

Insights from Explainable Artificial Intelligence of Pollution and Socioeconomic Influences for Respiratory Cancer Mortality in Italy
 , , , ,
, , , ,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
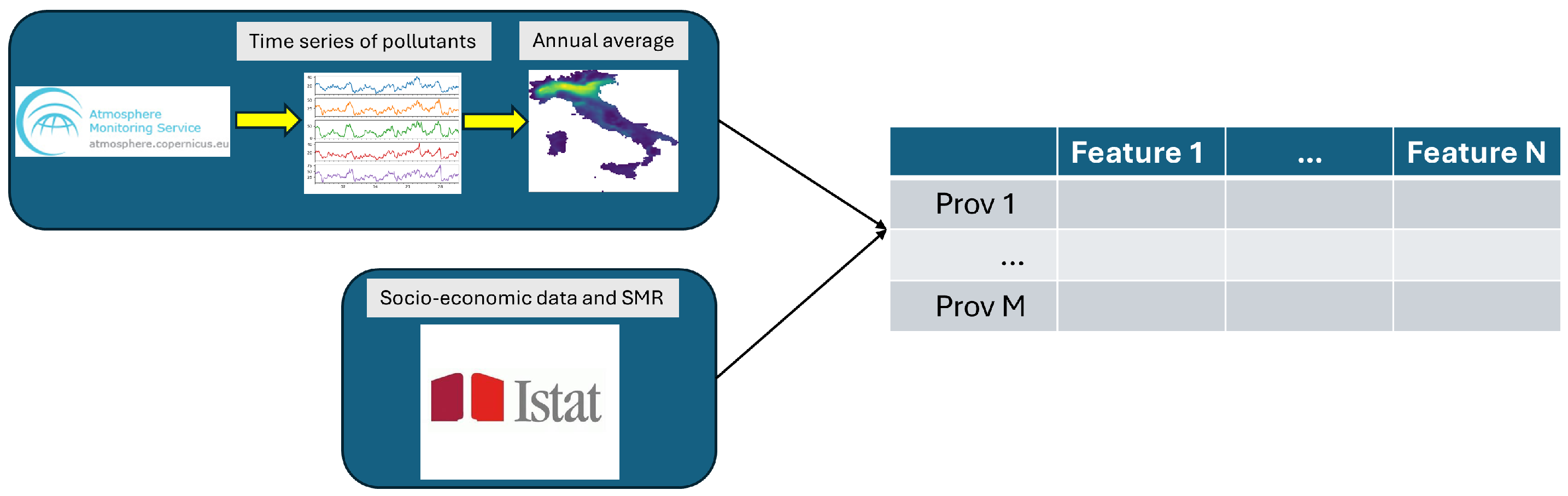
2.1. Pollutants Data and Socioeconomic Indices
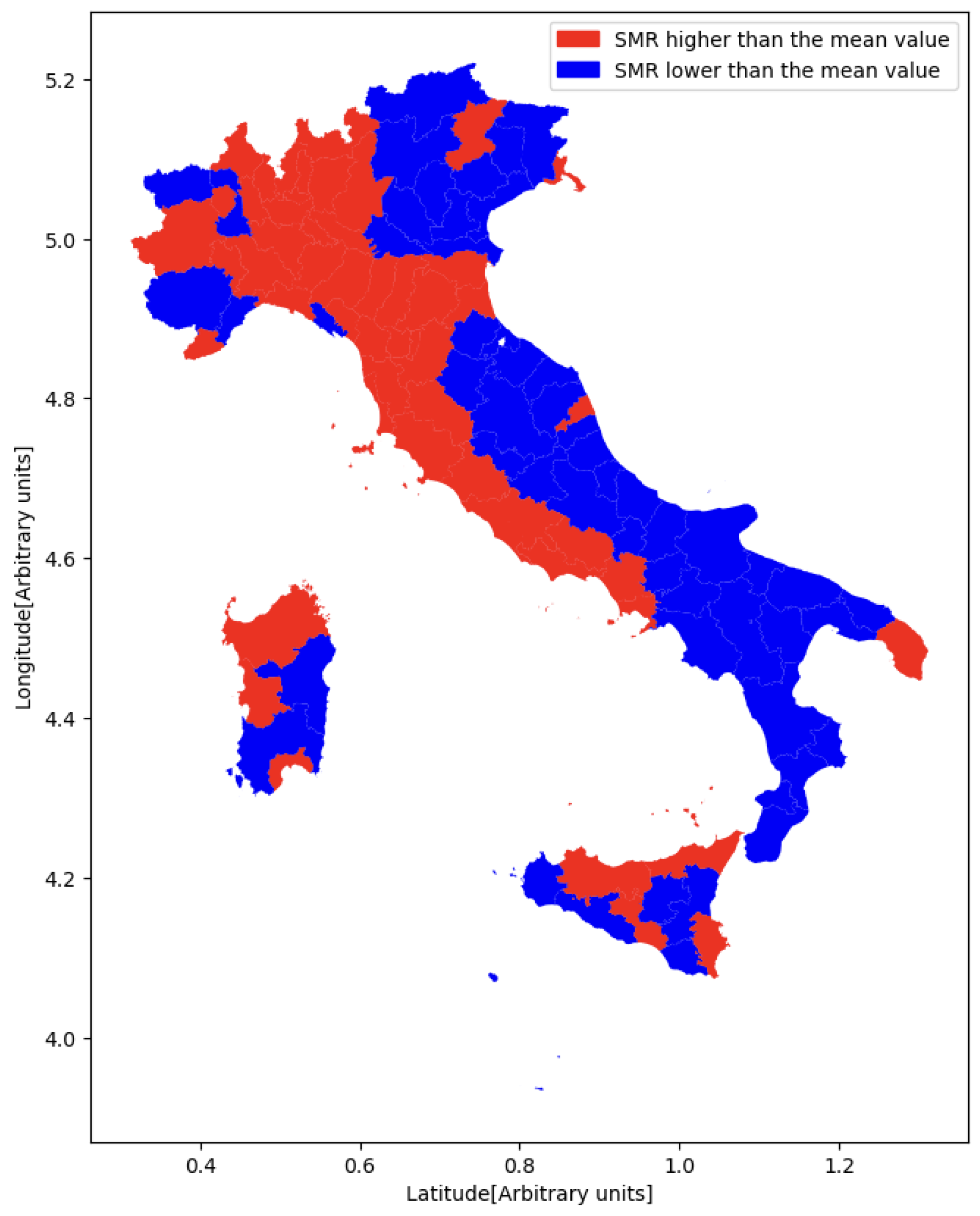
2.2. Standardized Mortality Ratio
2.3. Analysis Flowchart


2.4. Feature Correlation Analysis
2.5. Comparison of Classification Models
- Accuracy:
- AUC ROC: The area under the Receiver Operating Characteristic (ROC) curve;
- Recall:
- Precision:
- F1-score:
- Kappa:
2.6. Explainable Algorithm
3. Results
3.1. Performance of Classification Models
3.2. Interpreting Model Predictions: Insights from SHAP Analysis
4. Discussion
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wild, C.P. The exposome: From concept to utility. Int. J. Epidemiol. 2012, 41, 24–32. [Google Scholar] [CrossRef] [PubMed]
- Sogno, P.; Traidl-Hoffmann, C.; Kuenzer, C. Earth observation data supporting non-communicable disease research: A review. Remote Sens. 2020, 12, 2541. [Google Scholar] [CrossRef]
- United Nations Department of Economic and Social Affairs. The Sustainable Development Goals Report 2023: Special Edition; United Nations Department of Economic and Social Affairs: New York, NY, USA, 2023. [Google Scholar]
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed]
- Mahesh, P. Implementing precision medicine in best practices of chronic airway diseases. Indian J. Med. Res. 2019, 149, 802. [Google Scholar] [CrossRef]
- Hystad, P.; Demers, P.A.; Johnson, K.C.; Brook, J.; van Donkelaar, A.; Lamsal, L.; Martin, R.; Brauer, M. Spatiotemporal air pollution exposure assessment for a Canadian population-based lung cancer case-control study. Environ. Health 2012, 11, 22. [Google Scholar] [CrossRef] [PubMed]
- Tomczak, A.; Miller, A.B.; Weichenthal, S.A.; To, T.; Wall, C.; van Donkelaar, A.; Martin, R.V.; Crouse, D.L.; Villeneuve, P.J. Long-term exposure to fine particulate matter air pollution and the risk of lung cancer among participants of the Canadian National Breast Screening Study. Int. J. Cancer 2016, 139, 1958–1966. [Google Scholar] [CrossRef] [PubMed]
- Consonni, D.; Carugno, M.; De Matteis, S.; Nordio, F.; Randi, G.; Bazzano, M.; Caporaso, N.E.; Tucker, M.A.; Bertazzi, P.A.; Pesatori, A.C.; et al. Outdoor particulate matter (PM10) exposure and lung cancer risk in the EAGLE study. PLoS ONE 2018, 13, e0203539. [Google Scholar] [CrossRef] [PubMed]
