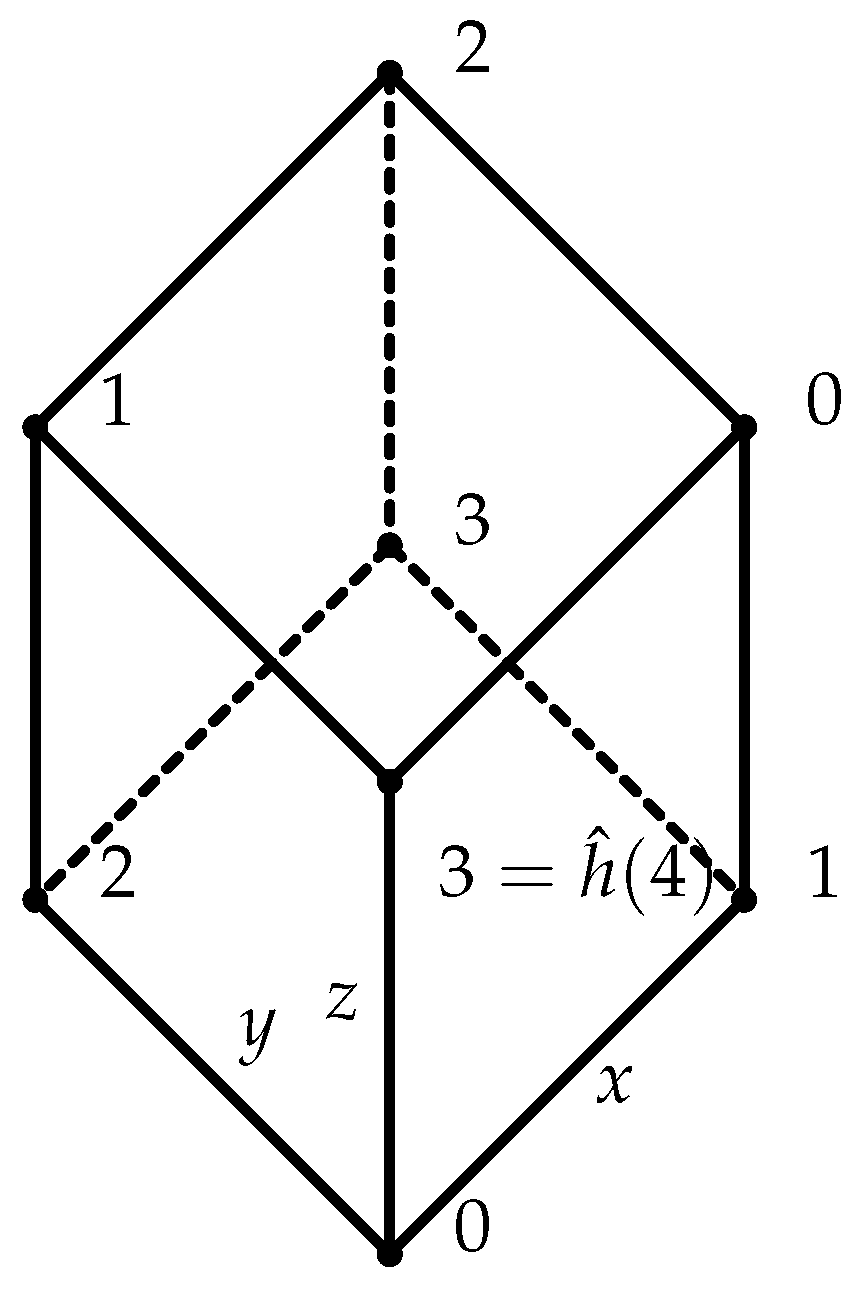
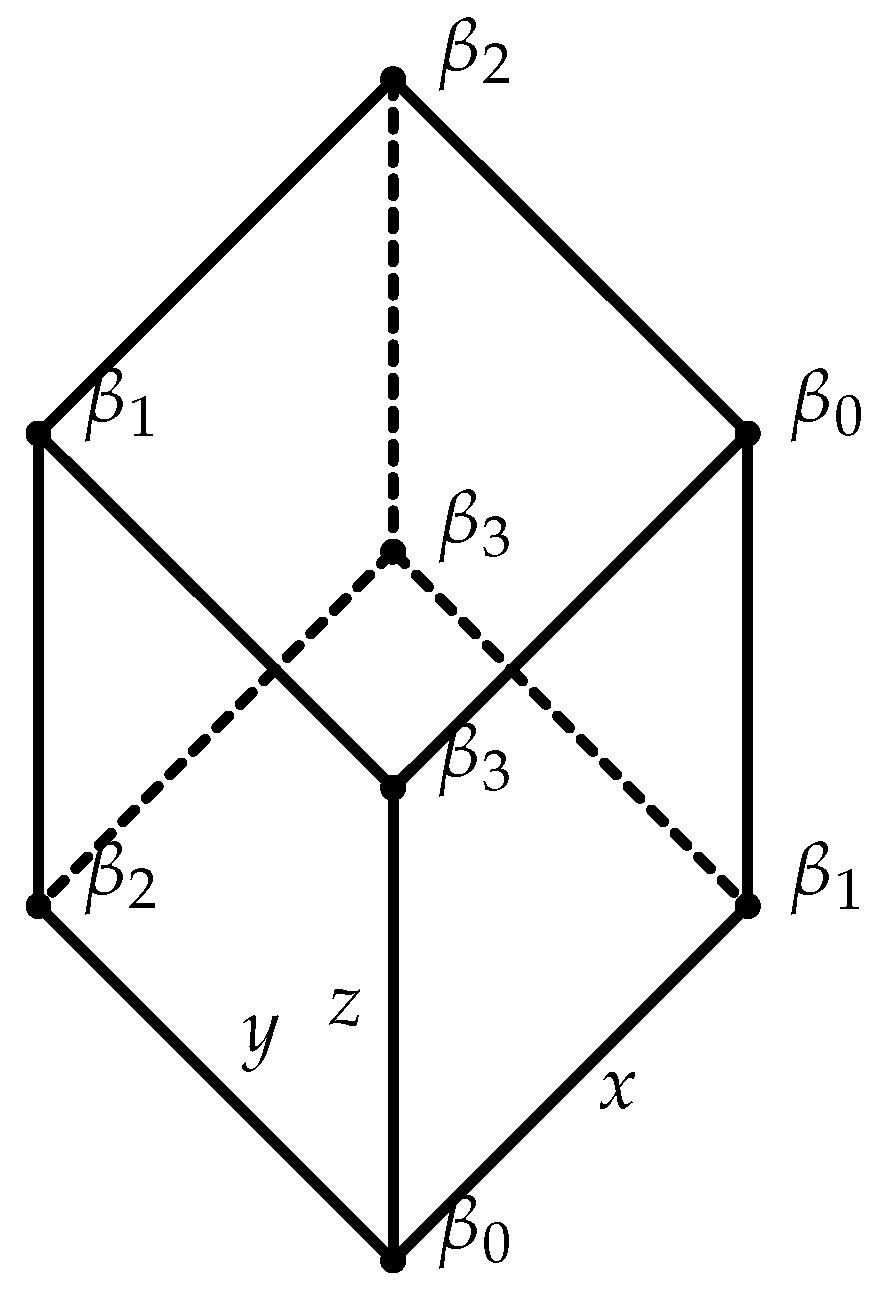
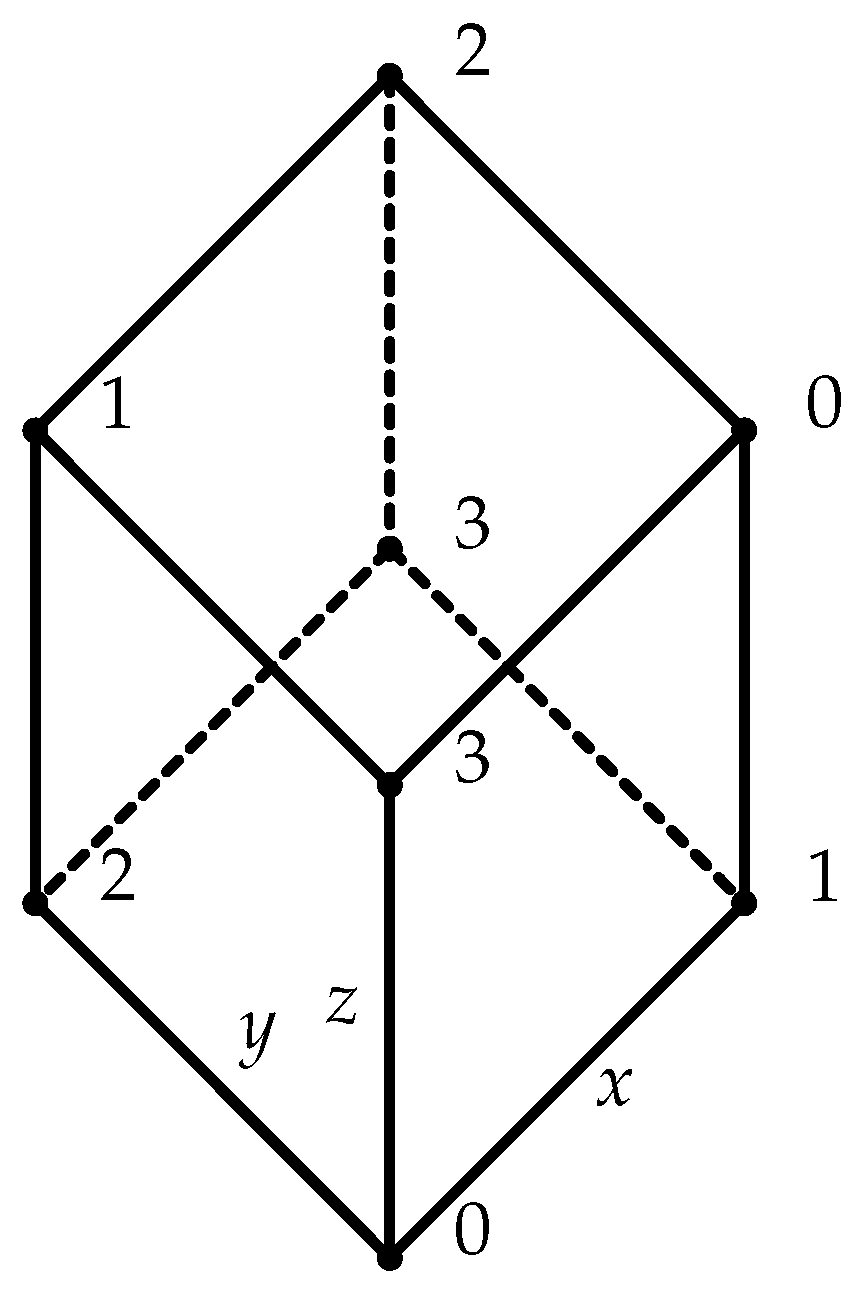
Example 2
([23]). Let (Figure 1) be a function such that
Define and by
respectively. Obviously, g is equivalent to (Figure 2) via and ν. However, by Proposition 4, there exists no of format (78) so that g is equivalent to any restriction of . Although, Lemma 5 ensures that there always exists a bigger field such that g admits a presentation of format (78), the size q must be strictly bigger than 4. For instance, let
Then, g has presentation (Figure 3) via and defined (symbolic-wise) by (95).
Proposition 4.
Proof.
Suppose , where , are injections, and with for all feasible i. We claim that and h are both surjective, since In particular, h is bijective. Therefore, , i.e., g admits a presentation . A contradiction to Lemma A3. ☐
As a consequence of Proposition 4, in the sense of Körner–Marton, in order to use LCoF to encode function g, the alphabet sizes of the three encoders need to be at least 5. However, LCoR offers a solution in which the alphabet sizes are 4, strictly smaller than using LCoF. Most importantly, the region achieved with linear coding over any finite field , is always a subset of the one achieved with linear coding over . This is proved in the following proposition.
