
Enhancing Crop Mapping through Automated Sample Generation Based on Segment Anything Model with Medium-Resolution Satellite Imagery

 , ,
, ,  , ,
, , 
Abstract
:1. Introduction
2. Study Areas and Datasets
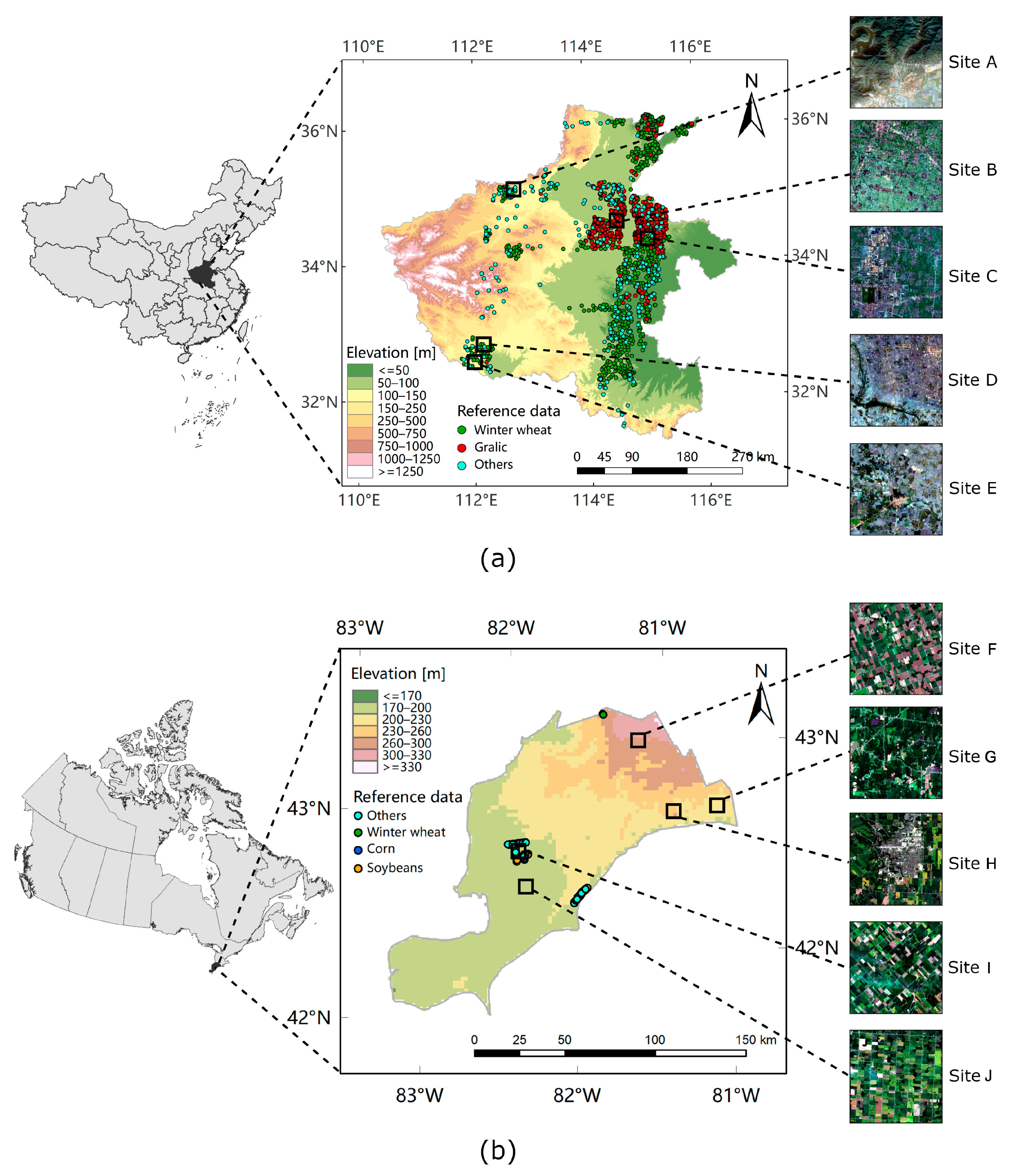
2.1. Study Areas
2.2. Medium-Resolution Satellite Imagery
2.3. Ground Truth Samples
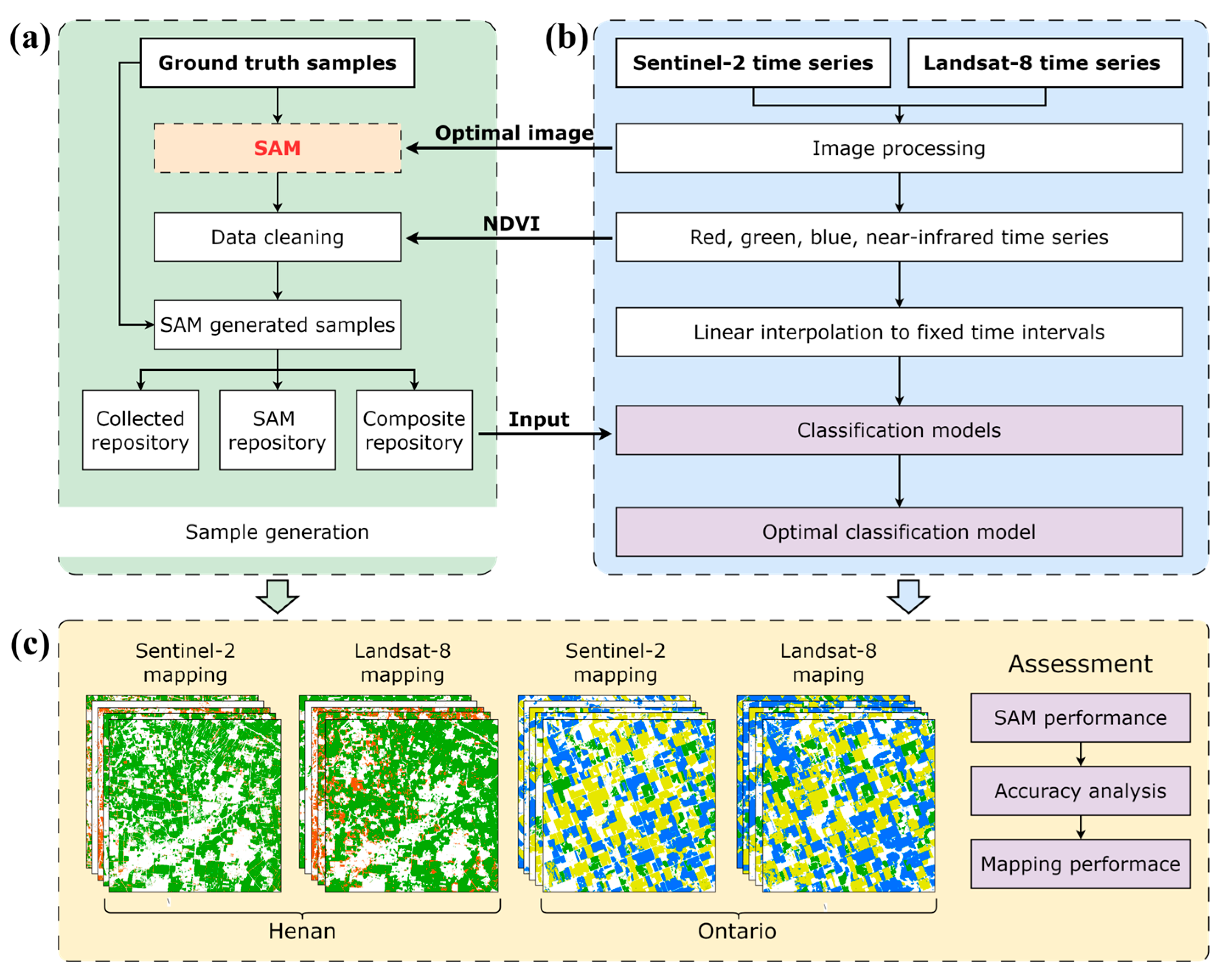
3. Methodology
3.1. Automated Sample Generation Based on SAM
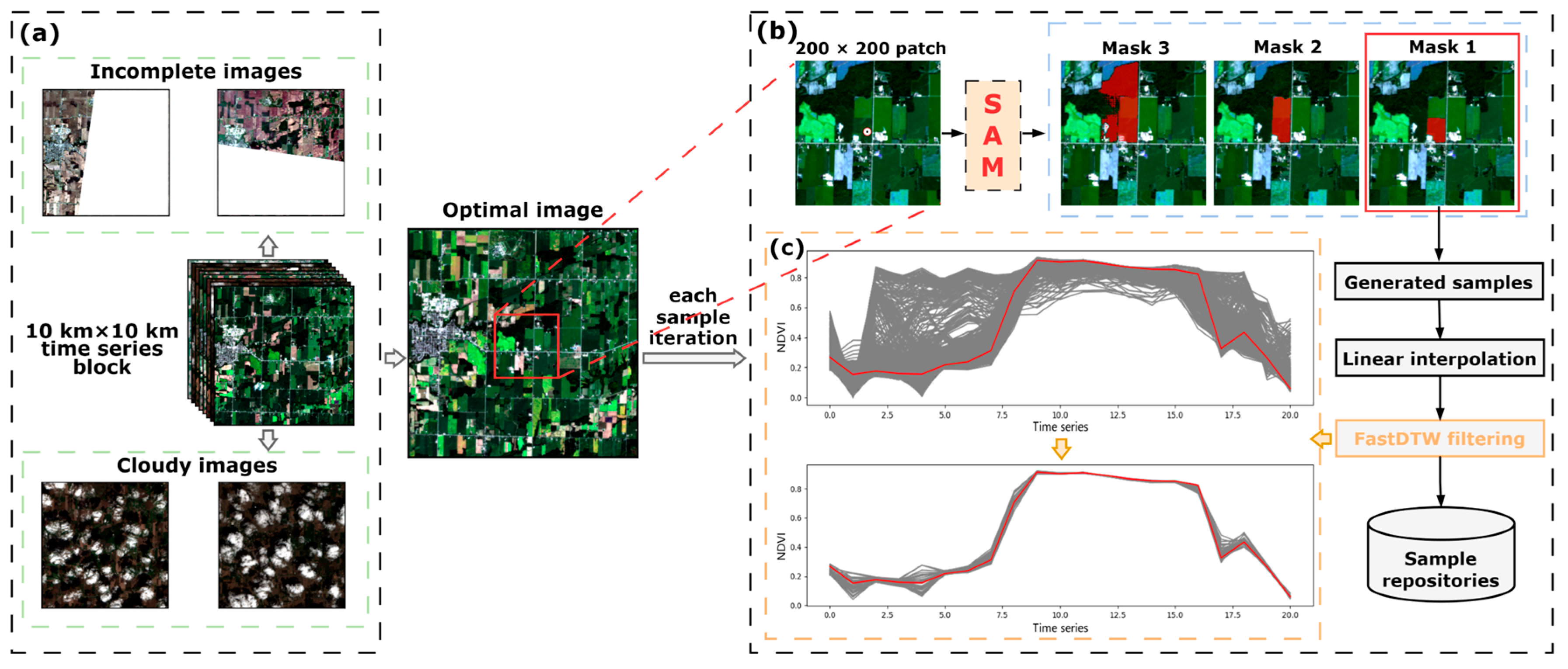
3.1.1. Image Optimization
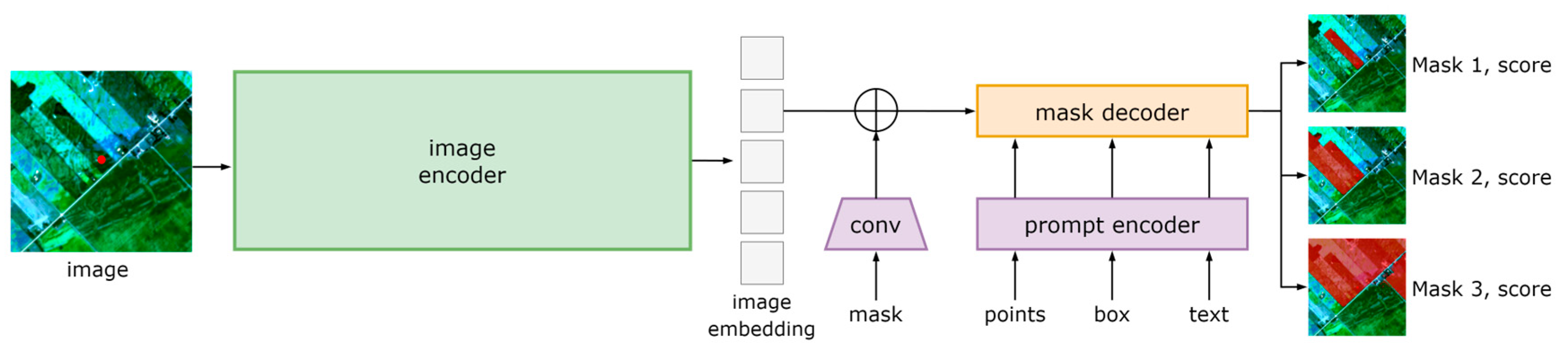
3.1.2. Mask Production
3.1.3. Sample Cleaning
3.2. Classification with Generated Samples
3.2.1. Samples Division
3.2.2. Model Establishment
3.2.3. Accuracy Evaluation
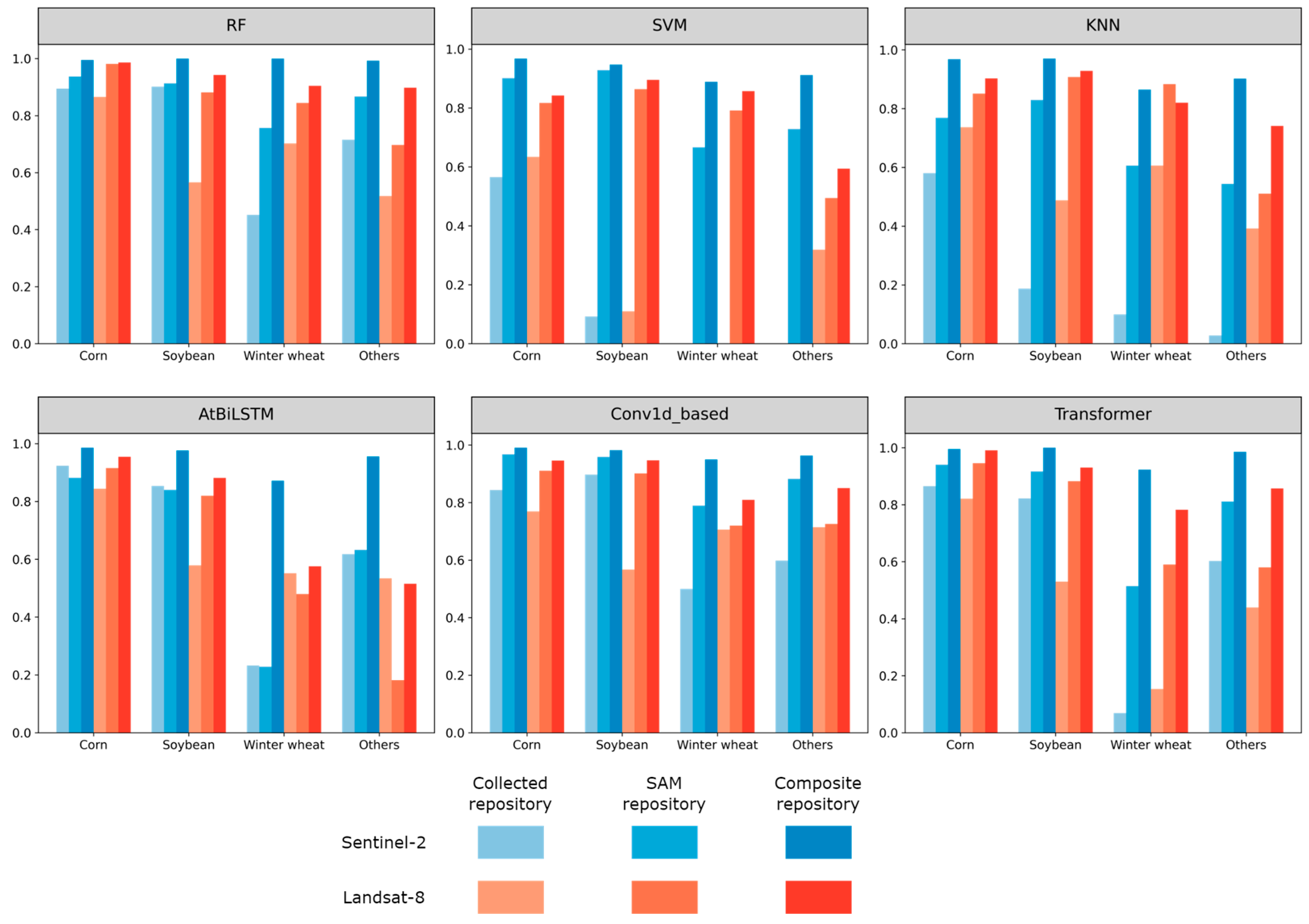
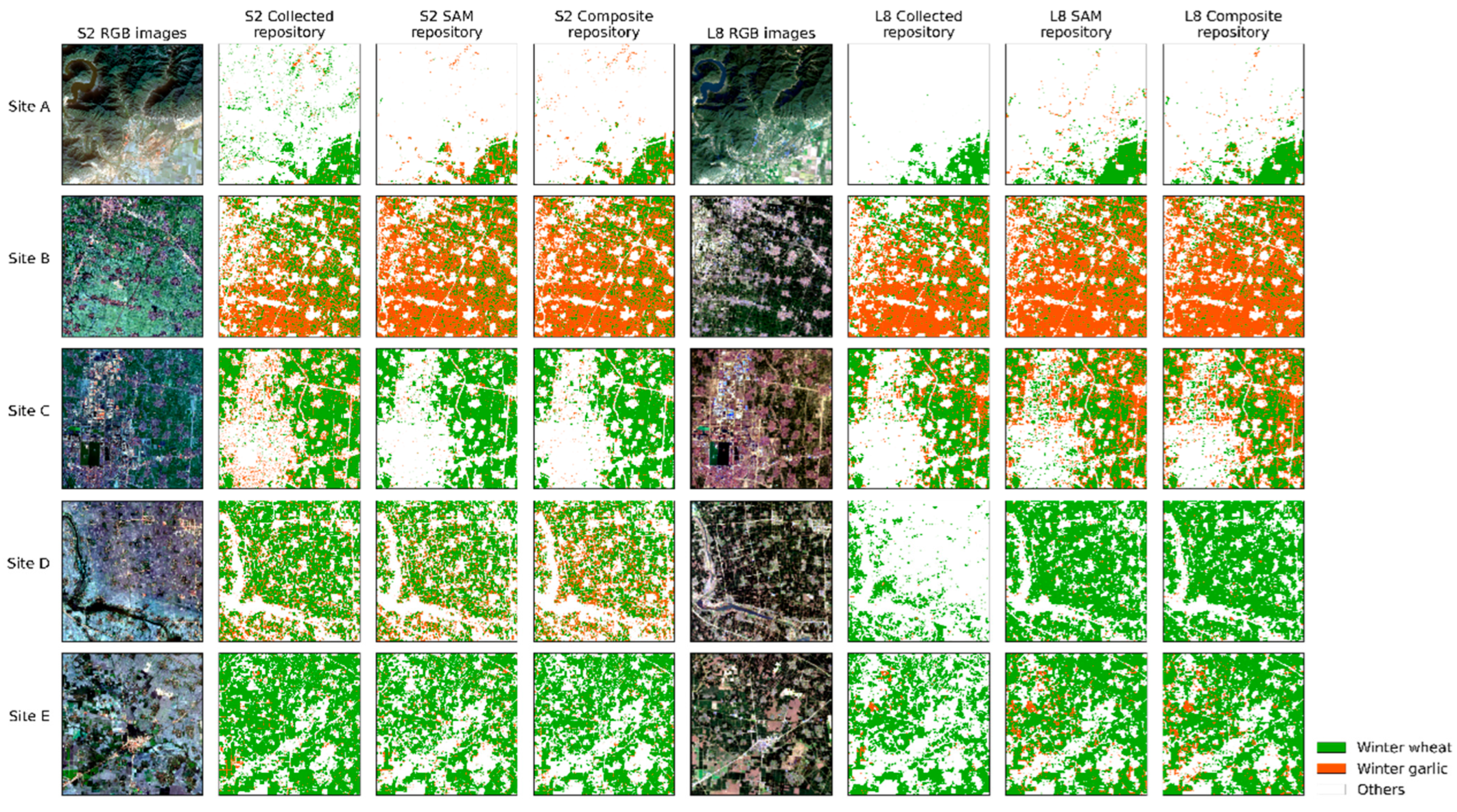
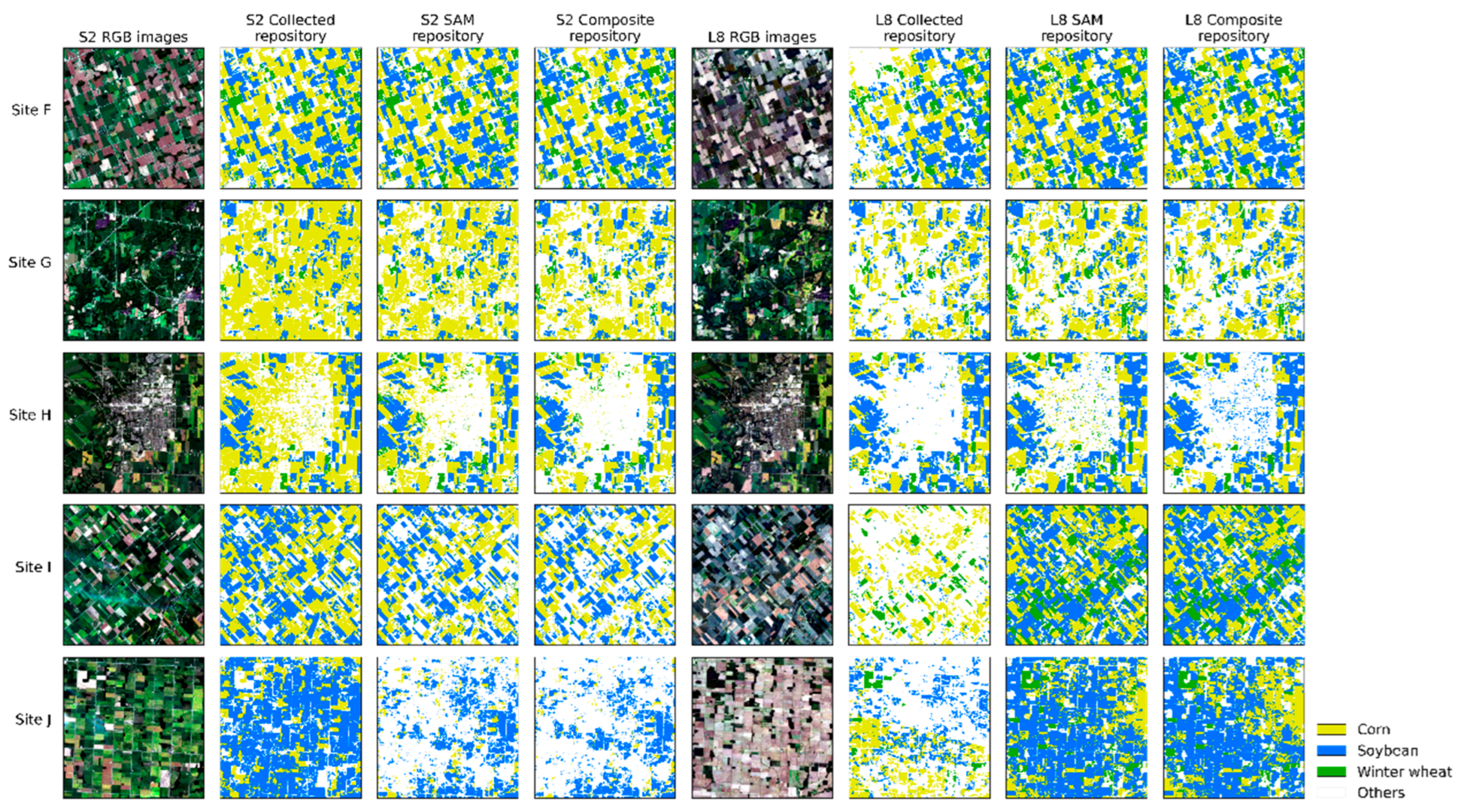
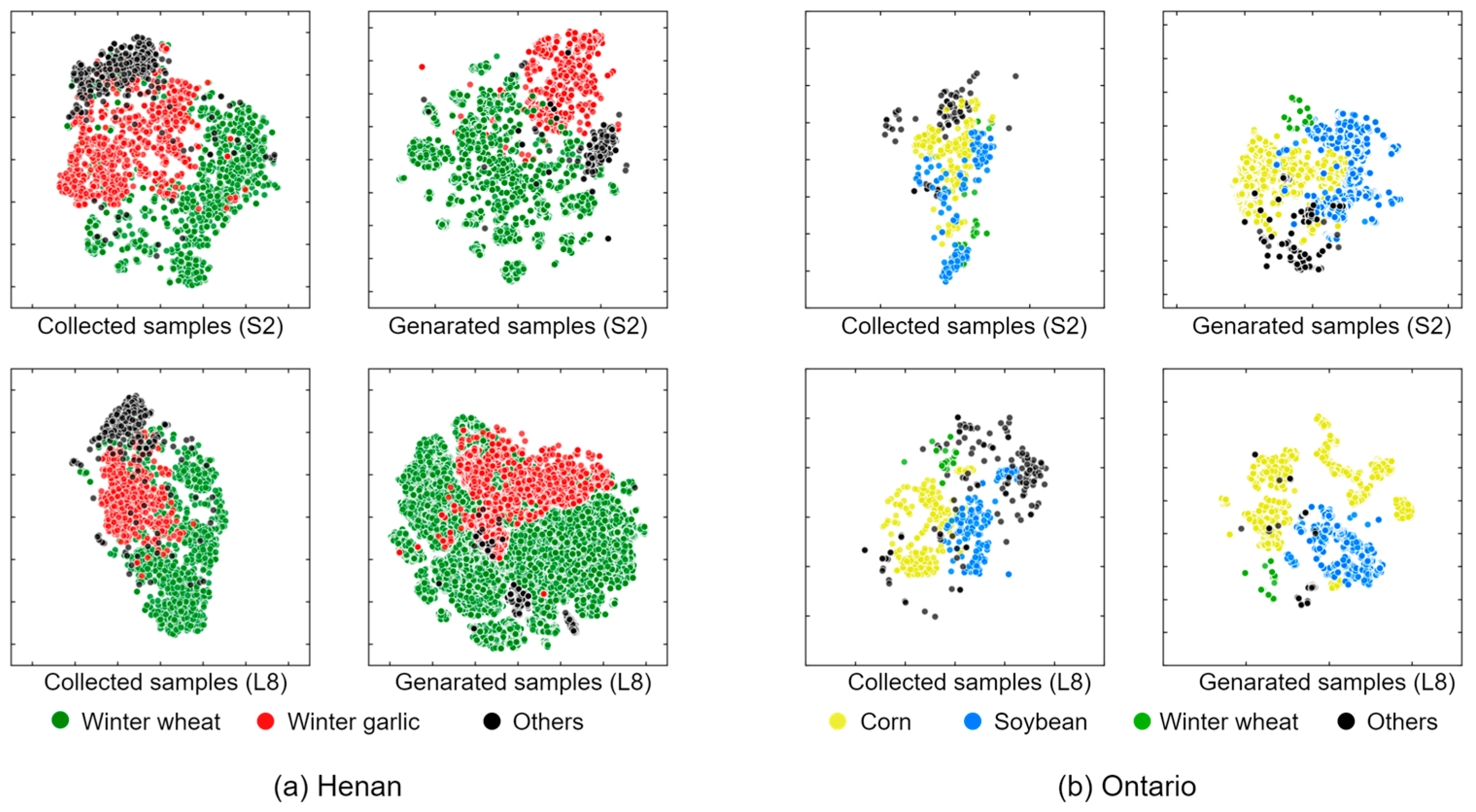
4. Results
4.1. The Performance of SAM on Parcel Segmentation
4.2. The Generated Samples and Analysis
4.3. Classification with Generated Samples
4.4. The Crop Mapping Performance Analysis
5. Discussion
5.1. The Capability of SAM on Medium-Resolution Satellite Imagery
5.2. The Effectiveness of the Proposed Sample Generation Method
5.3. Contributions and Future Work
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Satellite | Collected Repository | SAM Repository | Composite Repository |
|---|---|---|---|---|
| RF | S2 | 0.735 | 0.884 | 0.950 |
| L8 | 0.608 | 0.842 | 0.936 | |
| SVM | S2 | 0.672 | 0.850 | 0.868 |
| L8 | 0.705 | 0.751 | 0.796 | |
| KNN | S2 | 0.544 | 0.783 | 0.862 |
| L8 | 0.705 | 0.772 | 0.834 | |
| AtBiLSTM | S2 | 0.740 | 0.677 | 0.841 |
| L8 | 0.630 | 0.745 | 0.758 | |
| Conv1d-based | S2 | 0.550 | 0.800 | 0.859 |
| L8 | 0.438 | 0.693 | 0.773 | |
| Transformer | S2 | 0.598 | 0.753 | 0.916 |
| L8 | 0.652 | 0.756 | 0.861 |
