
Transferability of Machine Learning Models for Crop Classification in Remote Sensing Imagery Using a New Test Methodology: A Study on Phenological, Temporal, and Spatial Influences
 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Brandenburg Northwest | Brandenburg Southeast |
|---|---|---|
| Climate | Maritime climate [33]; Average yearly precipitation is approximately 293 mm [33]; Increased humidity can influence the growth and distribution of plant species [34,35]. | Climate is classified as continental and the average annual precipitation is around 610 mm [33]; The humidity is lower in the southeast compared to the northwest of Brandenburg [34,35]; This variance in humidity levels can impact the growth and distribution of plant species. |
| Geology | Limestones and calcareous marls dominate the northwestern part, indicating marine sedimentation [36,37]; Characterized by extensive lowlands, which are the result of crustal subsidence [36,37]. | Nutrient-poor sandy soils dominate [36,37]. |
| Hydrology | Extensive lowlands with alternating wet conditions [34,35]; Lowlands influence the water balance and the formation of gley and moor soils, which have a high water-storage capacity and contribute to the formation of wetlands [34,35]; Numerous watercourses shape the landscape and the water balance and contribute to the formation of flood plain landscapes [34,35]. | Nutrient-poor sandy soils characterize the area. These have a low water-storage capacity, which leads to the rapid runoff of precipitation into the watercourses [34,35]; Watercourses are not very pronounced and their influence on the water balance and landscape development is, therefore, lower [34,35]; The groundwater table of some areas is lower than in the northwest, which can lead to lower water availability and higher drought vulnerability [34,35]. |
| Soils | Gleye; boggy soils; sandy soils [36,37]. | Sandy soils, brown earth, pale earth, regosol, podsol [36,37]. |
| Vegetation | Humid conditions due to the large number of lowlands and the proximity of the Baltic Sea which favors the growth of wet and boggy soils and wet and boggy meadows [37,38,39]; The weather regions of the northwest are dominated by deciduous and mixed forests [37,38,39]; The main species are oak, beech, birch and pine [37,38,39]. | The sandy soils and continental climate of southeastern Brandenburg result in drier conditions. This favors the growth of dry and sandy soils as well as dry grasslands and heaths [37,38,39]; Pine forests dominate in the southeast of Brandenburg due to the low water-holding capacity of the sandy soils [37,38,39]. |
2.2. Satellite Data
