
Optimal Placement of Sensors in Traffic Networks Using Global Search Optimization Techniques Oriented towards Traffic Flow Estimation and Pollutant Emission Evaluation


Abstract
:1. Introduction
1.1. Main Contribution
1.2. Paper Outline
2. System Specifications and Problem Definition
- Urban network topology: the layout and connectivity of the urban road network, defining the spatial relationships between different sectors and links.
- State-space representation: a mathematical representation of the traffic model in state-space form, capturing the dynamics and interactions within the system.
- Sensor placement locations: identification of potential locations within the urban network where sensors (cameras, radar, motion sensors) can be strategically placed.
- Observer design: formulation of a state observer that utilizes the selected subset of sensors to estimate the traffic flow accurately.
2.1. Model Design
- Macroscopic traffic models encompass traffic flow models, which analyze overarching traffic patterns by considering factors like density, speed, and flow, often employing fluid dynamics’ principles for a macro-level perspective. They also include queuing models that investigate the dynamics of traffic queue formation and dissipation, focusing on critical points such as intersections, toll booths, and traffic signals.
- Mesoscopic traffic models examine traffic dynamics at an intermediate level. Link-based models focus on the specific dynamics of individual links or segments within a transportation network, capturing the traffic flow on particular road sections. Cell transmission models, on the other hand, segment the roadway into discrete cells, simulating vehicle movement from one cell to another while accounting for variables such as speed limits and traffic signals, offering a granular view of traffic behavior.
- Microscopic traffic models delve into the intricate behaviors of individual vehicles and drivers. Car-following models closely simulate the actions of individual vehicles, focusing on driver responses to preceding vehicles and including considerations such as acceleration, deceleration, and safe following distances. Meanwhile, agent-based models treat each driver as an independent decision-maker, exploring their unique decision-making processes, interactions with other drivers, and reactions to surrounding traffic conditions, providing a detailed analysis of driver behavior within the traffic system.
2.2. Improving the Model
- is a vector;
- The cost function is a scalar value;
- The subscript N means that the cost function is dependent on the number of data samples and becomes more accurate as N increases.
2.3. Observability Metric
- W is the observability Gramian defined as
- and represent the largest and smallest singular values of the observability Gramian, respectively.
- The trace of the Gramian is directly related to the average energy and can be interpreted as the average observability in all directions in the state space.
- In Equation (11), the smallest singular value of the Gramian is related to the energy of the least observable mode, while the largest is related to the energy of the most observable one; hence, the condition number K measures how balanced the observability is among all the modes.
- The rank of the Gramian is the dimension of the observable subspace.
2.4. Problem Definition
3. Observability-Based Sensor Selection
- Referring to the model (1), the subsequent output equation is taken into account.in which represents the matrix corresponding to the road sectors where sensors are to be installed, comprising p rows selected from the identity matrix based on the index set .
- The observability Gramian (12) is thus reformulated aswhere , (where n is the maximum number of streets contained in the road network, or equivalently, the maximum number of sensors that can be installed) are binary “‘activation variables”’ whose meaning can be summarized by the function
4. Simulated Annealing Heuristic
- The solution space (i.e., the set of all possible solutions):
- The objective function defined on the solution space.
5. Genetic Algorithms
6. Exhaustive Search Algorithms
- Generate candidates: create a list of all possible solutions within the defined search space.
- Evaluate candidates: evaluate the objective function or cost associated with each candidate solution.
- Select optimal solution: identify the solution with the minimum or maximum objective function value, depending on whether you are minimizing or maximizing.
- Repeat: continue this process until all possible solutions have been considered.
