
Detection of Compound Faults in Ball Bearings Using Multiscale-SinGAN, Heat Transfer Search Optimization, and Extreme Learning Machine




Abstract
1. Introduction
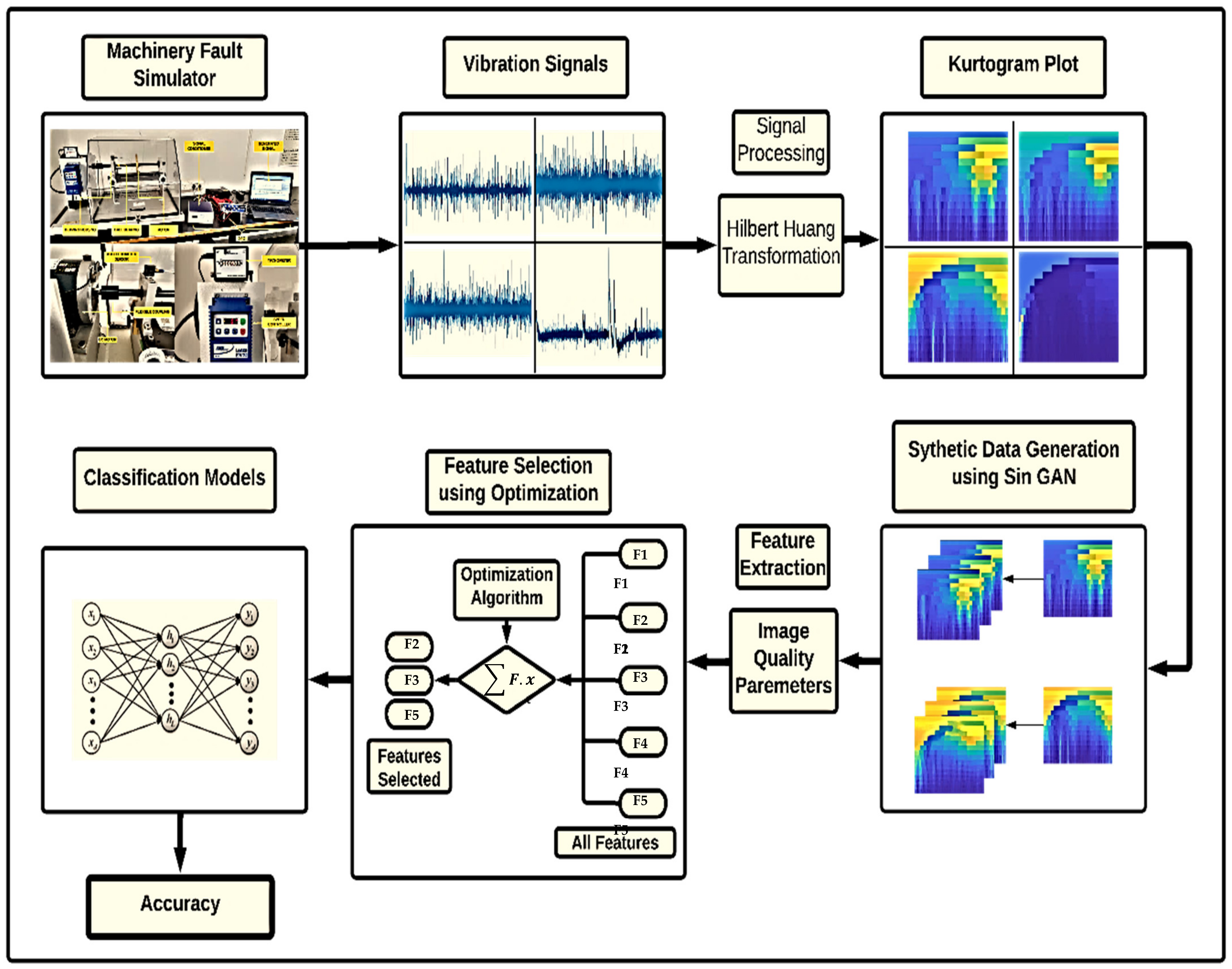
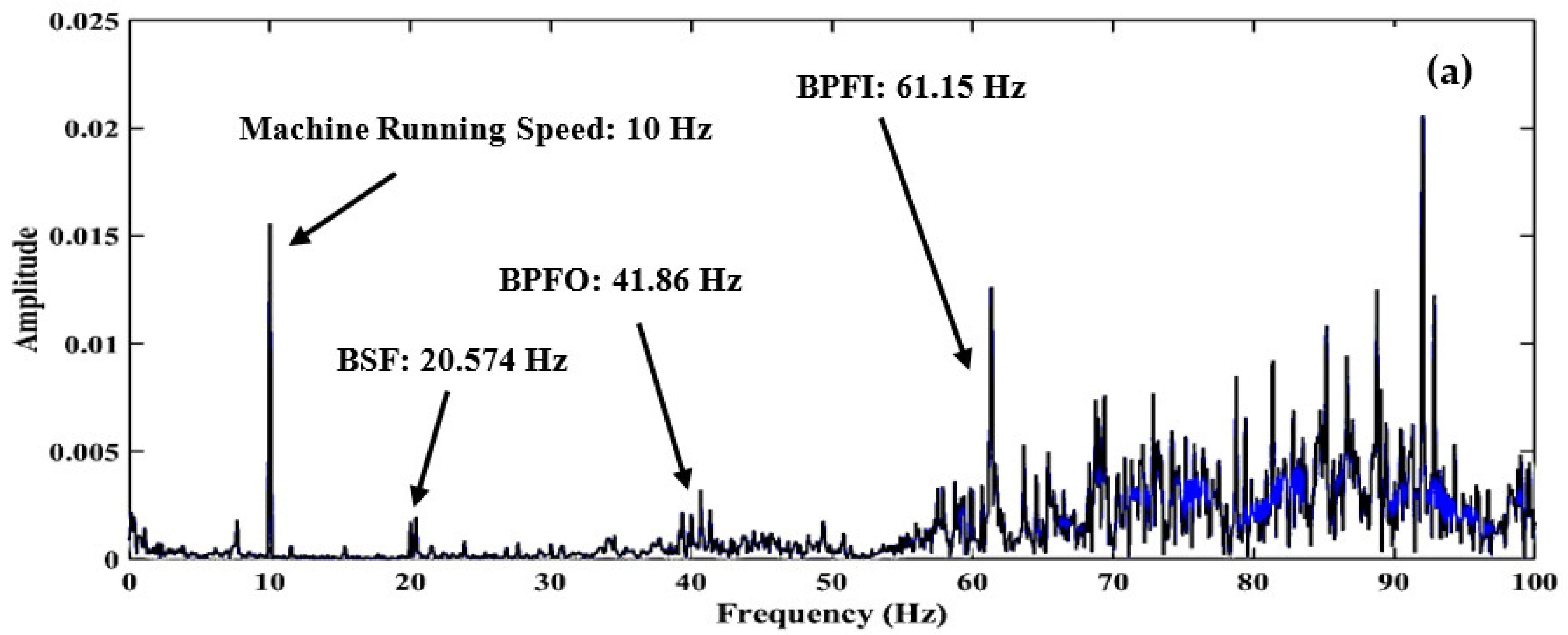
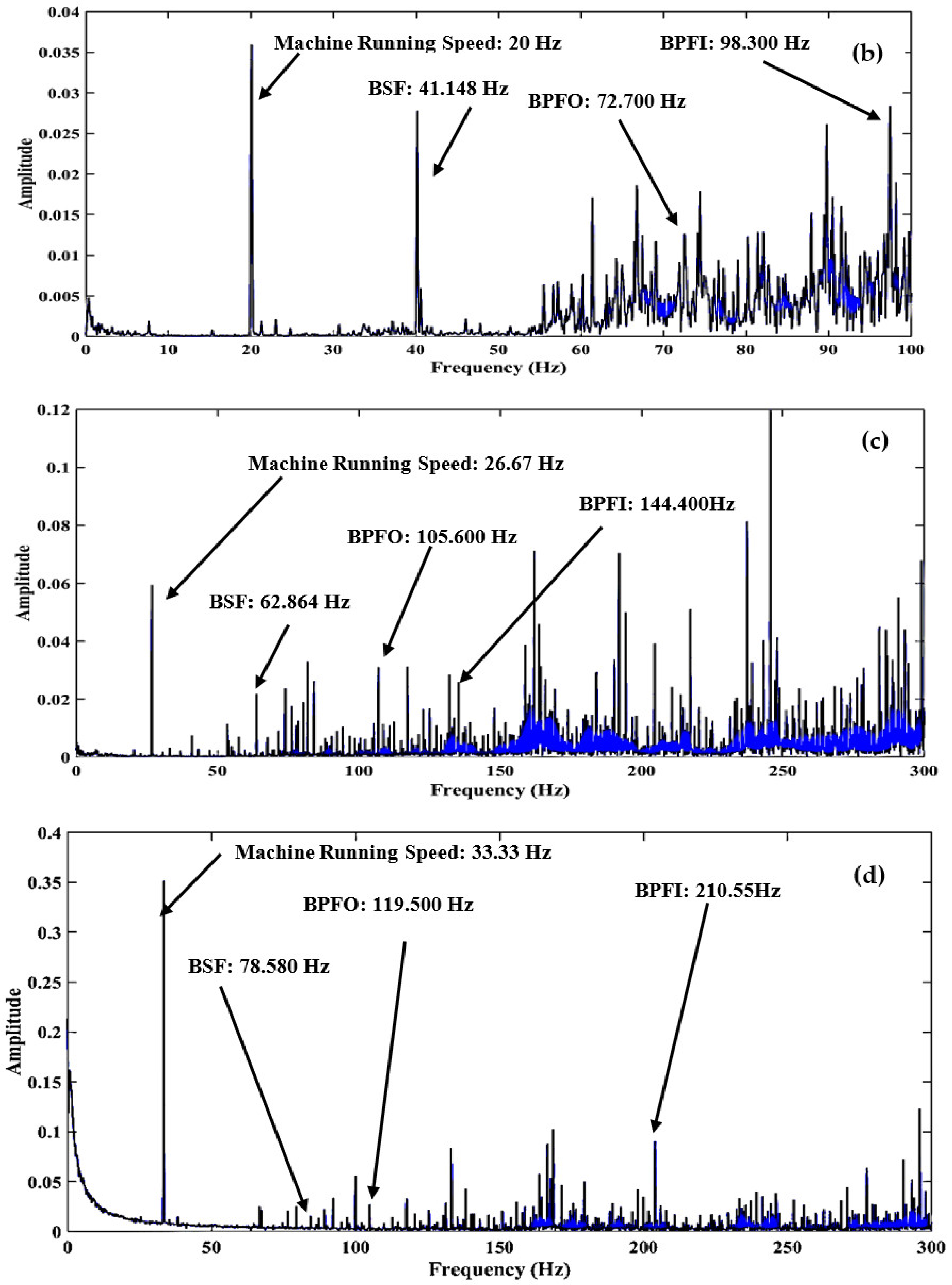
- Experiments were conducted to capture signals from compound faults, i.e., Inner Race Defect (IRD), Ball Defect (BD), and Outer Race Defect (ORD) in a single rolling element bearing with a variation in the rotational speed of the shaft.
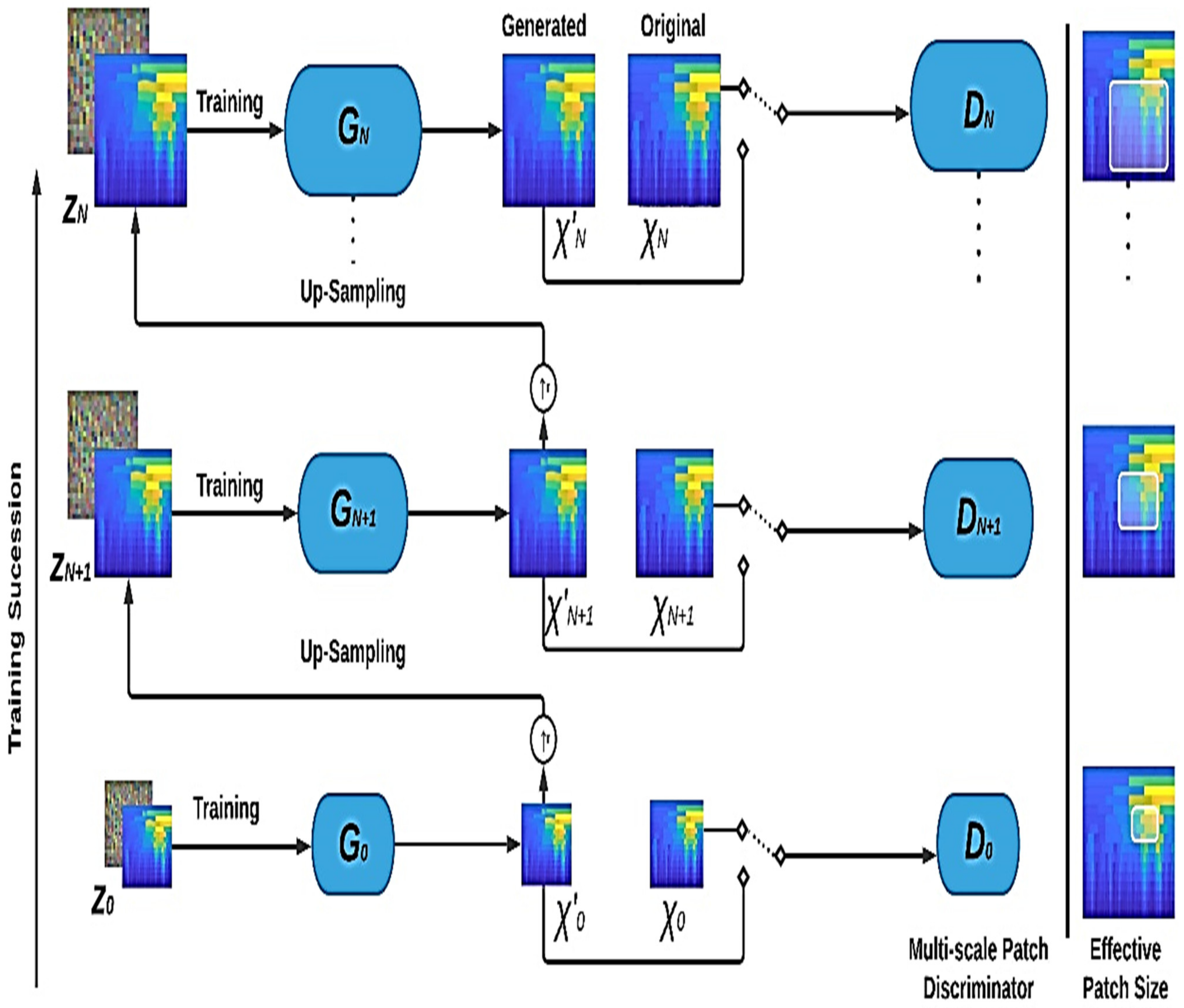
- To effectively develop machine-learning models, many images are required. Therefore, recently developed Multi-Scale Single Image Generative Adversarial Network (Multiscale-SinGAN) is utilized.
- TLBO and HTS metaheuristic algorithms were adapted and applied to select the optimal feature subset.