2.3. Reference Data (Digital Field Block Cadastre)
2.4. Approach to Crop Classification
| Index | Description | Sentinel-2 Formula | Resolution |
|---|---|---|---|
| ARVI [46] | Atmospherically Resistant Vegetation Index | 20 m | |
| EVI2 [47] | Enhanced Vegetation Index—Two-band | 20 m | |
| IRECI [48] | Inverted Red-Edge Chlorophyll Index | 20 m | |
| NDVI [49] | Normalized Difference Vegetation Index | 20 m | |
| NDWI [50] | Normalized Difference Water Index | 20 m | |
| RVI [51] | Ratio Vegetation Index | 20 m |
| Crops | Study Area | Total Parcel Fields | Mean Field Size (ha) | Area Std (ha) | Area Sum (ha) | Cloud-Free Observations | Cloud-Free Observations Per Class (%) | Cloud-Free Observations Total (%) |
|---|---|---|---|---|---|---|---|---|
| Agricultural | N | 1661 | 3.51 | 4.81 | 5839.65 | 6559 | 62.23 | 18.03 |
| grass | S | 504 | 3.37 | 7.07 | 1702.76 | 3981 | 37.77 | 10.94 |
| Winter | N | 981 | 19.06 | 18.66 | 18,700.98 | 3182 | 71.33 | 8.75 |
| rapeseed | S | 168 | 16.30 | 14.41 | 2739.88 | 1279 | 28.67 | 3.51 |
| Winter | N | 2563 | 11.00 | 12.58 | 28,208.82 | 8403 | 69.43 | 23.11 |
| rye | S | 609 | 10.66 | 13.38 | 6495.83 | 3700 | 30.57 | 10.17 |
| Winter | N | 1168 | 16.10 | 17.67 | 18,808.89 | 3608 | 68.27 | 9.92 |
| wheat | S | 244 | 12.62 | 14.96 | 3080.39 | 1677 | 31.73 | 4.61 |
| Silage | N | 1199 | 12.27 | 13.14 | 14,712.93 | 2551 | 64.26 | 7.01 |
| maize | S | 291 | 11.89 | 13.90 | 3460.84 | 1419 | 35.74 | 3.90 |
| Total training | 7572 | 86,271.27 | 24,303 | |||||
| Total validation | 1816 | 17,479.70 | 12,056 | |||||
| Total | 9388 | 103,750.97 | 36,359 |
| Feature | Formular | Input | Res. |
|---|---|---|---|
| Gray level co-occurrence matrices: | All features were applied to the following inputs: B02, B03, B04, B05, B06, B07, B8A, B11, B12, Water Vapour (WVP) [5], True Color Image (TCI) [5] VIs: ARVI, EVI2, IRECI, NDVI, NDWI, RVI | ||
| (1) Angular second moment (ASM) [69] | 20 m | ||
| (2) Contrast [69] | 20 m | ||
| (3) Correlation [69] | 20 m | ||
| (4) Dissimilarity [69] | 20 m | ||
| (5) Energy [69] | 20 m | ||
| (6) Homogeneity [69] | 20 m | ||
| Complex statistical measurements: | |||
| (7–9) D1, D2, D3 (k-means [55]) | 20 m | ||
| (10) Entropy | 20 m | ||
| Simple statistical measurements: | |||
| (11) Minimum | 20 m | ||
| (12) Maximum | 20 m | ||
| (13) Mean | 20 m | ||
| (14) Median | 20 m | ||
| (15) Standard deviation | 20 m | ||
| (16) Geometric mean | 20 m |
| Number (T) | Test Scenario | Influence |
|---|---|---|
| 1 | Trained on north (full season)/tested on south (full season) | |
| 2 | Trained on south (full season)/tested on north (full season) | Spatial |
