1. Introduction
Synthetic Aperture Radar automatic target recognition (SAR-ATR) has been a driving motivation for many years. Generally, the SAR-ATR system can be split into three stages: detection, low-level classification (LLC) and high-level classification (HLC). The first two stages that are also known as prescreening and discrimination together generate the focus-of-attention (FOA) module [
1]. It interfaces with the input SAR images and outputs a list of potential SAR targets as the input of the HLC stage. Finally, the HLC stage aims to classify the targets into different categories, which is the main focus of this paper.
Various methods have been proposed to implement the HLC stage, which can be concluded as three taxonomies: feature-based, model-based and semi-model-based according to [
1]. Feature-based approaches, extracting and preprocessing features from SAR target chips and training a classifier with them, are extensively used in the literature for HLC stage. To obtain a satisfactory classification performance, both the features and the classifiers should be carefully elaborately designed. On the one hand, various types of classifiers, such as sparse representation-based method [
2], Bayes classifier [
3], mean square error (MSE) classifier [
4], template-based classifiers [
5] and support vector machine (SVM) [
6], are selected to solve the problem. Among them, the sparse representation classification is popular in recent studies [
7,
8]. The improved joint sparse representation model was proposed to effectively combine multiple-view SAR images from the same physical target [
9]. Pan et al. [
10] designed a reweighted sparse representation based method to suppress the influence of the interference caused by objects near the targets. In addition, better performance is proved on the fusion of multiple classifiers than the single classifier [
11]. Liu et al. [
12] proposed a decision fusion method of sparse representation and SVM, fusing the results of two classifiers obeying Bayesian rule to make the decision. On the other hand, hand-crafted features, for example, geometrical feature [
13], principal components analysis (PCA) based features [
3] and Fourier descriptors [
6], as well as target chip templates [
4,
14], are extracted to feed into the classifiers conventionally. Due to the development of high-resolution SAR in recent years, new progress has been made to depict SAR images with more details. Carried in the magnitude of the radar backscatter, the scattering centers are considered as distinctive characteristics of SAR target images [
15]. As depicted in [
10], instead of using the scatter point extraction to describe the backscattering characteristic, a scatter cluster extraction method is proposed. Dense scale-invariant feature transform (SIFT) descriptors on multiple scales are used to train a global multi-scale dictionary by sparse coding algorithm [
16]. Based on the probabilistic graphical models, Srinivas et al. [
17] yields multiple SAR image representations and models each of them using graphs. The monogenic signal is performed to characterize the SAR images [
18]. Most of the studies have carried out the experiments on Moving and Stationary Target Acquisition and Recognition (MSTAR) public dataset to evaluate their methods. The best result among the hand-crafted methods can achieve 97.33% on the MSTAR dataset for the 10-class recognition task [
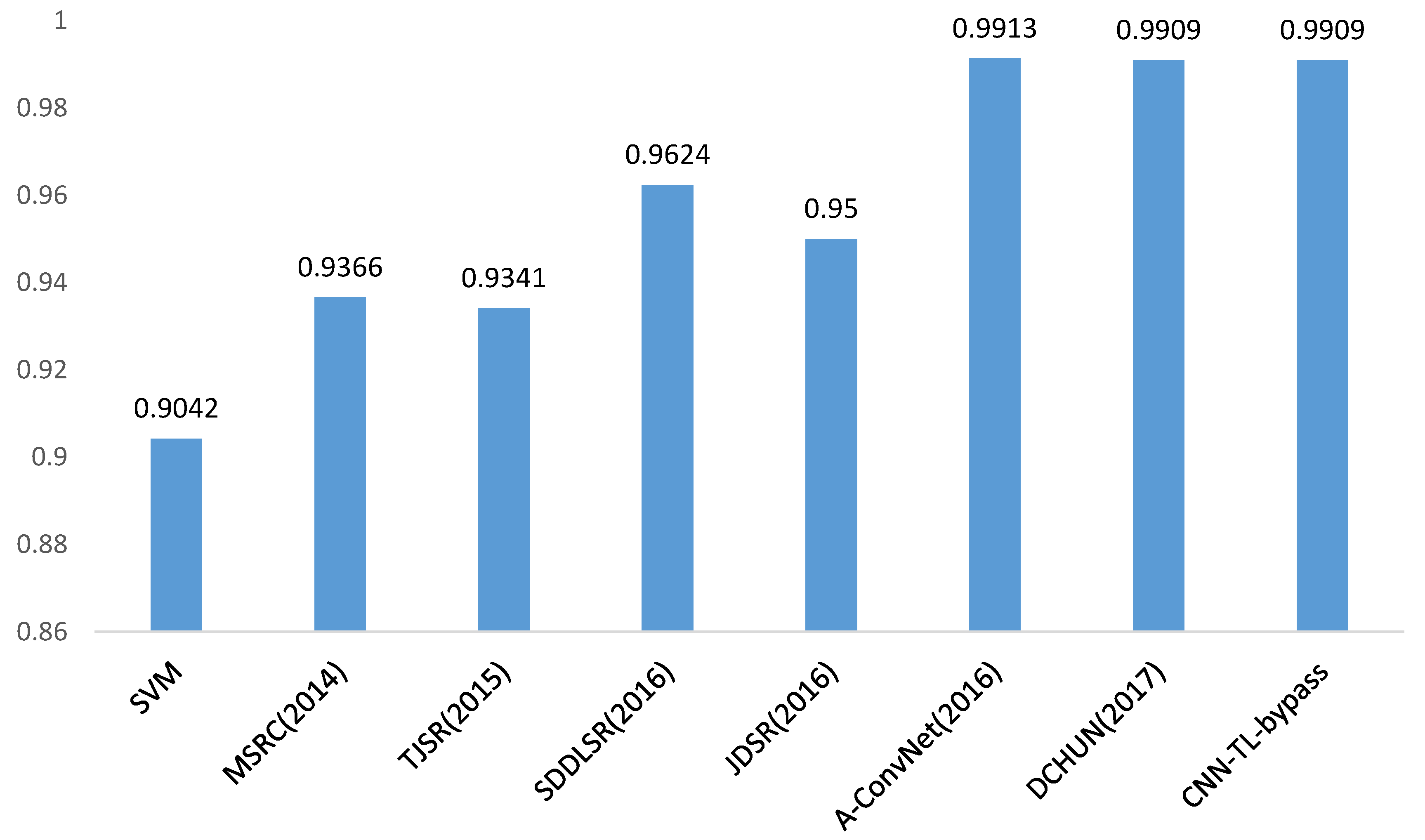
12].
