Identifying Drivers of Genetically Modified Seafood Demand: Evidence from a Choice Experiment


Department of Environmental and Natural Resource Economics, University of Rhode Island, Kingston, RI 02881, USA
*
Author to whom correspondence should be addressed.
Sustainability 2019, 11(14), 3934; https://doi.org/10.3390/su11143934
Submission received: 6 June 2019
/
Revised: 12 July 2019
/
Accepted: 15 July 2019
/
Published: 19 July 2019
(This article belongs to the Special Issue Sustainability in Food Choice and Consumer Preferences)
Abstract
:The aquaculture industry has expanded to fill the gap between plateauing wild seafood supply and growing consumer seafood demand. The use of genetic modification (GM) technology has been proposed to address sustainability concerns associated with current aquaculture practices, but GM seafood has proved controversial among both industry stakeholders and producers, especially with forthcoming GM disclosure requirements for food products in the United States. We conduct a choice experiment eliciting willingness-to-pay for salmon fillets with varying characteristics, including GM technology and GM feed. We then develop a predictive model of consumer choice using LASSO (least absolute shrinkage and selection operator)-regularization applied to a mixed logit, incorporating risk perception, ambiguity preference, and other behavioral measures as potential predictors. Our findings show that health and environmental risk perceptions, confidence and concern about potential health and environmental risks, subjective knowledge, and ambiguity aversion in the domain of GM foods are all significant predictors of salmon fillet choice. These results have important implications for marketing of foods utilizing novel food technologies. In particular, people familiar with GM technology are more likely to be open to consuming GM seafood or GM-fed seafood, and effective information interventions for consumers will include details about health and environmental risks associated with GM seafood.
1. Introduction
The global population is projected to reach nearly 10 billion people by 2050 [1]. Growing populations will necessarily result in increased demand for quality, safe, and diverse foods, and seafood is no exception. Annual global per capita seafood consumption has more than doubled since the 1960s to over 20 kg, making up over 16 percent of global animal protein intake and more than 6 percent of all protein consumed [2]. Part of this increase is likely due to targeted policy efforts meant to increase seafood consumption, particularly in women and children. In 2010, the United States Department of Agriculture (USDA) and Department of Health and Human Services (HHS) began focusing nutrition campaigns on seafood consumption. Specifically, USDA and HHS recommended pregnant and nursing women consume at least 8 to 12 ounces of a variety of seafood per week as part of a well-balanced diet, with similar recommendations for other adults and less for younger children
A complication associated with increased seafood demand is the fact that global harvest of wild fish has remained almost constant since the 1990s. The aquaculture industry expanded rapidly to fill the gap and meet global seafood demand, representing an increasing portion of global seafood supply (40.1% in 2011 compared to 46.8% in 2016) [2,3]. This trend is expected to continue in the foreseeable future, and will encourage more investment and technological innovations in the aquaculture sector. One unique innovation that has received much attention recently is the development of genetically-modified (GM) fish that grows faster, meatier, and more disease-tolerant while relying on less wild harvest resources for use in fish feed, for example. Looking at the experience of the agriculture industry in adoption of GM technologies, it is only a matter of time before the U.S. consumers and seafood supply chain are faced with decisions involving GM seafood. The question is whether the market will accept GM seafood, and will it advance the contribution of aquaculture in meeting the world’s seafood demand.
AquaBounty Technologies, Inc., a biotechnology firm located in Massachusetts, U.S. and Prince Edward Island., Canada, developed a GM Atlantic Salmon, marketed as AquAdvantage Salmon© carrying the tag line “the World’s Most Sustainable Salmon” [4]. AquAdvantage Salmon© grows to market weight twice as quickly as conventionally farmed salmon and requires less wild harvest species for feed, while it is also claimed to minimize environmental impacts by being grown in land-based facilities closer to metropolitan areas. All of this together is meant to address sustainability concerns associated with current open-ocean salmon farming practices. Another approach utilized by the aquaculture industry to address sustainability concerns is the use of alternate feed ingredients, such as insect meal [5]. AquAdvantage Salmon© has been sold as fillets in Argentina, Brazil and Canada, and approved for sale in the U.S. in 2015. However, the controversy surrounding the use of GM technology as a means of achieving a more sustainable, farmed salmon product [6] has halted AquAdvantage Salmon© from reaching the market until a clear GM labeling standard is put in place.
On 29 July 2016 the National Bioengineered Food Disclosure Standard (NBFDS) was signed into law [7] and was finalized in December 2018. The Standard is set to be fully implemented on 1 January 2020 [8]. As it currently stands, foods containing any of the commercially available GM foods and their derivatives will be subject to disclosure, while small food manufacturers, restaurants, animals fed with GM products, and foods certified under the National Organic Program are exempt [7]. Disclosure will be carried out via written text, a symbol similar to the USDA Organic symbol, or electronically using QR codes. A recent ruling by the U.S. Food and Drug administration motivated by the final NBFDS approval resulted in the import ban on GM salmon eggs being lifted [9]. This means that production of GM salmon in the U.S. is likely to begin in the near future with products reaching seafood counters by 2021 [10]. The NBFDS presents a unique challenge for strategic marketing of food products utilizing novel food technologies in a way that appeals to consumers’ growing interests for sustainably sourced and marketed products.
As the NBFDS is not yet implemented, we are in a unique position to investigate this prediction problem. Specifically, we investigate the potential impact of the NBFDS on demand for Atlantic Salmon using machine learning methodology. We analyze data collected from a nationally representative sample in an online discrete choice experiment distributed across the United States. We are one of the first studies to use machine learning techniques to study consumer food choice, as well as being one of the first to fully investigate demand for GM seafood. The results of this work will help the food industry identify the means through which to transform the seafood supply chain and marketing strategies into sustainable practices that will support predicted growth in population, food demand and greener trends.
New advances in machine learning are increasingly being adapted by economists to investigate policy prediction problems [11,12]. Machine learning methods excel at addressing these types of problems due to their ability to discover complex data structures that are not specified or known a priori. This is in stark contrast to many applied economic applications focused on parameter estimation and causal inference. Recent applications of machine learning in policy prediction problems include environmental monitoring [13], judicial behavior [14], changes in household diet [15,16], poverty quantification [17,18,19], tax policy evaluation [20], restaurant hygiene inspections [21], and highway procurement auctions [22].
We expand this literature by applying LASSO (least absolute shrinkage and selection operator) penalized regression as a variable selection tool to identify behavioral factors that predict consumer choice in the context of seafood purchases. Labels presented under current institutions, including the forthcoming NBFDS, act as a signal of quality and safety for consumers [23]. Generally, the information provided in a food label is expected to be a positive course of action by providing more information than was previously available. However, labels can be ineffective if the information is misperceived [24]. For example, consumers may over-estimate risks related to the labeled product, perceiving the label as a type of warning, resulting in the (unintended) effect of decreased consumption [23,25,26]. This ineffectiveness can be related to inferential processing on the part of the consumer. From a public policy standpoint, this is undesirable because label interpretation is reliant upon consumers’ perceptions, attitudes, and subjective beliefs [27,28]. This effect can be further exacerbated by the availability of additional information about food products making the distinction between information on the label itself and market provided information an important consideration. The research findings presented herein contributes to the academic literature by identifying unique mechanisms through which information impacts consumer purchase decisions. The most surprising result is that balanced information appears to only have significant negative effects on demand for GM and Organic salmon driven by environmental risk perception and confidence in environmental risk perception, respectively.
Studies have shown that risk perceptions, preferences, and other intangible aspects are becoming increasingly important in consumer food choice [27,29,30], but no work has addressed which subjective/behavioral measures are most important. Considering the controversy associated with the NBFDS itself and the use of GM technology in food production in general, perceptions, attitudes and other behavioral measures are likely to have significant influence on the effectiveness of the NBFDS and ultimately consumer choice. Considering the importance of behavioral measures and the forthcoming NBFDS, we have a unique opportunity to explore this policy prediction problem using machine learning techniques.
We seek to develop a predictive model of consumer choice by incorporating often-overlooked behavioral measures into our choice model [29]. Inclusion of these data and other “non-conventional” measures is important given the potentially significant effects they can have on predictive accuracy of choice models [31]. Developing an accurate predictive model that incorporates these data is particularly important in evaluating the potentially unintended consequences of policy interventions such as the NBFDS. If economists are interested in developing predictive models to promote as decision support tools for policy makers and food industry stakeholders alike, then balancing model complexity with predictive performance is a critical consideration, which is precisely the goal of LASSO. The advantage of using LASSO to address this consideration is that it provides a data-driven approach to identifying important factors that relate to individual behavior without relying on researcher intervention. In addition, overly complex predictive models may require large amounts of (potentially unavailable) data or may be difficult to implement. A clear benefit of applying LASSO, then, is that more parsimonious models require less data and are therefore easier to implement in applications outside of the initial, motivating project.
Our results show that behavioral measures do indeed play an important role in predicting consumer choice. Specifically, we find that risk perception, confidence in risk perceptions and concern about the risks associated with GM technology are the prominent behavioral factors in the health domain. Risk perception, confidence in risk perceptions, and concern are also important behavioral factors in the environmental domain. Both context specific subjective knowledge and ambiguity aversion have a significant influence on consumer choice of salmon fillets.