- Di Gilio, A.; Catino, A.; Lombardi, A.; Palmisani, J.; Facchini, L.; Mongelli, T.; Varesano, N.; Bellotti, R.; Galetta, D.; de Gennaro, G.; et al. Breath analysis for early detection of malignant pleural mesothelioma: Volatile organic compounds (VOCs) determination and possible biochemical pathways. Cancers 2020, 12, 1262. [Google Scholar] [CrossRef] [PubMed]
- Kamis, A.; Cao, R.; He, Y.; Tian, Y.; Wu, C. Predicting lung cancer in the United States: A multiple model examination of public health factors. Int. J. Environ. Res. Public Health 2021, 18, 6127. [Google Scholar] [CrossRef]
- Ahmed, Z.U.; Sun, K.; Shelly, M.; Mu, L. Explainable artificial intelligence (XAI) for exploring spatial variability of lung and bronchus cancer (LBC) mortality rates in the contiguous USA. Sci. Rep. 2021, 11, 24090. [Google Scholar] [CrossRef]
- Monaco, A.; Lacalamita, A.; Amoroso, N.; D’Orta, A.; Del Buono, A.; di Tuoro, F.; Tangaro, S.; Galeandro, A.I.; Bellotti, R. Random forests highlight the combined effect of environmental heavy metals exposure and genetic damages for cardiovascular diseases. Appl. Sci. 2021, 11, 8405. [Google Scholar] [CrossRef]
- Casciaro, G.; Cavaiola, M.; Mazzino, A. Calibrating the CAMS European multi-model air quality forecasts for regional air pollution monitoring. Atmos. Environ. 2022, 287, 119259. [Google Scholar] [CrossRef]
- Ladbury, C.; Zarinshenas, R.; Semwal, H.; Tam, A.; Vaidehi, N.; Rodin, A.S.; Liu, A.; Glaser, S.; Salgia, R.; Amini, A. Utilization of model-agnostic explainable artificial intelligence frameworks in oncology: A narrative review. Transl. Cancer Res. 2022, 11, 3853. [Google Scholar] [CrossRef] [PubMed]
- Roussel, C.; Böhm, K. Geospatial xai: A review. ISPRS Int. J. Geo-Inf. 2023, 12, 355. [Google Scholar] [CrossRef]
- Marécal, V.; Peuch, V.H.; Andersson, C.; Andersson, S.; Arteta, J.; Beekmann, M.; Benedictow, A.; Bergström, R.; Bessagnet, B.; Cansado, A.; et al. A regional air quality forecasting system over Europe: The MACC-II daily ensemble production. Geosci. Model Dev. 2015, 8, 2777–2813. [Google Scholar] [CrossRef]
- Thunis, P.; Degraeuwe, B.; Pisoni, E.; Meleux, F.; Clappier, A. Analyzing the efficiency of short-term air quality plans in European cities, using the CHIMERE air quality model. Air Qual. Atmos. Health 2017, 10, 235–248. [Google Scholar] [CrossRef] [PubMed]
- Hass, H.; Ebel, A.; Feldmann, H.; Jakobs, H.; Memmesheimer, M. Evaluation studies with a regional chemical transport model (EURAD) using air quality data from the EMEP monitoring network. Atmos. Environ. Part Gen. Top. 1993, 27, 867–887. [Google Scholar] [CrossRef]