| Model | Satellite | Collected Repository | SAM Repository | Composite Repository |
|---|---|---|---|---|
| RF | S2 | 0.751 | 0.857 | 0.995 |
| L8 | 0.525 | 0.831 | 0.923 | |
| SVM | S2 | 0.027 | 0.791 | 0.918 |
| L8 | 0.147 | 0.671 | 0.727 | |
| KNN | S2 | 0.073 | 0.607 | 0.923 |
| L8 | 0.384 | 0.728 | 0.813 | |
| AtBiLSTM | S2 | 0.687 | 0.664 | 0.954 |
| L8 | 0.520 | 0.614 | 0.734 | |
| Conv1d-based | S2 | 0.695 | 0.902 | 0.969 |
| L8 | 0.565 | 0.786 | 0.877 | |
| Transformer | S2 | 0.626 | 0.819 | 0.985 |
| L8 | 0.409 | 0.747 | 0.893 |
| Class | Test Set | Collected Repository | SAM Repository | Composite Repository | ||||
|---|---|---|---|---|---|---|---|---|
| Train Set | Val Set | Train Set | Val Set | Train Set | Val Set | |||
| Henan | Winter wheat | 522 | 417 | 105 | 6513 | 1628 | 6930 | 1733 |
| Winter garlic | 430 | 344 | 86 | 1353 | 338 | 1697 | 424 | |
| Others | 145 | 116 | 29 | 294 | 74 | 410 | 103 | |
| Ontario | Soybean | 82 | 66 | 17 | 7997 | 1999 | 8062 | 2016 |
| Corn | 108 | 86 | 22 | 12,717 | 3180 | 12,804 | 3201 | |
| Winter wheat | 19 | 15 | 4 | 421 | 105 | 436 | 109 | |
| Others | 71 | 56 | 14 | 1405 | 352 | 1462 | 366 | |
References
- Blickensdörfer, L.; Schwieder, M.; Pflugmacher, D.; Nendel, C.; Erasmi, S.; Hostert, P. Mapping of crop types and crop sequences with combined time series of Sentinel-1, Sentinel-2 and Landsat 8 data for Germany. Remote Sens. Environ. 2022, 269, 112831. [Google Scholar] [CrossRef]
- Karthikeyan, L.; Chawla, I.; Mishra, A.K. A review of remote sensing applications in agriculture for food security: Crop growth and yield, irrigation, and crop losses. J. Hydrol. 2020, 586, 124905. [Google Scholar] [CrossRef]
- Turkoglu, M.O.; D’Aronco, S.; Perich, G.; Liebisch, F.; Streit, C.; Schindler, K.; Wegner, J.D. Crop mapping from image time series: Deep learning with multi-scale label hierarchies. Remote Sens. Environ. 2021, 264, 112603. [Google Scholar] [CrossRef]