Proposition 5.
Let g be the function defined by (94), be the sample space of and be the distribution of . If
satisfying (89), then, in the sense of Körner–Marton, the region achieved with linear coding over contains the one, that is , obtained with linear coding over any finite field for computing g. Moreover, if is the whole domain of g, then .
Proof.
Let be a polynomial presentation of g with format (78). By Corollary 2 and Remark 20, we have
Assume that , where and are injections. Obviously, is a function of . Hence,
On the other hand, . Therefore,
and . In addition, we claim that , where , is not injective. Otherwise, , where , is bijective, hence, . A contradiction to Lemma A3. Consequently, . If , then (100) as well as (101) hold strictly, thus, . ☐
A more intuitive comparison (which is not as conclusive as Proposition 5) can be identified from the presentations of g given in Figure 2 and Figure 3. According to Corollary 2, linear encoders over field achieve
The one achieved by linear encoders over ring is
Clearly, , thus, contains . Furthermore, as long as
is strictly larger than , since . To be specific, assume that satisfies Table 1, we have
Based on Propositions 4 and 5, we conclude that LCoR dominates LCoF, in terms of achieving better coding rates with smaller alphabet sizes of the encoders for computing g. As a direct conclusion, we have:
Theorem 12.
In the sense of Körner–Marton, LCoF is not optimal.
Remark 23.
The key property underlying the proof of Proposition 5 is that the characteristic of a finite field must be a prime while the characteristic of a finite ring can be any positive integer larger than or equal to 2. This implies that it is possible to construct infinitely many discrete functions for which using LCoF always leads to a suboptimal achievable region compared to linear coding over finite non-field rings. Examples include for and prime (note: the characteristic of is which is not a prime). One can always find an explicit distribution of sources for which linear coding over strictly dominates linear coding over each and every finite field.
As mentioned, given by (79) is sometimes strictly smaller than . This was first shown by Ahlswede–Han [5] for the case of g being the modulo-two sum. Their approach combines the linear coding technique over a binary field with the standard random coding technique. In the following, we generalize the result of Ahlswede–Han ([5], Theorem 10) to the settings, where g is arbitrary, and, at the same time, LCoF is replaced by its generalized version, LCoR.