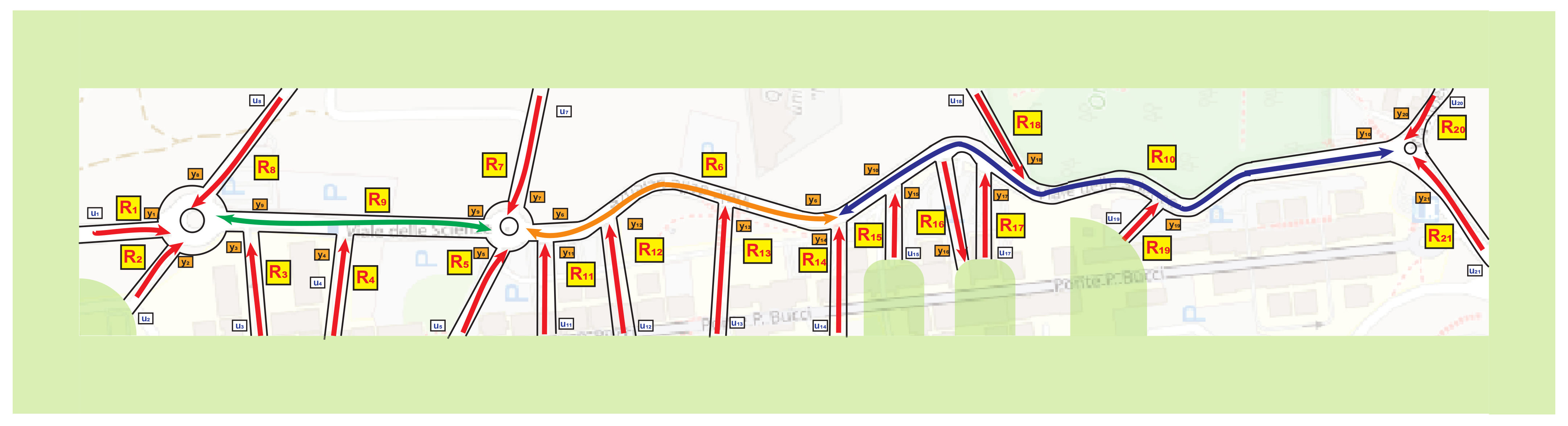
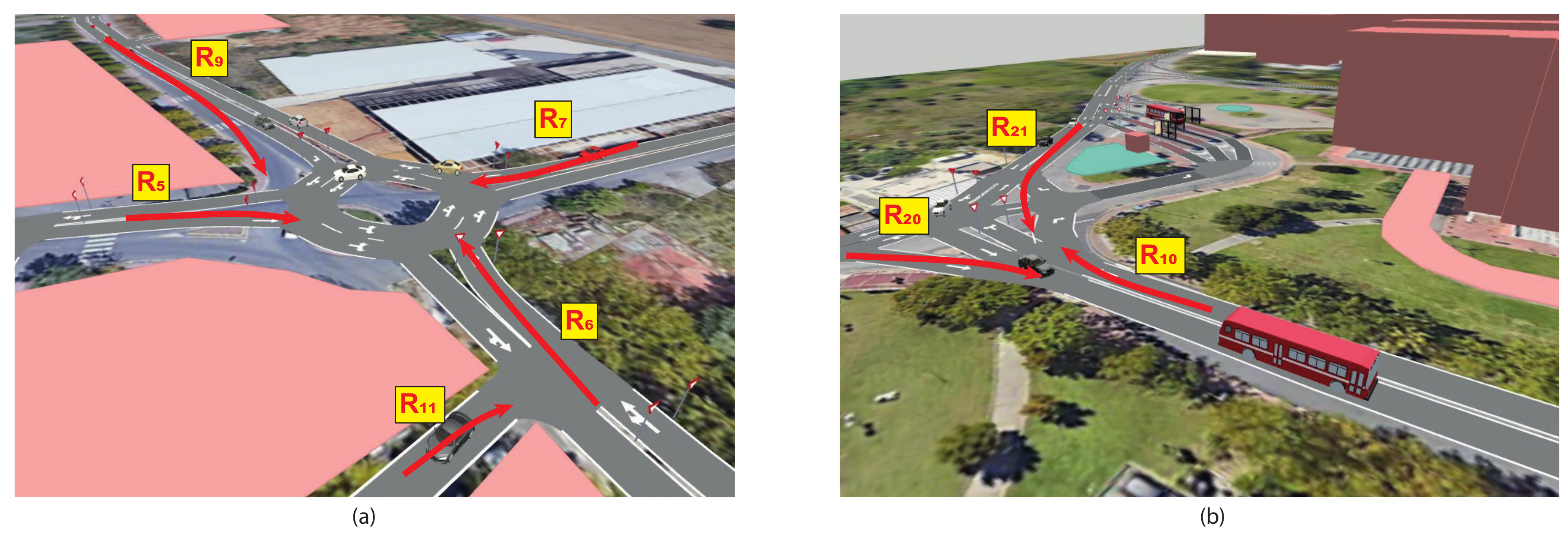
7. Results
- Computation time (i.e., the duration required to execute the sensor selection algorithm and obtain the solution): 94.5 [s].