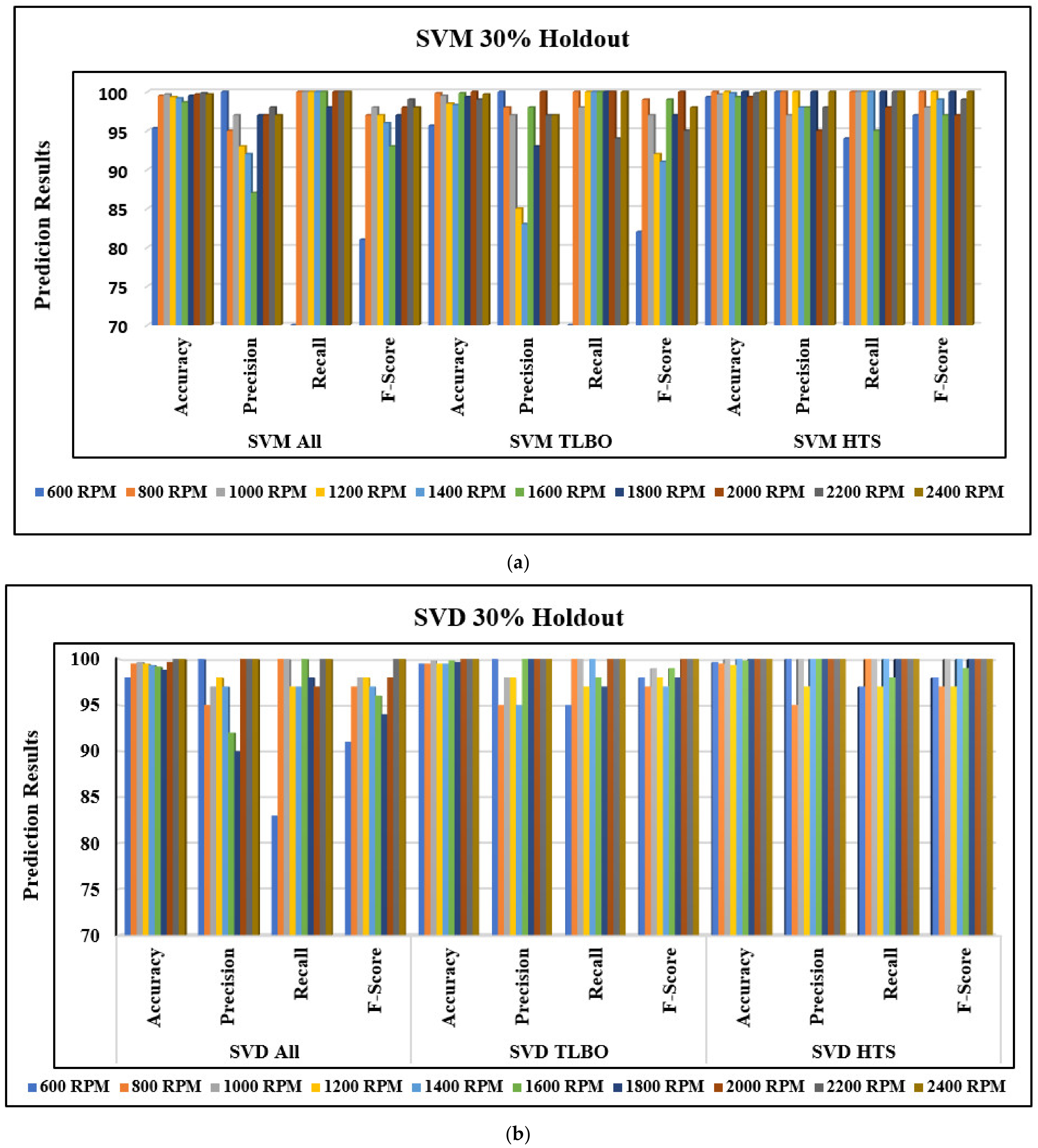
- The optimized features subset is evaluated with three classifiers, i.e., Support Vector Machine (SVM), Standardized Variable Distance (SVD), and Extreme Learning Machine (ELM), with 30% hold-out and ten-fold cross-validation accuracy to detect compound faults.
2. Materials and Methods
2.1. Hilbert–Huang Transform
2.2. Multiscale-SinGAN
2.3. Metaheuristic Optimization Algorithms