Consider function admitting
where and ’s are functions mapping to . By Lemma 5, a discrete function with a finite domain is always equivalent to a restriction of some function of format (107). We call from (107) a pseudo nomographic function over ring .
Theorem 13.
Let . If is of format (107), and satisfying
where , ; , , ’s are discrete random variables such that
and , , then .
Proof.
The proof can be completed by applying the tricks from Lemmas 2 and 3 to the approach generalized from Ahlswede–Han ([5], Theorem 10). Details are found in Appendix C. ☐
7. Conclusions
7.1. Right Linearity
Careful readers might have noticed that the encoders we used so far are actually left linear mappings. By symmetry, almost all related statements can be easily reproved for right linear mappings (encoders). As an example, the following corresponds to Theorem 2.
Theorem 14.
For any ,
where and , is achievable with (right) linear coding over the finite rings .
By time sharing,
where is given by (110), is achievable with (right) LCoR.
7.2. Field, Ring, Rng and Group
Conceptually speaking, LCoR is in fact a generalization of the linear coding technique proposed by Elias [2] and Csiszár [3] (LCoF), since a field must be a ring. However, as seen in Section 4, analyzing the decoding error for the ring version is in general substantially more challenging than in the case of the field version. Our approach crucially relies on the concept of ideals. A field contains no non-trivial ideal but itself. Because of this special property of fields, our general argument for finite rings will render to a simple one when only finite fields are considered.
Even though our analysis for the ring scenario is more complicated than that for finite field scenarios, linear encoders working over some finite rings are in general considerably easier to implement in practice. This is because the implementation of finite field arithmetic can be quite demanding. Normally, a finite field is given by its polynomial representation, operations are carried out based on the polynomial operations (addition and multiplication) followed by the polynomial long division algorithm. In contrast, implementing arithmetic of many finite rings is a straightforward task. For instance, the arithmetic of modulo integers ring , for any positive integer q, is simply the integer modulo q arithmetic.
In addition, it is also very interesting to consider instead linear coding over rngs. It will be even more intriguing should it turn out that the rng version outperforms the ring version in the computing problem (Problem 1), in the same manner that the ring version outperforms its field counterpart. It will also be interesting to see whether the idea of using rng provides more understanding of the problems from [6,8].
Some works, including [24,25,26], have proposed to implement coding over a simpler algebraic structure, that of a group. Seemingly, this corresponds to a more universal approach since both fields and rings are also groups. However, one subtle issue is often overlooked in this context. Namely, the set of rings (or rngs) is not a subset of the set of groups, since several non-isomorphic rings (or rngs) can be defined on one and the same group. For instance, given two distinct primes p and q, up to isomorphism,
- there are 2 finite rngs of order p, while there is only one group of order p;
- there are 4 finite rngs of order ;
- there are 11 finite rngs of order (if , then 4 of them are rings, namely , , and [27]), while there are only 2 groups of order , both of which are Abelian;
- there are 22 finite rngs of order ;
- there are 52 finite rngs of order 8;
- there are finite rngs of order (), while there are 5 groups of order , 3 of which are Abelian.
Therefore, there is no one-to-one correspondence between rings (field or rngs) and groups, in either direction. Furthermore, from the point of view of formulating a multivariate function, one is highly restricted by using groups, compared to rings (rng or field). Specifically, it is well-known that every discrete function defined on a finite domain is essentially a restriction of some polynomial function over a finite ring (rng or field). Although non-Abelian structures (non-Abelian groups) have the potential to lead to important non-trivial results [28], they are very difficult to handle theoretically and in practice. The performance of non-Abelian group block codes can be quite bad [29].
7.3. Final Remarks
This paper establishes achievability theorems regarding linear coding over finite rings for Slepian–Wolf data compression. Our results include related work from Elias [2] and Csiszár [3] regarding linear coding over finite fields as special cases in the sense of characterizing the achievable region. We have also proved that, for any Slepian–Wolf scenario, there always exists a sequence of linear encoders over some finite rings (non-field rings in particular) that achieves the data compression limit, the Slepian–Wolf region. Thus, with regard to existence, the optimality issue of linear coding over finite non-field rings for data compression is confirmed positively.
In addition, we also address the problem of source coding for computing, Problem 1. Results of Körner–Marton [4], Ahlswede–Han ([5], Theorem 10) and [7] are generalized to corresponding ring versions. Based on these, it is demonstrated that LCoR dominates its field counterpart for encoding (infinitely) many discrete functions.
Appendix A. Supporting Lemmata
Lemma A1.
Let be a finite ring, X and Y be two correlated discrete random variables, and be the sample space of X with . If contains one and only one proper non-trivial left ideal and , then there exists injection such that
Proof.