- Cardinality ;
- .
- .
- Computation time (i.e., the duration required to execute the sensor selection algorithm and obtain the solution): 89.6 [s].
- Cardinality ;
- .
- .
- The exhaustive search identified 12 sensor sets that ensured system observability;
- These solutions exhibited varying condition numbers (11);
- Sensor set number three coincided with the simulated annealing (SA) procedure’s solution and had the lowest condition number value, indicating optimal observability.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Sensor Sets | |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 | ||
| 9 | ||
| 10 | ||
| 11 | ||
| 12 |
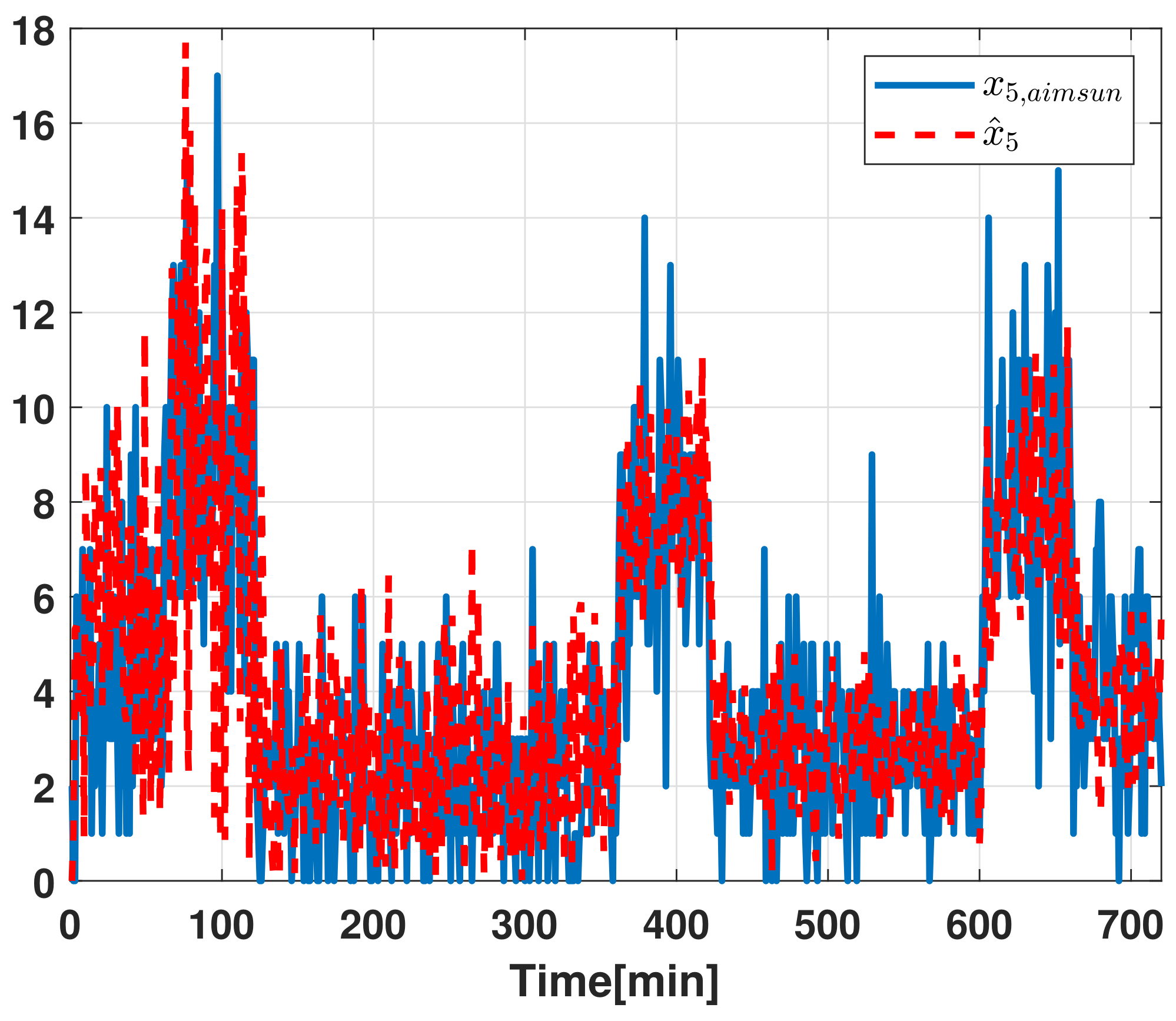
7.1. State Reconstruction Error
7.2. Validation
- Microsimulation: Aimsun Next uses microsimulation, allowing for a detailed modeling of individual vehicles and their interactions within a traffic network. This level of detail is crucial for understanding how traffic behaves in various scenarios.
