
An Accurate Approach for Predicting Soil Quality Based on Machine Learning in Drylands

 , , ,
, , ,  ,
,  ,
,  and
and
Abstract
:1. Introduction
- To propose an accurate approach for assessment soil quality, used in Egypt, using 16 features and their scores depending on Matlab codes. The codes are available for calculating the SQI for other regions, just by changing the dataset and updating the scoring criteria. A MATLAB program was developed to calculate soil quality, classify it, and compile the results into useful databases. This will contribute to big data analysis in a systematic, reliable, accurate, and timely manner compared to traditional methods.
- To use the artificial neural network model for SQI prediction with 306 datasets of soil samples based on one hidden layer with a number of neurons and one output layer. To improve the performance and generalization ability of the model, hyperparameter tuning and K-fold cross-validation were carried out in this paper. Then, the optimal number of neurons was determined to obtain the most effective and accurate predictive model in this study evaluating the metrics (MSE and R).
2. Materials and Methods
2.1. Experimental Zones and Soil Sampling
- (i)
- Chemical indicators: This group includes indicators such as cation exchange capacity (CEC), the percentage of calcium carbonate (CaCO3), the percentage of exchangeable sodium (ESP), gypsum (CaSO4), electrical conductivity (EC), and soil reaction (pH).
- (ii)
- Physical indicators: This group includes soil depth (SD), soil slope (SS), bulk density (BD), soil texture (ST), water holding capacity (WHC), and hydraulic conductivity (HC).
- (iii)
- Fertility indicators: This group includes soil organic matter (SOM), available nitrogen (AvN), available phosphorus (AvP), and available potassium (AvK).
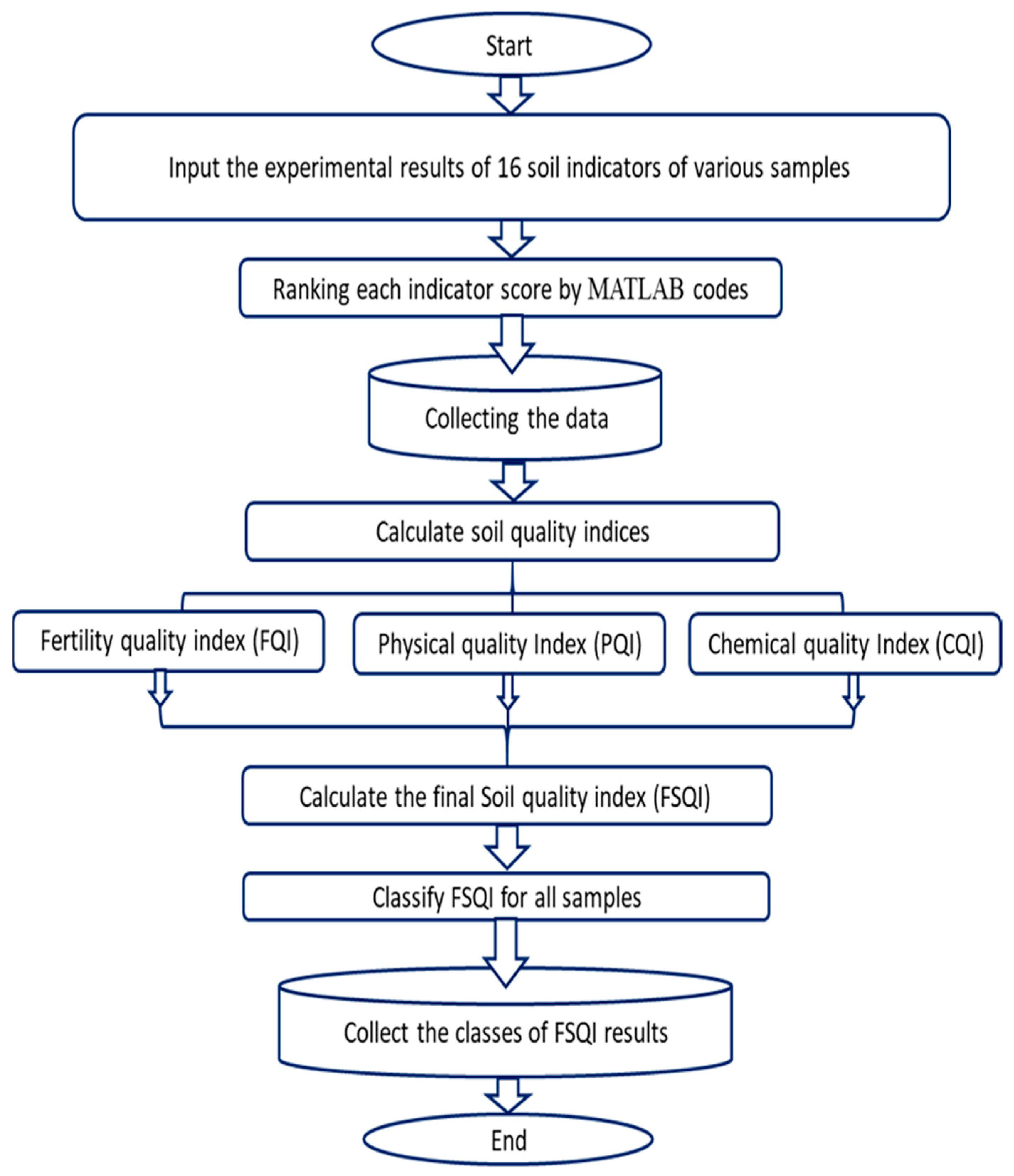
2.2. Soil Quality Index Database Using MATLAB Codes
- First, the experimental results of 16 soil indicators, that is, SOM, AvK, AvP, AvN, HC, WHC, BD, ST, SS, SD, CEC, CaSO4, CaCO3, ESP, pH, and EC for the various samples used in this study were added as inputs.