- Duarte, E.D.S.F.; Franke, P.; Lange, A.C.; Friese, E.; da Silva Lopes, F.J.; da Silva, J.J.; dos Reis, J.S.; Landulfo, E.; e Silva, C.M.S.; Elbern, H.; et al. Evaluation of atmospheric aerosols in the metropolitan area of São Paulo simulated by the regional EURAD-IM model on high-resolution. Atmos. Pollut. Res. 2021, 12, 451–469. [Google Scholar] [CrossRef]
- Hinestroza-Ramirez, J.E.; Lopez-Restrepo, S.; Yarce Botero, A.; Segers, A.; Rendon-Perez, A.M.; Isaza-Cadavid, S.; Heemink, A.; Quintero, O.L. Improving Air Pollution Modelling in Complex Terrain with a Coupled WRF–LOTOS–EUROS Approach: A Case Study in Aburrá Valley, Colombia. Atmosphere 2023, 14, 738. [Google Scholar] [CrossRef]
- Persson, C.; Langner, J.; Robertson, L. Air pollution assessment studies for Sweden based on the MATCH model and air pollution measurements. In Air Pollution Modeling and Its Application XI; Springer: Berlin/Heidelberg, Germany, 1996; pp. 127–134. [Google Scholar]
- Joly, M.; Josse, B.; Plu, M.; Arteta, J.; Guth, J.; Meleux, F. High-Resolution Air Quality Forecasts with MOCAGE Chemistry Transport Model. In Air Pollution Modeling and Its Application XXIV; Springer: Berlin/Heidelberg, Germany, 2016; pp. 563–565. [Google Scholar]
- Ots, R.; Loot, A.; Kaasik, M. Scale-dependent and seasonal performance of SILAM model in Estonia. In Air Pollution Modeling and its Application XXII; Springer: Berlin/Heidelberg, Germany, 2014; pp. 593–597. [Google Scholar]
- Van Loon, M.; Vautard, R.; Schaap, M.; Bergström, R.; Bessagnet, B.; Brandt, J.; Builtjes, P.; Christensen, J.; Cuvelier, C.; Graff, A.; et al. Evaluation of long-term ozone simulations from seven regional air quality models and their ensemble. Atmos. Environ. 2007, 41, 2083–2097. [Google Scholar] [CrossRef]
- Neary, L.; Kaminski, J.W.; Lupu, A.; McConnell, J.C. Developments and results from a global multiscale air quality model (GEM-AQ). In Air Pollution Modeling and Its Application XVII; Springer: Berlin/Heidelberg, Germany, 2007; pp. 403–410. [Google Scholar]
- Cazzolla Gatti, R.; Di Paola, A.; Monaco, A.; Velichevskaya, A.; Amoroso, N.; Bellotti, R. The spatial association between environmental pollution and long-term cancer mortality in Italy. Sci. Total Environ. 2023, 855, 158439. [Google Scholar] [CrossRef]
- Mayr, A.; Binder, H.; Gefeller, O.; Schmid, M. The evolution of boosting algorithms. Methods Inf. Med. 2014, 53, 419–427. [Google Scholar] [PubMed]
- Abdurrahman, M.H.; Irawan, B.; Setianingsih, C. A review of light gradient boosting machine method for hate speech classification on twitter. In Proceedings of the 2020 2nd International Conference on Electrical, Control and Instrumentation Engineering (ICECIE), Kuala Lumpur, Malaysia, 28 November 2020; pp. 1–6. [Google Scholar]
