1. Introduction
Cultivated land is the basis for human survival, development, and prosperity and is also a key element in ensuring food security. The “staple-crop-shifting” of cultivated land will lead to a decline in total food production, which will have a direct impact on food security, and continuous monitoring of food-producing areas is therefore essential. To address this challenge, the China Government has issued a series of announcements, such as “The Opinions On Preventing The Degradation Of Cultivated Land And Stabilizing Grain Production”, which call for strict adherence to the red line of cultivated land and the prevention of the tendency to degradation of cultivated land [
1,
2]. Cultivated land protection is imperative, and real-time and accurate information on the dynamic changes in the cultivation status of cultivated land is the key to monitoring “staple-food-shifting”.
Timely and accurate information on staple crops is the basis for monitoring and management of “staple-crop-shifting” [
3,
4]. Because remote sensing images are characterized by large-scale observation, multispectral information, and multitemporal sequences, they are widely used in crop classification and identification, area statistics, and change monitoring studies [
5,
6]. Utilizing satellite remote sensing data is an important method to improve the accuracy of crop identification [
7], and this technique has been widely used in the field of agricultural remote sensing and crop identification in wheat [
8], maize [
9,
10], and cotton [
4,
11].
Pixel-level-based classification and object-oriented classification are the two main approaches to crop classification using remote sensing. Pixel-level classification only considers the features of individual pixels and is prone to category confusion, especially among crops with similar spectral features, leading to “salt and pepper noise” [
12], and it is difficult to utilize the spatial relationship between pixels to capture information such as the shape and size of the objects or crops in the farmland. The object-oriented classification method uses segmented objects rather than pixels as processing units, which takes into account the spatial relationship between objects and can better capture the spatial information of farmland. By introducing features such as the shape, texture, and spectrum of an object, it is possible to reduce confusion between categories and improve classification accuracy [
13]. Many studies have used various object-oriented supervised machine learning classification algorithms for crop identification from satellite remote sensing data [
14,
15]. Common algorithms include Random Forest (RF), Support Vector Machine (SVM), Decision Tree (DT), k-Nearest Neighbor (KNN), and Neural Networks [
16,
17,
18,
19]. For example, Luo et al. [
20] conducted experiments on crop classification based on pixel-level and object-oriented methods in Heilongjiang farm areas, and the results showed that the overall accuracy of the object-oriented method was 3% higher than that of the pixel method, and the “salt and pepper noise” in crop mapping was significantly improved. Xue et al. [
21] classified crops based on Google Earth Engine (GEE) and the results showed that the combination of Simple Non-Iterative Clustering (SNIC) multiscale segmentation and Random Forest Classification based on time-series radar and optical remote sensing images can effectively reduce the “ salt and pepper noise ” in the classification and improve the classification accuracy up to 98.66%, with a kappa coefficient of 0.98, as compared to the pixel-based method. Zhu et al. [
22] used Sentinel-2 images combined with object-oriented and pixel-based methods to extract maize fall, and the results showed that the overall accuracy and kappa coefficient of multi-feature combined with object-oriented RF classification were 93.77% and 0.87, respectively, which were significantly higher than those of pixel-based methods. Wang et al. [
23] fused multi-source domestic high-resolution imagery and object-oriented methods for remote sensing identification of crops in the south, and the results showed that object-oriented crop classification based on GF-2 was better than that based on pixels, in which the overall accuracy was about 1.35% higher.
In recent years, with the increase in the number of satellite remote sensing image types and improvement in spatial resolution, scholars have proposed a variety of classification methods that comprehensively utilize multiple features, such as image spectra, textures, geometries, and spectral indices, which significantly improve classification accuracy [
24,
25]. While object-oriented methods make up for the lack of pixel-based methods, they also lead to an increase in the dimensionality of the feature space. However, not all features have a positive impact on classification, and several studies have found that too many input features may reduce classification accuracy and increase computational effort [
10,
26]. The feature selection (FS) technique is an efficient method to reduce redundant information and aims to find the optimal subset of features that have the highest relevance to the object and the lowest redundancy. Various FS methods have been widely used in object-based classification. For example, the feature selection (FS) technique is an efficient method to reduce redundant information, which aims to find the optimal subset of features that have maximum relevance to the object and minimum redundancy. Various FS methods are widely used in object-based classification. Zhang et al. [
27] constructed a feature selection method based on the optimal extraction cycle of features based on Sentinel-2 remote sensing images, which significantly improved the recognition accuracy of mountain rice, with the best overall classification accuracy and kappa coefficient of 86% and 0.81, respectively. Fu et al. [
28] demonstrated that the Random Forest Recursive Feature Elimination (RF_RFE) algorithm can provide more useful features and improve the crop identification accuracy after feature selection by 1.43% to 2.19%, 0.60% to 1.41%, and 1.99% to 2.18% in 2002, 2014, and 2022, respectively, compared to crop identification without feature optimization. Jin et al. [
3] used Decision Trees to construct the optimal feature space in order to achieve fine crop classification and used an object-oriented Random Forest classification algorithm to classify the multi-feature space, and the final overall accuracy and kappa coefficient were 90.18% and 0.877, which were greater than for the pixel-level and single-feature classification accuracies. In summary, there is no generalized FS method to obtain the optimal features for different machine learning classifiers, regions with different climatic conditions, and remote sensing data types. In addition, the impact of each FS method on the actual crop classification effect is still unclear, and the effectiveness of different algorithms for regional crop identification also needs to be further explored. Therefore, the utility and efficiency of FS methods need to be further investigated according to specific research objectives.