| 3 | Trained on mixed (full season)/tested on mixed (full season) | |
| 4 | Trained on (April–May) north/tested on (April–May) south | |
| 5 | Trained on (April–May) south/tested on (April–May) north | |
| 6 | Trained on (April–May) mixed/tested on (April–May) mixed | Phenological |
| 7 | Trained on April/tested on May | |
| 8 | Trained on May/tested on April (retrospective) | |
| 9 | Trained on June/tested on May (retrospective) | |
| 10 | Trained on day north/tested on day south | |
| 11 | Trained on day south/tested on day north | |
| 12 | Trained on day mixed/tested on day mixed | |
| 13 | Trained on April north/tested on April south | |
| 14 | Trained on April south/tested on April north | Temporal |
| 15 | Trained on May north/tested on May south | |
| 16 | Trained on May south/tested on May north | |
| 17 | Trained on June north/tested on June south | |
| 18 | Trained on June south/tested on June north | |
| 19 | Trained on Week north/tested on Week south | |
| 20 | Trained on Week south/tested on Week north |
2.5. Assessment of Accuracy and Generalization Capabilities
3. Results
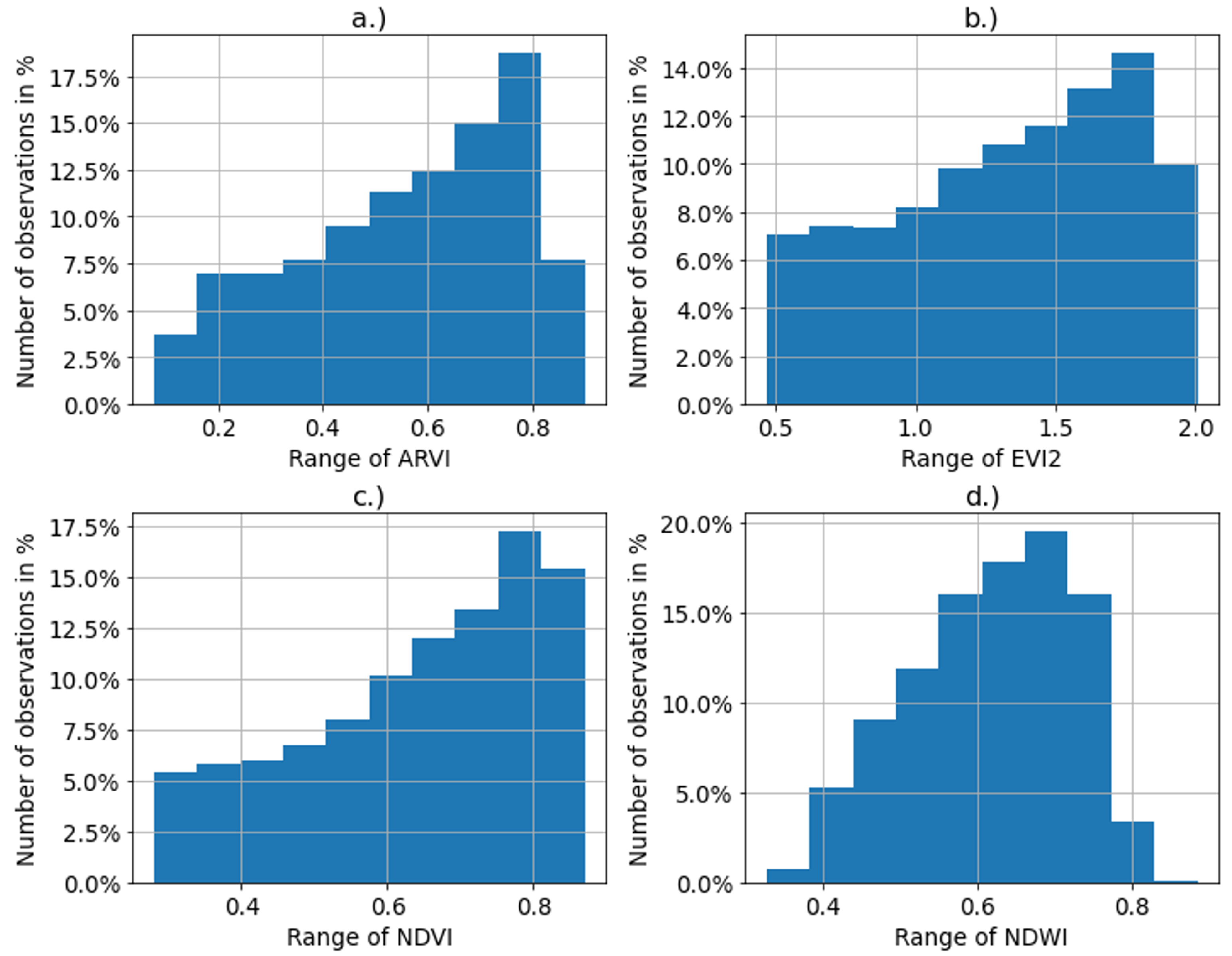
3.1. Extracted Features
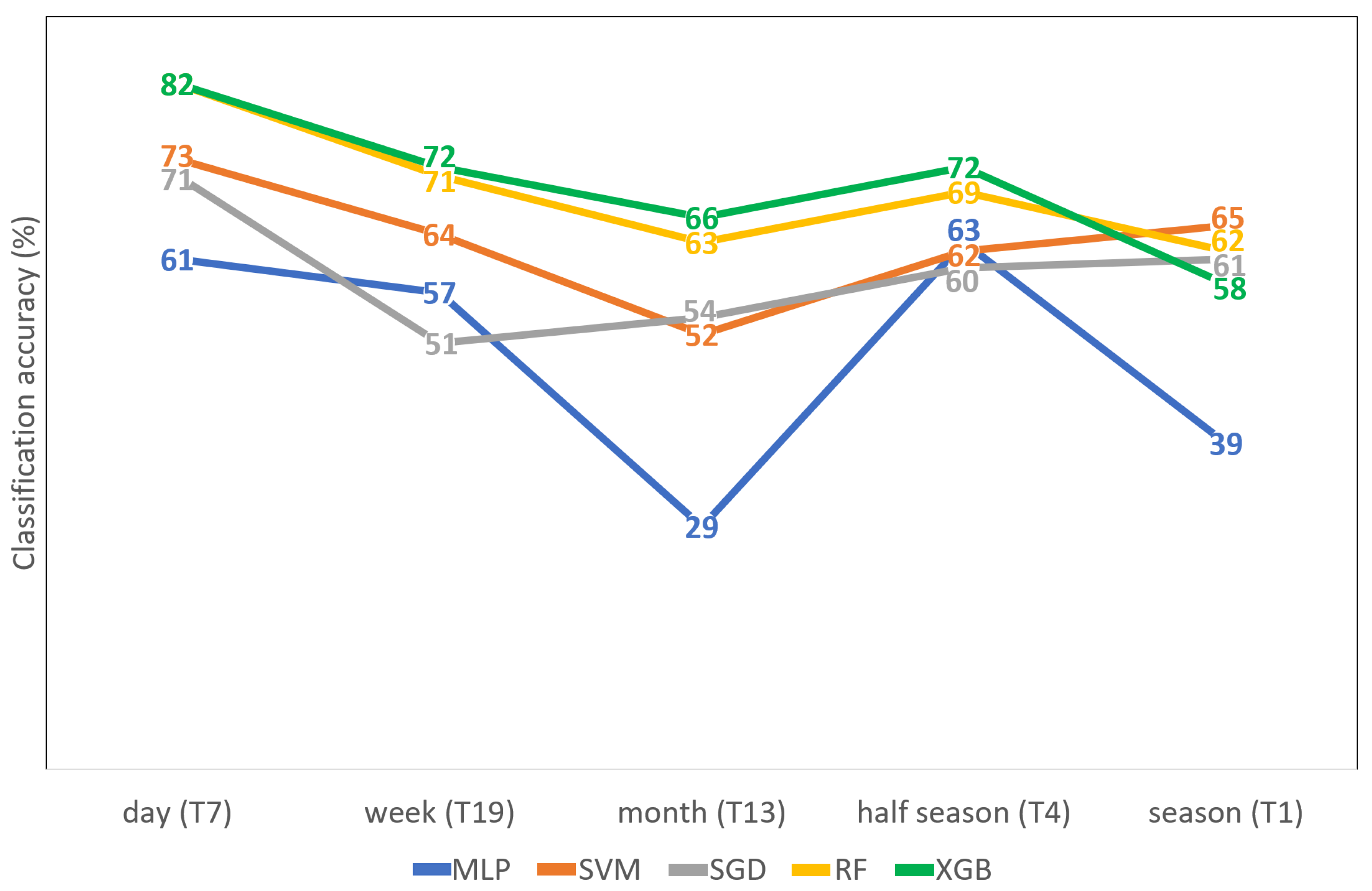
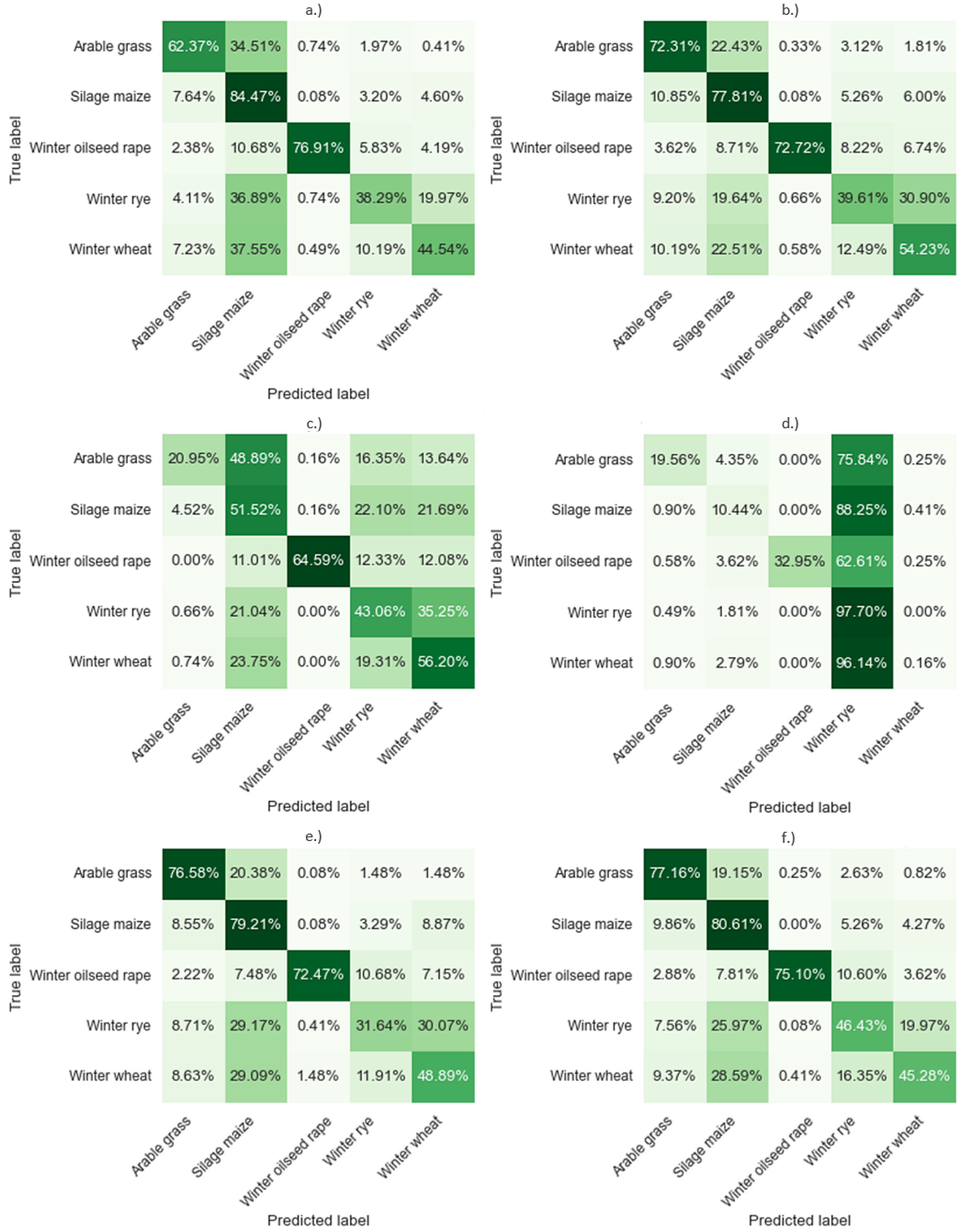
3.2. Interpretation of the Results
4. Discussion
4.1. Environmental Influencing Factors
4.2. Classification Results
4.3. Systematic Approach of the Testing Methodology
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1
| North | South | |||||
|---|---|---|---|---|---|---|
| Crop | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Agricultural grass | 81 | 89 | 85 | 74 | 62 | 68 |
| Silage maize | 81 | 83 | 82 | 41 | 84 | 56 |
| Winter rapeseed | 95 | 94 | 94 | 97 | 77 | 86 |
| Winter rye | 76 | 74 | 75 | 64 | 38 | 48 |
| Winter wheat | 82 | 76 | 79 | 60 | 45 | 51 |
| North | South | |||||
|---|---|---|---|---|---|---|
| Crop | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Agricultural grass | 77 | 84 | 80 | 68 | 72 | 70 |
| Silage maize | 78 | 81 | 79 | 51 | 78 | 62 |
| Winter rapeseed | 97 | 90 | 93 | 98 | 73 | 83 |
| Winter rye | 68 | 73 | 70 | 58 | 40 | 47 |
| Winter wheat | 79 | 69 | 74 | 54 | 54 | 54 |
| North | South | |||||
|---|---|---|---|---|---|---|
| Crop | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Agricultural grass | 78 | 85 | 82 | 78 | 21 | 33 |
| Silage maize | 79 | 81 | 80 | 33 | 52 | 40 |
| Winter rapeseed | 96 | 93 | 95 | 99 | 65 | 78 |
| Winter rye | 75 | 73 | 74 | 38 | 43 | 40 |
| Winter wheat | 79 | 74 | 76 | 40 | 56 | 47 |
| North | South | |||||
|---|---|---|---|---|---|---|