- Parmar, A.; Katariya, R.; Patel, V. A review on random forest: An ensemble classifier. In International Conference on Intelligent Data Communication Technologies and Internet of Things (ICICI) 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 758–763. [Google Scholar]
- Baby, D.; Devaraj, S.J.; Hemanth, J. Leukocyte classification based on feature selection using extra trees classifier: Atransfer learning approach. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 2742–2757. [Google Scholar] [CrossRef]
- Kataria, A.; Singh, M. A review of data classification using k-nearest neighbour algorithm. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 354–360. [Google Scholar]
- Azmi, S.S.; Baliga, S. An overview of boosting decision tree algorithms utilizing AdaBoost and XGBoost boosting strategies. Int. Res. J. Eng. Technol. 2020, 7, 6867–6870. [Google Scholar]
- McLachlan, G.J. Discriminant analysis. Wiley Interdiscip. Rev. Comput. Stat. 2012, 4, 421–431. [Google Scholar] [CrossRef]
- An, T.K.; Kim, M.H. A new diverse AdaBoost classifier. In Proceedings of the 2010 International conference on artificial intelligence and computational intelligence, Sanya, China, 23–24 October 2010; Volume 1, pp. 359–363. [Google Scholar]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Saritas, M.M.; Yasar, A. Performance analysis of ANN and Naive Bayes classification algorithm for data classification. Int. J. Intell. Syst. Appl. Eng. 2019, 7, 88–91. [Google Scholar] [CrossRef]
- Tharwat, A. Linear vs. quadratic discriminant analysis classifier: A tutorial. Int. J. Appl. Pattern Recognit. 2016, 3, 145–180. [Google Scholar] [CrossRef]
- Nick, T.G.; Campbell, K.M. Logistic regression. Top. Biostat. 2007, 273–301. [Google Scholar]
- Barletta, L.; Giusti, A.; Rottondi, C.; Tornatore, M. QoT estimation for unestablished lighpaths using machine learning. In Optical Fiber Communication Conference; Optica Publishing Group: Washington, DC, USA, 2017; p. Th1J-1. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Hamra, G.B.; Laden, F.; Cohen, A.J.; Raaschou-Nielsen, O.; Brauer, M.; Loomis, D. Lung Cancer and Exposure to Nitrogen Dioxide and Traffic: A Systematic Review and Meta-Analysis. Environ. Health Perspect. 2015, 123, 1107–1112. [Google Scholar] [CrossRef]
- Amoroso, N.; Cilli, R.; Maggipinto, T.; Monaco, A.; Tangaro, S.; Bellotti, R. Satellite data and machine learning reveal a significant correlation between NO2 and COVID-19 mortality. Environ. Res. 2022, 204, 111970. [Google Scholar] [CrossRef] [PubMed]