- Next, each indicator score was ranked in MATLAB environment according to Tables S1–S3.
- A special database was built to collect each indicator score for various samples under study.
- The soil quality indices were calculated as described in detail in Section 2.3.
- In this step, the final soil quality index (FSQI) was calculated as described in Section 2.3.
- The values of FSQI were classified for all samples.
- Finally, a new database, with the classes of FSQI results for each investigated sample was created.
2.3. Soil Quality Model
- x: the quality index
- S: the parameter’s score
- n: the parameter’s number
- CQI: chemical quality index
- EC: electric conductivity
- pH: soil reaction
- ESP: exchangeable sodium percentage in soil
- CaCO3: soil calcium carbonate
- CaSO4: percentage of gypsum
- CEC: cation exchange capacity
- PQI: physical quality index
- HC: hydraulic conductivity
- WHC: water holding capacity
- BD: bulk density
- ST: soil texture
- SS: soil slope
- SD: soil depth
- FQI: fertility quality index
- SOM: soil organic matter
- AvK: available potassium
- AvP: available phosphorus
- AvN: available nitrogen
- FSQI: the index of final soil quality
- CQI: the index of chemical quality
- PQI: the index of physical quality
- FQI: the index of fertility quality
2.4. Soil Quality Index (SQI) Assessment in Big Data
- Data analytics: The best way to organize big data analysis is to put it in the form of matrices so that we can keep track of the data.
- Data classification: Structured rules are used in big data classification using MATLAB.
- Comparison with traditional method calculations for quality (effectiveness and accuracy) and time consumption.
- Finally, validating the proposed program.
2.5. Soil Quality Prediction Using ANN
- -
- A training dataset of 245 data points is required to build the model. The obtained data is randomly divided into training sets of 70% and testing sets of 30%.
- -
- A test dataset of 61 data points is required to estimate the model’s performance.
- n: the number of experimental data sets
- : the actual soil quality value
- : the predicted soil quality value
- : the mean of the target output data
- N: the number of input parameters
- wi: the weighted average of input parameters
- xi: the input parameters
- b: the bias function
- : is the set of hyperparameters that produce the minimum target score
- x: is any value in the space X
- is the prior probability
- is the evidence, refers to the probability
- is the posterior probability
- Step one: Create an objective function that minimizes validation errors.
- Step two: Develop a surrogate probability model for the objective function.
- Step three: Determine the optimal hyperparameters for the surrogate probability model.
- Step four: Apply these hyperparameters to the actual objective function.
- Step five: Combine the new findings to improve the surrogate model.
- Step six: Repeat steps three to five until the maximum number of iterations is reached.
3. Results and Discussion
3.1. Soil Physicochemical Features
3.2. Soil Quality Index Using MATLAB Proposed Program
3.2.1. Scenario 1
3.2.2. Scenario 2
3.2.3. Scenario 3
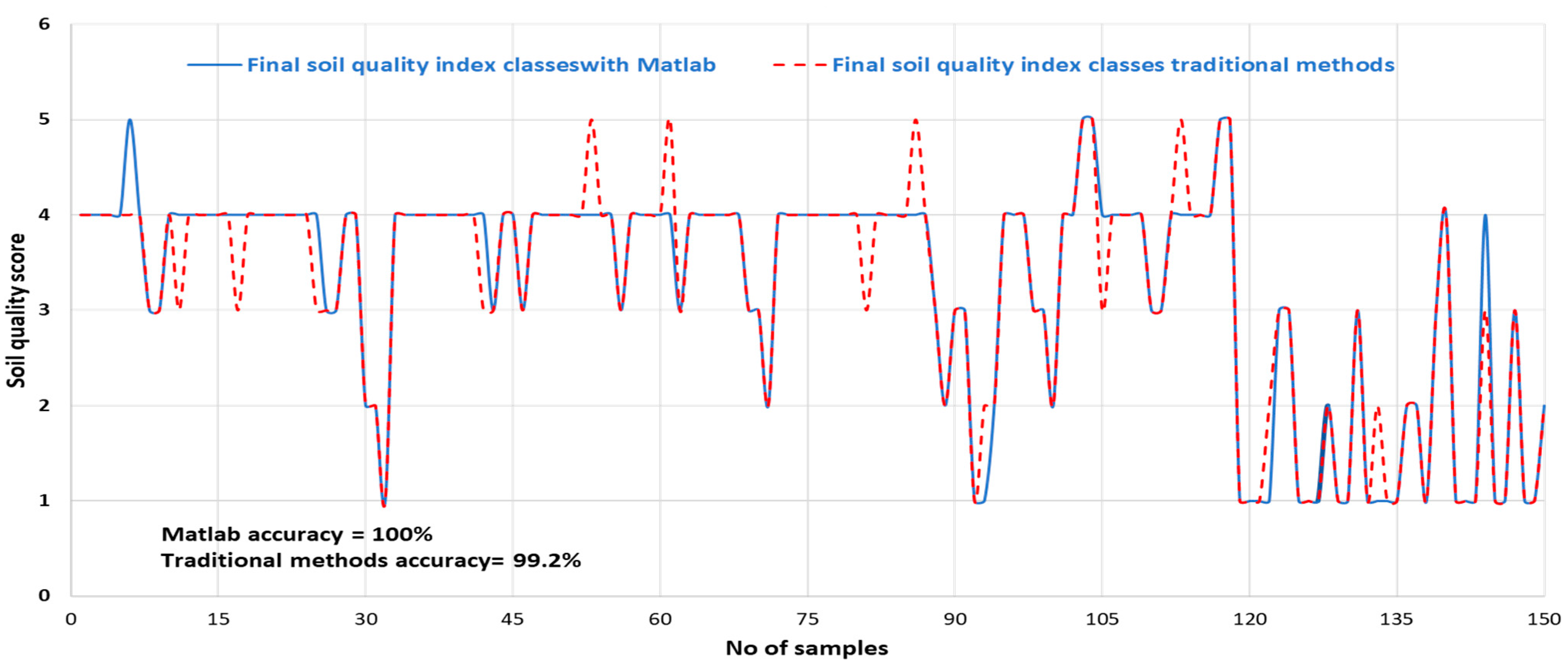
3.2.4. Comparison between the Final Soil Quality Index Class Calculations Using Matlab and Traditional Methods
3.3. ANN Training Phase
3.4. ANN Test Phase
3.5. Assessment of Soil Quality
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hunter, M.C.; Smith, R.G.; Schipanski, M.E.; Atwood, L.W.; Mortensen, D.A. Agriculture in 2050: Recalibrating targets for sustainable intensification. Bioscience 2017, 67, 386–391. [Google Scholar] [CrossRef]
- Tahmasebinia, F.; Tsumura, Y.; Wang, B.; Wen, Y.; Bao, C.; Sepasgozar, S.; Alonso-Marroquin, F. Floating Cities Bridge in 2050. In Smart Cities and Construction Technologies; IntechOpen: London, UK, 2020; p. 35. [Google Scholar]
- Shokr, M.S.; Abdellatif, M.A.; El Baroudy, A.A.; Elnashar, A.; Ali, E.F.; Belal, A.A.; Attia, W.; Ahmed, M.; Aldosari, A.A.; Szantoi, Z. Development of a spatial model for soil quality assessment under arid and semi-arid conditions. Sustainability 2021, 13, 2893. [Google Scholar] [CrossRef]
- Hendawy, E.; Belal, A.; Mohamed, E.; Elfadaly, A.; Murgante, B.; Aldosari, A.A.; Lasaponara, R. The prediction and assessment of the impacts of soil sealing on agricultural land in the North Nile Delta (Egypt) using satellite data and GIS modeling. Sustainability 2019, 11, 4662. [Google Scholar] [CrossRef]