Let
where is the set of all possible ’s (maximum can always be reached because is finite, but it is not uniquely attained by in general). Assume that is the sample space (not necessarily finite) of Y. Let , and . We have that
where
(Note: if . In addition, every element in can be uniquely expressed as .) Therefore, (A1) is equivalent to
where by the grouping rule for entropy ([19], p. 49). Let
The concavity of the function H implies that
At the same time,
by the definition of . We now claim that
Suppose otherwise, i.e., . Let be defined as
(Note: is an element of . It can be uniquely presented as for some i and j.) We have that
It is absurd that ! Therefore, (A8) is valid by (A10) and (A12), so is (A1). ☐
Lemma A2.
If both
are valid, and , then
Proof [30].
Without loss of generality, we assume that which implies that . Let , , be the binary entropy function. By the grouping rule for entropy ([19], p. 49), (A17) equals to
Since is a concave function and , then
Moreover, guarantees that
because , , and if . Therefore, and (A17) holds. ☐
Lemma A3.
No matter which finite field is chosen, g given by (94) admits no presentation , where for all feasible i.
Proof.
Suppose otherwise, i.e., for some injections and . By (94), we have
where . Since is injective, (A26) implies that either or by Proposition 2. Noticeable that , i.e., , otherwise, which contradicts the assumption that is injective. Thus, . Let . Obviously, because of the same reason that , and since . Therefore,
This contradicts the assumption that is injective. ☐
Remark A1.
As a special case, this lemma implies that no matter which finite field is chosen, g defined by (94) has no polynomial presentation that is linear over . In contrast, g admits presentation which is a linear function over .
Appendix B. Proofs of Lemmas 4 and 5
Appendix B.1. Proof of Lemma 4
Let p be a prime such that for some integer m, and choose to be a finite field of order . By ([31], Lemma 7.40), the number of polynomial functions in is . Moreover, the number of distinct functions with domain and codomain is also . Hence, any function is a polynomial function.
In the meanwhile, any injections () and give rise to a function
where is the inverse mapping of . Since must be a polynomial function as shown, the statement is established.
Remark A2.
Another proof involving Fermat’s little theorem can be found in [6].
Appendix B.2. Proof of Lemma 5
Let be a finite field such that for all and , and let be the splitting field of of order (one example of the pair and is the , where p is some prime, and its Galois extension of degree s). It is easily seen that is an s dimensional vector space over . Hence, there exist s vectors that are linearly independent. Let be an injection from to the subspace generated by vector . It is easy to verify that is injective since are linearly independent. Let be the inverse mapping of and be any injection. By ([31], Lemma 7.40), there exists a polynomial function such that Let . The statement is proved.
Remark A3.
In the proof, k is chosen to be injective because the proof includes the case that g is an identity function. In general, k is not necessarily injective.
Appendix C. Proof of Theorem 13
Choose , such that , , , , and , where , .
Appendix C.3. Encoding:
Fix the joint distribution p which satisfies (109). For all , let . For all , generate randomly strongly -typical sequences according to distribution and let be the set of these generated sequences. Define mapping as follows:
- If , then, , where is fixed.
- If , then for every , let . If and , then is set to be some element in ; otherwise is some fixed .
Define mapping by randomly choosing the value for each according to a uniform distribution.
Let . When n is big enough, we have . Randomly generate a matrix , and let () be the function .
Define the encoder as the follows
Appendix C.4. Decoding:
Upon observing at the decoder, the decoder claims that
is the function of the generated data, if and only if there exists one and only one
such that , and is the only element in the set
Appendix C.5. Error:
Assume that is the data generated by the jth source and let . An error happens if and only if one of the following events happens.
- E1:
- ;
- E2:
- There exists some , such that ;
- E3:
- , where and ;
- E4:
- There exists , , such that , ;
- E5:
- or , i.e., there exists , , such that and .
Let , where and for . In the following, we show that , .
(a). By the joint AEP ([18], Theorem 6.9), , .
(b). Let , . Then
For any , because the sequence and are drawn independently, we have
when n is big enough. Thus,
where (A42) holds true for all big enough n and the limit follow from the fact that , Therefore, , by (A38).
(c). By (109), it is obvious that forms a Markov chain for any two disjoint nonempty sets . Thus, if for all and , then . In the meantime, is also a Markov chain. Hence, if . Therefore, .
(d). For all , let and
By definition, and
where . Equality (A44) holds because the processes of choosing ’s and generating are done independently. (A45) follows from Lemma A4 and the definitions of ’s. (A46) is from Lemma A5.
Lemma A4.
Let . For any and positive integer n, choose a sequence () randomly from based on a uniform distribution. If is an ϵ-typical sequence with respect to Y, then
Proof.
Let be the event , , and . We have
since are generated independent. ☐
Lemma A5.
If , and
then, ,
(e). Let and . We have , because contains the event that and V is unique. Therefore,
Choose a small such that . Then
where (A53) is from Lemmas 2 and 3 (for all large enough n and small enough ) and (A54) is because for all .