In the field of remote sensing, the application of satellite remote sensing data has become an important tool for land use/land cover (LULC) classification studies. High-resolution satellite data, especially panchromatic/multispectral sensor (PMS) images from China’s Gaofen-6 (GF-6) satellite, offer the possibility of precise surface feature identification due to their high spatial resolution and enhanced spectral resolution. Gaofen-6 (GF-6), which was successfully launched on 2 June 2018, is a satellite specially designed for monitoring agricultural applications [
29], and it is mainly applied to industries such as precision agriculture observation and forestry resources survey. Regarding the research progress on LULC classification using GF-6 PMS data, several papers have reported the effectiveness of its application in urban land cover, agricultural monitoring, and forest resources survey [
30,
31,
32,
33]. These studies show the potential advantages of GF-6 satellite data in distinguishing fine-grained surface features, especially in the detailed delineation of farmland boundaries. In view of this, this study proposes an object-oriented multi-feature preference-based monitoring method for “non-food” monitoring of high-resolution imagery using GF-6 imagery, aiming to provide a new research idea for the accurate identification of food crops and cash crops. The specific objectives of this study are (1) to explore the methods applicable to the accurate identification of food crops in the northern border area, and to study the advantages of GF-6 remote sensing images in the identification; (2) to evaluate and compare key features and FS methods in grain crop identification; and (3) to explore the best combination of FS methods and machine learning classifiers to recognize various crop types.
5. Discussion and Future Work
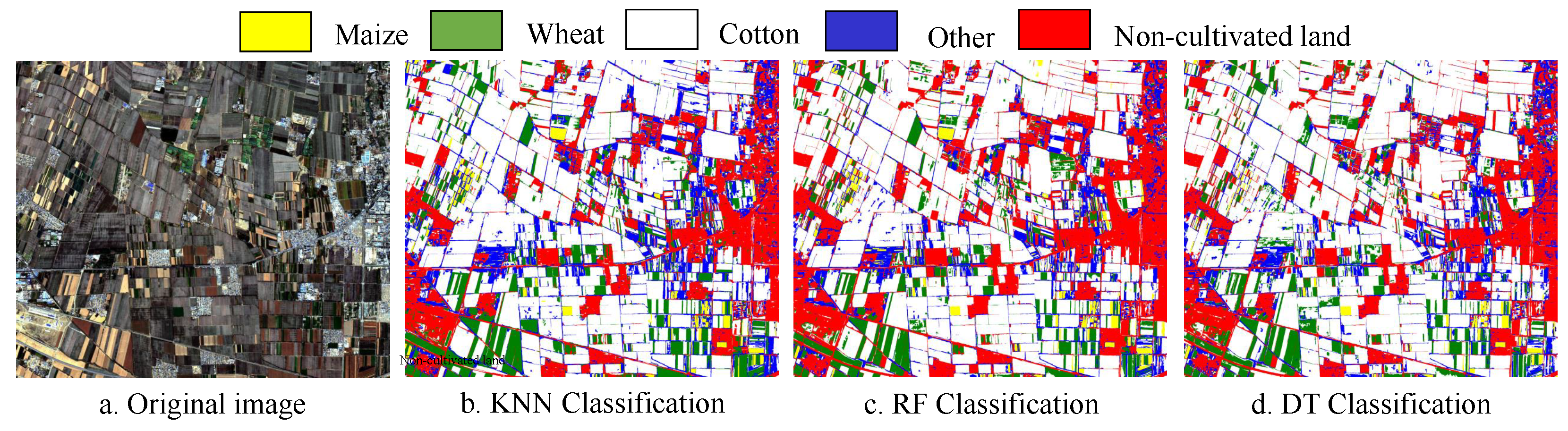
In terms of object-oriented classification, the KNN, RF, and DT models demonstrate superior performance. The KNN model achieves an OA value of 88.06% without the use of any FS method, surpassing the RF and DT models by 4.40% and 3.21%, respectively. This finding confirms the effectiveness of the KNN model in crop classification, as previously reported by Xiao et al. [
41].