- Ma, J.; Chen, Y.; Zhou, J.; Wang, K.; Wu, J. Soil quality should be accurate evaluated at the beginning of lifecycle after land consolidation for eco-sustainable development on the Loess Plateau. J. Clean. Prod. 2020, 267, 122244. [Google Scholar] [CrossRef]
- Semenkov, I.; Koroleva, T. Heavy metals content in soils of Western Siberia in relation to international soil quality standards. Geoderma Reg. 2020, 21, e00283. [Google Scholar] [CrossRef]
- Diaz-Gonzalez, F.A.; Vuelvas, J.; Correa, C.A.; Vallejo, V.E.; Patino, D. Machine learning and remote sensing techniques applied to estimate soil indicators—Review. Ecol. Indic. 2022, 135, 108517. [Google Scholar] [CrossRef]
- Bakhshandeh, E.; Hossieni, M.; Zeraatpisheh, M.; Francaviglia, R. Land use change effects on soil quality and biological fertility: A case study in northern Iran. Eur. J. Soil Biol. 2019, 95, 103119. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Bakhshandeh, E.; Hosseini, M.; Alavi, S.M. Assessing the effects of deforestation and intensive agriculture on the soil quality through digital soil mapping. Geoderma 2020, 363, 114139. [Google Scholar] [CrossRef]
- Shao, W.; Guan, Q.; Tan, Z.; Luo, H.; Li, H.; Sun, Y.; Ma, Y. Application of BP-ANN model in evaluation of soil quality in the arid area, northwest China. Soil Tillage Res. 2021, 208, 104907. [Google Scholar] [CrossRef]
- Jian, J.; Du, X.; Reiter, M.S.; Stewart, R.D. A meta-analysis of global cropland soil carbon changes due to cover cropping. Soil Biol. Biochem. 2020, 143, 107735. [Google Scholar] [CrossRef]
- Guo, L.; Sun, Z.; Ouyang, Z.; Han, D.; Li, F. A comparison of soil quality evaluation methods for Fluvisol along the lower Yellow River. Catena 2017, 152, 135–143. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, J.; Yin, H.; Xue, J.; Jia, L.; Zhen, X.; Chang, J.; Wang, S.; Yu, B. Assessing the effects of different long-term ecological engineering enclosures on soil quality in an alpine desert grassland area. Ecol. Indic. 2022, 143, 109426. [Google Scholar] [CrossRef]
- Kenge, R. Machine Learning, Its Limitations, and Solutions Over IT. Int. J. Inf. Technol. Model. Comput. 2020, 11, 73–83. [Google Scholar] [CrossRef]
- Suthaharan, S. Machine learning models and algorithms for big data classification. Integr. Ser. Inf. Syst 2016, 36, 1–12. [Google Scholar]
- Cravero, A.; Pardo, S.; Sepúlveda, S.; Muñoz, L. Challenges to Use Machine Learning in Agricultural Big Data: A Systematic Literature Review. Agronomy 2022, 12, 748. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed]
- Shi, T.; Zhang, J.; Shen, W.; Wang, J.; Li, X. Machine learning can identify the sources of heavy metals in agricultural soil: A case study in northern Guangdong Province, China. Ecotoxicol. Environ. Saf. 2022, 245, 114107. [Google Scholar] [CrossRef] [PubMed]
- Ismaili, M.; Krimissa, S.; Namous, M.; Htitiou, A.; Abdelrahman, K.; Fnais, M.S.; Lhissou, R.; Eloudi, H.; Faouzi, E.; Benabdelouahab, T. Assessment of soil suitability using machine learning in arid and semi-arid regions. Agronomy 2023, 13, 165. [Google Scholar] [CrossRef]
- Pant, J.; Pant, P.; Pant, R.; Bhatt, A.; Pant, D.; Juyal, A. Soil quality prediction for determining soil fertility in Bhimtal Block of Uttarakhand (India) using machine learning. Int. J. Anal. Appl. 2021, 19, 91–109. [Google Scholar]
- Pacci, S.; Kaya, N.S.; Turan, İ.D.; Odabas, M.S.; Dengiz, O. Comparative approach for soil quality index based on spatial multi-criteria analysis and artificial neural network. Arab. J. Geosci. 2022, 15, 104. [Google Scholar] [CrossRef]
- Alaboz, P.; Odabas, M.S.; Dengiz, O. Soil quality assessment based on machine learning approach for cultivated lands in semi-humid environmental condition part of Black Sea region. Arch. Agron. Soil Sci. 2023, 69, 3514–3532. [Google Scholar] [CrossRef]
- Shaddad, S.M. Geostatistics and proximal soil sensing for sustainable agriculture. In Sustainability of Agricultural Environment in Egypt: Part I: Soil-Water-Food Nexus; Springer: Cham, Switzerland, 2019; pp. 255–271. [Google Scholar]