Different from the hand-crafted feature extraction based method, the deep CNN based method automatically learns the feature from large-scale dataset, and achieves very impressive performance in object recognition. In computer vision domain, deep CNNs have rapidly developed in recent years. AlexNet [
19] proposed in 2012 attracted people’s attention to deep CNNs since the extraordinary performance on 1000-class object classification on ImageNet. Since then, more complex CNN architectures, such as VGG-16-Net [
20] and GoogLeNet [
21], were proposed with the recognition rate being improved gradually. Furthermore, the latest Res-Net [
22] achieved superhuman performance on ImageNet dataset at recognizing objects. Taking the tremendous progress deep learning has made in object recognition into consideration, deep CNNs are expected to solve the SAR target recognition problem as well. However, large-scale dataset is indispensable when training a deep CNN, such as ImageNet that contains about 22,000 classes and nearly 15 million labeled images, since there are millions of parameters to be determined in the network. Unfortunately, there exists no large-scale annotated SAR target dataset comparable to ImageNet, as data acquisition is expensive and quality annotation is costly. Limited by inadequate data in SAR target recognition, the current studies related to deep CNNs mainly focus on augmenting the training data [
23], designing a less complex network for a specific problem and making efforts on avoiding overfitting [
24]. Generally, the deeper and wider networks can develop more abstraction and more features. A relatively complex network is expected to extract rich hierarchical features of SAR targets; however, the limited labeled SAR target data remains a handicap to train the network well.
To address this problem, a more general method based on transfer learning is proposed in this paper. Transfer learning provides an effective way in training a