- Network modeling: the software enables users to create realistic models of road networks, including various types of intersections, signalized and unsignalized junctions, and different road types.
- Traffic demand modeling: Aimsun Next can simulate various traffic demand scenarios, helping users analyze the impact of changes in demand on the transportation system. This includes different modes of transportation such as private vehicles, public transit, pedestrians, and cyclists.
- Dynamic traffic assignment (DTA): the software supports dynamic traffic assignment, allowing for the modeling of real-time traffic conditions and the dynamic adaptation of routes by individual vehicles based on changing conditions.
- Simulation output and analysis: Aimsun Next provides detailed output data, including traffic flow, travel times, delays, and other performance metrics. This information helps users assess the effectiveness of different traffic management strategies and infrastructure improvements.
- Calibration and validation: the software allows users to calibrate and validate their models against real-world data, ensuring that the simulation results accurately reflect the observed behavior of the transportation system.
- Pollutant emission evaluation: Aimsun Next can model pollutant emissions for all vehicles in the simulation. The vehicle state (idling, cruising, accelerating, or decelerating) and the vehicle speed/acceleration are used to evaluate the emission from each vehicle for each simulation time step. This is done by referencing look-up tables for each pollutant, which give emissions for every relevant combination of vehicle behaviors and speed/acceleration.