- Asadi Nalivan, O.; Mousavi Tayebi, S.A.; Mehrabi, M.; Ghasemieh, H.; Scaioni, M. A hybrid intelligent model for spatial analysis of groundwater potential around Urmia Lake, Iran. Stoch. Environ. Res. Risk Assess. 2023, 37, 1821–1838. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Sha, T.; Zhang, W.; Shen, T.; Li, Z.; Mei, T. Deep Person Generation: A Survey from the Perspective of Face, Pose, and Cloth Synthesis. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Lin, L.-J. Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Monjardin, C.E.F.; Power, C.; Senoro, D.B.; De Jesus, K.L.M. Application of Machine Learning for Prediction and Monitoring of Manganese Concentration in Soil and Surface Water. Water 2023, 15, 2318. [Google Scholar] [CrossRef]
- Kolassa, J.; Reichle, R.; Liu, Q.; Alemohammad, S.; Gentine, P.; Aida, K.; Asanuma, J.; Bircher, S.; Caldwell, T.; Colliander, A. Estimating surface soil moisture from SMAP observations using a Neural Network technique. Remote Sens. Environ. 2018, 204, 43–59. [Google Scholar] [CrossRef] [PubMed]
- Ng, W.; Minasny, B.; Montazerolghaem, M.; Padarian, J.; Ferguson, R.; Bailey, S.; McBratney, A.B. Convolutional neural network for simultaneous prediction of several soil properties using visible/near-infrared, mid-infrared, and their combined spectra. Geoderma 2019, 352, 251–267. [Google Scholar] [CrossRef]
- El-Sayed, M.A.; Abd-Elazem, A.H.; Moursy, A.R.; Mohamed, E.S.; Kucher, D.E.; Fadl, M.E. Integration Vis-NIR Spectroscopy and Artificial Intelligence to Predict Some Soil Parameters in Arid Region: A Case Study of Wadi Elkobaneyya, South Egypt. Agronomy 2023, 13, 935. [Google Scholar] [CrossRef]
- Alqadhi, S.; Mallick, J.; Talukdar, S.; Alkahtani, M. An artificial intelligence-based assessment of soil erosion probability indices and contributing factors in the Abha-Khamis watershed, Saudi Arabia. Front. Ecol. Evol. 2023, 11, 1189184. [Google Scholar] [CrossRef]
- Suo, X.M.; Jiang, Y.T.; Mei, Y.A.; Li, S.K.; Wang, K.R.; Wang, C.T. Artificial neural network to predict leaf population chlorophyll content from cotton plant images. Agric. Sci. China 2010, 9, 38–45. [Google Scholar] [CrossRef]
- Kinhal, V.G.; Agarwal, P.; Gupta, H.O. Performance investigation of neural-network-based unified power-quality conditioner. IEEE Trans. Power Deliv. 2010, 26, 431–437. [Google Scholar] [CrossRef]
- Khalghani, M.R.; Khooban, M.H. A novel self-tuning control method based on regulated bi-objective emotional learning controller’s structure with TLBO algorithm to control DVR compensator. Appl. Soft Comput. 2014, 24, 912–922. [Google Scholar] [CrossRef]
- Bhat, S.A.; Huang, N.-F. Big data and ai revolution in precision agriculture: Survey and challenges. IEEE Access 2021, 9, 110209–110222. [Google Scholar] [CrossRef]
- Mazza, D.; Canuto, E. Fundamental Chemistry with Matlab; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Arinze Emmanuel, E.; Okafor Chukwuma, C. A Matlab® Program for Soil Classification Using Aashto Classification. IOSR J. Mech. Civ. Eng. 2015, 12, 58–62. [Google Scholar]
- Pawar, S.B.; Kolhe, P.; Jadhav, V.; Patil, A.; Gujar, B.; Bhange, H. Application of C programming language to determine soil phase relationship. Pharma Innov. J. 2022, SP-11, 1835–1841. [Google Scholar]
- Raorane, A.A.; Kulkarni, R.V. Role of MATLAB in Crop Yield Estimation. Int. J. Sci. Res. Comput. Sci. (IJSRCS) 2014, 2, 1–8. [Google Scholar]
- Abdellatif, M.A. A Remote Sensing and GIS Techniques Based Approach for the Quantitative Assessment of Soil Quality in Some Areas of Northwestren Coast. Ph.D. Thesis, Faculty of Agriculture, Tanta University, Cairo, Egypt, 2022. [Google Scholar]
- El-Baroudy, A.A. Using Remote Sensing and GIS Techniques for Monitoring Land Degradation in Some Areas of Nile Delta. Ph.D. Thesis, Faculty of Agriculture, Tanta University, Cairo, Egypt, 2005. [Google Scholar]
- El Behairy, R.A. Using New Techniques for Studying Land Resources in Some Areas of North West Nile Delta, Egypt. Master’s Thesis, Faculty of Agriculture, Tanta University, Cairo, Egypt, 2021. [Google Scholar]
- Food, Agriculture Organization of the United Nations Soil Resources Development and Conservation Service. Guidelines for Soil Profile Description; FAO Soil Resources Development and Conservation Service: Rome, Italy, 2006. [Google Scholar]
- Taxonomy, S. Keys to Soil Taxonomy; United State Department of Agriculture (USDA), Natural Resources Conservation Service: Washington, DC, USA, 2014.