To summarize, by (a)–(e), we have . The theorem is established.
Appendix D. On Coding over Abelian Groups
As discussed in Section 2, since in this paper we focus on linear encoding, we need to work over a field or a ring. In general, most of the existing coding literature assumes coding over fields, especially when the focus is on linear encoding. Some both traditional and recent work, including [9,10,11], has however also considered (Abelian) groups, while significantly fewer results are available for coding over rings. In this appendix we elaborate on the relation between coding over fields, rings and groups in order to clearly show that our results in this paper are not subsumed by previous work on coding over groups. To highlight this fact even further, the following constitutes a counterexample to illustrate that “linear” operations over groups are not well-defined: In the case of the Abelian group (p is a prime), there are at least three distinct definitions of multiplication to define rings over G. These rings are isomorphic to either
- the field which is commutative; or
- the non-field ringwhich is not commutative; or
- the product ring which is commutative.
Suppose “linear operation over group G” is defined with respect to some multiplicative operation “*”, at the same time, this linear scheme over G includes the three distinct linear coding schemes defined over , and simultaneously. We then conclude that the operation “*” is commutative and non-commutative at the same time, a contradiction.
To be more specific about the fundamental differences, beyond linearity, between coding over groups, as in e.g., [11], and coding over fields or rings we also provide the following list of additional remarks.
- (R1)
- Consider the example given in ([11], Section VIII.B.1) for reconstruction of the modulo-two sum of binary symmetric sources [4]. On ([11], p. 1509), it reads “Rate points achieved by embedding the function in the Abelian groups , are strictly worse than that achieved by embedding the function in while embedding in gives the Slepian–Wolf rate region for the lossless reconstruction of ” ( should be from the context, because coding over is not strictly worse than coding over for lossless reconstruct the original data [3].).Ref. [11] clearly states that group coding over for encoding the modulo-two sum of symmetric sources gives only the Slepian–Wolf region. On the contrary, consider either the finite field or the non-field ring(note: the underlying Abelian group defining and is ). We claim that linear coding over either or for encoding the modulo-two sum of symmetric sources gives the Körner–Marton region [4]. This is because linear coding over finite field, e.g., , is always optimal for the Slepian–Wolf problem, so is linear coding over non-field ring by Theorem 7. However, group coding over is not.It is well-known that the Körner–Marton region is often strictly larger than the Slepian–Wolf region. Linear coding over the non-field ring (field ), as a special case (nonlinear) coding over Abelian group must not achieve a region larger than the Slepian–Wolf region, leading to a contradiction.
- (R2)
- Row 2 of TABLE III in [11] states that group coding over (achieving sum rate ) is strictly worse than over the group (achieving sum rate 3) for lossless encoding of a quaternary function ([11], Section VIII.A). On the contrary, linear coding over the ring (with underlying Abelian group ) always achieves a region containing the one achieved by linear coding over ring . This is implied by Theorem 3. By direct calculation, we have that linear coding over the ring (achieving sum rate 3) is strictly better than what is achieved by coding over over the Abelian group (achieving sum rate ).
- (R3)
- Finally, we emphasize that according to the Fundamental Theorem of (Finite) Abelian Group ([12], Theorem 5.25), up to isomorphism, every finite Abelian group is a direct sum of cyclic groups of prime-power order ([12], Proposition 5.27). This implies that every finite Abelian group can be represented via direct sum of modulo integers. However, many finite rings are not (isomorphic to) direct product of modulo integers, e.g., finite fields (when q is a power of a prime but is not a prime), matrix rings (when is any positive integer) and all non-commutative rings. For a fixed order (e.g., with p being a prime), the number of finite rings is often significantly bigger than the number of finite Abelian groups. For instance, there are 4 rings of order 4 while there are 2 groups of order 4.
Acknowledgments
The authors would like to thank their colleagues Jinfeng Du and Mattias Andersson for assistance in proving Lemma A2. They are also very grateful to an anonymous reviewer of the paper [20] for suggesting an alternative proof of Lemma 3. This work was funded in part by the Swedish Research Council.
