A Hybrid Model for Forecasting Groundwater Levels Based on Fuzzy C-Mean Clustering and Singular Spectrum Analysis


Abstract
:1. Introduction
2. Forecasting Model
2.1. Fuzzy Time Series
2.2. A Brief Description of the Fuzzy C-mean Algorithm
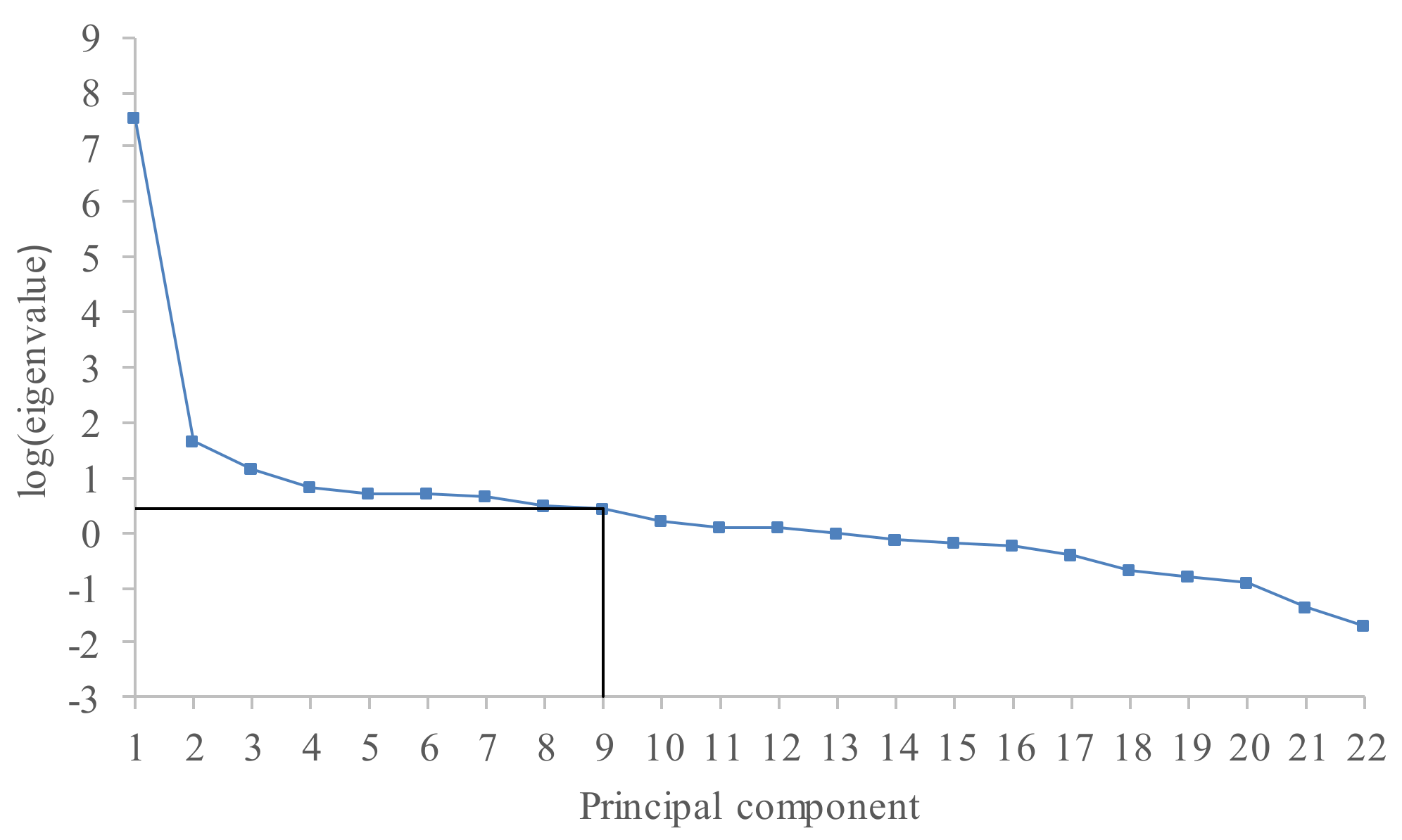
