Effects of Plot Positioning Errors on the Optimality of Harvest Prescriptions When Spatial Forest Planning Relies on ALS Data


Abstract
:1. Introduction
2. Materials and Methods
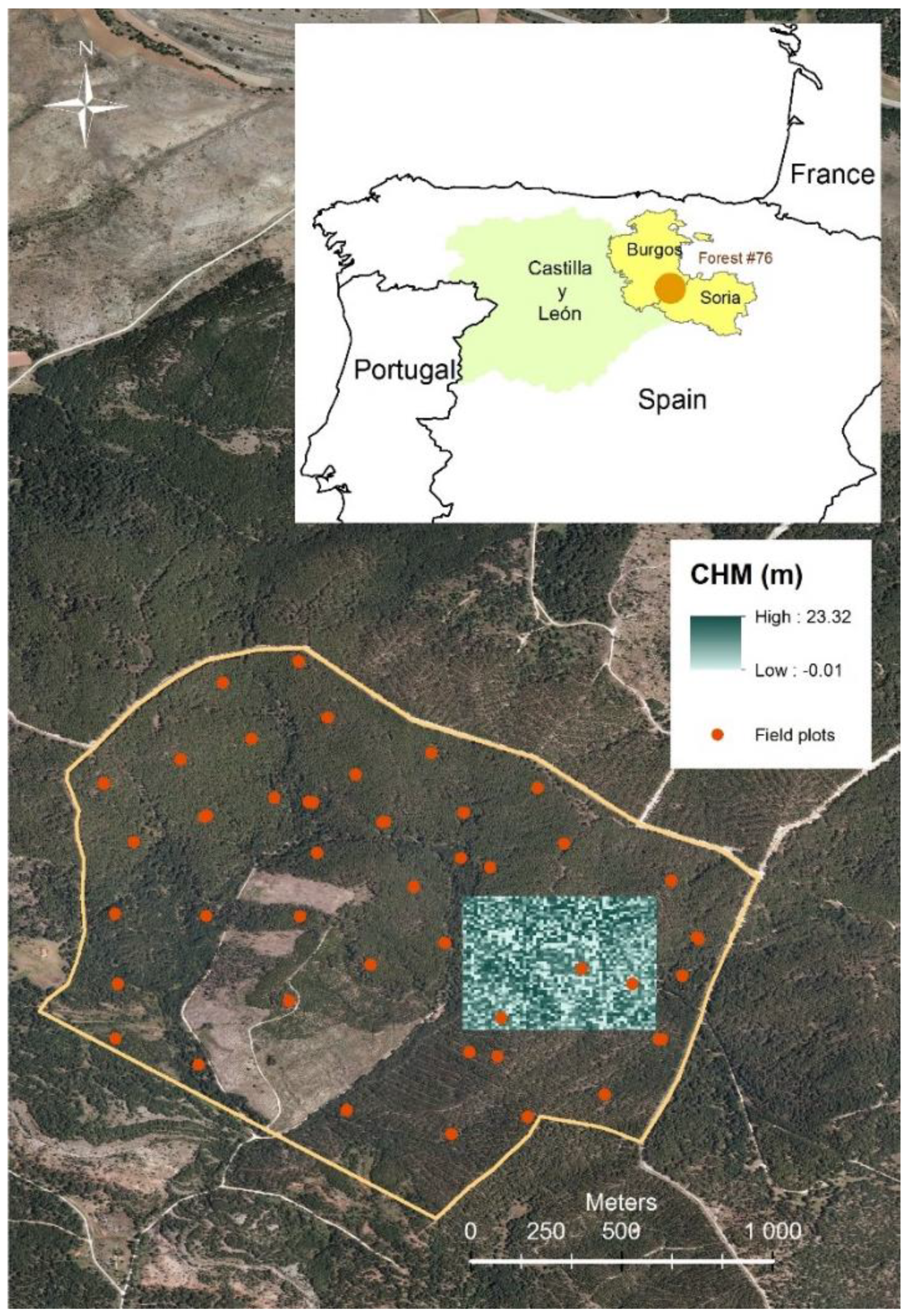
2.1. Study Area
2.2. Data: Sample Plots and Laser Scanning Information
2.3. Estimation of Forest Stand Attributes from ALS Data
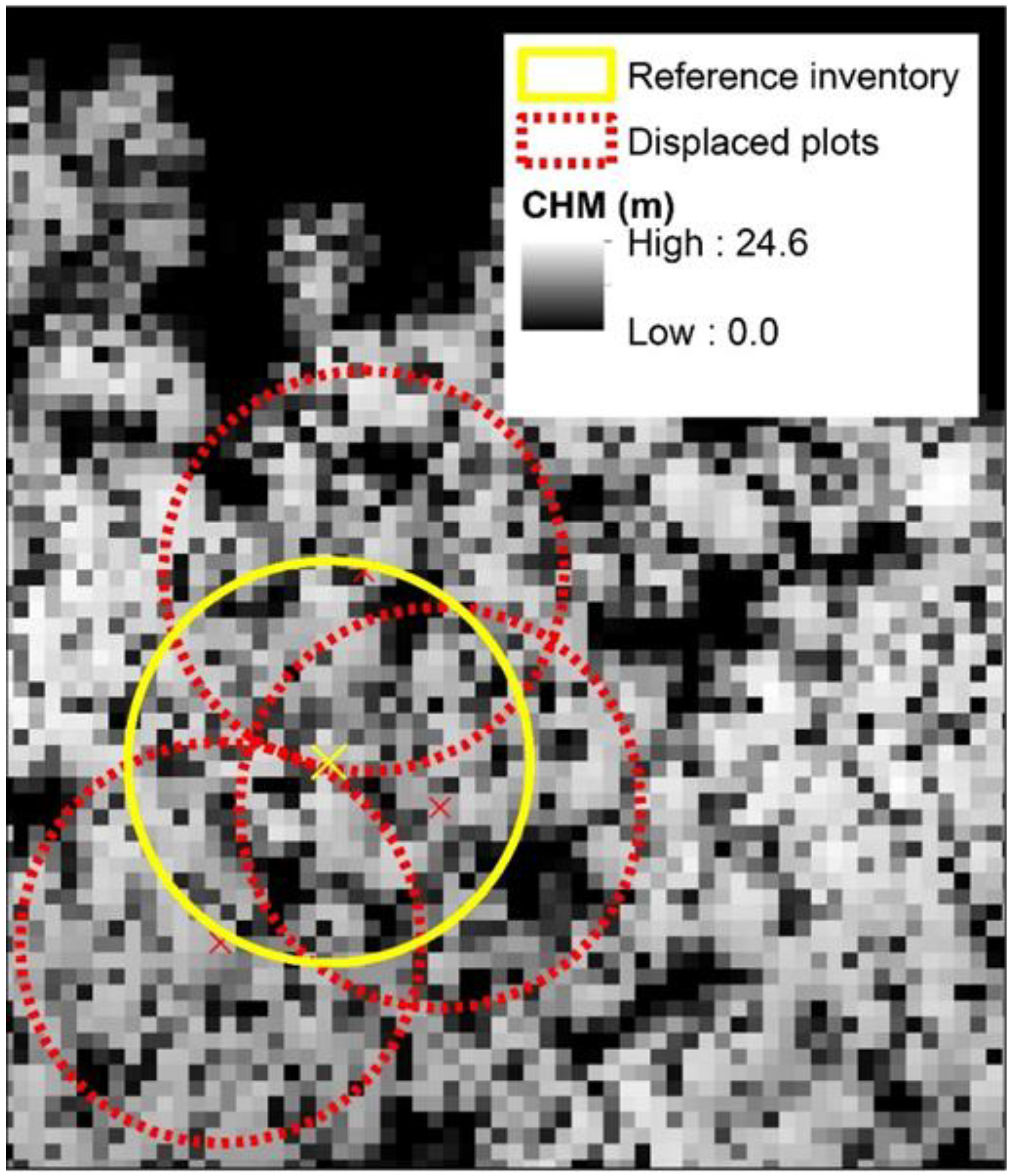
2.4. Simulating Plot Positioning Errors
2.5. Developing Forest Management Rules and Creating Treatment Schedules
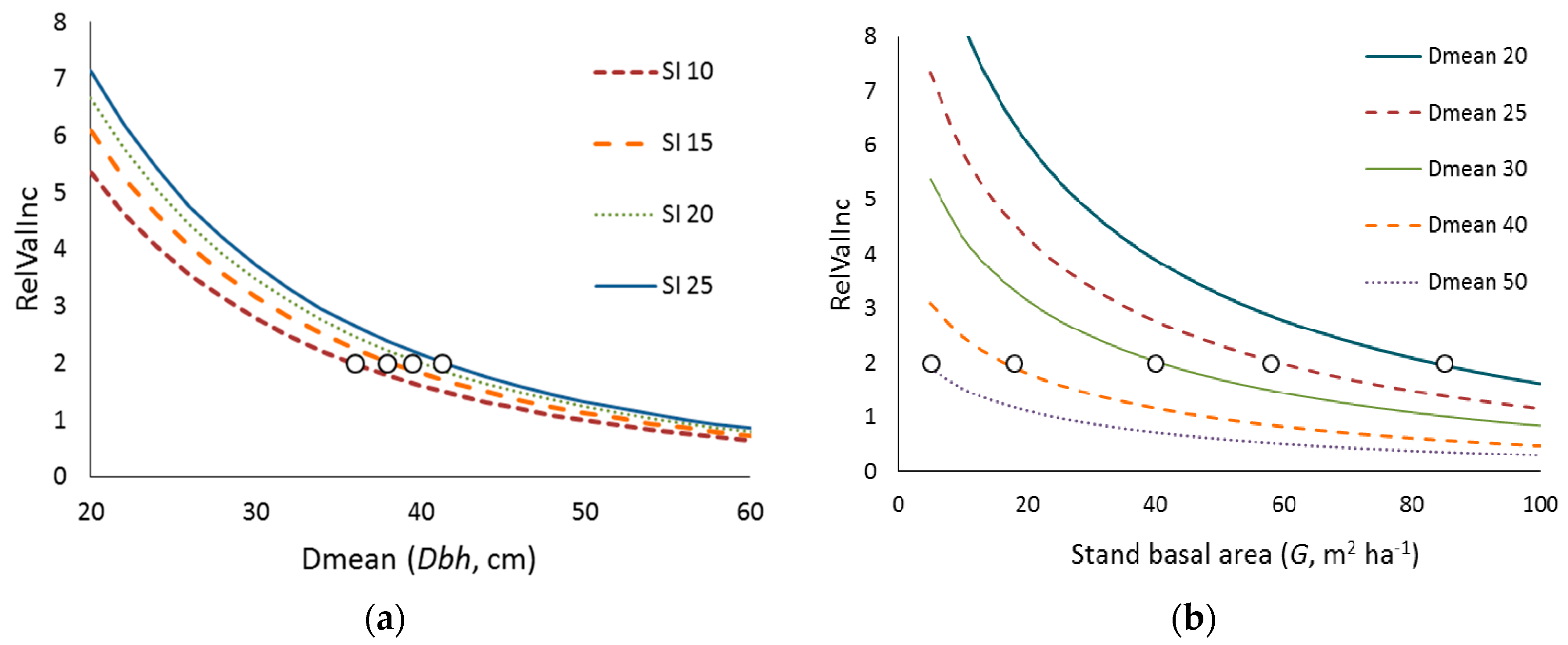
2.6. Planning Problem Formulation
- Maximization of the growing stock volume at the end of the plan (V2047, m3).
- Removal of 7500 m3 during each 10-year period (R1, R2, R3, m3).
- Maximization of the proportion of cut–cut borders of adjacent cells (CC).
- Maximization of the proportion of cut–cut borders of adjacent cells that are prescribed as final felling (CCFF).
- Minimization of the proportion of cut–non-cut borders of adjacent cells (CNC).
- Minimization of the proportion of cut–non-cut borders of adjacent cells that are prescribed as final felling (CNCFF).
2.7. Spatial Optimization
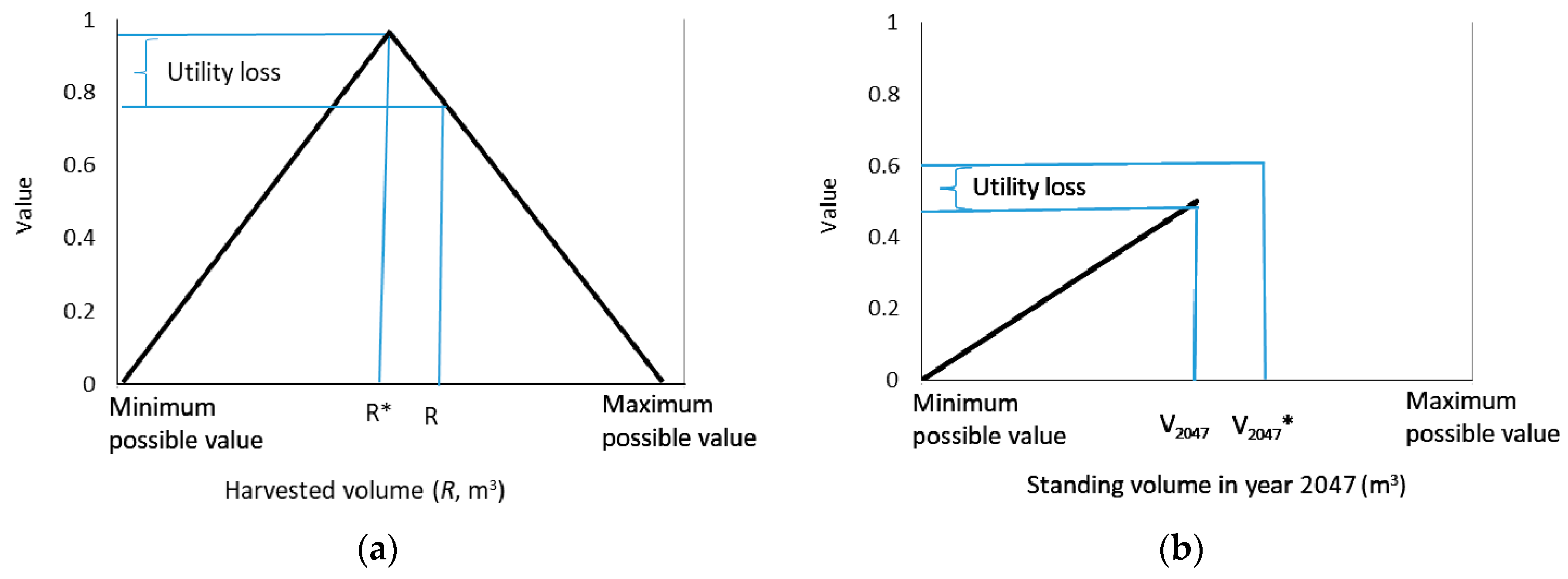
2.8. Achievement of Forest Management Objectives and Inoptimality Losses