Author Contributions
Sheng Huang contributed to the original idea, the analysis and proofs, and wrote the paper. Mikael Skoglund helped to polish the idea and the analysis, and wrote the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Slepian, D.; Wolf, J.K. Noiseless Coding of Correlated Information Sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Elias, P. Coding for Noisy Channels. IRE Conv. Rec. 1955, 3, 37–46. [Google Scholar]
- Csiszár, I. Linear Codes for Sources and Source Networks: Error Exponents, Universal Coding. IEEE Trans. Inf. Theory 1982, 28, 585–592. [Google Scholar] [CrossRef]
- Körner, J.; Marton, K. How to Encode The Modulo-Two Sum of Binary Sources. IEEE Trans. Inf. Theory 1979, 25, 219–221. [Google Scholar] [CrossRef]
- Ahlswede, R.; Han, T.S. On Source Coding with Side Information via a Multiple-Access Channel and Related Problems in Multi-User Information Theory. IEEE Trans. Inf. Theory 1983, 29, 396–411. [Google Scholar] [CrossRef]
- Huang, S.; Skoglund, M. Polynomials and Computing Functions of Correlated Sources. In Proceedings of the 2012 IEEE International Symposium on Information Theory, Cambridge, MA, USA, 1–6 July 2012; pp. 771–775. [Google Scholar]
- Huang, S.; Skoglund, M. Computing Polynomial Functions of Correlated Sources: Inner Bounds. In Proceedings of the International Symposium on Information Theory and Its Applications, Honolulu, HI, USA, 28–31 October 2012; pp. 160–164. [Google Scholar]
- Han, T.S.; Kobayashi, K. A Dichotomy of Functions F(X, Y) of Correlated Sources (X, Y) from the Viewpoint of the Achievable Rate Region. IEEE Trans. Inf. Theory 1987, 33, 69–76. [Google Scholar] [CrossRef]
- Como, G.; Fagnani, F. The Capacity of Finite Abelian Group Codes over Symmetric Memoryless Channels. IEEE Trans. Inf. Theory 2009, 55, 2037–2054. [Google Scholar] [CrossRef]
- Como, G. Group codes outperform binary-coset codes on nonbinary symmetric memoryless channels. IEEE Trans. Inf. Theory 2010, 56, 4321–4334. [Google Scholar] [CrossRef]
- Krithivasan, D.; Pradhan, S. Distributed Source Coding Using Abelian Group Codes: A New Achievable Rate-Distortion Region. IEEE Trans. Inf. Theory 2011, 57, 1495–1519. [Google Scholar] [CrossRef]
- Rotman, J.J. Advanced Modern Algebra, 2nd ed.; American Mathematical Society: Providence, RI, USA, 2010. [Google Scholar]
- Mullen, G.; Stevens, H. Polynomial functions (modm). Acta Math. Hung. 1984, 44, 237–241. [Google Scholar] [CrossRef]
- Hungerford, T.W. Algebra (Graduate Texts in Mathematics); Springer: New York, NY, USA, 1980. [Google Scholar]
- Lam, T.Y. A First Course in Noncommutative Rings, 2nd ed.; Springer: New York, NY, USA, 2001. [Google Scholar]
- Dummit, D.S.; Foote, R.M. Abstract Algebra, 3rd ed.; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Anderson, F.W.; Fuller, K.R. Rings and Categories of Modules, 2nd ed.; Springer: New York, NY, USA, 1992. [Google Scholar]
- Yeung, R.W. Information Theory and Network Coding, 1st ed.; Springer: New York, NY, USA, 2008. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Huang, S.; Skoglund, M. On achievability of linear source coding over finite rings. In Proceedings of the 2013 IEEE International Symposium on Information Theory Proceedings (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 1984–1988. [Google Scholar]
- Huang, S.; Skoglund, M. Encoding Irreducible Markovian Functions of Sources: An Application of Supremus Typicality; KTH Royal Institute of Technology: Stockholm, Sweden, 2013. [Google Scholar]
- Buck, R.C. Nomographic Functions are Nowhere Dense. Proc. Am. Math. Soc. 1982, 85, 195–199. [Google Scholar] [CrossRef]
- Huang, S.; Skoglund, M. Linear Source Coding over Rings and Applications. In Proceedings of the IEEE Swedish Communication Technologies Workshop, Lund, Sweden, 24–26 October 2012; pp. 1–6. [Google Scholar]
- Slepian, D. Group Codes for the Gaussian Channel. Bell Syst. Tech. J. 1968, 47, 575–602. [Google Scholar] [CrossRef]
- Ahlswede, R. Group Codes do not Achieve Shannon’s Channel Capacity for General Discrete Channels. Ann. Math. Stat. 1971, 42, 224–240. [Google Scholar] [CrossRef]
- Forney, G.D., Jr. On the Hamming distance properties of group codes. IEEE Trans. Inf. Theory 1992, 38, 1797–1801. [Google Scholar] [CrossRef]
- Singmaster, D.; Bloom, D.M. Rings of Order Four. Math. Assoc. Am. 1964, 71, 918–920. [Google Scholar] [CrossRef]
- Chan, T.H.; Grant, A. Entropy vector and network codes. In Proceedings of the IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007. [Google Scholar]
- Interlando, J.C.; Palazzo, R., Jr.; Elia, M. Group Block Codes Over Nonabelian Groups are Asymptotically Bad. IEEE Trans. Inf. Theory 1996, 42, 1277–1280. [Google Scholar] [CrossRef]
- Du, J.; KTH Royal Institute of Technology, Stockholm, Sweden; Andersson, M.; KTH Royal Institute of Technology, Stockholm, Sweden. Personal Communication, 2012.