When shopping for food, labels act as signals to consumers [23]. GM food labels will act as a signal of quality and safety for consumers deciding on what to purchase. This aligns with groups that advocate for consumer “right to know” about what goes into their food. Generally, information provided via a food label is expected to be a positive course of action, as labels are meant to correct for the lack of information previously available to consumers. In the case of GM foods, labels are desired to as an attempt correct the information asymmetry regarding food production processes of many food products available on the market. Advocates of the NBFDS cite unknown environmental and health consequences of production and consumption of GM products as justification for distinction of GM foods from conventional products as a means of facilitating informed consumer choice. The most prevalent issues in the discussion are unanticipated allergic responses, spread of pest resistance or herbicide tolerance to wild plants, and inadvertent harm to wildlife [32]. Aside from the tangible risks often associated with GM products, other studies have shown moral acceptability to be a significant predictor for the encouragement of biotechnology applications [33,34].
Bonroy and Constantatos [24] note that labels can be less effective at fixing the lack of information issue given consumer misperceptions of the information provided by the label. One form of misperception can be an over- or under- estimation of risks or benefits related to a product attribute [25]. This type of misperception is related to what Lusk and Rozan [23] call the “red flag effect” and is attributed to (undesired) inferential processing on the part of the consumer [27,28]. If one considers the varying attitudes and opinions as an alternate form of “advertising” for GM foods, it becomes clear that this ambiguous advertising may influence consumer evaluation of GM product safety and quality, and ultimately the magnitude of the “red flag” effect [35].
As is the case with GM foods, lack of information related to a specific decision or choice may lead to ambiguity in the consumer’s evaluation of the probability of an outcome, such as health or environmental impacts of GM food consumption. This transformation of information ambiguity to probability ambiguity can influence individual decision-making [36]. Even in the context of food-borne pathogens, few consumers know the odds of becoming ill from it and many consumers have ill-formed beliefs about their chances of actually becoming ill from a food-borne pathogen [37]. Further, when individuals seek out information in an attempt to gain more information on a topic, there is seldom consensus among interest groups, consumers, or the scientific community, particularly regarding GM foods as mentioned above [38].
It is common in situations of uncertain origin or outcome that lay peoples’ risk perceptions will differ from expert-provided technical risk estimates [39,40]. We know from the works discussed above that this difference in perception hinders the effectiveness of expert provided information meant to alleviate the information asymmetry [41]. We conjecture that the contrasting states of knowledge among interest groups and ultimately the information available to consumers, plays a significant role in driving consumer aversion to genetically modified food products. Given the lack of consensus on the consequences of genetic modification, we argue that this may reinforce consumer aversion to GM technology in food, and thus ambiguity aversion drives preferences for GM food and demand for a labeling regime such as NBFDS.
It is a natural extension to discuss risk perceptions along with ambiguity preferences in the evaluating the effectiveness of the NBFDS as these measures are often overlooked in explaining consumer demand for food products [29]. However, assessing risk perceptions’ effect on consumer choice can be difficult as comprehensive measurement of risk perception is not trivial.
Risk perception as a concept is multidimensional, meaning that a single question on a survey may not capture all the nuances of individual risk perception [40,42,43,44]. A large body of work exists in the risk communication field focused on measuring risk perceptions in the context of climate change. Van der Linden [42] discusses the fact that while the public might perceive some long-term changes in long-term climate conditions, psychological factors are often much more influential in determining public perception of climate change risk. We utilize a framework proposed by van der Linden [42] to measure and interpret our results. This framework breaks down risk perception into a hierarchy of components which allows us to identify the relative importance of each component of risk perception in explaining consumer demand for GM salmon under the NBFDS.
2. Materials and Methods
2.1. Data
We recruited 1043 survey participants via Amazon Mechanical Turk (denoted “Mturk”), a crowd-sourcing platform for computer-based tasks. The computer-based task was a Qualtrics survey, in which we implemented our choice experiment. This work was reviewed and approved by the University of Rhode Island’s Office of Research Integrity (Approval #1718-181), which required collection of informed consent forms from participants and measures to preserve participant anonymity. For recruitment, Mturk workers with greater than zero approved tasks, task approval rating greater than 97%, and located in the United States saw the survey announcement for a “20-minute Academic Study”. Eligible participants were (1) aged 18 years or older, (2) lived in the United States, (3) consumed seafood regularly, and (4) consumed salmon. We paid participants $2.00 upon completion of the survey. The average participant completed the full survey in 13.5 minutes. The final sample consists of a diverse group of respondents from every state in the United States aside from Delaware, Table 1 provides sample summary statistics. Compared to the most recent American Community Survey [45,46,47], our sample differs from the general population of the United States primarily in gender distribution (40.1% female compared to 50.8% in the ACS) and educational attainment (60% with Bachelor’s degree or higher compared to 31.2% in the ACS), consistent with previous summaries of the Mturk population [48]. We consider our sample to be sufficiently representative of U.S. seafood consumers given our screening criteria, acknowledging these previously identified nuances of the Mturk population.
We have further confidence in considering our sample to be sufficiently representative of the U.S. seafood consumers based on their prior preferences and attitudes related to GM food technology. Between 50–60% of our sample believe it is either “Very Important” or “Extremely Important” to label each of Organic, Non-GM, Contains GM ingredients, GM-fed, and GM food products. This is representative of the general sentiment of consumer “right to know” movements and use of information regarding food production methods identified in various academic work as well as independent polls. For example, a Pew Research Center poll [49] found that 89% of respondents (n = 1480) believe the general public should play at least a minor role in making policy decisions related to GM foods, while 40% of respondents believe the news media does not take the health risks of GM foods seriously enough.
As an alternate means of capturing prior preferences related to production process labeling, participants were asked to rank four food labels based on likelihood of purchasing a product displaying each label: Organic, Certified Non-GMO, Contains GM Ingredients, and Produced with Genetic Engineering. As we expected based on the prior preferences summarized above, participants ranked Organic as most likely to be purchased, followed by Certified Non-GMO, Contains GM ingredients, and Produced with Genetic Engineering. We did allow participants to rank multiple labels equally to indicate indifference. The rankings are indicative of an association between Organic and Certified Non-GMO labels and Contains GM Ingredients and Produced with Genetic Engineering labels as evidenced by their relative average rankings.
As we are studying GM food labels in the context of seafood, we also had participants rate their seafood purchase habits on a five-point Likert scale to indicate level of agreement with statements about seafood. As expected based on prior literature [50], participants have a general preference for seafood that is wild-caught, domestic, low-priced, freshest, and healthy for them. Data used for these and all following analyses are available as Supplementary Materials.
2.2. DCE and Survey Design
Our discrete choice experiment (DCE) was designed to simulate seafood purchase scenarios for fresh, farmed Atlantic Salmon fillets with different labels denoting presence or absence of genetic modification, country of origin, and price. The survey instrument also asked respondents questions about their food consumption habits, general attitudes toward food and technology, and specific attitudes toward GM foods. Table 2 summarizes the levels of each product attribute used in our DCE, which were chosen based on previous literature and current market conditions.
Participants were randomly assigned to one of four information treatment groups that differed in support of GM technology in food production:
In the Positive Information treatment, subjects were shown on the screen:
- Genetically modified organisms (crops and animals) produced for consumption have better taste, increased nutrients, greater resistance to disease and pests, and faster production compared to conventionally produced crops and animals.
- Genetically modified organisms can be more environmentally friendly because they conserve water, soil, and energy.
In the Negative Information treatment, subjects were shown on the screen:
- Genetically modified organisms (crops and animals) produced for consumption have potential health risks, including allergic reactions, resistance antibiotics, and unknown effects.
- Genetically modified organisms may require food producers to increase use of pesticides, herbicides, and other chemicals that can harm the water system and damage the soil.
In the Balanced Information treatment, subjects were shown both Positive Information and Negative Information treatments at once on the same screen, with positive information at top as ordered above. In the control group, or No Information treatment, subjects did not see the information screen at all. Each information treatment was presented as short bullet points as it is more attuned to the manner in which consumers receive food marketing information, such as social media and/or information pamphlets at food stores.
We used a full factorial design for the DCE meaning that each possible attribute combination was seen across survey participants. Due to the large number of total choices (4 × 5 × 3 = 60 total combinations for salmon) we blocked our choice sets into ten blocks, each containing six choice questions to reduce the cognitive burden on our participants. The design was created in STATA version 13 (StataCorp LP, College Station, TX, USA) with the user-written program dcreate [51,52]. Each respondent was randomly assigned to one choice set block. Each choice question had two choice alternatives plus a no purchase option. The order of each question in a given block was randomized for each participant. Figure 1 is an example fillet choice set.
2.2.1. Behavioral Measures
Prior to seeing the choice scenarios, participants answered questions regarding their knowledge level and risk perceptions related to GM technology. We refer to this series of questions as “behavioral measures” (including our ambiguity aversion measure discussed below). The knowledge questions specifically addressed participants’ (1) knowledge level about the facts and issues associated with GM technology, (2) risk perception of GM foods relative to foods produced without GM, (3) confidence in risk perception, and (4) concern level about potentially negative impacts of GM foods.