- Integration with other tools: Aimsun Next may offer integration capabilities with other transportation planning and modeling tools, allowing for a more comprehensive analysis of the entire transportation planning process.
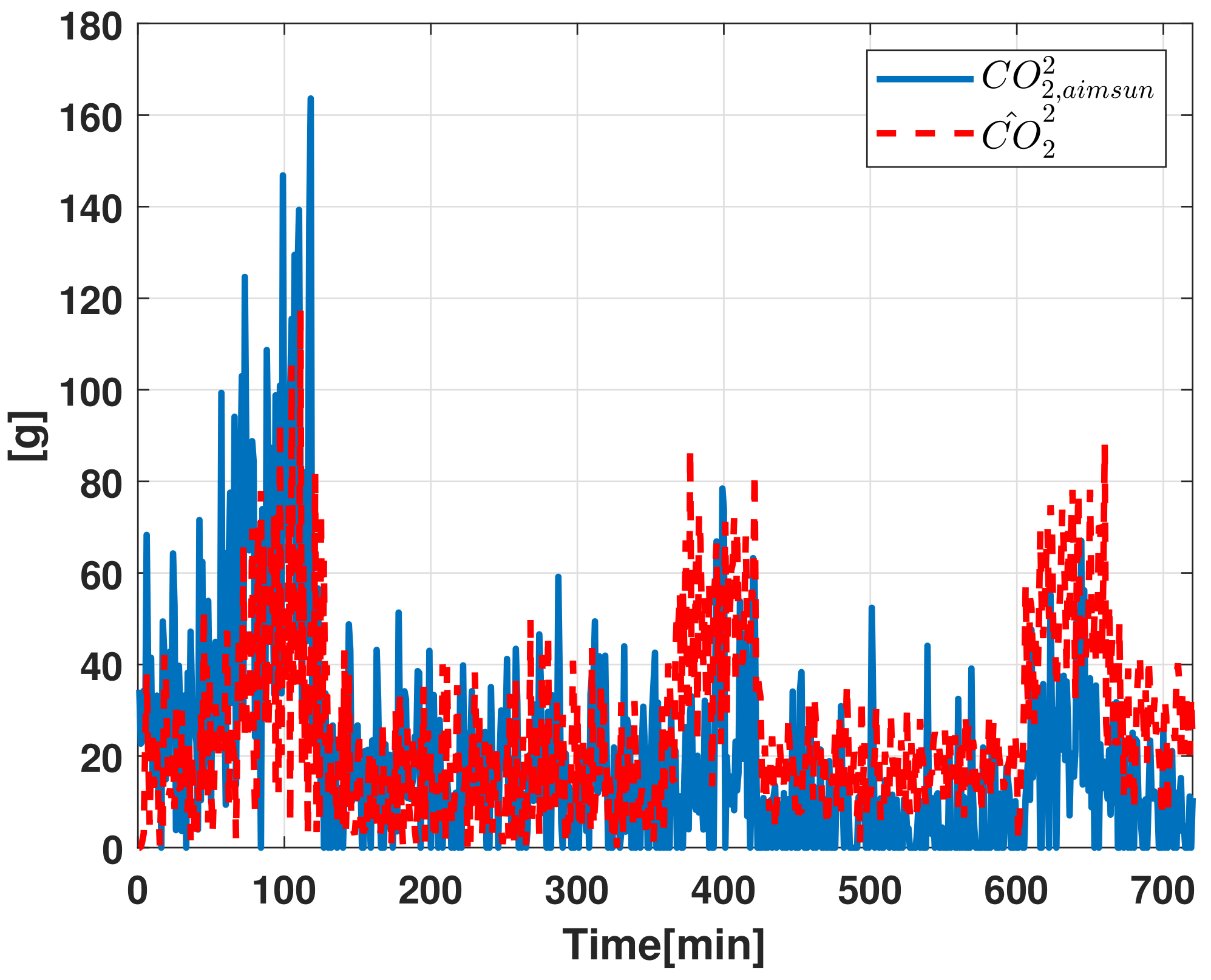
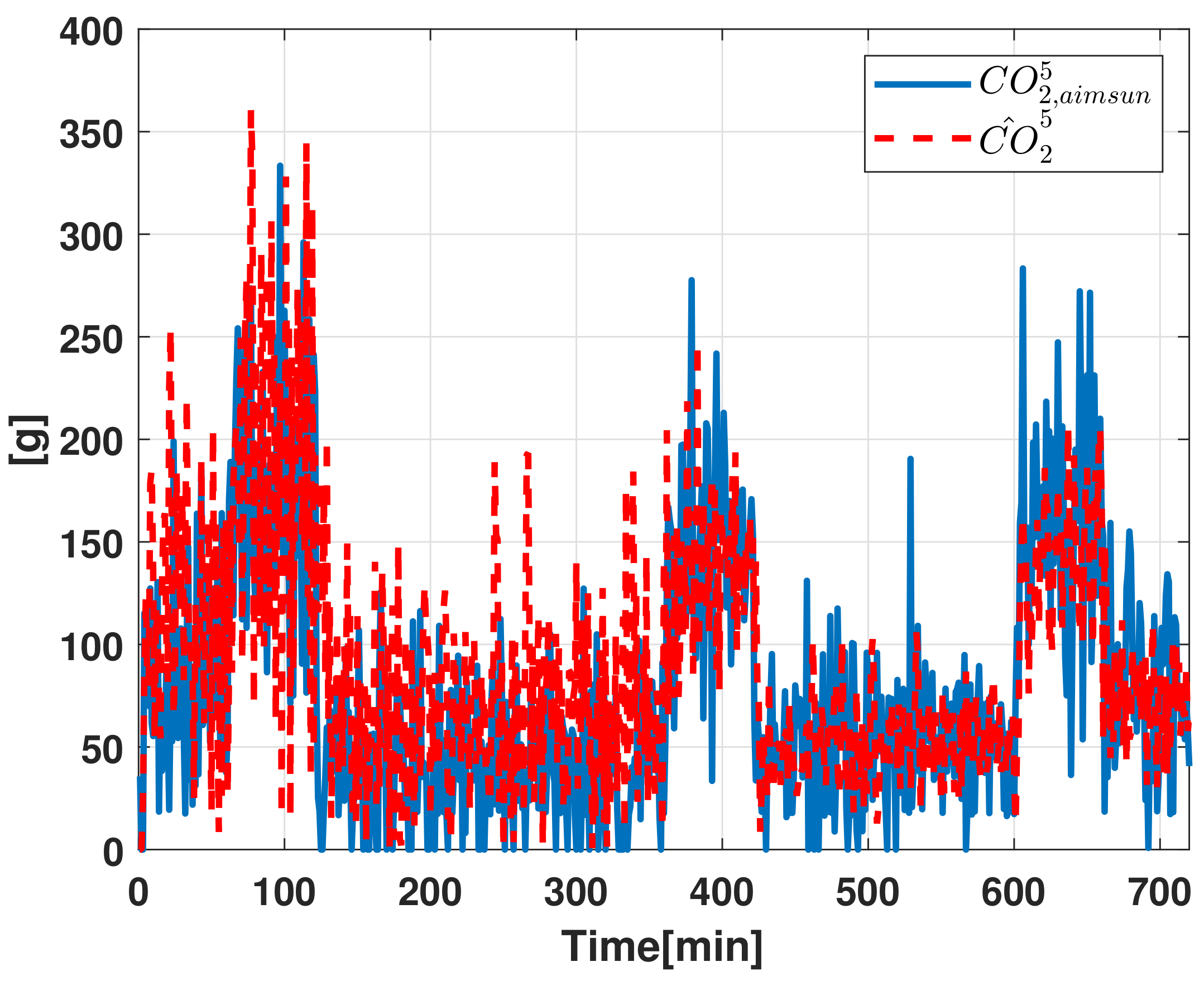
Pollutant Emission Evaluation
- The vehicle traffic estimate provided by the Luenberger state observer.
- The Aimsun Next “Pollutant Emission” data to reconstruct the information related to carbon dioxide () based on the estimated vehicle traffic.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Harmon, R.R.; Castro-Leon, E.; Bhide, S. Smart cities and the Internet of Things. In Proceedings of the 2015 Portland International Conference on Management of Engineering and Technology (PICMET), Portland, OR, USA, 2–6 August 2015; pp. 485–494. [Google Scholar] [CrossRef]
- Monzon, A. Smart cities concept and challenges: Bases for the assessment of smart city projects. In Proceedings of the 2015 International Conference on Smart Cities and Green ICT Systems (SMARTGREENS), Lisbon, Portugal, 20–22 May 2015; pp. 1–11. [Google Scholar]
- Kumar, B.; AbuAlhaija, M.; Alqasmi, L.; Dhakhri, M. Smart Cities: A New Age of Digital Insecurity. In Proceedings of the 2020 9th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 4–5 December 2020; pp. 267–272. [Google Scholar] [CrossRef]
- Ali, M.; Scandurra, P.; Moretti, F.; Blaso, L. Architecting a big data-driven software architecture for smart street lighting. In Proceedings of the 2023 IEEE 20th International Conference on Software Architecture Companion (ICSA-C), L’Aquila, Italy, 13–17 March 2023; pp. 1–10. [Google Scholar] [CrossRef]