3. Results
3.1. Impact of Plot Positioning Errors on the Estimated Stand Attributes
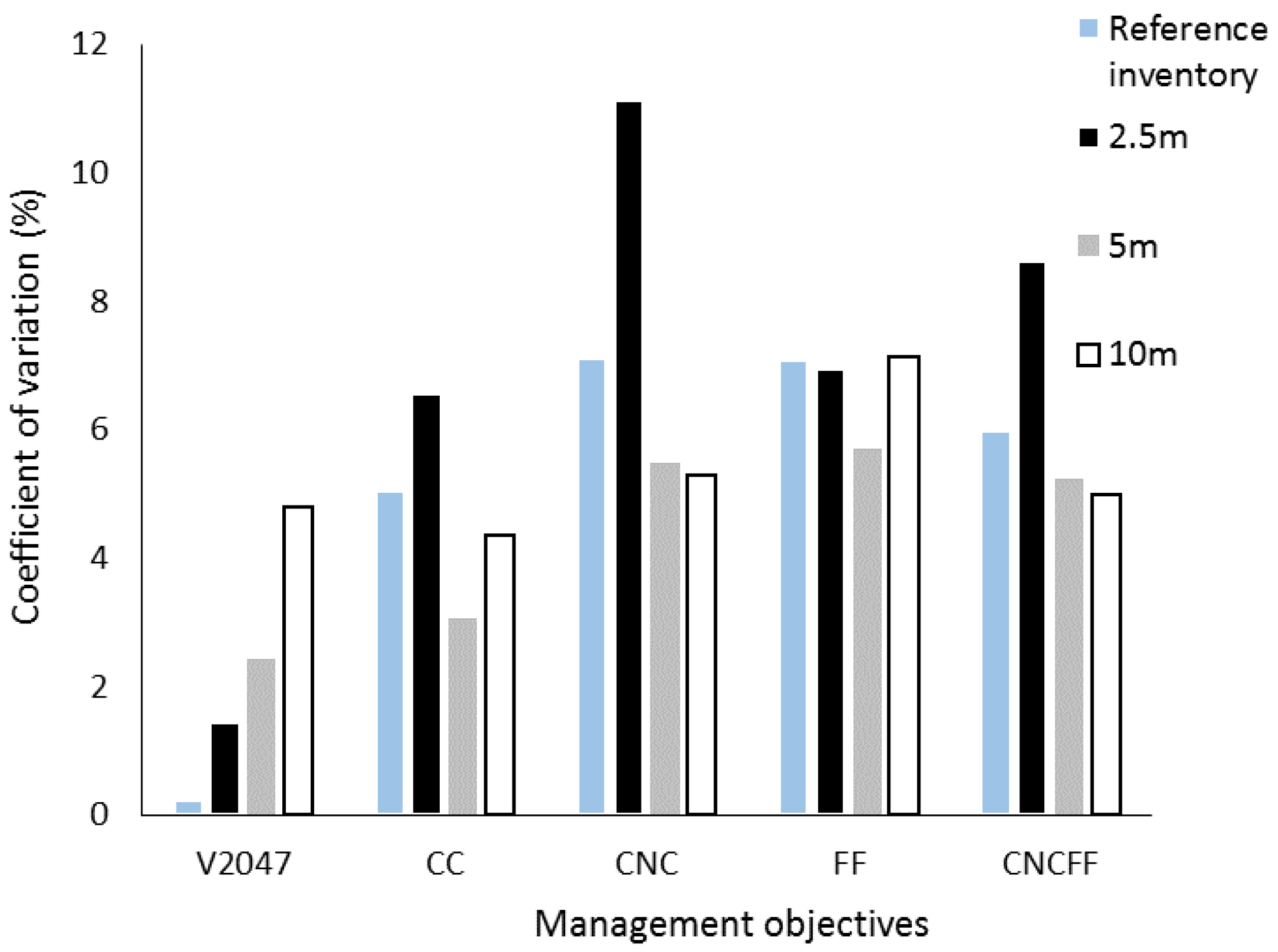
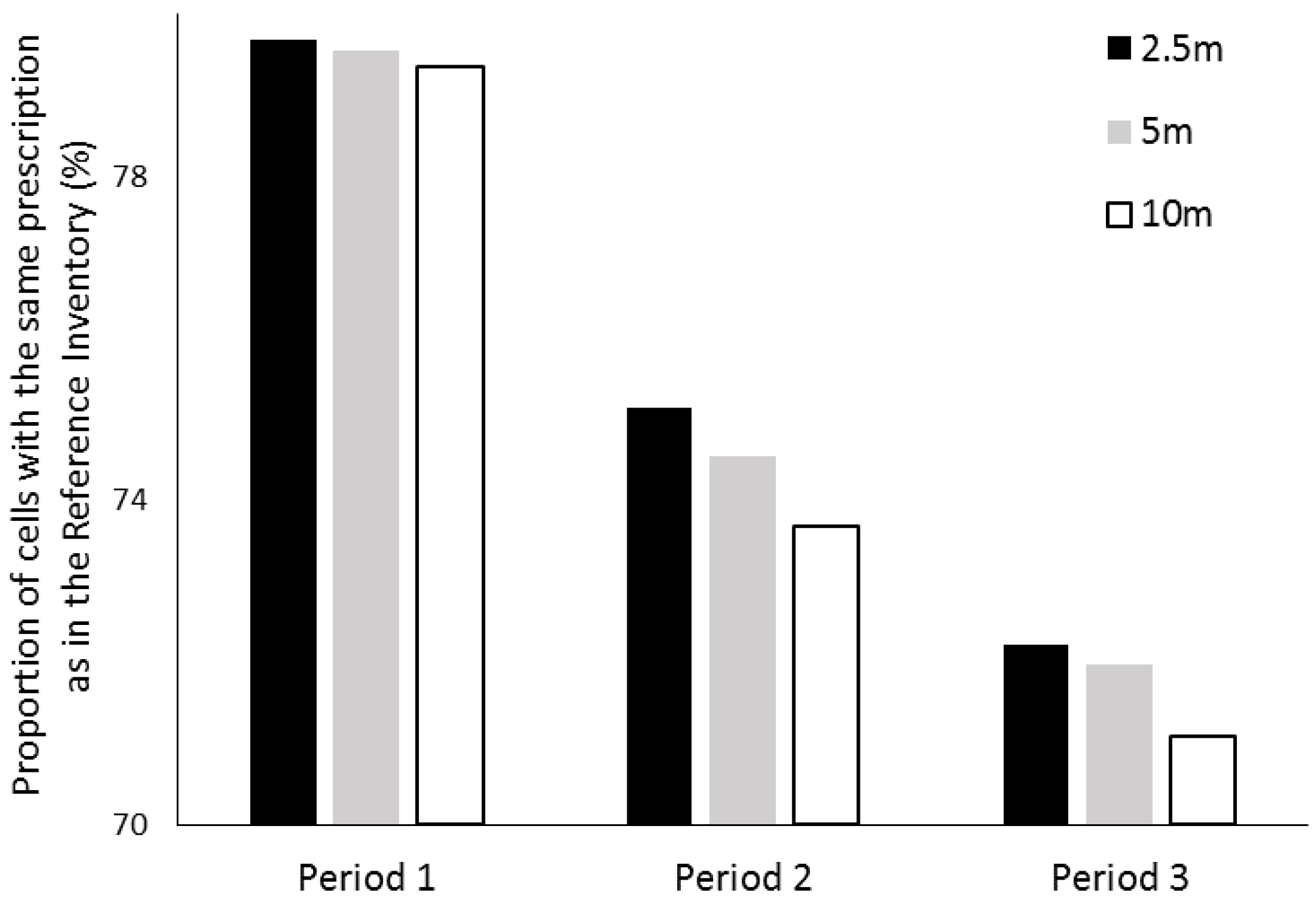
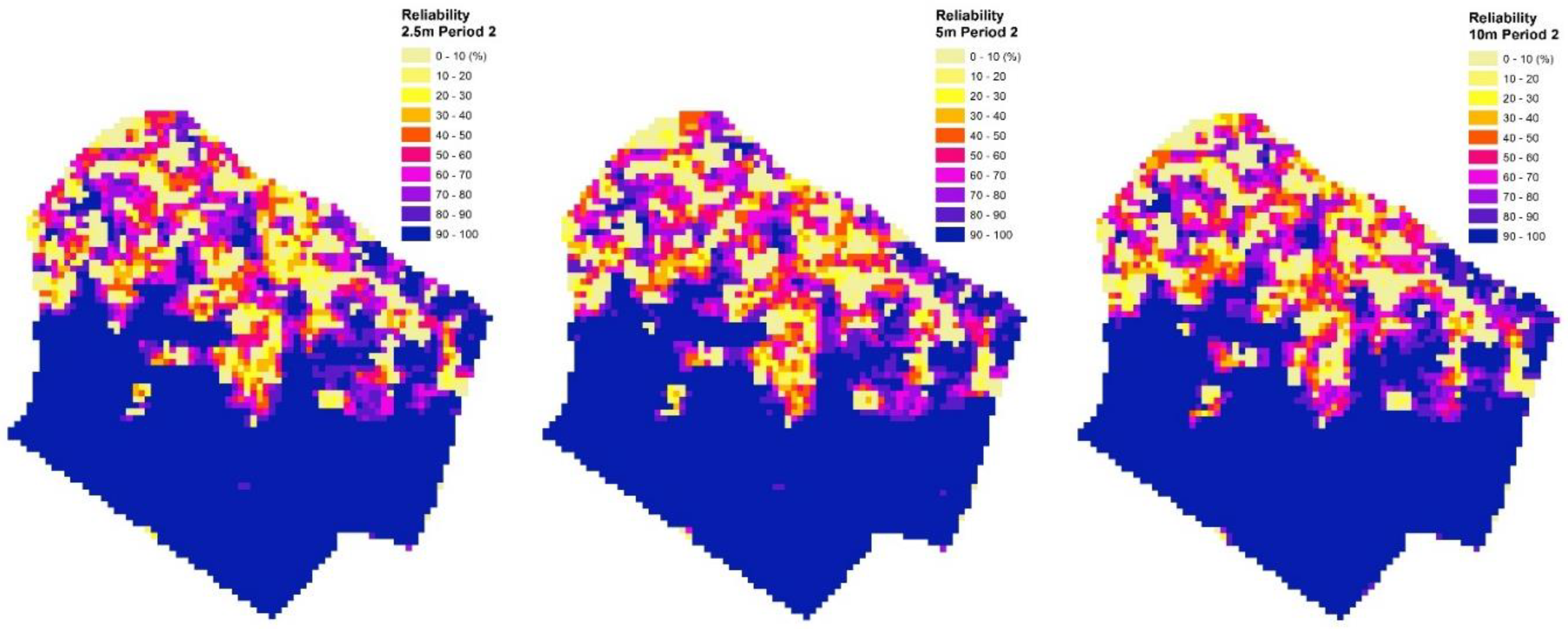
3.2. Impact of Plot Positioning Errors on Forest Management Goals and Prescriptions
3.3. Inoptimality: Utility and Yield Losses
4. Discussion
4.1. Effect of Plot Positioning Errors on the Estimation of Growing Stock Attributes
4.2. Effect of Plot Positioning Errors on Decision-Making in Forest Planning
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Baskent, E.Z.; Keles, S. Spatial forest planning: A review. Ecol. Model. 2005, 188, 145–173. [Google Scholar] [CrossRef]
- Öhman, K.; Eriksson, L.O. Aggregating harvest activities in long term forest planning by minimizing harvest area perimeters. Silva Fenn. 2010, 44, 77–89. [Google Scholar] [CrossRef]
- Weintraub, A.; Murray, A.T. Review of combinatorial problems induced by spatial forest harvesting planning. Discret. Appl. Math. 2006, 154, 867–879. [Google Scholar] [CrossRef]
- Pascual, A.; Pukkala, T.; Rodríguez, F.; de-Miguel, S. Using spatial optimization to create dynamic forest treatment units from small interpretation units of LiDAR inventory. Forests 2016, 7, 220. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Maltamo, M.; McRoberts, R.E.; Næsset, E. Introduction to Forestry Applications of Airborne Laser Scanning. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Maltamo, M., Ed.; Managing Forest Ecosystems; Springer: Dordrecht, The Netherlands, 2014. [Google Scholar]
- Næsset, E. Effects of different sensors, flying altitudes, and pulse repetition frequencies on forest canopy metrics and biophysical stand properties derived from small-footprint airborne laser data. Remote Sens. Environ. 2009, 113, 148–159. [Google Scholar] [CrossRef]
- Frazer, G.W.; Magnussen, S.; Wulder, M.A.; Niemann, K.O. Simulated impact of sample plot size and co-registration error on the accuracy and uncertainty of LiDAR-derived estimates of forest stand biomass. Remote Sens. Environ. 2011, 115, 636–649. [Google Scholar] [CrossRef]
- Maltamo, M.; Bollandsas, O.M.; Naesset, E.; Gobakken, T.; Packalen, P. Different plot selection strategies for field training data in ALS-assisted forest inventory. Forestry 2010, 84, 23–31. [Google Scholar] [CrossRef] [Green Version]
- Holmgren, J. Prediction of tree height, basal area and stem volume using airborne laser scanning. Scan. J. For. Res. 2004, 19, 543–553. [Google Scholar] [CrossRef]