| Crop | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Agricultural grass | 78 | 81 | 80 | 87 | 20 | 32 |
| Silage maize | 80 | 68 | 74 | 45 | 10 | 17 |
| Winter rapeseed | 95 | 94 | 95 | 100 | 33 | 55 |
| Winter rye | 65 | 61 | 63 | 23 | 98 | 38 |
| Winter wheat | 63 | 74 | 68 | 15 | 0 | 0 |
| North | South | |||||
|---|---|---|---|---|---|---|
| Crop | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Agricultural grass | 82 | 85 | 83 | 73 | 77 | 75 |
| Silage maize | 78 | 76 | 77 | 48 | 79 | 60 |
| Winter rapeseed | 90 | 95 | 92 | 97 | 72 | 83 |
| Winter rye | 65 | 58 | 61 | 54 | 32 | 40 |
| Winter wheat | 66 | 69 | 67 | 51 | 49 | 50 |
| North | South | |||||
|---|---|---|---|---|---|---|
| Crop | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Agricultural grass | 81 | 81 | 81 | 70 | 76 | 73 |
| Silage maize | 75 | 77 | 76 | 58 | 69 | 63 |
| Winter rapeseed | 94 | 92 | 93 | 94 | 79 | 86 |
| Winter rye | 71 | 70 | 70 | 57 | 53 | 55 |
| Winter wheat | 75 | 77 | 76 | 61 | 60 | 60 |
| North | South | |||||
|---|---|---|---|---|---|---|
| Crop | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Agricultural grass | 82 | 90 | 86 | 78 | 92 | 84 |
| Silage maize | 93 | 90 | 91 | 94 | 74 | 83 |
| Winter rapeseed | 98 | 98 | 98 | 98 | 95 | 97 |
| Winter rye | 77 | 77 | 77 | 67 | 78 | 72 |
| Winter wheat | 83 | 78 | 81 | 74 | 64 | 69 |
References
- United Nations. World Population Prospects 2017: Data Booklet; United Nations, Department of Economic and Social Affairs: New York, NY, USA, 2017. [Google Scholar]
- Tuomisto, H.; Scheelbeek, P.; Chalabi, Z.; Green, R.; Smith, R.; Haines, A.; Dangour, A. Effects of environmental change on agriculture, nutrition and health: A framework with a focus on fruits and vegetables. Wellcome Open Res. 2017, 2, 21. [Google Scholar] [CrossRef] [PubMed]
- Shankar, T.; Praharaj, S.; Sahoo, U.; Maitra, S. Intensive Farming: It’s Effect on the Environment. Int. Bimon. 2021, 12, 37480–37487. [Google Scholar]
- Funk, R.; Völker, L.; Deumlich, D. Landscape structure model based estimation of the wind erosion risk in Brandenburg, Germany. Aeolian Res. 2023, 62, 100878. [Google Scholar] [CrossRef]
- SUHET. Sentinel-2, User Handbook, 1st ed.; European Space Agency (ESA): Paris, France, 2013. [Google Scholar]
- Woodcock, C.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.; Helder, D.; Helmer, E.; et al. Free Access to Landsat Imagery. Science 2008, 320, 1011. [Google Scholar] [CrossRef] [PubMed]
- Blickensdörfer, L.; Schwieder, M.; Pflugmacher, D.; Nendel, C.; Erasmi, S.; Hostert, P. Mapping of crop types and crop sequences with combined time series of Sentinel-1, Sentinel-2 and Landsat 8 data for Germany. Remote Sens. Environ. 2022, 269, 112831. [Google Scholar] [CrossRef]