- Usda, N. Soil survey laboratory methods manual. In Soil Survey Investigations Report; Department of Agriculture, Natural Resources Conservation Service: Lincoln, NE, USA, 2004; No. 42. [Google Scholar]
- Read, S. ISO/IEC 17025; 2017-General requirements for the competence of testing and calibration laboratories. Vernier: Geneva, Switzerland, 2017.
- Karlen, D.L.; Ditzler, C.A.; Andrews, S.S. Soil quality: Why and how? Geoderma 2003, 114, 145–156. [Google Scholar] [CrossRef]
- El Behairy, R.A.; El Baroudy, A.A.; Ibrahim, M.M.; Kheir, A.M.; Shokr, M.S. Modelling and assessment of irrigation water quality index using GIS in semi-arid region for sustainable agriculture. Water Air Soil Pollut. 2021, 232, 352. [Google Scholar] [CrossRef]
- Shokr, M.S.; Abdellatif, M.A.; El Behairy, R.A.; Abdelhameed, H.H.; El Baroudy, A.A.; Mohamed, E.S.; Rebouh, N.Y.; Ding, Z.; Abuzaid, A.S. Assessment of Potential Heavy Metal Contamination Hazards Based on GIS and Multivariate Analysis in Some Mediterranean Zones. Agronomy 2022, 12, 3220. [Google Scholar] [CrossRef]
- El Behairy, R.A.; El Baroudy, A.A.; Ibrahim, M.M.; Mohamed, E.S.; Kucher, D.E.; Shokr, M.S. Assessment of soil capability and crop suitability using integrated multivariate and GIS approaches toward agricultural sustainability. Land 2022, 11, 1027. [Google Scholar] [CrossRef]
- Hammam, A.A.; Mohamed, W.S.; Sayed, S.E.-E.; Kucher, D.E.; Mohamed, E.S. Assessment of soil contamination using gis and multi-variate analysis: A case study in El-Minia Governorate, Egypt. Agronomy 2022, 12, 1197. [Google Scholar] [CrossRef]
- El Behairy, R.A.; El Baroudy, A.A.; Ibrahim, M.M.; Mohamed, E.S.; Rebouh, N.Y.; Shokr, M.S. Combination of GIS and Multivariate Analysis to Assess the Soil Heavy Metal Contamination in Some Arid Zones. Agronomy 2022, 12, 2871. [Google Scholar] [CrossRef]
- Watzinger, A. Microbial phospholipid biomarkers and stable isotope methods help reveal soil functions. Soil Biol. Biochem. 2015, 86, 98–107. [Google Scholar] [CrossRef]
- Istijono, B.; Harianti, M. Soil quality index analysis under horticultural farming in Sumani upper watershed. GEOMATE J. 2019, 16, 191–196. [Google Scholar]
- Moore, F.; Sheykhi, V.; Salari, M.; Bagheri, A. Soil quality assessment using GIS-based chemometric approach and pollution indices: Nakhlak mining district, Central Iran. Environ. Monit. Assess. 2016, 188, 214. [Google Scholar] [CrossRef] [PubMed]
- Dengiz, O. Parametric approach with linear combination technique in land evaluation studies. J. Agric. Sci. 2013, 19, 101–112. [Google Scholar]
- Şenol, H.; Alaboz, P.; Demir, S.; Dengiz, O. Computational intelligence applied to soil quality index using GIS and geostatistical approaches in semiarid ecosystem. Arab. J. Geosci. 2020, 13, 1–20. [Google Scholar] [CrossRef]
- Semih, Ç.; Barik, K. Hydraulic conductivity values of soils in different soil processing conditions. Alinteri J. Agric. Sci. 2020, 35, 132–138. [Google Scholar]
- Alam, M.; Mishra, A.; Singh, K.; Singh, S.K.; David, A. Response of sulphur and FYM on soil physico-chemical properties and growth, yield and quality of mustard (Brassica nigra L.). J. Agric. Phys. 2014, 14, 156–160. [Google Scholar]
- Fabrizio, A.; Tambone, F.; Genevini, P. Effect of compost application rate on carbon degradation and retention in soils. Waste Manag. 2009, 29, 174–179. [Google Scholar] [CrossRef]
- Palmer, J.; Thorburn, P.J.; Biggs, J.S.; Dominati, E.J.; Probert, M.E.; Meier, E.A.; Huth, N.I.; Dodd, M.; Snow, V.; Larsen, J.R. Nitrogen cycling from increased soil organic carbon contributes both positively and negatively to ecosystem services in wheat agro-ecosystems. Front. Plant Sci. 2017, 8, 731. [Google Scholar] [CrossRef] [PubMed]
- Ramos, F.T.; Dores, E.F.d.C.; Weber, O.L.d.S.; Beber, D.C.; Campelo Jr, J.H.; Maia, J.C.d.S. Soil organic matter doubles the cation exchange capacity of tropical soil under no-till farming in Brazil. J. Sci. Food Agric. 2018, 98, 3595–3602. [Google Scholar] [CrossRef] [PubMed]
- Alaboz, P.; Dengiz, O.; Demir, S. Barley yield estimation performed by ANN integrated with the soil quality index modified by biogas waste application. Zemdirb. Agric. 2021, 108, 217–226. [Google Scholar] [CrossRef]