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m crop type maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 41. [Google Scholar] [CrossRef] [PubMed]
- Xuan, F.; Dong, Y.; Li, J.; Li, X.; Su, W.; Huang, X.; Huang, J.; Xie, Z.; Li, Z.; Liu, H. Mapping crop type in Northeast China during 2013–2021 using automatic sampling and tile-based image classification. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103178. [Google Scholar] [CrossRef]
- Wen, Y.; Li, X.; Mu, H.; Zhong, L.; Chen, H.; Zeng, Y.; Miao, S.; Su, W.; Gong, P.; Li, B. Mapping corn dynamics using limited but representative samples with adaptive strategies. ISPRS J. Photogramm. Remote Sens. 2022, 190, 252–266. [Google Scholar] [CrossRef]
- Huang, H.; Wang, J.; Liu, C.; Liang, L.; Li, C.; Gong, P. The migration of training samples towards dynamic global land cover mapping. ISPRS J. Photogramm. Remote Sens. 2020, 161, 27–36. [Google Scholar] [CrossRef]
- Tran, K.H.; Zhang, H.K.; McMaine, J.T.; Zhang, X.; Luo, D. 10 m crop type mapping using Sentinel-2 reflectance and 30 m cropland data layer product. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102692. [Google Scholar] [CrossRef]
- Hao, P.; Di, L.; Zhang, C.; Guo, L. Transfer Learning for Crop classification with Cropland Data Layer data (CDL) as training samples. Sci. Total Environ. 2020, 733, 138869. [Google Scholar] [CrossRef]
- Jiang, D.; Chen, S.; Useya, J.; Cao, L.; Lu, T. Crop mapping using the historical crop data layer and deep neural networks: A case study in jilin province, china. Sensors 2022, 22, 5853. [Google Scholar] [CrossRef]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US department of agriculture, national agricultural statistics service, cropland data layer