1. Introduction
Scarcity of water is a major concern for the world. There is need to integrate the allocation and management of water supply, wastewater resources and stormwater in order to sustainably manage the scarce resource [
1]. A concept is introduced by utilizing stormwater through Storm Water Harvesting (SWH) and treat it as a resource, rather than a problem, to reduce the pressure on fresh water assets [
2]. This idea is promoted through public forums [
3] and SWH schemes are implemented on international [
4].
Although the SWH has the best potential to reduce the pressure on fresh water assets, the approach to determine the potential SWH sites is not yet fully developed [
5]. With the knowledge of geospatial technologies, efforts have been made to find the robust technique to shortlist and finalize the suitable sites for SWH. Thus, there is a need for a screening tool that can identify the potential suitable sites for SWH. Different researchers have identified and analyzed different approaches for shortlisting sites. The decision-making framework (DMF) that is appropriate for SWH scheme is primarily based on technical feasibility and financial costs with a focus on neighborhood-scale development [
6]. Recently, the focus of the researchers is to investigate the analogy of urban water supply and its associated energy consumption nexus [
7].
Geomatics techniques prove to be the best option to explore the suitability of sites as well as the availability of locations for SWH [
8]. Geographic Information System (GIS) facilitates the swift screening of potentially suitable SWH sites in the urban areas. It enables obtaining various parameters in spatial format, which decides the suitability for SWH sites. In India, the methodology to select potential sites for water harvesting were identified by adopting International Mission for Sustainability Development (IMSD) and Indian National Committee on Hydrology (INCOH) guidelines in GIS environment [
8,
9]. In [
9], various parameters, i.e., Geomorphology map, Land Use Land Cover (LULC), road, drainage and lineaments maps were prepared and the knowledge based weights were assigned to all the parameters to compute the ranking of the sites in the GIS environment.
Singh et al. [
10] defined some of the criterion for the site selection for various types of storage tanks, i.e., water harvesting structures, check dams, percolation tanks and farm ponds. The criterion suggested for water harvesting structures are that the slope should be less than 15 percent, land use class should be similar to agricultural area and type of soil should be silt loam with low infiltration capacity. In the approach [
10], the suitable sites were selected by integrating all the parameters in the GIS environment.
Satellite images, Digital Elevation Model (DEM) and soil map are essential to ascertain and assess the parameters suitable for SWH sites. With GIS techniques, spatial maps of LULC, soil, topography and runoff can be prepared and thus hydrological parameters can be computed and analyzed to cope for the increase in demand of water. The reservoir capacity can be computed by analyzing demand and runoff and subsequently deciding the structure that can be proposed for SWH. The focus should be to design the SWH structures considering the systematic and cost-effective design on a city wide scale. Furthermore, a GIS based screening methodology for identifying suitable SWH sites were developed [
11]. Various screening parameters such as Demand, ratio of Runoff to Demand and weighted Demand distance were evaluated for site selection.
Upon identifying the screening parameters, the parameters can be allocated weights based on existing practices such as Analytic hierarchy process [
12], Principal Component Analysis [
13,
14,
15,
16,
17], and entropy weight method [
18]. In the AHP method [
12], the weights are decided through pairwise comparisons. The method is based upon the opinion from the experts to define the relative scales. Then, the comparison is made between parameters on an absolute scale representing one parameter is more dominant with respect to the other. This method is adopted worldwide for group decision making in the fields such as business, shipbuilding, industry, government, healthcare and education, etc. It represents the decision that best suits the requirements of decision makers and does not a “correct” decision. Thus, it represents a comprehensive and rational framework that evaluates the solutions by representing and quantifying its elements that describes the overall goals.
In this concept, the planners structured their decision problem into a hierarchy that defines the problem in a simpler and systematic manner. The elements involved in the hierarchy can correlate any aspect of decision problem, good or bad, tangible or intangible, well or poorly understood, or anything that applies to the decision at hand. Once the hierarchy is built for the problem, the planners decide the importance of the elements by comparing the elements between each other with respect to their impacts.
