
AM-UNet: Field Ridge Segmentation of Paddy Field Images Based on an Improved MultiResUNet Network
Abstract
:1. Introduction
- (1)
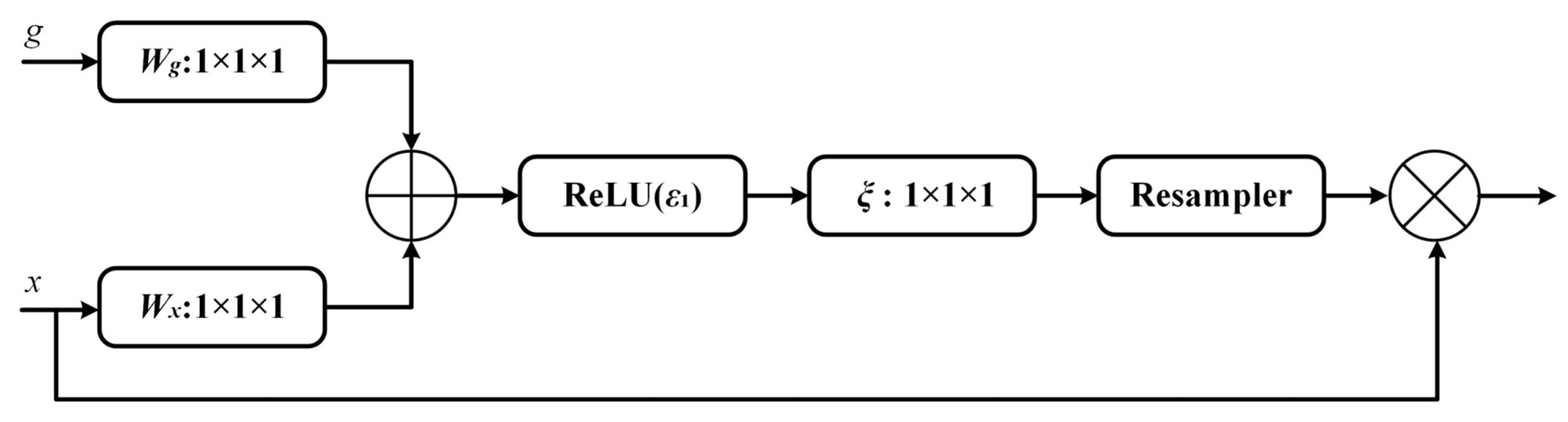
- Adding attention gate structure skip connections at the end of encoder–decoder skip connections in MultiResUNet, generating attention coefficients through sigmoid activation and passing them to the input coding layer using trilinear interpolation to highlight semantic regions related to the field ridges during up-sampling, and suppressing target-independent feature responses.
- (2)
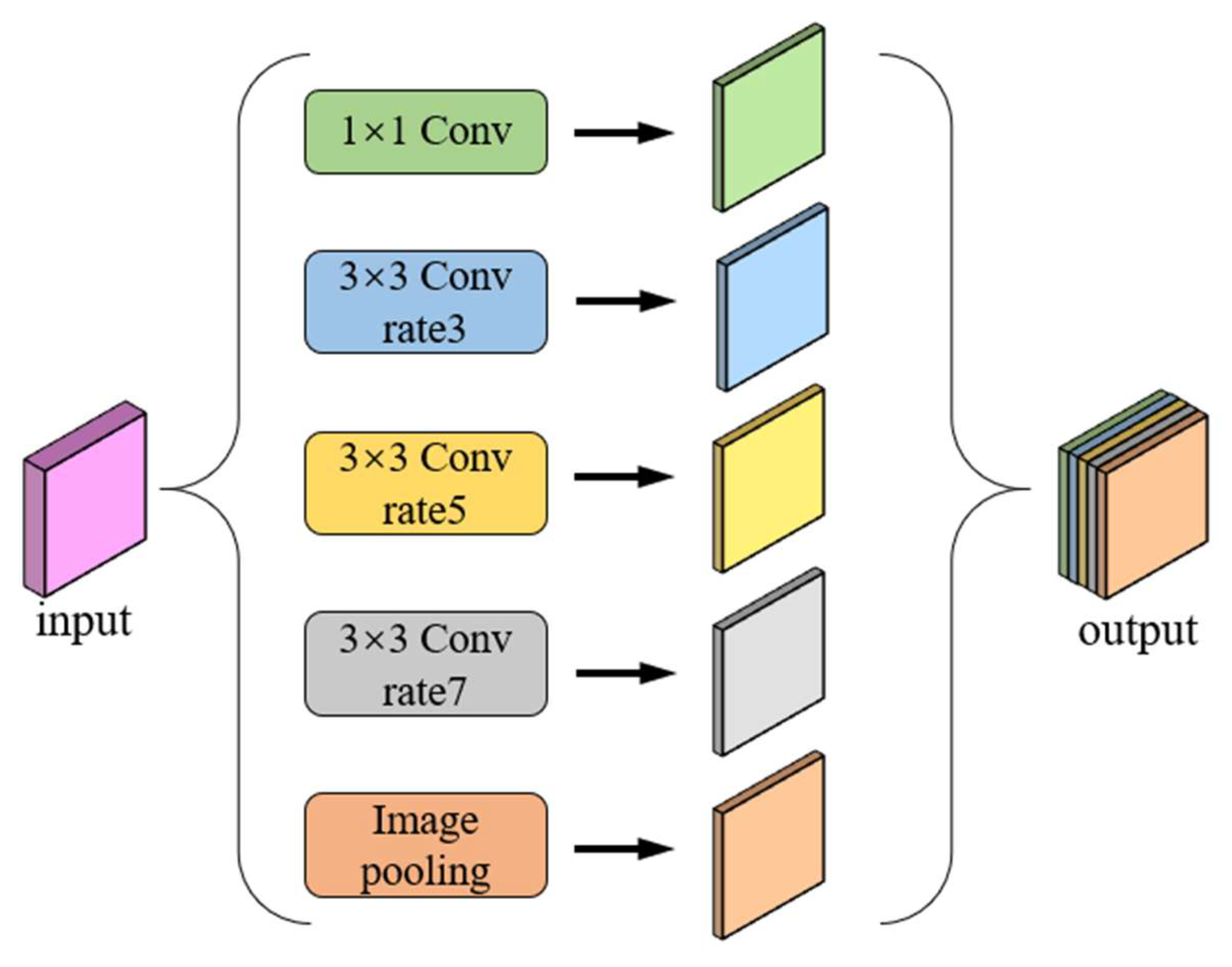
- Adding the ASPP module after the end of coding down-sampling, using a smaller combination of expansion rates to improve the identification of field ridge edge details, adding one-way parallel average pooling to integrate global information, and using 1 × 1 convolution to achieve channel dimensionality reduction after bilinear interpolation, in order to enhance the range of sensory fields for feature semantics and further improve the segmentation accuracy of the field ridge region.
2. Materials and Methods
2.1. Data Acquisition
2.2. Dataset Construction
2.3. Dataset Preparation
2.4. MultiResUNet Model
2.4.1. MultiResBlock Module
2.4.2. Res Path Structure
2.5. AM-UNet Semantic Segmentation Model for Paddy Field Ridges
2.5.1. Attention Gate (AG) mechanism
2.5.2. Atrous Spatial Pyramid Pooling (ASPP) Module
3. Results and Analysis
3.1. Platform Parameters
3.2. Evaluation Indices
3.3. Evaluation Index
3.4. Ablation Experiment
3.5. Comparison of the Performance of Different Models
4. Discussion
5. Conclusions
- (1)
- In this study, a segmentation model based on the MultiResUNet model was constructed to address the difficult problem of accurate segmentation of paddy field images representing the paddy field environment in southern China. The improved model introduces an attention gate (AG) at the end of the encoder–decoder skip connection in the MultiResUNet model, highlights the feature response of the field ridge region, and introduces an atrous spatial pyramid pooling (ASPP) module after down-sampling the encoder to improve the recognition accuracy regarding the small-scale edge details of field ridges. These improvements allow the model to realize the accurate recognition and segmentation of field ridge images in a complex environment, providing technical support for the development of vision-based automatic navigation systems for agricultural machines.