large network using scarce training data without overfitting. For deep CNNs, the neurons’ generality versus the specificity of different layers in transition has been analyzed in [
25], and it has been proved that the transferring features even from distant tasks outperform the random weights. Previous studies reveal the transferability of different layers in deep CNNs trained with ImageNet dataset, and the transferring results show better performance than other standard approaches on different datasets, such as medical image datasets [
26,
27], X-ray security screening images [
28] and the PASCAL Visual Object Classes (VOC) dataset [
29]. ImageNet is widely experienced as the source dataset in most transfer learning cases due to its abundant categories and significant number of images. However, the SAR images are formed by coherent interaction of the transmitted microwave with targets. The differences in imaging mechanisms result in the distinct characteristics between optical images and SAR data. For SAR images, the pixels refer to the backscattering properties of the ground features, representing a series of scattering centers, and the intensity of each pixel depends on a variety of factors, such as types, shapes and orientations of the scatterers in the target area. While the optical images show evident contours, edges and other details that can be easily distinguished by the human vision system.
Differently to [
26,
27,
28,
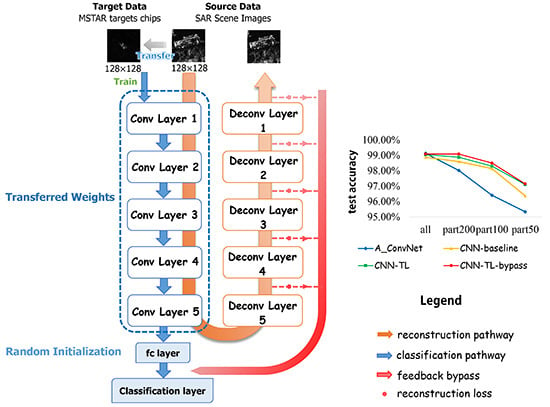
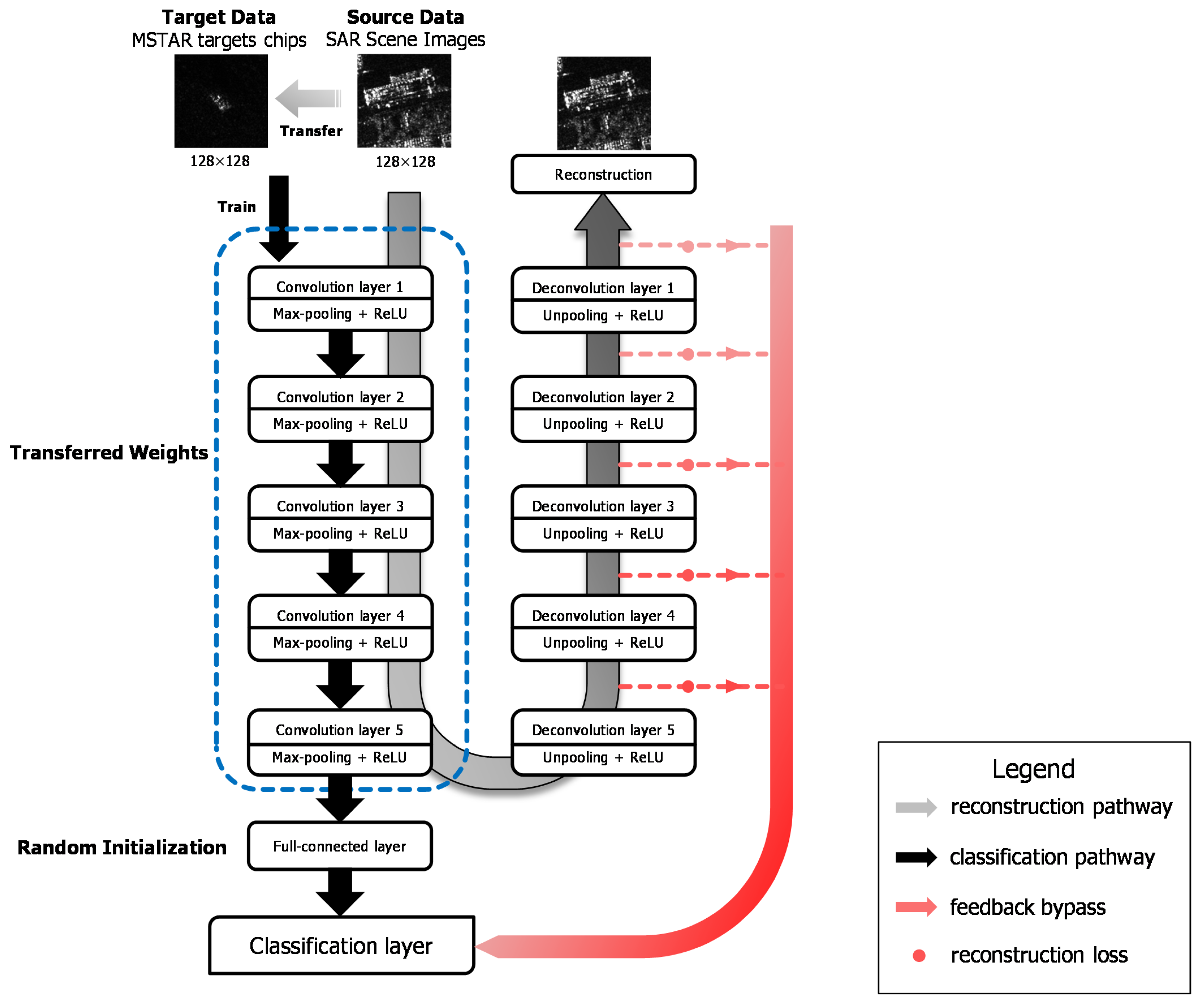
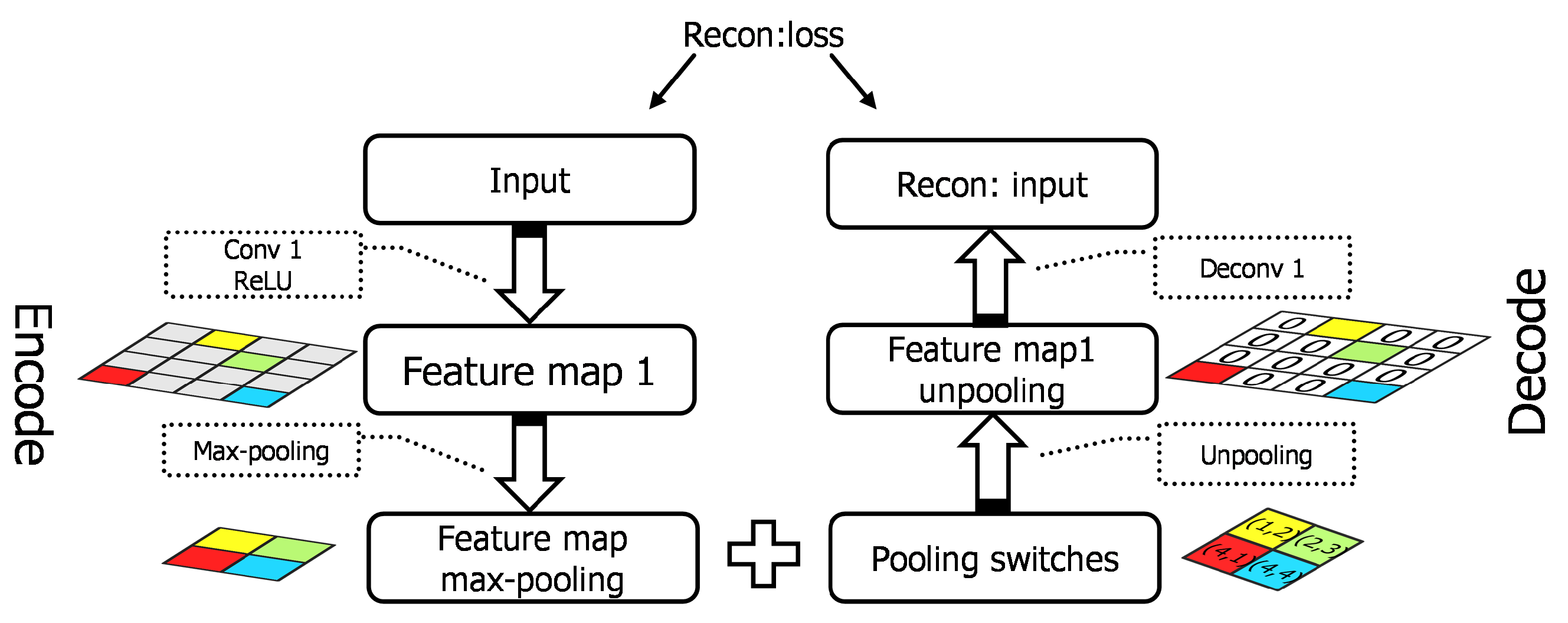
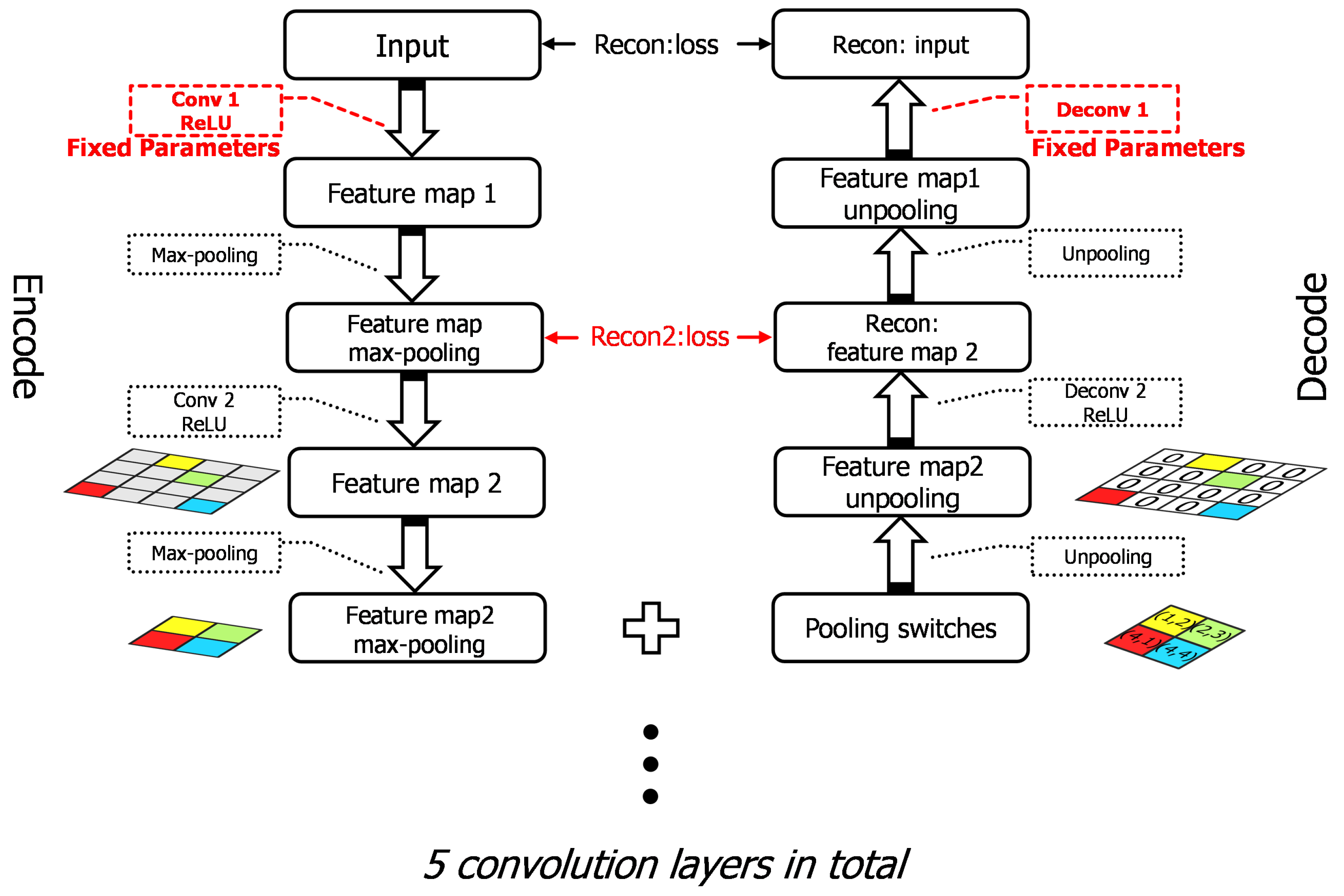
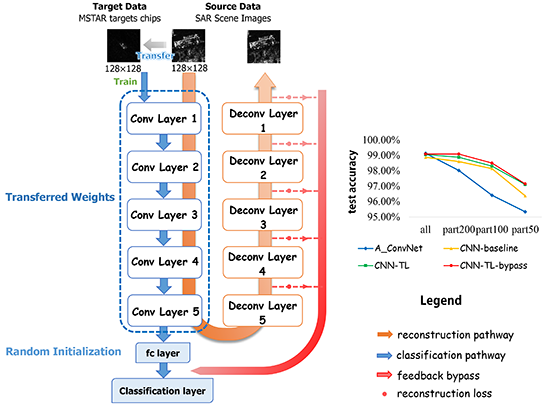
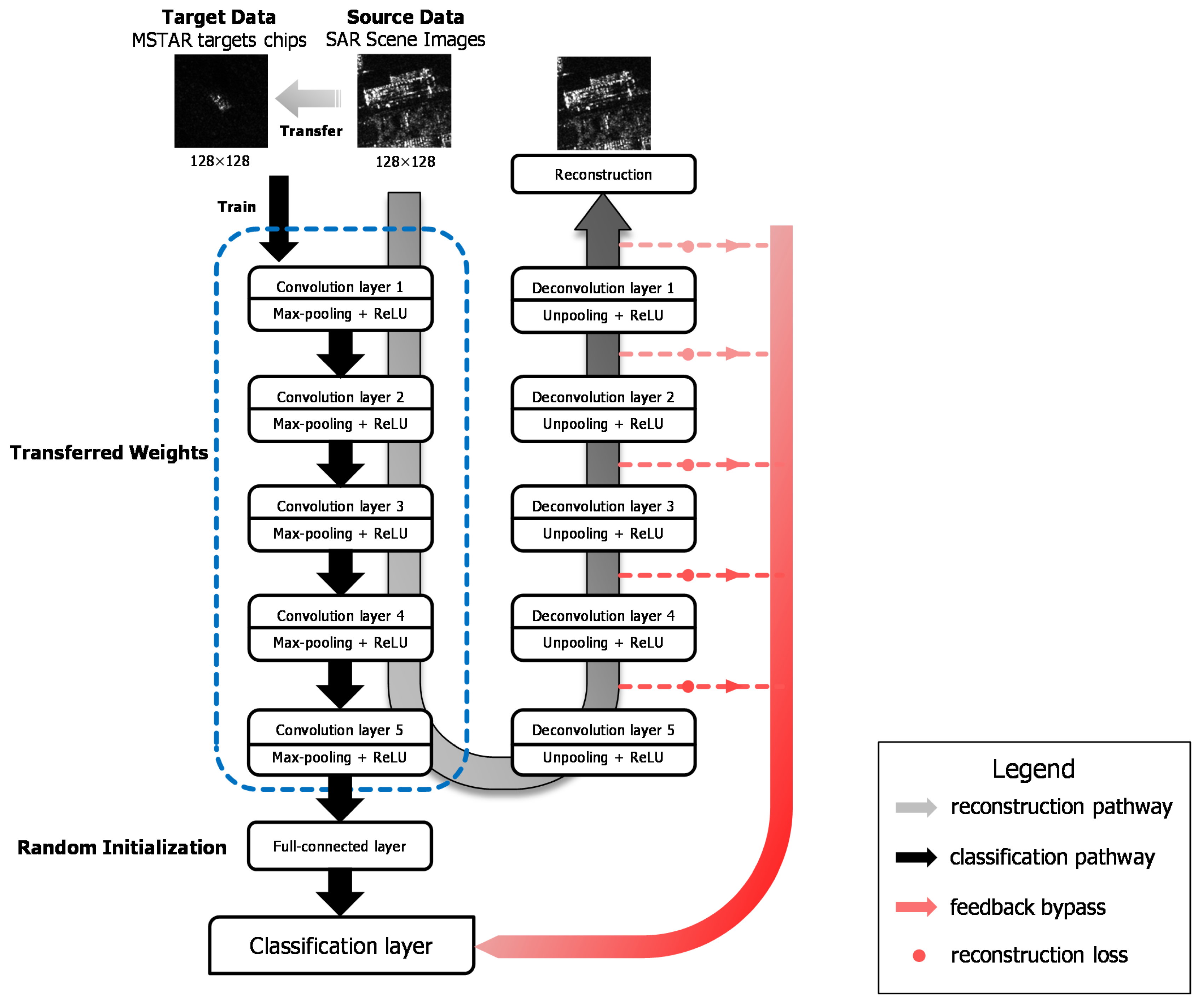
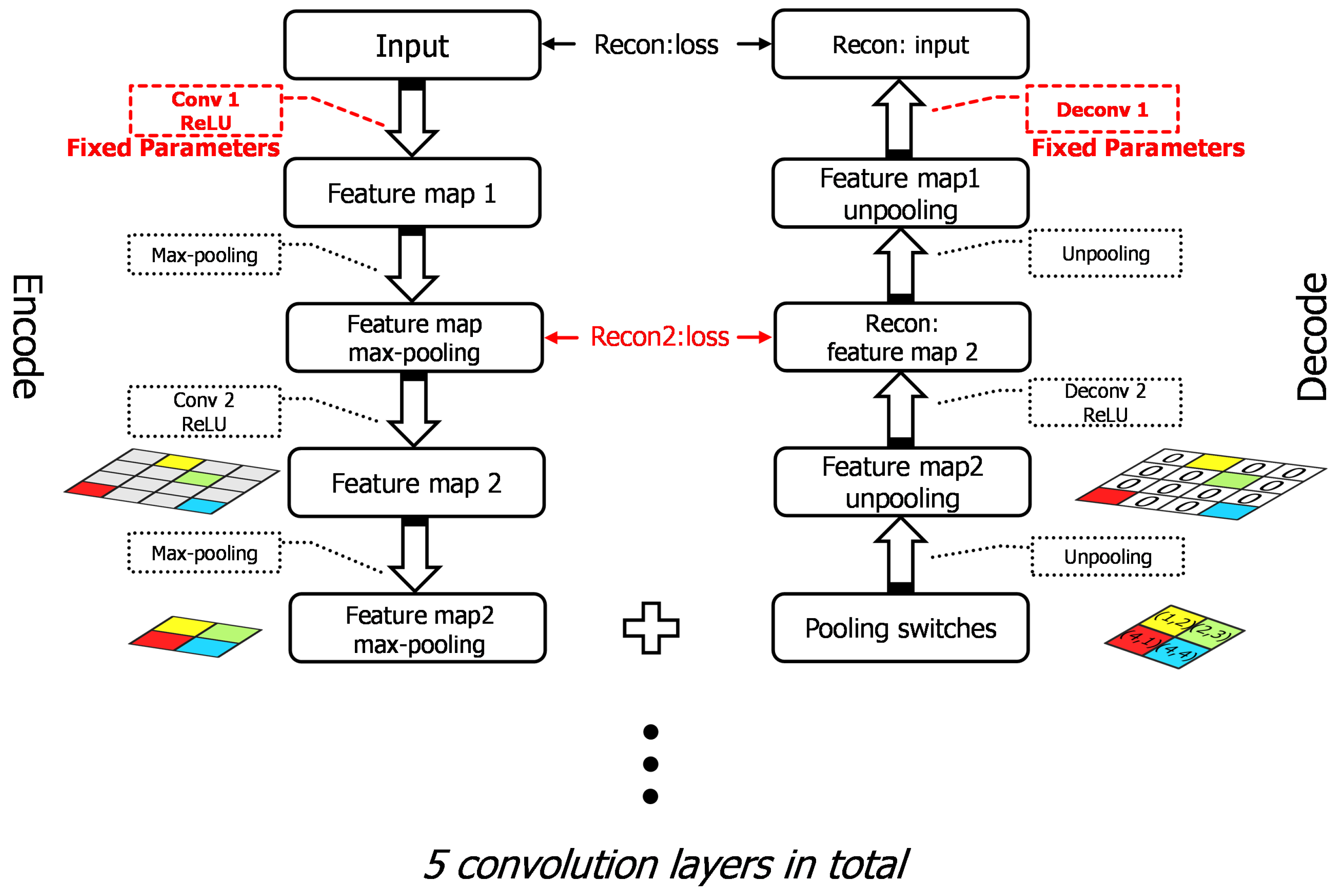
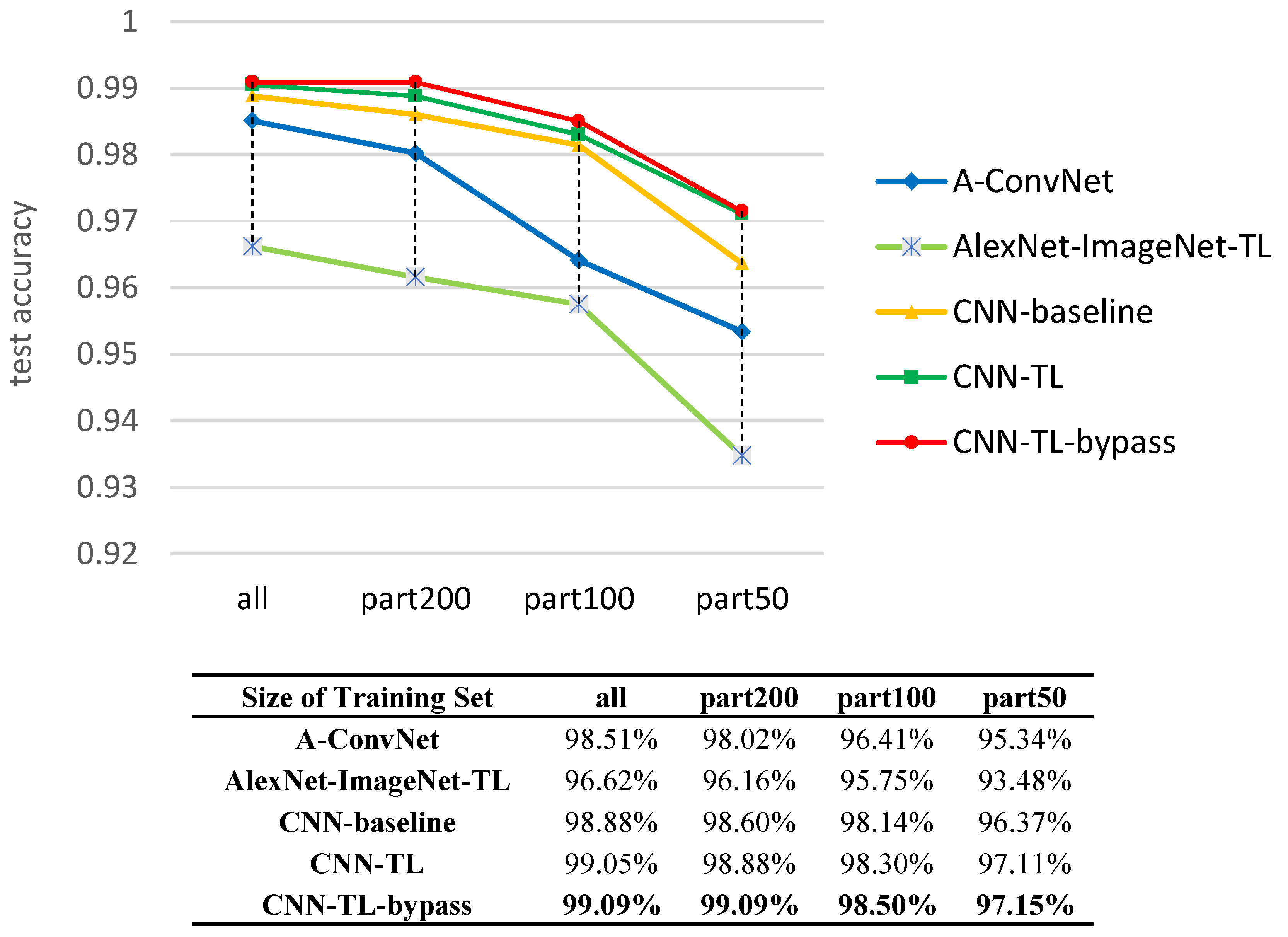
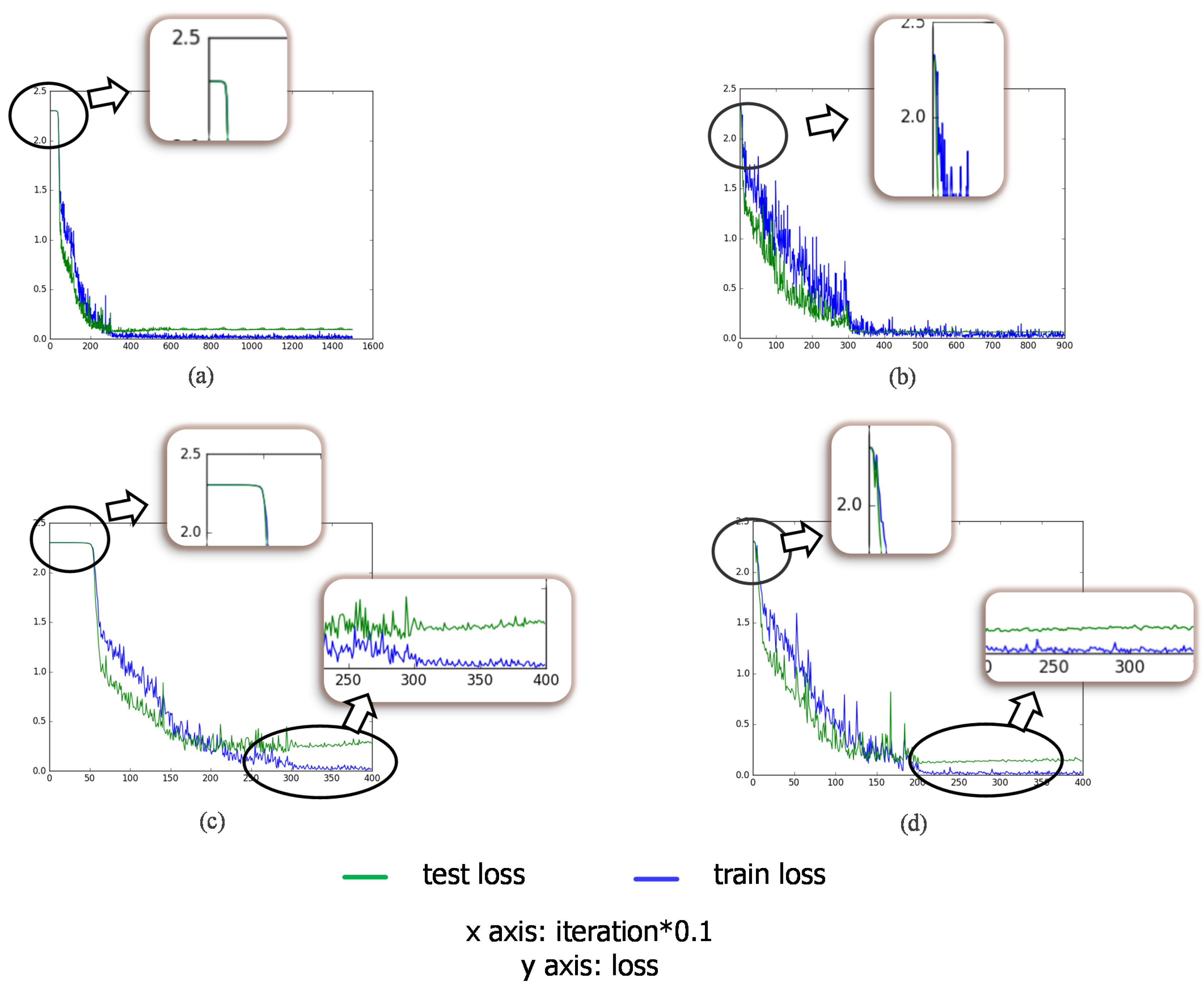
29], considering the distance between optical and SAR imagery, we adopt a large number of unlabeled SAR scene images, which are much more easily acquired