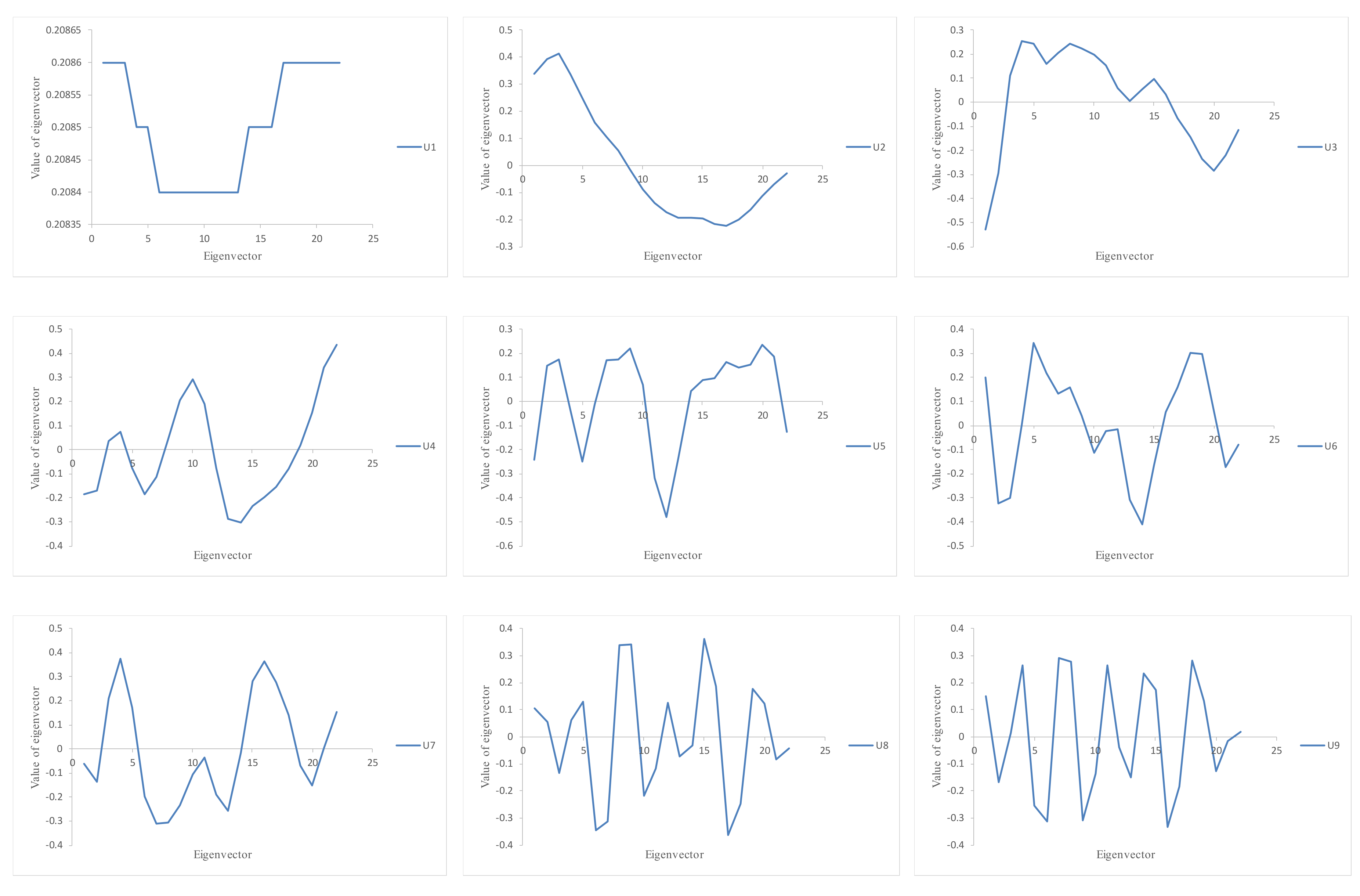
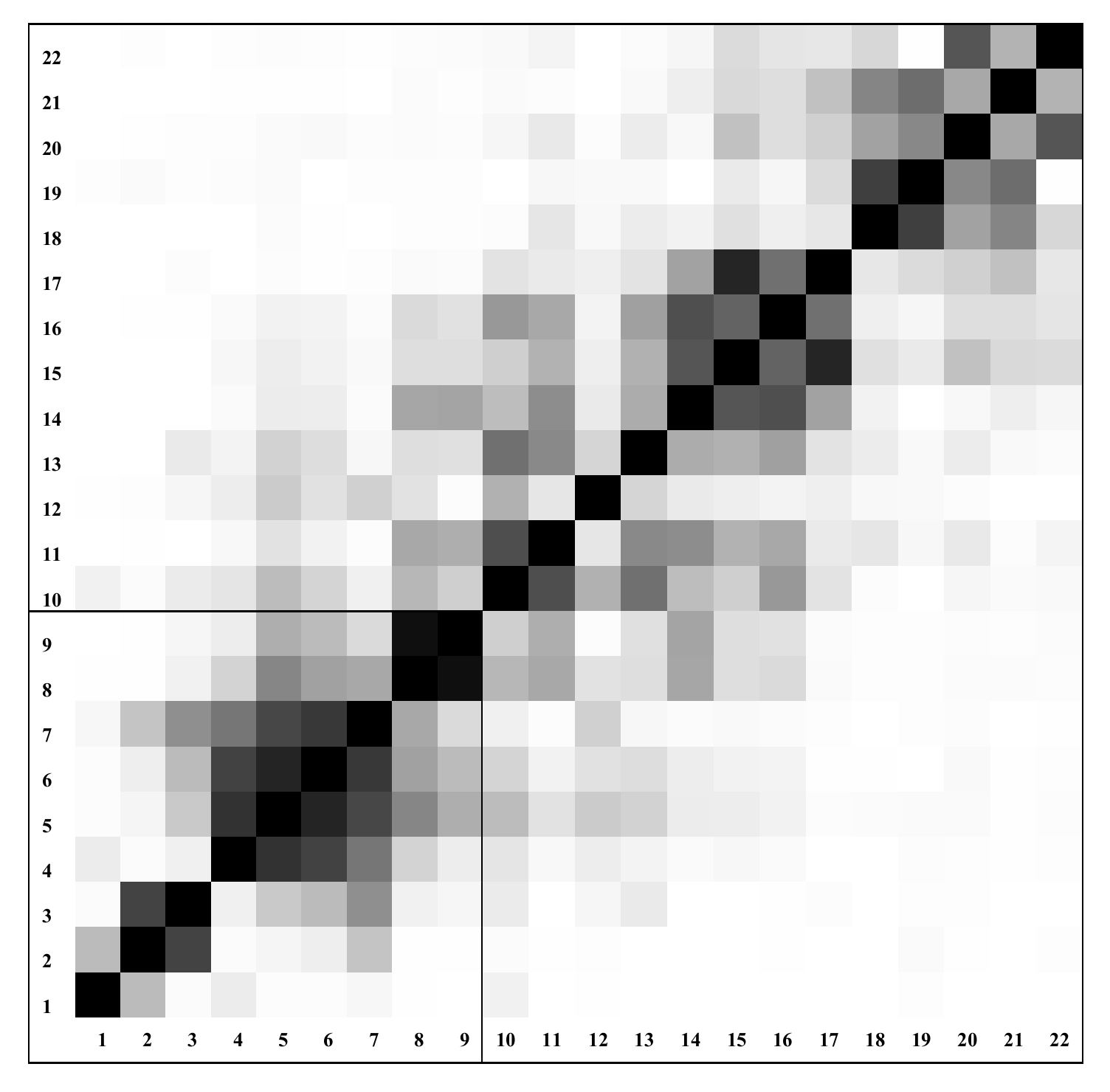
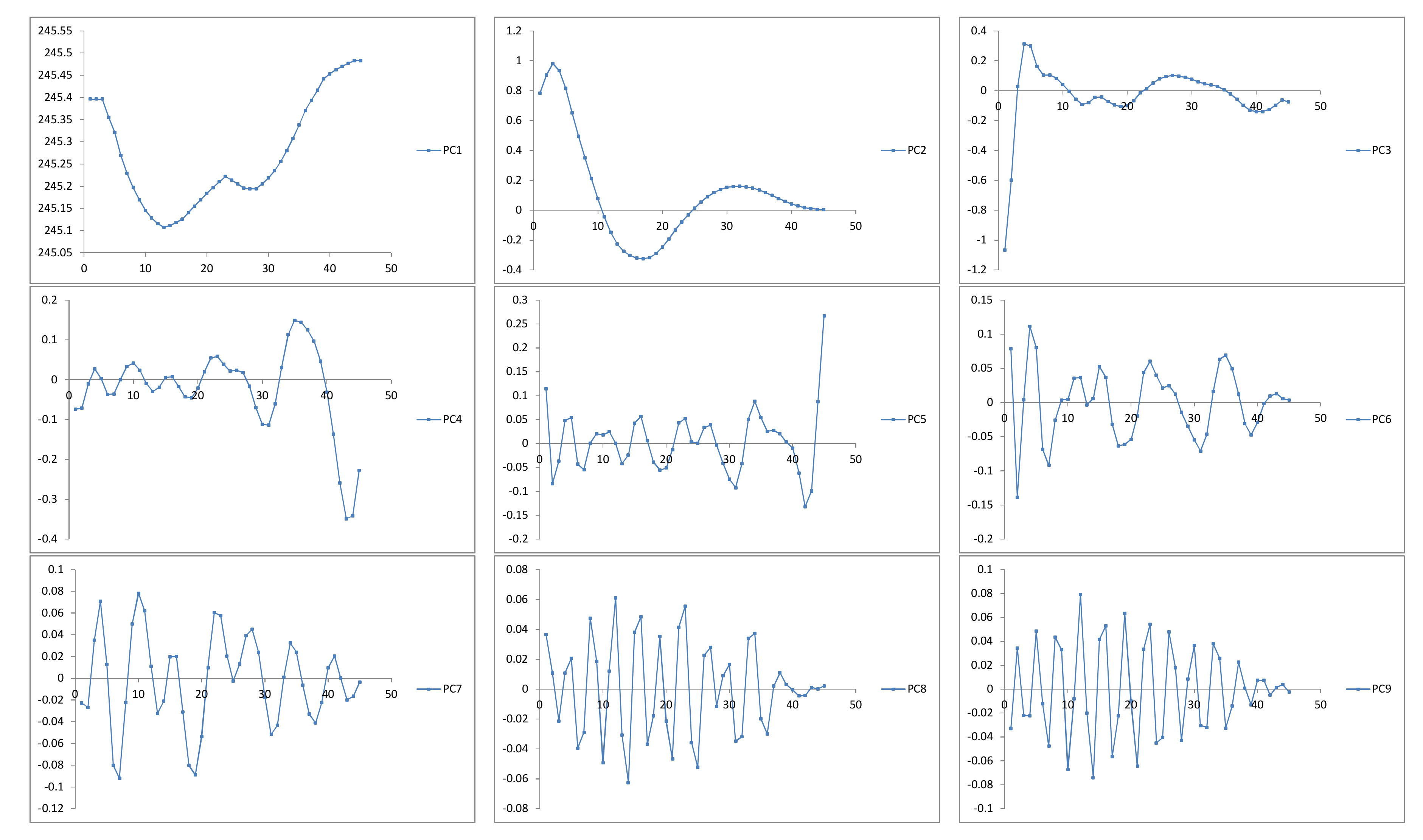
2.3. Forecasting Model Based on the Singular Spectrum Analysis
- —absolute value of the weighted Frobenius inner product,
- —the weighted norm
- —vector of weights.