However, there are limitations in adopting Saaty AHP methodology for allotting weights to the parameters [
19,
20,
21,
22,
23,
24,
25,
26,
27]. Some of the major drawbacks are (i) the computations made by the AHP are always guided by the decision maker’s experience and may involve the subjective judgments of individuals that constitute an important part in the decision process [
27]; (ii) the different methods of designing the hierarchies of the same problem may lead to contrasting results [
23,
24]; and (iii) the structure of the hierarchy follows the perception of the individual (or the group of individuals) and there is no possible alternative to this problem formulation [
25].
The Principal Component Analysis can be defined as a linear combination of optimally-weighted observed variables. This method removes the subjective decisions and totally depends on the data sets. In PCA, the most common used criterion for solving the number of components is to compute eigenvectors and eigenvalues [
13,
14,
15,
16,
17]. Weights are decided using eigenvalues.
The Entropy Weight method determines the weights associated with the information of values of all the screening parameters. The evaluation through the entropy method for determination of weight is claimed to be a very effective method for evaluating indicators [
18,
28,
29].
The use of different weight allocations methods is yet to be explored in ranking of storm water harvesting sites. It is also not known how these different weighing approaches can help the water planners. Hence, it is decided to explore the potential of these approaches for screening the potential sites for SWH in two case studies, in Melbourne, Australia [
11], and in Dehradun, India. The case study in India also includes a step-by-step illustration of ranking methodology. For comparative purposes as well as to assess the merits and demerits of using heuristic versus non-heuristic approaches, the screening parameters are adopted. This paper is organized in following subsections, i.e., methodology used, results, discussion and conclusions.
2. Methodology
The methodology for adopting weight allocation methods to rank SWH sites essentially involves three steps: (i) identification and evaluation of screening parameters; (ii) normalization to a common scale; and (iii) assigning weightage to the normalized parameters by using heuristic and non-heuristic approaches. Details of these three steps are discussed below.
2.1. Identification and Evaluation of Screening Parameters
The methodology used for shortlisting as well as finalizing suitable sites for SWH with the integration of remote sensing and GIS is described [
11]. The screening parameters discussed for shortlisting SWH sites are demand, ratio of runoff to demand and weighted demand distance. Variation of these screening parameters with radial distance from each identified hot spot needs to be established as a part of relative ranking of storm water harvesting sites. The process as such involves the following steps:
- (i)
Identification of hot spots,
- (ii)
Estimation of runoff,
- (iii)
Estimation of demand,
- (iv)
Weighted demand distance.
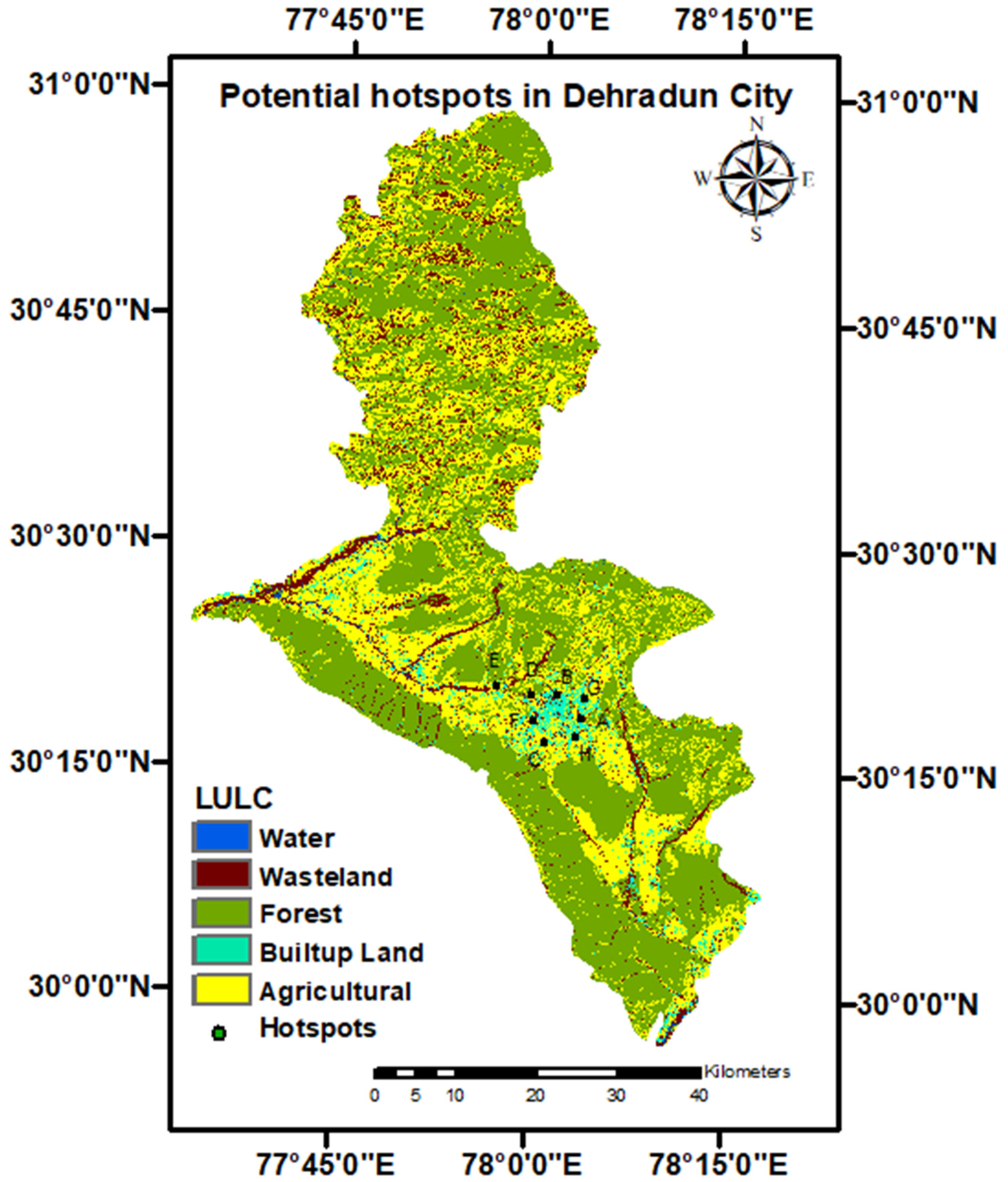
In step (i), with the use of DEM, the flow accumulation map is generated and the accumulated catchments are marked on the map. The points/locations of the intersections of the accumulated catchments can be the potential hotspots for the SWH structures where the flow can be trapped.
In step (ii), using precipitation, runoff can be computed using the Natural Resources Conservation Service- Curve Number (NRCS-CN) method [
30]. Runoff coefficients for different combinations of pervious-impervious layers and soil type for Indian conditions are described [
31]. The surface runoff can be computed by integrating the Land Use Land Cover map with the soil map of the area in the GIS environment [
32].
The physical distance from the site to the demand is very critical for considering the economic feasibility.
In step (iii), various demands are considered at different radii of influence, i.e., domestic, irrigation, industrial, commercial and for public uses. All demands are summed up to compute the total demand.
Ratio of runoff to demand assesses the match between the required runoff and the associated demand. It indicates the feasibility of whether the demand can be covered with the available runoff water.
In step (iv), weighted demand distance gives preference to sites close to high demand areas to minimize transport and water infrastructure costs. Thus, the parameter is computed for all the shortlisted potential hotspots.
All of the parameters are computed and analyzed at different radii of influence.
2.2. Normalization to a Common Scale
The inconsistency in the methodology is because of the variability in judging the parameters like high demand, high ratio of runoff to demand and low weighted demand distance, and also the range of the parameters varies differently. The methodology is proposed keeping in view all of these problems. Thus, to address this gap, all of the parameters are transformed to a common range and scale. This will help the water planners to make a quick decision in finalizing the suitable site for SWH.
Equations are proposed for all the parameters as follows:
(a) Demand:
where D
1 is lower value of range, D
2 is upper value of range, D
L is lowest demand of the area, D
U is highest demand of the area, and α and β are constants.
(b) Ratio of Runoff to Demand (RTD):
where RTD
1 is lower value of the range, RTD
2 is upper value of the range, RTD
L is lowest value of ratio of runoff to demand of the area, RTD
U is the highest value of ratio of runoff to demand of the area, and γ and δ are constants.