- Manyake, M.K.; Mathaba, T.N.D. An Internet of Things Framework for Control and Monitoring of Smart Public Lighting Systems: A Review. In Proceedings of the 2022 International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 4–5 August 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Casavola, A.; Franzé, G.; Gagliardi, G.; Tedesco, F. Improving Lighting Efficiency for Traffic Road Networks: A Reputation Mechanism Based Approach. IEEE Trans. Control Netw. Syst. 2022, 9, 1743–1753. [Google Scholar] [CrossRef]
- Georges, D. The use of observability and controllability gramians or functions for optimal sensor and actuator location in finite-dimensional systems. In Proceedings of the 1995 34th IEEE Conference on Decision and Control, New Orleans, LA, USA, 13–15 December 1995; Volume 4, pp. 3319–3324. [Google Scholar] [CrossRef]
- Ru, Y.; Hadjicostis, C.N. Optimal sensor selection for structural observability in discrete event systems modeled by Petri Nets. IFAC Proc. Vol. 2007, 40, 223–228. [Google Scholar] [CrossRef]
- Joshi, S.; Boyd, S. Sensor Selection via Convex Optimization. IEEE Trans. Signal Process. 2009, 57, 451–462. [Google Scholar] [CrossRef]
- Hinson, B.T. Observability-Based Guidance and Sensor Placement. Ph.D. Dissertation, University of Washington, Seattle, WA, USA, 2014. Available online: https://digital.lib.washington.edu/researchworks/bitstream/handle/1773/27387/Hinson_washington_0250E_14008.pdf?sequence=1 (accessed on 1 November 2023).