- Shokr, M.S.; Baroudy, A.A.E.L.; Fullen, M.A.; El-Beshbeshy, T.R.; Ali, R.R.; Elhalim, A.; Guerra, A.J.T.; Jorge, M.C.O. Mapping of Heavy Metal Contamination in Alluvial Soils of the Middle Nile Delta of Egypt. J. Environ. Eng. Landsc. Manag. 2016, 24, 218–231. [Google Scholar] [CrossRef]
- Abdellatif, M.A.; El Baroudy, A.A.; Arshad, M.; Mahmoud, E.K.; Saleh, A.M.; Moghanm, F.S.; Shaltout, K.H.; Eid, E.M.; Shokr, M.S. A GIS-based approach for the quantitative assessment of soil quality and sustainable agriculture. Sustainability 2021, 13, 13438. [Google Scholar] [CrossRef]
- Abuzaid, A.S.; Abdellatif, A.D.; Fadl, M.E. Modeling soil quality in Dakahlia Governorate, Egypt using GIS techniques. Egypt. J. Remote Sens. Space Sci. 2021, 24, 255–264. [Google Scholar] [CrossRef]
- El Behairy, R.A.; El Arwash, H.M.; El Baroudy, A.A.; Ibrahim, M.M.; Mohamed, E.S.; Rebouh, N.Y.; Shokr, M.S. Artificial Intelligence Integrated GIS for Land Suitability Assessment of Wheat Crop Growth in Arid Zones to Sustain Food Security. Agronomy 2023, 13, 1281. [Google Scholar] [CrossRef]
- El Baroudy, A. Mapping and evaluating land suitability using a GIS-based model. Catena 2016, 140, 96–104. [Google Scholar] [CrossRef]
- Baroudy, A.A.E.; Ali, A.M.; Mohamed, E.S.; Moghanm, F.S.; Shokr, M.S.; Savin, I.; Poddubsky, A.; Ding, Z.; Kheir, A.M.; Aldosari, A.A. Modeling land suitability for rice crop using remote sensing and soil quality indicators: The case study of the nile delta. Sustainability 2020, 12, 9653. [Google Scholar] [CrossRef]
- Staff, S. Soil Survey Manual in USDA Handbook 18; Ditzler, C., Scheffe, K., Monger, H.C., Eds.; Government Printing Office: Washington, DC, USA, 2017.
- Yao, R.-J.; Yang, J.-S.; Zhang, T.-J.; Gao, P.; Yu, S.-P.; Wang, X.-P. Short-term effect of cultivation and crop rotation systems on soil quality indicators in a coastal newly reclaimed farming area. J. Soils Sediments 2013, 13, 1335–1350. [Google Scholar] [CrossRef]
- Abrol, I.; Yadav, J.S.P.; Massoud, F. Salt-Affected Soils and Their Management; Food & Agriculture Organization: Rome, Italy, 1988. [Google Scholar]
- Hazelton, P.; Murphy, B. Interpreting Soil Test Results: What Do All the Numbers Mean? CSIRO Publishing: Collingwood, VA, Australia, 2016. [Google Scholar]
- Soltanpour, P. Determination of nutrient availability and elemental toxicity by AB-DTPA soil test and ICPS. In Advances in Soil Science; Springer: New York, NY, USA, 1991; Volume 16, pp. 165–190. [Google Scholar]
- Mohamed, E.S.; Baroudy, A.A.E.; El-Beshbeshy, T.; Emam, M.; Belal, A.; Elfadaly, A.; Aldosari, A.A.; Ali, A.M.; Lasaponara, R. Vis-nir spectroscopy and satellite landsat-8 oli data to map soil nutrients in arid conditions: A case study of the northwest coast of Egypt. Remote Sens. 2020, 12, 3716. [Google Scholar] [CrossRef]
- Mohamed, E.S.; Jalhoum, M.E.; Belal, A.A.; Hendawy, E.; Azab, Y.F.; Kucher, D.E.; Shokr, M.S.; El Behairy, R.A.; El Arwash, H.M. A Novel Approach for Predicting Heavy Metal Contamination Based on Adaptive Neuro-Fuzzy Inference System and GIS in an Arid Ecosystem. Agronomy 2023, 13, 1873. [Google Scholar] [CrossRef]
- Salman, M.S.; Kukrer, O.; Hocanin, A. Recursive inverse algorithm: Mean-square-error analysis. Digit. Signal Process. 2017, 66, 10–17. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation functions in neural networks. Towards Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Fei, R.; Guo, Y.; Li, J.; Hu, B.; Yang, L. An improved BPNN method based on probability density for indoor location. IEICE Trans. Inf. Syst. 2023, 106, 773–785. [Google Scholar] [CrossRef]
- Jain, A.K.; Chandrasekaran, B. 39 Dimensionality and sample size considerations in pattern recognition practice. Handb. Stat. 1982, 2, 835–855. [Google Scholar]
- Raudys, S.J.; Jain, A.K. Small sample size effects in statistical pattern recognition: Recommendations for practitioners. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 252–264. [Google Scholar] [CrossRef]
- Dayhoff, J. Pattern recognition with a pulsed neural network. In Proceedings of the Conference on Analysis of Neural Network Applications, Fairfax, VA, USA, 29–31 May 1991; pp. 146–159. [Google Scholar]
- Mehrotra, K.; Mohan, C.K.; Ranka, S. Elements of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: Hoboken, NJ, USA, 1998. [Google Scholar]