(c) Weighted Demand Distance:
where WD
1 is lower value of the range, WD
2 is upper value of the range, WD
L is lowest value of inverse weighted demand distance of the area, and WD
U is the highest value of inverse weighted demand distance of the area, ζ and η are constants.
Thus, by solving the above equations (1, 2, …, 6), α, β, γ, δ, ζ and η constants can be computed. After computing the constants, all the values of parameters of different sites are transformed to a new scale that ranges from D1 to D2 for demand, RTD1 to RTD2 for ratio of runoff to demand and WD1 to WD2 for inverse weighted demand distance by applying the following equations:
(b) Ratio of runoff to demand;
(c) Weighted demand distance;
where D
S is scaled demand, D
C is computed demand for each site, RTD
S is scaled ratio of runoff to demand, RTD
C is computed ratio of runoff to demand for each site, WD
S is scaled inverse weighted distance and WD
C is computed inverse weighted distance for each site.
Thus, by solving the above equations, each value of different parameters for all the shortlisted sites transforms into a common scale.
2.3. Determination of Weights
2.3.1. Saaty Heuristic Approach
The analytic hierarchy process (AHP) is a representation of complex problems by organizing and analyzing them in a more structured manner. It was developed by Thomas L. Saaty in the 1970s and has been applied worldwide for solving the complex problems [
12].
The following three-step procedure provides a good approximation of the synthesized priorities.
Step 1: Sum the values in each column of the pairwise comparison matrix.
Step 2: Divide each element in the pairwise matrix by its column total.
The resulting matrix is referred to as the normalized pairwise comparison matrix.
Step 3: Compute the average of the elements in each row of the normalized matrix.
These averages provide an estimate of the relative priorities of the elements being compared.
Computing the vector of criteria weights
(a) Creating a pairwise comparison matrix A.
Let A = m × m matrix; m = evaluation criteria; each entry ajk represents the importance of jth criteria with respect to kth criteria.
The relative importance between two elements or criteria is by allotting them weights on a scale from 1 to 9.
(b) Once the matrix A is built, the normalized pairwise comparison matrix A
norm is formed, by making the sum equal to 1 of the all of the entries in the column of the matrix A, i.e., each entry
of the matrix A
norm is computed as
(c) Finally, the criteria weight vector w (that is an m-dimensional column vector) is formed by averaging all the entries along the row of matrix A
norm, i.e.,
The AHP converts individual evaluations of relative importance of one parameter over another to numerical values, which can be analyzed over the entire range of the problem [
33]. A numerical weight or priority is derived using a matrix of such comparisons between various parameters.
2.3.2. Non-Heuristic Approaches
Principal Component Analysis (PCA) Method
PCA is defined as a linear combination of optimally-weighted observed variables. In PCA, the most common used criterion for solving the number of components is to compute eigenvectors and eigenvalues. To solve the eigenvalue problem, the following steps are followed.
Let A be a n × n matrix and consider the vector equation
where λ represents a scalar value.
Thus, if , it represents a solution for any value of λ. Eigenvalue or characteristics value of matrix A is that value of λ for which the equation has a solution with . The corresponding solutions are called eigenvectors or characteristic vectors of A.
(i) Compute the determinant of A − λI
With λ subtracted along the diagonal, this determinant starts with λn or −λn. It is a polynomial in λ of degree n.
(ii) Find the roots of this polynomial
By solving det (A − λI) = 0, the n roots are the n eigenvalues of A. It makes A − λI singular.
(iii) For each eigenvalue λ, solve (A − λI)x = 0 to find an eigenvector x.
Eigenvalues are used to decide weights in proportions to total of eigenvalues.
Entropy Weight Method
In this approach, the individual elements or criteria are assigned weights by determining entropy and entropy weight. Based on the principle of information theory, entropy is a measure of lack of information regarding a system. If the information entropy of the indicator is small, the amount of information provided by the indicator will be greater and the higher the weight will be, thereby playing a more important role in the comprehensive evaluation [
34]. The steps involved in the entropy weight method are (i) formation of the evaluation matrix; (ii) normalization of the evaluation matrix; and (iii) calculation of the entropy and the entropy weight
Let there be m parameters to be evaluated in a problem, n categories of evaluation criteria, and then the evaluation matrix is X = (xij)mxn, where xij represents the actual value of j-th criteria for the ith parameter. The calculation of entropy weight is as follows.