- Sigrist, P.; Coppin, P.; Hermy, P. Impact of forest canopy on quality and accuracy of GPS measurements. Int. J. Remote Sens. 1999, 20, 3595–3610. [Google Scholar] [CrossRef]
- Hasegawa, H.; Yoshimura, T. Estimation of GPS positional accuracy under different forest conditions using signal interruption probability. J. For. Res. 2008, 12, 1–7. [Google Scholar] [CrossRef]
- Mauro, F.; Valbuena, R.; Manzanera, J.; García-Abril, A. Influence of Global Navigation Satellite System errors in positioning inventory plots for tree-height distribution studies. Can. J. For. Res. 2011, 41, 11–23. [Google Scholar] [CrossRef]
- Næsset, E.; Jonmeister, T. Assessing point accuracy of DGPS under forest canopy before data acquisition, in the field, and after postprocessing. Scan. J. For. Res. 2002, 17, 351–358. [Google Scholar] [CrossRef]
- Camp, M.J.; Rachlow, J.L.; Cisneros, R.; Roon, D.; Camp, R.J. Evaluation of Global Positioning System telemetry collar performance in the tropical Andes of southern Ecuador. Natureza Conservação 2016, 14, 128–131. [Google Scholar] [CrossRef]
- Johnson, C.E.; Barton, C.C. Where in the world are my field plots? Using GPS effectively in environmental field studies. Front. Ecol. Environ. 2004, 2, 475–482. [Google Scholar] [CrossRef]