Then, the risk and perception series of questions was presented as follows:
- How much do you agree with the following statement?GM foods pose a greater [health, environmental] risk than foods produced without GM technology.
- How confident are you in your answer to the previous question?
- How concerned are you about GM foods leading to negative [health, environmental] impacts?
This series was asked separately for the health and environmental domains (i.e., which bracketed word actually appeared in the above questions). The risk perception series and self-reported knowledge level were measured on a five-point Likert scale.
We elicited this specific series of behavioral measures to capture the relationship between these variables in a similar manner as van der Linden [42]. In his work, van der Linden developed a “hierarchy of concern” (HoC) model to conceptualize public perception of climate change similar to Maslow’s “hierarchy of needs” framework for human motivation. The HoC establishes a transitive relationship between likelihood of an event, perceived seriousness, general concern, and personal worry. For reasoning similar to the climate change case, an individual may think that effects of consuming and/or producing genetically modified foods are likely to occur, but that does not imply that they perceive the issue to be serious. The relationship between each level of the hierarchy is comparable to the example above. The transitivity axiom is not a necessary condition for this framework to remain a useful tool for conceptualizing risk perceptions of genetic modification, climate change, or other issues. Figure 2 presents a pictorial representation of the hierarchy measured for our study.
The highest level in the HoC is personal worry. This level distinguishes concern at a societal versus a personal level. This distinction can be important as individuals often exhibit optimism bias in which they overestimate the likelihood of positive life events and underestimate the likelihood of negative events. The resulting bias translates into overestimates of risk perceptions if measures only rely on single question to capture concern level. Since we are not interested in analyzing the specific level of public concern about the risks of GM technology, we opted to only use a single-question measure of concern and personal worry levels. We purposely used a concern measure that could be subjectively interpreted as a means of capturing an overall level of concern about the risks of GM technology rather than only societal- or personal-level concern.
We are also interested in establishing the relationship food purchases have with subjective knowledge and ambiguity aversion. The relationship between subjective knowledge and ambiguity aversion was proposed and tested in Fox and Tversky’s [53] comparative ignorance hypothesis. The authors’ work concludes that as subjective knowledge (how knowledgeable you feel about a topic) increases, so too does ambiguity aversion. A related explanation lies in Heath and Tversky’s [54] competence hypothesis. Costa-Font [55] formally tests the link between these variables in the context of three food scares, which included GM food technology. One important result is the confirmation of subjective knowledge having a positive and significant effect on ambiguity aversion in line with the results of Fox and Tversky [53] and Heath and Tversky [54].
2.2.2. Ambiguity Aversion Elicitation
Along with the behavioral measures outlined above, we elicited participants’ aversion to ambiguity. We developed a domain-specific ambiguity aversion elicitation mechanism as there is evidence that effects of behavioral measures could depend on how measures are elicited (Petrolia 2016). Specifically, participants iterated through a series of choice menus that asked them to make a choice between a salmon fillet with a known chance of being GM and a fillet with an unknown chance of being GM. This method was developed as an adaption of that used by Dimmock, Kouwenberg, Mitchell, and Peijnenburg [56]. Figure 3 presents an example “lottery” menu. We are aware of only one other work that that framed an ambiguity measure in the context of a specific food product or category [55]. The measure used by Costa-Font relied on a single question that was asked participants to choose a country to live in (Country A or Country B) based on known or vague information about deaths associated with bovine spongiform encephalopathy. This was adapted from a measure used by Viscusi [57].
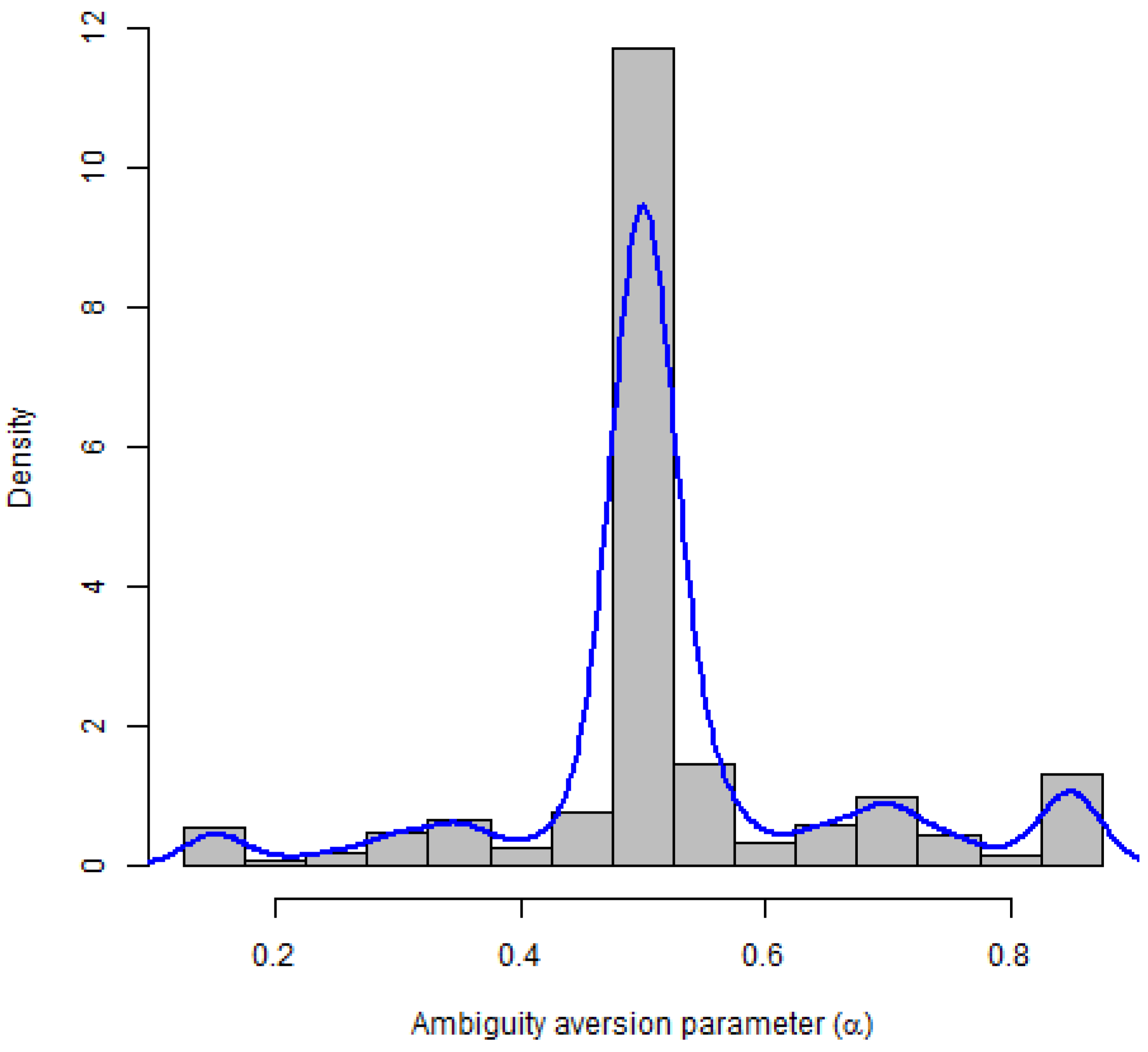
We truncated the tails of the distribution for elicitation purposes based on discussions with colleagues that have used this elicitation method in similar applications. Thus, our measure falls in the range [0.15, 0.85] rather than [0, 1.0]. The menus were designed in the loss frame based on current negative perceptions of GM technology. Participants are ambiguity averse if the individual level ambiguity aversion parameter is greater than 0.5. Based on this definition, 26.65% of our sample is considered ambiguity averse. Figure 4 presents the distribution of estimated ambiguity aversion in our sample.
2.3. Empirical Methods
2.3.1. Mixed Logit
Since every choice elicitation includes a no-purchase option in addition to the two fillets, we consider multinomial logit models to estimate choice. A random-parameters logit framework relaxes the independence assumption necessary in a traditional multinomial logit. This framework allows us to appropriately account for the panel structure of our data (there were six choice occasions in each block randomly assigned, one per subject), in which choice errors may not be independent within individuals. The model accounts for the panel structure by including a random intercept term for each participant and participant-choice set combination. All other covariates are specified as fixed effects (i.e., non-random effects, not to be confused with dummy variables used in fixed effects regression). Our empirical specification includes a total of 192 covariates that include an alternative specific constant (ASC) for the no-purchase alternative, choice set attributes (price, country of origin, and GM label; described in Table 2), and interactions of the behavioral measures with all choice set attributes. All choice set attributes are dummy-coded aside from price which was specified as a continuous covariate. The use of interaction terms allows us to link the behavioral measures to consumers’ seafood choice.