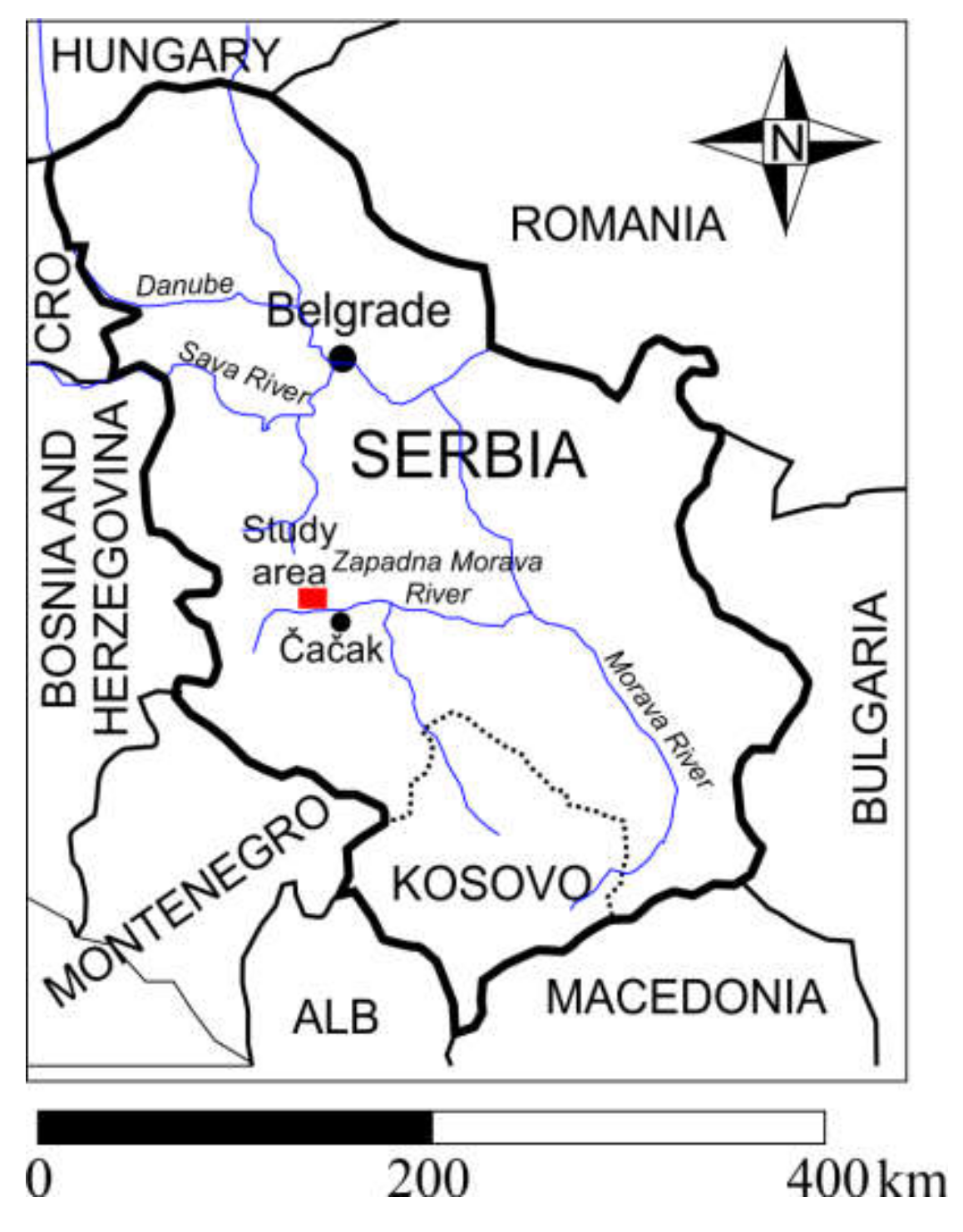
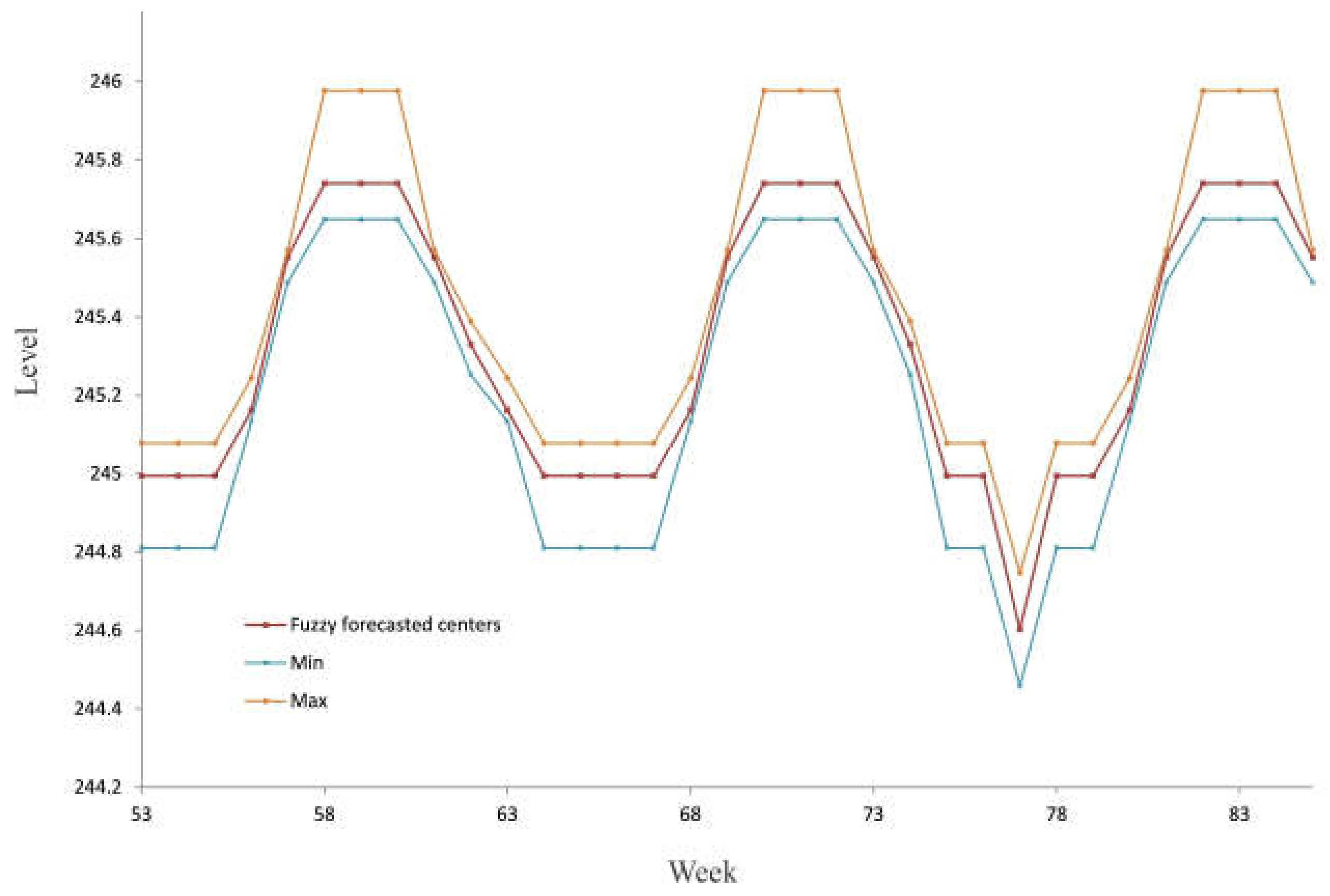
3. Numerical Example
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bear, J. Hydraulics of Groundwater; McGraw-Hill: New York, NY, USA, 1979. [Google Scholar]
- He, B.; Takase, K.; Wang, Y. Regional groundwater prediction model using automatic parameter calibration SCE method for a coastal plain of Seto Inland Sea. Water Resour. Manag. 2007, 21, 947–959. [Google Scholar] [CrossRef]
- Chang, F.; Chang, L.; Huang, C.; Kao, I. Prediction of monthly regional groundwater levels through hybrid soft-computing techniques. J. Hydrol. 2016, 541, 965–976. [Google Scholar] [CrossRef]
- Raghavendra, S.; Deka, P.C. Forecasting monthly groundwater level fluctuations in coastal aquifers using hybrid Wavelet packet-Support vector regression. Cogent Eng. 2005. [Google Scholar] [CrossRef]
- Emamgholizadeh, S.; Moslemi, K.; Karami, G. Prediction the Groundwater Level of Bastam Plain (Iran) by Artificial Neural Network (ANN) and Adaptive Neuro-Fuzzy Inference System (ANFIS). Water Resour. Manag. 2014, 28, 5433–5446. [Google Scholar] [CrossRef]
- Sahoo, S.; Madan, K.J. Groundwater-level prediction using multiple linear regression and artificial neural network techniques: A comparative assessment. Hydrogeol. J. 2013, 21, 1865–1887. [Google Scholar] [CrossRef]
- Polomčić, D.; Bajić, D. Application of Groundwater modeling for designing a dewatering system: Case study of the Buvač Open Cast Mine, Bosnia and Herzegovina. Geol. Croat. 2015, 68, 123–137. [Google Scholar] [CrossRef]
- Barco, J.; Hogue, T.S.; Girotto, M.; Kendall, D.R.; Putti, M. Climate signal propagation in southern California aquifers. Water Resour. Res. 2010. [Google Scholar] [CrossRef]
- Cao, G.; Zheng, C. Signals of short-term climatic periodicities detected in the groundwater of North China Plain. Hydrol. Process. 2015, 30, 515–533. [Google Scholar] [CrossRef]
- Dickinson, J.E.; Hanson, R.T.; Ferré, T.P.A.; Leake, S.A. Inferring time-varying recharge from inverse analysis of long-term water levels. Water Resour. Res. 2004. [Google Scholar] [CrossRef]
- James, S.C.; Doherty, J.E.; Eddebbarh, A. Practical Postcalibration Uncertainty Analysis: Yucca Mountain, Nevada. Groundwater 2009, 47, 851–869. [Google Scholar] [CrossRef] [PubMed]
- Markovic, D.; Koch, M. Stream response to precipitation variability: A spectral view based on analysis and modelling of hydrological cycle components. Hydrol. Process. 2014, 29, 1806–1816. [Google Scholar] [CrossRef]