- Wing, M.G.; Karsky, R. Standard and real-time accuracy and reliability of a mapping-grade GPS in a coniferous western Oregon forest. West. J. Appl. For. 2006, 21, 222–227. [Google Scholar] [CrossRef]
- Eid, T. Use of uncertain inventory data in forestry scenario models and consequential incorrect harvest decisions. Silva Fenn. 2000, 34, 89–100. [Google Scholar] [CrossRef]
- Holmgren, P.; Thuresson, T.; Holmgren, P.; Thuresson, T. Applying Objectively Estimated and Spatially Continuous Forest Parameters in Tactical Planning to Obtain Dynamic Treatment Units. For. Sci. 1997, 43, 317–326. [Google Scholar]
- Holopainen, M.; Mäkinen, A.; Rasinmäki, J.; Hyytiäinen, K.; Bayazidi, S.; Piëtila, I. Comparison of various sources of uncertainity in stand-level present value estimates. For. Pol. Econ. 2010, 12, 377–386. [Google Scholar] [CrossRef]
- Mäkinen, A. Uncertainty in Forest Simulators and Forest Planning Systems. Ph.D. Thesis, University of Helsinki, Helsinki, Finland, 2010. [Google Scholar]
- Pietilä, I.; Kangas, A.; Mäkinen, A.; Mehtätalo, L. Influence of growth prediction errors on the expected losses from forest decisions. Silva Fenn. 2010, 44, 829–843. [Google Scholar] [CrossRef]