- (2)
- The experimental results show that the segmentation accuracy, average intersection over union, and average F1 value of the optimized model in the validation set were 93.45%, 88.74%, and 93.95%, respectively, better than those obtained with the UNet, MultiResUNet, and PSPNet methods. When compared with the existing MultiResUNet model, the proposed model’s segmentation accuracy, intersection over union, and average F1 value were improved by 2.39, 2.76, and 1.89 percentage points, respectively, and the inference time for a single image was 168ms, enabling accurate and real-time segmentation of field ridges in a complex paddy field environment. Therefore, the introduction of the attention mechanism and spatial pyramid pooling significantly improved the segmentation effect of the model for paddy field ridge images.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, C.; Lin, H.; Li, Y.; Gong, L.; Miao, Z. Analysis on Status and Development Trend of Intelligent Control Technology for Agricultural Equipment. Trans. Chin. Soc. Agric. Mach. 2020, 51, 1–18. [Google Scholar]
- Li, D.; Li, Z. System Analysis and Development Prospect of Unmanned Farming. Trans. Chin. Soc. Agric. Mach. 2020, 51, 1–12. [Google Scholar]
- Lu, G.; Jin, T.; Shen, W. Research on the Development of Rice Moderate Scale and Mechanization in Small Paddy Area in the South. Agric. Mach. 2016, 12, 69–71. [Google Scholar] [CrossRef]
- Wang, J.; Weng, W.; Liu, J.; Wang, J.; Na, M. Design and Experiment of Bi-Directional Ridger for Paddy Field. Trans. Chin. Soc. Agric. Mach. 2019, 50, 40–48. [Google Scholar] [CrossRef]
- Varghese, V.; Shajahan, D.A.; Nath, A.G. Building Boundary Tracing and Regularization from LiDAR Point Cloud. In Proceedings of the 2016 International Conference on Emerging Technological Trends (ICETT), Kollam, India, 21–22 October 2016; IEEE: Kollam, India, 2016; pp. 1–6. [Google Scholar]
- Sun, P.; Zhao, X.; Xu, Z.; Wang, R.; Min, H. A 3D LiDAR Data-Based Dedicated Road Boundary Detection Algorithm for Autonomous Vehicles. IEEE Access 2019, 7, 29623–29638. [Google Scholar] [CrossRef]
- Chen, R.; Li, C.; Yang, G.; Yang, H.; Xu, B.; Yang, X.; Zhu, Y.; Lei, L.; Zhang, C.; Dong, Z. Extraction of Crown Information from Individual Fruit Tree by UAV LiDAR. Trans. Chin. Soc. Agric. Eng. 2020, 36, 50–59. [Google Scholar] [CrossRef]
- Chen, J.; Sun, J.; Chen, H.; Song, J. A Study on Real-Time Extraction of Rice and Wheat Harvest Boundary Line in Shadow Environment. J. Agric. Mech. Res. 2022, 44, 26–31. [Google Scholar]
- Hou, C. Research on Vision-Based Lane Line Detection Technology. Ph.D. Dissertation, Southwest Jiaotong University, Chengdu, China, 2017. [Google Scholar]
- Chen, X.; Yu, J. Monitoring Method for Machining Tool Wear Based on Machine Vision. J. ZheJiang Univ. (Eng. Sci.) 2021, 55, 896–904. [Google Scholar] [CrossRef]
- Pandey, R.; Lalchhanhima, R. Segmentation Techniques for Complex Image: Review. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; IEEE: Shillong, India, 2020; pp. 804–808. [Google Scholar]