- Lee, B.H.; Deininger, R.A. Optimal locations of monitoring stations in water distribution system. J. Environ. Eng. 1992, 118, 4–16. [Google Scholar] [CrossRef]
- Watson, J.P.; Greenberg, H.J.; Hart, W.E. A multipleobjective analysis of sensor placement optimization in water networks. In Proceedings World Water and Environment Resources; ASCE: New York, NY, USA, 2004. [Google Scholar]
- Ostfeld, A.; Salomons, E. Optimal layout of early warning detection stations for water distribution systems security. J. Water Resour. Plan. Manag. 2004, 130, 377–385. [Google Scholar] [CrossRef]
- Kessler, A.; Ostfeld, A.; Sinai, G. Detecting accidental contaminations in municipal water networks. J. Water Resour. Plan. Manag. 1998, 124, 192–198. [Google Scholar] [CrossRef]
- Kumar, A.; Kansal, M.L.; Arora, G. Discussion of ‘detecting accidental contaminations in municipal water networks’ by A. Kessler, A. Ostfeld, and G. Sinai. J. Water Resour. Plan. Manag. 1999, 125, 308–309. [Google Scholar] [CrossRef]
- Muller, H.H.; Castro, C.A. Genetic algorithm-based phasor measurement unit placement method considering observability and security criteria. IET Gener. Transm. Distrib. 2016, 10, 270–280. [Google Scholar] [CrossRef]
- Yuan, P.; Ai, Q.; Zhao, Y. Research on multi-objective optimal PMU placement based on error analysis theory and improved GASA. Proc. CSEE 2014, 34, 2178–2187. [Google Scholar]
- Prasad, S.; Kumar, D.M.V. Trade-offs in PMU and IED deployment for active distribution state estimation using multi-objective evolutionary algorithm. IEEE Trans. Instrum. Meas. 2018, 67, 1298–1307. [Google Scholar] [CrossRef]
- Chepuri, S.P.; Leus, G. Sensor selection for estimation, filtering, and detection. In Proceedings of the 2014 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 22–25 July 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Fu, Y.; Ling, Q.; Tian, Z. Distributed sensor allocation for multi-target tracking in wireless sensor networks. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 3538–3553. [Google Scholar] [CrossRef]
- Hernandez, M.L.; Kirubarajan, T.; Bar-Shalom, Y. Multisensor resource deployment using Posterior Cramer-Rao bounds. IEEE Trans. Aerosp. Electron. Syst. 2004, 40, 399–416. [Google Scholar] [CrossRef]
- Zhan, P.; Casbeer, D.W.; Swindlehurst, A.L. Adaptive mobile sensor positioning for multi-static target tracking. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 120–132. [Google Scholar] [CrossRef]
- Gagliardi, G.; Casavola, A.; D’Angelo, V. Traffic Sensors Selection for Complete Link Flow Observability through Simulated Annealing. IFAC-PapersOnLine 2023, 56, 10540–10545. [Google Scholar] [CrossRef]
- Gagliardi, G.; Casavola, A.; D’Angelo, V. Reliable Traffic Sensor Networks Via Fault-Tolerant Sensor Reconciliation Schemes. IFAC-PapersOnLine 2023, 56, 10558–10563. [Google Scholar] [CrossRef]
- Schizas, I.D. Distributed Informative-Sensor Identification via Sparsity-Aware Matrix Decomposition. IEEE Trans. Signal Process. 2013, 61, 4610–4624. [Google Scholar] [CrossRef]