- Islam, M.N.; Pukkala, T.; Kurttila, M.; Mehtätalo, L.; Heinonen, T. Effects of forest inventory errors on the area and spatial layout of harvest blocks. Eur. J. For. Res. 2012, 131, 1943–1955. [Google Scholar] [CrossRef]
- Gobakken, T.; Næsset, E. Assessing effects of positioning errors and sample plot size on biophysical stand properties derived from airborne laser scanner data. Can. J. For. Res. 2009, 39, 1036–1052. [Google Scholar] [CrossRef]
- Heinonen, T.; Kurttila, M.; Pukkala, T. Possibilities to aggregate raster cells through spatial optimization in forest planning. Silva Fenn. 2007, 41, 89–103. [Google Scholar] [CrossRef]
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. ISPRS 2000, 33, 111–118. [Google Scholar]
- Næsset, E. Determination of mean tree height of forest stands using airborne laser scanner data. ISPRS 1997, 52, 49–56. [Google Scholar] [CrossRef]
- McGaughey, R.J. FUSION/LDV: Software for LiDAR Data Analysis and Visualization. Version 3.30. U.S. Department of Agriculture Forest Service, Pacific Northwest Research Station, University of Washington, Seattle, Washington. Available online: http://forsys.cfr.washington.edu/fusion/ FUSION_manual.pdf (accessed on 15 February 2015).