program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Liu, D.; Xiong, Q.; Yang, N.; Ren, T.; Zhang, C.; Zhang, X.; Li, S. Crop mapping based on historical samples and new training samples generation in Heilongjiang Province, China. Sustainability 2019, 11, 5052. [Google Scholar] [CrossRef]
- Yu, Q.; Duan, Y.; Wu, Q.; Liu, Y.; Wen, C.; Qian, J.; Song, Q.; Li, W.; Sun, J.; Wu, W. An interactive and iterative method for crop mapping through crowdsourcing optimized field samples. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103409. [Google Scholar] [CrossRef]
- Tobler, W. On the first law of geography: A reply. Ann. Assoc. Am. Geogr. 2004, 94, 304–310. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, L.; Yu, Y.; Xi, X.; Ren, T.; Zhao, Y.; Zhu, D.; Zhu, A.-X. Cross-year reuse of historical samples for crop mapping based on environmental similarity. Front. Plant Sci. 2022, 12, 761148. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.N.; Luo, J.; Feng, L.; Yang, Y.; Chen, Y.; Wu, W. Long-short-term-memory-based crop classification using high-resolution optical images and multi-temporal SAR data. GISci. Remote Sens. 2019, 56, 1170–1191. [Google Scholar] [CrossRef]
- Labib, S.; Harris, A. The potentials of Sentinel-2 and LandSat-8 data in green infrastructure extraction, using object based image analysis (OBIA) method. Eur. J. Remote Sens. 2018, 51, 231–240. [Google Scholar] [CrossRef]
- Gui, B.; Bhardwaj, A.; Sam, L. Evaluating the Efficacy of Segment Anything Model for Delineating Agriculture and Urban Green Spaces in Multiresolution Aerial and Spaceborne Remote Sensing Images. Remote Sens. 2024, 16, 414. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Sun, W.; Liu, Z.; Zhang, Y.; Zhong, Y.; Barnes, N. An Alternative to WSSS? An Empirical Study of the Segment Anything Model (SAM) on Weakly-Supervised Semantic Segmentation Problems. arXiv 2023, arXiv:2305.01586. [Google Scholar]