- Varotto, L.; Zampieri, A.; Cenedese, A. Street Sensors Set Selection through Road Network Modeling and Observability Measures. In Proceedings of the 2019 27th Mediterranean Conference on Control and Automation (MED), Akko, Israel, 1–4 July 2019; pp. 392–397. [Google Scholar] [CrossRef]
- Gendreau, M.; Potvin, J.-Y. (Eds.) Handbook of Metaheuristics; International Series in Operations Research & Management Science 146; Springer Science+Business Media, LLC: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- Crosson, E.; Harrow, A.W. Simulated Quantum Annealing Can Be Exponentially Faster Than Classical Simulated Annealing. In Proceedings of the 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), New Brunswick, NJ, USA, 9–11 October 2016; pp. 714–723. [Google Scholar] [CrossRef]
- Coogan, S.; Arcak, M. A Compartmental Model for Traffic Networks and Its Dynamical Behavior. IEEE Trans. Autom. Control 2015, 60, 2698–2703. [Google Scholar] [CrossRef]
- Walter, G.G.; Contreras, M. Compartmental Modeling with Networks, 1st ed.; Birkhauser Boston, Inc.: Secaucus, NJ, USA, 1998. [Google Scholar]
- Ljung, L. System Identification: Theory for the User, 2nd ed.; Prentice Hall PTR: Lebanon, IN, USA, 1999. [Google Scholar]
- Liepins, G.E.; Hilliard, M.R. Genetic algorithms: Foundations and applications. Ann. Oper. Res. 1989, 21, 31–58. [Google Scholar] [CrossRef]
- Yang, M.D.; Yang, Y.F.; Su, T.C.; Huang, K.S. An Efficient Fitness Function in Genetic Algorithm Classifier for Landuse Recognition on Satellite Images. Sci. World J. 2014, 2014, 264512. [Google Scholar] [CrossRef] [PubMed]
- Tsai, C.-W.; Chiang, M.-C. Handbook of Metaheuristic Algorithms. In From Fundamental Theories to Advanced Applications; Elsevier Inc.: Amsterdam, The Netherlands, 2023. [Google Scholar] [CrossRef]
- Lingber, I. Adaptive simulated annealing (ASA): Lessons learned. Control Cybern. 1996, 25, 33–54. [Google Scholar] [CrossRef]
- Gallelli, V.; Guido, G.; Vitale, A.; Vaiana, R. Effects of calibration process on the simulation of rear-end conflicts at roundabouts. J. Traffic Transp. Eng. (Engl. Ed.) 2019, 6, 175–184. [Google Scholar] [CrossRef]
















| 3.9 | 3.2 | 1.9 | |||
| 2.6 | 9.4 | 1.4 | |||
| 0.1 | 0.5 | 0.7 | |||
| 1.6 | 1.5 | 0.7 | |||
| 2.9 | 0.9 | 5.7 | |||
| 4.6 | 1.2 | 0.2 | |||
| 2.7 | 1.5 | 13.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gagliardi, G.; Gallelli, V.; Violi, A.; Lupia, M.; Cario, G. Optimal Placement of Sensors in Traffic Networks Using Global Search Optimization Techniques Oriented towards Traffic Flow Estimation and Pollutant Emission Evaluation. Sustainability 2024, 16, 3530. https://doi.org/10.3390/su16093530
Gagliardi G, Gallelli V, Violi A, Lupia M, Cario G. Optimal Placement of Sensors in Traffic Networks Using Global Search Optimization Techniques Oriented towards Traffic Flow Estimation and Pollutant Emission Evaluation. Sustainability. 2024; 16(9):3530. https://doi.org/10.3390/su16093530
Chicago/Turabian StyleGagliardi, Gianfranco, Vincenzo Gallelli, Antonio Violi, Marco Lupia, and Gianni Cario. 2024. "Optimal Placement of Sensors in Traffic Networks Using Global Search Optimization Techniques Oriented towards Traffic Flow Estimation and Pollutant Emission Evaluation" Sustainability 16, no. 9: 3530. https://doi.org/10.3390/su16093530