2.3.1. Teaching–Learning-Based Optimization (TLBO) Algorithm
2.3.2. Heat Transfer Search (HTS) Algorithm
2.4. Machine-Learning Algorithms
2.4.1. Support Vector Machine
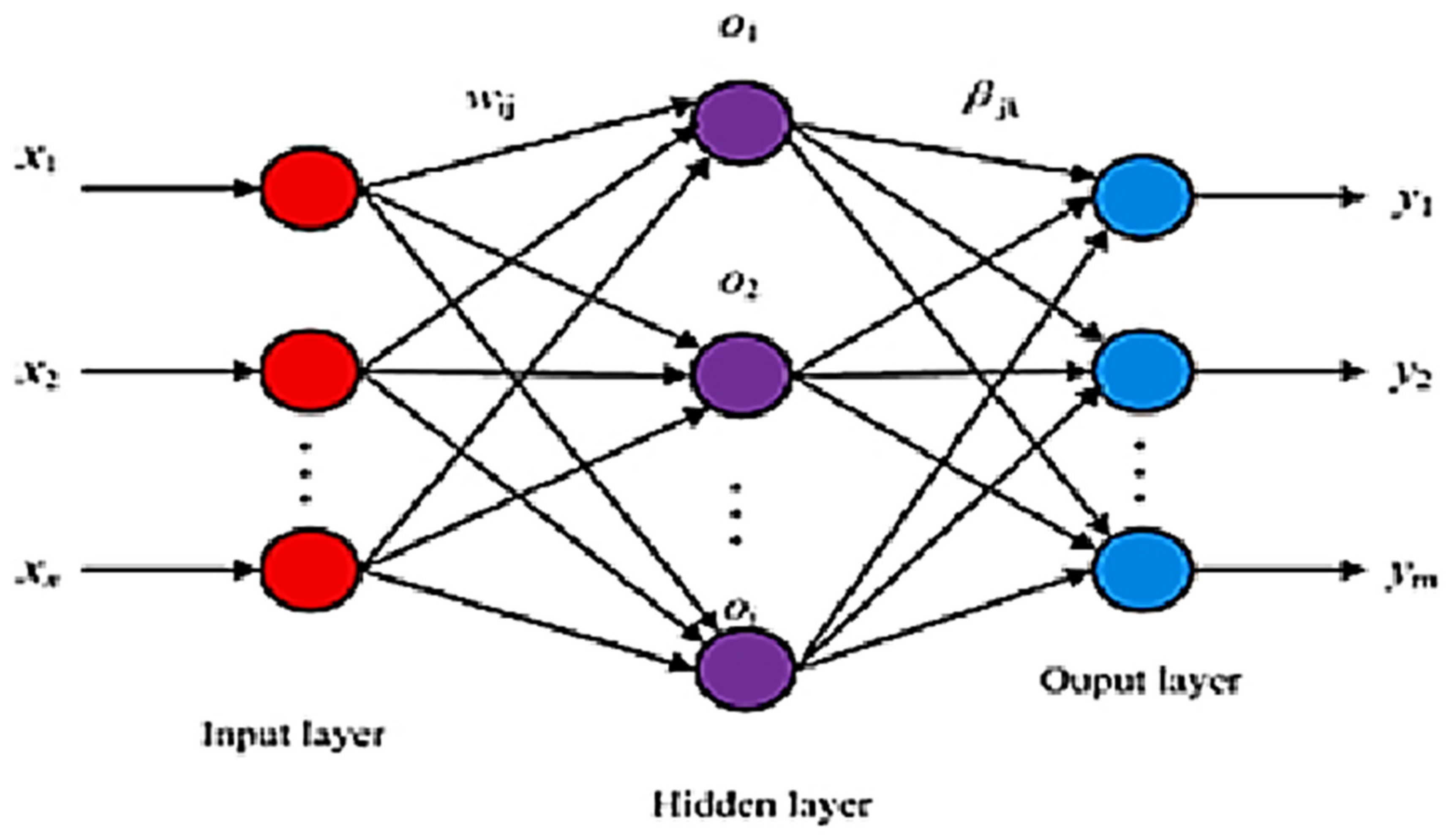
2.4.2. Extreme Learning Machine
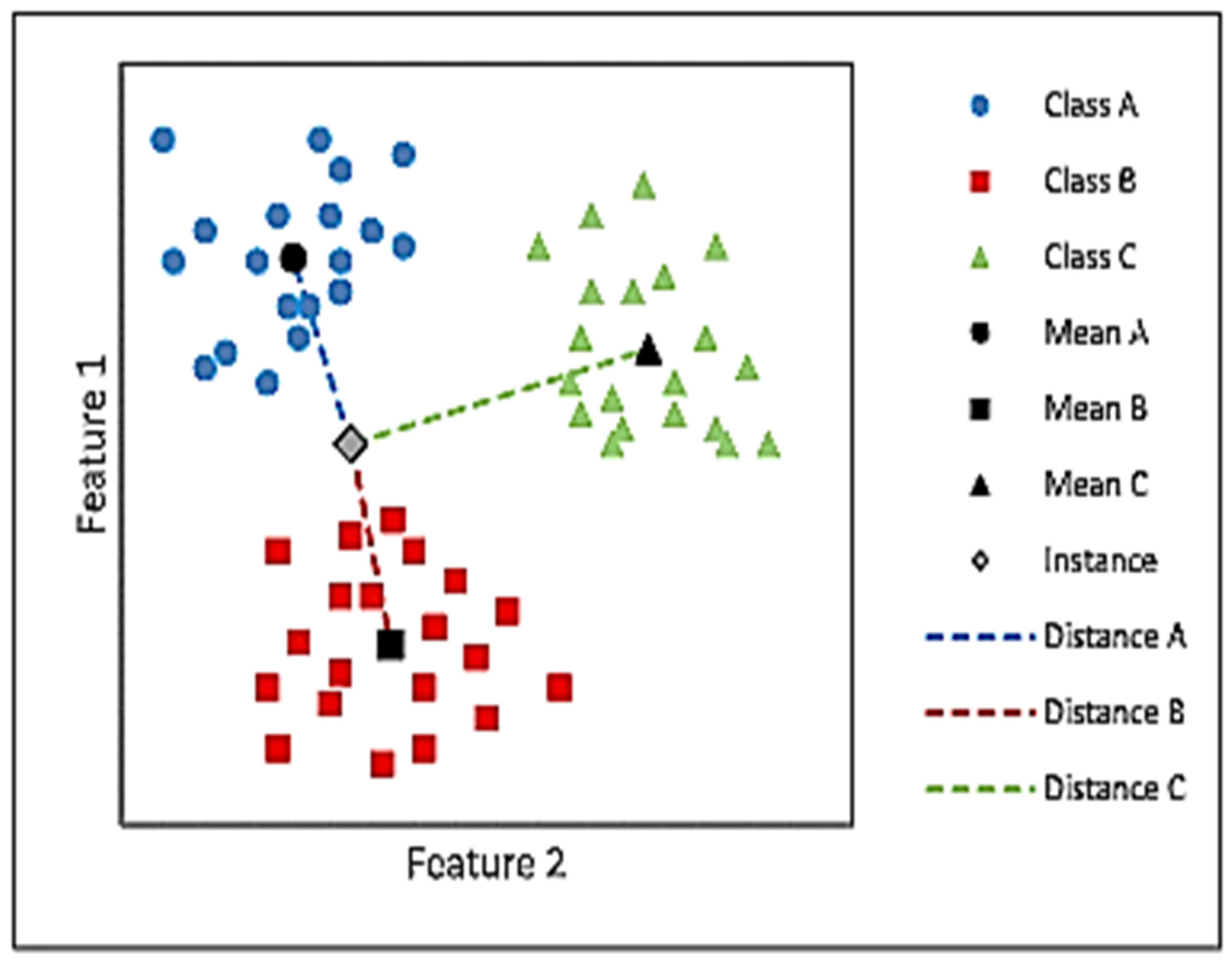
2.4.3. Standardized Variable Distance
2.5. Experimentation and Kurtogram Extraction
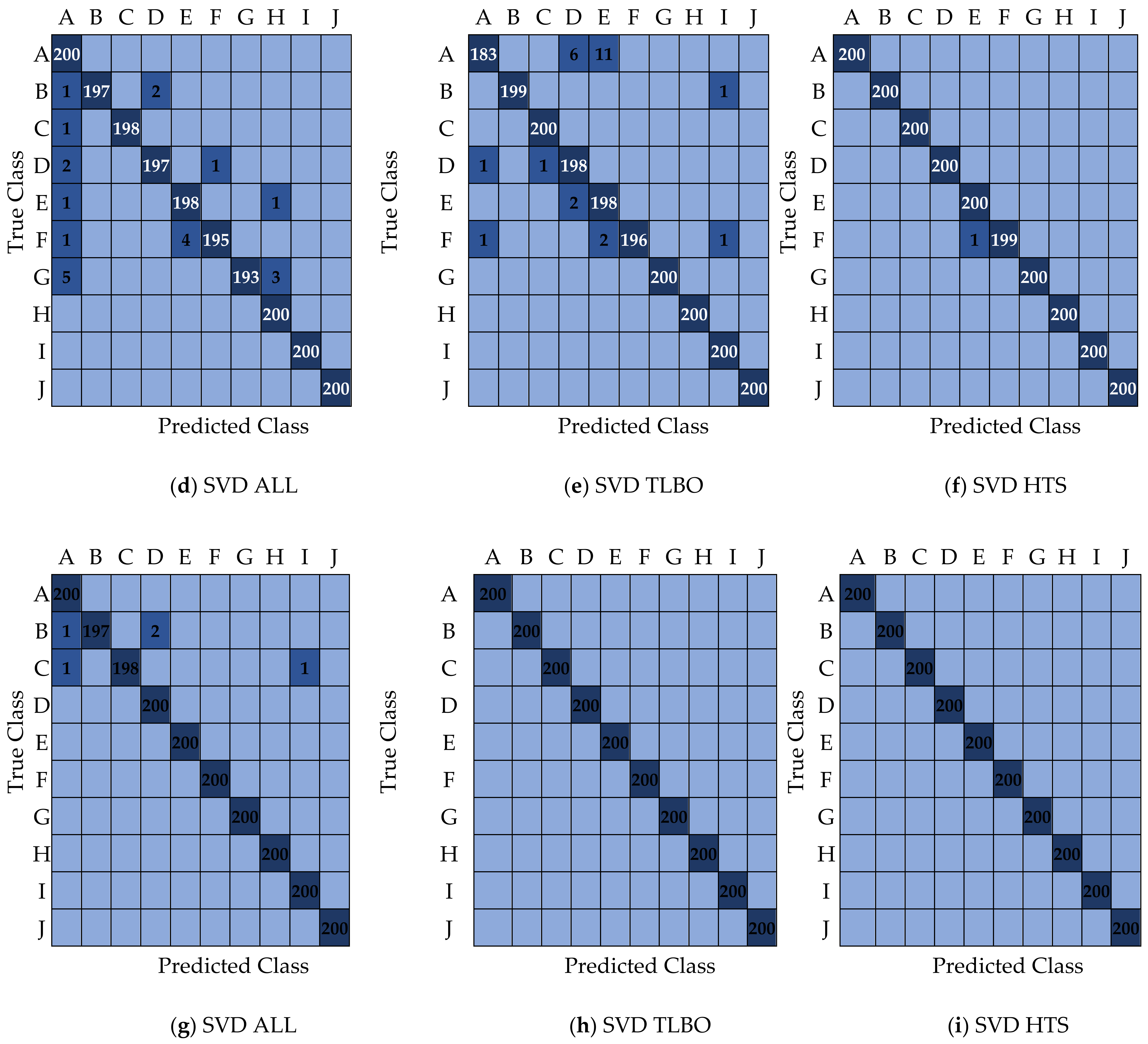
3. Results and Discussion