than SAR targets, as the source dataset instead of ImageNet. Specifically speaking, the pre-trained layers are obtained firstly by training a stacked convolutional auto-encoder on unlabeled SAR scene images. Two different target tasks are explored in our work, one of which is to reconstruct the SAR target data with the encoding and decoding convolutional layers and the other is to classify the SAR targets into specific categories. The reconstruction error in the first target task plays a feeding back role in the classification task to improve the results. We explore the transferability of those convolutional layers in the case of different distances between the source task and target task, discussing how to transfer the features according to the specific task. The transfer performance shows significant improvements in the MSTAR dataset, outperforming the state-of-the-art even in a reducing scale of training data. The main contributions in this paper are reflected in the following:
Firstly, this paper makes an attempt on transfer learning to solve the SAR target recognition problem for the first time and explores the appropriate source data to transfer from. We validate that it is better to adopt SAR scene images as the source data for transfer learning in SAR target recognition than optical imagery. Instead of using the existing model trained with labeled ImageNet dataset in most literature, the unlabeled SAR scene imagery is utilized to train the convolutional layers to be transferred to SAR recognition tasks later.
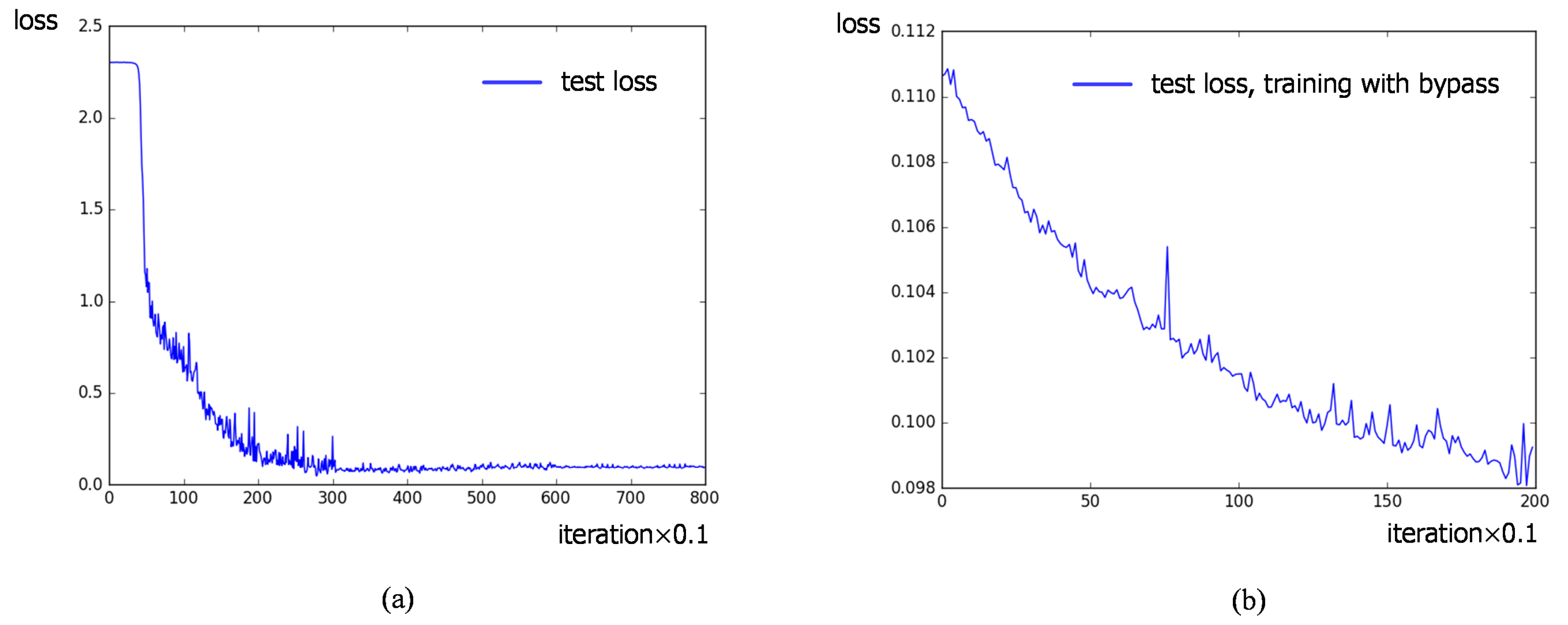
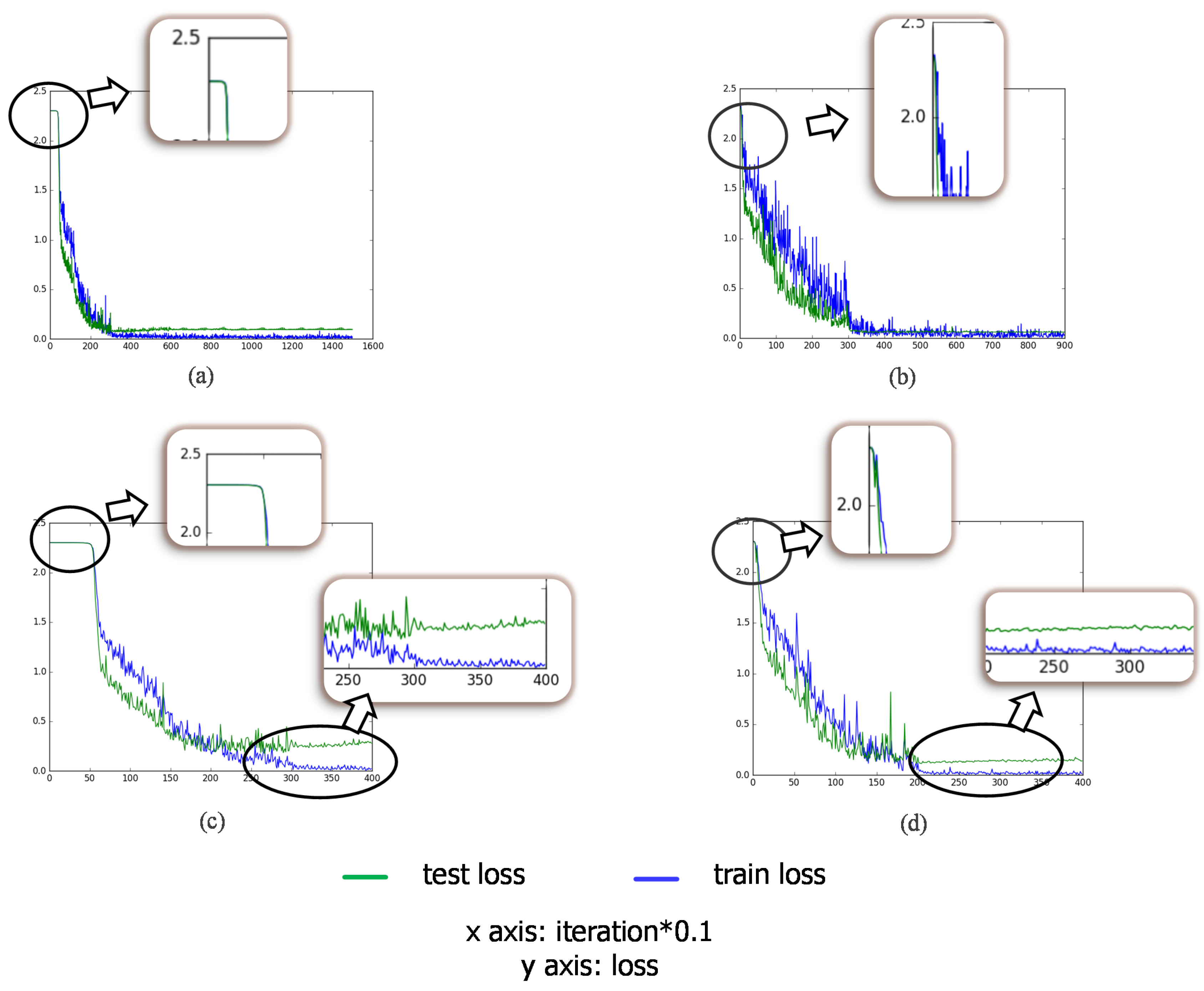
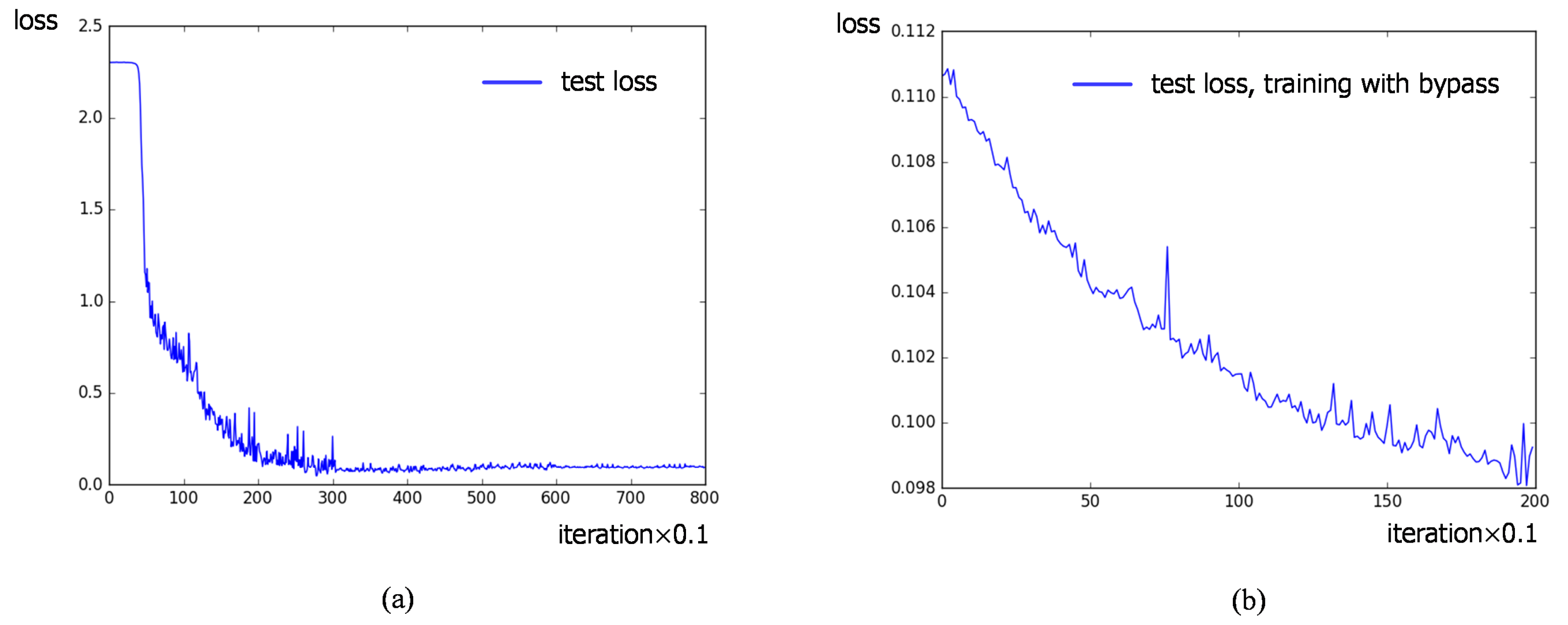
Secondly, two different target tasks are contained in our work. We explore the transferability of convolutional layers in different target tasks and verify that the the bypass extended from the reconstruction task with reconstruction errors can make an effort on classification task during transfer learning.