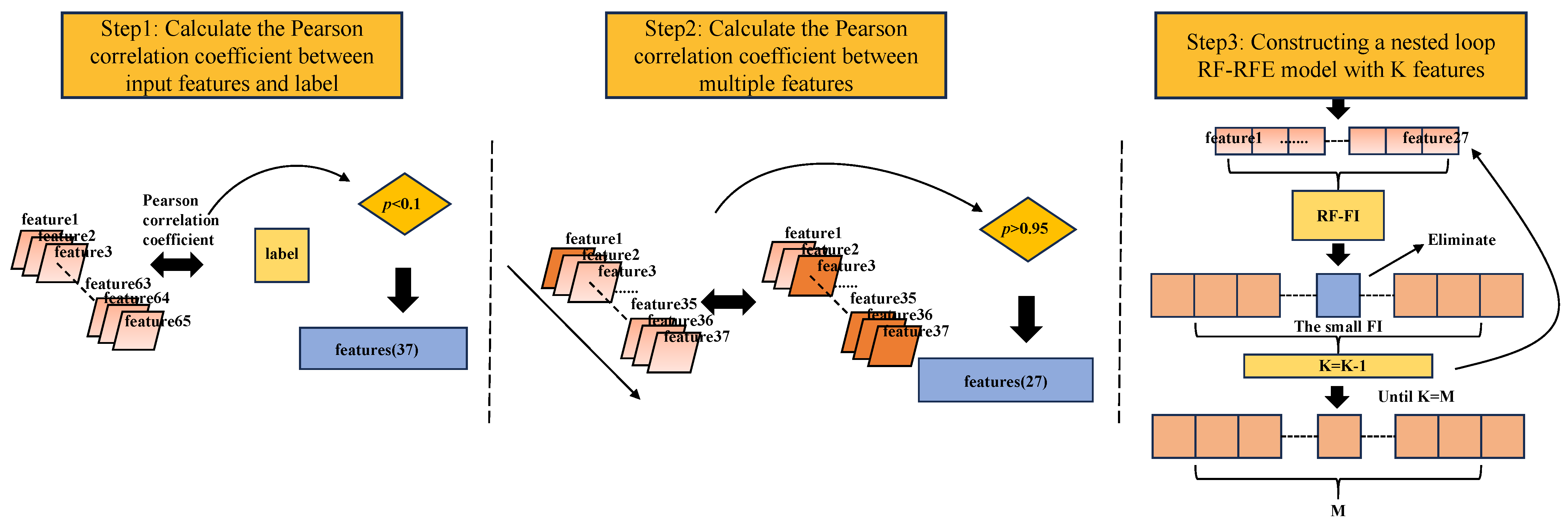
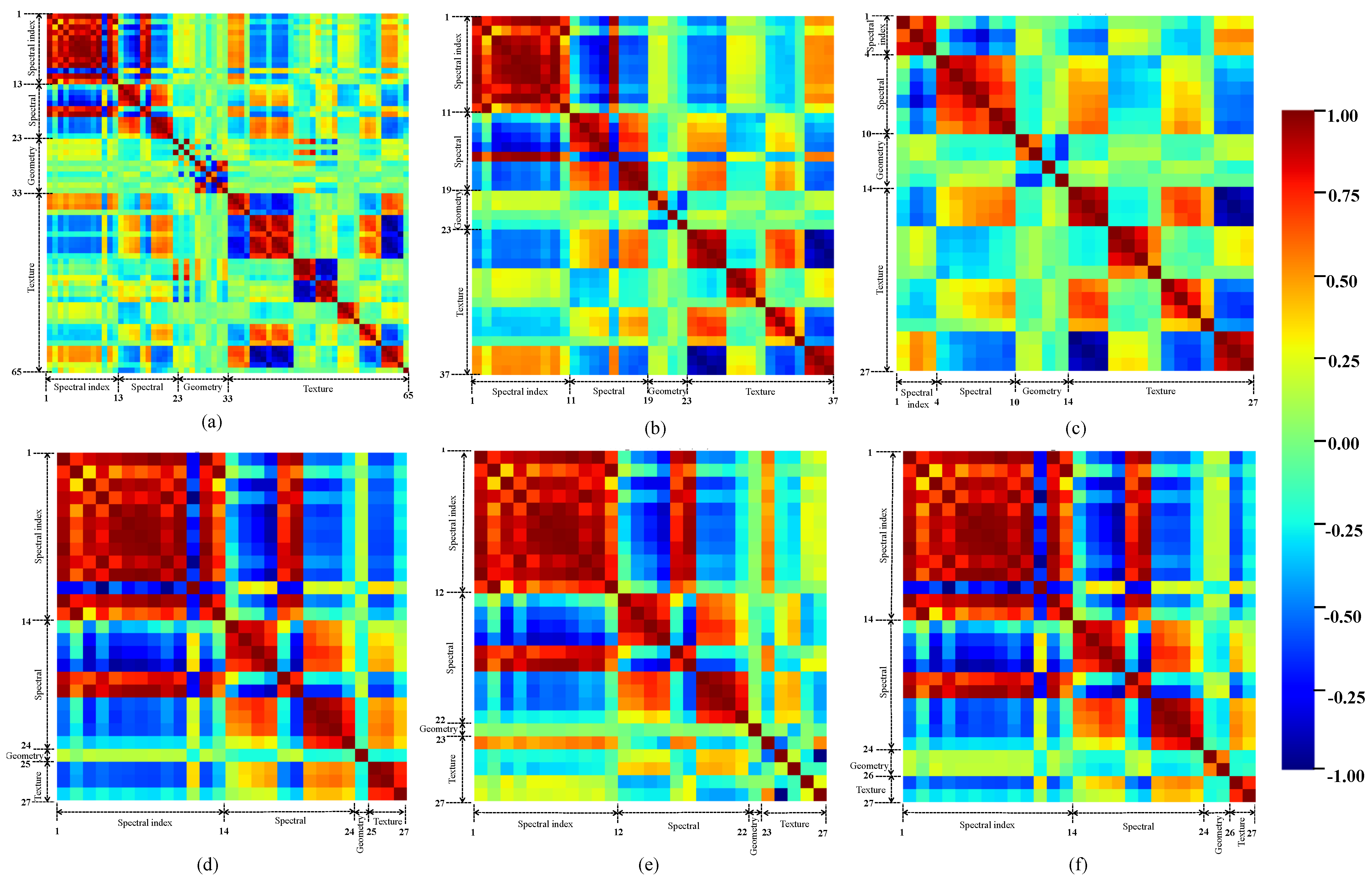
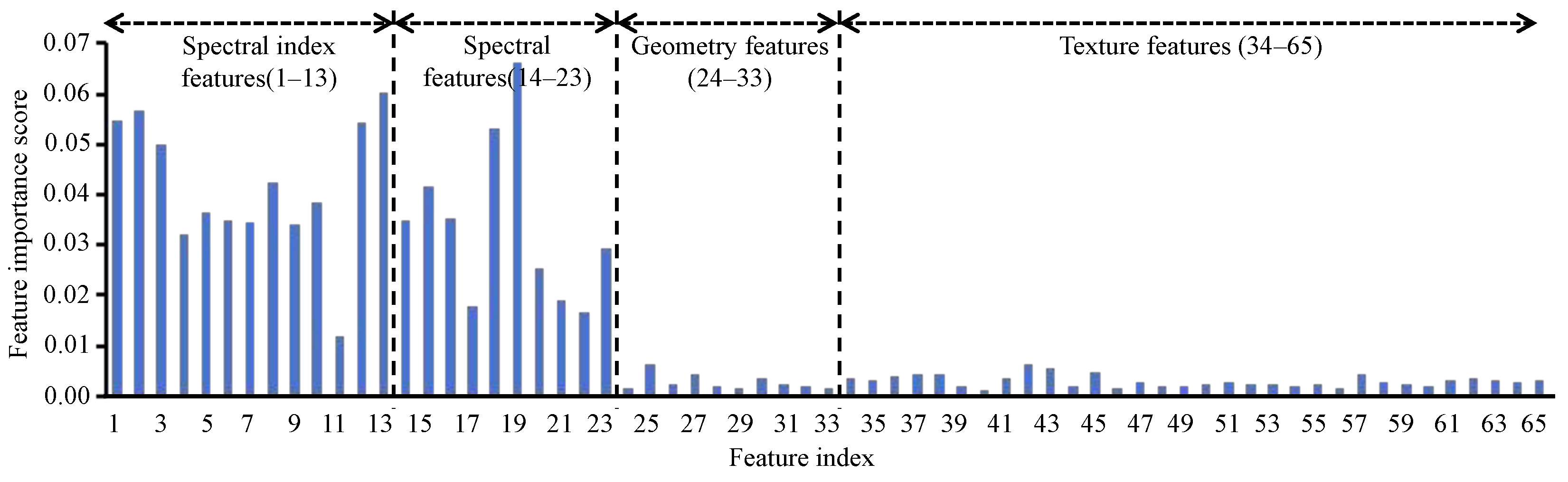
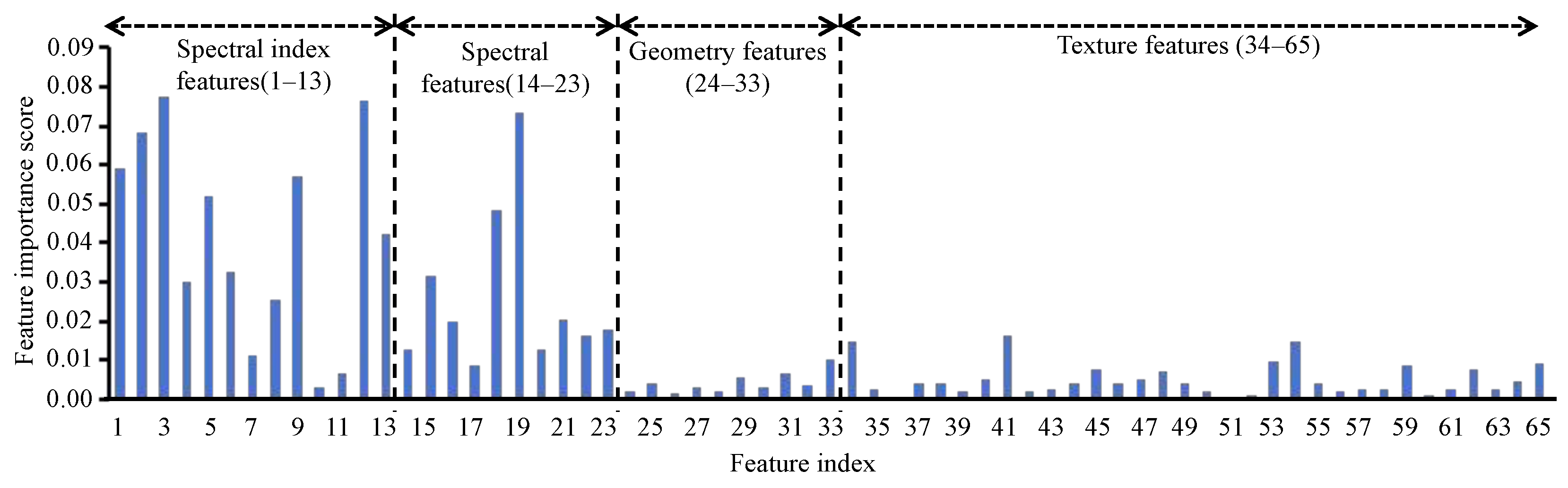
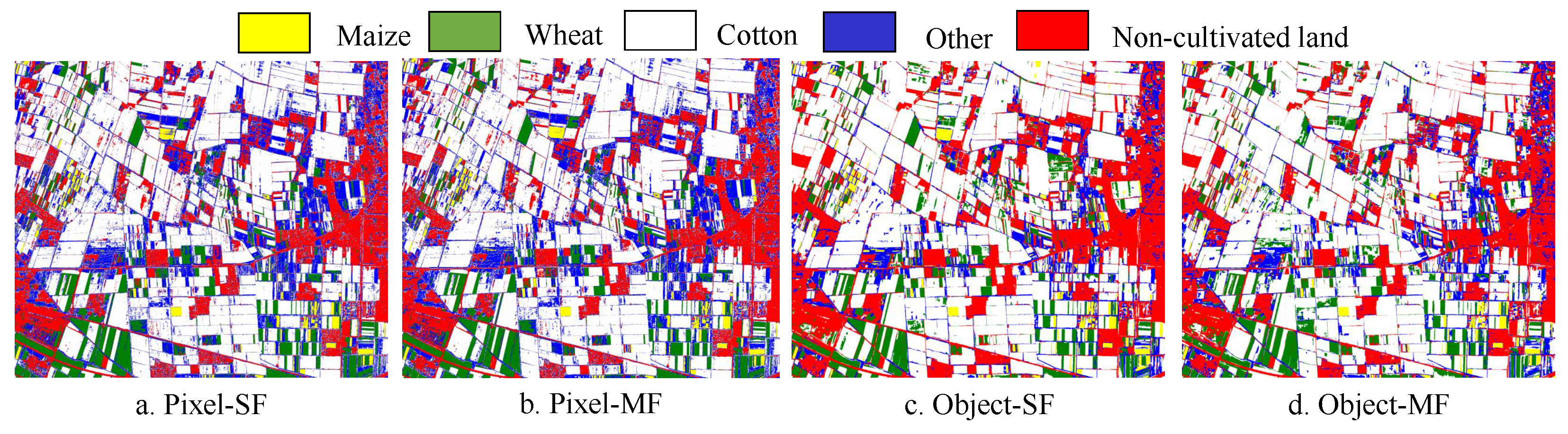
The results of this study confirm that FS methods play a crucial role in distinguishing crop types in different machine learning models, which is consistent with previous findings [
42,
43]. A robust FS method should be able to rank and reduce a large number of input features [
44]. In this study, we used the OF-RF-RFE method to select features and successfully reduced the initial sixty-five features to eight. Based on these eight features, the classification accuracy of the KNN model was improved by 2.60%. This indicates that the proposed OF-RF-RFE method is effective in crop classification. Compared with the OF-RF-FI algorithm and OF-XGBoost, the OF-RF-RFE algorithm performs better in feature selection for crop classification. GI, NDVI, RVI, Blue_Mean, Brightness, and Green_Mean are the features jointly selected by the three feature selection methods, which indicates that spectral and spectral index features have significant advantages in crop type identification [