- Qiao, Y.; Liu, H.; Meng, Z.; Chen, J.; Ma, L. Method for the Automatic Recognition of Cropland Headland Images Based on Deep Learning. Int. J. Agric. Biol. Eng. 2023, 16, 216–224. [Google Scholar] [CrossRef]
- Yu, Y.; Bao, Y.; Wang, J.; Chu, H.; Zhao, N.; He, Y.; Liu, Y. Crop Row Segmentation and Detection in Paddy Fields Based on Treble-Classification Otsu and Double-Dimensional Clustering Method. Remote Sens. 2021, 13, 901. [Google Scholar] [CrossRef]
- Peng, B.; Guo, Z.; Zhu, X.; Ikeda, S.; Tsunoda, S. Semantic Segmentation of Femur Bone from MRI Images of Patients with Hematologic Malignancies. In Proceedings of the 2020 IEEE Region 10 Conference (TENCON), Osaka, Japan, 16–19 November 2020; pp. 1090–1094. [Google Scholar]
- Trebing, K.; Stanczyk, T.; Mehrkanoon, S. SmaAt-UNet: Precipitation Nowcasting Using a Small Attention-UNet Architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- He, Y.; Zhang, X.; Zhang, Z.; Fang, H. Automated Detection of Boundary Line in Paddy Field Using MobileV2-UNet and RANSAC. Comput. Electron. Agric. 2022, 194, 106697. [Google Scholar] [CrossRef]
- Wang, S.; Su, D.; Jiang, Y.; Tan, Y.; Qiao, Y.; Yang, S.; Feng, Y.; Hu, N. Fusing Vegetation Index and Ridge Segmentation for Robust Vision Based Autonomous Navigation of Agricultural Robots in Vegetable Farms. Comput. Electron. Agric. 2023, 213, 108235. [Google Scholar] [CrossRef]
- Marshall, M.; Crommelinck, S.; Kohli, D.; Perger, C.; Yang, M.Y.; Ghosh, A.; Fritz, S.; de Bie, K.; Nelson, A. Crowd-Driven and Automated Mapping of Field Boundaries in Highly Fragmented Agricultural Landscapes of Ethiopia with Very High Spatial Resolution Imagery. Remote Sens. 2019, 11, 2082. [Google Scholar] [CrossRef]
- Xu, L.; Ming, D.; Zhou, W.; Bao, H.; Chen, Y.; Ling, X. Farmland Extraction from High Spatial Resolution Remote Sensing Images Based on Stratified Scale Pre-Estimation. Remote Sens. 2019, 11, 108. [Google Scholar] [CrossRef]
- Waldner, F.; Diakogiannis, F.I. Deep Learning on Edge: Extracting Field Boundaries from Satellite Images with a Convolutional Neural Network. Remote Sensing of Environment 2020, 245, 111741. [Google Scholar] [CrossRef]
- Hong, R.; Park, J.; Jang, S.; Shin, H.; Kim, H.; Song, I. Development of a Parcel-Level Land Boundary Extraction Algorithm for Aerial Imagery of Regularly Arranged Agricultural Areas. Remote Sens. 2021, 13, 1167. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Song, Z.; Zhang, Z.; Yang, S.; Ding, D.; Ning, J. Identifying Sunflower Lodging Based on Image Fusion and Deep Semantic Segmentation with UAV Remote Sensing Imaging. Comput. Electron. Agric. 2020, 179, 105812. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Diao, Z.; Guo, P.; Zhang, B.; Zhang, D.; Yan, J.; He, Z.; Zhao, S.; Zhao, C. Maize Crop Row Recognition Algorithm Based on Improved UNet Network. Comput. Electron. Agric. 2023, 210, 107940. [Google Scholar] [CrossRef]