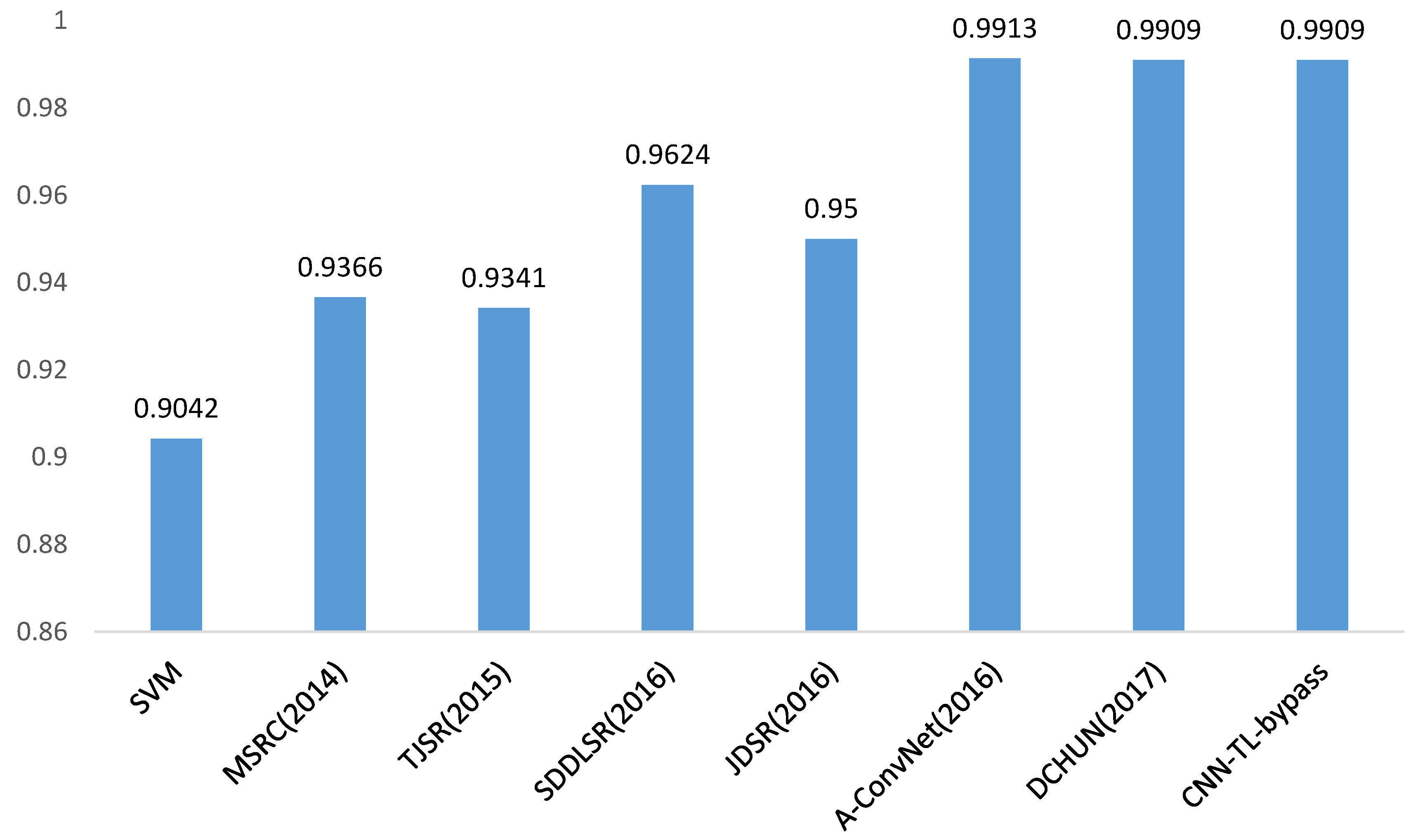
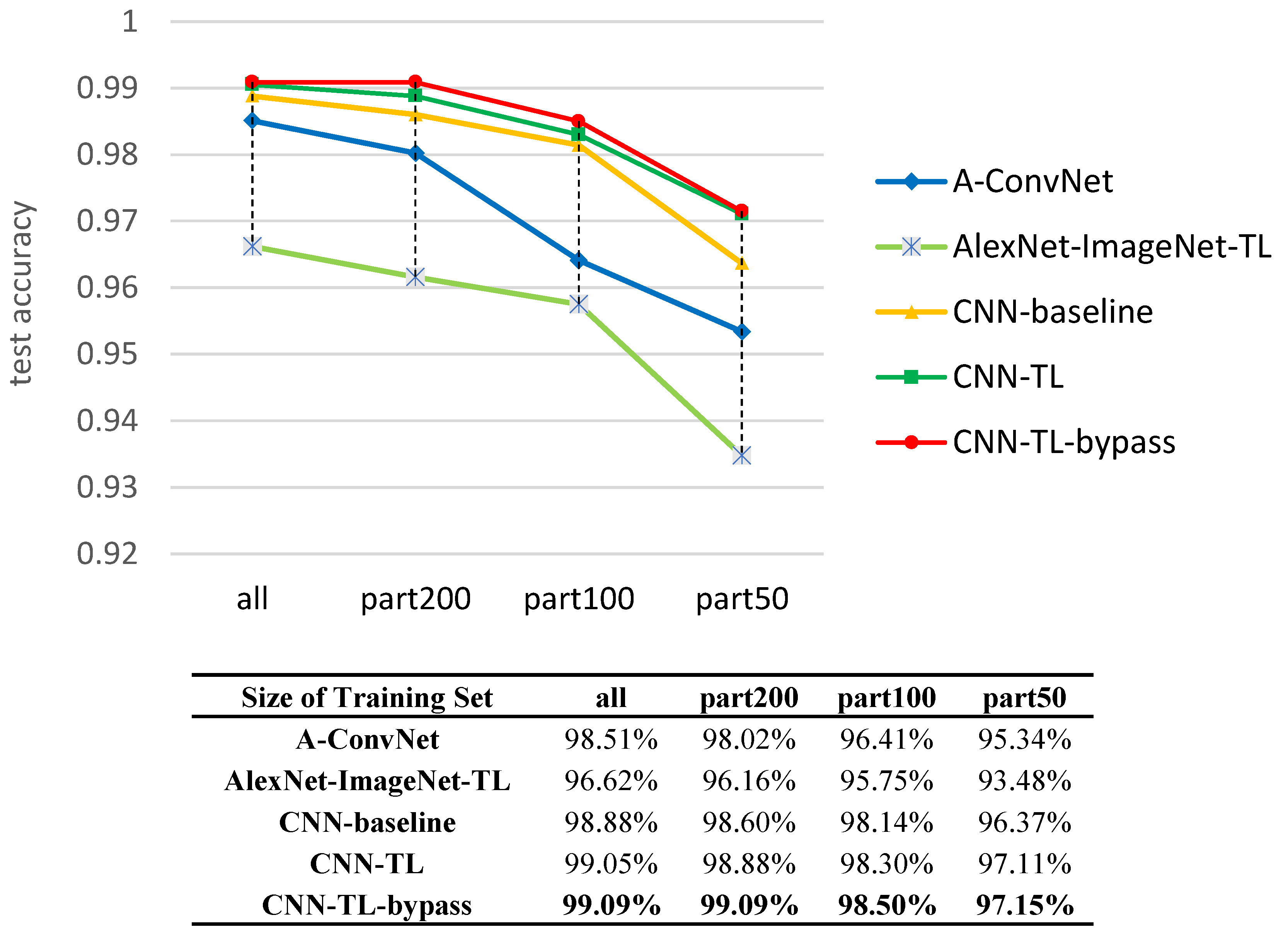
Thirdly, we demonstrate that the proposed method outperforms the state-of-the-art CNN based method in SAR target recognition with scarce data, which is the bottleneck for SAR target classification.
The rest of this paper is organized as follows. In
Section 2, we briefly present the related work.
Section 3 details the proposed method. Experimental results as well as the discussion are given in
Section 4, and
Section 5 concludes this paper.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}