4. Conclusions
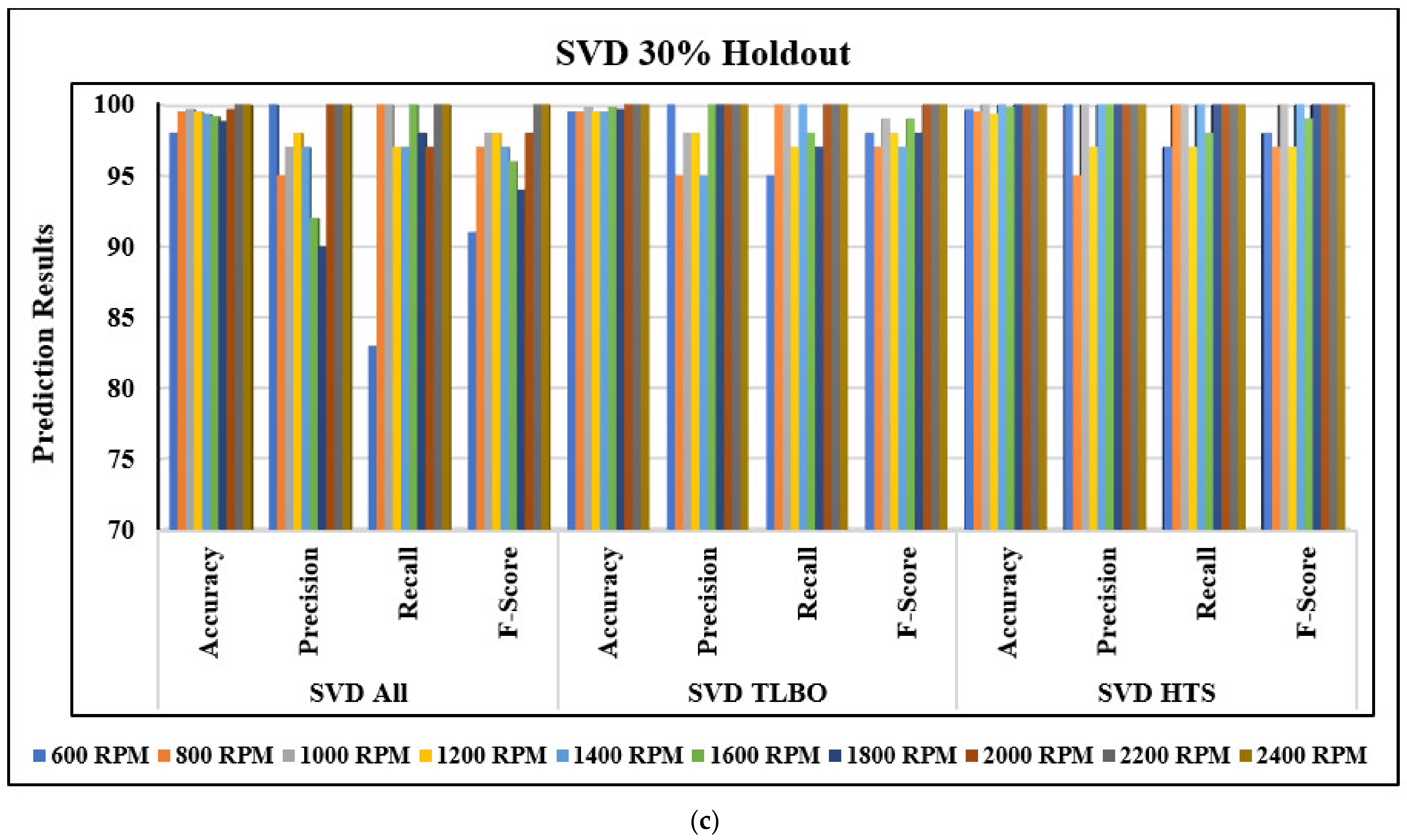
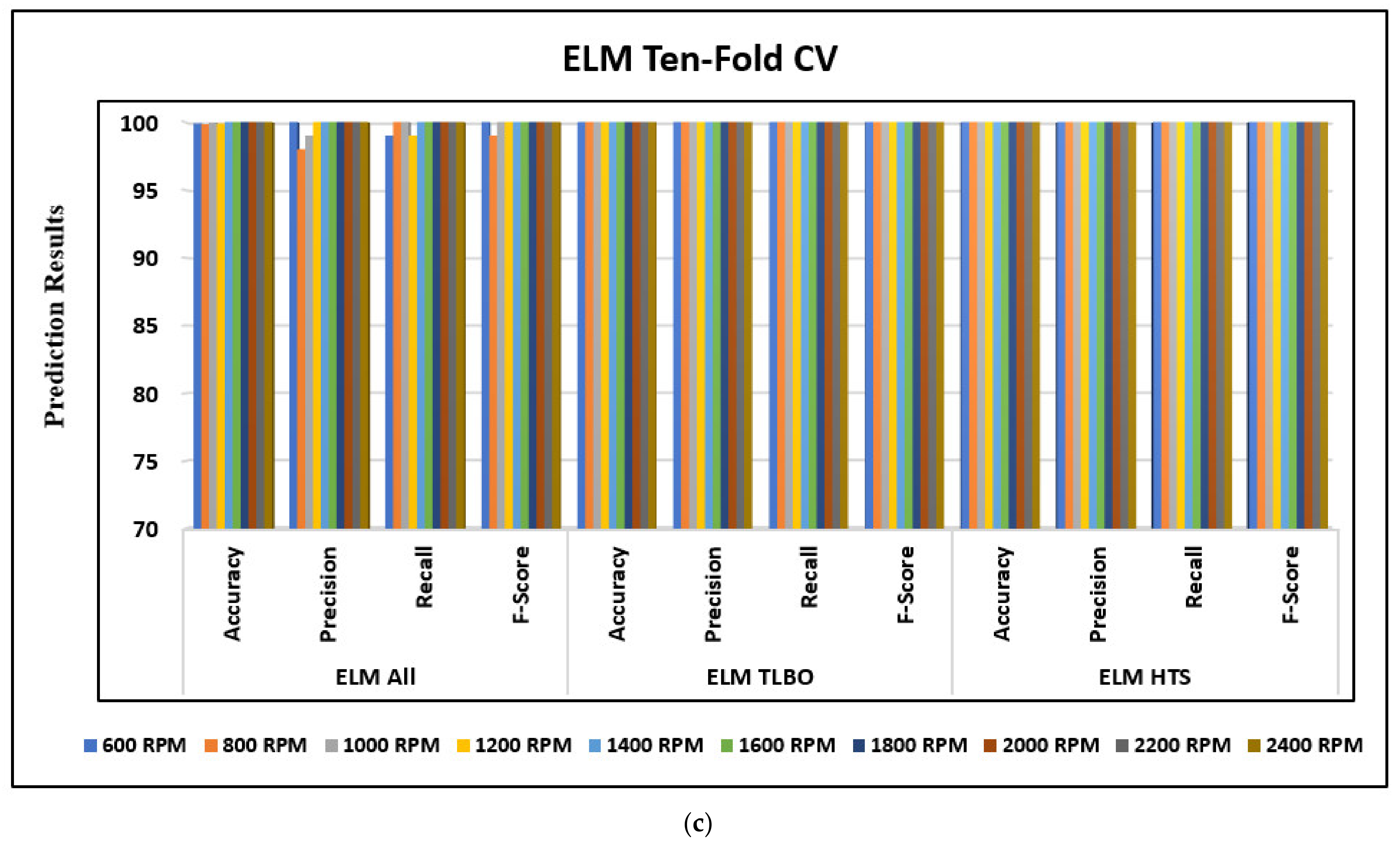
- Considering all IQP features with 30% hold-out testing, the maximum average accuracy to detect compound faults is observed as 99.8% with the ELM model.
- ELM-HTS and ELM-TLBO detect 100% compound faults with 30% hold-out testing, whereas the least average accuracy to detect compound faults is observed as 98.96% with SVM-TLBO.