2.3.2. LASSO Penalized Regression
We use the LASSO L1-regularization to select the most important behavioral measures for predicting participant choices [58]. Since these measures are correlated, the selection of a sparse model is based on the explicit assumption that there is a subset of our measures that is more important in predicting choice behavior. We follow Huseynov, Kassas, Segovia, and Palma [59] to reformulate the LASSO in a logit framework. All independent measures are standardized prior to estimating a maximum binomial likelihood to fit the LASSO to our training data. Specifying an individual’s non-selection probability as
we maximize the following log-likelihood:
where (“lambda”) can be interpreted as a constraint on the sum of the absolute values of the coefficients estimates (the vector), as in a typical LASSO applied to linear regression models.
is commonly referred to as the “tuning parameter” because it determines the strength of the penalty imposed on the model covariates. For small values of , the penalty imposed on the estimated parameters is small resulting in the recovery of the maximum likelihood estimates of the mixed logit coefficients. For sufficiently large values of , some coefficients are set to zero. This is the mechanism through which LASSO performs variable selection, making the stability of a necessary component of our empirical strategy.
We ran 100 iterations of a modified two-fold cross-validation LASSO routine to confirm the stability of the optimal tuning parameter. Each iteration of the cross-validation routine used a randomly selected 50-50 split (permutation) of the full data into training and test data sets. This split for cross validation routines has been shown to be optimal for a broad class of loss functions independent of the data distribution, and particularly in the case of classification via logistic regression [60]. For each iteration, the LASSO was fit on the training data and out-of-sample log-likelihood (OOSLL) was calculated using the test data. We fit 22 values of the tuning parameter ranging in penalty strength. This range is slightly smaller relative to other applications and defaults of popular software packages that typically evaluate 30–100 values of the tuning parameter, see for example Friedman, Hastie and Tibshirani [61]. We decided to focus our attention on this range of candidate tuning parameters based on preliminary analysis conducted using this data set. For each iteration and value of the tuning parameter, we recorded (1) variable selection, (2) in-sample Bayesian Information Criteria (BIC), and (3) OOSLL. The OOSLL values we report are calculated using the regularized model, in which the regression betas represent maximum a posteriori estimates given a Laplacian prior [62]. For further details on the theory and application of the LASSO, we recommend the seminal text authored by Hastie, Tibshirani, and Friedman [58].
We used the results from the routine described above to select the optimal tuning parameter, , based on average OOSLL and mean prediction accuracy across the replications. Once we determined the optimal tuning parameter, , we re-ran the LASSO on our full data set with that penalty term to generate the list of covariates with non-zero coefficient estimates. This set of covariates was used to estimate a naïve post-LASSO model fit, discussed below, to conduct inference on the effect of these covariates on seafood purchase decisions. We account for the use of this naïve post-LASSO inference method using bootstrapped standard errors based on 100 bootstrap replications. Below, we discuss the variables selected by this procedure in order to identify the important behavioral measures for consumer purchasing of GM seafood.
3. Results
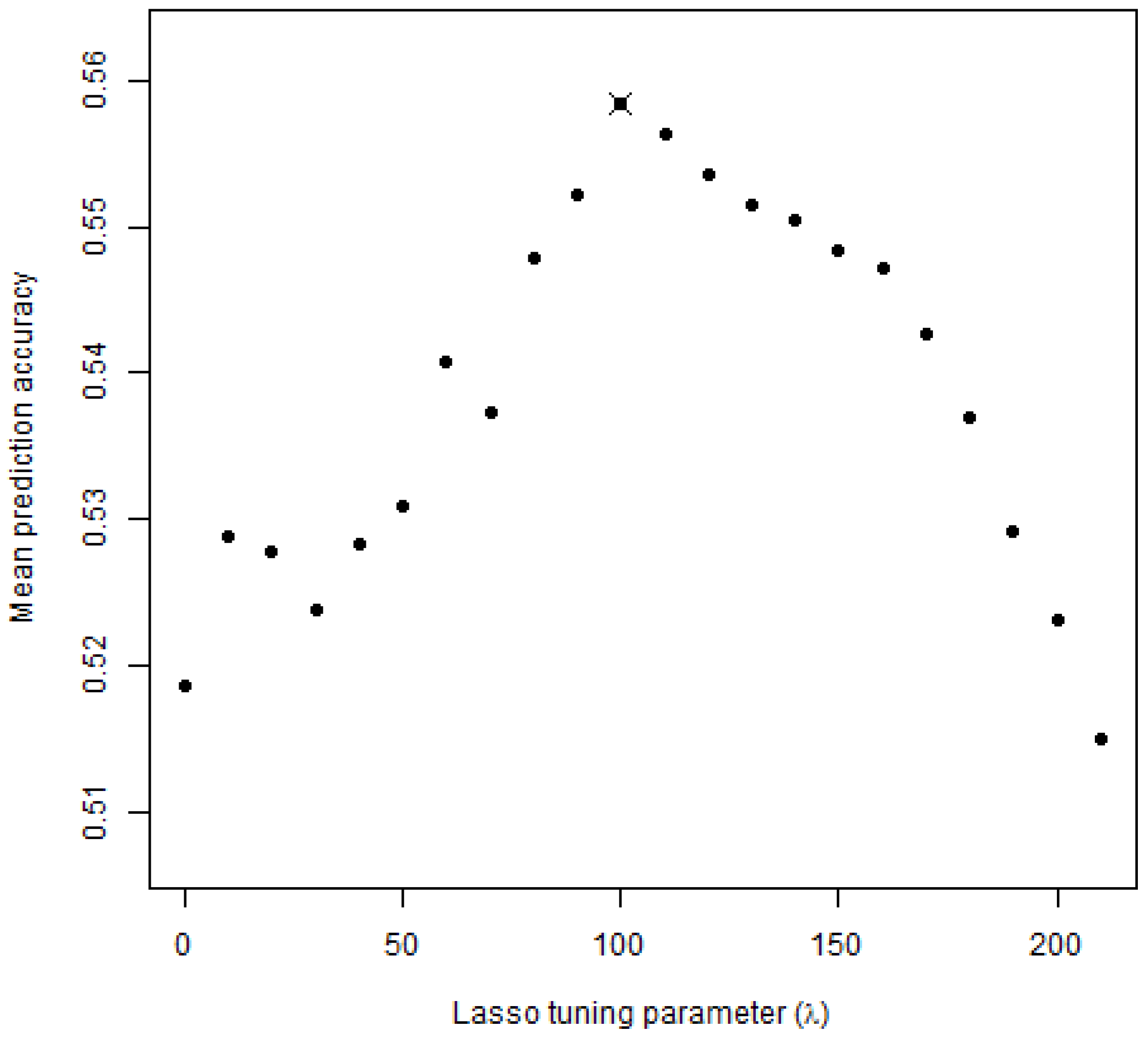
All models were fit implementing the R package glmmLasso [63,64]. We utilized Elastic Cloud Computing instances on Amazon Web Services to alleviate computing constraints. Based on the results of our replication analysis, the optimal tuning parameter is . Figure 5 plots the average OOSLL for each value of the tuning parameter we tested. Figure 6 plots average prediction accuracy at each value of the tuning parameter tested in our resampling analysis. These figures confirm that the optimal tuning parameter value maximizes both OOSLL and also average out-of-sample prediction accuracy.
The fitted model includes 155 covariates after LASSO regularization using , denoted Lasso* in the text and figures to follow. Table 3 summarizes the included covariates for direct effects and provides counts of behavioral measure interactions included in each approach. Prior to presenting our findings, a discussion about inference in regularized regression is necessary.
In an application such as ours where regularized regression is used for variable selection, we are using the data to “sparse” a full set of covariates into a sub-model that was not known or specified a priori. The problem arises due to the fact that when fitting the sub-model for the purposes of inference, we are looking at the data twice: once to determine the sub-set of covariates and once to test hypotheses [65]. There are a variety of methods proposed to deal with this selection bias like sample-splitting [66], simultaneous inference [66], exact post-selection inference methods [67,68], as well as double-selection methods [69]. All of these methods account for the regularization procedure to compute adjusted p-values, conditional on the particular sub-model being selected. However, under certain conditions, the naïve post-LASSO inference approach that simply refits the sparse model on the full data set (not accounting for regularization) can provide valid p-values and confidence intervals [65].
All the selective inference approaches mentioned above have been developed and validated in the context of models that assume only fixed (non-stochastic) parameter estimates. We are unaware of developments in the selective inference literature that address the case of selective inference issues in mixed models, as is the case for our work. It would be ideal to compute adjusted p-values and confidence intervals conditional on the regularization routine. However, given the lack of available methods for computing adjusted p-values and confidence intervals in the case of regularized mixed models, we are limited in the way we handle selective inference in our case. Thus, we report bootstrapped standard errors for each coefficient in our final models to account for potential issues associated with selection bias that is inherent in using a feature selection tool like LASSO. Bootstrapping standard errors, under the assumption that our empirical model is correct, allows us to quantify the uncertainty associated with our parameter estimates.
While we rely on a naïve post-LASSO approach outlined in the literature, we are confident in the validity of the inference given our relatively large sample size in relation to the number of considered covariates. In addition, we are not concerned with issues of endogeneity of our treatment conditions (GM labels) based on the fact that choice question blocks were randomly assigned to participants. This is the primary issue considered by Belloni, Chernozhukov, and Hansen [69]. We did evaluate the correlation between our controls and choice question assignment and found no evidence of statistically significant correlations. Any significant correlation observed would be spurious given the random assignment of choice question blocks.