- Waldhoff, G.; Lussem, U.; Bareth, G. Multi-Data Approach for remote sensing-based regional crop rotation mapping: A case study for the Rur catchment, Germany. Int. J. Appl. Earth Obs. Geoinf. 2017, 61, 55–69. [Google Scholar] [CrossRef]
- Muruganantham, P.; Wibowo, S.; Grandhi, S.; Samrat, N.H.; Islam, N. A Systematic Literature Review on Crop Yield Prediction with Deep Learning and Remote Sensing. Remote Sens. 2022, 14, 1990. [Google Scholar] [CrossRef]
- Gao, Q.; Zribi, M.; Escorihuela, M.J.; Baghdadi, N.; Segui, P.Q. Irrigation Mapping Using Sentinel-1 Time Series at Field Scale. Remote Sens. 2018, 10, 1495. [Google Scholar] [CrossRef]
- Santaga, F.S.; Benincasa, P.; Toscano, P.; Antognelli, S.; Ranieri, E.; Vizzari, M. Simplified and Advanced Sentinel-2-Based Precision Nitrogen Management of Wheat. Agronomy 2021, 11, 1156. [Google Scholar] [CrossRef]
- Berger, M.; Moreno, J.; Johannessen, J.A.; Levelt, P.F.; Hanssen, R.F. ESA’s sentinel missions in support of Earth system science. Remote Sens. Environ. 2012, 120, 84–90. [Google Scholar] [CrossRef]
- Thompson, N.C.; Ge, S.; Manso, G.F. The Importance of (Exponentially More) Computing Power. In Proceedings of the Academy of Management Annual Meeting Proceedings, Seattle, DC, USA, 5–9 August 2022. [Google Scholar]
- Molas, G.; Nowak, E. Advances in Emerging Memory Technologies: From Data Storage to Artificial Intelligence. Appl. Sci. 2021, 11, 11254. [Google Scholar] [CrossRef]
- Capra, M.; Bussolino, B.; Marchisio, A.; Masera, G.; Martina, M.; Shafique, M. Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead. IEEE Access 2020, 8, 225134–225180. [Google Scholar] [CrossRef]
- Lu, T.; Gao, M.; Wang, L. Crop classification in high-resolution remote sensing images based on multi-scale feature fusion semantic segmentation model. Front. Plant Sci. 2023, 14, 1196634. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Tian, J.; Tian, Q. Deep Learning Application for Crop Classification via Multi-Temporal Remote Sensing Images. Agriculture 2023, 13, 906. [Google Scholar] [CrossRef]
- Kang, J.; Zhang, H.; Yang, H.; Zhang, L. Support Vector Machine Classification of Crop Lands Using Sentinel-2 Imagery. In Proceedings of the 2018 7th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Hangzhou, China, 6–9 August 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ok, A. Evaluation of random forest method for agricultural crop classification. Eur. J. Remote Sens. 2012, 45, 421–432. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop Classification on Single Date SENTINEL-2 Imagery Using Random Forest and Suppor Vector Machine. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 425, 683–688. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Song, Q.; Hu, Q.; Zhou, Q.; Hovis, C.; Xiang, M.; Tang, H.; Wu, W. In-Season Crop Mapping with GF-1/WFV Data by Combining Object-Based Image Analysis and Random Forest. Remote Sens. 2017, 9, 1184. [Google Scholar] [CrossRef]