- Chen, J.; Wang, H.; Zhang, H.; Luo, T.; Wei, D.; Long, T.; Wang, Z. Weed Detection in Sesame Fields Using a YOLO Model with an Enhanced Attention Mechanism and Feature Fusion. Comput. Electron. Agric. 2022, 202, 107412. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garcia, A.; Orts, S.; Oprea, S.; Villena-Martinez, V.; Rodríguez, J.G. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2016. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Xie, S.; Huang, W.; Zhu, L.; Yang, C.; Zhang, S.; Fu, G. Vision Navigation System of Farm Based on Improved Floodfill Method. J. Chin. Agric. Mech. 2021, 42, 182. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Proportions | Images |
|---|---|---|
| Training dataset | 70% | 2380 |
| Validation dataset | 20% | 680 |
| Test dataset | 10% | 340 |
| Full data | 100% | 3400 |
| Method | IoU | P | F1 |
|---|---|---|---|
| Baseline | 85.71 | 90.84 | 91.77 |
| +AG | 86.31 | 91.39 | 92.51 |
| +ASPP | 87.04 | 91.76 | 93.15 |
| AG + ASPP | 88.78 | 93.56 | 94.01 |
| Type | UNet | PSPNet | MultiResUNet | AM-UNet | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | P | F1 | IoU | P | F1 | IoU | P | F1 | IoU | P | F1 | |
| Green vegetated ridges | 85.82 | 90.95 | 92.27 | 83.72 | 90.28 | 91.60 | 87.46 | 91.23 | 92.80 | 89.51 | 95.49 | 94.51 |
| Unvegetated ridges | 86.34 | 91.36 | 92.78 | 84.61 | 91.08 | 92.27 | 88.14 | 92.69 | 93.26 | 92.25 | 96.84 | 95.03 |
| Surface reflection | 82.89 | 89.17 | 91.06 | 81.24 | 88.46 | 90.20 | 84.83 | 90.23 | 91.69 | 87.13 | 92.18 | 93.68 |
| Surface shadows | 84.63 | 89.51 | 90.13 | 81.83 | 89.28 | 88.77 | 86.87 | 91.82 | 90.91 | 87.89 | 92.36 | 93.08 |
| Uneven surface distribution | 83.04 | 89.28 | 89.69 | 82.05 | 89.14 | 91.25 | 83.26 | 89.31 | 91.13 | 88.79 | 93.71 | 93.27 |
| Rutted marks | 82.72 | 88.86 | 91.52 | 80.27 | 88.13 | 89.71 | 85.36 | 91.09 | 92.55 | 86.87 | 90.14 | 94.14 |
| Average | 84.24 | 89.86 | 91.24 | 82.29 | 89.39 | 90.63 | 85.98 | 91.06 | 92.06 | 88.74 | 93.45 | 93.95 |
| Model | IoU/% | F1/% | Training Time/h | Inference Time/ms |
|---|---|---|---|---|
| PSPNet | 82.29 | 90.63 | 19.6 | 150 |
| UNet | 84.24 | 91.24 | 21.2 | 147 |
| MultiResUNet | 85.98 | 92.06 | 28.8 | 155 |
| AM-UNet | 88.74 | 93.95 | 31.2 | 168 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Fang, P.; Liu, X.; Liu, M.; Huang, P.; Duan, X.; Huang, D.; Liu, Z. AM-UNet: Field Ridge Segmentation of Paddy Field Images Based on an Improved MultiResUNet Network. Agriculture 2024, 14, 637. https://doi.org/10.3390/agriculture14040637
Wu X, Fang P, Liu X, Liu M, Huang P, Duan X, Huang D, Liu Z. AM-UNet: Field Ridge Segmentation of Paddy Field Images Based on an Improved MultiResUNet Network. Agriculture. 2024; 14(4):637. https://doi.org/10.3390/agriculture14040637
Chicago/Turabian StyleWu, Xulong, Peng Fang, Xing Liu, Muhua Liu, Peichen Huang, Xianhao Duan, Dakang Huang, and Zhaopeng Liu. 2024. "AM-UNet: Field Ridge Segmentation of Paddy Field Images Based on an Improved MultiResUNet Network" Agriculture 14, no. 4: 637. https://doi.org/10.3390/agriculture14040637