- Haykin, S. Neural networks: A guided tour. In Nonlinear Biomedical Signal Processing; Institute of Electrical and Electronics Engineers, Inc.: Piscataway, NJ, USA, 2000; Volume 1, pp. 53–68. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 1. [Google Scholar]
- Dayhoff, J.E. Neural Network Architectures: An Introduction; Van Nostrand Reinhold Co.: New York, NY, USA, 1990. [Google Scholar]
- Mockus, J.; Mockus, J. Global optimization and the Bayesian approach. In Bayesian Approach to Global Optimization: Theory and Applications; Springer: Dordrecht, The Netherlands, 1989; pp. 1–3. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers, Inc.: Burlington, MA, USA, 2012; Volume 25. [Google Scholar]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef]
- Nachshon, U. Cropland soil salinization and associated hydrology: Trends, processes and examples. Water 2018, 10, 1030. [Google Scholar] [CrossRef]
- Hammam, A.; Mohamed, E. Mapping soil salinity in the East Nile Delta using several methodological approaches of salinity assessment. Egypt. J. Remote Sens. Space Sci. 2020, 23, 125–131. [Google Scholar] [CrossRef]
- Abdel-Fattah, M.K.; Abd-Elmabod, S.K.; Aldosari, A.A.; Elrys, A.S.; Mohamed, E.S. Multivariate analysis for assessing irrigation water quality: A case study of the Bahr Mouise Canal, Eastern Nile Delta. Water 2020, 12, 2537. [Google Scholar] [CrossRef]
- Zalacáin, D.; Martínez-Pérez, S.; Bienes, R.; García-Díaz, A.; Sastre-Merlín, A. Salt accumulation in soils and plants under reclaimed water irrigation in urban parks of Madrid (Spain). Agric. Water Manag. 2019, 213, 468–476. [Google Scholar] [CrossRef]
- Qadir, M.; Schubert, S. Degradation processes and nutrient constraints in sodic soils. Land Degrad. Dev. 2002, 13, 275–294. [Google Scholar] [CrossRef]
- Jacobsen, S.-E.; Jensen, C.R.; Liu, F. Improving crop production in the arid Mediterranean climate. Field Crops Res. 2012, 128, 34–47. [Google Scholar] [CrossRef]
- Osman, K.T. Management of Soil Problems; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Von Wandruszka, R. Phosphorus retention in calcareous soils and the effect of organic matter on its mobility. Geochem. Trans. 2006, 7, 6. [Google Scholar] [CrossRef] [PubMed]
- Chi, C.; Zhao, C.; Sun, X.; Wang, Z. Reclamation of saline-sodic soil properties and improvement of rice (Oriza sativa L.) growth and yield using desulfurized gypsum in the west of Songnen Plain, northeast China. Geoderma 2012, 187, 24–30. [Google Scholar] [CrossRef]
- Temiz, C.; Cayci, G. The effects of gypsum and mulch applications on reclamation parameters and physical properties of an alkali soil. Environ. Monit. Assess. 2018, 190, 347. [Google Scholar] [CrossRef]
- Abdelsamie, E.A.; Abdellatif, M.A.; Hassan, F.O.; El Baroudy, A.A.; Mohamed, E.S.; Kucher, D.E.; Shokr, M.S. Integration of RUSLE Model, Remote Sensing and GIS Techniques for Assessing Soil Erosion Hazards in Arid Zones. Agriculture 2022, 13, 35. [Google Scholar] [CrossRef]
- Abdel-Fattah, M.K.; Mohamed, E.S.; Wagdi, E.M.; Shahin, S.A.; Aldosari, A.A.; Lasaponara, R.; Alnaimy, M.A. Quantitative evaluation of soil quality using Principal Component Analysis: The case study of El-Fayoum depression Egypt. Sustainability 2021, 13, 1824. [Google Scholar] [CrossRef]
- Bassouny, M.; Abuzaid, A. Impact of biogas slurry on some physical properties in sandy and calcareous soils, Egypt. Int. J. Plant Soil Sci. 2017, 16, 1–11. [Google Scholar] [CrossRef]
- Abuzaid, A.S.; Jahin, H.S. Profile distribution and source identification of potentially toxic elements in north Nile Delta, Egypt. Soil Sediment Contam. Int. J. 2019, 28, 582–600. [Google Scholar] [CrossRef]
- Mammadov, E.; Denk, M.; Riedel, F.; Lewinska, K.; Kaźmierowski, C.; Glaesser, C. Visible and near-infrared reflectance spectroscopy for assessment of soil properties in the Caucasus Mountains, Azerbaijan. Commun. Soil Sci. Plant Anal. 2020, 51, 2111–2136. [Google Scholar] [CrossRef]
- Fadl, M.; Abuzaid, A. Assessment of land suitability and water requirements for different crops in Dakhla Oasis, Western Desert, Egypt. Int. J. Plant Soil Sci. 2017, 16, 1–16. [Google Scholar] [CrossRef]