- Wang, D.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Scaling-up remote sensing segmentation dataset with segment anything model. arXiv 2023, arXiv:2305.02034. [Google Scholar]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4701117. [Google Scholar] [CrossRef]
- Ji, W.; Li, J.; Bi, Q.; Li, W.; Cheng, L. Segment anything is not always perfect: An investigation of sam on different real-world applications. arXiv 2023, arXiv:2304.05750. [Google Scholar] [CrossRef]
- Osco, L.P.; Wu, Q.; de Lemos, E.L.; Gonçalves, W.N.; Ramos, A.P.M.; Li, J.; Junior, J.M. The segment anything model (sam) for remote sensing applications: From zero to one shot. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103540. [Google Scholar] [CrossRef]
- Luo, L.; Qin, L.; Wang, Y.; Wang, Q. Environmentally-friendly agricultural practices and their acceptance by smallholder farmers in China—A case study in Xinxiang County, Henan Province. Sci. Total Environ. 2016, 571, 737–743. [Google Scholar] [CrossRef]
- Johansen, C.; Haque, M.; Bell, R.; Thierfelder, C.; Esdaile, R. Conservation agriculture for small holder rainfed farming: Opportunities and constraints of new mechanized seeding systems. Field Crops Res. 2012, 132, 18–32. [Google Scholar] [CrossRef]
- Laamrani, A.; Berg, A.A.; Voroney, P.; Feilhauer, H.; Blackburn, L.; March, M.; Dao, P.D.; He, Y.; Martin, R.C. Ensemble identification of spectral bands related to soil organic carbon levels over an agricultural field in Southern Ontario, Canada. Remote Sens. 2019, 11, 1298. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P. Conterminous United States crop field size quantification from multi-temporal Landsat data. Remote Sens. Environ. 2016, 172, 67–86. [Google Scholar] [CrossRef]