- Snyder, R. Leukemia and benzene. Int. J. Environ. Res. Public Health 2012, 9, 2875–2893. [Google Scholar] [CrossRef] [PubMed]
- Loomis, D.; Guyton, K.Z.; Grosse, Y.; El Ghissassi, F.; Bouvard, V.; Benbrahim-Tallaa, L.; Guha, N.; Vilahur, N.; Mattock, H.; Straif, K. Carcinogenicity of benzene. Lancet Oncol. 2017, 18, 1574–1575. [Google Scholar] [CrossRef] [PubMed]
- Ferrero, A.; Esplugues, A.; Estarlich, M.; Llop, S.; Cases, A.; Mantilla, E.; Ballester, F.; Iñiguez, C. Infants’ indoor and outdoor residential exposure to benzene and respiratory health in a Spanish cohort. Environ. Pollut. 2017, 222, 486–494. [Google Scholar] [CrossRef] [PubMed]
- D’Andrea, M.A.; Reddy, G.K. Health Risks Associated With Benzene Exposure in Children: A Systematic Review. Glob. Pediatr. Health 2018, 5, 2333794X18789275. [Google Scholar] [CrossRef] [PubMed]
- O’Dell, K.; Hornbrook, R.S.; Permar, W.; Levin, E.J.; Garofalo, L.A.; Apel, E.C.; Blake, N.J.; Jarnot, A.; Pothier, M.A.; Farmer, D.K.; et al. Hazardous air pollutants in fresh and aged western US wildfire smoke and implications for long-term exposure. Environ. Sci. Technol. 2020, 54, 11838–11847. [Google Scholar] [CrossRef]
- Jo, W.K.; Song, K.B. Exposure to volatile organic compounds for individuals with occupations associated with potential exposure to motor vehicle exhaust and/or gasoline vapor emissions. Sci. Total Environ. 2001, 269, 25–37. [Google Scholar] [CrossRef]
- Redondo-Sánchez, D.; Petrova, D.; Rodríguez-Barranco, M.; Fernández-Navarro, P.; Jiménez-Moleón, J.J.; Sánchez, M.J. Socio-economic inequalities in lung cancer outcomes: An overview of systematic reviews. Cancers 2022, 14, 398. [Google Scholar] [CrossRef] [PubMed]
- Wilms, R.; Mäthner, E.; Winnen, L.; Lanwehr, R. Omitted variable bias: A threat to estimating causal relationships. Methods Psychol. 2021, 5, 100075. [Google Scholar] [CrossRef]
- Clarke, K.A. The phantom menace: Omitted variable bias in econometric research. Confl. Manag. Peace Sci. 2005, 22, 341–352. [Google Scholar] [CrossRef]
- Pilotto, L.S.; Douglas, R.M.; Wilson, S.R. Respiratory effects associated with indoor nitrogen dioxide exposure in children. Int. J. Epidemiol. 1997, 26, 788–796. [Google Scholar] [CrossRef] [PubMed]
- Gamble, J.; Jones, W.; Minshall, S. Epidemiological-environmental study of diesel bus garage workers: Acute effects of NO2 and respirable particulate on the respiratory system. Environ. Res. 1987, 42, 201–214. [Google Scholar] [CrossRef] [PubMed]
- Kubota, K.; Murakami, M.; Takenaka, S.; Kawai, K.; Kyono, H. Effects of long-term nitrogen dioxide exposure on rat lung: Morphological observations. Environ. Health Perspect. 1987, 73, 157–169. [Google Scholar] [CrossRef]