- Masbruch, M.D.; Rumsey, C.A.; Gangopadhyay, S.; Susong, D.D.; Pruitt, T. Analyses of infrequent (quasi-decadal) large groundwater recharge events in the northern Great Basin: Their importance for groundwater availability, use, and management. Water Resour. Res. 2016, 52, 7819–7836. [Google Scholar] [CrossRef]
- Shun, T.; Duffy, C.J. Low-frequency oscillations in precipitation, temperature, and runoff on a west facing mountain front: A hydrogeologic interpretation. Water Resour. Res. 1999, 35, 191–201. [Google Scholar] [CrossRef]
- Tiwari, R.K.; Rajesh, R. Imprint of long-term solar signal in groundwater recharge fluctuation rates from Northwest China. Geophys. Res. Lett. 2014, 41, 3103–3109. [Google Scholar] [CrossRef]
- Yiou, P.; Baert, E.; Loutre, M.F. Spectral analysis of climate data. Surv. Geophys. 1996, 17, 619–663. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, B.; He, B.; Peng, Y.; Ren, M. Singular Spectrum Analysis and ARIMA Hybrid Model for Annual Runoff Forecasting. Water Resour. Manag. 2011, 25, 2683–2703. [Google Scholar] [CrossRef]
- Song, Q.; Chissom, B.S. Fuzzy time series and its models. Fuzzy Sets Syst. 1993, 54, 269–277. [Google Scholar] [CrossRef]
- Li, S.-T.; Cheng, Y.-C.; Lin, S.-Y. A FCM-based deterministic forecasting model for fuzzy time series. Comput. Math. Appl. 2008, 56, 3052–3063. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Enrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Lu, Y.H.; Ma, T.H.; Yin, C.H.; Xie, X.Y.; Tian, W.; Zhong, S.M. Implementation of the Fuzzy C-Means Clustering Algorithm in Meteorogical Data. Int. J. Database Theory Appl. 2013, 6, 1–18. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Wang, L. Improving fuzzy c-means clustering based on feature-weight learning. Pattern Recognit. Lett. 2004, 25, 1123–1132. [Google Scholar] [CrossRef]
- Chang, C.T.; Lai, J.Z.C.; Jeng, M.D. A fuzzy K-means clustering algorithm using cluster center displacement. J. Inf. Sci. Eng. 2011, 27, 995–1009. [Google Scholar]
- Pal, N.R.; Bezdek, J.C. On cluster validity for fuzzy c-means model. IEEE Trans. Fuzzy Syst. 1995, 1, 370–379. [Google Scholar] [CrossRef]
- Hassani, H.; Zhigljavsky, A. Singular Spectrum Analysis: Methodology and Application to Economics Data. J. Syst. Sci. Complex. 2009, 22, 372–394. [Google Scholar] [CrossRef]
- Harris, T.J.; Yuan, H. Filtering and frequency interpretations of Singular Spectrum Analysis. Physica D 2010, 239, 1958–1967. [Google Scholar] [CrossRef]
- Hassani, H.; Mahmoudvand, R. Multivariate Singular Spectrum Analysis: A general view and new vector forecasting approach. Int. J. Energy Stat. 2013, 1, 55–83. [Google Scholar] [CrossRef]