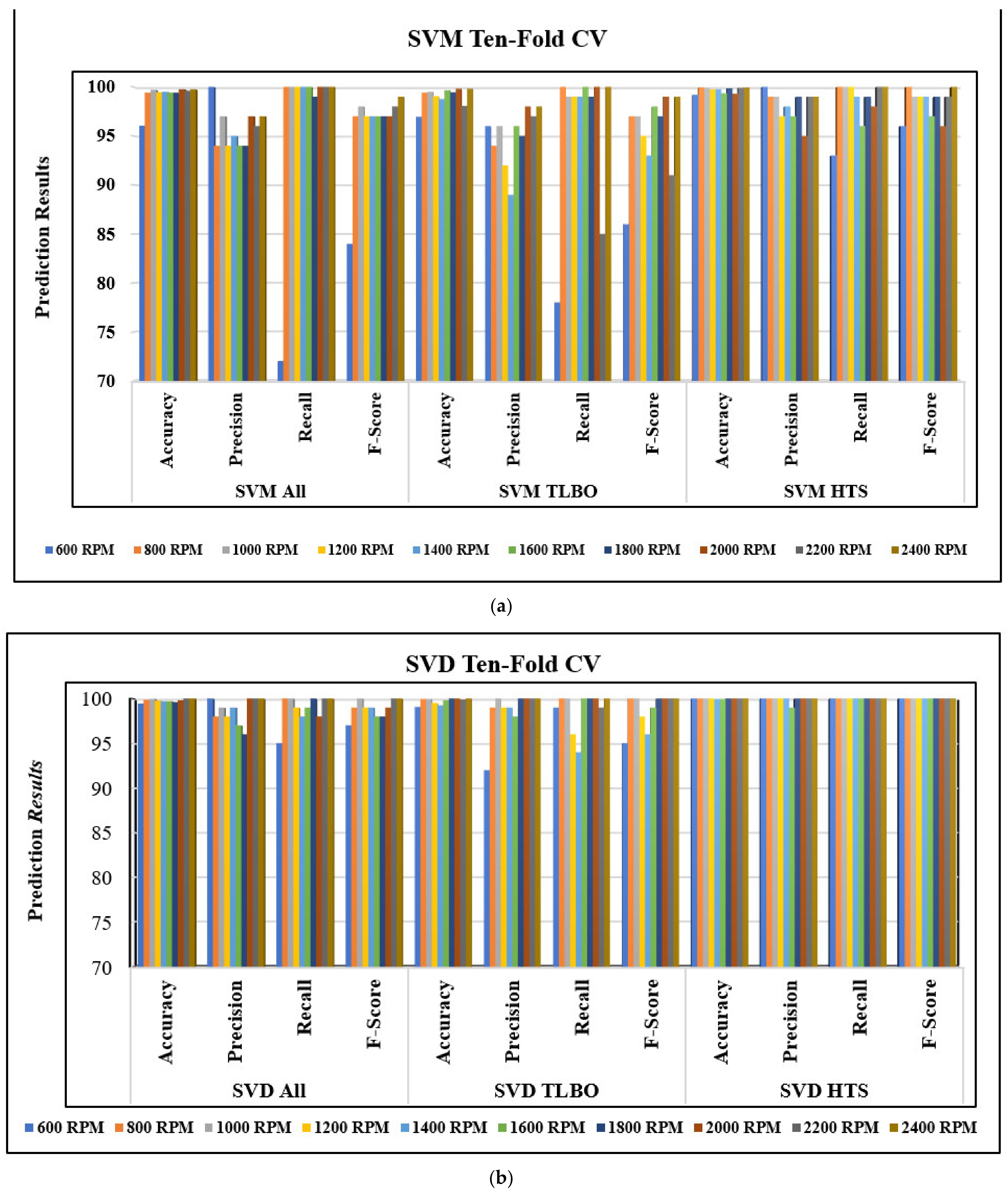
- With Ten-Fold CV and considering all IQP features, the maximum average accuracy to detect compound faults in REBs is reported as 99.9% with the ELM model.
- The maximum average compound fault detection accuracy of 100% is observed with ELM-HTS and ELM-TLBO. In contrast, the minimum average accuracy of 99.04% is reported from the SVM-TLBO model with the Ten-fold CV procedure.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Du, W. Multi-source information deep fusion for rolling bearing fault diagnosis based on deep residual convolution neural network. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2022, 236, 7576–7589. [Google Scholar] [CrossRef]
- Glowacz, A. Fault diagnosis of single-phase induction motor based on acoustic signals. Mech. Syst. Signal Process. 2019, 117, 65–80. [Google Scholar] [CrossRef]
- Venkatesh, S.; Sugumaran, V. A combined approach of convolutional neural networks and machine learning for visual fault classification in photovoltaic modules. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2021, 236, 148–159. [Google Scholar] [CrossRef]
- Cascales-Fulgencio, D.; Quiles-Cucarella, E.; García-Moreno, E. Computation and Statistical Analysis of Bearings’ Time- and Frequency-Domain Features Enhanced Using Cepstrum Pre-Whitening: A ML- and DL-Based Classification. Appl. Sci. 2022, 12, 10882. [Google Scholar] [CrossRef]
- Vakharia, V.; Gupta, V.; Kankar, P. Nonlinear dynamic analysis of ball bearings due to varying number of balls and centrifugal force. In Mechanisms and Machine Science, Proceedings of the 9th IFToMM International Conference on Rotor Dynamics, Milan, Italy, 22–25 September 2014; Springer: Cham, Switzerland, 2015; pp. 1831–1840. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, G.; Wu, D.; Wang, H. Rolling Bearing Fault Diagnosis Utilizing Variational Mode Decomposition Based Fractal Dimension Estimation Method. Measurement 2021, 181, 109614. [Google Scholar] [CrossRef]
- Gu, J.; Peng, Y. An Improved Complementary Ensemble Empirical Mode Decomposition Method and Its Application in Rolling Bearing Fault Diagnosis. Digit. Signal Process. 2021, 113, 103050. [Google Scholar] [CrossRef]
- Duan, R.; Liao, Y.; Yang, L.; Xue, J.; Tang, M. Minimum Entropy Morphological Deconvolution and Its Application in Bearing Fault Diagnosis. Measurement 2021, 182, 109649. [Google Scholar] [CrossRef]
- Anbu, S.; Thangavelu, A.; Ashok, S.D. Fuzzy C-Means Based Clustering and Rule Formation Approach for Classification of Bearing Faults Using Discrete Wavelet Transform. Computation 2019, 7, 54. [Google Scholar] [CrossRef]
- Gelman, L.; Persin, G. Novel Fault Diagnosis of Bearings and Gearboxes Based on Simultaneous Processing of Spectral Kurtoses. Appl. Sci. 2022, 12, 9970. [Google Scholar] [CrossRef]
- Bhupendra, M.K.; Miglani, A.; Kumar Kankar, P. Deep CNN-based damage classification of milled rice grains using a high-magnification image dataset. Comput. Electron. Agric. 2022, 195, 106811. [Google Scholar] [CrossRef]
- Vakharia, V.; Gupta, V.; Kankar, P. A multiscale permutation entropy-based approach to select wavelet for fault diagnosis of ball bearings. J. Vib. Control 2014, 21, 3123–3131. [Google Scholar] [CrossRef]
- Pan, T.; Chen, J.; Zhang, T.; Liu, S.; He, S.; Lv, H. Generative adversarial network in mechanical fault diagnosis under small sample: A systematic review on applications and future perspectives. ISA Trans. 2021, 128, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Liu, X.; Królczyk, G.; Sulowicz, M.; Glowacz, A.; Gardoni, P.; Li, Z. Damage Detection for Conveyor Belt Surface Based on Conditional Cycle Generative Adversarial Network. Sensors 2022, 22, 3485. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Gao, S.; Wang, X.; Miao, X.; Su, C.; Li, Y. ASM1D-GAN: An Intelligent Fault Diagnosis Method Based on Assembled 1D Convolutional Neural Network and Generative Adversarial Networks. J. Signal Process. Syst. 2019, 91, 1237–1247. [Google Scholar] [CrossRef]
- Lee, Y.O.; Jo, J.; Hwang, J. Application of deep neural network and generative adversarial network to industrial maintenance: A case study of induction motor fault detection. In Proceedings of the2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3248–3253. [Google Scholar] [CrossRef]
- Shah, M.; Vakharia, V.; Chaudhari, R.; Vora, J.; Pimenov, D.Y.; Giasin, K. Tool wear prediction in face milling of stainless steel using singular generative adversarial network and LSTM deep learning models. Int. J. Adv. Manuf. Technol. 2022, 121, 723–736. [Google Scholar] [CrossRef]
- Tubishat, M.; Ja’afar, S.; Alswaitti, M.; Mirjalili, S.; Idris, N.; Ismail, M.A.; Omar, M.S. Dynamic Salp Swarm Algorithm for Feature Selection. Expert Syst. Appl. 2021, 164, 113873. [Google Scholar] [CrossRef]