- Næsset, E.; Bollandsås, O.M.; Gobakken, T. Comparing regression methods in estimation of biophysical properties of forest stands from two different inventories using laser scanner data. Remote Sens. Environ. 2005, 94, 541–553. [Google Scholar] [CrossRef]
- Packalen, P.; Heinonen, T.; Pukkala, T.; Vauhkonen, J.; Maltamo, M. Dynamic Treatment Units in Eucalyptus Plantation. For. Sci. 2011, 57, 416–426. [Google Scholar]
- Palahi, M.; Pukkala, T.; Trasobares, A. Modelling the diameter distribution of Pinus sylvestris, Pinus nigra and Pinus halepensis forest stands in Catalonia using the truncated Weibull function. Forestry 2006, 79, 553–562. [Google Scholar] [CrossRef]
- Maltamo, M.; Suvanto, A.; Packalén, P. Comparison of basal area and stem frequency diameter distribution modelling using airborne laser scanner data and calibration estimation. For. Ecol. Manag. 2007, 247, 26–34. [Google Scholar] [CrossRef]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- González-Olabarria, J.R.; Rodríguez, F.; Fernández-Landa, A.; Mola-Yudego, B. Mapping fire risk in the Model Forest of Urbión (Spain) based on airborne LiDAR measurements. For. Ecol. Manag. 2012, 282, 149–156. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria; Available online: https://www.R-project.org/ (accessed on 25 March 2016).