- Skriver, H.; Mattia, F.; Satalino, G.; Balenzano, A.; Pauwels, V.; Verhoest, N.; Davidson, M. Crop Classification Using Short-Revisit Multitemporal SAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 423–431. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Spatial Transferability of Random Forest Models for Crop Type Classification Using Sentinel-1 and Sentinel-2. Remote Sens. 2022, 14, 1493. [Google Scholar] [CrossRef]
- Rusňák, T.; Kasanický, T.; Malík, P.; Mojžiš, J.; Zelenka, J.; Sviček, M.; Abrahám, D.; Halabuk, A. Crop Mapping without Labels: Investigating Temporal and Spatial Transferability of Crop Classification Models Using a 5-Year Sentinel-2 Series and Machine Learning. Remote Sens. 2023, 15, 3414. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Z.; Zhang, L.; Han, J.; Cao, J.; Zhang, J. Developing High-Resolution Crop Maps for Major Crops in the European Union Based on Transductive Transfer Learning and Limited Ground Data. Remote Sens. 2022, 14, 1809. [Google Scholar] [CrossRef]
- Ge, S.; Zhang, J.; Pan, Y.; Yang, Z.; Zhu, S. Transferable deep learning model based on the phenological matching principle for mapping crop extent. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102451. [Google Scholar] [CrossRef]
- Wenger, S.J.; Olden, J.D. Assessing transferability of ecological models: An underappreciated aspect of statistical validation. Methods Ecol. Evol. 2012, 3, 260–267. [Google Scholar] [CrossRef]
- Roberts, D.; Bahn, V.; Ciuti, S.; Boyce, M.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2016, 40, 913–929. [Google Scholar] [CrossRef]
- Löw, F.; Michel, U.; Dech, S.; Conrad, C. Impact of feature selection on the accuracy and spatial uncertainty of per-field crop classification using Support Vector Machines. ISPRS J. Photogramm. Remote Sens. 2013, 85, 102–119. [Google Scholar] [CrossRef]
- Wang, S.; Azzari, G.; Lobell, D.B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar] [CrossRef]
- Bundesamt, S. (Ed.) Statistisches Jahrbuch; Amt für Statistik Berlin-Brandenburg: Wiesbaden, Germany, 2020. [Google Scholar]
- Klima & Gjennomsnittsvær i Cottbus, Brandenburg, Tyskland. Available online: https://www.timeanddate.no/vaer/tyskland/cottbus/klima (accessed on 28 September 2023).