45].
Comparing our results with existing studies, Wang et al. [
46] achieved the highest OA of 77.12% by classifying large-scale regional crop types by combining four machine learning models and two deep learning models with time-series satellite data. Fu et al. [
28] constructed features based on multiscale segmentation and extracted crop information for the river valley area based on Landsat imagery. The OA was 86.97% and the kappa coefficient was 0.82. In comparison, this study used feature selection combined with the object-oriented KNN model to classify crops in Shihezi Reclamation Area with OA over 90.68% and kappa coefficient over 0.83. Our results show higher crop classification accuracy than previous studies, which suggests that the KNN model can be used to classify crops in Shihezi Reclamation Area by using the OF-RF-RFE method to optimize the feature subset and achieve better classification results.
In this study, we describe in detail the methodological framework adopted, including the selection of key algorithms, parameter settings, and the feature extraction and selection process. The methods were carefully designed to be adaptable to different regional datasets and environmental conditions. Our study area covers a wide range of crop types, including major food crops (maize and wheat) and important cash crops (cotton), which are grown globally, and thus our methods have good generalization capabilities and can be directly applied to other regions with similar crop types. Our proposed method is not only applicable to the mapping of large “non-food” areas but also significantly improves the accuracy of image classification, thus providing a new methodological reference for large-scale remote sensing monitoring, which is of great significance for the future monitoring of crop dynamics on arable land in other areas.
In this paper, some progress has been made in the monitoring research of “staple-crop-shifting” cultivated land by using GF-6 remote sensing images. It lays a foundation for future research, but there are still some important parts that need to be further explored and discussed in depth:
- (1)
The KNN algorithm for object-oriented multi-feature selection based on GF-6 remote sensing images is used to carry out the study of “staple-crop-shifting” cultivated land, and it has achieved good recognition accuracy and stability. With the continuous development of information technology, deep-learning-based methods have achieved remarkable results in the field of image processing. Therefore, in future research, we can further explore the comparative analysis of deep learning algorithms and the algorithm of this study in order to explore a more accurate and efficient monitoring method of “staple-crop-shifting”.
- (2)
This study focuses on the effects of different characteristic variables of cotton, maize, wheat, and other crops regarding the identification of “staple-crop-shifting” information of cultivated land in the study area, and the time span of identification is years. In future studies, we will focus on the contribution of different months of imagery data to crop type extraction in order to realize the integration of time series and features. In order to improve the applicability of the model, we will also conduct experimental work for more crop types and regions to validate and improve the model algorithm, and explore the temporal and spatial variations that affect the accuracy.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}