- Bernardi, A.C.d.C.; Grego, C.R.; Andrade, R.G.; Rabello, L.M.; Inamasu, R.Y. Spatial variability of vegetation index and soil properties in an integrated crop-livestock system. Rev. Bras. De Eng. Agrícola E Ambient. 2017, 21, 513–518. [Google Scholar] [CrossRef]
- Öztürk, E.; Dengiz, O. Assessment and selection of suitable microbasins for organic agriculture under subhumid ecosystem conditions: A case study from Trabzon Province, Turkey. Arab. J. Geosci. 2020, 13, 1222. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Soil Property | Unit | Min | Max | Mean | SD | CV, % | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|
| EC | dSm−1 | 0.55 | 129.70 | 5.46 | 10.91 | 199.8 | 6.73 | 61.33 |
| pH | - | 7.46 | 9.21 | 8.34 | 0.31 | 3.7 | 0.11 | −0.05 |
| ESP | % | 1.45 | 35.93 | 9.29 | 7.50 | 80.7 | 1.25 | 1.10 |
| CaCO3 | 0.21 | 34.42 | 9.15 | 8.15 | 89.1 | 0.94 | −0.08 | |
| CaSO4 | 0.07 | 9.68 | 1.21 | 1.32 | 108.5 | 2.89 | 12.16 | |
| CEC | cmolcKg−1 | 0.95 | 58.40 | 22.09 | 19.89 | 90.0 | 0.27 | −1.75 |
| HC | cmhr−1 | 0.29 | 33.42 | 9.71 | 8.57 | 88.2 | 0.54 | −0.88 |
| WHC | % | 3.01 | 53.04 | 23.32 | 19.30 | 82.8 | 0.21 | −1.83 |
| BD | gcm−3 | 1.16 | 1.68 | 1.43 | 0.12 | 8.5 | −0.46 | −0.88 |
| SS | % | 0.10 | 8.00 | 2.04 | 1.60 | 78.5 | 2.38 | 6.91 |
| SD | cm | 30.00 | 150.00 | 110.52 | 36.39 | 32.9 | −0.20 | −1.37 |
| SOM | % | 0.01 | 2.96 | 0.63 | 0.67 | 105.4 | 1.52 | 1.47 |
| AvK | mgKg−1 | 7.70 | 719.10 | 263.77 | 144.25 | 54.7 | 0.01 | −0.10 |
| AvP | 2.09 | 38.45 | 9.66 | 6.66 | 68.9 | 1.33 | 1.46 | |
| AvN | 3.10 | 98.91 | 28.78 | 26.50 | 92.1 | 0.96 | −0.43 |
| Comparison Face | Time-Consuming | Effectiveness | Accuracy | |||
|---|---|---|---|---|---|---|
| Scenario | Traditional Methods | MATLAB Program | Traditional Methods | MATLAB Program | Traditional Methods | MATLAB Program |
| Scenario 1; 150 samples | 18 h | 5 m | 90% | 100% | 99.2% | 100% |
| Scenario 2; 306 samples | 37 h | 5 m | 80% | 100% | 97.9% | 100% |
| Scenario 3; 700 samples | 84 h | 5 m | 70% | 100% | 97.8% | 100% |
| I/P No. | 16 | Outputs No. | 1 |
| No. of training samples | 245 | Max. training Epochs | 1000 |
| Hidden layers | 1 | Target Regression (R) | 1 |
| Target MSE | 0 | Target error | 1 × 10−3 |
| No. of Neurons for the Hidden Layers | 50 | 100 | 150 | 200 | 250 | 260 |
|---|---|---|---|---|---|---|
| MSE (Training) | 8.507 × 10−2 | 8.033 × 10−2 | 1.066 × 10−1 | 7.918 × 10−2 | 9.0237 × 10−2 | 9.651 × 10−2 |
| MSE (Test) | 1.385 × 10−1 | 1.28 × 10−1 | 1.285 × 10−1 | 1.856 × 10−1 | 9.880 × 10−2 | 1.424 × 10−1 |
| R (Training) | 9.668 × 10−1 | 9.69 × 10−1 | 9.69 × 10−1 | 9.694 × 10−1 | 9.650 × 10−1 | 9.627 × 10−1 |
| R (Test) | 9.559 × 10−1 | 9.518 × 10−1 | 9.518 × 10−1 | 9.306 × 10−1 | 9.664 × 10−1 | 9.531 × 10−1 |
| No. of total epochs for best performance | 565 | 997 | 873 | 147 | 327 | 162 |
| Unit | Epoch | Elapsed Time | Performance | Gradient | Mutation (Mu) | Validation Checks |
|---|---|---|---|---|---|---|
| Initial Value | 0 | - | 163 | 618 | 0.00500 | 0 |
| Current Value | 1000 | 1:13:35 | 0.0792 | 0.0151 | 0.500 | 0 |
| Objective Value | 1000 | - | 0.00 | 1 × 10−7 | 1.00 × 1010 | 0 |
| Classes | Symbol | Values | No. of Samples | % |
|---|---|---|---|---|
| Very high quality | C1 | ≥0.61 | 113 | 36.93 |
| high quality | C2 | 0.53–0.60 | 32 | 10.46 |
| Moderate quality | C3 | 0.45–0.52 | 96 | 31.37 |
| Low quality | C4 | 0.37–0.44 | 64 | 20.92 |
| Very low quality | C5 | ≤0.36 | 1 | 0.33 |
| Total | 306 | 100 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Behairy, R.A.; El Arwash, H.M.; El Baroudy, A.A.; Ibrahim, M.M.; Mohamed, E.S.; Rebouh, N.Y.; Shokr, M.S. An Accurate Approach for Predicting Soil Quality Based on Machine Learning in Drylands. Agriculture 2024, 14, 627. https://doi.org/10.3390/agriculture14040627
El Behairy RA, El Arwash HM, El Baroudy AA, Ibrahim MM, Mohamed ES, Rebouh NY, Shokr MS. An Accurate Approach for Predicting Soil Quality Based on Machine Learning in Drylands. Agriculture. 2024; 14(4):627. https://doi.org/10.3390/agriculture14040627
Chicago/Turabian StyleEl Behairy, Radwa A., Hasnaa M. El Arwash, Ahmed A. El Baroudy, Mahmoud M. Ibrahim, Elsayed Said Mohamed, Nazih Y. Rebouh, and Mohamed S. Shokr. 2024. "An Accurate Approach for Predicting Soil Quality Based on Machine Learning in Drylands" Agriculture 14, no. 4: 627. https://doi.org/10.3390/agriculture14040627