- Dave, V.; Singh, S.; Vakharia, V. Diagnosis of Bearing Faults Using Multi Fusion Signal Processing Techniques and Mutual Information. Indian J. Eng. Mater. Sci. 2020, 27, 878–888. [Google Scholar]
- Li, B.; Zhang, P.; Liang, S.; Ren, G. Feature extraction and selection for fault diagnosis of gear using wavelet entropy and mutual information. In Proceedings of the 2008 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; pp. 2846–2850. [Google Scholar] [CrossRef]
- Shen, J.; Xu, F. Method of fault feature selection and fusion based on poll mode and optimized weighted KPCA for bearings. Measurement 2022, 194, 110950. [Google Scholar] [CrossRef]
- Huang, N.; Wu, Z. A review on Hilbert-Huang transform: Method and its applications to geophysical studies. Rev. Geophys. 2008, 46, 1–23. [Google Scholar] [CrossRef]
- Shaham, T.R.; Dekel, T.; Michaeli, T. Singan: Learning a generative model from a single natural image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4570–4580. [Google Scholar] [CrossRef]
- Rao, R.; Savsani, V.; Vakharia, D. Teaching–Learning-Based Optimization: An optimization method for continuous non-linear large-scale problems. Inf. Sci. 2012, 183, 1–15. [Google Scholar] [CrossRef]
- Rao, R.; Patel, V. An elitist teaching-learning-based optimization algorithm for solving complex constrained optimization problems. Int. J. Ind. Eng. Comput. 2012, 3, 535–560. [Google Scholar] [CrossRef]
- Patel, V.; Savsani, V. Heat transfer search (HTS): A novel optimization algorithm. Inf. Sci. 2015, 324, 217–246. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vakharia, V.; Gupta, V.K.; Kankar, P.K. A comparison of feature ranking techniques for fault diagnosis of ball bearing. Soft Comput. 2016, 20, 1601–1619. [Google Scholar] [CrossRef]
- Huang, G.; Wang, D.; Lan, Y. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Sharma, N.; Deo, R. Wind speed forecasting in Nepal using self-organizing map-based online sequential extreme learning machine. Predict. Model. Energy Manag. Power Syst. Eng. 2021, 1, 437–484. [Google Scholar] [CrossRef]
- Malik, H.; Fatema, N.; Iqbal, A. Intelligent Data Analytics for Power Quality Disturbance Diagnosis Using Extreme Learning Machine (ELM). In Intelligent Data-Analytics for Condition Monitoring; Academic Press: Cambridge, MA, USA; pp. 91–114. [CrossRef]
- Elen, A.; Avuçlu, E. Standardized Variable Distances: A distance-based machine learning method. Appl. Soft Comput. 2021, 98, 106855. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Quality Parameters | Formula |
|---|---|
| Mean-Square Error (MSE) | |
| Peak Signal-to-Noise Ratio (PSNR) | |
| Signal-to-Noise Ratio (SNR) | |
| Structural Similarity Index for Measuring Image Quality (SSIM) | |
| Multi-Scale Structural Similarity Index for Measuring Image Quality (MSSIM) | |
| 2-D Correlation Coefficient | |
| 2-D Standard Deviation | |
| Entropy | |
| Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) | BRISQUE is a model that does not require transformations and instead calculates its characteristics from the image pixels. It is used to assess the quality of a picture by comparing it to a model with the same sort of distortion. With a lower BRISQUE score, higher perceptual quality can be achieved. |
| Natural Image Quality Evaluator (NIQE) | To determine the no-reference image quality score, NIQE can estimate image quality with arbitrary distortion, despite being trained on immaculate photos. The perceived quality improves when NIQE decreases. |
| Perception-Based Image Quality Evaluator (PIQE) | PIQE computes the quality score by evaluating block distortion and calculating the local variance of perceptibly distorted blocks. |
| S.No | MSE | PSNR | SNR | SSIM | MSSIM | BRISQUE | NIQE | PIQE | 2-D Corr. | 2-D Std Dev. | Entropy | Class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 63.58 | −18.03 | 23.50 | 0.37 | 0.65 | 36.12 | 7.06 | 64.31 | 0.98 | 36.27 | 7.37 | 0 |
| 2 | 80.40 | −19.05 | 22.48 | 0.35 | 0.66 | 33.12 | 7.96 | 65.57 | 0.97 | 35.25 | 7.25 | 0 |
| 3 | 42.16 | −16.25 | 25.28 | 0.38 | 0.69 | 40.13 | 6.15 | 65.52 | 0.98 | 35.79 | 7.31 | 0 |
| 4 | 45.06 | −16.54 | 24.99 | 0.39 | 0.69 | 43.00 | 6.93 | 64.01 | 0.98 | 35.08 | 7.33 | 0 |
| 5 | 49.04 | −16.91 | 24.62 | 0.39 | 0.70 | 37.48 | 8.07 | 65.53 | 0.98 | 36.15 | 7.34 | 0 |
| 6 | 68.41 | −18.35 | 23.18 | 0.35 | 0.64 | 31.37 | 6.63 | 65.30 | 0.97 | 35.26 | 7.25 | 1 |
| 7 | 12.32 | −10.90 | 28.74 | 0.42 | 0.75 | 40.76 | 6.48 | 61.96 | 0.99 | 29.33 | 7.08 | 1 |
| 8 | 19.23 | −12.84 | 26.80 | 0.37 | 0.69 | 41.52 | 6.65 | 66.11 | 0.99 | 29.03 | 7.08 | 1 |