3.1. Model Fit
In terms of overall model fit, Figure 5 and Figure 6 summarize the average OOSLL and average out-of-sample predication accuracy for each value of the tuning parameter. Prediction accuracy was determined by comparing predicted alternative choice and actual alternative choice for each participant-choice set pair. Predicted alternative choice was determined using the highest predicted choice probability among alternatives from each iteration of the resampling procedure and at each level of the penalty term. Similarly, the prediction accuracy is the percent of correct, out-of-sample predictions at each iteration in the resampling routine.
3.2. Behavioral Measures
As shown in Table 3, the regularized model fit on the full data set retained all of the direct effect attribute levels aside from the GM label attribute. All behavioral measures were retained in some form in in our modeling approach. Table 4 present the covariates with coefficient estimates significant at the 99% level based on bootstrapped standard errors for the Lasso*. This subset of covariates is materially the same whether or not we consider bootstrap standard errors. All covariates were standardized prior to model fitting. As such, we can directly interpret the magnitude of each coefficient as a measure of relative signal strength. We acknowledge that focusing only on covariates with 99% significance is an arbitrary decision. However, due to the large number of implicit hypothesis tests (155 for the Lasso* model) inherent in our analysis we only dedicate time to this subset. The interested reader is encouraged to contact the authors for further additional summary figures.
The first notable results are the Direct Effects in Table 4. For example, there is a significant and negative coefficient on fillet price, which is evidence our participants made rational choices in accordance with economic theory [70]. In terms of the other direct effect variables, we find results consistent with previous findings. Participants prefer salmon fillets that are Verified Non-GM while they dislike Fed-GM fillets. We also find that participants dislike imported salmon fillets relative to domestic based on the negative coefficients on the Norway and Chile attribute indicators. Finally, the No Purchase (ASC) direct effect can be interpreted simply as an intercept term. We now consider the significant behavioral interaction effects in Table 4.
3.3. Health Domain
In the health domain, concern about the health risks associated with GM technology is present in two of the four significant interactions. As concern level increases, Fed-GM labeled fillets become less attractive to consumers. A related observation is that concern level makes the no-purchase option more attractive. This would imply that consumers would rather not buy salmon fillets at all as their concern about the health risks of GM technology increased. Similarly, confidence in health risk perception makes the no-purchase option more attractive. Confidence in health risk perception level also increases the likelihood of purchasing organic salmon for those in the positive information treatment. This is somewhat unexpected as the information provides benefits of using GM technology in food production. However, we believe the confidence in risk perception is the driving force behind this effect. This is indicative of substitution away from GM salmon given strong prior confidence in health risk perceptions.
3.4. Environment Domain
In the environment domain, risk perception decreases the likelihood of purchasing a Fed-GM or GM fillet given the balanced information treatment. The fact that balanced information could not override the effects of prior risk perceptions provides further support for the negativity bias related to food technology identified in previous works [71,72]. The result that the interaction of confidence in environmental risk perception makes organic fillets less attractive for those in the balanced information treatment could be driven by those that are confident GM foods do not pose environmental risks. The justification for this interpretation is the fact that we are able to separate risk perception from confidence in the risk perception under the framework of the HoC. Specifically, higher confidence in risk perception does not necessarily imply a graver risk assessment.
We also see that increased confidence in environmental risk assessment of GM foods makes the no-purchase alternative less attractive in contrast to the same interaction in the health domain. This may be evidence that health risks are more salient on a personal-level, while environmental risks are more salient on a societal level, providing an exhibition of optimism bias as described by van der Linden [42]. Lastly, we also see that the interaction of confidence in environmental risk perception makes organic fillets less attractive for those in the balanced information.
3.5. Subjective Knowledge
There are two interactions with subjective knowledge in Table 4. We find a significant and positive effect of subjective knowledge on purchase likelihood of Fed-GM fillets, while subjective knowledge decreases the likelihood of selecting the no-purchase alternative. As subjective knowledge about GM technology in food production increases, so does likelihood of purchasing products in this category. Similarly, if consumers feel knowledgeable about GM technology in food, they perceive no or minimal information asymmetry about these food products and feel more confident making decisions that involve them. We consider these results consistent with the motivation behind “consumer right to know” campaigns.
3.6. Ambiguity Aversion
Domain-specific ambiguity aversion significantly increases the likelihood of purchasing Fed-GM salmon. If you are more competent or consider yourself more competent about GM technology in food, then you are more ambiguity averse in the domain of GM food. Thus, you prefer “betting” on purchases you are familiar with or feel knowledgeable about. If you know a product is not GM with certainty, then all bets are off. This ties directly back to the subjective knowledge measures, as we know from the literature that these measures increase together, specifically in this domain [55]. An alternate phrasing of the results uses the definition of an ambiguity-averse individual. As individual ambiguity aversion increases, so does the probability of losses they are willing to accept to avoid making a decision with an ambiguous outcome. So, ambiguity aversion in the GM domain implies that an individual would rather buy a fillet with a known high probability of being GM than a fillet with an unknown probability of being GM.
4. Discussion
As the global population continues to grow, there will be increasing demand for quality, safe, and diverse food options, especially seafood. We find that consumers’ perceptions, attitudes and behavioral measures do play an important role in predicting consumer choice of seafood products. Our results confirm basic intuitions about consumer preference for lower prices and non-GM foods, as well as preference for domestic origin of their seafood. We also find that health and environmental risk perceptions, confidence and concern about potential health risks, confidence and concern about environmental risks, subjective knowledge, and ambiguity aversion have a significant influence on consumer choice of salmon fillets. In the context of van der Linden’s Hierarchy of Concern framework, we see that risk perception, confidence, and concern about the risks associated with GM technology are the prominent behavioral factors in both the health and environment domain. Both context specific subjective knowledge and ambiguity aversion promote consumption of Fed-GM labeled salmon fillets, which is consistent with the competence hypothesis [54] and comparative ignorance hypothesis [53].
Our results show that familiarity with GM technology is an important component of demand for GM seafood, as well as the ultimate efficacy of the NBFDS at addressing the information asymmetry issue in the market for GM seafood. Further, we provide evidence that familiarity with the use of GM technology in food can promote consumption of these products. On the other side of this, however, is the fact that concern and confidence about the potential health and environmental risks associated with GM technology can push consumers out of the salmon market all together. These results indicate that while labels under the NBFDS can effectively promote informed consumer choice, the labels might unintentionally reduce overall salmon consumption, which is problematic given the already low levels of seafood consumption in the United States. This is particularly relevant given the recent lift of the import ban on AquAdvantage salmon eggs and large-scale production of the product.
In light of these findings, it is all the more pressing that future work focuses on using empirical techniques, like machine learning, to better understand how behavioral measures might lead to perverse outcomes of the NBFDS and other proposed food policy. We see strong opportunity to utilize available data sets such as those associated with the Eurbarometer and/or Pew Research Center surveys as a means of feasibly investigating this issue. Some additional considerations to explore as behavioral predictors might include measures of cultural cognition and social norms as they relate to scientific communication and public policy [73]. One specific area that would be valuable to explore is the consumer perception of the sustainability of GM seafood products. If advancements in the aquaculture industry, including GM technology, are utilized to address sustainability concerns, the ultimate efficacy of such advancements is dependent on consumer perceptions. As such, further investigation of consumers’ perception of the sustainability of industry innovations would be a valuable endeavor. These analyses will continue to build evidence in support of incorporating “non-conventional” data in models to improve predictive performance [59].
While we are proponents of using machine learning techniques to investigate consumer behavior, we do note that these methods have some inherent limitations that have implications for its use in policy evaluation via a DCE. From a practical standpoint, the primary limitation of these methods is the time and computational demands necessary for estimation. Whether policy makers have the resources to estimate such models could be a potential barrier to full utilization in the policy sector. Another limitation of using LASSO to analyze DCE data is that it does not allow for estimation of valid willingness-to-pay (WTP) measures typical of DCE studies. WTP estimates from such a method are invalid due to potential selection bias introduced by using the LASSO as a feature selection tool. The selection bias arises due to LASSO’s indifference between selecting from a group of correlated variables.
Regardless of the approach adopted, these models can only be as effective as the data available to decision makers. The European Union (EU) conducts the annual Eurobarometer to assess public opinion on various topics ranging from trust in national government to consumer habits regarding fishery and aquaculture products. A triennial special topic survey focuses on public perception of biotechnology in the EU and a variety of studies have used the publicly available data set to infer public perception of GM foods [34,74]. In the United States, the Pew Research Center conducts similar public surveys and provides data sets for public use. Our findings highlight important pathways through which information on food labels, as well as outside market information, can have heterogeneous effects on consumer purchase decisions. Specifically, we have reaffirmed the importance of measuring risk perceptions in a multidimensional manner as proposed by van der Linden and other scholars. These results are informative for those developing public surveys such as the EU and Pew Research Center of the most appropriate manner in which to gauge public perceptions and sentiments toward novel food technologies like genetic modification. A fuller understanding of the multidimensionality of public perception is particularly relevant to policy makers as regulatory measures for promoting sustainability in the food system develop concurrently with sustainable food innovations.
We propose that data sources like those mentioned above be more thoroughly utilized by policy makers to address the policy prediction problem associated with food process labels. Using these data with a model selection approach like LASSO can help to tease out important behavioral considerations that, as we have shown, are important in consumer decision making in the seafood market. Given current policy interventions that aim to promote consumption of seafood products through affecting the outside information available to consumers, these methods can be used to identify pathways through which these interventions are effective and, critically, can aid in targeting future policy initiatives or strategic marketing of food products more effectively.