- Qiu, B.; Lu, D.; Tang, Z.; Chen, C.; Zou, F. Automatic and adaptive paddy rice mapping using Landsat images: Case study in Songnen Plain in Northeast China. Sci. Total Environ. 2017, 598, 581–592. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Ye, S.; Liu, D.; Yao, X.; Tang, H.; Xiong, Q.; Zhuo, W.; Du, Z.; Huang, J.; Su, W.; Shen, S. RDCRMG: A raster dataset clean & reconstitution multi-grid architecture for remote sensing monitoring of vegetation dryness. Remote Sens. 2018, 10, 1376. [Google Scholar] [CrossRef]
- Huang, X.; Huang, J.; Li, X.; Shen, Q.; Chen, Z. Early mapping of winter wheat in Henan province of China using time series of Sentinel-2 data. GISci. Remote Sens. 2022, 59, 1534–1549. [Google Scholar] [CrossRef]
- Fisette, T.; Davidson, A.; Daneshfar, B.; Rollin, P.; Aly, Z.; Campbell, L. Annual space-based crop inventory for Canada: 2009–2014. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 5095–5098. [Google Scholar]
- Jensen, J.R. Remote Sensing of the Environment: An Earth Resource Perspective 2/e; Pearson Education: Noida, India, 2009. [Google Scholar]
- Dong, X.-L.; Gu, C.-K.; Wang, Z.-O. Research on shape-based time series similarity measure. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 1253–1258. [Google Scholar]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef]
- Jeong, Y.-S.; Jeong, M.K.; Omitaomu, O.A. Weighted dynamic time warping for time series classification. Pattern Recognit. 2011, 44, 2231–2240. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, Y.; Zhong, R.; Lin, Z.; Xu, J.; Jiang, H.; Huang, J.; Li, H.; Lin, T. DeepCropMapping: A multi-temporal deep learning approach with improved spatial generalizability for dynamic corn and soybean mapping. Remote Sens. Environ. 2020, 247, 111946. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Rußwurm, M.; Lefèvre, S.; Körner, M. Breizhcrops: A satellite time series dataset for crop type identification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2-2020, 1545–1551. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wang, X.; Zhang, J.; Xun, L.; Wang, J.; Wu, Z.; Henchiri, M.; Zhang, S.; Zhang, S.; Bai, Y.; Yang, S. Evaluating the effectiveness of machine learning and deep learning models combined time-series satellite data for multiple crop types classification over a large-scale region. Remote Sens. 2022, 14, 2341. [Google Scholar] [CrossRef]
- Nowakowski, A.; Mrziglod, J.; Spiller, D.; Bonifacio, R.; Ferrari, I.; Mathieu, P.P.; Garcia-Herranz, M.; Kim, D.-H. Crop type mapping by using transfer learning. Int. J. Appl. Earth Obs. Geoinf. 2021, 98, 102313. [Google Scholar] [CrossRef]
- Zhan, W.; Luo, F.; Luo, H.; Li, J.; Wu, Y.; Yin, Z.; Wu, Y.; Wu, P. Time-Series-Based Spatiotemporal Fusion Network for Improving Crop Type Mapping. Remote Sens. 2024, 16, 235. [Google Scholar] [CrossRef]

















| Study Area | Class | Numbers |
|---|---|---|
| Henan Province | Winter wheat | 1044 |
| Winter garlic | 860 | |
| Others | 290 | |
| Ontario | Soybean | 165 |
| Corn | 216 | |
| Winter wheat | 38 | |
| Others | 141 |
| Study Area | Class | Collected Samples | Generated Samples (S2) | Generated Samples (L8) |
|---|---|---|---|---|
| Henan Province | Winter wheat | 522 | 8141 | 76,688 |
| Winter garlic | 430 | 1691 | 6513 | |
| Others | 145 | 368 | 1257 | |
| Ontario | Soybean | 83 | 9996 | 2881 |
| Corn | 108 | 15,897 | 2922 | |
| Winter wheat | 19 | 526 | 452 | |
| Others | 70 | 1757 | 151 |
| Model | Satellite | Collected Repository | SAM Repository | Composite Repository |
|---|---|---|---|---|
| RF | S2 | 0.840 | 0.930 | 0.970 |
| L8 | 0.770 | 0.909 | 0.963 | |
| SVM | S2 | 0.796 | 0.909 | 0.921 |