- Wendel, M. Das Klima Norddeutschlands; VerlagGRIN Verlag: Munich, Germany, 2007; p. 29. [Google Scholar]
- Gerstengarbe, F.; Badeck, F.W.; Hattermann, F.; Krysanova, V.; Lahmer, W.; Lasch, P.; Stock, M.; Suckow, F.; Wechsung, F.; Werner, P. Studie zur Klimatischen Entwicklung im Land Brandenburg bis 2055 und 55 deren Auswirkungen auf den Wasserhaushalt, Die Forst- und Landwirtschaft Sowie Die Ableitung Erster Perspektive; Ministerium für Landwirtschaft, Umwelt und Klimaschutz des Landes Brandenburg: Potsdam, Germany, 2003; Volume 83, p. 96. [Google Scholar]
- Stackebrandt, W. Atlas zur Geologie von Brandenburg: Im Maßstab 1:1,000,000; Landesamt für Bergbau, Geologie und Rohstoffe Brandenburg: Cottbus, Germany, 2010. [Google Scholar]
- Remy, T.H.D. Jahrestagung der Floristisch-Soziologischen Arbeitsgemeinschaft (FlorSoz) in Potsdam 2011; Tuexenia: Potsdam, Germany, 2011. [Google Scholar]
- Hofmann, G.; Pommer, U. Potentielle Natürliche Vegetation von Brandenburg und Berlin: Mit Karte im Maßstab 1:200,000; Eberswalder Forstliche Schriftenreihe, Ministerium für Ländliche Entwicklung, Umwelt und Verbraucherschutz des Landes Brandenburg, Referat Presse- und Öffentlichkeitsarbeit; Ministry of Rural Development, Environment and Consumer Protection: Potsdam, Germany, 2005. [Google Scholar]
- Theuerkauf, M. Younger Dryas cold stage vegetation patterns of central Europe—Climate, soil and relief controls. Boreas 2012, 41, 391–407. [Google Scholar] [CrossRef]
- Hoppe, H. Crop Type Classification in the Federal State Brandenburg Using Machine Learning Models and Multi-Temporal, Multispectral Sentinel-2 Imagery. Master’s Thesis, Stralsund University of Applied Sciences, Faculty of Economics, Stralsund, Germany, 2021. [Google Scholar]
- Amt für Statistik Berlin-Brandenburg. Statistischer Bericht C II 7– j/18—Besondere Ernte- und Qualitätsermittlung im Land Brandenburg 2018; Statistik Berlin Brandenburg: Potsdam, Germany, 2019. [Google Scholar]
- Louis, J.; Debaecker, V.; Pflug, B.; Main-Knorn, M.; Bieniarz, J.; Mueller-Wilm, U.; Cadau, E.; Gascon, F. SENTINEL-2 SEN2COR: L2A Processor for Users. In Proceedings of the Proceedings Living Planet Symposium 2016, Prague, Czech Republic, 9–13 May 2016; Spacebooks Online. Ouwehand, L., Ed.; ESA Special Publications (on CD). 2016; Volume SP-740, pp. 1–8. [Google Scholar]
- Oehmichen, G. Auf Satellitendaten basierende Ableitungen von Parametern zur Beschreibung Terrestrischer Ökosysteme: Methodische Untersuchung zur Ableitung der Chlorophyll(a+b)- Konzentration und des Blattflächenindexes aus Fernerkundungsdaten. UFO Dissertation, UFO, Atelier für Gestaltung und Verlag, Hamburg, Germany, 2004. [Google Scholar]
- Witt, H. Die Spektralen und Räumlichen Eigenschaften von Fernerkundungssensoren bei der Ableitung von Landoberflächenparametern; Technical Report; Institut für Planetenforschung; Institut für Weltraumsensorik: Berlin, Germany, 1998; Institut für Planetenforschung. [Google Scholar]
- Ministerium für Landwirtschaft, Umwelt und Klimaschutz des Landes Brandenburg. GEOBROKER der Internetshop der LGB. Agrarantragsdaten—Produktmetadaten Geobroker–Der Internetshop der LGB. Available online: https://geobroker.geobasis-bb.de/gbss.php?MODE=GetProductInformation&PRODUCTID=996f8fd1-c662-4975-b680-3b611fcb5d1f (accessed on 6 June 2022).
- Kaufman, Y.; Tanre, D. Atmospherically resistant vegetation index (ARVI) for EOS-MODIS. IEEE Trans. Geosci. Remote Sens. 1992, 30, 261–270. [Google Scholar] [CrossRef]
- Jiang, Z.; Huete, A.R.; Didan, K.; Miura, T. Development of a two-band enhanced vegetation index without a blue band. Remote Sens. Environ. 2008, 112, 3833–3845. [Google Scholar] [CrossRef]
- Frampton, W.J.; Dash, J.; Watmough, G.R.; Milton, E.J. Evaluating the capabilities of Sentinel-2 for quantitative estimation of biophysical variables in vegetation. ISPRS J. Photogramm. Remote Sens. 2013, 82, 83–92. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Deering, D.W.; Schell, J.A.; Harlan, J.C. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation. [Great Plains Corridor]. In Proceedings of the Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation. [Great Plains Corridor], College Station, TX, USA, 27 January 1973. [Google Scholar]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Birth, G.S.; Mcvey, G.R. Measuring the Color of Growing Turf with a Reflectance Spectrophotometer1. Agron. J. 1968, 60, 640–643. [Google Scholar] [CrossRef]
- Kang, Y.; Hu, X.; Meng, Q.; Zou, Y.; Zhang, L.; Liu, M.; Zhao, M. Land Cover and Crop Classification Based on Red Edge Indices Features of GF-6 WFV Time Series Data. Remote Sens. 2021, 13, 4522. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop Type Classification Using Fusion of Sentinel-1 and Sentinel-2 Data: Assessing the Impact of Feature Selection, Optical Data Availability, and Parcel Sizes on the Accuracies. Remote Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Wang, L.; Wang, J.; Liu, Z.; Zhu, J.; Qin, F. Evaluation of a deep-learning model for multispectral remote sensing of land use and crop classification. Crop J. 2022, 10, 1435–1451. [Google Scholar] [CrossRef]
- OpenCV. OpenCV: Clustering. Available online: https://docs.opencv.org/4.x/d5/d38/group__core__cluster.html#ga9a34dc06c6ec9460e90860f15bcd2f88 (accessed on 28 June 2022).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2000, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. arXiv 2016, arXiv:1603.02754. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- von der Malsburg, C. Frank Rosenblatt: Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. In Brain Theory; Springer: Berlin/Heidelberg, Germany, 1986; pp. 245–248. [Google Scholar] [CrossRef]
- Anaconda Inc. Anaconda Software Distribution; Anaconda, Inc.: Austin, TX, USA, 2020. [Google Scholar]
- QGIS Development Team. QGIS Geographic Information System; Open Source Geospatial Foundation: Beaverton, OR, USA, 2009. [Google Scholar]
- Microsoft Corporation. Microsoft Excel; Microsoft Corporation: Redmond, WA, USA.