- Atkinson, R.W.; Butland, B.K.; Anderson, H.R.; Maynard, R.L. Long-term concentrations of nitrogen dioxide and mortality: A meta-analysis of cohort studies. Epidemiology 2018, 29, 460. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa |
|---|---|---|---|---|---|---|
| et | 0.78 ± 0.19 | 0.75 ± 0.17 | 0.73 ± 0.26 | 0.82 ± 0.18 | 0.75 ± 0.23 | 0.57 ± 0.37 |
| lgb | 0.74 ± 0.10 | 0.86 ± 0.13 | 0.71 ± 0.16 | 0.80 ± 0.18 | 0.73 ± 0.10 | 0.47 ± 0.21 |
| rf | 0.72 ± 0.21 | 0.80 ± 0.16 | 0.70 ± 0.25 | 0.78 ± 0.23 | 0.70 ± 0.22 | 0.44 ± 0.42 |
| xgb | 0.70 ± 0.16 | 0.78 ± 0.18 | 0.68 ± 0.24 | 0.75 ± 0.18 | 0.67 ± 0.19 | 0.39 ± 0.32 |
| gbc | 0.68 ± 0.18 | 0.77 ± 0.19 | 0.68 ± 0.18 | 0.72 ± 0.21 | 0.68 ± 0.16 | 0.36 ± 0.36 |
| ada | 0.67 ± 0.28 | 0.72 ± 0.17 | 0.68 ± 0.21 | 0.67 ± 0.17 | 0.67 ± 0.17 | 0.34 ± 0.36 |
| qda | 0.65 ± 0.12 | 0.77 ± 0.14 | 0.50 ± 0.17 | 0.73 ± 0.23 | 0.58 ± 0.16 | 0.30 ± 0.26 |
| lr | 0.64 ± 0.13 | 0.68 ± 0.17 | 0.56 ± 0.22 | 0.71 ± 0.20 | 0.59 ± 0.17 | 0.28 ± 0.26 |
| knn | 0.64 ± 0.16 | 0.69 ± 0.15 | 0.58 ± 0.14 | 0.69 ± 0.21 | 0.62 ± 0.15 | 0.27 ± 0.32 |
| lda | 0.62 ± 0.13 | 0.66 ± 0.21 | 0.50 ± 0.18 | 0.70 ± 0.22 | 0.55 ± 0.16 | 0.23 ± 0.26 |
| dt | 0.61 ± 0.21 | 0.61 ± 0.21 | 0.61 ± 0.21 | 0.64 ± 0.22 | 0.61 ± 0.19 | 0.21 ± 0.42 |
| nb | 0.55 ± 0.08 | 0.47 ± 0.17 | 0.17 ± 0.13 | 0.60 ± 0.44 | 0.25 ± 0.18 | 0.09 ± 0.14 |
| dummy | 0.50 ± 0.04 | 0.50 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romano, D.; Novielli, P.; Diacono, D.; Cilli, R.; Pantaleo, E.; Amoroso, N.; Bellantuono, L.; Monaco, A.; Bellotti, R.; Tangaro, S. Insights from Explainable Artificial Intelligence of Pollution and Socioeconomic Influences for Respiratory Cancer Mortality in Italy. J. Pers. Med. 2024, 14, 430. https://doi.org/10.3390/jpm14040430
Romano D, Novielli P, Diacono D, Cilli R, Pantaleo E, Amoroso N, Bellantuono L, Monaco A, Bellotti R, Tangaro S. Insights from Explainable Artificial Intelligence of Pollution and Socioeconomic Influences for Respiratory Cancer Mortality in Italy. Journal of Personalized Medicine. 2024; 14(4):430. https://doi.org/10.3390/jpm14040430
Chicago/Turabian StyleRomano, Donato, Pierfrancesco Novielli, Domenico Diacono, Roberto Cilli, Ester Pantaleo, Nicola Amoroso, Loredana Bellantuono, Alfonso Monaco, Roberto Bellotti, and Sabina Tangaro. 2024. "Insights from Explainable Artificial Intelligence of Pollution and Socioeconomic Influences for Respiratory Cancer Mortality in Italy" Journal of Personalized Medicine 14, no. 4: 430. https://doi.org/10.3390/jpm14040430