Supplementary Materials
The following are available online at https://www.mdpi.com/2071-1050/11/14/3934/s1.
Author Contributions
M.J.W. is responsible for software, validation, formal analysis, investigation, data curation, writing—original draft preparation, visualization, project administration and funding acquisition under supervision of T.W.S. Both M.J.W. and T.W.S. contributed to conceptualization, methodology, resources, and writing—review and editing.
Funding
This research is made possible by the partial support of the University of Rhode Island Coastal Institute.
Acknowledgments
The authors thank Ben Blachly, Jason Walsh, Vasu Gaur, David Bidwell, Hiro Uchida, Maya Vadiveloo and the anonymous reviewers for helpful comments and suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- United Nations, Department of Economics and Social Affairs, Population Division. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables; United Nations: New York, NY, USA, 2017. [Google Scholar]
- Food and Agricultural Organization of the United Nations. State of World Fisheries and Aquaculture 2016—Contributing to Food Security and Nutrition for All; Food and Agricultural Organization of the United Nations: Rome, Italy, 2016. [Google Scholar]
- Food and Agricultural Organization of the United Nations. State of World Fisheries and Aquaculture 2018—Meeting the Sustainable Development Goals; Food and Agricultural Organization of the United Nations: Rome, Italy, 2018. [Google Scholar]
- AquaBounty Technologies, Inc. AquaBounty Technologies. Available online: https://aquabounty.com/ (accessed on 30 May 2019).
- Ferrer Llagostera, P.; Kallas, Z.; Reig, L.; Amores de Gea, D. The use of insect meal as a sustainable feeding alternative in aquaculture: Current situation, Spanish consumers’ perceptions and willingness to pay. J. Clean. Prod. 2019, 229, 10–21. [Google Scholar] [CrossRef]
- Smith, M.D.; Asche, F.; Guttormsen, A.G.; Wiener, J.B. Genetically Modified Salmon and Full Impact Assessment. Science 2010, 330, 1052–1053. [Google Scholar] [CrossRef] [PubMed]
- Agricultural Marketing Act of 1946, 7 United States Code §§ 1639-1639c. 2016. Available online: https://www.congress.gov/114/plaws/publ216/PLAW-114publ216.pdf (accessed on 10 October 2017).
- Boudreau, C. USDA Eyes Dec. 1 for Final GMO Labeling Rule. POLITICO Pro 2018. Available online: https://subscriber.politicopro.com/agriculture/whiteboard/2018/09/usda-eyes-dec-1-for-final-gmo-labeling-rule-1904831 (accessed on 16 November 2018).
- Blank, C. FDA Lifts Import Alert on GE Salmon, Clears Way for AquaBounty. Available online: https://www.seafoodsource.com/news/supply-trade/fda-lifts-import-alert-on-ge-salmon-clears-way-for-aquabounty (accessed on 10 March 2019).
- Blank, C. GE Salmon Advancing in the US with FDA’s Blessing. Available online: https://www.seafoodsource.com/news/aquaculture/ge-salmon-advancing-in-the-us-with-fda-blessing (accessed on 3 May 2018).
- Mullainathan, S.; Spiess, J. Machine Learning: An Applied Econometric Approach. J. Econ. Perspect. 2017, 31, 87–106. [Google Scholar] [CrossRef]
- Kleinberg, J.; Ludwig, J.; Mullainathan, S.; Obermeyer, Z. Prediction Policy Problems. Am. Econ. Rev. 2015, 105, 491–495. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hino, M.; Benami, E.; Brooks, N. Machine learning for environmental monitoring. Nat. Sustain. 2018, 1, 583–588. [Google Scholar] [CrossRef]
- Kleinberg, J.; Lakkaraju, H.; Leskovec, J.; Ludwig, J.; Mullainathan, S. Human Decisions and Machine Predictions. Q. J. Econ. 2017, 133, 237–293. [Google Scholar] [PubMed]
- Hut, S.; Oster, E. Changes in Household Diet: Determinants and Predictability; National Bureau of Economic Research: Cambridge, MA, USA, 2018. [Google Scholar]
- Oster, E. Diabetes and Diet: Purchasing Behavior Change in Response to Health Information. Am. Econ. J. Appl. Econ. 2018, 10, 308–348. [Google Scholar] [CrossRef]
- Blumenstock, J. Fighting poverty with data. Science 2016, 353, 753–754. [Google Scholar] [CrossRef] [PubMed]
- Jean, N.; Burke, M.; Xie, M.; Davis, W.M.; Lobell, D.B.; Ermon, S. Combining satellite imagery and machine learning to predict poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [Green Version]
- Blumenstock, J.; Cadamuro, G.; On, R. Predicting poverty and wealth from mobile phone metadata. Science 2015, 350, 1073–1076. [Google Scholar] [CrossRef] [Green Version]
- Andini, M.; Ciani, E.; de Blasio, G.; D’Ignazio, A.; Salvestrini, V. Targeting with machine learning: An application to a tax rebate program in Italy. J. Econ. Behav. Organ. 2018, 156, 86–102. [Google Scholar] [CrossRef]
- Kang, J.S.; Kuznetsova, P.; Luca, M.; Choi, Y. Where Not to Eat? Improving Public Policy by Predicting Hygiene Inspections Using Online Reviews. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1443–1448. [Google Scholar]
- Kim, J.-M.; Jung, H. Predicting bid prices by using machine learning methods. Appl. Econ. 2019, 51, 2011–2018. [Google Scholar] [CrossRef]
- Lusk, J.L.; Rozan, A. Public Policy and Endogenous Beliefs: The Case of Genetically Modified Food. J. Agric. Resour. Econ. 2008, 33, 270–289. [Google Scholar]
- Bonroy, O.; Constantatos, C. On the Economics of Labels: How Their Introduction Affects the Functioning of Markets and the Welfare of All Participants. Am. J. Agric. Econ. 2014, 97, 239–259. [Google Scholar] [CrossRef] [Green Version]
- Marette, S.; Roosen, J. Bans and Labels with Controversial Food Technologies. In The Oxford Handbook of the Economics of Food Consumption and Policy; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Liu, S.; Huang, J.-C.; Brown, G.L. Information and Risk Perception: A Dynamic Adjustment Process. Risk Anal. 1998, 18, 689–699. [Google Scholar] [CrossRef]
- Messer, K.D.; Costanigro, M.; Kaiser, H.M. Labeling Food Processes: The Good, the Bad and the Ugly. Appl. Econ. Perspect. Policy 2017, 39, 407–427. [Google Scholar] [CrossRef]
- Steenkamp, J.-B. Conceptual model of the quality perception process. J. Bus. Res. 1990, 21, 309–333. [Google Scholar] [CrossRef]
- Lusk, J.L.; Coble, K.H. Risk Perceptions, Risk Preference, and Acceptance of Risky Food. Am. J. Agric. Econ. 2005, 87, 393–405. [Google Scholar] [CrossRef]
- Petrolia, D.R. Risk preferences, risk perceptions, and risky food. Food Policy 2016, 64, 37–48. [Google Scholar] [CrossRef] [Green Version]
- Loewenstein, G. Emotions in Economic Theory and Economic Behavior. Am. Econ. Rev. 2000, 90, 426–432. [Google Scholar] [CrossRef] [Green Version]
- Curtis, K.R.; McCluskey, J.J.; Wahl, T.I. Consumer Acceptance of Genetically Modified Food Products in the Developing World. AgBioForum 2004, 7, 70–75. [Google Scholar]
- Amin, L.; Azad, M.A.; Gausmian, M.H.; Zulkifli, F. Determinants of Public Attitudes to Genetically Modified Salmon. PLoS ONE 2014, 9, e86174. [Google Scholar] [CrossRef]
- Gaskell, G.; Allum, N.; Wagner, W.; Kronberger, N.; Torgersen, H.; Hampel, J.; Bardes, J. GM Foods and the Misperception of Risk Perception. Risk Anal. 2004, 24, 185–194. [Google Scholar] [CrossRef] [Green Version]
- Hoch, S.J.; Ha, Y.-W. Consumer Learning: Advertising and the Ambiguity of Product Experience. J. Consum. Res. 1986, 13, 221–233. [Google Scholar] [CrossRef]
- Snow, A. Ambiguity and the value of information. J. Risk Uncertain. 2010, 40, 133–145. [Google Scholar] [CrossRef]