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- The Pandas Development Team. pandas-dev/pandas: Pandas 2020. [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Kühn, D.; Auriegel, A.; Müller, H.; Rosskopf, N. Charakterisierung der Böden Brandenburgs Hinsichtlich Ihrer Verbreitung, Eigenschaften und Potenziale mit Einer Präsentation Gemittelter Analytischer Untersuchungsergebnisse Einschließlich von Hintergrundwerten (Korngrößenzusammensetzung, Bodenphysik, Bodenchemie); Brandenburger Geowissenschaftliche Beiträge: Cottbus, Germany, 2015. [Google Scholar]
- Peña, J.M.; Gutiérrez, P.A.; Hervás-Martínez, C.; Six, J.; Plant, R.E.; López-Granados, F. Object-Based Image Classification of Summer Crops with Machine Learning Methods. Remote Sens. 2014, 6, 5019–5041. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. In Proceedings of the Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation, 04, Santiago de Compostela, Spain, 21–23 March 2005; Volume 3408, pp. 345–359. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop classification in a heterogeneous agricultural environment using ensemble classifiers and single-date Sentinel-2A imagery. Geocarto Int. 2021, 36, 2141–2159. [Google Scholar] [CrossRef]
- Wijesingha, J.; Dzene, I.; Wachendorf, M. Spatial-temporal transferability assessment of remote sensing data models for mapping agricultural land use. In Proceedings of the Spatial-Temporal Transferability Assessment of Remote Sensing Data Models for Mapping Agricultural Land Use, 04, Vienna, Austria, 24–28 April 2023. [Google Scholar] [CrossRef]
- Arias, M.; Campo-Bescós, M.A.; Álvarez Mozos, J. Crop Classification Based on Temporal Signatures of Sentinel-1 Observations over Navarre Province, Spain. Remote Sens. 2020, 12, 278. [Google Scholar] [CrossRef]
- Agency, E.S. Copernicus Open Access Hub. Available online: https://scihub.copernicus.eu/ (accessed on 6 June 2022).





| Month | Description |
|---|---|
| April | High contrast between daytime highs and nighttime lows (near frostline). |
| May | Growth was slowed down due to the temperature differences between day and night. Sunshine was 120% to 160% above the typical value. Low precipitation and heat severely dried out the topsoil. |
| June | Winter barley matured too early. In some areas, soil temperature exceeded air temperature significantly. |
| July | Many cereal crops became prematurely ripe. Drought stress led to lower yields. |
| Precision [72] | Recall [72] | F1-Score [72] | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Crop | N | S | N | S | N | S | |||
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| Agricultural grass | 79 | 72 | −8.86 | 88 | 77 | −12.50 | 83 | 75 | −9.63 |
| Silage maize | 82 | 50 | −39.02 | 80 | 81 | 1.25 | 81 | 62 | −23.45 |
| Winter wheat | 82 | 61 | −25.60 | 75 | 45 | −40.00 | 78 | 52 | −33.33 |
| Winter rye | 75 | 57 | −24.00 | 75 | 46 | −38.66 | 75 | 51 | −32.00 |
| Winter rapeseed | 95 | 99 | 4.21 | 93 | 75 | −19.35 | 94 | 85 | −9.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoppe, H.; Dietrich, P.; Marzahn, P.; Weiß, T.; Nitzsche, C.; Freiherr von Lukas, U.; Wengerek, T.; Borg, E. Transferability of Machine Learning Models for Crop Classification in Remote Sensing Imagery Using a New Test Methodology: A Study on Phenological, Temporal, and Spatial Influences. Remote Sens. 2024, 16, 1493. https://doi.org/10.3390/rs16091493
Hoppe H, Dietrich P, Marzahn P, Weiß T, Nitzsche C, Freiherr von Lukas U, Wengerek T, Borg E. Transferability of Machine Learning Models for Crop Classification in Remote Sensing Imagery Using a New Test Methodology: A Study on Phenological, Temporal, and Spatial Influences. Remote Sensing. 2024; 16(9):1493. https://doi.org/10.3390/rs16091493
Chicago/Turabian StyleHoppe, Hauke, Peter Dietrich, Philip Marzahn, Thomas Weiß, Christian Nitzsche, Uwe Freiherr von Lukas, Thomas Wengerek, and Erik Borg. 2024. "Transferability of Machine Learning Models for Crop Classification in Remote Sensing Imagery Using a New Test Methodology: A Study on Phenological, Temporal, and Spatial Influences" Remote Sensing 16, no. 9: 1493. https://doi.org/10.3390/rs16091493