- Hassani, H. Singular Spectrum Analysis: Methodology and Comparison. J. Data Sci. 2007, 5, 239–257. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
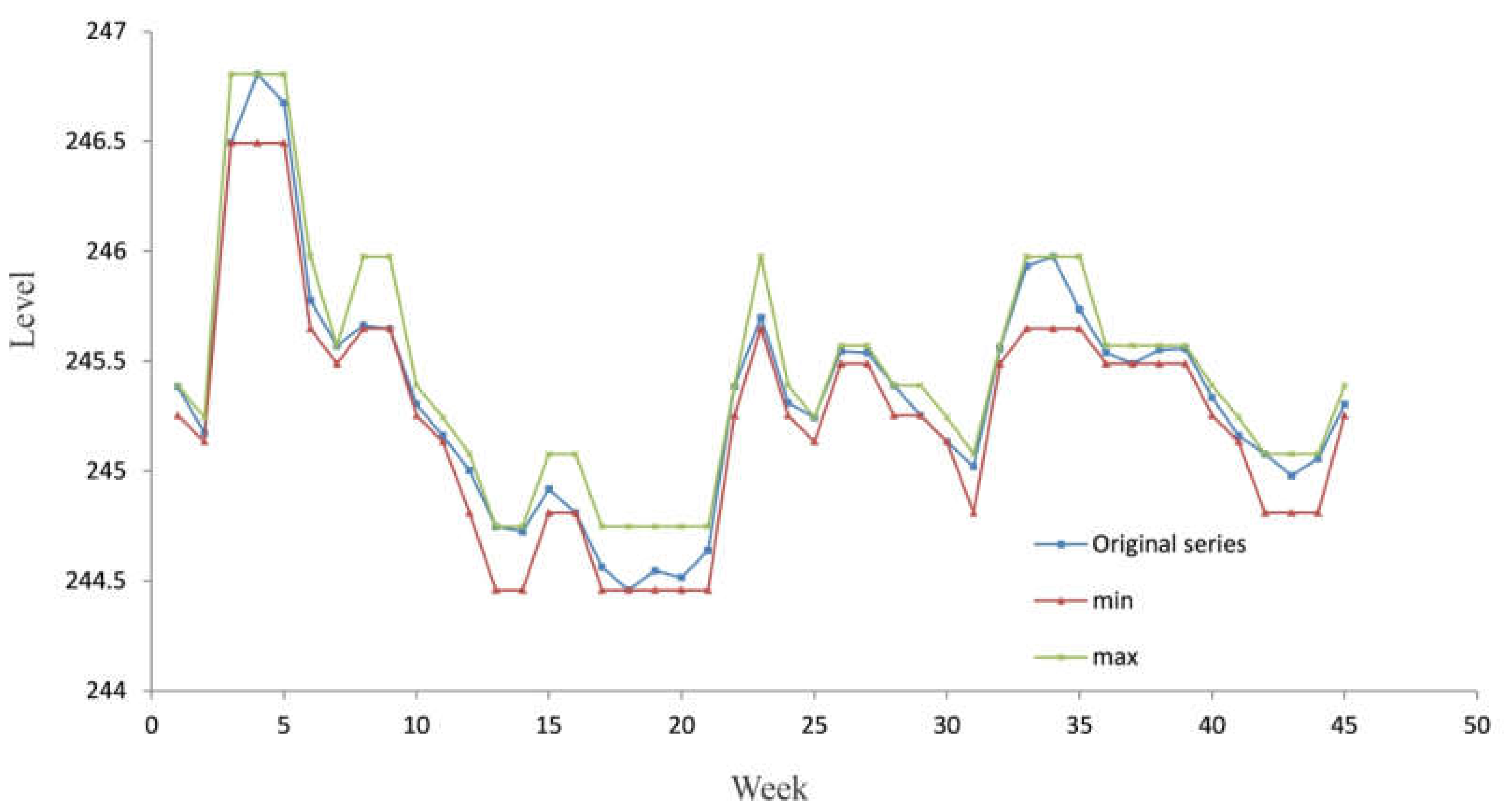
| Week | Level | Week | Level | Week | Level | Week | Level |
|---|---|---|---|---|---|---|---|
| 1 | 245.384 | 14 | 244.725 | 27 | 245.539 | 40 | 245.335 |
| 2 | 245.173 | 15 | 244.918 | 28 | 245.389 | 41 | 245.161 |
| 3 | 246.492 | 16 | 244.810 | 29 | 245.253 | 42 | 245.078 |
| 4 | 246.806 | 17 | 244.564 | 30 | 245.134 | 43 | 244.980 |
| 5 | 246.676 | 18 | 244.458 | 31 | 245.021 | 44 | 245.057 |
| 6 | 245.776 | 19 | 244.547 | 32 | 245.559 | 45 | 245.303 |
| 7 | 245.571 | 20 | 244.515 | 33 | 245.932 | 46 | 245.584 |
| 8 | 245.663 | 21 | 244.639 | 34 | 245.977 | 47 | 245.694 |
| 9 | 245.648 | 22 | 245.386 | 35 | 245.735 | 48 | 245.785 |
| 10 | 245.304 | 23 | 245.698 | 36 | 245.539 | 49 | 245.794 |
| 11 | 245.162 | 24 | 245.311 | 37 | 245.489 | 50 | 245.551 |
| 12 | 245.002 | 25 | 245.244 | 38 | 245.552 | 51 | 245.400 |
| 13 | 244.747 | 26 | 245.547 | 39 | 245.556 | 52 | 245.159 |
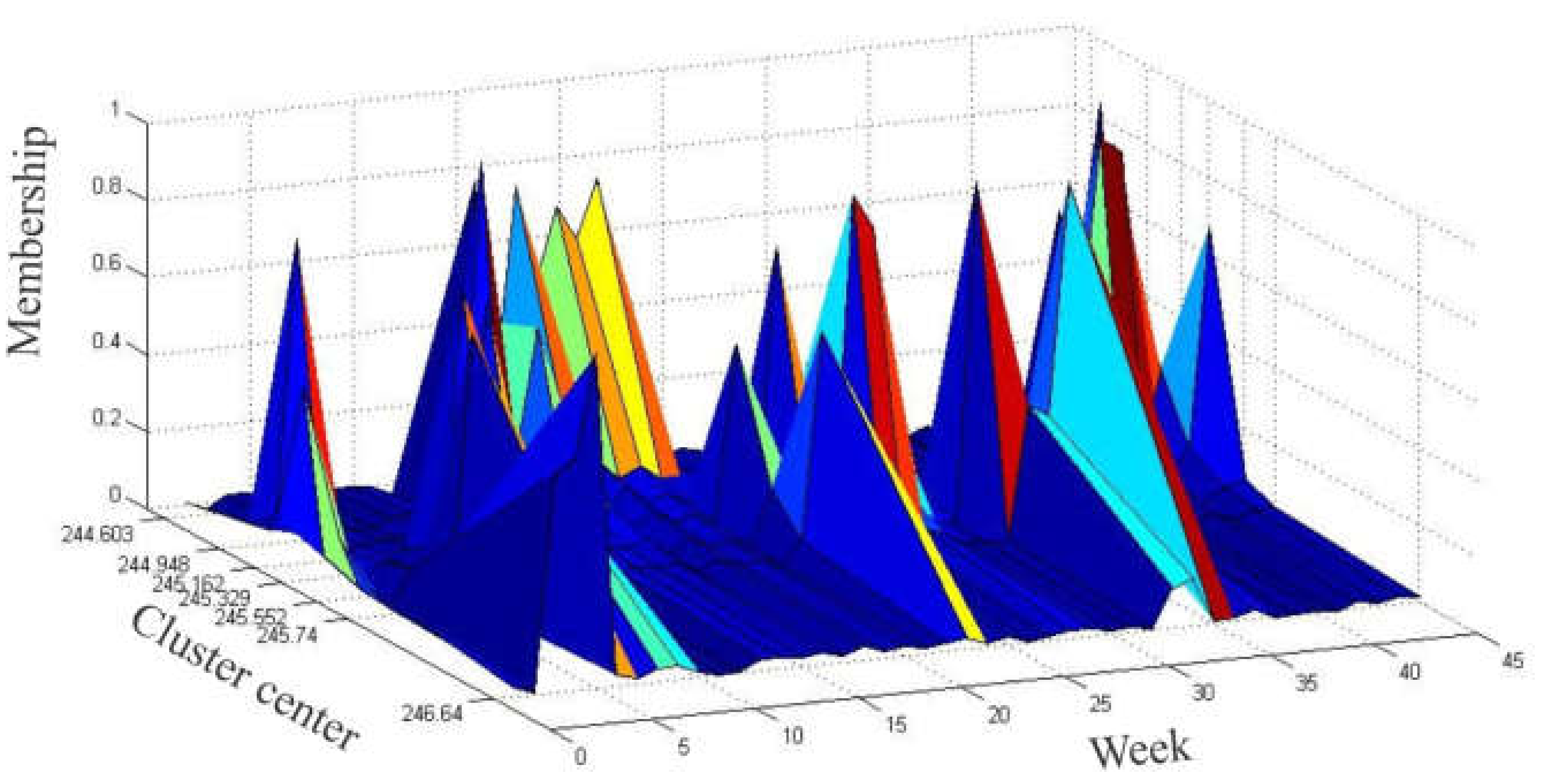
| Week | Membership Values | Cluster Center | Interval | Fuzzy State | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| No. | c1 | c2 | c3 | c4 | c5 | c6 | c7 | m | [min;max] | Am |
| 1 | 0.0353 | 0.0708 | 0.1244 | 0.5061 | 0.1638 | 0.0776 | 0.0220 | 245.329 | [245.253;245.389] | A4 |
| 2 | 0.0150 | 0.0480 | 0.8394 | 0.0543 | 0.0225 | 0.0150 | 0.0058 | 245.162 | [245.133;245.244] | A3 |
| 3 | 0.0443 | 0.0559 | 0.0630 | 0.0720 | 0.0891 | 0.1113 | 0.5643 | 246.641 | [246.492;246.806] | A7 |
| 4 | 0.0450 | 0.0548 | 0.0603 | 0.0672 | 0.0791 | 0.0930 | 0.6005 | 246.641 | [246.492;246.806] | A7 |
| 5 | 0.0146 | 0.0179 | 0.0199 | 0.0224 | 0.0269 | 0.0322 | 0.8661 | 246.641 | [246.492;246.806] | A7 |
| 6 | 0.0216 | 0.0324 | 0.0413 | 0.0568 | 0.1135 | 0.7052 | 0.0293 | 245.740 | [245.648;245.976] | A6 |
| 7 | 0.0144 | 0.0242 | 0.0341 | 0.0577 | 0.7744 | 0.0822 | 0.0130 | 245.552 | [245.488;245.570] | A5 |
| 8 | 0.0309 | 0.0490 | 0.0654 | 0.0981 | 0.2959 | 0.4272 | 0.0335 | 245.740 | [245.648;245.976] | A6 |
| 9 | 0.0318 | 0.0509 | 0.0685 | 0.1044 | 0.3480 | 0.3628 | 0.0335 | 245.740 | [245.648;245.976] | A6 |
| 10 | 0.0250 | 0.0567 | 0.1240 | 0.6708 | 0.0703 | 0.0401 | 0.0131 | 245.329 | [245.253;245.389] | A4 |
| 11 | 0.0010 | 0.0034 | 0.9893 | 0.0034 | 0.0015 | 0.0010 | 0.0004 | 245.162 | [245.133;245.244] | A3 |
| 12 | 0.0169 | 0.8950 | 0.0420 | 0.0206 | 0.0122 | 0.0091 | 0.0041 | 244.994 | [244.810;245.078] | A2 |