- Kivi, P.A.; Shogren, J.F. Second-Order Ambiguity in Very Low Probability Risks: Food Safety Valuation. J. Agric. Resour. Econ. 2010, 35, 443–456. [Google Scholar]
- Viscusi, W.K.; Magat, W.A.; Huber, J. Smoking Status and Public Responses to Ambiguous Scientific Risk Evidence. South. Econ. J. 1999, 66, 250–270. [Google Scholar] [CrossRef]
- Kaptan, G.; Fischer, A.R.H.; Frewer, L.J. Extrapolating understanding of food risk perceptions to emerging food safety cases. J. Risk Res. 2018, 21, 996–1018. [Google Scholar] [CrossRef]
- Hansen, J.; Holm, L.; Frewer, L.; Robinson, P.; Sandøe, P. Beyond the knowledge deficit: Recent research into lay and expert attitudes to food risks. Appetite 2003, 41, 111–121. [Google Scholar] [CrossRef]
- Frewer, L.J.; Howard, C.; Hedderley, D.; Shepherd, R. The Elaboration Likelihood Model and Communication About Food Risks. Risk Anal. 1997, 17, 759–770. [Google Scholar] [CrossRef]
- van der Linden, S. Determinants and Measurement of Climate Change Risk Perception, Worry, and Concern. In The Oxford Encyclopedia of Climate Change Communication; Nisbet, M.C., Schafer, M., Markowitz, E., Ho, S., O’Neill, S., Thaker, J., Eds.; Oxford University Press: Oxford, UK, 2017; Volume 1. [Google Scholar]
- Meagher, K.D. Public perceptions of food-related risks: A cross-national investigation of individual and contextual influences. J. Risk Res. 2018, 22, 919–935. [Google Scholar] [CrossRef]
- Slovic, P. Trust, Emotion, Sex, Politics, and Science: Surveying the Risk-Assessment Battlefield. Risk Anal. 1999, 19, 689–701. [Google Scholar] [CrossRef] [Green Version]
- United States Census Bureau. DP05: ACS Demographic and Housing Estimates. In 2016 American Community Survey 1-Year Estimates; United States Census Bureau’s American Community Survey Office: Washington, DC, USA, 2017. [Google Scholar]
- United States Census Bureau. S1501: Educational Attainment. In 2016 American Community Survey 1-Year Estimates; United States Census Bureau’s American Community Survey Office: Washington, DC, USA, 2017. [Google Scholar]
- United States Census Bureau. S2501: Occupancy Characteristics. In 2016 American Community Survey 1-Year Estimates; United States Census Bureau’s American Community Survey Office: Washington, DC, USA, 2017. [Google Scholar]
- Goodman, J.K.; Paolacci, G. Crowdsourcing Consumer Research. J. Consum. Res. 2017, 44, 196–210. [Google Scholar] [CrossRef]
- Funk, C.; Kennedy, B. The New Food Fights: U.S. Public Divides Over Food Science; Pew Research Center: Washington, DC, USA, 2016. [Google Scholar]
- Carlucci, D.; Nocella, G.; De Devitiis, B.; Viscecchia, R.; Bimbo, F.; Nardone, G. Consumer purchasing behaviour towards fish and seafood products. Patterns and insights from a sample of international studies. Appetite 2015, 84, 212–227. [Google Scholar] [CrossRef]
- StataCorp. Stata Statistical Software: Release 13; StataCorp LLC: College Station, TX, USA, 2013. [Google Scholar]
- Hole, A.R. DCREATE: Stata Module to Create Efficient Designs for Discrete Choice Experiments; Boston College Department of Economics: Boston, MA, USA, 2015. [Google Scholar]
- Fox, C.R.; Tversky, A. Ambiguity Aversion and Comparative Ignorance. Q. J. Econ. 1995, 110, 585–603. [Google Scholar] [CrossRef]
- Heath, C.; Tversky, A. Preference and belief: Ambiguity and competence in choice under uncertainty. J. Risk Uncertain. 1991, 4, 5–28. [Google Scholar] [CrossRef]
- Costa-Font, M. Understanding Food Scares: The Role of Ambiguity Aversion and Analogical Reasoning. Hum. Ecol. Risk Assess. Int. J. 2013, 19, 661–673. [Google Scholar] [CrossRef]
- Dimmock, S.G.; Kouwenberg, R.; Mitchell, O.S.; Peijnenburg, K. Estimating ambiguity preferences and perceptions in multiple prior models: Evidence from the field. J. Risk Uncertain. 2015, 51, 219–244. [Google Scholar] [CrossRef] [Green Version]
- Viscusi, W.K. Alarmist Decisions with Divergent Risk Information. Econ. J. 1997, 107, 1657–1670. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Huseynov, S.; Kassas, B.; Segovia, M.S.; Palma, M.A. Incorporating biometric data in models of consumer choice. Appl. Econ. 2018, 51, 1514–1531. [Google Scholar] [CrossRef]
- Afendras, G.; Markatou, M. Optimality of Training/Test Size and Resampling Effectiveness of Cross-Validation Estimators of the Generalization Error. arXiv 2015, arXiv:1511.02980. [Google Scholar]
- Friedman, J.H.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Groll, A. glmmLasso: Variable Selection for Generalized Linear Mixed Models by L1-Penalized Estimation; R Package Version 1.5.1.; The R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Version 3.5.2; The R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Zhao, S.; Shojaie, A.; Witten, D. In Defense of the Indefensible: A Very Naive Approach to High-Dimensional Inference. arXiv 2017, arXiv:1705.05543. [Google Scholar]
- Berk, R.; Brown, L.; Buja, A.; Zhang, K.; Zhao, L. Valid post-selection inference. Ann. Stat. 2013, 41, 802–837. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.D.; Sun, D.L.; Sun, Y.; Taylor, J.E. Exact post-selection inference, with application to the lasso. Ann. Stat. 2016, 44, 907–927. [Google Scholar] [CrossRef]
- Tibshirani, R.J.; Taylor, J.; Lockhart, R.; Tibshirani, R. Exact Post-Selection Inference for Sequential Regression Procedures. J. Am. Stat. Assoc. 2016, 111, 600–620. [Google Scholar] [CrossRef] [Green Version]
- Belloni, A.; Chernozhukov, V.; Hansen, C. Inference on Treatment Effects after Selection among High-Dimensional Controls. Rev. Econ. Stud. 2013, 81, 608–650. [Google Scholar] [CrossRef]
- Mas-Colell, A.; Whinston, M.D.; Green, J.R. Microeconomic Theory; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Mizerski, R.W. An Attribution Explanation of the Disproportionate Influence of Unfavorable Information. J. Consum. Res. 1982, 9, 301–310. [Google Scholar] [CrossRef]
- Kahneman, D.; Knetsch, J.L.; Thaler, R.H. Anomalies: The endowment effect, loss aversion, and status quo bias. J. Econ. Perspect. 1991, 5, 193–206. [Google Scholar] [CrossRef]
- Kahan, D.M.; Jenkins-Smith, H.; Braman, D. Cultural cognition of scientific consensus. J. Risk Res. 2011, 14, 147–174. [Google Scholar] [CrossRef]
- Gaskell, G.; Hohl, K.; Gerber, M.M. Do closed survey questions overestimate public perceptions of food risks? J. Risk Res. 2017, 20, 1038–1052. [Google Scholar] [CrossRef]
Figure 1.
Example choice set.

Figure 2.
Hierarchy of concern framework. This framework is adapted from van der Linden (2017). “Risk Perception” is a measure of whether an individual believes there are risk associated with a scenario, e.g., GM food, “Confidence” refers to the perceived likelihood risks will occur, and “Concern” is the level of worry about the potential risks.
Figure 2.
Hierarchy of concern framework. This framework is adapted from van der Linden (2017). “Risk Perception” is a measure of whether an individual believes there are risk associated with a scenario, e.g., GM food, “Confidence” refers to the perceived likelihood risks will occur, and “Concern” is the level of worry about the potential risks.

Figure 3.
Example ambiguity aversion elicitation menu.

Figure 4.
Histogram and smoothed density plot of ambiguity aversion parameter.