- Tiberius, C.C.J.M.; Borre, K. Are GPS Data Normally Distributed. In Geodesy Beyond; Schwarz, K.P., Ed.; International Association of Geodesy Symposia; Springer: Berlin/Heidelberg, Germany, 2000; Volume 121. [Google Scholar]
- Palahi, M.; Pukkala, T.; Perez, E.; Trasobares, A. Herramientas de soporte a la decisión en la planificación y gestión forestal. Montes 2004, 78, 40–48. [Google Scholar]
- González-Olabarria, J.R.; Pukkala, T. Integrating risk considerations in landscape-level forest planning. For. Ecol. Manag. 2011, 261, 278–287. [Google Scholar] [CrossRef]
- Heinonen, T.; Pukkala, T. A Comparison of one- and two- compartment neighbourhoods in heuristic search with spatial forest management goals. Silva Fenn. 2004, 38, 319–332. [Google Scholar] [CrossRef]
- Jin, X.; Pukkala, T.; Li, F. Fine-tuning heuristic methods for combinatorial optimization in forest planning. Eur. J. For. Res. 2016, 135, 765–779. [Google Scholar] [CrossRef]
- Borges, J.; Hoganson, H.M.; Falcão, O. Heuristics in multi-objective forest management. In Multi-Objective Forest Planning; Managing Forest Ecosystems; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002; Volume 6, pp. 119–151. [Google Scholar]
- Borders, B.E.; Harrison, W.M.; Clutter, M.L.; Shiver, B.D.; Souter, R.A. The value of timber inventory information for management planning. Can. J. For. Res. 2008, 28, 2287–2294. [Google Scholar] [CrossRef]
- Packalen, P.; Strunk, J.L.; Pitkänen, J.A.; Temesgen, H.; Maltamo, M. Edge-Tree Correction for Predicting Forest Inventory Attributes Using Area-Based Approach With Airborne Laser Scanning. JSTARS 2015, 8, 1274–1280. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measured Variables | Min | Mean | Max |
|---|---|---|---|
| Diameter at breast height (cm) | 10.0 | 28.7 | 55.7 |
| Tree height (m) | 7.1 | 14.8 | 22.0 |
| Stand density (trees ha−1) | 260.0 | 604.0 | 1080.0 |
| Stand basal area (m2 ha−1) | 21.2 | 47.4 | 72.1 |
| Stand volume (m3 ha−1) | 102.1 | 363.9 | 640.0 |
| Dominant height (m) | 11.9 | 17.3 | 21.8 |
| Age (year) | 33.0 | 56.4 | 74.0 |
| Displacement | Stand Density Model (Tree ha−1) | Stand Basal Area Model (m2 ha−1) | Dominant Height Model (m) | |||
|---|---|---|---|---|---|---|
| RMSE (%) | R2 | RMSE (%) | R2 | RMSE (%) | R2 | |
| Reference | 25.6 | 0.56 | 14.6 | 0.85 | 4.6 | 0.91 |
| 2.5 m | 26.9 | 0.47 | 15.3 | 0.82 | 4.6 | 0.91 |
| 5 m | 28.8 | 0.39 | 16.2 | 0.80 | 4.9 | 0.90 |
| 10 m | 30.9 | 0.31 | 18.6 | 0.73 | 6.9 | 0.85 |
| Displacement | N Predictions (Tree ha−1) | G Predictions (m2 ha−1) | V Predictions (m3 ha−1) | |||||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | Stdcells | Mean | Std | Stdcells | Mean | Std | |
| Reference | 546.5 | - | 298.6 | 34.9 | - | 20.4 | 345.1 | - |
| 2.5 m | 549.6 | 11.5 | 291.7 | 34.8 | 0.1 | 20.2 | 345.2 | 4.0 |
| 5 m | 562.9 | 22.5 | 278.9 | 35.2 | 0.4 | 19.9 | 348.3 | 6.8 |
| 10 m | 626.9 | 57.9 | 261.1 | 36.5 | 1.2 | 18.5 | 361.4 | 10.5 |
| V2047 (m3 103) | R1 (m3) | R2 (m3) | R3 (m3) | Prod Loss (m3) | Prod Loss (%) | Total Utility | Utility Loss (%) | |
|---|---|---|---|---|---|---|---|---|
| Reference | 55.25 | 7500 | 7500 | 7500 | - | 0.885 | - | |
| 2.5 m | 54.01 | 7818 | 7937 | 7950 | 36 | 0.42 | 0.860 | 2.82 |
| 5 m | 53.71 | 7887 | 8005 | 8076 | 109 | 1.26 | 0.858 | 2.99 |
| 10 m | 53.61 | 7816 | 7888 | 8009 | 406 | 4.68 | 0.855 | 3.35 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pascual, A.; Pukkala, T.; De-Miguel, S. Effects of Plot Positioning Errors on the Optimality of Harvest Prescriptions When Spatial Forest Planning Relies on ALS Data. Forests 2018, 9, 371. https://doi.org/10.3390/f9070371
Pascual A, Pukkala T, De-Miguel S. Effects of Plot Positioning Errors on the Optimality of Harvest Prescriptions When Spatial Forest Planning Relies on ALS Data. Forests. 2018; 9(7):371. https://doi.org/10.3390/f9070371
Chicago/Turabian StylePascual, Adrián, Timo Pukkala, and Sergio De-Miguel. 2018. "Effects of Plot Positioning Errors on the Optimality of Harvest Prescriptions When Spatial Forest Planning Relies on ALS Data" Forests 9, no. 7: 371. https://doi.org/10.3390/f9070371