- Lidl, R.; Niederreiter, H. Finite Fields, 2nd ed.; Gambridge University Press: New York, NY, USA, 1997. [Google Scholar]
Figure 1.
.
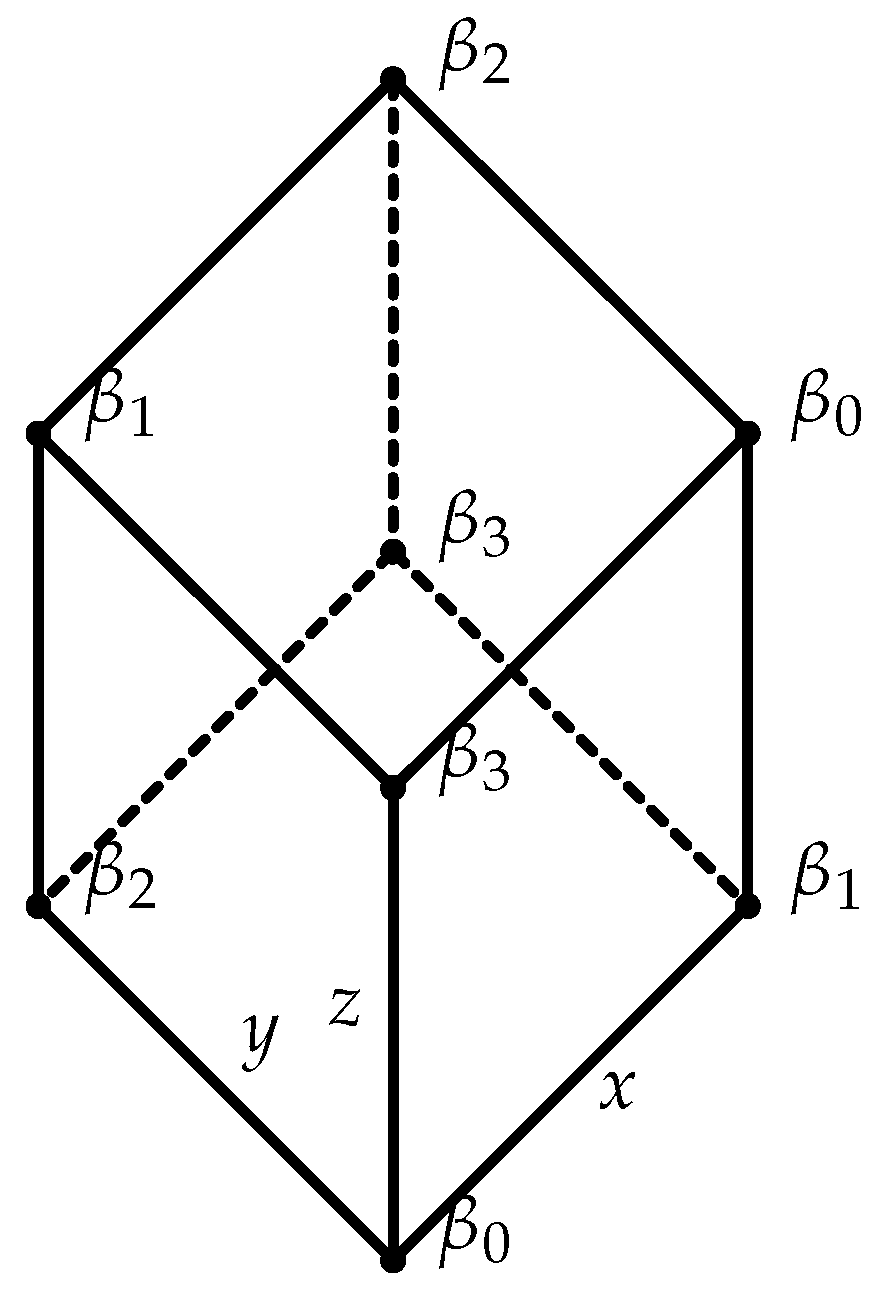
Figure 2.
.

Figure 3.
.

{kind=link}
{kind=link}
{kind=link}
Table 1.
Distribution p.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Huang, S.; Skoglund, M. On Linear Coding over Finite Rings and Applications to Computing. Entropy 2017, 19, 233. https://doi.org/10.3390/e19050233
AMA Style
Huang S, Skoglund M. On Linear Coding over Finite Rings and Applications to Computing. Entropy. 2017; 19(5):233. https://doi.org/10.3390/e19050233
Chicago/Turabian StyleHuang, Sheng, and Mikael Skoglund. 2017. "On Linear Coding over Finite Rings and Applications to Computing" Entropy 19, no. 5: 233. https://doi.org/10.3390/e19050233
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.