(i) Normalize the evaluation matrix, X to obtain R = (r
ij)
mxn where r
ij is the j
th evaluating object for i
th indicator and r
ij [0,1]. This will in turn generate a positive indicator for the variables:
(ii) Calculate entropy weight value ‘
H’. the j-th index value of information entropy is computed as
Here, .
Where, K is a positive constant, relevant to the number of sampling stations, s of the system. When the samples are completely in disordered state, K = 1/ln (s).
(iii) Calculate the j-th index weight as,
4. Discussion
The storm water harvesting sites in Melbourne and Dehradun were ranked according to the different possible combinations of parameters with equal weights and then by applying various methods for assigning weights to the parameters for both the sites. All the potential hotspot sites both for Melbourne city and Dehradun city are evaluated using the combination of all three parameters.
Table 4 and
Table 6 show the ranks of different sites in Melbourne city and Dehradun city. In this study, the main focus is to remove subjectivity from the approaches used for ranking water harvesting sites. A definitive approach based on principal components and entropy is introduced to assign the weights. Initially, the sites are shortlisted by using DEM for the study area and applying the concept of accumulated catchments. For the similar sites, different radii of influence are used in order to rank the sites. The use of different heuristics as well non-heuristic approaches is demonstrated using three screening parameters Demand, ratio of Runoff to Demand and weighted Demand distance. The top ranking sites are well captured in
Table 5 and
Table 6 using PCA and entropy based approaches, as evident from the sites selected in the paper [
11].
It is noted that the objective here is not to select the best site that has rank one in either of approaches. Instead, the utility of these approaches should be viewed in terms of screening of a few most feasible sites. With the allocation of weights, the ranking is done for the sites in Australia and India, and the suitable sites are thus matched with the sites suggested by Inamdar et al. [
11] for the Australian site. For the Australian site, the sequence of finalizing suitable sites by Inamdar et al. [
11] is based on ranking of sites using only one attribute at a time. To explain it further, the site having the highest rank for attribute Demand is “14b”; similarly, the site having the highest rank for attribute ratio of runoff to demand is “69b”, and likewise for attribute weighted distance, the site is “52a”. It is interesting to see that no aggregation of these attributes has been done by Inamdar et al. [
11].
The top ranked sites for the Australian site through a non-heuristic approach comes out to be “14b”, “69b”, “41c”, “44b”, and “44c”. It is interesting to observe that the sites finalized by our approach matches with the sites finalized by Inamdar et al. [
11] with the help of planners.
The present approach considers a unified view of all attributes and provides an integrated score. This integrated score forms the basis for selecting a few top sites. This practice of aggregating attributes is widely used in literature [
35,
36]. It is needless to emphasize that ranking based on “n” attributes will create a pool of “n” options, whereas the present approach will provide only one aggregated score. Thus, the alternatives evolved in the present approach will provide a smaller pool for alternatives to be picked up.
Thus, this methodology reduces a large pool of data sets and also provides the reliable shortlisted sites suitable for stormwater harvesting. Once a pool of the top, say 5 to 10 sites, is identified, more rigorous analysis using financial, social, environmental aspects can be adopted to choose most appropriate sites suitable for a specific location. The results obtained by non- heuristic approaches, i.e., entropy weight method and PCA are in the good agreement with the results obtained by concerning various water planners of Melbourne city and Dehradun city. As a non-heuristic approach does not involve subjectivity and capture the sites of Inamdar et al. [
11], certainly there is a merit in using non-heuristic approaches. Utility value of the study is that it provides a rational procedure to rank the sites and this procedure is consistent with a similar application in other disciplines. The work is significant as it removes the ad hoc approach of selecting the sites based on isolated attributes and subjectivity in ranking is also avoided using this approach.
Thus, this methodology reduces time and subjectivity in creating a set of few suitable storm water harvesting sites uses from which planners can take a quick and efficient decision in finalizing suitable sites for Storm Water Harvesting at a specific location.




{kind=link}