| 9 | 17.52 | −12.44 | 27.20 | 0.37 | 0.67 | 38.66 | 6.95 | 64.58 | 0.99 | 28.57 | 7.07 | 1 |
| 10 | 20.05 | −13.02 | 26.62 | 0.37 | 0.69 | 42.00 | 6.56 | 62.55 | 0.99 | 29.14 | 7.05 | 1 |
| 11 | 9.84 | −9.93 | 28.11 | 0.28 | 0.69 | 30.56 | 7.24 | 63.83 | 0.99 | 20.43 | 6.39 | 9 |
| 12 | 9.85 | −9.94 | 28.11 | 0.28 | 0.69 | 31.55 | 7.08 | 63.46 | 0.99 | 20.42 | 6.38 | 9 |
| 13 | 9.89 | −9.95 | 28.09 | 0.28 | 0.69 | 28.32 | 7.31 | 61.63 | 0.99 | 20.42 | 6.39 | 9 |
| 14 | 9.89 | −9.95 | 28.09 | 0.28 | 0.70 | 30.21 | 6.37 | 63.16 | 0.99 | 20.42 | 6.39 | 9 |
| 15 | 9.93 | −9.97 | 28.07 | 0.28 | 0.70 | 29.52 | 5.76 | 62.87 | 0.99 | 20.43 | 6.39 | 9 |
| S. No | SNR | 2-D Corr. | 2-D Std Dev. | Entropy | Class |
|---|---|---|---|---|---|
| 1 | 36.12 | 7.06 | 0.98 | 36.27 | 0 |
| 2 | 33.12 | 7.96 | 0.97 | 35.25 | 0 |
| 3 | 40.13 | 6.15 | 0.98 | 35.79 | 0 |
| 4 | 43.00 | 6.93 | 0.98 | 35.08 | 0 |
| 5 | 37.48 | 8.07 | 0.98 | 36.15 | 0 |
| 6 | 31.37 | 6.63 | 0.97 | 35.26 | 1 |
| 7 | 40.76 | 6.48 | 0.99 | 29.33 | 1 |
| 8 | 41.52 | 6.65 | 0.99 | 29.03 | 1 |
| 9 | 38.66 | 6.95 | 0.99 | 28.57 | 1 |
| 10 | 42.00 | 6.56 | 0.99 | 29.14 | 1 |
| 11 | 30.56 | 7.24 | 0.99 | 20.43 | 9 |
| 12 | 31.55 | 7.08 | 0.99 | 20.42 | 9 |
| 13 | 28.32 | 7.31 | 0.99 | 20.42 | 9 |
| 14 | 30.21 | 6.37 | 0.99 | 20.42 | 9 |
| 15 | 29.52 | 5.76 | 0.99 | 20.43 | 9 |
| S.No | BRISQUE | NIQE | 2-D Corr. | 2-D Std Dev. | Class |
|---|---|---|---|---|---|
| 1 | 23.50 | 0.98 | 36.27 | 7.37 | 0 |
| 2 | 22.48 | 0.97 | 35.25 | 7.25 | 0 |
| 3 | 25.28 | 0.98 | 35.79 | 7.31 | 0 |
| 4 | 24.99 | 0.98 | 35.08 | 7.33 | 0 |
| 5 | 24.62 | 0.98 | 36.15 | 7.34 | 0 |
| 6 | 23.18 | 0.97 | 35.26 | 7.25 | 1 |
| 7 | 28.74 | 0.99 | 29.33 | 7.08 | 1 |
| 8 | 26.80 | 0.99 | 29.03 | 7.08 | 1 |
| 9 | 27.20 | 0.99 | 28.57 | 7.07 | 1 |
| 10 | 26.62 | 0.99 | 29.14 | 7.05 | 1 |
| 11 | 28.11 | 0.99 | 20.43 | 6.39 | 9 |
| 12 | 28.11 | 0.99 | 20.42 | 6.38 | 9 |
| 13 | 28.09 | 0.99 | 20.42 | 6.39 | 9 |
| 14 | 28.09 | 0.99 | 20.42 | 6.39 | 9 |
| 15 | 28.07 | 0.99 | 20.43 | 6.39 | 9 |
| 30% Hold-Out Accuracy (%) | Ten-Fold CV Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Data Set | SVM | SVD | ELM | SVM | SVD | ELM |
| All Features | 99.03 | 99.36 | 99.8 | 99.19 | 99.78 | 99.96 |
| TLBO Features | 98.96 | 99.73 | 100 | 99.04 | 99.74 | 100 |
| HTS Features | 99.73 | 99.83 | 100 | 99.69 | 100 | 100 |
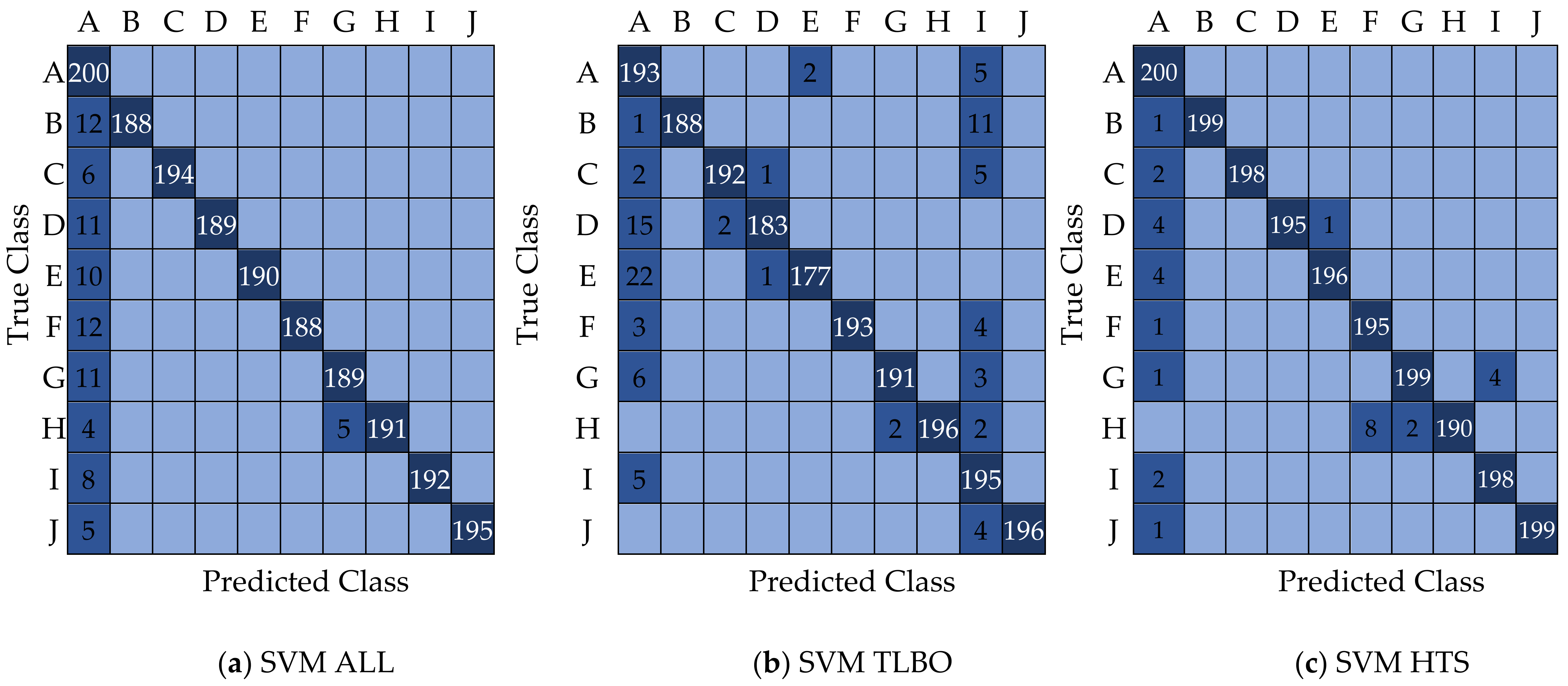
| HTS (Redundant Features) | TLBO (Redundant Features) | |||||||
|---|---|---|---|---|---|---|---|---|
| 30% Hold-Out Misclassification Accuracy (%) | 30% Hold-Out Classification Accuracy (%) | Ten-Fold CV Misclassification Accuracy (%) | Ten-Fold CV Classification Accuracy (%) | 30% Hold-Out Classification Accuracy (%) | 30% Hold-Out Classification | Ten-Fold CV Classification Accuracy (%) | Ten-Fold CV Classification Accuracy (%) | |
| SVM | 2.5 | 97.50 | 6.41 | 93.59 | 1 | 99 | 3.23 | 96.77 |
| SVD | 2.64 | 97.36 | 2.89 | 97.11 | 1.40 | 98.60 | 1.13 | 98.87 |
| ELM | 3.9 | 96.10 | 8.31 | 91.69 | 3.0 | 97 | 8.49 | 91.59 |
| SVM | ELM | SVD | ||
| Features | Validation | Time (In Seconds) | Time (In Seconds) | Time (In Seconds) |
| All | 30% hold-out | 0.03131 | 1.7495 | 3.278 |
| Ten-fold CV | 0.2476 | 22.508 | 31.557 | |
| HTS | 30% hold-out | 0.0203 | 1.621 | 2.57 |
| Ten-fold CV | 0.133 | 22.175 | 21.36 | |
| TLBO | 30% hold-out | 0.0193 | 1.666 | 2.930 |
| Ten-fold CV | 0.1114 | 23.302 | 25.5 | |
| Redundant HTS | 30% hold-out | 0.153 | 1.716 | 4.51 |
| Ten-fold CV | 2.065 | 22.304 | 42.46 | |
| Redundant TLBO | 30% hold-out | 1.0609 | 1.7201 | 4.865 |
| Ten-fold CV | 16.151 | 22.869 | 47.98 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suthar, V.; Vakharia, V.; Patel, V.K.; Shah, M. Detection of Compound Faults in Ball Bearings Using Multiscale-SinGAN, Heat Transfer Search Optimization, and Extreme Learning Machine. Machines 2023, 11, 29. https://doi.org/10.3390/machines11010029
Suthar V, Vakharia V, Patel VK, Shah M. Detection of Compound Faults in Ball Bearings Using Multiscale-SinGAN, Heat Transfer Search Optimization, and Extreme Learning Machine. Machines. 2023; 11(1):29. https://doi.org/10.3390/machines11010029
Chicago/Turabian StyleSuthar, Venish, Vinay Vakharia, Vivek K. Patel, and Milind Shah. 2023. "Detection of Compound Faults in Ball Bearings Using Multiscale-SinGAN, Heat Transfer Search Optimization, and Extreme Learning Machine" Machines 11, no. 1: 29. https://doi.org/10.3390/machines11010029
APA StyleSuthar, V., Vakharia, V., Patel, V. K., & Shah, M. (2023). Detection of Compound Faults in Ball Bearings Using Multiscale-SinGAN, Heat Transfer Search Optimization, and Extreme Learning Machine. Machines, 11(1), 29. https://doi.org/10.3390/machines11010029