| 13 | 0.3888 | 0.2257 | 0.1345 | 0.0959 | 0.0693 | 0.0563 | 0.0295 | 244.603 | [244.458;244.747] | A1 |
| 14 | 0.4420 | 0.1997 | 0.1231 | 0.0890 | 0.0650 | 0.0530 | 0.0281 | 244.603 | [244.458;244.747] | A1 |
| 15 | 0.1219 | 0.4989 | 0.1568 | 0.0931 | 0.0604 | 0.0466 | 0.0223 | 244.994 | [244.810;245.078] | A2 |
| 16 | 0.2692 | 0.3011 | 0.1578 | 0.1070 | 0.0749 | 0.0598 | 0.0304 | 244.994 | [244.810;245.078] | A2 |
| 17 | 0.7671 | 0.0707 | 0.0509 | 0.0398 | 0.0308 | 0.0259 | 0.0147 | 244.603 | [244.458;244.747] | A1 |
| 18 | 0.5110 | 0.1384 | 0.1055 | 0.0852 | 0.0679 | 0.0579 | 0.0340 | 244.603 | [244.458;244.747] | A1 |
| 19 | 0.7030 | 0.0891 | 0.0648 | 0.0510 | 0.0397 | 0.0334 | 0.0191 | 244.603 | [244.458;244.747] | A1 |
| 20 | 0.6147 | 0.1130 | 0.0837 | 0.0665 | 0.0522 | 0.0442 | 0.0255 | 244.603 | [244.458;244.747] | A1 |
| 21 | 0.7641 | 0.0765 | 0.0520 | 0.0394 | 0.0298 | 0.0247 | 0.0136 | 244.603 | [244.458;244.747] | A1 |
| 22 | 0.0359 | 0.0717 | 0.1254 | 0.4969 | 0.1685 | 0.0793 | 0.0224 | 245.329 | [245.253;245.389] | A4 |
| 23 | 0.0235 | 0.0365 | 0.0479 | 0.0697 | 0.1763 | 0.6189 | 0.0273 | 245.740 | [245.648;245.976] | A6 |
| 24 | 0.0200 | 0.0448 | 0.0955 | 0.7378 | 0.0584 | 0.0329 | 0.0106 | 245.329 | [245.253;245.389] | A4 |
| 25 | 0.0440 | 0.1130 | 0.3447 | 0.3298 | 0.0914 | 0.0569 | 0.0202 | 245.162 | [245.133;245.244] | A3 |
| 26 | 0.0059 | 0.0101 | 0.0145 | 0.0257 | 0.9100 | 0.0288 | 0.0051 | 245.552 | [245.488;245.570] | A5 |
| 27 | 0.0118 | 0.0203 | 0.0293 | 0.0527 | 0.8210 | 0.0550 | 0.0100 | 245.552 | [245.488;245.570] | A5 |
| 28 | 0.0366 | 0.0729 | 0.1268 | 0.4829 | 0.1759 | 0.0820 | 0.0230 | 245.329 | [245.253;245.389] | A4 |
| 29 | 0.0432 | 0.1087 | 0.3098 | 0.3665 | 0.0937 | 0.0577 | 0.0202 | 245.329 | [245.253;245.389] | A4 |
| 30 | 0.0351 | 0.1337 | 0.6489 | 0.0949 | 0.0444 | 0.0307 | 0.0123 | 245.162 | [245.133;245.244] | A3 |
| 31 | 0.0441 | 0.6939 | 0.1305 | 0.0597 | 0.0347 | 0.0256 | 0.0114 | 244.994 | [244.810;245.078] | A2 |
| 32 | 0.0056 | 0.0095 | 0.0136 | 0.0235 | 0.9131 | 0.0297 | 0.0050 | 245.552 | [245.488;245.570] | A5 |
| 33 | 0.0537 | 0.0760 | 0.0926 | 0.1183 | 0.1879 | 0.3709 | 0.1006 | 245.740 | [245.648;245.976] | A6 |
| 34 | 0.0577 | 0.0808 | 0.0974 | 0.1226 | 0.1871 | 0.3351 | 0.1194 | 245.740 | [245.648;245.976] | A6 |
| 35 | 0.0044 | 0.0068 | 0.0088 | 0.0124 | 0.0276 | 0.9345 | 0.0055 | 245.740 | [245.648;245.976] | A6 |
| 36 | 0.0121 | 0.0208 | 0.0301 | 0.0541 | 0.8164 | 0.0563 | 0.0103 | 245.552 | [245.488;245.570] | A5 |
| 37 | 0.0342 | 0.0613 | 0.0928 | 0.1903 | 0.4745 | 0.1206 | 0.0263 | 245.552 | [245.488;245.570] | A5 |