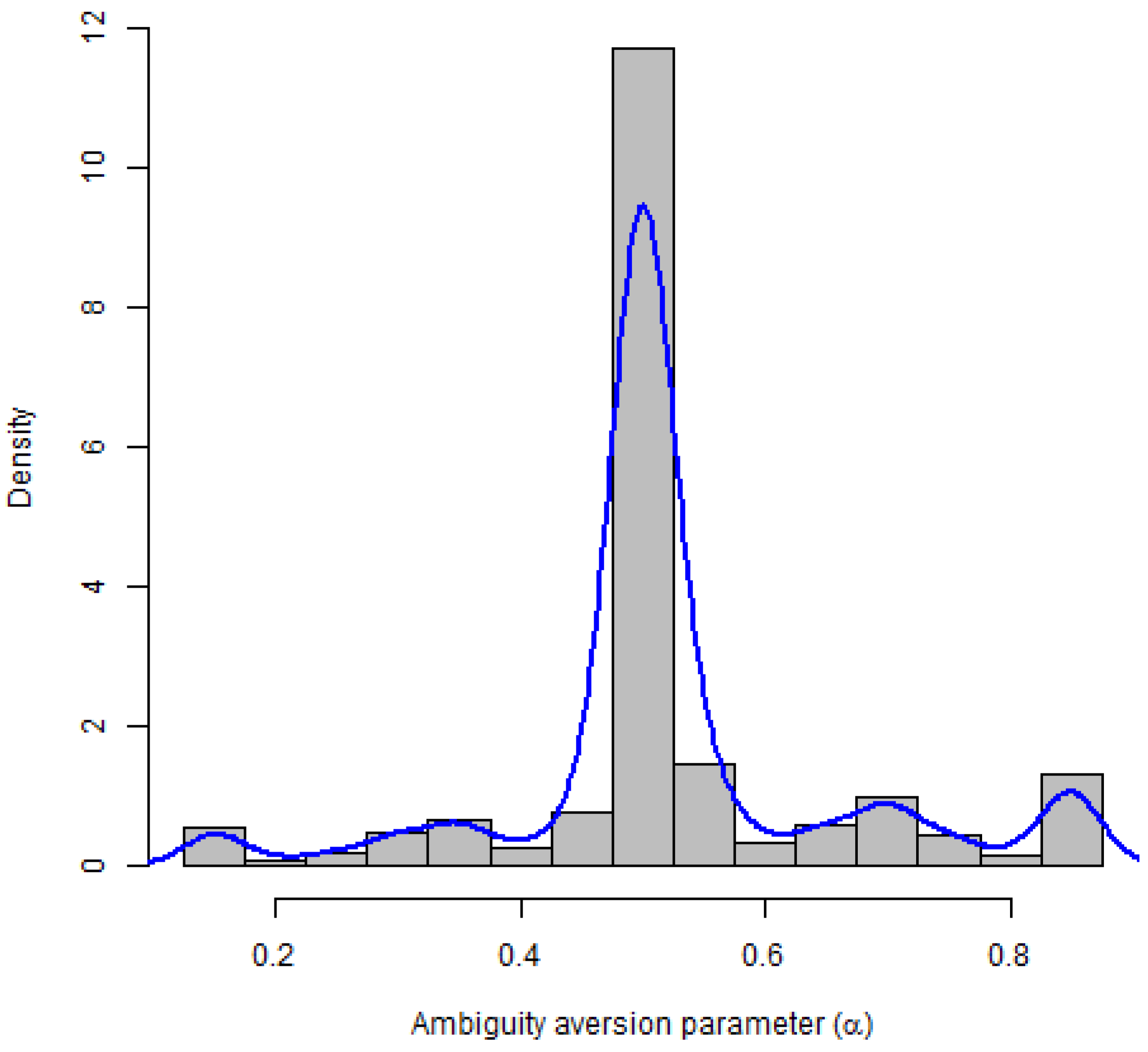
Figure 5.
Mean out-of-sample log-likelihood. The point marked X denotes the maximal, mean out-of-sample log-likelihood of model fit, corresponding to = 100.
Figure 5.
Mean out-of-sample log-likelihood. The point marked X denotes the maximal, mean out-of-sample log-likelihood of model fit, corresponding to = 100.

Figure 6.
Mean out-of-sample prediction accuracy. The point marked X denotes the maximal, mean out-of-sample prediction accuracy of model fit, corresponding to = 100.
Figure 6.
Mean out-of-sample prediction accuracy. The point marked X denotes the maximal, mean out-of-sample prediction accuracy of model fit, corresponding to = 100.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Sample summary statistics.
| Mean | SD | 2016 ACS 1 | |
|---|---|---|---|
| Age | 35.9 | 11.0 | 37.7 |
| Female (%) | 40.1 | 49.0 | 51.60 |
| Income (%) | |||
| Less than $49,999 | 48.5 | 50.0 | 45.4 |
| $50,000–99,999 | 37.1 | 48.3 | 30.0 |
| $100,000–149,999 | 5.8 | 23.5 | 13.5 |
| Greater than $150,000 | 2.7 | 16.2 | 11.1 |
| Education (%) | |||
| Less than high school | 0.4 | 6.3 | 12.5 |
| High School degree | 9.4 | 29.2 | 27.2 |
| Some college or Associate’s | 29.0 | 45.4 | 29.0 |
| Bachelor’s degree | 42.5 | 49.5 | 19.3 |
| Graduate or professional degree | 57.5 | 49.5 | 11.9 |
| Household size (%) | |||
| 1 | 19.5 | 39.7 | 27.7 |
| 2 | 26.7 | 44.2 | 33.7 |
| 3 | 24.2 | 42.9 | 15.7 |
| 4 | 18.8 | 39.1 | 13.1 |
| 5 | 6.8 | 25.2 | 6.0 |
| 6 | 3.0 | 17.1 | 2.3 |
| 7 or more | 0.9 | 9.5 | 1.5 |
| Race (%) | |||
| White | 74.7 | 43.5 | 73.3 |
| Black or African American | 13.5 | 34.2 | 12.6 |
| Hispanic or Latino | 7.0 | 25.5 | 17.3 |
| Native American or Alaska Native | 1.8 | 13.5 | 0.8 |
| Asian | 4.3 | 20.2 | 5.2 |
| Native Hawaiian or Pacific Islander | 0.4 | 6.2 | 0.2 |
| Other | 0.9 | 9.3 | 4.8 |
| Observations | 1043 |
1 2016 ACS (American Community Survey) column reports mean values from the 2016ACS, except age which is reported as a median. ACS summary of household size includes both family and nonfamily households.
Table 2.
DCE attributes and levels.
| Atlantic Salmon Fillets | |
|---|---|
| Price | 6.49 |
| 9.99 | |
| 13.49 | |
| 16.99 | |
| GM Label | No Label |
| Organic | |
| Verified Non-GM | |
| GM-Fed | |
| GM | |
| Origin | U.S. |
| Norway | |
| Chile | |
Table 3.
Summary of retained covariates in Lasso* model.
| Variable | Retained |
|---|---|
| Direct Effects 1 | |
| No Purchase (ASC) | Y |
| Fillet Price | Y |
| Organic | Y |
| Verified Non-GM | Y |
| Fed with GM Soy | Y |
| GM | N |
| Both GM | Y |
| Norway | Y |
| Chile | Y |
| Information 1 | |
| Positive × Organic | Y |
| Positive × Verified Non-GM | Y |
| Positive × Fed with GM Soy | N |
| Positive × GM | Y |
| Positive × Both GM | Y |
| Negative × Organic | Y |
| Negative × Verified Non-GM | Y |
| Negative × Fed with GM Soy | Y |
| Negative × GM | N |
| Negative × Both GM | Y |
| Balanced × Organic | Y |
| Balanced × Verified Non-GM | Y |
| Balanced × Fed with GM Soy | Y |
| Balance × GM | Y |
| Balance × Both GM | Y |
| Health domain interactions (# included) | |
| Risk perception | 18 |
| Confidence in risk perception | 15 |
| Concern about risks | 19 |
| Environmental domain interactions (# included) | |
| Risk perception | 19 |
| Confidence in risk perception | 15 |
| Concern about risks | 18 |
| Subjective Knowledge about GM (# included) | 15 |
| Ambiguity aversion (# included) | 15 |
| Average out-of-sample log-likelihood (S.E.) | −2896.167 (2.934) |
| Average OOS prediction accuracy (S.E.) | 0.558 (0.002) |
| Average McFadden’s R-squared (S.E.) | 0.492 (0.0005) |
| Total covariates retained | 155 |
1 “Y” indicates a variable was retained, “N” indicates variable was excluded by regularization, respectively.
Table 4.
Significant covariates (99% level), Lasso* fit on full sample.
| Fillet Choice 1 | ||
|---|---|---|
| Coefficient | Bootstrap Standard Error | |
| Direct Effects | ||
| No Purchase (ASC) | −1.89 | 0.11 |
| Fillet Price ($) | −0.95 | 0.04 |
| Verified Non-GM | 0.47 | 0.18 |
| Fed with GM Soy | −0.70 | 0.10 |
| Norway | −0.22 | 0.02 |
| Chile | −0.32 | 0.02 |
| Health domain interactions | ||
| No Purchase (ASC) × Confidence | 0.23 | 0.09 |
| Positive × Organic × Confidence | 0.27 | 0.11 |
| No Purchase (ASC) × Concern | 0.49 | 0.08 |
| Fed with GM Soy × Concern | −0.43 | 0.10 |
| Environment domain interactions | ||
| Balanced × Fed with GM Soy × Risk Perception | −0.35 | 0.11 |
| Balanced × GM × Risk Perception | −0.34 | 0.10 |
| No Purchase (ASC) × Confidence | −0.21 | 0.08 |
| Balanced × Organic × Confidence | −0.29 | 0.10 |
| Subjective knowledge interactions | ||
| No Purchase (ASC) | −0.32 | 0.07 |
| Fed with GM Soy | 0.39 | 0.06 |
| Ambiguity aversion interactions | ||
| Fed with GM Soy | 0.24 | 0.07 |
1 Coefficients on risk perception, concern, confidence, subjective knowledge, and ambiguity aversion are standardized. All other covariates are indicator variables to denote label attributes or experimental conditions.
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Weir, M.J.; Sproul, T.W. Identifying Drivers of Genetically Modified Seafood Demand: Evidence from a Choice Experiment. Sustainability 2019, 11, 3934. https://doi.org/10.3390/su11143934
AMA Style
Weir MJ, Sproul TW. Identifying Drivers of Genetically Modified Seafood Demand: Evidence from a Choice Experiment. Sustainability. 2019; 11(14):3934. https://doi.org/10.3390/su11143934
Chicago/Turabian StyleWeir, Michael J., and Thomas W. Sproul. 2019. "Identifying Drivers of Genetically Modified Seafood Demand: Evidence from a Choice Experiment" Sustainability 11, no. 14: 3934. https://doi.org/10.3390/su11143934
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.