| L8 | 0.829 | 0.858 | 0.883 | |
| KNN | S2 | 0.722 | 0.868 | 0.917 |
| L8 | 0.831 | 0.868 | 0.904 | |
| AtBiLSTM | S2 | 0.843 | 0.793 | 0.904 |
| L8 | 0.783 | 0.853 | 0.859 | |
| Conv1d-based | S2 | 0.714 | 0.880 | 0.915 |
| L8 | 0.665 | 0.823 | 0.870 | |
| Transformer | S2 | 0.758 | 0.847 | 0.949 |
| L8 | 0.799 | 0.859 | 0.920 |
| Model | Satellite | Collected Repository | SAM Repository | Composite Repository |
|---|---|---|---|---|
| RF | S2 | 0.822 | 0.900 | 0.996 |
| L8 | 0.679 | 0.872 | 0.946 | |
| SVM | S2 | 0.245 | 0.850 | 0.942 |
| L8 | 0.357 | 0.749 | 0.797 | |
| KNN | S2 | 0.293 | 0.720 | 0.945 |
| L8 | 0.568 | 0.785 | 0.865 | |
| AtBiLSTM | S2 | 0.780 | 0.763 | 0.968 |
| L8 | 0.668 | 0.674 | 0.797 | |
| Conv1d-based | S2 | 0.775 | 0.932 | 0.979 |
| L8 | 0.691 | 0.849 | 0.913 | |
| Transformer | S2 | 0.733 | 0.872 | 0.989 |
| L8 | 0.594 | 0.811 | 0.925 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Yan, S.; Alexandridis, T.; Yao, X.; Zhou, H.; Gao, B.; Huang, J.; Yang, J.; Li, Y. Enhancing Crop Mapping through Automated Sample Generation Based on Segment Anything Model with Medium-Resolution Satellite Imagery. Remote Sens. 2024, 16, 1505. https://doi.org/10.3390/rs16091505
Sun J, Yan S, Alexandridis T, Yao X, Zhou H, Gao B, Huang J, Yang J, Li Y. Enhancing Crop Mapping through Automated Sample Generation Based on Segment Anything Model with Medium-Resolution Satellite Imagery. Remote Sensing. 2024; 16(9):1505. https://doi.org/10.3390/rs16091505
Chicago/Turabian StyleSun, Jialin, Shuai Yan, Thomas Alexandridis, Xiaochuang Yao, Han Zhou, Bingbo Gao, Jianxi Huang, Jianyu Yang, and Ying Li. 2024. "Enhancing Crop Mapping through Automated Sample Generation Based on Segment Anything Model with Medium-Resolution Satellite Imagery" Remote Sensing 16, no. 9: 1505. https://doi.org/10.3390/rs16091505