| 38 | 0.0004 | 0.0007 | 0.0010 | 0.0017 | 0.9939 | 0.0020 | 0.0003 | 245.552 | [245.488;245.570] | A5 |
| 39 | 0.0032 | 0.0055 | 0.0078 | 0.0135 | 0.9506 | 0.0166 | 0.0028 | 245.552 | [245.488;245.570] | A5 |
| 40 | 0.0063 | 0.0136 | 0.0268 | 0.9171 | 0.0212 | 0.0114 | 0.0035 | 245.329 | [245.253;245.389] | A4 |
| 41 | 0.0021 | 0.0071 | 0.9780 | 0.0070 | 0.0030 | 0.0020 | 0.0008 | 245.162 | [245.133;245.244] | A3 |
| 42 | 0.0616 | 0.3513 | 0.3464 | 0.1162 | 0.0616 | 0.0442 | 0.0187 | 244.994 | [244.810;245.078] | A2 |
| 43 | 0.0325 | 0.8208 | 0.0670 | 0.0349 | 0.0213 | 0.0161 | 0.0074 | 244.994 | [244.810;245.078] | A2 |
| 44 | 0.0621 | 0.4504 | 0.2681 | 0.1035 | 0.0569 | 0.0413 | 0.0178 | 244.994 | [244.810;245.078] | A2 |
| 45 | 0.0251 | 0.0569 | 0.1246 | 0.6696 | 0.0705 | 0.0402 | 0.0131 | 245.329 | [245.253;245.389] | A4 |
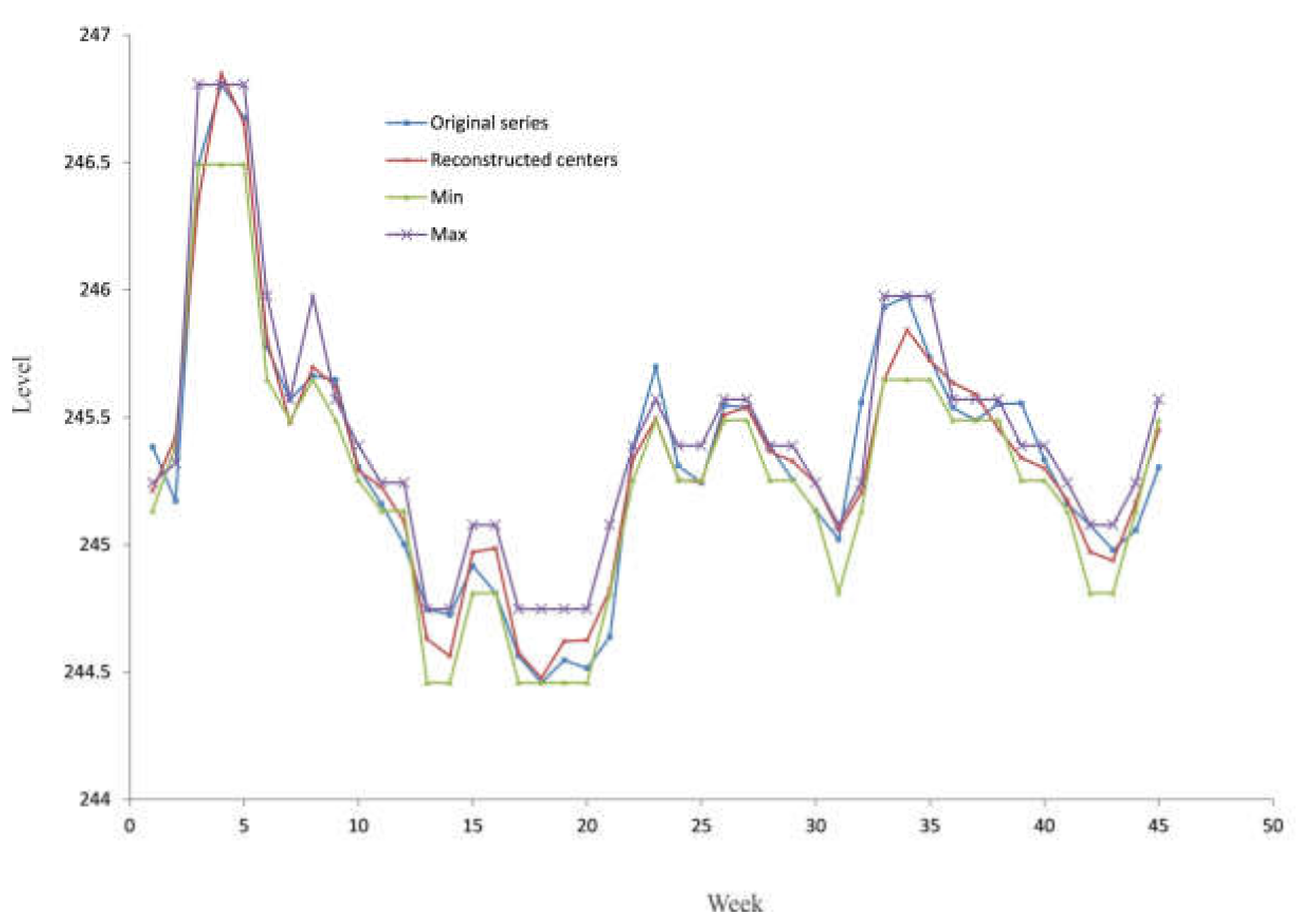
| Week | s(t) | Am | cm | |||
|---|---|---|---|---|---|---|
| 1 | 245.384 | A4 | 245.329 | 245.212 | 245.162 | A3 |
| 2 | 245.173 | A3 | 245.162 | 245.425 | 245.329 | A4 |
| 3 | 246.492 | A7 | 246.641 | 246.355 | 246.641 | A7 |
| 4 | 246.806 | A7 | 246.641 | 246.848 | 246.641 | A7 |
| 5 | 246.676 | A7 | 246.641 | 246.656 | 246.641 | A7 |
| 6 | 245.776 | A6 | 245.740 | 245.805 | 245.740 | A6 |
| 7 | 245.571 | A5 | 245.552 | 245.478 | 245.552 | A5 |
| 8 | 245.663 | A6 | 245.740 | 245.697 | 245.740 | A6 |
| 9 | 245.648 | A6 | 245.740 | 245.624 | 245.552 | A5 |
| 10 | 245.304 | A4 | 245.329 | 245.291 | 245.329 | A4 |
| 11 | 245.162 | A3 | 245.162 | 245.229 | 245.162 | A3 |
| 12 | 245.002 | A2 | 244.994 | 245.090 | 245.162 | A3 |
| 13 | 244.747 | A1 | 244.603 | 244.631 | 244.603 | A1 |
| 14 | 244.725 | A1 | 244.603 | 244.563 | 244.603 | A1 |
| 15 | 244.918 | A2 | 244.994 | 244.971 | 244.994 | A2 |
| 16 | 244.810 | A2 | 244.994 | 244.987 | 244.994 | A2 |
| 17 | 244.564 | A1 | 244.603 | 244.576 | 244.603 | A1 |
| 18 | 244.458 | A1 | 244.603 | 244.478 | 244.603 | A1 |
| 19 | 244.547 | A1 | 244.603 | 244.621 | 244.603 | A1 |
| 20 | 244.515 | A1 | 244.603 | 244.626 | 244.603 | A1 |
| 21 | 244.639 | A1 | 244.603 | 244.825 | 244.994 | A2 |
| 22 | 245.386 | A4 | 245.329 | 245.339 | 245.329 | A4 |
| 23 | 245.698 | A6 | 245.740 | 245.496 | 245.552 | A5 |
| 24 | 245.311 | A4 | 245.329 | 245.255 | 245.329 | A4 |
| 25 | 245.244 | A3 | 245.162 | 245.246 | 245.329 | A4 |
| 26 | 245.547 | A5 | 245.552 | 245.510 | 245.552 | A5 |
| 27 | 245.539 | A5 | 245.552 | 245.540 | 245.552 | A5 |
| 28 | 245.389 | A4 | 245.329 | 245.367 | 245.329 | A4 |
| 29 | 245.253 | A4 | 245.329 | 245.329 | 245.329 | A4 |
| 30 | 245.134 | A3 | 245.162 | 245.242 | 245.162 | A3 |
| 31 | 245.021 | A2 | 244.994 | 245.059 | 244.994 | A2 |
| 32 | 245.559 | A5 | 245.552 | 245.206 | 245.162 | A3 |
| 33 | 245.932 | A6 | 245.740 | 245.647 | 245.740 | A6 |
| 34 | 245.977 | A6 | 245.740 | 245.843 | 245.740 | A6 |
| 35 | 245.735 | A6 | 245.740 | 245.724 | 245.740 | A6 |
| 36 | 245.539 | A5 | 245.552 | 245.636 | 245.552 | A5 |
| 37 | 245.489 | A5 | 245.552 | 245.592 | 245.552 | A5 |
| 38 | 245.552 | A5 | 245.552 | 245.453 | 245.552 | A5 |
| 39 | 245.556 | A5 | 245.552 | 245.341 | 245.329 | A4 |
| 40 | 245.335 | A4 | 245.329 | 245.301 | 245.329 | A4 |
| 41 | 245.161 | A3 | 245.162 | 245.174 | 245.162 | A3 |
| 42 | 245.078 | A2 | 244.994 | 244.972 | 244.994 | A2 |
| 43 | 244.980 | A2 | 244.994 | 244.938 | 244.994 | A2 |
| 44 | 245.057 | A2 | 244.994 | 245.165 | 245.162 | A3 |
| 45 | 245.303 | A4 | 245.329 | 245.452 | 245.552 | A5 |
| Error | MAPE (%) | R2 |
|---|---|---|
| 0.000382 | 0.943 | |
| 0.000404 | 0.931 |
| Week | s(t) | Am | cm | |||
|---|---|---|---|---|---|---|
| 46 | 245.584 | A5 | 245.552 | 245.646 | 245.552 | A5 |
| 47 | 245.694 | A6 | 245.740 | 245.736 | 245.740 | A6 |
| 48 | 245.785 | A6 | 245.740 | 245.697 | 245.740 | A6 |
| 49 | 245.794 | A6 | 245.740 | 245.519 | 245.552 | A5 |
| 50 | 245.551 | A5 | 245.552 | 245.345 | 245.329 | A4 |
| 51 | 245.400 | A4 | 245.329 | 245.280 | 245.329 | A4 |
| 52 | 245.159 | A3 | 245.162 | 245.208 | 245.162 | A3 |
| Error | MAPE (%) | R2 |
|---|---|---|
| 0.000490 | 0.522 | |
| 0.000384 | 0.649 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Polomčić, D.; Gligorić, Z.; Bajić, D.; Cvijović, Č. A Hybrid Model for Forecasting Groundwater Levels Based on Fuzzy C-Mean Clustering and Singular Spectrum Analysis. Water 2017, 9, 541. https://doi.org/10.3390/w9070541
Polomčić D, Gligorić Z, Bajić D, Cvijović Č. A Hybrid Model for Forecasting Groundwater Levels Based on Fuzzy C-Mean Clustering and Singular Spectrum Analysis. Water. 2017; 9(7):541. https://doi.org/10.3390/w9070541
Chicago/Turabian StylePolomčić, Dušan, Zoran Gligorić, Dragoljub Bajić, and Čedomir Cvijović. 2017. "A Hybrid Model for Forecasting Groundwater Levels Based on Fuzzy C-Mean Clustering and Singular Spectrum Analysis" Water 9, no. 7: 541. https://doi.org/10.3390/w9070541
APA StylePolomčić, D., Gligorić, Z., Bajić, D., & Cvijović, Č. (2017). A Hybrid Model for Forecasting Groundwater Levels Based on Fuzzy C-Mean Clustering and Singular Spectrum Analysis. Water, 9(7), 541. https://doi.org/10.3390/w9070541